CERN: Correcting Errors in Raw Nanopore Signals Using Hidden Markov Models
Nanopore sequencing can read substantially longer sequences of nucleic acid molecules than other sequencing methods, which has led to advances in genomic analysis such as the gapless human genome assembly. By analyzing the raw electrical signal reads…
Authors: Simon Ambrozak, Ulysse McConnell, Bhargav Srinivasan
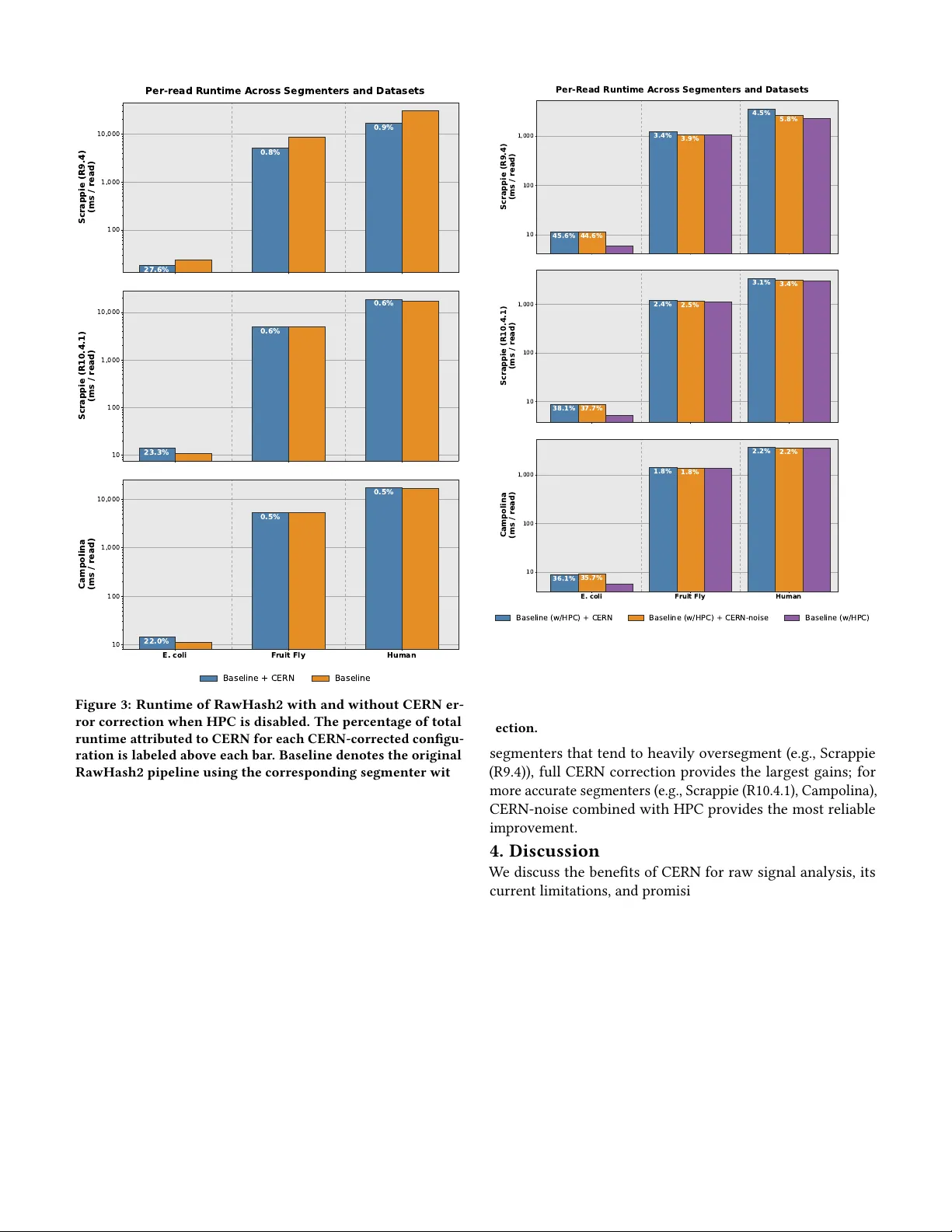
CERN: Correcting Errors in Raw Nanopore Signals Using Hidden Markov Models Simon Ambrozak 1 Ulysse McConnell 2 Bhargav Srinivasan 1 Burak Ozkan 3 Can Firtina 1 1 University of Maryland 2 ETH Zurich 3 Bilkent University Abstract: Nanopore sequencing can read substantially longer sequences of nucleic acid mole cules than other se quencing meth- ods, which has led to advances in genomic analysis such as the gapless human genome assembly . By analyzing the raw electrical signal reads that nanop ore sequencing generates from molecules, existing works can map these reads without translating them into DNA characters (i.e., basecalling), allowing for quick and ecient analysis of se quencing data. However , raw signals often contain errors due to noise and mistakes when processing them, which limits the overall accuracy of raw signal analysis. Our goal in this work is to detect and correct errors in raw signals to improve the accuracy of raw signal analyses. T o this end, we propose CERN, a mechanism that trains and utilizes a Hidden Markov Model (HMM) to accurately correct signal errors. Our extensive evaluation on various datasets including E. coli , Fruit Fly , and Human genomes shows that CERN 1) consistently improv es the overall mapping accuracy of the underlying raw signal analysis tools, 2) minimizes the burden on segmentation algorithm optimization with newer nanopore chemistries, and 3) functions without causing substantial computational ov erhead. W e conclude that CERN provides an eective mechanism to systematically identify and correct the errors in raw nanopore signals before further analysis, which can enable the development of a new class of error correction mechanisms purely designed for raw nanopore signals. Source Code: CERN is available at https://github.com/ STORMgroup/CERN . W e also provide the scripts to fully repro- duce our results on our GitHub page. 1. Introduction Nanopore sequencing technology has enabled the high- throughput sequencing of ver y long nucleic acid molecules (e .g., DNA), called long reads , often excee ding thousands of bases in length [ 1 – 23 ]. These long reads are particularly use- ful for many applications in genomics such as identifying complex and repetitive regions of genomes [ 24 ], and con- structing gapless assemblies [ 25 ]. T o sequence these long molecules, nanopore sequencing produces series of noisy elec- trical signals based on the ionic current disruptions that nucleic acid molecules generate as each nucleotide passes thr ough a nanometer-scale pore, called a nanopore . Apart fr om the capabilities to produce ultra long reads up to a fe w million bases, nanopor e sequencing provides two unique benets. First, nanopore sequencing enables stopping the se- quencing process of a read (i.e ., Read Until [ 26 ]) or the entire sequencing run (i.e., Run Until [ 27 ]) without fully sequenc- ing, a technique known as adaptive sampling . This can lead to signicant reductions in sequencing time and cost. T o de cide if a sequencing process should stop early , tools can analyze raw nanopore signals as these signals are generated in real- time . Second, the small scale of nanop ores allows for portable handheld sequencers which can be used in mobile and resource- constrained environments without access to cloud computing. Such situations might require minimal computational latency for eective adaptive sampling. With capabilities including ultra long reads, adaptive sampling and portable sequencing, many analysis pipelines use nanop ore sequencing for various applications such as telomere-to-telomere gapless genome as- sembly [ 25 ], metagenomics [ 28 ], complex structural variant detection [ 29 ], and in-the-eld analyses such as continuous outbreak tracing [ 30 ]. T o enable many of these applications, raw nanopore electri- cal signals are mainly analyzed in two ways. First, the most common approach is to translate these raw nanopore signals into human-readable nucleotide sequence, which is known as basecalling . T o accurately translate from noisy electrical sig- nals to nucleotide sequences, these basecalling techniques com- monly rely on comple x machine learning (ML) models [ 31 – 48 ] that usually combine several layers of CNNs [ 43 ], transform- ers [ 47 ], and decoders such as CRF [ 49 ] or CTC [ 43 ]. How- ever , these approaches are usually costly and require resource- intensive devices such as GP Us [ 31 , 32 , 34 , 36 – 50 ]. Second, to avoid the signicant computational demand of basecalling, several approaches [ 26 , 51 – 68 ] directly analyze raw nanopore signals without base calling them. These raw signal analysis approaches pro vide substantial benets in terms of the com- putational resources they r equire compared to a pipeline that uses computationally costly basecalling with GP Us or CP Us. Reducing the computational overhead is particularly useful for scalability (i.e ., how many pr ocessing units or CP U threads needed to process the entir e o w cell in real-time), latency (i.e., how quickly a real-time decision can be made), and energy reasons ( e.g., what is the required power draw and total energy from a mobile device). Although existing raw signal analysis appr oaches provide substantial b enets in terms of lower computational over- head, they generally exhibit lower accuracy than the anal- yses pipelines that use basecalling. This is mainly because 1) basecalling techniques are heavily optimized for very accu- rate translation from noisy electrical signals and 2) the signal processing algorithms used in raw signal analysis are prone to making errors, which usually propagates to the later steps in signal analysis and reduces the overall accuracy of these approaches. A common initial processing step in raw signal analyses aims to identify the segments in electrical signals, called e vents , 1 before further processing the signals. Each event usually cor- responds to the series of ele ctrical signals measured when a particular sequence of nucleotides of a xed length k (i.e., k-mer) pass through a nanopore. By identifying events, raw signal analyses techniques can dierentiate between signal re- gions that correspond to sequencing of each successive k-mer of a nucleic acid mole cule for further processing. For example, the state-of-the-art raw signal mapping tool, RawHash2 [ 59 ], uses the average signal value of each event to generate a hash value from several consecutive quantized event values before performing a hash-based seeding. Existing lightweight segmen- tation algorithms, such as the rolling t-test in Scrappie [ 69 ], aim to nd statistically signicant changes within a window of sig- nals to identify events. Howev er , these approaches inher ently generate a large number of spurious events from a raw signal, often called o versegmentation errors [ 64 ], and they require op- timizing their parameters depending on the nanopore versions (i.e., chemistries such as R9.4 and R10.4.1) [ 70 ], which heavily impacts the accuracy of downstream analysis (discussed in Section 3.2). Due to the signicant impact that the overseg- mentation errors cause in raw signal analyses, a recent work, Campolina [ 70 ], proposes a deep learning-based design for accurately identifying segmented regions while r educing the over-segmentation issues. Such deep learning-base d works have potential in both 1) performing more accurate segmen- tation and 2) subsequently improving the downstream raw signal analysis. However , these deep learning approaches are mainly practical when using GP Us, as their CP U executions are substantially slower than lightweight statistical segmentation algorithms [ 70 ]. T o naively and quickly correct these ov ersegmentation er- rors, the most common approach used in sev eral raw signal works [ 53 , 58 – 60 , 64 ] is to perform homopolymer compression (HPC) to quickly identify consecutive events with similar sig- nal amplitudes and compress them into one (e.g., by picking the rst event in a homop olymer run), similar to error cor- rection mechanisms in assembly [ 71 ] and in read mapping tools [ 72 ] for base called se quences. Although HPC signi- cantly improves the overall raw signal analysis by reducing some of the oversegmentation err ors, it can remove error-free and informative events, and accuracy is still limited by the underlying segmentation algorithm. T o our knowledge, there is no error correction mechanism that can systemically learn from the errors that a segmentation algorithm can make for raw nanopore signals. Our goal is to substantially impr ove the accuracy of raw sig- nal analysis approaches that rely on segmentation algorithms by 1) correcting the errors that these algorithms make and 2) reducing their dependency on correct parameter setting for dierent nanopore chemistries. T o this end, we propose CERN, the rst mechanism that corrects raw signal events by learn- ing from the errors that a segmentation algorithm makes. T o eectively model typical event sequences, CERN uses spe cic probabilistic graph structure, Hidden Markov Models (HMMs), which ar e trained and utilized in three key steps. First, to learn from the ideal sequence of events, we update the probabilities of the HMM in the rst phase of our training step by using noise-free synthetic data. Second, to adapt the mo del to error patterns of specic segmentation algorithms, the next phase of training uses experimentally generated segmented events. The nal trained model provides us with a robust representation of event sequences tuned to a specic segmentation algorithm. Third, we use a modied decoding algorithm that nds the most likely path through the trained HMM, called the Viterbi algorithm , to identify and correct errors in real-world nanop ore event sequences. Our extensive e valuations on various segmentation al- gorithms using several datasets generate d using the latest nanopore chemistry (i.e ., R10.4.1) show that CERN can be used to consistently impr ove the accuracy of raw signal analysis ap- proaches that use a segmentation algorithm, such as raw signal mapping, without substantially increasing the computational overhead of these approaches. CERN makes the following key contributions: • W e propose CERN, the rst tool that corr ects nanopore event sequences by systemically learning from the errors that a segmentation algorithm makes. • W e show CERN’s framework is exible for ne-tuning to maximize its error correction benets with various segmen- tation algorithms and nanopore chemistries. • W e show that CERN reduces the parameter optimization requirement for newer chemistries, as segmentation param- eters designed for an older nanopore chemistr y (R9.4) can be used with a newer chemistry (R10.4.1) without requiring parameter re-optimization by correcting errors with CERN. • W e show that CERN-corrected events consistently impro ve the accuracy of the state-of-the-art raw signal analysis tool, RawHash2. • W e show that CERN adds minimal computational overhead, accounting for less than 1% of the total read mapping runtime for larger genomes. • W e show that CERN can complement the commonly used ho- mopolymer compression (HPC) mechanism, where applying the noise correction mode of CERN with HPC consistently improves accuracy acr oss all tested congurations. • W e identify new directions for impr oving raw signal analy- ses, as well as challenges to over come. • W e provide the open source implementation for training and using CERN at https://github.com/STORMgroup/CERN . 2. Methods 2.1. Overview CERN is a mechanism to correct the errors that segmentation algorithms make in raw nanopore event sequences by learning from these errors using Hidden Markov Mo dels (HMMs), as shown in Figure 1. T o achieve this, CERN uses a Gaussian HMM traine d via the Baum- W elch (BW) algorithm [ 73 ] in two stages, followed by a modied Viterbi algorithm for event correction during inference. CERN corrects raw nanop ore ev ents in three key steps. First, to build a base HMM that can eectively model nanopore 2 …A T T CG A CA G A… T r aining Signals Ba um-W el ch T r aining Sparse HMM Synthetic DNA Sequence P or e model-based E v ent s 0.97 -1.20 1.35 . . . . . . Se gment ed E v ent s -0. 4 2 0.13 1.96 . . . . . . Ba um-W el ch T r aining NEMO HMM Inf er ence Signals Se gment ed E v ent s 0.63 0.22 -1.21 . . . . . . E v ent Corr ection Corr ect ed E v ent s a ) b ) c ) R epeat until conv er gence Figure 1: O ver view of CERN. events without being inuenced by segmentation noise or biased toward a specic DNA sequence ( a ), CERN trains an HMM on synthetic, error-free event sequences derived from a nanopore pore mo del using the BW algorithm, which produces a sparsely connecte d HMM. Se cond, to enable the HMM to learn the error patterns of a specic segmentation algorithm ( b ), CERN reintroduces the missing transitions into the sparse HMM to make the HMM fully connected and trains the model on experimentally generated segmented events using the BW algorithm. W e refer to the resulting models as nanop ore event modeling HMMs (NEMO-HMMs). Third, to correct errors in a given sequence of input events during inference ( c ), CERN runs a modied Viterbi algorithm using the trained NEMO- HMM and interprets the resulting state path to 1) identify and remove oversegmentation errors and 2) reduce noise in the event values. 2.2. HMM T raining CERN trains the HMM using the BW algorithm in two stages: rst on synthetic data to build a base mo del , and then on ex- perimental data to learn segmentation-specic error patterns. Training on Synthetic Data. In the rst stage of training (Figure 1a), CERN trains the HMM on synthetic, error-free event sequences to build a base model that captures the ex- pected signal characteristics of nanop ore events. Training on synthetic data is important for three reasons. First, it avoids the risk of the HMM learning from segmentation errors that are present in real nanop ore data. Second, the learned emission means are accurate and noise-fr ee, allowing for the HMM to detect some amount of noise in experimental data. Third, it prevents the mo del from becoming biased toward a specic genome or DNA sequence. T o initialize the HMM, CERN begins with uniform initial state distributions and uniform transition probabilities, exclud- ing self-transitions. Each state is initialized with a Gaussian emission distribution with mean µ sampled uniformly b etween − 0.5 and 0.5 and standard deviation σ = 2. Using broad initial emission distributions allows the BW algorithm to eectively adapt the emission parameters to the observed data. T o generate synthetic training sequences, CERN randomly generates DNA sequences of long lengths (e.g., 100,000 bp long sequence) and obtains its expected nanopore event sequence by using a pore model , which describes the expe cted signal value for each possible k-mer inside the nanop ore. CERN then runs the BW algorithm using the initial HMM and the synthetic event sequence. Since the BW algorithm tends to converge to local minima when run on a single se quence, CERN generates a new random DNA sequence and its corresponding event se- quence each time the model converges and continues training. W e nd that this iterative approach r esults in more stable train- ing and better model parameters. Between each iteration of BW training, CERN trims transitions with probability p < 0.001 by setting them to zero, which produces a sparsely connected HMM that accelerates both subsequent training iterations and inference. On the nal iteration, after conv ergence, CERN generates a de Bruijn sequence that contains ev er y possible 10-mer ex- actly once and trains the HMM on the corresponding event sequence using the BW algorithm. Since this sequence cov- ers every possible transition b etween consecutive 9-mers, this step mitigates potential biases incurred during the previous training iterations on randomly generated sequences. Training on Experimental Data. In the second stage of training (Figure 1b), CERN trains the HMM on experimentally generated segmented events to learn the error patterns of a specic segmentation algorithm. T o enable this, CERN reintroduces the missing (i.e., zero- probability ) transitions that were remo ved during the rst stage of training into the sparse HMM. Self-transitions are initialized with an estimate of the oversegmentation rate for the target segmentation algorithm. The remaining reintroduced non- self-transitions are uniformly initialized such that the sum of these new transitions leaving each state equals the estimated undersegmentation rate. W e observe that small variations in these values have little ee ct on the training outcome, but reasonable initialization improves training stability . CERN then trains the HMM on experimentally generated events using 3 the BW algorithm. Since dierent segmentation algorithms produce dierent error patterns, CERN repeats this se cond stage of training separately for each segmentation algorithm, producing one distinct NEMO-HMM for correcting the ev ents output by each segmentation method. 2.3. Ecient Inference via a Modied Viterbi Algo- rithm During the rst stage of training, the HMM be comes sparsely connected due to transition trimming, which allows the Viterbi algorithm to run eciently by considering fewer transitions at each timestep. However , the second stage of training r ein- troduces all pre viously removed transitions, causing the HMM to become densely connected again. T o exploit the ecient sparse structure learned during the rst stage while also re- taining the non-sparse transitions learned from experimental data, CERN uses a modied Viterbi algorithm. T o achieve this, CERN tracks 1) transitions b elonging to the original sparse structure ( sparse transitions ) and 2) the ones reintroduced in the second stage ( non-sparse transitions ) of training. At each timestep of the modied Viterbi algorithm, CERN considers all sparse transitions but restricts the non- sparse transitions to only 1) self-transitions and 2) transitions from the state with the largest log-likelihood at the pre vious timestep. This heuristic allows CERN to perform inference on the underlying sparse HMM while only considering two additional predecessors per state at each timestep, substantially reducing the computational cost compared to the standard Viterbi algorithm while producing nearly identical results. 2.4. Correcting Ev ents Using the trained NEMO-HMM and the mo died Viterbi algo- rithm, CERN corrects errors in ev ent sequences in two ways, as shown in Figure 2: 1) removing oversegmentation errors and 2) reducing noise in event values. It is possible to run CERN with both mechanisms, or to only use one of the two. Removing Oversegmentation Errors. T o identify the ov er- segmentation errors, CERN uses the Viterbi paths where a state takes a transition to its own state (i.e., self-transition) one or more times in a row . Since the path remains in the same state for multiple events, CERN interprets this as the same event being duplicated or oversegmented. T o correct an oversegmentation error , CERN replaces these o versegmented events with a single event whose value is the average of the oversegmented events. Reducing Noise in Event V alues. After removing overseg- mentation errors, CERN reduces noise in the remaining event values. T o this end, CERN computes the dierence b etween each event value and the emission mean of the HMM state it is aligned with in the Viterbi path. These dierences represent how far each ev ent deviates from the model’s expectation. Due to the relatively small number of states in the HMM compared to the number of possible 9-mers, these dierences are not expected to b e zero. Therefore, to detect local noise, CERN takes a windowed average of the dierences between event val- ues and state means. This windowed average is subsequently NEMO HMM Inf er ence Signals 0.63 0.22 -1.21 Se gment ation -0.30 -1.38 Vit erbi 5 1 6 2 6 Vit erbi P ath E v ent Mer ging & Noise R ed uction 0.62 0.23 -1.30 -0.31 R a w E v ent s Corr ect ed E v ent s Figure 2: Error correction pipeline in CERN. The Viterbi path of states through the trained NEMO-HMM is used to identify and correct erroneous events. subtracted from the central event value in the middle of the window to produce the noise-adjusted sequence. This step is only performe d after stay errors have b een removed. The windowed approach r ecognizes larger scale dierences in se- quential ev ent values that may be represented as skewed signal values, and thus accounts for noise in the sequencing metho d. 3. Results 3.1. Evaluation Methodology W e evaluate CERN by integrating it into the state-of-the-art raw signal mapping tool, RawHash2 [ 59 ]. RawHash2 per- forms segmentation, sketching, seeding, and chaining on raw nanopore events to map raw signals to a reference genome. W e measure the impact of CERN on the accuracy (i.e., F1 score) and runtime of RawHash2 read mapping. Segmentation Algorithms. W e evaluate CERN with three segmentation congurations. The rst two are based on the t-test-based segmentation algorithm in Scrappie [ 69 ]. Scrap- pie’s segmentation algorithm performs a rolling W elch’s t-test with windows of dierent lengths to identify points in the raw signal to dete ct signicant changes. The rst segmen- tation conguration uses the t-test parameters optimized for the R9.4 chemistry , which we call Scrappie (R9.4). The se cond segmentation conguration uses the parameters optimized for the R10.4.1 chemistry , called Scrappie (R10.4.1). The third segmentation algorithm is a deep learning-based tool, called Campolina [ 70 ]. Campolina provides more accurate but slow er segmentation than Scrappie. W e integrate all of these segmen- tation algorithms within RawHash2 to perform end-to-end raw signal mapping. Training Conguration. W e initialize the HMM with 196 states and train it using the Baum- W elch (BW) algorithm on the expected R10.4.1 nanopore events of randomly generated 100,000 bp DNA sequences for 30 iterations. After the rst stage of training, we train the HMM on the expected events of a de Bruijn sequence containing ev er y 10-mer exactly once. The pore model we reference for converting DNA sequences to expected event sequences is the dna _ r10.4.1 _ 400bps _ 9mer model generated by Uncalled4 [ 56 ]. 4 For each of the three segmentation algorithms, we train a distinct NEMO-HMM by running the second stage of training on 2,000,000 ev ents generated from the E. coli sequencing data, resulting in three NEMO-HMMs for corr ecting Scrappie (R9.4), Scrappie (R10.4.1), and Campolina events, respectively . W e use a separate set of reads from E. coli for this training than those used for evaluation to avoid training and evaluating on the same data. Datasets. W e evaluate CERN on three datasets of raw nanopore reads generated using the R10.4.1 chemistry , as shown in T able 1: D1 ( E. coli ), D2 ( D. melanogaster or Fruit Fly), and D3 ( H. sapiens or Human). For each dataset, we evaluate the mapping of 10,000 reads before and after error correction with CERN. Ground Truth. T o generate the ground truth read-mappings, we basecall each read using Dorado, then map the basecalled reads using minimap2. T o generate the number of true posi- tives, false positives, true negatives, and false negatives, we uti- lize Uncalled4’s pafstats function to compare the RawHash read mappings and the minimap2 read mappings. More de- tails on the tool versions used can be found in Supplementar y T able S10. Evaluation Setup. W e compare four congurations: 1) no cor- rection (Baseline), 2) homopolymer compression (HPC), which is the most commonly used error reduction mechanism in prior raw signal analysis works [ 53 , 58 , 59 , 64 ], 3) CERN correction, and 4) CERN in combination with HPC (HPC+CERN). For the combined conguration, we evaluate both the full CERN cor- rection and CERN-noise, which applies only the noise correc- tion mechanism of CERN without r emoving ov ersegmentation errors. When combined, CERN is applied rst and then HPC is applied during RawHash2 mapping. W e run CERN error correction using a single EPYC-7313 CP U core with 32 GB of RAM. Each read mapping test uses RawHash2 with 16 EPY C-7313 cores and 256 GB of RAM. W e use the sensitive preset of RawHash2 for the D1 and D2 datasets and the fast preset for the D3 dataset. Events are loaded using the --events-file ag for both corrected and uncorrected events. W e disable the built-in HPC when evalu- ating congurations without HPC. When measuring runtimes, we measure only the CERN error correction and RawHash2 read mapping steps, e xcluding index creation and segmenta- tion. W e provide the parameter settings and versions for each tool in Supplementary T ables S9 and S10 respectively . W e provide the scripts to fully r eproduce our results on the GitHub repository at https://github.com/STORMgroup/CERN . 3.2. Read Mapping Accuracy CERN vs. Baseline and HPC. T able 2 shows the F1 scores of RawHash2 read mapping with no error correction (Base- line), HPC, and CERN correction across three segmentation algorithms on the D1, D2, and D3 datasets. Extended results reporting F1 score, recall, precision, and the percentage of reads mapped across all tested congurations are available in Supplementary T ables S3, S4, and S5. W e make four key observations. First, CERN consistently improves the F1 score over the base- line across all combinations, while HPC does not. CERN pro- vides especially large improvements when paired with Scrappie (R9.4), increasing the F1 score from 0.177 to 0.693 on D1, from 0.324 to 0.814 on D2, and from 0.001 to 0.757 on D3. W e believe this is because Scrappie (R9.4) tends to heavily oversegment R10.4.1 signals, and one of the primary ways CERN corrects events is by identifying and removing these oversegmentation errors. In contrast, HPC reduces accuracy in se veral cases ( e.g., from 0.882 to 0.843 for Campolina on D2), as it can remove cor- rect and informative events along with err oneous ones. More detailed results on the eects of CERN and HPC can be found in Supplementary T ables S6 and S7. Second, CERN outperforms HPC in all cases except one: on D1 with Scrappie (R10.4.1), where HPC achie ves an F1 of 0.649 compared to 0.633 for CERN. This demonstrates that CERN is a more accurate and general-purpose error corr ection mechanism than HPC across dierent segmentation algorithms and datasets in most cases. Third, CERN-corrected Scrappie (R9.4) ev ents achieve sub- stantially higher accuracy than uncorrected Scrappie (R10.4.1) events across all datasets (e.g., 0.693 vs. 0.612 on D1, 0.814 vs. 0.737 on D2, 0.757 vs. 0.693 on D3). On D1 and D2, CERN-corrected Scrappie (R9.4) ev ents even outperform CERN- corrected Scrappie (R10.4.1) events (e.g., 0.814 vs. 0.742 on D2). Since Scrappie (R9.4) heavily oversegments the signal, w e be- lieve this provides CERN with more information ab out the underlying signal structure than Scrappie (R10.4.1), allowing CERN to perform better as it excels at merging ov ersegmented events. This result demonstrates that CERN can reduce the dependency of raw signal analysis on chemistry- specic segmentation parameter optimization, as seg- mentation parameters designed for an older chemistr y (R9.4) can be eectively used with a newer chemistry (R10.4.1) when corrected by CERN. Fourth, CERN improves accuracy for both t-test-base d (Scrappie (R9.4), Scrappie (R10.4.1)) and deep learning-based (Campolina) segmentation algorithms. The F1 scores with Campolina are substantially higher than those with the t-test- based segmenters across all congurations, since Campolina provides more accurate segmentation with fewer ov er- and un- dersegmentation errors. Even in this case, CERN still provides improvements, showing that CERN can benet raw signal anal- ysis even when the underlying segmentation algorithm is al- ready highly accurate. Supplementar y T able S2 also shows that the highest F1 score observed for each dataset was achieved by using Campolina in combination with CERN. Combining CERN with HPC. T able 3 shows the F1 scor es when combining CERN with HPC, wher e CERN is applied rst and RawHash2 is then run with its built-in HPC. W e evaluate three congurations: HPC alone, CERN-noise combined with HPC, and full CERN combined with HPC. W e make three key observations. First, applying CERN-noise in combination with HPC con- 5 T able 1: Details of datasets used in our evaluation. Organism Chemistry Flow Cell Reads A vg. Length Basecaller Data Source D1 E. coli CFT073 R10.4.1 e8.2 FLO-MIN114 10,000 776 Dorado SUP v1.4.0 [ 74 ] D2 D. melanogaster R10.4.1 e8.2 FLO-MIN114 10,000 6,561 Dorado SUP v0.9.2 [ 75 ] D3 H. sapiens (HG002) R10.4.1 e8.2 FLO-PRO114M 10,000 18,728 Dorado SUP v1.4.0 [ 76 ] All datasets use R10.4.1 e8.2 nanopore chemistry at 400 bases/sec translocation sp eed. D1 and D3 are sampled at 5,000 Hz; D2 at 4,000 Hz. Each dataset contains 10,000 raw nanopore reads subsampled from the original run. T able 2: F1 scores of RawHash2 read mapping across multiple datasets, segmentation algorithms, and error correction mech- anisms. Dataset Segmentation Baseline HPC CERN D1 ( E. coli ) Scrappie (R9.4) 0.177 0.510 0.693 Scrappie (R10.4.1) 0.612 0.649 0.633 Campolina 0.811 0.768 0.819 D2 (Fruit Fly) Scrappie (R9.4) 0.324 0.656 0.814 Scrappie (R10.4.1) 0.737 0.723 0.742 Campolina 0.882 0.843 0.886 D3 (Human) Scrappie (R9.4) 0.001 0.006 0.757 Scrappie (R10.4.1) 0.693 0.696 0.762 Campolina 0.864 0.832 0.865 T able 3: F1 scores across datasets and segmentation algorithms using HPC with varying CERN congurations. CERN-noise applies only the noise correction mechanism of CERN without event merging. Dataset Segmentation HPC CERN-noise + HPC CERN + HPC D1 ( E. coli ) Scrappie (R9.4) 0.510 0.515 0.682 Scrappie (R10.4.1) 0.649 0.656 0.641 Campolina 0.768 0.772 0.768 D2 (Fruit Fly) Scrappie (R9.4) 0.656 0.660 0.786 Scrappie (R10.4.1) 0.723 0.732 0.716 Campolina 0.843 0.846 0.839 D3 (Human) Scrappie (R9.4) 0.006 0.007 0.703 Scrappie (R10.4.1) 0.696 0.700 0.723 Campolina 0.832 0.836 0.823 sistently increases the F1 score compared to HPC alone across all combinations. This demonstrates both the standalone ef- fectiveness of the noise correction mechanism and the ability of CERN and HPC to complement each other for a consistent improvement in accuracy . Second, full CERN combine d with HPC substantially in- creases the F1 score compared to HPC alone for Scrappie (R9.4) across all datasets (e .g., from 0.006 to 0.703 on D3). Since Scrap- pie (R9.4) heavily oversegments the signal, applying CERN rst allows the oversegmented ev ents to b e accurately merged before HPC compresses the resulting sequence. Third, for Scrappie (R10.4.1) and Campolina, full CERN com- bined with HPC does not consistently improve the F1 score compared to HPC alone. There are cases where the F1 score slightly decreases (e .g., from 0.843 to 0.839 for Campolina on D2), and cases where it increases ( e.g., from 0.696 to 0.723 for Scrappie (R10.4.1) on D3). W e b elieve this inconsistency arises because both CERN and HPC aim to remov e stay errors: when the underlying segmenter does not heavily oversegment (as in Scrappie (R10.4.1) and Campolina), applying both mechanisms can remove a r elatively large number of correct ev ents, leading to information loss. For these segmenters, using CERN-noise with HPC provides a more r eliable conguration, as it avoids redundant event merging while still beneting from the noise correction. 3.3. Computational Overhead Runtime of CERN without HPC. Figure 3 shows the runtime of RawHash2 read mapping with no correction and CERN correction across all datasets and segmentation algorithms. The exact runtimes of CERN can b e found in T able S1. W e make two key observations. First, CERN adds a very small computational overhead com- pared to the read mapping step, especially for larger genomes. For the D2 and D3 datasets, CERN correction accounts for less than 1% of the total read mapping runtime. For the D1 dataset, the overhead is higher (22–28%), which we attribute to the already very fast read mapping times for this small genome (below 25 ms per read on average). Second, CERN substantially reduces the total read mapping runtime for Scrappie (R9.4)-segmented reads compared to the baseline without correction. Since Scrappie (R9.4) heavily over- segments the signal, CERN merges many events in each read, reducing the event sequence length and ther eby spee ding up the mapping process. This brings the mapping runtime of Scrappie (R9.4)-segmented reads closer to that of Scrappie (R10.4.1) and Campolina segmented reads. Runtime of CERN with HPC. HPC-corrected reads map substantially faster than all other congurations. This is be- cause HPC compresses both the quer y reads and the reference index in RawHash2, resulting in shorter sequences on b oth sides and thus higher thr oughput. This runtime advantage can be seen clearly in Supplementary T able S6. This motivates the combined evaluation with CERN, as analyzed below . Figure 4 shows the runtime of RawHash2 read mapping when using HPC in combination with CERN. W e make two key observations. First, combining CERN with HPC brings the total runtime of CERN-corrected RawHash2 much closer to that of RawHash2 with HPC alone, particularly for the D2 and D3 datasets. This shows that CERN can improve the accuracy of a raw signal 6 100 1,000 10,000 Scrappie (R9.4) (ms / read) 27.6% 0.8% 0.9% 10 100 1,000 10,000 Scrappie (R10.4.1) (ms / read) 23.3% 0.6% 0.6% E. coli F ruit Fly Human 10 100 1,000 10,000 Campolina (ms / read) 22.0% 0.5% 0.5% Per-read Runtime Across Segmenters and Datasets Baseline + CERN Baseline Figure 3: Runtime of RawHash2 with and without CERN er- ror correction when HPC is disable d. The percentage of total runtime attributed to CERN for each CERN-corrected congu- ration is lab eled above each bar . Baseline denotes the original RawHash2 pipeline using the corresponding segmenter with- out CERN error correction. analysis pipeline while adding minimal computational over- head when used in combination with HPC. Second, when used with HPC, the share of total runtime attributed to CERN increases compared to the conguration without HPC, since HPC reduces the mapping time. How ever , the CERN ov erhead generally remains below 5% for the D2 and D3 datasets. For D1, the ov erhead is substantially higher (up to 46%), which is again due to the already very fast mapping times for this small genome. These results show that CERN is practical for real-time raw signal analysis pipelines, as its computational cost is negligible relative to the downstream read mapping step for datasets of typical size. W e conclude that CERN provides consistent improvements in read mapping accuracy across dierent segmentation algo- rithms and datasets while adding minimal computational over- head to the raw signal analysis pipeline. The best-performing conguration depends on the segmentation algorithm: for 10 100 1,000 Scrappie (R9.4) (ms / read) 45.6% 44.6% 3.4% 3.9% 4.5% 5.8% 10 100 1,000 Scrappie (R10.4.1) (ms / read) 38.1% 37.7% 2.4% 2.5% 3.1% 3.4% E. coli F ruit Fly Human 10 100 1,000 Campolina (ms / read) 36.1% 35.7% 1.8% 1.8% 2.2% 2.2% Per-Read Runtime Across Segmenters and Datasets Baseline (w/HPC) + CERN Baseline (w/HPC) + CERN-noise Baseline (w/HPC) Figure 4: Runtime of RawHash2 with HPC and varying CERN congurations. The percentage of total runtime attributed to CERN for each CERN-corrected conguration is lab eled ab ove each bar . Baseline denotes the original RawHash2 pipeline using the corresponding segmenter without CERN error cor- rection. segmenters that tend to heavily oversegment ( e.g., Scrappie (R9.4)), full CERN correction provides the largest gains; for more accurate segmenters ( e.g., Scrappie (R10.4.1), Campolina), CERN-noise combine d with HPC provides the most reliable improvement. 4. Discussion W e discuss the benets of CERN for raw signal analysis, its current limitations, and promising dir ections for future work. Benets for Raw Signal Analysis. The primary benet of CERN is its ability to improve the accuracy of raw signal analy- sis tools that rely on segmentation algorithms. The motivation behind raw signal analysis is to perform analyses faster and with few er computational resour ces than basecalling, enabling real-time decision-making and large-scale analyses. This ef- ciency comes at the cost of accuracy , as signal processing algorithms are inherently mor e error-prone than basecalling, which has be come highly accurate with the release of the R10.4.1 nanopore chemistry [ 77 ]. By correcting the errors that segmentation algorithms introduce, CERN can alleviate the impact of noisy and erroneous events on downstream raw sig- 7 nal analyses without requiring the computational overhead of basecalling. Additionally , CERN can reduce the burden of chemistry- specic segmentation parameter optimization. Our results show that applying CERN to Scrappie (R9.4), a segmenter that severely oversegments R10.4.1 signals, results in read map- ping accuracy that is substantially higher than using Scrappie (R10.4.1) without correction across all datasets. In some cases, CERN-corrected Scrappie (R9.4) ev ents even outperform CERN- corrected Scrappie (R10.4.1) events. This suggests that an ef- fective strategy could be to apply CERN to a computationally inexpensive segmentation algorithm that tends to overseg- ment, rather than investing eort in optimizing segmentation parameters for each new chemistry . Such an approach can im- prove accuracy while saving the eort required for parameter tuning. Limitations. There are two main limitations that CERN cur- rently faces. First, CERN does not address undersegmentation errors. During our e valuations, we nd that CERN struggles to model missing events as well as other comple x segmentation errors that distort the signal more heavily than event dupli- cation or small amounts of noise. In our initial eorts, we nd that attempting to model these complex errors also signif- icantly increases the error correction runtime. W e expect that a me chanism capable of detecting and correcting such com- plex segmentation errors would likely r equire computational resources comparable to basecalling, which would reduce the practical benets of raw signal analysis. However , it is possible that alternativ e model designs could better capture and corr ect these patterns. Second, CERN does not support nucleic acid modications such as methylation. The synthetic DNA sequences used to train CERN contain only unmodied bases, for two reasons. First, the pore model les that CERN relies on for generating expected event sequences describe only unmodied bases. Sec- ond, incorporating base modications substantially expands the k-mer space: considering a single modication type in R10.4.1 chemistr y increases the number of possible 9-mers from 4 9 = 262 , 144 to 5 9 = 1 , 953 , 125. This expansion greatly increases the complexity of mo deling nanopore events and would most likely require a larger HMM with more states, increasing the runtime of CERN. Future W ork. W e identify promising directions for future work. The area of correcting raw nanopore signals remains under-explored. CERN is the rst mechanism that system- atically applies learned nanopore dynamics to corr ect errors in event sequences. W e believe there is an opportunity for tools that can detect sequences or regions of a sequence that are highly erroneous. Such detection could b e used to ag high-error reads to pre vent further processing, or to leverage Read Until technology [ 26 ] to eject a read during sequencing and begin generating a new one that is more likely to contain high-quality information. While CERN addresses a key challenge in raw signal anal- ysis by correcting segmentation errors, sev eral opportunities remain to extend this work. Investigating new methods of error correction, addressing undersegmentation errors, and supporting modied bases has the potential to further improve the accuracy and scope of raw signal analyses. 5. Conclusion W e introduce CERN, the rst mechanism that corrects raw nanopore event se quences by learning from the errors that seg- mentation algorithms make using Hidden Markov Models. W e nd that CERN 1) consistently improves the read mapping accu- racy of the state-of-the-art raw signal analysis tool, RawHash2, across all tested segmentation algorithms and datasets, 2) re- duces the dep endency of raw signal analysis on chemistry- specic segmentation parameter optimization, as segmentation parameters designed for an older nanopore chemistry (R9.4) can be eectively used with a newer chemistr y (R10.4.1) when corrected by CERN, and 3) adds minimal computational over- head. W e show that CERN-corrected events from a segmenter optimized for R9.4 chemistry (Scrappie (R9.4)) achieve substan- tially higher mapping accuracy on R10.4.1 data than uncor- rected events from a segmenter optimized for R10.4.1 (Scrappie (R10.4.1)) across all datasets, demonstrating that CERN can al- leviate the burden of re-optimizing segmentation parameters for each new nanopore chemistry . W e also show that CERN improves accuracy for both lightweight statistical segmenters and more accurate deep learning-based segmenters, indicat- ing that CERN pro vides general-purpose benets regardless of the underlying segmentation approach. W e hope and believe that CERN enables future work. Correcting raw nanopore signals is an under-explored area, and CERN demonstrates that learned models of nanop ore dynamics can systematically improve e vent quality . W e believe this can inspire a new class of error correction mechanisms designed specically for raw nanopore signals. Acknowledgments W e thank the STORM Research Group members for their fee d- back. STORM Research Group acknowledges the generous gifts from AMD . References [1] G. Menestrina, “Ionic channels formed byStaphyloco ccus aureus alpha-toxin: V oltage- dependent inhibition by divalent and trivalent cations, ” The Journal of Membrane Biology , vol. 90, no. 2, pp. 177–190, Jun. 1986. [2] G. M. Cherf et al. , “ Automated forward and reverse ratcheting of DNA in a nanopore at 5- Å precision, ” Nature Biote chnology , vol. 30, no. 4, pp. 344–348, Apr . 2012. [3] E. A. Manrao et al. , “Reading DNA at single-nucleotide resolution with a mutant Msp A nanopore and phi29 DNA polymerase, ” Nature Biotechnology , vol. 30, no. 4, pp. 349–353, Apr . 2012. [4] A. H. Laszlo et al. , “Decoding long nanopore sequencing reads of natural DNA, ” Nature Biotechnology , vol. 32, no. 8, pp. 829–833, A ug. 2014. [5] D. Deamer et al. , “Three decades of nanopore se quencing, ” Nature Biotechnology , vol. 34, no. 5, pp. 518–524, May 2016. [6] J. J. K asianowicz et al. , “Characterization of individual polynucleotide molecules using a membrane channel, ” Proceedings of the National Academy of Sciences , vol. 93, no. 24, pp. 13 770–13 773, Nov . 1996. [7] A. Meller et al. , “Rapid nanopore discrimination between single polynucleotide molecules, ” Proceedings of the National Academy of Sciences , vol. 97, no. 3, pp. 1079– 1084, Feb. 2000. [8] D. Stoddart et al. , “Single-nucleotide discrimination in immobilize d DNA oligonu- cleotides with a biological nanopore, ” Proceedings of the National Academy of Sciences , vol. 106, no. 19, pp. 7702–7707, May 2009. [9] A. H. Laszlo et al. , “Detection and mapping of 5-methylcytosine and 5- hydroxymethylcytosine with nanopore Msp A, ” Proceedings of the National Academy of Sciences , vol. 110, no. 47, pp. 18 904–18 909, Nov . 2013. [10] J. Schreiber et al. , “Error rates for nanopore discrimination among cytosine, methyl- 8 cytosine, and hydro xymethylcytosine along individual DNA strands, ” Proceedings of the National Academy of Sciences , vol. 110, no. 47, pp. 18 910–18 915, Nov . 2013. [11] T . Z. Butler et al. , “Single-molecule DNA detection with an engineered MspA protein nanopore, ” Proceedings of the National Academy of Sciences , vol. 105, no. 52, pp. 20 647– 20 652, Dec. 2008. [12] I. M. Derrington et al. , “Nanopore DNA sequencing with MspA, ” Proceedings of the National Academy of Sciences , vol. 107, no. 37, pp. 16 060–16 065, Sep. 2010. [13] L. Song et al. , “Structure of Staphylococcal a-Hemolysin, a Heptameric Transmem- brane Pore, ” Science , vol. 274, no. 5294, pp. 1859–1865, Dec. 1996. [14] B. W alker et al. , “A pore-forming protein with a metal-actuated switch, ” Protein Engineering, Design and Selection , vol. 7, no. 5, pp. 655–662, May 1994. [15] Z. L. W escoe et al. , “Nanop ores Discriminate among Five C5-Cytosine V ariants in DNA, ” Journal of the American Chemical So ciety , vol. 136, no. 47, pp. 16 582–16 587, Nov . 2014. [16] K. R. Lieberman et al. , “Processive Replication of Single DNA Molecules in a Nanop ore Catalyzed by phi29 DNA Polymerase, ” Journal of the American Chemical Society , vol. 132, no. 50, pp. 17 961–17 972, Dec. 2010. [17] S. M. Bezrukov et al. , “Dynamics and Free Energy of Polymers Partitioning into a Nanoscale Pore, ” Macromolecules , vol. 29, no. 26, pp. 8517–8522, Jan. 1996. [18] M. Akeson et al. , “Microsecond Time-Scale Discrimination Among Polycytidylic Acid, Polyadenylic Acid, and Polyuridylic Acid as Homopolymers or as Segments Within Single RNA Molecules, ” Biophysical Journal , vol. 77, no. 6, pp. 3227–3233, Dec. 1999. [19] D. Stoddart et al. , “Nucleobase Recognition in ssDNA at the Central Constriction of the a-Hemolysin Pore, ” Nano Letters , vol. 10, no. 9, pp. 3633–3637, Sep. 2010. [20] N. Ashkenasy et al. , “Recognizing a Single Base in an Individual DNA Strand: A Step T oward DNA Sequencing in Nanopores, ” A ngewandte Chemie International Edition , vol. 44, no. 9, pp. 1401–1404, Feb . 2005. [21] D. Stoddart et al. , “Multiple Base-Recognition Sites in a Biological Nanopore: Two Heads are Better than One, ” A ngewandte Chemie International Edition , vol. 49, no. 3, pp. 556–559, Jan. 2010. [22] S. M. Bezrukov and J. J. Kasianowicz, “Current noise re veals protonation kinetics and number of ionizable sites in an open protein ion channel, ” P hysical Review Letters , vol. 70, no. 15, pp. 2352–2355, Apr . 1993. [23] J.- Y. Zhang et al. , “A single-molecule nanopore sequencing platform, ” bioRxiv , p. 2024.08.19.608720, 2024. [24] M. D. Noy es et al. , “Long-read sequencing of families rev eals increased germline and postzygotic mutation rates in repetitive dna, ” Nature Communications , 2026. [25] S. Nurk et al. , “The complete sequence of a human genome, ” Science , vol. 376, no. 6588, pp. 44–53, 2022. [26] M. Loose et al. , “Real-time selective sequencing using nanopore technology, ” Nature Methods , vol. 13, no. 9, pp. 751–754, Sep. 2016. [27] A. Payne et al. , “Readsh enables targeted nanopore sequencing of gigabase-sized genomes, ” Nature Biotechnology , vol. 39, no. 4, pp. 442–450, Apr . 2021. [28] L. Zhong et al. , “Nanopore-based metagenomics analysis reveals microbial presence in amniotic uid: A prospective study , ” Heliyon , vol. 10, no. 6, Mar . 2024. [29] M. Cretu Stancu et al. , “Mapping and phasing of structural variation in patient genomes using nanopore sequencing, ” Nature Communications , vol. 8, no. 1, p . 1326, Nov . 2017. [30] J. Quick et al. , “Real-time , portable genome sequencing for Ebola surveillance, ” Nature , vol. 530, no. 7589, pp. 228–232, Feb . 2016. [31] M. B. Cavlak et al. , “TargetCall: Eliminating the W asted Computation in Basecalling via Pre-Basecalling Filtering, ” Frontiers in Genetics , Sep. 2024. [32] Z. Xu et al. , “Fast-bonito: A Faster Deep Learning Based Basecaller for Nanopore Sequencing, ” Articial Intelligence in the Life Sciences , vol. 1, p. 100011, 2021, publisher: Elsevier . [33] P. Perešíni et al. , “Nanopore base calling on the edge, ” Bioinformatics , 2021. [34] V . Boža et al. , “DeepNano: Deep recurrent neural networks for base calling in MinION nanopore reads, ” PLOS One , 2017. [35] V . Boža et al. , “DeepNano-blitz: a fast base caller for MinION nanopore sequencers, ” Bioinformatics , vol. 36, no. 14, pp. 4191–4192, Jul. 2020. [36] Oxford Nanopore Technologies, “Dorado, ” 2024. [Online]. A vailable: https: //github.com/nanoporetech/dorado [37] Oxford Nanopore T echnologies, “Guppy , ” 2017. [38] X. Lv et al. , “ An end-to-end Oxford nanopore basecaller using convolution-augmented transformer , ” in BIBM , 2020. [39] G. Singh et al. , “RUBICON: a framework for designing ecient deep learning-based genomic basecallers, ” Genome Biology , 2024. [40] Y .-z. Zhang et al. , “Nanopore base calling from a p erspective of instance segmentation, ” BMC Bioinformatics , vol. 21, no. 3, p. 136, Apr . 2020. [41] X. Xu et al. , “Lokatt: a hybrid DNA nanopore basecaller with an explicit duration hidden Markov model and a residual LSTM network, ” BMC Bioinformatics , vol. 24, no. 1, p. 461, Dec. 2023. [42] J. Zeng et al. , “Causalcall: Nanopore Basecalling Using a T emporal Convolutional Network, ” Frontiers in Genetics , vol. 10, 2020. [43] H. T eng et al. , “Chiron: translating nanopore raw signal directly into nucleotide sequence using deep learning, ” GigaScience , vol. 7, no. 5, p. giy037, May 2018. [44] H. Konishi et al. , “Halcyon: an accurate basecaller exploiting an encoder–decoder model with monotonic attention, ” Bioinformatics , vol. 37, no. 9, pp. 1211–1217, Jun. 2021. [45] Y .-M. Y eh and Y .-C. Lu, “MSRCall: a multi-scale deep neural network to basecall Oxford Nanopore sequences, ” Bioinformatics , vol. 38, no. 16, pp. 3877–3884, Aug. 2022. [46] B. Noordijk et al. , “baseLess: lightweight detection of sequences in raw MinION data, ” Bioinformatics Advances , vol. 3, no. 1, p . vbad017, Jan. 2023. [47] N. Huang et al. , “SA Call: A Neural Network Basecaller for O xford Nanopor e Sequenc- ing Data Based on Self-Attention Mechanism, ” IEEE/ACM Transactions on Computa- tional Biology and Bioinformatics , vol. 19, no. 1, pp. 614–623, 2022. [48] N. Miculinic et al. , “MinCall - MinION end2end convolutional deep learning basecaller , ” arXiv , 2019. [49] Oxford Nanop ore T echnologies, “Bonito, ” 2021. [Online]. Available: https: //github.com/nanoporetech/bonito [50] A. Sneddon et al. , “Language-Informed Basecalling Architecture for Nanopore Dir ect RNA Sequencing, ” in MLCB , D. A. Knowles et al. , Eds., vol. 200, Nov . 2022, pp. 150–165. [51] F. Eris et al. , “RawBench: A Comprehensive Benchmarking Framework for Raw Nanopore Signal Analysis T echniques, ” in ACM-BCB , New Y ork, N Y , USA, 2025. [52] Y . Bao et al. , “SquiggleNet: real-time, direct classication of nanopore signals, ” Genome Biology , vol. 22, no. 1, p. 298, Oct. 2021. [53] H. Zhang et al. , “Real-time mapping of nanopore raw signals, ” Bioinformatics , vol. 37, no. Supplement_1, pp. i477–i483, Jul. 2021. [54] S. Kovaka et al. , “T argeted nanopore sequencing by real-time mapping of raw elec- trical signal with UNCALLED, ” Nature Biote chnology , vol. 39, no. 4, pp. 431–441, Apr . 2021. [55] A. Senanayake et al. , “De epSelectNet: deep neural network based sele ctive sequencing for oxford nanopore sequencing, ” BMC Bioinformatics , vol. 24, no. 1, p. 31, Jan. 2023. [56] S. Kovaka et al. , “Uncalled4 improves nanopore DNA and RNA mo dication detection via fast and accurate signal alignment, ” Nature Methods , vol. 22, no. 4, pp. 681–691, Apr . 2025. [57] J. Lindegger et al. , “RawAlign: Accurate, Fast, and Scalable Raw Nanopore Signal Mapping via Combining Seeding and Alignment, ” IEEE Access , 2024. [58] C. Firtina et al. , “RawHash: enabling fast and accurate real-time analysis of raw nanopore signals for large genomes, ” Bioinformatics , 2023. [59] C. Firtina et al. , “RawHash2: Mapping Raw Nanopore Signals Using Hash-Based Seeding and Adaptive Quantization, ” Bioinform. , 2024. [60] C. Firtina et al. , “Rawsamble: overlapping raw nanopore signals using a hash-based seeding mechanism, ” Bioinformatics , vol. 42, no. 3, p. btag087, Mar . 2026. [61] P. J. Shih et al. , “Ecient real-time selective genome sequencing on resource- constrained devices, ” GigaScience , 2023. [62] H. Sadasivan et al. , “Rapid Real-time Squiggle Classication for Read Until Using RawMap, ” Arch. Clin. Biomed. Res. , 2023. [63] T . Dunn et al. , “SquiggleFilter: An accelerator for portable virus detection, ” in MICRO , 2021. [64] V . S. Shivakumar et al. , “Sigmoni: classication of nanopore signal with a compressed pangenome index, ” Bioinform. , 2024. [65] H. Sadasivan et al. , “ Accelerated Dynamic Time Warping on GP U for Selective Nanopore Sequencing, ” Journal of Biote chnology and Biomedicine , vol. 7, pp. 137–148, 2024. [66] H. Gamaarachchi et al. , “GP U accelerate d adaptive banded event alignment for rapid comparative nanopore signal analysis, ” BMC Bioinformatics , vol. 21, no. 1, p. 343, Aug. 2020. [67] S. Samarasinghe et al. , “Energy Ecient Adaptive Banded Event Alignment using OpenCL on FPGAs, ” in ICIAfS , 2021, pp. 369–374. [68] M. Soysal et al. , “MARS: Processing-In-Memory Acceleration of Raw Signal Genome Analysis Inside the Storage Subsystem, ” in ICS , 2025, pp. 513–534. [69] Oxford Nanop ore T echnologies, “Scrappie, ” 2019. [Online]. Available: https: //github.com/nanoporetech/scrappie [70] S. Bakić et al. , “Campolina: a deep neural framework for accurate segmentation of nanopore signals, ” Genome Biology , Jan. 2026. [71] J. R. Miller et al. , “ Aggressive assembly of pyr osequencing reads with mates, ” Bioin- formatics , vol. 24, no. 24, pp. 2818–2824, Dec. 2008. [72] H. Li, “Minimap2: pair wise alignment for nucle otide sequences, ” Bioinformatics , vol. 34, no. 18, pp. 3094–3100, Sep . 2018. [73] L. Rabiner , “A tutorial on hidden Markov models and sele cted applications in spee ch recognition, ” Proceedings of the IEEE , vol. 77, no. 2, pp. 257–286, 1 1989. [Online]. A vailable: https://doi.org/10.1109/5.18626 [74] M. B. Hall et al. , “Benchmarking reveals superiority of deep learning variant callers on bacterial nanopore sequence data, ” eLife , vol. 13, p. RP98300, Oct. 2024. [75] Oxford Nanopore Technologies, “Oxford Nanopore Op en Data: Drosophila melanogaster sequencing, ” https://labs.epi2me.io/open- data- dmelanogaster- bkim/, 2023, accessed via s3://ont-open-data/contrib/melanogaster _ bkim _ 2023.01/ . [76] Oxford Nanopore T echnologies, “Oxford Nanopore Open Data: Sequencing Genome in a Bottle samples, ” https://epi2me.nanoporetech.com/giab- 2023.05/, 2023, accessed via s3://ont-open-data/giab _ 2023.05/ . [77] N. D. Sanderson et al. , “Evaluation of the accuracy of bacterial genome reconstruction with Oxford Nanop ore R10.4.1 long-read-only sequencing, ” Micr obial Genomics , v ol. 10, no. 001246, 2024. 9 Supplementar y Material for CERN: Correcting Errors in Raw Nanop ore Signals Using Hidden Markov Mo dels A. Extended Results A.1. Error Correction Runtime In Supplementar y T able S1, we show the average runtime of the CERN error correction me chanism per read for each of the evaluated segmentation methods. T able S1: Runtime of the CERN error correction step per read (ms), by dataset and segmentation method. Dataset Campolina Scrappie (R9.4) Scrappie (R10.4.1) E. coli 3.21 5.13 3.24 D . melanogaster 25.37 42.66 29.13 H. sapiens 79.14 156.77 106.57 A.2. Best Congurations In Supplementary T able S2 we report the best conguration for each dataset in terms of F1 scores. T able S2: Best conguration for F1 score p er dataset and mapper . Dataset Segmenter HPC Corrected F1 Pr ecision Recall Mapped (%) Time/Read (ms) E. coli Campolina ✗ ✓ 0.819 0.988 0.700 64.54 11.41 D . melanogaster Campolina ✗ ✓ 0.886 0.981 0.809 73.56 5,268.56 H. sapiens Campolina ✗ ✓ 0.865 0.984 0.771 76.79 16,909.48 1 A.3. Results by Dataset W e show extended results for the datasets E. coli (D1) in Supplementary T able S3, D . melanogaster (D2) in Supplementary T able S4, and H. sapiens (D3) in Supplementary T able S5. For each conguration of segmentation method, HPC and error correction we report mapping quality metrics in terms of F1 score , precision, recall and percentage of reads mapped, as well as performance in terms of average time spent per read. T able S3: Full results for E. coli (D1). Segmenter HPC Corrected F1 Precision Recall Mapped (%) Time/Read (ms) Campolina ✗ ✓ 0.819 0.988 0.700 64.54 11.41 Campolina ✗ ✗ 0.811 0.987 0.688 63.44 11.40 Campolina ✓ ✓ 0.768 0.984 0.630 58.19 5.68 Campolina ✓ ✗ 0.768 0.983 0.630 58.23 5.61 Scrappie (R9.4) ✗ ✓ 0.693 0.973 0.538 50.02 13.44 Scrappie (R9.4) ✗ ✗ 0.177 0.740 0.100 12.32 23.47 Scrappie (R9.4) ✓ ✓ 0.682 0.975 0.525 48.80 6.12 Scrappie (R9.4) ✓ ✗ 0.510 0.947 0.349 33.31 5.96 Scrappie (R10.4.1) ✗ ✓ 0.633 0.963 0.471 44.25 10.66 Scrappie (R10.4.1) ✗ ✗ 0.612 0.952 0.452 42.74 10.59 Scrappie (R10.4.1) ✓ ✓ 0.641 0.968 0.479 44.82 5.26 Scrappie (R10.4.1) ✓ ✗ 0.649 0.968 0.488 45.59 5.23 T able S4: Full results for D. melanogaster (D2). Segmenter HPC Corrected F1 Precision Recall Mapped (%) Time/Read (ms) Campolina ✗ ✓ 0.886 0.981 0.809 73.56 5,268.56 Campolina ✗ ✗ 0.882 0.979 0.803 72.96 5,321.80 Campolina ✓ ✓ 0.839 0.984 0.731 66.29 1,381.14 Campolina ✓ ✗ 0.843 0.985 0.737 66.92 1,365.82 Scrappie (R9.4) ✗ ✓ 0.814 0.978 0.697 69.15 5,028.94 Scrappie (R9.4) ✗ ✗ 0.324 0.590 0.224 30.86 8,711.60 Scrappie (R9.4) ✓ ✓ 0.786 0.985 0.654 64.82 1,210.98 Scrappie (R9.4) ✓ ✗ 0.656 0.983 0.493 48.72 1,059.97 Scrappie (R10.4.1) ✗ ✓ 0.742 0.976 0.598 59.81 4,997.97 Scrappie (R10.4.1) ✗ ✗ 0.737 0.976 0.593 59.34 4,925.79 Scrappie (R10.4.1) ✓ ✓ 0.716 0.982 0.563 56.42 1,176.10 Scrappie (R10.4.1) ✓ ✗ 0.723 0.982 0.572 57.41 1,111.64 T able S5: Full results for H. sapiens (D3). Segmenter HPC Corrected F1 Precision Recall Mapped (%) Time/Read (ms) Campolina ✗ ✓ 0.865 0.984 0.771 76.79 16,909.48 Campolina ✗ ✗ 0.864 0.986 0.769 76.48 16,708.65 Campolina ✓ ✓ 0.823 0.990 0.704 70.05 3,589.38 Campolina ✓ ✗ 0.832 0.988 0.718 71.49 3,533.06 Scrappie (R9.4) ✗ ✓ 0.757 0.989 0.613 61.04 16,825.26 Scrappie (R9.4) ✗ ✗ 0.001 0.010 0.001 5.89 30,035.58 Scrappie (R9.4) ✓ ✓ 0.703 0.992 0.545 54.23 3,353.98 Scrappie (R9.4) ✓ ✗ 0.006 0.342 0.003 0.82 2,267.24 Scrappie (R10.4.1) ✗ ✓ 0.762 0.984 0.622 62.03 18,776.94 Scrappie (R10.4.1) ✗ ✗ 0.693 0.961 0.542 54.70 17,622.24 Scrappie (R10.4.1) ✓ ✓ 0.723 0.989 0.570 56.79 3,311.65 Scrappie (R10.4.1) ✓ ✗ 0.696 0.988 0.538 53.63 3,051.84 2 A.4. Ablation Results for HPC In Supplementary T able S6 we report the ee ct of HPC on mapping quality and p erformance for each dataset and conguration. That is, for each conguration of segmentation method and error correction we report the dierence between using and not using HPC. Improvements in a metric ar e displayed in teal, regressions in red. T able S6: Ee ct of homopolymer compression (HPC): dierence (HPC on − HPC o ). Dataset Segmenter Corrected ∆ F1 ∆ Precision ∆ Recall ∆ Mappe d (%) ∆ Time/Read (ms) E. coli Campolina ✓ -0.051 -0.004 -0.070 -6.35 -5.73 Campolina ✗ -0.043 -0.005 -0.058 -5.21 -5.79 Scrappie (R9.4) ✓ -0.011 +0.001 -0.013 -1.22 -7.32 Scrappie (R9.4) ✗ +0.333 +0.206 +0.249 +20.99 -17.51 Scrappie (R10.4.1) ✓ +0.008 +0.005 +0.007 +0.57 -5.40 Scrappie (R10.4.1) ✗ +0.036 +0.015 +0.036 +2.85 -5.36 D . melanogaster Campolina ✓ -0.048 +0.003 -0.077 -7.27 -3,887.42 Campolina ✗ -0.040 +0.006 -0.067 -6.04 -3,955.98 Scrappie (R9.4) ✓ -0.028 +0.008 -0.044 -4.33 -3,817.96 Scrappie (R9.4) ✗ +0.332 +0.392 +0.269 +17.86 -7,651.63 Scrappie (R10.4.1) ✓ -0.026 +0.006 -0.035 -3.39 -3,821.87 Scrappie (R10.4.1) ✗ -0.015 +0.006 -0.021 -1.93 -3,814.15 H. sapiens Campolina ✓ -0.042 +0.006 -0.067 -6.74 -13,320.10 Campolina ✗ -0.032 +0.002 -0.050 -4.99 -13,175.59 Scrappie (R9.4) ✓ -0.054 +0.003 -0.068 -6.81 -13,471.28 Scrappie (R9.4) ✗ +0.004 +0.331 +0.002 -5.07 -27,768.34 Scrappie (R10.4.1) ✓ -0.039 +0.005 -0.052 -5.24 -15,465.29 Scrappie (R10.4.1) ✗ +0.004 +0.027 -0.004 -1.07 -14,570.40 3 A.5. Ablation Results for Error Correction In Supplementary T able S7 we r eport the eect of CERN’s error correction mechanism on mapping quality and performance for each dataset and conguration. That is, for each conguration of segmentation method and HPC we r eport the dierence between using and not using error correction. Improvements in a metric ar e displayed in teal, regressions in red. T able S7: Ee ct of CERN error correction: dierence ( corrected − uncorrected) for each conguration. Dataset Segmenter HPC ∆ F1 ∆ Precision ∆ Recall ∆ Mappe d (%) ∆ Time/Read (ms) E. coli Campolina ✗ +0.008 +0.001 +0.012 +1.10 +0.01 Campolina ✓ +0.000 +0.002 +0.000 -0.04 +0.07 Scrappie (R9.4) ✗ +0.516 +0.233 +0.437 +37.70 -10.03 Scrappie (R9.4) ✓ +0.172 +0.028 +0.176 +15.49 +0.16 Scrappie (R10.4.1) ✗ +0.020 +0.011 +0.020 +1.51 +0.07 Scrappie (R10.4.1) ✓ -0.008 +0.000 -0.009 -0.77 +0.03 D . melanogaster Campolina ✗ +0.004 +0.002 +0.005 +0.60 -53.24 Campolina ✓ -0.004 -0.001 -0.006 -0.63 +15.32 Scrappie (R9.4) ✗ +0.489 +0.387 +0.473 +38.29 -3,682.66 Scrappie (R9.4) ✓ +0.130 +0.003 +0.161 +16.10 +151.01 Scrappie (R10.4.1) ✗ +0.004 +0.000 +0.005 +0.47 +72.18 Scrappie (R10.4.1) ✓ -0.007 +0.000 -0.009 -0.99 +64.46 H. sapiens Campolina ✗ +0.001 -0.002 +0.003 +0.31 +200.83 Campolina ✓ -0.008 +0.003 -0.014 -1.44 +56.32 Scrappie (R9.4) ✗ +0.755 +0.979 +0.612 +55.15 -13,210.32 Scrappie (R9.4) ✓ +0.697 +0.650 +0.542 +53.41 +1,086.74 Scrappie (R10.4.1) ✗ +0.069 +0.023 +0.080 +7.33 +1,154.70 Scrappie (R10.4.1) ✓ +0.027 +0.001 +0.032 +3.16 +259.81 4 A.6. Read Mapping Runtime In Supplementary Table S8, we summarize the eect of CERN error correction on read mapping spe ed across dierent congura- tions. For each combination of dataset, segmentation method, and HPC setting, we report the time per read (ms) for both the Baseline and CERN variants. Lower values indicate better runtime performance. T able S8: All-in-one runtime summary across datasets. Segmentation Baseline (w/o HPC) CERN (w/o HPC) Baseline ( w HPC) CERN (w HPC) Read Mapping Spe ed ( E. coli ) Campolina 11.40 11.41 5.61 5.68 Scrappie (R9.4) 23.47 13.44 5.96 6.12 Scrappie (R10.4.1) 10.59 10.66 5.23 5.26 Read Mapping Spe ed ( D. melanogaster ) Campolina 5321.80 5268.56 1365.82 1381.14 Scrappie (R9.4) 8711.60 5028.94 1059.97 1210.98 Scrappie (R10.4.1) 4925.79 4997.97 1111.64 1176.10 Read Mapping Spe ed ( H. sapiens ) Campolina 16708.65 16909.48 3533.06 3589.38 Scrappie (R9.4) 30035.58 16825.26 2267.24 3353.98 Scrappie (R10.4.1) 17622.24 18776.94 3051.84 3311.65 5 B. Conguration B.1. Parameters In Supplementary T able S9, we list the parameters used for each tool and dataset. For minimap2 [ 72 ], we use the same parameter setting for all datasets. For the Dorado sup er-accurate (SUP) basecaller , we use the model trained for the corresponding data sampling frequency (i.e. 4 kHz or 5 kHz). T able S9: Parameters we use in our evaluation for each tool and dataset in mapping. T ool E. coli D . melanogaster H. sapiens Minimap2 -x map-ont Dorado GP U (SUP) basecaller dna_r10.4.1_e8.2_400bps_sup@ v4.1.0 / 4.1.0 / 5.0.0 RawHash2 -r10 -x sensitive -chunk-size 99999 -r10 -x sensitive –chunk-size 99999 -r10 -x fast –chunk-size 99999 B.2. V ersions Supplementary T able S10 lists the v ersion and the link to the corr esponding versions of each tool we use in our experiments. Scripts to reproduce all experiments can be found on https://github.com/STORMgroup/CERN . W e use Dorado 1.4.0 for D1 and D3 and 0.9.2 for D2 due to the dierences in the library kit versions used when sequencing these datasets. T able S10: V ersions of each tool and library . T ool V ersion Link to the Source Code RawHash2 2.1 https://github.com/STORMgroup/RawHash2/ Minimap2 2.24-r1122 https://github.com/lh3/minimap2/releases/tag/v2.24 Dorado 0.9.2 https://github.com/nanoporetech/dorado/releases/tag/v0.9.2 Dorado 1.4.0 https://github.com/nanoporetech/dorado/releases/tag/v1.4.0 Uncalled4 4.1.0 https://github.com/skovaka/uncalled4/releases/tag/4.1.0 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment