상태 의존성에 따른 시점 불일치 확률 제어 이론
본 논문은 현재 상태가 목표 함수에 직접 영향을 주는 경우, 즉 상태‑의존적 선호 파라미터가 시간에 따라 업데이트되는 상황에서 발생하는 시점 불일치(stochastic time‑inconsistent) 문제를 다룬다. 저자들은 비마르코프적 균형 동적계획법을 마르코프적 형태로 전환하고, Itô‑Kunita‑Wentzell 공식에 기반한 ‘대각선 계산(diagonal calculus)’을 이용해 연속적인 상태 흐름에 따라 변하는 연속 가치 흐름을 …
저자: Dylan Possamaï, Mateo Rodriguez Polo
본 논문은 연속시간 확률 제어에서 “현재 상태가 목표 함수에 직접 들어가는” 형태의 시점 불일치(time‑inconsistent) 문제를 체계적으로 다룬다. 전통적인 최적 제어는 Bellman의 동적계획법(DPP)을 기반으로 하여, 초기 시점에 정의된 가치함수가 모든 미래 시점에서도 동일하게 적용된다는 시간‑일관성을 전제로 한다. 그러나 할인률이 비지수적이거나, 평균‑분산, 편차‑위험 등 비선형 기대값이 포함된 경우, 혹은 현재 상태가 선호 파라미터(예: 위험 회피도, 목표 기준점)로 사용되는 경우에는 이러한 일관성이 깨진다. 특히, 논문이 집중하는 상태‑의존적 선호 파라미터는 매 시점마다 현재 상태 \(X_t\) 로 업데이트되므로, 각 “자아(self)”가 직면하는 목표 함수가 서로 달라진다. 이로 인해 전통적인 전역 최적해는 존재하지 않으며, 대신 “균형(equilibrium) 전략”이라는 게임‑이론적 개념이 필요하다.
논문은 먼저 비마르코프적 균형 DPP(히에라르다와 포사마이, 2021)를 소개하고, 이를 마르코프적 상황에 맞게 변형한다. 핵심 아이디어는 “연속 가치 흐름”을 하나의 확장된 가치 필드 \(V(t,x,\xi)\) 로 정의하는 것이다. 여기서 \(\xi\) 는 현재 시점의 참조 파라미터이며, 시간 \(s>t\) 에서는 \(\xi\) 가 실제 상태 \(X_s\) 로 교체된다. 따라서 균형 가치가 필요한 순간은 필드의 대각선 \(\{(t,x,\xi):\xi = x\}\) 에 해당한다. 이 대각선을 정확히 추적하기 위해 저자들은 Itô‑Kunita‑Wentzell 공식을 활용한다. 이 공식은 임의의 반변량 필드 \(F(t,X_t,\xi_t)\) 를 평가할 때 발생하는 추가 드리프트와 확산항을 명시적으로 제공한다. 결과적으로, 대각선 흐름은 마르코프식 BSDE 시스템으로 변환된다.
구체적인 BSDE는 두 개 이상의 연계된 방정식으로 구성된다. 첫 번째 방정식은 균형 가치 \(Y_t\) 와 그 확산계수 \(Z_t\) 를 정의하고, 두 번째 방정식은 최적 피드백 제어 \(\alpha_t = \phi(t,X_t,Y_t,Z_t)\) 를 제공한다. 생성자(generator)에는 상태‑의존적 파라미터 업데이트에 의해 발생하는 추가 항이 포함되며, 이는 기존의 확장 HJB PDE에서 나타나는 “대각선 항”과 정확히 일치한다. 중요한 점은 이 BSDE 체계가 부드러운 해를 요구하지 않으며, 일반적인 Lipschitz 조건만으로 존재와 유일성을 보장한다는 것이다.
다음으로 논문은 시간‑의존적 할인 문제와의 연관성을 설명한다. 비지수 할인률 \(\delta(t)\) 를 고려하면, 할인 함수 자체가 시간에 따라 변하므로 이는 사실상 “시간을 상태에 포함시키는(state‑augmentation)” 방식으로 재구성될 수 있다. 즉, 새로운 상태 변수 \(\tau_t = t\) 를 도입하면, 할인률은 \(\delta(\tau_t)\) 형태의 상태‑의존적 파라미터가 된다. 이때 기존 할인문헌에서 사용된 BSDE는 현재 제시한 일반 이론의 특수 경우이며, 대각선 계산을 통해 자연스럽게 도출된다.
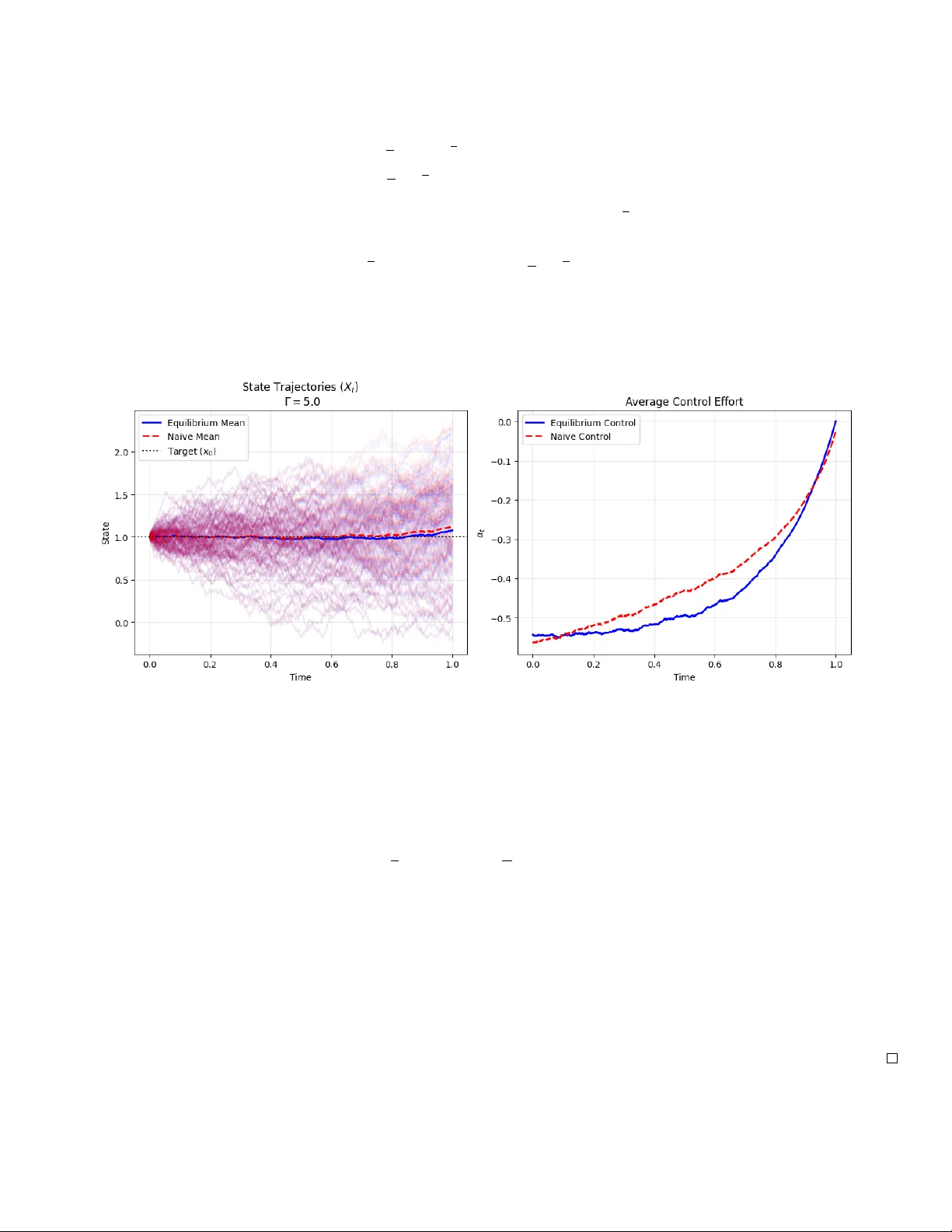
이론적 결과를 검증하기 위해 저자들은 선형‑이차(LQ) 조절 문제에 적용한다. 시스템 동역학은
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기