A Schrödinger Eigenfunction Method for Long-Horizon Stochastic Optimal Control
High-dimensional stochastic optimal control (SOC) becomes harder with longer planning horizons: existing methods scale linearly in the horizon $T$, with performance often deteriorating exponentially. We overcome these limitations for a subclass of li…
Authors: Louis Claeys, Artur Goldman, Zebang Shen
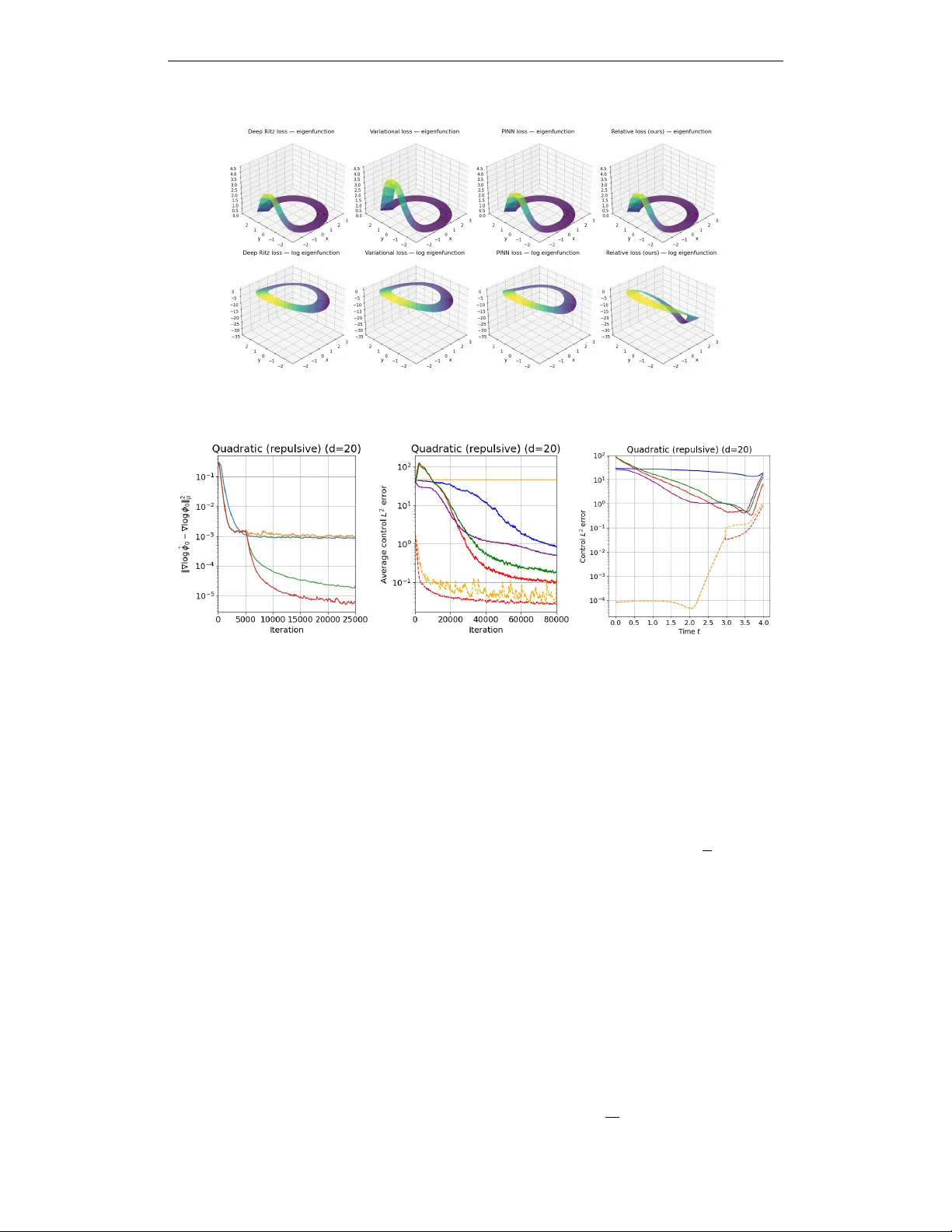
Published as a conference paper at ICLR 2026 A S C H R Ö D I N G E R E I G E N F U N C T I O N M E T H O D F O R L O N G - H O R I Z O N S T O C H A S T I C O P T I M A L C O N T R O L Louis Claeys ETH Zürich, Department of Mathematics louis.claeys@live.be Artur Goldman ETH Zürich, ETH AI Center Institute for Machine Learning artur.goldman@ai.ethz.ch Zebang Shen ETH Zürich, Institute for Machine Learning zebang.shen@inf.ethz.ch Niao He ETH Zürich, Institute for Machine Learning, niao.he@inf.ethz.ch A B S T R AC T High-dimensional stochastic optimal control (SOC) becomes harder with longer planning horizons: existing methods scale linearly in the horizon T , with per- formance often deteriorating exponentially . W e overcome these limitations for a subclass of linearly-solvable SOC problems—those whose uncontrolled drift is the gradient of a potential. In this setting, the Hamilton-Jacobi-Bellman equa- tion reduces to a linear PDE go verned by an operator L . W e prove that, under the gradient drift assumption, L is unitarily equi valent to a Schrödinger operator S = − ∆ + V with purely discrete spectrum, allowing the long-horizon control to be efficiently described via the eigensystem of L . This connection provides two key results: first, for a symmetric linear-quadratic regulator (LQR), S matches the Hamiltonian of a quantum harmonic oscillator, whose closed-form eigensystem yields an analytic solution to the symmetric LQR with arbitrary terminal cost. Second, in a more general setting, we learn the eigensystem of L using neural networks. W e identify implicit reweighting issues with existing eigenfunction learning losses that degrade performance in control tasks, and propose a nov el loss function to mitigate this. W e e valuate our method on sev eral long-horizon benchmarks, achieving an order-of-magnitude impro vement in control accuracy compared to state-of-the-art methods, while reducing memory usage and runtime complexity from O ( T d ) to O ( d ) . 1 I N T R O D U C T I O N Stochastic optimal control (SOC) concerns the problem of directing a stochastic system, typically modeled by a stochastic dif ferential equation (SDE), to minimize an e xpected total cost. SOC has found applications in v arious domains, e.g. stochastic filtering (Mitter, 1996), rare e vent simulation in molecular dynamics (Hartmann & Schütte, 2012; Hartmann et al., 2014), robotics (Gorodetsky et al., 2018) and finance (Pham, 2009). Built on the principle of dynamic programming, the global optimality condition of SOC can be expressed by the Hamilton-Jacobi-Bellman (HJB) equation. In this paper , we focus on the affine contr ol setting commonly considered in the literature (Fleming & Rishel, 1975; Kappen, 2005b; Fleming & Soner, 2006; Y ong & Zhou, 1999; Domingo-Enrich et al., 2024b; Nüsk en & Richter, 2021; Carius et al., 2022; Holdijk et al., 2023), where the control af fects the state of the system linearly . This setting is of interest since the optimal control will exactly match the gradient of the v alue function of SOC problem and hence the corresponding HJB equation can be drastically simplified. A canonical special case of this affine-control frame work is the linear–quadratic regulator (LQR), in which the uncontrolled dynamics follo w an Ornstein–Uhlenbeck linear SDE and both the running cost and the terminal cost are quadratic. One can show that in the LQR setting the value function retains a quadratic form—indeed, it is quadratic at terminal time because the terminal cost is quadratic—and 1 Published as a conference paper at ICLR 2026 that the optimal feedback control is linear w .r .t. the state. Consequently , the associated SOC problem admits an explicit solution via the finite-dimensional matrix Riccati dif ferential equation (v an Handel, 2007) T o obtain the optimal control in more general settings requires numerical procedures. For low- dimensional problems, classical grid-based PDE solvers may be used, but these suf fer from the curse of dimensionality . This has led to several works proposing the use of neural netw orks (NN) to solve the HJB equation in more complex high-dimensional settings, either through a forward-backward stochastic differential equation (FBSDE) approach (Han et al., 2018; Ji et al., 2022; Andersson et al., 2023; Beck et al., 2019) or so-called iterati ve dif fusion optimization (IDO) methods, which sample controlled trajectories through simulation and update the NN parameter using stochastic gradients from automatic dif ferentiation (Nüsken & Richter, 2021; Domingo-Enrich et al., 2024b;a). A more comprehensiv e re view on e xisting methods for short-horizon SOC can be found in Appendix C. Figure 1: Performance degradation as time horizon T increases for dif ferent methods (see Appendix E for details). While these methods hav e proven successful, their perfor- mance suffers as the time horizon T grows . Both the memory requirement and per-iteration runtime increase at least lin- early in T . Additionally , it holds that error estimates for the deep FBSDE method worsen as T increases (Han & Long, 2020, Theorem 4), and for IDO methods using importance sampling the weight variance may increase exponentially in T (Liu et al., 2018). These limitations were observed em- pirically in Assabumrungrat et al. (2024); Domingo-Enrich et al. (2024b), and were reproduced in our experiments (see Figure 1). Linearly-solvable HJB. The HJB equation is in general nonlinear . Howe ver , in the special case where the system’ s dif fusion coefficient matches the affine-control mapping, the Cole–Hopf transform can eliminate the nonlinearity (Evans, 2022). Specifically , let V ( x, t ) denote the value function of the SOC problem and define a new function ψ := exp( − V ) . Under this transformation, the HJB is equiv alently re written as the follo wing linear PDE ∂ t ψ ( x, t ) = L ψ ( x, t ) , ψ ( x, T ) = ψ T ( x ) (1) for some linear operator L . Moreover , the optimal control u , which e xactly matches the gradient of the value function − ∂ x V , can be obtained as u ∗ = ∂ x log ψ (Kappen, 2005b). Figure 2: Diminishing returns from in- creasing the number of eigenfunctions for an LQR in d = 20 dimensions. W orking with a linear PDE brings se veral clear bene- fits ov er a nonlinear one, such as a simplified analysis — questions of well - posedness and solution regularity of the PDE become much more tractable — b ut more impor - tantly algorithmic insight: One can borrow ideas from the finite - dimensional linear ODE ˙ u ( t ) + A u ( t ) = 0 , where A is a real symmetric matrix. This ODE has a closed - form solution u ( t ) = e − At u (0) , and because the matrix expo- nential e − At acts simply on A ’ s eigenv alues, expanding u (0) in the corresponding eigen vectors yields an ef ficient numerical scheme. While the domain of the operator L is infinite - dimensional (acting on functions rather than finite vectors), the same exponential - integrator principle applies (Theorem 1), and we can write ψ t = e ( t − T ) L ψ T , where e s L s ≥ 0 is a semi- group (Renardy & Rogers, 2006, Chapter 12). Of course, carrying it out in an infinite - dimensional setting introduces additional technical challenges that must be carefully addressed. In particular , expanding ψ T as a series of eigenfunctions requires L to possess a discr ete spectrum , i.e. one can find an orthonormal basis of eigenfunctions ( ϕ i ) i ∈ N and corresponding eigen v alues λ 0 < λ 1 ≤ · · · such that L ϕ i = λ i ϕ i for all i ∈ N . Under this assumption, the optimal control can be informally written as u ∗ ( x, t ) = ∂ x log ϕ 0 ( x ) + O e − ( λ 1 − λ 0 )( T − t ) for any fix ed t as T → ∞ , (2) 2 Published as a conference paper at ICLR 2026 where O hides eigenfunctions ϕ i with i ≥ 1 . A precise statement can be found in Theorem 3. T o turn the abov e formula into a practical, long-horizon SOC algorithm, we need (1) Spectral verification. Prov e that L indeed has a discrete spectrum; (2) Eigenfunction identification. Compute the spatial deriv ati ve of the principal eigenfunction ϕ 0 . Our approach: Reduction to Schrödinger operator . In this paper, to guarantee the spectral verification, we assume that the drift of the dynamics is the gradient of a potential . Such problems of controlling a diffusion process with gradient drift show up in overdamped molecular dynamics (Schütte et al., 2012), mean-field games (Bakshi et al., 2019; Grover et al., 2018), the control of particles with interaction potentials (Carrillo et al., 2020; T otzeck & Pinnau, 2020), as well as social models for opinion formation (Castellano et al., 2009; Albi et al., 2017). In this setting, the operator L in (1) is unitarily equiv alent to the Schrödinger operator ˜ L = − ∆ + V , where ∆ is the Laplacian and V is an effecti ve potential determined by the original drift and running cost. Because ˜ L is kno wn to ha ve a purely discrete spectrum on L 2 and unitary equi valence preserves the spectral properties, the operator L in (1) like wise enjoys a discrete spectrum. This result forms the basis of our new framew ork for long-horizon SOC, where the problem is reformulated as learning the eigensystem of a Schrödinger operator . Indeed, (2) shows that the top eigenfunction ϕ 0 determines the long-term control, with corrections decaying exponentially with rate λ 1 − λ 0 . W e address the problem of eigenfunction identification in the following tw o scenarios: • Closed-f orm solution for LQR with non-quadratic terminal cost. When the drift is linear with a symmetric coef ficient matrix and the running cost is quadratic in the state, the resulting Schrödinger operator ˜ L coincides with the Hamiltonian of the quantum harmonic oscillator . Its eigen v alues and eigenfunctions are kno wn explicitly (see Lemma 4 or Grif fiths & Schroeter (2018)), i.e. { λ i , ϕ i } i ∈ N are av ailable in closed form. Consequently , our frame work yields a fully explicit expression for the corresponding SOC. This remov es the requirement of quadratic terminal cost in the the classical LQR solution. • Neural netw ork-based appr oach f or general gradient drift. For general gradient–drift dynamics, we introduce a hybrid neural-network method to approximate the optimal control ef ficiently: Rather than attempting to learn the full spectrum of L —which is prohibitively expensiv e and yields rapidly diminishing returns (fig. 2)—we exploit the exponential decay of the higher modes w .r .t. T − t in eq. (2). Concretely , whene ver T − t exceeds a modest threshold (in our experiments T − t ≥ 1 ), it suffices to approximate the control using only the top eigenfunction ϕ 0 . For the remaining period ( t very close to T ), we switch to established FBSDE/IDO solvers to handle the short-horizon SOC. W e propose a novel deep learning strategy for the task of learning the eigenfunction, tailored to SOC. While such a task has been extensi vely studied in the literature, pre vious approaches either optimize a v ariational Ritz objectiv e (E & Y u, 2018; Zhang et al., 2022; Cabannes & Bach, 2024) or minimize the residual norm ∥L ψ − λψ ∥ 2 (Jin et al., 2022; Zhang et al., 2024; Nusken & Richter, 2023). Howe ver , these losses implicitly reweight spatial regions, causing them to fail to learn the control in regions where the v alue function V is large—the most crucial areas. T o eliminate this bias, we introduce a r elative eigenfunction loss, ∥L ψ /ψ − λ ∥ 2 , which remov es the undesired weighting and robustly reco vers the dominant eigenpair needed for control synthesis. Our contributions are summarized as follo ws: • W e provide a ne w perspectiv e on finite-horizon gradient-drift SOC problems, linking their solution to the eigensystem of a Schrödinger operator (Theorem 3). This yields a previously unreported closed-form solution to the symmetric LQR with arbitrary terminal cost (Theorem 4). • W ith this frame work, we introduce a new procedure for solving SOC problems ov er long horizons by learning the operator’ s eigenfunctions with neural networks. W e show that existing eigenfunction solvers can be ill-suited for this task due to an implicit re weighting in the used loss, and propose a new loss function to remedy this. • W e perform experiments in different settings to ev aluate the proposed method against state-of- the-art SOC solvers, sho wing roughly an order of magnitude impro vement in control L 2 error on sev eral high-dimensional ( d = 20) long-horizon problems. 3 Published as a conference paper at ICLR 2026 2 P R E L I M I N A R I E S 2 . 1 S T O C H A S T I C O P T I M A L C O N T R O L Fix a filtered probability space (Ω , F , ( F t ) t ≥ 0 , P ) , and denote ( W t ) t ≥ 0 a Brownian motion in this space. Let ( X u t ) t ≥ 0 denote the random variable taking v alues in R d defined through the SDE d X u t = ( b ( X u t ) + σ u ( X u t , t )) d t + p β − 1 σ d W t , X u 0 ∼ p 0 (3) where u : R d × [0 , T ] → R d is the control, b : R d → R d is the base drift, σ ∈ R d × d is the diffusion coefficient (assumed in vertible) and β ∈ R + 0 is an in verse temperature characterizing the noise le vel. Note that we assume the drift and noise to be time-independent, in contrast to Nüsken & Richter (2021); Domingo-Enrich et al. (2024b). Under some regularity conditions on the coefficients and control u described in Appendix A, the SDE (3) has a unique strong solution. In stochastic optimal control, we view the dynamics ( b, σ, β ) as giv en and consider the problem of finding a control u which minimizes the cost functional J ( u ; x, t ) = E " Z T t 1 2 ∥ u ( X u t , t ) ∥ 2 + f ( X u t ) d t + g ( X u T ) X t = x # (4) where f : R d → R denotes the running cost and g : R d → R denotes the terminal cost. W e denote this optimal control as u ∗ ( x, t ) = arg min u ∈U J ( u ; x, t ) , with U the set of admissible controls. T o analyze this problem, one defines the value function V , which is defined as the minimum achiev able cost when starting from x at time t , V ( x, t ) := inf u ∈U J ( u ; x, t ) . (5) In this case, the optimal control u ∗ that minimizes the objectiv e (4) is obtained from the v alue function through the relation u ∗ = − σ T ∇ V , as described in (Nüsken & Richter, 2021, Theorem 2.2). Hamilton-Jacobi-Bellman equation. A well-known fundamental result is that when the value function V is sufficiently regular , it satisfies the following partial differential equation, called the Hamilton-Jacobi-Bellman (HJB) equation (Fleming & Rishel, 1975): ∂ t V + K V = 0 in R d × [0 , T ] , V ( · , T ) = g on R d , (6) where K V = 1 2 β T r ( σ σ T ∇ 2 V ) + b T ∇ V − 1 2 ∥ σ T ∇ V ∥ 2 + f . (7) The so-called verification theor em states (in some sense) the conv erse: if a function V satisfying the abov e PDE is suf ficiently regular , it coincides with the v alue function (5) corresponding to (3) - (4) , see (Fleming & Rishel, 1975, Section VI.4) and (Pa vliotis, 2014, Sec. 2.3). A linear PDE reformulation Although the HJB equation (6) is nonlinear in general, it was sho wn in Kappen (2005b) that for a specific class of optimal control problems (which includes the formulation (3) - (4) ), a suitable transformation allo ws for a linear reformulation of (6) . More specifically , when parametrizing V ( x, t ) = − β − 1 log ψ ( x, 1 2 β ( T − t )) , the nonlinear terms cancel, and (6) becomes ∂ τ ψ + L ψ = 0 , ψ ( · , 0) = ψ 0 , where L ψ = − T r ( σ σ T ∇ 2 ψ ) − 2 β b T ∇ ψ + 2 β 2 f · ψ , ψ 0 = exp( − β g ) , (8) and we have introduced the variable τ = (2 β ) − 1 ( T − t ) . This is precisely the abstract form (1) , but with a time re versal. For more details on this result, we refer to Appendix B. T o simplify the presentation, we will often assume w .l.o.g. that σ = I (see Appendix A), so that T r ( σ σ T ∇ 2 ) = ∆ . 2 . 2 E I G E N F U N C T I O N S O L U T I O N S Consider a Hilbert space H with inner product ⟨· , ·⟩ , and a linear operator L : D ( L ) → H defined on a dense subspace D ( L ) ⊂ H . Then we hav e the following standard definition: Definition 1 An element ϕ ∈ H with ϕ = 0 is an eigenfunction of L if ther e exists a λ ∈ C such that L ϕ = λϕ . The value λ is called an eigen v alue of L (corr esponding to ϕ ), and the dimension of the null space of L − λI is called the multiplicity of λ . 4 Published as a conference paper at ICLR 2026 In a finite-dimensional setting, the study of a linear operator A is drastically simplified when we hav e access to an orthonormal basis of eigen vectors. Similarly , some operators admit a countable set of eigenfunctions ( ϕ i ) i ∈ N which forms an orthonormal basis of the Hilbert space H . When such an eigensystem exists, the follo wing theorem prov en in Appendix B gi ves a solution to the PDE (8) in terms of the eigensystem. A rigorous connection between this solution to (8) and solutions to (6) is explored in Appendix B. Theorem 1 (Restatement of Theor em VIII.7 in (Reed & Simon, 1980)) Let L be an essentially self-adjoint 1 , densely defined oper ator on H which admits an orthonormal basis of eigenfunctions ( ϕ i , λ i ) i ∈ N . Assume further that the λ i ar e bounded fr om below (write λ 0 ≤ λ 1 ≤ . . . ) and do not have a finite accumulation point. Then a solution to the abstract e volution pr oblem in (8) is given by ψ ( τ ) = X i ∈ N e − λ i τ ⟨ ϕ i , ψ 0 ⟩ ϕ i . (9) While we originally aimed to solve the HJB equation (6), in this work, we solv e the linear PDE (8) as surrogate. In Section B.7, we show that under standard growth and re gularity assumptions, the above semigroup solution coincides with the unique viscosity solution of the original HJB equation, up to an in verse Hope-Cole transformation. See Theorem 10 for a formal statement. 3 O U R F R A M E W O R K 3 . 1 S P E C T R A L P RO P E RT I E S O F T H E S C H R Ö D I N G E R O P E R A T O R In order to apply Theorem 1, we must establish conditions under which the operator L in (8) satisfies the required properties. In order for L to be symmetric, we assume (A1) The drift b in (3) is described by a gradient field: b ( x ) = −∇ E ( x ) . Define the measure µ on R d with density µ ( x ) = exp ( − 2 β E ( x )) , and consider the weighted Lebesgue space L 2 ( µ ) . Note that we do not require µ to be a finite measure. Under the assumption (A1) , the operator appearing in (8) becomes the following operator on L 2 ( µ ) : L : D ( L ) ⊂ L 2 ( µ ) → L 2 ( µ ) : ψ 7→ L ψ = − ∆ ψ + 2 β ⟨∇ E , ∇ ψ ⟩ + 2 β 2 f ψ . (10) Under mild regularity conditions, we can further show that L is essentially self-adjoint (Appendix B). Furthermore, it can be shown (Appendix B) that U L U − 1 = − ∆ + β 2 ∥∇ E ∥ 2 − β ∆ E + 2 β 2 f (11) where U : L 2 ( µ ) → L 2 ( R d ) : ψ 7→ e − β E ψ is a unitary operator, so that L is unitarily equiv alent to the well-kno wn Schrödinger operator S = − ∆ + V on L 2 ( R d ) , which forms the cornerstone of the mathematical formulation of quantum physics. Its properties ha ve been studied to great e xtent (Reed & Simon, 1978), allo wing us to in voke well-kno wn results on the properties of the Schrödinger operator to study the behavior of L . In particular , the following assumption on E and f is enough to guarantee that L satisfies all the desired properties (see Appendix B). (A2) For the ener gy E and running cost f , V := β ∥∇ E ∥ 2 − ∆ E + 2 β f satisfies V ∈ L 2 loc ( R d ) , ∃ C ∈ R , ∀ x ∈ R d : C ≤ V ( x ) , and V ( x ) → ∞ as ∥ x ∥ → ∞ . Theorem 2 (Restatement of (Reed & Simon, 1978), Theor em XIII.67, XIII.64, XIII.47) Suppose (A2) is satisfied. Then the operator L in (10) is densely defined and essentially self-adjoint. Mor eover , it admits a countable, orthonormal basis of eigenfunctions. In addition, the eigen values ar e bounded fr om below and do not have a finite accumulation point, the lowest eig en value λ 0 has multiplicity one, and the associated eigenfunction (called the ground state , or in our conte xt the top eigenfunction ) can be chosen to be strictly positive . Remark 1 Pr evious studies have linked the Schrödinger operator to optimal control in contexts distinct fr om ours: for example, Schütte et al. (2012) and Bakshi et al. (2020) analyze the stationary HJB equation K V ∞ = λ (see Remark 2), whereas Kalise et al. (2025) explor es distribution-level contr ol of the F okker–Planck equation. 1 An operator is called essentially self-adjoint if its closure is self-adjoint. See Reed & Simon (1980) and Reed & Simon (1975) for more details. 5 Published as a conference paper at ICLR 2026 3 . 2 E I G E N F U N C T I O N C O N T RO L From the previous discussion, we obtain the follo wing result, which links the eigenfunctions of L with the optimal control problem. Theorem 3 Suppose (A1) - (A2) are satisfied. Then L satisfies all assumptions in Theor em 1, hence the solution of the optimal contr ol pr oblem (3) - (4) is given by u ∗ ( x, t ) = β − 1 ∇ log ϕ 0 ( x ) + ∇ log 1 + X i> 0 ⟨ e − β g , ϕ i ⟩ µ ⟨ e − β g , ϕ 0 ⟩ µ e − 1 2 β ( λ i − λ 0 )( T − t ) ϕ i ( x ) ϕ 0 ( x ) !! . (12) wher e ( ϕ i , λ i ) i ∈ N is the orthonormal eigensystem of L defined in (10) , and λ 0 < λ 1 ≤ . . . . Thus, the long-term optimal control ( t ≪ T ) is giv en by β − 1 ∇ log ϕ 0 , and the corrections decay exponentially , moti vating truncation of the series in (12). 3 . 3 C L O S E D - F O R M S O L U T I O N F O R T H E S Y M M E T R I C L Q R When E and f are quadratic, the Schrödinger operator associated with the optimal control system is the Hamiltonian for the harmonic oscillator , which has an exact solution (Appendix B): Theorem 4 Suppose b ( x ) = − Ax for some symmetric matrix A ∈ R d × d , and f ( x ) = x T P x for some matrix P ∈ R d × d such that A T A + 2 P is positive definite, and has diagonalization U T Λ U . Then the orthonormal eigensystem of the operator L given in (10) is described thr ough ϕ α ( x ) = exp − β 2 x T − A + U T Λ 1 / 2 U x ( λπ ) d/ 4 d Y i =1 Λ 1 / 8 ii p 2 α i ( α i !) H α i p β (Λ 1 / 4 U x ) i , (13) λ α = β − T r ( A ) + d X i =1 Λ 1 / 2 ii (2 α i + 1) ! . (14) wher e α ∈ N d and H i denotes the i th physicist’s Hermite polynomial. W e can bijectively map α ∈ N d to i ∈ N by ordering the eigen values (14) , yielding the same repr esentation as before . Combined with Theorem 3, this yields a closed-form solution for the optimal control problem with symmetric linear drift, quadratic running cost and arbitrary terminal rew ard. 4 N U M E R I C A L M E T H O D S W e propose a hybrid method with tw o components: Far from the terminal time T , we learn the top eigenfunction ϕ 0 and simply use ∂ x log ϕ 0 as the control (c.f. eq. (2)); Close to the terminal time, e.g. t ≥ T − 1 , we use an existing solver to learn an additi ve short-horizon correction to the control. 4 . 1 L E A R N I N G E I G E N F U N C T I O N S In absence of a closed-form solution, a wide range of numerical techniques exist for solving the eigen v alue problem for the operator L in (10) . Classically , the eigenfunction equation is projected onto a finite-dimensional subspace to yield a Galerkin/finite element method, see Chaitin-Chatelin (1983). In high dimensions, these methods often perform poorly , motiv ating deep learning approaches which differ from each other mainly in the loss function used. W e will only discuss methods for learning a single eigenfunction, referring to Appendix C for extensions to multiple eigenfunctions. An ov erview of the deep leraning algorithm for learning eigenfunctions is gi ven in Algorithm 1 in Appendix E. PINN loss Based on the success of physics-informed neural networks (PINNs) (Raissi et al., 2019), one idea is to design a loss function that attempts to enforce the equation L ϕ = λϕ via an L 2 loss, as done in Jin et al. (2022). The idea is to consider some density ρ on R d , and define the loss function R ρ PINN ( ϕ ) = ∥L [ ϕ ] − λϕ ∥ 2 ρ + α R ρ reg ( ϕ ) , R ρ reg ( ϕ ) = ( ∥ ϕ ∥ 2 ρ − 1) 2 (15) 6 Published as a conference paper at ICLR 2026 Figure 3: Learned controls (arrows) and V 0 for different eigenfunction losses. Existing methods fail to learn the correct control in regions where V 0 is large due to implicit re weighting. where α > 0 is a regularizer to a void the tri vial solution ϕ = 0 . The eigenv alue λ is typically also modeled as a trainable parameter of the model, or obtained through other estimation procedures. V ariational loss A second class of loss functions is based on the variational characterization of the eigensystem of L . Since L is essentially self-adjoint with orthogonal eigenbasis in a subset of L 2 ( µ ) ( µ is defined below (A1) ), it holds that (see (Reed & Simon, 1978, Theorem XIII.1)) λ 0 = inf ψ ∈ L 2 ( µ ) ⟨ ψ , L ψ ⟩ µ ⟨ ψ , ψ ⟩ µ (16) where the infimum is obtained when L ψ = λ 0 ψ . This motiv ates the loss functions R V ar , 1 ( ϕ ) = ⟨ ϕ, L ϕ ⟩ µ ⟨ ϕ, ϕ ⟩ µ + α R µ reg ( ϕ ) , R V ar , 2 ( ϕ ) = ⟨ ϕ, L ϕ ⟩ µ + α R µ reg ( ϕ ) . (17) The first of these, sometimes called the deep Ritz loss , was introduced in E & Y u (2018), and the second was described in Cabannes & Bach (2024); Zhang et al. (2022). These loss functions do not require prior knowledge of the eigen value λ 0 . 4 . 1 . 1 I M P L I C I T R E W E I G H T I N G I N P R E V I O U S A P P R OA C H E S The exponential decay of the correction term in eq. (2) suggests that the optimal control u ∗ can be approximated by the spatial deriv ati ve of logarithm of the top eigenfunction. W e therefore parameterize in our implementation ϕ = exp( − β V 0 ) , where V 0 is some neural network and β is the temperature constant. This choice also enforces the strict positivity of ϕ , which matches the same property of ϕ 0 established in Theorem 2. Adopting such a parameterization, for the PINN and variational losses, it holds that R ρ PINN ( e − β V 0 ) = 4 β 4 e − β V 0 K V 0 − λ 0 2 β 2 2 ρ + α R ρ reg ( e − β V 0 ) (18) R V ar , 2 ( e − β V 0 ) = 2 β 2 Z e − 2 β V 0 K V 0 d µ + α R µ reg ( e − β V 0 ) (19) where K is the HJB operator (7) . Because both (18) and (19) incorporate an exponential f actor that vanishes where V 0 is large, these losses become effecti vely blind to errors in high- V 0 regions and are only able to learn where V 0 is small. This pathology is illustrated in Figure 3: Consider a 2D R I N G energy landscape E , whose minimizers lie on a circle, and a cost f that grows linearly with the x -coordinate (see the full setup in Section E). The true optimal control remains tangential to the circle. In contrast, the controls obtained via the PINN and v ariational eigenfunction losses collapse in regions of lar ge V 0 , deviating sharply from the e xpected direction. 4 . 1 . 2 O U R A P P R OA C H : R E M O V I N G I M P L I C I T R E W E I G H T I N G V I A R E L A T I V E L O S S Based on this observation, we propose to modify (15) to R ρ Rel ( ϕ ) = L ϕ ϕ − λ 2 ρ + α R ρ reg ( ϕ ) . (20) 7 Published as a conference paper at ICLR 2026 This loss function, which we call the r elative loss , eliminates the implicit re weighting of the stationary HJB equation. Indeed, the same computation as before yields R ρ Rel ( e − β V 0 ) = 4 β 4 K V 0 − λ 0 2 β 2 2 ρ + α R ρ reg ( e − β V 0 ) . (21) As a result, the relativ e loss remains sensitive e ven in re gions where ϕ = e − β V 0 becomes small. This can also be empirically observed in the R I N G task, as illustrated in Figure 3. Instead of learning V 0 and λ 0 jointly , a natural idea is to combine the benefits of the abo ve loss functions by first training with a variational loss (17) to obtain an estimate for the eigen v alue λ 0 and a good initialization of V 0 , and then ‘fine-tune’ using (20) . In practice, we also observed that this initialization is necessary for the relativ e loss (20) to con ver ge. Remark 2 W e note that ther e is an alternative interpretation of (21) based on a separate class of contr ol problems in which ther e is no terminal cost g , and an infinite-horizon cost is minimized, yielding a stationary or ergodic optimal control (K ushner, 1978). In this setting, u is related to a time-independent value function V ∞ which satisfies a stationary HJB equation of the form K V ∞ = λ . In low dimensions, these pr oblems ar e solved thr ough classical techniques such as basis e xpansions or grid-based methods, with no in volvement of neural networks (T odor ov, 2009). 4 . 2 O U R H Y B R I D M E T H O D : C O M B I N I N G E I G E N F U N C T I O N S A N D S H O RT - H O R I Z O N S O LV E R S For both IDO and FBSDE methods, every iteration requires the numerical simulation of an SDE, yielding a linear increase in computation cost with the time horizon T . W e propose to leverage the eigenfunction solution giv en in Theorem 3 in order to scale these methods to longer time horizons as follows: first, parametrize the top eigenfunction as ϕ θ 0 0 = exp( − β V θ 0 0 ) for a neural network V θ 0 0 , and learn the parameters θ 0 using the relati ve loss, as well as the first two eigen v alues λ 0 , λ 1 (see Appendix E). Next, choose some cutof f time T cut < T and parametrize the control as u θ ( x, t ) = ( β − 1 ∇ log ϕ θ 0 0 0 ≤ t ≤ T cut , β − 1 ∇ log ϕ θ 0 0 ( x ) + e − 1 2 β ( λ 1 − λ 0 )( T − t ) v θ 1 ( x, t ) T cut < t ≤ T . (22) This control can then be used in an IDO/FBSDE algorithm to optimize the parameters θ 1 of the additiv e correction v θ 1 , a second neural network, near the terminal time. Crucially , this only requires simulation of the system in the interval [ T cut , T ] , significantly reducing the ov erall computational burden and reducing the time comple xity of the algorithm from O ( T d ) to O ( d ) . Choice of T cut . Increasing T cut → T raises computational cost, whereas choosing T cut too small degrades performance; this reflects the fundamental trade-off in selecting this parameter . One heuristic for choosing an appropriate order of magnitude is to observe that we would like the correction term giv en by the infinite series in Eq. (12) to be small for all t ≤ T cut . Even without access to the inner products or eigenfunctions, we may consider the approximation exp − 1 2 β ( λ 1 − λ 0 )( T − T cut ) = ε, which yields T − T cut = − 2 β λ 1 − λ 0 log ε. Since we obtain empirical estimates of λ 0 and λ 1 , this expression pro vides a practical guideline for determining the scale of T cut , and thus can be implemented in practice. 5 E X P E R I M E N T S T o ev aluate the benefits of the proposed method, we consider four different settings, Q UA D R AT I C ( I S OT RO P I C ) , Q UA D R AT I C ( A N I S OT RO P I C ) , D O U B L E W E L L , and R I N G . An additional setting Q U A D R A T I C ( R E P U L S I V E ) with nonconfining energy is discussed in Appendix E. The first three are high-dimensional benchmark problems adapted from Nüsken & Richter (2021), modified to be long- horizon problems, where a ground truth can be obtained. Detailed information on the experimental 8 Published as a conference paper at ICLR 2026 Method Algorithm/Loss Control objectiv e EIGF (ours) Relative loss 73 . 33 ± 0 . 02 IDO Log-variance loss 74 . 52 ± 0 . 02 IDO Adjoint Matching 74 . 69 ± 0 . 02 IDO Relativ e Entropy 75 . 63 ± 0 . 02 IDO SOCM Did not con ver ge T able 1: Opinion dynamics, final control objectiv e (smaller is better). setups, including computational costs, is given in Appendix E. The code for the described e xperiments is av ailable online 2 . Figure 4: Comparison of the different eigenfunction losses (EMA). Figure 4 shows the results of the v arious eigenfunction losses. For the Q U A D R A T I C settings, we can compute ∇ log ϕ 0 exactly , and see that the relativ e loss significantly improves upon existing loss functions for approximating this quantity (with the error measured in L 2 ( µ ) ). For the other settings, the resulting control ∇ log ϕ 0 yields the lowest v alue of the control objecti ve for the relati ve loss. In Figure 5, we sho w the result of using the learned eigenfunctions in the IDO algorithm using the combined algorithm described in the previous section, and compare it with the standard IDO/FBSDE methods. In each setting, we obtain a lower L 2 error using the combined method, typically by an order of magnitude. The bottom row of Figure 5 shows how the error behaves as a function of t ∈ [0 , T ] : the pure eigenfunction method achiev es superior performance for t → 0 , but performs worse closer to the terminal time T . The IDO method has constant performance in [0 , T ] , and the combined method combines the merits of both to provide the lo west ov erall L 2 error . 5 . 1 O P I N I O N M O D E L I N G : D E G R O OT M O D E L W e additionally consider a networked control problem inspired by opinion formation. W e model N = 10 agents with state X t ∈ R 10 and dynamics dX t = ( L − I ) X t − γ X t + u ( X t ) dt + dW t , (23) where L ∈ R 10 × 10 is a symmetric interaction matrix with L ii = 0 . 5 and L i,i ± 1 = 0 . 25 (all other entries are zero), and we set γ = 0 . 1 . W e use the non-quadratic running cost f ( x ) = 10 X i =1 ( x 2 i − 1) 2 , (24) and terminal cost g ( x ) = 0 , with parameters λ = 1 . 0 and time horizon T = 10 . 0 . T able 1 reports the final control objectiv e (mean ± std) after 80 , 000 training iterations. 6 C O N C L U S I O N In this work, we hav e introduced a new perspectiv e on a class of stochastic optimal control problems with gradient drift, showing that the optimal control can be obtained from the eigensystem of a 2 https://github .com/lclaeys/eigenfunction-solv er 9 Published as a conference paper at ICLR 2026 Figure 5: A verage L 2 control error (EMA) as a function of iteration (top row) and L 2 error as a function of t ∈ [0 , T ] (bottom ro w). Schrödinger operator . W e ha ve inv estigated the use of deep learning methods to learn the eigensystem, introducing a new loss function for this task. W e have sho wn ho w this approach can be combined with existing IDO methods, yielding an improv ement in L 2 error of roughly an order of magnitude ov er state-of-the-art methods in se veral long-horizon e xperiments, and ov ercoming the increase in computation cost typically associated with longer time horizons. Limitations The main drawback of the proposed approach is that it is currently limited to problems with gradient drift. When the operator L is not e ven symmetric, it may no longer have real eigenv alues. Nonetheless, the top eigenfunction may still be real and nondegenerate with real eigen v alue, so that the long-term behaviour of the control is still described by an eigenfunction (Ev ans, 2022, Theorem 6.3). A second limitation is that there is no a priori method for determining an appropriate cutoff time T cut , this is a hyperparameter that should be decided based on the application and the spectral gap λ 1 − λ 0 . A C K N O W L E D G E M E N T S The work is supported by ETH research grant, Swiss National Science Foundation (SNSF) Project Funding No. 200021-207343, and SNSF Starting Grant. Artur Goldman is supported by the ETH AI Center through an ETH AI Center doctoral fellowship. 10 Published as a conference paper at ICLR 2026 R E F E R E N C E S Giacomo Albi, Y oung Pil Choi, Massimo Fornasier , and Dante Kalise. Mean Field Control Hierarchy. Applied Mathematics and Optimization , 76(1):93–135, August 2017. ISSN 0095-4616. doi: 10.1007/s00245- 017- 9429- x. Kristoffer Andersson, Adam Andersson, and C. W . Oosterlee. Conv ergence of a Robust Deep FBSDE Method for Stochastic Control. SIAM Journal on Scientific Computing , 45(1):A226–A255, February 2023. ISSN 1064-8275. doi: 10.1137/22M1478057. Rawin Assab umrungrat, K entaro Minami, and Masanori Hirano. Error Analysis of Option Pricing via Deep PDE Solvers: Empirical Study. In 2024 16th IIAI International Congr ess on Advanced Applied Informatics (IIAI-AAI) , pp. 329–336. IEEE Computer Society , July 2024. ISBN 979-8- 3503-7790-3. doi: 10.1109/IIAI- AAI63651.2024.00068. Kaiv alya Bakshi, Piyush Grov er , and Ev angelos A Theodorou. On mean field games for agents with langevin dynamics. IEEE T ransactions on Contr ol of Network Systems , 6(4):1451–1460, 2019. Kaiv alya Bakshi, David D Fan, and Evangelos A Theodorou. Schrödinger approach to optimal control of large-size populations. IEEE T ransactions on Automatic Control , 66(5):2372–2378, 2020. Miłosz Baranie wicz. Ground state decay for schr \ " odinger operators with confining potentials. arXiv pr eprint arXiv:2407.09267 , 2024. Christian Beck, W einan E, and Arnulf Jentzen. Machine learning approximation algorithms for high- dimensional fully nonlinear partial dif ferential equations and second-order backw ard stochastic differential equations. J ournal of Nonlinear Science , 29(4):1563–1619, August 2019. ISSN 0938-8974, 1432-1467. doi: 10.1007/s00332- 018- 9525- 3. Dimitri Bertsekas and Stev en E. Shrev e. Stochastic Optimal Contr ol: The Discrete-T ime Case . Athena Scientific, December 1996. ISBN 978-1-886529-03-8. Samuel Biton. Nonlinear monotone semigroups and viscosity solutions. In Annales de l’Institut Henri P oincaré C, Analyse non linéair e , volume 18, pp. 383–402. Else vier , 2001. J. Frédéric Bonnans, Élisabeth Ottenwaelter , and Housnaa Zidani. A fast algorithm for the two dimensional HJB equation of stochastic control. ESAIM: Modélisation mathématique et analyse numérique , 38(4):723–735, 2004. ISSN 1290-3841. doi: 10.1051/m2an:2004034. Susanne C. Brenner and L. Ridgway Scott. The Mathematical Theory of F inite Element Methods , volume 15 of T exts in Applied Mathematics . Springer, New Y ork, NY , 2008. ISBN 978-0-387- 75933-3 978-0-387-75934-0. doi: 10.1007/978- 0- 387- 75934- 0. Stev e Brooks, Andre w Gelman, Galin Jones, and Xiao-Li Meng (eds.). Handbook of Markov Chain Monte Carlo . Chapman and Hall/CRC, Ne w Y ork, May 2011. ISBN 978-0-429-13850-8. doi: 10.1201/b10905. V ivien Cabannes, Bobak Kiani, Randall Balestriero, Y ann LeCun, and Alberto Bietti. The ssl interplay: Augmentations, inductiv e bias, and generalization. In International Conference on Machine Learning , pp. 3252–3298. PMLR, 2023. V ivien A. Cabannes and Francis Bach. The Galerkin method beats Graph-Based Approaches for Spectral Algorithms. In Pr oceedings of The 27th International Confer ence on Artificial Intelligence and Statistics , pp. 451–459. PMLR, April 2024. Elisa Calzola, Elisabetta Carlini, Xavier Dupuis, and Francisco Silv a. A semi-Lagrangian scheme for Hamilton–Jacobi–Bellman equations with oblique deri vati ves boundary conditions. Numerische Mathematik , 153(1):49–84, January 2023. doi: 10.1007/s00211- 022- 01336- 6. Jan Carius, René Ranftl, Farbod Farshidian, and Marco Hutter . Constrained stochastic optimal control with learned importance sampling: A path integral approach. The International J ournal of Robotics Resear ch , 41(2):189–209, 2022. 11 Published as a conference paper at ICLR 2026 E. Carlini, A. Festa, and N. Forcadel. A Semi-Lagrangian Scheme for Hamilton–Jacobi–Bellman Equations on Networks. SIAM Journal on Numerical Analysis , 58(6):3165–3196, January 2020. ISSN 0036-1429. doi: 10.1137/19M1260931. José A. Carrillo, Edgard A. Pimentel, and V ardan K. V oskanyan. On a mean field optimal control problem. Nonlinear Analysis , 199:112039, October 2020. ISSN 0362-546X. doi: 10.1016/j.na. 2020.112039. Claudio Castellano, Santo Fortunato, and V ittorio Loreto. Statistical physics of social dynamics. Revie ws of Modern Physics , 81(2):591–646, May 2009. doi: 10.1103/RevModPhys.81.591. Françoise Chaitin-Chatelin. Spectral Appr oximation of Linear Operator s . Academic Press, 1983. ISBN 978-0-12-170620-3. Michael G Crandall, Hitoshi Ishii, and Pierre-Louis Lions. User’ s guide to viscosity solutions of second order partial dif ferential equations. Bulletin of the American mathematical society , 27(1): 1–67, 1992. Francesca Da Lio and Oli vier Ley . Uniqueness results for second-order bellman–isaacs equations under quadratic gro wth assumptions and applications. SIAM journal on contr ol and optimization , 45(1):74–106, 2006. Francesca Da Lio and Olivier Ley . Con vex hamilton-jacobi equations under superlinear growth conditions on data. Applied Mathematics & Optimization , 63(3):309–339, 2011. Edward Brian Davies and Barry Simon. Ultracontractivity and the heat kernel for schrödinger operators and dirichlet laplacians. Journal of Functional Analysis , 59(2):335–395, 1984. Carles Domingo-Enrich. A T axonomy of Loss Functions for Stochastic Optimal Control, October 2024. Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer , and Rick y T . Q. Chen. Adjoint Matching: Fine-tuning Flow and Dif fusion Generati ve Models with Memoryless Stochastic Optimal Control. In The Thirteenth International Confer ence on Learning Repr esentations , October 2024a. Carles Domingo-Enrich, Jiequn Han, Brandon Amos, Joan Bruna, and Ricky T . Chen. Stochastic Optimal Control Matching. Advances in Neural Information Pr ocessing Systems , 37:112459– 112504, December 2024b. W einan E and Bing Y u. The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving V ariational Problems. Communications in Mathematics and Statistics , 6(1):1–12, March 2018. ISSN 2194-671X. doi: 10.1007/s40304- 018- 0127- z. W einan E, Jiequn Han, and Arnulf Jentzen. Deep Learning-Based Numerical Methods for High- Dimensional Parabolic P artial Differential Equations and Backward Stochastic Dif ferential Equa- tions. Communications in Mathematics and Statistics , 5(4):349–380, December 2017. ISSN 2194-671X. doi: 10.1007/s40304- 017- 0117- 6. W einan E, Martin Hutzenthaler , Arnulf Jentzen, and Thomas Kruse. Multilevel Picard iterations for solving smooth semilinear parabolic heat equations. P artial Differ ential Equations and Applica- tions , 2(6):80, Nov ember 2021. ISSN 2662-2971. doi: 10.1007/s42985- 021- 00089- 5. Alexandre Ern and Jean-Luc Guermond. Theory and Practice of F inite Elements , volume 159 of Applied Mathematical Sciences . Springer , New Y ork, NY , 2004. ISBN 978-1-4419-1918-2 978-1-4757-4355-5. doi: 10.1007/978- 1- 4757- 4355- 5. Lawrence C Ev ans. P artial differ ential equations , volume 19. American Mathematical Society , 2022. W endell Fleming and Raymond Rishel. Deterministic and Stochastic Optimal Contr ol . Springer , Ne w Y ork, NY , 1975. ISBN 978-1-4612-6382-1 978-1-4612-6380-7. doi: 10.1007/978- 1- 4612- 6380- 7. W endell H Fleming and H Mete Soner . Contr olled Markov pr ocesses and viscosity solutions . Springer , 2006. 12 Published as a conference paper at ICLR 2026 Emmanuel Gobet, Jean-Philippe Lemor , and Xavier W arin. A regression-based Monte Carlo method to solve backward stochastic differential equations. The Annals of Applied Probability , 15(3): 2172–2202, August 2005. ISSN 1050-5164, 2168-8737. doi: 10.1214/105051605000000412. Alex Gorodetsky , Sertac Karaman, and Y oussef Marzouk. High-dimensional stochastic optimal control using continuous tensor decompositions. The International Journal of Robotics Resear ch , 37(2-3):340–377, 2018. David J. Grif fiths and Darrell F . Schroeter . Intr oduction to Quantum Mechanics . Cambridge Uni versity Press, 3 edition, 2018. Piyush Grover , Kaiv alya Bakshi, and Evangelos A. Theodorou. A mean-field game model for homogeneous flocking. Chaos: An Inter disciplinary J ournal of Nonlinear Science , 28(6):061103, June 2018. ISSN 1054-1500. doi: 10.1063/1.5036663. Jiequn Han and Jihao Long. Con ver gence of the deep BSDE method for coupled FBSDEs. Pr obability , Uncertainty and Quantitative Risk , 5(1):5, July 2020. ISSN 2367-0126. doi: 10.1186/s41546- 020- 00047- w. Jiequn Han, Arnulf Jentzen, and W einan E. Solving high-dimensional partial differential equations using deep learning. Pr oceedings of the National Academy of Sciences , 115(34):8505–8510, August 2018. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.1718942115. Carsten Hartmann and Christof Schütte. Efficient rare e v ent simulation by optimal nonequilibrium forcing. Journal of Statistical Mec hanics: Theory and Experiment , 2012(11):P11004, Nov ember 2012. ISSN 1742-5468. doi: 10.1088/1742- 5468/2012/11/P11004. Carsten Hartmann, Ralf Banisch, Marco Sarich, T omasz Bado wski, and Christof Schütte. Charac- terization of Rare Events in Molecular Dynamics. Entr opy , 16(1):350–376, January 2014. ISSN 1099-4300. doi: 10.3390/e16010350. Dan Hendrycks and Ke vin Gimpel. Gaussian Error Linear Units (GELUs), June 2023. Lars Holdijk, Y uanqi Du, Ferry Hooft, Priyank Jaini, Berend Ensing, and Max W elling. Stochastic Optimal Control for Collectiv e V ariable Free Sampling of Molecular T ransition Paths. Advances in Neural Information Pr ocessing Systems , 36:79540–79556, December 2023. Max Jensen and Iain Smears. On the Con ver gence of Finite Element Methods for Hamilton–Jacobi– Bellman Equations. SIAM Journal on Numerical Analysis , 51(1):137–162, January 2013. ISSN 0036-1429. doi: 10.1137/110856198. Shaolin Ji, Shige Peng, Y ing Peng, and Xichuan Zhang. Solving Stochastic Optimal Control Problem via Stochastic Maximum Principle with Deep Learning Method. J. Sci. Comput. , 93(1), October 2022. ISSN 0885-7474. doi: 10.1007/s10915- 022- 01979- 5. Henry Jin, Marios Mattheakis, and Pavlos Protopapas. Physics-informed neural networks for quantum eigen v alue problems. In 2022 International Joint Confer ence on Neur al Networks (IJCNN) , pp. 1–8. IEEE, 2022. Kamil Kaleta, Mateusz Kwa ´ snicki, and József L ˝ orinczi. Contractivity and ground state domination properties for non-local schrödinger operators. Journal of Spectral Theory , 8(1):165–189, 2018. Dante Kalise, Lucas M. Moschen, Grigorios A. Pavliotis, and Urbain V aes. A Spectral Approach to Optimal Control of the Fokker -Planck Equation, March 2025. H J Kappen. Path integrals and symmetry breaking for optimal control theory . Journal of Statistical Mechanics: Theory and Experiment , 2005(11):P11011, November 2005a. ISSN 1742-5468. doi: 10.1088/1742- 5468/2005/11/P11011. Hilbert J. Kappen. Linear Theory for Control of Nonlinear Stochastic Systems. Physical Review Letters , 95(20):200201, Nov ember 2005b. doi: 10.1103/PhysRevLett.95.200201. H. J. Kushner . Optimality conditions for the average cost per unit time problem with a diffusion model. SIAM Journal on Contr ol and Optimization , 16(2):330–346, 1978. doi: 10.1137/0316021. 13 Published as a conference paper at ICLR 2026 Jun S. Liu. Monte Carlo Strate gies in Scientific Computing . Springer Series in Statistics. Springer , New Y ork, NY , 2004. ISBN 978-0-387-76369-9 978-0-387-76371-2. doi: 10.1007/ 978- 0- 387- 76371- 2. Qiang Liu, Lihong Li, Ziyang T ang, and Dengyong Zhou. Breaking the Curse of Horizon: Infinite- Horizon Of f-Policy Estimation. In Advances in Neural Information Pr ocessing Systems , v olume 31. Curran Associates, Inc., 2018. Francis A. Longstaff and Eduardo S. Schwartz. V aluing American Options by Simulation: A Simple Least-Squares Approach. May 2001. S.K. Mitter . Filtering and stochastic control: A historical perspective. IEEE Control Systems Magazine , 16(3):67–76, June 1996. ISSN 1941-000X. doi: 10.1109/37.506400. Nikolas Nüsken and Lorenz Richter . Solving high-dimensional Hamilton–Jacobi–Bellman PDEs using neural networks: Perspectiv es from the theory of controlled diffusions and measures on path space. P artial Differ ential Equations and Applications , 2(4):48, June 2021. ISSN 2662-2971. doi: 10.1007/s42985- 021- 00102- x. Nikolas Nusken and Lorenz Richter . Interpolating Between BSDEs and PINNs: Deep Learning for Elliptic and P arabolic Boundary V alue Problems. Journal of Mac hine Learning , 2(1):31–64, March 2023. ISSN 2790-203X. Grigorios A. Pa vliotis. Stochastic Pr ocesses and Applications: Diffusion Pr ocesses, the F okker - Planck and Lange vin Equations , volume 60 of T exts in Applied Mathematics . Springer , New Y ork, NY , 2014. ISBN 978-1-4939-1322-0 978-1-4939-1323-7. doi: 10.1007/978- 1- 4939- 1323- 7. Huyên Pham. Continuous-T ime Stochastic Contr ol and Optimization with F inancial Applications , volume 61 of Stoc hastic Modelling and Applied Pr obability . Springer, Berlin, Heidelber g, 2009. ISBN 978-3-540-89499-5 978-3-540-89500-8. doi: 10.1007/978- 3- 540- 89500- 8. M. Raissi, P . Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framew ork for solving forward and in verse problems in volving nonlinear partial differential equations. Journal of Computational Physics , 378:686–707, 2019. ISSN 0021-9991. doi: https:// doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/science/ article/pii/S0021999118307125 . M. Reed and B. Simon. IV : Analysis of Operators . Methods of Modern Mathematical Physics. Elsevier Science, 1978. ISBN 9780125850049. Michael Reed and Barry Simon. II: F ourier analysis, self-adjointness , volume 2. Elsevier , 1975. Michael Reed and Barry Simon. Methods of modern mathematical physics: Functional analysis , volume 1. Gulf Professional Publishing, 1980. Michael Renardy and Robert C Rogers. An intr oduction to partial differ ential equations , volume 13. Springer Science & Business Media, 2006. Gareth O. Roberts and Jeffrey S. Rosenthal. Optimal Scaling of Discrete Approximations to Lange vin Diffusions. Journal of the Royal Statistical Society . Series B (Statistical Methodology) , 60(1): 255–268, 1998. ISSN 1369-7412. Christof Schütte, Stefanie W inkelmann, and Carsten Hartmann. Optimal control of molecular dynamics using Markov state models. Mathematical Pr ogramming , 134(1):259–282, August 2012. ISSN 1436-4646. doi: 10.1007/s10107- 012- 0547- 6. Emanuel T odorov . Eigenfunction approximation methods for linearly-solvable optimal control problems. In 2009 IEEE Symposium on Adaptive Dynamic Pro gramming and Reinforcement Learning , pp. 161–168, March 2009. doi: 10.1109/ADPRL.2009.4927540. Surya T . T okdar and Robert E. Kass. Importance sampling: A revie w . WIREs Computational Statistics , 2(1):54–60, 2010. ISSN 1939-0068. doi: 10.1002/wics.56. 14 Published as a conference paper at ICLR 2026 Claudia T otzeck and René Pinnau. Space mapping-based receding horizon control for stochastic interacting particle systems: Dogs herding sheep. Journal of Mathematics in Industry , 10(1):11, April 2020. ISSN 2190-5983. doi: 10.1186/s13362- 020- 00077- 1. A T ychonof f. Théorèmes d’unicité pour l’équation de la chaleur . Sb. Math. , 42(2):199–216, 1935. Ramon van Handel. Stochastic Calculus, F iltering and Stochastic Contr ol . Lecture Notes for ACM 217: Advanced T opics in Stochastic Analysis, Princeton. 2007. Pauli V irtanen, Ralf Gommers, Tra vis E. Oliphant, Matt Haberland, T yler Reddy , David Cournapeau, Evgeni Burovski, Pearu Peterson, W arren W eckesser , Jonathan Bright, Stéfan J. van der W alt, Matthew Brett, Joshua W ilson, K. Jarrod Millman, Nikolay Mayoro v , Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey , ˙ Ilhan Polat, Y u Feng, Eric W . Moore, Jake V anderPlas, Denis Laxalde, Josef Perktold, Robert Cimrman, Ian Henriksen, E. A. Quintero, Charles R. Harris, Anne M. Archibald, Antônio H. Ribeiro, Fabian Pedregosa, Paul van Mulbregt, and SciPy 1.0 Contributors. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Natur e Methods , 17:261–272, 2020. doi: 10.1038/s41592- 019- 0686- 2. Jiongmin Y ong and Xun Y u Zhou. Stochastic Contr ols . Springer , New Y ork, NY , 1999. ISBN 978-1-4612-7154-3 978-1-4612-1466-3. doi: 10.1007/978- 1- 4612- 1466- 3. Sen Zhang, Jian Zu, and Jingqi Zhang. Deep learning method for finding eigenpairs in Sturm- Liouville eigen v alue problems. Electr onic Journal of Dif fer ential Equations , 2024(01-83):53–17, September 2024. ISSN 1072-6691. doi: 10.58997/ejde.2024.53. W ei Zhang, Tiejun Li, and Christof Schütte. Solving eigen value PDEs of metastable diffusion processes using artificial neural networks. Journal of Computational Physics , 465, 2022. doi: 10.1016/j.jcp.2022.111377. Xun Y u Zhou, Jiongmin Y ong, and Xunjing Li. Stochastic v erification theorems within the framew ork of viscosity solutions. SIAM Journal on Contr ol and Optimization , 35(1):243–253, 1997. 15 Published as a conference paper at ICLR 2026 C O N T E N T S 1 Introduction 1 2 Preliminaries 4 2.1 Stochastic optimal control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 Eigenfunction solutions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3 Our framework 5 3.1 Spectral properties of the Schrödinger operator . . . . . . . . . . . . . . . . . . . 5 3.2 Eigenfunction control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3.3 Closed-form solution for the symmetric LQR . . . . . . . . . . . . . . . . . . . . 6 4 Numerical methods 6 4.1 Learning eigenfunctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 4.1.1 Implicit reweighting in pre vious approaches . . . . . . . . . . . . . . . . . 7 4.1.2 Our approach: Removing implicit reweighting via relati ve loss . . . . . . . 7 4.2 Our hybrid method: combining eigenfunctions and short-horizon solvers . . . . . . 8 5 Experiments 8 5.1 Opinion modeling: de Groot model . . . . . . . . . . . . . . . . . . . . . . . . . . 9 6 Conclusion 9 A T echnical details/assumptions 17 A.1 Regularity conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Simplifying assumption: σ σ T = I . . . . . . . . . . . . . . . . . . . . . . . . . . 17 B Proofs/deriv ations 17 B.1 Cole-Hopf transformation (8) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 B.2 Proof of Theorem 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 B.3 Unitary equi valence (11) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.4 Essential self-adjointness of L . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.5 Proof of Theorem 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.6 Proof of Theorem 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 B.7 Semigroup and V iscosity solutions . . . . . . . . . . . . . . . . . . . . . . . . . . 21 C Loss functions 24 C.1 Existing methods for short-horizon SOC . . . . . . . . . . . . . . . . . . . . . . . 24 C.2 Extending to multiple eigenfunctions . . . . . . . . . . . . . . . . . . . . . . . . . 24 C.3 Estimating λ i . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 C.4 Empirical loss & sampling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 C.5 Logarithmic re gularization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 C.6 FBSDE Loss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 C.7 IDO loss functions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 D Algorithms 29 E Experimental Details 30 E.1 Setting configurations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 E.2 Model architecture and training . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 E.3 Computational cost . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 E.4 Further details on the R I N G setting . . . . . . . . . . . . . . . . . . . . . . . . . . 32 E.5 Details on Figure 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 E.6 Additional experiment: repulsive potential . . . . . . . . . . . . . . . . . . . . . . 33 E.7 Control objectiv es . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 16 Published as a conference paper at ICLR 2026 A T E C H N I C A L D E TA I L S / A S S U M P T I O N S A . 1 R E G U L A R I T Y C O N D I T I O N S Follo wing Fleming & Soner (2006), we make the following assumptions, which guarantee that the SDE (3) has a unique strong solution. 1. The coef ficient b is Lipschitz in and satisfies the linear growth condition ∃ C > 0 : ∥ b ( x ) − b ( y ) ∥ ≤ C ∥ x − y ∥ . (25) ∃ C ′ > 0 : ∥ b ( x ) ∥ ≤ C ′ (1 + ∥ x ∥ ) . (26) A . 2 S I M P L I F Y I N G A S S U M P T I O N : σ σ T = I Since σ ∈ R d × d was assumed in vertible, the matrix σ σ T is positiv e definite, and hence there exists a diagonalization σ σ T = U Λ U T where U U T = I and Λ = diag (( λ i ) d i =1 ) for λ i > 0 . Consider now the change of variables y = Λ − 1 / 2 U T x . Then it holds that ∇ x ψ = U Λ − 1 / 2 ∇ x ψ , ∇ 2 x ψ = U Λ − 1 / 2 ∇ 2 y ψ Λ − 1 / 2 U T (27) and in particular T r ( σ σ T ∇ 2 x ψ ) = T r ( U Λ U T ∇ 2 x ψ ) = T r ( ∇ 2 y ψ ) = ∆ y ψ . Thus the PDE (8) can be written in terms of y as ∂ t ψ + − ∆ y − 2 β b T U Λ − 1 / 2 ∇ y + 2 β 2 f ψ = 0 (28) B P R O O F S / D E R I V A T I O N S B . 1 C O L E - H O P F T R A N S F O R M A T I O N (8) Let V denote the value function defined in (5) , satisfying the HJB equation (6) . The so-called Cole- Hopf transformation consists of setting V = − β − 1 log ˜ ψ , leading to a linear PDE for ˜ ψ , which is called the desirability function . T o obtain the form (8) , we set V ( x, t ) = − β − 1 log ψ x, 1 2 β ( T − t ) . The deriv ati ves of V and ψ are then related through ∂ t V = 1 2 β 2 ∂ t ψ ψ , ∇ V = − β − 1 ∇ ψ ψ , (29) ∂ 2 V ∂ x i ∂ x j = − β − 1 1 ψ 2 ψ ∂ 2 ψ ∂ x i ∂ x j − ∂ ψ ∂ x i ∂ ψ ∂ x j , (30) = ⇒ T r ( σ σ T ∇ 2 V ) = X i,j σ 2 ij ∂ 2 V ∂ x i ∂ x j = − β − 1 1 ψ T r ( σ σ T ∇ 2 ψ ) + β − 1 1 ψ 2 ∥ σ T ∇ ψ || 2 . (31) Plugging these expressions into (6) gi ves 1 ψ 1 2 β 2 ∂ t ψ − 1 2 β 2 T r ( σ σ T ∇ 2 ψ ) − β − 1 b T ∇ ψ + f = 0 . (32) Multiplying with 2 β 2 ψ and combining with the terminal condition V ( x, T ) = g ( x ) shows that the linear PDE for ψ giv en in (8) is equiv alent to the HJB equation (6). B . 2 P R O O F O F T H E O R E M 1 W e begin with an informal ar gument. Recall that we are interested in solving the abstract ev olution equation Find ψ : [0 , T ] → D ( L ) such that ∂ t ψ ( t ) + L ψ ( t ) = 0 , ψ (0) = ψ 0 . (33) 17 Published as a conference paper at ICLR 2026 Now , since ( ϕ i ) i ∈ N forms an orthonormal basis, it holds that ψ ( t ) = P i ∈ N a i ( t ) ϕ i , where a i ( t ) = ⟨ ψ i ( t ) , ϕ ⟩ . Hence the PDE in (33) becomes X i ∈ N d a i ( t ) d t + λ i a i ( t ) ϕ i = 0 (34) after formally interchanging the series e xpansion and deri vati v es. Since the ϕ i are orthogonal, this equation is satisfied if and only if a i ( t ) = a i (0) e − λ i t for each i . Formally establishing (9) can be achiev ed through the theory of semigroups. Essentially , we want to formally define the semigroup e − t L t ≥ 0 and sho w that it forms the solution operator to (33) . W e begin by recalling the follo wing definition. Definition 2 The set of bounded linear operators on H is given by B ( H ) = ( L : H → H : L is linear and ∥L∥ op = sup f ∈H , ∥ f ∥ =1 ∥L ( f ) ∥ < ∞ ) (35) The following result, sometimes called the functional calculus form of the spectral theorem, allo ws us to define h ( L ) for bounded Borel functions h . Lemma 1 (Reed & Simon, 1980, Theor em VIII.5) Suppose L is a self-adjoint operator on H . Then there exists a unique map ˆ ϕ from the bounded Borel functions on R into B ( H ) which satisfies • If L ψ = λψ , then ˆ ϕ ( h ) ψ = h ( λ ) ψ . In particular , when L admits a countable orthonormal basis of eigenfunctions ( ϕ i ) with eigen v alues λ i , this operator is giv en by ˆ ϕ ( h ) ψ = h ( L ) ψ := X i ∈ N h ( λ i ) ⟨ ϕ i , ψ ⟩ ϕ i . (36) The next result makes use of the defined semigroup and leads to the desired representation. Note that we indeed consider a bounded function of the operator , as we consider it only for t ≥ 0 and assume that the operator is bounded from below . Theorem 5 (Reed & Simon, 1980, Theorem VIII.7) Suppose L is self-adjoint and bounded from below , and define T ( t ) = e − t L for t ≥ 0 . Then (a) T (0) = I . (b) For e very ϕ ∈ D ( L ) , it holds that d d t T ( t ) ψ t =0 = lim h → 0 T (0 + h ) ψ − T (0) ψ h = −L T (0) ψ = −L ψ (37) Pr oof of Theor em 1 Combining (a) and (b) of the Theorem 5 sho ws that ψ ( t ) := T ( t ) ψ 0 satisfies d d t ψ ( t ) = d d h T ( t + h ) ψ 0 h =0 = −L T ( t ) ψ 0 = −L ψ ( t ) , ψ (0) = T (0) ψ 0 = ψ 0 , (38) which is exactly the claim of Theorem 1. The last remark we make is that in Theorem 1 we only assume essential self-adjointness of L , while above results operate with self-adjoint operators. Thus, the above theorems hold true for the closure L of the operator L . Howe ver , note that L is densely defined and has eigenfunctions which mak e up an orthonormal basis of both its domain and L 2 ( µ ) . Thus, the same representation (9) as for L holds for L . □ 18 Published as a conference paper at ICLR 2026 B . 3 U N I T A RY E Q U I V A L E N C E (11) First, notice that U : L 2 ( µ ) → L 2 ( R d ) : ψ 7→ e − β E ψ is indeed a unitary transformation, since ∀ ψ , φ ∈ L 2 ( µ ) : ⟨ U ψ , U φ ⟩ L 2 ( R d ) = Z e − 2 β E ψ φ d x = ⟨ ψ , φ ⟩ µ . (39) T o establish equi valence, we compute ∇ ( e β E ψ ) = e β E ( ∇ ψ + β ∇ E ψ ) , (40) ∆( e β E ψ ) = e β E (∆ ψ + 2 β ⟨∇ E , ∇ ψ ⟩ + β ∆ E + β 2 ∥∇ E ∥ 2 ψ ) , (41) 2 β ⟨∇ E , ∇ ( e β E ψ ) ⟩ = e β E (2 β ⟨∇ E , ∇ ψ ⟩ + 2 β 2 ∥∇ E || 2 ψ ) . (42) Putting this together giv es L ( U − 1 ψ ) = L ( e β E ψ ) = e β E − ∆ ψ + β 2 ∥∇ E ∥ 2 ψ − β ∆ E ψ + 2 β 2 f e β E ψ , (43) from which the result (11) follows. B . 4 E S S E N T I A L S E L F - A D J O I N T N E S S O F L W e will first sho w the following relation ⟨ φ, L ψ ⟩ µ = ⟨∇ φ, ∇ ψ ⟩ µ + 2 β 2 ⟨ φ, f ψ ⟩ µ (44) from which it is clear that L is symmetric on C ∞ 0 ( R d ) . Indeed, using the di vergence theorem, for ψ , ϕ ∈ C ∞ 0 ( R d ) one obtains that ⟨ ψ , − ∆ φ ⟩ µ = − Z ψ ∆ φ e − 2 β E d x (45) = Z ( ⟨∇ ψ , ∇ φ ⟩ − 2 β ψ ⟨∇ φ, ∇ E ⟩ ) e − 2 β E d x (46) = ⟨∇ ψ , ∇ φ ⟩ µ − 2 β ⟨ ψ , ⟨∇ E , ∇ φ ⟩⟩ µ , (47) which immediately shows the result. While for matrices the notions of symmetry and self-adjointness are equi valent, the situation becomes more delicate for general (possibly unbounded) linear operators. In our case we can use the follo wing result on the essential self-adjointness of the Schrödinger operator . Lemma 2 (Reed & Simon, 1975, Theor em X.28) Let V ∈ L 2 loc ( R d ) with V ≥ 0 pointwise. Then S = − ∆ + V is essentially self-adjoint on C ∞ 0 ( R d ) . Note, that C ∞ 0 ( R d ) is dense in L 2 ( R d ) . Thus, operator L is also densely defined as its domain contains U − 1 ( C ∞ 0 ( R d )) . The essential self-adjointness of L follows from the unitary equiv alence with the Schrödinger operator as unitary transformation preserves essential self-adjointness of the transformed operator . B . 5 P R O O F O F T H E O R E M 2 As we hav e shown, the operator L is unitarily equiv alent to the Schrödinger operator defined through S : D ( S ) ⊂ L 2 ( R d ) → L 2 ( R d ) : h 7→ − ∆ h + V h (48) with V = β 2 ∥∇ E ∥ 2 − β ∆ E + 2 β 2 f . All the properties mentioned in the statement of Theorem 2 remain unchanged under unitary equi valence (both the assumptions on the operator and the conclu- sions regarding the spectral properties). Hence it is sufficient to sho w the result for the Schrödinger operator S associated with L . This is precisely the content of the following theorem, prov en in Reed & Simon (1978), combined with observations in section B.4. 19 Published as a conference paper at ICLR 2026 Theorem 6 (Reed & Simon, 1978, Theor em XIII.67, XIII.64, XIII.47) Suppose V ∈ L 1 loc ( R d ) is bounded from below and lim | x |→∞ V ( x ) = ∞ . Then the Schrodinger operator S = − ∆ + V has compact resolvent, and in particular a purely discrete spectrum and an orthonormal basis of eigenfunctions in L 2 ( R d ) . The spectrum σ ( S ) is bounded from below and the eigenv alues do not hav e a finite accumulation point. If in addition V ∈ L 2 loc ( R d ) , the smallest eigen v alue has multiplicity one, and the corresponding eigenfunction can be taken to be strictly positi ve. B . 6 P R O O F O F T H E O R E M 4 The result relies on the fact that the Schrödinger operator associated with L has a quadratic potential, for which the eigenfunctions can be computed exactly . Indeed, the following is a standard result that can be found in many te xtbooks on quantum mechanics (Griffiths & Schroeter, 2018): Lemma 3 Consider the Sc hrödinger operator in d = 1 with quadr atic potential, S : D ( S ) ⊂ L 2 ( R ) → L 2 ( R ) : ψ 7→ − d 2 ψ d x 2 + x 2 ψ . (49) The eigen values of S ar e given by λ n = 2 n + 1 , and the normalized eigenfunctions ar e given by ϕ n ( x ) = 1 π 1 / 4 1 √ 2 n n ! H n ( x ) e − x 2 / 2 (50) wher e H n denotes the n -th physicist’ s Hermite polynomial defined thr ough H 0 ( x ) = 1 , H 1 ( x ) = 2 x, H n +1 ( x ) = 2 xH n ( x ) − 2 nH n − 1 ( x ) . (51) These satisfy the generating function r elation e 2 xt − t 2 = ∞ X n =0 H n ( x ) t n n ! . (52) This result can be easily extended to higher dimensions: Lemma 4 Consider now the d -dimensional Harmonic oscillator: S : D ( S ) ⊂ L 2 ( R d ) → L 2 ( R d ) : ψ 7→ − ∆ ψ + x T Ax ψ . (53) wher e A ∈ R d × d is symmetric and positive definite . Denote A = U T Λ U the diagonalization of A . Then the eigen values ar e inde xed by the multi-index α ∈ N d , and ar e given by λ α = d X i =1 Λ 1 / 2 i (2 α i + 1) . (54) The associated normalized eigenfunctions ar e ϕ α ( x ) = 1 π d/ 4 exp − 1 2 x T U T Λ 1 / 2 U x d Y i =1 Λ 1 / 8 i p 2 α i ( α i )! H α i ((Λ 1 / 4 U x ) i ) (55) Pr oof. W e begin by introducing the v ariable y = Λ 1 / 4 U x . This gives x T Ax = y T Λ 1 / 2 y (56) ∆ x ψ = T r (Λ 1 / 2 ∇ 2 y ψ ) (57) so that we can write − ∆ x ψ + x T Axψ = d X i =1 Λ 1 / 2 i − ∂ 2 ψ ∂ y 2 + y 2 i ψ (58) Thus, the d -dimensional harmonic oscillator decouples into d rescaled one-dimensional oscillators. Since L 2 ( R d ) ∼ = N d i =1 L 2 ( R ) (after completion), this means that the eigenfunctions are gi ven by the 20 Published as a conference paper at ICLR 2026 product of the one-dimensional eigenfunctions. Hence the spectrum is index ed by α ∈ N d and the eigenfunctions are, expressed in the v ariable y , ϕ α ( y ) = 1 π d/ 4 d Y i =1 1 p 2 α i ( α i !) H α i ( y i ) e − y 2 i / 2 (59) T o get the eigenfunctions in the x variable, we transform back and note that the abov e expression is normalized as R ϕ α ( y ) 2 d y = 1 , while we need R ϕ α ( x ) 2 d x = 1 . Using the fact that d y = det(Λ 1 / 4 )d x , this yields the final normalized eigenfunctions as ϕ α ( x ) = 1 π d/ 4 exp − 1 2 x T U T Λ 1 / 2 U x d Y i =1 Λ 1 / 8 i p 2 α i ( α i )! H α i ((Λ 1 / 4 U x ) i ) (60) and the eigen v alues as λ α = d X i =1 Λ 1 / 2 i (2 α i + 1) . (61) □ Now consider the operator L as defined in (10) , with b ( x ) = − Ax and f ( x ) = x T P x . Since A is symmetric, it holds that b = −∇ E with E ( x ) = 1 2 x T Ax . It follows that L is unitarily equiv alent with the Schrödinger operator with potential V = − β ∆ E + β 2 ∥∇ E ∥ 2 + 2 β 2 f = − β T r ( A ) + β 2 x T ( A T A + 2 P ) x. (62) The first term gi ves a constant shift to the eigen values, b ut otherwise we are precisely dealing with the d -dimensional harmonic oscillator , whose eigensystem is described in Lemma 4. Hence the eigen v alues are precisely (14) , and the eigenfunctions of the original operator L are then obtained by multiplying with e β 2 x T Ax , which yields (13). B . 7 S E M I G R O U P A N D V I S C O S I T Y S O L U T I O N S Plan of the section. W e work with two linked equations on R d × [0 , T ] : the HJB equation (6) and the linear parabolic PDE (8) obtained from (6) via the (monotone) Cole–Hopf transform. Our goal is to produce the optimal control u ∗ by first solving the linear PDE, then applying the in verse Cole–Hopf transform to obtain a value function candidate V ′ . This program raises two issues which hav e to be addressed: 1. Nonuniqueness in unbounded domains. On R d (e ven with the same terminal/boundary data), second-order finite-horizon HJB and linear parabolic equations may admit multiple solutions unless one restricts to an appropriate growth class; see T ychonoff (1935) for a classical example of this phenomenon. 2. V erification. T o identify u ∗ from a solution of (6) one uses a verification theorem. These theorems require the candidate V ′ to be a (sufficiently re gular) viscosity solution (Crandall et al., 1992) lying in a class where comparison (hence uniqueness) holds, see (Fleming & Soner, 2006, Section V .9) for an example of such result. In our approach we fix a specific semigr oup solution of the linear PDE and use it to define V ′ via the inv erse Cole–Hopf map. Specifically , we have V ′ ( x, t ) = − β − 1 log ψ ( x, 1 2 β ( T − t )) , where ψ ( x, t ) = ( e − t L ψ 0 )( x ) . The central task is therefore to (a) place this V ′ in a uniqueness class for (6) and (b) confirm the hypotheses of a verification theorem. In the following text we establish suf ficient conditions under which the task is solved. V erification theorem and Comparison (uniqueness) in R d under growth constraints. There are sev eral ways to establish that the value function V (5) is a unique solution of HJB equation (6) in some growth class for the gi ven terminal conditions. In general it is obtained with a use of Dynamic Programming Principle. Howe v er , this approach is not so simple in the case of unbounded controls and non-smooth viscosity solutions. W e refer to (Zhou et al., 1997; Fleming & Soner, 2006; Da Lio & Ley, 2006; 2011) for an ov erview of ways to establish connection between value function and 21 Published as a conference paper at ICLR 2026 viscosity solutions, as well as results regarding existence and uniqueness of viscosity solutions in appropriate growth classes. Follo wing Da Lio & Ley (2011) we introduce class of functions ˜ C p . W e say that a locally bounded function u : R d × [0; T ] → R is in the class ˜ C p if for some C > 0 we hav e | u ( x, t ) | ≤ C (1 + ∥ x ∥ p ) , ∀ ( x, t ) ∈ R d × [0; T ] . (63) Now , we can formulate the following Theorem 7 (Da Lio & Le y, 2006, Thm. 3.1)+(Da Lio & Le y, 2011, Thm. 3.2) Suppose that in (6) we hav e • b satisfies (25) and (26), and σ = I • Running cost f satisfies: ∃ C 1 > 0 : ∀ x ∈ R d : | f ( x ) | ≤ C 1 (1 + ∥ x ∥ p ) • T erminal condition satisfies g ∈ ˜ C p Then there exists 0 ≤ τ < T such that (6) has a unique continuous viscosity solution in R d × [ τ ; T ] in the class ˜ C p . Moreov er , this unique solution is the value function V (5). Remark 3 See discussion in (Da Lio & Le y, 2011, Remark 3.1) why we can’t hope to obtain existence in Theor em 7 on a whole interval [0; T ] . Gro wth of semigroup solution From previous paragraphs it is clear that one way to provide a link between proposed V ′ and solutions of (6) is to to establish gro wth rates on V ′ . Specifically , following Theorem 7 we want to sho w that V ′ ∈ ˜ C p . There are other ways to establish connection between solutions, see Biton (2001), (Fleming & Soner, 2006, Section VI). Howe ver , we choose to pursue a path related to growth conditions of spectral elements of Schrödinger operator (Davies & Simon, 1984; Baranie wicz, 2024). Theorem 8 (Davies & Simon, 1984, Thm. 6.1, Thm. 6.3) Let S = − ∆ + V on R d with ground state ϕ 0 > 0 (normalized in L 2 ( R d ) ) and suppose that there e xist C 1 , C 3 > 0 and C 2 , C 4 ∈ R such that, for all x with ∥ x ∥ large, C 3 ∥ x ∥ b + C 4 ≤ V ( x ) ≤ C 1 ∥ x ∥ a + C 2 , where a 2 + 1 < b ≤ a. Then S is intrinsically ultracontr active (IUC) . Moreover , there exist constants C 5 , C 7 > 0 and C 6 , C 8 ∈ R such that, as ∥ x ∥ → ∞ , C 5 ∥ x ∥ b 2 +1 + C 6 ≤ − log ϕ 0 ( x ) ≤ C 7 ∥ x ∥ a 2 +1 + C 8 . (64) Pr oof. Intrinsic ultracontractivity under the stated growth is exactly (Davies & Simon, 1984, Thm. 6.3). The upper growth bound in (64) is the estimate − log ϕ 0 ( x ) ≤ C ∥ x ∥ a 2 +1 stated explicitly in (Davies & Simon, 1984, Eq. (6.4)). For the lo wer bound in (64) , tak e a comparator W ( x ) = ˜ c ∥ x ∥ b with 0 < ˜ c < C 3 ; then W → ∞ and V − W → ∞ , so the ground states satisfy ϕ ( V ) 0 ≤ C ϕ ( W ) 0 by the comparison Lemma (Davies & Simon, 1984, Lem. 6.2). (Davies & Simon, 1984, App. B) constructs WKB-type barriers for − ∆ + W and gi v es pointwise upper bounds of the form ϕ ( W ) 0 ( x ) ≤ C ′ ∥ x ∥ − β exp {− κ ∥ x ∥ 1+ b 2 } for large ∥ x ∥ (see the JWKB ansatz and subharmonic comparison in (Davies & Simon, 1984, App. B, esp. Lem. B.1–B.3)); combining yields the stated lo wer bound on − log ϕ 0 . □ Remark 4 Note that we use ultracontr activity properties of S which r equir e gr owth of V to be at least as ∥ x ∥ 2+ ε , ε > 0 . The characterization of operator contractivity pr operties is fully given in (Davies & Simon, 1984, Thm. 6.1) and does not allow for slower or ders of gr owth. This restriction on gr owth of V is encoded thr ough condition a 2 + 1 < b ≤ a . Theorem 9 Let V = β ∥∇ E ∥ 2 − ∆ E + 2 β f , S = U L U − 1 = − ∆ + V . 22 Published as a conference paper at ICLR 2026 wher e U − 1 f = e β E f . Let ψ ( x, t ) = ( e − t L ψ 0 )( x ) and define the candidate value function V ′ ( x, t ) = − β − 1 log ψ x, 1 2 β ( T − t ) . Assume the hypotheses of Theor em 8 for V . F inally , let us suppose that ther e exist 0 < m ≤ M so that m ≤ ψ 0 U − 1 ϕ 0 ≤ M , ∀ x ∈ R d , (65) wher e ϕ 0 is a gr ound state of Shrödinger operator S . Then, uniformly for all t ∈ [0 , T ] , ther e e xist constants C 1 , C 3 > 0 and C 2 , C 4 ∈ R such that, as ∥ x ∥ → ∞ , C 1 ∥ x ∥ b 2 +1 + C 2 ≤ V ′ ( x, t ) + E ( x ) ≤ C 3 ∥ x ∥ a 2 +1 + C 4 . (66) Pr oof. Recall that the ground state of L is an eigenfunction φ 0 = U − 1 ϕ 0 , where ϕ 0 is a ground state of Shrödinger operator S . Let us introduce the ground state transformed semigroup: P φ 0 t g ( x ) := e λ 0 t φ 0 ( x ) ( e − t L ( φ 0 g ))( x ) Thus, we hav e a representation ψ ( x, t ) = ( e − t L ψ 0 )( x ) = e − λ 0 t φ 0 ( x ) P φ 0 t ψ 0 φ 0 ( x ) It is kno wn, that semigroup P φ 0 t g ( x ) is Marko v , see Kaleta et al. (2018). Using the fact that P φ 0 t g ( x ) is Markov and (65) we ha ve the tw o-sided bound for all t ∈ [0; T ] e − λ 0 t φ 0 ( x ) m ≤ ( e − t L ψ 0 )( x ) ≤ e − λ 0 t φ 0 ( x ) M which leads to a bound λ 0 T − t 2 β 2 − β − 1 log M − β − 1 log ϕ 0 − E ( x ) ≤ V ′ ( x, t ) ≤ λ 0 T − t 2 β 2 − β − 1 log m − β − 1 log ϕ 0 − E ( x ) (67) Applying growth bounds on ground state of Shrödinger operator from Theorem 8 leads to the desired bound. □ Remark 5 Note that definition of ˜ C p (63) r equir es a gr owth bound on coor dinate x uniformly for all t ∈ [0; T ] . Unfortunately , analysis based pur ely on spectral pr operties of operator leads to non-uniform gr owth bounds depending on t , which blow up when t → 0 for e − t L (for example, note that constants in (Davies & Simon, 1984, Thm. 3.2) depend on time). F or this r eason and for simplicity we intr oduced assumption (65) on boundary conditions. Relationship between semigroup-based and viscosity solution Finalising ev erything in this section, we formulate the following result which addresses the questions raised abo ve. Theorem 10 Consider HJB equation (6) . Let V = β ∥∇ E ∥ 2 − ∆ E + 2 β f . Assume the following: • b ( x ) = −∇ E ( x ) satisfies (25) and (26) , and σ = I . • V satisfies Assumption (A2) . Moreo ver , there e xist C 1 , C 3 > 0 and C 2 , C 4 ∈ R such that, for all x with ∥ x ∥ lar ge, C 3 ∥ x ∥ b + C 4 ≤ V ( x ) ≤ C 1 ∥ x ∥ a + C 2 , wher e a 2 + 1 < b ≤ a. (68) • Let ϕ 0 be the gr ound state of operator S = − ∆ + V . Assume g ∈ ˜ C a and there exist 0 < m ≤ M so that m ≤ exp( − β g ) exp( β E ( x )) ϕ 0 ≤ M , ∀ x ∈ R d , (69) 23 Published as a conference paper at ICLR 2026 Then ther e exists 0 ≤ τ < T such that function V ′ ( x, t ) = − β − 1 log ψ ( x, 1 2 β ( T − t )) , wher e ψ ( x, t ) = ( e − t L ψ 0 )( x ) and L and ψ 0 ar e fr om (8) , is a unique continuous viscosity solution of (6) on R d × [ τ ; T ] in the class ˜ C a/ 2+1 . Mor eover , it coincides with value function V (5) on R d × [ τ ; T ] . Pr oof. Under Assumption (A2) Theorem 6 holds. Theorem 6 ensures that operators S and L hav e some good properties and ground state ϕ 0 is positiv e. Under the stated assumptions Theorem 7 and Theorem 9 hold. Under growth assumptions (26) and (68) Theorem 9 gi ves us that V ′ ∈ ˜ C a/ 2+1 ⊆ ˜ C a which has to be the unique viscosity solution in ˜ C a giv en by Theorem 7 on R d × [ τ ; T ] , which coincides with value function V (5) on R d × [ τ ; T ] . □ Remark 6 Note that assumption (69) is r ealistic under rapid gr owth of V , taking in account gr owth bounds on the gr ound state (64) and b ( x ) = ∇ E ( x ) in (26) , and does not contradict g ∈ ˜ C a . C L O S S F U N C T I O N S C . 1 E X I S T I N G M E T H O D S F O R S H O RT - H O R I Z O N S O C Grid-based solvers In low dimensions ( d ≤ 3 ), classical techniques for numerically solving PDEs can be used. These include finite difference (Bonnans et al., 2004) and finite element methods (Jensen & Smears, 2013; Ern & Guermond, 2004; Brenner & Scott, 2008), as well as semi-Langrangian schemes (Calzola et al., 2023; Carlini et al., 2020) and multi-lev el Picard iteration (E et al., 2021). FBSDE solvers In another line of work, the SOC problem is transformed into a pair of forw ard- backward SDEs (FBSDEs). These are solved through dynamic programming (Gobet et al., 2005; Longstaf f & Schwartz, 2001) or deep learning methods which parametrize the solution to the FBSDE using a neural network (Han et al., 2018; E et al., 2017; Andersson et al., 2023). IDO methods In recent years, man y methods ha ve been proposed which parametrize the control u θ directly , and optimize it by rolling out simulations of the system (3) under the current control. Authors of Nüsken & Richter (2021) coined the term iterative diffusion optimization (IDO) , ar guing that man y of these methods can be vie wed from a common perspecti ve gi v en in Algorithm 2 (Appendix E). This class of algorithms contains state-of-the art methods such as SOCM and adjoint matching (Holdijk et al., 2023; Domingo-Enrich et al., 2024a). W e describe the most commonly used loss functions in Appendix C. C . 2 E X T E N D I N G T O M U LT I P L E E I G E N F U N C T I O N S PINN loss The most common way to e xtend the PINN loss (15) to multiple eigenfunctions is to define R k PINN ( ϕ ) = k X i =0 ∥L [ ϕ i ] − λ i ϕ i ∥ 2 ρ + α norm ( ∥ ϕ i ∥ 2 ρ − 1) 2 + α orth X j = i ⟨ ϕ i , ϕ j ⟩ 2 µ (70) for α norm , α orth > 0 . Here we have denoted ϕ : R d → R k +1 . The main difference is the addition of the orthogonal regularization term, which both ensures that the same eigenfunction is not learned twice, and attempts to speed up learning by enforcing the kno wn property that eigenfunctions with different eigen values are orthogonal w .r .t. the inner product ⟨· , ·⟩ µ . V ariational loss A similar idea is used to generalize the variational loss (17) . The following result shows that the variational principle (16) can be extended to multiple eigenfunctions by imposing orthogonality . Theorem 11 (Zhang et al., 2022, Theor em 1) Let k ∈ N , and let L be a self-adjoint operator with discrete spectrum which admits an orthonormal basis of eigenfunctions, and whose eigen values are bounded below . Furthermore, let ω 0 ≥ . . . ≥ ω k > 0 be real numbers. Then it holds that k X i =0 ω i λ i = inf f 0 ,...,f k ∈H k X i =0 ω i ⟨ f i , L f i ⟩ (71) 24 Published as a conference paper at ICLR 2026 where the infimum is taken ov er all ( f i ) k i =0 ⊂ H such that ∀ i, j ∈ { 0 , . . . , k } : ⟨ f i , f j ⟩ = δ ij (72) Pr oof. The proof of this result is giv en in Zhang et al. (2022). □ Based on this result, the follo wing generalization of the v ariational loss is proposed in Zhang et al. (2022): R k V ar ( ϕ ) = k X i =0 ⟨ ϕ i , L ϕ i ⟩ + α E µ ϕϕ T − I 2 F , (73) where we have written ∥ · ∥ F for the Frobenius norm and α > 0 . This loss was also studied in Cabannes et al. (2023), where it w as noted that the minimizers of the v ariational loss (17) - (73) are not obtained at the eigenfunctions. Instead, the following characterization of the minimizers of (73) was obtained. Lemma 5 (Cabannes et al., 2023, Lemma 2) Suppose that H = L 2 ( µ ) . Then it holds that arg min ψ 0 ,...,ψ k ∈H R k V ar ( ψ ) = ( U ˜ ϕ | U U T = I , ˜ ϕ i = s 1 − λ i 2 α + ϕ i ) (74) where ( ϕ i , λ i ) denotes the orthonormal eigensystem of L . C . 3 E S T I M A T I N G λ i The main adv antage of the variational loss (17) , (73) is that it does not require the eigen v alues of L to be av ailable. Howe v er , Lemma 5 shows that the minimizers of R k V ar do not coincide exactly with the eigenfunctions of L , so we cannot nai vely compute ⟨ ϕ, L ϕ ⟩ µ to obtain the eigen v alues. Instead, the following lemma sho ws ho w to obtain the eigenv alues and eigenfunctions from an element in the minimizing set (74). Lemma 6 Suppose it holds that ψ = U ˜ ϕ , wher e U U T = I and ˜ ϕ i = q 1 − λ i 2 α ϕ i for each i , and α > λ k 2 . Then the first k + 1 eigenfunctions and eig en values ar e given by ϕ = D − 1 / 2 U T ψ , λ i = 2 β (1 − D ii ) (75) wher e U D U T = E µ [ ψ ψ T ] is the diagonalization of the second moment matrix of ψ . Pr oof. By definition of ψ , we have E µ [ ψ ψ T ] = U E µ [ ˜ ϕ ˜ ϕ T ] U T (76) = U I − 1 2 α Λ U T (77) where Λ = diag ( λ i ) and we hav e used the orthonormality property of the eigenfunctions. From this, we obtain that D = I − β 2 Λ , ψ = U D 1 / 2 ϕ (78) which concludes the proof. □ In light of this result, we can estimate the second moment matrix E µ [ ψ ψ T ] , apply a diagonalization algorithm, and obtain the eigenfunctions and eigen v alues using (75). C . 4 E M P I R I C A L L O S S & S A M P L I N G Rewriting variational loss Recalling the equation (44), ⟨ φ, L ψ ⟩ µ = ⟨∇ φ, ∇ ψ ⟩ µ + 2 β 2 ⟨ φ, f ψ ⟩ µ , (79) we see that it is possible to e valuate inner products of the form ⟨ φ, L ψ ⟩ µ by only ev aluating φ, ψ and its deri vati ves. This av oids the expensi ve computation of the second order deri v ativ es of the neural network, making the v ariational losses less memory-intensi ve than the other loss functions, which requires explicit computation of L ϕ . 25 Published as a conference paper at ICLR 2026 Estimation of inner products All of the loss functions discussed for learning eigenfunctions contain inner products of the form ⟨ ψ , ϕ ⟩ µ . T o obtain an empirical loss, these quantities most be approximated. When µ is a density , this is done using a Monte Carlo estimate ⟨ φ, ψ ⟩ µ = Z φψ d µ = E µ [ φψ ] ≈ 1 m m X i =1 φ ( X i ) ψ ( X i ) , X i ∼ µ. (80) Since µ ( x ) ∝ exp( − 2 β E ( x )) , we can employ Mark ov Chain Monte Carlo (MCMC) techniques in order to obtain the samples ( X i ) (Brooks et al., 2011). In particular , when training the eigenfunctions, we can store m samples in memory and apply some number of MCMC steps in each iteration to update these samples. Alternativ ely , one can pre-sample a large dataset of samples from µ . Non-confining energy . In general, µ may not be a finite measure, for instance when we have a repulsiv e LQR ( E = − 1 2 ∥ x ∥ 2 ). In this case, the inner products can no longer be estimated directly from samples, b ut may still be computed by using importance sampling techniques (Liu, 2004; T okdar & Kass, 2010). In the case where the measure defined through µ ( x ) = exp( − 2 β E ( x )) is not finite but ¯ µ ( x ) = exp(2 β E ( x )) is, we can apply importance sampling with ¯ µ , so that the inner products are obtained as ⟨ φ, ψ ⟩ µ = Z φψ e − 2 β E ( x ) d x = E ¯ µ ¯ φ ¯ ψ (81) where we have defined ¯ φ = e − 2 β E φ and ¯ ψ = e − 2 β E ψ . For stable training, it is then advisable to parametrize ¯ ϕ := ϕe − 2 β E instead of ϕ . C . 5 L O G A R I T H M I C R E G U L A R I Z A T I O N As discussed in the main text, the PINN and relati ve eigenfunction losses (15)-(20) ha ve the form R ( ϕ ) = R main ( ϕ ) + α R reg ( ϕ ) , R reg ( ϕ ) = ( ∥ ϕ ∥ 2 ρ − 1) 2 . (82) for some α > 0 . W e observe in our experiments that this regularizer is sometimes not strong enough, and the netw ork may still con v erge to ϕ = 0 . For this reason, we instead use a logarithmic re gularizer R reg ( ϕ ) = (log ∥ ϕ ∥ ρ ) 2 (83) The behaviour is e xactly the same as before for ∥ ϕ ∥ ρ ≈ 1 , since log(1 + x ) = x + O ( x 2 ) as x → 0 , but this re gularizer av oids the con ver gence to ϕ = 0 . C . 6 F B S D E L O S S W e briefly discuss the Rob ust FBSDE loss for stochastic optimal control introduced in Andersson et al. (2023). The main idea is that the solution to the HJB equation (6) can be written down as a pair of SDEs, as the following lemma illustrates. Lemma 7 Suppose σ = I . Then it holds that the solution to the pair of FBSDEs dX t = ( b ( X t , t ) − Z t )d t + √ λ d W t , X 0 ∼ p 0 , (84) d Y t = − f ( X t , t ) − 1 2 ∥ Z t ∥ 2 d t + √ λ ⟨ Z t , d W t ⟩ , Y T = g ( X T ) (85) is given by Z t = ∂ x V ( X t , t ) and Y t = V ( X t , t ) . This pair of SDEs can be transformed in a v ariational formulation which is amenable to deep learning, as described in detail in Andersson et al. (2023). Using the Marko v property of the FBSDE, one can show that Z t = ζ ( t, X t ) for some function ζ : [0 , T ] × R d → R d , and that the FBSDE problem can be reformulated as the following v ariational problem: minimize ζ Ψ α ( ζ ) = E [ Y ζ 0 ] + α E h | Y ζ T − g ( X ζ T ) | i , where Y ζ 0 = g ( X ζ T ) + R T 0 f ( X ζ t , t ) + 1 2 ∥ Z ζ t ∥ 2 d t − R T 0 ⟨ Z ζ t , dW t ⟩ X ζ t = X 0 + R t 0 b ( s, X ζ s ) − Z ζ s d t + R t 0 λ d W s Y ζ t = E [ Y ζ 0 ] − R t 0 f ( X ζ s , s ) + 1 2 ∥ Z ζ s ∥ 2 d s + R t 0 ⟨ Z ζ s , d W s ⟩ , Z ζ t = ζ ( t, X ζ t ) , t ∈ [0 , T ] (86) 26 Published as a conference paper at ICLR 2026 Parametrizing ζ as a neural network, we can then simulate the stochastic processes in (86) and define the loss function as R F B S D E ( u ; X u ) = E [ Y ζ 0 ] + α E h | Y ζ T − g ( X ζ T ) | i , with ζ = − u (87) For more details we refer to the rele v ant work Andersson et al. (2023). C . 7 I D O L O S S F U N C T I O N S The IDO algorithm described in Algorithm 2 (Appendix D) is rather general, and a large number of algorithms can be obtained by specifying different loss functions. For a detailed discussion of the v arious loss functions and the relations between the resulting algorithms, we refer to Domingo-Enrich (2024); Domingo-Enrich et al. (2024b). Here, we go o ver the loss functions that were used for the experiments in this paper . Adjoint loss The most straightforward choice of loss is to simply use the objecti ve of the control, and define R ( u ; X u ) = Z T 0 1 2 ∥ u ( X u t , t ) ∥ 2 + f ( X u t ) d t + g ( X u T ) . (88) This loss is also called the r elative entr opy loss . When con verting this to an empirical loss, there are two options. The discrete adjoint method consists of first discretizing the objectiv e and then differentiating w .r .t. the parameters. Howe ver , this requires storing the numerical solver in memory and can hence be quite memory-intensiv e. The continuous adjoint method instead analytically computes deriv ati ves w .r .t. the state space. T o this end, define the adjoint state as a ( t, X u ; u ) := ∇ X t Z T t 1 2 ∥ u ( X u t , t ) ∥ 2 + f ( X u t ) d t ′ + g ( X u T ) ! , (89) where X u solves (3). Then the dynamics of a can be computed as d a t = ∇ X u t ( b ( X u t , t ) + σ ( t ) u ( X u t , t ) T a ( t ; X u , u )d t + ∇ X u t ( f ( X u t , t ) + 1 2 ∥ u ( X u t , t ) ∥ 2 d t, (90) a ( T ; X u , u ) = ∇ g ( X u T ) . (91) The path of a is obtained by solving the abov e equations backwards in time gi ven a trajectory ( X u t ) and control u . Finally , the deriv ativ e of the relativ e entropy loss (88) is then computed as ∂ θ R = 1 2 Z T 0 ∂ ∂ θ ∥ u ( X ¯ u t , t ) ∥ 2 d t + Z T 0 ∂ u ( X ¯ u t , t ) ∂ θ T σ ( t ) a ( t ; X ¯ u t , ¯ u )d t, (92) where the notation ¯ u means that we do stop gradients w .r .t. θ from flowing through these values. Both the discrete and continuous adjoint method hav e been shown to w ork well in practice (Nüsken & Richter, 2021; Bertsekas & Shreve, 1996; Domingo-Enrich, 2024). Howe ver , their training can be unstable due to the non-con ve xity of the problem. V ariance and log-variance For the second class of loss functions, let ( X v t ) denote the solution to (3), with u replaced by v . Then we can define e Y u,v T = − Z T 0 ( u · v )( X v s , s )d s − Z T 0 f ( X v s , s )d s − Z T 0 u ( X v s , s ) · d W s + Z T 0 ∥ u ( X v s , s ) ∥ 2 d s. (93) The variance and log-variance loss are then defined as R V ar ( u ) = V ar ( e e Y u,v T − g ( X v T ) ) , (94) R log − v ar ( u ) = V ar ( e Y u,v T − g ( X v T )) . (95) It can be shown that these losses are minimized when u = u ∗ , irrespectiv e of the choice of v . In Nüsken & Richter (2021), it was shown that these loss functions are closely connected to the FBSDE formulation of the SOC problem. 27 Published as a conference paper at ICLR 2026 SOCM The Stochastic Optimal Control Matching (SOCM) loss, introduced in Domingo-Enrich et al. (2024b), is one of the most recently introduced IDO losses. It is described in the following theorem, where we adapt the notation λ = β − 1 : Theorem 12 (Domingo-Enrich et al., 2024b, Theor em 1) For each t ∈ [0 , T ] , let M t : [ t, T ] → R d × d be an arbitrary matrix-valued dif ferentiable function such that M t ( t ) = Id . Let v ∈ U be an arbitrary control. Let R SOCM : L 2 ( R d × [0 , T ]; R d ) × L 2 ([0 , T ] 2 ; R d × d ) → R be the loss function defined as R SOCM ( u, M ) := E " 1 T Z T 0 ∥ u ( X v t , t ) − w ( t, v, X v , W, M t ) ∥ 2 dt × α ( v , X v , W ) # , (96) wher e X v is the pr ocess contr olled by v (i.e., dX v t = ( b ( X v t , t ) + σ ( t ) v ( X v t , t )) dt + √ λσ ( t ) dW t and X v 0 ∼ p 0 ), and w ( t, v , X v , W, M t ) = σ ( t ) ⊤ − Z T t M t ( s ) ∇ x f ( X v s , s ) ds − M t ( T ) ∇ g ( X v T ) + Z T t ( M t ( s ) ∇ x b ( X v s , s ) − ∂ s M t ( s )) ( σ − 1 ) ⊤ ( s ) v ( X v s , s ) ds + λ 1 / 2 Z T t ( M t ( s ) ∇ x b ( X v s , s ) − ∂ s M t ( s )) ( σ − 1 ) ⊤ ( s ) dW s ! , α ( v , X v , B ) = exp − λ − 1 Z T 0 f ( X v t , t ) dt − λ − 1 g ( X v T ) − λ − 1 / 2 Z T 0 ⟨ v ( X v t , t ) , dW t ⟩ − λ − 1 2 Z T 0 ∥ v ( X v t , t ) ∥ 2 dt ! . (97) L SOCM has a unique optimum ( u ∗ , M ∗ ) , wher e u ∗ is the optimal contr ol. The proof hinges on the path integral representation described in Kappen (2005a) and using a reparametrization trick to compute its gradients. W e refer the reader to the relev ant work Domingo- Enrich et al. (2024b) for more details. The reason why this method outperforms other IDO losses is as follows: the loss (96) can be seen as minimizing the discrepancy between u and a target vector field w . The addition of the parametrized matrix M allows the v ariance of this weight to be reduced, making it easier to learn. The do wnside of this method is that the variance of the importance weight α can blow up in more complex settings or with poor initialization, with the method failing to con ver ge as a result. Adjoint Matching The most recently introduced IDO loss, adjoint matching , was proposed in Domingo-Enrich et al. (2024a), and was proposed in the context of finetuning diffusion models. It is based on two observ ations. Firstly , one can write down a re gression objectiv e that does not hav e an importance weighting α by using the adjoint state a defined earlier . Lemma 8 (Domingo-Enrich et al., 2024a, Pr oposition 2) Define the basic adjoint matching objective as R B asic − Ad j − M atch ( u ; X u ) = 1 2 Z T 0 ∥ u ( X t , t ) + σ ( t ) T a ( t ; X u , ¯ u ) ∥ 2 d t, ¯ u = stopgrad ( u ) . (98) wher e ¯ u = stopgrad ( u ) means that the gradients of ¯ u w .r .t. the parameters θ of the contr ol u ar e artificially set to zer o. Then the gradient of this loss w .r .t. θ is equal to (92) , the gr adient of the loss in the continuous adjoint method. Consequently , the only critical point of E X u ∼ P u [ R B asic − Ad j − M atch ] is the optimal contr ol u ∗ . Secondly , it is observed that some terms in the SDE for the adjoint state (90) hav e expectation zero under the trajectories of the optimal control. Indeed, it holds by definition of the value function and adjoint state that ∇ V ( x, t ) = E [ a ( t, X u ∗ , u ∗ ) | X t = x ] (99) 28 Published as a conference paper at ICLR 2026 and hence, since u ∗ = − σ ∇ V , we get E X ∼ P u ∗ u ∗ ( x, t ) T ∇ x u ∗ ( x, t ) + a ( t, X, u ∗ ) T σ ( t ) u ∗ ( x, t ) | X t = x = 0 (100) This motiv ates dropping the terms with e xpectation zero in (90), yielding the loss function R Ad j − M atch ( u ; X ) = 1 2 Z T 0 ∥ u ( X t , t ) + σ ( t ) ˜ a ( t ; X , ¯ u ) ∥ 2 d t, ¯ u = stopgrad ( u ) , (101) where d d t ˜ a ( t ; X ) = − (˜ a ( t ; X ) T ∇ x b ( X t , t ) + ∇ x f ( X t , t )) , (102) ˜ a ( T , X ) = ∇ x g ( X T ) . (103) The v alue ˜ a is called the lean adjoint state . The claimed benefit of this method is that the resulting loss is a simple least-squares regression objectiv e with no importance weighting, allowing it to a void the problem of high variance importance weights. W e refer to the original work Domingo-Enrich et al. (2024a) for a more in-depth discussion and proofs related to the adjoint matching loss. D A L G O R I T H M S W e giv e an ov erview of the algorithm used for eigenfunction learning in Algorithm 1, and for the IDO method in Algorithm 2. Algorithm 1 Deep learning for eigenfunctions 1: Parametrize the eigenfunctions ( ϕ θ i i ) , choose loss functions ( R i ) . 2: Fix a batch size m , number of iterations N , regularization α > 0 , learning rate η > 0 . 3: Generate m samples ( X i ) m i =1 from µ , for instance using an MCMC scheme. 4: for n = 0 , . . . , N − 1 do 5: (optional) Update the samples ( X i ) m i =1 using a sampling algorithm. 6: Compute an m -sample Monte-Carlo estimate b R i ( ϕ θ i i ) of the loss R i ( ϕ θ i i ) . 7: Compute the gradients ∇ θ i c R i ( ϕ θ i i ) for the current parameters θ i , and update θ i using Adam. 8: end for 9: Estimate the eigen values λ i from the learned functions ϕ θ i i 10: return eigenfunction estimates ( ϕ θ i i ) , eigen v alue estimates ( λ i ) . Algorithm 2 Iterativ e Dif fusion Optimization ( I D O ) 1: Parametrize the control u θ ∈ U , θ ∈ R p , and choose a loss function R . 2: Fix a batch size m , number of iterations N , number of timesteps K , learning rate η > 0 . 3: for i = 0 , . . . , N − 1 do 4: Simulate m trajectories of (3) with control u = u θ using a K -step discretization scheme. 5: Compute an m -sample Monte-Carlo estimate b R ( u θ ) of the loss R ( u θ ) . 6: Compute the gradients ∇ θ b R ( u θ ) for the current parameters θ and update using Adam. 7: end for 8: return the lear ned control u θ ≈ u ∗ . 29 Published as a conference paper at ICLR 2026 E E X P E R I M E N T A L D E TA I L S E . 1 S E T T I N G C O N FI G U R A T I O N S T o e valuate the learned controls, we will use three dif ferent metrics: 1. The contr ol objective is the value we are trying to minimize, E " Z T 0 1 2 ∥ u ( X u t , t ) ∥ 2 + f ( X u t ) d t + g ( X u T ) # . (104) It can be estimated by simulating trajectories of (3) . Unless mentioned otherwise, we estimate it using 65536 trajectories and report the standard deviation of the estimate. 2. The contr ol L 2 err or at time t is given by E x ∼ P u ∗ t ∥ u ( x, t ) − u ∗ ( x, t ) ∥ 2 , (105) where P u ∗ t denotes the density over R d induced by the trajectory (3) under the optimal control at time t . 3. The aver age contr ol L 2 err or is the above quantity a veraged o ver the entire trajectory , E t ∼ [0 ,T ] E x ∼ P u ∗ t ∥ u ( x, t ) − u ∗ ( x, t ) ∥ 2 . (106) These are also the metrics reported in previous works Domingo-Enrich et al. (2024b); Domingo- Enrich (2024); Nüsken & Richter (2021). The L 2 error is introduced because, after the control u is sufficiently close to the optimal control u ∗ , the expectation (104) requires increasingly more Monte Carlo samples to distinguish u from the optimal control. In this case the L 2 error is a more precise metric for determining how close a gi v en control is to the optimal control. For all e xperiments, we trained the neural netw orks in volved using Adam with learning rate η = 10 − 4 . For the IDO methods, we use a batch size of m = 64 . For the eigenfunction learning, we sample from µ using the Metropolis-Adjusted Langevin Algorithm (Roberts & Rosenthal, 1998). Unless mentioned otherwise, we sample m = 65536 samples, updating these in ev ery iteration with 100 MCMC steps with a timestep size of ∆ t = 0 . 01 after a warm-up phase of 1000 steps. For more details, we refer to the code in the supplementary material, which contains a description of all hyperparameters used. Q U A D R A T I C The first setting we consider has E ( x ) = 1 2 x T Ax, f ( x ) = x T P x, g ( x ) = x T Qx, (107) where A ∈ R d × d is symmetric, Q ∈ R d × d is positi ve definite and P ∈ R d × d . This type of control problem is more widely known as the linear quadratic regulator . The optimal control is given by u ∗ ( x, t ) = − 2 F t x , where F t solves the Riccati equation (see (v an Handel, 2007, Theorem 6.5.1)) d F t d t − A T F t − F t A − 2 F t F T t + P = 0 , F T = Q. (108) W e consider three dif ferent configurations: • ( I S OT RO P I C ) W e set d = 20 , A = I , P = I , Q = 0 . 5 I , β = 1 , T = 4 , x 0 ∼ N (0 , 0 . 5 I ) , taking K = 200 time discretization steps for the simulation of the SDE. • ( R E P U L S I V E ) Exactly the same as isotropic, but with A = − I . • ( A N I S O T R O P I C ) W e set d = 20 , A = diag ( e a i ) , P = U diag ( e p i ) U T , Q = 0 . 5 I , β = 1 , T = 4 , x 0 ∼ N (0 , 0 . 5 I ) , taking K = 200 time discretization steps for the simulation of the SDE. The v alues a i , p i are sampled i.i.d. from N (0 , 1) , and the matrix U is a random orthogonal matrix sampled using scipy.stats.ortho_group (V irtanen et al., 2020) at the start of the simulation. 30 Published as a conference paper at ICLR 2026 D O U B L E W E L L The second setting we consider is the d -dimensional double well defined through E ( x ) = d X i =1 κ i ( x 2 i − 1) 2 , f ( x ) = d X i =1 ν i ( x 2 i − 1) 2 , g ( x ) = 0 . (109) where d = 10 , and κ i = 5 , ν i = 3 for i = 1 , 2 , 3 and κ i = ν i = 1 for i ≥ 4 . In addition, we again set T = 4 , β = 1 and use K = 400 discretization steps. This problem is similar to the one considered in Nüsken & Richter (2021) and Domingo-Enrich et al. (2024b), the difference being that we consider a longer horizon ( T = 4 instead of T = 1 ) and consider a nonzero running cost in order to have nontrivial long-term beha viour . This problem is considered a highly nontrivial benchmark problem, since the double well in each dimension creates a total of 2 d = 1024 local minima, making this setting highly multimodal. The ground truth is not av ailable in closed form, but can be approximated efficiently by noticing that the energy and running cost are a sum of one-dimensional terms, and hence we can compute the solution by solving d one-dimensional problems using a classical solver . R I N G The final setting considers the setup E ( x ) = α ∥ x ∥ 2 − 2 R 2 ∥ x ∥ 2 , f ( x ) = 2 x 1 , g ( x ) = 0 , (110) where α = 1 , R = 5 / √ 2 . This energy is noncon ve x and has its minimizers lying on the hypersphere with radius R . This setting serves to highlight the difference between the relati ve eigenfunction loss (20) and the other eigenfunction losses, and for visualization purposes will be done in d = 2 . In addition, we set T = 5 , β = 1 and x 0 = ( R, 0) . The energy landscape and running cost are visualized in Figure 6. The goal of the controller is essentially to guide the system to the left hand side of the xy -plane while being constrained by the potential to stay close to the circle of radius R . This setting requires a smaller timestep for stable simulation, we take K = 500 . Figure 6: Energy function (left) and running cost (right) for the R I N G setting in d = 2 . E . 2 M O D E L A R C H I T E C T U R E A N D T R A I N I N G Architectur e For the IDO methods, we use the exact same architecture as in Domingo-Enrich et al. (2024b). They argue that the control can be viewed as the analog of a score function in diffusion models, and hence they use a simplified U-Net architecture, where each of the up-/do wnsampling steps is a fully connected layer with ReLU activ ations. As in their work, we use three downsampling and upsampling steps, with widths 256, 128 and 64. For the eigenfunction models, we use the same architecture, b ut replace the ReLU activ ation with the GELU activ ation function x 7→ x Φ( x ) , where Φ is the cdf of a standard normal distribution (Hendrycks & Gimpel, 2023). This is done because the eigenfunction losses require e valuating the deriv ati ves of the netw ork w .r .t. the inputs, hence requiring a smoother activ ation function. T raining For the eigenfunction method, we train using the follo wing procedure: 1. Start training the top eigenfunction using the deep Ritz loss (17) . Every 100 iterations, we estimate the eigen v alue λ 0 , and continue training until the v ariance of these estimates (computed with EMA 0.5) is below 10 − 4 and we hav e reached at least 5000 iterations. 31 Published as a conference paper at ICLR 2026 T able 2: Iteration times by method and loss Experiment Iteration time ( s ) Method Loss COMBINED Adjoint Matching 0.332 Log variance 0.328 Relative entr opy 0.419 SOCM 0.432 EIGF Deep ritz loss 0.227 PINN 0.662 Relative loss 0.662 V ariational loss 0.228 FBSDE FBSDE 0.443 IDO Adjoint Matching 0.230 Log variance 0.212 Relative entr opy 0.413 SOCM 0.799 2. Fix λ 0 , and continue training the top eigenfunction using a loss function of choice among (15) , (17) , (20) . Start training the excited state using the v ariational loss R V ar in (73) with k = 1 and regularization parameter α = | λ 0 | . For the combined methods, we first train the eigenfunction and eigen values using the method abov e with R Rel for 80 000 iterations, and then start training with an IDO loss using the control parametrization (22) . W e resample the trajectories in [0 , T cut ] (which only use the eigenfunction control) ev ery L = 100 iterations in order to hav e a di verse set of starting positions at T = T cut . E . 3 C O M P U TA T I O N A L C O S T T able 2 shows the computation cost per iteration for the different algorithms for the Q UA D R A T I C ( R E P U L S I V E ) setting, measured in seconds/iteration when ran in isolation on a single GPU. All experiments where carried out on an NVIDIA H100 NV GPU. E . 4 F U RT H E R D E TA I L S O N T H E R I N G S E T T I N G The R I N G setting serves as an illustrati ve example the difference between the ’absolute’ eigenfunction losses and our relativ e eigenfunction loss. As shown in Figure 4, the relativ e loss obtains a drastically lower control objectiv e than the absolute losses. T o further understand this, consider the shape of the learned eigenfunctions for the different losses, sho wn in Figure 7. From the top ro w , it is clear that the learned eigenfunctions for the different methods are all very close in terms of the distance induced by ∥ · ∥ µ . Howev er , while the learned eigenfunctions look similar in L 2 ( µ ) , the logarithm of the learned eigenfunctions v aries drastically , and hence the resulting control ∇ log ϕ (shown in Figure 3) dif fers greatly - the control learned by the relativ e loss correctly guides the system along the circle in the ne gativ e x direction, while the other controls are not learned correctly for x ≥ 0 . The name ’ relati ve loss’ comes from the analogy with absolute and r elative errors, | x − x ∗ | < ϵ vs. x x ∗ − 1 < ϵ ⇐ ⇒ | log x − log x ∗ | < ϵ + O ( ϵ 2 ) . (111) In essence, since the resulting control is giv en by ∇ log ϕ , the quantity of interest is the r elative error of the learned eigenfunction, while existing methods are designed to minimize the absolute error . E . 5 D E TA I L S O N F I G U R E 1 W e giv e here some details on the motiv ating plot sho wn in Figure 1. The value sho wn is the control L 2 error of each of the dif ferent methods in the Q UA D R A T I C ( R E P U L S I V E ) setting. Each algorithm was run for 30k iterations, and the v alues reported are the mean and 5%-95% quantiles over the last 32 Published as a conference paper at ICLR 2026 Figure 7: Learned eigenfunctions (top row) and their logarithms (bottom ro w) for the R I N G setting with different loss functions. Figure 8: L 2 error of ∇ log ϕ for different eigenfunctions (left), a verage control L 2 error for different methods (middle) and control L 2 error over time (right). Legend is the same as in Figure 4 and Figure 5. 1000 iterations. The E I G F + I D O ( O U R S ) label refers to the combined method, where we first train the eigenfunctions until con ver gence and then train using the relativ e entropy loss. E . 6 A D D I T I O N A L E X P E R I M E N T : R E P U L S I V E P OT E N T I A L Figure 8 sho ws the same plots discussed in the main text for the Q U A D R A T I C ( R E P U L S I V E ) setting, where we obtain similar results. The reported eigenfunction error is measured in L 2 ( µ ) instead of L 2 ( µ ) . Additionally , for this experiment setting we have tested the performance of “er godic” control estimator . It is based only on the first eigenfunction, i.e. β − 1 ∇ log ϕ θ 0 0 is used for the whole time range. The performance of such an estimator is presented in Figure 9 by a curve labeled EIGF . It can be seen, that this approach reduces the error do wn with growth of time horizon T . Howe v er , using our proposed approach with control as in (22) , which corresponds to EIGF+IDO curve, leads to a significant improv ement. E . 7 C O N T R O L O B J E C T I V E S As mentioned before, the control objecti ve is the final metric for e v aluating the performance of the dif ferent algorithms, but due to variance of the Monte Carlo estimator the dif ference between methods can be quite small. W e report the control objectiv es for all experiments at con ver gence in T able 3 and T able 4. The value reported is the mean v alue of the control objectiv e ov er N = 65536 simulations, and the error is the standard deviation of these estimates, di vided by √ N . 33 Published as a conference paper at ICLR 2026 Figure 9: In this experiment EIGF method uses an ergodic estimator based only on the first eigenfunc- tion. EIFG+IDO curve corresponds to the application of the proposed controller (22) with Relati ve Entropy loss. The figure shows L 2 control error for different methods after 30000 iterations. T able 3: Control objecti ve for the different methods in the Q U A D R A T I C ( I S OT R O P I C ) and Q UA D R A T I C ( R E P U L S I V E ) settings. The SOCM method did not con verge, and hence the dynamics di v erge. Q U A D R A T I C ( I S OT RO P I C ) Q U A D R A T I C ( R E P U L S I V E ) Method Loss IDO Relative entr opy 32.7870 ± 0.014 112.5172 ± 0.051 Log variance 32.7850 ± 0.014 114.0552 ± 0.053 SOCM 73.1062 ± 0.062 nan ± nan Adjoint matching 32.7754 ± 0.014 113.4554 ± 0.052 COMBINED Relative entropy 32.7763 ± 0.014 112.3444 ± 0.050 (ours) Log variance 32.7740 ± 0.014 150.0721 ± 0.12 SOCM 32.7717 ± 0.014 112.3960 ± 0.050 Adjoint matching 32.7725 ± 0.014 114.7020 ± 0.055 FBSDE FBSDE 32.7979 ± 0.014 112.6393 ± 0.051 T able 4: Control objectiv e for the dif ferent methods in the Q U A D R A T I C ( A N I S OT RO P I C ) and D O U B L E W E L L settings. Q U A D R A T I C ( A N I S O T R O P I C ) D O U B L E W E L L Method Loss IDO Relative entr opy 38.9967 ± 0.022 35.2688 ± 0.010 Log variance 31.3664 ± 0.016 32.8645 ± 0.0094 SOCM 112.2728 ± 0.18 41.7215 ± 0.013 Adjoint matching 31.3584 ± 0.016 34.8713 ± 0.010 COMBINED Relative entropy 31.3476 ± 0.016 32.6130 ± 0.0088 (ours) Log variance 32.5115 ± 0.047 32.9080 ± 0.0088 SOCM 31.3483 ± 0.016 32.4421 ± 0.0088 Adjoint matching 31.3497 ± 0.016 32.5638 ± 0.0088 FBSDE FBSDE 31.3854 ± 0.016 35.1890 ± 0.011 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment