Scoring Rules with Normalized Upper Order Statistics for Tail Inference
This paper proposes a scoring-rule-based method for ranking predictive distributions in the Fréchet domain that is able to distinguish between different tail indices. The approach is built on normalized order statistics and exploits proper scoring ru…
Authors: Martin Bladt, Christoffer Øhlenschlæger
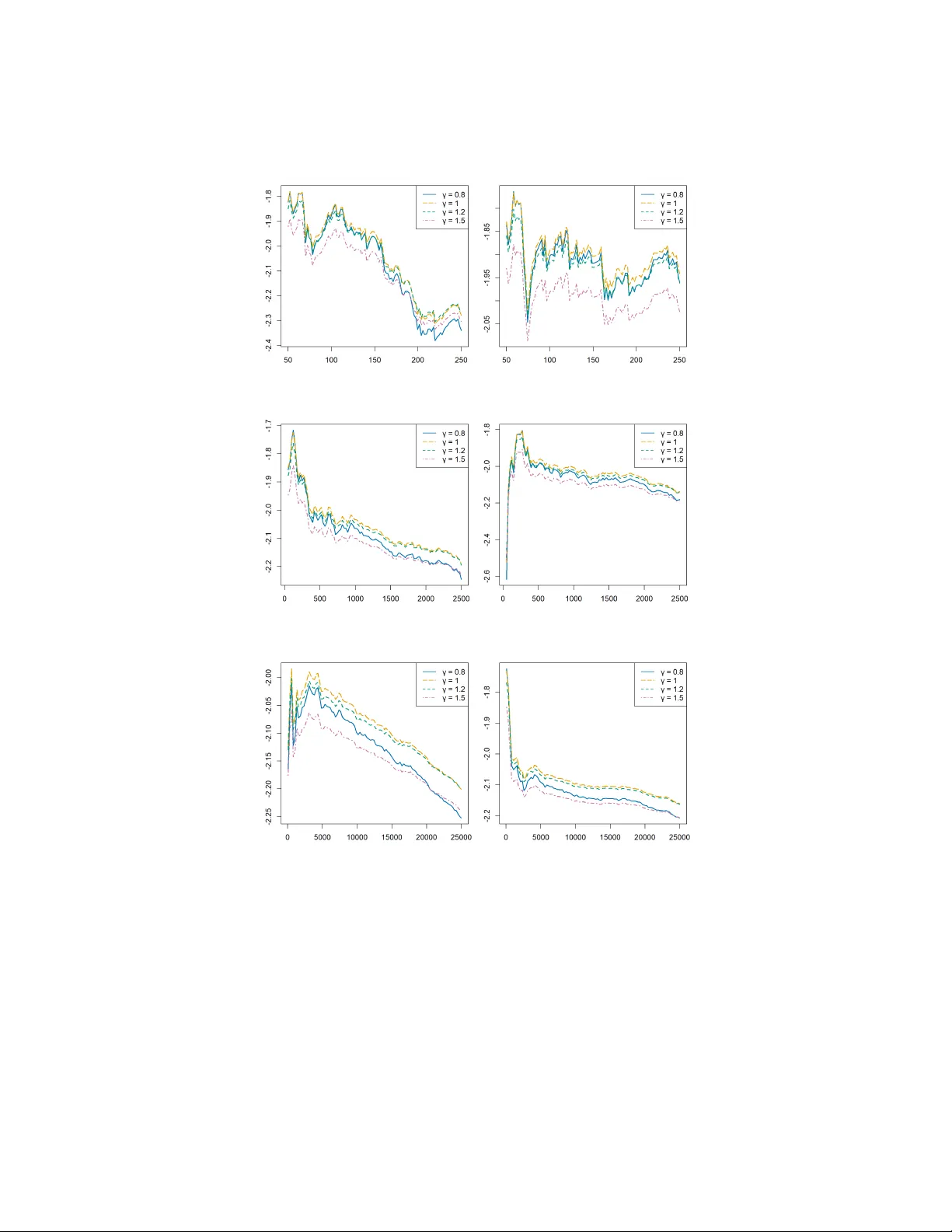
Scoring R ules with Normalized Upp er Order Statistics for T ail Inference Martin Bladt and Christoffer Øhlensc hlæger Dep artment of Mathematic al Scienc es, University of Cop enhagen Universitetsp arken 5, 2100 Cop enhagen Ø, Denmark e-mail: martinbladt@math.ku.dk ; choh@math.ku.dk Abstract: This paper prop oses a scoring-rule-based metho d for ranking predictive distributions in the F réchet domain that is able to distinguish between different tail indices. The approac h is built on normalized order statistics and exploits proper scoring rules to compare tail limit distri- butions in a distributional framework, with direct relev ance for insurance claim-severit y tails. On the theoretical side, consistency and asymptotic normality for empirical tail scores based on normalized upper order statis- tics are obtained through residual estimation theory . Sim ulation results demonstrate that the scoring-rule-based approac h is capable of discrimi- nating b et ween different tail b eha viors in finite samples and that trends in the scaling ha ve only a minor impact on stabilit y . W e further sho w that optimizing scoring rules (equiv alently , minimizing the asso ciated loss form) yields consisten t tail-index estimators and that the classical Hill estimator arises as a sp ecial case. The p erformance of the proposed metho d is inv es- tigated and compared with the Hill estimator across a range of tail indices. Lastly , w e analyze an automobile claim-severit y data set to demonstrate how scoring rules can b e used to rank predictive mo dels based on tail pre- dictions in actuarial settings. Keyw ords and phrases: extreme v alues, scoring rules, tail index, predic- tive distribution. 1. In tro duction Flo o ds, earthquak es, and other catastrophic even ts o ccur infrequently , yet they can generate substan tial financial losses. A sound understanding of b oth the frequency and the sev erity of suc h extremes is therefore essen tial for actuar- ial risk assessmen t. T o mo del suc h phenomena, Extr eme V alue The ory (EVT) pro vides a fundamental framework and is a standard to ol in actuarial science and risk management (e.g., [ 8 ]). In practice, ho wev er, risk assessments hav e traditionally relied primarily on p oint forecasts. By adopting predictive distri- butions, one obtains a more complete description of risk, and a growing bo dy of literature has therefore fo cused on distributional approaches to uncertaint y quan tification (see, e.g., [ 3 , 17 , 15 ]). Assessment of predictiv e distributions typi- cally inv olv es tw o complementary asp ects: c alibr ation , which examines whether predicted probabilities are statistically consistent with observed outcomes, and sc oring rules , whic h provide a principled w ay to compare and rank different pre- dictiv e distributions ([ 11 , 10 ]). In actuarial applications, mo del selection rarely in v olves choosing b etw een a clearly correct and a clearly incorrect sp ecification. 1 /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 2 Practitioners t ypically face sev eral comp eting mo dels, so a data-driven rank- ing provides an ob jective and repro ducible basis for pricing, reserving, and risk comm unication. In addition, the full ranking can guide the selection of alterna- tiv e models when practical considerations such as interpretabilit y , robustness, or regulatory constraints are taken into accoun t. Accordingly , this pap er prop oses a metho d for ranking predictive distributions in the F réc het domain based on prop er scoring rules and normalized upp er order statistics. Because this approach relies on scoring-rule comparisons, it is crucial that the scoring rule remains pr op er , i.e., E Y ∼ F [ S ( F , Y )] ≥ E Y ∼ F [ S ( G, Y )] , for all predictiv e distributions G , where S ( · , · ) denotes the scoring rule and Y ∼ F represen ts the true data-generating distribution. Prop erness ensures that the forecaster is incen tivized to issue their genuine predictive distribution [ 11 ]. The dangers of using improp er scoring rules can b e seen in [ 16 ], which demonstrate how misassessmen t of extreme even ts can lead forecasters to issue predictions that are more extreme than they actually b eliev e. Against this background, there is a v ast literature on predictiv e distributions and extreme even ts. One common approac h is to employ weigh ted scoring rules, whic h allow greater emphasis to b e placed on large observ ations, for example b y using a weigh t function of the form w ( y ) = 1 { y ≥ t } for some threshold t . Studies inv estigating prop er weigh ted scoring rules include [ 12 ], [ 13 ], [ 1 ], [ 21 ] and [ 22 ]. In addition to their theoretical contributions, several of these studies pro vide empirical illustrations of ho w weigh ted scoring rules can b e applied to ev aluate tail p erformance. A central concern in this literature is the abilit y of predictive distributions to differen tiate b etw een tail indices. [ 19 ] shows that the widely used Contin uous Rank ed Probability Score (CRPS) fails to distinguish b etw een predictive distri- butions with different tail indices. [ 4 ] extend the result by pro ving that no prop er scoring rule can discriminate b etw een tail indices, i.e., it is alwa ys p ossible to construct tw o comp eting predictive distributions with distinct tail indices whose scoring rule v alues are arbitrarily close. [ 2 ] strengthen this finding b y showing that this limitation cannot be ov ercome b y taking the maximum ov er m ultiple scoring rules. The studies conclude that scoring rules are unsuitable when the ob jectiv e is to assess or compare tail indices. Our approach addresses this limitation by basing ev aluation on normalized upp er order statistics rather than the full sample. This ensures that the limiting distribution dep ends solely on the tail index and thereby allo ws meaningful dis- crimination b etw een predictiv e distributions with differen t tail b ehaviors. More- o v er, the framew ork supp orts in v estigation of b oth the asymptotic tail index of predictiv e distributions and the statistical properties of the corresponding order statistics (see Remark 11 ). Complemen tary to this line of work, there has also b een in terest in assessing the calibration of predictiv e distributions with a fo cus on the extremes. This topic is explored in [ 2 ], where the concept of tail calibration is introduced. The /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 3 authors demonstrate that tail calibration can serv e as a useful to ol for distin- guishing b etw een distributions with different tail b eha viors, and they dev elop practical metho ds to assess and impro ve the calibration of predictiv e distribu- tions. Notably , the framework of tail calibration is not limited to the F réchet domain but can also b e applied to the Gum b el and W eibull domains. Bey ond mo del ranking, this pap er inv estigates the use of scoring-rule opti- mization as an estimation metho d for the tail index. More precisely , let S ( X , θ ) b e a strictly prop er scoring rule and let ( x 1 , x 2 , . . . , x n ) b e an i.i.d. sample. Then, the scoring-rule estimator is defined as ˆ θ S = arg max θ n X i =1 S ( x i , θ ) . [ 5 ] sho ws that, under regularit y conditions, this estimator is consistent and asymptotically Gaussian. In addition, the asso ciated estimating equation is sho wn to b e unbiased. This places minimum scoring rule inference within the broader framework of M -estimation (see, e.g., [ 14 ]). Scoring-rule estimators hav e also found applications in the applied sciences, for instance in w eather fore- casting [ 9 ], where CRPS is used. F or a comprehensiv e revie w of scoring-rule inference, see [ 20 ]. Finally , we in v estigate the effect of heterogeneous scaling on our prop osed metho d. In the extreme v alue theory literature, this setting has b een studied theoretically by [ 7 ]. Through sim ulation studies, w e assess whether the prop osed approac h remains robust under such heterogeneous scaling. T o illustrate the practical implementation of the proposed framew ork, w e ana- lyze the usautoBI (USA utoBI) b o dily injury claims data from the CASdatasets pac kage in R . In this application, five Pareto predictive distributions are com- pared and ranked using the proposed scoring-rule approac h. W e further consider t w o data partitions based on p olicyholder characteristics. While one split leads to the same ranking as in the full sample, the other results in a differen t ordering of the mo dels, indicating that tail b ehavior v aries across subp opulations. In summary , our contributions are threefold: first, we prop ose a scoring-rule framew ork for tail-mo del ranking based on normalized upp er order statistics; second, we provide asymptotic justification and sho w ho w score optimization yields a consistent tail-index estimator with Hill as a sp ecial case; and third, w e illustrate the framework in simulation studies and in a real claim-sev erity application. The pap er is organized as follows. Section 2 in tro duces the core concepts from b oth the scoring rule and extreme v alue theory literature that are used throughout the pap er. Section 3 presents the main theoretical results and Sec- tion 4 in tro duces our prop osed metho d. Section 5 inv estigates the finite-sample p erformance of our metho d through sim ulation studies, demonstrating promis- ing results ev en for relatively small sample sizes. Finally , Section 6 applies the prop osed scoring rule framework to a claim severit y dataset. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 4 2. Bac kground and Preliminaries 2.1. Pr op er Sc oring Rules T o fix notation, we follo w [ 11 ]. Let Ω be a sample space and let A be a σ -algebra of subsets of Ω . Then we denote P as the conv ex class of probability measures. Before defining the score function, w e introduce the term quasi-integrable. Definition 1 ( P -quasi-in tegrable) . f is quasi-inte gr able with r esp e ct to P ∈ P if it is A me asur able and if either f + or f − has a r e al inte gr al. f is P -quasi- inte gr able if it is quasi-inte gr able with r esp e ct to al l P ∈ P . With this setup, a scoring rule is defined as Definition 2 (Scoring rule) . A ny S : P × Ω → R is a sc oring rule if it is P -quasi-inte gr able for al l P ∈ P . With this notation, we write S ( P , Q ) := E Q [ S ( P , X )] = Z S ( P , ω ) d Q ( ω ) (2.1) where Q, P ∈ P , and X is a random v ariable with la w Q . If P and Q hav e distribution functions F and G , resp ectively , we adopt the notation S ( P , Q ) = S ( F , G ) . A natural requirement of a scoring rule is that it is proper, which has the follo wing definition. Definition 3 (Prop er scoring rule) . Sc oring rule S is pr op er r elative to P if S ( Q, Q ) ≥ S ( P, Q ) for al l P , Q ∈ P . It is strictly pr op er if the e quation holds with e quality if and only if P = Q . A ccordingly , using proper scoring rules incentivizes the forecaster to report their honest b elief ab out the distribution. Therefore, the forecaster has no in- cen tiv e to distort or strategically alter their forecast. T w o widely used scoring rules are the logarithmic score (LogS) and the con- tin uous ranked probability score (CRPS). The former is defined as LogS( F , G ) := Z log g ( x ) dF ( x ) , where g denotes the density of G . The CRPS can be view ed as a sp ecial case of the Energy score and, unlike the logarithmic score, it do es not require the existence of a densit y . More generally , the Energy score with parameter β ∈ (0 , 2) is defined as ES β ( F , G ) := 1 2 E ∥ X − X ′ ∥ β − E ∥ X − Y ∥ β , /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 5 where X , X ′ ∼ F and Y , Y ′ ∼ G are indep endent random v ariables. The CRPS coincides with ES β for β = 1 . Throughout the pap er, we use the score orien tation in Definition 3 , so larger v alues are preferable. F or loss-type criteria, w e work with the equiv alent trans- formed score S = − L , which yields the same ranking and optimizer. 2.2. Extr eme V alue The ory F r amework A central result in Extreme V alue Theory is the Fisher–Tipp ett–Gnedenk o the- orem, whic h states that suitably normalized maxima con v erge in distribution to one of three p ossible types: Gumbel, F réc het, or W eibull. These domains of at- traction corresp ond to fundamentally different tail b ehaviors in the underlying distribution. See [ 6 ] for more information. The F réc het domain, also referred to as the hea vy-tailed domain, encom- passes distributions whose surviv al function decays according to a p ow er law. Suc h distributions hav e infinite right endp oints and exhibit polynomially de- creasing tails, implying that extreme ev ents o ccur with non-negligible probabil- it y . F ormally , a distribution function G is said to b elong to the F réchet domain of attraction if its surviv al function is regularly v arying. That is, there exists a constan t γ > 0 such that lim t →∞ 1 − G ( tx ) 1 − G ( t ) = x − 1 /γ , x > 0 . (2.2) The parameter γ , called the tail index , quantifies the hea viness of the tail. When ( 2.2 ) holds, we say that the surviv al function 1 − G is regularly v arying with index − 1 /γ , and write 1 − G ∈ R − 1 /γ . An equiv alent c haracterization can b e expressed in terms of the tail quan tile function U ( x ) = inf { y ∈ R : G ( y ) ≥ 1 − 1 /x } , x > 1 . If 1 − G ∈ R − 1 /γ , then the associated tail quantile function U is regularly v arying with index γ , that is, U ∈ R γ Against this bac kground, in this paper w e let ( Y 1 , Y 2 , . . . , Y n ) b e an i.i.d. sample with common distribution function G . Throughout the pap er w e assume that 1 − G ∈ R − 1 /γ G . This implies that Y is in the F réc het domain with tail index γ G . W e now in tro duce the tail counterpart of G , which is given by G t ( x ) = G ( tx ) − G ( t ) 1 − G ( t ) for t ≥ 1 . W e denote G ◦ as the limit distribution of G t and we call it the tail distribution . Y ◦ denotes a random v ariable with distribution G ◦ . As Y is in the F réc het domain, we obtain 1 − G ◦ ( x ) = lim t →∞ 1 − G t ( x ) = x − 1 /γ G , i.e., G t con v erges to a Pareto distribution with parameter 1 /γ G . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 6 3. Asymptotic Results In this section, we present results on consistency and asymptotic normalit y for scoring rules based on normalized order statistics. W e also establish consistency for a tail-index estimator obtained b y optimizing the empirical score. T o supp ort the use of scoring rules for ranking tail mo dels, it is imp ortant to establish their large-sample properties. Consistency is a fundamen tal require- men t for any metho d aimed at tail ev aluation, as it ensures that the correct mo del is identified in the limit. Although asymptotic normality is not strictly necessary , it is highly useful since it makes it possible to assess whether differ- ences in scores b etw een comp eting mo dels are statistically significant. F or clarity , define the empirical tail score S k ( F ) := 1 k k X i =1 S F , Y n,n − i +1 Y n,n − k , based on the top k order statistics. In score form, models are ranked by larger v alues of S k ( F ) . 3.1. Sc oring with Normalize d Upp er Or der Statistics W e b egin with consistency . Consistency and asymptotic normality follo w di- rectly from [ 18 ] (Theorem 2.1 and Theorem 4.5). Here the assumptions and theorem are restated in our notation. Assumption 1. L et S : P × [1 , ∞ ) → R b e an a.e. c ontinuous function for P ∈ P , and such that | S ( P , y ) | ≤ Ay (1 − δ ) /γ for some A > 0 and δ ∈ (0 , 1) . This assumption is mild and do es not imp ose a substantial restriction. Most commonly used scoring rules are contin uous, and the requirement that the scor- ing rule be dominated is imp osed to guarantee the existence of the exp ectation. Theorem 2. L et A ssumption 1 hold. In addition, assume that k , n → ∞ and k /n → 0 . L et Y n, 1 ≤ Y n, 2 ≤ · · · ≤ Y n,n denote the or der statistics of the sample. Then S k ( F ) → E [ S ( F , Y ◦ )] in pr ob ability, wher e Y ◦ has distribution G ◦ . In practical terms, this result ensures that empirical tail scores conv erge to their p opulation targets when k is chosen in the standard EVT regime. W e next turn to asymptotic normality , whic h follows as a direct consequence of Theorem 4.5 in [ 18 ]. T o establish this result, it is necessary to con trol the /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 7 gro wth rate of k . W e therefore in tro duce the following notation. Let ξ ∈ R , define the function h ξ : (0 , ∞ ) → R b y h ξ ( x ) = Z x 1 y ξ − 1 dy = x ξ − 1 ξ , if ξ = 0 , log x, if ξ = 0 . W e may no w restate Theorem 4.5 of [ 18 ] in our notation. Theorem 3. L et G b e a d.f. with tail quantile function U satisfying lim t →∞ U ( tx ) /U ( t ) − x γ G a ( t ) = ± x γ G h ξ ( x ) , x ≥ 1 , (3.1) for some γ G > 0 , ξ ≤ 0 and a ∈ R ξ satisfying a ( t ) → 0 as t → ∞ . L et F ∈ P b e a fixe d c andidate distribution use d in the sc or e c omp arison. L et S : P × [1 , ∞ ) → R b e an absolutely c ontinuous function for P ∈ P with ∂ S ∂ y such that ∂ S ∂ y ≤ Ay ρ − 1 , y ≥ 1 , for some A > 0 and some ρ < (2 γ G ) − 1 . If k satisfies √ k a ( n ) → 0 when k → ∞ and n k → ∞ , then √ k S k ( F ) − E [ S ( F, Y ◦ )] ! d − → N (0 , V ar( S ( F , Y ◦ ))) . (3.2) This normal approximation pro vides a direct basis for uncertaint y quan tifi- cation when comparing score levels across comp eting tail mo dels. The following corollary shows under which conditions Theorem 2 and Theo- rem 3 are applicable for LogS and ES. Corollary 4. L et F γ denote a Par eto distribution with tail index γ . W e have that 1. E [LogS( F γ , Y ◦ )] exists for al l γ > 0 . The varianc e is given by V ar(LogS( F γ , Y ◦ )) = − 1 γ − 1 2 γ 2 G . 2. E [ES β ( F γ , Y ◦ )] is finite if and only if β < 1 γ . F or β = 1 (CRPS), the vari- anc e is V ar(ES 1 ( F γ , Y ◦ )) = 1 1 − 2 γ G − 2 a 1 − (1+ p ) γ G + a 2 1 − 2 pγ G − 1 1 − γ G − a 1 − pγ G 2 , wher e a = 2 γ γ − 1 and p = 1 − 1 γ , whenever the displaye d moments ar e finite. In those c ases, the assumptions of The or em 2 and The or em 3 ar e also satisfie d. Pr o of. W e verify the conditions separately for LogS and ES β . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 8 First consider LogS. W e hav e E [LogS( F γ , Y ◦ )] = Z ∞ 1 | LogS( F γ , y ) | y − 1 − 1 /γ G d y ≤ C 1 Z ∞ 1 y − 1 − 1 /γ G d y + C 2 Z ∞ 1 log( y ) y − 1 − 1 /γ G d y + C 3 Z ∞ 1 log( y ) 2 y − 1 − 1 /γ G d y , ≤ C 4 Z ∞ 1 y − 1 − κ < ∞ where C 1 , C 2 , C 3 , C 4 and κ are some p ositive constants. If w e denote the density of F γ as f γ , we hav e S ( F γ , y ) = log( f γ ( y )) = log(1 /γ ) − 1 γ + 1 log( y ) . This expression is contin uous for y > 1 and is dominated by Ay (1 − δ ) /γ . F urther, w e hav e ∂ S ∂ y = − 1 γ + 1 y − 1 and this deriv ative is dominated b y Ay ρ − 1 . Next consider ES β : ES β ( F γ , y ) = Z ∞ 1 | x − y | β d F γ ( x ) − 1 2 Z ∞ 1 Z ∞ 1 | x − x ′ | β d F γ ( x ) d F γ ( x ′ ) . F or y ≥ 1 , this expression is absolutely contin uous. W e first b ound the first in tegral: Z ∞ 1 | x − y | β dF ( x ) ≤ A 1 Z y 1 ( y − 1) β x − 1 /γ − 1 d x + Z ∞ y x β − 1 /γ − 1 d x ≤ A 2 y β − 1 /γ − 1 for some constan ts A 1 , A 2 > 0 . This quantit y is finite and is dominated b y Ay (1 − δ ) /γ . Next, for the second integral, it is enough to verify finiteness since it do es not dep end on y : Z ∞ 1 Z ∞ 1 | x − x ′ | β d F γ ( x ) d F γ ( x ′ ) ≤ Z ∞ 1 x β − 2 /γ − 1 − ( A 1 + Z ∞ 1 x ′ β − 1 /γ − 1 d x ′ ) x − 1 /γ − 1 d x (3.3) for some constant A 1 > 0 . The inner integral is finite if and only if β < 1 γ . Moreo v er, note that Z ∞ 1 x β − 2 /γ − 1 − A 3 x − 1 /γ − 1 d x, /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 9 where A 3 is a constant, is finite if and only if β ≤ 2 γ . Consequently , ( 3.3 ) is finite if and only if β < 1 γ . Therefore, using the calculations ab o v e, we hav e E [ES( F γ , Y ◦ )] ≤ A 4 E [( Y ◦ ) − 1 ] ≤ A 4 , for some constant A 4 . Lastly , w e hav e ∂ S ∂ y ≤ A 5 y β − 1 /γ − 2 , where A 5 is a constant, is dominated b y Ay ρ − 1 for β < 1 γ . Therefore b oth scoring rules satisfy the required conditions, which prov es the claim. Remark 5. T o evaluate the varianc e in ( 3 ) , γ G is typic al ly substitute d by an empiric al estimate. A s our aim is to sc or e c omp eting pr e dictive distributions, we find it mor e informative to c ompute the varianc e by setting γ G e qual to the tail index of the pr e dictive distribution. T ak en together, Theorems 2 – 3 and Corollary 4 justify a practical w orkflow: compute empirical tail scores ov er a range of k , compare candidates by the score level, and use the asymptotic v ariance to assess whether observed score differences are practically meaningful. 3.2. T ail Index Estimation via Sc or e Optimization Bey ond their use for ranking predictive distributions, we also inv estigate whether scoring rules can be employ ed for estimating the tail index. In this section, w e assume that the predictiv e distribution is Pareto, denoted b y F γ , where γ is the candidate tail index. The parameter space is taken to b e [ γ L , γ U ] , with 0 < γ L < γ U . F or shorthand, define S k ( γ ) := 1 k k X i =1 S F γ , Y n,n − k + i Y n,n − k . W e are no w in a p osition to state the result. Theorem 6. A ssume that S is c ontinuous and a strictly pr op er sc oring rule. F urther assume A ssumption 1 and that for γ ∈ [ γ L , γ U ] , S ( F γ , z ) ≤ D ( z ) , wher e E [ D ( Y ◦ )] < ∞ . L et γ G ∈ [ γ L , γ U ] , and let k , n → ∞ with k /n → 0 . Then ˆ γ k ( S ) := ar gmax γ ∈ [ γ L ,γ U ] 1 k k X i =1 S F γ , Y n,n − k + i Y n,n − k P − → γ G . (3.4) W e first establish the following uniform conv ergence lemma. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 10 Lemma 7. A ssume A ssumption 1 and that γ 7→ S ( F γ , z ) is c ontinuous for e ach z . F urther assume that for γ ∈ [ γ L , γ U ] , we have S ( F γ , Y ◦ ) ≤ D ( Y ◦ ) with E [ D ( Y ◦ )] < ∞ . Then sup γ ∈ [ γ L ,γ U ] | S k ( γ ) − E [ S ( F γ , Y ◦ )] | P − → 0 as k , n/k → ∞ . Pr o of. Let u ( z , θ , τ ) := sup γ : | γ − θ |≤ τ | S ( F γ , z ) − S ( F θ , z ) | . Then u ( Y ◦ , θ , τ ) is almost surely con tinuous in τ . Since S can b e dominated b y a random v ariable with finite moment, the same holds for u ( Y ◦ , θ , τ ) . Hence, by the dominated conv ergence theorem, E [ u ( Y ◦ , θ , τ )] → 0 as τ → 0 . No w use compactness of the parameter space to co v er it by finitely man y balls B ( θ m , τ m ) , m = 1 , . . . , M . By c ho osing M sufficien tly large (equiv alently , the radius sufficiently small), we can ensure that for each ball µ m := E u ( Y ◦ , θ m , τ m ) < ε (3.5) for any given ε > 0 . F or a given γ ∈ B m w e hav e | S k ( γ ) − E [ S ( F γ , Y ◦ )] | ≤| S k ( γ ) − S k ( θ m ) | (3.6) + | S k ( θ m ) − E [ S ( F θ m , Y ◦ )] | (3.7) + | E [ S ( F θ m , Y ◦ )] − E [ S ( F γ , Y ◦ )] | . (3.8) F or ( 3.6 ), note that | S k ( γ ) − S k ( θ m ) | ≤ 1 k k X i =1 u Y n,n − k + i Y n,n − k , θ m , τ m − µ m ! + µ m . As S ( F γ , z ) ≤ Ay (1 − δ ) /γ ≤ Ay (1 − δ ) /γ L , we get u ( z , θ m , τ m ) ≤ A 1 y (1 − δ ) /γ L for some constant A 1 . By Theorem 2 , and since µ m can b e made arbitrarily small b y selecting a large M , ( 3.6 ) can be made arbitrarily small. Lik ewise, ( 3.7 ) con v erges to 0 by Theorem 2 , while ( 3.8 ) can b e made arbitrarily small b y ( 3.5 ). Altogether, this shows that for an y γ ∈ B ( θ m , τ m ) , the quantit y | S k ( γ ) − E [ S ( F γ , Y ◦ )] | can b e made arbitrarily small by choosing M sufficiently large. Since this holds for each of the finitely man y balls in the cov er, it also holds after taking the suprem um ov er γ ∈ [ γ L , γ U ] for M sufficiently large, which concludes the pro of. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 11 Pr o of. By Lemma 7 , we hav e sup γ ∈ [ γ L ,γ U ] | S k ( γ ) − E [ S ( F γ , Y ◦ )] | P − → 0 (3.9) as k , n/k → ∞ . Using ( 3.9 ), we get that S k ( ˆ γ ) ≥ S k ( γ G ) ≥ E [ S ( F γ G , Y ◦ )] − o P (1) . (3.10) Using ( 3.10 ) and ( 3.9 ), w e get that E [ S ( F γ G , Y ◦ )] − E [ S ( F ˆ γ , Y ◦ )] ≤ S k ( ˆ γ ) + o P (1) − E [ S ( F ˆ γ , Y ◦ )] (3.11) ≤ sup γ ∈ [ γ L ,γ U ] | S k ( γ ) − E [ S ( F γ , Y ◦ )] | + o P (1) P − → 0 (3.12) as k , n/k → ∞ . Since S is a strictly prop er scoring rule, we also hav e sup γ : | γ − γ G |≥ ε E [ S ( F γ , Y ◦ )] < E [ S ( F γ G , Y ◦ )] . Hence, for every ε > 0 , there exists an η > 0 such that E [ S ( F ˆ γ , Y ◦ )] < E [ S ( F γ G , Y ◦ )] − η when | ˆ γ − γ G | ≥ ε. Therefore, {| ˆ γ − γ G | ≥ ε } ⊂ { E [ S ( F ˆ γ , Y ◦ )] < E [ S ( F γ G , Y ◦ )] − η } , and as the righ t-hand side conv erges to 0 in probability by ( 3.12 ), the left-hand side also conv erges to 0. Under these conditions, it follo ws that the standard Hill estimator arises as a sp ecial case of ˆ γ k . Corollary 8. F or a given sample ( Y 1 , . . . , Y n ) , the γ that maximizes L o gS is the Hil l estimator. That is argmax γ 1 k k X i =1 log f ◦ γ Y [ n,n − i +1] Y [ n,n − k ] = 1 k k X i =1 log Y [ n,n − i +1] Y [ n,n − k ] . (3.13) Remark 9. [ 18 ] shows that, under mild c onditions on h , the estimator of the form 1 k k X i =1 h Y [ n,n − i +1] Y [ n,n − k ] attains the smal lest asymptotic varianc e when h = log . This suggests that it is inher ently difficult to c onstruct a sc oring-rule-b ase d estimator ˆ γ k that outp er- forms the Hil l estimator in terms of asymptotic efficiency. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 12 Notably , Log S and E S β satisfy the same conditions as in Corollary 4 . Corollary 10. The assumptions of The or em 6 ar e satisfie d when 1. using Log S for al l γ > 0 ; 2. using E S β with β < 1 γ U . Pr o of. F or LogS, the mapping z 7→ Log S ( F γ , z ) is contin uous, and Log S is strictly prop er. The calculations in the pro of of Corollary 4 verify the remaining assumptions required by Theorem 6 . F or E S β , the mapping z 7→ E S β ( F γ , z ) is contin uous, and E S β is strictly prop er. The calculations in the pro of of Corollary 4 verify the remaining as- sumptions required by Theorem 6 . 4. Metho dology for T ail-Model Ranking and Estimation T o operationalize the framework, w e compare predictive tail mo dels through their implied limit distributions. The same scoring-rule machinery then ranks these limit distributions and, in turn, differen tiates b etw een mo dels with dif- feren t tail indices. Candidate limit distributions ma y arise either as limits of full-supp ort predictive mo dels or as direct tail-index candidates. F ormally , for F ∈ F and any prop er scoring rule, S , w e hav e E [ S ( G ◦ , Y ◦ )] ≥ E [ S ( F , Y ◦ )] , where Y ◦ ∼ G ◦ . If S is a strictly prop er scoring rule, w e hav e equality if and only if G ◦ = F . As G ◦ is a Pareto distribution it is entirely described b y the tail index, γ , and hence E [ S ( G ◦ , Y ◦ )] = E [ S ( F , Y ◦ )] if and only if F has the same tail index as G ◦ . T o connect this p opulation comparison with sample quantities, note that ( V t k, 1 , V t k, 2 , . . . , V t k,k ) d = Y n,n − k +1 Y n,n − k , Y n,n − k +2 Y n,n − k , . . . , Y n,n Y n,n − k Y n,n − k = t, where ( V t i ) k i =1 are i.i.d. random v ariables with distribution G t . As G t → G ◦ when t → ∞ , a natural estimator for E [ S ( F , Y ◦ )] is 1 k k X i =1 S F , Y n,n − i +1 Y n,n − k . (4.1) Consequen tly , this in tro duces an additional tuning parameter, k . It should b e c hosen small enough for G t to pro vide a go o d appro ximation to G ◦ , y et large enough to ensure that the reduced sample remains sufficiently large for reliable inference. The EVT literature offers several metho ds for selecting k , most of /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 13 whic h are based on identifying a range of v alues ov er which the estimator ex- hibits stabilit y . In the simulation studies, w e inv estigate this stability b ehavior. In practice, we implement the pro cedure in the following wa y . First, choose a candidate set { F 1 , . . . , F m } and a grid K of v alues for k . Next, compute S k ( F j ) for each j and k ∈ K . Then identify a stabilit y range K stab ⊆ K , where the ordering is not driv en by erratic local fluctuations. Finally , rep ort the ranking based on both p oint wise curv es k 7→ S k ( F j ) and the a verage score ov er the stable range, ¯ S ( F j ) := 1 |K stab | X k ∈K stab S k ( F j ) . This separates the statistical comparison (score level) from the threshold-sensitivity diagnostic (stability ov er k ). Remark 11. A n imp ortant question is how to cho ose F . One p ossibility is to let F b e the tail c ounterp art of an entir e pr op ose d pr e dictive distribution. The se c ond option is to let F b e a Par eto distribution. In the latter c ase, we ne e d to c alculate the tail index fr om the pr e dictive distribution, which c an then b e plugge d into the Par eto distribution. If one is inter este d solely in the tail index, we would r e c ommend the se c ond option, as the amount of noise is r e duc e d. However, if one is not only c onc erne d with asymptotic pr op erties but also with how the pr e dictive distribution b ehaves ab ove a high thr eshold, then it may b e of p articular inter est to use the tail c ounterp art F Y n,n − k , which r esembles the use of thr eshold-weighte d sc oring rules. Remark 12. A pr actic al issue is the choic e of sc oring rule. Two of the most widely use d sc oring rules in the liter atur e ar e Log S and C RP S . Notably, the Log S r e quir es the pr e dictive distribution to admit a density. This is unpr ob- lematic when F is sp e cifie d as a Par eto distribution, for which the density is available in close d form. However, if one inste ad works with F t , evaluation of the c orr esp onding density may b e unavailable or c omputational ly cumb ersome. In such situations, the C RP S pr ovides a c onvenient alternative, sinc e it c an b e c ompute d dir e ctly fr om the distribution function and ther efor e do es not r e quir e density evaluation. Building on this, as an estimator for ( 3.4 ), w e propose a grid-searc h version based on ( 4.1 ). Let Γ b e a finite set of tail indices; then the estimator is argmax γ ∈ Γ 1 k k X i =1 S F γ , Y n,n − i +1 Y n,n − k . (4.2) F or loss-oriented criteria such as the Energy score, this is equiv alent to mini- mizing the asso ciated loss ov er Γ . 5. Sim ulation Study This section explores our theoretical results through three simulation studies. First, w e in v estigate the abilit y of ( 4.1 ) to differentiate betw een tail indices. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 14 Next, we assess robustness when the scaling v aries systematically across obser- v ations. Lastly , we examine the finite-sample b ehavior of the estimator in ( 4.2 ) for Energy-score-based tail-index estimation, compared with the classical Hill estimator. A cross all studies, the primary diagnostic is stabilit y of the score or estimator curv e ov er k : reliable b ehavior should p ersist ov er a non-negligible k -range rather than at isolated grid p oints. 5.1. R anking T ail Mo dels: Baseline Setting In the baseline setting, the purpose of the simulation study is to assess how well a Log S rule can identify the true tail index of a heavy-tailed distribution, and ho w this dep ends on the threshold level and the sample size. Samples of size n ∈ { 10 3 , 10 4 , 10 5 } are generated from heavy-tailed distri- butions with true tail index γ G = 1 . W e consider t wo parametric families of distributions, namely the F réchet and the Burr distributions. The F réc het dis- tribution is sp ecified by the distribution function F ( x ) = exp − x − s , x > 0 , where the shape parameter is set to s = 1 /γ G . The Burr distribution is giv en b y F ( x ) = 1 − 1 + x c − t , x > 0 , with shap e parameters c hosen as c = 1 /γ G and t = 1 . With these parameteri- zations, b oth distributions are characterized b y the same tail index γ G . Within each sample, the threshold parameter k ranges from 50 to n/ 4 and is ev aluated on an evenly spaced grid of 100 p oints. F or eac h v alue of k , four logarithmic scores are computed by taking F to b e a Pareto distribution with tail index γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } . Using this setup, the empirical criterion is computed via ( 4.1 ). In Figure 1 , the resulting scores of a single realization are plotted as functions of k , with one curv e corresp onding to eac h v alue of γ . If the scoring rule is w ell aligned with the true tail b ehavior, the candidate v alue γ = γ G = 1 should yield the highest log score across a broad range of k . T o formalize this comparison, for each fixed k the candidate v alues are ranked according to their empirical logarithmic scores. In particular, the highest-ranked v alue is argmax γ ∈{ 0 . 8 , 1 , 1 . 2 , 1 . 5 } LogS k ( γ ) , with the remaining candidates ordered according to their corresp onding scores. F or the smaller sample sizes n = 10 3 and n = 10 4 , and in particular for the Burr mo del, the curve corresp onding to γ = 1 is not systematically abov e the comp et- ing curv es; instead, the candidate v alues γ = 0 . 8 and γ = 1 . 2 often attain similar /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 15 or larger scores ov er substan tial ranges of k . By contrast, clearer signals app ear in the remaining cases, esp ecially for n = 10 5 and for the F réchet mo del, where the curve corresp onding to γ = 1 tends to dominate ov er a noticeable region of smaller k . This pattern is consisten t with the exp ected bias-v ariance trade-off in tail inference: with larger n , a wider low er- k region supp orts stable discrimi- nation of the correct tail index. This visual impression is further supp orted b y a Monte Carlo exp eriment rep orted in Figure 2 . F or each configuration, 100 indep enden t samples are generated and the empirical logarithmic score is com- puted for the candidate v alues γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } across the same range of thresholds. F or eac h v alue of k /n , w e record whether the score is maximized at the true v alue γ = 1 , and plot the resulting proportion of suc h o ccurrences across the simulations. In b oth the F réchet and Burr cases, when n = 10 3 there is no clear tendency for the prop ortion to approach one as k /n go es to 0. As the sample size increases, how ever, the prop ortion rises in b oth mo dels. F or F réc het data-generating distributions this increase is particularly strong. When n = 10 5 the prop ortion is equal to one across the entire range of k /n , indicating that the correct tail index is almost alwa ys selected. In the Burr case the increase is observ ed only for smaller v alues of k /n , indicating that the correct tail index is consisten tly fav ored only further into the tail. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 16 (a) F réchet DGP , n = 10 3 (b) Burr DGP , n = 10 3 (c) F réchet DGP , n = 10 4 (d) Burr DGP , n = 10 4 (e) F réchet DGP , n = 10 5 (f ) Burr DGP , n = 10 5 Fig 1: Empirical logarithmic scores in ( 4.1 ) (vertical axis) plotted against the n um b er of upp er order statistics k (horizontal axis) for candidate tail indices γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } . Left panels use F réchet data-generating distributions, right panels use Burr distributions, and rows corresp ond to n = 10 3 , 10 4 , 10 5 . Higher curv es indicate b etter tail fit; the true v alue is γ G = 1 . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 17 (a) F réchet DGP (b) Burr DGP Fig 2: Prop ortion of sim ulations (based on 100 Mon te Carlo replications) in whic h the empirical logarithmic score in ( 4.1 ) is maximized at the true tail index γ = 1 among candidate v alues γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } , plotted against the relative n um b er of upp er order statistics k /n . The left plot uses F réchet data-generating distributions and the right plot uses Burr distributions. Curves corresp ond to sample sizes n = 10 3 , 10 4 , 10 5 . Higher v alues indicate that the logarithmic score more frequently identifies the true tail index. 5.2. R anking T ail Mo dels under Heter o gene ous Sc aling Next, to assess the robustness of our results in practice, w e in v estigate the effect of systematic v ariation in the scaling of the observ ations. Sp ecifically , we sim ulate indep endent baseline hea vy-tailed v ariables Z from Burr and F réc het distributions and multiply each realization b y a scaling factor. That is, Y i = X i Z i . W e follo w the same setup as in Section 5.1 to generate the baseline heavy- tailed v ariable Z . W e consider tw o differen t structures for the scaling factors X : (i) X 1 i = i n . (ii) X 2 i = 1 . 5 + 0 . 5 sin 6 i n π . Both scaling structures imply that X i ∈ [ 1 , 2] . In the first case, the scaling in- creases monotonically across the observ ations. In contrast, the second structure is p erio dic and completes three cycles ov er the sample. Imp ortan tly , in this simulation design the tail index is constant across all observ ations. The only source of heterogeneity arises from the scaling comp o- nen t. Consequently , the tail heaviness of the distribution remains unchanged, while only the scale v aries across i . Under this setup, the mo del corresp onding to γ = 1 correctly sp ecifies the tail index of the data-generating pro cess. There- fore, we would expect the logarithmic score (LogS) to attain its highest v alue at γ = 1 . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 18 Figures 3 and 4 presen t the results of a single realization, while Figure 5 rep orts the prop ortion results. The figures are constructed in the same manner as those in the previous section and are therefore not describ ed in further detail. The same k -grid and candidate set as in Section 5.1 are used, so changes in b eha vior can be attributed to the scaling mechanism. Even in the presence of heterogeneous scaling, the qualitative conclusions of Section 5.1 remain v alid. In particular, the logarithmic score con tin ues to fav or the correct tail index for sufficien tly large sample sizes and appropriate c hoices of k , and the most reliable inference is still concentrated in a stable low er- k region. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 19 (a) Linear scaling X i = X 1 i , n = 10 3 (b) Sinusoidal scaling X i = X 2 i , n = 10 3 (c) Linear scaling X i = X 1 i , n = 10 4 (d) Sinusoidal scaling X i = X 2 i , n = 10 4 (e) Linear scaling X i = X 1 i , n = 10 5 (f ) Sinusoidal scaling X i = X 2 i , n = 10 5 Fig 3: Empirical logarithmic scores (vertical axis) versus k (horizontal axis) for F réchet baseline samples with heterogeneous scaling, Y i = X i Z i , where Z i has tail index γ G = 1 . Candidate tail indices are γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } . Left panels use X 1 i = i/n , right panels use X 2 i = 1 . 5 + 0 . 5 sin(6 π i/n ) , and rows corresp ond to n = 10 3 , 10 4 , 10 5 . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 20 (a) Linear scaling X i = X 1 i , n = 10 3 (b) Sinusoidal scaling X i = X 2 i , n = 10 3 (c) Linear scaling X i = X 1 i , n = 10 4 (d) Sinusoidal scaling X i = X 2 i , n = 10 4 (e) Linear scaling X i = X 1 i , n = 10 5 (f ) Sinusoidal scaling X i = X 2 i , n = 10 5 Fig 4: Empirical logarithmic scores (vertical axis) versus k (horizontal axis) for Burr baseline samples with heterogeneous scaling, Y i = X i Z i , where Z i has tail index γ G = 1 . Candidate tail indices are γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } . Left panels use X 1 i = i/n , righ t panels use X 2 i = 1 . 5 + 0 . 5 sin(6 π i/n ) , and rows corresp ond to n = 10 3 , 10 4 , 10 5 . /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 21 (a) F réchet DGP , Linear scaling X i = X 1 i (b) F réchet DGP , Sinusoidal scal- ing X i = X 2 i (c) Burr DGP , Linear scaling X i = X 1 i (d) Burr DGP , Sinusoidal scaling X i = X 2 i Fig 5: Prop ortion of sim ulations (based on 100 Mon te Carlo replications) in whic h the empirical logarithmic score in ( 4.1 ) is maximized at the true tail index γ = 1 among candidate v alues γ ∈ { 0 . 8 , 1 , 1 . 2 , 1 . 5 } , plotted against the relative n um b er of upper order statistics k /n . The top panels correspond to F réchet data-generating distributions and the b ottom panels to Burr distributions. The left panels use a linearly v arying scale, while the righ t panels use a sin usoidally v arying scale. Curves corresp ond to sample sizes n = 10 3 , 10 4 , 10 5 . Higher v alues indicate that the logarithmic score more frequently identifies the true tail index. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 22 5.3. Finite-Sample Performanc e of Sc or e-Optimization Estimators (a) T rue tail index γ G = 0 . 33 (b) T rue tail index γ G = 0 . 66 (c) T rue tail index γ G = 1 (d) T rue tail index γ G = 1 . 33 Fig 6: T ail-index estimates ˆ γ k (v ertical axis) as functions of the num b er of upper order statistics k (horizon tal axis) for F réchet samples with n = 10 4 . P anels v ary the true tail index γ G . Each panel compares the Hill estimator with three Energy-score estimators based on β 1 , β 2 , β 3 ; the horizon tal reference line marks γ G . W e now examine the finite-sample b ehavior of tail-index estimators based on the Energy score, ˆ γ k ( E S β ) . Their performance is compared with that of the classical Hill estimator o ver a range of tail indices. Recall that the parameter β must satisfy β < 1 /γ U . In implementation terms, this corresp onds to maximizing the transformed score − E S β , equiv alently minimizing E S β . Samples of size n = 10 4 are generated from F réchet distributions. Compan- ion Burr runs w ere also conducted but are not sho wn, as they displa y the same qualitativ e sensitivit y in k and β and were omitted for brevity . As in the previ- ous sim ulation studies, the remaining parameters are c hosen analogously . The n um b er of upp er order statistics k is v aried ov er 25 equally spaced v alues b e- t w een 50 and n/ 4 . The energy score was ev aluated for candidate v alues of γ on /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 23 a grid γ ∈ [ 0 . 8 γ G , 2 γ G ] , consisting of 150 equidistant points. T o study the sensitivity of the estimator to the parameter β in the score, three different v alues w ere considered, β 1 = 1 2 γ G − 0 . 001 , β 2 = 0 . 8 β 1 , β 3 = 0 . 7 β 1 . F or each tail index γ G , the estimated v alues ˆ γ k obtained from the three energy- score-based estimators and the Hill estimator are plotted against k . The true v alue γ G is shown as a horizontal reference line. Figure 6 rep orts the F réchet results for a single realization. In panels 6a and 6b , the choice of β has limited impact and the Energy-score estimators are broadly comp etitive. In panel 6c , the sensitivity to β b ecomes more visible, and the resulting estimates are substantially larger than those obtained using the Hill estimator. Finally , panel 6d shows that all three estimators substan tially o v erestimate γ . Across all panels, the Hill estimator is at least as stable and generally closer to the target. Hence, in this setup, Energy-score optimization do es not outperform Hill, which is in line with Remark 9 . This conclusion is further supp orted by T able 1 , which is based on the same simulation framework. The rep orted bias and v ariance are estimated from 100 indep endent simulation runs using the usual sample mean and sample v ariance of the estimates. The results in the table sho w that the Energy Score and the Hill estimator exhibit similar p erformance when γ = 0 . 33 , whereas the Hill estimator increasingly outp erforms the Energy Score as γ increases. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 24 k = 0 . 05 n k = 0 . 15 n k = 0 . 25 n V ariance Bias V ariance Bias V ariance Bias γ = 0 . 33 Hill 2.08e-04 0.00366 8.15e-05 0.01279 5.57e-05 0.02307 β 1 2.07e-04 0.00371 9.53e-05 0.01219 7.69e-05 0.02136 β 2 2.07e-04 0.00419 8.24e-05 0.01277 5.80e-05 0.02253 β 3 2.12e-04 0.00416 8.37e-05 0.01312 5.95e-05 0.02322 γ = 0 . 66 Hill 8.72e-04 0.00610 3.03e-04 0.02672 2.38e-04 0.04826 β 1 1.23e-02 0.05526 1.37e-02 0.10129 1.41e-02 0.13600 β 2 9.61e-03 0.04575 9.59e-03 0.08487 9.56e-03 0.11612 β 3 8.53e-03 0.04166 7.92e-03 0.07785 7.65e-03 0.10767 γ = 1 Hill 1.64e-03 0.01710 5.48e-04 0.04377 3.82e-04 0.07129 β 1 1.06e-01 0.43068 8.80e-02 0.61519 7.02e-02 0.71168 β 2 1.03e-01 0.40435 8.82e-02 0.57565 7.44e-02 0.67230 β 3 1.00e-01 0.39098 8.73e-02 0.55495 7.49e-02 0.64991 γ = 1 . 33 Hill 3.38e-03 0.01640 1.24e-03 0.05424 7.36e-04 0.09525 β 1 1.32e-01 1.02901 3.08e-02 1.25598 8.37e-03 1.30751 β 2 1.34e-01 1.02740 3.17e-02 1.25459 8.63e-03 1.30783 β 3 1.35e-01 1.02740 3.21e-02 1.25416 8.64e-03 1.30793 T able 1 Bias and varianc e of the Hil l estimator and thr ee Ener gy-sc or e base d estimators c orr esponding to β 1 , β 2 , and β 3 , c ompute d fr om 100 simulated samples dr awn fr om a F r échet distribution with sample size n = 10 4 . R esults ar e r eporte d for differ ent values of the extr eme value index γ and for thr e e choic es of the number of upp er or der statistics k . 6. Empirical Application: USA utoBI Claim Severit y The empirical analysis is based on the usautoBI (USAutoBI) automobile b o dily injury claims dataset from the CASdatasets pac kage in R . The dataset contains 1 , 340 observ ations and 8 v ariables, including the economic loss amount ( LOSS ), measured in thousands of U.S. dollars. The data w ere collected in 2002 b y the Insurance Researc h Council. The v ariable LOSS is observed for all observ ations, whereas some observ ations con tain missing v alues in other v ariables. A ccord- ingly , all observ ations are retained in analyses that do not rely on subsetting. When subsetting on v ariables with missing v alues, observ ations with missing en tries are excluded. No additional data transformations are applied. W e let Y denote the economic loss amount. In contrast to the previous sections, the esti- mator is ev aluated for all integer v alues of k ≥ 10 , rather than on a predefined grid. F ollowing the metho dology in Section 4 , the empirical workflo w is: (i) assess F réchet-domain plausibility using a tail QQ diagnostic; (ii) define a finite set of candidate Pareto tail models; (iii) compute score curves o v er k ; and (iv) base the final ordering on a stable low er- k region, supplemen ted with uncertain t y bands. Figure 7 summarizes the full-sample diagnostics. Panel (a) shows a Pareto quan tile–quan tile plot for the upp er tail, and the near-linear pattern supp orts F réchet-domain b eha vior. Panels (b)–(c) displa y logarithmic score curves as /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 25 functions of k for five Pareto candidates with γ ∈ { 0 . 3 , 0 . 5 , 0 . 8 , 1 , 1 . 3 } , where panel (c) fo cuses on the lo w er 25% of the k -range. Within this low er k -range, rankings v ary somewhat with k , so we follow the standard EVT stabilit y principle. The models with γ = 0 . 8 and γ = 1 most often ac hieve the highest scores and are rank ed jointly first; γ = 1 . 3 is ranked second, γ = 0 . 5 third, and γ = 0 . 3 fourth. P anel (d) rep orts the p oint wise 95% confidence interv al for the score at γ = 1 , computed as in Remark 5 . More precisely , we consider the interv al γ ± 1 . 96 · − 1 γ − 1 γ √ k , ev aluated at γ = 1 . The in terv al o verlaps the scores for γ = 0 . 5 , γ = 0 . 8 , and γ = 1 . 3 ov er relev ant k v alues, so the lead of γ = 0 . 8 and γ = 1 should b e in terpreted cautiously . This interv al is point wise in k , not a simultaneous confidence band ov er the full range. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 26 (a) Upp er-tail Pareto QQ-plot (b) LogS versus k o ver the full range (c) LogS versus k for the low er 25% of the range (d) Poin twise 95% CI for the score at γ = 1 Fig 7: USAutoBI claim severit y analysis ( n = 1 , 340 ). P anel (a) compares the- oretical P areto upp er-tail quantiles (horizontal axis) with empirical quantiles (v ertical axis). P anels (b)–(c) plot logarithmic score (vertical axis) against the n um b er of upp er order statistics k (horizontal axis) for five Pareto predictive distributions with γ ∈ { 0 . 3 , 0 . 5 , 0 . 8 , 1 , 1 . 3 } . Panel (c) is a zo om of panel (b) ov er the low er 25% of the k -range. Panel (d) shows the p oin t wise 95% confidence in terv al for the score of the γ = 1 mo del. T o assess subgroup v ariation, additional insight is obtained by rep eating the score analysis on subsamples. Figure 8 rep orts splits by sex (Figures 8a and 8b ) and attorney in volv ement (Figures 8c and 8d ), using the same low er- k range as in Figure 7c . The sex-based split is defined using the v ariable CLMSEX , where F and M denote female and male, resp ectiv ely; observ ations with missing v alues (12 in total) are excluded. The split by attorney inv olvemen t is based on the v ariable ATTORNEY , where 1 indicates the presence of an attorney and 0 otherwise. F or the sex split, the ranking is broadly consistent with the full sample: γ = 0 . 8 and γ = 1 attain the highest scores, with o v erlapping uncertain ty bands. In con trast, the attorney split yields a different ordering for claims without attorney represen tation (Figure 8c ), where γ = 0 . 5 scores highest and γ = 0 . 3 b ecomes /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 27 comp etitiv e. This suggests a lighter tail in the non-attorney subsample, which is plausible if smaller claims are less lik ely to inv olve legal representation. As usual for observ ational subgroup analyses, this in terpretation is descriptive and do es not isolate causal effects of cov ariates. (a) F emale subsample ( n = 742 ) (b) Male subsample ( n = 586 ) (c) No-attorney subsample ( n = 655 ) (d) Attorne y subsample ( n = 685 ) Fig 8: Subset analyses of the USAutoBI claim sev erity data. Each panel plots logarithmic score (vertical axis) against the num b er of upper order statistics k (horizon tal axis) ov er the low er 25% of the k -range, for the same five Pareto candidates used in Figure 7 . Panels (a)–(b) split by sex; panels (c)–(d) split by attorney inv olvemen t. 7. Concluding Remarks This pap er prop oses a scoring-rule-based framework for ranking predictive dis- tributions in the F réchet domain based on normalized order statistics. By em- b edding extreme v alue limit theory in to a scoring-rule persp ective, we show ho w prop er scoring rules can b e applied to compare tails in a principled man- ner. Within this framew ork, we derive conditions under which the logarithmic score and the CRPS (as a sp ecial case of the Energy score) are w ell defined and applicable. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 28 W e further show that optimizing scoring rules yields consistent tail-index estimators and that the classical Hill estimator arises as a sp ecial case. The first tw o simulation studies sho w that the prop osed approach can suc- cessfully distinguish b et w een different tail indices in finite samples and that its p erformance remains stable when the scaling has a trend. In the third sim ula- tion study , w e observ e that estimation based on Energy-score optimization is less efficien t than the classical Hill estimator. Lastly , we conduct an empirical analysis of automobile claim severit y data, in whic h five comp eting P areto tail mo dels are ev aluated and ranked using the proposed scoring-rule framew ork. The analysis illustrates how the method can b e applied in practice, ho w the resulting ranking supp orts mo del selection, and how differences in tail b ehavior across data partitions can b e iden tified. A current limitation is that the analysis focuses on the F réchet domain and on a small set of standard scoring rules. F uture w ork ma y consider alternative scoring rules within the prop osed framework and study their impact on mo del ranking and tail-index estimation. A ckno wledgements AI to ols w ere used exclusively for language editing. All results, analysis, and conclusions are the authors’ own. Comp eting In terest None to declare. F unding The first author was supported by the Carlsb erg F oundation, gran t CF23-1096. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 29 References [1] Allen, S. (2024). W eighted scoringRules : Emphasizing Particular Out- comes When Ev aluating Probabilistic F orecasts. Journal of Statistic al Soft- war e 110 1–26. [2] Allen, S. , K oh, J. , Segers, J. and Ziegel, J. (2025). T ail calibration of probabilistic forecasts. Journal of the A meric an Statistic al A sso ciation . [3] Benedetti, R. (2010). Scoring R ules for F orecast V erification. Monthly W e ather R eview 138 203–211. [4] Brehmer, J. R. and Strok orb, K. (2019). Why scoring functions cannot assess tail prop erties. Eletr onic Journal of Statistics 13 4015–4034. [5] D a wid, A. P. , Musio, M. and Ventura, L. (2016). Minimum Scoring R ule Inference. Sc andinavian Journal of Statistics 43 123–138. [6] De Haan, L. and Ferreira, A. (2006). Extr eme V alue The ory: A n In- tr o duction 3 . Springer. [7] Einmahl, J. H. J. , de Haan, L. F. M. and Zhou, C. (2016). Statistics of heteroscedastic extremes. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) 78 31–51. [8] Embrechts, P. , Klüppelberg, C. and Mikosch, T. (1997). Mo del ling Extr emal Events for Insur anc e and Financ e . Sto chastic Mo del ling and A p- plie d Pr ob ability 33 . Springer-V erlag, Berlin, Heidelb erg. [9] Friederichs, P. and Thorarinsdottir, T. L. (2012). F orecast verifi- cation for extreme v alue distributions with an application to probabilistic p eak wind prediction. Envir onmetrics 23 579–594. [10] Gneiting, T. , Balabdaoui, F. and Rafter y, A. E. (2007). Probabilis- tic forecasts, calibration and sharpness. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) 69 243–268. [11] Gneiting, T. and Rafter y, A. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the A meric an Statistic al A sso ciation 102 . [12] Gneiting, T. and Ranjan, R. (2011). Comparing Density F orecasts Using Threshold- and Quantile-W eigh ted Scoring Rules. Journal of Business & Ec onomic Statistics 29 411–422. [13] Holzmann, H. and Klar, B. (2017). F o cusing on regions of interest in forecast ev aluation. A nnals of A pplie d Statistics 11 1997–2024. [14] Huber, P. J. and Ronchetti, E. M. (2009). R obust Statistics , 2 ed. John Wiley & Sons. [15] Klein, N. , Smith, M. S. and Nott, D. J. (2023). Deep distributional time series mo dels and the probabilistic forecasting of intrada y electricit y prices. Journal of A pplie d Ec onometrics 38 493–511. [16] Lerch, S. , Thorarinsdottir, T. L. , Ra v azzolo, F. and Gneiting, T. (2017). F orecaster’s Dilemma: Extreme Even ts and F orecast Ev aluation. Statistic al Scienc e 32 106–127. [17] R uiz-Abellón, M. C. , Fernández-Jiménez, L. A. , Guillamón, A. and Gabaldón, A. (2024). Applications of Probabilistic F orecasting in Demand Resp onse. A pplie d Scienc es 14 9716. /Sc oring Rules with Normalize d Upp e r Or der Statistics for T ail Infer enc e 30 [18] Segers, J. (2001). Residual estimators. Journal of Statistic al Planning and Infer enc e 98 15-27. [19] T aillarda t, M. , Fougères, A.-L. , Na veau, P. and de F ondev- ille, R. (2023). Ev aluating probabilistic forecasts of extremes using con tin- uous rank ed probabilit y score distributions. International Journal of F or e- c asting 39 1448–1459. [20] W a ghmare, K. and Ziegel, J. (2025). Prop er scoring rules for estimation and forecast ev aluation. arXiv pr eprint . Revised version (v3) submitted 31 July 2025. [21] Wessel, J. B. , Ferr o, C. A. T. , Ev ans, G. R. and Kw asniok, F. (2025). Impro ving Probabilistic F orecasts of Extreme Wind Sp eeds by T raining Statistical P ost-pro cessing Mo dels with W eighted Scoring Rules. Monthly W e ather R eview 153 1489–1511. [22] Ólafsdóttir, E. , Rootzén, H. and Bolin, D. (2024). Lo cally tail-scale in v ariant scoring rules for ev aluation of extreme v alue forecasts. Interna- tional Journal of F or e c asting 40 981–995.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment