What If Consensus Lies? Selective-Complementary Reinforcement Learning at Test Time
Test-Time Reinforcement Learning (TTRL) enables Large Language Models (LLMs) to enhance reasoning capabilities on unlabeled test streams by deriving pseudo-rewards from majority voting consensus. However, existing TTRL methods rely exclusively on pos…
Authors: Dong Yan, Jian Liang, Yanbo Wang
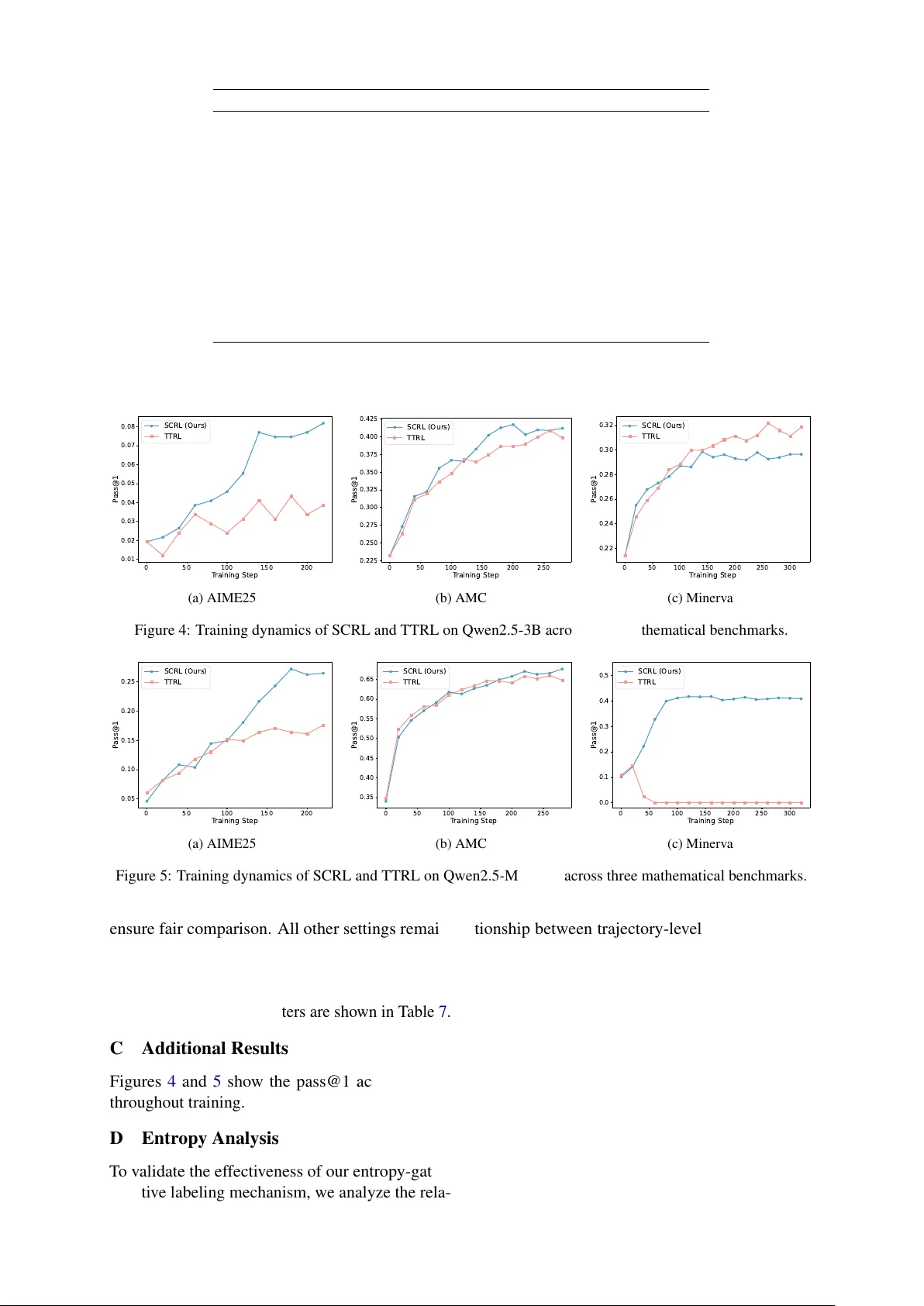
What If Consensus Lies? Selectiv e-Complementary Reinf or cement Lear ning at T est T ime Dong Y an 1,2 , Jian Liang 1,2 * , Y anbo W ang 1,2 , Shuo Lu 2 , Ran He 1,2 , Tieniu T an 1,2,3 1 School of Artificial Intelligence, Uni versity of Chinese Academy of Sciences 2 NLPR & MAIS, Institute of Automation, Chinese Academy of Sciences 3 Nanjing Uni versity yandong2025@ia.ac.cn, liangjian92@gmail.com Abstract T est-T ime Reinforcement Learning (TTRL) en- ables Large Language Models (LLMs) to en- hance reasoning capabilities on unlabeled test streams by deri ving pseudo-re wards from ma- jority v oting consensus. Howe ver , existing TTRL methods rely exclusiv ely on positiv e pseudo-labeling strategies. Such reliance be- comes vulnerable under challenging scenar - ios where answer distributions are highly dis- persed, resulting in weak consensus that in- advertently reinforces incorrect trajectories as supervision signals. In this paper , we propose SCRL (Selectiv e-Complementary Reinforce- ment Learning), a robust test-time reinforce- ment learning framework that ef fecti vely mit- igates label noise amplification. SCRL devel- ops Selectiv e Positi ve Pseudo-Labeling, which enforces strict consensus criteria to filter un- reliable majorities. Complementarily , SCRL introduces Entropy-Gated Negati ve Pseudo- Labeling, the first negati ve supervision mech- anism in TTRL, to reliably prune incorrect trajectories based on generation uncertainty . Extensiv e experiments on multiple reasoning benchmarks demonstrate that SCRL achiev es substantial improv ements over baselines, while maintaining robust generalization and training stability under constrained rollout b udgets. Our code is av ailable at https://github .com/Jasper- Y an/SCRL . 1 Introduction Reinforcement Learning with V erifiable Re wards (RL VR) ( Jaech et al. , 2024 ; Shao et al. , 2024 ; Y ang et al. , 2025a ) has significantly adv anced the reason- ing capabilities of Lar ge Language Models (LLMs) , enabling state-of-the-art performance in v erifiable domains such as mathematics and coding ( Gao et al. , 2024 ; Setlur et al. , 2024 ; W ang et al. , 2024 ). Guided by ground-truth labels or rule-based veri- fication signals, RL VR allows polic y optimization * Corresponding Author Fre qu en c y 𝑎 1 𝑎 2 𝑎 3 𝑎 4 𝑎 5 𝒚 + = 𝒂 𝟑 Unre li ab le Poli cy Upda te Nois e Am pl if ic at io n Fre qu en c y 𝑎 1 𝑎 2 𝑎 3 𝑎 4 𝑎 5 Dis pe rs ed Ans w er Dis tri bu ti on Dis pe rs ed Ans w er Dis tri bu ti on 𝒚 + = ∅ 𝓝 − = { 𝒂 𝟒 , 𝒂 𝟓 } Policy Upda te W e ak Con s en s us W e ak Con s en s us (a ) (b) M aj ority V oti ng SCRL Figure 1: Comparison of pseudo-labeling strategies un- der weak consensus. (a) Majority voting assigns the positiv e label despite dispersed answer distrib ution. (b) SCRL abstains from positi ve labeling when consensus is insufficient and identifies ne gati v e labels. to directly reinforce trajectories that lead to cor- rect outcomes. Howe v er , the reliance on extensi ve manually-annotated data creates a fundamental lim- itation: as task complexity and diversity gro w , ac- quiring high-quality supervision becomes increas- ingly difficult. T o bridge this gap, T est-Time Re- inforcement Learning (TTRL) has emerged as a critical paradigm for unsupervised reasoning ( Zuo et al. , 2025 ; Y ang et al. , 2025b ; Jayalath et al. , 2025 ; Y uan et al. , 2025 ). TTRL allo ws models to self- improv e on unlabeled test streams by generating di verse rollouts and lev eraging majority v oting con- sensus to deri ve pseudo-re w ards for policy updates. While TTRL of fers a promising direction for un- supervised reasoning, existing methods ( Zuo et al. , 2025 ; Y u et al. , 2025b ; W en et al. , 2025 ; W ang et al. , 2025a ) that rely on majority v oting and its v ariants, such as soft-weighted consensus and self- play mechanisms, face inherent limitations rooted in their e xclusi ve focus on positi ve pseudo-labeling. These methods require substantial rollout b udgets 1 to achiev e reliable consensus; howe ver , on chal- lenging problems, the answer distrib ution remains highly dispersed ev en with extensi v e sampling. As sho wn in Figure 1 (a), this dispersion weak ens the consensus, which may result in incorrect trajecto- ries being utilized as supervision signals ( Stahlberg et al. , 2022 ; Liu et al. , 2025a ). Consequently , the model prematurely con verges to ward spurious so- lutions through policy optimization ( Shi and Jin , 2025 ; Huang et al. , 2024 ). Note that when roll- out budgets are constrained, this vulnerability is particularly pronounced, where insuf ficient sam- pling cov erage increases consensus instability . In addition, while identifying a correct answer is dif fi- cult under high uncertainty , recognizing incorrect answers is comparativ ely reliable. Nevertheless, existing methods overlook the potential of negati ve labeling. As illustrated in Figure 1 (b), when credi- ble positi ve consensus is absent, a robust strate gy is to employ negati ve labels to prune the search space, which allo ws the model to eliminate errors and update to ward more promising regions without prematurely committing to any single answer . T o address these critical issues, we propose SCRL ( S electi ve- C omplementary R einforcement L earning), a robust frame work that effecti vely miti- gates label noise amplification in unsupervised test- time reinforcement learning. SCRL de velops Selec- tive P ositive Pseudo-Labeling which enforces strict consensus and mar gin criteria, ensuring that posi- ti ve supervision is only pro vided when the answer distribution e xhibits sharp concentration and clear separation from alternati ves. This mechanism can pre vent the amplification of unreliable majorities when the answer distribution is dispersed. Com- plementing this, SCRL introduces Entr opy-Gated Ne gative Pseudo-Labeling , the first mechanism in test-time reinforcement learning that integrates neg- ati ve supervision to identify and penalize incorrect trajectories. By isolating answers that exhibit both lo w frequency and high uncertainty , the model re- liably prunes implausible solutions without elimi- nating potentially correct lo w-frequency answers. T o calibrate the reinforcement magnitude based on consensus strength, we design Dynamic Rewar d Shaping that integrates credible positive signals with informati ve ne gati ve signals, enabling SCRL to maintain exploration capacity while systemati- cally narro wing the search space and achiev e robust unsupervised reinforcement learning. Extensi ve experiments on multiple reasoning benchmarks consistently demonstrate that SCRL significantly outperforms baseline methods, par- ticularly on challenging problems and under con- strained rollout b udgets. Our contributions can be summarized as follo ws: • W e propose SCRL, a test-time reinforcement learning framew ork that mitigates label-noise amplification under weak consensus. • SCRL incorporates strict consensus criteria to filter unreliable majorities, restricting positive supervision to concentrated distributions. • SCRL introduces negati v e supervision in test- time reinforcement learning for the first time, which eliminates implausible trajectories with- out discarding potentially valid rare solutions. • Extensi ve experiments consistently demon- strate that SCRL outperforms baselines par- ticularly under constrained rollout budgets, while ablation studies and label-quality analy- ses v alidate the necessity of each component. 2 Related W ork 2.1 RL f or Reasoning Reinforcement learning (RL) has emerged as a critical approach for enhancing the instruction- follo wing and complex reasoning capabilities of LLMs. Reinforcement Learning from Human Feedback (RLHF) ( Ouyang et al. , 2022 ) aligns base models with human preferences via annotated preference data and policy optimization methods ( Schulman et al. , 2017 ; Rafailov et al. , 2023 ; Meng et al. , 2024 ; Cui et al. , 2025 ). T o reduce reliance on human labels, Reinforcement Learning with V erifiable Rew ards (RL VR) ( Shao et al. , 2024 ; Y u et al. , 2025a ; Feng et al. , 2025 ) replaces prefer- ence re wards with v erifiable signals, enabling ob- jecti ve and automated ev aluation which has prov en especially effecti v e in math and code domains ( Y ang et al. , 2025a ; Lambert et al. , 2024 ; W ang et al. , 2025b ; Guo et al. , 2025 ). Furthermore, Rein- forcement Learning from Internal Feedback (RLIF) ( Zhao et al. , 2025b ; Shafayat et al. , 2025 ; Prasad et al. , 2025 ; Liu et al. , 2025b ) deriv es intrinsic re- wards from the model’ s confidence, entropy or self- consistency across its reasoning paths ( T an et al. , 2025 ; Zhang et al. , 2025b , a ; Zhao et al. , 2025a ; Y an et al. , 2025 ). For e xample, Intuitor ( Zhao et al. , 2025b ) utilizes the model’ s confidence as a sparse intrinsic reward to reinforce high confidence rea- soning paths, while EMPO ( Zhang et al. , 2025b ) 2 Qu e ry LLM Rollou ts A n sw e r Di stri b u tio n E n tro p y En tr o p y - Gated N eg ati v e Pseu d o - L ab el i n g Nega tiv e La be li ng Ru le ( , , ) Neg a tiv e S e t Sel ecti v e Po si ti v e Pseu d o - L ab el i n g Co ns e ns us Ch e c k ( , ) W e a k Co ns e ns us (Abs t ain) S tron g Co ns e ns us (Pos it iv e Label ) D y n am i c R ew ard Sh ap i n g R ew a r d C al i b r at i on Poli cy Op ti mi z at i o n R ew a r d s Figure 2: Overvie w of the SCRL frame work. SCRL addresses test-time label noise through three components: selectiv e positi ve pseudo-labeling enforces strict consensus thresholds to pre v ent reinforcing unreliable majorities; entropy-gated ne gati ve pseudo-labeling identifies ne gati ve labels by isolating answers that are both rare and exhibit high uncertainty , pruning the search space without eliminating valid candidates; dynamic rew ard shaping constructs distribution-a ware re wards that scale with consensus strength and penalize uncertainty trajectories. incenti vizes reasoning by minimizing the predic- ti ve entropy of LLM outputs in a latent semantic space. Our work belongs to the RLIF paradigm and uniquely le verages both positi ve and neg ativ e sig- nals deriv ed from the model’ s output distribution to enable robust test-time reinforcement learning. 2.2 Unsupervised Reasoning at T est Time T est-T ime Reinforcement Learning (TTRL) has emerged as a crucial paradigm for adapting LLMs to unlabeled test streams, utilizing majority voting consensus as a verifiable pseudo-re ward for online policy optimization ( Zuo et al. , 2025 ; W ei et al. , 2025 ; Y u et al. , 2025b ; Liu et al. , 2025a ; W ang et al. , 2025a ; Prabhudesai et al. , 2025 ; W u et al. , 2025 ; T ang et al. , 2025 ; Zhou et al. , 2025 ). Re- cent research has focused on rob ust unsupervised re ward estimation: RESTRAIN ( Y u et al. , 2025b ) employs soft-weighted pseudo-labels and penalizes lo w-confidence responses to enhance training sta- bility , while Self-Harmony ( W ang et al. , 2025a ) utilizes a self-play mechanism to verify positiv e labels. SPINE ( W u et al. , 2025 ) stabilizes training by restricting updates to high-entropy forking to- kens, whereas ETTRL ( Liu et al. , 2025a ) enhances ef ficiency through entropy-fork tree rollouts to mit- igate early-stage estimation bias. MM-UPT ( W ei et al. , 2025 ) extends this paradigm to the multi- modal domain, v alidating the approach for complex vision-language reasoning tasks. Howe v er , relying solely on v oting-based methods for positi v e label assignment can amplify noise when consensus is weak. Our work introduces selective positi ve label- ing with strict consensus criteria and complements it with negati ve labeling to prune the search space without premature con v ergence. 3 Method In this section, we propose SCRL ( S elective- C omplementary R einforcement L earning), a ro- bust framework for test-time reinforcement learn- ing to mitigate label noise amplification in un- supervised settings. As illustrated in Figure 2 , SCRL consists of three components: Selecti ve Posi- ti ve Pseudo-Labeling (Section 3.2 ), Entropy-Gated Negati ve Pseudo-Labeling (Section 3.3 ), and Dy- namic Re ward Shaping (Section 3.4 ). 3.1 Preliminaries W e adopt the Grouped Relativ e Policy Optimiza- tion (GRPO) ( Shao et al. , 2024 ) as our main RL algorithm. For a giv en query q , the policy samples a group of G responses O = { o 1 , . . . , o G } from the sampling policy π old . Each response recei ves a re- ward R i and GRPO constructs a group-normalized adv antage ˆ A i shared across tokens: ˆ A i = R i − µ σ . (1) The parameters θ are updated by maximizing the 3 objecti ve: J GRP O ( θ ) = E q ∼Q , O∼ π old 1 G G X i =1 1 | o i | | o i | X t =1 min ρ i,t ˆ A i , clip ( ρ i,t , 1 − ϵ, 1 + ϵ ) ˆ A i , (2) where ρ i,t = π θ ( o i,t | q , o i, τ marg , (4) otherwise, y + = ∅ . The threshold τ pos pre vents positi ve labeling when the top-ranked answer has insuf ficient support, while the margin threshold τ marg enforces separation from the second-rank ed answer , pre venting unreliable majorities from be- ing reinforced as supervision signals. When y + = ∅ , we simply av oid positive reinforcement learn- ing, shifting the learning focus to the negati ve pseudo-labeling described in Section 3.3 . 3.3 Entropy-Gated Negati ve Pseudo-Labeling When the answer distribution is dispersed, rein- forcing any single trajectory with a positiv e label is unreliable. Ne vertheless, the model’ s responses still contain useful signal: while correct answers are dif ficult to identify with confidence, incorrect answers can be detected more reliably . By con- structing high-confidence ne gati ve labels, we can prune the search space and encourage the model to update toward more plausible regions without forcing a premature collapse ( Zhu et al. , 2025 ). Entropy-based uncertainty estimation Gi v en responses { o i } N i =1 and the answer distrib ution A = { a j } K j =1 with counts n j and proportions p j , we distinguish between low-frequency but valid an- swers and incorrect responses by computing an uncertainty measure from the policy . The Shan- non entropy of the next-tok en distrib ution ov er the vocab ulary V at step t is: h i,t = − X v ∈V π old ( v | o i τ marg then 8: y + ← a j ∗ 9: end if 10: f or i = 1 to N do 11: f or t = 1 to | o i | do 12: h i,t ← − X v ∈V π old ( v | q , o i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment