원시 나노포어 신호 오류 교정과 HMM 기반 CERN
CERN은 합성 데이터와 실제 세그멘테이션 결과를 이용해 숨은 마르코프 모델(HMM)을 두 단계에 걸쳐 학습하고, 수정된 Viterbi 알고리즘으로 과분할(oversegmentation) 오류와 신호 잡음을 동시에 정정한다. 이를 통해 RawHash2와 같은 기존 원시 신호 매핑 도구의 정확도를 크게 향상시키면서 전체 파이프라인의 연산 비용은 1% 이하로 유지한다.
저자: Simon Ambrozak, Ulysse McConnell, Bhargav Srinivasan
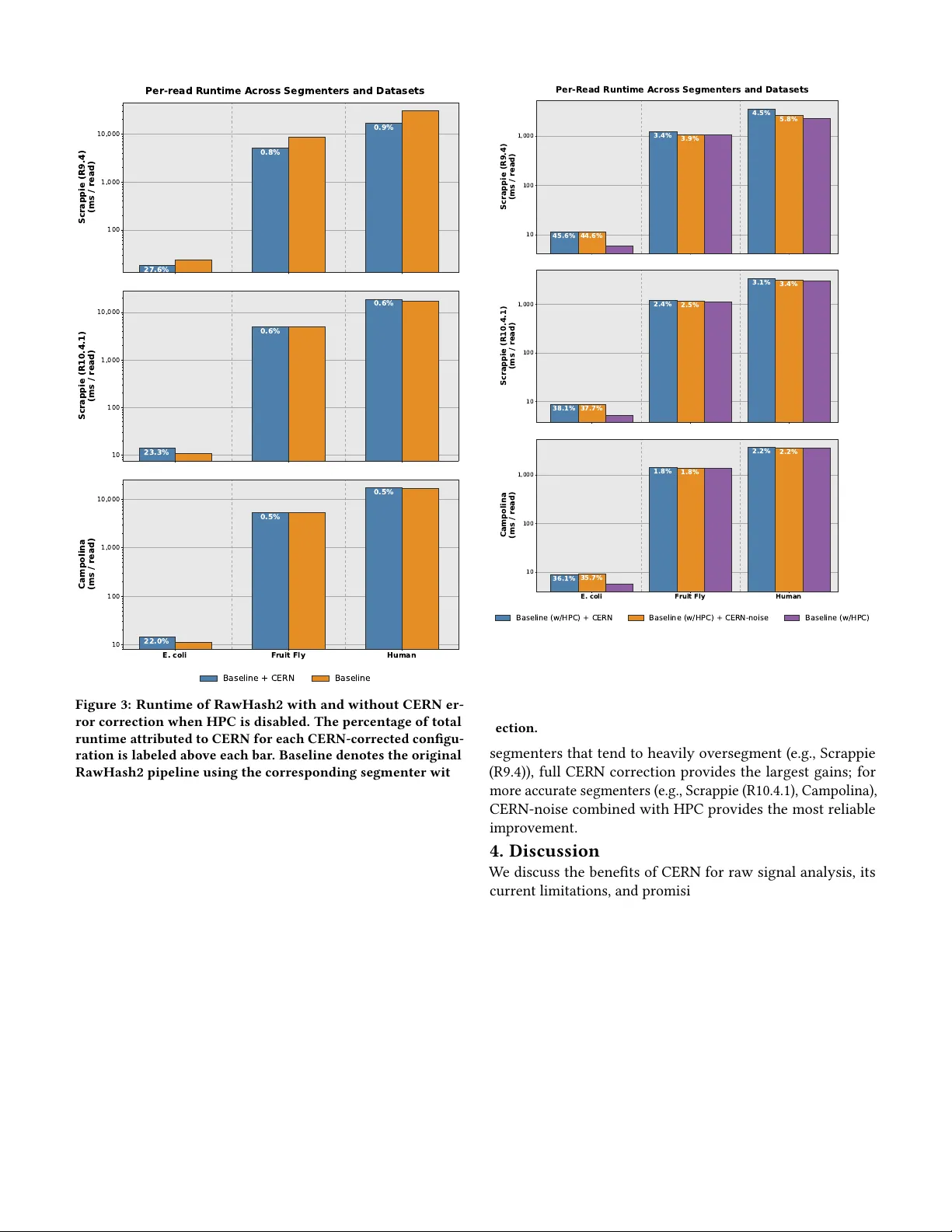
본 논문은 나노포어 시퀀싱에서 원시 전류 신호를 직접 활용하는 분석 파이프라인이 직면한 핵심 문제, 즉 세그멘테이션 단계에서 발생하는 과분할 및 잡음 오류를 해결하기 위해 ‘CERN’이라는 새로운 오류 교정 메커니즘을 제안한다. 기존의 통계 기반 롤링 t‑test 세그멘터는 파라미터 튜닝이 필요하고 과분할을 일으키며, 최신 딥러닝 기반 세그멘터는 GPU 의존도가 높아 실시간 분석에 부적합한 단점이 있다. 이러한 배경에서 저자들은 숨은 마르코프 모델(HMM)을 선택해 오류 패턴을 학습하고, 수정된 Viterbi 알고리즘으로 효율적인 추론을 수행한다.
CERN의 학습 과정은 두 단계로 구성된다. 첫 번째 단계에서는 합성 DNA 서열과 나노포어 포어 모델을 이용해 잡음이 전혀 없는 이상적인 이벤트 시퀀스를 생성한다. 초기 HMM은 균등한 상태 전이와 넓은 가우시안 방출 분포(μ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기