컨센서스가 거짓일 때: 테스트 시 강화학습을 위한 선택‑보완 학습 SCRL
SCRL은 테스트‑시 강화학습에서 약한 다수결 컨센서스로 인한 라벨 노이즈 증폭을 방지하기 위해, 엄격한 양성 라벨링과 엔트로피 기반 부정 라벨링을 결합한 프레임워크이다. 양성 라벨은 높은 빈도와 충분한 마진을 만족할 때만 부여하고, 빈도가 낮고 불확실성이 큰 답변을 부정 라벨로 지정해 탐색 공간을 효율적으로 축소한다. 동적 보상 설계로 컨센서스 강도와 불확실성을 반영해 안정적인 정책 업데이트를 가능하게 하며, 다양한 수학·코딩·멀티모달 추론 …
저자: Dong Yan, Jian Liang, Yanbo Wang
본 논문은 테스트‑시 강화학습(Test‑Time Reinforcement Learning, TTRL)에서 다수결 기반 의사라벨이 약한 컨센서스 상황에 취약하다는 문제점을 지적한다. 기존 방법들은 긍정적인 의사라벨만을 사용해 정책을 강화하는데, 답변 분포가 고르게 퍼져 있으면 가장 빈도가 높은 답변조차 잘못된 경우가 빈번하다. 이러한 ‘라벨 노이즈 증폭’은 특히 롤아웃 예산이 제한된 상황에서 심각해진다.
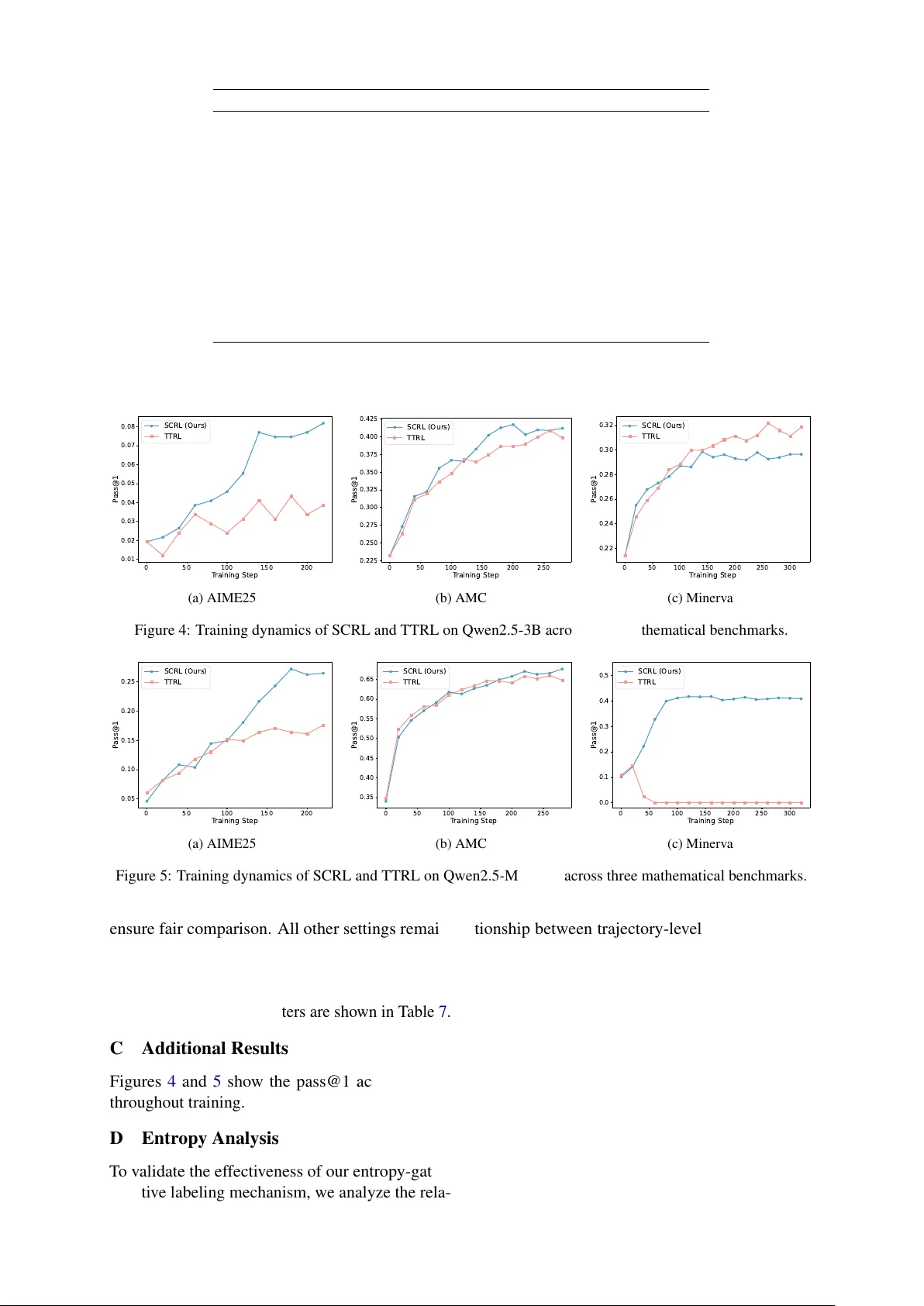
이를 해결하기 위해 제안된 SCRL은 세 가지 핵심 모듈로 구성된다. 첫 번째 모듈인 **Selective Positive Pseudo‑Labeling**은 다수결 결과에 추가적인 신뢰 기준을 부여한다. 구체적으로, 최고 빈도 p₁이 사전 정의된 임계값 τₚₒₛ를 초과하고, 두 번째 빈도 p₂와의 차이가 τₘₐᵣ𝓰보다 클 때만 양성 라벨 y⁺를 부여한다. 이 조건을 만족하지 않으면 양성 라벨을 포기하고, 이후 단계에서 부정 라벨링에 의존한다.
두 번째 모듈인 **Entropy‑Gated Negative Pseudo‑Labeling**은 답변의 희소성과 불확실성을 동시에 고려한다. 각 롤아웃에 대해 토큰 수준 엔트로피 hᵢ,ₜ를 계산하고 평균 궤적 엔트로피 ¯hᵢ를 구한다. 답변 aⱼ에 대한 평균 엔트로피 ¯Hⱼ가 전체 평균 ¯H보다 크고, 빈도 pⱼ가 τₙₑ𝓰 이하인 경우를 부정 라벨 집합 N⁻에 포함한다. 이렇게 하면 ‘희귀하지만 불확실한’ 답변을 명시적으로 패널티함으로써 탐색 공간을 효율적으로 축소하고, 정답일 가능성이 있는 희귀 답변을 완전히 배제하지 않는다.
세 번째 모듈인 **Dynamic Reward Shaping**은 위 두 라벨링 결과를 기반으로 보상을 동적으로 조정한다. 보상 함수 Rᵢ = p(aᵢ)·I
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기