Federated fairness-aware classification under differential privacy
Privacy and algorithmic fairness have become two central issues in modern machine learning. Although each has separately emerged as a rapidly growing research area, their joint effect remains comparatively under-explored. In this paper, we systematic…
Authors: Gengyu Xue, Yi Yu
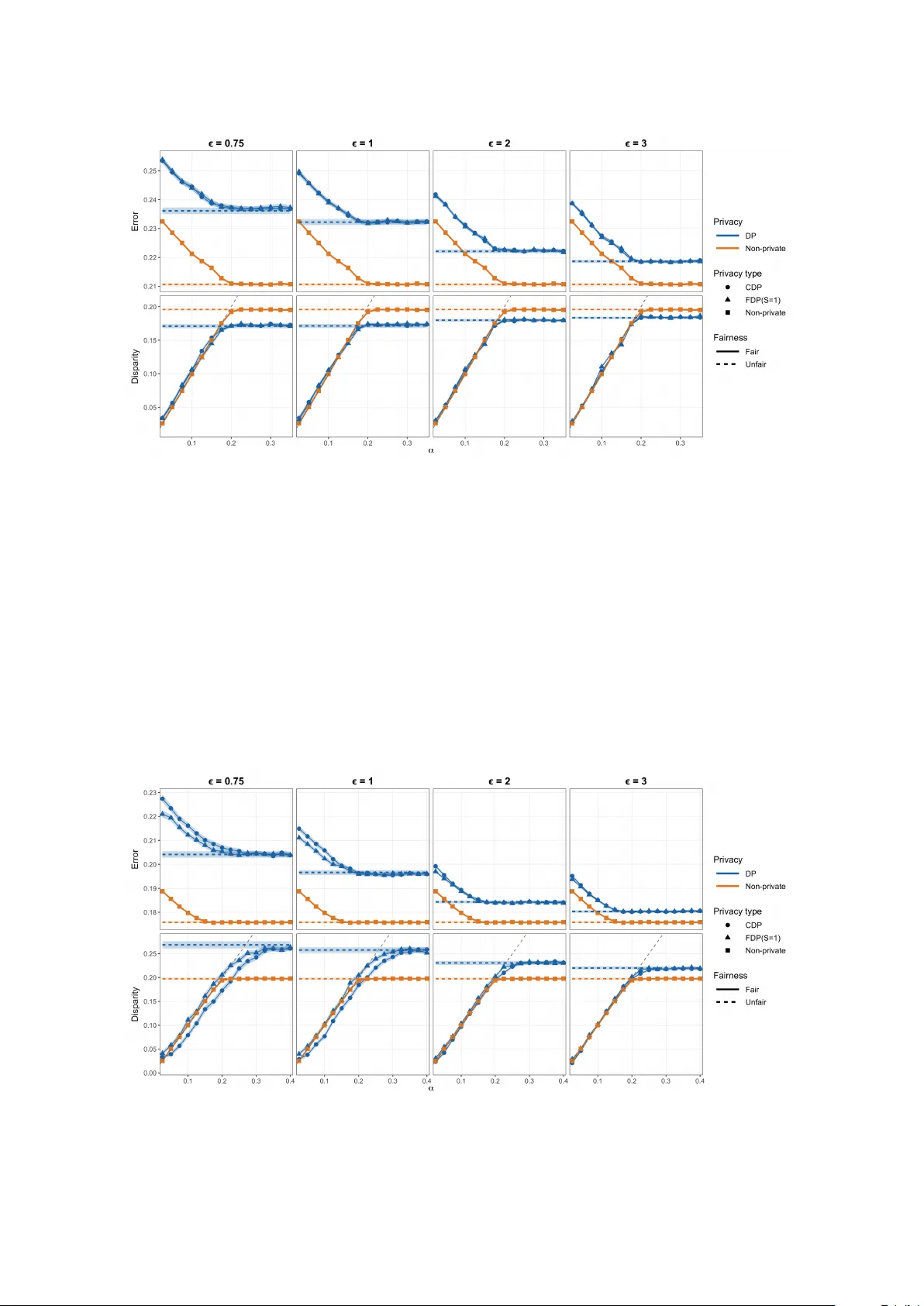
F ederated fairness-a w are classification under differen tial priv acy Gengyu Xue and Yi Y u Departmen t of Statistics, Universit y of W arwic k Marc h 26, 2026 Abstract Priv acy and algorithmic fairness ha ve b ecome tw o central issues in mo dern machine learning. Although each has separately emerged as a rapidly gro wing research area, their join t effect remains comparativ ely under-explored. In this pap er, w e systematically study the join t impact of differen tial priv acy and fairness on classification in a federated setting, where data are distributed across m ultiple serv ers. T argeting demographic disparity constrained classification under federated differen tial priv acy , we propose a tw o-step algorithm, namely FDP-F air. In the sp ecial case where there is only one server, w e further prop ose a simple yet p o werful algorithm, namely CDP-F air, serving as a computationally-light weigh t alternative. Under mild structural assumptions, theoretical guaran tees on priv acy , fairness and excess risk con trol are established. In particular, w e disentangle the source of the priv ate fairness-aw are excess risk in to a) intrinsic cost of classification, b) cost of priv ate classification, c) non-priv ate cost of fairness and d) priv ate cost of fairness. Our theoretical findings are complemented b y extensive numerical exp eriments on b oth synthetic and real datasets, highligh ting the practicalit y of our designed algorithms. 1 In tro duction Recen t adv ances in modern tec hnology hav e made it increasingly easier to collect, store, and analyse large volumes of data. While these developmen ts bring substantial benefits, the gro wing a v ailabilit y of data has also raised significant public concerns. Among these, priv acy concerns due to use of sensitive data and ethical c hallenges caused b y algorithmic unfairness ha ve emerged as t wo cen tral issues, attracting increasing attention from both researchers and the public. T o address priv acy concerns, differen tial priv acy (DP; Dw ork et al. , 2006 ) has emerged as one of the most principled approac hes with wide applications in Go ogle (e.g. Song et al. , 2021 ), Meta (e.g. Y ousefp our et al. , 2021 ) and the US Census Bureau (e.g. United States Census Bureau , 2021 ), to name but a few. F rom a statistical p ersp ectiv e, substantial analyses hav e also been carried out in v arious settings to quan tify the cost of priv acy constrain ts on statistical accuracy across a range of problems, such as mean estimation (e.g. Karwa and V adhan , 2017 ), density estimation (e.g. Butucea et al. , 2020 ), classification (e.g. Auddy et al. , 2025 ) and non-p arametric regression (e.g. Cai et al. , 2024 ). Alongside priv acy , ensuring fairness in algorithmic decision-making has emerged as another k ey c hallenge. Empirical studies hav e shown that algorithms ma y inherit biases from data, leading to ethical concerns (e.g. Angwin et al. , 2022 ). In resp onse, leading companies suc h as Link edIn (e.g. Qui ˜ nonero Candela et al. , 2023 ) and Meta (e.g. Bak alar et al. , 2021 ) hav e prop osed practical frameworks to mitigate fairness issues and protect vulnerable groups in prac- tice. F rom a metho dological persp ectiv e, existing approac hes to algorithmic fairness are often broadly categorised into pre-pro cessing (e.g. Calmon et al. , 2017 ; Johndrow and Lum , 2019 ), 1 in-pro cessing (e.g. Celis et al. , 2019 ; Cho et al. , 2020 ), and p ost-pro cessing (e.g. Zeng et al. , 2024a ; Hou and Zhang , 2024 ) strategies, dep ending on the stage at whic h fairness constrain ts are incorp orated. W e refer readers to Pessac h and Shm ueli ( 2022 ) for a comprehensiv e review of recen t developmen ts. Despite b eing well studied separately , DP and fairness hav e received relatively less attention when considered join tly . Prior empirical w ork indicates that differen tial priv acy can deteriorate fairness in v arious settings (e.g. Bagdasary an et al. , 2019 ; Ganev et al. , 2022 ). F rom a theoretical p ersp ectiv e, Mangold et al. ( 2023 ) further study the impact of DP on fairness when fairness measures are point wise Lipsc hitz contin uous. By incorp orating fairness directly in to the ob jective function, Zhou and Bassily ( 2024 ) focus on priv ate w orst-group risk minimisation under the min- max fairness framework introduced b y Martinez et al. ( 2020 ). In the context of classification, Jagielski et al. ( 2019 ) consider multi-class priv ate fair classification under lab el-central DP when only sensitive features are protected. Ghouk asian and Aso o deh ( 2024 ) design a p ost-pro cessing metho d for priv ate group-wise classifiers, targeting demographic disparity . More recently , Say et al. ( 2025 ) consider multi-class classification under DP by extending the framework in Denis et al. ( 2024 ) using output p erturbation and noisy gradient descen t. How ev er, to the b est of our kno wledge, most prior works lack rigorous theoretical guarantees on both fairness and excess risk con trol, and are typically developed under a single-serv er data setting, where all data are assumed to b e centrally stored and pro cessed by a single trusted en tity . Algorithms with theoretical guaran tees for distributed fairness-aw are classification under priv acy constraints are y et to b e explored. 1.1 List of contributions In this pap er, we systematically study the problem of classification under demographic disparity (Definition 4 ) in a distributed learning setup with m ultiple servers, adhering to federated DP (Definition 2 ) constraints. This setting is graphically illustrated in Figure 1 and has wide-ranging applications, for instance, analysing data from patients across different hospitals (e.g. Li et al. , 2020 ) and cross-organisation collab orations (e.g. Heyndrickx et al. , 2023 ), among many others. W e summarise the main con tributions of the pap er as follo ws. • T o the b est of our knowledge, this is the first work to systematically study priv ate dis- tributed fairness-aw are classification. W e prop ose a tw o-step p ost-pro cessing algorithm, detailed in Algorithm 1 . In the first step, due to the co existence of scalar and functional outputs, we employ v arious Gaussian mechanisms, adding univ ariate Gaussian noise to scalars and Gaussian pro cesses to functional outputs. In the second step, to determine the adjusted decision threshold under federated DP , we in tro duce a no vel priv ate tree-based algorithm that av oids rep eated priv acy comp osition arising from summation estimations in the optimisation problem. • In the sp ecial case when there is only one server, we further show that a new and simpler algorithm, Algorithm 5 , is sufficient for fair classification under central DP , in con trast to the more complex tree-based pro cedure in Algorithm 3 . Notably , Algorithm 5 and its theoretical guaran tees provide a no v el priv ate mechanism for optimising a functional ob ject without incurring functional priv acy , and is of indep enden t interest. • W e further establish finite-sample theoretical guarantees for the prop osed algorithms in terms of priv acy , fairness and excess risk control. In particular, we sho w that b oth Algo- rithms 1 and 5 satisfy fairness constrain ts with high probabilit y while main taining satisfac- tory classification p erformance under DP , with the cost of priv acy and fairness explicitly quan tified. W e separate the source of excess risk into decoupled terms, corresp onding 2 to the in trinsic hardness of classification, the priv acy and fairness constrain ts. These re- sults provide a rigorous theoretical foundation for the decision makers to understand the trade-offs b et ween priv acy , fairness and excess risk. • Systematic numerical exp eriments on b oth sim ulated and real datasets are carried out in Section 5 . These results further supp ort our theoretical findings in Section 4 and highlight the practicalit y . Notation. F or a p ositive in teger a , denote [ a ] = { 1 , . . . , a } . Let ⌈ a ⌉ b e the smallest integer greater than or equal to a and ⌊ a ⌋ b e the greatest integer less than or equal to a . F or a, b ∈ R , let a ∨ b = max { a, b } and a ∧ b = min { a, b } . F or v ∈ R p , let ∥ v ∥ 1 , ∥ v ∥ 2 and ∥ v ∥ ∞ b e ℓ 1 -, ℓ 2 - and ℓ ∞ -norms. F or a sequence of p ositive num b ers { a n } and a sequence of random v ariables { X n } , denote X n = O p ( a n ) if lim M →∞ lim sup n P ( | X n | ≥ M a n ) = 0. W e write X n = e O p ( a n ) if there exists k > 0 suc h that X n = O p ( a n (log n ) k ). F or tw o sequences of p ositive num bers { a n } and { b n } , denote a n ≲ b n , a n ≳ b n , and a n ≍ b n , if there exists some constan ts c, C > 0 suc h that a n /b n ≤ C , b n /a n ≤ C and c ≤ a n /b n ≤ C . W rite a n ≲ log b n , a n ≍ log b n and a n = log b n , if a n ≲ b n , a n ≍ b n and a n = b n up to p oly-logarithmic factors. F or d ∈ N + and an y vector s = ( s 1 , . . . , s d ) ⊤ ∈ N d , define | s | = P d i =1 s i , s ! = s 1 ! · · · s d ! and the asso ciated partial differential op erator D s = ∂ | s | ∂ x s 1 1 ··· ∂ x s d d . F or any function f : R d → R that is ⌊ β ⌋ -times contin uously differen tiable at p oint x 0 , denote f β x 0 the T aylor p olynomial of degree ⌊ β ⌋ at x 0 , defined as f β x 0 ( x ) = P | s |≤⌊ β ⌋ ( x − x 0 ) s s ! D s f ( x 0 ). F or a constan t L > 0, let H β ( L ) b e the class of H¨ older s mo oth functions f : R p → R suc h that f is ⌊ β ⌋ -times differen tiable for all x ∈ R d and satisfies | f ( x ) − f β x 0 ( x ) | ≤ L | x − x 0 | β , for all x, x 0 ∈ R d . 2 Problem formulation In this section, we formally presen t the mo del setup and federated DP in Section 2.1 , then intro- duce fairness constraints and present the framework of distributed fairness-a w are classification in Section 2.2 . 2.1 Setup and federated differential priv acy Supp ose w e ha ve N total indep enden t and iden tically distributed samples D = { ( X i , A i , Y i ) , i ∈ [ N total ] } , where X i ∈ [0 , 1] d is the standard d -dimensional feature, A i ∈ { 0 , 1 } is the sensitiv e fea- ture (e.g. race and gender) and Y i ∈ { 0 , 1 } is the binary label. W e further assume that these data are distributed across S servers, with server s ∈ [ S ] holding a dataset D s = { ( X s i , A s i , Y s i ) } N s i =1 of size N s , where P S s =1 N s = N total . Figure 1: An illustration of the framew ork w e consider in the problem of fairness-aw are classifi- cation in a distributed setting. 3 With the setup abov e, w e now in tro duce the federated DP constrain ts. At a high lev el, it is a v ariant of DP tailored to distributed settings, ensuring only priv ate information is shared across serv ers. T o formally define federated DP , w e b egin with the definition of central DP ( Dw ork et al. , 2006 ), whic h is arguably the most fundamen tal notion of DP and is imp osed within each serv er under our setting. F ormally speaking, given a dataset D , a priv acy mec hanism Q ( ·| D ) is a conditional distribution of the priv ate information given data D . Let Z ∈ Z denote the priv atised data and σ ( Z ) denote the sigma-algebra on Z . W e require the priv acy mec hanism to satisfy the follo wing. Definition 1 (Cen tral differential priv acy , CDP) . F or ϵ > 0 and δ ≥ 0 , the privacy me chanism Q is said to satisfy ( ϵ, δ ) -CDP if Q ( Z ∈ A | D ) ≤ e ϵ Q ( Z ∈ A | D ′ ) + δ , for al l A ∈ σ ( Z ) and D and D ′ that differ by at most one data entry, denote d by D ∼ D ′ . Motiv ated by federated learning, F ederated DP is in tro duced and has been applied in v arious settings under v arious names, e.g. Li et al. ( 2024 ), Cai et al. ( 2024 ), Xue et al. ( 2024 ), Auddy et al. ( 2025 ), and man y more. In this pap er, we fo cus on the non-interactiv e setting, in which no communication or interaction b etw een servers is allo wed. Let Z s ∈ Z denote the priv atised information output b y server s and σ ( Z ) denote the sigma-algebra on Z . Definition 2 (F ederated differen tial priv acy , FDP) . F or S ∈ Z + , denote ( ϵ , δ ) = { ( ϵ s , δ s ) } S s =1 the c ol le ction of privacy p ar ameters wher e ϵ s > 0 and δ s ≥ 0 , s ∈ [ S ] . We say that a privacy me chanism Q satisfies ( ϵ , δ ) -FDP, if for any s ∈ [ S ] , the tr anscript Z s ∈ Z shar e d to the c entr al server satisfies an ( ϵ s , δ s ) -CDP c onstr aint, i.e. Q ( Z s ∈ A |D s ) ≤ e ϵ s Q ( Z s ∈ A |D ′ s ) + δ s , for al l A ∈ σ ( Z ) and D s and D ′ s that differ by at most one data entry. In b oth Definitions 1 and 2 , the strength of the priv acy is con trolled by ( ϵ, δ ). The parameter ϵ con trols the strength of the priv acy constrain t, with smaller v alues of ϵ corresp onding to stronger priv acy . The parameter δ ≥ 0 controls the level of priv acy leak age. 2.2 F airness-aw are classification Ha ving introduced the FDP constrain ts, we next presen t the fairness constraints, i.e. demo- graphic disparity (Definition 4 ), and formulate the fairness-aw are classification problem in this subsection. Definition 3 (Randomised classifier) . F or any x ∈ [0 , 1] d and a ∈ { 0 , 1 } , a r andomise d classifier f ∈ F is a me asur able function such that f ( x, a ) = P ( b Y f = 1 | X = x, A = a ) , wher e b Y f = b Y f ( x, a ) is the pr e dicte d lab el, i.e. b Y f |{ X = x, A = a } ∼ Bernoulli ( f ( x, a )) . Definition 4 (Demographic disparity) . F or a given classifier f ∈ F , the demo gr aphic disp arity ( DD ) is define d as DD( f ) = P { b Y f ( X , 1) = 1 | A = 1 } − P { b Y f ( X , 0) = 1 | A = 0 } . Let F b e the class of measurable functions f : [0 , 1] d ×{ 0 , 1 } → [0 , 1]. F or a presp ecified α ≥ 0, w e define the α -fair Bay es optimal classifier as the randomised classifier (Definition 3 ), f ∗ DD ,α , 4 whic h minimises the misclassification error R ( f ∗ DD ,α ) = P ( b Y f ∗ DD ,α ( X , A ) = Y ) while satisfying the α -demographic disparity , i.e. f ∗ DD ,α ∈ arg min f ∈F { R ( f ) : | DD( f ) | ≤ α } . (1) The Bay es fairness-aw are classifier defined in ( 1 ) has b een previously studied in Zeng et al. ( 2024a ), where it is sho wn that the optimal fairness-aw are classifier can b e obtained by shifting the Ba yes decision rule through an adjusted threshold. Sp ecifically , f ∗ DD ,α ( x, a ) = 1 , η a ( x ) ≥ 1 2 + τ ∗ DD ,α (2 a − 1) 2 π a , 0 , η a ( x ) < 1 2 + τ ∗ DD ,α (2 a − 1) 2 π a , (2) where τ ∗ DD ,α = arg min τ ∈ R | τ | : | DD( τ ) | ≤ α (3) is the magnitude of the adjusted threshold, and for an y a ∈ { 0 , 1 } and x ∈ [0 , 1] d , η a ( x ) = P ( Y = 1 | A = a, X = x ), π a,y = P ( A = a, Y = y ) and π a = P ( A = a ). Our goal in this pap er is to construct an estimator for f ∗ DD ,α under FDP defined in Defini- tion 2 . R emark 1 . In this pap er, we fo cus on classification with demographic disparit y , whic h con trols the difference in the probability of predicting the p ositive lab el across sensitive groups. W e would lik e to remark that, with minor modifications, our algorithm can b e generalised to accommodate other bilinear disparit y measures (Definition 6 , Definition 3.3 in Zeng et al. , 2024a ), such as disparit y of opp ortunity (DO) and predictive disparity (PD). 3 F ederated differentially priv ate fair classifier under demographic disparit y In this section, we presen t our tw o-step plug-in FDP-F air classifier in Algorithm 1 . Building on the Ba yes optimal fairness-a w are classifier in ( 2 ), the construction of Algorithm 1 relies on estimating three key quantities: regression functions η a , class probabilities π a , and the fairness threshold parameter τ ∗ DD ,α . The algorithm is organised in tw o steps. S1 pro duces estimators of η a and π a . In S2 , w e estimate τ ∗ DD ,α through a priv ate threshold searc h pro cedure building up on binary tree constructions in Algorithm 2 , which itself relies on the auxiliary pro cedures giv en in Algorithms 3 and 4 . F or notational clarity , in Algorithm 1 , w e decomp ose the data for serv er s ∈ [ S ] as D s = D s 0 , 1 ∪ D s 0 , 0 ∪ D s 1 , 1 ∪ D s 1 , 0 , where for a, y ∈ { 0 , 1 } , D s a,y = { ( X s i , A s i = a, Y s i = y ) } . W e further denote the i -th feature in D s a,y b y X s,i a,y for i ∈ [ |D s a,y | ]. F or any kernel function K : R d → R + , let the scaled k ernel function b e K h ( x ) = h − d K ( x/h ), for an y x ∈ R d and bandwidth 0 < h < 1. The k ey comp onents of Algorithm 1 are outlined b elo w. Estimation of class probabilit y π a and regression function η a . In S1. of Algorithm 1 , site-wise estimators of π s a and η s a are constructed from the training data using empirical and k ernel density estimators, resp ectively . T o preserve FDP , w e utilise Gaussian mechanisms for b oth scalars used in estimating π a ’s and functions in estimating η a ’s. The resulting priv atised site-wise estimators are then aggregated at the cen tral server through weigh ted sums, yielding global estimators while maintaining FDP constraints. 5 Binary tree construction. T o estimate the priv ate threshold, e τ DD ,α , w e approximate the original contin uous optimisation problem in ( 3 ) using discretisation. F or each discretised can- didate, we further reduce it to ev aluating tail counts utilising binary trees, where coun ts in dy adic interv als are organised hierarc hically , enabling efficien t priv acy budget allo cation across a sufficien tly fine ev aluation grids. Sp ecifically , by considering the random v ariables Z s,a,y = 2(2 a − 1) e π a { e η a ( X s a,y ) − 1 / 2 } , for eac h ev aluated τ ∈ R , we can rewrite the empirical plug-in estimator of DD, d DD( τ ) = S X s =1 µ s d DD s ( τ ) = S X s =1 µ s " 1 ˘ n s, 1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 1 n 2 e π 1 { e η 1 ( ˘ X s,i 1 ,y ) − 1 / 2 } ≥ τ o − 1 ˘ n s, 0 X y ∈{ 0 , 1 } ˘ n s, 0 ,y X i =1 1 n − 2 e π 0 { e η 0 ( ˘ X s,i 0 ,y ) − 1 / 2 } ≤ τ o # , (4) as d DD( τ ) = S X s =1 µ s × n P y coun t of Z s, 1 ,y larger than τ P y T otal count of Z s, 1 ,y − P y coun t of Z s, 0 ,y less than τ P y T otal count of Z s, 0 ,y o . Giv en the fact that | τ ∗ DD ,α | ≤ min { π 0 , π 1 } in Theorem 11 , we partition the in terv al [ − 1 , 1] in to equal-sized subin terv als and arrange them in a m ulti-lay er binary tree. F or each server s ∈ [ S ] and sensitiv e group a ∈ { 0 , 1 } , the coun t of Z s,a,y falling into binary subinterv als across all la yers is computed and priv atised using Gaussian mechanisms. The resulting site-wise binary trees are then aggregated at the central server via weigh ted av eraging, where the weigh ts are c hosen according to the v ariances of the corresp onding site-level estimators, similar to S1 . R emark 2 . With the binary tree construction in Algorithm 3 , changing a single data p oin t affects at most one no de p er tree-level, resulting in constant-order ℓ 2 -sensitivit y used in the Gaussian mec hanism. Moreo ver, since the tree depth is logarithmic b y selection in Theorem 2 , only a lo garithmic num b er of priv acy compositions is required. This leads to a substan tial impro vemen t in accuracy compared to standard discretisation approaches in priv ate nonparametric estimation, where a p olynomial num b er of comp ositions is needed. W e defer more discussions on tree depth selection un til after presenting theoretical results in Theorem 2 in Section 4 . Monotonicit y correction. The aggregation of Gaussian noise across different leav es in the binary tree means that the ev aluated g DD across grids is no longer guaranteed to b e monotonically non-increasing, which is a crucial prop erty of the true DD function underlying the deriv ation of τ ∗ DD ,α in ( 3 ). T o preserv e this structure, we in tro duce Algorithm 4 , which fits, with high probabilit y , a non-increasing sequence of { g DD( τ j ) } while con trolling the induced bias. 3.1 Sp ecial case: Central differen tial priv acy In the sp ecial case when S = 1 and N 1 = N , Definition 2 reduces to CDP as defined in Definition 1 . Rather than implementing Algorithm 1 , which targets the general setting when S > 1, we present in this subsection a simplified yet p o werful algorithm dedicated to the CDP setting, giv en in Algorithm 5 . Compared with Algorithm 1 , the main difference lies in Algorithm 5 S2. , which is the estimation of adjusted threshold τ ∗ DD ,α . Instead of using the noisy binary tree based algorithm, 6 Algorithm 1 FDP-F air classifier under demographic disparity . INPUT: Data D , disparit y lev el α , Kernel function K , bandwidth parameters h , w eights { ν s } s ∈ [ S ] and { µ s } s ∈ [ S ] , constan t C ρ , C ω > 0, smallest in terv al length θ , tolerance η . F or eac h s ∈ [ S ], let n s = ⌈ N s / 2 ⌉ and ˘ n s = N s − n s . Split the data in each site in to training data { ( X s i , A s i , Y s i ) } n s i =1 and calibration data { ( X s i , A s i , Y s i ) } N s i = n s +1 = { ˘ X s i , ˘ A s i , ˘ Y s i } ˘ n s i =1 . W e further denote n s,a,y = |{ ( X s i , A s i = a, Y s i = y ) } n s i =1 | and n s,a = |{ ( X s i , A s i = a, Y s i ) } n s i =1 | . S1. Estimating regression function η a and class probabilities π a using training data adhering to federated differen tial priv acy constraints. S1.1 F or s ∈ [ S ], a ∈ { 0 , 1 } , generate w s a i . i . d . ∼ N (0 , σ 2 s ), where σ s = 4 p 2 log (5 /δ s ) / ( n s ϵ s ). Calculate e π a = S X s =1 ν s e π s a , where e π s a = n s,a, 0 + n s,a, 1 n s + w s a . S1.2 Let { W s k,a ( · ) } k,a ∈{ 0 , 1 } ,s ∈ [ S ] } b e indep enden t mean zero Gaussian pro cesses with cov ari- ance k ernels Cov( W s k,a ( ℓ ) , W s k,a ( t )) = K { ( ℓ − t ) /h } , ℓ, t ∈ [0 , 1] d . F or any x ∈ [0 , 1] d and s ∈ [ S ], denote e p s X | A = a ( x | a ) = 1 n s,a X y ∈{ 0 , 1 } n s,a,y X i =1 K h ( X s,i a,y − x ) + 8 p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 1 ,a ( x ) , and e p s X,Y | A = a ( x, y | a ) = 1 n s,a n s,a, 1 X i =1 K h ( X s,i a, 1 − x ) + 8 p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 2 ,a ( x ) , Denote e p X | A = a ( x | a ) = P S s =1 ν s e p s X | A = a ( x | a ) and e η a ( x ) = 1 e p X | A = a ( x | a ) P S s =1 ν s e p s X,Y | A = a ( x, 1 | a ). S2. Estimating the optimal threshold using calibration data. Set e τ DD ,α = FDP.Threshold.Search ( {{ ˘ X i , ˘ A i , ˘ Y i } ˘ n s i =1 } S s =1 , { µ s } s ∈ [ S ] , { e η a , e π a } a ∈{ 0 , 1 } , C ρ , C ω , θ , η ). ▷ See Algorithm 2 . OUTPUT: e f DD ,α ( x, a ) with e f DD ,α ( x, a ) = 1 , e η a ( x ) ≥ 1 2 + e τ DD ,α (2 a − 1) 2 e π a , 0 , e η a ( x ) < 1 2 + e τ DD ,α (2 a − 1) 2 f π a . 7 Algorithm 2 FDP.Threshold.Search ( ˘ D , { µ s } s ∈ [ S ] , { e η a , e π a } a ∈{ 0 , 1 } , C ρ , C ω , θ , η ). INPUT: Data ˘ D , w eigh t { µ s } s ∈ [ S ] , estimated regression functions and class probabilities { e η a , e π a } a ∈{ 0 , 1 } with bandwidth h , constan t C ρ , C ω > 0, minimum bin length θ , tolerance η . Set the num b er of lay ers at M := log 2 ( θ − 1 ) + 1 and tolerance at ρ ∗ = C ρ ρ , where ρ is given in ( 6 ). S1 Binary tree construction: Run FDP.Binar y.Tree ( ˘ D , { e η a , e π a } a ∈{ 0 , 1 } , M ) detailed in Algorithm 3 . S2 Estimation of disparity v alue in cen tral serv er: Construct ev aluation grids G := { τ 1 , . . . , τ 2 M +1 } , where τ j = − 1 + ( j − 1)2 1 − M for j ∈ [2 M + 1]. With the binary tree given in S1 , calculate N s, 1 = N s, 1 , 1 , 1 + N s, 1 , 1 , 2 , N s, 0 = N s, 0 , 1 , 1 + N s, 0 , 1 , 2 , and for an y j ∈ [2 M ] T ail s,a ( τ j ) = M X ℓ =1 2 ℓ X k =1 N s,a,ℓ,k 1 n ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j o . Then for an y τ ∈ G , set g DD( τ ) = P S s =1 µ s g DD s ( τ ), where g DD s ( τ ) = T ail s, 1 ( τ ) N s, 1 − N s, 0 − T ail s, 0 ( τ ) N s, 0 . Set { g DD ↓ ( τ i ) } i ∈ [2 M +1] = Non.increasing ( { g DD( τ i ) } i ∈ [2 M +1] , { µ s } s ∈ [ S ] , C ω , η ). ▷ See Algorithm 4 S3 Threshold selection: if | g DD ↓ (0) | ≤ α then Set e τ DD ,α = 0. else Set e τ DD ,α = arg min τ ∈G {| τ | : | g DD ↓ ( τ ) | ∈ [ α − ρ ∗ , α + ρ ∗ ] } . end if OUTPUT: e τ DD ,α 8 Algorithm 3 FDP.Binar y.Tree ( ˘ D , { e η a , e π a } a ∈{ 0 , 1 } , M ). INPUT: Data ˘ D , estimated regression functions and class probabilities { e η a , e π a } a ∈{ 0 , 1 } , n umber of la yers M . for s = 1 , . . . , S ; a = 0 , 1; ℓ = 1 , . . . , M and k = 1 , . . . , 2 ℓ do Generate indep enden tly ˘ w s,a,ℓ,k ∼ N 0 , 4 log (1 /δ s ) /ϵ s + 2 ϵ s / M . end for for s = 1 , . . . , S do for a = 0 , 1 do F or any y ∈ { 0 , 1 } and i ∈ [ ˘ n s,a,y ], calculate Z s,i,a,y := 2(2 a − 1) e π a { e η a ( ˘ X s,i a,y ) − 1 / 2 } . for j = 1 , . . . , 2 M do Let coun t s,a,M ,j = X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 n − 1 + ( j − 1)2 1 − M ≤ Z s,i,a,y < − 1 + j 2 1 − M o . for ℓ = M − 1 , . . . , 1 do for k = 1 , . . . , 2 ℓ do Set coun t s,a,ℓ,k = coun t s,a,l +1 , 2 k − 1 + coun t s,a,l +1 , 2 k . end for end for end for for ℓ = 1 , . . . , M do for k = 1 , . . . , 2 ℓ do Calculate N s,a,ℓ,k = coun t s,a,ℓ,k + ˘ w s,a,ℓ,k . end for end for end for end for OUTPUT: Collection of priv ate trees {{ N s,a,ℓ,k } M , 2 ℓ ℓ =1 ,k =1 } a ∈{ 0 , 1 } ,s ∈ [ S ] . 9 Algorithm 4 Non.increasing ( { g i } i ∈ [2 M +1] , { µ s } s ∈ [ S ] , C ω , M , η ) INPUT: Sequence of p oin ts { g i } i ∈ [2 M +1] , weigh t { µ s } s ∈ [ S ] , constant C ω , binary tree lay ers M , tolerance η . Set the tolerance level ω = C ω v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s . if g i ≥ . . . ≥ g 2 M +1 then Break and return { g i } i ∈ [2 M +1] . else Initialise the algorithm by setting f 1 = g 1 + ω . for i = 2 , . . . , 2 M + 1 do Set f i = min { f i − 1 , g i + ω } . if f i < g i − ω then Break and return NULL . else Con tin ue end if end for end if OUTPUT: Sequence of non-increasing num bers { f i } i ∈ [2 M +1] . w e show that shifting the empirical DD v ertically by a correctly calibrated Gaussian noise is sufficien t. The key idea is illustrated in Figure 2 . Figure 2: Graphical illustration of S2. of Algorithm 5 when α = 0 . 1. Giv en the fact that the empirical DD, d DD in ( 4 ) with S = 1, is monotonically non-increasing (Theorem 12 ), the optimisation problems b τ DD ,α = arg min τ ∈ R {| τ | : | d DD( τ ) | ≤ α } is equiv alen t to finding the smallest cut-off p oint in magnitude at which d DD( τ ) first reaches the fairness threshold α or − α . Therefore, to construct a priv ate cut-off p oint e τ DD ,α , instead of adding noise directly to the cut-off p oint, we shift the d DD function itself. Geometrically , this corresp onds to p erturbing the d DD curv e in the vertical direction (i.e. y -axis). As a result, the lo cation at whic h the p erturb ed d DD curve crosses the threshold is shifted horizontally , pro ducing a priv acy- preserving cut-off p oint. By adding correctly calibrated noise and ensuring that each p oint wise 10 release of the d DD function at any given τ satisfies CDP , we are able to sho w that the induced release of the cut-off p oint e τ DD ,α also satisfies CDP . W e defer the formal priv acy guarantees to Theorem 1 in Section 4 . Algorithm 5 CDP-F air classifier under demographic disparity . INPUT: Data D , disparity lev el α , bandwidth parameters h . Let n = ⌊ N / 2 ⌋ and ˘ n = N − n . Split the data in each site into training data { ( X i , A i , Y i ) } n i =1 and calibration data { ( X i , A i , Y i ) } N i = n +1 = { ˘ X i , ˘ A i , ˘ Y i } ˘ n i =1 . W e further denote ˘ n a = |{ ( X i , A i = a, Y i ) } n s i =1 | . S1. Implement S1 in Algorithm 1 with S = 1 to estimate regression function η a and class probabilities π a using training data adhering to central DP constraints. S2. Estimate the optimal threshold using calibration data. Generate ˘ w ∼ N (0 , σ 2 ), where σ = 2 p 2 log (1 . 25 /δ ) / ( { ˘ n 0 ∧ ˘ n 1 } ϵ ). Calculate g DD( τ ) = 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n e η 1 ( ˘ X i 1 ,y ) ≥ 1 2 + τ 2 e π 1 o − 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n e η 0 ( ˘ X i 0 ,y ) ≥ 1 2 − τ 2 e π 0 o + ˘ w . Set e τ DD ,α = arg min τ ∈ R {| τ | : | g DD( τ ) | ≤ α } . OUTPUT: e f DD ,α ( x, a ) with e f DD ,α ( x, a ) = 1 , e η a ( x ) ≥ 1 2 + e τ DD ,α (2 a − 1) 2 e π a , 0 , e η a ( x ) < 1 2 + e τ DD ,α (2 a − 1) 2 f π a . 4 Theoretical prop erties In this section, we pro vide theoretical guaran tees on priv acy , fairness, and excess risk control for Algorithms 1 and 5 . 4.1 Assumptions T o kick off, we list a few assumptions b elo w. Assumption 1 (Class and feature probabilit y) . We assume that the fol lowing holds for any a ∈ { 0 , 1 } . a Ther e exists an absolute c onstant 0 < C π < 1 such that the class pr ob ability π a = P ( A = a ) ≥ C π . b Ther e exists an absolute c onstant L > 0 such that p X | A = a ∈ H β ( L ) . We further assume that inf x ∈ [0 , 1] d p X | A = a ( x | a ) ≥ C p for an absolute c onstant C p > 0 . Assumption 2 (Kernel function) . L et the kernel function K : R d → R + satisfy the fol lowing c onditions. a Ther e exists an absolute c onstant C K > 0 such that sup x ∈ R d K ( x ) ≤ C K . b We assume that the function K is Lipschitz, i.e. ther e exists an absolute c onstant C Lip > 0 such that for any x, y ∈ R d , | K ( x ) − K ( y ) | ≤ C Lip ∥ x − y ∥ 2 . 11 c The kernel function K is adaptive to H¨ older class H β ( L ) , i.e. for L > 0 and any f ∈ H β ( L ) , it holds that sup x ∈ [0 , 1] d | R [0 , 1] d K h ( x − u ) f ( u ) d u − f ( x ) | ≤ C adp h β , wher e C adp > 0 is an absolute c onstant only dep ending on L . In Assumption 1 a , w e assume that the class probabilities are b ounded aw a y from 0 and 1, essen tial to ensure that a sufficient n umber of samples for each group can b e observ ed. In Assumption 1 b , w e further regulate the smo othness and b oundedness of the p er-sensitive class densit y of feature distributions. Similar assumptions are commonly seen in the literature of non-parametric statistics (e.g. Madrid Padilla et al. , 2023 ; Auddy et al. , 2025 ). Assumption 2 provides standard k ernel assumptions in the nonparametric literature (e.g. Kim et al. , 2019 ; Madrid P adilla et al. , 2023 ), holding for v arious k ernels, such as uniform, Epanec hniko v and Gaussian. In particular, Assumption 2 c holds for any β -v alid k ernel func- tions. 1 Assumption 3 (Regression function) . R e c al l τ ∗ DD ,α , the optimal magnitude of the adjuste d thr eshold for fairness, define d in ( 2 ) . Supp ose the fol lowing holds for any a ∈ { 0 , 1 } . a The class-wise r e gr ession function is H¨ older c ontinuous in x over [0 , 1] d , i.e. ther e exists L > 0 such that η a ( x ) ∈ H β ( L ) . b F or any τ ∈ R , denote T a ( τ ) = 1 / 2 + τ (2 a − 1) / (2 π a ) . We assume that the mar gin c on dition holds in a smal l neighb ourho o d ar ound T a ( τ ∗ DD ,α ) , i.e. for a given smal l ϖ > 0 , ther e exists absolute c onstants C m , γ ≥ 0 such that for any κ > 0 , sup | ξ |≤ ϖ P {| η a ( X ) − T a ( τ ∗ DD ,α + ξ ) | ≤ κ } ≤ C m κ γ . c In addition to Assumption 3 b , in the c ase when | DD( τ ∗ DD ,α ) | = α , we assume that ther e exists an absolute c onstant c m > 0 such that for any smal l κ in the neighb ourho o d of 0 , | DD( τ ∗ DD ,α + κ ) − DD( τ ∗ DD ,α ) | ≥ c m | κ | γ . In Assumption 3 , we provide assumptions on class-wise regression functions η a , a ∈ { 0 , 1 } , sp ecifically for the task of fairness-a ware classification. Similar assumptions can also b e found in Zeng et al. ( 2024b ). Assumption 3 b characterises the decay rate of the regression function within a band of width ϖ around the decision boundary . This assumption is a mild modification of the margin condition commonly used in the non-parametric classification literature (e.g. Audib ert and Tsybako v , 2007 ; Zeng et al. , 2024a ). Assumption 3 b enables us to obtain theoretical guarantees on the estimation error of DD o v er the critical range relev ant for searc hing the adjusted threshold e τ DD ,α . Theoretically , it suffices for ϖ to b e larger than the order ρ 1 /γ , where ρ is given in ( 6 ). Assumption 3 c further controls the steepness of DD in a small neighbourho o d of τ ∗ DD ,α for the purp ose of threshold τ ∗ DD ,α estimation. The smaller the gamma, the steep er the DD near the b oundary , the easier the estimation task. A t a high level, Assumption 3 c can also b e treated as lo wer b ound counterpart for Assumption 3 b since by definition we hav e c m | κ | γ ≤ | DD( τ ∗ DD ,α ) − DD( τ ∗ DD ,α + κ ) | ≤ P n | η 1 ( X ) − T 1 ( τ ∗ DD ,α ) | < | κ | 2 π 1 o + P n | η 0 ( X ) − T 0 ( τ ∗ DD ,α ) | < κ 2 π 0 o . 1 F or a fixed β > 0, a function K : R d → R + is a β -v alid kernel if R R d K ( x ) d x = 1, ∥ K ∥ L p < ∞ for all p ≥ 1, R R d ∥ x ∥ s K ( x ) d x < ∞ and R R d x s K ( x ) d x = 0 for all s = ( s 1 , . . . , s d ) ∈ Z d suc h that 1 ≤ P d i =1 s i ≤ ⌊ β ⌋ , where for x = ( x 1 , . . . , x d ) ∈ R d , x s = Q d i =1 x s i i . See e.g. Definition A.1 in Rigollet and V ert ( 2009 ). 12 4.2 Priv acy and fairness control With the ab o ve assumptions, we establish the priv acy and fairness guarantee of Algorithms 1 and 5 in this subsection. Theorem 1. Denote e f FDP DD ,α and e f CDP DD ,α the output of Algorithms 1 and 5 r esp e ctively. Then under Assumptions 1 , 2 and 3 , the fol lowing holds. 1. A lgorithm 1 is ( ϵ , δ ) -FDP and Algorithm 5 is ( ϵ, δ ) -CDP. 2. It holds that DD( e f CDP DD ,α ) ≤ α + e O p r 1 N + r 1 N 2 ϵ 2 , (5) wher e the pr ob ability of DD( e f CDP DD ,α ) is taken over the test sample c onditioning on tr aining data, and p in e O p c aptur es the r andomness of tr aining data. 3. F or absolute c onstants C 1 , C 2 , C 3 > 0 , we further assume that min s ∈ [ S ] N 2 s ϵ 2 s ≥ C 1 ; ϖ given in Assumption 3 b satisfying ϖ ≥ C 2 ρ 1 /γ ; and DD(0) / ∈ [ α − ζ , α ] ∪ [ − α, − α + ζ ] wher e ρ = ( v u u t S X s =1 ν 2 s N s h d + max s ∈ [ S ] ν s N s h d + h β + v u u t S X s =1 ν 2 s N 2 s ϵ 2 s h 2 d ) γ + v u u t S X s =1 µ 2 s N s + max s ∈ [ S ] µ s N s + v u u t S X s =1 µ 2 s N 2 s ϵ 2 s , (6) and C 3 ρ ≤ ζ < α . Then if we initialise Algorithm 1 with the bin width θ = C 1 ρ 1 /γ , it holds that DD( e f FDP DD ,α ) ≤ α + e O p ( ρ ) , wher e the pr ob ability of DD( e f FDP DD ,α ) is taken over the test sample c onditioning on tr aining data, and p in e O p c aptur es the r andomness of tr aining data. Theorem 1 is a direct consequence of Prop ositions 4 , 5 , 19 , 20 in the App endix. It demon- strates that b oth Algorithms 1 and 5 satisfy the priv acy constraints, while at the same time only inflate the pre-sp ecified disparity level by a small offset term. As constructed in S2. of Algorithm 5 , the magnitude of the offset term asso ciated to e f CDP DD ,α , N − 1 / 2 + ( N ϵ ) − 1 , is determined by the high-probability upper bound on | g DD( e τ DD ,α ) − DD( e τ DD ,α ) | , whic h captures b oth the deviation of the empirical distribution from its p opulation counterpart, i.e. | d DD( e τ DD ,α ) − DD( e τ DD ,α ) | , and the v ariance introduced by the Gaussian noise, i.e. | ˘ w | . The parametric rate, N − 1 / 2 , is commonly observ ed for plug-in t yp e estimators in the existing lit- erature on fairness-aw are classification without priv acy constrain ts (e.g. Hou and Zhang , 2024 ; Hu et al. , 2025 ). Under additional CDP constraints, as exp ected, this classical parametric rate is accompanied b y a standard additional priv ate parametric rate (e.g. Cai et al. , 2021 ) of or- der ( N ϵ ) − 1 . Similar results on disparity con trol under CDP constrain ts can also b e found in Ghouk asian and Aso o deh ( 2024 ). F or e f FDP DD ,α output by Algorithm 1 , the disparity level will exceed the desired threshold up to the order of ρ , larger than the corresp onding excess in ( 5 ) for the CDP case when S = 1. Unlik e CDP , priv acy comp ositions during the communication b et ween servers prohibit infinite 13 p oin twise ev aluation of DD as discussed in Remark 2 , thereb y making the construction of a direct plug-in optimisation-based algorithm infeasible. The higher inflation term is primarily driv en b y the discretisation error in tro duced by the noisy binary tree construction in Algorithm 3 , and corresp onds to the estimation error of DD p er ev aluation. R emark 3 . W e would like to remark that if one instead insists on con trolling the p opulation unfairness DD( e f FDP DD ,α ) and DD( e f CDP DD ,α ) b elow α with large probability , then pro vided that α ≳ ρ or α ≳ N − 1 / 2 + ( N ϵ ) − 1 , it suffices to adjust the input of Algorithm 1 and Al g or ithm 5 by α − ρ and α − N − 1 / 2 + ( N ϵ ) − 1 resp ectiv ely . 4.3 Excess risk control W e next present the excess risk control of Algorithm 1 , with the excess risk con trol of Algorithm 5 deferred to Theorem 6 in Section B.3 . Note that for any f ∈ F , the ordinary excess risk R ( f ) − R ( f ∗ DD ,α ), where f ∗ DD ,α is the optimal Ba yes fairness-aw are classifier given in ( 1 ), ma y b e negative as f ⋆ DD ,α do es not neces- sarily minimise the excess risk, i.e. f ⋆ DD ,α / ∈ arg min f ∈F R ( f ). T o mak e the excess risk con trol meaningful, we resort to the quan tity | R ( f ) − R ( f ∗ DD ,α ) | , which can b e further decomp osed as the non-negativ e fairness-a ware excess risk d fair ( f , f ⋆ DD ,α ) (Definition 5 ) and a disparit y cost, namely | R ( f ) − R ( f ∗ DD ,α ) | ≤ d fair ( f , f ∗ DD ,α ) + | τ ∗ DD ,α | · | DD( f ∗ DD ,α ) − DD( f ) | (e.g. Prop osition 4.2 in Zeng et al. , 2024b ). Definition 5 (F airness-aw are excess risk under DD, Definition 4.1 in Zeng et al. , 2024b ) . L et α ≥ 0 and let f ∗ DD ,α b e an α -fair Bayes-optimal classifier in ( 1 ) . F or any classifier f : [0 , 1] d × { 0 , 1 } → [0 , 1] , the fairness-awar e exc ess risk under DD is define d as d fair ( f , f ∗ DD ,α ) = 2 X a ∈{ 0 , 1 } π a h Z f ( x, a ) − f ∗ DD ,α ( x, a ) n 1 2 + τ ∗ DD ,α (2 a − 1) 2 π a − η a ( x ) o d P X | A = a ( x ) i . R emark 4 . An imp ortant prop ert y of fairness-a ware excess risk is that d fair ( f , f ∗ DD ,α ) ≥ 0 for all f ∈ F since it follo ws from ( 2 ) that f ( x, a ) − f ∗ DD ,α ( x, a ) ≤ 0 whenever η a ( x ) ≥ 1 / 2 + ( τ ∗ DD ,α (2 a − 1)) / (2 π a ), and vice versa. In the case when f ∗ DD ,α ( x, a ) is automatically fair, d fair ( f , f ∗ DD ,α ) reduces to standard excess risk, and it holds that d fair ( f , f ∗ DD ,α ) = R ( f ) − R ( f ∗ DD ,α ). W e are now ready to prese n t the excess risk control for Algorithm 1 in Theorem 2 . Theorem 2. L et C 1 > 0 b e an absolute c onstant. Under the same assumptions and notation as in The or em 1 . 3 , if we initialise Algorithm 1 with the bin width θ = C 1 ρ 1 /γ , then the fol lowing holds. 1. The fairness-awar e exc ess risk satisfies d fair ( e f FDP DD ,α , f ∗ DD ,α ) = e O p "( v u u t S X s =1 ν 2 s N s h d + max s ∈ [ S ] ν s N s h d + h β + v u u t S X s =1 ν 2 s N 2 s ϵ 2 s h 2 d ) (1+ γ ) + 1 { τ ∗ DD ,α = 0 } ( v u u t S X s =1 µ 2 s N s + max s ∈ [ S ] µ s N s + v u u t S X s =1 µ 2 s N 2 s ϵ 2 s ) 1+ γ γ # . 2. In the fairness-imp acte d r e gime when τ ∗ DD ,α = 0 , cho ose the b andwidth h opt ∈ R + as the smal lest p ositive r e al numb er satisfying h − 2 β opt ≍ h d opt S X s =1 ( N s ∧ N 2 s ϵ 2 s h d opt ) + n S X s =1 ( N s ∧ N 2 s ϵ 2 s ) o 1 /γ , (7) 14 and pick the weights ν s = u s P S j =1 u j , wher e u s = N s ∧ N 2 s ϵ 2 s h d opt , (8) and µ s = u ′ s P S s =1 u ′ s , wher e u ′ s = N s ∧ N 2 s ϵ 2 s . (9) Then it holds that d fair ( e f FDP DD ,α , f ∗ DD ,α ) = e O p h β (1+ γ ) opt , (10) and | R ( e f FDP DD ,α ) − R ( f ∗ DD ,α ) | = d fair ( e f FDP DD ,α , f ∗ DD ,α ) + | τ ∗ DD ,α | e O p ( h β γ opt ) . 3. In the automatic al ly fair r e gime when τ ∗ DD ,α = 0 , cho ose the b andwidth h opt ∈ R + as the smal lest p ositive r e al numb er satisfying h − 2 β opt ≍ h d opt S X s =1 ( N s ∧ N 2 s ϵ 2 s h d opt ) , and pick the same weights as ( 8 ) and ( 9 ) . Then it holds that d fair ( e f FDP DD ,α , f ∗ DD ,α ) = e O p h β (1+ γ ) opt , and | R ( e f FDP DD ,α ) − R ( f ∗ DD ,α ) | = d fair ( e f DD ,α , f ∗ DD ,α ) + | τ ∗ DD ,α | e O p ( h β γ opt ) . W e defer the pro of of Theorem 2 to Section C.3 . Theorem 2 is the first time in literature, pro viding finite-sample guarantees for excess risk in fairness-a ware classification under FDP constrain ts. T o optimise for a heterogeneous distributed setting, w e choose the bandwidth h b y balancing the bias and v ariance trade-offs, and select weigh ts { ν s } s and { µ s } s that are prop ortional to the effective sample size at each server. T o b etter interpret the results of d fair ( e f DD ,α , f ∗ DD ,α ) in Theorems 2 . 2 and 2 . 3 , we presen t in Theorem 3 the fairness-aw are excess risk control for the homogeneous setting. Corollary 3. Under the same assumptions as in The or em 2 , in a homo gene ous setting when N s = N and ϵ s = ϵ for al l s ∈ [ S ] , if we pick weights as ν s = µ s = S − 1 , b andwidth as h opt ≍ ( S N ) − (1+ γ ) 2 β + d + ( S N 2 ϵ 2 ) − (1+ γ ) 2 β +2 d + 1 τ ∗ DD ,α = 0 } · ( S N ) − 1+ γ 2 γ β + ( S N 2 ϵ 2 ) − 1+ γ 2 γ β and the bin width as θ ≍ ( S N ) − β 2 β + d + ( S N 2 ϵ 2 ) − β 2 β +2 d + ( S N ) − 1 2 γ + ( S N 2 ϵ 2 ) − 1 2 γ , it holds that d fair ( e f DD ,α , f ∗ DD ,α ) = e O p ( S N ) − β (1+ γ ) 2 β + d + ( S N 2 ϵ 2 ) − β (1+ γ ) 2 β +2 d + 1 τ ∗ DD ,α = 0 } · ( S N ) − 1+ γ 2 γ + ( S N 2 ϵ 2 ) − 1+ γ 2 γ . (11) 15 R emark 5 (Choice of bandwidth h ) . The c hoice of bandwidth, h opt , in Theorem 3 is guided by solving equation ( 7 ), which matches the bias with four v ariance terms arising from priv acy and fairness constrain ts. W e w ould lik e to remark that, in the homogeneous case, it suffices to c ho ose h opt = ( S N ) − (1+ γ ) 2 β + d + ( S N 2 ϵ 2 ) − (1+ γ ) 2 β +2 d without affecting the final rate. The choice of h opt via ( 7 ) in Theorem 2 is solely to present the final rate for d fair ( e f FDP DD ,α , f ∗ DD ,α ) in ( 10 ) more clearly in the form h β (1+ γ ) opt . A t a high level, the upp er b ound in Theorem 3 is of the form d fair ( e f DD ,α , f ∗ DD ,α ) ≤ in trinsic cost of classificataion + cost of priv acy in classification + non-priv ate cost of fairness + priv ate cost of fairness , where the cost of priv acy corresp onds to the terms in volving ϵ , and the cost of fairness corre- sp onds to the terms that are active when τ ∗ DD ,α = 0. This result decouples the excess risk into differen t sources regarding the priv acy and fairness constraints. When τ ∗ DD ,α = 0, w e are in the automatically fair regime and f ∗ DD ,α in ( 2 ) reduces to the unconstrained groupwise Bay es optimal classifier, indicating that the latter is in trinsically fair. Consequen tly , imp osing fairness constraints incurs no additional excess risk. In this case, our results in ( 11 ) recov er the excess risk b ound, i.e. R ( e f DD ,α ) − R ( f ∗ DD ,α ), for FDP non-parametric classification without fairness constrain ts, and matc h the minimax optimal results in Auddy et al. ( 2025 ). The cost of priv acy is reflected in a reduction of the effectiv e sample size from S N to S N 2 ϵ 2 and a loss in the exp onent due to an additional dep endence on the dimension d in the denominator. When fairness constrain ts are in effect, i.e. τ ∗ DD ,α = 0, the tw o additional terms ( S N ) − (1+ γ ) / (2 γ ) and ( S N 2 ϵ 2 ) − (1+ γ ) / (2 γ ) in ( 11 ) together quan tify the cost of fairness, arising from the estimation of e τ DD ,α . The former term represen ts the non-priv ate cost of fairness and echoes the rate in Zeng et al. ( 2024b ), which studies fairness-aw are classification in a single-serv er setting without priv acy constrain ts. The latter one reflects the additional cost induced b y FDP constraints. Equiv alently , the cost of fairness can b e rewritten as { ( S N ) − 1 / 2 + ( S N 2 ϵ 2 ) − 1 / 2 } (1+ γ ) /γ , where the term inside the brac ket is the standard parametric rate under FDP (e.g. Li et al. , 2024 ). This parametric term inside the brac ket also highlights the imp ortance of the binary tree based construction in Algorithm 1 . A naive approach to estimate the adjusted threshold τ ∗ DD ,α migh t b e a plug-in optimisation problem, based on p erturbing site-wise empirical DD using Gaussian pro cesses (e.g. Hall et al. , 2013 ) then aggregating. Ho wev er, due to the non- smo othness of d DD s in ( 4 ), additional smo othing is required, which in turn in tro duces non- parametric rates inside the brack et and leads to strictly weak er guaran tees. Moreov er, the term (1 + γ ) in the numerator of the exp onent in the cost of fairness is link ed to the margin assumption in Assumption 3 b , and similar structures are commonly seen in the existing literature (e.g. Audib ert and Tsybako v , 2007 ). The term γ in the denominator of the exp onent is a consequence of lo cal steepness of DD around τ ∗ DD ,α in Assumption 3 c . The steepness, in turn, implies that | e τ DD ,α − τ ∗ DD ,α | ≤ | DD( e τ DD ,α ) − DD( τ ∗ DD ,α ) | 1 /γ and characterises the 1 /γ -type rate in the exp onent. Apart from the choices of bandwidth and site -wise w eights, another imp ortant ingredient in the analysis is the choice of the bin width θ ≍ ρ 1 /γ in the noisy binary tree construction (Algorithm 3 ), since discretising the search interv al introduces bias into the estimation. The bin width θ is therefore chosen to balance the discretisation bias, i.e. | DD( τ ∗ G ) − DD( τ ∗ DD ,α ) | ≲ θ γ , and the error asso ciated with DD estimation, i.e. | g DD ↓ ( τ ∗ G ) − DD( τ ∗ G ) | ≲ ρ , where τ ∗ G is the closed p oin t to τ ∗ DD ,α in the searc hing grids. This c hoice subsequen tly ensures that the optimisation problem in S3 of Algorithm 2 admits a feasible solution and, moreo ver, limits 16 priv acy comp osition across lay ers to a p oly-logarithmic num b er of times, as the tree depth satisfies M = log 2 ( θ − 1 ) + 1 ≍ log 2 ( S N ∧ S N 2 ϵ 2 ). More discussions can b e found in Remark 2 . 5 Numerical exp erimen ts In this section, we conduct n umerical exp erimen ts to demonstrate the effectiveness of Algo- rithms 1 and 5 . Exp erimen ts with sim ulated and real datasets are demonstrated in Sec- tions 5.1 and 5.2 , resp ectively . The co de for repro ducing all exp erimen ts can b e found at https://github.com/GengyuXue/DP_Fair_classification . 5.1 Sim ulated data analysis In this subsection, w e carried out indep endent exp erimen ts for Algorithms 1 and 5 on simulated datasets to supp ort our theoretical findings in Section 4 . 5.1.1 Numerical exp erimen ts for CDP-F air in Algorithm 5 W e consider the case when d = 2, where X = ( X 1 , X 2 ). W e generate the sensitive feature A according to π 1 = P ( A = 1) = 0 . 3 and the standard feature ( X 1 , X 2 ) by X 1 | A = 1 ∼ Beta(4 , 2), X 1 | A = 0 ∼ Beta(4 . 5 , 2) and X 2 ∼ Unif(0 , 1). Giv en X = ( x 1 , x 2 ) and A = a , the lab el Y is then generated b y following η a ( x 1 , x 2 ) = 1 2 + 1 π arctan n 12( x 1 + x 2 − 1) − 0 . 3(2 a − 1) o . W e generate training datasets with size N = { 5000 , 7000 , 9000 } and ev aluate p erformance on an indep enden tly generated test dataset of size 4000. The priv acy parameter is set as ϵ ∈ { 0 . 75 , 1 , 2 , 3 , 4 } . The priv acy leak age parameter is c hosen as δ = ( N / 2) − 2 . The kernel K is chosen to b e the Gaussian kernel ( C K = 1), and the bandwidth h is selec ted via a three-fold cross-v alidation. Specifically , w e choose the bandwidth that attains the low est misclassification error on the training data without incorp orating fairness constraints. T o generate the Gaussian pro cess noise added to the regression functions, we p erform an eigen-decomp osition of the corresp onding cov ariance matrix and retain only the first 35 leading eigencomp onen ts for computational efficiency . F or simplicity , we assume that the class proba- bilities { π a } a ∈{ 0 , 1 } are known and only use their non-priv ate empirical coun terparts during the implemen tation. During implementation, the training set D is randomly split into tw o equal- sized subsets, D 1 ∪ D 2 . One subset is used to estimate e η a ( S1 in Algorithm 5 ), while the other is used to estimate the threshold e τ DD ,α ( S2 in Algorithm 5 ). Let e f 1 denote the classifier estimated using D 1 for mo del estimation and D 2 for threshold calibration, and let e f 2 denote the classifier constructed with the roles of D 1 and D 2 rev ersed. T o mitigate the randomness caused by ran- dom splitting, we adopt a cross-fitting approac h and define the final probabilistic classifier as the a verage e f = ( e f 1 + e f 2 ) / 2. W e rep ort the mean misclassification errors and empirical disparities along with their cor- resp onding 95% confidence bands o ver 200 iterations in Figure 3 . F or comparisons, we also calculate the oracle misclassification error for group-wise classifiers with and without fairness constrain ts by simulations on an indep enden t dataset of sample size 200000. The sim ulated Ba yes risk for the group-wise classifier without fairness constrain t is 0 . 106, and the in trinsic demographic disparity is 0 . 559. The simulated Bay es risk for the fairness-aw are Ba yes classifier is plotted in dashed grey . Across all sample sizes, Figure 3 exhibits the exp ected priv acy , fairness and accuracy trade- off as sho wn in Theorem 6 in Section B.3 . Our designed classifier CDP-F air successfully keeps 17 the empirical disparities b elo w the diagonal reference y = x for each α in the second row of Figure 3 , indicating that the target disparit y level is resp ected. In terms of classification accuracy , relaxing the fairness constrain t (i.e. increasing α ) yields a noticeable reduction in misclassification error when the fairness constraint is active (i.e. small α ). Once α exceeds a critical threshold, the fairness constrain t b ecomes inactive and the error curv es flatten. Moreo ver, w eakening the priv acy constraint (i.e. increasing ϵ ) reduces the excess risk for each fixed α , with the p erformance con verging tow ards the oracle b enchmark as ϵ grows. Finally , under fixed priv acy and fairness parameters ( α, ϵ ), increasing the sample size N leads to uniformly smaller misclassification error, and the difference in p erformance betw een CDP-F air and the oracle Ba y es fairness-a ware classifier b ecomes less significant when ϵ is large. Figure 3: Means and 95% confidence bands for misclassification errors and empirical disparities of Algorithm 5 when N ∈ { 5000 , 7000 , 9000 } . The grey dashed line represents y = x . 5.1.2 Numerical exp erimen ts for FDP-F air in Algorithm 1 T o demonstrate the effectiveness of FDP-F air classifier in Algorithm 1 , we generate data follo w- ing the same mec hanism as describ ed in Section 5.1.1 , then distribute across v arious serv ers. In this subsection, w e consider a homogeneous setting where N s = N = 2000, ϵ s = ϵ ∈ { 0 . 75 , 1 , 2 , 3 , 4 , 10 } , δ s = δ = ( N/ 2) − 2 and v ary the num ber of servers S ∈ { 4 , 5 , 6 } . W e train the classifier using the distributed training data of total size N total = S N , then test the trained classifier on an indep endent sample of size 2000. In order to implemen t Algorithm 1 , four tuning parameters need to b e selected: band- width h , constan ts C ω and C ρ and minim um interv al length θ . F or all exp erimen ts, follow- ing the same approach as in Section 5.1.1 , we select h with a three-fold cross-v alidation on a randomly chosen site. T o select θ , we utilise our theoretical results and select θ suc h that M = max {⌊ log 2 P S s =1 min { N s , N 2 s ϵ 2 s } ⌋ + 1 , 6 } . F or illustrativ e purp oses, we fix C ω = 0 . 1 and ρ = 0 . 03 throughout the exp eriments. Sensitivity analysis for C ω and ρ when S = 3, N s = 2000 and α = 0 . 3 are also carried out and defer the results to Section A.2 . T o ensure the feasibilit y of Algorithm 4 in the high priv acy regime when the g DD curve fluctuates significan tly , w e adjust Algorithm 4 to Algorithm 6 detailed in Section A.1 in practice. A t a high lev el, Algorithm 6 outputs a sequence that is as close to non-increasing as p ossible, sub ject to bias control. 18 W e rep ort the mean misclassification errors and empirical disparities along with their corre- sp onding 95% confidence bands o v er 200 iterations in Figure 4 . Overall, the patterns in Figure 4 closely mirror those observed in Section 5.1.1 and are consistent with our theoretical results de- tailed in Theorem 2 . In particular, as S increases, the total training sample size S N grows, whic h leads to uniformly b etter misclassification error. Figure 4: Means and 95% confidence bands for misclassification errors and empirical disparities of Algorithm 1 when N s = 2000 and S ∈ { 4 , 5 , 6 } . The grey dashed line represen ts y = x . 5.1.3 Effect of the num ber of serv ers S T o further study the effect of the distributed nature of data across servers, we consider below the case when a fixed total of N total = 7200 data p oints are equally distributed across S ∈ { 1 , 2 , 3 , 4 , 5 } servers. In the case when S = 1, w e further apply CDP-F air in Algorithm 5 . T uning parameters are selected follo wing the same pro cedure as describ ed in Section 5.1.2 ( C ω = 0 . 1, ρ = 0 . 03). After initial training, w e use an indep endent sample of size 2500 to test the p erformance of the trained classifier. The results are collected in Figure 5 . The results in Figure 5 highligh t the effect of data decentralisation on b oth accuracy and disparit y control. When S = 1, FDP-F air p erforms comparably to CDP-F air, yielding nearly iden tical misclassification errors and empirical disparities across α . As S increases, i.e. when the same amoun t of data is distributed across more servers, the misclassification error of FDP-F air deteriorates. Intuitiv ely , distributing a fixed total sample size N total across more servers reduces the lo cal sample size p er server, which increases estimation error at the server level. Moreo ver, aggregating output across serv ers also necessitates additional priv acy-preserving communication, in tro ducing extra noise. This phenomenon further echoes our theoretical results in Theorem 2 . 5.2 Real data analysis In this section, we compare the p erformances of CDP-F air and FDP-F air with classifiers that satisfy either priv acy and fairness constraints or none, on t wo widely used datasets: AdultCensus and La w school entrance datasets (e.g. Zeng et al. , 2024a ). F or the priv acy-only baseline, w e implemen t CDP-F air with the fairness step S2 remo ved. F or the fairness-only baseline, we adopt the p ost-pro cessing approach of Zeng et al. ( 2024b ), using 19 Figure 5: Means and 95% confidence bands for misclassification errors and empirical disparities of Algorithms 1 and 5 when N total = 7200 and S ∈ { 1 , 2 , 3 , 4 , 5 } . The grey dashed line represen ts y = x . k ernel densit y estimators to obtain the initial regression function estimates. As an unconstrained b enc hmark, we use a naive plug-in implemen tation of the group-wise Bay es classifier without priv acy or fairness constraints. Finally , we implemen t CDP-F air and FDP-F air with S = 1 follo wing the same pro cedure detailed in Section 5.1 , and set C ω = 0 . 1 and ρ = 0 . 02 throughout. 5.2.1 AdultCensus dataset With the AdultCensus dataset, w e aim to classify whether an individual’s ann ual income exceeds $ 50000. W e select age, w orkclass, and education lev el as features X , and take gender as the protected attribute A . The full dataset contains n total = 48842 observ ations. In each exp eriment, w e randomly selected 70% of the data as the training set, and the rest 30% is used as the test dataset. The exp eriment is rep eated for 200 times, and we rep ort the mean and 95% confidence band in Figure 6 . T o reflect the p ost-pro cessing nature of CDP-F air and FDP-F air, all unfair classifiers are trained using only half of the av ailable training samples. As exp ected, imp osing priv acy constraints deteriorates classification accuracy . F or a fixed fairness level α , priv acy-preserving classifiers incur larger misclassification errors than their non- priv ate counterparts. As ϵ increases, the gap steadily narrows, and p erformance mo ves tow ards the non-priv ate regime. In terms of disparity control, classifiers trained without any fairness constrain ts are substan tially unfair, with empirical disparities remaining well ab ov e the pre- scrib ed tolerance for a wide range of small α . By contrast, CDP-F air and FDP-F air successfully satisfy the fairness requiremen t, with empirical disparities con trolled b elo w the target level α . Moreo ver, as ϵ increases, CDP-F air and FDP-F air conv erge to the fair non-priv ate b enchmark of Zeng et al. ( 2024a ). Finally , the CDP and FDP implemen tations yield very similar p erformance, as evidenced b y the close ov erlap of their curves across all panels. 5.2.2 La w sc ho ol en trance dataset W e further apply our algorithms to a selected subset of the Law sc ho ol en trance dataset with n total = 40000. W e aim to classify if a student gets admitted to la w school using the standard 20 Figure 6: Means and 95% confidence bands for misclassification errors and empirical disparities on the AdultCensus dataset. features X , such as LSA T scores, undergraduate GP A and more. The protected attribute A is tak en as race, i.e. white vs non-white. Numerical results are summarised in Figure 7 . Similar trends as in Section 5.2.1 are observed. One difference compared with Figure 6 is that in the disparit y plots of Figure 7 , once the fairness constraint b ecomes inactive for the fair non-priv ate benchmark, the empirical disparities of CDP-F air and FDP-F air contin ue to increase, though they still remain b elo w the presp ecified threshold. This gap diminishes as ϵ increases. W e attribute this b ehaviour to the bias induced by the data-selection step. In the high-priv acy regime, P ( e Y = 1 | A = 1) can b e driven close to 0, while P ( e Y = 1 | A = 0) b ecomes comparativ ely larger than in the non-priv ate case, due to a higher frequency of e η 0 taking v alues close to 1. Figure 7: Means and 95% confidence bands for misclassification errors and empirical disparities on the La w school entrance dataset. 21 6 Conclusion In this pap er, w e study priv ate fairness-aw are classification in a distributed setting. T o the b est of our kno wledge, this is the first time seen in the literature. T o handle the decentralised nature of data analysis, w e prop ose a tw o-step plug-in classifier, FDP-fair, whic h is built up on Gaussian mec hanisms and priv ate binary trees. In the sp ecial case when there is only one serv er, we further provide a simplified yet effective algorithm, CDP-F air. Under appropriate assumptions, theoretical guarantees for priv acy , fairness and excess risk con trols are provided, which are further supp orted by extensiv e numerical exp eriments on b oth s yn thetic and real datasets. W e en visage sev eral p oten tial e xtensions. Firstly , our algorithms dep end on the av ailability of sensitive features A , whic h ma y b e restricted in certain practical settings due to priv acy concerns. When sensitiv e features are av ailable during training but not testing, one p ossible w ay is to predict A using standard feature X (e.g. Zeng et al. , 2024a ; Hou and Zhang , 2024 ). In the case when A is a v ailable but sub ject to priv acy constraints, one may instead adopt a lab el lo cal DP framework (e.g. Zhao et al. , 2025 ), under whic h only noisy versions of A are released for use in the analysis. Secondly , in some scenarios, data from different serv ers may differ in distribution. Existing literature, e.g. Auddy et al. ( 2025 ), attempts to study differen tially priv ate transfer learning in non-parametric classifications. It w ould b e interesting to further inv estigate the effect of data heterogeneity under fairness constraints. Ac kno wledgemen ts Xue is supp orted by EPSRC programme grant EP/Z531327/1. Y u is partially supp orted by the Philip Lev erhulme Prize and EPSRC programme grant EP/Z531327/1. References Adler, R. J. and T a ylor, J. E. (2007). R andom fields and ge ometry . Springer. Angwin, J., Larson, J., Mattu, S., and Kirc hner, L. (2022). Machine bias. In Ethics of data and analytics , pages 254–264. Auerbach Publications. Auddy , A., Cai, T. T., and Chakrab orty , A. (2025). Minimax and adaptive transfer learning for nonparametric classification under distributed differential priv acy constraints. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , page qk af070. Audib ert, J.-Y. and Tsybako v, A. B. (2007). F ast learning rates for plug-in classifiers. The A nnals of Statistics , 35(2):608 – 633. Bagdasary an, E., P oursaeed, O., and Shmatik ov, V. (2019). Differen tial priv acy has disparate impact on mo del accuracy . A dvanc es in neur al information pr o c essing systems , 32. Bak alar, C., Barreto, R., Bergman, S., Bogen, M., Chern, B., Corb ett-Davies, S., Hall, M., Kloumann, I., Lam, M., Candela, J. Q., et al. (2021). F airness on the ground: Applying algorithmic fairness approac hes to pro duction systems. arXiv pr eprint arXiv:2103.06172 . Bousquet, O. (2002). A b ennett concentration inequalit y and its application to suprema of empirical pro cesses. Comptes R endus Mathematique , 334(6):495–500. Butucea, C., Dub ois, A., Kroll, M., and Saumard, A. (2020). Lo cal differential priv acy: Elb ow effect in optimal density estimation and adaptation ov er Beso v ellipsoids. Bernoul li , 26(3):1727 – 1764. 22 Cai, T. T., Chakrab orty , A., and V uursteen, L. (2024). Optimal federated learning for non- parametric regression with heterogeneous distributed differential priv acy constraints. arXiv pr eprint arXiv:2406.06755 . Cai, T. T., W ang, Y., and Zhang, L. (2021). The cost of priv acy: Optimal rates of con vergence for parameter estimation with differential priv acy . The A nnals of Statistics , 49(5):2825–2850. Calmon, F., W ei, D., Vinzam uri, B., Natesan Ramamurth y , K., and V arshney , K. R. (2017). Optimized pre-processing for discrimination prev ention. A dvanc es in Neur al Information Pr o- c essing Systems , 30. Celis, L. E., Huang, L., Kesw ani, V., and Vishnoi, N. K. (2019). Classification with fairness constrain ts: A meta-algorithm with prov able guarantees. In Pr o c e e dings of the c onfer enc e on fairness, ac c ountability, and tr ansp ar ency , pages 319–328. Cho, J., Hwang, G., and Suh, C. (2020). A fair classifier using kernel density estimation. A dvanc es in Neur al Information Pr o c essing Systems , 33:15088–15099. Denis, C., Elie, R., Hebiri, M., and Hu, F. (2024). F airness guarantees in multi-class classification with demographic parit y . Journal of Machine L e arning R ese ar ch , 25(130):1–46. Dudley , R. M. (2016). Vn sudako v’s work on exp ected suprema of gaussian pro cesses. In High Dimensional Pr ob ability VII: The Car g` ese V olume , pages 37–43. Springer. Durrett, R. (2019). Pr ob ability: the ory and examples , volume 49. Cambridge universit y press. Dv oretzky , A., Kiefer, J., and W olfo witz, J. (1956). Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator. The Annals of Mathematic al Statistics , pages 642–669. Dw ork, C., McSherry , F., Nissim, K., and Smith, A. (2006). Calibrating noise to sensitivity in priv ate data analysis. In The ory of crypto gr aphy c onfer enc e , pages 265–284. Springer. Dw ork, C., Roth, A., et al. (2014). The algorithmic foundations of differen tial priv acy . F ounda- tions and tr ends ® in the or etic al c omputer scienc e , 9(3–4):211–407. Ganev, G., Oprisanu, B., and De Cristofaro, E. (2022). Robin ho o d and matthew effects: Differen tial priv acy has disparate impact on synthetic data. In International Confer enc e on Machine L e arning , pages 6944–6959. PMLR. Ghouk asian, H. and Aso o deh, S. (2024). Differentially priv ate fair binary classifications. In 2024 IEEE International Symp osium on Information The ory (ISIT) , pages 611–616. IEEE. Hall, R., Rinaldo, A., and W asserman, L. (2013). Differential priv acy for functions and functional data. The Journal of Machine L e arning R ese ar ch , 14(1):703–727. Heyndric kx, W., Mervin, L., Morawietz, T., Sturm, N., F riedric h, L., Zalewski, A., Pen tina, A., Hum b eck, L., Oldenhof, M., Niwa y ama, R., et al. (2023). Mello ddy: Cross-pharma federated learning at unpreceden ted scale unlo c ks b enefits in qsar without compromising proprietary information. Journal of chemic al information and mo deling , 64(7):2331–2344. Hou, X. and Zhang, L. (2024). Finite-sample and distribution-free fair classification: Optimal trade-off b etw een excess risk and fairness, and the cost of group-blindness. arXiv pr eprint arXiv:2410.16477 . 23 Hu, X., Xue, G., Lin, Z., and Y u, Y. (2025). F airness-a ware ba yes optimal functional classifica- tion. arXiv pr eprint arXiv:2505.09471 . Hung, E. K. and Y u, Y. (2025). Optimal cox regression under federated differential priv acy: co efficien ts and cumulativ e hazards. arXiv pr eprint arXiv:2508.19640 . Jagielski, M., Kearns, M., Mao, J., Oprea, A., Roth, A., Sharifi-Malv a jerdi, S., and Ullman, J. (2019). Differen tially priv ate fair learning. In International Confer enc e on Machine L e arning , pages 3000–3008. PMLR. Johndro w, J. E. and Lum, K. (2019). An algorithm for remo ving sensitive information. The A nnals of Applie d Statistics , 13(1):189–220. Karw a, V. and V adhan, S. (2017). Finite sample differen tially priv ate confidence interv als. arXiv pr eprint arXiv:1711.03908 . Kim, J., Shin, J., Rinaldo, A., and W asserman, L. (2019). Uniform conv ergence rate of the k ernel densit y estimator adaptive to intrinsic volume dimension. In International Confer enc e on Machine L e arning , pages 3398–3407. PMLR. Li, M., Tian, Y., F eng, Y., and Y u, Y. (2024). F ederated transfer learning with differen tial priv acy . arXiv pr eprint arXiv:2403.11343 . Li, X., Gu, Y., Dv ornek, N., Staib, L. H., V entola, P ., and Duncan, J. S. (2020). Multi-site fmri analysis using priv acy-preserving federated learning and domain adaptation: Abide results. Me dic al image analysis , 65:101765. Madrid P adilla, C. M., Xu, H., W ang, D., MADRID P ADILLA, O. H., and Y u, Y. (2023). Change p oint detection and inference in m ultiv ariate non-parametric mo dels under mixing conditions. A dvanc es in Neur al Information Pr o c essing Systems , 36:21081–21134. Mangold, P ., Perrot, M., Bellet, A., and T ommasi, M. (2023). Differential priv acy has b ounded impact on fairness in classification. In International Confer enc e on Machine L e arning , pages 23681–23705. PMLR. Martinez, N., Bertran, M., and Sapiro, G. (2020). Minimax pareto fairness: A multi ob jective p ersp ectiv e. In International c onfer enc e on machine le arning , pages 6755–6764. PMLR. Massart, P . (1990). The tight c onstan t in the dvoretzky-kiefer-w olfo witz inequalit y . The annals of Pr ob ability , pages 1269–1283. P essach, D. and Shmueli, E. (2022). A review on fairness in machine learning. A CM Computing Surveys (CSUR) , 55(3):1–44. Qui ˜ nonero Candela, J., W u, Y., Hsu, B., Jain, S., Ramos, J., Adams, J., Hallman, R., and Basu, K. (2023). Disentangling and op erationalizing ai fairness at linkedin. In Pr o c e e dings of the 2023 A CM Confer enc e on F airness, A c c ountability, and T r ansp ar ency , pages 1213–1228. Rigollet, P . and V ert, R. (2009). Optimal rates for plug-in estimators of density lev el sets. Bernoul li , 15(4):1154 – 1178. Sa y , L., Denis, C., and Pinot, R. (2025). F airness meets priv acy: Integrating differen tial priv acy and demographic parit y in multi-class classification. arXiv pr eprint arXiv:2511.18876 . Smith, J., Asghar, H. J., Gioiosa, G., Mrab et, S., Gasp ers, S., and Tyler, P . (2021). Making the most of parallel comp osition in differential priv acy . arXiv pr eprint arXiv:2109.09078 . 24 Song, S., Steink e, T., Thakk ar, O., and Thakurta, A. (2021). Ev ading the curse of dimensionalit y in unconstrained priv ate glms. In International Confer enc e on Artificial Intel ligenc e and Statistics , pages 2638–2646. PMLR. United States Census Bureau (2021). Census bureau sets k ey parameters to protect pri- v acy in 2020 census results. https://www.census.gov/newsroom/press- releases/2021/ 2020- census- key- parameters.html . V an Der V aart, A. W. and W ellner, J. A. (1996). W eak conv ergence. In We ak c onver genc e and empiric al pr o c esses: with applic ations to statistics , pages 16–28. Springer. V ersh ynin, R. (2018). High-dimensional pr ob ability: An intr o duction with applic ations in data scienc e , volume 47. Cambridge universit y press. Xue, G., Lin, Z., and Y u, Y. (2024). Optimal estimation in priv ate distributed functional data analysis. arXiv pr eprint arXiv:2412.06582 . Y ousefpour, A., Shilov, I., Sablayrolles, A., T estuggine, D., Prasad, K., Malek, M., Nguyen, J., Ghosh, S., Bharadwa j, A., Zhao, J., et al. (2021). Opacus: User-friendly differential priv acy library in p ytorch. arXiv pr eprint arXiv:2109.12298 . Zeng, X., Cheng, G., and Dobriban, E. (2024a). Ba yes-optimal fair classification with linear disparit y constraints via pre-, in-, and p ost-pro cessing. arXiv pr eprint arXiv:2402.02817 . Zeng, X., Cheng, G., and Dobriban, E. (2024b). Minimax optimal fair classification with b ounded demographic disparity . arXiv pr eprint arXiv:2403.18216 . Zhao, P ., Ma, C., Shen, L., W ang, S., and F an, R. (2025). On theoretical limits of learning with lab el differen tial priv acy . arXiv pr eprint arXiv:2502.14309 . Zhou, X. and Bassily , R. (2024). Differentially priv ate worst-group risk minimization. In F orty- first International Confer enc e on Machine L e arning . 25 App endices All tec hnical details and additional numerical results are collected in the Appendices. Additional n umerical exp eriments are presen ted in Section A . W e provide all pro ofs related to Algorithms 5 and 1 in App endices B and C , resp ectively . F or completeness, additional background results are pro vided in Section D . Throughout the appe ndix, with a slight abuse of notation, unless sp ecifically stated other- wise, let C 1 , C 2 , . . . > 0 denote constan ts whose v alues may v ary from place to place and dep end on d . Let b · s denote standard empirical estimators without priv acy constrain ts for site s , s ∈ [ S ], and b · the aggregated one. Similarly , let e · s denote the site-wise estimators that satisfy priv acy constrain ts, and let e · denote the aggregated one in the central server. F or notational simplicity , throughout the app endix, we write e τ = e τ DD ,α . A Additional numerical exp erimen ts A.1 Additional algorithm T o ensure the feasibilit y of the Algorithm 4 in the high priv acy regime when the DD curve fluctuates significan tly , we adjust Algorithm 4 to Algorithm 6 detailed b elo w in practice. Algorithm 6 Non.increasing (numerical) ( { g i } i ∈ 2 M +1 , { µ s } s ∈ [ S ] , C ω , M , η ) INPUT: Sequence of num b er { g i } i ∈ 2 M +1 , weigh t { µ s } s ∈ [ S ] , constants C ω , binary tree la yer M , tolerance η . Set the tolerance level ω = C ω v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s . if g i ≥ . . . ≥ g 2 M +1 then Break and return { g i } i ∈ [2 M +1] . else Initialize f n = min { g n + ω , 1 } . for i = n − 1 , n − 2 , . . . , 1 do Set f i ← min min { g i + ω , 1 } , max(max { g i − ω , 0 } , f i +1 ) . end for end if OUTPUT: { f i } i ∈ 2 N +1 . A.2 Sensitivit y analysis Under the same setup detailed in Section 5.1.2 , w e carry out sensitivit y analysis for tuning parameters C ω and ρ in a setting where S = 3, n s = 2000, n test = 2000 and α = 0 . 3. Numerical exp erimen ts are collected in Figures 8 and 9 b elow. As detailed in Algorithm 1 , ρ determines the tolerance band used in selecting e τ through the optimisation problem e τ = arg min τ ∈G {| τ | : | g DD ↓ ( τ ) | ∈ [ α − ρ, α + ρ ] } . Since g DD ↓ ( · ) is, with high probability , a monotonically non-increasing function, c ho osing the feasible τ ∈ G with the smallest magnitude tends to pic k a threshold for which g DD ↓ ( e τ ) lies near the upper end of the admissible band, i.e. closer to α + ρ . Consequen tly , a larger ρ t ypically leads to a larger disparity 26 of e f , p otentially exceeding α , yet remaining b elo w α + ρ . This b ehaviour is precisely illustrated in Figure 8 . In Algorithm 6 , C ω con trols the bias incurred when constructing a sequence that is as close to non-increasing as p ossible. Based on the numerical results in Figure 9 , the p erformance is not particularly sensitive to C ω in terms of either misclassification error or empirical disparity . The slightly upw ard trend in the disparity plot is mainly b ecause a larger C ω increases the p ossibilities that the adjusted sequence is non-increasing, whic h can in turn lead to a slightly more accurate c hoice of e τ . How ev er, the corresp onding effect on misclassification error is less significan t. Figure 8: Sensitivity analysis for ρ . The grey dotted lines are y = 0 . 3 and y = 0 . 3 + ρ , resp ectiv ely . Figure 9: Sensitivit y analysis for C ω . The grey dotted line represents y = 0 . 3. B Theoretical guarantee for Algorithm 5 B.1 Priv acy guaran tee Prop osition 4. Algorithm 5 is ( ϵ, δ ) -CDP. Pr o of. W e divide the pro of into tw o steps, with the first step quantifying the sensitivity param- eters used in Lemmas 38 and 39 , and the second step inv olving DP comp ositions. Step 1: Upp er b ound on sensitivit y In this step, we upp er b ound ℓ 2 sensitivities for terms of in terests in the calculation of e π a , e p X | A = a , e η a and g DD. Without loss of generality , w e consider the case when A 1 = a = 1 and Y 1 = 1. W e further assume that only the first data p oint in the dataset changes i.e. D = { ( X i , A i , Y i ) } i ∈ [ n ] , D ′ = ( X ′ 1 , A ′ 1 , Y ′ 1 ) ∪ { ( X i , A i , Y i ) } i ∈ [ n ] \{ 1 } . Similar 27 notation is considered for the calibration data ˘ D and ˘ D ′ . Fiv e general cases are considered b elo w, and other cases can b e justified similarly: Case 1: A 1 = A ′ 1 , X 1 = X ′ 1 and Y 1 = Y ′ 1 ; Case 2: A 1 = A ′ 1 , X 1 = X ′ 1 and Y 1 = Y ′ 1 ; Case 3: A 1 = A ′ 1 , X 1 = X ′ 1 and Y 1 = Y ′ 1 ; Case 4: A 1 = A ′ 1 , ( X 1 , Y 1 ) = ( X ′ 1 , Y ′ 1 ); Case 5: A 1 = A ′ 1 , ( X 1 , Y 1 ) = ( X ′ 1 , Y ′ 1 ). • F or e π a : 1. Cases 1-3: Since A 1 = A ′ 1 in these cases, we hav e that n a, 0 + n a, 1 = n ′ a, 0 + n ′ a, 1 . Thus, ∆ = n a, 0 + n a, 1 n − n ′ a, 0 + n ′ a, 1 n = 0 . 2. Cases 4 and 5: Since A 1 = A ′ 1 in these cases, we hav e that | n a, 0 + n a, 1 − ( n ′ a, 0 + n ′ a, 1 ) | = 1. Th us, ∆ = n a, 0 + n a, 1 n − n ′ a, 0 + n ′ a, 1 n = 1 n . • F or e p X | A = a : The pro of follows from a similar argument as the one on Auddy et al. ( 2025 ). Denote ∥ · ∥ K the RKHS norm of the space given by linear com bination { P i θ i K { ( X i − · ) /h } : θ i ∈ R } . W e also rewrite 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) = 1 n a n X i =1 K h ( X i − x ) 1 { A i = a } . 1. Cases 1-3: Since A 1 = A ′ 1 in these cases, we ha ve that ∆ K = 1 n a n X i =1 K h ( X i − · ) 1 { A i = a } − 1 n ′ a n X i =1 K h ( X ′ i − · ) 1 { A ′ i = a } K = 1 n a K h ( X 1 − · ) − K h ( X ′ 1 − · ) K ≤ 2 √ C K n a h d , the last inequalit y follows from Assumption 2 a . 2. Cases 4 and 5: Since A 1 = A ′ 1 in these t wo cases, we hav e that n ′ a = n a − 1 and ∆ K = 1 n a n X i =1 K h ( X i − · ) 1 { A i = a } − 1 n a − 1 n X i =1 K h ( X ′ i − · ) 1 { A ′ i = a } K ≤ 1 n a − 1 1 − n a − 1 n a n X i =2 K h ( X i − · ) 1 { A i = a } K + 1 n a K h ( X 1 − · ) K ≤ 2 √ C K n a h d . 28 • F or e η a : The pro of is very similar to the pro of of e p X | A = a . Rewrite 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) = 1 n a n X i =1 Y i K h ( X i − x ) 1 { A i = 1 } . 1. Cases 1 and 3: In these tw o cases, we ha ve that A 1 = A ′ 1 = 1 and 1 = Y 1 = Y ′ 1 = 0. Th us, ∆ K = 1 n a n X i =1 Y i K h ( X i − · ) 1 { A i = 1 } − 1 n a n X i =1 Y ′ i K h ( X ′ i − · ) 1 { A ′ i = 1 } K = 1 n a Y 1 K h ( X 1 − · ) K ≤ √ C K n a h d . 2. Case 2: In this case, we ha ve that A 1 = A ′ 1 = 1 and Y 1 = Y ′ 1 = 1. Th us, ∆ K = 1 n a Y 1 K h ( X 1 − · ) − Y ′ 1 K h ( X ′ 1 − · ) K ≤ 2 √ C K n a h d . 3. Cases 4 and 5: w e hav e that 1 = A 1 = A ′ 1 = 0. Th us, ∆ K = 1 n a n X i =1 Y i K h ( X i − · ) 1 { A i = 1 } − 1 n a − 1 n X i =1 Y ′ i K h ( X ′ i − · ) 1 { A ′ i = 1 } K = 1 n a ( n a − 1) n X i =2 Y i K h ( X i − · ) 1 { A i = 1 } K + 1 n a Y 1 K h ( X 1 − · ) K ≤ 2 √ C K n a h d . • F or g DD( τ ): Rewrite 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n e η 1 ( ˘ X i 1 ,y ) ≥ 1 2 + τ 2 e π 1 o − 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n e η 0 ( ˘ X i 0 ,y ) ≥ 1 2 − τ 2 e π 0 o = 1 ˘ n 1 ˘ n X i =1 1 n e η 1 ( ˘ X i ) ≥ 1 2 + τ 2 e π 1 o 1 { A i = 1 } − 1 ˘ n 0 ˘ n X i =1 1 n e η 0 ( ˘ X i ) ≥ 1 2 − τ 2 e π 0 o 1 { A i = 0 } . 1. Cases 1-3: In these three cases, we hav e that A 1 = A ′ 1 = 1, therefore, it holds that ∆ = 1 ˘ n 1 1 n e η 1 ( ˘ X 1 ) ≥ 1 2 + τ 2 e π 1 o − 1 n e η 1 ( ˘ X ′ 1 ) ≥ 1 2 + τ 2 e π 1 o ≤ 1 ˘ n 1 . 2. Cases 4-6: In these three cases, we hav e that 1 = A 1 = A ′ 1 = 0. Therefore, w e ha ve that ˘ n ′ 1 = ˘ n 1 − 1 and ˘ n ′ 0 = ˘ n 0 + 1. Th us, ∆ ≤ 1 ˘ n 1 ( ˘ n 1 − 1) n X i =2 1 n e η 1 ( ˘ X i ) ≥ 1 2 + τ 2 e π 1 o 1 { A i = 1 } − 1 ˘ n 0 ( ˘ n 0 + 1) n X i =2 1 n e η 0 ( ˘ X i ) ≥ 1 2 − τ 2 e π 0 o 1 { A i = 0 } 29 + 1 ˘ n 1 1 n e η 1 ( ˘ X 1 ) ≥ 1 2 + τ 2 e π 1 o − 1 ˘ n 0 + 1 1 n e η 0 ( ˘ X ′ 1 ) ≥ 1 2 − τ 2 e π 0 o ≤ 1 ˘ n 1 + 1 ˘ n 0 + 1 ≤ 2 ˘ n 0 ∧ ˘ n 1 . Step 2: DP guaran tee. In this step we will show that the final output is ( ϵ, δ )-DP . Step 2-1: Priv acy guaran tee for each estimator. By Step 1 and Lemmas 38 and 39 , it holds that e π 0 and e π 1 are ( ϵ/ 4 , δ / 4)-DP eac h; e p X | A =0 and e p X | A =1 are ( ϵ/ 4 , δ / 4)-DP eac h; e η 0 and e η 1 are ( ϵ/ 4 , δ / 4)-DP each; and g DD( τ ) is ( ϵ, δ )-DP for a given τ ∈ R . T o sho w the priv acy guaran tee for e τ , note that for any τ ≥ 0, we hav e that P ( e τ ≤ τ |D , ˘ D ) ≤ P ( g DD( τ ) ≤ α |D , ˘ D ) ≤ e ϵ P ( g DD ′ ( τ ) ≤ α |D , ˘ D ′ ) + δ , where the first inequality follo ws from the fact that g DD( τ ) is a non-increasing function as shown in Theorem 12 and g DD( e τ ) ≤ α , the second inequality follo ws as g DD( τ ) is ( ϵ, δ )-DP by the Gaussian mechanism. Consider the following set: A = { t ≥ 0 : g DD ′ ( t ) ≤ α } . In the case when g DD ′ ( τ ) ≤ α , we ha ve τ ∈ A and A is non-empty . Define τ A = inf A and we ha ve τ A ≤ τ . Recall, b y construction, we ha ve that e τ ′ = arg min t ∈ R {| t | : | g DD ′ ( t ) | ≤ α } , which is the first time the fairness regime is hit. Consequently , w e ha ve that e τ ′ ≤ τ A , and further { g DD ′ ( τ ) ≤ α } ⊆ { e τ ′ ≤ τ } . Th us, P ( e τ ≤ τ |D , ˘ D ) ≤ e ϵ P ( g DD ′ ( τ ) ≤ α |D , ˘ D ′ ) + δ ≤ e ϵ P ( e τ ′ ≤ τ |D , ˘ D ′ ) + δ . By a similar and even simpler argument, for any τ < 0, w e also hav e that P ( e τ ≤ τ |D , ˘ D ) ≤ P ( g DD( τ ) ≤ − α |D , ˘ D ) ≤ e ϵ P ( g DD ′ ( τ ) ≤ − α |D , ˘ D ′ ) + δ ≤ e ϵ P ( e τ ′ ≤ τ |D , ˘ D ′ ) + δ , where the last inequality follows since g DD ′ is a non-increasing function and the fact that g DD ′ ( τ ) ≤ − α implies g DD ′ ( t ) ≤ − α for all t ≥ τ , hence e τ ′ ≤ τ . Th us, combining b oth cases together, w e show that the release of e τ is ( ϵ, δ )-DP . Step 2-2: DP comp osition. In S1 of Algorithm 5 , since e p X | A =1 and e p X | A =0 are computed using disjoint dataset, by parallel comp osition, if each of them satisfies ( ϵ/ 4 , δ / 4)-DP , then b oth of them together are guaran teed to b e ( ϵ/ 4 , δ / 4)-DP . A similar idea follo ws for e η 1 and e η 0 . Therefore, together with the fact that e π 0 and e π 1 are each ( ϵ/ 4 , δ / 4)-DP , by Theorem 40 , w e can sho w that S1 is ( ϵ, δ )-CDP . In S2 , we use an indep enden t calibration dataset; th us, by the parallel comp osition prop erty of DP (e.g. Smith et al. , 2021 ), w e hav e that Algorithm 5 is ( ϵ, δ )-DP . B.2 Disparit y con trol Prop osition 5 (F airness guaran tee) . F or any α > 0 , let e f DD ,α denote the classifier output by A lgorithm 5 , we have, for any η ∈ (0 , 1 / 2) , that P n | DD( e f DD ,α ) | ≤ α + C 1 r log(1 /η ) ˘ n + C 2 r log(1 /η ) log (1 /δ ) ˘ n 2 ϵ 2 o ≥ 1 − η , 30 wher e C 1 , C 2 > 0 ar e absolute c onstants and the pr ob ability in DD( e f DD ,α ) is taken over the test sample c onditioning on tr aining data and P is taken over the tr aining data. Pr o of. With a slight abuse of notation, in this pro of, denote D = { e η 0 , e η 1 , e π 0 , e π 1 } . Conditioning on D , b y the Dvoretzky–Kiefer–W olfo witz inequalit y ( Dvoretzky et al. , 1956 ; Massart , 1990 ), w e hav e, for an y a ∈ { 0 , 1 } and t > 0, P h sup τ ∈ R 1 ˘ n a X y ∈{ 0 , 1 } ˘ n a,y X i =1 1 n e η a ( ˘ X i a,y ) ≥ 1 2 + τ (2 a − 1) 2 e π a o − P X | A = a n e η a ( X ) ≥ 1 2 + τ (2 a − 1) 2 e π a D o ≥ t D i ≤ C 1 exp( − 2 ˘ n a t 2 ) . T aking another exp ectation o ver D , we hav e b y the T ow er prop ert y that P h sup τ ∈ R 1 ˘ n a X y ∈{ 0 , 1 } ˘ n a,y X i =1 1 n e η a ( ˘ X i a,y ) ≥ 1 2 + τ (2 a − 1) 2 e π a o − P X | A = a n e η a ( X ) ≥ 1 2 + τ (2 a − 1) 2 e π a D o ≥ t i ≤ C 1 exp( − 2 ˘ n a t 2 ) . (12) Additionally , b y standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ), w e hav e with probabilit y at least 1 − η / 6 that | ˘ w | ≤ C 2 p log(1 /δ ) log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } ϵ . Consequen tly , taking t = C 3 p log(1 /η ) / { ˘ n 0 ∧ ˘ n 1 } and by a union b ound argumen t, w e hav e with probabilit y at least 1 − η / 2 that | DD( e f DD ,α ) | = P X | A =1 n e η 1 ( X ) ≥ 1 2 + e τ DD ,α 2 e π 1 D o − P X | A =0 n e η 0 ( X ) ≥ 1 2 − e τ DD ,α 2 e π 0 D o ≤ 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n e η 1 ( ˘ X i 1 ,y ) ≥ 1 2 + e τ DD ,α 2 e π 1 o − 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n e η 0 ( ˘ X i 0 ,y ≥ 1 2 − e τ DD ,α 2 e π 0 o + C 4 s log(1 /η ) ˘ n 0 ∧ ˘ n 1 ≤ | g DD( e τ DD ,α ) | + | ˘ w | + C 4 s log(1 /η ) ˘ n 0 ∧ ˘ n 1 ≤ α + C 4 s log(1 /η ) ˘ n 0 ∧ ˘ n 1 + C 2 p log(1 /δ ) log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } ϵ , where the first inequalit y follows from the triangle inequalit y and ( 12 ), the second inequalit y follo ws from the triangle inequality and the definition of g DD, and the last inequality follo ws from the construction in S2 of Algorithm 5 . The final result holds by a further union b ound argumen t with the even t { ˘ n 1 ≍ ˘ n 2 ≍ ˘ n } in Theorem 18 . 31 B.3 Excess risk control Theorem 6. Supp ose Assumptions 1 , 2 and 3 holds. Denote ρ = C 1 hn r log { ( h − d ∨ n ) /η } nh d + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 h 2 d + h β o γ + r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 i , and we further assume that DD(0) / ∈ [ α − ζ , α ] ∪ [ − α, − α + ζ ] wher e ρ ≤ ζ < α . Then for any min { n, ˘ n } ≥ 4 C 2 1 log(1 /η ) /C 2 π and absolute c onstants C 1 , . . . , C 7 > 0 , the fol lowing holds. 1. F or any η ∈ (0 , 1 / 2) such that nh d ≥ C 2 log { ( h − d ∨ n ) /η } , n 2 ϵ 2 h 2 d ≥ C 3 log(1 /δ ) log(1 /η ) , ˘ nϵ 2 ≥ C 4 log(1 /δ ) log(1 /η ) , then it holds with pr ob ability at le ast 1 − η that d fair ( e f DD ,α , f ∗ DD ,α ) ≤ C 5 h r log { ( h − d ∨ n ) /η } nh d + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 h 2 d + h β + 1 { τ ∗ DD ,α = 0 } · n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ i 1+ γ . 2. A dditional ly, if n ≍ ˘ n ≍ N up to p oly-lo garithmic factors, then (a) In the fairness-imp acte d r e gime when τ ∗ DD ,α = 0 , set the b andwidth as h = C 6 { N − 1 2 β + d ∨ ( N 2 ϵ 2 ) − 1 2 β +2 d ∨ N − 1 2 γ β ∨ ( N 2 ϵ 2 ) − 1 2 γ β } , it then holds that d fair ( e f DD ,α , f ∗ DD ,α ) = O p n N − β (1+ γ ) 2 β + d ∨ ( N 2 ϵ 2 ) − β (1+ γ ) 2 β +2 d ∨ N − 1+ γ 2 γ ∨ ( N 2 ϵ 2 ) − 1+ γ 2 γ o , and | R ( e f DD ,α ) − R ( f ∗ DD ,α ) | ≤ d fair ( e f DD ,α , f ∗ DD ,α ) + | τ ∗ DD ,α | · O p { N − 1 2 ∨ ( N 2 ϵ 2 ) − 1 } . (b) In the automatic al ly fair r e gime when τ ∗ DD ,α = 0 , pick the b andwidth h = C 7 { N − 1 2 β + d ∨ ( N 2 ϵ 2 ) − 1 2 β +2 d } , then it holds that R ( e f DD ,α ) − R ( f ∗ DD ,α ) = d fair ( e f DD ,α , f ∗ DD ,α ) = O p n N − β (1+ γ ) 2 β + d ∨ ( N 2 ϵ 2 ) − β (1+ γ ) 2 β +2 d o . Pr o of of The or em 6 . T o pro ve Theorem 6 , it suffices to pro ve Theorem 6 ( 1 ), as Theorem 6 ( 2 ) is a direct consequence. F or notational simplicity , throughout the pro of, we write τ ∗ DD ,α = τ ∗ and e τ DD ,α = e τ . Denote T ∗ a = 1 2 + τ ∗ (2 a − 1) 2 π a , and e T a = 1 2 + e τ (2 a − 1) 2 e π a T o control the fairness-aw are risk, we hav e d fair ( e f DD ,α , f ∗ DD ,α ) 32 = 2 X a ∈{ 0 , 1 } π a h Z e f DD ,α ( x, a ) − f ∗ DD ,α ( x, a ) T ∗ a − η a ( x ) d P X | A = a ( x ) i = 2 X a ∈{ 0 , 1 } π a h Z 1 { e η a ( x ) ≥ e T a } − 1 { η a ( x ) ≥ T ∗ a } T ∗ a − η a ( x ) d P X | A = a ( x ) i = 2 X a ∈{ 0 , 1 } π a h Z 1 { 0 > η a ( x ) − T ∗ a ≥ η a ( x ) − e η a ( x ) + e T a − T ∗ a } T ∗ a − η a ( x ) d P X | A = a ( x ) i − 2 X a ∈{ 0 , 1 } π a h Z 1 { 0 ≤ η a ( x ) − T ∗ a < η a ( x ) − e η a ( x ) + e T a − T ∗ a } T ∗ a − η a ( x ) d P X | A = a ( x ) i ≤ 2 X a ∈{ 0 , 1 } π a h Z 1 | η a ( x ) − T ∗ a | ≤ ∥ e η a − η a ∥ ∞ + | e T a − T ∗ a | T ∗ a − η a ( x ) d P X | A = a ( x ) i ≤ C 1 max a ∈{ 0 , 1 } ( ∥ e η a − η a ∥ ∞ + | e T a − T ∗ a | ) 1+ γ , (13) where the last inequality follo ws from Assumption 3 . Consider the follo wing tw o ev ents, E 1 = n ∥ e η a − η a ∥ ∞ ≤ C 2 n r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o , a ∈ { 0 , 1 } o , and E 2 = n | e T a − T ∗ a | ≤ ε T , a ∈ { 0 , 1 } o , (14) where ε T = C 3 h r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 + 1 { τ ∗ = 0 } · h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ ii . By Lemmas 7 and 18 and a union b ound argumen t on a ∈ { 0 , 1 } , we hav e that P ( E 1 ) ≥ 1 − η / 2. T o control the probability of E 2 happ ening, note that | e T a − T ∗ a | ≤ e τ e π a − τ ∗ π a ≤ | e τ | · 1 e π a − 1 π a + 1 π a | e τ − τ | = ( I ) + ( I I ) . T o con trol ( I ), first note that b y Lemmas 9 and 11 , w e ha ve that with probabilit y at least 1 − η / 6 that | e τ | ≤ | τ ∗ | + C 4 1 { τ ∗ = 0 } · h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ i ≤ min { π 0 , π 1 } + C 5 ≤ C 6 . 33 Also, b y a Theorem 17 and a similar argumen t leading to ( 21 ), it holds with probability at least 1 − η / 6 that, for a ∈ { 0 , 1 } , 1 e π a − 1 π a ≤ C 7 n r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 o . T o control ( I I ), by Theorem 9 , w e hav e with probabilit y at least 1 − η / 6 that ( I I ) ≤ C 7 C π 1 { τ ∗ = 0 } · h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ i . Applying a union b ound argumen t, w e thus hav e that P ( E 2 ) ≥ 1 − η / 2. Hence, a further union b ound argument giv es P ( E 1 ∩ E 2 ) ≥ 1 − η and the Lemma thus follo ws by conditioning on E 1 ∩ E 2 happ ening. B.3.1 Upp er b ound on ∥ e η a − η a ∥ ∞ Lemma 7. Under the same assumptions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P h ∥ e η a − η a ∥ ∞ ≥ C 1 n s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β oi ≤ η . Pr o of. By the triangle inequality , we hav e that ∥ e η a − η a ∥ ∞ ≤ 1 e p X | A = a ( ·| a ) n 1 n a n a, 1 X i =1 K h ( X i a, 1 − · ) o − η a ( · ) ∞ + 8 p 2 C K log(5 /δ ) n a ϵh d W 2 ,a ( · ) e p X | A = a ( ·| a ) ∞ = ( I ) + ( I I ) . (15) Step 1: Upp er b ound on T erm ( I ) . T o control ( I ), note that ( I ) = sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) n 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) o − p X,Y | A = a ( x, 1 | a ) p X | A = a ( x | a ) ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) n 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) − Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u o + sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) n Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u − p X,Y | A = a ( x, 1 | a ) o + sup x ∈ [0 , 1] d p X,Y | A = a ( x, 1 | a ) e p X | A = a ( x | a ) − p X,Y | A = a ( x, 1 | a ) p X | A = a ( x | a ) = ( I ) 1 + ( I ) 2 + ( I ) 3 . T o control ( I ) 1 , w e hav e that ( I ) 1 ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) − Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u . 34 Therefore, b y a union b ound argumen t and Lemmas 8 and 14 , it holds that P n ( I ) 1 ≥ C 1 s log { ( h − d ∨ n a ) /η } n a h d o ≤ η 6 . T o control ( I ) 2 , w e hav e that ( I ) 2 ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u − p X,Y | A = a ( x, 1 | a ) ≤ C adp h β sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) , where the last inequality follows from Assumption 2 c and the fact that b oth η a and p X | A = a are H¨ older ov er [0 , 1] d under Assumptions 1 b and 3 a . Therefore, by Theorem 14 , it holds that P n ( I ) 2 ≥ C 2 h β o ≤ η / 6 . T o control ( I ) 3 , note that ( I ) 3 ≤ sup x ∈ [0 , 1] d p X,Y | A = a ( x, 1 | a ) · sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) − 1 p X | A = a ( x | a ) ≤ C 3 sup x ∈ [0 , 1] d e p X | A = a ( x | a ) − p X | A = a ( x | a ) e p X | A = a ( x | a ) p X | A = a ( x | a ) ≤ C 3 sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) p X | A = a ( x | a ) · sup x ∈ [0 , 1] d e p X | A = a ( x | a ) − p X | A = a ( x | a ) ≤ C 3 C p sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d e p X | A = a ( x | a ) − p X | A = a ( x | a ) , where the second inequality follo ws from the fact that p X,Y | A = a is contin uous o ver [0 , 1] d , hence is b ounded, and the fourth inequality follo ws from Assumption 1 b . Th us, b y a union b ound argumen t and Lemmas 13 and 14 , it holds that P h ( I ) 3 ≥ C 4 n s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β oi ≤ η 6 . Th us, by another union b ound, we hav e that P h ( I ) ≥ C 5 n s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β oi ≤ η 2 . (16) Step 2: Upp er b ound on ( I I ) . Note that ( I I ) ≤ 8 p 2 C K log(8 /δ ) n a ϵh d sup x ∈ [0 , 1] d W 2 ,a ( x ) · sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) . 35 Therefore, b y a union b ound argumen t and Lemmas 14 and 16 , we hav e that P n ( I I ) ≥ C 6 p log(1 /δ ) log(1 /η ) n a ϵh d o ≤ η 2 . (17) Step 3: Com bine results. The lemma thus follo ws by substituting the results in ( 16 ) and ( 17 ) in to ( 15 ), and a union b ound argumen t. Lemma 8. Under the same assumptions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n sup x ∈ [0 , 1] d 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) − Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u ≥ C 1 s log { ( h − d ∨ n a ) /η } n a h d o ≤ η . Pr o of. The pro of follows a similar argument to the one in the pro of of Theorem 15 . Here, we only include the difference. With a slight abuse of notation, w e aggregate all data p oints with A i = a together and rewrite 1 n a n a, 1 X i =1 K h ( X i a, 1 − x ) = 1 n a n a X i =1 Y i a K h ( X i a − x ) . Note that for any x ∈ [0 , 1] d , under Assumption 2 a , we hav e that | Y i a K h ( X i a − x ) | = 1 h d Y i a K X i a − x h ≤ C K h − d , and also E n 1 n a n a X i =1 Y i a K h ( X i a − x ) o = 1 n a n a X i =1 X y ∈{ 0 , 1 } Z y K h ( u − x ) p X,Y | A = a ( u, y | a ) d u = Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u. T o control the v ariance, we observ e that for an y i ∈ [ n a ], V ar { Y i a K h ( X i a − x ) } ≤ E n 1 h 2 d ( Y i a ) 2 K X i a − x h 2 o ≤ 1 h 2 d E n K X i a − x h 2 o ≤ C 1 h 2 d Z h d K ( t ) 2 d t ≤ C 1 C 2 K h − d , (18) where the second inequality follo ws from the fact that | Y i a | ≤ 1, the third inequality follo ws from Assumption 1 b and the last inequalit y follo ws from Assumption 2 a . Therefore, b y the Bernstein inequalit y for b ounded distributions (e.g. Theorem 2.8.4 in V ershynin , 2018 ), it holds that for an y 0 < t < 1, P n 1 n a n a X i =1 Y i a K h ( X i a − x ) − Z u K h ( u − x ) p X,Y | A = a ( u, 1 | a ) d u ≥ t o 36 ≤ 2 exp − n a t 2 C 1 C 2 K h − d + C K th − d ≤ C 2 exp( − n a h d t 2 ) . The rest of the pro of to control the sup-norm is by a similar argument using the cov ering lemma as in Step 2 in the pro of of Theorem 15 , hence is omitted here. B.3.2 Upp er b ound on | e τ − τ ∗ | Lemma 9. Supp ose the same assumptions as in The or em 6 hold. If we additional ly assume that ϖ ≥ C 1 h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ i , wher e ϖ is given in Assumption 3 b , then P h | e τ − τ ∗ | ≥ C 2 1 { τ ∗ = 0 } · h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ ii ≤ η . Pr o of. T ake t = C 1 h r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β + n r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 o 1 /γ i , b y assumption, we hav e that 0 < t ≤ ϖ . Consider the ev ent E DD = {| g DD( τ ∗ + t ) − DD( τ ∗ + t ) | ≤ ρ DD } ∩ {| g DD( τ ∗ − t ) − DD( τ ∗ − t ) | ≤ ρ DD } ∩ {| g DD( τ ∗ ) − DD( τ ∗ ) | ≤ ρ DD } , where ρ DD = C 2 hn r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o γ + r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 i . W e ha ve by Theorem 10 and a union b ound argument that P ( E DD ) ≥ 1 − η . The rest of the pro of is constructed conditionally on E DD happ ening. Case 1: When | DD(0) | ≤ α − ρ DD . In this case, we hav e τ ∗ = 0. Moreov er, on the even t E DD , b y the triangle inequality , we hav e | g DD(0) | ≤ | DD(0) | + ρ DD ≤ α . Consequen tly , P ( | e τ − τ ∗ | = 0) ≥ P ( E DD ). Case 2: When α − ρ DD ≤ | DD(0) | ≤ α . Since by the assumption in Theorem 6 , we hav e that DD(0) / ∈ [ α − ρ DD , α ) ∪ ( − α, − α + ρ DD ] ⊆ [ α − ζ , α ) ∪ ( − α, − α + ζ ]. This case will therefore nev er happ en. 37 Case 3: When τ ∗ > 0 and DD( τ ∗ ) = α . This is similar to Case 3 in the pro of of Lemma 13 in Hu et al. ( 2025 ). It holds that P ( e τ > τ ∗ + t ) ≤ P { g DD( τ ∗ + t ) > α , E DD } + P ( E c DD ) = P { g DD( τ ∗ + t ) − DD( τ ∗ + t ) > DD( τ ∗ ) − DD( τ ∗ + t ) , E DD } + P ( E c DD ) ≤ P ( ρ DD > c m t γ ) + P ( E c DD ) = P ( E c DD ) , where the first inequality follows from Theorem 12 , the second inequality follows from Assump- tion 3 c and the last inequality follows as t ≥ c − 1 /γ m ρ 1 /γ DD . Similarly , as t ≥ c − 1 /γ m ρ 1 /γ DD , it also holds that P ( e τ < τ ∗ − t ) ≤ P { g DD( τ ∗ − t ) < α , E DD } + P ( E c DD ) ≤ P { DD( τ ∗ − t ) − g DD( τ ∗ − t ) > DD( τ ∗ − t ) − DD( τ ∗ ) , E DD } + P ( E c DD ) ≤ P ( ρ DD > c m t γ , E DD ) + P ( E c DD ) = P ( E c DD ) . Case 4: when τ ∗ < 0 and DD( τ ∗ ) = − α . This is similar to Case 4 in the pro of of Lemma 13 in Hu et al. ( 2025 ). Most of the pro of follo ws from a similar idea as the one to the pro of of Case 3 , and we omit it here. Lemma 10. R e c al l that ϖ is the p ar ameter given in Assumption 3 b . Under the same assump- tions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) that sup | κ |≤ ϖ P h | g DD( τ ∗ + κ ) − DD( τ ∗ + κ ) | ≥ C 1 hn r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o γ + r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 ii ≤ η . Pr o of. With a sligh t abuse of notation, in this pro of, denote D = { e η 0 , e η 1 , e π 0 , e π 1 } . By triangle inequalit y , it holds that sup | κ |≤ ϖ | g DD( τ ∗ + κ ) − DD( τ ∗ + κ ) | ≤ sup | κ |≤ ϖ | g DD( τ ) − E { g DD( τ ) |D }| + sup | κ |≤ ϖ | E { g DD( τ ∗ + κ ) |D } − DD( τ ∗ + κ ) | = ( I ) + ( I I ) , where E { g DD( τ ) |D } is given by E { g DD( τ ) |D } = P X | A =1 n e η 1 ( X ) ≥ 1 2 + τ 2 e π 1 D o − P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ 2 e π 0 D o , (19) and DD( τ ) is DD( τ ) = P X | A =1 n η 1 ( X ) ≥ 1 2 + τ 2 π 1 o − P X | A =0 n η 0 ( X ) ≥ 1 2 − τ 2 π 0 o . (20) 38 Step 1: Upp er b ound on ( I ) . T o control ( I ), b y the Dvoretzky–Kiefer–W olfowitz inequalit y ( Dv oretzky et al. , 1956 ; Massart , 1990 ), w e hav e, for an y a ∈ { 0 , 1 } and t 1 > 0, P h sup τ ∈ R 1 ˘ n a X y ∈{ 0 , 1 } ˘ n a,y X i =1 1 n e η a ( ˘ X i a,y ) ≥ 1 2 + τ (2 a − 1) 2 e π a o − P X | A = a n e η a ( X ) ≥ 1 2 + τ (2 a − 1) 2 e π a D o ≥ t 1 D i ≤ C 1 exp( − 2 n a t 2 1 ) . Moreo ver, by standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ), we ha ve that for any t 2 > 0, P ( | ˘ w | ≥ t 2 ) ≤ C 2 exp( − t 2 2 /σ 2 2 ) , where σ 2 = 2 p 2 log (1 . 25 /δ ) / ( { ˘ n 0 ∧ ˘ n 1 } ϵ ) is giv en in Algorithm 5 . T aking t 1 = C 3 s log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } , and t 2 = C 4 s log(1 /δ ) log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } 2 ϵ 2 , b y a union b ound argument, it holds with probabilit y at least 1 − η / 2 that ( I ) ≤ C 5 n s log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } + s log(1 /δ ) log(1 /η ) { ˘ n 0 ∧ ˘ n 1 } 2 ϵ 2 o . Step 2: Upp er b ound on ( I I ) . Denote T ∗ a = 1 / 2 + τ ∗ (2 a − 1) / (2 π a ). W e hav e that sup | κ |≤ ϖ P X | A =1 n e η 1 ( X ) ≥ 1 2 + τ ∗ + κ 2 e π 1 D o − P X | A =1 n η 1 ( X ) ≥ 1 2 + τ ∗ + κ 2 π 1 o ≤ sup | κ |≤ ϖ Z 1 n e η 1 ( x ) ≥ 1 2 + τ ∗ 2 e π 1 + κ 2 e π 1 o − 1 n η 1 ( x ) ≥ T ∗ 1 + κ 2 π 1 o P X | A =1 , D ( x ) ≤ sup | κ |≤ ϖ Z 1 n η 1 ( x ) − T ∗ 1 − κ 2 π 1 ≤ ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ + κ | 2 · 1 e π 1 − 1 π 1 o P X | A =1 , D ( x ) ≤ sup | κ |≤ ϖ Z 1 n η 1 ( x ) − T ∗ 1 − κ 2 π 1 ≤ ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 o P X | A =1 , D ( x ) ≤ C m ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 γ , where the last inequality follo ws from Assumption 3 b . Consider the follo wing even ts: E 1 = n ∥ e η a − η a ∥ ∞ ≤ C 6 n r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o , a ∈ { 0 , 1 } o E 2 = n | e π a − π a | ≤ C 7 n r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 o , a ∈ { 0 , 1 } o and E 3 = { C 8 n ≤ n a ≤ n and C 9 ˘ n ≤ ˘ n a ≤ ˘ n, a ∈ { 0 , 1 }} . 39 By Lemmas 7 , 17 and 18 and a union bound argumen t, we hav e that P ( E 1 ∩ E 2 ∩ E 3 ) ≥ 1 − η / 4. On the ev ent E 2 , it holds from the triangle inequality that e π 1 ≥ π 1 − C 7 n r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 oo ≥ C π 2 , where the last inequality follo ws from Assumption 1 a . Consequently , we hav e that 1 e π 1 − 1 π 1 = | e π 1 − π 1 | e π 1 · π 1 ≤ 2 C 2 π | e π 1 − π 1 | . (21) Th us, we hav e that ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 γ ≤ C 10 n r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β (22) + r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 o γ ≤ C 11 n r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o γ , (23) where the first inequality follows from Theorem 11 and the last inequalit y follows on the ev ent E 3 . Similarly , we hav e that sup | κ |≤ ϖ P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 e π 0 D o − P X | A =1 n η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 π 0 o ≤ sup | κ |≤ ϖ Z 1 n e η 0 ( x ) ≥ 1 2 − τ ∗ 2 e π 0 − κ 2 e π 0 o − 1 n η 0 ( x ) ≥ T ∗ 0 − κ 2 π 0 o P X | A =0 , D ( x ) ≤ sup | κ |≤ ϖ Z 1 n η 0 ( x ) − T ∗ 0 + κ 2 π 0 ≤ ∥ e η 0 − η 0 ∥ ∞ + | τ ∗ + κ | 2 · 1 e π 0 − 1 π 0 o P X | A =0 , D ( x ) ≤ C m ∥ e η 0 − η 0 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 0 − 1 π 0 γ . By a similar argumen t leading to ( 23 ), we hav e that with probability at least 1 − η / 4, we hav e that sup | κ |≤ ϖ P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 e π 0 D o − P X | A =1 n η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 π 0 o ≤ C 12 n r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o γ . By a union b ound argument, we hav e with probability at least 1 − η that ( I I ) ≤ C 13 hn r log { ( h − d ∨ n ) /η } nh d + p log(1 /δ ) log(1 /η ) nϵh d + h β o γ + r log(1 /η ) ˘ n + r log(1 /δ ) log(1 /η ) ˘ n 2 ϵ 2 i . 40 Lemma 11. It holds that | τ ∗ DD ,α | ≤ min { π 0 , π 1 } . Pr o of. Recall that g DD ,τ ( x, a ) = 1 { η a ( x ) ≥ 1 / 2 + τ (2 a − 1) / (2 π a ) } . Note that if τ = π 1 , then g DD ,τ ( x, 1) = 0 for all x ∈ [0 , 1] d . Also, DD( π 1 ) = − P X | A =0 n η 0 ( X ) ≥ 1 2 − π 1 2 π 0 o ( = − 1 , π 1 ≥ π 0 , ≤ 0 , π 1 < π 0 . (24) If τ = π 0 , then g DD ,τ ( x, 0) = 1 for all x ∈ [0 , 1] d . Then it holds that DD( π 0 ) = P X | A =1 n η 1 ( X ) ≥ 1 2 + π 0 2 π 1 o − 1 ≤ 0 . (25) If τ = − π 1 , then g DD ,τ ( x, 1) = 1 for all x ∈ [0 , 1] d . Then it holds that DD( − π 1 ) = 1 − P X | A =0 n η 0 ( X ) ≥ 1 2 + π 1 2 π 0 o ≥ 0 . If τ = − π 0 , then g DD ,τ ( x, 0) = 0 for all x ∈ [0 , 1] d . Then it holds that DD( − π 0 ) = P X | A =1 n η 1 ( X ) ≥ 1 2 − π 0 2 π 1 o ( ≥ 0 , π 1 < π 0 , = 1 , π 1 ≥ π 0 . Th us by Theorem 43 (i), ( 24 ) and ( 25 ), if DD(0) > α = DD( τ ∗ DD ,α ) > 0 ≥ { DD( π 1 ) ∨ DD( π 0 ) } , w e then hav e 0 < τ ∗ DD ,α < min { π 0 , π 1 } . Similarly , if DD(0) < − α = DD( τ ∗ DD ,α ) < 0 ≤ { DD( − π 1 ) ∧ DD( − π 0 ) } , we then hav e that max {− π 0 , − π 1 } < τ ∗ DD ,α < 0 F urthermore, we hav e that if | DD(0) | ≤ α , then τ ∗ DD ,α = 0. Th us, the lemma follows. Lemma 12. g DD( · ) and d DD( · ) ar e non-incr e asing functions in τ . Pr o of. F or any τ 1 < τ 2 , w e hav e that g DD( τ 1 ) − g DD( τ 2 ) = d DD( τ 1 ) − d DD( τ 2 ) = 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n e η 1 ( ˘ X i 1 ,y ) ≥ 1 2 + τ 1 2 e π 1 o − 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n e η 0 ( ˘ X i 0 ,y ) ≥ 1 2 − τ 1 2 e π 0 o − 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n e η 1 ( ˘ X i 1 ,y ) ≥ 1 2 + τ 2 2 e π 1 o + 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n e η 0 ( ˘ X i 0 ,y ) ≥ 1 2 − τ 2 2 e π 0 o = 1 ˘ n 1 X y ∈{ 0 , 1 } ˘ n 1 ,y X i =1 1 n 1 2 + τ 1 2 e π 1 ≤ e η 1 ( ˘ X i 1 ,y ) < 1 2 + τ 2 2 e π 1 o + 1 ˘ n 0 X y ∈{ 0 , 1 } ˘ n 0 ,y X i =1 1 n 1 2 − τ 2 2 e π 0 ≤ e η 0 ( ˘ X i 0 ,y ) < 1 2 − τ 1 2 e π 0 o 41 ≥ 0 . Th us, the lemma follows. B.3.3 Upp er b ound on ∥ e p X | A = a − p X | A = a ∥ ∞ Lemma 13. Under same assumptions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P " ∥ e p X | A = a − p X | A = a ∥ ∞ ≥ C 1 ( s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β )# ≤ η . Pr o of. Note that ∥ e p X | A = a − p X | A = a ∥ ∞ ≤ sup x ∈ [0 , 1] d 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − p X | A = a ( x | a ) + 8 p 2 C K log(5 /δ ) n a ϵh d sup x | W 1 ,a ( x ) | ≤ sup x ∈ [0 , 1] d 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − Z u K h ( u − x ) p X | A = a ( u | a ) d u + sup x Z u K h ( u − x ) p X | A = a ( u | a ) d u − p X | A = a ( x | a ) + 8 p 2 C K log(5 /δ ) n a ϵh d sup x | W 1 ,a ( x ) | = ( I ) + ( I I ) + ( I I I ) . T o control ( I ), by Theorem 15 , we hav e that P ( ( I ) ≥ C 1 s log { ( h − d ∨ n a ) /η } n a h d ) ≤ η 2 . T o control ( I I ), by Asssumptions 1 b and 2 c , it holds that ( I I ) ≤ C adp h β . T o control ( I I I ), by Theorem 16 , it holds that P ( ( I I I ) ≥ C 2 p log(1 /δ ) log(1 /η ) n a ϵh d ) ≤ η 2 . The lemma th us follows by a union b ound argument. Lemma 14. Under the same assumption as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n C 1 ≤ inf x ∈ [0 , 1] d e p X | A = a ( x ) ≤ sup x ∈ [0 , 1] d e p X | A = a ( x ) ≤ C 2 o ≥ 1 − η . 42 Pr o of. Consider the even t E 1 = ( ∥ e p X | A = a − p X | A = a ∥ ∞ ≤ C 1 ( s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β )) . By Theorem 13 , it holds that P ( E 1 ) ≥ 1 − η . The rest of the pro of is constructed on the even t E 1 . Denote t = C 1 ( s log { ( h − d ∨ n a ) /η } n a h d + p log(1 /δ ) log(1 /η ) n a ϵh d + h β ) , x ∗ = min arg inf x ∈ [0 , 1] d e p X | A = a ( x ) and x ∗ = min arg sup x ∈ [0 , 1] d e p X | A = a ( x ). By the triangle in- equalit y , we hav e that e p X | A = a ( x ∗ ) ≤ p X | A = a ( x ∗ ) + t ≤ C 3 , where the second inequality follows from the fact that p X | A = a ( x | a ) is H¨ older contin uous ov er a compact in terv al in Assumption 1 b , hence b ounded. Similarly , we ha ve that e p X | A = a ( x ∗ ) ≥ p X | A = a ( x ∗ ) − t ≥ C p − t ≥ C p / 2 , where the second inequality follo ws from Assumption 1 b . The lemma th us follows. Lemma 15. Under the same assumptions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n sup x ∈ [0 , 1] d 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − Z u K h ( u − x ) p X | A = a ( u | a ) d u ≥ C 1 s log { ( h − d ∨ n a ) /η } n a h d o ≤ η . Pr o of. Step 1: upp er bound for an y x ∈ [0 , 1] d . Note that for any x ∈ [0 , 1] d , under Assumption 2 a , w e hav e that | K h ( X i a,y − x ) | = 1 h d K X i a,y − x h ≤ C 1 h − d , and also E n 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) o − Z u K h ( u − x ) p X | A = a ( u | a ) d u = 0 b y construction. T o compute the v ariance, w e observe that for each y ∈ { 0 , 1 } and i ∈ [ n a,y ], V ar K h ( X i a,y − x ) ≤ E n 1 h 2 d K X i a,y − x h 2 o ≤ 1 h 2 d Z K u − x h 2 p X | A = a ( u | a ) d u ≤ C 2 h 2 d Z h d K ( t ) 2 d t ≤ C 3 h − d , 43 where the third inequality follo ws from Assumption 1 b and the last inequality follo ws from Assumption 2 a . Therefore, b y the Bernstein inequality for b ounded distributions (e.g. Theorem 2.8.4 in V ersh ynin , 2018 ), it holds that for any 0 < t < 1, P n 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − Z u K h ( u − x ) p X | A = a ( u | a ) d u ≥ t o ≤ 2 exp − n a t 2 / 2 C 3 h − d + C 1 h − d t/ 3 ≤ C 4 exp( − n a h d t 2 ) . (26) Step 2: upp er b ound on the sup-norm. Denote T a ( x ) = 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − Z u K h ( u − x ) p X | A = a ( u | a ) d u. F or an y ν ∈ (0 , 1), denote Q = N ( ν , ∥ · ∥ 2 , [0 , 1] d ) the cardinality of an ν -net of [0 , 1] d with respect to the ℓ 2 norm. By standard co vering lemma (e.g. Proposition 4.2.12 in V ersh ynin , 2018 ), w e ha ve that Q ≤ ( C 1 √ d/ν ) d . W e further let { z 1 , . . . , z Q } b e a ν -cov ering of [0 , 1] d and also let S j = { x ∈ [0 , 1] d : ∥ x − z j ∥ 2 ≤ ν } , j ∈ [ Q ]. It then follows that sup x ∈ [0 , 1] d |T a ( x ) | ≤ max j ∈ [ Q ] n |T a ( z j ) | + sup x ∈ S j |T a ( x ) − T a ( z j ) | o ≤ max j ∈ [ Q ] |T a ( z j ) | + max j ∈ [ Q ] sup x ∈ S j |T a ( x ) − T a ( z j ) | = ( I ) + ( I I ) . T o control ( I ), by ( 26 ) and a union b ound argument, we hav e that P n ( I ) ≥ t 2 o ≤ C 5 exp n log( Q ) − n a h d t 2 o . (27) T o control ( I I ), note that ( I I ) ≤ max j ∈ [ Q ] sup x ∈ S j 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − x ) − 1 n a X y ∈{ 0 , 1 } n a,y X i =1 K h ( X i a,y − z j ) + max j ∈ [ Q ] sup x ∈ S j Z u K h ( u − x ) p X | A = a ( u | a ) d u − Z u K h ( u − z j ) p X | A = a ( u | a ) d u ≤ 2 C Lip h − ( d +1) max j ∈ [ Q ] sup x ∈ S j ∥ x − z j ∥ 2 ≤ 2 C Lip h − ( d +1) ν = t/ 2 , (28) where the second inequality follows from Assumption 2 b and the last equality follo ws b y setting ν = h d +1 t/ (4 C Lip ). Therefore, applying a union b ound argumen t to ( 27 ) and ( 28 ), w e ha ve that P n sup x ∈ [0 , 1] d |T a ( x ) | ≥ t o ≤ C 6 exp n d log √ d h d +1 t − n a h d t 2 o . The lemma th us follows by taking t = C 7 s log { ( h − d ∨ n a ) /η } n a h d . 44 Lemma 16. F or any a ∈ { 0 , 1 } , η ∈ (0 , 1 / 2) and k ∈ { 1 , 2 } , it holds that P n sup x ∈ [0 , 1] d | W k,a ( x ) | ≥ C 1 p log(1 /η ) o ≤ η . Pr o of. The pro of follows from a similar argumen t as the one in the pro of of Lemma 3 in Auddy et al. ( 2025 ). W e first control E { sup x ∈ [0 , 1] d W k,a ( x ) } . By Dudley’s theorem (e.g. Dudley , 2016 ), w e hav e that E ( sup x ∈ [0 , 1] d W k,a ( x ) ) ≤ K (0) + C 1 Z 1 0 r log n 1 + 2 ν d o d ν ≤ C 2 √ d = C 3 . Also, b y the construction of the pro cess W k,a in Algorithm 5 , we ha ve that sup x ∈ [0 , 1] d E { W k,a ( x ) 2 } = K (0) ≤ C K , where the inequalit y follo w from Assumption 2 a . Therefore, b y the Borell–TIS inequality (e.g. Theorem 2.1.1 in Adler and T aylor , 2007 ), it holds that P h sup x ∈ [0 , 1] d W k,a ( x ) − E sup x ∈ [0 , 1] d W k,a ( x ) ≥ t i ≤ 2 exp − t 2 2 C K . Therefore, b y the triangle inequality , it holds that P n sup x ∈ [0 , 1] d W k,a ( x ) ≥ C 4 p log(1 /η ) o ≤ η . Similarly , we can also prov e a result for the pro cess − W k,a . Thus, the lemma follows by a union b ound argumen t. B.3.4 Upp er b ound on | e π a − π a | Lemma 17. Under the same assumptions as in The or em 6 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P h | e π a − π a | ≥ C 1 n r log(1 /η ) n + r log(1 /δ ) log(1 /η ) n 2 ϵ 2 oi ≤ η . Pr o of. F or a ∈ { 0 , 1 } , consider the sequence of b ounded random v ariables { 1 { A i = a }} n i =1 . W e ha ve that e π a = n a, 0 + n a, 1 n + w a = 1 n n X i =1 1 { A i = a } + w a . By Ho effding’s inequality for general b ounded random v ariables (e.g. Theorem 2.2.6 in V er- sh ynin , 2018 ), we hav e that, for t 1 > 0, P 1 n n X i =1 1 { A i = a } − π a ≥ t 1 ≤ C 1 exp( − t 2 1 n ) . Moreo ver, by standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ), we ha ve that for any t 2 > 0, P ( | w a | ≥ t 2 ) ≤ C 2 exp( − t 2 2 /σ 2 1 ) , 45 where σ 1 = 4 p 2 log (5 /δ ) / ( nϵ ) is giv en in Algorithm 5 . T aking t 1 = C 3 r log(1 /η ) n , and t 2 = C 4 r log(1 /δ ) log(1 /η ) n 2 ϵ 2 , the lemma th us follows by a union b ound argument. Lemma 18. F or any min { n, ˘ n } ≥ 4 C 2 1 log(1 /η ) /C 2 π , it holds for any η ∈ (0 , 1 / 2) that P n C 2 n ≤ n a ≤ n, and C 3 ˘ n ≤ ˘ n a ≤ ˘ n, a ∈ { 0 , 1 } o ≥ 1 − η . Pr o of. F or a ∈ { 0 , 1 } , consider the sequence of indicator random v ariables { 1 { A i = a }} n i =1 , then we hav e that n a = P n i =1 1 { A i = a } and E [ P n i =1 1 { A i = a } ] = π a n . Consequently , b y Ho effding’s inequalit y for general b ounded random v ariables (e.g. Theorem 2.2.6 in V ersh ynin , 2018 ), it holds for any t > 0 that P ( | n a − π a n | ≥ t ) ≤ C 1 exp − t 2 n . T aking t = C 2 p n log (1 /η ), we hav e that with probability at least 1 − η / 4 that n a ≥ π a n − C 2 p n log (1 /η ) ≥ C π n − C π n 2 = C π n 2 , where the second inequalit y follo ws from Assumption 1 a for an y n ≥ 4 C 2 2 log(1 /η ) /C 2 π . The pro of for the calibration data ˘ D are similar. The lemma th us follows by applying a union b ound argumen t. C Theoretical guarantee for Algorithm 1 C.1 Priv acy guaran tee Prop osition 19. Algorithm 1 is ( ϵ , δ ) -FDP. Pr o of. Most of the pro of follo ws from the same argument as the pro of of Theorem 4 . W e only include the difference here. By a similar argument as the pro of of Theorem 4 , in Step S1 , ( ϵ , δ )-FDP is guaran teed b ecause for each site s ∈ [ S ], { e π s a , e p s X | A = a , e p s X,Y | A = a } a ∈{ 0 , 1 } together satisfies ( ϵ, δ )-CDP . In step S2 , namely Algorithm 2 , ( ϵ , δ )-FDP is also guaranteed. Each lev el ℓ ∈ [ M ] of the binary tree from server s and sensitive attribute a is given by b ℓ,a ( D s ) = X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 { τ 1 ≤ Z s,i,a,y ≤ τ 2 M − ℓ +1 } , . . . , X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 { τ (2 ℓ − 1)2 M − ℓ +1 ≤ Z s,i,a,y ≤ 1 } , whic h is a vector of dimension 2 ℓ con taining coun ts for the bin { [ τ ( k − 1)2 M − ℓ +1 , τ k 2 M − ℓ +1 ] } 2 ℓ k =1 . When w e app end tw o trees together side b y side, then if w e change one en try in D s , only tw o en- tries in b ℓ ( D s ) = ( b ℓ, 1 ( D s ) , b ℓ, 0 ( D s )) will shift by one. Therefore, w e hav e that sup D s ∼D ′ s ∥ b ℓ ( D s ) − b ℓ ( D ′ s ) ∥ 2 2 ≤ 2. Since this holds for all lev els ℓ ∈ [ M ], b y Lemma 30 in Hung and Y u ( 2025 ), releasing {{ N s,a,ℓ,k } M , 2 ℓ ℓ =1 ,k =1 } a ∈{ 0 , 1 } is therefore ( ϵ s , δ s )-CDP for eac h server. 46 C.2 Disparit y con trol Prop osition 20. Under the same assumptions as in The or em 1 . 3 , we have that P | DD( e f DD ,α ) | ≤ α + C 1 ρ ≥ 1 − η , wher e ρ is given in ( 29 ) and the pr ob ability in DD( e f DD ,α ) is taken over the test sample c ondi- tioning on tr aining data and P is taken over the tr aining data. Pr o of. By Lemmas 25 , 27 and the extra assumption that ϖ ≥ ρ 1 /γ , w e hav e with probability at least 1 − η that | g DD ↓ ( e τ ) − DD( e τ ) | ≤ C 1 ρ. Th us, by triangle inequality and the design in Algorithm 2 , w e hav e that | DD( e τ ) | ≤ | g DD ↓ ( e τ ) | + C 1 ρ ≤ α + C 2 ρ. C.3 Excess risk control Pr o of of The or em 2 . Theorem 2 is a direct consequence of Theorem 21 . Note that with the c hoice of θ = ρ 1 /γ , it holds that M = log 2 ( θ − 1 ) + 1 = C 1 log S X s =1 { N s ∧ N 2 s ϵ s } , where C 1 > 0 is a constant dep ending on γ , d and β . Thus the effect of M in Theorem 21 are only up to p oly-logarithmic factors. Prop osition 21 (F airness aw are excess risk) . Supp ose Assumptions 1 , 2 and 3 hold. Denote ρ = C 1 "( v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d ) γ + v u u t S X s =1 µ 2 s log(1 /η ) ˘ n s + max s ∈ [ S ] µ s log(1 /η ) ˘ n s + v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s # . (29) and we further assume that DD(0) / ∈ [ α − ζ , α ] ∪ [ − α, − α + ζ ] , wher e ρ ≤ ζ < α . Then for any min { n, ˘ n } ≳ log ( S/η ) , min s ∈ [ S ] ˘ n 2 s,a ϵ 2 s ≥ C 2 M 2 log(1 /δ s ) log ( S/η ) and η ∈ (0 , 1 / 2) , it holds with pr ob ability at le ast 1 − η that d fair ( e f DD ,α , f ∗ DD ,α ) ≲ 1 { τ ∗ = 0 } " v u u t S X s =1 µ 2 s log(1 /η ) ˘ n s + max s ∈ [ S ] µ s log(1 /η ) ˘ n s + v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s # 1+ γ γ + " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # 1+ γ . 47 Pr o of. Most of the pro of follo ws from a similar argument used in the pro of of Theorem 6 . W e only include the difference here. T o con trol the fairness-a ware excess risk, using a similar argumen t leading to ( 13 ), we hav e that d fair ( e f DD ,α , f ∗ DD ,α ) ≤ C 1 max a ∈{ 0 , 1 } ( ∥ e η a − η a ∥ ∞ + | e T a − T ∗ a | ) 1+ γ . Consider the follo wing even t, E 1 = ( ∥ e η a − η a ∥ ∞ ≤ C 2 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # , a ∈ { 0 , 1 } ) , and E 2 = n | e T a − T ∗ a | ≤ C 3 ϵ T o , where ϵ T = 1 { τ ∗ = 0 } ρ 1 /γ + v u u t S X s =1 ν 2 s log(1 /η ) n s + v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s . The lemma th us follows b y Lemmas 22 , 25 , 36 and a similar argument as the one in the pro of of Theorem 6 . C.3.1 Upp er b ound on ∥ e η a − η a ∥ ∞ Lemma 22. Under the same assumptions as in The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P h ∥ e η a − η a ∥ ∞ ≥ C 1 " v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + max s ∈ [ S ] ν s log( h − d /η ) n s,a h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d #) ≤ η . Pr o of. By the triangle inequality , we hav e that ∥ e η a − η a ∥ ∞ ≤ S X s =1 ν s e p X | A = a ( ·| a ) n 1 n s,a n s,a, 1 X i =1 K h ( X s,i a, 1 − · ) o − η a ( · ) ∞ + 1 e p X | A = a ( ·| a ) S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 2 ,a ( · ) ∞ = ( I ) + ( I I ) . Step 1: Upp er b ound on ( I ) . T o control ( I ), note that ( I ) = sup x ∈ [0 , 1] d S X s =1 ν s e p X | A = a ( x | a ) n 1 n s,a n s,a, 1 X i =1 K h ( X s,i a, 1 − x ) o − p X,Y | A = a ( x, 1 | a ) p X | A = a ( x | a ) 48 ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) S X s =1 ν s n 1 n s,a n s,a, 1 X i =1 K h ( X s,i a, 1 − x ) − Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ o + sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) n Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ − p X,Y | A = a ( x, 1 | a ) o + sup x ∈ [0 , 1] d p X,Y | A = a ( x, 1 | a ) e p X | A = a ( x | a ) − p X,Y | A = a ( x, 1 | a ) p X | A = a ( x | a ) = ( I ) 1 + ( I ) 2 + ( I ) 3 . T o control ( I ) 1 , w e hav e that ( I ) 1 ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d S X s =1 n s,a, 1 X i =1 ν s n s,a K h ( X s,i a, 1 − x ) − Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ . Therefore, b y a union b ound argumen t and Theorem 23 and Theorem 34 , it holds that P n ( I ) 1 ≥ C 1 v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + C 2 max s ∈ [ S ] ν s log( h − d /η ) n s,a h d o ≤ η 6 . T o control ( I ) 2 , w e hav e that ( I ) 2 ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ − p X,Y | A = a ( x, 1 | a ) ≤ C adp h β sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) , where the last inequality follows from Assumption 2 c and the fact that b oth η a and p X | A = a are H¨ older ov er [0 , 1] d under Assumptions 1 b and 3 a . Therefore, by Theorem 34 , it holds that P n ( I ) 2 ≥ C 3 h β o ≤ η / 6 . T o control ( I ) 3 , note that ( I ) 3 ≤ sup x ∈ [0 , 1] d p X,Y | A = a ( x, 1 | a ) · sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) − 1 p X | A = a ( x | a ) ≤ C 4 sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) p X | A = a ( x | a ) · sup x ∈ [0 , 1] d e p X | A = a ( x | a ) − p X | A = a ( x | a ) ≤ C 4 C p sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d e p X | A = a ( x | a ) − p X | A = a ( x | a ) , where the first inequality follo ws from the fact that p X,Y | A = a is contin uous o ver [0 , 1] d , hence is b ounded, and the fourth inequality follows from Assumption 1 b . Th us, by applying a union b ound argumen t to the even ts in Theorem 33 and Theorem 34 , it holds that P " ( I ) 3 ≥ C 5 ( v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d 49 + max s ∈ [ S ] ν s log( h − d /η ) n s,a h d + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d )# ≤ η 6 . Th us, by another union b ound, we hav e that P " ( I ) ≥ C 6 ( v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + max s ∈ [ S ] ν s log( h − d /η ) n s,a h d + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d + h β )# ≤ η 2 . Step 2: Upp er b ound on ( I I ) . Note that ( I I ) ≤ sup x ∈ [0 , 1] d 1 e p X | A = a ( x | a ) · sup x ∈ [0 , 1] d S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 2 ,a ( x ) . Therefore, b y applying a union b ound argumen t to Theorem 34 and Theorem 24 , it holds that P ( ( I I ) ≥ C 7 v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d ) ≤ η 2 . Step 3: The lemma th us follows by another union b ound argument. Lemma 23. Under the same assumptions as in The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n sup x ∈ [0 , 1] d S X s =1 n s,a, 1 X i =1 ν s n s,a K h ( X s,i a, 1 − x ) − Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ ≥ C 1 v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + C 2 max s ∈ [ S ] ν s log( h − d /η ) n s,a h d o ≤ η . Pr o of. The pro of follows from a similar argument to the one in the pro ofs of Lemmas 8 and 15 ; w e only include the difference here. With a slight abuse of notation, w e aggregate all data points with S = s and A s i = a together, and write S X s =1 n s,a, 1 X i =1 ν s n s,a K h ( X s,i a, 1 − x ) = S X s =1 n s,a X i =1 ν s n s,a Y s,i a K h ( X s,i a − x ) . Note that for any x ∈ [0 , 1] d , under Assumption 2 a , we hav e that max s ∈ [ S ] max i ∈ [ n s,a, 1 ] ν s n s,a Y s,i a K h ( X s,i a − x ) ≤ max s ∈ [ S ] C K ν s n s,a h d , and also E n S X s =1 n s,a X i =1 ν s n s,a Y s,i a K h ( X s,i a − x ) o = S X s =1 ν s n s,a n s,a X i =1 X y ∈{ 0 , 1 } Z ℓ y K h ( ℓ − x ) p X,Y | A = a ( ℓ, y | a ) d ℓ 50 = S X s =1 ν s Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ = Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ. T o control the v ariance, we ha ve V ar n S X s =1 n s,a X i =1 ν s n s,a Y s,i a K h ( X s,i a − x ) o = S X s =1 n s,a X i =1 ν 2 s n 2 s,a V ar Y s,i a K h ( X s,i a − x ) ≤ C 1 C 2 K S X s =1 ν 2 s n s,a h d , where the first inequalit y follo ws from the indep endence prop ert y across and within eac h serv er and the second inequality follo ws from a similar argument leading to ( 18 ). Therefore, by the Bernstein inequalit y for b ounded distributions (e.g. Theorem 2.8.4 in V ersh ynin , 2018 ), it holds that for an y t < 1 that P n S X s =1 n s,a X i =1 ν s n s,a Y s,i a K h ( X s,i a − x ) − Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ ≥ t o ≤ C 2 exp n − t 2 S X s =1 ν 2 s n s,a h d + max s ∈ [ S ] ν s t n s,a h d − 1 o . The rest of the pro of to control the sup-norm is similar to the argumen t in Step 2 in the pro of of Theorem 15 . With the notation, we can show that T a ( x ) = S X s =1 n s,a X i =1 ν s n s,a Y s,i a K h ( X s,i a − x ) − Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ satisfies that max j ∈ Q max x ∈ S j |T a ( x ) − T a ( z j ) | ≤ S X s =1 n s,a X i =1 ν s n s,a max j ∈ Q max x ∈ S j Y s,i a K h ( X s,i a − x ) − Y s,i a K h ( X s,i a − z j ) + max j ∈ Q max x ∈ S j Z ℓ K h ( ℓ − x ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ − Z ℓ K h ( ℓ − z j ) p X,Y | A = a ( ℓ, 1 | a ) d ℓ ≤ 2 C Lip h − ( d +1) max j ∈ Q max x ∈ S j ∥ x − z j ∥ 2 . The rest of the pro of to con trol the sup norm follows from the same argumen t using the co vering lemma, and w e omit it here. Lemma 24. Under the same assumptions as in The or em 2 , for any a ∈ { 0 , 1 } , k ∈ { 1 , 2 } and η ∈ (0 , 1 / 2) , it holds that P ( sup x ∈ [0 , 1] d S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s k,a ( x ) ≥ C 1 v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d ) ≤ η . 51 Pr o of. The pro of follows from a similar argumen t to the pro of of Theorem 16 . Let Z ( x ) = S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s k,a ( x ) . Note that b y the standard property of Gaussian random v ariables, it holds that Z is a mean-zero Gaussian pro cess, with cov ariance function Co v ( Z ( ℓ ) , Z ( t )) = C 1 S X s =1 ν 2 s log(1 /δ s ) n 2 s,a ϵ 2 s h 2 d K ℓ − t h , for all ℓ, t ∈ [0 , 1] d . Also note that E { Z ( ℓ ) − Z ( t ) } 2 = C 2 S X s =1 ν 2 s log(1 /δ s ) n 2 s,a ϵ 2 s h 2 d n K (0) − K ℓ − t h o ≤ C 2 S X s =1 C Lip ν 2 s log(1 /δ s ) n 2 s,a ϵ 2 s h 2 d ∥ ℓ − t ∥ 2 h ≤ C 3 S X s =1 ν 2 s log(1 /δ s ) n 2 s,a ϵ 2 s h 2 d ∥ ℓ − t ∥ 2 h := S X s =1 C 2 ι 2 s ∥ ℓ − t ∥ 2 h . Since N ([0 , 1] d , ∥ · ∥ 2 , κ ) ≤ κ − d , w e hav e that N ([0 , 1] d , d z , κ ) ≤ P s ι 2 s κ 2 h d , where N is the cov ering num b er and d z is defined as d z ( ℓ, t ) = q E { Z ( ℓ ) − Z ( t ) } 2 . By Dudley’s theorem (e.g. Dudley , 2016 ), it holds that E sup x ∈ [0 , 1] d Z ( x ) ≤ Z ∞ 0 q log {N ([0 , 1] d , d z , κ ) } d κ ≤ Z √ C K P S s =1 ι 2 s 0 q log {N ([0 , 1] d , d z , κ ) } d κ ≤ C 4 v u u t d S X s =1 ι 2 s log h − 1 S X s =1 ι 2 s ≤ C 5 v u u t d S X s =1 ι 2 s log( h − 1 ) , where the second inequalit y follows as sup x ∈ [0 , 1] d V ar( Z ( x )) = K (0) P S s =1 ι 2 s and the last in- equalit y follows as P S s =1 ι 2 s ≤ 1. Moreo ver, by the Borell–TIS inequality (e.g. Theorem 2.1.1 in Adler and T a ylor , 2007 ), it holds that for any t > 0, P n sup x ∈ [0 , 1] d Z ( x ) − E sup x ∈ [0 , 1] d Z ( x ) ≥ t o ≤ 2 exp n − t 2 2 S X s =1 ν 2 s log(1 /δ s ) n 2 s,a ϵ 2 s h 2 d − 1 o . 52 Therefore, b y the triangle inequality , it holds that P ( sup x ∈ [0 , 1] d Z ( x ) | ≥ C 6 v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d ) ≤ η . Similarly , we can also provide the results for the pro cess − Z ( x ). The lemm a th us follows. C.3.2 Upp er b ound on | e τ − τ ∗ | Lemma 25. L et e τ b e the output of Algorithm 2 and denote ρ = C 1 "( v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d ) γ + v u u t S X s =1 µ 2 s log(1 /η ) ˘ n s + max s ∈ [ S ] µ s log(1 /η ) ˘ n s + v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s # . (30) Supp ose Assumptions 1 , 2 and 3 hold. We further assume that DD(0) / ∈ [ α − ζ , α ] ∪ [ − α, − α + ζ ] , wher e ρ ≤ ζ < α . T ake θ = ρ 1 /γ , we have that P | e τ − τ ∗ | ≥ C 2 ρ 1 /γ 1 { τ ∗ = 0 } ≤ η , whenever ϖ ≥ ρ 1 /γ . Pr o of. The pro of is a consequence of Theorem 26 . Denote τ ∗ G ∈ G as the smallest p oint among the closest p oints to τ ∗ in the grid. W e will consider three cases b elo w. Denote E = | g DD ↓ ( τ ∗ G + κ ) − DD( τ ∗ G + κ ) | ≤ ρ ∩ | g DD ↓ ( τ ∗ G − κ ) − DD( τ ∗ G − κ ) | ≤ ρ ∩ | g DD ↓ ( τ ∗ ) − DD( τ ∗ ) | ≤ ρ ∩ { Output of Alg or ithm 4 is v alid and non-increasing } ∩ ( i ) , ( ii ) , ( iii ) in T heor em 26 , where κ > 0 (to b e sp ecified) is a scalar multiplicativ e of θ , i.e. τ ∗ G + κ, τ ∗ G − κ ∈ G and τ ∗ G − κ < τ ∗ < τ ∗ G + κ . By Lemmas 27 , 28 and Theorem 26 , we hav e that P ( E c ) ≤ η when κ is chosen such that | κ | + θ ≤ ϖ . Case 1: τ ∗ = 0 . In this case, b y Theorem 26 , we hav e that e τ = 0. Hence, P ( e τ = τ ∗ ) ≥ P ( E ). Case 2: τ ∗ > 0 . In the case when τ ∗ > 0, we hav e that DD( τ ∗ ) = α and P ( e τ > τ ∗ G + κ ) ≤ P { g DD ↓ ( τ ∗ G + κ ) > g DD ↓ ( e τ ) , E } + P ( E c ) = P { g DD ↓ ( τ ∗ G + κ ) − DD( τ ∗ G + κ ) > g DD ↓ ( e τ ) − DD( τ ∗ G + κ ) , E } + P ( E c ) ≤ P { g DD ↓ ( τ ∗ G + κ ) − DD( τ ∗ G + κ ) > α − ρ − DD( τ ∗ G + κ ) , E } + P ( E c ) = P { g DD ↓ ( τ ∗ G + κ ) − DD( τ ∗ G + κ ) > DD( τ ∗ ) − ρ − DD( τ ∗ G + κ ) , E } + P ( E c ) ≤ P (2 ρ > ( κ − θ ) γ ) + P ( E c ) = P ( E c ) , where the first inequality follows from the construction of Algorithm 4 and e τ is the one with the minim um absolute v alue; the second inequality follows from the fact that g DD ↓ ( e τ ) ≥ α − ρ as 53 sho wn in Theorem 26 ( iii ); the third inequalit y follo ws by Assumption 3 c , DD( τ ∗ ) > DD( τ ∗ G + κ ), | τ ∗ − τ ∗ G − κ | = τ ∗ G + κ − τ ∗ ≥ κ − θ and E ; and the last equalit y follo ws b y taking κ = (2 1 /γ + 1) ρ 1 /γ . Similarly , by taking κ = 2(2 1 /γ + 1) ρ 1 /γ , w e hav e that P ( e τ < τ ∗ G − κ ) ≤ P { g DD ↓ ( τ ∗ G − κ ) ≤ g DD ↓ ( e τ ) , E } + P ( E c ) = P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) ≥ DD( τ ∗ G − κ ) − g DD ↓ ( e τ ) , E } + P ( E c ) ≤ P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) ≥ DD( τ ∗ G − κ ) − α − ρ, E } + P ( E c ) = P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) ≥ DD( τ ∗ G − κ ) − DD( τ ∗ ) − ρ, E } + P ( E c ) ≤ P (2 ρ ≥ ( κ − θ ) γ ) + P ( E c ) = P ( E c ) , where the second inequality follo ws from the fact that g DD ↓ ( e τ ) ≤ α + ρ . Case 3: τ ∗ < 0 . The proof of Case 3 is similar to the pro of of Case 2 . W e include the difference here for completeness. In the case when τ ∗ < 0, w e hav e DD( τ ∗ ) = − α and b y taking κ = 2(2 1 /γ + 1) ρ 1 /γ , w e hav e P ( e τ > τ ∗ G + κ ) ≤ P { g DD ↓ ( τ ∗ G + κ ) ≥ g DD ↓ ( e τ ) , E } + P ( E c ) ≤ P { g DD ↓ ( τ ∗ G + κ ) − DD( τ ∗ G + κ ) ≥ DD( τ ∗ ) − DD( τ ∗ G + κ ) − ρ, E ) + P ( E c ) ≤ P { 2 ρ ≥ DD( τ ∗ ) − DD( τ ∗ G + κ ) , E ) + P ( E c ) ≤ P (2 ρ ≥ ( κ − θ ) γ ) + P ( E c ) = P ( E c ) . Similarly , P ( e τ < τ ∗ G − κ ) ≤ P { g DD ↓ ( τ ∗ G − κ ) < g DD ↓ ( e τ ) , E } + P ( E c ) = P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) > DD( τ ∗ G − κ ) − g DD ↓ ( e τ ) , E } + P ( E c ) ≤ P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) > DD( τ ∗ G − κ ) − ( − α + ρ ) , E } + P ( E c ) = P { DD( τ ∗ G − κ ) − g DD ↓ ( τ ∗ G − κ ) > DD( τ ∗ G − κ ) − DD( τ ∗ ) − ρ, E } + P ( E c ) ≤ P (2 ρ ≥ ( κ − θ ) γ ) + P ( E c ) = P ( E c ) , where the last inequality follo ws by choosing κ = (2 1 /γ + 1) ρ 1 /γ . Com bine three cases together, w e hav e that with probability at least 1 − η that | e τ − τ ∗ G | ≤ 2(2 1 /γ + 1) ρ 1 /γ . Therefore, the lemma follows by the triangle inequalit y with the fact that | τ ∗ G − τ ∗ | ≤ θ ≤ ρ 1 /γ . Prop osition 26. L et e τ b e the output of Algorithm 2 and denote ρ = C 1 " v u u t S X s =1 ν 2 s M log( h − d /η ) n s h d + max s ∈ [ S ] ν s M log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s M log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # γ + v u u t S X s =1 µ 2 s M log(1 /η ) ˘ n s + max s ∈ [ S ] µ s M log(1 /η ) ˘ n s + v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s . 54 Supp ose Assumptions 1 , 2 and 3 hold. We further assume that ϖ ≥ ( ρ ) 1 /γ and DD(0) / ∈ [ α − ζ , α ] ∪ [ − α, − α + ζ ] , wher e ρ ≤ ζ < α . Then the fol lowing events uniformly hold with pr ob ability at le ast 1 − η . (i) If τ ∗ = 0 , then we have e τ = 0 . (ii) In the c ase when τ ∗ = 0 , by cho osing θ = C 2 ρ 1 /γ , the solution of the optimisation pr oblem in A lgorithm 2 arg min τ ∈G {| τ | : | g DD ↓ ( τ ) | ∈ [ α − C 3 ρ, α + C 3 ρ ] } exists. (iii) In the c ase when τ ∗ > 0 , it holds that | g DD ↓ ( e τ ) − α | ≤ C 3 ρ . Also, in the c ase when τ ∗ < 0 , it holds that | g DD ↓ ( e τ ) + α | ≤ C 3 ρ . Pr o of. By c ho osing θ = C 2 ρ 1 /γ , we can alwa ys find | κ | ≤ θ ≤ ϖ suc h that the closest p oints to τ ∗ in the grid is τ ∗ G = τ ∗ + κ ∈ G . With suc h κ , consider the following even t E = | g DD ↓ ( τ ∗ G ) − DD( τ ∗ G ) | ≤ ρ ∩ | g DD ↓ ( τ ∗ ) − DD( τ ∗ ) | ≤ ρ ∩ { Output of Alg or ithm 4 is v alid and non-increasing } . By Lemmas 27 and 28 and a union b ound argument, we hav e that P {E } ≥ 1 − η . Pro of for ( i ) . In the case when τ ∗ = 0, we ha ve that τ ∗ G = 0 and | DD(0) | ≤ α − ζ ≤ α − ρ . Conditioning on E , we hav e with probabilit y at least 1 − η that | g DD ↓ (0) | ≤ | DD(0) | + ρ ≤ α. Therefore, S3 in Algorithm 2 will giv e us e τ = 0. Pro of for ( ii ) . T o show the solution exists, we will divide the pro of in to 2 cases. • In the case when τ ∗ > 0, w e hav e that DD( τ ∗ ) = α . Note that b y choosing θ = ( ρ ∗ ) 1 /γ , w e hav e | τ ∗ − τ ∗ G | ≤ θ ≤ ϖ and it holds with probabilit y at least 1 − η that | g DD ↓ ( τ ∗ G ) − α | ≤ | g DD ↓ ( τ ∗ G ) − DD( τ ∗ G ) | + | DD( τ ∗ G ) − DD( τ ∗ ) | ≤ ρ + (2 C m ) / (2 C π ) γ | τ ∗ G − τ ∗ | γ ≤ { 1 + (2 C m C γ 2 ) / (2 C π ) γ } ρ, where the first inequalit y follows from the triangle inequalit y , the second inequality follo ws from E and Theorem 32 and the third inequality follows since | τ ∗ G − τ ∗ | ≤ θ . • In the case when τ ∗ < 0, we ha ve that DD( τ ∗ ) = − α . Similarly , with probability at least 1 − η that | g DD ↓ ( τ ∗ G ) + α | ≤ | g DD ↓ ( τ ∗ G ) − DD( τ ∗ G ) | + | DD( τ ∗ G ) − DD( τ ∗ ) | ≤ C 3 ρ. Hence τ ∗ G is one solution to the optimisation problem in S3 . Pro of for ( iii ) . Similar to the pro of of ( ii ), w e will show this b y considering tw o cases sep erately . • When τ ∗ > 0, in this case, b y the pro of of ( ii ), w e hav e that τ ∗ G ≥ 0 is one solu tion satisfying | g DD ↓ ( τ ∗ G ) − α | ≤ C 3 ρ . Since e τ is the one with the minimum absolute v alue while satisfying the fairness constrain t, it suffices for us to show there do es not exists any τ ′ ∈ G , | τ ′ | ≤ τ ∗ G suc h that | g DD ↓ ( τ ′ ) + α | ≤ C 3 ρ . This can b e e asily v erified by the fact that { g DD ↓ ( τ ) } τ ∈G is a non-increasing sequence of p oin ts, hence w e must hav e g DD ↓ ( τ ′ ) ≥ g DD ↓ ( τ ∗ G ) ≥ 0 whenever τ ′ ≤ τ ∗ G . 55 • When τ ∗ < 0, we ha v e τ ∗ G ≤ 0 and | g DD ↓ ( τ ∗ G ) + α | ≤ C 3 ρ . Similar to the previous case, using Theorem 28 , it can b e easily show that there do es not exist any τ ′ ∈ G , τ ′ > τ ∗ G suc h that | g DD ↓ ( τ ′ ) − α | ≤ C 3 ρ . Lemma 27. Supp ose the same assumptions as in The or em 1 hold. F or any η ∈ [0 , 1 / 2] , denote ρ = " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # γ + v u u t S X s =1 µ 2 s log(1 /η ) ˘ n s + max s ∈ [ S ] µ s log(1 /η ) ˘ n s + v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s . Then we have that P n sup τ ∈G : | τ − τ ∗ |≤ ϖ | g DD ↓ ( τ ) − DD( τ ) | ≥ C 1 ρ o ≤ η , wher e ϖ is given in Assumption 3 b . Pr o of. With a sligh t abuse of notation, in this proof, denote D = { e η 0 , e η 1 , e π 0 , e π 1 } . By the triangle inequalit y , it holds that sup τ ∈G : | τ − τ ∗ |≤ ϖ | g DD ↓ ( τ ) − DD( τ ) | ≤ sup τ ∈G | g DD( τ ) − E { g DD( τ ) |D }| + sup τ ∈G : | τ − τ ∗ |≤ ϖ | E { g DD( τ ) |D } − DD( τ ) | + sup τ ∈G | g DD ↓ ( τ ) − g DD( τ ) | = ( I ) + ( I I ) + ( I I I ) , (31) where E { g DD( τ ) |D } is given by E { g DD( τ ) |D } = P X | A =1 n e η 1 ( X ) ≥ 1 2 + τ 2 e π 1 D o − P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ 2 e π 0 D o , and DD( τ ) is DD( τ ) = P X | A =1 n η 1 ( X ) ≥ 1 2 + τ 2 π 1 o − P X | A =0 n η 0 ( X ) ≥ 1 2 − τ 2 π 0 o . Step 1: Upp er b ound on ( I ) . F or any τ ∈ G , d DD s ( τ ) = 1 ˘ n s, 1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 1 n e η 1 ( ˘ X s,i 1 ,y ) ≥ 1 2 + τ 2 e π 1 o − 1 ˘ n s, 0 X y ∈{ 0 , 1 } ˘ n s, 0 ,y X i =1 1 n e η 0 ( ˘ X s,i 0 ,y ) ≥ 1 2 − τ 2 e π 0 o . Then w e hav e that for τ j ∈ G , g DD s ( τ j ) = d DD s ( τ j ) + ˘ n s, 1 N s, 1 − 1 1 ˘ n s, 1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 1 n e η 1 ( ˘ X s,i 1 ,y ) ≥ 1 2 + τ j 2 e π 1 o 56 − ˘ n s, 0 N s, 0 − 1 1 ˘ n s, 0 X y ∈{ 0 , 1 } ˘ n s, 0 ,y X i =1 1 n e η 0 ( ˘ X s,i 0 ,y ) ≥ 1 2 − τ j 2 e π 0 o + 1 N s, 1 M X ℓ =1 2 ℓ X k =1 ˘ w s, 1 ,ℓ,k 1 n ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j o − 1 N s, 0 M X ℓ =1 2 ℓ X k =1 ˘ w s, 0 ,ℓ,k 1 n ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j o . Consequen tly , sup τ ∈G | g DD( τ ) − E { g DD( τ ) |D }| = sup τ ∈G S X s =1 µ s g DD s ( τ ) − S X s =1 µ s E { g DD( τ ) |D } ≤ sup τ ∈G S X s =1 µ s d DD s ( τ ) − E { g DD( τ ) |D + 2 sup τ ∈G max a ∈{ 0 , 1 } S X s =1 µ s ˘ n s,a N s,a − 1 1 ˘ n s,a X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 n e η a ( ˘ X s,i a,y ) ≥ 1 2 + (2 a − 1) τ j 2 e π a o + 2 M sup ℓ,k,a S X s =1 µ s ˘ w s,a,ℓ,k N s, 1 ∧ N s, 0 = ( I ) 1 + ( I ) 2 + ( I ) 3 , where the second inequality follo ws from the fact that M X ℓ =1 2 ℓ X k =1 1 { ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j } ≤ M , for all j. Step 1-1: Upp er b ound on ( I ) 1 . T o control ( I ) 1 , denote b F s,a ( τ ) = 1 ˘ n s,a X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 n e η a ( ˘ X s,i a,y ) ≥ 1 2 + (2 a − 1) τ 2 e π a o = 1 ˘ n s,a X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 f τ ,a ( ˘ X s,i a,y ) , and F s,a ( τ ) = P X | A = a n e η a ( X ) ≥ 1 2 + (2 a − 1) τ 2 e π a D o = E n f τ ,a ( X ) D , A = a o . Then b y the triangle inequality , we hav e that ( I ) 1 ≤ sup τ ∈G S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) + sup τ ∈G S X s =1 µ s b F s, 0 ( τ ) − F s, 0 ( τ ) ≤ X a ∈{ 0 , 1 } sup τ ∈G S X s =1 ˘ n s,a,y X i =1 X y ∈{ 0 , 1 } µ s ˘ n s,a f τ ,a ( ˘ X s,i a,y ) − E { f τ ,a ( ˘ X s,i a,y ) |D , A = a } 57 When a = 1, note that max s ∈ [ S ] max y ∈{ 0 , 1 } max i ∈ [ ˘ n s, 1 ,y ] µ s n s, 1 f τ , 1 ( ˘ X s,i 1 ,y ) − E { f τ , 1 ( ˘ X s,i 1 ,y ) |D , A = 1 } ≤ max s ∈ [ S ] µ s ˘ n s, 1 , and sup τ ∈G V ar n S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) D o ≤ S X s =1 µ 2 s ˘ n s, 1 , where the last inequalit y follo ws from the indep endence b etw een samples within and across S servers conditional on D . Therefore, b y the Bennett concentration inequalit y for empirical pro cesses (e.g. Theorem 2.3 in Bousquet , 2002 ), it holds that P " sup τ ∈G S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) ≥ E n sup τ ∈G S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) D o + v u u t 2 t S X s =1 µ 2 s ˘ n s, 1 + t 3 max s ∈ [ S ] µ s ˘ n s, 1 D # ≤ exp( − t ) . T o control the exp ectation term, by the symmetrisation lemma (e.g. Lemma 2.3.1 in V an Der V aart and W ellner , 1996 ), it holds that E h sup τ ∈G S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) D i ≤ E h sup τ : | τ |≤ 1 S X s =1 µ s b F s, 1 ( τ ) − F s, 1 ( τ ) D i ≤ 2 E h sup τ : | τ |≤ 1 S X s =1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 µ s ˘ n s, 1 ξ s,i,y f τ , 1 ( ˘ X s,i 1 ,y ) D i , where { ξ s,i,y } is a sequence of i.i.d. Rademac her random v ariables. Conditioning on the samples { ˘ X s,i 1 ,y } and p o oling the data together, we can sort the v alues of { e η a ( ˘ X s,i a,y ) } in descending order and rewrite sup τ : | τ |≤ 1 S X s =1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 µ s ˘ n s, 1 ξ s,i,y f τ , 1 ( ˘ X s,i 1 ,y ) = sup τ : | τ |≤ 1 N X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j f τ , 1 ( ˘ X j ) , where N = P S s =1 P y ∈{ 0 , 1 } ˘ n s, 1 ,y and s ( j ) giv es the server label of the rank j v alue of { e η a ( ˘ X s,i a,y ) } . Since f τ , 1 ( · ) is an indicator function to test if the v alue of η 1 ( · ) exceeds the threshold 1 / 2 + τ / (2 e π 1 ), finding the τ ∗ , which gives the sup of the sum, is equiv alen t to finding the r ∗ -th v alue of sorted η 1 ( ˘ X s,i 1 ,y ) suc h that the sum | P r ∗ j =1 µ s ( j ) ξ j / ˘ n s ( j ) , 1 | is maximised. Th us, we hav e that sup τ : | τ |≤ 1 N X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j f τ , 1 ( ˘ X j ) = max r ∗ ∈ [ N ] r ∗ X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j . Since { S r = P r j =1 µ s ( j ) ξ j / ˘ n s ( j ) , 1 } is a martingale sequence, by Do ob’s maximal inequality (e.g. Theorem 4.4.4 in Durrett , 2019 ), we hav e that E ξ h max r ∗ ∈ [ N ] r ∗ X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j 2 D i ≤ 4 E ξ h N X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j 2 D i = 4 N X j =1 µ 2 s ( j ) ˘ n 2 s ( j ) , 1 = 4 S X s =1 µ 2 s ˘ n s, 1 . 58 T aking another exp ectation o ver { e η a ( ˘ X s,i a,y ) } and applying Jensen’s inequality lead to E h sup τ : | τ |≤ 1 S X s =1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 µ s ˘ n s, 1 ξ s,i,y f τ , 1 ( ˘ X s,i 1 ,y ) D i = E h max r ∗ ∈ [ N ] r ∗ X j =1 µ s ( j ) ˘ n s ( j ) , 1 ξ j D i ≤ 2 v u u t S X s =1 µ 2 s ˘ n s, 1 . A similar justification can also b e applied to the case when a = 0. Therefore, by a union b ound argumen t and tow er prop erty , w e hav e that P h ( I ) 1 ≥ C 1 n v u u t S X s =1 µ 2 s log(1 /η ) ˘ n s, 1 ∧ ˘ n s, 0 + max s ∈ [ S ] µ s log(1 /η ) ˘ n s, 1 ∧ ˘ n s, 0 oi ≤ η 9 . (32) Step 1-2: Upp er b ound on ( I ) 2 . Denote ι a,s,τ = 1 ˘ n s,a X y ∈{ 0 , 1 } ˘ n s,a,y X i =1 1 n e η a ( ˘ X s,i a,y ) ≥ 1 2 + (2 a − 1) τ 2 e π a o , and by construction, we ha ve that sup τ ,a,s ι 2 a,s,τ ≤ 1. Also, b y Theorem 31 , w e ha ve with probabilit y at least 1 − η / 18 that ( I ) 2 = 2 sup τ ∈G max a ∈{ 0 , 1 } S X s =1 µ s ι a,s,τ N s,a ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 ≤ C 2 sup τ ∈G max a ∈{ 0 , 1 } S X s =1 µ s ι a,s,τ ˘ n s,a ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 . Moreo ver, using the indep endence prop erty b et ween { ˘ w } s,a,ℓ,k and conditioning on { ι a,s,τ } S s =1 , w e the hav e that S X s =1 µ s ι a,s,τ ˘ n s,a ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 ∼ N 0 , S X s =1 8 µ 2 s ι 2 a,s M log(1 /δ s ) ˘ n 2 s,a ϵ 2 s . Consequen tly , the standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ) giv es us P n S X s =1 µ s ι a,s,τ ˘ n s,a ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 ≥ v u u t C 3 S X s =1 µ 2 s M log(1 /δ s ) log (1 /η ) ˘ n 2 s,a ϵ 2 s { ι a,s,τ } s ∈ [ S ] o ≤ P n S X s =1 µ s ι a,s,τ ˘ n s,a ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 ≥ C 3 v u u t S X s =1 µ 2 s ι 2 a,s M log(1 /δ s ) log (1 /η ) ˘ n 2 s,a ϵ 2 s { ι a,s,τ } s ∈ [ S ] o ≤ η 18 . Th us, by the tow er prop ert y and a union b ound argumen t, we hav e that P " ( I ) 2 ≥ C 15 v u u t S X s =1 µ 2 s M 2 log(1 /δ s ) log (1 /η ) { ˘ n s, 1 ∧ ˘ n s, 0 } 2 ϵ 2 s # ≤ η 9 . (33) Step 1-3: Upp er b ound on ( I ) 3 . On the even t in Theorem 31 , we ha ve with probability at least 1 − η / 10 that ( I ) 3 ≤ 2 M sup ℓ,k,a S X s =1 µ s ˘ w s,a,ℓ,k ˘ n s, 1 ∧ ˘ n s, 0 . 59 Note that the standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ershynin , 2018 ) giv es S X s =1 µ s ˘ w s,a,ℓ,k ˘ n s, 1 ∧ ˘ n s, 0 ∼ N 0 , S X s =1 4 µ 2 s M log(1 /δ s ) { ˘ n s, 1 ∧ ˘ n s, 0 } 2 ϵ 2 s . Therefore, by the standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ershynin , 2018 ) and a union b ound argument, we hav e P " ( I ) 3 ≥ C 4 v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) { ˘ n s, 1 ∧ ˘ n s, 0 } 2 ϵ 2 s # ≤ η 9 . (34) Step 2: Upp er b ound on ( I I ) . This is very similar to Step 2 in the pro of of Theorem 10 . W e only include the difference here. Denote T ∗ a = 1 / 2 + τ ∗ (2 a − 1) / (2 π a ) and write τ = τ ∗ + κ . It holds that sup κ : | κ |≤ ϖ P X | A =1 n e η 1 ( X ) ≥ 1 2 + τ ∗ + κ 2 e π 1 D o − P X | A =1 n η 1 ( X ) ≥ 1 2 + τ ∗ + κ 2 π 1 o = sup κ : | κ |≤ ϖ Z 1 n e η 1 ( x ) ≥ 1 2 + τ ∗ 2 e π 1 + κ 2 e π 1 o − 1 n η 1 ( x ) ≥ T ∗ 1 + κ 2 π 1 o P X | A =1 , D ( x ) ≤ sup κ : | κ |≤ ϖ Z 1 n η 1 ( x ) − T ∗ 1 − κ 2 π 1 ≤ ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ + κ | 2 · 1 e π 1 − 1 π 1 o P X | A =1 , D ( x ) ≤ sup κ : | κ |≤ ϖ Z 1 n η 1 ( x ) − T ∗ 1 − κ 2 π 1 ≤ ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 o P X | A =1 , D ( x ) ≤ C m ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 γ , where the last inequality follo ws from Assumption 3 b . Consider the follo wing even ts: E 1 = ( ∥ e η a − η a ∥ ∞ ≤ C 5 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # , a ∈ { 0 , 1 } ) , E 2 = ( | e π a − π a | ≤ C 6 ( v u u t S X s =1 ν 2 s log(1 /η ) n s + v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s ) , a ∈ { 0 , 1 } ) , and E 3 = { C 7 n s ≤ n s,a ≤ n s and C 8 ˘ n s ≤ ˘ n s,a ≤ ˘ n s , a ∈ { 0 , 1 } , s ∈ [ S ] } . By Lemmas 22 , 36 and Theorem 37 and a union bound argument, w e hav e that P ( E 1 ∩ E 2 ∩ E 3 ) ≥ 1 − η / 3. Under E 2 , it holds from the triangle inequality that e π 1 ≥ π 1 − C 9 ( v u u t S X s =1 ν 2 s log(1 /η ) n s + v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s ) ≥ C π 2 , 60 where the last inequality follo ws from Assumption 1 a . Consequently , we hav e that 1 e π 1 − 1 π 1 = | e π 1 − π 1 | e π 1 · π 1 ≤ 2 C 2 π | e π 1 − π 1 | . Th us, we hav e with probabilit y at least 1 − η / 6 that ∥ e η 1 − η 1 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 1 − 1 π 1 γ ≤ C 10 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d + v u u t S X s =1 ν 2 s log(1 /η ) n s + v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s # γ ≤ C 11 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s, 1 ϵ 2 s h 2 d # γ , (35) where the first inequality follows from Theorem 11 and the last inequalit y follows under E 3 . Similarly , we hav e that sup κ : | κ |≤ ϖ P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 e π 0 D o − P X | A =1 n η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 π 0 o ≤ sup κ : | κ |≤ ϖ Z 1 n η 0 ( x ) − T ∗ 0 + κ 2 π 0 ≤ ∥ e η 0 − η 0 ∥ ∞ + | τ ∗ + κ | 2 · 1 e π 0 − 1 π 0 o P X | A =0 , D ( x ) ≤ C m ∥ e η 0 − η 0 ∥ ∞ + | τ ∗ | + ϖ 2 · 1 e π 0 − 1 π 0 γ . By a similar argumen t leading to ( 35 ), we hav e that with probability at least 1 − η / 6, we hav e that sup κ : | κ |≤ ϖ P X | A =0 n e η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 e π 0 D o − P X | A =1 n η 0 ( X ) ≥ 1 2 − τ ∗ + κ 2 π 0 o ≤ C 12 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # γ . By a union b ound argument, we hav e with probability at least 1 − η / 3 that ( I I ) ≤ C 13 " v u u t S X s =1 ν 2 s log( h − d /η ) n s h d + max s ∈ [ S ] ν s log( h − d /η ) n s h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s ϵ 2 s h 2 d # γ . (36) 61 Step 3: Upper b ound on ( I I I ) . By Theorem 28 , w e hav e with probabilit y at least 1 − η / 3 that ( I I I ) ≤ ω = C 14 v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s (37) Step 4: The lemma thus follo ws b y applying a union b ound argument, Theorem 37 , and substituting the results in ( 32 ), ( 33 ), ( 34 ), ( 36 ) and ( 37 ) into ( 31 ). Lemma 28. Denote { f i } i ∈ [2 M +1] the output of A lgorithm 4 with input se quenc e { g DD( τ i ) } i ∈ [2 M +1] . It holds with pr ob ability at le ast 1 − η that A lgorithm 4 wil l output a non-incr e asing se quenc e f 1 , . . . , f 2 M +1 satisfying sup i ∈ [2 M +1] | f i − g DD( τ i ) | ≤ ω . Pr o of. By construction, if Algorithm 4 do es not output NULL , then the lemma follows. There- fore, in the rest of the proof, it suffices for us to show that for all i ∈ [2 M + 1], with large probabilit y , f i = min { f i − 1 , g DD( τ i ) + ω } ≥ g DD( τ i ) − ω . W e will show this b y an induction argumen t. Denote E = ( g DD( τ 1 ) ≥ g DD( τ 2 ) − ω , for all τ 1 , τ 2 ∈ G , τ 1 ≤ τ 2 ) . By Theorem 29 , w e hav e that P ( E ) ≥ 1 − η . The rest of the pro of is constructed conditioning on E happ ening. Consider another sequence { h i } i ∈ [2 M +1] , where h i = sup j ≥ i g DD( τ j ) − ω . By construction, we ha ve that { h i } is non-increasing. Moreov er, since for all j ≥ i , w e ha ve that g DD( τ i ) ≥ g DD( τ j ) − ω . It holds that g DD( τ i ) ≥ sup j ≥ i g DD( τ j ) − ω = h i ≥ g DD( τ i ) − ω . (38) With the newly defined sequence { h i } , w e prov e the lemma by induction. F or the base case when i = 1, we ha ve that f 1 = g DD( τ 1 ) + ω ≥ g DD( τ 1 ) − ω . Also, f 1 ≥ g DD( τ 1 ) ≥ h 1 b y construction. Next, supp ose that min { f l − 1 , g DD( τ l ) + ω } ≥ g DD( τ l ) − ω and f l ≥ h l for l ∈ [2 M + 1] \{ 1 } . W e wan t to show min { f l , g DD( τ l +1 ) + ω } ≥ g DD( τ l +1 ) − ω and f l +1 ≥ h l +1 . By construction, w e hav e that h l +1 ≤ g DD( τ ℓ +1 ) ≤ g DD( τ ℓ +1 ) + ω . Also, since { h l } is non- increasing, w e hav e that h ℓ +1 ≤ h ℓ ≤ f ℓ . Combine the t wo b ounds together, w e hav e that h ℓ +1 ≤ min { f ℓ , g DD( τ ℓ +1 ) + ω } = f ℓ +1 . In addition, since h ℓ +1 ≥ g DD( τ ℓ +1 ) − ω b y ( 38 ). W e ha ve shown that g DD( τ ℓ +1 ) − ω ≤ h ℓ +1 ≤ f ℓ +1 . Thus, the induction step holds and the condition f i < g DD( τ i ) − ω is nev er satisfied under E . Lemma 29. Supp ose the same assumptions as in The or em 2 hold. F or any η ∈ (0 , 1 / 2) , it holds that P " g DD( τ 1 ) ≥ g DD( τ 2 ) − C 1 v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s , for al l τ 1 , τ 2 ∈ G , τ 1 ≤ τ 2 # ≥ 1 − η . 62 Pr o of. Note we can rewrite g DD( τ ) = d DD( τ ) + ε 0 ( τ ) , where for an y τ = τ j ∈ G , ε 0 ( τ ) = S X s =1 µ s " ˘ n s, 1 N s, 1 − 1 1 ˘ n s, 1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 1 n e η 1 ( ˘ X s,i 1 ,y ) ≥ 1 2 + τ 2 e π 1 o − ˘ n s, 0 N s, 0 − 1 1 ˘ n s, 0 X y ∈{ 0 , 1 } ˘ n s, 0 ,y X i =1 1 n e η 0 ( ˘ X s,i 0 ,y ) ≥ 1 2 − τ 2 e π 0 o + 1 N s, 1 M X ℓ =1 2 ℓ X k =1 ˘ w s, 1 ,ℓ,k 1 n ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j o − 1 N s, 0 M X ℓ =1 2 ℓ X k =1 ˘ w s, 0 ,ℓ,k 1 n ( k − 1)2 M − ℓ + 1 ≥ j and ( ⌈ k / 2 ⌉ − 1)2 M − ℓ +1 + 1 < j o # , and d DD( · ) is defined in Theorem 30 . By a similar argumen t to con trol ( I ) 2 and ( I ) 3 in Step 1-3 in the pro of of Theorem 27 , we hav e with probabilit y at least 1 − η that sup τ ∈G | ε 0 ( τ ) | ≤ C 1 v u u t S X s =1 µ 2 s M 4 log(1 /δ s ) log ( M /η ) ˘ n 2 s ϵ 2 s . Consequen tly , the lemma follo ws by the fact that d DD is non-increasing as shown in Theorem 30 and a union b ound argument ov er all p ossible c hoices of τ 1 , τ 2 ∈ G . Corollary 30. F or any τ ∈ G , denote d DD( τ ) = P S s =1 ν s d DD s ( τ ) , wher e d DD s ( τ ) = 1 N s, 1 X y ∈{ 0 , 1 } ˘ n s, 1 ,y X i =1 1 n e η 1 ( ˘ X s,i 1 ,y ) ≥ 1 2 + τ 2 e π 1 o − 1 N s, 0 X y ∈{ 0 , 1 } ˘ n s, 0 ,y X i =1 1 n e η 0 ( ˘ X s,i 0 ,y ) ≥ 1 2 − τ 2 e π 0 o . Then we have that d DD( · ) is a non-incr e asing function. Pr o of. Theorem 30 follo ws from a similar argumen t as Theorem 12 . W e omit the proof here. Lemma 31. If we additional ly assume that min s ∈ [ S ] ˘ n 2 s,a ϵ 2 s ≥ C 1 M log(1 /δ s ) log ( S/η ) , then P n C 1 ˘ n s,a ≤ N s,a ≤ C 2 ˘ n s,a , for al l s ∈ [ S ] , a ∈ { 0 , 1 } o ≥ 1 − η . Pr o of. By construction in Algorithm 2 , since for any s, i, a, y , we hav e e π a ∈ [0 , 1] , e η ∈ [0 , 1], hence Z s,i,a,y ∈ [ − 1 , 1], and we hav e that for any a ∈ { 0 , 1 } , N s,a = ˘ n s,a + ˘ w s,a, 1 , 1 + ˘ w s,a, 1 , 2 . 63 By standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ) and a union b ound argumen t, we hav e that with probabilit y at least 1 − η that for all s ∈ [ S ] and a ∈ { 0 , 1 } , | N s,a − ˘ n s,a | ≤ C 1 s M log(1 /δ s ) log ( S/η ) ϵ 2 s . Hence, by using a similar argumen t as the one used in the pro of of Theorem 18 , the lemma holds whenev er min s ∈ [ S ] ˘ n 2 s,a ϵ 2 s ≥ C 2 M log(1 /δ s ) log ( S/η ). Lemma 32. Under Assumption 3 b , we have for any smal l ρ in the neighb ourho o d of 0 , | DD( τ ∗ + ρ ) − DD( τ ∗ ) | ≤ (2 C m ) / (2 C π ) | ρ | γ . Pr o of. By definition, we hav e that for any ρ > 0, we hav e 0 < DD( τ ∗ ) − DD( τ ∗ + ρ ) = P n 1 2 + τ ∗ 2 π 1 ≤ η 1 ( X ) < 1 2 + τ ∗ + ρ 2 π 1 o + P n 1 2 − τ ∗ + ρ 2 π 0 ≤ η 0 ( X ) < 1 2 − τ ∗ 2 π 0 o = P n 0 ≤ η 1 ( X ) − T ∗ 1 < ρ 2 π 1 o + P n − ρ 2 π 0 ≤ η 0 ( X ) − T ∗ 0 < 0 o ≤ P n | η 1 ( X ) − T ∗ 1 | < ρ 2 π 1 o + P n | η 0 ( X ) − T ∗ 0 | < ρ 2 π 0 o ≤ 2 C m (2 C π ) γ ρ γ , where the last inequality follo ws from Assumption 3 b . Similarly , when ρ < 0, we hav e that 0 < DD( τ ∗ + ρ ) − DD( τ ∗ ) = P n ρ 2 π 1 ≤ η 1 ( X ) − T ∗ 1 < 0 o + P n 0 ≤ η 0 ( X ) − T ∗ 0 < − ρ 2 π 0 o ≤ P n | η 1 ( X ) − T ∗ 1 | < − ρ 2 π 1 o + P n | η 0 ( X ) − T ∗ 0 | < − ρ 2 π 0 o ≤ 2 C m (2 C π ) γ ( − ρ ) γ . Therefore, w e hav e that for any small ρ in the neighbourho o d of 0, | DD( τ ∗ + ρ ) − DD( τ ∗ ) | ≤ C 2 | ρ | γ . C.3.3 Upp er b ound on ∥ e p X | A = a − p X | A = a ∥ ∞ Lemma 33. Under the same assumptions as in The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P ( ∥ e p X | A = a − p X | A = a ∥ ∞ ≥ C 1 " v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + max s ∈ [ S ] ν s log( h − d /η ) n s,a h d + h β + v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d #) ≤ η . 64 Pr o of. The proof is similar to the argument used in the pro of of Theorem 13 . By the triangle inequalit y , we hav e that ∥ e p X | A = a − p X | A = a ∥ ∞ ≤ sup x ∈ [0 , 1] d S X s =1 ν s n s,a X y ∈{ 0 , 1 } n s,a,y X i =1 K h ( X s,i a,y − x ) − p X | A = a ( x | a ) + sup x ∈ [0 , 1] d S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 1 ,a ( x ) ≤ sup x ∈ [0 , 1] d S X s =1 ν s n s,a X y ∈{ 0 , 1 } n s,a,y X i =1 K h ( X s,i a,y − x ) − Z x K h ( u − 1) p X | A = a ( u | a ) d u + sup x ∈ [0 , 1] d Z x K h ( u − 1) p X | A = a ( u | a ) d u − p X | A = a ( x | a ) + sup x ∈ [0 , 1] d S X s =1 8 ν s p 2 C K log(8 /δ s ) n s,a ϵ s h d W s 1 ,a ( x ) = ( I ) + ( I I ) + ( I I I ) . T o control ( I ), by Theorem 35 , we hav e that P n ( I ) ≥ C 1 v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + C 2 max s ∈ [ S ] ν s log( h − d /η ) n s,a h d o ≤ η 2 . T o control ( I I ), by Assumptions Assumption 1 b and 2 c , we hav e that ( I I ) ≤ C adp h β . T o control ( I I I ), by Theorem 24 , w e hav e that P n ( I I I ) ≥ C 3 v u u t S X s =1 ν 2 s log(1 /δ s ) log ( h − 1 /η ) n 2 s,a ϵ 2 s h 2 d o ≤ η 2 . The lemma th us follows from a union b ound argumen t. Corollary 34. Under the same assumption of The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n C 1 ≤ inf x ∈ [0 , 1] d e p X | A = a ( x ) ≤ sup x ∈ [0 , 1] d e p X | A = a ( x ) ≤ C 2 o ≥ 1 − η . Pr o of. The proof follo ws from Theorem 33 and a similar argumen t used in the pro of of Theo- rem 14 . W e omit the pro of here. 65 Corollary 35. Under the same assumption of The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P n sup x ∈ [0 , 1] d S X s =1 ν s n s,a X y ∈{ 0 , 1 } n s,a,y X i =1 K h ( X s,i a,y − x ) − Z x K h ( u − 1) p X | A = a ( u | a ) d u ≥ C 1 v u u t S X s =1 ν 2 s log( h − d /η ) n s,a h d + C 2 max s ∈ [ S ] ν s log( h − d /η ) n s,a h d o ≤ η . Pr o of. The pro of follows from similar argumen ts to the pro ofs of Lemmas 15 and 23 . W e omit it here. C.3.4 Upp er b ound on | e π a − π a | Lemma 36. Under the same assumptions as in The or em 2 , it holds for any η ∈ (0 , 1 / 2) and a ∈ { 0 , 1 } that P " | e π a − π a | ≥ C 1 ( v u u t S X s =1 ν 2 s log(1 /η ) n s + v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s )# ≤ η . Pr o of. Consider the sequence of b ounded random v ariables 1 { A s i = a } N a i =1 , and w e hav e that e π a = S X s =1 ν s n s,a, 0 + n s,a, 1 n s + w s a = S X s =1 n s X i =1 ν s 1 { A s i = a } n s + S X s =1 ν s w s a . By general Ho effding’s inequality (e.g. Theorem 2.6.2 in V ersh ynin , 2018 ), w e hav e that for an y t 1 > 0, P S X s =1 n s X i =1 ν s 1 { A s i = a } n s − π a ≥ t 1 ≤ C 1 exp − t 2 1 P S s =1 ν 2 s n s ! . Moreo ver, by standard prop erties of Gaussian random v ariables, we hav e that S X s =1 ν s w s a ∼ N 0 , S X s =1 ν 2 s σ 2 s , where σ = 4 p 2 log (5 /δ s ) / ( n s ϵ s ). Thus standard Gaussian tail prop erties (e.g. Prop osition 2.1.2 in V ersh ynin , 2018 ) gives for any t 2 > 0, P S X s =1 ν s w s a ≥ t 2 ≤ C 2 exp − t 2 2 P S s =1 ν 2 s log(1 /δ s ) n 2 s ϵ 2 s ! . T aking t 1 = C 3 v u u t S X s =1 ν 2 s log(1 /η ) n s , and t 2 = C 4 v u u t S X s =1 ν 2 s log(1 /δ s ) log (1 /η ) n 2 s ϵ 2 s , the lemma th us follows by a union b ound argument. Corollary 37. F or any min { n s , ˘ n s } ≥ 4 C 2 1 log( S/η ) /C 2 π , it holds that P n C 2 n s ≤ n s,a ≤ n s , and C 3 ˘ n s ≤ ˘ n s,a ≤ ˘ n s , a ∈ { 0 , 1 } , s ∈ [ S ] o ≥ 1 − η . Pr o of. The proof follo ws from Theorem 36 and a similar argumen t used in the pro of of Theo- rem 18 . W e omit it here. 66 D Additional background W e collect some bac kground results that are used throughout the pap er. D.1 Additional background related to DP Lemma 38 (Gaussian mechanism for univ ariate output, Theorem 3.22 in Dwork et al. , 2014 ) . L et f b e a function f : D → R such that ∆( f ) = sup D ∼ D ′ | f ( D ) − f ( D ′ ) | is finite. Then for any ϵ, δ > 0 , the me chanism M ( D ) = f ( D ) + p 2 log (1 . 25 /δ )∆( f ) Z /ϵ is ( ϵ, δ ) -CDP, wher e Z ∼ N (0 , 1) . Lemma 39 (Gaussian mechanism for functional output, Corollary 9 in Hall et al. , 2013 ) . L et G b e a Gaussian pr o c ess with me an zer o and c ovarianc e function K . We further denote K the RKHS sp ac e asso ciate d with kernel K with RKHS norm ∥ · ∥ K . Then for any function f : D → K , the p oint-wise r ele ase of f D ( · ) + p 2 log (2 /δ )∆ K ( f ) ϵ G ( · ) is ( ϵ, δ ) -CDP, wher e ∆ K ( f ) = sup D ∼ D ′ ∥ f D − f D ′ ∥ K and f D ( · ) is a shorthand notion for f ( D )( · ) . Lemma 40 (Comp osition of DP , e.g. Theorem 3.16 in Dw ork et al. ( 2014 )) . F or ϵ 1 , ϵ 2 > 0 and δ 1 , δ 2 ≥ 0 . Supp ose that algorithms M 1 and M 2 ar e ( ϵ 1 , δ 1 ) -DP and ( ϵ 2 , δ 2 ) -DP r esp e ctively. It then holds that the c omp osition M 1 ◦ M 2 is ( ϵ 1 + ϵ 2 , δ 1 + δ 2 ) -DP. D.2 Additional background related to F airness Definition 6 (Definitions 3.2 and 3.3 in Zeng et al. , 2024a ) . We c al l a disp arity me asur e D : F → [0 , 1] line ar if for al l P , ther e is a weighting function w D , P : [0 , 1] d × { 0 , 1 } → R such that for al l f ∈ F , D( f ) = X a ∈{ 0 , 1 } Z [0 , 1] d f ( x, a ) w D ( x, a ) d P X,A ( x, a ) . We further c al l the disp arity me asur e D biline ar if for al l P , ther e is s D ,a and b D ,a dep ending on a ∈ { 0 , 1 } such that for al l x ∈ [0 , 1] d , w D ( x, a ) = s D ,a · η a ( x ) + b D ,a . Prop osition 41 (Prop osition 3.4 in Zeng et al. , 2024a ) . The disp arity me asur e DD in Defini- tion 4 is biline ar with weighting functions define d for al l x, a by w DD ( x, a ) = (2 a − 1) π a . Thus we have s DD ,a = 0 and b DD ,a = (2 a − 1) /π a . Theorem 42 (Theorem 4.2 in Zeng et al. , 2024a ) . Assume that η a ( X ) is a c ontinuous r andom variable for a ∈ { 0 , 1 } . F or any τ ∈ R and a given biline ar disp arity me asur e D in Definition 6 , denote the classifier g D ,τ ( x, a ) = 1 , (2 − τ s D ,a ) η a ( x ) ≥ 1 + τ b D ,a , 0 , (2 − τ s D ,a ) η a ( x ) < 1 + τ b D ,a , and let D( τ ) = D( g D ,τ ) . Then, for any α ≥ 0 , the α -fair Bayes optimal classifier is f ∗ D ,α = g D ,τ ∗ D ,α , wher e τ ∗ D ,α = arg min τ ∈ R | τ | : | D( τ ) | ≤ α . 67 Prop osition 43 (Prop osition 4.1 in Zeng et al. , 2024a ) . R e c al l that D ( τ ) = D ( g D,τ ) , wher e g D,τ is define d in The or em 42 . Then, under the assumptions in The or em 42 , the fol lowing pr op erties hold. (i) The disp arity D ( τ ) is c ontinuous and non-incr e asing. (ii) The misclassific ation R ( g D,τ ) is non-incr e asing with r esp e ct to τ on ( −∞ , 0) and non- de cr e asing with r esp e ct to τ on (0 , + ∞ ) . 68
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment