머신 텍스트 탐지의 한계와 가능성: 다중 아키텍처·도메인·공격 조건 종합 벤치마크
본 논문은 HC3와 ELI5 두 대규모 인간‑LLM 페어링 데이터셋을 활용해, 통계 기반, 변형 트랜스포머, CNN, 스타일로메트릭 XGBoost, 퍼플렉시티 기반, LLM‑as‑detector 등 6가지 탐지 패러다임을 종합 평가한다. 변형 트랜스포머는 동일 도메인에서 거의 완벽한 AUROC(≥0.994)를 기록하지만, 도메인·LLM 전이 시 성능 급락한다. XGBoost 스타일로메트릭 모델은 변형 트랜스포머와 동등한 인‑도메인 성능을 보이며…
저자: Madhav S. Baidya, S. S. Baidya, Chirag Chawla
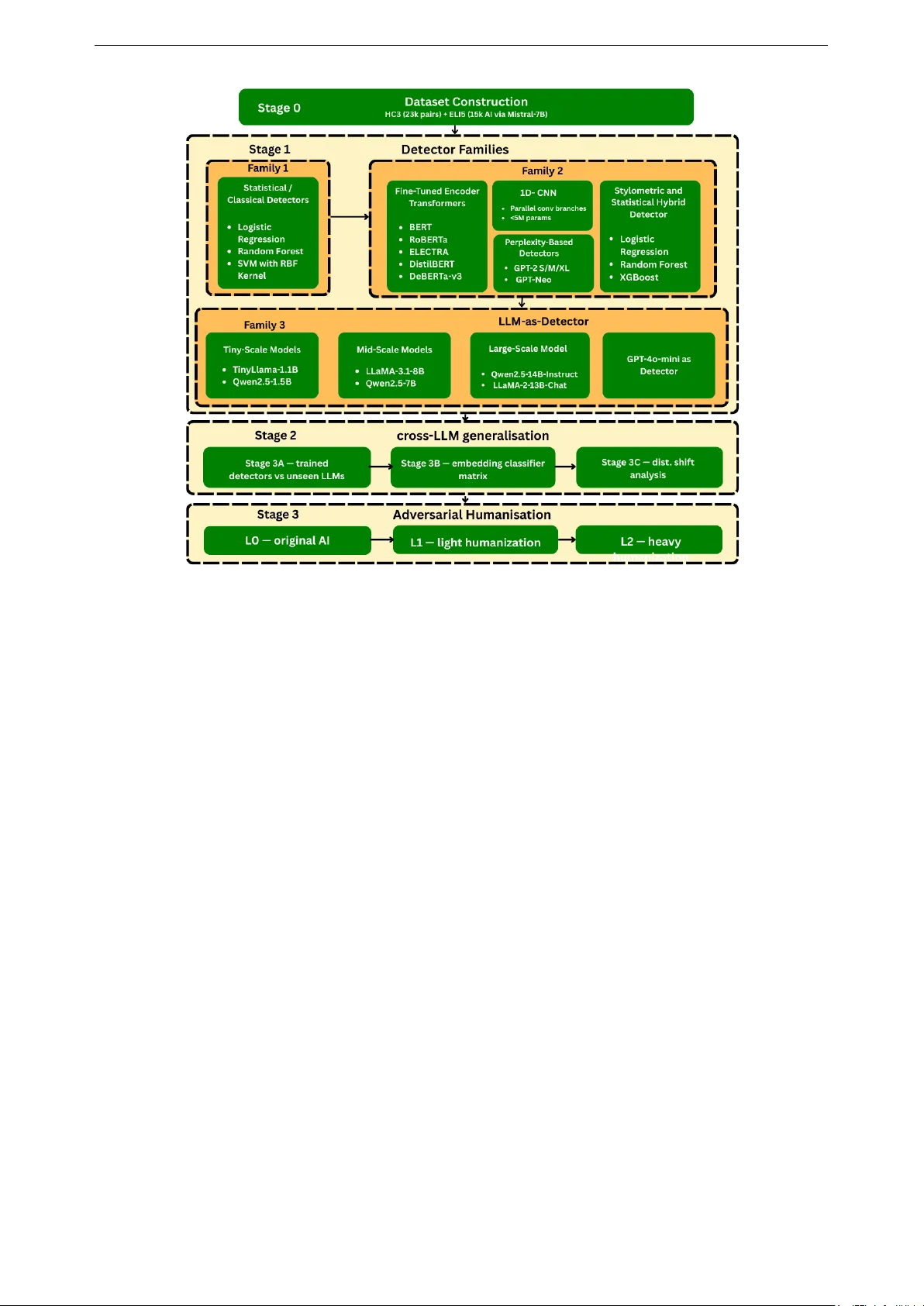
본 논문은 대규모 LLM 생성 텍스트 탐지기의 실제 적용 가능성을 평가하기 위해, 두 개의 정교하게 구축된 데이터셋 HC3와 ELI5를 기반으로 포괄적인 벤치마크를 설계하였다. HC3는 인간‑ChatGPT 페어링을 5개 도메인에 걸쳐 23 363쌍(총 46 726 텍스트)으로 구성하고, ELI5는 인간‑Mistral‑7B 페어링을 15 000쌍(총 30 000 텍스트)으로 만든 뒤, 인간과 AI 텍스트 길이를 ±20% 범위 내에서 매칭하여 길이 편향을 제거하였다.
탐지기군은 크게 여섯 가지 패러다임으로 나뉜다. 첫 번째는 22개의 손수 만든 언어·통계 특징을 이용한 클래식 머신러닝 모델이며, XGBoost 기반 하이브리드 스타일로메트릭 파이프라인을 포함한다. 두 번째는 BERT, RoBERTa, ELECTRA, DistilBERT, DeBERTa‑v3 등 다섯 종류의 변형 트랜스포머를 각각 인간‑LLM 페어링 데이터에 fine‑tune한 것이다. 세 번째는 1D‑CNN 구조를 적용한 얕은 신경망이며, 네 번째는 스타일로메트릭과 통계 특징을 결합한 XGBoost 모델이다. 다섯 번째는 GPT‑2·GPT‑Neo 계열 언어 모델을 이용한 퍼플렉시티 기반 비지도 탐지기로, 텍스트의 언어 모델 확률을 직접 측정한다. 마지막 여섯 번째는 다양한 규모(1.1B–14B) LLM을 프롬프트 기반 zero‑shot 혹은 few‑shot 방식으로 활용한 LLM‑as‑detector이며, GPT‑4o‑mini까지 포함한다.
실험은 세 단계로 진행된다. ① 인‑도메인(같은 데이터셋) 평가에서는 변형 트랜스포머가 AUROC 0.994 이상, 정확도 98% 수준으로 거의 완벽한 성능을 보였다. XGBoost 스타일로메트릭도 AUROC 0.992로 변형 트랜스포머와 실질적으로 동등했으며, 피처 중요도 분석을 통해 ‘문장‑레벨 퍼플렉시티 변동’과 ‘AI‑phrase density’가 핵심 구분 요인임을 밝혀냈다. ② 교차‑LLM·교차‑도메인 평가에서는 모든 모델이 성능 저하를 겪었으며, 특히 변형 트랜스포머는 AUROC가 0.70 이하로 떨어졌다. 이는 모델이 학습된 데이터의 도메인·생성기 특성에 과도하게 의존한다는 증거다. XGBoost는 상대적으로 완만한 저하를 보였지만, 여전히 0.85 수준에 머물렀다. 퍼플렉시티 기반 탐지는 최신 LLM 출력이 인간보다 낮은 퍼플렉시티를 보이는 ‘극성 역전’ 현상을 발견했으며, 인간 텍스트에 가중치를 부여해 보정하면 AUROC ≈0.91을 달성했다. ③ 인간화 공격 단계에서는 L0(원본), L1(경미한 인간화), L2(강도 높은 인간화) 세 수준의 LLM‑기반 재작성으로 텍스트를 변형시켰다. 모든 탐지기는 L1·L2에서 AUROC가 0.6 이하로 급락했으며, 특히 스타일로메트릭과 퍼플렉시티 기반이 가장 큰 타격을 입었다. LLM‑as‑detector는 전반적으로 낮은 성능을 보였으며, 특히 ‘생성기‑탐지기 동일 모델’ 상황에서 0.5 수준에 가까운 무작위 추측에 머물렀다.
논문은 또한 ‘generator‑detector identity problem’이라는 현상을 강조한다. 탐지기에 사용된 LLM과 동일하거나 유사한 모델을 탐지기에 프롬프트할 경우, 모델이 자신의 생성 스타일을 인식하지 못해 성능이 급격히 떨어진다. 이는 실제 서비스에서 동일 모델을 탐지기로 활용하려는 시도가 비효율적임을 시사한다.
결론적으로, 변형 트랜스포머는 현재 가장 높은 인‑도메인 성능을 제공하지만, 도메인·LLM 전이와 인간화 공격에 취약하다. XGBoost 스타일로메트릭은 약간 낮은 성능에도 불구하고 해석 가능성과 경량성을 제공해 실용적인 대안이 될 수 있다. 퍼플렉시티 기반 비지도 탐지는 간단하면서도 보정만으로 강력한 성능을 보이며, 향후 라벨이 없는 데이터에 적용 가능성이 크다. LLM‑as‑detector는 현재로서는 보조적인 역할에 머물며, 프롬프트 설계와 모델 규모 확대가 성능 향상에 한계가 있음을 보여준다. 향후 연구는 도메인‑불변 표현 학습, 멀티‑LLM 앙상블, 그리고 인간화 공격에 대한 방어 메커니즘을 개발하는 방향으로 나아가야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기