양자 슈뢰딩거 연산자를 이용한 장기 시계열 확률 최적 제어
** 본 논문은 제어 입력이 상태에 선형으로 작용하고, 무제어 드리프트가 포텐셜의 그래디언트인 경우에 한해, HJB 방정식을 선형 PDE로 변환하고 이를 슈뢰딩거 연산자와 단위동형 관계시킴으로써 이산 스펙트럼을 확보한다. 이를 기반으로 대칭 LQR의 해를 양자 조화진동자 해와 연결해 닫힌 형태의 해를 제시하고, 일반적인 경우에는 신경망으로 주된 고유함수를 학습한다. 기존 손실이 공간을 편향하는 문제를 해결하기 위해 상대 고유함수 손실을 도입…
저자: Louis Claeys, Artur Goldman, Zebang Shen
**
본 논문은 고차원 확률 최적 제어 문제에서 시간 horizon이 길어질수록 발생하는 계산·통계적 어려움을 해결하기 위해, “gradient‑drift” 라는 특수한 구조를 활용한다. 먼저, 제어가 상태에 선형으로 작용하고, 무제어 드리프트 b(x)가 어떤 포텐셜 E(x)의 그래디언트인 경우, HJB 방정식은 Cole‑Hopf 변환 ψ=exp(−βV) 를 통해 선형 PDE ∂ₜψ=Lψ 로 변환된다. 여기서 L은 확률적 흐름에 대한 생성자 역할을 하며, 가중치 측도 μ(x)=exp(−2βE(x))에 대해 자기‑adjoint이다. 핵심 수학적 결과는 단위연산자 Uψ=e^{−βE}ψ 를 적용하면 L이 슈뢰딩거 연산자 S=−Δ+V와 단위동형 관계가 된다는 점이다. V는 원래 포텐셜과 실행 비용 f에 의해 정의된 효과적 포텐셜이며, V(x)→∞ (x→∞) 를 만족하면 S는 순수 이산 스펙트럼을 가진다. 따라서 L도 이산 고유값 λ₀≤λ₁≤…와 정규 직교 고유함수 ϕ_i를 갖는다.
이 스펙트럼 구조를 이용하면 ψ(t)=∑_i e^{−λ_i (T−t)}⟨ϕ_i,ψ_T⟩ϕ_i 로 전개할 수 있다. 최적 제어는 u* = ∇_x log ψ 이므로, 장기 horizon에서는 가장 작은 고유값에 대응하는 ϕ₀가 지배한다. 구체적으로, T→∞ 일 때 u*(x,t)≈∇_x log ϕ₀(x) + O(e^{−(λ₁−λ₀)(T−t)}). 따라서 고유값 차가 클수록 수렴이 빠르고, 고차 모드의 영향은 무시해도 된다.
논문은 이 이론을 두 가지 실용적 상황에 적용한다. 첫 번째는 대칭 LQR이다. 여기서는 b(x)=−Ax (A 대칭 양정), f(x)=½xᵀQx (Q 양정)이며, 포텐셜 E(x)=½xᵀAx 로 잡는다. 이 경우 L은 양자 조화진동자 해와 동일해 고유값과 고유함수가 Hermite 다항식과 가우시안으로 명시적으로 주어진다. 따라서 임의의 비제곱형 종단 비용 g(x)도 ψ_T=e^{−βg} 를 Hermite 기저에 투영해 닫힌 형태의 최적 제어를 얻을 수 있다. 이는 기존 LQR 해가 Riccati 방정식에 의존하고 종단 비용이 2차형이어야 한다는 제한을 완전히 없앤다.
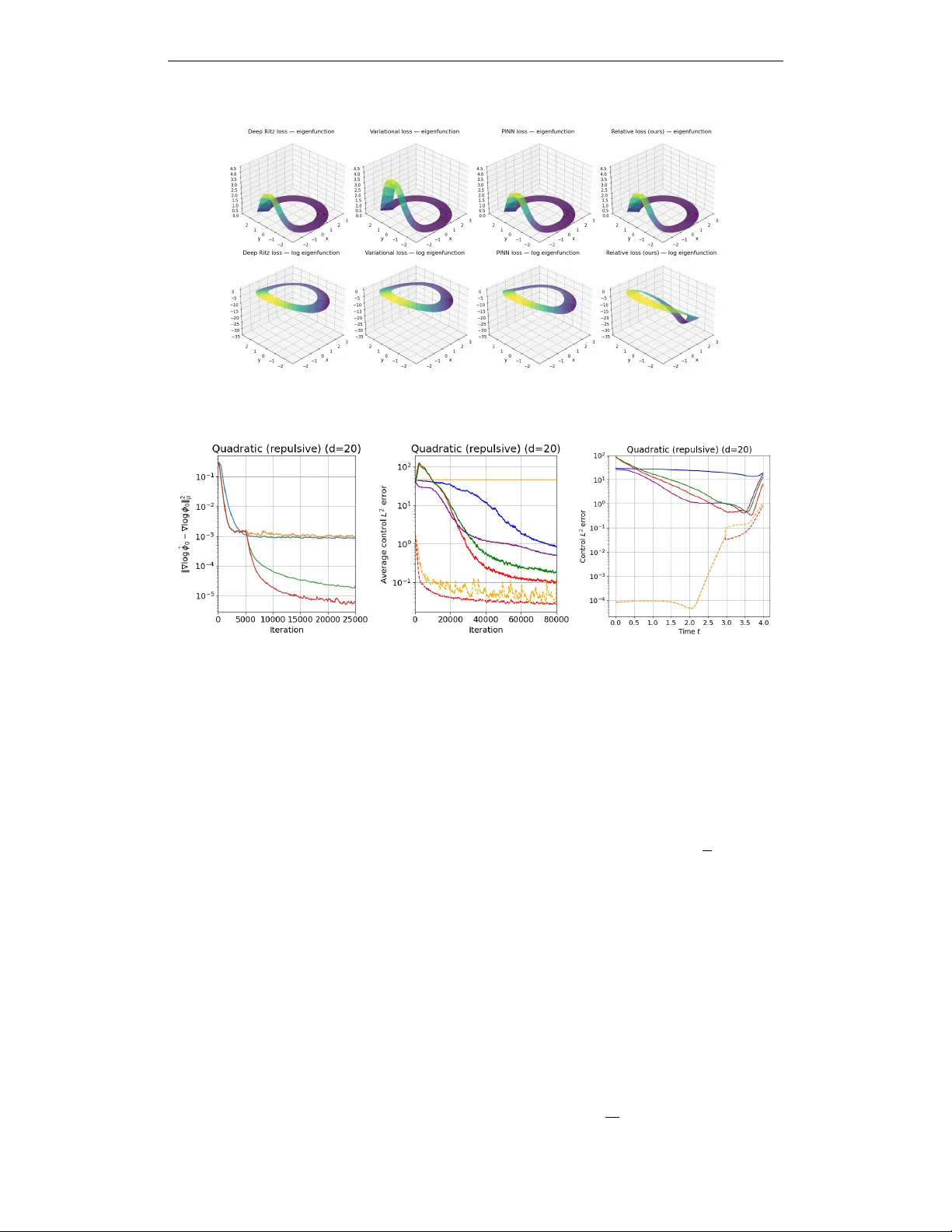
두 번째는 일반적인 gradient‑drift 문제이다. 여기서는 고유함수를 직접 구할 수 없으므로, 신경망 ϕ_θ(x)와 스칼라 λ_θ를 학습한다. 기존 고유함수 학습 방법은 Ritz 변분법(⟨ψ, Lψ⟩/⟨ψ,ψ⟩) 혹은 잔차 손실 ‖Lψ−λψ‖² 를 최소화하지만, μ‑measure에 따라 가중치가 달라져 비용이 큰 영역을 과소평가한다. 논문은 이를 “implicit reweighting”이라 부르고, 이를 해결하기 위해 상대 고유함수 손실 ℓ_rel(θ)=‖Lψ_θ/ψ_θ−λ_θ‖² 를 제안한다. 이 손실은 ψ_θ가 0에 가까운 영역에서도 정상화된 비율을 최소화하므로, 전체 상태공간에 걸쳐 균등한 학습이 가능하다. 추가로, 고유값 순서를 보장하기 위해 λ₀<λ₁… 제약을 라그랑주 승수 형태로 포함한다.
학습된 ϕ₀를 이용한 제어는 û(x,t)=∇_x log ϕ₀(x) 로 간단히 계산된다. 그러나 이 근사는 T−t가 충분히 큰 경우에만 정확하므로, 저자는 하이브리드 전략을 제시한다. (i) 장기 구간 (T−t≥τ₀, τ₀≈1)에서는 ϕ₀만 사용해 제어를 계산하고, (ii) 남은 짧은 구간에서는 기존 FBSDE 혹은 IDO 기반 방법을 적용해 정확한 단기 제어를 보완한다. 이렇게 하면 메모리 사용량이 O(d) (상태 차원만)로 감소하고, 시간 복잡도도 O(d)·iteration 수준으로 유지된다.
실험에서는 d=20 차원의 여러 베이스라인(Deep FBSDE, IDO, MPPI 등)과 다양한 horizon T∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기