빠른 적응을 위한 정책·가치 통합 분해
이 논문은 정책과 가치 함수를 동일한 저차원 목표 임베딩 G로 연결하는 bilinear actor‑critic 구조를 제안한다. 사전 학습 단계에서 가치 베이스 yₖ와 정책 베이스 Yₖ를 학습하고, 목표 g에 따라 Gₖ(g)만을 추정하면 새로운 과제에 즉시 적응할 수 있다. MuJoCo Ant 환경의 다방향 보행 실험에서 기존 MLP 대비 학습 효율이 높고, 미학습 방향에서도 제로샷 성능을 유지한다. 또한, G‑공간이 행동 방향·속도와 직접 연…
저자: Cristiano Capone, Luca Falorsi, Andrea Ciardiello
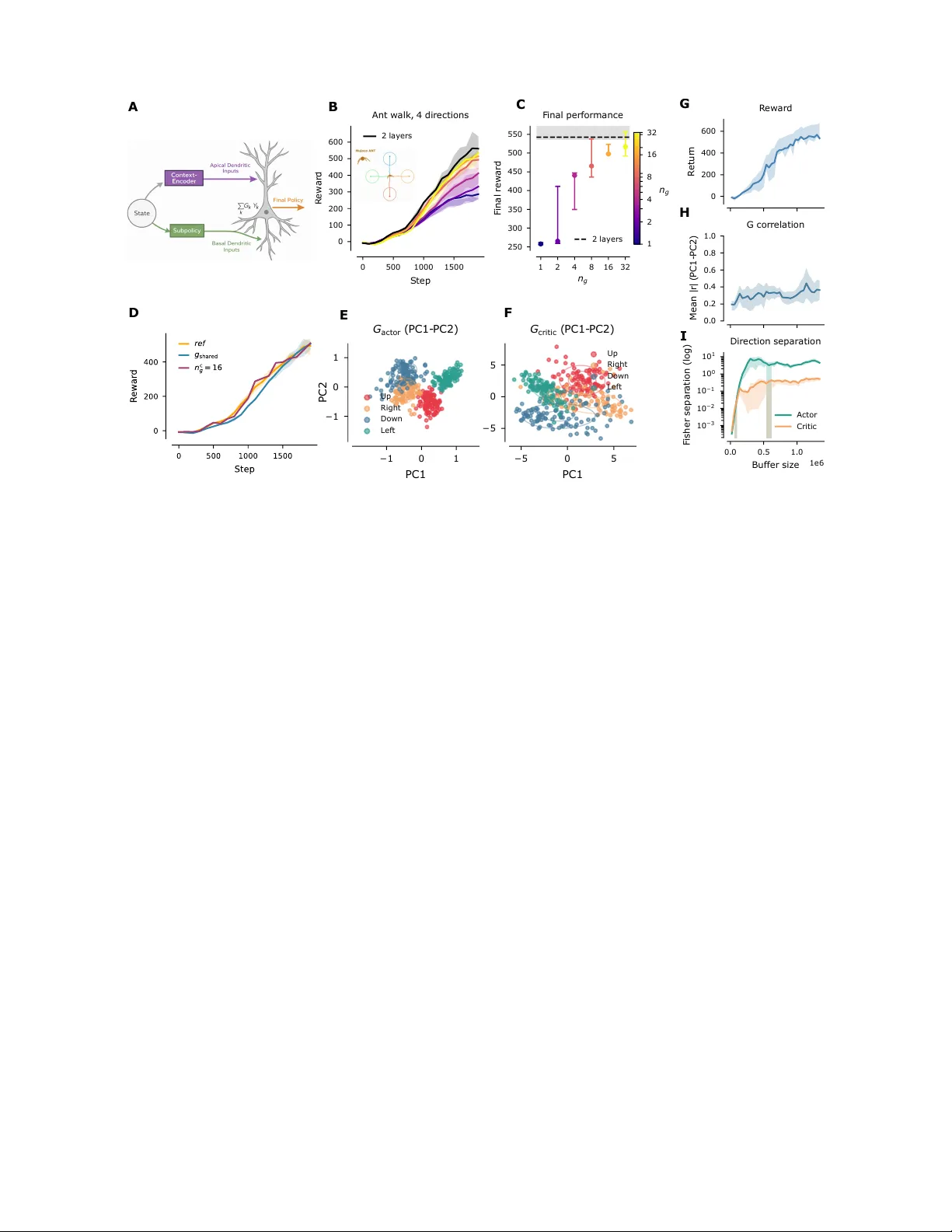
본 논문은 강화학습에서 목표가 자주 변하는 복잡한 제어 시스템에 대한 빠른 적응 메커니즘을 제안한다. 기존의 Soft Actor‑Critic(SAC)과 같은 최신 actor‑critic 알고리즘은 높은 성능을 보이지만, 목표가 바뀔 때마다 전체 네트워크를 재학습해야 하는 비효율성을 가지고 있다. 이를 해결하고자 저자들은 정책과 가치 함수를 동일한 저차원 목표 임베딩 G와 결합한 bilinear 구조를 설계하였다.
**1. 배경 및 관련 연구**
- 모듈화·분해 접근법: Ensemble Q‑learning, MoE, REDQ 등은 여러 전문가 네트워크를 결합해 견고성을 높인다.
- Successor Features(SF): 가치 함수를 상태‑특정 특징과 보상 가중치로 분리해 전이 학습을 가능하게 한다.
- 기존 방법들은 보상 구조가 사전에 정의돼 있거나, 복잡한 게이팅 메커니즘을 필요로 한다.
**2. 제안 방법**
- **Bilinear Critic**: Q(s,a,g)=∑ₖ Gₖ(g)·yₖ(s,a) 로, yₖ는 가치 베이스, Gₖ(g)는 목표에 의존하는 스칼라 게이팅.
- **Bilinear Actor**: μ(s,g)=∑ₖ Gₖ(g)·Yₖ(s) 로, Yₖ는 정책 베이스.
- **공유 게이팅 G**: 정책과 가치가 동일한 G를 사용함으로써 파라미터 수를 절감하고, actor‑critic 간의 그래디언트 정렬을 촉진한다.
- **학습 과정**: 사전 학습 단계에서 yₖ와 Yₖ를 동시에 학습하고, Gₖ(g)는 목표 g를 입력받는 작은 네트워크로 구현한다. 학습이 끝난 후 베이스는 고정하고, 새로운 목표에 대해서는 Gₖ(g)만을 한 번의 순전파로 추정한다(제로샷 적응).
**3. 생물학적 영감**
곱셈적 게이팅은 L5 피라미드 뉴런에서 관찰되는 게인 모듈레이션과 유사하다. 상위 피질 입력이 하위 감각 입력의 이득을 조절하듯, 목표 g가 베이스 정책·가치의 스케일을 조절한다. 이는 모델이 해석 가능하고, 신경과학적 원리를 반영한다는 점에서 의미가 있다.
**4. 실험 설정**
- 환경: MuJoCo Ant, 8가지 방향(0°,45°,…315°)을 목표 g로 지정하는 다방향 보행 과제.
- 비교 대상: 2‑층 MLP 기반 SAC, 기존 MoE 기반 방법 등.
- 평가 지표: 학습 효율(수렴 속도), 최종 평균 보상, 제로샷 방향 전이 성능, G‑공간의 해석 가능성.
**5. 주요 결과**
- **학습 효율**: 단일‑층 bilinear 모델이 2‑층 MLP보다 빠르게 보상을 상승시켰으며, 최종 성능도 동등하거나 약간 우수했다.
- **공유 vs. 독립 G**: 정책과 가치가 동일한 G를 공유해도 성능 저하가 없으며, 파라미터 수와 최적화 복잡도가 감소했다.
- **제로샷 전이**: 사전 학습되지 않은 중간 방향에서도 G를 선형 보간해 목표를 달성, 기존 방법 대비 성능 격차가 작았다.
- **해석 가능성**: G‑공간의 각 차원을 조작하면 이동 방향과 속도가 연속적으로 변함을 확인. 특히, 속도 조절은 명시적 목표가 없었음에도 자동으로 나타났다.
- **온라인 적응**: Gₖ를 직접 업데이트하는 간단한 규칙으로 실시간 목표 변화를 추적 가능, 전체 네트워크 재학습 없이도 보상을 유지했다.
**6. 논의 및 한계**
- 베이스 수 K와 G 차원의 선택이 성능에 민감; 과소/과다 설정 시 표현력이 제한될 수 있다.
- 현재 실험은 연속적인 방향 목표에 국한, 복잡한 다목표 혹은 비선형 보상 구조에 대한 일반화는 추가 검증이 필요.
- G‑공간이 고차원 목표를 충분히 표현하려면 더 큰 차원 또는 비선형 게이팅이 필요할 가능성이 있다.
**7. 결론**
정책·가치 함수를 동일한 목표 임베딩 G와 결합한 bilinear actor‑critic 구조는 빠른 제로샷 적응, 해석 가능한 제어 인터페이스, 그리고 생물학적 타당성을 동시에 제공한다. 실험 결과는 기존 깊은 네트워크 대비 학습 효율과 전이 성능에서 경쟁력을 보여주며, 향후 복잡한 다목표 강화학습 시스템에 적용 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기