Breaking the Capability Ceiling of LLM Post-Training by Reintroducing Markov States
Reinforcement learning (RL) has become a standard paradigm for post-training and aligning Large Language Models (LLMs), yet recent evidence suggests it faces a persistent "capability ceiling": unlike classical RL systems that discover novel strategie…
Authors: Yurun Yuan, Tengyang Xie
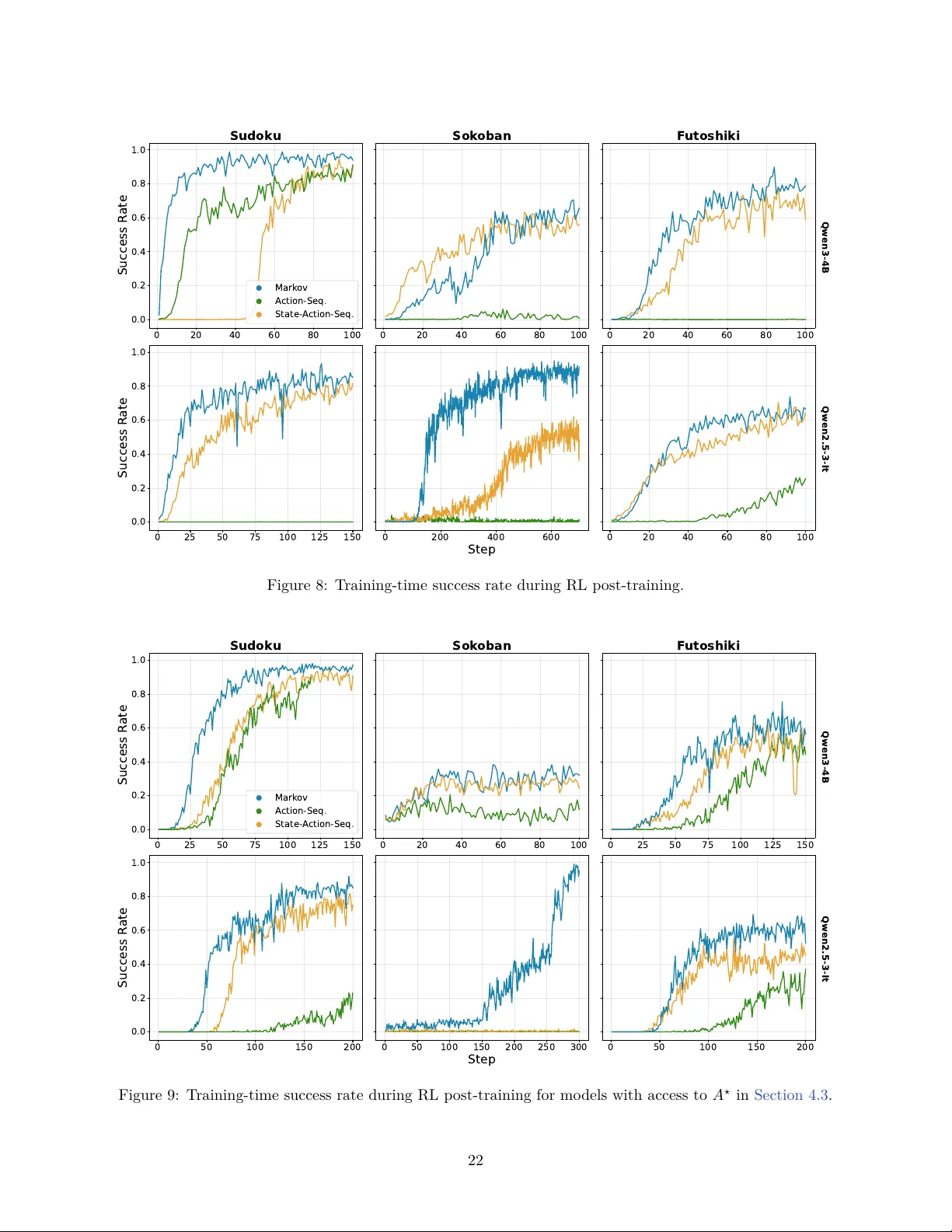
Breaking the Capabilit y Ceiling of LLM P ost-T raining b y Rein tro ducing Mark o v States Y urun Y uan † T engy ang Xie ∗ † † UW-Madison Marc h 23, 2026 Abstract Reinforcemen t learning (RL) has b ecome a standard paradigm for p ost-training and aligning Large Language Mo dels (LLMs), y et recen t evidence suggests it faces a p ersisten t “capabilit y ceiling”: unlike classical RL systems that disco ver nov el strategies, RL for LLMs often acts as a mere refiner of patterns already latent in pre-trained weigh ts. In this work, w e identify a fundamental structural b ottlenec k: while classical RL relies on compact, informative Marko v states, current LLM post-training form ulations are tethered to an ev er-expanding history of actions. W e revisit a classical principle long central to RL yet absent from LLM post-training: explicit Mark ov states. Theoretically , w e pro vide rigorous guarantees demonstrating that lev eraging estimated Marko v states can significantly reduce sample complexity . Empirically , we sho w that introducing Marko v states consisten tly breaks the p erformance b oundaries of standard RL post-training across a suite of complex logic puzzles. Our findings suggest that moving b ey ond “history-as-state” modeling in fav or of structured Mark ovian representations is essen tial for unlo c king op en-ended discov ery and genuinely new reasoning capabilities in Generative AI. 1 In tro duction Reinforcemen t learning (RL) has emerged as the definitiv e paradigm for p ost-training and aligning Large Language Mo dels (LLMs), enabling breakthroughs in complex reasoning, mathematical problem-solving, and agen tic b eha vior ( Jaech et al. , 2024 ; Guo et al. , 2025 ). By shifting from static sup ervised fine-tuning to dynamic environmen t interaction, RL allo ws mo dels to explore v ast solution spaces. In the prev ailing RL p ost-training paradigm, LLMs are form ulated as agen ts where the action space consists of discrete tokens and the state is defined by the concatenation of all preceding actions ( Guo et al. , 2025 ). Despite these successes, growing evidence suggests that RL primarily functions as a mec hanism for sharpening searc h within regions already reachable by the base mo del, rather than fundamentally expanding its solution space ( Y ue et al. , 2025 ; W u et al. , 2025a ; Shao et al. , 2025 ; Y eo et al. , 2025 ). While some contemporary studies claim that RL can elicit nov el capabilities, these gains t ypically manifest as mo dest extensions of the pre-training b oundary or are con tingent upon dense rew ard shaping or sp ecialized domain-sp ecific designs ( Zhang et al. , 2025 ; Sun et al. , 2025 ; Y uan et al. , 2025a ). F oster et al. ( 2025 ) pro vide theoretical evidence that significan t capability expansion is often computationally prohibitive, as the cost of disco very is lo wer-bounded b y either the exponential complexit y of the parameter search space or the inheren t limitations of the base mo del’s co verage. This “capabilit y ceiling”, ho wev er, app ears to b e a unique artifact of the LLM–RL intersection rather than an inheren t limitation of RL itself. In classical RL environmen ts—ranging from rob otic manipulation to complex Email: { yurun_yuan , tx }@cs.wisc.edu ∗ Corresponding author 1 b oard games—RL has b een serving as a p o werful disco very engine rather than a mere capability refiner. F or example, systems like AlphaZero ( Silver et al. , 2017 ) and MuZero ( Schritt wieser et al. , 2020 ) demonstrated the ability to transcend hu man kno wledge, developing no vel strategic patterns and sup erh uman heuristics that were entirely absen t from their initial programming or training data. The presence of a p erformance plateau in RL p ost-training for LLMs indicates that current form ulations may be structurally constrained, necessitating a rethink of foundational assumptions. A critical distinction emerges when comparing classical RL with its application to LLMs. In classical RL applications, such as robotics or board games lik e Go, the Mark ov states are central: a compact representation that encapsulates all information necessary for optimal future decision-making. In con trast, current LLMs op erate o ver a cumulativ e sequence of previous tokens, relying on an eve r-expanding, inheren tly noisy history rather than a distilled, Mark ovian representation. Therefore, we argue that this “capability ceiling” is a consequence of the action-se quenc e-b ase d formulation and hypothesize that the rein tro duction of the Marko v states is the k ey to unlo c king genuinely new reasoning capabilities and impro ving generalization. In this pap er, we revisit a classical RL principle, explicit Marko v state (estimation), and demonstrate its critical imp ortance for LLM p ost-training. W e provide both theoretical foundations and empirical evidence sho wing that this simple idea yields significant impro vemen ts o ver traditional history-dep enden t formulations. Our primary contributions are as follows: • Breaking the Capability Ceiling: Through extensive b enc hmarking on a suite of complex logic puzzles, w e sho w that mo dels with explicit Marko v states consistently surpass the p erformance b oundaries of traditional RL p ost-training, ac hieving high success rates on tasks where history-dep enden t mo dels plateau or fail. • Robust Generalization: W e demonstrate that Mark ov models exhibit sup erior out-of-distribution (OOD) generalization, effectively solving puzzles with higher structural complexity and searc h depth than those encountered during training. • Sample Efficiency Guarantees: W e pro vide theoretical guarantees demonstrating that Marko vian learning achiev es significan tly low er sample complexity compared to standard action-sequence-based form ulations. T aken together, our findings suggest that the path tow ard artificial general intelligence and open-ended capabilit y gro wth ma y require moving b ey ond “history-as-state” mo deling in fa vor of Marko vian states that b etter align with the underlying logic of complex reasoning tasks. 2 Preliminaries 2.1 Mark o v Decision Pro cess, Policies, and V alue F unctions RL provides a framework for sequen tial decision-making problems where an agent in teracts with an environmen t to maximize cumulativ e rewards. In the con text of Mark ov Decision Processes (MDPs), which provide the theoretical foundation for RL, we consider an episodic finite-horizon framework. F ormally , a horizon- H episo dic MDP M = ( H , S , A , P , r , ρ ) consists of a (p otentially very large) state space S , an action space A , a probabilit y transition function P : S × A → ∆( S ) , a reward function r : S × A → R , and an initial state distribution ρ ∈ ∆( S ) . The state space is typically lay ered such that S = S 1 ∪ S 2 ∪ · · · ∪ S H , where S h is the set of states reachable at step h . A p olicy π : S → ∆( A ) maps states to distributions ov er actions and induces a distribution o ver tra jectories τ = ( s 1 , a 1 , . . . , s H , a H ) and rewards ( r 1 , . . . , r H ) , where the initial state is sampled as s 1 ∼ ρ , and for h = 1 , . . . , H : a h ∼ π ( s h ) , r h = r ( s h , a h ) , and s h +1 ∼ P ( s h , a h ) . W e let E τ ∼ π [ · ] and P τ ∼ π [ · ] denote exp ectation and probability under this process, and E π [ · ] and P π [ · ] for brevity when τ is not explicitly mentioned. The exp ected cum ulative rew ard of a policy π is given by J ( π ) = E τ ∼ π [ r ( τ )] , where r ( τ ) = P H h =1 r ( s h , a h ) . The v alue function and Q -function of π is defined as V π h ( s ) : = E π h P H ℓ = h r ℓ ( s ℓ , a ℓ ) | s h = s i , Q π h ( s, a ) : = E π h P H ℓ = h R ℓ ( s ℓ , a ℓ ) | s h = s, a h = a i . A dditionally , the adv antage function A π represen ts the relativ e benefit of taking a sp ecific action a compared to follo wing the p olicy π on a verage, defined as: A π h ( s, a ) : = Q π h ( s, a ) − 2 V π h ( s ) . W e denote the optimal p olicy as π ⋆ (i.e., π ⋆ ∈ argmax π J ( π ) ) and its asso ciated v alue, Q , and adv antage functions as V ⋆ , Q ⋆ , and A ⋆ , resp ectiv ely . 2.2 Reinforcemen t Learning for Language Mo dels In the context of language mo dels, the mo del serves as the p olicy π , and the input and output of the mo del maps to the state s and action a resp ectiv ely . In the single-turn setting where x ∼ ρ denotes the input prompt and y 1 , y 2 , . . . , y H denote the output tokens, we can define s 1 : = x and s h : = ( x, y 1 , . . . , y h − 1 ) for h > 1 , with a h : = y h for h = 1 , . . . , H . In the m ulti-turn setting, which consists of multiple in teraction turns ( x (1) , y (1) 1: H ) , ( x (2) , y (2) 1: H ) , and so forth, we can adapt the transition function accordingly . Here, y ( i ) 1: H is a shorthand notation for the sequence of tokens y ( i ) 1 , y ( i ) 2 , . . . , y ( i ) H in the i -th turn. F or instance, if a state-action pair ( s, a ) contains the complete resp onse for one turn (e.g., in a conv ersation with three or more turns), where s = ( x (1) , y (1) 1: H , x (2) , y (2) 1: H − 1 ) and a = y (2) H , the next state would transition to s ′ = ( x (1) , y (1) 1: H , x (2) , y (2) 1: H , x (3) ) . In standard RL, the ob jectiv e is to find a p olicy π that maximizes the exp ected cumulativ e reward J ( π ) = E τ ∼ π [ r ( τ )] . In many practical applications, particularly in the context of large language mo dels, it is b eneficial to incorp orate a regularization term that encourages the learned p olicy to stay close to a reference p olicy π ref . This leads to the KL-regularized RL ob jectiv e ( Ziebart et al. , 2008 ; Ziebart , 2010 ; Neu et al. , 2017 ; Ouyang et al. , 2022 ; Xie et al. , 2024 ; Y uan et al. , 2025b ) J β ( π ) = E τ ∼ π [ r ( τ )] − β · E τ ∼ π log π ( τ ) π ref ( τ ) , where β > 0 is a regularization parameter that controls the strength of the p enalt y D KL ( π ∥ π ref ) = E τ ∼ π h log π ( τ ) π ref ( τ ) i , kno wn as the Kullback-Leibler div ergence. W e use π ⋆ β ∈ argmax π J β ( π ) to denote the KL-regularized optimal p olicy . Pro ximal P olicy Optimization (PPO; Sch ulman et al. , 2017 ) and Group Relative P olicy Optimization (GRPO; Shao et al. , 2024 ) represent the primary algorithmic frameworks curren tly utilized for reinforcement learning p ost-training and alignmen t. They in tro duce a clipp ed surrogate ob jective to constrain p olicy up dates: J ( θ ) = E ( s h ,a h ) ∼ π θ old h min π θ ( a h | s h ) π θ old ( a h | s h ) b A h ( s h , a h ) , clip π θ ( a h | s h ) π θ old ( a h | s h ) , 1 − ε, 1 + ε b A h ( s h , a h ) i , where b A h is the adv antage estimate, and ε is a hyperparameter. In PPO, the adv antage b A h is t ypically computed using Generalized Adv antage Estimation (GAE; Sch ulman et al. , 2015b ) to estimate the adv antage of the KL regularized rew ard r ( s h , a h ) − β log π ( a h | s h ) π ref ( a h | s h ) . GRPO is a policy-based metho d that, in practical implemen tations for LLMs like DeepSeek-R1, samples G resp onses o (1) , . . . , o ( G ) for eac h prompt x and computes adv an tages b y normalizing rewards within eac h prompt group. This resp onse-lev el adv an tage b A ( i ) is then used to replace the step-wise adv antage function b A h ( s h , a h ) in the objective J ( θ ) . GRPO ob jectiv e then accommo dates the KL-regularization at the end. GRPO is often considered a simpler alternative to PPO for post-training LLMs. This is partly b ecause PPO t ypically inv olv es training a separate critic net work and incorp orates more complex mechanisms for p olicy updates. In the con text of LLMs, the full complexity of PPO migh t not alwa ys b e necessary , leading to the adoption of more streamlined p olicy gradient metho ds lik e GRPO. 3 Rein tro ducing Mark o v States to LLM P ost-T raining 3.1 Limits of Curren t RL for LLMs Despite the empirical success of RL in improving the reasoning p erformance of large language mo dels ( Guo et al. , 2025 ; Jaech et al. , 2024 ), it remains debated whether RL can induce capabilities that fundamentally exceed those acquired during pre-training. A growing b ody of evidence suggests that RL primarily rew eights or amplifies reasoning patterns already latent in the base mo del, rather than creating genuinely nov el capabilities ( Y ue et al. , 2025 ; W u et al. , 2025a ; Shao et al. , 2025 ; Y eo et al. , 2025 ). 3 Con versely , rep orts of emergent capabilities under RL typically rely on restrictive training designs ( Y uan et al. , 2025a ; Zhang et al. , 2025 ; Sun et al. , 2025 ). These mechanisms guide learning tow ard known solution manifolds, suggesting that the observed gains reflect con trolled extrap olation within a limited hypothesis space rather than the discov ery of new reasoning tra jectories. Recen t work ( F oster et al. , 2025 ) also pro vides theoretical evidence for this fundamental boundary . Let C cov ( π ⋆ β ) : = max s,a π ⋆ β ( y | x ) π ref ( y | x ) b e the cov erage coefficient of the base mo del π ref w.r.t. the sequence of tokens, whic h con trols the qualit y of pass@ k p erformance of the base mo del. The hop e for emergen t capabilities under RL is that: if b oth the statistical and computational complexity of RL were muc h smaller than C cov ( π ⋆ β ) (e.g., Xie et al. 2024 sho ws that the statistical complexit y can b e m uch smaller than C cov ( π ⋆ β ) in certain cases), then RL could yield significant gains b ey ond the base mo del’s pass@ k p erformance. Ho wev er, F oster et al. ( 2025 ) establish the following lo wer b ound on computational complexit y: under the KL-regularized RL ob jectiv e, achieving a near-optimal p olicy requires the num b er of sampling oracle calls (and runtime) T comp to b e lo wer-bounded b y Ω min C cov ( π ⋆ β ) , exp R max β , ev en for the linearly-parameterized softmax p olicy class. R max is an upp er b ound on the reward r ( τ ) . This low er b ound reveals a strict “discov ery” b ottlenec k: for RL to find a near-optimal p olicy efficien tly , an algorithm is forced to either (1) rely on the base mo del to already cov er the optimal resp onse with small C cov ( π ⋆ β ) , whic h in turn implies that the base mo del’s pass@ k p erformance is already reasonable, or (2) resort to brute-force exploration ov er the resp onse space, at a cost that gro ws exponentially as e R max /β . In particular, if the base mo del’s pass@ k p erformance is p oor (i.e., C cov ( π ⋆ β ) is large), RL is pushed into the exp onen tial-cost regime, making the disco very of truly nov el solutions computationally in tractable. Collectiv ely , these findings point to a ceiling of current RL-based p ost-training paradigms: rather than expanding the mo del’s solution space, RL predominan tly sharp ens search within regions already accessible to the base mo del, yielding at most mo dest extensions b ey ond its pre-training b oundary . This motiv ates re-examining the foundations of RL for LLMs and casts doubt on whether existing approac hes alone can supp ort open-ended capabilit y gro wth. 3.2 A Didactic Example End Figure 1: The Combination L o ck problem with hori- zon H . A t eac h state S h , the correct action A + h adv ances the agent to the next state; the incorrect action A − h resets it to the starting p osition. 0 100k 200k 300k 400k 500k 600k 700k 800k Step 0.0 0.2 0.4 0.6 0.8 1.0 Success R ate Mark ov A ction-Seq. Success R ate F urthest State 0 2 4 6 8 F urthest State Figure 2: Comparison of Marko v agen t and action- sequence agent on Combination L o ck task. W e fo cus on t wo metrics: the success rate in reaching the final goal state and the furthest state reached before the agen t triggers an incorrect action. W e start with an empirical analysis on a didactic task: the Combination L o ck problem. As illustrated in Figure 1 , this environmen t consists of H linearly ordered states, ( S 1 , S 2 , · · · , S H ) , and tw o discrete actions. The agent begins at S 1 ; selecting the correct action A + h adv ances the agen t to the next state, while an incorrect c hoice A − h resets it to the starting p osition. Each transition incurs a rew ard of − 1 , except for 4 Algorithm 1 Action-Sequence Mo dels ( Figure 3(a) ) 1: Input: Initial state s 1 2: for h = 1 , . . . , H do 3: Sample action a h ∼ π ( · | s 1 , a 1: h − 1 ) 4: App end a h to history sequence 5: end for Algorithm 2 Marko vian Mo dels ( Figure 3(b) ) 1: Input: Initial state s 1 2: for h = 1 , . . . , H do 3: Sample action a h ∼ π ( · | s h ) 4: Up date state s h +1 ← P ( s h , a h ) 5: end for the final goal state, which yields a reward of 0 and terminates the episo de. Consequently , the agent m ust memorize the sequence of H correct actions ( A + 1 , A + 2 , · · · , A + H ) to reach the goal. W e instantiate this task with a horizon of H = 10 and ev aluate tw o multila yer p erceptron (MLP)-based agen ts that approach the problem from distinct mo deling p erspectives. The first netw ork is Mark ov-state-based, receiving the encoded representation of the current Mark ov state s h as input. The second is action-sequence- based, whose input is the concatenation of all previous actions ( a 1 , . . . , a h − 1 ) . Both agents are trained via Deep Q-Learning ( Mnih et al. , 2015 ) to select the action a h that maximizes cum ulative rew ard. W e ev aluate p erformance using t wo k ey metrics: the success rate in reac hing the final goal state and the furthest state reac hed b efore the agent triggers an incorrect action. As shown in Figure 2 , the Marko v agent successfully memorizes the correct actions and stabilizes within 30k steps, while the action-sequence agent fails to reach the goal even after 800k steps. The substantial p erformance gap b et ween the t wo paradigms is not surprising. F or the Mark ov agen t, the input space coincides with the state space and contains only H distinct v alues while the action-sequence agen t op erates ov er an input space consisting of full action histories, suggesting that incorp orating Mark ov states in the inputs is essential for solving this task efficiently . (a) Action-Sequence Mo dels. (b) Marko v Mo dels. Figure 3: Comparison of action-sequence-based models and our Mark ovian Mo dels. F or action-sequence mo dels, the new action ( a h ) is app ended to the existing action history and fed bac k into the mo del as the input for the subsequent prediction. F or Marko v mo dels, the next action a h is combined with the current state s h and passed through a state transition function P to obtain the next state s h +1 , which is the input for the subsequent prediction. 3.3 Mark o v States in LLM P ost-T raining In contrast to the evidence in Section 3.2 , con temp orary LLM p ost-training practices predominantly adopt an action-sequence-based formulation, where the history of actions is treated as the state, as sho wn in Algorithm 1 . Here, an “action” is broadly defined: it ma y represent a single token, a seman tic step tow ard the final solution, or an iteration of resp onse-refinement. The pronounced mismatc h b et ween prev ailing p ost-training practices and our insights motiv ates us to rethink ab out the RL p ost-training paradigm. Mark ov State Estimation. W e reintroduce explicit Mark ov states in to the LLM training pipeline. As illustrated in Algorithm 2 , the newly generated action a h , instead of b eing simply app ended to the previous actions, is com bined with the curren t state s h and passed through a state transition function P . The resulting 5 state s h +1 is then used as the input for the next decision step. By construction, s h +1 preserv es all information necessary for future actions while discarding irrelev ant noise from the in teraction history . In practice, the state transition function may b e realized b y an environmen t that in ternally maintains a Marko v state, a rule-based mechanism implementing the transition logic, or a learned model that approximates the underlying transition dynamics. Approac h Sudoku Sok oban F utoshiki Qw en3-4B A ction-seq. 92.3 2.5 0.2 Markov 97.1 76.1 75.0 T able 1: Comparison of action-sequence mo dels and Mark ov mo dels on logical reasoning tasks. A cross all tasks, Marko v mo dels consistently outp erform their action-sequence counterparts by a substantial margin. Empirical Evidence. T o empirically v alidate the adv antages of incorp orating Mark ov states, we conduct exp erimen ts on a set of synthetic, con trollable tasks with well-defined Mark ov state represen tations. In particular, we consider a suite of logical reasoning games, including Sudoku, Sokoban, and F utoshiki. F or eac h task, we p ost-train mo dels using b oth action-sequence-based and Marko v paradigms with the same RL algorithm. W e also train a separate state transition estimation model. As summarized in T able 1 , Mark ov mo dels consistently outperform their action-sequence counterparts b y a substantial margin, even on tasks where action-sequence mo dels exhibit near-zero accuracy . W e defer full exp erimen tal details and comprehensiv e ev aluation results to Section 4 . Broader Implications and Applications. The applicability of Marko vian language mo dels extends w ell b ey ond synthetic b enchmarks to a wide range of real-world settings. In many domains, the Mark ov states are ac c essible during training and our paradigm can easily fit in. T o illustrate this broader p oten tial, we outline several representativ e scenarios: (1) Co ding: In m ulti-turn co de debugging, the state represents a snapshot of the current co debase together with relev ant execution or compiler logs, and evolv es through actions such as code edits or test executions. In con trast, an action-sequence-based agent observ es only its history of prop osed changes, without explicitly reasoning ov er the resulting co de snapshot. ( T eam , 2025 ; Hui et al. , 2024 ). (2) Mathematical reasoning: The state consists of the set of established lemmas and in termediate results, with each new inference transitioning the system tow ard a more complete pro of ( Hub ert et al. , 2025 ; Chen et al. , 2025 ). (3) Iterative resp onse refinement: The state is restricted to the most recen t draft, and the transition function P o verwrites the previous version with the refined output. This design enables the mo del to reason ov er the current solution while av oiding redundan t noise from its own edit history ( Y uan and Xie , 2025 ). Standard action-sequence-based baselines ignore these Marko vian structures, while our paradigm suggests that aligning the agent’s represen tation with the efficient underlying Mark ov structure enables it to solve complex, long-horizon tasks that are otherwise intractable. 4 Exp erimen ts In this section, we rep ort comprehensiv e experiments and analyses of Marko vian learning and comparison to its counterparts. T asks and Datasets. T o accurately obtain Marko v states in LLM reasoning, we implemen t three syn thetic logical tasks from Reasoning-Gym ( Sto jano vski et al. , 2025 ): Sudoku, Sok oban, and F utoshiki. These grid- based puzzles c hallenge a mo del’s capacity for logical analysis, constrain t satisfaction, and spatial reasoning. Crucially , the configuration of the b oard at any giv en step serves as a fully observ able Marko v state; every discrete action deterministically up dates this configuration to form the subsequent state, yielding an explicit state tra jectory for training and analysis. 6 Approac h In Distribution Out Of Distribution Sudoku Sok oban F utoshiki Sudoku Sok oban F utoshiki A vg Pass A vg P ass A vg Pass A vg Pass A vg Pass A vg Pass Qw en3-4B A ction-sequenc e + SFT W arm-up 16.1 98.0 0.2 22.0 0.0 5.0 3.1 64.0 0.0 1.0 0.0 0.0 + RL p ost-training 93.5 97.0 2.3 4.0 0.1 7.0 69.2 82.0 0.0 0.0 0.0 0.0 Markov + SFT W arm-up 34.2 100.0 0.4 28.0 0.1 11.0 8.7 86.0 0.0 3.0 0.0 0.0 + RL p ost-training 97.1 98.0 76.1 81.0 75.0 85.0 77.8 82.0 31.6 37.0 42.6 53.0 State-action-se quence + SFT W arm-up 8.6 96.0 1.4 61.0 0.3 20.0 1.9 62.0 0.2 15.0 0.0 1.0 + RL p ost-training 91.1 96.0 57.4 67.0 44.4 55.0 71.2 82.0 30.2 34.0 16.9 21.0 Qw en2.5-3B-It A ction-sequenc e + SFT W arm-up 0.3 23.0 0.5 37.0 6.6 94.0 0.0 0.0 0.0 3.0 0.3 28.0 + RL p ost-training 0.0 0.0 1.0 1.0 61.3 84.0 0.0 0.0 0.0 0.0 24.9 56.0 Markov + SFT W arm-up 20.0 99.0 0.2 14.0 8.5 98.0 2.9 75.0 0.0 1.0 0 .3 26.0 + RL p ost-training 86.0 94.0 89.7 93.0 79.8 96.0 56.4 68.0 66.9 72.0 28.3 67.0 State-action-se quence + SFT W arm-up 22.4 100.0 0.6 41.0 16.6 100.0 2.4 71.0 0.0 1.0 1.1 60.0 + RL p ost-training 83.0 90.0 43.6 50.0 67.4 94.0 57.1 69.0 20.4 23.0 25.2 75.0 T able 2: P erformance comparison of different approac hes. W e sample 128 solutions p er question and rep ort A vg@128 and P ass@128 . Mo dels and T raining Pip elines. W e use π mkv to denote the Marko v mo dels and π act - seq to denote the action-sequence mo dels. App endix C.7 provides illustrative examples of how mo dels op erate on these tasks. Exp erimen ts are conducted with Qw en3-4B ( T eam , 2025 ) and Qwen2.5-3B-Instruct ( T eam , 2024 ), training a separate mo del for each task. F or each mo del, we first p erform a brief task-sp ecific SFT warm-start stage to establish task understanding and output formatting. W e then p ost-train with GRPO ( Shao et al. , 2024 ) in an interactiv e setting, where the agen t acts in the true environmen t with ground-truth transition dynamics P ⋆ . The agen t receiv es a sparse terminal reward: 1 for solving the instance and 0 otherwise. In addition, we train a state prediction mo del b P based on Qw en2.5-3B-Instruct via SFT to predict the next state b s h +1 from the current state and action. A t test time, b P replaces the environmen t P ⋆ , enabling deploymen t without en vironment access. Implemen tation Details. W e implemen t our metho ds and baselines in the rLLM framew ork ( T an et al. , 2025 ), largely following the recommended hyperparameter settings. W e in tentionally require the mo dels to output only the next action without chain-of-though t. This is b ecause the base mo del is natively trained to solve these puzzles end-to-end; when allow ed to reason step by step, it often b eha ves like an implicit transition mo del, forecasting future b oard states inside its reasoning trace (see App endix C.8 for an illustration). This b eha vior undermines the goal of decomp osing the problem in to progressiv e steps. By constraining the mo del to outputting only the action, w e delegate state-transition computation to an external state prediction mo del, ensuring that the p olicy conditions on an explicit next state rather than implicitly inferring it during generation. 7 1 2 4 8 16 32 64 128 256 512 1024 k (log scale) 0.0 0.2 0.4 0.6 0.8 P ass@k A ction-Seq Mark ov SF T -war mup RL post-train Figure 4: P ass@ k accuracy for Qwen3-4B-based mo d- els on F utoshiki. While action-sequence mo dels rarely impro ve SFT Pass@ k , Mark ov mo dels consistently surpass their base mo dels’ limits. 0 20 40 60 80 100 Step 0.0 0.2 0.4 0.6 0.8 1.0 R ewar d A ction-Seq. Mark ov Qwen3 Sudok u Qwen2.5 F utoshiki Figure 5: T raining rew ard curves. Marko v mo dels reac h higher rewards in fewer training steps, pro vid- ing empirical evidence of low er sample complexity . 4.1 Main Results W e compare the p erformance of π mkv and π act - seq in T able 2 on t wo ev aluation settings: (1) in-distribution (ID) tests, matched to the training set in difficulty and complexity , and (2) out-of-distribution (OOD) b enc hmarks, whic h are harder than training and t ypically require more decision steps, thereb y probing generalization to greater reasoning depth. F or each question, we sample k = 128 solutions at temp erature 1 . 0 and rep ort the arithmetic mean of success across all samples, denoted as A vg@128 , and the probabilit y that at least one of the 128 samples is correct, denoted as P ass@128 . A cross b oth settings, π mkv consisten tly impro ves one-shot accuracy and Pass@ 128 . The gains are most pronounced on challenging tasks where π act - seq attains near-zero p erformance—for example, Sok oban and F utoshiki with Qwen3-4B, and Sudoku and Sokoban with Qw en2.5-3B-Instruct. On OOD b enc hmarks, Mark ov mo dels generalize strongly , outp erforming action-sequence mo dels on ev ery task. W e further examine how the mo dels’ capabilit y b oundaries shift b y analyzing Pass@ k accuracy as k scales. W e use the results of Qwen3-4B on F utoshiki as an example and sho w it in Figure 4 . W e find that action-sequence mo dels fail to extend or ev en main tain the Pass@ k of SFT mo dels, a result consisten t with the findings from Y ue et al. ( 2025 ). In contrast, Mark ov models break through the capability boundaries of the base mo dels, remarkably extending Pass@ k . Ev aluation on other tasks is deferred to App endix C.1 . W e also observ e faster training-time conv ergence for Marko v mo dels. Using Sudoku with Qw en3-4B and F utoshiki with Qwen2.5-3B-Instruct as representativ e cases, Figure 5 sho ws that π mkv reac hes higher rewards in fewer training steps, providing empirical evidence of low er sample complexit y . 4.2 F actors Behind the Success of Mark o v Mo dels T o understand why π mkv consisten tly outp erforms π act - seq , we decomp ose their differences into tw o factors: (1) explicit access to Mark ov states s h , and (2) the use of a Mark ovian structure. T o isolate these effects, we introduce an in termediate baseline, the state-action-sequence mo del π st - act - seq , which conditions on the full history of states and actions. Concretely , at step h , π st - act - seq predicts the next action a h giv en ( { ( s i , a i ) } h − 1 i =1 , s h ) = ( s 1 , a 1 , s 2 , a 2 , · · · , a h − 1 , s h ) . Unlik e π act - seq , π st - act - seq has access to the true state sequence; ho wev er, it still predicts actions from the entire trajectory and is therefore not Marko vian. As a result, comparing π act - seq to π st - act - seq quan tifies the b enefit of exp osing Mark ov states, while comparing π st - act - seq to π mkv isolates the additional gains attributable to the Marko v prop ert y . In the follo wing, w e show that access to Marko v states is essen tial for effective RL learning, and that enforcing a Marko v decision structure further improv es p erformance. Explicit Mark o v State Conditioning. The comparison of π act - seq and π st - act - seq in T able 2 shows that state-action-sequence mo dels substantially improv e logical-reasoning p erformance, breaking the p erformance ceiling of action-sequence-based RL training. By conditioning on an explicit state pro vided by an external transition mo del, it no longer needs to reconstruct the current board configuration implicitly in its latent 8 space, offloading the burden of state trac king and prediction. During training, a clear state represen tation enables rewards to b e correctly attributed to state-action pairs, rather than to en tangled or partially inferred tra jectories. A t test time, using an explicit state reduces brittleness caused b y noisy internal state estimates and makes the p olicy’s input unam biguous. Mark ovian Prop ert y . Given access to Mark ov states, enforcing a Marko vian policy structure further impro ves training efficiency . As sho wn in T able 2 , Mark ov models consistently outp erform state-action- sequence mo dels. This empirical finding is in line with theoretical conclusion that Marko v learning has exp onen tially low er sample complexity . While it may seem coun terintuitiv e that state-action-sequence mo dels p erform w orse despite having more input information, this extra con text is often a liability rather than an asset. Under the Marko v assumption, the curren t state has enco ded all past information relev ant to future decision-making. Consequently , the additional historical con text provided to state-action-sequence mo dels is redundant and may introduce spurious correlations that complicate learning. T o further prob e what the state-action-sequence mo del actually uses after training, we presen t a controlled ablation in App endix C.3 showing that state-action-sequence mo dels rely primarily on the curren t state: removing access to the current state causes performance to collapse, while retaining only the last state preserves a substantial fraction of accuracy . 4.3 The RL Challenge A ddressed b y Marko v Mo dels The challenges of RL can b e largely summarized as the need to balance explor ation of unknown actions, cr e dit assignment under dela yed and sparse rewards, and gener alization from limited exp erience to large or unseen state spaces ( Sutton et al. , 1998 ; Kaelbling et al. , 1996 ). Among these challenges, generalization critically dep ends on ho w the agen t represents and mo dels the en vironment state. In this section, we will show that Mark ov mo dels greatly impro ve generalization. T o isolate generalization from other factors, we introduce tw o diagnostic v ariants: π A ⋆ mkv and π A ⋆ act - seq . They follo w the same training pip eline as π mkv and π act - seq , except that (1) we remov e the SFT warm-up stage and directly train on the base mo dels, and (2) we replace the estimated resp onse-lev el adv antage b A ( i ) used in GRPO ob jectiv e (see Section 2.2 ) with the ground-truth optimal adv antage A ⋆ defined in Section 2.1 . Practically , A ⋆ can b e obtained using task-dependent rule-based algorithms, detailed in Appendix D.3 . In this w ay , the credit-assignmen t difficult y during training is largely remov ed through pro viding A ⋆ and conv erting the original sparse reward into a dense, per-step learning signal. Exploration is also con trolled: the final softmax la yer of the language mo del functions as Boltzmann exploration mechanism, and we use the same sampling temp erature across all mo dels. Under these controls, remaining performance differences primarily reflect differences in generalization. As rep orted in T able 3 , π A ⋆ mkv consisten tly outp erforms π A ⋆ act - seq across mo dels and tasks. The Mark ov prop ert y enables the model to treat distinct action histories as equiv alent whenev er they induce the same state, thereby promoting generalization to unseen problems. In contrast, action-sequence-based models m ust explicitly learn this equiv alence; previously unseen action sequences may induce erroneous predictions even when they corresp ond to the same underlying Mark ov state. W e defer the full results in App endix C.6 . 4.4 A dditional Results Bey ond our main results, we provide additional analyses in App endix C . W e rep ort training-time rew ard curv es demonstrating faster conv ergence of Marko v mo dels ( App endix C.2 ). W e also conduct an ablation on the fraction of SFT steps used for p olicy initialization, showing that Marko v mo dels achiev e higher rewards with fewer SFT steps ( Appendix C.4 ). Finally , we examine the role of Marko v states in purely sup ervised settings and find that the Marko v prop ert y plays a limited role under SFT alone ( App endix C.5 ). 9 Approac h Sudoku Sok oban 1 F utoshiki Qw en3-4B A ction-seq. w/ A ∗ 90.8 18.2 54.8 Markov w/ A ∗ 97.8 33.0 64.8 Qw en2.5-3B-It A ction-seq. w/ A ∗ 28.9 0.2 44.1 Markov w/ A ∗ 83.4 94.2 54.2 1 Given the capabilit y constraints of the base mo dels, we use low er-complexity Sokoban tasks in this section. T able 3: P erformance comparison of π A ⋆ mkv , π A ⋆ act - seq , and π A ⋆ st - act - seq on in-distribution b enc hmarks. 5 Theoretical Analysis In this section, we rigorously pro ve that the introduction of Marko v states enables the mo dels to ac hieving higher performance with low er sample complexity . Throughout this section, we assume the underlying en vironment is deterministic, gov erned by a ground-truth transition function s h +1 = P ( s h , a h ) . 1 W e also assume the reward is b ounded r h ∈ [ 0 , 1] for all h . T w o learning paradigms are formalized as b elo w. (1) A ction-se quenc e-b ase d le arning : The policy conditions on the initial state and the action history: a h ∼ π ( · | s 1 , a 1: h − 1 ) , where a 1: h − 1 is a shorthand notation for the sequence a 1 , a 2 , · · · , a h − 1 . (2) A ppr oximate Markovian le arning : The agen t has access to an approximate transition function b P : S × A → S that estimates the true dynamics P ⋆ . At eac h step h , the agent observes the appro ximate Mark ov state b s h ← b P ( b s h − 1 , a h − 1 ) (when h = 2 , b s 1 : = s 1 ), and selects action a h ∼ π ( · | b s h ) . This setting captures practical scenarios where Mark ov states are appro ximately reco vered via a learned world mo del or rule-based state extractor. W e consider a general p olicy optimization framework applicable to b oth learning paradigms. Sp ecifically , for each t in { 1 , 2 , . . . , T } , the learning algorithm updates the curren t p olicy π ( t ) using an approximated adv antage b A π ( t ) , yielding π ( t +1) . This algorithmic framework is sk etched in Algorithm 3 . W e make the follo wing assumption on the resulting p olicies. Assumption 1 (Optimization error) . F or action-se quenc e-b ase d mo dels, 1 T T X t =1 H X h =1 E π ⋆ h b A π ( t ) ( s 1 , a 1: h ) i ≤ H ε opt ; and for appr oximate Markovian le arning, 1 T T X t =1 H X h =1 E π ⋆ h b A π ( t ) ( b s h , a h ) i ≤ H ε opt . As detailed in App endix B.2 , when PPO-st yle algorithms are emplo yed, the optimization error satisfies ε opt = O p 1 /T . W e next b ound the error of the estimated adv an tage function b A π ( t ) ( x h , a h ) , as stated in Assumption 2 . 1 This assumption naturally holds for many reasoning tasks, including the logical puzzles in our exp erimen ts as w ell as settings like co de editing and mathematical pro of construction, where actions deterministically up date the problem state. 10 Assumption 2 (Adv antage estimation error) . W e assume E π ( t ) b A π ( t ) ( x h , a h ) − A π ( t ) ( x h , a h ) 2 ≤ ε 2 stat for al l h , wher e x h = ( s 1 , a 1 , . . . , a h − 1 ) for the action-se quenc e-b ase d le arning and x h = b s h for appr oximate Markovian le arning. W e further define the state-action o ccupancy as d π h ( s, a ) = E τ ∼ π [ I [ s h = s, a h = a ]] and o verload the notation for action-sequence o ccupancy: d π h ( s ′ 1 , a ′ 1: h ) = E τ ∼ π [ I [ s 1 = s ′ 1 , a 1: h = a ′ 1: h ]] . Under these assumptions, w e deriv e the p erformance guaran tee for action-sequence-based learning in Prop osition 1 . Prop osition 1 (Performance guaran tee of action-sequence-based learning) . F or the p ar adigm of action- se quenc e-b ase d le arning, supp ose A ssumption 1 and A ssumption 2 hold, then we have J ( π ⋆ ) − max t J ( π ( t ) ) ≤ H ε opt + H v u u u t max t,h E π ( t ) d π ⋆ h ( s 1 , a 1: h ) d π ( t ) h ( s 1 , a 1: h ) ! 2 ε stat . F or approximate Mark ovian learning, w e additionally assume the accuracy of the learned transition mo del, formalized in Assumption 3 , and derive the p erformance guaran tee in Prop osition 2 . Assumption 3 (State transition mo del accuracy) . we assume appr oximate tr ansition mo del satisfies Pr h b P ( s, a ) = P ( s, a ) i ≤ ε P for al l s ∈ S , a ∈ A . Prop osition 2 (Performance guarantee of approximate Marko vian learning) . F or the p ar adigm of appr oximate Markovian le arning, supp ose A ssumption 1 , A ssumption 2 , and A ssumption 3 hold, then we have J ( π ⋆ ) − max t J ( π ( t ) ) ≤ H ε opt + H v u u u t max t,h E π ( t ) d π ⋆ h ( s h , a h ) d π ( t ) h ( s h , a h ) ! 2 ε stat + 2 H 3 ε P . The pro of of Prop osition 1 and Prop osition 2 is deferred to App endix B.3 . Comparing Prop osition 1 and Prop osition 2 highligh ts the key benefit of introducing an approximate transition mo del. In the action-sequence-based learning ( Prop osition 1 ), the density ratio d π ⋆ h ( s 1 ,a 1: h ) d π ( t ) h ( s 1 ,a 1: h ) is defined ov er full action histories, whose space grows exponentially with the horizon H . Bounding this ratio in the worst case requires the learning p olicy π ( t ) to cov er an exponentially large history space, leading to prohibitive sample complexity (essentially scaling as |A| H ). This is consistent with the computational lo wer bound of F oster et al. ( 2025 ): the cov erage coefficient C cov ( π ⋆ β ) captures the same fundamental difficult y of cov ering the optimal p olicy ov er an exp onen tially large resp onse space. In con trast, the b ound for approximate Marko vian learning ( Prop osition 2 ) effectiv ely dep ends on the density ratio of the true underlying Mark ov states: d π ⋆ h ( s h ,a h ) d π ( t ) h ( s h ,a h ) , despite the agent operating on appro ximate states b s h . Pro vided that the true task has a compact state structure (e.g., p olynomial in H ), this ratio is muc h easier to b ound, implying an exp onen tial reduction in v ariance. App endix B.4 illustrates this distinction using Combination L o ck as an example task. This improv emen t comes at the cost of an additive bias term O H 3 ε P , which is p olynomial in the horizon and controlled b y the transition mo del accuracy . This presents a fav orable trade-off: by p aying a p olynomial pric e for appr oximate state tr ansitions, we avoid the p otential ly exp onential c over age c ost inher ent in action- se quenc e-b ase d le arning. This is particularly significan t in ligh t of the computational barrier established b y F oster et al. ( 2025 ), where action-sequence RL is forced to pay either the co verage cost C cov ( π ⋆ β ) or the exp onen tial exploration cost e R max /β —in tro ducing Marko v states sidesteps this b ottlenec k by reducing the effectiv e co verage requiremen t from action histories to the compact state space. 11 6 Conclusion In this work, w e rein tro duce Marko v states into LLM post-training and demonstrate their potential to o vercome the p erformance plateau of contemporary p ost-training paradigms. W e hop e this persp ectiv e motiv ates future w ork to incorporate Mark ovian structure in to real-w orld, complex tasks, pa ving the w ay to ward more scalable and open-ended capability growth in generative AI. A c kno wledgemen ts W e ackno wledge supp ort of the D ARP A AIQ A ward. This work used the DeltaAI system at the National Cen ter for Sup ercomputing Applications [aw ard O AC 2320345] through allo cation CIS251426 from the A dv anced Cyberinfrastructure Co ordination Ecosystem: Services & Supp ort (ACCESS) program, which is supp orted by U.S. National Science F oundation grants # 2138259, # 2138286, # 2138307, # 2137603, and # 2138296. References Milad Agha johari, Kamran Chitsaz, Amirhossein Kazemnejad, Sarath Chandar, Alessandro Sordoni, Aaron Courville, and Siv a Reddy . The mark ovian thinker: Arc hitecture-agnostic linear scaling of reasoning. arXiv pr eprint arXiv:2510.06557 , 2025. Qi Cai, Zh uoran Y ang, Chi Jin, and Zhaoran W ang. Prov ably efficient exploration in p olicy optimization. In International Confer enc e on Machine L e arning , pages 1283–1294. PMLR, 2020. Nicolo Cesa-Bianchi and Gáb or Lugosi. Pr e diction, le arning, and games . Cam bridge universit y press, 2006. Jiang jie Chen, W enxiang Chen, Jiac heng Du, Jinyi Hu, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, W enlei Shi, et al. Seed-pro ver 1.5: Mastering undergraduate-lev el theorem pro ving via learning from exp erience. arXiv pr eprint arXiv:2512.17260 , 2025. Ching-An Cheng, T engyang Xie, Nan Jiang, and Alekh Agarwal. Adv ersarially trained actor critic for offline reinforcemen t learning. In International Confer enc e on Machine L e arning , pages 3852–3878. PMLR, 2022. Prateek Chhikara, Dev Khan t, Saket Aryan, T aranjeet Singh, and Deshra j Y adav. Mem0: Building pro duction- ready ai agents with scalable long-term memory . arXiv pr eprint arXiv:2504.19413 , 2025. Ey al Ev en-Dar, Sham M Kakade, and Yisha y Mansour. Online marko v decision pro cesses. Mathematics of Op er ations R ese ar ch , 34(3):726–736, 2009. Dylan J F oster, Zakaria Mhammedi, and Dhruv Rohatgi. Is a go o d foundation necessary for efficien t reinforce- men t learning? the computational role of the base mo del in exploration. arXiv pr eprint arXiv:2503.07453 , 2025. Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized mark ov decision pro cesses. In International c onfer enc e on machine le arning , pages 2160–2169. PMLR, 2019. Da ya Guo, Dejian Y ang, Haow ei Zhang, Junxiao Song, R uoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, P eiyi W ang, Xiao Bi, et al. Deepseek-r1: Incen tivizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. Elad Hazan et al. Introduction to online conv ex optimization. F oundations and T r ends ® in Optimization , 2 (3-4):157–325, 2016. Thomas Hub ert, Rishi Meh ta, Laurent Sartran, Miklós Z Horváth, Goran Žužić, Eric Wieser, Aja Huang, Julian Schritt wieser, Y annick Sc hro ec ker, Hussain Maso om, et al. Olympiad-lev el formal mathematical reasoning with reinforcement learning. Natur e , pages 1–3, 2025. 12 Bin yuan Hui, Jian Y ang, Zeyu Cui, Jiaxi Y ang, Da yiheng Liu, Lei Zhang, Tianyu Liu, Jia jun Zhang, Bow en Y u, Kai Dang, et al. Qw en2. 5-co der technical report. arXiv pr eprint arXiv:2409.12186 , 2024. Aaron Jaec h, A dam Kalai, Adam Lerer, A dam Richardson, Ahmed El-Kishky , Aiden Lo w, Alec Helyar, Aleksander Madry , Alex Beutel, Alex Carney , et al. Op enai o1 system card. arXiv pr eprint arXiv:2412.16720 , 2024. Xiang Ji, Sanjeev Kulkarni, Mengdi W ang, and T engyang Xie. Self-pla y with adv ersarial critic: Prov able and scalable offline alignment for language mo dels. arXiv pr eprint arXiv:2406.04274 , 2024. Leslie P ack Kaelbling, Michael L Littman, and Andrew W Mo ore. Reinforcemen t learning: A surv ey . Journal of artificial intel ligenc e r ese ar ch , 4:237–285, 1996. Sham M Kakade. A natural p olicy gradient. A dvanc es in neur al information pr o c essing systems , 14, 2001. Sham M. Kakade and John Langford. Approximately optimal appro ximate reinforcement learning. In International Confer enc e on Machine L e arning , 2002. URL https://api.semanticscholar.org/CorpusID: 31442909 . Y ucheng Li, Bo Dong, F rank Guerin, and Chenghua Lin. Compressing context to enhance inference efficiency of large language mo dels. In Pr o c e e dings of the 2023 c onfer enc e on empiric al metho ds in natur al language pr o c essing , pages 6342–6353, 2023. Zongqian Li, Yinhong Liu, Yixuan Su, and Nigel Collier. Prompt compression for large language models: A surv ey . In Pr o c e e dings of the 2025 Confer enc e of the Nations of the A meric as Chapter of the A sso ciation for Computational Linguistics: Human L anguage T e chnolo gies (V olume 1: L ong Pap ers) , pages 7182–7195, 2025. Miao Lu, W eiwei Sun, W eihua Du, Zhan Ling, Xuesong Y ao, Kang Liu, and Jiecao Chen. Scaling llm m ulti-turn rl with end-to-end summarization-based context managemen t. arXiv pr eprint arXiv:2510.06727 , 2025. V olo dym yr Mnih, K oray Ka vukcuoglu, Da vid Silver, Andrei A Rusu, Jo el V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-lev el con trol through deep reinforcement learning. natur e , 518(7540):529–533, 2015. Gergely Neu, Anders Jonsson, and Vicenç Gómez. A unified view of entrop y-regularized marko v decision pro cesses. arXiv pr eprint arXiv:1705.07798 , 2017. Long Ouyang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ain wright, P amela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ra y , et al. T raining language mo dels to follow instructions with h uman feedbac k. A dvanc es in neur al information pr o c essing systems , 35:27730–27744, 2022. Charles Pac ker, Sarah W o o ders, Kevin Lin, Vivian F ang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: T ow ards llms as op erating systems. arXiv pr eprint arXiv:2310.08560 , 2023. Mihir Prabh udesai, Lili Chen, Alex Ippoliti, Katerina F ragkiadaki, Hao Liu, and Deepak Pathak. Maximizing confidence alone improv es reasoning. arXiv pr eprint arXiv:2505.22660 , 2025. Zile Qiao, Guoxin Chen, Xuanzhong Chen, Donglei Y u, W enbiao Yin, Xinyu W ang, Zhen Zhang, Baixuan Li, Huifeng Yin, Kuan Li, et al. W ebresearcher: Unleashing unbounded reasoning capability in long-horizon agen ts. arXiv pr eprint arXiv:2509.13309 , 2025. Soum ya Rani Samineni, Durgesh Kalwar, Karthik V almeekam, Ka ya Stec hly , and Subbarao Kam bhampati. Rl in name only? analyzing the structural assumptions in rl p ost-training for llms. arXiv pr eprint arXiv:2505.13697 , 2025. Julian Schritt wieser, Ioannis Antonoglou, Thomas Hub ert, Karen Simony an, Laurent Sifre, Simon Schmitt, Arth ur Guez, Edward Lo c khart, Demis Hassabis, Thore Graep el, et al. Mastering atari, go, c hess and shogi b y planning with a learned mo del. Natur e , 588(7839):604–609, 2020. 13 John Sch ulman, Sergey Levine, Pieter Abb eel, Mic hael Jordan, and Philipp Moritz. T rust region p olicy optimization. In International c onfer enc e on machine le arning , pages 1889–1897. PMLR, 2015a. John Sc hulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abb eel. High-dimensional con tinuous con trol using generalized adv antage estimation. arXiv pr eprint arXiv:1506.02438 , 2015b. John Sch ulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Pro ximal p olicy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. R ulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng, Yiping W ang, Sewoong Oh, Simon Shaolei Du, Nathan Lam b ert, Sewon Min, Ranjay Krishna, et al. Spurious rewards: Rethinking training signals in rlvr. arXiv pr eprint arXiv:2506.10947 , 2025. Zhihong Shao, P eiyi W ang, Qihao Zh u, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingch uan Zhang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathematical reasoning in op en language mo dels. arXiv pr eprint arXiv:2402.03300 , 2024. Guangming Sheng, Chi Zhang, Zilingfeng Y e, Xibin W u, W ang Zhang, Ru Zhang, Y anghua P eng, Haibin Lin, and Chuan W u. Hybridflo w: A flexible and efficient rlhf framew ork. arXiv pr eprint arXiv: 2409.19256 , 2024. Da vid Silver, Thomas Hub ert, Julian Schri ttwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering c hess and shogi by self-pla y with a general reinforcemen t learning algorithm. arXiv pr eprint arXiv:1712.01815 , 2017. Zafir Sto jano vski, Oliver Stanley , Jo e Sharratt, Richard Jones, Ab dulhak eem Adefio ye, Jean Kaddour, and Andreas Köpf. Reasoning gym: Reasoning environmen ts for reinforcemen t learning with v erifiable rew ards, 2025. URL . Yiy ou Sun, Y uhan Cao, Pohao Huang, Haoyue Bai, Hannaneh Ha jishirzi, Nouha Dziri, and Dawn Song. Rl grokking recip e: How do es rl unlo c k and transfer new algorithms in llms? arXiv pr eprint arXiv:2509.21016 , 2025. Ric hard S Sutton, Andrew G Barto, et al. R einfor c ement le arning: A n intr o duction . MIT press Cambridge, 1998. Sijun T an, Michael Luo, Colin Cai, T arun V enkat, Kyle Montgomery , Aaron Hao, Tianhao W u, Arnav Balyan, Manan Ro ongta, Chenguang W ang, Li Erran Li, Raluca Ada P opa, and Ion Stoica. rllm: A framework for p ost-training language agen ts. https://pretty- radio- b75.notion.site/rLLM- A- Framework- for- Post- T raining- Language- Agents- 21b81902c146819db63cd98a54ba5f31 , 2025. Notion Blog. Qw en T eam. Qwen2.5: A party of foundation mo dels, September 2024. URL https://qwenlm.github.io/b log/qwen2.5/ . Qw en T eam. Qwen3 tec hnical rep ort, 2025. URL . F engwei T eng, Quan Shi, Zhao yang Y u, Jiayi Zhang, Y uyu Luo, Chenglin W u, and Zhijiang Guo. Atom of though ts for marko v llm test-time scaling. arXiv pr eprint arXiv:2502.12018 , 2025. Scott Viteri, Max Lamparth, Peter Chatain, and Clark Barrett. Marko vian transformers for informative language mo deling. arXiv pr eprint arXiv:2404.18988 , 2024. F ang W u, W eihao Xuan, Ximing Lu, Ming jie Liu, Yi Dong, Zaid Harc haoui, and Y ejin Choi. The invisible leash: Why rlvr ma y or may not escape its origin. arXiv pr eprint arXiv:2507.14843 , 2025a. Xixi W u, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Y u, Dingch u Zhang, Y ong Jiang, et al. Resum: Unlo c king long-horizon searc h intelligence via context summarization. arXiv pr eprint arXiv:2509.13313 , 2025b. 14 T engyang Xie, Ching-An Cheng, Nan Jiang, Paul Mineiro, and Alekh Agarw al. Bellman-consisten t pessimism for offline reinforcement learning. A dvanc es in neur al information pr o c essing systems , 34:6683–6694, 2021. T engyang Xie, Dylan J F oster, Akshay Krishnamurth y , Corby Rosset, Ahmed A wadal lah, and Alexander Rakhlin. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf. arXiv pr eprint arXiv:2405.21046 , 2024. Am y Xin, Jinxin Liu, Zijun Y ao, Zhic heng Lee, Sh ulin Cao, Lei Hou, and Juanzi Li. A tomr: Atomic operator- emp o w ered large language mo dels for heterogeneous knowledge reasoning. arXiv pr eprint arXiv:2411.16495 , 2024. W ujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Jun tao T an, and Y ongfeng Zhang. A-mem: Agentic memory for llm agents. arXiv pr eprint arXiv:2502.12110 , 2025. Edw ard Y eo, Y uxuan T ong, Morry Niu, Graham Neubig, and Xiang Y ue. Demystifying long c hain-of-thought reasoning in llms. arXiv pr eprint arXiv:2502.03373 , 2025. Lifan Y uan, W eize Chen, Y uchen Zhang, Ganqu Cui, Hanbin W ang, Ziming Y ou, Ning Ding, Zhiyuan Liu, Maosong Sun, and Hao Peng. F rom f ( x ) and g ( x ) to f ( g ( x )) : Llms learn new skills in rl by comp osing old ones. arXiv pr eprint arXiv:2509.25123 , 2025a. Y urun Y uan and T engyang Xie. Reinforce LLM reasoning through multi-agen t reflection. In F orty-se c ond International Confer enc e on Machine L e arning , 2025. URL https://openreview.net/forum?id=6k3oFS3L bl . Y urun Y uan, F an Chen, Zeyu Jia, Alexander Rakhlin, and T engyang Xie. T ra jectory b ellman residual minimization: A simple v alue-based metho d for llm reasoning. arXiv pr eprint arXiv:2505.15311 , 2025b. Y ang Y ue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai W ang, Shiji Song, and Gao Huang. Does rein- forcemen t learning really incen tivize reasoning capacity in llms b ey ond the base mo del? arXiv pr eprint arXiv:2504.13837 , 2025. Charlie Zhang, Graham Neubig, and Xiang Y ue. On the interpla y of pre-training, mid-training, and rl on reasoning language mo dels. arXiv pr eprint arXiv:2512.07783 , 2025. W anjun Zhong, Lianghong Guo, Qiqi Gao, He Y e, and Y anlin W ang. Memorybank: Enhancing large language mo dels with long-term memory . In Pr o c e e dings of the AAAI Confer enc e on A rtificial Intel ligenc e , volume 38, pages 19724–19731, 2024. P ei Zhou, Ja y Pujara, Xiang Ren, Xin yun Chen, Heng-T ze Cheng, Quo c V Le, Ed Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. Self-disco ver: Large language mo dels self-compose reasoning structures. A dvanc es in Neur al Information Pr o c essing Systems , 37:126032–126058, 2024. Brian D Ziebart. Mo deling purp oseful adaptive b ehavior with the principle of maximum c ausal entr opy . Carnegie Mellon Universit y , 2010. Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, and Anind K Dey . Maxim um en tropy inv erse reinforcemen t learning. AAAI Confer enc e on A rtificial Intel ligenc e , 8:1433–1438, 2008. Y uxin Zuo, Kaiy an Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Y uchen Zhang, Xinw ei Long, Ermo Hua, et al. Ttrl: T est-time reinforcement learning. arXiv pr eprint arXiv:2504.16084 , 2025. 15 App endix A Related W ork Debate on RL Post-T raining. An active debate has emerged regarding whether RL can endow mo dels with reasoning capabilities that fundamentally exceed those acquired during pre-training. A gro wing b ody of w ork suggests that RL primarily refines, reweigh ts, or selectively amplifies reasoning patterns already latent in the base mo del, rather than inducing gen uinely nov el capabilities ( Shao et al. , 2024 ; Y ue et al. , 2025 ; W u et al. , 2025a ; Shao et al. , 2025 ; Y eo et al. , 2025 ). This view is further reinforced by recen t self-improv ement metho ds that eliminate environmen t interaction or external reward signals altogether, yet ac hieve comparable gains ( Prabh udesai et al. , 2025 ; Zuo et al. , 2025 ), indicating that impro vemen t often arises from internal redistribution of probability mass rather than exploratory discov ery . In contrast, w orks rep orting emergent capabilities under RL t ypically dep end on restrictiv e training designs, suc h as prerequisite domain knowledge ( Y uan et al. , 2025a ), carefully curated task difficulty ( Zhang et al. , 2025 ), or explicitly designed warm-up phases and partial reward shaping ( Sun et al. , 2025 ). These mec hanisms substan tially constrain the optimization landscape and guide learning to ward known solution manifolds, suggesting that the observ ed gains reflect controlled extrapolation within a narrow h yp othesis space rather than the discov ery of fundamen tally new reasoning tra jectories. F urthermore, Samineni et al. ( 2025 ) offers a critical reassessmen t of the prev ailing “history-as-state” form ulation in RL p ost-training. Combining theoretical arguments with empirical evidence, they show that mainstream RL p ost-training methods are effectiv ely equiv alent to outcome-conditioned sup ervised learning, implying that—under this formulation—RL has not meaningfully exceeded the represen tational or optimization capabilities of sup ervised learning. Con text Managemen t. A growing bo dy of w ork addresses context-length explosion b y reducing the amoun t of information carried forw ard, either through compression ( Li et al. , 2023 , 2025 ) or by external memory mechanisms ( P ack er et al. , 2023 ; Chhikara et al. , 2025 ; Xu et al. , 2025 ; Zhong et al. , 2024 ). These metho ds typically discard irrelev ant details and condense salient information into compact summaries to op erate o ver long contexts. In agentic AI, related context managemen t tec hniques aim to prev ent un b ounded gro wth of interaction histories b et ween an agen t and its environmen t, thereby alleviating context limits and impro ving the stability of long-horizon training ( W u et al. , 2025b ; Lu et al. , 2025 ). Replacing the full history with a concise summary breaks the strict “history-as-state” formulation. How ever, it only app e ars to yield a Mark ovian state—compression alone does not ensure the Marko v property . A Mark ov state must b e a sufficient statistic for optimal future control: any t wo histories mapp ed to the same state should induce iden tical conditional transition and reward distributions. Existing summarization-based approac hes do not enforce this sufficiency , leaving the p olicy to implicitly learn equiv alence across exp onentially man y tra jectories. Moreo ver, without internalizing the en vironment’s transition dynamics, a summarization mo del ma y not reliably pro duce v alid Mark ov states from action sequences. Mark ov LLM Reasoning. A few works mitigate reliance on historical information by decomp osing problems into atomic reasoning steps and exploring Marko vian reasoning processes ( Xin et al. , 2024 ; T eng et al. , 2025 ; Zhou et al. , 2024 ). As an example, A tom of Thoughts (A OT) ( T eng et al. , 2025 ) prop oses a test-time reasoning framework that iteratively transforms a problem in to a sequence of answ er-equiv alent but progressiv ely simpler sub questions. A t eac h iteration, the current question is decomp osed into a temp orary dep endency structure and then contracted into a new sub question, whic h serves as a Mark ov state for the next step, eliminating reliance on historical reasoning traces. These work fo cuses on improving test-time abilities through planning and decomp osition. A dditionally , Marko vian Thinker ( Aghajohari et al. , 2025 ) structures LLM reasoning into fixed-size ch unks, limiting the length of eac h reasoning step. They find that during RL training the p olicy learns to write a textual state near the end of each c hunk sufficient for seamless con tinuation of reasoning after reset. Although their work suggests a sp ecific w ay to obtain fixed-size textual state, our work systematically show cases and 16 analyzes the b enefits of in tro ducing Mark ov states without additional assumptions on the metho d of state generation. F urthermore, Viteri et al. ( 2024 ) prop ose a framew ork that aims at mitigating unfaithful c hain-of-thought reasoning. It consists of a Chain-of-Thought (CoT) generator and a do wnstream p olicy that pro duces the final answer conditioned solely on the generated CoT, thereby treating the CoT as a load-b earing Marko v state. Finally , W ebResearcher ( Qiao et al. , 2025 ) can b e view ed as applying explicit Marko v state estimation to DeepResearc h, training a single model to predict b oth the next state and the next action. How ever, its primary contribution is a new training algorithm for DeepResearch agen ts, while our w ork presen ts a fo cused study on the impact of Marko v prop ert y . B Theoretical Analysis of Mark o vian Efficiency In this section, we pro vide theoretical analysis regarding the b enefit of Marko v states additional to Section 5 . B.1 General Policy Optimization Proto col Algorithm 3 General P olicy Optimization Proto col 1: Initialize: Initial policy π (1) and total iterations T . 2: for t = 1 to T do 3: Estimate approximate adv antage function b A π ( t ) based on current p olicy π ( t ) . 4: Up date policy to obtain π ( t +1) b y optimizing ob jectiv e inv olving b A π ( t ) : π ( t +1) ← Optimize π ( t ) , b A π ( t ) 5: end for 6: Return: Sequence of p olicies π (1) , π (2) , . . . , π ( T +1) This p olicy optimization proto col encompasses man y p opular algorithms. F or PPO, the function Optimize is defined as Optimize π ( t ) , b A π ( t ) = argmax π E π ( t ) h min π ( a h | s h ) π ( t ) ( a h | s h ) b A π ( t ) h ( s h , a h ) , clip π ( a h | s h ) π ( t ) ( a h | s h ) , 1 − ε, 1 + ε b A π ( t ) h ( s h , a h ) i . F or GRPO, Optimize is Optimize π ( t ) , b A π ( t ) = argmax π E x ∼ ρ, { o ( i ) } G i =1 ∼ π ( t ) ( ·| x ) " 1 G G X i =1 1 | o i | | o i | X h =1 ( min π ( a ( i ) h | s ( i ) h ) π ( t ) ( a ( i ) h | s ( i ) h ) b A π ( t ) ( i ) , clip π ( a ( i ) h | s ( i ) h ) π ( t ) ( a ( i ) h | s ( i ) h ) , 1 − ϵ, 1 + ϵ b A π ( t ) ( i ) − β D KL ( π ∥ π ref ) )# , B.2 Discussion of Assumption 1 T o argue the v alidity of Assumption 1 , we consider the connection betw een the natural p olicy gradient ( Kakade , 2001 ) and KL-regularized policy optimization in pro ximal p olicy optimization ( Sc hulman et al. , 2015a , 2017 ; Cai et al. , 2020 ). F or ease of presen tation, we define x h to b e the essen tial state at time step h ( x h = ( s 1 , a 1 , . . . , a h − 1 ) for the action-sequence-based learning and x h = b s h for approximate Marko vian learning). With this notation, we consider the following RL ob jectiv es π ( t +1) ← argmax π H X h =1 E π ( t ) π ( a h | x h ) π ( t ) ( a h | x h ) b A π ( t ) ( x h , a h ) − β D KL ( π ( · | x h ) ∥ π ( t ) ( · | x h )) . 17 This ob jectiv e can b e view ed as the approximation of popular RL algorithms for LLMs (we omit clipping and m ultiple rollouts b elo w, since our fo cus is on conv ergence b eha vior). W e can rewrite that ob jectiv e as π ( t +1) ← argmax π H X h =1 E x h ∼ π ( t ) h b A π ( t ) ( x h , π ) − β D KL ( π ( · | x h ) ∥ π ( t ) ( · | x h )) i , where A ( x, π ) : = E a ∼ π [ A ( x, a )] . Then, we can easily verify that one global optimum of this ob jectiv e is π ( t +1) ( · | x h ) ∝ π ( t ) ( · | x h ) · exp 1 β b A π ( t ) ( x h , · ) , whic h implies Assumption 1 with ε opt = O ( p 1 /T ) . There is a rich literature studied or used this argument from online learning ( Cesa-Bianchi and Lugosi , 2006 ; Even-Dar et al. , 2009 ; Hazan et al. , 2016 ; Neu et al. , 2017 ; Geist et al. , 2019 ) to recen t RL adv ances ( Cai et al. , 2020 ; Xie et al. , 2021 ; Cheng et al. , 2022 ; Ji et al. , 2024 ). B.3 Pro of of Prop osition 1 and Prop osition 2 W e first introduce an episo dic version of p erformance difference lemma ( Kakade and Langford , 2002 ). Lemma 3 (Performance difference lemma) . F or any p olicy π ′ and π , we have J ( π ′ ) − J ( π ) = H X h =1 E ( s h ,a h ) ∼ d π ′ h [ A π h ( s h , a h )] W e provide the pro of for these performance guaran tees b elo w. Pr o of of Pr op osition 1 . F or each π ( t ) , we ha ve J ( π ⋆ ) − 1 T T X t =1 J ( π ( t ) ) = 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( s 1 , a 1 , . . . , a h ) i = 1 T T X t =1 H X h =1 E π ⋆ h b A π ( t ) ( s 1 , a 1 , . . . , a h ) i | {z } (I) + 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( s 1 , a 1 , . . . , a h ) − b A π ( t ) ( s 1 , a 1 , . . . , a h ) i | {z } (II) . F or a fixed h , let x h = ( s 1 , a 1 , . . . , a h − 1 ) and τ h = ( s 1 , a 1: h ) = ( x h , a h ) . The first equation is a direct application of Lemma 3 , treating ( s 1 , a 1 , . . . , a h − 1 ) as the essen tial state x h . T erm (I) can b e b ounded as ≤ H ε opt b y Assumption 1 . W e now bound the term (I I). W e hav e: E π ⋆ h A π ( t ) ( τ h ) − b A π ( t ) ( τ h ) i = X τ h ∈S 1 ×A h d π ⋆ h ( τ h )( A π ( t ) ( τ h ) − b A π ( t ) ( τ h )) = X τ h ∈S 1 ×A h d π ( t ) h ( τ h ) d π ⋆ h ( τ h ) d π ( t ) h ( τ h ) ( A π ( t ) ( τ h ) − b A π ( t ) ( τ h )) ≤ v u u u t E π ( t ) d π ⋆ h ( τ h ) d π ( t ) h ( τ h ) ! 2 q E π ( t ) [( A π ( t ) ( τ h ) − b A π ( t ) ( τ h )) 2 ] 18 ≤ v u u u t E π ( t ) d π ⋆ h ( τ h ) d π ( t ) h ( τ h ) ! 2 ε stat . Therefore, T erm (I I) ≤ H v u u u t max t,h E π ( t ) d π ⋆ h ( s 1 , a 1: h ) d π ( t ) h ( s 1 , a 1: h ) ! 2 ε stat Summing up the b ounds of term (I) and (II) concludes our pro of. Pr o of of Pr op osition 2 . F or each π ( t ) , we ha ve J ( π ⋆ ) − 1 T T X t =1 J ( π ( t ) ) = 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( s h , a h ) i = 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( s h , a h ) − A π ( t ) ( b s h , a h ) i + 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( b s h , a h ) i = 1 T T X t =1 H X h =1 E π ⋆ h b A π ( t ) ( b s h , a h ) i | {z } (I) + 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( b s h , a h ) − b A π ( t ) ( b s h , a h ) i | {z } (II) + 1 T T X t =1 H X h =1 E π ⋆ h A π ( t ) ( s h , a h ) − A π ( t ) ( b s h , a h ) i | {z } (II I) , where the first equation is a direct application of Lemma 3 . T erm (I) can b e b ounded as ≤ H ε opt b y Assumption 1 . F or term (I II), recall that Pr( s h = b s h ) ≤ H ε P , and therefore term (I II) is b ounded as: E π ⋆ h A π ( t ) ( s h , a h ) − A π ( t ) ( b s h , a h ) i ≤ Pr( s h = b s h ) · max s, b s,a | A π ( t ) ( s, a ) − A π ( t ) ( b s, a ) | ≤ ( H ε P ) · 2 H = 2 H 2 ε P . Next, for term (I I), let ∆( s, a ) = A π ( t ) ( s, a ) − b A π ( t ) ( s, a ) . This term can b e b ounded as: E π ⋆ [∆( b s h , a h )] = E π ⋆ [ E [∆( b s h , a h ) | s h , a h ]] = X s,a d π ( t ) ( s, a ) d π ⋆ ( s, a ) d π ( t ) ( s, a ) E [∆( b s h , a h ) | s, a ] ≤ v u u t E π ( t ) " d π ⋆ ( s h , a h ) d π ( t ) ( s h , a h ) 2 # p E π ( t ) [( E [∆( b s h , a h ) | s h , a h ]) 2 ] (Cauc hy-Sc hw arz) ≤ v u u t E π ( t ) " d π ⋆ ( s h , a h ) d π ( t ) ( s h , a h ) 2 # p E π ( t ) [∆( b s h , a h ) 2 ] (Jensen’s inequality) 19 = v u u t E π ( t ) " d π ⋆ ( s h , a h ) d π ( t ) ( s h , a h ) 2 # ε stat . Summing up the b ounds of term (I), (I I), and (I I I) concludes our pro of. B.4 Illustration of the Theoretical Analysis with Combination Lo c k s 1 h + 1 h − 1 h ++ 2 h + − 2 h − + 2 Correct W rong Correct W rong . . . . . . (a) Non-Mark o vian (History T ree) State space grows as O ( |A| H ) . Exp onen tial Cov erage Needed. s 1 s 2 s 3 . . . s H Correct Correct W rong W rong W rong (b) Mark o vian (State Chain) State space grows as O ( H ) . Linear Cov erage Sufficien t. Figure 6: Visual comparison of the state space complexity for the Combination Lock problem. As shown in Figure 6 , the state space complexity diverges significantly dep ending on ho w the agent represents its environmen t. In the action-sequence-based learning, the agent treats the en tire history of actions as its state, which can b e visualized as a History T r e e . E ach unique sequence of mov es is treated as a distinct no de in this tree. Consequently , the state space grows exponentially as O ( |A| H ) . T o learn an optimal p olicy in this regime, the agent requires exponential co verage of the history space, leading to the prohibitiv ely high sample complexity . In contrast, the Marko vian formulation represen ts the environmen t as a State Chain . By mapping all action histories to a Marko v state s h , the agent collapses the complex tree structure in to a linear progression of length H . This representation ensures that the state space grows only linearly , O ( H ) , making linear cov erage sufficien t for conv ergence. B.5 Pro ofs for Supp orting Lemmas Pr o of of L emma 3 . Let us prov e by induction. When H = 1 , the tra jectory consists of a single step, and the statement is trivial. No w assume that for horizon k the statement holds for any p olicy π ′ and π : J k ( π ′ ) − J k ( π ) = k X h =1 E ( s h ,a h ) ∼ d π ′ h [ A π h ( s h , a h )] . F or H = k + 1 , w e expand J k +1 ( π ′ ) − J k +1 ( π ) : J k +1 ( π ′ ) − J k +1 ( π ) = E π ′ " k +1 X h =1 r ( s h , a h ) # − E π " k +1 X h =1 r ( s h , a h ) # = E π ′ " k +1 X h =2 r ( s h , a h ) # − E π ′ [ V π 2 ( s 2 )] (I) 20 1 2 4 8 16 32 64 128 256 512 1024 0.2 0.4 0.6 0.8 1.0 P ass@k Sudoku 1 2 4 8 16 32 64 128 256 512 1024 k (log scale) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Sok oban 1 2 4 8 16 32 64 128 256 512 1024 0.0 0.2 0.4 0.6 0.8 F utoshiki A ction-Seq Mark ov SF T -war mup RL post-train Figure 7: Pass@ k accuracy for Qwen3-4B-based models. While action-sequence mo dels rarely improv e SFT P ass@ k , Marko v mo dels consistently surpass their base mo dels’ limits. + E π ′ [ r ( s 1 , a 1 )] + E π ′ [ V π 2 ( s 2 )] − E π " k +1 X h =1 r ( s h , a h ) # (I I) T erm I corresp onds to the difference b et ween exp ected returns of π ′ and π on an MDP with horizon k . Apply the inductive h yp othesis to term I, w e hav e E π ′ " k +1 X h =2 r ( s h , a h ) # − E ′ π [ V π 2 ( s 2 )] = H X h =2 E ( s h ,a h ) ∼ d π ′ h [ Q π h ( s h , a h ) − V π h ( s h )] F or term I I, w e hav e E π ′ [ r ( s 1 , a 1 )] + E π ′ [ V π 2 ( s 2 )] − E π " k +1 X h =1 r ( s h , a h ) # = E π ′ [ Q π 1 ( s 1 , a 1 )] − E π [ V π 1 ( s 1 )] = E s 1 ∼ d π ′ 1 E a 1 ∼ π ′ ( ·| s 1 ) [ Q π 1 ( s 1 , a 1 )] − V π 1 ( s 1 ) Summing up term I and I I concludes our proof. C A dditional Results C.1 P ass@ k P erformance W e presents Qwen3-4B’s P ass@ k accuracy as k scales ( Figure 7 ). Several distinct patterns emerge. F or less c hallenging tasks like Sudoku, where SFT-warm up mo dels already achiev e high Pass@ 1024 , both Marko v and action-sequence mo dels sharp en P ass@ 1 p erformance, with Marko v mo dels holding a slight adv antage. Ho wev er, on more difficult tasks like Sok oban and F utoshiki, action-sequence mo dels fail to extend or even main tain the Pass@ k of SFT mo dels. In contrast, Mark ov mo dels break through the capability boundaries of the base mo dels, remarkably extending P ass@ k . C.2 T raining Success Rate W e rep ort the training-time success rate during RL p ost-training in Figure 8 . F or the experiments in Section 4.3 , the corresponding training dynamics are shown in Figure 9 . A cross nearly all tasks and mo del v ariants, Marko v mo dels conv erge faster and achiev e higher final success rates than action-sequence mo dels. In tro ducing Marko v states partially alleviates the slo w-growth issue of action-sequence models in state–action-sequence v ariants, but a noticeable p erformance gap relative to Mark ov models remains. 21 0 20 40 60 80 100 0.0 0.2 0.4 0.6 0.8 1.0 Success R ate Sudoku Mark ov A ction-Seq. State- A ction-Seq. 0 20 40 60 80 100 Sok oban 0 20 40 60 80 100 F utoshiki 0 25 50 75 100 125 150 0.0 0.2 0.4 0.6 0.8 1.0 Success R ate 0 200 400 600 Step 0 20 40 60 80 100 Qwen3-4B Qwen2.5-3-It Figure 8: T raining-time success rate during RL p ost-training. 0 25 50 75 100 125 150 0.0 0.2 0.4 0.6 0.8 1.0 Success R ate Sudoku Mark ov A ction-Seq. State- A ction-Seq. 0 20 40 60 80 100 Sok oban 0 25 50 75 100 125 150 F utoshiki 0 50 100 150 200 0.0 0.2 0.4 0.6 0.8 1.0 Success R ate 0 50 100 150 200 250 300 Step 0 50 100 150 200 Qwen3-4B Qwen2.5-3-It Figure 9: T raining-time success rate during RL p ost-training for mo dels with access to A ⋆ in Section 4.3 . 22 0 10 20 30 40 50 0.0 0.2 0.4 0.6 0.8 R ewar d Action-Seq. 21% 43% 64% 86% 100% T raining r ewar d A vg r ewar d in 25-50 0 10 20 30 40 50 Step Mark ov 0 10 20 30 40 50 State-Action-Seq. Figure 10: Ablation on the degree of SFT warm-up dataset. Exp erimen ts are conducted with Qw en2.5-3B-It on Sudoku. C.3 Dep endence on the Curren t State in State-Action-Sequence Mo dels Approac h Sudoku Sok oban F utoshiki Qw en3-4B State-action-se q. 89.1 58.2 44.2 History-only 0.0 1.7 0.0 L ast-state-only 39.2 3.1 26.6 T able 4: Analysis of the fo cus of the state-action-sequence mo dels. History-only : the mo del is restricted to previous states and actions without access to the current state. Last-state-only : the mo del observes only the most recent state. All ev aluations are conducted with the ground-truth state transition P ⋆ . T o further probe what the state-action-sequence mo del actually uses after training, W e test whether the mo del treats the current state as a sufficient statistic of the history . W e ev aluate tw o con trolled v ariants: (1) History-only , which remov es the curren t state s h and pro vides only previous states and actions { ( s i , a i ) } h − 1 i =0 , and (2) Last-state-only , whic h keeps only the most recent state s h and discards the full history . T able 4 sho ws a stark pattern: History-only p erformance collapses to near zero across tasks, while Last-state-only retains a non-trivial fraction of the full state-action-sequence accuracy . Overall, these results indicate that w ell-trained state-action-sequence mo dels rely primarily on the current state, with the action/state history con tributing comparativ ely little, consistent with the view that they tend to internalize the Mark ov prop ert y of the state represen tation. C.4 Ablation on the Degree of SFT W arm-up T o assess how the degree of SFT w arm - up affects subsequen t RL, w e run an ablation ov er the fraction of SFT steps used to initialize the p olicy . W e first train a base mo del with SFT to completion, saving in termediate c heckpoints at 21%, 43%, 64%, 86%, and 100% of the total SFT steps. F or each chec kp oin t, we then launch a fresh RL run, initializing the p olicy from that c heckpoint while keeping all other RL settings fixed. As shown in Figure 10 , 21% SFT is insufficient for all three approaches, with reward remaining at zero throughout RL. Con tinuing the w armup to 43%, the reward of Mark ov and State-A ction-Seq starts ascending, whereas the A ction-Seq. model still fails to escap e the zero - rew ard plateau. Remarkably , even when fully SFT ed (100%), the Action-Seq. model never reac hes the final reward ac hieved b y the 43%-SFT Marko v mo del, highlighting that the Marko v formulation is inheren tly easier for RL, more sample - efficien t, and less reliant on hea vy SFT. Comparing Marko v and State-A ction-Seq., w e observe that with 43% SFT the latter learns more slowly and con verges to slightly lo wer rew ard, but as the SFT fraction increases the State-Action-Seq. mo del gradually 23 in ternalizes the Marko v structure of the en vironment and matches the performance of the Marko v baseline. C.5 Mark o v States in SFT Approac h In Distribution Out Of Distribution Sudoku Sok oban F utoshiki Sudoku Sok oban F utoshiki A vg Pass A vg Pass A vg Pass A vg Pass A vg P ass A vg P ass Qw en3-4B A ction-seq. 76.0 100.0 2.2 79.0 57.9 100.0 35.8 98.0 0.1 10.0 13.0 100.0 Markov 82.4 100.0 56.2 94.0 62.5 100.0 45.1 99.0 13.0 66.0 15.5 99.0 State-A ction-seq. 70.4 100.0 53.6 98.0 61.0 100.0 33.1 99.0 14.9 58.0 14.8 100.0 Qw en2.5-3B-It A ction-seq. 48.0 100.0 5.3 87.0 12.4 99.0 11.4 94.0 1.0 27.0 0.8 49.0 Markov 51.3 100.0 52.5 93.0 36.6 100.0 14.0 98.0 15.8 65.0 5.0 94.0 State-A ction-seq. 62.0 100.0 35.7 95.0 50.3 100.0 19.9 97.0 5.5 58.0 9.4 98.0 T able 5: P erformance comparison of different approac hes for SFT. W e ha ve demonstrated the imp ortance of Marko v states in RL p ost-training due to its low er sample complexity , it is interesting to inv estigate the case in supervised learning. Therefore, we SFT the mo dels and show the ev aluation results in T able 5 . By comparing the approaches across mo dels and tasks, w e conclude t wo findings: (1) Action-sequence models consisten tly p erforms worse than Marko v mo dels and state-action-sequence mo dels, most significan tly on Sokoban, indicating the b enefits of Marko v states even in the sup ervised learning paradigm. By conditioning on an explicit (predicted) state pro vided by an external transition mo del, mo dels with Marko v states no longer need to reconstruct the current b oard configuration implicitly in its latent space, thereby offloading the burden of state tracking and prediction, therefore low er the sample complexity . (2) The gap b etw een Mark ov models and state-action-sequence mo dels shrinks or b ecomes unclear. This is b ecause the SFT ob jectiv e is to maximize likelihoo d from fixed offline tra jectories rather than exploratory disco very . Unlike RL, whic h requires expansiv e co verage to reliably explore, SFT bypasses the need for the significan t sample complexity reduction. Consequently , the Marko v property is less critical in sup ervised settings. C.6 Ev aluation Results of Mo dels with Access to A ⋆ W e present the full ev aluation results on π A ⋆ mkv , π A ⋆ act - seq , and π A ⋆ st - act - seq in T able 6 as a supplement to Section 4.3 . C.7 Examples of Solving Problems in Multiple Steps A ction-Seq. Mo del π act - seq State s 0 Here is the initial b oard state: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 24 Approac h In Distribution Out Of Distribution Sudoku Sok oban 1 F utoshiki Sudoku Sok oban 1 F utoshiki A vg Pass A vg Pass A vg Pass A vg P ass A vg P ass A vg Pass Qw en3-4B A ction-seq. w/ A ∗ 90.8 93.0 18.2 23.0 54.8 71.0 61.0 78.0 2.7 8.0 11.7 21.0 Markov w/ A ∗ 97.8 100.0 33.0 33.0 64.8 73.0 80.9 85.0 4.0 4.0 25.2 35.0 State-A ction-seq. w/ A ∗ 94.0 98.0 19.8 25.0 51.6 69.0 73.7 83.0 3.9 8.0 14.4 32.0 Qw en2.5-3B-It A ction-seq. w/ A ∗ 28.9 44.0 0.2 5.0 44.1 63.0 2.9 9.0 0.0 0.0 3.8 16.0 Markov w/ A ∗ 83.4 86.0 94.2 97.0 54.2 59.0 48.8 57.0 82.5 87.0 26.3 36.0 State-A ction-seq. w/ A ∗ 84.8 92.0 0.2 1.0 51.9 71.0 45.8 59.0 0.0 0.0 11.2 26.0 1 Given the capability constraints of the base mo dels, we use lo wer-complexit y Sokoban tasks in this section. T able 6: Performance comparison of π A ∗ mkv , π A ∗ act - seq , and π A ∗ st - act - seq to show the difference of their generalization. _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? A ction a 0 \b o xed{0,7,5} State s 1 Here is the initial b oard state: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 Here is the history of mov es made so far: A ction tak en: Fill cell at (0, 7) with 5 What is your immediate next mov e? A ction a 1 \b o xed{8,0,6} State s 2 Here is the initial b oard state: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 25 Here is the history of mov es made so far: A ction tak en: Fill cell at (0, 7) with 5 A ction tak en: Fill cell at (8, 0) with 6 What is your immediate next mov e? · · · Mark ov Mo del π mkv State s 0 Curren t board state: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? A ction a 0 \b o xed{0,7,5} State s 1 Curren t board state: 3 6 4 8 1 9 2 5 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? A ction a 1 \b o xed{8,0,6} · · · State-A ction-Seq. Mo del π st - act - seq State s 0 Here is the curren t b oard state: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 26 _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? A ction a 0 \b o xed{0,7,5} State s 1 Here is the history of mov es made so far: State of the b oard: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 A ction tak en: Fill cell at (0, 7) with 5 Here is the curren t b oard state: 3 6 4 8 1 9 2 5 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? A ction a 1 \b o xed{8,0,6} State s 2 Here is the history of mov es made so far: State of the b oard: 3 6 4 8 1 9 2 _ 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 A ction tak en: Fill cell at (0, 7) with 5 27 State of the b oard: 3 6 4 8 1 9 2 5 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 A ction tak en: Fill cell at (8, 0) with 6 Here is the curren t b oard state: 3 6 4 8 1 9 2 5 7 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 6 7 9 1 4 5 _ 2 3 What is your immediate next mov e? · · · C.8 Thinking Mo de Hinders Mo dels from Solving Problems in Multiple Steps As discussed in Section 4 , we in tentionally disable the mo del’s reasoning mo de and require it to output only the discrete action, without test-time chain-of-though t. In this section, we use the following example to sho w that mo dels with enabled thinking mo de fails to decomp ose the problem into independent, progressiv e decision steps. Output of Qwen3-4B with thinking mo de enabled System prompt Y ou are playing Sudoku, a logic-based num b er placemen t puzzle. R ules: - Fill the grid with num b ers from 1 to 9. - Each n umber must app ear exactly once in each ro w, column, and 3x3 subgrid. - Empty cells are represented b y underscores (_). Please provide only your next mo ve in the format: \b o xed{ro w, col, num b er} where ro w and col are 0-indexed and num b er is b et ween 1 and 9. User prompt Curren t board state: 3 6 4 8 1 9 2 _ 7 28 5 9 8 3 7 2 6 1 4 _ 2 _ 5 6 4 9 3 8 8 1 5 4 3 6 7 9 2 9 _ 6 2 8 7 5 4 1 2 4 _ _ 5 1 3 8 6 4 8 2 6 9 3 1 7 5 1 5 3 7 2 8 4 6 9 _ 7 9 1 4 5 _ 2 3 What is your immediate next mov e? Please provide only your next mo ve in the format: \b o xed{ro w, col, num b er} where ro w and col are 0-indexed and num b er is b et ween 1 and 9. Mo del output Oka y , let’s try to figure out the next mo ve for this Sudoku puzzle. First, I need to lo ok at the curren t b oard state and see where I can find a cell that has only one p ossible num b er that can fit. Let me start by going through each ro w, column, and subgrid to chec k for an y missing num b ers. · · · So existing n umbers are 4,8,5,6,2,3,9. Missing are 1,7. Therefore, row 2 column 2 can b e 1 or 7. Also, the subgrid (top-left) for row 2 column 2 is rows 0-2, columns 0-2. Existing n umbers in that subgrid are 3,6,4 (ro w 0), 5,9,8 (row 1), and ro w 2: _,2,_. So existing num b ers are 3,6,4,5,9,8,2. Missing are 1,7. Therefore, row 2 column 2 can b e 1 or 7. So no unique mov e here. Therefore, not helpful. So the p ossible mo ves are ro w 0 column 7 (5), ro w 8 column 0 (6), ro w 8 column 6 (8), ro w 5 column 2 (7). So which one is the next mov e? The problem is that the user may hav e a unique next mov e. But in the given puzzle, there might be multiple p ossibilities. Ho wev er, the user w ants the next mov e, so ma yb e the first one that is determined. Since row 0 column 7 is uniquely determined as 5, that’s a v alid mov e. Therefore, I think that is the correct answer. T o determine the **immediate next mov e** in the given Sudoku puzzle, we examine the current state of the b oard for an y cell that can b e uniquely filled based on the rules of Sudoku: eac h num b er from 1 to 9 must app ear exactly once in every ro w, column, and 3x3 subgrid. — ### Analyzing the Cell at Row 0, Column 7 The current v alue in the row is: “ ‘ 3 6 4 8 1 9 2 _ 7 “ ‘ This is **Row 0**, and the empty cell is at **Column 7**. Let’s determine what num b er can go here. - The existing num b ers in **Ro w 0** are: 3, 6, 4, 8, 1, 9, 2, 7. - The missing num b er in the ro w is **5**. No w c heck if **5** is v alid in **Column 7**: - Column 7 v alues are: 1, 3, 9, 4, 8, 7, 6, 2 (from rows 1 to 8). - So **5** is not in column 7 → it is **v alid**. Next, chec k the **subgrid** for **Row 0, Column 7** (the top-right 3x3 subgrid, rows 0–2, columns 7–8): - Existing v alues: 7 (from row 0, col 8), 1 (ro w 1, col 7), 4 (ro w 1, col 8), 3 (ro w 2, col 7), 8 (row 2, col 8). - No 5 is in the subgrid → v alid. Hence, **5 is the only num b er that can go in to Row 0, Column 7**. — ### Final Answer 0 , 7 , 5 This example illustrates the mo del’s b eha vior as an implicit transition mo del; it forecasts future b oard states within its reasoning trace and solves the problem holistically rather than through decomp osition. 29 D Implemen tation Details D.1 Datasets As discussed in Section 4 , we use three logical tasks during training and b enc hmarking. In this section, we pro vide details on these datasets for a more comprehensiv e setup description and repro ducibility . Dataset Sizes. As detailed in Section 4 , we in tro duce a SFT w arm-up phase b efore RL post-training. W e use SFT dataset of different sizes to warm up differen t mo dels on v arious tasks, due to the differences in base mo del capabilities and task complexities. The sizes are listed in T able 7 . All mo dels are trained for 1 ep o c h. Mo del Sudoku Sok oban F utoshiki Qw en3-4B 4,000 4,000 4,000 Qw en2.5-3B-It 7,000 6,000 10,000 T able 7: SFT warm-up dataset sizes for each mo del on v arious tasks. In RL p ost-training phase, w e use a dataset of 10,000 samples for Sudoku, 6,000 samples for Sokoban, and 6,000 samples for F utoshiki. W e additionally synthesize 100 problems as test set for each task. F or exp erimen ts in App endix C.5 , we use larger SFT datasets than the one used in SFT w arm-up, whose sizes are listed in T able 8 . All mo dels are trained with 1 ep och, except that Qwen2.5-3B-It is trained for 2 ep ochs on Sudoku dataset. Mo del Sudoku Sok oban F utoshiki Qw en3-4B 18,000 20,000 24,000 Qw en2.5-3B-It 18,000 × 2 24,000 32,000 T able 8: SFT dataset sizes for each model on v arious tasks used in App endix C.5 . In exp erimen ts conducted in App endix C.4 , we use the same dataset of size 18,000 training Qw en2.5-3B-It on Sudoku problems. Dataset Difficulties. W e synthesize the datasets using v arious configurations for different tasks. Details are presented in T able 9 . Benc hmark Sudoku Sok oban F utoshiki T rain set & ID T ests Board size: 9 × 9 Num b er of blanks: 6 Board size: 9 × 9 Minimal num b er of steps: 6–10 Board size: 5 × 5 Num b er of blanks: 8–10 OOD T ests Board size: 9 × 9 Num b er of blanks: 10 Board size: 9 × 9 Minimal num b er of steps: 12–14 Board size: 5 × 5 Num b er of blanks: 12–14 T able 9: Configurations of different tasks used in training and testing. An exception is the Sok oban dataset used in Section 4.3 . Given the capability constraints of the base mo dels, w e use lo wer-complexit y Sokoban tasks. F or in-distribution b enc hmarks, the minimal n umber of steps is b et w een 2 ∼ 4 ; for out-of-distribution b enc hmarks, it is b et ween 4 ∼ 6 . D.2 T raining W e use rLLM ( T an et al. , 2025 ) as the training and inference framew ork, which is back ed by VERL ( Sheng et al. , 2024 ). W e follow the most default h yp erparameter during training. Sp ecifically , w e adopt a KL 30 div ergence coefficient of 0 . 001 , a learning rate of 1 × 10 − 6 , a batch size of 128 , and sample 8 responses for each group. The mini-batch size is set to 128, except for training Qwen2.5-3B-It on Sokoban after SFT warm-up, where a size of 64 is used. F or SFT warm-up stage, w e use VERL Sheng et al. ( 2024 ) to train the mo dels. The batch size is set to 256 and the learning rate is chosen as 5 × 10 − 6 . D.3 T raining Details in Section 4.3 In Section 4.3 , we use A ⋆ to replace the estimated adv antaged b A ( i ) in GRPO. Particularly , the orginal ob jectiv e of GRPO is J GRPO ( θ ) = E x ∼ ρ, { o ( i ) } G i =1 ∼ π θ old ( ·| x ) " 1 G G X i =1 1 | o i | | o i | X h =1 ( min π θ ( a ( i ) h | s ( i ) h ) π θ old ( a ( i ) h | s ( i ) h ) b A ( i ) , clip π θ ( a ( i ) h | s ( i ) h ) π θ old ( a ( i ) h | s ( i ) h ) , 1 − ϵ, 1 + ϵ b A ( i ) − β D KL ( π ∥ π ref ) )# , (1) where b A ( i ) = r ( x,o ( i ) ) − mean( { r ( x,o (1) ) ,...,r ( x,o ( G ) ) } ) std( { r ( x,o (1) ) ,...,r ( x,o ( G ) ) } ) . Here, a h represen ts the h -th token and s h is the concatenation of all previous tok ens. Replacing b A ( i ) with A ⋆ , the ob jectiv e b ecomes J GRPO A ⋆ ( θ ) = E x ∼ ρ, { o ( i ) } G i =1 ∼ π θ old ( ·| x ) " 1 G G X i =1 1 | o i | | o i | X h =1 ( min π θ ( a ( i ) h | s ( i ) h ) π θ old ( a ( i ) h | s ( i ) h ) A ⋆ ( i ) , clip π θ ( a ( i ) h | s ( i ) h ) π θ old ( a ( i ) h | s ( i ) h ) , 1 − ϵ, 1 + ϵ A ⋆ ( i ) − β D KL ( π ∥ π ref ) )# , where the adv antage of the optimal p olicy A ⋆ ( i ) is calculated by the single-step resp onse o i . Consider a resp onse o . Let ˜ s denote the current state (i.e., the board configuration for Marko v mo dels, and the history sequence for action-sequence and state–action-sequence models), and let ˜ a denote the action represen ted by resp onse o (i.e., the row index, column index, and v alue to fill for Sudoku and F utoshiki; or the mov emen t direction for Sokoban). The computation of A ⋆ ( ˜ s, ˜ a ) is task dep enden t. F or Sudoku and F utoshiki, we set the discount factor to γ = 1 . F or an y v alid b oard state ˜ s , the task is alw ays solv able, and thus V ⋆ ( ˜ s ) = 1 . If action ˜ a transitions ˜ s to another v alid state ˜ s ′ —that is, the filled n umber do es not violate any constraints and mak es progress tow ard the final solution—then Q ⋆ ( ˜ s, ˜ a ) = 1 ; otherwise, Q ⋆ ( ˜ s, ˜ a ) = 0 . Consequen tly , A ⋆ ( ˜ s, ˜ a ) = 0 if action ˜ a can still lead to a correct final solution, and − 1 otherwise. F or Sokoban, w e use a discount factor of γ = 0 . 5 . Let n denote the minimum num b er of steps required to reac h the goal from state ˜ s , and let n ′ denote the minimum num b er of steps after taking action ˜ a . The v alue n ′ ma y b e infinite if ˜ a leads to an unsolv able state. By definition, the optimal v alue and action-v alue functions are given b y V ⋆ ( ˜ s ) = γ n − 1 , Q ⋆ ( ˜ s, ˜ a ) = γ n ′ − 1 . Therefore, A ⋆ ( ˜ s, ˜ a ) = γ n ′ − 1 − γ n − 1 . In practice, we compute n and n ′ using breadth-first search. 31 D.4 State Prediction Mo dels W e train a state prediction mo del b P based on Qwen2.5-3B-Instruct via SFT to predict the next state s h +1 from the current state s h and action a h . Particularly , we first collect triplets ( s, a, s ′ ) from the en vironment P ⋆ , where s ′ = P ( s, a ) . W e then use ( s, a ) as prompt and SFT the base mo del to predict s ′ . In practice, we use 174k samples to train a state prediction mo del for Sudoku, 91k samples for Sok oban, and 108k samples for F utoshiki. A t test time, b P replaces the en vironment P ⋆ , enabling deployme nt without en vironment access. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment