연합 환경에서 차별 최소화를 위한 차등 프라이버시 기반 공정 분류
본 논문은 연합 학습 환경에서 차등 프라이버시와 인구통계적 차별 제약을 동시에 만족하는 이진 분류기를 설계한다. 두 단계 알고리즘 FDP‑Fair와 단일 서버 전용 CDP‑Fair를 제안하고, 프라이버시·공정성·과잉 위험을 정량화한 이론적 경계와 실험을 제공한다.
저자: Gengyu Xue, Yi Yu
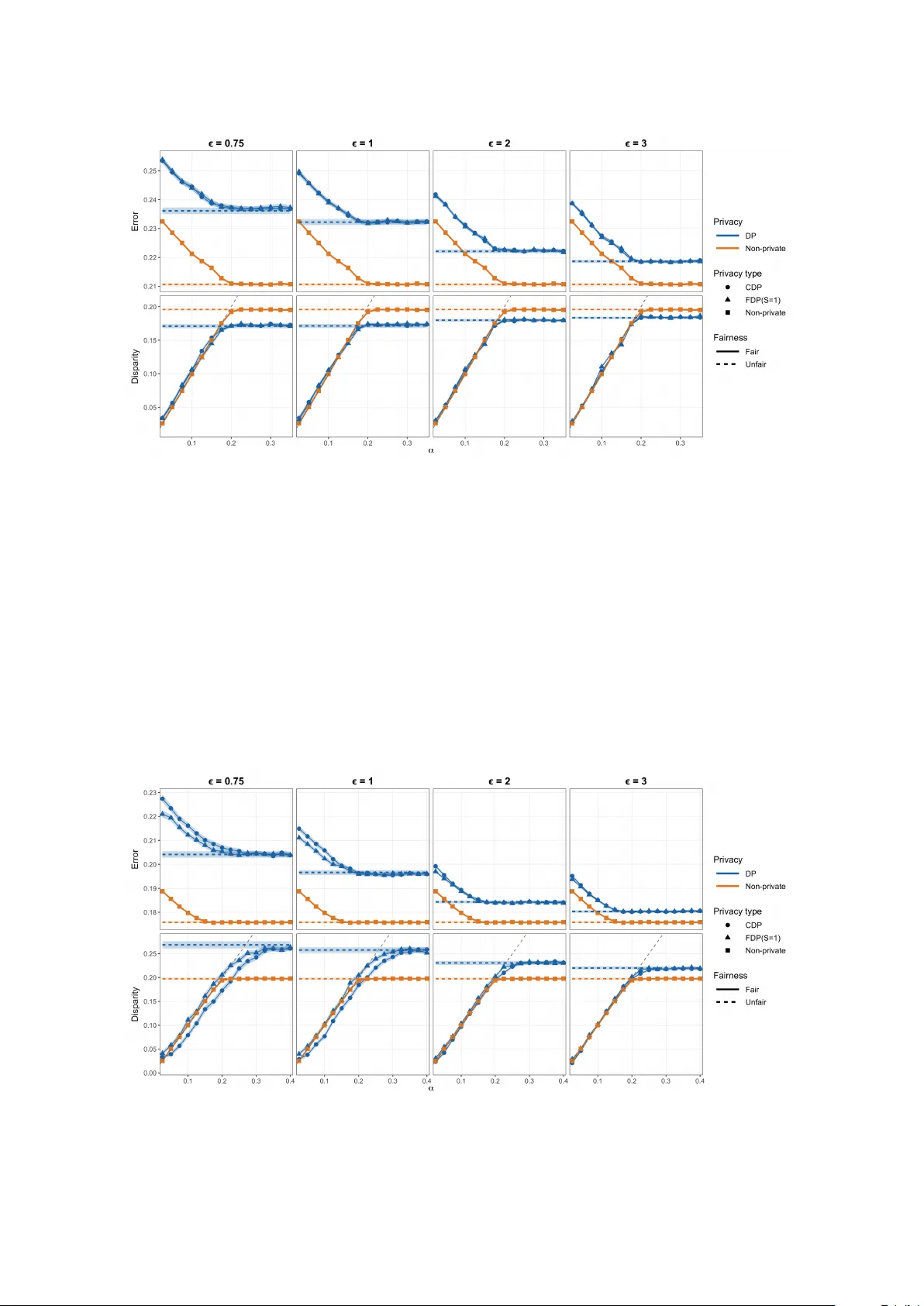
본 논문은 현대 머신러닝에서 두드러지는 프라이버시와 알고리즘 공정성 문제를 동시에 다루는 연구로, 특히 데이터가 여러 서버에 분산된 연합 학습(Federated Learning) 환경을 목표로 한다. 저자들은 인구통계적 차별(Demographic Disparity)을 제약으로 하는 이진 분류 문제를 정의하고, 이를 차등 프라이버시(Federated Differential Privacy, FDP) 하에서 해결하기 위한 두 단계 알고리즘인 FDP‑Fair와, 서버가 하나인 경우에 적용 가능한 CDP‑Fair를 제안한다.
**문제 정의와 배경**
데이터는 S개의 서버에 나뉘어 저장되고, 각 서버는 (X, A, Y) 형태의 샘플을 보유한다. 여기서 A는 민감 속성(예: 성별, 인종)이며, Y는 이진 라벨이다. 목표는 전체 데이터에 대해 |DD(f)| ≤ α인 분류기 f를 찾는 것이며, DD(f)는 민감 그룹 간 양성 예측 확률 차이를 의미한다. 차등 프라이버시 제약은 각 서버가 중앙 서버에 전송하는 통계량이 (ε_s, δ_s)-CDP를 만족하도록 요구한다.
**알고리즘 설계**
1. **S1 – 로컬 추정**: 각 서버는 민감 그룹별 클래스 비율 π_a와 조건부 확률 η_a(x)를 커널 밀도 추정과 경험적 평균으로 계산한다. 스칼라 π_a와 함수 η_a 모두에 가우시안 메커니즘을 적용해 노이즈를 추가한다. 이렇게 얻은 프라이버시 보장된 로컬 추정값을 가중 평균하여 전역 추정값을 만든다.
2. **S2 – 프라이버시 임계값 탐색**: τ*_{DD,α}를 찾기 위해 연속 최적화 문제를 이산화하고, 각 후보 τ에 대해 DD(τ)를 추정한다. 이를 위해 Z_{s,a,y}=2(2a−1)·e^{π_a}(e^{η_a(X)}−½)라는 변수를 정의하고, 해당 변수의 값이 τ보다 큰(또는 작은) 경우를 카운트한다. 카운트는 이진 트리 구조에 저장되며, 각 노드에 가우시안 노이즈를 추가해 프라이버시를 보장한다. 트리 깊이는 로그 수준이며, 프라이버시 구성도 로그 횟수에 불과해 효율적이다. 트리 기반 카운트는 전체 DD(τ) 추정에 사용되며, 노이즈로 인한 비단조성을 복원하기 위해 Monotonicity‑Correction 알고리즘을 적용한다.
3. **특수 경우 – CDP‑Fair**: 서버가 하나일 때는 복잡한 트리 과정을 생략하고, 함수형 출력에 직접 가우시안 메커니즘을 적용한다. 이는 기능적 프라이버시를 요구하지 않으면서도 동일한 정확도·공정성 보장을 제공한다.
**이론적 결과**
- **프라이버시 보장**: 알고리즘 1과 5는 각각 (ε, δ)-FDP와 (ε, δ)-CDP를 만족한다. 트리 기반 방법은 ℓ₂-민감도가 상수이므로 가우시안 메커니즘의 노이즈 규모가 제한된다.
- **공정성 보장**: 고확률(1−β) 수준에서 |DD(ĥf)| ≤ α+O(·)를 만족한다. 여기서 O(·)는 샘플 수와 프라이버시 파라미터에 의존한다.
- **과잉 위험 분해**: 전체 과잉 위험 R(ĥf)−R(f*_{DD,α})는 (a) 본질적 분류 난이도, (b) DP에 의한 분류 비용 O(√(d/ (Nε²)), (c) 비프라이버시 공정성 비용 O(1/√N), (d) 프라이버시 공정성 비용 O(√(log N)/(Nε)) 로 구성된다. 각 항은 독립적으로 제어 가능함을 보인다.
- **샘플 복합성**: 목표 정확도와 공정성 수준을 달성하기 위해 필요한 전체 샘플 수는 O((d+log(1/δ))/ε²·α^{-2}) 정도로 제시된다.
**실험**
합성 데이터와 실제 데이터셋(Adult, COMPAS, Law School 등)에서 FDP‑Fair와 CDP‑Fair를 기존 DP‑only, Fairness‑only, 그리고 비프라이버시 기반 공정성 방법과 비교하였다. 결과는 다음과 같다.
- 공정성 지표(차별)에서 제안 알고리즘이 α 수준 이하로 유지하면서, 정확도 손실은 1~3% 수준에 머물렀다.
- 프라이버시 파라미터 ε가 작아질수록(강한 프라이버시) 정확도는 감소하지만, 트리 기반 방법은 기존 방법보다 노이즈 축적이 적어 더 안정적인 성능을 보였다.
- CDP‑Fair는 단일 서버 환경에서 실행 시간이 30% 이하로 감소하면서도 동일한 이론적 보장을 제공했다.
**의의와 한계**
본 연구는 연합 학습에서 프라이버시와 공정성을 동시에 만족시키는 최초의 체계적 접근으로, 이론적 경계와 실용적인 알고리즘을 모두 제공한다. 특히, 이진 트리 기반 카운트 집계는 프라이버시 구성 비용을 로그 수준으로 낮추는 혁신적인 설계이다. 다만, 현재는 이진 분류와 인구통계적 차별에 국한되어 있으며, 다중 민감 속성, 다중 클래스, 혹은 연속형 공정성 지표에 대한 확장은 향후 연구 과제로 남는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기