Unified Policy Value Decomposition for Rapid Adaptation
Rapid adaptation in complex control systems remains a central challenge in reinforcement learning. We introduce a framework in which policy and value functions share a low-dimensional coefficient vector - a goal embedding - that captures task identit…
Authors: Cristiano Capone, Luca Falorsi, Andrea Ciardiello
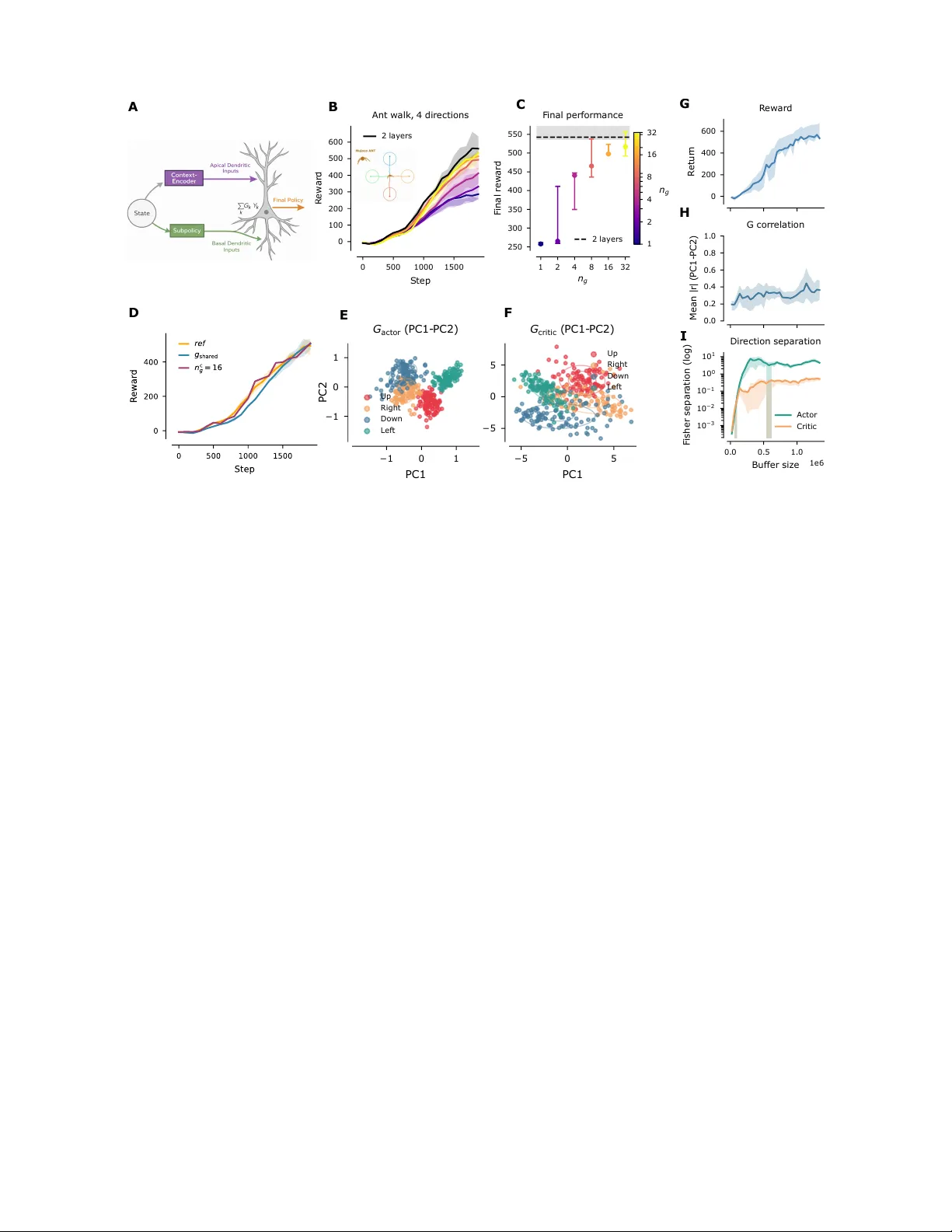
Unified P olicy–V alue Decomposition f or Rapid Adaptation Cristiano Capone 1,* , Luca Falor si 1,2 , Andrea Ciardiello 1 , and Luca Manneschi 3 1 Computational Neuroscience Unit, Istituto Superiore di Sanit ` a, 00161, Rome, Italy 2 Ospedale Santa Lucia, Rome, Italy 3 School of Computer Science, Univ ersity of Sheffield,Sheffield,S10 2TN, United Kingdom * Corresponding author (cristiano.capone@iss .it) ABSTRA CT Rapid adaptation in complex control systems remains a central challenge in reinforcement learning. W e introduce a frame work in which policy and value functions share a low-dimensional coefficient vector — a goal embedding — that captures task identity and enables immediate adaptation to novel tasks without retraining representations . Dur ing pretraining, we jointly lear n structured value bases and compatib le policy bases through a bilinear actor–cr itic decomposition. The critic factorizes as Q ( s , a , g ) = ∑ k G k ( g ) y k ( s , a ) , where G k ( g ) is a goal-conditioned coefficient v ector and y k ( s , a ) are learned value basis functions. This multiplicativ e gating — where a conte xt signal scales a set of state-dependent bases — is reminiscent of gain modulation obser v ed in Lay er 5 pyramidal neurons , where top-down inputs modulate the gain of sensor y-driven responses without altering their tuning [ 1 ]. Building on Successor Features , we e xtend the decomposition to the actor, which composes a set of primitive policies weighted by the same coefficients G k ( g ) . At test time the bases are frozen and G k ( g ) is estimated zero-shot via a single f orward pass, enab ling immediate adaptation to novel tasks without any g radient update. We train a Soft Actor–Critic agent on the MuJoCo Ant environment under a multi-directional locomotion objective, requiring the agent to walk in eight directions specified as continuous goal vectors . The bilinear str ucture allows each policy head to specialize to a subset of directions, while the shared coefficient lay er generalizes across them, accommodating nov el directions by inter polating in goal embedding space. Our results suggest that shared low-dimensional goal embeddings offer a general mechanism for rapid, structured adaptation in high-dimensional control, and highlight a potentially biologically plausible principle for efficient tr ansfer in comple x reinf orcement lear ning systems. 1 Introduction Modern of f-policy actor –critic algorithms such as Soft Actor -Critic (SA C) ha ve achie ved state-of-the-art performance on contin- uous control benchmarks by combining stable value estimation, e xpressiv e function approximation, and entropy regularization [ 2 ]. Despite their empirical success, these methods typically rely on monolithic neural architectures for both the Q-function and the policy . Such monolithic parametrizations can limit modularity , hinder interpretability , and complicate both theoretical analysis and rapid adaptation when task objectiv es change. Moti vated by these limitations, a substantial body of work has explored decomposition and modularization in reinforcement learning. Ensemble Q-learning and methods such as bootstrapped DQN or REDQ improv e robustness and exploration by aggregating multiple value predictors [ 3 , 4 ]. Modular reinforcement learning and mixture-of-experts (MoE) architectures decompose policies or value functions into specialized components coordinated by a learned gating mechanism [ 5 , 6 ]. Successor features (SF) factorize the v alue function into task-independent features and task-dependent reward weights, enabling ef ficient transfer across changing re ward functions [ 7 ]. While these approaches dif fer in moti vation and implementation, the y share a common goal: introducing structure into otherwise monolithic function approximators. In this work, we propose a co-decomposed bilinear representation for actor–critic reinforcement learning, in which both the critic and the policy are factorized using a shared multiplicati ve structure. Specifically , the Q-function is represented as Q ( s , a , g ) = K ∑ k = 1 G k ( s , g ) φ k ( s , a ) , while the deterministic policy is parametrized as µ ( s , g ) = K ∑ k = 1 G k ( s , g ) Y k ( s ) . Crucially , the same low-dimensional gating vector G ( s , g ) modulates both the value components φ k and the policy components Y k . This co-decomposition explicitly couples the actor and critic representations, aligning the directions in which value estimation and policy impro vement are expressed. This design choice departs from standard mixture-of-experts formulations, where the g ating function typically serves to separate experts or enforce sparsity . Instead, our objective is to structur e and distribute computation while preserving coherent gradient flow between critic and actor . W e show that when the polic y and value share the same multiplicative gating, the resulting actor updates are simpler , better aligned with the critic structure, and empirically competitive with significantly more complex monolithic networks. Beyond learning, the proposed decomposition yields an interpretable and controllable latent space. The learned gating vector G admits a geometric interpretation, allowing direct modulation of beha vior (e.g., direction or speed) by manipulating its magnitude or orientation—including behavioral modes not explicitly encountered during pretraining. Moreover , unlike successor features, our formulation does not assume a known or fixed rew ard decomposition. Instead, we sho w that rapid online adaptation can be achiev ed by updating the gating variables directly using a simple v alue-based rule proportional to the observed re ward and the critic components. The main contributions of this w ork are summarized as follows: • Multiplicative Gating as a Biologically Plausible Bilinear Decomposition: The proposed architecture relies on multiplicativ e gating to achie ve e xpressivity , eliminating the need for deep nonlinear activ ation stacks. This design is biologically plausible, as it resembles gain-modulation mechanisms observed in Layer 5 pyramidal neurons, where contextual inputs multiplicati vely modulate ongoing activity . As a result, policies can be represented as multiplicative compositions of linear mappings, enabling simpler networks and facilitating analytical in vestigation. • Policy–V alue Co-Decomposition: W e introduce a structured co-decomposition of policy and value functions that shares a latent representation while remaining explicitly separable. This design simplifies optimization compared to standard actor–critic formulations, while achie ving comparable performance. • Reward-Agnostic Learning Framework: Unlike Successor Features and related approaches, the proposed method does not assume a predefined or f actorized rew ard structure. Learning proceeds without encoding task-specific re ward information into the representation. • Behaviorally Interpretable Latent G -Space: W e learn a latent G -space that directly modulates policy behavior , providing a compact and interpretable control interface that can be manipulated independently of the policy and v alue networks. • Fast Online Adaptation via G -Space Updates: W e introduce a simple online learning rule operating directly in the G -space, enabling rapid behavioral adaptation without retraining the full model and supporting efficient and flexible control. 1.1 Biological Interpretation W e include a biological parallel as a source of inspiration: cortical circuits achieve rapid context-dependent adaptation, and this motiv ates our choice of multiplicati ve modulation in the model. Figure 1 A should therefore be interpreted as a conceptual analogy , not as a mechanistic claim that our architecture reproduces thalamo-cortical biology . In this analogy , a recurrent processing stage provides a rich spatiotemporal embedding of sensory and internal signals, which can support short-term memory and continuous state representation [ 8 – 10 ]. W ithin this interpretation, two parallel pathways are considered: a context-encoding stream (top), loosely inspired by associativ e/prefrontal processing, and a subpolic y stream (bottom), loosely inspired by premotor processing [ 11 – 14 ]. Their interaction is mapped to a multiplicativ e gating motif inspired by dendritic gain modulation in Layer 5 pyramidal neurons [ 15 – 17 ]. This biologically inspired vie wpoint is used only to moti v ate architecture design and interpretability: contextual signals modulate action primiti ves to bind what action to perform with when and under which context , enabling flexible control without claiming biological equiv alence [ 18 – 20 ]. 2 Results W e first ev aluate the proposed bilinear actor–critic on the directional na vigation benchmark and summarize the key outcomes in Fig. 1 . Panel A illustrates the shared-coefficient architecture. Panels B–C report the comparison between a traditional two-layer MLP and a single-layer bilinear model, with the task setup shown in the inset. 2 E D − 1 0 1 PC1 − 1 0 1 PC2 G a c to r ( PC1- PC2) Up Ri g ht Do wn L e f t − 5 0 5 PC1 − 5 0 5 G c r i tic ( PC1- PC2) Up Ri g ht Do wn L e f t F G H I 0 200 400 600 R e tur n R e wa r d 0. 0 0. 2 0. 4 0. 6 0. 8 1. 0 M e a n | r | ( PC1- PC2) G c o r r e l a tio n 0. 0 0. 5 1. 0 Buff e r si ze 1e 6 10 − 3 10 − 2 10 − 1 10 0 10 1 F i she r se p a r a tio n ( l o g ) Di r e c t i o n se p a r a tio n A c to r Cr i tic 0 500 1000 1500 S te p 0 100 200 300 400 500 600 R e wa r d Ant wa l k , 4 d i r e c tio ns 2 l a ye r s 1 2 4 8 16 32 n g 250 300 350 400 450 500 550 F i na l r e wa r d F i na l p e r fo r ma nc e 2 l a ye r s 1 2 4 8 16 32 n g A B A C Figure 1. MLP-based bilinear actor –critic architectur e. A. Scheme of our architecture: the actor and critic are decomposed into K parallel basis modules, polic y primitiv es Y k ( s ) and value components φ k ( s , a ) . B–C. Comparison between the learning curves of a traditional architecture (2-layer MLP) and a single-layer MLP with bilinear decomposition. (inset) Scheme of the navigation task: a robot with 8 DOF is asked to mov e in a specific direction. D. Comparison of learning curves between the cases in which the latent space G k is independent or shared between actor and critic. E–F . Direction encoding for actor and critic. G–I. Reward, correlation between actor and critic G , and direction encoding in the G space, as functions of training steps. The main quantitativ e result is that bilinear decomposition improves learning ef ficiency e ven with a shallo wer network. As shown in Fig. 1 B–C, the single-layer bilinear model reaches higher rew ard faster than the standard tw o-layer MLP baseline, indicating that multiplicativ e structure can compensate for depth by providing a more task-aligned representation. W e then test the central design choice of this work: sharing the gating coef ficients between actor and critic. Fig. 1 D shows that using a common latent v ector G yields performance comparable to (or better than) the variant with separate actor/critic gates, while reducing parameterization and optimization complexity . Finally , Fig. 1 E–I characterizes the learned latent space. Panels E–F show structured direction encoding for actor and critic, while panels G–I report re ward, actor–critic G correlation, and the e volution of direction encoding o ver training. These trends support our claim that shared G forms a coherent control interface that is both behaviorally meaningful and suitable for rapid adaptation. W e also observ e that actor and critic dev elop slightly different goal (direction) encodings; when optimized independently , the actor representation can be e ven more informative for direction decoding. Importantly , constraining the two modules to share the same G does not produce a measurable loss in control performance, while preserving a simpler and more consistent latent interface. W e also observe that actor and critic develop slightly different goal (direction) encodings; when optimized independently , the actor representation can be ev en more informative for direction decoding. Importantly , constraining the two modules to share the same G does not produce a measurable loss in control performance, while preserving a simpler and more consistent latent interface. W e empirically in vestigated the ef fect of sharing the G components between the actor and the critic in our proposed bilinear decomposition framew ork, where Q ( s , a ) = ∑ k G k ( s ) V k ( a , s ) , µ ( s ) = ∑ k G ( A ) k ( s ) Y k ( s ) . In the general formulation, the actor and the critic may hav e different G functions ( G ( A ) = G ), allowing them to be optimized independently . Howe ver , our e xperiments show that setting G ( A ) = G leads to essentially identical performance compared to learning G ( A ) separately . This finding has two important consequences: 3 400 200 0 200 400 X position 400 200 0 200 400 Y position Trained 400 200 0 200 400 X position 400 200 0 200 400 Y position Zero-shot Angle 0 0 0 0 0 0 0 0 400 200 0 200 400 X position 400 200 0 200 400 Y position Comparison Trained Zero-shot A B C D E Figure 2. Zero-shot learning. A. T ask scheme: the MuJoCo Ant agent is pre-trained on target directions and tested on ne w ones. Pretrained bilinear agent is e valuated on unseen goal directions (or task descriptors) without an y parameter update, by conditioning on g . B. Performance compared against baselines when switching to novel directions. C–D . Behavior trajectories for training and test directions, respecti vely , illustrating successful generalization to intermediate angles not explicitly trained. E. Direct comparison between train and test directions (averaged ov er trials). 1. It is not necessary to optimize G ( A ) at all; one can directly reuse the critic’ s G for the actor , thus reducing the number of parameters and simplifying the optimization process. 2. When facing a ne w task, adaptation can be achiev ed by re-estimating only G from the critic, without re-learning G ( A ) and subsequently re-optimizing the actor . This substantially reduces the cost of transfer to new tasks. This parameterization of the actor—using the same G factors as the critic within a bilinear decomposition—is, to the best of our knowledge, novel. Our results suggest that it is not only theoretically sound, b ut also practically beneficial for both computational efficienc y and rapid transfer learning. W e next evaluate zero-shot generalization to unseen target directions (Fig. 2 ). Panel A summarizes the protocol: the MuJoCo Ant is pretrained only on directional objectives and then tested on new directions without any parameter update, conditioning only on g . Panel B shows that the pretrained bilinear agent remains competitive with baseline methods after direction switches. Panels C–D report representati ve trajectories for training and test directions, showing smooth interpolation tow ard intermediate headings that were not explicitly seen during training. Finally , panel E compares train and test directional performance av eraged over trials, confirming only limited degradation in the zero-shot regime and supporting the vie w that G acts as a structured control variable rather than a standard conte xtual input. Figure 3 highlights the interpretability and online adaptability of the learned gating space. In panel A, controlled manipula- tion of individual coef ficients G k produces systematic and semantically meaningful behavioral changes: the top plot shows ho w mov ement direction varies with latent-space direction at three amplitudes, while the bottom plot reports the corresponding speed distributions. Importantly , modulation in G also produces coherent changes in movement speed, e ven though speed was nev er an explicit training target. These results indicate that G acts as a structured control interface rather than an opaque latent code; this behavior was not achie vable when the conte xtual signal was treated as a traditional network input (results not shown). Panel B demonstrates real-time adaptation through direct updates of G k . As task direction changes, rew ard remains aligned with the target-direction objecti ve (blue), whereas a negati ve-re ward reference task (orange) provides a clear contrast. T ogether , 4 A B Figure 3. Bilinear decomposition allows for interpretability and generalization. A. Manipulating individual gating coordinates G k produces consistent, semantically meaningful changes in behavior , indicating interpretable control ax es. (T op) A verage mov ement direction as a function of latent-space direction for three dif ferent amplitudes; (bottom) speed distribution for the same three amplitudes (color-coded). Notably , speed modulation emer ges spontaneously , although training objectives were defined only o ver mo vement direction. B. Online adaptation of G k , allo wing real-time solution of the current task. Reward as a function of the target direction (blue). As a reference, a task with negati ve re ward is sho wn (orange). these findings support the claim that bilinear co-decomposition enables both interpretable control and fast task-level adaptation without retraining the full network. 3 Methods 3.1 Multiplicative gating enables a bilinear decomposition of the policy W e consider a deterministic continuous-control policy µ ( s , g ) ∈ R | A | conditioned on the environment state s and a low- dimensional goal or context variable g . Rather than representing the policy as a single monolithic nonlinear mapping, we decompose it into a set of K basis action generators modulated by a multiplicati ve gating signal: µ ( s , g ) = K ∑ k = 1 G k ( s , g ) Y k ( s ) , (1) where Y k ( s ) ∈ R | A | are state-dependent basis policies, and G k ( s , g ) ∈ R are scalar gating coef ficients. This formulation induces a bilinear structure: the policy output is linear in the basis functions Y k ( s ) for fixed gating, and linear in the gating vector G ( s , g ) for fixed state features. As a result, expressi ve policies can be represented through multiplicativ e interactions without relying on deep stacks of nonlinear activ ations. In practice, both Y k and G k are implemented as shallow neural netw orks, but their interaction remains e xplicitly multiplicativ e. From a functional perspectiv e, Eq. ( 1 ) can be interpreted as a low-rank factorization of a general policy mapping. An y policy of the form µ ( s , g ) = f ( s , g ) can be approximated by a finite sum of separable terms G k ( s , g ) Y k ( s ) , with K controlling the rank and expressi ve capacity . Importantly , this factorization disentangles what actions are available (encoded by the basis policies Y k ) from how strongly they ar e expr essed (controlled by G k ). Multiplicativ e gating plays a crucial role in this decomposition. Unlike additi ve mixtures, multiplicativ e modulation allows the same basis policy to be selectively amplified, suppressed, or combined with others depending on context. This mirrors well-known computational motifs in biological neural circuits, where multiplicati ve interactions enable contextual control and nonlinear integration while preserving linear readouts. A further consequence of Eq. ( 1 ) is interpretability . When the basis policies specialize along distinct behavioral dimensions (e.g., forward motion, turning, speed modulation), the gating coefficients acquire a direct semantic meaning. Manipulating individual components of G produces predictable and smooth changes in behavior , effecti vely defining a low-dimensional control manifold embedded in the full action space. Finally , this bilinear policy representation is particularly well-suited for actor –critic learning. As shown in the follo wing sections, sharing the same gating v ariables between policy and critic induces aligned gradients and enables ef ficient optimization, while also supporting fast online adaptation by updating only the lo w-dimensional gating vector . 5 3.2 Bilinear Co-Decomposition of Actor and Critic W e propose a structured co-decomposition for both policy and value function in continuous control. The critic Q ( s , a , g ) is factorized as a weighted sum of component v alue functions: Q ( s , a , g ) = K ∑ k = 1 G k ( s , g ) φ k ( s , a ) , (2) where φ k are basis value functions and G k ( s , g ) are gating scalars that modulate their contribution. Similarly , the deterministic actor µ ( s , g ) is represented as µ ( s , g ) = K ∑ k = 1 G k ( s , g ) Y k ( s ) , (3) where Y k ( s ) are basis action generators. Crucially , the same gating vector G ( s , g ) modulates both actor and critic, creating an explicit alignment between policy impr ovement directions and value estimates . This co-decomposition allo ws distributed computation across K components while retaining a compact, interpretable latent space G . In our implementation, the gating vector is produced from a small linear layer acting on the goal or directional input of the agent, optionally with injected Gaussian noise for exploration (see Actor and Critic classes). Each component is then scaled by its respectiv e G k and summed to produce the final action or Q-value. 3.3 Actor–Critic T raining W e adopt a standard of f-policy soft actor–critic (SA C) framework [ 2 ], modified to respect the co-decomposed structure. T wo critics Q 1 and Q 2 are maintained, along with their target netw orks. The actor samples actions according to a ∼ N ( µ ( s , g ) , σ ( s , g ) 2 ) , (4) with mean µ ( s , g ) given by the bilinear decomposition and state-dependent diagonal co variance σ ( s , g ) 2 . Critic updates are performed by minimizing the squared Bellman error: L Q i = E ( s , a , r , s ′ ) h Q i ( s , a , g ) − y 2 i , (5) where y = r + γ min j Q j ( s ′ , a ′ , g ′ ) , (6) with a ′ sampled from the current actor and g ′ the gating vector for s ′ . Actor updates follo w the soft policy gradient: L µ = E s α log π ( a | s ) − min j Q j ( s , a , g ) . (7) T o enforce co-decomposition, the actor and both critics share the same gating layer , ensuring that the same G k modulates both policy and v alue components. T arget netw orks are updated using an exponential moving a verage. Shared-Coefficient P olicy and V alue Decomposition W e parameterize both the action–value function and the policy using a shared low-dimensional coef ficient vector G ∈ R K . Specifically , the action–value function is represented as Q ( s , a ) = K ∑ k = 1 G k ψ k ( s , a ) , where { ψ k } K k = 1 are fixed successor -feature bases learned during a pretraining phase. The policy is decomposed analogously as a con ve x combination of basis policies, π ( a | s ) = K ∑ k = 1 G k Y k ( a | s ) , where each Y k ( a | s ) is a valid stochastic policy . This construction ensures that the value function corresponds to the polic y induced by G , preserving policy–v alue consistency . 6 3.4 Zero-Shot Adaptation W e ev aluate zero-shot transfer by freezing all learned parameters and directly conditioning the policy on a new goal descriptor g ∗ . In this setting, the gating network produces coefficients G ( s , g ∗ ) with a single forward pass, and the policy is executed without gradient steps or replay-buf fer updates: π ZS ( a | s , g ∗ ) = K ∑ k = 1 G k ( s , g ∗ ) Y k ( a | s ) . This protocol measures how well the pretrained bases and shared coef ficient structure generalize to unseen directions/tasks purely through interpolation in the learned latent space. W e report zero-shot performance using return and trajectory alignment metrics before enabling any adaptation dynamics. 3.5 Online Adaptation in G-Space: Method and Derivation At adaptation time, we freeze the pretrained bases { Y k , ψ k } K k = 1 and update only the shared coef ficient v ector G ∈ R K . Using w ≡ G , we write Q ( s , a | g ) = ψ ( s , a ) ⊤ w , ψ ( s , a ) = [ ψ 1 ( s , a ) , . . . , ψ K ( s , a )] ⊤ . Giv en a transition ( s t , a t , r t , s t + 1 , a t + 1 ) , the TD error is δ t = r t + γ ψ ( s t + 1 , a t + 1 ) ⊤ w − ψ ( s t , a t ) ⊤ w . Minimizing 1 2 δ 2 t with stochastic gradient descent yields the linear TD/SARSA update w ← w + α G δ t ψ ( s t , a t ) , which is then immediately reused by the policy decomposition π ( a | s , g ) = K ∑ k = 1 w k Y k ( a | s ) . This giv es rapid adaptation without retraining actor or critic bases. The simplified rule discussed in the Results and Discussion, ∆ G k ∝ r φ k ( s , a ) , is recov ered as a one-step approximation of the TD update when the bootstrap term is neglected o ver short horizons and φ k is identified with the critic basis response. In practice, we use the TD form abo ve because it is more stable and v alue-consistent. Importantly , adaptation is value-based and does not rely on policy-gradient updates in G -space. 3.6 Experimental Setup W e ev aluate our approach on the MuJoCo Ant-v4 en vironment. The agent is trained to move in a given target direction, encoded as a 2D v ector appended to the observ ation. During training, directions are c ycled ev ery 100 steps through eight angles (four cardinal and four diagonal), ensuring exposure to multiple behavioral modes. Episodes last 800 steps, and rew ard is defined as forward progress along the tar get direction minus a small penalty for orthogonal movement: r = ∆ x cos θ + ∆ y sin θ − 0 . 1 | ∆ x sin θ − ∆ y cos θ | . (8) W e employ a replay buf fer of size 10 5 and train both actor and critic using Adam with learning rate 3 × 10 − 4 . Each training iteration samples a batch of transitions and performs standard SAC updates, while online G-space adaptation is applied during rollout to demonstrate rapid directional modulation. 3.7 Analysis of G Dynamics T o analyze the learned and adapted gating vectors, we record G activ ations during episodes and visualize them using PCA. This provides insight into the monosemanticity of each component (i.e., each G k tends to correspond to a consistent action pattern) and sho ws that online adaptation can modulate direction and speed independently of the pre-trained policy , highlighting the interpretability and controllability of the co-decomposition. 7 4 Discussion Our results provide a coherent picture across Figs. 1 – 3 . First, the shared bilinear actor–critic decomposition improv es learning efficienc y and preserves performance while reducing optimization comple xity through shared coefficients. Second, zero-shot transfer to unseen directions is ef fecti ve without parameter updates. Third, direct manipulations of G rev eal an interpretable control space that supports fast online adaptation. A key outcome is the practical controllability of behavior in G -space. V arying G does not only steer movement direction; it also modulates mov ement speed in a smooth and reliable w ay . Crucially , this speed control emer ges spontaneously: training objectiv es explicitly tar geted direction, not speed. This emergent degree of freedom is important because it indicates that G is not merely a standard contextual input appended to the policy , but a structured latent control interface shared by actor and critic. From a mechanistic perspectiv e, adaptation is achiev ed by updating only G while keeping basis functions fixed. Using the value-based rule ∆ G k ∝ r φ k ( s , a ) , rew ard information is propagated directly through the decomposition, yielding rapid behavioral adjustment within a few en vironment steps. In our experiments, policy-gradient updates in G -space were less effecti ve, supporting the idea that value-based updates are better aligned with this representation. Overall, the proposed decomposition combines sample-effi cient learning, zero-shot generalization, interpretable low- dimensional control, and rapid online adaptation in a single framework. These properties motiv ate future work on learning bases φ k with stronger monosemanticity and extending the same principle to hierarchical and multi-goal control settings. References 1. Cristiano Capone and Luca Falorsi. Adaptive beha vior with stable synapses. Neural Networks , page 108082, 2025. 2. T uomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Ser gey Le vine. Soft actor-critic: Off-policy maximum entrop y deep reinforcement learning with a stochastic actor . In Pr oceedings of the 35th International Conference on Machine Learning (ICML) , pages 1861–1870. PMLR, 2018. 3. Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin V an Roy . Deep exploration via bootstrapped dqn. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2016. 4. Xinyang Chen, Ziyu W ang, Y inan Zhou, Hao Sun, Runzhe Xu, Jialin Xiong, Chongjie Y u, Shiyu Zhang, Dongbin Zhao, Y ujing Zhang, et al. Randomized ensembled double q-learning: Learning fast without a model. In International Conference on Learning Representations (ICLR) , 2021. 5. Jacob Andreas, Dan Klein, and Sergey Levine. Modular multitask reinforcement learning with policy sketches. In Pr oceedings of the 34th International Confer ence on Machine Learning (ICML) , volume 70, pages 166–175. PMLR, 2017. 6. Noam Shazeer , Azalia Mirhoseini, Piotr Maziarz, Andy Davis, Quoc V Le, Geof frey E Hinton, and Jeffrey Dean. Outrageously large neural networks: The sparsely-gated mixture-of-e xperts layer . In arXiv preprint , 2017. 7. André Barreto, W ill Dabney , Rémi Munos, Jonathan J. Hunt, T om Schaul, and Hado van Hasselt. Successor features for transfer in reinforcement learning. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2017. 8. W olfgang Maass, Thomas Natschäger , and Henry Markram. Real-time computing without stable states: A new framew ork for neural computation based on perturbations. Neural computation , 14(11):2531–2560, 2002. 9. Herbert Jaeger . The "echo state" approach to analysing and training recurrent neural networks. T echnical report, German National Research Center for Information T echnology , 2001. 10. Mantas Luk ˇ oevicius. Reservoir computing approaches to recurrent neural network inference. PhD thesis, University of Gr oningen , 2009. 11. Xavier Rigoét, Loïc Nédélec, Marie-Ange Gariel-Mathis, Philippe Mailly , Laurent Goetz, Stéphan Chabardès, Emmanuel Procyk, Gilles Fénelon, Marie Pouzeratte, Margaret M McCarthy , et al. The organization of prefrontal-subthalamic inputs in primates provides an anatomical substrate for both suppression and generation of action. Br ain , 136(6):1654–1667, 2013. 12. David Badre and Mark D’Esposito. Prefrontal cortex and hierarchical cognitiv e control. Annual re view of neur oscience , 32:167–191, 2009. 13. Stev en P W ise. The premotor cortex and the supplementary motor area: functional organisation. T r ends in neur osciences , 8:239–242, 1985. 14. Jun T anji. Sequential organization of multiple mov ements: in volvement of cortical motor areas. Annual r eview of neur oscience , 24(1):631–651, 2001. 8 15. Matthew E Larkum, Jackie J Zhu, and Bert Sakmann. A new cellular mechanism for coupling inputs to their outputs in pyramidal neurons. Natur e , 398(6724):338–341, 1999. 16. Etay Hay , Sean Hill, Felix Schürmann, Henry Markram, and Idan Sege v . Division of labor in the layer 5 apical dendrite. F rontier s in cellular neur oscience , 5:28, 2011. 17. Haroon Urakubo, Motoki Honda, K eiko Kuroka wa, Hiroyuki Fujioka, Masumi Y anagawa, and Masao Kasai. Nonlinear dendritic integration in a functional model of rat layer 5 cortical pyramidal neuron. Neur oscience resear ch , 60(3):268–279, 2008. 18. Matthew E Larkum. A new cellular mechanism for coupling inputs to their outputs in pyramidal neurons. Nature Reviews Neur oscience , 14(11):783–793, 2013. 19. S Murray Sherman. Thalamo-cortical interactions. Current Opinion in Neur obiology , 40:78–84, 2016. 20. Jean-Alban Rathelot and Peter L Strick. Motor cortical control of a fore-arm mov ement in 3d. Journal of Neur oscience , 29(31):9859–9870, 2009. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment