정규화된 상위 순위통계를 활용한 스코어링 규칙 기반 꼬리 지수 추정
본 논문은 프레셰 도메인에서 예측 분포를 비교·선택하기 위해 정규화된 상위 순위통계와 적절한 스코어링 규칙을 결합한 새로운 프레임워크를 제안한다. 이 방법은 꼬리 지수 차이를 구별할 수 있으며, 점수 최적화를 통해 일관된 꼬리 지수 추정량을 얻고, 기존 Hill 추정기를 특수 경우로 포함한다. 이론적 일관성·정규성 증명과 시뮬레이션·실제 자동차 손해 데이터 분석을 통해 성능을 검증한다.
저자: Martin Bladt, Christoffer Øhlenschlæger
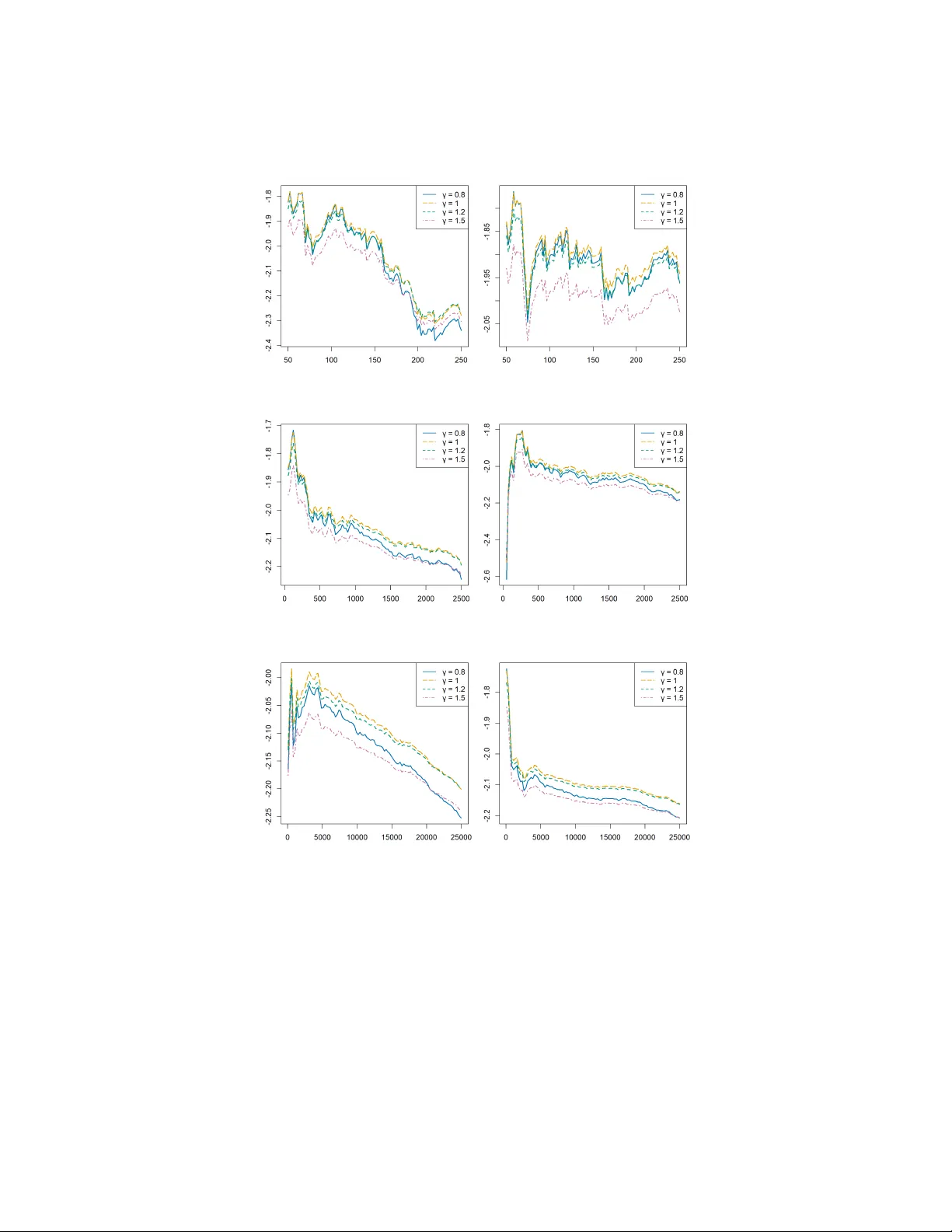
본 논문은 프레셰 도메인(heavy‑tail)에서 예측 분포를 비교·선택하기 위한 새로운 스코어링 규칙 기반 프레임워크를 제시한다. 전통적인 스코어링 규칙(예: 로그 스코어, 연속 순위 확률 점수)은 전체 분포에 대한 적합도는 평가하지만, 꼬리 지수(γ)의 차이를 구별하지 못한다는 한계가 있다. 이를 해결하기 위해 저자들은 “정규화된 상위 순위통계”라는 변환을 도입한다. 표본의 상위 k개 순위통계 Y_{n,n−i+1}를 t_n = Y_{n,n−k} 로 나누어 Y^{*}_i = Y_{n,n−i+1}/t_n (i=1,…,k) 로 정의한다. 이 변환은 k/n→0, k→∞ 조건 하에서 한계 분포가 Pareto(γ) 형태가 되므로, 스코어링 규칙의 기대값이 오직 γ에만 의존하게 된다.
스코어링 규칙 S(F,·)는 연속이고, |S(F,y)| ≤ A y^{(1−δ)/γ} (δ∈(0,1))와 같은 지배 조건을 만족하면, 정규화된 상위 순위통계에 대한 경험적 점수
S_k(F)= (1/k)∑_{i=1}^k S(F, Y^{*}_i)
는 확률적으로 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기