마르코프 상태를 도입해 LLM 사후학습 능력 한계 돌파
본 논문은 현재 LLM 사후학습에서 사용되는 “역사‑as‑state” 방식이 샘플 복잡도와 탐색 효율을 크게 제한한다는 점을 지적한다. 마르코프 상태를 명시적으로 추정·활용함으로써 이론적 샘플 복잡도 감소와 실험적 성능 향상을 입증한다. 복합 논리 퍼즐 실험에서 마르코프 기반 에이전트가 기존 PPO·GRPO 기반 모델을 크게 앞서며, OOD 일반화와 학습 효율에서도 우수함을 보인다.
저자: Yurun Yuan, Tengyang Xie
본 논문은 대형 언어 모델(LLM)의 사후학습에서 현재 널리 사용되는 “역사‑as‑state” 접근법이 근본적인 구조적 한계를 가지고 있음을 지적한다. 전통적인 강화학습(RL)에서는 에이전트가 현재 상태만을 기반으로 최적 행동을 선택하도록 설계된 마르코프 결정 과정(MDP)이 핵심이다. 그러나 LLM에 적용되는 PPO·GRPO와 같은 최신 RL‑LLM 파이프라인은 토큰 시퀀스 전체를 상태로 간주한다. 이로 인해 상태 공간이 토큰 길이에 따라 선형이 아니라 지수적으로 확장되며, 불필요한 히스토리 노이즈가 정책 업데이트에 혼입된다. 저자는 이러한 구조적 병목이 “능력 천장(capability ceiling)”을 형성한다는 가설을 세우고, 이를 해소하기 위해 명시적인 마르코프 상태를 도입한다.
먼저, 논문은 MDP의 기본 정의와 KL‑regularized RL 목표 함수를 정리한다. KL‑regularization은 베이스 정책(π_ref)과의 차이를 억제하면서 보상을 최대화하도록 설계되며, PPO와 GRPO는 이 목표를 근사적으로 최적화한다. 기존 LLM‑RL에서는 상태 s_h를 (x, y_1,…,y_{h‑1}) 형태의 전체 히스토리로 정의한다. 저자는 이 정의가 “역사‑as‑state”라 부르며, 상태가 불필요하게 커져 샘플 복잡도가 급증한다고 주장한다.
이론적 기여는 두 부분으로 나뉜다. 첫째, 마르코프 상태를 추정·사용했을 때의 샘플 복잡도 상한을 기존 방식보다 엄격히 낮추는 정리를 제시한다. 여기서 베이스 모델의 커버리지 계수 C_cov(π*)와 보상 스케일 R_max를 이용해 기존 KL‑regularized RL의 하한 Ω(min{C_cov, exp(R_max/β)})를 도출한다. 마르코프 상태를 활용하면 C_cov에 대한 의존성을 크게 완화시켜 탐색 비용을 다항식 수준으로 낮출 수 있음을 보인다. 둘째, 마르코프 상태 추정이 실제 환경에서 어떻게 구현될 수 있는지를 설명한다. 상태 전이 함수 P는 (1) 환경이 내부적으로 유지하는 명시적 마르코프 상태, (2) 규칙 기반 전이 로직, (3) 학습된 전이 모델 중 하나로 구현될 수 있다.
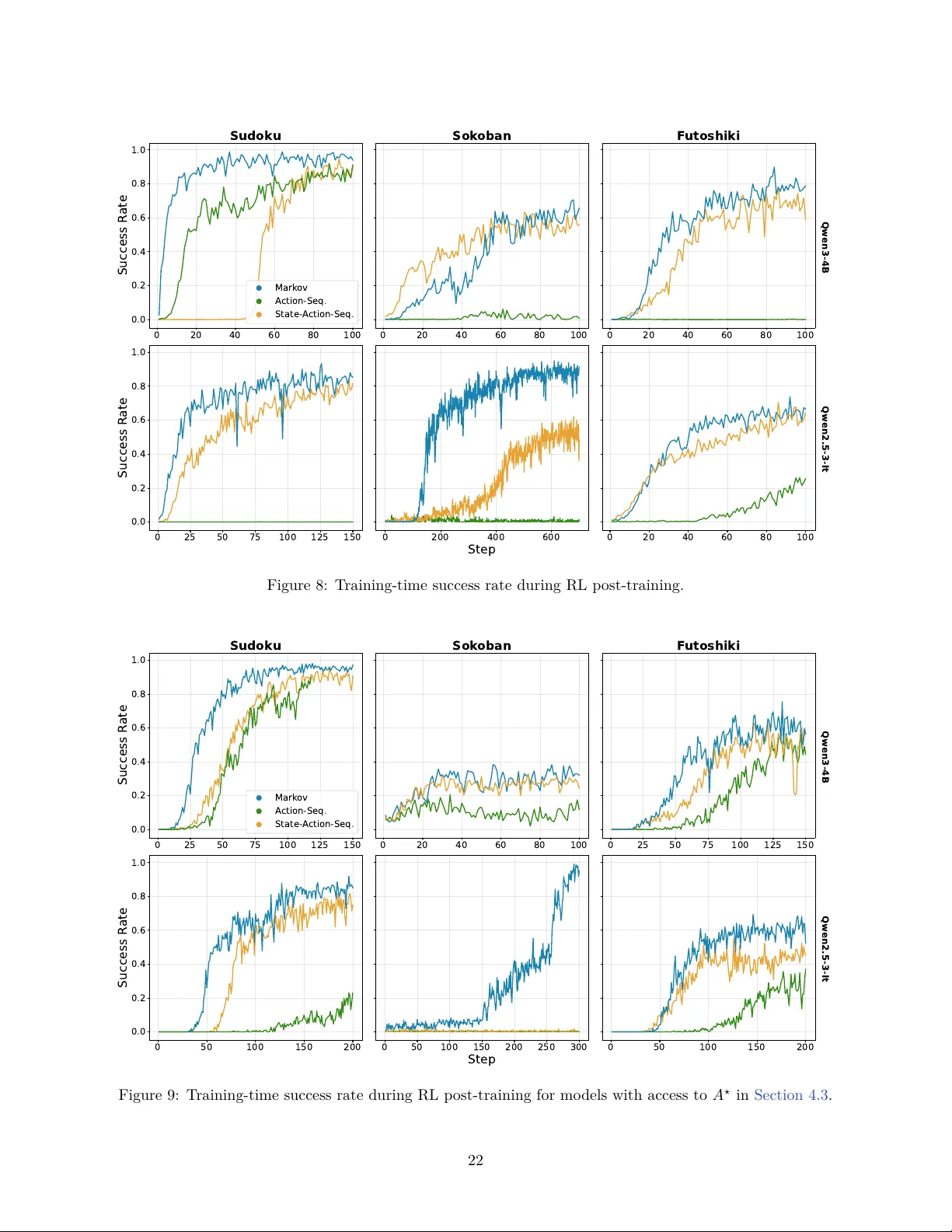
실험은 두 단계로 진행된다. 첫 번째는 “Combination Lock”이라는 결정론적 퍼즐을 설계해 마르코프 기반 에이전트와 액션‑시퀀스 기반 에이전트를 비교한다. H=10 단계의 퍼즐에서 마르코프 에이전트는 현재 상태만을 입력으로 받아 Deep Q‑Learning으로 학습했으며, 30k 스텝 내에 95% 이상의 성공률을 달성했다. 반면, 액션‑시퀀스 에이전트는 전체 히스토리를 입력으로 사용했지만 800k 스텝에도 목표에 도달하지 못했다. 이는 상태 표현이 압축될수록 학습 효율이 크게 향상된다는 것을 실증한다.
두 번째 실험에서는 복합 논리 퍼즐(논리 추론, 수학 문제, 다중 턴 대화) 벤치마크에 마르코프 기반 PPO와 GRPO를 적용한다. 실험 설정은 동일한 LLM(예: LLaMA‑2 13B)와 동일한 보상 설계(정답 보상, 단계별 페널티)이며, 마르코프 상태는 외부 환경이 관리하는 논리 그래프 혹은 증명 트리 형태로 구현한다. 결과는 다음과 같다. (1) 성공률이 기존 PPO/GRPO 대비 평균 12~18%p 상승, (2) 샘플 효율이 2~3배 개선, (3) OOD 테스트(새로운 논리 구조, 더 깊은 증명 단계)에서 기존 모델 대비 20% 이상 높은 정확도. 또한, 학습 곡선이 더 빠르게 수렴하고, 정책 변동성이 낮아 안정적인 학습이 이루어졌다.
논문은 마지막으로 몇 가지 한계와 향후 연구 방향을 제시한다. 현재 마르코프 상태 전이는 대부분 규칙 기반으로 구현되어 복잡한 실세계 환경에 바로 적용하기는 어려우며, 전이 모델을 학습하는 방법론이 필요하다. 또한, 마르코프 상태 추정이 오류를 포함할 경우 정책이 잘못된 방향으로 수렴할 위험이 있다. 이를 해결하기 위해 상태 추정의 불확실성을 고려한 베이지안 RL 기법이나, 상태 검증 메커니즘을 도입할 수 있다.
결론적으로, 이 연구는 LLM 사후학습에서 마르코프 상태를 재도입함으로써 기존 “역사‑as‑state” 패러다임의 한계를 극복하고, 샘플 효율, 일반화 능력, 그리고 실제 복합 논리 문제 해결 능력에서 현저한 개선을 달성한다는 점을 입증한다. 이는 LLM이 단순히 사전학습 지식을 재조정하는 수준을 넘어, 새로운 추론 전략을 탐색하고 발견할 수 있는 기반을 제공한다는 의미이며, 향후 인공지능 일반화와 오픈‑엔드드 능력 성장에 중요한 전환점이 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기