Here, there and everywhere: state-dependent time-inconsistent stochastic control
This paper addresses the challenge of time-inconsistent stochastic control within a continuous-time framework. Its primary focus lies in uncovering a probabilistic representation, specifically in the shape of a system of backward stochastic different…
Authors: Dylan Possamaï, Mateo Rodriguez Polo
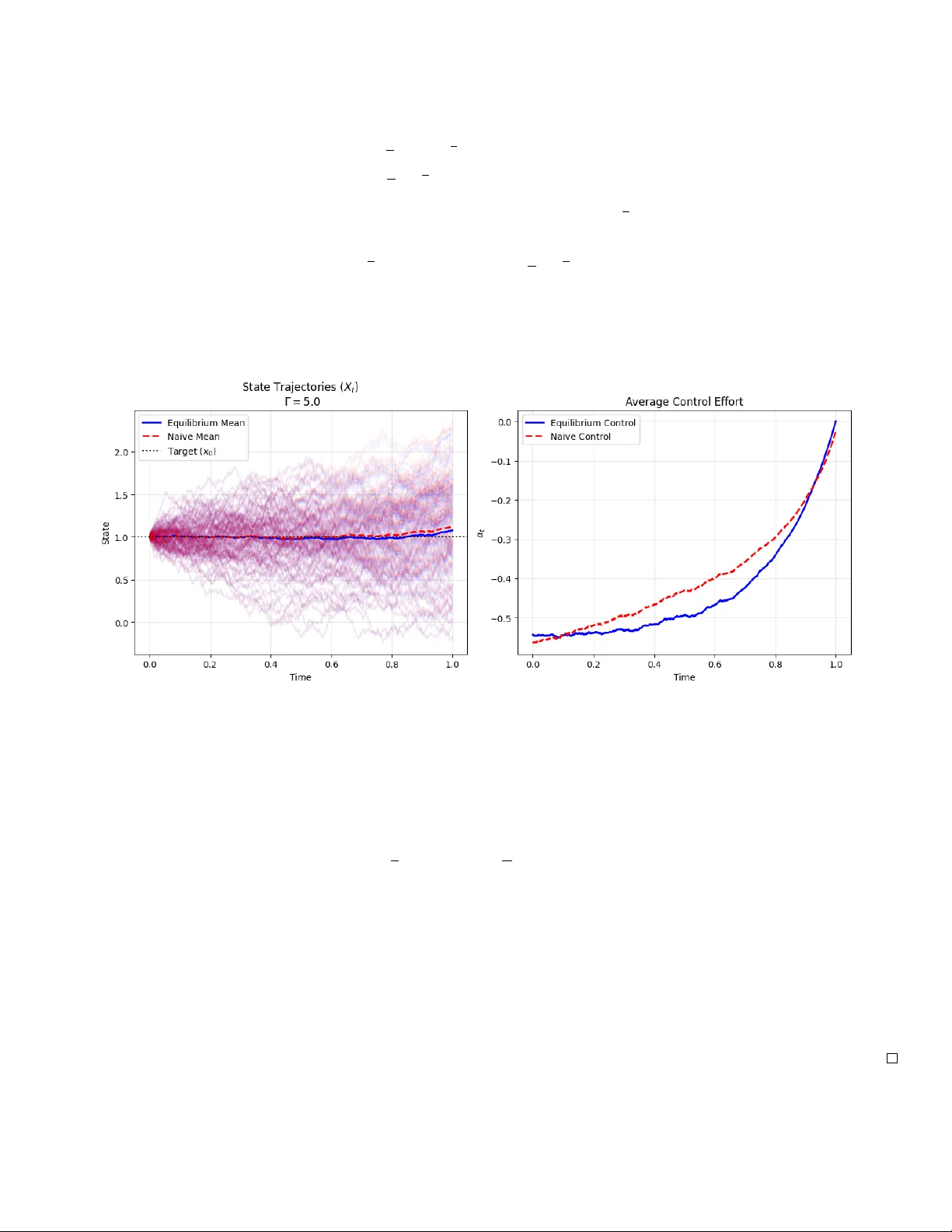
Here, there and ev erywhere: state-dep enden t time-inconsisten t sto c hastic con trol Dylan Possamaï ∗ Mateo R odriguez Polo † Marc h 24, 2026 Abstract This pap er addresses the challenge of time-inconsisten t stochastic con trol within a con tinuous-time framework. Its primary fo cus lies in unco vering a probabilistic represen tation, specifically in the shap e of a system of backw ard sto c hastic differen tial equations (BSDEs). These equations encapsulate the equilibrium v alue function essential for resolving cases where the presen t state affecting the target functional triggers the inconsistency . Additionally , the pap er offers an application exemplifying this theory through the time-inconsistent linear–quadratic regulator. 1 In tro duction Classical stochastic con trol is largely built around an in tertemp oral consistency principle: the p olicy that is optimal when the problem is p osed at time 0 remains optimal when the same optimisation is reconsidered at any later time t , conditional on the information a v ailable at t . This prop ert y is the backbone of Bellman’s dynamic programming principle (DPP). It allows one to propagate v alue functions through conditioning and concatenation, and it leads to tractable characterisations of optimal feedbac k controls via Hamilton–Jacobi–Bellman (HJB) equations and verification arguments; see, for instance, Fleming and Soner [ 16 ], or Y ong and Zhou [ 50 ]. A large and imp ortan t family of economically and financially motiv ated ob jectiv es violates this principle. In a time-inc onsistent con trol problem, the contin uation criterion used by the agent at time t differs from the criterion that will b e used at a later date s > t . As a consequence, a plan designed at time 0 is t ypically not self-enforcing: when time t arrive s, the agent re- optimises and may deviate from the original plan even when the underlying dynamics hav e not changed. Time inconsistency therefore fundamen tally alters the nature of the problem. Since a global optimum in the classical sense is no longer necessarily meaningful, the relev an t solution concept m ust b e reconsidered, and one needs new analytical tools to replace the missing DPP . A natural resolution, going bac k to Strotz [ 44 ], is to interpret time inconsistency as an intr ap ersonal dynamic game in which the ‘pla yers’ are the agent’s successiv e selves. This viewp oin t clarifies three canonical b eha vioural b enc hmarks. A pr e-c ommitte d agen t computes an optim um at time 0 and follo ws it regardless of future incentiv es. A naive agent re-optimises o ver time as if the current plan w ould never b e revised again. The sophistic ate d (game-theoretic) agen t studied in this pap er instead seeks a self-enforcing, subgame-p erfect strategy: no self has an incentiv e to deviate, giv en that later selves will also b eha v e optimally from their own p ersp ectiv e. In discrete time, this ‘consistent planning’ paradigm is classical Phelps and P ollak [ 39 ], P ollak [ 40 ], P eleg and Y aari [ 38 ], and it also provides b eha vioural foundations for quasi-hyperb olic and more general forms of discounting Laibson [ 32 ], O’Donoghue and Rabin [ 36 ]. W e will illustrate the quantitativ e gap b et ween precommitmen t, naiv ety and sophistication in our linear–quadratic example in Section 4 , and remark that analogous tw o-lay er game-theoretic structures also arise when time inconsistency in teracts with strategic considerations in multi-pla yer games [ 41 ]. In contin uous time, equilibrium notions are necessarily lo cal. A ‘current self ’ is allow ed to deviate only on a short time interv al, while taking the contin uation b eha viour of future selves as fixed, so that equilibrium controls are lo cally optimal in the sense of an infinitesimal deviation analysis. Sev eral equilibrium concepts coexist in the sto c hastic control literature, reflecting both mo delling c hoices (op en-loop versus feedback strategies) and analytical requirements (how deviations are measured, and what regularit y is imp osed on the candidate strategy). The strong/weak equilibrium distinction of Huang and Zhou [ 25 ] and the ∗ ETH Zürich, Mathematics department, Switzerland, dylan.possamai@math.ethz.ch. This author gratefully ackno wledges partial supp ort by the SNF pro ject MINT 205121-219818. † ETH Zürich, Mathematics department, Switzerland, mateo.ro driguezpolo@math.ethz.ch. This author gratefully acknowledges partial supp ort by the SNF pro ject MINT 205121-219818. 1 subsequen t analysis of equilibrium notions in He and Jiang [ 19 ] mak e this particularly transparent. A related, widely used notion is that of r e gular e quilibrium , which is tailored to the extended HJB approac h and is closely connected to the solv abilit y of equilibrium PDE systems Lindensjö [ 33 ], Björk, Khapko, and Murgo ci [ 8 ]. In this pap er w e fo cus on feedback equilibria in the sense of lo cal deviations, as this is the natural notion for dynamic programming. Time inconsistency can b e generated by sev eral conceptually distinct mechanisms, and the contin uous-time literature reflects this diversit y . First, and perhaps most prominen tly , non-exp onential disc ounting destroys stationarit y: the discount factor dep ends on the ev aluation time and induces a re-weigh ting of future pa yoffs as time passes. In contin uous time this mechanism motiv ated the pioneering equilibrium analysis of Ekeland and Lazrak [ 12 ; 13 ], Ekeland and Pirvu [ 14 ]. It remains a b enc hmark class and has b een revisited in general Marko vian settings; see, for instance, Björk, Khapko, and Murgo ci [ 7 ; 8 ]. Second, nonline ar dep endenc e on c onditional exp e ctations breaks the DPP even when discounting is exp onential. The paradig- matic example is the mean–v ariance criterion, whic h in tro duces a v ariance term (a nonlinear function of an exp ectation) into the objective and is central in dynamic Marko witz p ortfolio selection. Equilibrium form ulations for mean–v ariance and related deviation–risk criteria hav e b een developed in, among man y others, Basak and Chabakauri [ 2 ], Björk, Murgo ci, and Zhou [ 6 ], Gu, Si, and Zheng [ 17 ]. This line of work has also motiv ated robust and ambiguit y-av erse formulations, where time inconsistency and mo del uncertaint y interact; see, e.g. , Pun [ 42 ]. Time inconsistency also in teracts with additional mo delling features such as regime switching and discrete interv en tions; equilibrium analyses of time-inconsistent sto c hastic switc hing problems can b e found in, for instance, Mei and Y ong [ 35 ]. Third, and this is the focus of the present pap er, time inconsistency may stem from state-dep endent pr efer enc e p ar ameters . In many mo dels the criterion dep ends on a parameter that is up dated as the state ev olves—w ealth-dep enden t risk av ersion, mo ving targets, relativ e-p erformance b enc hmarks, or endogenous reference p oin ts. When this parameter is r e c alibr ate d by eac h future self, different selves effectively face differen t ob jectiv e functionals even if discoun ting is exp onential and the reward structure is otherwise time-homogeneous. State-dep enden t risk av ersion in deviation–risk criteria provides one family of examples [ 6 ; 17 ; 42 ], but the mechanism is broader: the preference parameter may itself b e the state used as a reference p oin t, as in the criterion considered in ( 1.1 ) b elo w. A further imp ortan t class, closely related to nonlinear exp ectation criteria, arises in r e cursive (BSDE-type) ob jectiv es: time inconsistency can emerge from a lack of flo w prop ert y in the bac kw ard component and from non-separable aggregation. This has led naturally to equilibrium c haracterisations in terms of flows of forward–bac kward SDEs and, more generally , bac kward stochastic V olterra integral equations (BSVIEs); see W ei, Y ong, and Y u [ 47 ], Hamaguchi [ 18 ], W ang and Y ong [ 45 ], Mastrogiacomo and T arsia [ 34 ]. Finally , time-inconsistent stopping (and mixed con trol–stopping) problems form a parallel and active strand of the literature, where the game-theoretic equilibrium concept takes a differen t form but shares the same conceptual origin. W e refer to Christensen and Lindensjö [ 10 ; 11 ], Bayraktar, Zhang, and Zhou [ 3 ], Bo dnariu, Christensen, and Lindensjö [ 9 ] for representati ve recen t works and for further references. W e concentrate on a Marko vian controlled diffusion in w eak formulation and on objective functionals of the form J ( t, x, α ) : = E P t,x,α Z T t f s, x, X s , α s d s + ξ ( x, X T ) , ( t, x, α ) ∈ [0 , T ] × R n × A , (1.1) where X denotes the controlled state, α is the control, and the crucial feature is the app earance of the curr ent state x as an additional argument in b oth the running and terminal pay off. When the same problem is re-ev aluated at time s > t , the parameter x is up dated to X s , so the contin uation criterion differs from ( 1.1 ) even if the con trol law is kept fixed. Suc h state-dep enden t up dating is natural whenever pay offs are formulated relativ e to a moving target or a reference point that ev olves with the system, rather than b eing fixed at time 0 . A t a formal level, criteria of the form ( 1.1 ) are encompassed b y the general Marko vian equilibrium frameworks of [ 4 ; 7 ; 8 ]. The k ey insight in these framew orks is that equilibrium b eha viour is describ ed not by a single v alue function but by an extended ob ject (an ‘equilibrium v alue function’ together with auxiliary functions) whose diagonal captures the contin uation v alues faced b y eac h self. How ever, the existing Marko vian literature at this level of generality pro ceeds primarily via verific ation-typ e results: one p ostulates an extended HJB system (a coupled system of nonlinear PDEs in m ultiple v ariables) and prov es that an y sufficiently smo oth solution yields an equilibrium control. This approac h was pioneered and systematised in [ 4 ; 7 ] and remains central in the monograph [ 8 ]. Parallel approaches based on Pon tryagin-t ype maximum principles lead to equilibrium c haracterisations in terms of flows of forw ard–backw ard SDEs, esp ecially in linear–quadratic settings; see Hu, Jin, and Zhou [ 23 ], Hu, Jin, and Zhou [ 24 ] and the references therein. There are also contributions fo cusing on the existence of closed-lo op equilibria in more general mo dels and on the relationship b et ween different equilibrium notions; see, e.g. , Y ong [ 49 ], Huang and Zhou [ 25 ], He and Jiang [ 19 ], W ang and Zheng [ 46 ]. 2 Despite this substantial progress, genuinely state-dep enden t time inconsistency raises conceptual and technical obstacles that, in our view, hav e not b een fully resolv ed at the level of dynamic programming. The key difficult y is that the preference parameter driving the inconsistency b ecomes sto c hastic once it is up dated to the current state. F rom a dynamic programming viewp oin t, the equilibrium ob ject is therefore not a single scalar v alue function: one must keep track of a family of contin uation v alues indexed b y a reference parameter (the ‘reference state’), together with a consistent mechanism that selects the correct diagonal when the parameter is up dated along the state pro cess. In smo oth PDE approaches this manifests in the need to solv e an extended HJB system on an enlarged state space and to ev aluate the solution along a diagonal. Outside smo oth settings, how ever, it is not a priori clear how to interpret this diagonal, how it ev olves along the diffusion, and how it in teracts with the equilibrium definition based on local deviations. By contrast, the most complete rigorous dynamic programming foundations currently a v ailable in the time-inconsisten t litera- ture fo cus on mec hanisms where the preference parameter is either deterministic (as in non-exp onen tial discounting) or enters through conditional exp ectations (as in mean–v ariance and deviation–risk criteria). In these cases one can often set up a flow of v alue functions indexed by the initial time or by auxiliary exp ectation v ariables and derive extended HJB systems, FBSDE flo ws, and/or BSVIE characterisations [ 2 ; 12 ; 13 ; 14 ; 23 ; 45 ]. Recen t w orks hav e also developed dynamic programming and viscosit y-solution metho ds for the resulting extended HJB systems in sp ecific settings Karnam, Ma, and Zhang [ 30 ], Xu and Y ang [ 48 ]. The non-Marko vian theory of Hernández and Possamaï [ 21 ] provides a very general equilibrium DPP and BSDE represen tation for sophisticated agents, but does not cov er the Marko vian sp ecialisation required for state-dep enden t reference parameters. T o the b est of our knowledge, a ful ly rigor ous dynamic programming treatment of time inconsistency stemming from state- dep endent pr efer enc e up dating of the form ( 1.1 ) has b een missing. While state dep endence is present in the general Marko vian framew orks abov e, existing results in that direction are predominantly verification-t yp e. They do not derive a dynamic programming principle that is b oth necessary and sufficien t and that explicitly propagates the state-dependent preference parameter through time. Providing suc h a dynamic programming principle, and turning it in to a concrete probabilistic represen tation, is the cen tral ob jectiv e of the presen t pap er. W e develop a rigorous and op erational dynamic programming theory for state-dep endent time-inconsistent sto c hastic control in contin uous time. W e work in weak formulation for a controlled diffusion with uncon trolled volatilit y , and w e seek feedback equilibrium controls. The analysis is probabilistic throughout, and the main output is an equilibrium DPP together with a Mark ovian system of backw ard sto chastic differen tial equations (BSDEs) charac terising the equilibrium v alue. The starting p oin t is the non-Mark ovian equilibrium DPP of [ 21 ]. In the state-dep enden t Marko vian setting, this suggests that the equilibrium v alue at ( t, x ) should b e understo o d as the diagonal of a flow of con tinuation v alues indexed by a reference parameter. T urning this into a tractable Mark ovian ob ject requires a wa y to ev aluate such a flow along the random curve giv en by the state pro cess when the reference parameter is up dated. The key to ol enabling this step is the Itô–Kunita– W entzell formula Kunita [ 31 ]. Roughly sp eaking, the Itô–Kunita–W entzell formula allo ws us to compute the semimartingale decomp osition of a random field ev aluated along a sto c hastic flo w. In our context, it provides a clean and explicit ‘diagonal calculus’ for the equilibrium flow and mak es the additional drift terms generated by state dep endence transparent. The resulting BSDE system yields a probabilistic counterpart to extended HJB systems that is compatible with lo w regularity . It also clarifies the role of diagonal ob jects that app ear throughout the equilibrium literature (b oth in PDE and FBSDE form ulations) and that are intimately connected to the lo cal deviation structure of equilibrium definitions [ 19 ; 23 ; 25 ]. F or completeness, we recall that BSDE methods pla y a central role in sto c hastic con trol, both as a probabilistic representation of PDEs and as a natural language for recursiv e criteria; see, e.g. , Pardoux and Protter [ 37 ], El Karoui, Peng, and Quenez [ 15 ]. A second theme of the pap er is a unification of time-dep endent and state-dep endent time inconsistency . In standard (time- consisten t) optimal control, explicit time dep endence can alw ays b e reduced to state dep endence by augmen ting the state with a clo c k v ariable [ 16 ; 50 ]. While this observ ation is classical, it has not b een systematically exploited at the lev el of equilibrium dynamic programming for sophisticated agents. The reason is that, without a complete treatmen t of state- dep enden t preference up dating, the reduction is essentially formal: one may embed time into an enlarged state space, but one still needs to understand ho w the equilibrium flo w and its diagonal b eha v e when the preference parameter b ecomes a comp onen t of the state. Our probabilistic approach, and in particular the Itô–Kunita–W en tzell based diagonal calculus, makes this reduction trans- paren t and explicit in the equilibrium setting. It shows that non-exp onen tial discoun ting can b e viewed as a sp ecial instance of state-dep endent preference up dating (with the ‘reference’ b eing the augmented state, i.e. the clo c k), and it clarifies how the BSDE systems app earing in the discounting literature are recov ered as a degenerate case of the general state-dep enden t theory . In that sense, the present w ork do es more than recall the classical state-augmentation trick: it pro vides the missing state-dep enden t equilibrium theory that makes the reduction operational. 3 The presen t pap er provides, to our knowledge, the first complete Marko vian dynamic programming theory for time inconsis- tency driv en by state-dep enden t preference updating. Concretely , our contributions can b e summarised as follo ws. ( i ) Equilibrium DPP and Markovian BSDE char acterisation for state dep endenc e. W e establish an equilibrium DPP for the criterion ( 1.1 ) and derive a Marko vian system of BSDEs whose solution c haracterises b oth the equilibrium v alue and the equilibrium feedback con trol. This yields a probabilistic analogue of the extended HJB approach whic h do es not require smo oth PDE solutions and which makes the diagonal structure explicit. ( ii ) A tr ansp ar ent diagonal c alculus via the Itô–K unita–W entzel l formula. W e sho w that the Itô–Kunita–W en tzell formula pro vides the correct probabilistic mechanism behind the diagonal terms that app ear in equilibrium conditions. This clarifies and complements the extended HJB viewp oin t of [ 4 ; 7 ; 8 ], and it connects the Mark ovian state-dependent setting to the general non-Mark ovian equilibrium DPP of [ 21 ]. ( iii ) R e duction of time dep endenc e to state dep endenc e in the e quilibrium setting. W e mak e explicit how time-dep endent mec hanisms such as non-exp onen tial discoun ting can b e embedded into the state-dep enden t framew ork via state augmentation. W e then sho w ho w the corresponding equilibrium BSDE systems arise as a degenerate case of our general theory . T o our kno wledge, this “time as state” reduction has not previously b een p oin ted out and exploited in a dynamic programming framew ork for sophisticated equilibrium con trols. ( iv ) A tr actable il lustr ation: a time-inc onsistent line ar–quadr atic r e gulator. W e apply the general results to a time-inconsistent linear–quadratic regulator, where we obtain existence and characterisation results in a concrete class and provide n umerical exp erimen ts comparing equilibrium, naive, and precommitted con trols. The theory dev elop ed here fits naturally within the growing probabilistic approach to time-inconsistent con trol. On the one hand, it complements the general non-Marko vian equilibrium theory of [ 21 ] by providing an explicit Marko vian sp ecialisation adapted to state-dep enden t preference parameters, and by connecting it to the extended HJB paradigm through a concrete BSDE system. On the other hand, it provides a rigorous dynamic programming underpinning for Marko vian state-dep enden t mo dels that ha ve previously b een handled mainly through smo oth verification arguments. Time-inconsisten t preferences also arise in other domains, including contracting problems with sophisticated agents, where the failure of commitmen t interacts with moral hazard. W e refer to [ 22 ] for recen t developmen ts in that direction and note that, while our fo cus is on Mark ovian diffusion control, the present results strengthen the conceptual bridge b et ween Marko vian state-dep enden t models and the general non-Mark ovian probabilistic theory . The rest of the pap er is organised as follo ws. Section 2 in tro duces the time-inconsistent control problem and the equilibrium concept. Section 3 states the main results, including the equilibrium DPP and the BSDE characterisation. Section 4 studies the linear–quadratic regulator example and compares equilibrium and naive controls. Finally , Section 5 discusses the reduction of time dep endence to state dep endence and its implications for non-exp onen tial discoun ting. Notations: Throughout thi s paper we take the con ven tion ∞ − ∞ : = −∞ , and we fix a time horizon T > 0 . R + and R ⋆ + denote the sets of non-negative and p ositive real num b ers, resp ectiv ely . Given ( E , ∥ · ∥ ) a Banach space, a p ositiv e integer p , and a non-negative integer q , C p q ( E ) (resp. C p q,b ( E ) ) will denote the space of functions from E to R p which are at least q times contin uously differentiable (resp. and b ounded with b ounded deriv atives). Whenev er E = [0 , T ] (resp. q = 0 or b is not sp ecified), we suppress the dep endence on E (resp. on q or b ), e.g. C p denotes the space of contin uous functions from [ 0 , T ] to R p . F or an y ( x, y ) ∈ C k × C k , we write ∥ x − y ∥ ∞ : = sup t ∈ [0 ,T ] ∥ x ( t ) − y ( t ) ∥ . F or any dimension k ∈ N ⋆ and radius R > 0 , we de note by ¯ B R the closed ball of radius R centred at the origin in R k . That is ¯ B R : = y ∈ R k : ∥ y ∥ ≤ R . Given ( x, ˜ x ) ∈ C p × C p and t ∈ [0 , T ] , we define their concatenation x ⊗ t ˜ x ∈ C p by ( x ⊗ t ˜ x )( r ) : = x ( r ) 1 { r ≤ t } + ( x ( t ) + ˜ x ( r ) − ˜ x ( t )) 1 { r ≥ t } , r ∈ [0 , T ] . F or φ ∈ C p q ( E ) with q ≥ 2 , ∂ 2 xx φ will denote its Hessian matrix. F or ( u, v ) ∈ R p × R p , u · v will denote their usual inner pro duct, and ∥ u ∥ the corresponding norm. F or p ositive integers m and n , we denote by M m,n ( R ) the space of m × n matrices with real en tries, and we simplify notations by setting M n ( R ) : = M n,n ( R ) . T r[ M ] denotes the trace of a matrix M ∈ M n ( R ) . F or (Ω , G ) a measurable space, Prob(Ω) denotes the collection of all probability measures on (Ω , G ) . F or P ∈ Prob(Ω) and a filtration G , G P : = ( G P t ) t ∈ [0 ,T ] , denotes the P -completion of G . W e recall that for any t ∈ [0 , T ] , G P t : = G t ∨ σ ( N P ) , where N P : = { N ⊆ Ω : ∃ B ∈ G , N ⊆ B , and P [ B ] = 0 } . G P + denotes the right limit of G P , i.e. G P t + : = T ε> 0 G P t + ε , t ∈ [0 , T ) , and G P T + : = G P T . F or ( s, t ) ∈ [0 , T ] 2 , with s ≤ t , T s,t ( F ) denotes the collection of [ s, t ] -v alued F –stopping times. 4 2 Time-inconsisten t sto chastic control W e fix tw o p ositiv e integers n and d , which represen t resp ectiv ely the dimension of the pro cess controlled b y the agent, and the dimension of the Bro wnian motion driving this controlled pro cess. W e fix a time horizon T > 0 , and consider the canonical space Ω : = C ([0 , T ] , R n ) , with canonical pro cess X , and whose generic elements we denote ω . W e let F b e the Borel σ -algebra on Ω (for the top ology of uniform conv ergence), and we denote by F X : = ( F X t ) t ∈ [0 ,T ] the natural filtration of X . W e let A b e a closed subset of R k for some p ositiv e integer k , where the controls will take v alues. Remark 2.1. Note that we do not assume that A is c omp act. This wil l al low the c ase tr e ate d in Section 4 to b e include d in our the ory. However, we wil l later assume that the Hamiltonian in ( 3.8 ) is attaine d, either due to c omp actness of A or c o er civity of the c o efficients. Remark 2.2. W e r estrict our attention to Euclide an action sp ac es primarily to facilitate the heuristic derivations in Section 3 , which r ely on differ entiation with r esp e ct to the c ontr ol variable. However, the rigor ous r esults of this p ap er ( sp e cific al ly the ne c essity and verific ation the or ems ) r ely solely on me asur able sele ction ar guments. Conse quently, our the ory extends str aightforwar d ly to the c ase wher e A is a close d subset of an arbitr ary Polish sp ac e. 2.1 Probabilistic setting W e will follow a similar setting to the one in Hernández and P ossamaï [ 21 ] restricting to a Marko vian framework, and working exclusiv ely under the weak formulation. W e fix a b ounded Borel measurable map σ : [0 , T ] × R n − → R n × d , an initial condition x 0 ∈ R n , and assume that there is a unique solution, denoted by P , to the martingale problem for whic h X is an ( F X , P ) – lo cal martingale, such that X 0 = x 0 with P -probability 1 , and d[ X ] t = σ ( t, X t ) σ ⊤ ( t, X t )d t , P –a.s.. Enlarging the original probabilit y space if necessary (see Stro ock and V aradhan [ 43 , Theorem 4.5.2]), we can find an R d -v alued Brownian motion W suc h that X t = x 0 + Z t 0 σ ( r , X r )d W r , t ∈ [0 , T ] . W e now let F : = ( F t ) t ∈ [0 ,T ] b e the P –augmentation of F X . W e recall that uniqueness of the solution to the martingale problem implies that the predictable martingale represen tation prop ert y holds for ( F , P ) -martingales, whic h can b e represented as sto c hastic integrals with resp ect to X (see Jaco d and Shiryaev [ 27 , Theorem I II.4.29]). W e also mention that the right- con tinuit y of F guaran tees that ( F , P ) satisfies the Blumenthal zero–one la w and, in particular, all F 0 -measurable random v ariables are deterministic. W e can then in tro duce our drift functional b : [0 , T ] × Ω × A − → R d , which is assumed to b e Borel-measurable with resp ect to all its arguments. Let us recall that for an y A -v alued, F -predictable pro cess α suc h that E P exp Z T 0 b ( r , X r , α r ) · d W r − 1 2 Z T 0 b ( r , X r , α r ) 2 d r < ∞ , (2.1) w e can define the probabilit y measure P α on (Ω , F T ) , whose density with resp ect to P is giv en by d P α d P : = exp Z T 0 b ( r , X r , α r ) · d W r − 1 2 Z T 0 b ( r , X r , α r ) 2 d r . Moreo ver, by Girsanov’s theorem, the pro cess W α : = W − R · 0 b ( r , X r , α r )d r is an R d -v alued, ( F , P α ) –Bro wnian motion and we ha ve X t = x 0 + Z t 0 σ ( r , X r ) b ( r , X r , α r )d r + Z t 0 σ ( r , X r )d W α r , t ∈ [0 , T ] , P –a.s. W e define A to b e the set of all contin uous pro cesses such that condition ( 2.1 ) holds. Let us emphasise that w e are working under the so-called w eak formulation of the problem. This means that the state process X is fixed and, in con trast to the t ypical strong formulation, the Brownian motion, and the probability measure are not fixed. Indeed, the c hoice of α corresp onds to the c hoice of probability measure P α and th us impacts the distribution of pro cess X . Let us no w recall the celebrated result on the existence of a w ell-b eha ved ω -by- ω versions of the conditional exp ectation. W e also introduce the concatenation of a measure and a sto c hastic kernel. Recall Ω is a Polish space and F is a countably generated σ -algebra. F or P ∈ Prob(Ω) and τ ∈ T 0 ,T ( F ) , F τ is also countably generated, so there exists an asso ciated regular conditional probabilit y distribution (r.c.p.d. for short) ( P τ x ) x ∈ Ω , see Stro o c k and V aradhan [ 43 , Theorem 1.3.4], satisfying ( i ) for every x ∈ Ω , P τ x is a probability measure on (Ω , F ) ; 5 ( ii ) for every E ∈ F , the mapping x 7− → P τ x [ E ] is F τ -measurable; ( iii ) the family ( P τ x ) x ∈ Ω is a version of the conditional probabilit y measure of P given F τ , that is to say that for every P -in tegrable, F -measurable random v ariable ξ , we hav e E P [ ξ |F τ ]( x ) = E P τ x [ ξ ] , for P – a.e. x ∈ Ω ; ( iv ) for ev ery x ∈ Ω , P τ x [Ω x τ ] = 1 , where Ω x τ : = { x ′ ∈ Ω : x ′ ( r ) = x ( r ) , 0 ≤ r ≤ τ ( x ) } . Moreo ver, for P ∈ Prob(Ω) and an F τ -measurable sto chastic kernel ( Q τ x ) x ∈ Ω suc h that Q τ x [Ω x τ ] = 1 , for ev ery x ∈ Ω , the concatenated probabilit y measure is defined by P ⊗ τ Q · [ A ] : = Z Ω P (d x ) Z Ω 1 A ( x ⊗ τ ( x ) ˜ x ) Q x (d ˜ x ) , ∀ A ∈ F . (2.2) The follo wing result, see [ 43 , Theorem 6.1.2], gives a rigorous c haracterisation of the concatenation pro cedure. Theorem 2.3 (Concatenated measure) . Consider a sto chastic kernel ( Q ω ) ω ∈ Ω , and let τ ∈ T 0 ,T ( F ) . Supp ose the map ω 7− → Q ω is F τ -me asur able and Q ω [Ω ω τ ] = 1 for al l ω ∈ Ω . Given P ∈ Prob(Ω) , ther e is a unique pr ob ability me asur e P ⊗ τ ( · ) Q · on (Ω , F ) such that P ⊗ τ ( · ) Q · e quals P on (Ω , F τ ) and ( δ ω ⊗ τ ( ω ) Q ω ) ω ∈ Ω is an r.c.p.d . of P ⊗ τ ( · ) Q · |F τ . F or some t ∈ [0 , T ] , supp ose that τ ≥ t , that M : [ t, T ] × Ω − → R is a right-c ontinuous, F –pr o gr essively me asur able function after t , such that M t is P ⊗ τ ( · ) Q · -inte gr able, that for al l r ∈ [ t, T ] , ( M r ∧ τ ) r ∈ [ t,T ] is an ( F , P ) -martingale, and that ( M r − M r ∧ τ ( ω ) ) r ∈ [ t,T ] is an ( F , Q ω ) -martingale, for al l ω ∈ Ω . Then ( M r ) r ∈ [ t,T ] is an ( F , P ⊗ τ ( · ) Q · ) -martingale. In particular, for an F -measurable function ξ , E P ⊗ τ P τ · [ ξ ] = E P [ E P [ ξ |F τ ]] = E P [ ξ ] . This is the classical to wer property . A dditionally , the rev erse implication in the last statement in Theorem 2.3 holds b y [ 43 , Theorem 1.2.10]. In particular, the exp osition ab o ve means that we can ensure the existence of probabilit y measures indexed by ( t, x, α ) ∈ [0 , T ] × R n × A under which the state pro cess satisfies, for s ∈ [ t, T ] X s = x + Z s t σ ( r , X r ) b ( r , X r , α r )d r + Z s t σ ( r , X r )d W α r , t ∈ [0 , T ] , P t,x,α –a.s. , where W α is a Brownian motion with resp ect to P t,x,α : = ( P α ) t x . 2.2 T arget functional Let us introduce the running and terminal pay off functionals J ( t, x, α ) : = E P t , x , α Z T t f ( s, x, X s , α s )d s + ξ ( x, X T ) , (2.3) where f : [0 , T ] × R n × R n × A − → R and ξ : R n × R n − → R are Borel-measurable functions. W e will refer to f as the running pa yoff function and ξ as the terminal pa yoff function. W e will sometimes refer to a more generic pa yoff functional of the form J ( t, x, y , α ) : = E P t , x , α Z T t f ( s, y , X s , α s )d s + ξ ( y , X T ) , ( t, x, α ) ∈ [0 , T ] × R n × A . Note that we ha ve that J ( t, x, x, α ) = J ( t, x, α ) , justifying our nomenclature. As in tro duced earlier, we remark that the app earance of x in b oth functions in the rew ard functional creates the time-inconsistency . The goal of the controller will b e, roughly sp eaking, to choose α to maximise ( 2.3 ). How ever, since their preferences c hange ov er time, it is not clear what we mean mathematically b y this. In the next subsection, we in tro duce the precise notion of controls that we will b e interested in. 2.3 Game formulation W e recall that a strategy profile is sub-game p erfe ct if it prescrib es a Nash equilibrium in any sub-game. In our framework, ev ery play er together with a past tra jectory define a new sub-game. This motiv ates the idea b ehind the definition of an equilibrium mo del, see among others Björk and Murgo ci [ 4 ], Ekeland and Lazrak [ 12 ] and Strotz [ 44 ]. The intuition b ehind this consideration is that at each p oin t in time a differen t play er stands (which can b e though t of different versions of one-self ), and w e intuitiv ely try to achiev e a sub-game p erfect strategy . Let α ∈ A be an action, ( t, x ) ∈ [0 , T ] × R n an arbitrary initial condition, and ℓ ∈ (0 , T − t ] . W e recall that α ⊗ τ α ⋆ : = α 1 [ t,τ ) + α ⋆ 1 [ τ ,T ] . 6 Definition 2.4 ( Equilibrium c ontr ol ) . L et α ⋆ ∈ A b e an admissible c ontr ol. W e say that α ⋆ is an e quilibrium c ontr ol, if for any ε > 0 , we have that ℓ ε > 0 , wher e ℓ ε := inf ℓ > 0 : ∃ α ∈ A , P [ {∃ t ∈ [0 , T ] , J ( t, X t , α ⋆ ) < J ( t, X t , α ⊗ ℓ α ⋆ ) − εℓ } ] > 0 . In this c ase, we write α ⋆ ∈ E . Remark 2.5. W e c an show that one c an r e c over the essenc e of the classic al definition in [ 5 ] in the fol lowing sense: assume that α ⋆ is an e quilibrium c ontr ol as in the pr evious definition, and let ε > 0 . Then, ther e exists some ℓ ε > 0 and a set ˜ Ω with P [ ˜ Ω] = 1 with J ( t, X t , α ⋆ ) − J ( t, X t , α ⊗ ℓ α ⋆ ) ≥ − εℓ, ∀ ( ℓ, X t , α ) ∈ (0 , ℓ ε ) × ˜ Ω × A. Now, as ε was arbitr ary, we c an take a se quenc e ε n = 1 /n , n ∈ N ⋆ , with their c orr esp onding sets ˜ Ω n , and on Ω ⋆ : = T n ∈ N ⋆ ˜ Ω n we have that lim inf ℓ ↓ 0 J ( t, X t , α ⋆ ) − J ( t, X t , α ⊗ ℓ α ⋆ ) ℓ ≥ 0 . In the rest of the do cumen t w e fix some ( t, x ) ∈ [0 , T ] × R n and study the problem v ( t, x ) : = J ( t, x, α ⋆ ) , ( t, x ) ∈ [0 , T ] × R n , α ⋆ ∈ E . (P) Thanks to the weak uniqueness assumption, v is w ell-defined for all ( t, x ) ∈ [0 , T ] × R n and Borel-measurable. Remark 2.6. ( P ) is fundamental ly differ ent fr om the pr oblem of maximising A ∋ α 7− → J ( t, x, α ) . In ( P ) , one finds α ⋆ ∈ A first and then defines the value function. This c ontr asts with the classic al formulation of optimal c ontr ol pr oblems. Se c ond, the pr evious maximisation wil l find player t ’s so-c al le d pr e-c ommitte d str ate gy. 2.4 F unctional spaces In this section, we introduce the spaces of pro cesses that w e will b e using throughout this pap er. W e first recall the standard spaces of square-integrable pro cesses • S 2 ( R n , F , P ) : the space of F –progressively measurable, càdlàg pro cesses Y taking v alues in R n suc h that ∥ Y ∥ 2 S 2 ( R n , F , P ) : = E P sup t ∈ [0 ,T ] ∥ Y t ∥ 2 < ∞ . • H 2 ( R d , F , P ) : the space of F -predictable pro cesses Z taking v alues in R d suc h that ∥ Z ∥ 2 H 2 ( R d , F , P ) : = E P Z T 0 ∥ Z t ∥ 2 d t < ∞ . F or the deriv ativ e processes, which dep end on the parameter y ∈ R n , w e require well-posedness uniform on compact sets. T ow ard this purp ose, w e introduce the spaces of lo cally square-in tegrable random fields. Definition 2.7 (Lo cally uniform random fields) . L et U = ( U y ) y ∈ R n and V = ( V y ) y ∈ R n b e two families of sto chastic pr o c esses indexe d by y . • W e say U ∈ S 2 loc ( R n , F , P ) if the map y 7− → U y is c ontinuous fr om R n to S 2 ( R n , F , P ) , and b ounde d on c omp act sets. That is, for any c omp act set K ⊂ R n sup y ∈ K ∥U y ∥ S 2 ( R n , F , P ) < ∞ . • W e say V ∈ H 2 loc ( R d , F , P ) if the map y 7− → V y is c ontinuous fr om R d to H 2 ( R d , F , P ) , and for any c omp act set K ⊂ R d sup y ∈ K ∥V y ∥ H 2 ( R d , F , P ) < ∞ . The sp ac es ar e e quipp e d with the top olo gy induc e d by the family of semi-norms { sup y ∈ ¯ B R ∥ · ∥} R> 0 . 7 2.4.1 A uxiliary w eighted functional spaces and norms T o carry out the pro of of well-posedness, we introduce the sp ecific p olynomial weigh t function ρ : R n − → R + defined b y ρ ( y ) : = (1 + ∥ y ∥ 2 ) − k , where k ≥ 1 is a fixed integer chosen sufficiently large relative to the growth rate m app earing in Assumption 3.11 . Sp ecifically , w e require 2 k ≥ m , as w e will see later. Remark 2.8 (General growth conditions) . The choic e of the weight function ρ has b e en made for pr esentation purp oses and to dir e ctly enc omp ass the LQR example that we wil l pr esent in Section 4 . Se e also Remark 3.13 . F or any β > 0 and dimension d ∈ N ⋆ , w e define the follo wing Banach spaces for processes on [0 , T ] . • H 2 β ( R d , F , P ) is the space of R d -v alued, F -predictable pro cesses Z suc h that ∥ Z ∥ 2 H 2 β ( R d , F , P ) : = E P Z T 0 e β t ∥ Z t ∥ 2 d t < ∞ . • S 2 β ( R d , F , P ) is the space of R d -v alued, F -optional càdlàg pro cesses Y such that ∥ Y ∥ 2 S 2 β ( R d , F , P ) : = E P sup t ∈ [0 ,T ] e β t ∥ Y t ∥ 2 < ∞ . Note that the norms are equiv alen t for all v alues of β since [0 , T ] is compact. Let U = ( U y t ) y ∈ R n b e a random field where, for eac h y , U y is a pro cess. W e define the weigh ted spaces: • S 2 , 2 β ,ρ ( R d , F , P ) is the space of random fields U suc h that U y ∈ S 2 β ( R d , F , P ) for all y , the map y 7− → U y is contin uous from R n to S 2 β ( R d , F , P ) , and ∥ U ∥ 2 S 2 , 2 β,ρ ( R d , F , P ) : = sup y ∈ R n n ρ ( y ) ∥ U y ∥ 2 S 2 β ( R d , F , P ) o < ∞ . • H 2 , 2 β ,ρ ( R d , F , P ) is the space of random fields V such that V y ∈ H 2 β ( R d , F , P ) for all y , the map y 7− → V y is contin uous from R n to H 2 β ( R d ) , and ∥ V ∥ 2 H 2 , 2 β,ρ ( R d , F , P ) : = sup y ∈ R n n ρ ( y ) ∥ V y ∥ 2 H 2 β ( R d , F , P ) o < ∞ . W e define the global pro duct space K n,d β for the tuple ( Y , Z , ∂ Y , ∂ Z, ∂ ∂ Y , ∂ ∂ Z ) , which will solve the BSDE system ( 3.7 ), to b e introduced in Section 3 : K n,d β ( F , P ) : = S 2 β ( R , F , P ) × H 2 β ( R d , F , P ) | {z } V alue proce ss ( Y ,Z ) × S 2 , 2 β ,ρ ( R n , F , P ) × H 2 , 2 β ,ρ ( R n × d , F , P ) | {z } Gradient process ( ∂ Y ,∂ Z ) × S 2 , 2 β ,ρ ( R n × n , F , P ) × H 2 , 2 β ,ρ ( R n × n × d , F , P ) | {z } Hessian pro cess ( ∂ ∂ Y ,∂ ∂ Z ) . (2.4) Prop osition 2.9 (Banach structure) . The sp ac e K n,d β ( F , P ) is a Banach sp ac e. Pr o of. The spaces S 2 β ( R , F , P ) and H 2 β ( R d , F , P ) are standard spaces of square-integrable pro cesses and are well-kno wn to b e Banac h spaces (actually Hilb ert spaces). The weigh ted spaces S 2 , 2 β ,ρ ( R n , F , P ) (resp. S 2 , 2 β ,ρ ( R n × n , F , P ) ) and H 2 , 2 β ,ρ ( R n × d , F , P ) (resp. H 2 , 2 β ,ρ ( R n × n × d , F , P ) ) are defined as spaces of contin uous functions y 7− → U y from R n (resp. R n × n ) into the Banach spaces S 2 β ( R n , F , P ) (resp. S 2 β ( R n × n , F , P ) ) and H 2 β ( R n × d , F , P ) (resp. H 2 β ( R n × n × d , F , P ) ), equipp ed with a supremum norm w eighted by ρ ( y ) 1 / 2 . Since ρ is strictly p ositiv e, these are weigh ted spaces of b ounded contin uous functions taking v alues in a Banach space. By standard functional analysis results, the space of b ounded contin uous functions from a top ological space in to a Banach space is itself a Banac h space under the suprem um norm. Since K β ( F , P ) is a finite Cartesian pro duct of Banach spaces, it is itself a Banac h space. T o further motiv ate these spaces at this point, let us present the follo wing lemma, that asserts that they hold Definition 2.7 . 8 Lemma 2.10 (Embedding of weigh ted spaces) . L et β > 0 and k ≥ 0 . L et U = ( U y ) y ∈ R n b e a r andom field b elonging to the weighte d sp ac e S 2 , 2 β ,ρ ( R n , F , P ) . Then, U b elongs to the lo c al ly uniform sp ac e S 2 loc ( R n , F , P ) . Similarly, H 2 , 2 β ,ρ ( R n , F , P ) ⊂ H 2 loc ( R n , F , P ) . Pr o of. Let U ∈ S 2 , 2 β ,ρ ( R n , F , P ) . By definition, there exists a constant C U < ∞ such that sup z ∈ R n ∥U z ∥ 2 S 2 β ( R n , F , P ) (1 + ∥ z ∥ 2 ) k = C U . (2.5) W e must show that for an y compact set K ⊂ R n , the standard S 2 ( R n , F , P ) norm is uniformly b ounded. Let K be an arbitrary compact subset of R n . Since K is b ounded, there exists a radius R > 0 suc h that ∥ y ∥ ≤ R for all y ∈ K . First, we relate the β -weigh ted time norm to the standard norm. Since t ∈ [0 , T ] , we hav e e β t ≥ 1 . Thus, for an y pro cess Y ∥ Y ∥ 2 S 2 ( R n , F , P ) = E P sup t ∈ [0 ,T ] ∥ Y t ∥ 2 ≤ E P sup t ∈ [0 ,T ] e β t ∥ Y t ∥ 2 = ∥ Y ∥ 2 S 2 β ( R n , F , P ) . Next, w e handle the parameter weigh t. F or any y ∈ K ∥U y ∥ 2 S 2 ( R n , F , P ) ≤ ∥U y ∥ 2 S 2 β ( R n , F , P ) = (1 + ∥ y ∥ 2 ) k ∥U y ∥ 2 S 2 β ( R n , F , P ) (1 + ∥ y ∥ 2 ) k ≤ (1 + R 2 ) k sup z ∈ R n ∥U z ∥ 2 S 2 β ( R n , F , P ) (1 + ∥ z ∥ 2 ) k = (1 + R 2 ) k C U . The righ t-hand side is a finite constant independent of y ∈ K . Th us, sup y ∈ K ∥U y ∥ S 2 ( R n , F , P ) < ∞ . Con tinuit y of y 7− → U y in the standard norm follows immediately from the contin uity in the weigh ted norm, as the weigh t function (1 + ∥ y ∥ 2 ) − k is smo oth and b ounded aw a y from zero on compacts. Therefore, U ∈ S 2 loc ( R n , F , P ) . The remaining result is prov ed in an analogous wa y . 3 Main results In this section, we present the core theoretical contributions of this pap er. W e characterise the equilibrium strategies for state-dep enden t time-inconsisten t control problems through a probabilistic approach. The roadmap will b e as follows: ( i ) we first pro vide an informal deriv ation of the system of backw ard sto chastic differen tial equations (BSDEs) that c har- acterises the equilibrium, building intuition from the extended HJB equation; ( ii ) we then establish an extended dynamic programming principle (DPP), which generalises the Bellman principle b y accoun ting for the c hanging preferences of the agen t; ( iii ) we deriv e the BSDE system (as a necessary condition for equilibria) and pro ve a verification theorem (the sufficiency coun terpart); ( iv ) w e prov e the well-posedness (existence and uniqueness) of this system. 3.1 An informal deriv ation of the BSDE system The purp ose of this section is to informally justify the BSDE system that will b e at the heart of this work. This deriv ation will be based on the extended HJB equation [ 8 , Definition 15.4], and th us we will remain in the Marko vian, feedback control (meaning we lo ok for an equilibrium con trol α ⋆ that is a deterministic feedbac k function of the time and state, i.e. , α ⋆ t = α ⋆ ( t, X t ) for some Borel-measurable map α ⋆ ), and we will use the w eak formulation all along. F or simplicity in this deriv ation, let n = d = 1 and let the dynamics of the state pro cess ( X t ) t ≥ 0 under P α b e given by X t = x 0 + Z t 0 σ ( r , X r ) b ( r , X r , α r )d r + Z t 0 σ ( r , X r )d W α r , t ∈ [0 , T ] . (3.1) Once again, the pay off functional is given by J ( t, x, α ) : = E P t , x , α Z T t f ( s, x, X s , α s )d s + ξ ( x, X T ) , ( t, x ) ∈ [0 , T ] × R . 9 F or a fixed control α ⋆ , w e let V ( t, x ) : = J ( t, x, α ⋆ ) denote the equilibrium v alue function and J ( t, x, y ) denote the auxiliary v alue function with fixed preference parameter y , defined as J ( t, x, y ) : = E P t , x , α ⋆ Z T t f ( s, y , X s , α ⋆ s )d s + ξ ( y , X T ) , ( t, x, y ) ∈ [0 , T ] × R × R . A ccording to the theory developed in Björk and Murgoci [ 5 ], the pair ( V , J ) must satisfy the extended HJB system, which w e present now particularised for our case. F or any ( t, x ) ∈ [0 , T ] × R n and action a ∈ A , we define the infinitesimal generator L a t acting on smo oth functions ϕ ∈ C 2 ( R n ) b y L a t ϕ ( x ) : = b ( t, x, a ) σ ( t, x ) ∇ x ϕ ( x ) + 1 2 T r σ ( t, x ) σ ( t, x ) ⊤ ∇ 2 xx ϕ ( x ) . F or ( t, x, y ) ∈ [0 , T ) × R × R , the system is ∂ t V ( t, x ) + sup a ∈ A n f ( t, x, x, a ) + b ( t, x, a ) σ ( t, x ) ∂ x V ( t, x ) − ∂ y J ( t, x, x ) o + 1 2 σ 2 ( t, x ) ∂ 2 xx V ( t, x ) − σ 2 ( t, x ) ∂ 2 xy J ( t, x, x ) − 1 2 σ 2 ( t, x ) ∂ 2 y y J ( t, x, x ) = 0 , ∂ t J ( t, x, y ) + L α ⋆ ( t,x ) t J ( t, x, y ) + f ( t, y , x, α ⋆ ( t, x )) = 0 , V ( T , x ) = ξ ( x, x ) , J ( T , x, y ) = ξ ( y , x ) . (3.2) The equilibrium con trol α ⋆ ( t, x ) is defined as the argumen t attaining the suprem um in the first equation. Note that in the second equation, the generator L α ⋆ ( t,x ) t acts on the v ariable x with y fixed. Note that the equilibrium control, which maximises the supremum in the first equation, appears in the second equation. Sim ultaneously , the function J ( t, x, y ) is part of the first equation. Hence, the system is very entangled and it is hard to determine its well-posedness using analytical tec hniques. Within the supremum in ( 3.2 ), the effectiv e gradient acting on the drift is not the standard ∂ x V , but the difference ∂ x V − ∂ y J . This sp ecific structure motiv ates the definition of our Hamiltonian b elow. The diffusion part includes the standard Hessian ∂ xx V corrected b y the mixed deriv ativ e σ 2 ∂ xy J and the parameter Hessian 1 2 σ 2 ∂ y y J . T o derive the BSDE system, w e differen tiate the second equation in ( 3.2 ) with resp ect to y to find the dynamics of the deriv ativ es J y ( t, x ) : = J ( t, x, y ) . F or ( t, x, y ) ∈ [0 , T ) × R × R ∂ t + L α ⋆ ( t,x ) t ∂ y J y ( t, x ) + ∂ y f ( t, y , x, α ⋆ ( t, x )) = 0 , ∂ t + L α ⋆ ( t,x ) t ∂ 2 y y J y ( t, x ) + ∂ 2 y y f ( t, y , x, α ⋆ ( t, x )) = 0 . (3.3) W e now define the sto chastic pro cesses corresp onding to these quantities along the equilibrium tra jectory X t Y t = V ( t, X t ) , Z t = σ ( t, X t ) ∂ x V ( t, X t ) , t ∈ [0 , T ] , ∂ Y y t = ∂ y J ( t, y , X t ) , ∂ Z y t = σ ( t, X t ) ∂ 2 xy J ( t, y , X t ) , t ∈ [0 , T ] , y ∈ R , ∂ ∂ Y y t = ∂ 2 y y J ( t, y , X t ) , ∂ ∂ Z y t = σ ( t, X t ) ∂ 3 xy y J ( t, y , X t ) , t ∈ [0 , T ] , y ∈ R . Applying Itô’s formula to Y t , the drift is given b y ( ∂ t + L α ⋆ ( t, X t ) ) V ( t, X t ) . By rearranging the first equation of the extended HJB system, we can express this op erator as ∂ t + L α ⋆ ( t,X t ) ) V ( t, X t ) = − f t, X t , X t , α ⋆ ( t, X t ) + b t, X t , α ⋆ ( t, X t ) σ ( t, X t ) ∂ y J ( t, X t , X t ) + σ ( t, X t ) ∂ 2 xy J ( t, X t , X t ) + 1 2 σ 2 ( t, X t ) ∂ 2 y y J ( t, X t , X t ) . Substituting the pro cess definitions ( e.g. , σ ∂ y J = σ ∂ Y X t ), the driver for Y t b ecomes f ( t, X t , X t , α ⋆ ( t, X t )) − b ( t, X t , α ⋆ ( t, X t ))( σ ( t, X t ) ∂ Y X t t ) − σ ( t, X t ) ∂ Z X t t − 1 2 σ 2 ( t, X t ) ∂ ∂ Y X t t . 10 W e define the extended Hamiltonian H to encapsulate the maximisation problem. F or argumen ts ( t, x, z , γ , η , ρ ) representing ( t, X t , Z t , ∂ Y t , ∂ ∂ Y t , ∂ Z t ) in R H ( t, x, z , γ , η , ρ ) : = sup a ∈ A f ( t, x, x, a ) + b ( t, x, a )( z − σ ( t, x ) γ ) − σ ( t, x ) ρ − 1 2 σ 2 ( t, x ) η . (3.4) W e assume, for simplicit y in this exp ository section, that there exists a unique A -v alued, Borel-measurable map V ⋆ satisfying the maximisation condition. The resulting BSDE system, under the reference measure P , is Y t = ξ ( X T , X T ) + Z T t H r , X r , Z r , ∂ Y X r r , ∂ ∂ Y X r r , ∂ Z X r r d r − Z T t Z r d W r , t ∈ [0 , T ] , ∂ Y y t = ∂ y ξ ( y , X T ) + Z T t ∂ y f r , y , X r , α ⋆ r + ∂ Z y r b ( r , X r , α ⋆ r ) d r − Z T t ∂ Z y r d W r , t ∈ [0 , T ] , y ∈ R n , ∂ ∂ Y y t = ∂ 2 y y ξ ( y , X T ) + Z T t ∂ 2 y y f r , y , X r , α ⋆ r + ∂ ∂ Z y r b ( r , X r , α ⋆ r ) d r − Z T t ∂ ∂ Z y r d W r , t ∈ [0 , T ] , y ∈ R n . (3.5) One might ask why the system requires three equations ( including the Hessian ∂ ∂ Y ) when the original problem is characterised b y V and J . The reason lies in the second-order adjustment terms that appear in the equation for V . In the con text of BSDEs, the pro cess ∂ Z y carries the information of the mixed deriv ativ e ( sp ecifically σ ∂ 2 xy J ) . T o write our system, we need the dynamics of the gradien t ∂ Y y . How ev er, as seen in ( 3.3 ), the dynamics of the first deriv ative dep ends on the second deriv ativ es, such as ∂ 2 y y J . Therefore, to determine the evolution of the gradien t, we must simultaneously use the Hessian pro cess ∂ ∂ Y y . 3.2 Assumptions W e require the follo wing regularity assumptions for the v alidity of our main results. Assumption 3.1 (Regularity and gro wth of the co efficien ts) . W e assume the fol lowing c onditions on the pr oblem data ( i ) contin uit y: the functions b, σ, f , and ξ ar e c ontinuous in al l their ar guments ; ( ii ) regularity of the state dynamics: the drift b : [0 , T ] × R n × A → R d is Lipschitz-c ontinuous with r esp e ct to the state variable x , uniformly in ( t, a ) . That is, ther e exists K > 0 such that for al l t ∈ [0 , T ] , a ∈ A , and ( x, x ′ ) ∈ R n × R n ∥ b ( t, x, a ) − b ( t, x ′ , a ) ∥ ≤ K ∥ x − x ′ ∥ ; ( iii ) regularity and growth of the cost: for every fixe d ( t, x, a ) , the c ost functions y 7− → f ( t, x, y , a ) and y 7− → ξ ( y , x ) b elong to C 2 ( R n ) . Mor e over, the functions and their p artial derivatives satisfy a p olynomial gr owth c ondition. Ther e exist c onstants C > 0 and m ≥ 1 such that for al l ( t, x, y , a ) ∈ [0 , T ] × R n × R n × A | f ( t, x, y , a ) | + ∥∇ y f ( t, x, y , a ) ∥ + ∥∇ 2 y y f ( t, x, y , a ) ∥ + | ξ ( y , x ) | + ∥∇ y ξ ( y , x ) ∥ + ∥∇ 2 y y ξ ( y , x ) ∥ ≤ C 1 + ∥ x ∥ m + ∥ y ∥ m + ∥ a ∥ m ; ( iv ) in tegrability of the state: for any admissible c ontr ol α ∈ A and any p ≥ 1 , the c ontr ol le d state pr o c ess X admits finite moments of or der p , uniformly in time E P α sup t ∈ [0 ,T ] ∥ X t ∥ p < ∞ ; ( v ) non-degeneracy: the diffusion matrix σ : [0 , T ] × R n → R n × d is b ounde d and ful l r ank. The Lipschitz-con tin uity of the co efficients ensures that the state pro cess remains well-behav ed under reasonable con trols. W e formalise this in the following lemma, whic h justifies the in tegrability of the p olynomial costs. Lemma 3.2 (Momen t estimates for the state pro cess) . L et Assumption 3.1 . ( ii ) hold. L et α ∈ A b e an admissible c ontr ol such that the drift b α ( t, x ) : = b ( t, x, α t ) satisfies the line ar gr owth c ondition ∥ b α ( t, x ) ∥ ≤ C (1 + ∥ x ∥ ) , ∀ ( t, x ) ∈ [0 , T ] × R n . This holds, for instanc e, if α is b ounde d or is a line ar fe e db ack c ontr ol as in the LQR c ase. Then, for any p ≥ 1 , the state pr o c ess X admits finite moments of or der p under the c ontr ol le d me asur e P α , uniformly in time E P α sup t ∈ [0 ,T ] ∥ X t ∥ p < ∞ . Pr o of. This is a standard result in the theory of sto c hastic differen tial equations. Under the linear growth condition on the drift b α and the diffusion σ (implied by Assumption 3.1 . ( ii ) ), the existence of moments of all orders follows from standard estimates, suc h as those in [ 29 , Theorem 5.2.2.9]. 11 3.3 The extended dynamic programming principle As with all time-inconsistent problems, the classical Bellman principle fails b ecause the cost functional changes with the state as time adv ances. How ever, we manage to pro ve an equalit y w e call extended dynamic programming principle that resem bles a classical DPP , and in fact implies it in the absence of x in the rew ard functional. Theorem 3.3 (Extended dynamic programming principle) . L et Assumption 3.1 hold and let α ⋆ ∈ E b e an e quilibrium c ontr ol. Then, for any t ∈ [0 , T ] , for al l s ∈ [0 , t ] and x ∈ R n , we have v ( s, x ) = sup α ∈A E P s , x , α " v ( t, X t ) + Z t s f ( r, X r , X r , α r ) − b ( r , X r , α r ) · σ ( r , X r ) ⊤ E P r , X r , α ⋆ ∇ y ξ ( X r , X T ) + Z T r ∇ y f u, X r , X u , α ⋆ u d u − T r " σ ( r , X r ) σ ( r , X r ) ⊤ E P r , X r , α ⋆ ∇ 2 y x ξ ( X r , X T ) + Z T r ∇ 2 y x f u, X r , X u , α ⋆ u d u # − 1 2 T r " σ ( r , X r ) σ ( r , X r ) ⊤ E P r , X r , α ⋆ ∇ 2 y y ξ ( X r , X T ) + Z T r ∇ 2 y y f u, X r , X u , α ⋆ u d u #! d r # . (3.6) F urthermor e, the e quilibrium c ontr ol α ⋆ attains the supr emum in ( 3.6 ) . The three last rows represent the cost of time-inconsistency: the drift in v alue caused solely by the up dating of preferences along the path. This result is the main building blo c k for the rest of the theory developed in this pap er. See Section A for the proof. 3.4 A necessity result W e recall that, for a fixed equilibrium con trol α ⋆ , w e will v ery often use the follo wing notation J ( t, x, y ) : = E P t , x , α ⋆ Z T t f ( u, y , X u , α ⋆ u )d u + ξ ( y , X T ) , t ∈ [0 , T ] , y ∈ R n . In other words, J ( t, x, y ) represents the pa yoff under the equilibrium control if we were to freeze the parameter y . The next theorem guaran tees that smo oth equilibrium controls implicitly define solutions to ( 3.7 ). Using the extended DPP , we can formally characterise the equilibrium via the system of BSDEs ( 3.7 ). W e identify the scalar v alue pro cess Y t = v ( t, X t ) , the gradien t vector pro cess ∂ Y y t = ∂ y J ( t, X t , y ) , and the Hessian matrix pro cess ∂ ∂ Y y t = ∂ 2 y y J ( t, X t , y ) . Y t = ξ ( X T , X T ) + Z T t H r , X r , Z r , ∂ Y X r r , ∂ ∂ Y X r r , ∂ Z X r r d r − Z T t Z r d W r , t ∈ [0 , T ] . ∂ Y y t = ∇ y ξ ( y , X T ) + Z T t ∇ y f ( r, y, X r , α ⋆ r ) + ∂ Z y r b ( r , X r , α ⋆ r ) d r − Z T t ∂ Z y r d W r , t ∈ [0 , T ] , y ∈ R n , ∂ ∂ Y y t = ∇ 2 y y ξ ( y , X T ) + Z T t ∇ 2 y y f ( r, y, X r , α ⋆ r ) + ∂ ∂ Z y r b ( r , X r , α ⋆ r ) d r − Z T t ∂ ∂ Z y r d W r , t ∈ [0 , T ] , y ∈ R n . (3.7) Here, the extended Hamiltonian H is defined to match the v ariables introduced in the informal deriv ation. F or a state x ∈ R n , it takes as arguments the co-state z ∈ R d , the parameter gradient γ ∈ R n , the parameter Hessian η ∈ M n ( R ) , and the mixed consistency term ρ ∈ M n,d ( R ) H ( t, x, z , γ , η , ρ ) : = sup a ∈ A f ( t, x, x, a ) + b ( t, x, a ) · ( z − σ ( t, x ) ⊤ γ ) − 1 2 T r σ ( t, x ) σ ( t, x ) ⊤ η − T r σ ( t, x ) ρ ⊤ . (3.8) Remark 3.4 (Dimensionalit y of the adjoint processes) . L et us clarify the dimensions of the pr o c esses app e aring in the system ( 3.7 ) . L et us r e c al l that the state pr o c ess X takes values in R n and the Br ownian motion W in R d . • V alue pro cess: Y is sc alar-value d in R . Its volatility Z takes values in R d . 12 • Gradient pro cess: ∂ Y takes values in R n (r epr esenting ∇ y J ). Its volatility ∂ Z is define d as a matrix in R n × d . This sp e cific dimension is r e quir e d by the Hamiltonian term T r[ σρ ] in ( 3.8 ) . Sinc e σ ∈ R n × d , the variable ρ ( identifie d with ∂ Z ) must b e in R n × d for the pr o duct σ ρ ⊤ to b e a squar e matrix in R n × n . • Hessian pro cess: ∂ ∂ Y takes values in R n × n ( r epr esenting ∇ 2 y y J ) . Conse quently, its volatility ∂ ∂ Z is a r ank-3 tensor in R n × n × d , r epr esenting the sensitivity of e ach entry of the Hessian matrix to the d c omp onents of the Br ownian motion. Remark 3.5 (Consistency with the classical theory) . The Hamiltonian define d in ( 3.8 ) includes the terms involving γ , η , and ρ , which differ fr om the standar d Hamiltonian in time-c onsistent sto chastic c ontr ol. These terms r epr esent the inconsistency adjustmen t . Inde e d, c onsider a standar d time-c onsistent pr oblem wher e the c ost functions f and ξ do not dep end on the p ar ameter y . In this c ase, the auxiliary value function J ( t, x, y ) is indep endent of y , implying that the derivatives ∇ y J , ∇ 2 y y J , and ∇ 2 xy J vanish. Conse quently, the inputs γ , η , and ρ ar e zer o, and the Hamiltonian r e duc es to H ( t, x, z , 0 , 0 , 0) = sup a ∈ A f ( t, x, a ) + b ( t, x, a ) · z . Thus, we r e c over the standar d Hamiltonian fr om the classic al sto chastic c ontr ol the ory. Let us define what we mean b y the solution to suc h a system. Definition 3.6. W e say that ( Y , Z, ∂ Y , ∂ Z , ∂ ∂ Y , ∂ ∂ Z ) is a solution to the system ( 3.7 ) if ( i ) the system of e quations ( 3.7 ) holds P –a.s. ; ( ii ) the value pr o c ess and its c ontr ol satisfy the standar d inte gr ability Y ∈ S 2 ( R , F , P ) , Z ∈ H 2 ( R d , F , P ); ( iii ) the derivative r andom fields b elong to the lo c al ly uniform sp ac es. That is, for any ψ ∈ { ∂ Y , ∂ ∂ Y } and ϕ ∈ { ∂ Z , ∂ ∂ Z } ψ ∈ S 2 loc ( R k 1 , F , P ) , ϕ ∈ H 2 loc ( R k 2 , F , P ) , wher e k 1 and k 2 r epr esent the right dimensions of the derivative r andom fields. In other words, we ask the pro cesses to b e in the classical spaces for the solution of BSDEs, but we additionally ask that the norms of the families indexed by the parameter y are uniformly b ounded in the sense of the norm of con vergence ov er compact subsets. Compared with the definition of solution given in Hernández and Possamaï [ 21 ], where the space in whic h the uni-parametric family to ok v alues was already compact, we need to consider a w eaker norm. Theorem 3.7 (Necessity) . L et Assumption 3.1 hold and let α ⋆ ∈ A b e an e quilibrium c ontr ol in the sense of Definition 2.4 . A ssume that the e quilibrium value function V ( t, x ) : = J ( t, x, α ⋆ ) b elongs to C 1 , 2 ([0 , T ) × R n ) ∩ C 0 ([0 , T ] × R n ) and the p ar ametric function J ( t, x, y ) : = E P t , x , α ⋆ Z T t f ( s, y , X s , α ⋆ s )d s + ξ ( y , X T ) , b elongs to C 1 , 2 , 2 ([0 , T ) × R n × R n ) ∩ C 0 ([0 , T ] × R n × R n ) . Then, the pr o c esses ( Y , Z, ∂ Y , ∂ Z , ∂ ∂ Y , ∂ ∂ Z ) define d by Y t : = V ( t, X t ) , Z t : = ∇ x V ( t, X t ) σ ( t, X t ) , t ∈ [0 , T ] , ∂ Y y t : = ∇ y J ( t, X t , y ) , ∂ Z y t : = ∇ 2 y x J ( t, X t , y ) σ ( t, X t ) , t ∈ [0 , T ] , y ∈ R n , ∂ ∂ Y y t : = ∇ 2 y y J ( t, X t , y ) , ∂ ∂ Z y t : = ∇ 3 xy y J ( t, X t , y ) σ ( t, X t ) , t ∈ [0 , T ] , y ∈ R n , pr ovide d they b elong to the suitable sp ac es state d in Definition 3.6 , solve the BSDE system ( 3.7 ) . F urthermor e, α ⋆ satisfies the optimality c ondition α ⋆ t ∈ argmax a ∈ A n f ( t, X t , X t , a ) + b ( t, X t , a ) · Z t − σ ( t, X t ) ⊤ ∂ Y X t t o , d t ⊗ P –a.e. (3.9) The proof can b e found in Section B . Remark 3.8 (Structure of the inconsistency adjustmen t) . In the optimality c ondition ab ove, it is imp ortant to note that the auxiliary function J ( t, x, y ) and the pr o c ess ∂ Y X t t ar e define d for a fixe d e quilibrium str ate gy α ⋆ . 13 3.5 V erification theorem W e now present the v erification theorem, whic h states that a solution to the deriv ed BSDE system, satisfying the Hamiltonian maximisation condition, yields an equilibrium con trol. Theorem 3.9 (V erification) . L et Assumption 3.1 hold. A ssume ther e exists a solution ( Y , Z , ∂ Y , ∂ Z , ∂ ∂ Y , ∂ ∂ Z ) to the system ( 3.7 ) in the sense of Definition 3.6 . Define the c andidate fe e db ack c ontr ol pr o c ess α ⋆ = ( α ⋆ t ) t ∈ [0 ,T ] by the c ondition that it maximises the extende d Hamiltonian α ⋆ t ∈ argmax a ∈ A f ( t, X t , X t , a ) + b ( t, X t , a ) · Z t − σ ( t, X t ) ⊤ ∂ Y X t t , d t ⊗ d P –a.e. (3.10) Supp ose further that ( i ) the c ontr ol pr o c ess α ⋆ is admissible, i.e. , α ⋆ ∈ A ; ( ii ) the function v ( t, x ) identifie d with Y via Y t = v ( t, X t ) b elongs to C 1 , 2 ([0 , T ) × R n ) ∩ C 0 ([0 , T ] × R n ) . Then, α ⋆ is an e quilibrium c ontr ol, and Y t is the asso ciate d value pr o c ess, i.e. , Y t = J ( t, X t , α ⋆ ) . The proof can b e found in Section C . Remark 3.10 (Existence of a measurable equilibrium feedback) . In the statement of Theorem 3.9 , we define d the c andidate c ontr ol α ⋆ via the maximisation of the Hamiltonian, assuming that an admissible, me asur able sele ction of the ar gmax exists. L et us briefly mention why assuming this is p erfe ctly r e asonable in our setting. Consider the set-value d map Φ : [0 , T ] × R n × R d × R n ⇒ A define d by the set of maximisers Φ( t, x, z , γ ) : = argmax a ∈ A f ( t, x, x, a ) + b ( t, x, a ) · ( z − σ ( t, x ) ⊤ γ ) . Under Assumption 3.1 , the c o efficients b, σ, and f ar e c ontinuous in al l ar guments. Conse quently, the function b eing maximise d is jointly c ontinuous in (( t, x, z , γ ) , a ) , which implies that the map Φ has a me asur able gr aph and takes close d values. Sinc e the action sp ac e A is a close d subset of a Polish sp ac e ( and assuming the maximum is attaine d, e.g. , if A is c omp act or under suitable c o er civity c onditions ) , the Kuratowski–R yll–Nardzewski selection theorem ( or r ather, a c or ol lary of it, se e, e.g. , [ 1 , Theorem 17.18] ) guar ante es the existenc e of a Bor el-me asur able function V ⋆ : [0 , T ] × R n × R d × R n − → A such that V ⋆ ( t, x, z , γ ) ∈ Φ( t, x, z , γ ) for al l inputs. Defining the pr o c ess α ⋆ t : = V ⋆ ( t, X t , Z t , ∂ Y X t t ) yields an F -pr e dictable c ontr ol c andidate. 3.6 W ell-posedness of the solution W e finish with a result guaran teeing existence of solutions in the sense of Definition 3.6 . W e first define the driver functions G 1 and G 2 corresp onding to the second and third equations of the system ( 3.7 ). W e denote the arguments by ( t, x, y , z , γ , v , v ) , where z represents the volatilit y of the v alue pro cess Z t , γ represents the inconsistency term ∂ Y X t t , and v , v represent the deriv ativ e volatilities ∂ Z y t and ∂ ∂ Z y t , respectively . G 1 ( t, x, y , z , γ , v ) : = ∇ y f ( t, y , x, α ⋆ ) + v b ( t, x, α ⋆ ) , G 2 ( t, x, y , z , γ , v ) : = ∇ 2 y y f ( t, y , x, α ⋆ ) + v b ( t, x, α ⋆ ) , where α ⋆ : = V ⋆ ( t, x, z , γ ) (see Remark 3.10 ). Assumption 3.11 (Drivers integrabilit y and regularity) . L et Θ : = ( z , u , v , v ) b e the ve ctor of inputs for the drivers ( r epr esenting the Z , ∂ Y , ∂ Z , and ∂ ∂ Z c omp onents r esp e ctively ) . W e assume ther e exist a c onstant C > 0 such that: ( i ) Regularity of the Hamiltonian driver H . The driver of the value pr o c ess satisfies a Lipschitz-c ontinuity c ondition. F or any t, x and inputs Θ , Θ ′ | H ( t, x, Θ) − H ( t, x, Θ ′ ) | ≤ C ∥ Θ − Θ ′ ∥ . ( ii ) Structure of the deriv ative drivers G ∈ { G 1 , G 2 } . The drivers for the gr adient and Hessian pr o c esses satisfy a Lipschitz- c ontinuity c ondition. F or any p ar ameter y and input ve ctor Θ | G ( t, x, y , Θ) − G ( t, x, y , Θ ′ ) | ≤ C ∥ Θ − Θ ′ ∥ . 14 ( iii ) Integrabilit y of source terms. The terminal c onditions and the drivers evaluate d at the nul l input ve ctor Θ 0 : = 0 satisfy the fol lowing inte gr ability r e quir ements • v alue process source: the diagonal terminal c ost and the b ase Hamiltonian ar e squar e-inte gr able E P ξ ( X T , X T ) 2 + Z T 0 H ( t, X t , Θ 0 ) 2 d t < ∞ ; • deriv ativ e fields source: the p ar ameter-dep endent sour c e terms have finite weighte d norms sup y ∈ R n ρ ( y ) E P ∇ y ξ ( y , X T ) 2 + ∇ 2 y y ξ ( y , X T ) 2 + Z T 0 2 X i =1 G i ( t, X t , y , Θ 0 ) 2 d t < ∞ . Note that the integrabilit y of the state pro cess X is already guaranteed by Assumption 3.1 . ( iv ) , whic h is essential to ensure that these p olynomial b ounds result in integrable random v ariables. Now we are able to state our uniqueness and existence result. Theorem 3.12 (W ell-p osedness) . Under Assumptions 3.1 and 3.11 , ther e exists a weighting p ar ameter β > 0 such that the BSDE system ( 3.7 ) admits a unique solution in the weighte d sp ac e K β . Conse quently, this solution also satisfies the c onditions of Definition 3.6 . W e remark that Assumption 3.11 imp oses strong Lipschitz-con tinuit y requirements, and that the inconsisten t linear–quadratic regulator is not cov ered b y our result. Our p oint here is to present a general w ell-p osedness result, and demonstrate the kind of tec hniques and spaces that are necessary to consider. W e b eliev e that a result where H , G 1 and G 2 ha ve a sto chastic Lipschitz co efficien t prop ortional to 1 + ∥ X t ∥ 2 + ∥ Z t ∥ (which is exactly what is required to cov er the linear–quadratic example) is ac hiev able and we leav e it as an open problem for future research. W e will conten t ourselv es here to mention that the literature on BSDEs whose generators hav e BMO Lipschitz-con tin uity constants, see Imkeller, Réveillac, and Rich ter [ 26 ], or quadratic BSVIEs, see Hernández [ 20 ], should be a go od starting p oin t. Remark 3.13 (Dep endency of the functional spaces on the driver’s growth) . The definition of the weighte d sp ac e K β involving the p olynomial weight ρ ( y ) : = (1 + ∥ y ∥ 2 ) − k is not intrinsic to the gener al the ory but is a sp e cific choic e made to ac c ommo date the p olynomial gr owth as the one we have on the LQR c ase. 4 An example: the linear–quadratic time-inconsisten t regulator After introducing all our results, we presen t a full study of a time-inconsistent problem whose inconsistency comes fully from the presence of the current state v ariable in the reward functional. 4.1 Problem setting W e consider the linear–quadratic regulator (LQR) problem with a state-dep enden t terminal cost, a classical example in the literature of time-inconsisten t control (see Björk, Khapko, and Murgo ci [ 8 ; 24 ]). F or simplicity , we tak e the dimension of the state process to b e n = d = 1 . The state pro cess X evolv es according to the linear dynamics d X t = ¯ aX t + ¯ bα t d t + σ d W t , X 0 = x 0 . (4.1) The ob jectiv e is to minimise the squared distance of the terminal state from the current state, p enalised by the control effort. Hence, the cost functional is giv en by J ( t, x, α ) : = E P t , x , α Z T t 1 2 α 2 s d s + Γ 2 ( X T − x ) 2 . (4.2) Here, w e iden tify f ( t, y , x, a ) = 1 2 a 2 and ξ ( y , x ) = Γ 2 ( x − y ) 2 . The app earance of the current state x in the terminal cost ξ creates the time-inconsistency . Example 4.1 (Motiv ation: the p olitical economy of debt managemen t) . Consider a government managing its national debt r atio X . The dynamics ar e governe d by the inter est r ate gap ¯ a ( gr owth r ate of debt ) and fisc al adjustments α ( surplus/deficit sp ending ) d X t = ¯ aX t + ¯ bα t d t + σ d W t . 15 The government aims at minimising the c ost of fisc al interventions (tax distortions), r epr esente d by 1 2 α 2 t . However, the terminal obje ctive exhibits r efer enc e p oint adaptation. A government at time t c ommits to bringing the debt X T close to their curr ent observe d level X t . They p enalise deviations fr om this inherite d b aseline r ather than an absolute historic al zer o J ( t, x, α ) = E P t , x , α Z T t 1 2 α 2 s d s + Γ 2 ( X T − x ) 2 . This cr e ates a time-inc onsistent pr efer enc e structur e: as the debt drifts, futur e administr ations c ontinuously r eset the tar get x to the new pr evailing debt level, le ading to the ‘ drifting go alp ost ’ phenomenon that we wil l analyze shortly. 4.2 Equilibrium controls represen tation F ollowing the general theory in Section 3 , the equilibrium v alue function and the asso ciated dual pro cesses are characterised b y the BSDE system ( 3.7 ). F or the LQR problem, this system corresp onds to, under P Y t = Z T t H r , X r , Z r , ∂ Y X r r , ∂ ∂ Y X r r , ∂ Z X r r d r − Z T t Z r · d W r , t ∈ [0 , T ] , ∂ Y y t = Γ( y − X T ) + Z T t ∂ Z y r σ − 1 (¯ aX r + ¯ bα ⋆ r )d r − Z T t ∂ Z y r · d W r , t ∈ [0 , T ] , ∂ ∂ Y y t = Γ , t ∈ [0 , T ] . (4.3) The extended Hamiltonian H corresponds to: H ( t, x, z , γ , η , ρ ) : = inf a ∈ R 1 2 a 2 + (¯ ax + ¯ ba ) σ − 1 z − ( ¯ ax + ¯ ba ) γ − 1 2 σ 2 η − σ ρ. The equilibrium control α ⋆ is the minimiser of this Hamiltonian. The first-order conditions yield a + ¯ bσ − 1 z − ¯ bγ = 0 ⇐ ⇒ a = − ¯ b ( σ − 1 z − γ ) . Remark 4.2 (Sign conv en tion) . The gener al the ory in Section 3 is formulate d as a maximisation pr oblem, with the agent se eking to maximise the functional J . The line ar–quadr atic example studie d in this se ction is inste ad a minimisation pr oblem: the agent incurs a quadr atic running c ost 1 2 α 2 and a quadr atic terminal p enalty Γ 2 ( X T − x ) 2 , b oth non-ne gative, and se eks to minimise their exp e cte d sum. T o emb e d this within the gener al fr amework it suffic es to r eplac e J by − J thr oughout, or e quivalently to r eplac e sup by inf in the Hamiltonian ( 3.8 ) and r everse the ine quality in the e quilibrium c ondition 2.4 . A l l structur al r esults—the extende d DPP , the BSDE char acterisation, the ne c essity and verific ation the or ems—c arry over verb atim under this sign change. In the notation of this se ction we, ther efor e , write the Hamiltonian as an infimum and identify f ( t, y , x, a ) = 1 2 a 2 and ξ ( y , x ) = Γ 2 ( x − y ) 2 . Remark 4.3 (V erification of assumptions) . The LQR pr oblem fits within the fr amework of Assumption 3.1 . Thus, Theo- rem 3.7 and Theorem 3.9 apply to this c ase. In p articular, al l e quilibria that satisfy the hyp otheses of Theorem 3.7 must satisfy the ab ove BSDE . The fact that Theorem 3.12 c annot b e use d her e simply pr events us fr om stating that the e quilibrium we ar e deriving b elow is unique. Substituting the BSDE v ariables Z t and ∂ Y X t t , w e obtain the feedbac k form α ⋆ t = ¯ b ∂ Y X t t − σ − 1 Z t . (4.4) T o explicitly solve this system, w e make use of Theorem 3.9 by lo oking for a decoupling field J ( t, x, y ) such that J ( t, X t , y ) = Y y t . This function m ust solve the following parametrised PDE ∂ t J + (¯ ax + ¯ bα ⋆ ) ∂ x J + 1 2 σ 2 ∂ xx J + 1 2 ( α ⋆ ) 2 = 0 , J ( T , x, y ) = Γ 2 ( x − y ) 2 . (4.5) Lemma 4.4 (Deriv ation of the Riccati system) . A ssume that the value function admits the quadr atic Ansatz J ( t, x, y ) = A ( t ) x 2 + B ( t ) y 2 + C ( t ) xy + D ( t ) x + F ( t ) y + H ( t ) . (4.6) Then, the e quilibrium c ontr ol is line ar in x α ⋆ ( t, x ) = − ¯ b (2 A ( t ) + C ( t )) x . (4.7) 16 The time-dep endent c o efficients satisfy the fol lowing system of or dinary differ ential e quations A ′ + 2¯ aA − 2 ¯ b 2 A (2 A + C ) + 1 2 ¯ b 2 (2 A + C ) 2 = 0 , A ( T ) = Γ / 2 , C ′ + ¯ aC − ¯ b 2 C (2 A + C ) = 0 , C ( T ) = − Γ , H ′ − 1 2 ¯ b 2 D 2 + σ 2 A = 0 , H ( T ) = 0 , (4.8) with B ( t ) ≡ Γ / 2 , D ( t ) ≡ 0 and F ( t ) ≡ 0 . Pr o of. W e derive the system by substituting the A nsatz in to the equilibrium condition and the PDE. First, recall the identifica- tions from the Mark ovian setting: Z t = σ ∂ x V ( t, x ) and ∂ Y X t t = ∂ y J ( t, x, y ) | y = x , where V ( t, x ) = J ( t, x, x ) is the equilibrium v alue function. Using the A nsatz ( 4.6 ), the deriv atives are ∂ x J ( t, x, y ) = 2 A ( t ) x + C ( t ) y + D ( t ) , ∂ y J ( t, x, y ) = 2 B ( t ) y + C ( t ) x + F ( t ) . The equilibrium v alue function is V ( t, x ) = ( A + B + C ) x 2 + ( D + F ) x + H . Thus, ∂ x V ( t, x ) = 2( A + B + C ) x + ( D + F ) . Substituting these in to the control formula ( 4.4 ) (noting that σ − 1 Z t = ∂ x V ( t, x ) implies the term ¯ b ( ∂ Y − σ − 1 Z ) corresp onds to ¯ b ( ∂ y J − ∂ x V ) ): α ⋆ ( t, x ) = ¯ b 2 B x + C x + F − 2( A + B + C ) x + D + F = − ¯ b (2 A + C ) x + D . Let us define the feedback gains K ( t ) : = ¯ b (2 A ( t ) + C ( t )) and Λ( t ) : = ¯ bD ( t ) , so α ⋆ = − K x − Λ . Now, substitute J and α ⋆ in to the PDE ( 4.5 ). W e expand all terms fully ( A ′ x 2 + B ′ y 2 + C ′ xy + D ′ x + F ′ y + H ′ ) | {z } ∂ t J +(¯ ax − ¯ bK x − ¯ b Λ) (2 Ax + C y + D ) | {z } ∂ x J + 1 2 σ 2 (2 A ) | {z } ∂ xx J + 1 2 ( K 2 x 2 + 2 K Λ x + Λ 2 ) | {z } ( α ⋆ ) 2 = 0 . Matc hing co efficien ts for each monomial term • x 2 : A ′ + 2 A (¯ a − ¯ bK ) + 1 2 K 2 = 0 . Substituting K A ′ + 2¯ aA − 2 ¯ b 2 A (2 A + C ) + 1 2 ¯ b 2 (2 A + C ) 2 = 0 . • xy : C ′ + C (¯ a − ¯ bK ) = 0 = ⇒ C ′ + ¯ aC − ¯ b 2 C (2 A + C ) = 0 . • x : D ′ + D (¯ a − ¯ bK ) − 2 A ¯ b Λ + K Λ = 0 . Substituting Λ = ¯ bD D ′ + D (¯ a − ¯ bK ) − 2 A ¯ b 2 D + ¯ bK D = D ′ + ¯ aD − 2 ¯ b 2 AD = 0 . • y 2 : B ′ = 0 . Boundary condition B ( T ) = Γ / 2 = ⇒ B ( t ) ≡ Γ / 2 . • y : F ′ − C ¯ b Λ = 0 = ⇒ F ′ − ¯ b 2 C D = 0 . This implies F ′ = 0 = ⇒ F ( t ) ≡ 0 . • constant: H ′ − D ¯ b Λ + σ 2 A + 1 2 Λ 2 = 0 . Since D ≡ 0 = ⇒ Λ ≡ 0 , this simplifies to H ′ + σ 2 A = 0 . Finally , note that since D ( t ) ≡ 0 , the affine part of the con trol v anishes, and α ⋆ ( t, x ) = − K ( t ) x . 4.3 Comparison of strategies W e compare the performance of the sophisticated (equilibrium) agent against the naive agent. More precisely , we consider ( i ) e quilibrium str ate gy: defined b y α ⋆ ( t, x ) = − K eq ( t ) x , where K eq ( t ) = ¯ b (2 A ( t ) + C ( t )) is derived from Lemma 4.4 . ( ii ) naive str ate gy: the naive feedback law α naive ( t, x ) = − K naive ( t ) x is deriv ed b y solving a standard time-consistent LQR problem at each instant t , where the agent treats the current state as a fixed target y = X t for the remaining horizon [ t, T ] . 17 By p ostulating a quadratic v alue function V ( s, x ; y ) = P ( s ) x 2 + Q ( s ) xy + R ( s ) y 2 + M ( s ) x + N ( s ) y + L ( s ) , the HJB equation for a fixed parameter y yields the follo wing system for the principal co efficien ts P ′ ( t ) + 2 aP ( t ) − 2 b 2 P ( t ) 2 = 0 , P ( T ) = Γ / 2 , Q ′ ( t ) + ( a − 2 b 2 P ( t )) Q ( t ) = 0 , Q ( T ) = − Γ . Solving for Q ( t ) via an integrating factor and ev aluating the optimal control a ∗ = − b (2 P ( t ) x + Q ( t ) y ) on the diagonal where y = x leads directly to: K naive ( t ) = b 2 P ( t ) − Γ exp Z T t ( a − 2 b 2 P ( u )) du !! . (4.9) W e simulate the trajectories of the state pro cess X under b oth strategies using an Euler–Maruy ama discretisation. W e use the parameters T = 1 , ¯ a = 0 . 5 , ¯ b = 1 , σ = 0 . 5 , x 0 = 1 , and Γ = 5 . 0 . Figure 1: Comparison of state tra jectories (left) and control effort (right). The equilibrium strategy (blue) maintains the state slightly near the target x 0 = 1 . 0 with mo derate effort. The naive strategy (red dashed) applies more control initially . T o rigorously quantify the p erformance gap, we compute the exact exp ected time- 0 cost J (0 , x 0 ) for b oth strategies. Since b oth strategies are linear feedback laws of the form α ( t, x ) = − K ( t ) x , w e can derive the cost analytically . Prop osition 4.5 (Exact cost) . F or a line ar c ontr ol α t = − K ( t ) X t , the exp e cte d c ost is J (0 , x 0 , α ) = Z T 0 1 2 K ( t ) 2 S ( t )d t + Γ 2 S ( T ) − 2 x 0 m ( T ) + x 2 0 , (4.10) wher e m ( t ) = E P α [ X t ] and S ( t ) = E P α [ X 2 t ] ar e the first two moments of the state pr o c ess under the c ontr ol le d me asur e P α , satisfying the ODEs m ′ ( t ) = (¯ a − ¯ bK ( t )) m ( t ) , S ′ ( t ) = 2(¯ a − ¯ bK ( t )) S ( t ) + σ 2 , (4.11) with initial c onditions m (0) = x 0 , S (0) = x 2 0 . Pr o of. The state dynamics under the measure P α are given b y d X t = (¯ a − ¯ bK ( t )) X t d t + σ d W α t . T aking exp ectations yields the ODE for m ( t ) . Applying Itô’s formula to X 2 t giv es d( X 2 t ) = (2(¯ a − ¯ bK ) X 2 t + σ 2 )d t + 2 σ X t d W α t . T aking exp ectations under P α yields the ODE for S ( t ) . Substituting E P α [ α 2 t ] = K ( t ) 2 S ( t ) and expanding the terminal term yields the cost formula. The sensitivit y analysis in Figure 2 , computed using Prop osition 4.5 , confirms that the sophisticated strategy yields a strictly lo wer cost for all Γ > 0 , with the gap widening as Γ increases. This is coherent with the in tuition that the parameter Γ incen tivises co operation b et ween past and future v ersions of the con trollers by increasing the scale of the quadratic p enalt y . 18 Figure 2: Sensitivity analysis. The total exp ected cost J (0 , x 0 ) is plotted against the inconsistency parameter Γ . The equilibrium strategy consistently outp erforms the naiv e strategy as the p enalt y parameter increases. 5 Time-dep endency as a particular case of state-dep endence The primary fo cus of this pap er has b een the dep endence of preferences on the current state x . How ev er, the v ast ma jorit y of the literature on time-inconsistent control fo cuses on a different source of inconsistency: time-dep endent preferences. The canonical example is non-exp onen tial discoun ting ( e.g. , h yp erb olic or quasi-hyperb olic discoun ting), where the agen t’s v aluation of future rew ards dep ends on the sp ecific time t at whic h the v aluation is made. A natural question arises: is the theory dev elop ed here for state-dep enden t inconsistency compatible with the existing theory for time-dep endent inconsistency? In this section, we show that our result is, in fact, a strict generalisation of [ 21 ] in the Marko vian, uncontrolled volatilit y case. W e achiev e this by viewing the initial time t not as an indep enden t parameter, but as a comp onen t of the initial state vector. By augmen ting the state process, we can cov er the time-dep enden t problem p erfectly in our state-dep enden t framew ork. Remark 5.1. Note that the non-Markovian c ase is not fe asible in our setting, sinc e the pr esenc e of the curr ent state in the r ewar d functional c omp els us to lo ok for fe e db ack str ate gies that dep end on the curr ent state exclusively. However, we b elieve that the extension to c ontr ol le d volatility should b e p ossible, although te chnic al ly involve d. 5.1 General problem form ulation Let us consider a rew ard functional where the running cost f and the terminal cost ξ depend explicitly on the initialisation time t . W e define the cost functional for an agent initialised at time t with state x as ˜ J ( t, x, α ) : = E P t , x , α Z T t f ( s, t, X s , α s )d s + ξ ( t, X T ) . (5.1) Here, the distinction b et ween the v ariable t and the v ariable s is crucial • s ∈ [ t, T ] is the running time, representing the evolution of the system; • t ∈ [0 , T ] is the preference parameter, representing the current time from the p ersp ectiv e of the agent. F or example, in non-exp onen tial discoun ting, one might hav e f ( s, t, X s , α s ) = h ( s − t ) U ( X s , α s ) , where h ( · ) is the discount function. The inconsistency arises b ecause the discoun t factor h ( s − t ) c hanges as the initial time t mov es forw ard. 5.2 The augmented state technique T o apply the theory from Section 3 , we m ust recast the dep endence on the parameter t as a dep endence on a state v ariable. W e accomplish this b y introducing the augmen ted state pro cess. Let X b e a pro cess v alued in R n +1 defined for s ∈ [0 , T ] by X s : = s X s . 19 The dynamics of this augmented pro cess under the con trol α are given by d X s = 1 σ ( s, X s ) b ( s, X s , α s ) d s + 0 1 × d σ ( s, X s ) d W α s , initialised at X t = t x = : x . (5.2) W e can no w define the augmen ted cost functions ˜ f and ˜ ξ on the augmen ted space R n +1 × R n +1 (where the first co ordinate represen ts the time comp onen t) ˜ f s ( x , z , a ) : = f ( s, x 1 , z 2 : n +1 , a ) , ˜ ξ ( x , z ) : = ξ ( x 1 , z 2 : n +1 ) . Using this notation, the time-dep endent functional ( 5.1 ) can be rewritten exactly in the form of our state-dep enden t problem J ( x , α ) = E P x , α Z T t ˜ f s ( x , X s , α s )d s + ˜ ξ ( x , X T ) . (5.3) This reform ulation allows us to apply Theorem 3.9 directly . The parameter of the problem is no w the vector x = ( t, x ) . 5.3 Sanit y c hec k: reco v ering the non-exp onen tial discounting system W e now demonstrate that applying our general BSDE system to this augmen ted set-up recov ers the sp ecific system derived in [ 21 ] for the purely time-dep endent case. In the augmented framework, the equilibrium v alue function Y s is accompanied by a gradien t pro cess ∂ Y y . Since the parameter is y = ( t, x ) , this gradient decomp oses into tw o components: ∂ Y y s = ∂ Y ( t ) s ∂ Y ( x ) s ! . Here, ∂ Y ( t ) represen ts the sensitivit y of the v alue to the initial time (the time-inconsistency term), while ∂ Y ( x ) represen ts the sensitivit y to the initial state (the spatial inconsistency term). Assume the problem’s time inconsistency comes purely from the app earance of the present time (as in [ 21 ]). This means the preferences depend on t , but not on x as a parameter. In other w ords ∂ x f ( s, t, y , a ) = 0 , and ∂ x ξ ( t, y ) = 0 . Let us examine the BSDE for the gradient comp onen t (the second line of Condition ( 3.7 )) applied to our augmen ted set-up. ( i ) The sp atial c omp onent ( ∂ Y ( x ) ) : since the drivers ∂ x f and ∂ x ξ are zero, the BSDE for the spatial gradient ∂ Y ( x ) b ecomes a homogeneous linear BSDE with zero terminal condition. By uniqueness, ∂ Y ( x ) s ≡ 0 . This aligns with exp ectation: if preferences do not dep end on the initial state x , the inconsistency adjustment for x v anishes. ( ii ) The inc onsistency adjustment: Recall that in our general framework, the driver of the BSDE for Y contains the inconsis- tency adjustmen t term corresp onding to the op erator L α ⋆ ( y ) . F or the augmented state X , this is defined as: K s : = b X s ( X s , α ⋆ s ) · ∂ y J ( s, X s , X s ) + 1 2 T r Σ s ( X s )Σ s ( X s ) ⊤ ∂ 2 yy J ( s, X s , X s ) + T r Σ s ( X s )Σ s ( X s ) ⊤ ∂ 2 xy J ( s, X s , X s ) , where y = ( t, x ) denotes the preference parameter in the augmen ted set-up, and Σ s ( X s ) is the diffusion matrix of the augmen ted pro cess. W e compute these terms explicitly . The augmented state dynamics d X s = (1 , b ) ⊤ d s + (0 , σ ) ⊤ d W s imply that the co efficien ts are vectors and matrices in R n +1 b X = 1 σ ( s, X s ) b ( s, X s , α ⋆ s ) , Σ = 0 1 × d σ ( s, X s ) , ΣΣ ⊤ = 0 0 1 × n 0 n × 1 σ ( s, X s ) σ ( s, X s ) ⊤ . Since ∂ x J = 0 , the deriv ativ es with resp ect to y simplify . The Jacobian ∂ y J is ( ∂ t J , 0) ⊤ , and the Hessian matrices hav e zeros in all entries except p otentially the top-left (time-time), whic h do es not interact with the non-zero blo c k of ΣΣ ⊤ . Sp ecifically T r 0 0 0 σ 2 ∂ 2 tt J 0 0 0 = 0 . The mixed deriv ative term trace is similarly zero. Th us, the total inconsistency adjustmen t reduces to the drift term: K s = b X · ∂ y J = ∂ t J ( s, X s , X s ) . This confirms that the extra drift in the Hamiltonian is exactly the time-deriv ative of the v alue function with resp ect to the initial time. The BSDE for the time-deriv ative comp onen t ∂ Y ( t ) s is then obtained directly from our general system ( 3.7 ) d ∂ Y ( t ) s = − ∂ t f ( s, s, X s , α ⋆ s ) + Z s · b ( s, X s , α ⋆ s ) d s + Z s · d W s , ∂ Y ( t ) T = ∂ t ξ ( t, X T ) . (5.4) This reco vers the structure of the adjoint equation derived [ 21 ]. 20 References [1] C. D. Aliprantis and K. Border. Infinite dimensional analysis: a hitchhiker’s guide . Springer-V erlag Berlin Heidelb erg, third edition, 2006. [2] S. Basak and G. Chabakauri. Dynamic mean–v ariance asset allo cation. The R eview of Financial Studies , 23(8):2970–3016, 2010. [3] E. Ba yraktar, J. Zhang, and Z. Zhou. Equilibrium concepts for time-inconsisten t stopping problems in con tinuous time. Mathematic al Financ e , 31(1):508–530, 2021. [4] T. Björk and A. Murgo ci. A general theory of Marko vian time inconsisten t sto chastic control problems. T ec hnical rep ort, Sto c kholm Sc ho ol of Economics and Aarhus Unive rsity , 2010. [5] T. Björk and A. Murgo ci. A theory of Mark ovian time-inconsistent sto c hastic control in discrete time. Financ e and Sto chastics , 18(3):545–592, 2014. [6] T. Björk, A. Murgoci, and X. Y. Zhou. Mean–v ariance p ortfolio optimization with state-dep enden t risk a version. Math- ematic al Financ e , 24(1):1–24, 2014. [7] T. Björk, M. Khapk o, and A. Murgo ci. On time-inconsistent stochastic control in contin uous time. Financ e and Sto chas- tics , 21(2):331–360, 2017. [8] T. Björk, M. Khapko, and A. Murgo ci. Time-inc onsistent c ontr ol the ory with financ e applic ations . Springer finance. Springer Cham, 2021. [9] A. Bo dnariu, S. Christensen, and K. Lindensjö. Local time pushed mixed stopping and smo oth fit for time-inconsisten t stopping problems. A rXiv pr eprint arXiv:2206.15124 , 2022. [10] S. Christensen and K. Lindensjö. On finding equilibrium stopping times for time-inconsisten t Marko vian problems. SIAM Journal on Contr ol and Optimization , 56(6):4228–4255, 2018. [11] S. Christensen and K. Lindensjö. Time-inconsistent stopping, my opic adjustmen t and equilibrium stability: with a mean–v ariance application. Banach Center Public ations , 122:53–76, 2020. [12] I. Ek eland and A. Lazrak. Being serious ab out non-commitment: subgame perfect equilibrium in con tin uous time. T echnical rep ort, Universit y of British Columbia, 2006. [13] I. Ekeland and A. Lazrak. The golden rule when preferences are time inconsistent. Mathematics and Financial Ec onomics , 4(1):29–55, 2010. [14] I. Ekeland and T. A. Pirvu. In vestmen t and consumption without commitment. Mathematics and Financial Ec onomics , 2(1):57–86, 2008. [15] N. El Karoui, S. P eng, and M.-C. Quenez. Backw ard sto c hastic differential equations in finance. Mathematic al Financ e , 7(1):1–71, 1997. [16] W. H. Fleming and H. M. Soner. Contr ol le d Markov pr o c esses and visc osity solutions , volume 25 of Sto chastic mo del ling and applie d pr ob ability . Springer-V erlag New Y ork, second edition, 2006. [17] J.-W. Gu, S. Si, and H. Zheng. Constrained utility deviation-risk optimization and time-consistent HJB equation. SIAM Journal on Contr ol and Optimization , 58(2):866–894, 2020. [18] Y. Hamaguc hi. Extended backw ard stochastic Volterra integral equations and their applications to time-inconsistent sto c hastic recursiv e control problems. Mathematic al Contr ol and R elate d Fields , 11(2):433–478, 2021. [19] X. D. He and Z. Jiang. On the equilibrium strategies for time-inconsistent problems in con tinuous time. SIAM Journal on Contr ol and Optimization , 59(5):3860–3886, 2021. [20] C. Hernández. On quadratic m ultidimensional type-i BSVIEs, infinite families of BSDEs and their applications. Sto chastic Pr o c esses and their Applic ations , 162:249–298, 2023. [21] C. Hernández and D. Possamaï. Me, m yself and I: a general theory of non-Mark ovian time-inconsisten t sto c hastic control for sophisticated agents. The A nnals of A pplie d Pr ob ability , 33(2):1396–1458, 2023. 21 [22] C. Hernández and D. Possamaï. Time-inconsisten t contract theory . Mathematic al Financ e , 34(3):1022–1085, 2024. [23] Y. Hu, H. Jin, and X. Y. Zhou. Time-inconsisten t sto c hastic linear–quadratic con trol. SIAM Journal on Contr ol and Optimization , 50(3):1548–1572, 2012. [24] Y. Hu, H. Jin, and X. Y. Zhou. Time-inconsistent sto c hastic linear–quadratic control: c haracterization and uniqueness of equilibrium. SIAM Journal on Contr ol and Optimization , 55(2):1261–1279, 2017. [25] Y.-J. Huang and Z. Zhou. Strong and weak equilibria for time-inconsistent sto c hastic control in contin uous time. Math- ematics of Op er ations R ese ar ch , 46(2):428–451, 2021. [26] P . Imk eller, A. Réveillac, and A. Rich ter. Differentiabilit y of quadratic BSDEs generated by con tinuous martingales. The A nnals of A pplie d Pr ob ability , 22(1):285–336, 2012. [27] J. Jaco d and A. N. Shiryaev. Limit the or ems for sto chastic pr o c esses , v olume 288 of Grund lehr en der mathematischen Wissenschaften . Springer-V erlag Berlin Heidelb erg, 2003. [28] M. Jeanblanc, M. Y or, and M. Chesney . Mathematic al metho ds for financial markets . Springer finance. Springer London, 2009. [29] I. Karatzas and S. E. Shreve. Br ownian motion and sto chastic c alculus , volume 113 of Gr aduate texts in mathematics . Springer-V erlag New Y ork, second edition, 1998. [30] C. Karnam, J. Ma, and J. Zhang. Dynamic approaches for some time inconsistent problems. The A nnals of A pplie d Pr ob ability , 27(6):3435–3477, 2017. [31] H. Kunita. Some extensions of Itô’s formula. Séminair e de pr ob abilités de Str asb our g , XV:118–141, 1981. [32] D. Laibson. Golden eggs and hyperb olic discoun ting. The Quarterly Journal of Ec onomics , 112(2):443–477, 1997. [33] K. Lindensjö. A regular equilibrium solves the extended HJB system. Op er ations R ese ar ch L etters , 47(5):427–432, 2019. [34] E. Mastrogiacomo and M. T arsia. Subgame-p erfect equilibrium strategies for time-inconsistent recursiv e sto c hastic control problems. Journal of Mathematic al A nalysis and A pplic ations , 527(2):127425, 2023. [35] H. Mei and J. Y ong. Equilibrium strategies for time-inconsistent sto chastic switching systems. ESAIM: Contr ol, Opti- misation and Calculus of V ariations , 25(64):1–60, 2019. [36] T. O’Donogh ue and M. Rabin. Doing it no w or later. The A meric an Ec onomic R eview , 89(1):103–124, 1999. [37] É. P ardoux and P . E. Protter. Sto c hastic Volterra equations with anticipating co efficients. The A nnals of Pr ob ability , 18 (4):1635–1655, 1990. [38] B. Peleg and M. E. Y aari. On the existence of a consistent course of action when tastes are changing. The R eview of Ec onomic Studies , 40(3):391–401, 1973. [39] E. S. Phelps and R. A. Pollak. On second-b est national saving and game-equilibrium growth. The R eview of Ec onomic Studies , 35(2):185–199, 1968. [40] R. A. Pollak. Consisten t planning. The R eview of Ec onomic Studies , 35(2):201–208, 1968. [41] D. Possamaï and C. Rossato. V ariance strikes back: sub-game–perfect Nash equilibria in time-inconsisten t N -play er games, and their mean-field sequel. A rXiv pr eprint arXiv:2512.08745 , 2025. [42] C. S. Pun. Robust time-inconsisten t sto c hastic control problems. A utomatic a , 94:249–257, 2018. [43] D. W. Stro ock and S. R. S. V aradhan. Multidimensional diffusion pr o c esses , volume 233 of Grund lehr en der mathema- tischen Wissenschaften . Springer-V erlag Berlin Heidelb erg, 1997. [44] R. H. Strotz. Myopia and inconsistency in dynamic utility maximization. The R eview of Ec onomic Studies , 23(3):165–180, 1955. [45] H. W ang and J. Y ong. Time-inconsistent sto c hastic optimal con trol problems and bac kward sto c hastic Volterra in tegral equations. ESAIM: Contr ol, Optimisation and Calculus of V ariations , 27(22):1–40, 2021. 22 [46] T. W ang and H. Zheng. Closed-loop equilibrium strategies for general time-inconsistent optimal control problems. SIAM Journal on Contr ol and Optimization , 59(5):3152–3178, 2021. [47] Q. W ei, J. Y ong, and Z. Y u. Time-inconsistent recursive sto c hastic optimal control problems. SIAM Journal on Contr ol and Optimization , 55(6):4156–4201, 2017. [48] Y. Xu and S. Y ang. Dynamic programming principle for a con trolled FBSDE system and asso ciated extended HJB equation. A rXiv pr eprint arXiv:2203.14274 , 2022. [49] J. Y ong. Time-inconsisten t optimal control problems and the equilibrium HJB equation. Mathematic al Contr ol & R elate d Fields , 2(3):271–329, 2012. [50] J. Y ong and X. Y. Zhou. Sto chastic c ontr ols: Hamiltonian systems and HJB e quations , volume 43 of Sto chastic mo del ling and applie d pr ob ability . Springer-V erlag New Y ork, 1999. A Pro of of the extended dynamic programming principle In this section, we provide the detailed pro of of Theorem 3.3 . W e rely on the definition of equilibrium and the regularity of the v alue function with resp ect to the preference parameter. W e define the auxiliary v alue function Ψ( t, x ; y ) as the exp ected future rew ard from state x at time t under a fixed equilibrium strategy α ⋆ , ev aluated with the fixed preference parameter y Ψ( t, x ; y ) : = E P t , x , α ⋆ Z T t f ( u, y , X u , α ⋆ u )d u + ξ ( y , X T ) . (A.1) By definition, the equilibrium v alue function corresp onds to the diagonal restriction v ( t, x ) = Ψ( t, x ; x ) . W e assume throughout this section that the regularity conditions in Assumption 3.1 hold. Before we start, let us introduce a tec hnical lemma from the theory of sto chastic calculus that turns out to b e the crucial step in understanding the dynamic of the process that we are interested in. Lemma A.1 (Itô–Kunita–W entzell’s form ula) . L et f ( t, x ) b e a family of F -adapte d and me asur able sto chastic pr o c esses, c ontinuous in ( t, x ) ∈ ( R + × R d ) , P –a.s. satisfying ( i ) for e ach t ≥ 0 , R d ∋ x 7− → f ( t, x ) ∈ R is C 2 ; ( ii ) ther e is some m ∈ N ⋆ such that for e ach x ∈ R d , f ( t, x ) is a c ontinuous ( F , P ) –semi-martingale with d f ( t, x ) = m X j =1 f j t ( x )d M j t , wher e for any j ∈ { 1 , . . . , m } M j is a c ontinuous ( F , P ) –semi-martingale, and for any x ∈ R d , f j ( x ) is an F –adapte d and me asur able sto chastic pr o c esses c ontinuous in ( t, x ) , such that R d ∋ x 7− → f j ( x ) ∈ R is C 1 . L et X = ( X 1 , . . . , X d ) b e a c ontinuous ( F , P ) –semi-martingale. Then f ( t, X t ) = f (0 , X 0 ) + m X j =1 Z t 0 f j s ( X s )d M j s + d X i =1 Z t 0 ∂ x i f ( s, X s )d X i s + m X j =1 d X i =1 Z t 0 ∂ x i f j s ( X s )d[ X i , M j ] s + 1 2 d X j =1 d X i =1 Z t 0 ∂ 2 x i x j f ( s, X s )d[ X i , X j ] s . (A.2) Remark A.2. Note that, in p articular, the Itô–K unita–W entzel l’s formula says that, with the assumptions of the the or em, the c omp osition of an Itô pr o c ess and a one-p ar ametric family of Itô pr o c esses is again an Itô pr o c ess, which is not such a trivial statement. W e readily see that if the pro cess X is a constant x , we are left with the original decomp osition of the pro cess f ( t, x ) . This v ersion of the theorem w as obtained from Jeanblanc, Y or, and Chesney [ 28 , Theorem 1.5.3.2], and we present it here without pro of, referring to Kunita [ 31 , Theorem 1]. Let us mov e now to the pro of of the extended DPP . W e will divide most of the work in Lemmas C.1 , A.4 and A.5 . 23 Lemma A.3. L et ( t, x ) ∈ [0 , T ] × R n . L et τ ∈ T t,T b e an F –stopping time b ounde d by t + δ for some deterministic c onstant δ > 0 . F or any admissible c ontr ol α ∈ A ( t, x ) , the fol lowing ine quality holds v ( t, x ) ≥ E P t , x , α v ( τ , X τ ) + Z τ t f ( u, x, X u , α u )d u + Ψ( τ , X τ ; x ) − Ψ( τ , X τ ; X τ ) − r ( δ ) , (A.3) wher e r ( δ ) is a non-ne gative err or term satisfying the asymptotic pr op erty r ( δ ) = o ( δ ) as δ − → 0 . F urthermor e, if α = α ⋆ , the e quality holds with r ( δ ) ≡ 0 . Pr o of. W e b egin by constructing a sp ecific p erturbation of the equilibrium strategy . As usual, let ˆ α : = α ⊗ τ α ⋆ b e the concatenated con trol defined b y ˆ α s ( ω ) : = α s ( ω ) 1 [ t,τ ( ω )) ( s ) + α ⋆ s ( ω ) 1 [ τ ( ω ) ,T ] ( s ) . This strategy follows the arbitrary control α until the stopping time τ , and reverts to the equilibrium strategy α ⋆ thereafter. By Definition 2.4 , the strategy α ⋆ is optimal against lo cal deviations up to a first-order error. In other words, for small enough δ J ( t, x, α ⋆ ) ≥ J ( t, x, ˆ α ) − o ( δ ) . The left-hand side is, by the definition of the v alue function, exactly v ( t, x ) . W e now analyze the righ t-hand side, J ( t, x, ˆ α ) . By the definition of the cost functional, we hav e J ( t, x, ˆ α ) = E P t , x , α Z τ t f ( u, x, X u , α u )d u + Z T τ f ( u, x, X u , α ⋆ u )d u + ξ ( x, X T ) . Note that the probability measure P t,x,α go verns the dynamics in [ t, τ ] , while the dynamics in ( τ , T ] is go verned b y α ⋆ giv en the state in τ . W e apply the tow er prop ert y of conditional exp ectations, conditioning on the σ -algebra F τ J ( t, x, ˆ α ) = E P t , x , α " Z τ t f ( u, x, X u , α u )d u + E P t , x , ˆ α Z T τ f ( u, x, X u , α ⋆ u )d u + ξ ( x, X T ) F τ # . By the prop erties of the concatenated measure in tro duced in Theorem 2.3 , the conditional distribution of the pro cess after τ giv en F τ is precisely given by the kernel P τ ,X τ ,α ⋆ . Consequently , the inner conditional exp ectation satisfies E P t , x , ˆ α Z T τ f ( u, x, X u , α ⋆ u )d u + ξ ( x, X T ) F τ = E P τ , X τ , α ⋆ Z T τ f ( u, x, X u , α ⋆ u )d u + ξ ( x, X T ) . Comparing this to the definition in ( A.1 ), we identify the right-hand side precisely as the auxiliary v alue function Ψ( τ , X τ ; x ) . Substituting this back into the expansion of J , we obtain J ( t, x, ˆ α ) = E P t , x , α Z τ t f ( u, x, X u , α u )d u + Ψ( τ , X τ ; x ) . Using the initial inequality v ( t, x ) ≥ J ( t, x, ˆ α ) − o ( δ ) , w e hav e v ( t, x ) ≥ E P t , x , α Z τ t f ( u, x, X u , α u )d u + Ψ( τ , X τ ; x ) − o ( δ ) . Finally , we introduce the equilibrium v alue function at time τ . Recall that v ( τ , z ) = Ψ( τ , z ; z ) . W e add and subtract v ( τ , X τ ) = Ψ( τ , X τ ; X τ ) inside the exp ectation Ψ( τ , X τ ; x ) = v ( τ , X τ ) + Ψ( τ , X τ ; x ) − Ψ( τ , X τ ; X τ ) . Plugging this decomp osition in to the inequality yields the result ( A.3 ). Lemma A.4. Fix a time horizon S > t and N ∈ N ⋆ . L et Π N : = { t 0 , t 1 , . . . , t N } b e a p artition of the interval [ t, S ] , wher e t 0 = t and t N = S . F or any admissible c ontr ol α v ( t, x ) ≥ E P α " v ( S, X S ) + N − 1 X i =0 Z t i +1 t i f ( u, X t i , X u , α u )d u + N − 1 X i =0 Ψ t i +1 , X t i +1 ; X t i ) − Ψ( t i +1 , X t i +1 ; X t i +1 ) # − o (1) . (A.4) 24 Pr o of. W e pro ceed by backw ard induction or simple iteration. Consider the interv al [ t i , t i +1 ] . W e apply Lemma A.3 condi- tioned on the filtration F t i , with the preference parameter frozen at the state X t i . This gives v ( t i , X t i ) ≥ E P α v ( t i +1 , X t i +1 ) + Z t i +1 t i f ( u, X t i , X u , α u )d u + ∆ i F t i − o ( t i +1 − t i ) , where ∆ i : = Ψ( t i +1 , X t i +1 ; X t i ) − Ψ( t i +1 , X t i +1 ; X t i +1 ) . T aking exp ectations under P α and summing these inequalities from i = 0 to N − 1 leads to a telescoping sum for the v alue function terms v ( t i , X t i ) , lea ving only the initial term v ( t, x ) and the terminal term v ( S, X S ) , plus the cumulativ e sums of the running costs and the adjustment terms ∆ i . No w w e conclude the pro of of the extended dynamic programming principle in Theorem 3.3 by sho wing that the sums in Lemma A.4 conv erge to the terms we exp ect. Lemma A.5 (Conv ergence of the discrete inequality) . L et (Π N ) N ∈ N ⋆ b e a se quenc e of p artitions of [ t, S ] whose mesh size tends to 0 . The discr ete ine quality in Lemma A.4 c onver ges to the fol lowing inte gr al formulation v ( t, x ) ≥ E P α v ( S, X S ) + Z S t f ( u, X u , X u , α u )d u − Z S t b ( u, X u , α u ) · ∂ y Ψ( u, X u ; X u ) + 1 2 T r σ ( u, X u ) σ ⊤ ( u, X u ) ∂ 2 y y Ψ( u, X u ; X u ) + T r σ ( u, X u ) σ ⊤ ( u, X u ) ∂ 2 xy Ψ( u, X u ; X u ) d u # . Pr o of. T o rigorously analyse the conv ergence of the discrete sums app earing in Lemma A.4 , we in tro duce the time-discretisation map τ N : [ t, S ] − → { t 0 , . . . , t N − 1 } defined by τ N ( u ) : = t i for u ∈ [ t i , t i +1 ) . This notation allows us to express the discrete Riemann sums as contin uous stochastic integrals o ver the full interv al [ t, S ] , facilitating the use of dominated con vergence argumen ts. Part 1 : c onver genc e of the running c ost. W e consider the Riemann sum approximating the running cost I Π N : = N − 1 X i =0 Z t i +1 t i f ( u, X t i , X u , α u )d u. Using the discretisation map τ N , w e rewrite this sum as a single global in tegral I Π N = Z S t f ( u, X τ N ( u ) , X u , α u )d u. W e claim that I Π N con verges to R S t f ( u, X u , X u , α u )d u in L 1 ( R , F , P α ) . Indeed, we can apply the dominated conv ergence theorem under the measure P α 1. p ointwise c onver genc e: the tra jectories of X are contin uous P –a.s. (and thus P α –a.s.). As the mesh size | Π N | − → 0 , w e ha ve τ N ( u ) − → u , implying X τ N ( u ) − → X u for all u . Since f is con tin uous in its arguments, the in tegrand f ( u, X τ N ( u ) , X u , α u ) con verges p oin twise to f ( u, X u , X u , α u ) for d t ⊗ P α –almost ev ery ( u, ω ) ; 2. domination: w e seek a uniform integrable b ound. By the p olynomial gro wth assumption on f (Assumption 3.1 ), there exist constan ts C > 0 and m ≥ 1 such that for all u ∈ [ t, S ] f ( u, X τ N ( u ) , X u , α u ) ≤ C 1 + ∥ X τ N ( u ) ∥ m + ∥ X u ∥ m ≤ 2 C 1 + sup s ∈ [ t,S ] ∥ X s ∥ m = : Z . Since w e hav e Z ∈ L 1 ( R , F , P α ) due to Assumption 3.1 , w e can conclude. Part 2 : c onver genc e of the adjustment term. W e now turn to the inconsistency adjustment sum A Π N : = N − 1 X i =0 ∆ i , ∆ i : = Ψ( t i +1 , X t i +1 ; X t i ) − Ψ( t i +1 , X t i +1 ; X t i +1 ) . All exp ectations in the following are taken under P α , the measure induced by the arbitrary control α . Fix a partition interv al [ t i , t i +1 ] and decomp ose ∆ i = Ψ( t i +1 , X t i +1 ; X t i ) − Ψ( t i , X t i ; X t i ) | {z } T erm I − v ( t i +1 , X t i +1 ) − v ( t i , X t i ) | {z } T erm I I . 25 T erm I. Apply Itô’s form ula to r 7− → Ψ( r, X r ; X t i ) under P α , holding the preference parameter X t i fixed. W riting L α r r = L α ⋆ r r + ( L α r r − L α ⋆ r r ) and using the PDE ( ∂ t + L α ⋆ r r )Ψ( · , · ; y ) = − f ( · , y , · , α ⋆ r ) , w e obtain Ψ( t i +1 , X t i +1 ; X t i ) − Ψ( t i , X t i ; X t i ) = Z t i +1 t i h − f ( r, X t i , X r , α ⋆ r ) + b ( r , X r , α r ) − b ( r , X r , α ⋆ r ) · σ ( r , X r ) ⊤ ∂ x Ψ( r , X r ; X t i ) i d r + M ( i ) , I , where M ( i ) , I is a sto chastic integral against W α and hence a true P α –martingale b y the p olynomial growth of ∂ x Ψ and Assumption 3.1 . T aking the conditional exp ectation E P α [ · | F t i ] eliminates M ( i ) , I . T erm II. Since v ( r , x ) = Ψ( r, x ; x ) , applying the chain rule for spatial deriv atives gives ∂ x v ( r , x ) = ∂ x Ψ( r , x ; x ) + ∂ y Ψ( r , x ; x ) , ∂ 2 xx v ( r , x ) = ∂ 2 xx Ψ( r , x ; x ) + 2 ∂ 2 xy Ψ( r , x ; x ) + ∂ 2 y y Ψ( r , x ; x ) . Applying Lemma A.1 (Itô–Kunita–W entzell form ula) to v ( r , X r ) under P α , substituting these identities, and using the PDE for Ψ to simplify ∂ t Ψ + L α r r Ψ = − f ( r, X r , X r , α ⋆ r ) + ( b ( r , X r , α r ) − b ( r , X r , α ⋆ r )) · σ ( r , X r ) ⊤ ∂ x Ψ( r , X r ; X r ) , w e find E P α v ( t i +1 , X t i +1 ) − v ( t i , X t i ) | F t i = E P α Z t i +1 t i h − f ( r, X r , X r , α ⋆ r ) + b ( r , X r , α r ) − b ( r , X r , α ⋆ r ) · σ ( r , X r ) ⊤ ∂ x Ψ( r , X r ; X r ) + L α r r, ( y ) Ψ( r , X r ; X r ) i d r F t i , where w e define the generator acting exclusively on the y -v ariable under the arbitr ary control α as: L α r r, ( y ) Ψ : = b ( r , X r , α r ) · σ ( r , X r ) ⊤ ∂ y Ψ + 1 2 T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 y y Ψ + T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 xy Ψ . Combining. Subtracting T erm I I from T erm I, taking the unconditional exp ectation E P α , summing ov er i , and rewriting the result as a single integral via the discretisation map τ N yields: E P α A Π N = E P α Z S t h f ( r, X r , X r , α ⋆ r ) − f ( r, X τ N ( r ) , X r , α ⋆ r ) + b ( r , X r , α r ) − b ( r , X r , α ⋆ r ) · σ ( r , X r ) ⊤ ∂ x Ψ( r , X r ; X τ N ( r ) ) − ∂ x Ψ( r , X r ; X r ) − L α r r, ( y ) Ψ( r , X r ; X r ) i d r . Passage to the limit. As | Π N | → 0 , we hav e X τ N ( r ) → X r , P –a.s. by the contin uity of the tra jectories. By the contin uit y of f and ∂ x Ψ in all their arguments, the first t wo lines of the integrand conv erge p oin twise to zero. Sp ecifically: • f ( r, X r , X r , α ⋆ r ) − f ( r, X τ N ( r ) , X r , α ⋆ r ) − → 0 p oint wise; • ∂ x Ψ( r , X r ; X τ N ( r ) ) − ∂ x Ψ( r , X r ; X r ) − → 0 point wise. Since for any fixed ( r, ω ) the ev aluated state and controls are finite, the drift difference ( b α r − b α ⋆ r ) acts as a finite m ultiplier, guaranteeing that the entire cross-term point wise conv erges to zero. Both terms are uniformly dominated by the integrable random v ariable Z constructed in Part 1 (scaled by constan ts dep ending on the Lipschitz contin uity of b and the p olynomial growth of ∂ x Ψ from Assumption 3.1 ). Applying the dominated conv ergence theorem under P α giv es: lim | Π N |→ 0 E P α A Π N = − E P α Z S t L α r r, ( y ) Ψ( r , X r ; X r )d r . Substituting the explicit form of L α r r, ( y ) Ψ and combining with Part 1 yields the integral inequality stated in the lemma. With these lemmata, we can finally conclude the pro of of the extended dynamic programming principle. 26 Pr o of of The or em 3.3 . Lemma A.5 establishes that for any admissible control α ∈ A , the v alue function satisfies the integral inequalit y v ( t, x ) ≥ E P α v ( S, X S ) + Z S t f ( u, X u , X u , α u )d u − Z S t b ( u, X u , α u ) · ∇ y Ψ( u, X u ; X u ) + 1 2 T r σ ( u, X u ) σ ⊤ ( u, X u ) ∇ 2 y y Ψ( u, X u ; X u ) + T r σ ( u, X u ) σ ⊤ ( u, X u ) ∇ 2 xy Ψ( u, X u ; X u ) d u # . T o conclude the proof, w e must show that equalit y holds when α = α ⋆ . Recall from Lemma A.3 that if we c ho ose the equilibrium control α ⋆ , the lo cal error term r ( δ ) is identically zero. This implies that the discrete-time inequality b ecomes an equalit y at every step of the iteration in Lemma A.4 . Sp ecifically , for α = α ⋆ , the telescoping sum argumen t holds exactly without an y o (1) error terms. Consequen tly , passing to the limit as the mesh size | Π N | − → 0 in the equality case pro ceeds identically to the inequalit y case, but with equalities throughout. Th us v ( t, x ) = E P t , x , α ⋆ " v ( S, X S ) + Z S t f ( u, X u , X u , α ⋆ u )d u − Z S t b u ( X u , α ⋆ u ) · ∇ y Ψ( u, X u ; X u ) + 1 2 T r σ u σ ⊤ u ∇ 2 y y Ψ( u, X u ; X u ) + T r σ u σ ⊤ u ∇ 2 xy Ψ( u, X u ; X u ) d u # . Finally , we recall the definition of the auxiliary function Ψ( u, x ; y ) as the exp ected reward with fixed parameter y . Differentiat- ing under the exp ectation sign (justified by Assumption 3.1 ), w e observ e that the deriv ativ es ∇ y Ψ , ∇ 2 y y Ψ , and ∇ 2 xy Ψ ev aluated at ( u, X u ; X u ) corresp ond exactly to the exp ectation terms app earing in the theorem statement ( 3.6 ), thereby concluding the pro of. B Pro of of the necessit y theorem Before pro ving the main necessity result, we establish the following consequence of the extended dynamic programming principle. Lemma B.1 (Martingale optimality prop ert y) . L et α ⋆ ∈ A b e an e quilibrium c ontr ol satisfying the extende d DPP identity ( 3.6 ) . Define the inc onsistency adjustment term K t ( a ) for any a ∈ A by K t ( a ) : = b ( t, X t , a ) · σ ( t, X t ) ⊤ ∇ y J ( t, X t , X t ) + T r 1 2 ∇ 2 y y J ( t, X t , X t ) + ∇ 2 xy J ( t, X t , X t ) σ ( t, X t ) σ ( t, X t ) ⊤ , t ∈ [0 , T ] . Then, the pr o c ess M α ⋆ define d by M α ⋆ t : = v ( t, X t ) + Z t 0 f ( r, X r , X r , α ⋆ r ) − K r ( α ⋆ r ) d r , t ∈ [0 , T ] , is an ( F , P α ⋆ ) -martingale. F urthermor e, for any arbitr ary admissible c ontr ol α ∈ A , the c orr esp onding pr o c ess M α is a ( F , P α ) –sup er-martingale. Pr o of. W e prov e the martingale prop ert y for α ⋆ . Fix 0 ≤ s ≤ t ≤ T . W e compute the conditional exp ectation of the increment E P α ⋆ M α ⋆ t − M α ⋆ s | F s = E P α ⋆ v ( t, X t ) − v ( s, X s ) + Z t s f ( r, X r , X r , α ⋆ r ) − K r ( α ⋆ r ) d r F s . By the Marko v property of the state pro cess X and the feedback nature of α ⋆ , we can rewrite the conditional expectation using the exp ectation starting at time s E P α ⋆ M α ⋆ t − M α ⋆ s F s = E P s,X s ,α ⋆ v ( t, X t ) + Z t s f ( r, X r , X r , α ⋆ r ) − K r ( α ⋆ r ) d r − v ( s, X s ) . 27 W e now compare this expression with the extended DPP ( 3.6 ). Observe that the exp ectation terms app earing in ( 3.6 ) are tak en under the measure P r,X r ,α ⋆ . These terms corresp ond precisely to the deriv atives ∇ y J ( r, X r , X r ) , ∇ 2 y y J ( r, X r , X r ) , and ∇ 2 xy J ( r, X r , X r ) app earing in our definition of K r ( α ⋆ r ) . Consequently , the in tegral term inv olving K r exactly cancels the inconsistency cost terms in the extended DPP , lea ving the martingale difference equal to zero. With this in mind, we go on to provide a rigorous pro of of Theorem 3.7 . W e assume the existence of a smo oth equilibrium con trol α ⋆ and smo oth v alue functions V and J , and we show that they necessarily induce a solution to the BSDE system ( 3.7 ) and satisfy the Hamiltonian maximisation condition. Pr o of of The or em 3.7 . The pro of pro ceeds in three steps: first, we identify the auxiliary pro cesses for the parameter deriv a- tiv es; second, we deriv e the dynamics of the v alue function using the extended DPP; and third, we v erify the Hamiltonian maximisation condition. Let us start by sho wing that the deriv ativ e pro cesses satisfy ( 3.7 ). Recall the definition of the auxiliary v alue function with fixed preference parameter y ∈ R n J ( t, x, y ) : = E P t,x,α ⋆ Z T t f ( s, y , X s , α ⋆ s )d s + ξ ( y , X T ) . By the classical F eynman–Kac theorem, for each fixed y , the function ( t, x ) 7− → J ( t, x, y ) solves the linear PDE ∂ t J ( t, x, y ) + L α ⋆ ( t,x ) t J ( t, x, y ) + f ( t, y , x, α ⋆ ( t, x )) = 0 , ( t, x, y ) ∈ [0 , T ) × R n × R n , (B.1) with terminal condition J ( T , x, y ) = ξ ( y , x ) . By the h yp othesis of Theorem 3.7 , J is of class C 1 , 2 with resp ect to the spatial and parameter v ariables. W e can therefore differen tiate ( B.1 ) with resp ect to the parameter y . Note that the deriv atives of the cost functions ∂ y f and ∂ y ξ exist b y Assumption 3.1 . Let v y ( t, x ) : = ∂ y J ( t, x, y ) denote the gradient with resp ect to y . It satisfies the linearised PDE ∂ t v y ( t, x ) + L α ⋆ ( t,x ) t v y ( t, x ) + ∂ y f ( t, y , x, α ⋆ ( t, x )) = 0 , ( t, x, y ) ∈ [0 , T ) × R n × R n , v y ( T , x ) = ∂ y ξ ( y , x ) , ( x, y ) ∈ R n × R n . This is a standard linear parab olic equation. The probabilistic representation of its solution is given by the BSDE ∂ Y y t = ∂ y ξ ( y , X T ) + Z T t ∂ y f ( r, y, X r , α ⋆ r )d r − Z T t ∂ Z y r · d W α ⋆ r , t ∈ [0 , T ] , where w e identify ∂ Y y t = ∂ y J ( t, X t , y ) and ∂ Z y t = σ ( t, X t ) ⊤ ∂ 2 xy J ( t, X t , y ) . W e also let α ⋆ t : = α ⋆ ( t, X t ) , abusing notations sligh tly . Ho wev er, the system ( 3.7 ) is written under the reference measure P (where W is an ( F , P ) –Bro wnian motion), not P α ⋆ . Recall that d W α ⋆ r = d W r − b ( r , X r , α ⋆ r )d r . Substituting this change of measure in to the equation ab o ve yields ∂ Y y t = ∂ y ξ ( y , X T ) + Z T t ∂ y f ( r, y, X r , α ⋆ r ) + ∂ Z y r · b ( r , X r , α ⋆ r ) d r − Z T t ∂ Z y r · d W r . This matches exactly the second equation of the system ( 3.7 ). The deriv ation for the Hessian pro cess ∂ ∂ Y y follo ws an identical argumen t by differentiating the PDE t wice. Let us now address the dynamics of the pro cess Y .W e start by determining its driver, keeping in mind that Y t : = V ( t, X t ) . By Itô’s formula d Y t = ∂ t V ( t, X t ) + L α ⋆ t t V ( t, X t ) d t + ∇ x V ( t, X t ) ⊤ σ ( t, X t )d W α ⋆ t . T o identify the drift term ∂ t V + L α ⋆ V , we use the extended DPP (Theorem 3.3 ). Since α ⋆ is an equilibrium control, Lemma B.1 implies that the pro cess M t : = V ( t, X t ) + Z t 0 f ( r, X r , X r , α ⋆ r ) − K r ( α ⋆ r ) d r , t ∈ [0 , T ] , is an ( F , P α ⋆ ) -martingale. Thus, the drift of M must v anish. Calculating it and setting it to zero giv es ∂ t V ( t, X t ) + L α ⋆ t t V ( t, X t ) | {z } Drift of V + f ( t, X t , X t , α ⋆ t ) − K t ( α ⋆ t ) | {z } Drift from integral = 0 , d t ⊗ P –a.e. 28 Therefore, the generator of the v alue function is given by ∂ t V ( t, X t ) + L α ⋆ t t V ( t, X t ) = − f ( t, X t , X t , α ⋆ t ) + K t ( α ⋆ t ) , d t ⊗ P –a.e. (B.2) W e now define the BSDE v ariables for the v alue function. Let Z t : = σ ( t, X t ) ⊤ ∇ x V ( t, X t ) , t ∈ [0 , T ] . Under the reference measure P , the dynamics of Y is d Y t = ∂ t V ( t, X t ) + L α ⋆ t t V ( t, X t ) − Z t · b ( t, X t , α ⋆ t ) d t + Z t · d W t . Substituting the generator expression from ( B.2 ) and expanding K t d Y t = b ( t, X t , α ⋆ t ) · σ ( t, X t ) ⊤ ∇ y J ( t, X t , X t ) − f ( t, X t , X t , α ⋆ t ) + 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∇ 2 y y J ( t, X t , X t ) + T r σ ( t, X t ) σ ( t, X t ) ⊤ ∇ 2 xy J ( t, X t , X t ) − Z t · b ( t, X t , α ⋆ t ) d t + Z t · d W t . W e identify the terms with the BSDE v ariables defined ab o ve ∂ Y X t t = ∇ y J ( t, X t , X t ) , ∂ ∂ Y X t t = ∇ 2 y y J ( t, X t , X t ) , ∂ Z X t t = σ ( t, X t ) ⊤ ∇ 2 xy J ( t, X t , X t ) , t ∈ [0 , T ] . The driv er b ecomes driv er t = f ( t, X t , X t , α ⋆ t ) + b ( t, X t , α ⋆ t ) · ( Z t − σ ( t, X t ) ⊤ ∂ Y X t t ) − 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∂ ∂ Y X t t − T r σ ( t, X t ) ∂ Z X t t . This matches the drift of the first equation of ( 3.7 ), provided that α ⋆ maximises the Hamiltonian, which is what we are left to pro ve. T o do so, we compare the dynamics of the equilibrium v alue function under α ⋆ v ersus an arbitrary control α . Since we know M α ⋆ is an ( F , P α ⋆ ) -martingale, w e hav e that its drift is exactly zero ∂ t V ( t, X t ) + L α ⋆ t t V ( t, X t ) + f ( t, X t , X t , α ⋆ ) − K t ( α ⋆ t ) = 0 . (B.3) Using Lemma B.1 we also hav e that its drift must b e non-p ositiv e ∂ t V ( t, X t ) + L α t t V ( t, X t ) + f ( t, X t , X t , α ) − K t ( α t ) ≤ 0 . (B.4) No w we simply we subtract the equality ( B.3 ) from the inequality ( B.4 ). Note that terms not dep ending on the con trol cancel out immediately • the time deriv ativ e ∂ t V cancels; • the second-order diffusion term in L α ⋆ t and L α t in volv es 1 2 σ ( t, x ) σ ( t, x ) ⊤ ∇ 2 xx V . Since volatilit y is uncontrolled, this term is iden tical for b oth α and α ⋆ and cancels; • the second-order trace term inside the inconsistency adjustment K t (see Lemma B.1 ) also dep ends only on σ ( x ) (see Remark 3.8 ). It is iden tical in b oth equations and also cancels. W e are left with the first-order terms b ( t, X t , α t ) · σ ( t, X t ) ⊤ ∇ x V + f ( t, X t , X t , α t ) − b ( t, X t , α t ) · σ ( t, X t ) ⊤ ∂ y J ( t, X t , X t ) − b ( t, X t , α ⋆ t ) · σ ( t, X t ) ⊤ ∇ x V + f ( t, X t , X t , α ⋆ t ) − b ( t, X t , α ⋆ t ) · σ ( t, X t ) ⊤ ∂ y J ( t, X t , X t ) ≤ 0 . Rearranging this inequality to isolate the terms dependent on a and identifying σ − 1 Z t = ∇ x V and ∂ Y X t t = ∇ y J ( t, X t , X t ) , w e obtain: f ( t, X t , X t , α t ) + b ( t, X t , α t ) · Z t − σ ( t, X t ) ⊤ ∂ Y X t t ≤ f ( t, X t , X t , α ⋆ t ) + b ( t, X t , α ⋆ t ) · Z t − σ ( t, X t ) ⊤ ∂ Y X t t . Since this holds for any arbitrary admissible control α t , it implies that α ⋆ t maximises the expression d t ⊗ d P -a.e., concluding the proof. 29 C Pro of of the v erification theorem In this section we present the pro of of Theorem 3.9 . W e will start by proving that the BSDE system, which was introduced informally in Section 3 , has a close relation to the problem. Let us introduce the following notation: h t ( y , x, z , a ) = f ( t, y , x, a ) + z · b ( t, x, a ) . W e also denote by L α t, ( y ) the generator asso ciated with the control α but acting on the v ariable y . F or a function ψ ( y ) , we define: L α t t, ( y ) ψ ( y ) : = b ( t, X t , α t ) · σ ( t, X t ) ⊤ ∇ y ψ ( y ) + 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∇ 2 y y ψ ( y ) . In the spirit of Hernández and Possamaï [ 21 ], for a control pro cess α ∈ A and an initial condition ( t, x ) for the state pro cess X , w e define the following auxiliary processes ( Y y ,α , Z y ,α ) . F or a fixed parameter y ∈ R n , they solve the BSDE Y y ,α s = ξ ( y , X T ) + Z T s h u y , X u , Z y ,α u , α u d u − Z T s Z y ,α u d W u , s ∈ [ t, T ] , ∂ Y y ,α s = ∇ y ξ ( y , X T ) + Z T s ∇ y f ( u, y , X u , α u ) + ∂ Z y ,α u b ( u, X u , α u ) d u − Z T s ∂ Z y ,α u d W u , s ∈ [ t, T ] , ∂ ∂ Y y ,α s = ∇ 2 y y ξ ( y , X T ) + Z T s ∇ 2 y y f ( u, y , X u , α u ) + ∂ ∂ Z y ,α u b ( u, X u , α u ) d u − Z T s ∂ ∂ Z y ,α u d W u , s ∈ [ t, T ] . (C.1) W e see that the structure of the system is the same as the one of ( 3.7 ), and w e will imp ose the same concept of solution. W e start the analysis with the follo wing lemma. Lemma C.1. W e have that Y y ,α t = J ( t, x, y , α ) . Pr o of. W e work under the probabilit y measure P t,x,α , under which X t = x and the dynamics on [ t, T ] are controlled by α . Recall that under this measure, the Brownian motion is W α . Substituting the dynamics of X in to the first equation of ( C.1 ), w e hav e d Y y ,α u = − h u ( y , X u , Z y ,α u , α u ) − Z y ,α u · b ( u, X u , α u ) d u + Z y ,α u · d W α u , u ∈ [ t, T ] . The drift term simplifies to − f ( u, y , X u , α u ) . Integrating from t to T Y y ,α t = ξ ( y , X T ) + Z T t f ( u, y , X u , α u )d u − Z T t Z y ,α u · d W α u . T aking exp ectations under P t,x,α eliminates the sto c hastic integral: Y y ,α t = E P t , x , α Z T t f ( u, y , X u , α u )d u + ξ ( y , X T ) . By definition, the right-hand side is exactly the cost functional J ( t, x, y , α ) . In other w ords, the pro cess Y y ,α t captures the dynamics of the rew ard functional if we fix the v alue y . Note that this could ha ve been deduced from the PDE of J , as it is easy to show that Y y ,α ⋆ t = J ( t, X t , y ) . The idea now is to fix an equilibrium con trol α ⋆ and to understand the corresp onding pro cess Y X t ,α ⋆ t . One key observ ation is that it can b e understoo d from tw o p erspectives: ( i ) from that of ( C.1 ), fixing the v alue of y = X t and considering the resulting dynamics. This sho ws that Y X t ,α ⋆ t = J ( t, x, x, α ⋆ ) = V ( t, x ) = V ( t, X t ); ( ii ) or seen as an Itô pro cess: w e hav e defined a uni-parametric family of pro cesses, and consider Y X t ,α ⋆ t as a comp osition of the family with a pro cess. In other words, we let the sup erscript parameter change as time adv ances. In the informal deriv ation of the BSDE system, we wrote Y t = V ( t, X t ) . The first goal of the section is that, starting from the BSDE system ( 3.7 ), we can reco ver this rigorously . As we already hav e that Y X t ,α ⋆ t = V ( t, X t ) , we must sho w now that Y X t ,α ⋆ t = Y t under suitable assumptions, which happ en to b e the ones introduced in Section 3 . 30 Prop osition C.2. L et Assumption 3.1 hold. L et ( Y , Z , ∂ Y , ∂ Z , ∂ ∂ Y , ∂ ∂ Z ) b e a solution to ( 3.7 ) in the sense of Definition 3.6 with α ⋆ t = V ⋆ ( t, X t , Z t , ∂ Y X t t ) . Then, we have that under P α ⋆ Y t = Y X t ,α ⋆ t , t ∈ [0 , T ] . Pr o of. As the equilibrium con trol α ⋆ maximises the Hamiltonian H , we substitute the optimal drift into the first equation of ( 3.7 ). Recall that the Hamiltonian is given by: H ( t, x, z , γ , η , ρ ) = f ( t, x, x, α ⋆ t ) + b ( t, x, α ⋆ t ) · ( z − σ ( t, x ) ⊤ γ ) − 1 2 T r σ ( t, x ) σ ( t, x ) ⊤ η − T r σ ( t, x ) ρ ⊤ . Th us, the dynamics of Y under the reference measure P is d Y t = − f ( t, X t , X t , α ⋆ t ) + b ( t, X t , α ⋆ t ) · Z t − σ ( t, X t ) ⊤ ∂ Y X t t − 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∂ ∂ Y X t t − T r σ ( t, X t )( ∂ Z X t t ) ⊤ d t + Z t d W t . W e c hange the measure to P α ⋆ using the transformation d W t = d W α ⋆ t + b ( t, X t , α ⋆ t )d t . The term Z t · b ( t, X t , α ⋆ t ) arising from the Girsano v transformation cancels with the term − b ( t, X t , α ⋆ t ) · Z t inside the Hamiltonian driver. This yields the following dynamics for Y under P α ⋆ Y t = ξ ( X T , X T ) + Z T t f ( u, X u , X u , α ⋆ u ) + b ( u, X u , α ⋆ u ) · σ ( u, X u ) ⊤ ∂ Y X u u + 1 2 T r σ ( u, X u ) σ ( u, X u ) ⊤ ∂ ∂ Y X u u + T r σ ( u, X u ) ∂ ( Z X u u ) ⊤ d u − Z T t Z u · d W α ⋆ u . (C.2) No w we apply the Itô–Kunita–W entzell formula to the comp osed pro cess Y X t ,α ⋆ t . F rom the auxiliary system ( C.1 ), for a fixed y , the pro cess Y y ,α ⋆ satisfies the dynamics under P α ⋆ d Y y ,α ⋆ u = − f ( u, y , X u , α ⋆ u )d u + Z y ,α ⋆ u · d W α ⋆ u . The dynamics of the comp osition Y X t ,α ⋆ t is giv en by d Y X t ,α ⋆ t = d Y y ,α ⋆ t y = X t + ∂ y Y X t ,α ⋆ t · d X t + 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∂ 2 y y Y X t ,α ⋆ t d t + T r σ ( t, X t )( ∂ Z X t ,α ⋆ t ) ⊤ d t, where ∂ Z X t ,α ⋆ denotes the gradient of the field ∇ y Z y ,α ⋆ | y = X t . Substituting d X t = σ ( t, X t ) b ( t, X t , α ⋆ t )d t + σ ( t, X t )d W α ⋆ t d Y X t ,α ⋆ t = − f ( t, X t , X t , α ⋆ t ) + ∂ y Y X t ,α ⋆ t · σ ( t, X t ) b ( t, X t , α ⋆ t ) + 1 2 T r σ ( t, X t ) σ ( t, X t ) ⊤ ∂ 2 y y Y X t ,α ⋆ t + T r σ ( t, X t )( ∂ Z X t ,α ⋆ t ) ⊤ d t + Z X t ,α ⋆ t + ∂ y Y X t ,α ⋆ t · σ ( t, X t ) · d W α ⋆ t . Rearranging the drift term ∂ y Y · σ b = b · σ ⊤ ∂ y Y , and identifying the cross-v ariation trace term T r[ σ ( ∂ Z ) ⊤ ] with the Hamiltonian term T r[ σ ∂ Z ] , we observe that Y X t ,α ⋆ satisfies the exact same linear BSDE as Y deriv ed in ( C.2 ). Sp ecifically , we iden tify the v ariable Z t with the diffusion term Z X t ,α ⋆ t + σ ⊤ t ( X t ) ∂ Y X t t , and we identify the auxiliary field deriv ativ es ∂ y Y and ∂ 2 y y Y with the solution pro cesses ∂ Y and ∂ ∂ Y (whic h satisfy the same equations by uniqueness). Th us, b y the uniqueness of solutions to BSDEs, we conclude Y t = Y X t ,α ⋆ t . W e remark that we hav e managed to arrive at the BSDE system that we had deduced from the PDE system app earing in [ 8 ] from purely probabilistic arguments, namely the Itô–Kunita–W en tzell form ula. With the cen tral Prop osition C.2 prov en, w e mo ve on with the pro of of Theorem 3.9 . Pr o of of The or em 3.9 . Let ( t, x ) b e a fixed pair in [ 0 , T ] × R n and let α b e an arbitrary admissible con trol in A . W e aim to v erify the equilibrium condition given in Definition 2.4 . F or a strictly p ositiv e time step ℓ > 0 , we consider the concatenated con trol strategy ˆ α defined by ˆ α : = α ⊗ ℓ α ⋆ . W e analyse the difference betw een the cost of this p erturbed strategy and the cost of the equilibrium strategy , J ( t, x, ˆ α ) − J ( t, x, α ⋆ ) . 31 Recall that the v alue function is defined as v ( t, x ) = J ( t, x, α ⋆ ) . W e expand the cost of the p erturb ed strategy using the definition of the cost functional J ( t, x, ˆ α ) = E P t,x,α Z t + ℓ t f ( r, x, X r , α r )d r + Z T t + ℓ f ( r, x, X r , α ⋆ r )d r + ξ ( x, X T ) = E P t,x,α Z t + ℓ t f ( r, x, X r , α r )d r + E P t,x,α Z T t + ℓ f ( r, x, X r , α ⋆ r )d r + ξ ( x, X T ) F t + ℓ . Using the concatenated measure prop ert y , we iden tify the conditional exp ectation as the auxiliary v alue function Y , ev aluated with the fixed preference parameter x under the equilibrium control α ⋆ : J ( t, x, ˆ α ) = E P t,x,α Z t + ℓ t f ( r, x, X r , α r )d r + Y x,α ⋆ t + ℓ . W e add and subtract the equilibrium v alue function at time t + ℓ , which satisfies the relation v ( t + ℓ, X t + ℓ ) = Y X t + ℓ ,α ⋆ t + ℓ . This yields J ( t, x, ˆ α ) = E P t,x,α Z t + ℓ t f ( r, x, X r , α r )d r + v ( t + ℓ, X t + ℓ ) + I , where the term I captures the cost of inconsistency due to the changing preference parameter I : = E P t,x,α Y x,α ⋆ t + ℓ − Y X t + ℓ ,α ⋆ t + ℓ . Since w e assumed that v ( t, x ) is in C 1 , 2 ([0 , T ) × R n ) , let us apply Itô’s formula to the pro cess v ( s, X s ) on the interv al [ t, t + ℓ ] under the measure P t,x,α . Note that d X r = b ( r , X r , α r )d r + σ ( r , X r )d W α r . v ( t + ℓ, X t + ℓ ) = v ( t, x ) + Z t + ℓ t ∂ t v ( r , X r ) + b ( r , X r , α r ) · ∂ x v ( r , X r ) + 1 2 T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 xx v ( r , X r ) d r + Z t + ℓ t ∂ x v ( r , X r ) · σ ( r , X r )d W α r . T aking exp ectations under P t,x,α eliminates the sto chastic integral . Indeed, we identify the in tegrand ∂ x v ( r , X r ) · σ ( r , X r ) as the pro cess Z r from the BSDE gov erning v . By Definition 3.6 , we hav e Z ∈ H 2 ( R d , F , P t,x,α ) . Consequently , the sto c hastic in tegral is a true martingale with zero exp ectation. Substituting this into the expression for J ( t, x, ˆ α ) , we obtain J ( t, x, ˆ α ) − v ( t, x ) = E P t,x,α Z t + ℓ t f ( r, x, X r , α r ) + ∂ t v ( r , X r ) + b ( r , X r , α r ) · ∂ x v ( r , X r ) + 1 2 T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 xx v ( r , X r ) d r + I . T o analyse I , w e apply Condition ( A.2 ) to the map y 7− → Y y ,α ⋆ t + ℓ along the pro cess X r for r ∈ [ t, t + ℓ ] . This yields Y X t + ℓ ,α ⋆ t + ℓ − Y x,α ⋆ t + ℓ = Z t + ℓ t ∂ Y X r ,α ⋆ t + ℓ · d X r + 1 2 Z t + ℓ t T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ ∂ Y X r ,α ⋆ t + ℓ d r . Substituting the dynamics d X r = b ( r , X r , α r )d r + σ ( r , X r )d W α r , w e isolate the stochastic integral term: Z t + ℓ t ∂ Y X r ,α ⋆ t + ℓ · σ ( r , X r )d W α r . T aking exp ectations under P t,x,α , this term v anishes. Indeed, for any fixed parameter y , the pro cess ∂ Y y solv es a linear BSDE whose driver ∇ y f and terminal condition ∇ y ξ ha ve p olynomial growth in y and x (Assumption 3.1 - ( iii ) ). Standard BSDE estimates ( e.g. , [ 15 , Prop osition 2.1]) imply that the solution ∂ Y y inherits this p olynomial gro wth. Consequently , when ev aluated at y = X r , the integrand ∂ Y · σ has p olynomial gro wth in X r . Giv en the finite moments of X (Assumption 3.1 - ( iv ) ), the in tegrand b elongs to H 2 ( R d , F , P t,x,α ) , making the integral a true martingale with zero mean. W e are th us left with the drift terms I = − E P t , x , α Z t + ℓ t b ( r , X r , α r ) · σ ( r , X r ) ⊤ ∂ y Y X r ,α ⋆ t + ℓ + 1 2 T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 y y Y X r ,α ⋆ t + ℓ d r . W e now combine the results. W e add and subtract t wo sp ecific terms inside the integral 32 1. the running cost ev aluated at the current state preference f ( r, X r , X r , α r ); 2. the generator adjustment term ev aluated at the current time L α r r, ( y ) Y X r ,α ⋆ r . Grouping these terms appropriately , w e obtain the following decomp osition J ( t, x, ˆ α ) − v ( t, x ) = E P t,x,α " Z t + ℓ t ∂ t v ( r , X r ) + L α r r v ( r , X r ) + f ( r, X r , X r , α r ) − L α r r, ( y ) Y X r ,α ⋆ r | {z } T erm A: Hamiltonian gap d r # + E P t,x,α " Z t + ℓ t f ( r, x, X r , α r ) − f ( r, X r , X r , α r ) | {z } T erm B: preference approximation d r # + E P t,x,α " Z t + ℓ t L α r r, ( y ) Y X r ,α ⋆ r − L α r r, ( y ) Y X r ,α ⋆ t + ℓ | {z } T erm C: continuit y error d r # . Analysis of term A. This term measures the lo cal sub-optimalit y of the con trol α . Let I r denote the integrand I r : = ∂ t v ( r , X r ) + L α r r v ( r , X r ) + f ( r, X r , X r , α r ) − L α r r, ( y ) Y X r ,α ⋆ r . W e identify ∂ t v using the first equation of the BSDE system ( 3.7 ). Under the reference measure P , the drift of the pro cess Y r = v ( r, X r ) is given by the driver − H . Comparing this with the drift obtained from Itô’s formula applied to v ( r , X r ) , we establish the identit y ∂ t v ( r , X r ) = − H r , X r , Z r , ∂ Y X r r , ∂ ∂ Y X r r , ∂ Z X r r − 1 2 T r σ ( r , X r ) σ ( r , X r ) ⊤ ∂ 2 xx v ( r , X r ) , d r ⊗ P –a.e. (C.3) Substituting this expression into I r , and expanding the op erators L α r and L α r ( y ) , w e observe tw o key cancellations ( i ) the diffusion term 1 2 T r[ σ σ ⊤ ∂ 2 xx v ] from the generator L α r v cancels with the corresp onding term in ( C.3 ) ; ( ii ) the inconsistency terms inv olving ∂ 2 y y J and ∂ 2 xy J app earing in L α r ( y ) Y dep end only on the volatilit y σ (which is con trol- indep enden t) and cancel exactly with the inconsistency adjustment terms included in the definition of the extended Hamiltonian H . Consequen tly , the in tegrand reduces to the difference b et ween the Hamiltonian ob jectiv e ev aluated at the arbitrary control α r and its maximum v alue I r = f ( r, X r , X r , α r ) + b ( r , X r , α r ) · Z r − σ ( r , X r ) ⊤ ∂ Y X r r − sup a ∈ A f ( r, X r , X r , a ) + b ( r , X r , a ) · Z r − σ ( r , X r ) ⊤ ∂ Y X r r . Th us, I r ≤ 0 almost surely , and w e readily obtain Z t + ℓ t I r d r ≤ 0 , P t,x,α –a.s. Analysis of term B. W e use the Lipschitz-con tinuit y of f with resp ect to its first parameter (Assumption 3.1 ). Let L b e the Lipsc hitz-contin uity constan t. Then ∥ T erm B ∥ = f ( r, x, X r , α r ) − f ( r, X r , X r , α r ) ≤ L ∥ x − X r ∥ . T aking the exp ectation under P t,x,α E P t , x , α Z t + ℓ t T erm B d r ≤ L Z t + ℓ t E P t,x,α [ ∥ X r − x ∥ ]d r . Using standard moment estimates for SDEs with linear growth co efficien ts (see [ 29 , Corollary 2.5.12]), we hav e E P t,x,α [ ∥ X r − x ∥ ] ≤ C (1 + ∥ x ∥ ) √ r − t . Thus Z t + ℓ t √ r − t d r = 2 3 ( r − t ) 3 / 2 t + ℓ t = 2 3 ℓ 3 / 2 = o ( ℓ ) . 33 Analysis of term C. This term arises from the time-contin uit y of the inconsistency adjustment. W e analyse the integral of the difference ∆ r : = L α r r, ( y ) Y X r ,α ⋆ r − L α r r, ( y ) Y X r ,α ⋆ t + ℓ . Recall that the op erator L α ( y ) is linear in the deriv atives ∂ y Y · ,α ⋆ and ∂ 2 y y Y · ,α ⋆ , with co efficien ts b and σ that satisfy linear gro wth conditions. Since the solution to the auxiliary BSDE system b elongs to the space S 2 ( R d , F , P ) , the mappings r 7− → ∂ y Y · ,α ⋆ r and r 7− → ∂ 2 y y Y · ,α ⋆ r are contin uous with resp ect to time in the norm of L 2 ( P t,x,α ) . F urthermore, the state pro cess X defines a mapping r 7− → X r whic h is con tinuous with resp ect to time in L p ( P t,x,α ) for any p ≥ 1 . By Hölder’s inequalit y , the comp osition app earing in ∆ r is con tinuous with resp ect to time in L 1 ( P t,x,α ) . Therefore, we readily obtain: E P t,x,α Z t + ℓ t ∆ r d r = Z t + ℓ t o (1)d r = o ( ℓ ) . Com bining the non-p ositivit y of T erm A with the o ( ℓ ) estimates for T erms B and C, we obtain J ( t, x, ˆ α ) − v ( t, x ) ≤ 0 + o ( ℓ ) + o ( ℓ ) . This confirms that the equilibrium strategy α ⋆ pro vides a higher pay off than the p erturbed strategy ˆ α up to first order, thereb y satisfying the definition of an equilibrium con trol. Remark C.3. This r esult motivates Definition 2.4 in the fol lowing sense: one c ould ar gue that it would make sense to al low for impr ovements of or der o ( ℓ k ) , sinc e the use of k = 1 in our definition c ould se em arbitr ary at first. However, we se e her e that k = 1 is exactly the p ower that we ne e d to guar ante e the r esult. D W ell-p osedness of the BSDE system In this section, we provide the rigorous pro of for the existence and uniqueness of the solution to the system ( 3.7 ). W e adopt a fixed-p oin t approach on the full system of three equations. T o handle the linear gro wth of the v alue function deriv atives (t ypical in linear–quadratic problems), we work in w eighted spaces that allo w for polynomial growth in the parameter y . W e also sho w that our w ork implies the existence of solutions in the sense of Definition 3.6 . T o ease the notation, we will denote by C an arbitrary constant that may change line by line. W e first introduce and prov e the follo wing standard a priori estimate (similar to El Karoui, Peng, and Quenez [ 15 , Prop osition 2.1]). Lemma D.1 (A Priori Estimates and Contraction) . L et ( δ Y , δ Z ) b e the solution to the line arize d BSDE with driver differ enc e δ f : − d( δ Y t ) = δ f t d t − δ Z t d W t , δ Y T = 0 . (D.1) F or β sufficiently lar ge, the fol lowing estimate holds: ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C β ∥ δ f ∥ 2 H 2 β ( R , F , P ) . (D.2) Pr o of. W e start by applying Itô’s form ula to the pro cess e β t | δ Y t | 2 : d( e β t | δ Y t | 2 ) = β e β t | δ Y t | 2 d t + e β t 2 δ Y t · d( δ Y t ) + | δ Z t | 2 d t = e β t β | δ Y t | 2 + | δ Z t | 2 − 2 δ Y t · δ f t d t + 2 e β t δ Y t · δ Z t d W t . In tegrating from 0 to T , taking exp ectations, and using the fact that δ Y T = 0 and the stochastic integral is a martingale, we get: E Z T 0 e β s β | δ Y s | 2 + | δ Z s | 2 d s ≤ 2 E Z T 0 e β s δ Y s · δ f s d s . W e now use Y oung’s inequality , 2 ab ≤ β 2 a 2 + 2 β b 2 on the right-hand side: 2 δ Y s · δ f s ≤ β 2 | δ Y s | 2 + 2 β | δ f s | 2 . 34 Substituting this back into the integral equality: E Z T 0 e β s β | δ Y s | 2 + | δ Z s | 2 d s ≤ E Z T 0 e β s β 2 | δ Y s | 2 + 2 β | δ f s | 2 d s . Subtracting the term β 2 ∥ δ Y ∥ 2 H 2 β from both sides yields: β 2 ∥ δ Y ∥ 2 H 2 β + ∥ δ Z ∥ 2 H 2 β ≤ 2 β ∥ δ f ∥ 2 H 2 β . This inequalit y immediately giv es tw o b ounds: 1. ∥ δ Y ∥ 2 H 2 β ≤ 4 β 2 ∥ δ f ∥ 2 H 2 β . 2. ∥ δ Z ∥ 2 H 2 β ≤ 2 β ∥ δ f ∥ 2 H 2 β . Note that the b ound for ∥ δ Z ∥ 2 H 2 β is the one we need, and that we residually obtained a strong b ound for ∥ δ Y ∥ 2 H 2 β that will also b e useful later. The latter will help us prov e our desired b ound for ∥ δ Y ∥ 2 S 2 β . T o b ound the supremum, we return to the integral form of the pro cess e β t | δ Y t | 2 . By integrating the Itô differential from t to T and using the terminal condition δ Y T = 0 , w e hav e: e β t | δ Y t | 2 + Z T t e β s ( β | δ Y s | 2 + | δ Z s | 2 )d s = Z T t 2 e β s δ Y s · δ f s d s − Z T t 2 e β s δ Y s · δ Z s d W s . The in tegral term on the left-hand side is non-negative. Thus: e β t | δ Y t | 2 ≤ Z T t 2 e β s | δ Y s || δ f s | d s + Z T t 2 e β s δ Y s · δ Z s d W s . W e no w tak e the supremum ov er t ∈ [ 0 , T ] on b oth sides, follow ed b y the exp ectation. F or the first term on the right (the drift), w e effectively b ound it by the in tegral ov er [0 , T ] : E sup t ∈ [0 ,T ] e β t | δ Y t | 2 ≤ E Z T 0 e β s | 2 δ Y s · δ f s | d s | {z } Drift part + 2 E sup t ∈ [0 ,T ] Z t 0 e β s δ Y s · δ Z s d W s | {z } Martingale M t . Using Y oung’s inequalit y for the drift: E " sup t ∈ [0 ,T ] e β t | δ Y t | 2 # ≤ E Z T 0 e β s β | δ Y s | 2 + 1 β | δ f s | 2 d s + 2 E " sup t ∈ [0 ,T ] | M t | # ≤ C β ∥ δ f ∥ 2 H 2 β + 2 E " sup t ∈ [0 ,T ] | M t | # . Here, we used that the term β ∥ δ Y ∥ 2 is b ounded by C β ∥ δ f ∥ 2 . T o b ound the martingale term, we apply the Burkholder-Da vis- Gundy inequalit y in its L 1 form: E " sup t ∈ [0 ,T ] Z t 0 e β s δ Y s δ Z s d W s # ≤ 3 E Z T 0 e 2 β s | δ Y s | 2 | δ Z s | 2 d s ! 1 / 2 ≤ 3 E sup r ∈ [0 ,T ] e β r/ 2 | δ Y r | ! Z T 0 e β s | δ Z s | 2 d s ! 1 / 2 . Using again Y oung’s inequality ab ≤ 1 4 a 2 + C b 2 , and putting everything together: E " sup t ∈ [0 ,T ] e β t | δ Y t | 2 # ≤ C β ∥ δ f ∥ 2 H 2 β + 1 2 E " sup r ∈ [0 ,T ] e β r | δ Y r | 2 # + C E " Z T 0 e β s | δ Z s | 2 d s # . 35 The middle term in the RHS can b e absorb ed into the left-hand side of our supremum estimate. The last term is prop ortional to ∥ δ Z ∥ 2 H 2 β , whic h we already b ounded by 2 β ∥ δ f ∥ 2 . Concluding, w e get: ∥ δ Y ∥ 2 S 2 β + ∥ δ Z ∥ 2 H 2 β ≤ C β ∥ δ f ∥ 2 H 2 β , whic h is what w e wan ted to pro ve. W e also present this immediate corollary , which will prov e useful when proving that the central map in the pro of of Theo- rem 3.12 is a contraction. Corollary D.2. Consider two r e al BSDEs − d Y t = f t d t − Z t · d W t and − d Y ′ t = f ′ t d t − Z ′ t · d W t , taking values in R . A ssume that Y T = Y ′ T . L et δ Y : = Y − Y ′ , δ Z : = Z − Z ′ , and δ f t : = f t − f ′ t . Supp ose that ther e exists a c onstant K > 0 and a non-ne gative pr o c ess ϕ ∈ H 2 β ( R , F , P ) such that | δ f t | ≤ K | δ Y t | + ∥ δ Z t ∥ + ϕ t , d t ⊗ d P –a.e. Then, for β lar ge enough, ther e exists a c onstant C such that ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C β ∥ ϕ ∥ 2 H 2 β ( R , F , P ) . Pr o of. F rom Lemma D.1 we hav e that there exists C such that: ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C K β T ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) + ∥ ϕ ∥ 2 H 2 β ( R , F , P ) ! ≤ C K max (1 , T ) β ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) + ∥ ϕ ∥ 2 H 2 β ( R , F , P ) ! , where w e implicitly used: ∥ δ Y ∥ 2 H 2 β = E Z T 0 e β t | δ Y t | 2 dt ≤ T ∥ δ Y ∥ 2 S 2 β . Rearranging, w e get: β − C K max (1 , T ) β ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C β ∥ ϕ ∥ 2 H 2 β ( R , F , P ) . Assuming, for instance, that β > 2 C K max (1 , T ) , w e hav e that: ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ 2 C β ∥ ϕ ∥ 2 H 2 β ( R , F , P ) . No w we are ready to prov e our existence and uniqueness result for weigh ted spaces: Pr o of of The or em 3.12 . W e pro ceed by constructing a contraction mapping on the Banac h space K β . W e define the map Φ : K β − → K β as follows. Let w = ( y , z , u, v , u , v ) b e a fixed input tuple in K β . This input serves as the bac kground pro cesses frozen in the driv ers. W e define the output W = ( Y , Z, U, V , U , V ) = Φ( w ) as the unique solution to the following decoupled system of BSDEs d Y t = − H t, X t , Z t , u X t t , u X t t , v X t t d t + Z t · d W t , (D.3) d U y t = − G 1 t, X t , y , z t , v y t , u y t d t + V y t · d W t , (D.4) d U y t = − G 2 t, X t , y , z t , v y t , v y t d t + V y t · d W t . (D.5) In this system, the underlined terms indicate that the driv ers depend on the input w rather than the solution v ariables b eing solv ed for. Sp ecifically , the first equation for Y dep ends on the diagonal terms of the input fields ( u, u , v ) ev aluated at the random state X t . The second and third equations are parameterised by y ∈ R n and dep end on the input fields ev aluated at 36 that sp ecific parameter y . Since the system is decoupled and the drivers satisfy the Lipschitz and gro wth conditions from Assumption 3.11 , standard BSDE theory guaran tees that a unique solution W exists for any given input w . Step 1. Let us prov e that the map Φ is w ell-defined, that is, that for ev ery input w in K n,d β and W = Φ( w ) , w e ha ve that W ∈ K n,d β . W e must th us v erify that each comp onen t of the solution vector W = ( Y , Z, U, V , U , V ) has a finite norm in its resp ectiv e w eighted space. ( i ) The value pr o c esses ( Y , Z ) . The pair ( Y , Z ) solves the BSDE Y t = ξ ( X T , X T ) + Z T t H r , X r , Z r , u X r r , u X r r , v X r r d r − Z T t Z r d W r , t ∈ [0 , T ] . By the standard a priori estimates for BSDEs with Lipschitz contin uous drivers (see, e.g. , El Karoui, Peng, and Quenez [ 15 , Proposition 2.1], where we take f 2 = 0 and ξ 2 = 0 ), the squared norm of the solution in S 2 β ( R , F , P ) × H 2 β ( R d , F , P ) is b ounded by the square-integrabilit y of the terminal condition and the driver ev aluated at zero volatilit y . Sp ecifically , there exists a constant C > 0 dep ending on T and the Lipschitz constant of H such that ∥ Y ∥ 2 S 2 β ( R , F , P ) + ∥ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C E P e β T | ξ ( X T , X T ) | 2 + Z T 0 e β r H r , X r , 0 , u X r r , u X r r , v X r r 2 d r . Using the Lipschitz contin uity of H with resp ect to the inputs Θ : = ( z , u, u , v ) and the growth assumption on the base term H ( · , 0) , w e hav e H r , X r , 0 , u X r r , u X r r , v X r r 2 ≤ 2 H ( r, X r , 0 , 0 , 0 , 0) 2 + 2 K 2 ∥ u X r r ∥ 2 + ∥ u X r r ∥ 2 + ∥ v X r r ∥ 2 . The base term E P [ R T 0 | H ( r, X r , 0 , 0 , 0 , 0) | 2 d r ] is finite by Assumption 3.11 - ( iii ) . T o b ound the input terms, w e rely on the embedding of the weigh ted spaces. Recall that for any input field, sa y u ∈ S 2 , 2 β ,ρ , we ha ve the p oin twise b ound ∥ u y r ∥ 2 ≤ ρ ( y ) − 1 ∥ u ∥ 2 S 2 , 2 β,ρ ( R , F , P ) . Substituting the random parameter y = X r E P Z T 0 e β r ∥ u X r r ∥ 2 d r ≤ E P sup t ∈ [0 ,T ] ρ ( X t ) − 1 ∥ u ∥ 2 S 2 , 2 β,ρ ( R , F , P ) . Since ρ ( x ) − 1 has p olynomial growth and X admits finite moments of all orders (Assumption 3.1 ), the exp ectation E P [sup t ∈ [0 ,T ] ρ ( X t ) − 1 ] is finite. An iden tical argument applies to u and v . Consequently , the right-hand side of the a priori estimate is finite, implying ( Y , Z ) ∈ S 2 β ( R , F , P ) × H 2 β ( R d , F , P ) . ( ii ) The gr adient pr o c esses ( U, V ) . F or any fixed parameter y ∈ R n , the pair ( U y , V y ) solv es a BSDE driven by G 1 . Applying the standard a priori estimate (see [ 15 ]) yields: ∥ U y ∥ 2 S 2 β ( R n , F , P ) + ∥ V y ∥ 2 H 2 β ( R n × d , F , P ) ≤ C E P e β T |∇ y ξ ( y , X T ) | 2 + Z T 0 e β t G 1 t, X t , y , z t , v y t , u y t 2 d t . By Assumption 3.11 . ( ii ) , the driver G 1 is Lipschitz contin uous with resp ect to the input v ariables Θ : = ( z , v , u ) . There- fore, w e can b ound the squared driv er by the source term (at zero input) and the norms of the inputs: G 1 t, X t , y , z t , v y t , u y t 2 ≤ C G 1 ( t, X t , y , 0) 2 + ∥ z t ∥ 2 + ∥ v y t ∥ 2 + ∥ u y t ∥ 2 . T o verify that these pro cesses b elong to K β , we multiply the entire estimate by the weigh t ρ ( y ) and take the supremum o ver y ∈ R n . The inequality splits in to tw o parts (a) sour c e terms: by Assumption 3.11 - ( iii ) , the source terms hav e finite w eighted norms. Sp ecifically sup y ∈ R n ρ ( y ) E P |∇ y ξ ( y , X T ) | 2 + Z T 0 G 1 ( t, X t , y , 0) 2 d t < ∞ ; (b) input terms: the inputs belong to K β , so their weigh ted norms are finite sup y ∈ R n ρ ( y ) E P Z T 0 e β t ∥ z t ∥ 2 + ∥ v y t ∥ 2 + ∥ u y t ∥ 2 d t ≤ C ∥ z ∥ 2 H 2 β ( R d , F , P ) + ∥ v ∥ 2 H 2 , 2 β,ρ ( R n , F , P ) + ∥ u ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) < ∞ . 37 Com bining these b ounds prov es that the output pair ( U, V ) has a finite weigh ted norm, i.e. , ( U, V ) ∈ S 2 , 2 β ,ρ ( R n , F , P ) × H 2 , 2 β ,ρ ( R n × d , F , P ) . ( iii ) The Hessian pr o c esses ( U , V ) . The argument is strictly identical to the gradient case, as the driver G 2 satisfies the same condition. Th us, W ∈ K β ( F , P ) . Step 2. Next, to prov e that Φ is a contraction for a sufficien tly large β , let us consider tw o arbitrary inputs w and w ′ in K β ( F , P ) . Let W = Φ( w ) and W ′ = Φ( w ′ ) b e their corresp onding outputs. W e denote the differences by δ w = w − w ′ and δ W = W − W ′ . Our goal is to derive an estimate for ∥ δ W ∥ K β ( F , P ) in terms of ∥ δ w ∥ K β ( F , P ) . ( i ) Estimation of the value pr o c ess ( Y , Z ) . Consider the first equation for the v alue pro cess Y , which is scalar-v alued. The difference in the drivers, denoted by δ H t , is b ounded p oin twise by the differences in the solution comp onen ts and the inputs. Let us define the scalar aggregate error pro cess ϕ t for the inputs as: ϕ t : = ∥ δ z t ∥ + ∥ δ u X t t ∥ + ∥ δ u X t t ∥ + ∥ δ v X t t ∥ . By the Lipschitz contin uity of the Hamiltonian H (Assumption 3.11 ), we hav e the p oint wise b ound | δ H t | ≤ C ( | δ Y t | + ∥ δ Z t ∥ + ϕ t ) . Applying corollary D.2 to the scalar BSDE for δ Y , we obtain the following bound in the standard w eighted spaces: ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ C β ∥ ϕ ∥ 2 H 2 β ( R , F , P ) = C β E P Z T 0 e β t ϕ 2 t d t . T o relate this integral to the norms of the random fields in K β , we use the inequality ( a + b + c + d ) 2 ≤ 4( a 2 + b 2 + c 2 + d 2 ) to separate the components of ϕ t . W e then bound the integral of each term using the moment constan t M X : = E P [sup t ∈ [0 ,T ] (1 + ∥ X t ∥ 2 ) k ] . F or instance, for the gradien t term δ u , w e hav e: E P Z T 0 e β t ∥ δ u X t t ∥ 2 d t = E P ρ ( X t ) ρ ( X t ) Z T 0 e β t ∥ δ u X t t ∥ 2 d t ≤ C E P sup t ∈ [0 ,T ] (1 + ∥ X t ∥ 2 ) k ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) ≤ C M X ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) , Applying iden tical estimates for the Hessian term δ u (in the weigh ted S 2 , 2 space) and the volatilit y gradient term δ v (in the w eighted H 2 , 2 space), and b ounding the integrals, we arrive at the final estimate for the v alue process: ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) ≤ 3 C M X β ∥ δ z ∥ 2 H 2 β ( R d , F , P ) + ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) + ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) . (D.6) ( ii ) Estimation of the gr adient pr o c ess ( U, V ) . Next, we consider the system for the gradient ( D.4 ). F or a fixed parameter y ∈ R n , the difference in the driv er G 1 satisfies the Lipschitz condition stated in Assumption 3.11 ∥ ∆ G 1 ( t, X t , y ) ∥ ≤ C ∥ δ V y t ∥ + ∥ δ z t ∥ + ∥ δ v y t ∥ + ∥ δ u y t ∥ . W e apply the stability estimate from corollary D.2 for this fixed y (or rather, a lifted version of it to R n ), and follow the same reasoning as in Step 1. W e obtain: ∥ δ U y ∥ 2 S 2 β ( R n , F , P ) + ∥ δ V y ∥ 2 H 2 β ( R n × d , F , P ) ≤ C β E P Z T 0 e β t ∥ δ z t ∥ 2 + ∥ δ v y t ∥ 2 + ∥ δ u y t ∥ 2 d t . W e now lift this p oin twise estimate to the functional space norm. W e m ultiply the entire inequality by the fixed weigh t ρ ( y ) , and take the supremum. Using that 2 sup( a 2 + b 2 ) ≥ sup( a 2 ) + sup( b 2 ) , and p oten tially changing the constants, w e obtain: ∥ δ U ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) + ∥ δ V ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) ≤ C C ρ β ∥ δ z ∥ 2 H 2 β ( R d , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) + ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) . (D.7) 38 ( iii ) Estimation of the Hessian pr o c ess ( U , V ) . The analysis for the Hessian system ( D.5 ) mirrors that of the gradien t exactly . The driv er G 2 satisfies the same Lipschitz condition. Mu ltiplying by ρ ( y ) , taking the suprem um, and using the large β estimate yields ∥ δ U ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) + ∥ δ V ∥ 2 H 2 , 2 β,ρ ( R n × n × d , F , P ) ≤ C C ρ β ∥ δ z ∥ 2 H 2 β ( R d , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × n × d , F , P ) . (D.8) ( iv ) Conclusion. W e sum the inequalities ( D.6 ), ( D.7 ), and ( D.8 ). Let ∥ δ W ∥ 2 K β denote the total squared norm of the difference in the output, whic h is the sum of the squared norms of all comp onen ts. Similarly , let ∥ δ w ∥ 2 K β denote the norm of the input difference. Combining the estimates, we find ∥ δ W ∥ 2 K β ( F , P ) = ∥ δ Y ∥ 2 S 2 β ( R , F , P ) + ∥ δ Z ∥ 2 H 2 β ( R d , F , P ) + ∥ δ U ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) + ∥ δ V ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) + + ∥ δ U ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) + ∥ δ V ∥ 2 H 2 , 2 β,ρ ( R n × n × d , F , P ) ≤ ˜ C β ∥ δ z ∥ 2 H 2 β ( R d , F , P ) + ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × d , F , P ) + ∥ δ u ∥ 2 S 2 , 2 β,ρ ( R n × n , F , P ) + ∥ δ v ∥ 2 H 2 , 2 β,ρ ( R n × n × d , F , P ) ≤ ˜ C β ∥ δ w ∥ 2 K β ( F , P ) , where ˜ C dep ends only on the Lipschitz-con tin uity constants, the weigh t parameter k , the maturit y T and the moments of X . By choosing β > ˜ C , the factor ˜ C β b ecomes strictly less than 1. This prov es that the map Φ is a contraction on the Banac h space K β ( F , P ) when β > ˜ C . Consequen tly , b y the Banach fixed-p oin t theorem, there exists a unique fixed p oin t W ⋆ ∈ K β ( F , P ) such that W ⋆ = Φ( W ⋆ ) . This fixed p oin t is the unique solution to the BSDE system ( 3.7 ) in K β ( F , P ) . The second part of the theorem is a direct consequence of Lemma 2.10 . 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment