Detecting the Machine: A Comprehensive Benchmark of AI-Generated Text Detectors Across Architectures, Domains, and Adversarial Conditions
The rapid proliferation of large language models (LLMs) has created an urgent need for robust and generalizable detectors of machine-generated text. Existing benchmarks typically evaluate a single detector on a single dataset under ideal conditions, …
Authors: Madhav S. Baidya, S. S. Baidya, Chirag Chawla
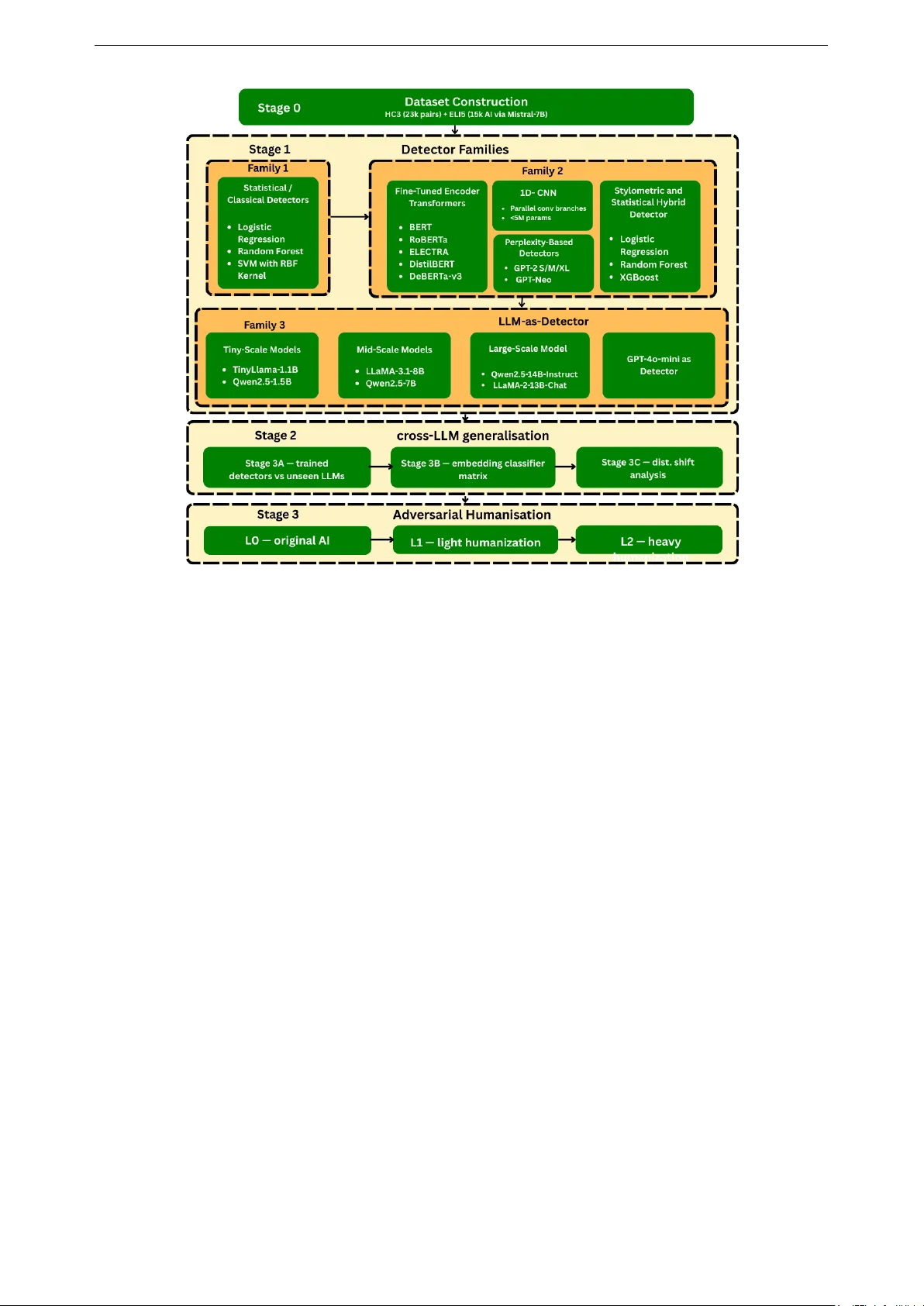
Detecting the Mac hine: A Comprehensiv e Benc hmark of AI-Generated T ext Detectors Across Arc hitectures, Domains, and Adv ersarial Conditions Madha v S. Baidy a 1 , S. S. Baidy a 2 , Chirag Cha wla 1 1 Indian Institute of T ec hnology (BHU), V aranasi, India 2 Indian Institute of T ec hnology Guw ahati, India madhavsukla.baidya.chy22@itbhu.ac.in, saurav.baidya@iitg.ac.in, chirag.chawla.chy22@itbhu.ac.in Abstract The rapid proliferation of large language mo dels ( llm s) has created an urgen t need for robust, generalizable detectors of machine-generated text. Existing b enchmarks typically ev aluate a single detector t yp e on a single dataset under ideal conditions, leaving critical questions about cross-domain transfer, cross- llm generalization, and adversarial robustness unansw ered. This w ork presents a comprehensiv e b enchmark that systematically ev aluates a broad sp ectrum of detection approac hes across tw o carefully constructed corp ora: HC3 (23,363 paired h uman– ChatGPT samples across fiv e domains, 46,726 texts after binary expansion) and ELI5 (15,000 paired human–Mistral-7B samples, 30,000 texts). The approaches ev aluated span classical statis- tical classifiers, five fine-tuned enco der transformers (BER T, RoBER T a, ELECTRA, DistilBER T, DeBER T a-v3), a shallo w 1D-CNN, a st ylometric-hybrid X GBo ost pip eline, p erplexity-based unsup ervised detectors (GPT-2/GPT-Neo family), and llm -as-detector prompting across four mo del scales including GPT-4o-mini. All detectors are further ev aluated zero-shot against outputs from five unseen open-source llm s with distributional shift analysis, and sub jected to iterative adv ersarial humanization at three rewriting intensities (L0–L2). A principled length-matc hing prepro cessing step is applied throughout to neutralize the well-kno wn length confound. Our cen tral findings are: ( i ) fine-tuned transformer enco ders ac hieve near-perfect in-distribution aur oc ( ≥ 0 . 994) but degrade univ ersally under domain shift; ( ii ) an XGBoost st ylometric h ybrid matc hes transformer in-distribution p erformance while remaining fully interpretable, with sen tence-level p erplexit y co efficient of v ariation and AI-phrase densit y as the most discriminativ e features; ( iii ) llm -as-detector prompting lags far behind fine-tuned approaches — the b est op en-source result is Llama-2-13b-c hat-hf CoT at aur oc 0 . 898, while GPT-4o-mini zero-shot reaches 0 . 909 on ELI5 — and is strongly confounded by the generator–detector identit y problem; ( iv ) p erplexity-based detectors reveal a critical p olarity inv ersion — mo dern llm outputs are systematically lower p erplexit y than h uman text — that, once corrected, yields effectiv e aur oc of ≈ 0 . 91; and ( v ) no detector generalizes robustly across llm sources and domains simultaneously . Keyw ords: AI-generated text detection, large language models, benchmark ev aluation, transformer fine-tuning, adversarial robustness, st ylometry , domain generalization, perplexity , cross-LLM generalization Preprin t — arXiv Detecting the Machine Con ten ts 1 In tro duction 3 2 Related W ork 4 2.1 Sup ervised Detection Approac hes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 Unsup ervised and Zero-Shot Approac hes . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.3 LLM-as-Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 2.4 Adv ersarial Humanization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 3 Datasets and Prepro cessing 5 3.1 HC3 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 3.2 ELI5 Dataset and Mistral-7B Augmen tation . . . . . . . . . . . . . . . . . . . . . . 5 3.3 Binary Dataset Preparation and Length Matc hing . . . . . . . . . . . . . . . . . . . 6 4 Detector F amilies: Architecture and Implemen tation 6 4.1 Statistical / Classical Detectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2 Fine-T uned Enco der T ransformers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2.1 BER T ( bert-base-uncased ) . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2.2 RoBER T a ( roberta-base ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2.3 ELECTRA ( google/electra-base-discriminator ) . . . . . . . . . . . . . 7 4.2.4 DistilBER T ( distilbert-base-uncased ) . . . . . . . . . . . . . . . . . . . . 8 4.2.5 DeBER T a-v3 ( microsoft/deberta-v3-base ) . . . . . . . . . . . . . . . . . . 8 4.3 Shallo w 1D-CNN Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 4.4 St ylometric and Statistical Hybrid Detector . . . . . . . . . . . . . . . . . . . . . . . 8 4.5 P erplexity-Based Detectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 4.6 LLM-as-Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 5 Exp erimen tal Results: Detector F amilies 9 5.1 Statistical / Classical Detectors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 5.2 Fine-T uned Enco der T ransformers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 5.3 Shallo w 1D-CNN Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 5.4 St ylometric and Statistical Hybrid Detector . . . . . . . . . . . . . . . . . . . . . . . 14 5.5 Stage 1 Key Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 6 LLM-as-Detector and Con trastive Likelihoo d Detection 15 6.1 Prompting P aradigms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 6.2 Tin y-Scale Mo dels: TinyLlama-1.1B-Chat-v1.0and Qwen2.5-1.5B . . . . . . . . . . . 15 6.3 Mid-Scale Mo dels:Llama-3.1-8B-Instruct and Qw en2.5-7B . . . . . . . . . . . . . . . 16 6.4 Large-Scale Mo dels: LLaMA-2-13B-Chat . . . . . . . . . . . . . . . . . . . . . . . . 16 6.5 Large-Scale Mo dels: Qwen2.5-14B-Instruct . . . . . . . . . . . . . . . . . . . . . . . 17 6.6 GPT-4o-mini as Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 6.7 Con trastive Likelihoo d Detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 7 P erplexit y-Based Detectors 19 7.1 Metho d . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 7.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 8 Cross-LLM Generalization Study 20 8.1 Exp erimen tal Design and Dataset Construction . . . . . . . . . . . . . . . . . . . . . 20 8.2 Neural Detector Cross-LLM Ev aluation . . . . . . . . . . . . . . . . . . . . . . . . . 21 8.3 Em b edding-Space Generalization via Classical Classifiers . . . . . . . . . . . . . . . . 21 8.4 Distribution Shift Analysis in Represen tation Space . . . . . . . . . . . . . . . . . . . 22 9 Adv ersarial Humanization 23 1 Preprin t — arXiv Detecting the Machine 10 Discussion 24 10.1 The Cross-Domain Challenge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 10.2 The Generator–Detector Identit y Problem . . . . . . . . . . . . . . . . . . . . . . . . 25 10.3 The Perplexit y Inv ersion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 10.4 In terpretability vs. Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 10.5 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 11 F uture W ork 25 12 Conclusion 25 13 Implementation Details 28 13.1 F amily 1 — Statistical Machine Learning Detectors . . . . . . . . . . . . . . . . . . . 28 13.2 F amily 2 — Fine-T uned Enco der T ransformers . . . . . . . . . . . . . . . . . . . . . 28 13.3 F amily 3 — Shallow 1D-CNN Detector . . . . . . . . . . . . . . . . . . . . . . . . . . 29 13.4 F amily 4 — Stylometric and Statistical Hybrid Detector . . . . . . . . . . . . . . . . 29 13.5 F amily 5 — LLM-as-Detector . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 A Hyp erparameter T ables 31 A.1 Enco der T ransformer Common T raining Proto col . . . . . . . . . . . . . . . . . . . . 31 A.2 Enco der T ransformer Mo del Sp ecifications . . . . . . . . . . . . . . . . . . . . . . . . 31 A.3 1D-CNN Hyp erparameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 A.4 St ylometric Hybrid Hyp erparameters . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 A.5 llm -as-Detector Configuration Summary . . . . . . . . . . . . . . . . . . . . . . . . . 32 A.6 CoT Ensem ble Parameters by Mo del . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 B Prompt T emplates 32 B.1 Zero-Shot Prompts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 B.2 F ew-Shot Prompt Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 B.3 Chain-of-Though t Prompts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 2 Preprin t — arXiv Detecting the Machine 1 In tro duction The widespread deploymen t of instruction-tuned large language mo dels — including ChatGPT, Mistral, LLaMA, and their successors [Bro wn et al., 2020, Ouyang et al., 2022, Bommasani et al., 2021] — has fundamentally altered the landscap e of written communication. These systems pro duce text that is, by many surface measures, indistinguishable from human writing [Floridi and Chiriatti, 2020], giving rise to serious so cietal concerns around academic integrit y , journalistic authen ticity , disinformation, and the erosion of trust in digital communication. The dev elopmen t of robust, practical detectors for machine-generated text has consequently b ecome one of the most active researc h frontiers in natural language pro cessing [Mitchell et al., 2023, Gehrmann et al., 2019]. Despite substan tial progress, the field suffers from a critical metho dological fragmentation. Existing work ev aluates detectors in isolation, on single datasets, under idealized conditions that do not reflect the deplo ymen t environmen t. Key questions remain empirically underexplored: How much do es a dete ctor’s p erformanc e de gr ade when the test-time llm differs fr om the tr aining-time gener ator? Which ar chite ctur al families gener alize most r obustly acr oss domains? Can interpr etable, lightweight dete ctors match the p erformanc e of massive fine-tune d tr ansformers? Do es pr ompting lar ge mo dels with structur e d r e asoning c onstitute a viable dete ction str ate gy? What happ ens to al l dete ctor families under adversarial text humanization? This paper addresses these questions through a large-scale, multi-stage b enc hmark that spans the full sp ectrum of detection paradigms. Our contributions are: T o supp ort repro ducibility and further researc h, w e mak e our implementation and ev aluation pip eline a v ailable at our GitHub repository . 1. Benc hmark design and datasets. W e construct tw o carefully con trolled corp ora — HC3 (paired h uman–ChatGPT, 5 domains, 46,726 samples after length matching) and ELI5 (paired h uman–Mistral-7B, single domain, 30,000 samples) — with a principled length-matching step that prev ents detectors from exploiting the length confound [Ipp olito et al., 2020]. 2. Three detector families (Stage 1). W e implemen t and rigorously ev aluate under in-distribution and cross-domain conditions: ( a ) classical statistical classifiers on a 22-feature hand-crafted feature set; ( b ) fiv e fine-tuned enco der transformers — BER T [Devlin et al., 2019], RoBER T a [Liu et al., 2019], ELECTRA [Clark et al., 2020], DistilBER T [Sanh et al., 2019], DeBER T a-v3 [He et al., 2021]; ( c ) a shallow 1D-CNN [Kim, 2014]; ( d ) a st ylometric-hybrid X GBo ost [Chen and Guestrin, 2016] pip eline with 60+ features including sentence-lev el p erplexit y and AI-phrase densit y; ( e ) perplexity-based unsupervised detectors (GPT-2/GPT-Neo family); and ( f ) llm -as- detector prompting across four mo del scales (1.1B–14B parameters) including GPT-4o-mini via the Op enAI API. 3. Cross-llm generalization (Stage 2). All Stage 1 detectors are ev aluated zero-shot against outputs from five unseen op en-source llm s (TinyLlama-1.1B, Qwen2.5-1.5B, Qw en2.5-7B,Llama- 3.1-8B-Instruct, LLaMA-2-13B), complemen ted b y embedding-space generalization via classical classifiers and distributional shift analysis in DeBER T a represen tation space. 4. Adv ersarial h umanization (Stage 3). All detectors are ev aluated under three lev els of iterativ e LLM-based rewriting (L0: original, L1: light humanization, L2: heavy humanization) using Qwen2.5-1.5B-Instruct as the rewriting mo del, probing robustness to the most practical ev asion strategy a v ailable to adversarial users. 3 Preprin t — arXiv Detecting the Machine Figure 1. Overview of the b enchmark pip eline. Stage 0 constructs t wo paired corp ora ( HC3 : 23k human– ChatGPT pairs; ELI5 : 15k human–Mistral-7B pairs) with length-matched prepro cessing. Stage 1 ev aluates three detector families: F amily 1 (classical statistical classifiers), and F amily 2 (fine-tuned enco der transformers — BER T, RoBER T a, ELECTRA, DistilBER T, DeBER T a-v3; 1D-CNN; p erplexity-based detectors; stylometric- h ybrid XGBoost), and F amily 3 ( llm -as-detector prompting at four scales including GPT-4o-mini). Stage 2 ev aluates cross- llm generalization via neural detectors, embedding-space classifier matrices , and distributional shift analysis. Stage 3 applies adv ersarial h umanization at three levels (L0–L2) using an instruction-tuned rewriter. All families are ev aluated under a unified five-metric suite ( aur oc , aupr c , eer , Brier Score, FPR@95%TPR). 2 Related W ork 2.1 Sup ervised Detection Approac hes Early work on machine-generated text detection relied on statistical features such as p erplexity under reference language models [Solaiman et al., 2019], n-gram statistics, and st ylometric signals [Juola, 2006, Stamatatos, 2009, Ipp olito et al., 2020]. The introduction of transformer-based detectors substan tially adv anced the field: mo dels suc h as GRO VER [Zellers et al., 2019] demonstrated that the b est generators also serv e as the b est discriminators. Subsequen t work fine-tuned general-purp ose enco ders (BER T, RoBER T a) on paired human/ llm corp ora, achieving high in-distribution accuracy [Ro driguez et al., 2022]. The HC3 corpus [Guo et al., 2023] in tro duced a systematic m ulti-domain b enc hmark for ChatGPT detection that has b ecome a de-facto standard. Several subsequen t studies ha ve inv estigated domain transfer [Uc hendu et al., 2020], adversarial robustness [W olff and W olff, 2022], and the effect of prompt engineering on detectability . Commercial detection to ols ha ve also b een deplo yed [Op enAI, 2023], though their generalization across llm families remains p o orly c haracterized. 2.2 Unsup ervised and Zero-Shot Approac hes DetectGPT [Mitc hell et al., 2023] exploits the observ ation that llm -generated text tends to lie in lo cal probabilit y maxima of the generating mo del, using p erturbation-based curv ature estimation 4 Preprin t — arXiv Detecting the Machine as a detection signal. Statistical visualization to ols such as GL TR [Gehrmann et al., 2019] provide complemen tary token-lev el detection signals. P erplexit y thresholding under reference mo dels has b een widely studied [La vergne et al., 2008], though as w e sho w, the direction of the p erplexity signal is coun ter-in tuitive in the mo dern llm era. W atermarking sc hemes [Kirchen bauer et al., 2023] provide a complemen tary but generator-controlled approach that requires coop eration from the mo del provider. 2.3 LLM-as-Detector The use of large mo dels as zero-shot or few-shot classifiers for their own outputs has b een explored in sev eral recen t studies [Zeng et al., 2023, Bhattac harjee et al., 2023]. A consisten t finding is that prompting-based detection underp erforms fine-tuned approaches, particularly on out-of-distribution text. Chain-of-thought prompting has b een shown to impro ve classification accuracy for models with sufficien t instruction-following capacity [Ko jima et al., 2022, W ei et al., 2022], a finding we confirm and extend across four mo del scales. 2.4 Adv ersarial Humanization P araphrase-based attacks [Krishna et al., 2023], st yle transfer, and direct human editing hav e all b een demonstrated to substantially reduce detector accuracy . The challenge of adv ersarial robustness remains largely unsolv ed, particularly for unsup ervised detection metho ds. Our Stage 2 ev aluation systematically c haracterizes ho w iterativ e llm -based rewriting at tw o intensit y levels degrades all detector families simultaneously , filling a gap left by prior w ork that typically ev aluates a single detector family under a single attac k strategy . 3 Datasets and Prepro cessing 3.1 HC3 Dataset The HC3 (Human-ChatGPT Comparison) corpus [Guo et al., 2023] w as loaded from the Hello- SimpleAI/HC3 rep ository via the Hugging F ace datasets library . It provides question–answ er pairs across m ultiple domains, with each entry containing one question, a list of human answers, and a list of ChatGPT answ ers. W e flattened the corpus into a structured paired format — one ro w p er question with a single human answer and a single ChatGPT answer — yielding 47,734 paired examples across six domain splits (T able 1). F ollo wing exact-duplicate remo v al on the question field, the corpus w as reduced to 23,363 unique records. T able 1. Domain distribution of the HC3 corpus after flattening and deduplication. Domain Unique Pairs reddit eli5 16,153 finance 3,933 medicine 1,248 open qa 1,187 wiki csai 842 T otal 23,363 3.2 ELI5 Dataset and Mistral-7B Augmen tation The ELI5 dataset [F an et al., 2019] w as loaded from sentence-transformers/eli5 via the Hugging F ace hub. It is a human-only question-answering corpus sourced from the Reddit comm unit y r/explainlikeimfive , containing 325,475 training samples with plain-language explanations of complex topics. No llm -generated answers exist in the raw ELI5 data. T o create a balanced h uman– llm paired corpus, w e used Mistral-7B-Instruct-v0.2 to generate AI answ ers for a random sample of 15,000 ELI5 questions. The generation pipeline was optimized for throughput on an NVIDIA A100 GPU (T able 2). 5 Preprin t — arXiv Detecting the Machine T able 2. Mistral-7B generation configuration for ELI5 augmentation. P arameter V alue Mo del mistralai/Mistral-7B-Instruct-v0.2 Precision FP16 (no quantization) A ttention Flash Atten tion 2 Compilation torch.compile (reduce-ov erhead) Batc h size 48 Max new tokens 150 T emp erature 0.7 T op- p 0.9 Eac h question w as formatted using Mistral’s [INST] instruction template and fed through the mo del in batc hes. Generated tokens were decoded with the prompt stripp ed, yielding clean answer strings. 3.3 Binary Dataset Preparation and Length Matching AI-generated text detection is form ulated as a binary classification problem. Rather than treating eac h question–answer pair as a unit, ev ery individual answer is treated as an indep endent text sample lab eled either human (0) or l lm (1). This decoupling reflects the actual deploymen t setting, where detectors receiv e isolated text snipp ets with no access to the corresp onding question. This con version yielded p erfectly balanced binary corp ora: • HC3 binary : 46,726 samples (23,363 human + 23,363 llm ) • ELI5 binary : 30,000 samples (15,000 human + 15,000 llm ) A critical length-matc hing step was applied before splitting. It is well-documented that llm - generated answers are systematically longer than human answ ers [Ipp olito et al., 2020]; without correction, a classifier can ac hieve high accuracy by learning resp onse length — a spurious, non- linguistic shortcut that collapses under any length-normalized adv ersarial condition. Eac h h uman answ er was therefore matched with an llm answer falling within ± 20% of its w ord coun t, ensuring statistically comparable length distributions across classes. Stratified 80/20 train/test splits were then constructed, preserving exact class balance (T able 3). T able 3. T rain/test split sizes after length matc hing and stratification. Dataset T rain T est HC3 36,968 (18,484 p er class) 9,242 ELI5 22,862 (11,431 p er class) 5,716 The t wo datasets are kept separate throughout all ev aluations: HC3 represents a formal, m ulti- domain corpus with ChatGPT as the llm source, while ELI5 represen ts a con versational, single- domain corpus with Mistral-7B as the source. This separation enables cross-dataset generalization analysis. 4 Detector F amilies: Arc hitecture and Implemen tation All detectors output a contin uous detectability score in [0 , 1] representing the probabilit y that a giv en text is llm -generated. Each sup ervised family is trained and ev aluated under four conditions: in-distribution (same dataset for train and test) and cross-distribution (train on one dataset, test on the other), pro ducing a 2 × 2 ev aluation grid p er detector. Unsup ervised and zero-parameter families are ev aluated on b oth test sets without training. 6 Preprin t — arXiv Detecting the Machine 4.1 Statistical / Classical Detectors This family op erates en tirely on hand-crafted linguistic features with no learned represen tations. The feature extractor computes 22 in terpretable signals organized into seven categories: (i) Surface statistics : w ord count, character count, sentence coun t, av erage word length, a verage sen tence length. (ii) Lexical diversit y : type-token ratio, hapax legomena ratio. (iii) Punctuation and formatting : comma densit y , p erio d density , question mark ratio, excla- mation ratio. (iv) Rep etition metrics : bigram rep etition rate, trigram rep etition rate. (v) En trop y measures : Shannon en tropy ov er w ord-frequency distribution, sentence-length en tropy . (vi) Syntactic complexity : sen tence-length v ariance and standard deviation. (vii) Discourse markers : hedging-word density , certaint y-w ord densit y , connector-w ord densit y , con traction ratio, burstiness. Three classifiers are trained on this feature v ector: Logistic Regression (L2 p enalty , interpretable linear baseline); Random F orest (100 trees, max depth 10, bo otstrap sampling); and SVM with RBF Kernel (Platt-scaled probabilities). 4.2 Fine-T uned Enco der T ransformers All transformer mo dels share a common fine-tuning proto col: the pre-trained enco der is loaded with a t w o-class classification head app ended to the [CLS] tok en representation, then fine-tuned end-to-end for one ep o ch on binary human/ llm lab els. T raining uses AdamW ( lr = 2 × 10 − 5 , w eigh t deca y = 0 . 01), linear w armup ov er 6% of training steps, drop out increased to 0.2, a 10% held-out v alidation split for early stopping (patience = 3), and aur oc as the mo del-selection criterion. Mixed precision (FP16) is used throughout. Batc h size is 32 (train) and 64 (ev al). The detectability score is the softmax probabilit y assigned to the llm class. 4.2.1 BER T ( bert-base-uncased ) BER T [Devlin et al., 2019] uses bidirectional masked language mo deling pre-training, pro cessing full tok en sequences with atten tion ov er b oth left and right con text. The base v ariant has 12 transformer la yers, 12 attention heads, hidden size 768, in termediate size 3,072, and ≈ 110M parameters. T ok enization uses W ordPiece with a 30,522-token vocabulary; sequences are truncated to 512 tok ens. 4.2.2 R oBER T a ( roberta-base ) RoBER T a [Liu et al., 2019] improv es up on BER T by remo ving the next-sen tence prediction ob jective, training on 10 × more data with larger batches, using dynamic masking, and employing a Byte- P air Enco ding tokenizer (50,265-token vocabulary). It shares the same 12-lay er, 768-hidden, 125M parameter arc hitecture but b enefits from more robust pre-training. 4.2.3 ELECTRA ( google/electra-base-discriminator ) ELECTRA [Clark et al., 2020] replaces mask ed language mo deling with a replaced-token detection ob jective: a small generator corrupts tokens and the discriminator is trained to identify which tokens w ere replaced. This produces more sample-efficien t pre-training, as ev ery token p osition contributes a training signal (vs. ≈ 15% in BER T). ELECTRA’s token-lev el discriminativ e pre-training makes it particularly sensitiv e to lo cal stylistic anomalies common in llm outputs. 7 Preprin t — arXiv Detecting the Machine 4.2.4 DistilBER T ( distilbert-base-uncased ) DistilBER T [Sanh et al., 2019] is a knowledge-distilled compression of BER T, retaining 97% of BER T’s language understanding at 60% of its parameter count ( ≈ 66M parameters, 6 lay ers). Distillation uses a soft-lab el cross-en tropy loss against the teacher BER T’s output distribution, combined with cosine em b edding alignmen t. DistilBER T is particularly attractiv e for deplo ymen t-scale detection systems due to its significan tly reduced inference latency . 4.2.5 DeBER T a-v3 ( microsoft/deberta-v3-base ) DeBER T a-v3 [He et al., 2021] in tro duces t wo arc hitectural adv ances o ver RoBER T a. First, disen- tangle d attention : each tok en is represented b y tw o separate vectors — one for conten t and one for relativ e p osition — with atten tion w eigh ts computed across all four con tent-position cross-interactions. Second, DeBER T a-v3 adopts ELECTRA-style replaced tok en detection for pre-training rather than mask ed language mo delling. The base mo del has approximately 184M parameters. Implemen tation. A critical consideration for DeBER T a-v3 is precision handling. The disentan- gled atten tion mec hanism produces gradient magnitudes that underflo w in BF16’s 7-bit mantissa, rendering mixed-precision training numerically unsafe for this architecture. T raining is therefore conducted in full FP32 throughout ( fp16=False , bf16=False , with an explicit model.float() cast at initialization). Checkpoint reloading is disabled entirely ( save strategy="no" , load best - model at end=False ), and final in-memory weigh ts are used directly for prediction — this av oids the La y erNorm parameter naming inconsistency b et w een sa v ed and reloaded chec kp oints that is a kno wn fragilit y of DeBER T a-v3 under the HuggingF ace T rainer. Explicit gradient clipping ( max grad - norm=1.0 ) is applied for training stabilit y . token type ids are in tentionally omitted, as DeBER T a-v3 do es not use segment IDs. DeBER T a-v3 uses AdamW ( lr = 2 × 10 − 5 , w eight deca y= 0 . 01), 500 w armup steps (fixed, not ratio-based), 1 ep o ch, batc h size 16. 4.3 Shallo w 1D-CNN Detector The 1D-CNN detector is a light w eight neural mo del targeting lo cal n -gram patterns rather than global sequence con text, following the architecture of Kim [2014]. It follows the arc hitecture: Em b edding → Parallel 1D-Conv → Global Max P o ol → Dense Head → σ A shared em b edding lay er (v o cab size 30,000, dim 128) pro jects token IDs in to dense vectors. F our parallel con volutional branches with kernel sizes { 2 , 3 , 4 , 5 } eac h pro duce 128 feature maps (Batc hNorm + ReLU). Global max p o oling extracts the most salient activ ation p er filter, pro ducing a 512-dimensional concatenated feature vector. A tw o-lay er dense head (512 → 256 → 1) with drop out (0.4) and sigmoid output pro duces the detectability score. T exts are truncated to 256 tok ens (shorter than the transformer maxim um of 512, as lo cal n -gram patterns are captured in shorter windo ws). T otal parameter coun t is under 5M — in tentionally constrained to prob e whether shallow learned representations can bridge the gap b etw een handcrafted features and full transformer fine-tuning. T raining uses Adam ( lr = 10 − 3 ), ReduceLROnPlateau sc heduling (factor 0.5, patience 1), gradient clipping (norm 1.0), and early stopping (patience = 3) o ver up to 10 ep o chs. 4.4 St ylometric and Statistical Hybrid Detector This family substan tially extends the classical feature set from 22 to 60+ features across eight categories, adding: • AI phrase density : frequency of structurally AI-c haracteristic phrases ( e.g. , “it is w orth noting”, “in summary”, “to summarize”). • F unction word frequency profiles : ov erall function word ratio plus p er-word frequency for the 10 most common function w ords. 8 Preprin t — arXiv Detecting the Machine • Punctuation entrop y : Shannon en tropy o ver the punctuation character distribution — llm text tends to ward low er entrop y (more uniform punctuation). • Readabilit y indices : Flesc h Reading Ease, Flesch-Kincaid Grade, Gunning F og, SMOG Index, ARI, Coleman-Liau Index. • POS tag distribution (spaCy): normalized frequency of 10 POS categories. • Dep endency tree depth : mean and maxim um parse-tree depth across sentences. • Sen tence-lev el p erplexity (GPT-2 Small): mean, v ariance, standard deviation, and co efficient of v ariation (CV) of p er-sen tence p erplexity . The CV is particularly diagnostic: llm text exhibits uniformly low p erplexit y (low CV), while human text v aries considerably across sentences (high CV). Three classifiers are trained: Logistic Regression (L2, lbfgs solv er), Random F orest (300 trees, max depth 12), and X GBo ost [Chen and Guestrin, 2016] (400 estimators, learning rate 0.05, depth 6, subsample 0.8). All features are standardized via StandardScaler . 4.5 P erplexit y-Based Detectors P erplexit y-based detection is an unsup ervised, training-free approac h that exploits the distributional o verlap b etw een autoregressive reference mo dels and llm -generated text. Because GPT-2 and GPT-Neo family mo dels share training corpus o v erlap with mo dern llm generators, they assign systematically lower p erplexit y to llm -generated text than to human-written text. The detectabilit y score is therefore an in v ersion of the ra w p erplexity signal. Fiv e reference mo dels are ev aluated: GPT-2 Small (117M), GPT-2 Medium (345M), GPT-2 XL (1.5B), GPT-Neo-125M, and GPT-Neo- 1.3B. F ull implemen tation details and the sliding-window strategy for long texts are describ ed in Section 7. 4.6 LLM-as-Detector The llm -as-detector paradigm treats generativ e language mo dels as zero-parameter classifiers, deriving detectabilit y scores from constrained deco ding logits (for lo cal mo dels) or structured rubric scores (for API models). Fiv e op en-source mo dels spanning 1.1B to 14B parameters are ev aluated (Tin yLlama-1.1B, Qwen2.5-1.5B, Qwen2.5-7B, LLaMA-3.1-8B, LLaMA-2-13B-Chat), along with GPT-4o-mini via the Op enAI API. F ull implemen tation details including prompt p olarity correction, task prior subtraction, and the h ybrid confidence-logit scoring scheme are describ ed in Section 6. 5 Exp erimen tal Results: Detector F amilies 5.1 Statistical / Classical Detectors T ables 4–6 rep ort results for Logistic Regression, Random F orest, and SVM with RBF kernel. T able 4. Logistic Regression results across ev aluation conditions. Condition auro c Brier Log Loss Mean Human Mean llm hc3 to hc3 0.8882 0.1334 0.4411 0.2838 0.7319 hc3 to eli5 0.7406 0.2116 0.6474 0.4246 0.6508 eli5 to eli5 0.8446 0.1605 0.4909 0.3251 0.6760 eli5 to hc3 0.7429 0.2496 0.9063 0.2006 0.4580 9 Preprin t — arXiv Detecting the Machine T able 5. Random F orest results across ev aluation conditions. Condition auro c Brier Log Loss Mean Human Mean llm hc3 to hc3 0.9767 0.0679 0.2438 0.1889 0.8173 hc3 to eli5 0.7829 0.1922 0.5815 0.3830 0.6086 eli5 to eli5 0.9618 0.0869 0.3014 0.2348 0.7811 eli5 to hc3 0.6337 0.3193 1.1636 0.1643 0.2903 T able 6. SVM (RBF Kernel) results across ev aluation conditions. Condition auro c Brier Log Loss Mean Human Mean llm hc3 to hc3 0.7993 0.1835 0.5486 0.3700 0.6318 hc3 to eli5 0.6933 0.2348 0.6639 0.5196 0.6686 eli5 to eli5 0.7924 0.1857 0.5512 0.3740 0.6287 eli5 to hc3 0.5992 0.3169 1.5852 0.2083 0.3191 Figure 2. Calibration curv es for classical detectors across four ev aluation settings. P oints close to the diagonal indicate well-calibrated confidence scores, while systematic deviations reflect ov er- or under-confidence. Key Observ ation. Random F orest achiev es the strongest in-distribution p erformance ( auroc = 0 . 977 on HC3 ) among classical detectors but suffers the largest cross-domain degradation (eli5 - to hc3: 0 . 634), suggesting it ov erfits to dataset-sp ecific surface statistics rather than generalizable linguistic signals. 5.2 Fine-T uned Enco der T ransformers T ables 7–11 rep ort full results for each fine-tuned enco der. 10 Preprin t — arXiv Detecting the Machine T able 7. BER T ( bert-base-uncased ) results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9947 0.9041 0.0906 0.5747 0.1927 0.9999 0.8071 hc3 to eli5 0.9489 0.8396 0.1472 0.8720 0.2319 0.9147 0.6828 eli5 to eli5 0.9943 0.9388 0.0572 0.3315 0.1245 0.9996 0.8751 eli5 to hc3 0.9083 0.8548 0.1393 0.8719 0.2100 0.9170 0.7070 T able 8. RoBER T a ( roberta-base ) results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9994 0.9679 0.0303 0.2204 0.0642 1.0000 0.9357 hc3 to eli5 0.9741 0.7967 0.1926 1.4401 0.4054 0.9991 0.5937 eli5 to eli5 0.9998 0.9645 0.0331 0.2264 0.0711 0.9999 0.9289 eli5 to hc3 0.9657 0.9045 0.0932 0.7082 0.1129 0.9214 0.8085 T able 9. ELECTRA ( google/electra-base-discriminator ) results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9972 0.8639 0.1298 0.8663 0.2731 0.9996 0.7265 hc3 to eli5 0.9597 0.8492 0.1450 0.9868 0.2770 0.9725 0.6955 eli5 to eli5 0.9975 0.9605 0.0359 0.1804 0.0821 0.9986 0.9166 eli5 to hc3 0.9318 0.8790 0.1161 0.6408 0.1630 0.9140 0.7511 T able 10. DistilBER T ( distilbert-base-uncased ) results. Condition auro c Acc. Brier Log Loss Hum. llm hc3 to hc3 0.9968 0.9502 0.0460 0.2698 0.0999 0.9997 hc3 to eli5 0.9578 0.8835 0.1088 0.6235 0.1250 0.8907 eli5 to eli5 0.9983 0.9692 0.0288 0.1503 0.0647 0.9993 eli5 to hc3 0.9309 0.8702 0.1229 0.7205 0.1397 0.8768 T able 11. DeBER T a-v3 ( microsoft/deberta-v3-base ) results. Condition auro c Acc. Brier Log Loss Hum. llm hc3 to hc3 0.9913 0.8888 0.1100 0.9803 0.2225 0.9991 hc3 to eli5 0.8762 0.5728 0.4245 4.0517 0.8532 0.9997 eli5 to eli5 0.9530 0.7794 0.2089 1.2387 0.4377 0.9998 eli5 to hc3 0.8890 0.7749 0.2148 1.3764 0.4147 0.9662 11 Preprin t — arXiv Detecting the Machine (a) Detectabilit y score distributions. (b) Calibration curv es. (c) R OC curves. Figure 3. P erformance analysis of DistilBER T across four ev aluation conditions. T op: score distributions indicating class separability . Middle: reliabilit y diagrams assessing calibration. Bottom: ROC curv es illustrating discrimination p erformance. DistilBER T ac hieves near-transformer p erformance at approximately 60% of BER T’s parameter count. 5.3 Shallo w 1D-CNN Detector T able 12 rep orts 1D-CNN results. Figure 4 sho ws training curv es and score distributions; Figure 5 sho ws the degradation curve under progressive humanization. T able 12. 1D-CNN results across ev aluation conditions. Condition auro c Acc. Brier Log Loss Hum. llm hc3 to hc3 0.9995 0.9916 0.0067 0.0262 0.0093 0.9862 hc3 to eli5 0.8303 0.7124 0.2446 1.0887 0.1192 0.5275 eli5 to eli5 0.9982 0.9748 0.0191 0.0666 0.0477 0.9844 eli5 to hc3 0.8432 0.6866 0.2752 1.4723 0.0730 0.4455 12 Preprin t — arXiv Detecting the Machine (a) T raining loss and v alidation AUC across ep o chs. (b) Detectabilit y score distributions across ev aluation conditions. Figure 4. T raining dynamics and detectabilit y b ehavior of the 1D-CNN detector. T op: rapid con v ergence to high v alidation A UC on b oth datasets. Bottom: score distributions indicating strong separabilit y b etw een h uman and llm text. Figure 5. 1D-CNN degradation curve under progressive text humanization. The x -axis represents the fraction of human tokens mixed into otherwise llm -generated text. The steep, smo oth decline confirms that the 1D-CNN is highly sensitive to ev en small amounts of human-st yle n -gram patterns. Key Observ ation. The 1D-CNN ac hieves near-p erfect in-distribution aur oc (0 . 9995 on HC3 ) — comp etitiv e with full transformers — while ha ving 20 × few er parameters. Cross-domain p erformance drops to 0 . 83–0 . 84, indicating that learned n -gram patterns are domain-sp ecific but still substan tially more transferable than pure classical features. 13 Preprin t — arXiv Detecting the Machine 5.4 St ylometric and Statistical Hybrid Detector T ables 13–15 report results for all three classifiers trained on the extended st ylometric feature set. Figure 6 sho ws the aur oc heatmap across classifiers and ev aluation conditions, and T able 13. St ylometric Hybrid — Logistic Regression results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9721 0.9243 0.0580 0.2093 0.1273 0.8753 0.7480 hc3 to eli5 0.6731 0.6296 0.2539 0.8110 0.3668 0.5502 0.1834 eli5 to eli5 0.9448 0.8807 0.0897 0.3003 0.1823 0.8166 0.6343 eli5 to hc3 0.7348 0.6650 0.2669 1.2185 0.2006 0.4941 0.2935 T able 14. St ylometric Hybrid — Random F orest results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9981 0.9785 0.0189 0.0854 0.0731 0.9362 0.8631 hc3 to eli5 0.8557 0.7516 0.1768 0.5586 0.1699 0.5628 0.3929 eli5 to eli5 0.9934 0.9605 0.0395 0.1626 0.1371 0.8759 0.7388 eli5 to hc3 0.8848 0.6589 0.2100 0.6123 0.1164 0.4363 0.3199 T able 15. St ylometric Hybrid — X GBo ost results. Condition auro c Acc. Brier Log Loss Hum. llm Sep. hc3 to hc3 0.9996 0.9928 0.0059 0.0226 0.0179 0.9912 0.9733 hc3 to eli5 0.8633 0.7252 0.2270 0.9451 0.0673 0.5033 0.4361 eli5 to eli5 0.9971 0.9732 0.0197 0.0714 0.0529 0.9620 0.9091 eli5 to hc3 0.9037 0.7275 0.2281 0.9624 0.0439 0.4808 0.4369 Figure 6. Stylometric h ybrid aur oc heatmap. Rows corresp ond to classifiers (Logistic Regression, Random F orest, XGBoost), while columns represen t the four ev aluation conditions (eli5-to-eli5, eli5-to-hc3, hc3-to-eli5, hc3-to-hc3). Cell colors range from red (0.5) to dark green (1.0). XGBoost dominates across all conditions; the cross-domain eli5-to-hc3 aur oc of 0 . 904 represents a substantial improv emen t ov er the classical Stage 1 Random F orest (0 . 634). Key Observ ation. XGBoost on the full st ylometric feature set achiev es aur oc = 0 . 9996 in- distribution — on par with fine-tuned transformers — while remaining fully interpretable. The extended feature set (particularly sen tence-level p erplexity CV, connector densit y , and AI-phrase densit y) substan tially impro ves cross-domain p erformance ov er the classical Stage 1 feature set alone, with X GBo ost eli5 to hc3 reaching 0 . 904 versus Random F orest’s 0 . 634 in the classical setting. 14 Preprin t — arXiv Detecting the Machine 5.5 Stage 1 Key Conclusions 1. Fine-tuned enco der transformers dominate all other families. RoBER T a ac hieves the highest in-distribution aur oc (0 . 9994 on HC3 ), confirming that task-sp ecific fine-tuning on paired h uman/ llm data is the most effective detection strategy . 2. Cross-domain degradation is univ ersal and substantial. Every detector family suffers a uroc drops of 5–30 p oints when trained on one dataset and tested on the other, indicating that no curren t detector generalizes robustly across llm sources and domains. 3. The 1D-CNN ac hieves near-transformer in-distribution p erformance with 20 × few er parameters. Its cross-domain p erformance (0 . 83–0 . 84) reveals that learned n -gram patterns are dataset-sp ecific rather than univ ersally generalizable. 4. DeBER T a-v3 is comp etitive in-distribution but severely miscalibrated cross-domain. F ollo wing FP32 precision correction, it reac hes a uroc 0 . 991 ( HC3 ) and 0 . 953 ( ELI5 ) in- distribution. Cross-domain transfer exp oses a critical failure: hc3 to eli5 accuracy collapses to 0 . 573 (log loss 4 . 052) despite aur oc 0 . 876, indicating well-ordered but p o orly calibrated scores — consisten t with ov erfitting to HC3 ’s formal register. 5. The XGBoost stylometric h ybrid matc hes transformer in-distribution p erformance while remaining fully in terpretable. Sen tence-level p erplexity CV, connector density , and AI-phrase densit y are the most discriminative features. 6. Length matching w as critical. Without the ± 20% length normalization, classical detectors w ould hav e trivially exploited the well-kno wn length disparity b et w een human and llm answ ers, inflating rep orted p erformance. 6 LLM-as-Detector and Con trastiv e Lik eliho o d Detection This section ev aluates generative llm s as zero-parameter AI-text detectors across six mo del scales — from sub-2B to a fron tier API mo del — under three prompting regimes. The pip eline incorp orates calibrated threshold analysis alongside fixed-threshold ev aluation, and a hybrid confidence-logit scoring sc heme for Chain-of-Thought outputs. 6.1 Prompting P aradigms Zero-Shot prompting presents only a system instruction and target text. Detection scores are deriv ed via constrained deco ding: the next-token log-probability distribution is read at the final prompt p osition, and a soft [0 , 1] detectability score is computed from the softmax of log P ( llm ) v ersus log P ( human ), yielding a con tinuous score without generation. F ew-Shot prompting augments the zero-shot prompt with k lab eled examples dra wn from the training p o ol ( k = 3 for sub-2B mo dels; k = 5 otherwise), with TF-IDF based seman tic retriev al used for larger mo dels to select maximally informative demonstrations. Chain-of-Though t (CoT) prompting instructs the mo del to reason across structured linguistic dimensions b efore delivering a final VERDICT . CoT scoring emplo ys a hybrid confidence-logit sc heme: when the mo del pro duces a parseable numerical confidence estimate alongside its verdict, this is com bined with the logit-derived soft score at the verdict token p osition using equal weigh ting; otherwise, the logit-only score is used. CoT is restricted to mo dels with sufficien t instruction- follo wing capacity; sub-2B mo dels are excluded. Three threshold strategies are rep orted: fixed at 0.5 ( acc@0.5 ), calibrated at the score median ( acc@median ), and optimal Y ouden-J ( acc@optimal ). 6.2 Tin y-Scale Mo dels: Tin yLlama-1.1B-Chat-v1.0and Qw en2.5-1.5B Both mo dels are ev aluated under zero-shot and few-shot regimes on 500 balanced samples p er dataset, loaded in FP16 with device map="auto" . 15 Preprin t — arXiv Detecting the Machine T able 16. Tiny-scale llm -as-detector results. Mo del Regime Dataset auro c acc@0.5 acc@median acc@optimal Tin yLlama-1.1B-Chat-v1.0 Zero-Shot HC3 0.5653 0.558 0.534 0.558 Tin yLlama-1.1B-Chat-v1.0 Zero-Shot ELI5 0.5072 0.524 0.510 0.524 Tin yLlama-1.1B-Chat-v1.0 F ew-Shot HC3 0.6198 0.614 0.600 0.614 Tin yLlama-1.1B-Chat-v1.0 F ew-Shot ELI5 0.5860 0.580 0.566 0.580 Qw en2.5-1.5B-Instruct Zero-Shot HC3 0.5221 0.436 0.530 0.574 Qw en2.5-1.5B-Instruct Zero-Shot ELI5 0.5205 0.470 0.512 0.562 Qw en2.5-1.5B-Instruct F ew-Shot HC3 0.4794 0.450 0.518 0.536 Qw en2.5-1.5B-Instruct F ew-Shot ELI5 0.6340 0.484 0.620 0.620 Both mo dels p erform near c hance across all conditions ( aur oc 0.48–0.63), confirming that detection as a meta-cognitive task do es not emerge at sub-2B scale. The threshold analysis surfaces a qualitatively imp ortant finding: Qwen2.5-1.5B-Instructzero-shot scores cluster systematically ab o ve 0.5 (median ≈ 0.75–0.80), y et aur oc remains near c hance — a sc or e-c ol lapsing pattern in whic h the mo del emits uniformly high detectabilit y scores regardless of lab el, yielding po or rank ordering rather than a polarity inv ersion. TinyLlama’s few-shot median score shifts from ≈ 0 . 26 (zero-shot) to ≈ 0 . 69 (few-shot), reflecting a format-induced distributional shift rather than improv ed class discrimination. 6.3 Mid-Scale Mo dels:Llama-3.1-8B-Instruct and Qw en2.5-7B Both 8B mo dels are ev aluated under all three regimes. Zero-shot and few-shot use constrained deco ding on 500 samples; CoT uses full autoregressive generation (max 400 tok ens, greedy deco ding) on 70 samples. T able 17. Mid-scale llm -as-detector results. FP/FN denote false positive/negativ e counts. Mo del Regime Dataset auro c acc@0.5 acc@optimal FP FN Llama-3.1-8B-Instruct Zero-Shot HC3 0.7295 0.680 0.680 48 120 Llama-3.1-8B-Instruct Zero-Shot ELI5 0.7508 0.670 0.702 106 57 Llama-3.1-8B-Instruct F ew-Shot HC3 0.5027 0.546 0.550 53 172 Llama-3.1-8B-Instruct F ew-Shot ELI5 0.5961 0.574 0.578 77 140 Llama-3.1-8B-Instruct CoT HC3 0.6771 0.629 0.657 11 18 Llama-3.1-8B-Instruct CoT ELI5 0.5988 0.586 0.600 15 13 Qw en2.5-7B-Instruct Zero-Shot HC3 0.6902 0.656 0.666 70 102 Qw en2.5-7B-Instruct Zero-Shot ELI5 0.6638 0.620 0.632 60 130 Qw en2.5-7B-Instruct F ew-Shot HC3 0.4579 0.484 0.502 132 126 Qw en2.5-7B-Instruct F ew-Shot ELI5 0.5042 0.524 0.542 125 113 Qw en2.5-7B-Instruct CoT HC3 0.6388 0.514 0.657 31 2 Qw en2.5-7B-Instruct CoT ELI5 0.7808 0.614 0.743 20 3 Llama-3.1-8B-Instructac hieves comp etitive zero-shot aur oc of 0.730–0.751, demonstrating that gen uine detection signal emerges at 8B scale without in-con text examples. How ever, few-shot prompting mark edly degrades p erformance ( a uroc 0.503–0.596). Qw en2.5-7B CoT on ELI5 ac hieves 0.781, the highest among mid-scale mo dels. 6.4 Large-Scale Mo dels: LLaMA-2-13B-Chat Pip eline Design Llama-2-13b-c hat-hf is ev aluated under all three regimes, loaded with 4-bit NF4 quantization (double quan tization, FP16 compute dtype). Zero-shot and few-shot use 200 samples p er dataset; CoT uses 30 samples with full generation (max 400 tok ens, greedy deco ding). 16 Preprin t — arXiv Detecting the Machine T ok en-level debug analysis revealed that Llama-2-13b-chat-hfexhibits a strong unconditional “no” bias. Rather than inv erting this p ost-ho c, the pip eline resolves it structurally via prompt p olarit y sw apping : the mo del is asked “W as this text written by a human?” with yes = h uman and no = AI-generated . Additionally , a task-sp ecific prior is computed b y av eraging yes/no logits o ver 50 real task prompts dra wn from the ev aluation p o ol; subtracting this prior remov es task-level marginal bias while preserving sample-discriminativ e signal. The CoT prompt frames the task as a stylometric analysis — av oiding the term “AI detection” to circum v ent LLaMA-2’s safety-orien ted refusal behaviors. The mo del scores sev en linguistic dimensions on a 0–10 scale. The h ybrid confidence-logit ensem ble weigh ts confirmed confidence and logit scores at 0.6/0.4 when confidence falls outside the dead zone [0 . 40 , 0 . 60]; otherwise the logit score is used alone. T able 18. Llama-2-13b-chat-hfdetection results ( n = 200 zero/few-shot; n = 30 CoT ). Regime Dataset auroc acc@0.5 acc@median acc@optimal FP FN Zero-Shot HC3 0.8124 0.715 0.710 0.760 21 36 Zero-Shot ELI5 0.8098 0.750 0.755 0.760 28 22 F ew-Shot HC3 0.6678 0.635 0.630 0.660 28 45 F ew-Shot ELI5 0.6374 0.590 0.620 0.620 38 44 CoT HC3 0.8778 0.833 0.867 0.867 2 4 CoT ELI5 0.8978 0.733 0.800 0.867 2 3 The corrected pipeline yields substantially improv ed results relative to the original implemen tation ( aur oc 0.363–0.705 attributable to p olarity and prior misconfiguration). Zero-shot aur oc of 0.810– 0.812 is consistent across b oth datasets, and CoT p eaks at 0.878 and 0.898 on HC3 and ELI5 resp ectiv ely — the strongest CoT results among all op en-source mo dels. 6.5 Large-Scale Mo dels: Qw en2.5-14B-Instruct Pip eline Design Qw en2.5-14B-Instruct is ev aluated under all three regimes using the same swapped polarity conv ention, loaded with 4-bit NF4 quantization and BFloat16 compute dtype. The original implemen tation suffered from 86.7–90.0% unknown rates due to t wo failure modes: premature generation termination when eos token id w as used as pad token id , and an insufficient max new tokens=350 budget. The corrected pip eline sets pad token id explicitly and increases max new tokens to 500. T ask framing adopts “forensic linguist performing authorship attribution analysis” to minimize safet y-motiv ated refusals. T able 19. Qwen2.5-14B-Instruct detection results ( n = 200 zero/few-shot; n = 30 CoT ). Regime Dataset auro c acc@0.5 acc@median acc@optimal FP FN Zero-Shot HC3 0.6686 0.680 0.660 0.680 31 33 Zero-Shot ELI5 0.7294 0.690 0.655 0.695 41 21 F ew-Shot HC3 0.3153 0.385 0.390 0.500 52 71 F ew-Shot ELI5 0.4262 0.470 0.465 0.500 59 47 CoT HC3 0.6622 0.700 0.667 0.733 4 4 CoT ELI5 0.8000 0.733 0.667 0.767 4 3 6.6 GPT-4o-mini as Detector GPT-4o-mini is ev aluated via the Op enAI API using a structured 7-dimension rubric scoring proto col across three regimes. Unlike lo cal mo dels — where constrained logit deco ding is used — GPT- 17 Preprin t — arXiv Detecting the Machine T able 20. Qwen2.5-14B-Instruct CoT comp onent analysis: hybrid vs. logit-only scoring. Dataset Score Type n auroc Accuracy % of T otal HC3 conf+logit 11 0.6250 0.727 36.7% HC3 logit only 19 0.6429 0.684 63.3% ELI5 conf+logit 15 0.8519 0.800 50.0% ELI5 logit only 15 0.7593 0.667 50.0% 4o-mini emplo ys a rubric-based elicitation strategy that forces the mo del to commit to sev en indep enden t dimension scores (hedging/form ulaic language, resp onse completeness, p ersonal v oice, lexical uniformity , structural neatnes s, resp onse fit, formulaic tells) b efore pro ducing a final AI SCORE ∈ [0 , 100]. This design circum ven ts the known rlhf -induced suppression of numeric probability outputs. A full five-metric ev aluation suite is applied with 1,000-iteration b o otstrap confidence in terv als ( n = 200 for zero-shot/few-shot; n = 50 for CoT ). T able 21. GPT-4o-mini ( llm -as-detector) results. All score directions v erified correct. Mo del Regime Data auro c Acc.@0.5 Acc.@Opt. Sep. GPT-4o-mini ZS HC3 0.8470 0.7600 0.7900 +0.311 GPT-4o-mini ZS ELI5 0.9093 0.8800 0.8800 +0.419 GPT-4o-mini FS HC3 0.7163 0.7000 0.7000 +0.187 GPT-4o-mini FS ELI5 0.7824 0.6800 0.7400 +0.246 GPT-4o-mini CoT HC3 0.8056 0.7800 0.8000 +0.279 GPT-4o-mini CoT ELI5 0.7744 0.7600 0.8000 +0.261 Finding 1: Structured rubric prompting outp erforms constrained deco ding. GPT-4o- mini ac hiev es the highest zero-shot a uroc of all five mo dels ev aluated (0 . 8470 vs. 0 . 8124 on HC3 ; 0 . 9093 vs. 0 . 8098 on ELI5 relativ e to LLaMA-2-13B). T able 22. Zero-shot to few-shot auroc degradation on HC3 . Mo del ZS auro c FS auro c ∆ Qw en2.5-14B-Instruct 0.6686 0.3153 − 0 . 353 Qw en2.5-7B-Instruct 0.6902 0.4579 − 0 . 232 Llama-3.1-8B-Instruct 0.7295 0.5027 − 0 . 227 Llama-2-13b-c hat-hf 0.8124 0.6678 − 0 . 145 GPT-4o-mini 0.8470 0.7163 − 0 . 131 Finding 2: GPT-4o-mini degrades least under few-shot prompting. Finding 3: CoT underperforms zero-shot for GPT-4o-mini. aur oc drops from 0 . 8470 to 0 . 8056 on HC3 (∆ = − 0 . 041) and from 0 . 9093 to 0 . 7744 on ELI5 (∆ = − 0 . 135). Adding p er-dimension reasoning to an already-explicit rubric introduces noise rather than precision. Finding 4: ELI5 i s easier than HC3 under zero-shot. GPT-4o-mini achiev es aur oc 0 . 9093 on ELI5 versus 0 . 8470 on HC3 (∆ = +0 . 062). ELI5 ’s Mistral-7B-generated text carries stronger st ylistic markers than HC3 ’s ChatGPT-3.5 text. Stage 1b Conclusions Detection capabilit y scales non-monotonically with parameter coun t. Sub-2B mo dels p erform near random ( aur oc 0.48–0.63); meaningful discrimination first app ears at 8B and consoli- dates at 13B (Llama-2-13b-chat-hf zero-shot: 0.810–0.812). Qwen2.5-14B zero-shot (0.669–0.729) 18 Preprin t — arXiv Detecting the Machine underp erforms Llama-2-13b-c hat-hf at the same regime, indicating that RLHF alignmen t strategy and prompt p olarity interact with scale in wa ys that confound simple parameter-coun t comparisons. Prompt p olarit y correction and task prior subtraction are necessary conditions for v alid constrained deco ding. Naive constrained deco ding without prior correction pro duces systematically in verted or near-random scores due to RLHF-induced unconditional resp onse biases. CoT prompting provides the largest and most consistent gains, contingen t on correct implemen tation. Llama-2-13b-chat-hf CoT p eaks at a uroc 0.878–0.898, Qwen2.5-7B-Instruct CoT reac hes 0.781 on ELI5 . CoT gains are contingen t on sufficien t generation budget, correct pad - token id handling, safety-neutral prompt framing, and a robust m ulti-fallbac k verdict parser. F ew-shot prompting is consisten tly harmful across all mo del scales. F ew-shot degrades aur oc relative to zero-shot:Llama-3.1-8B-Instruct (0.503–0.596 vs. 0.730– 0.751), Llama-2-13b-c hat-hf (0.637–0.668 vs. 0.810–0.812), Qw en2.5-14B-Instruct(0.315–0.426), and GPT-4o-mini on HC3 (0.7163 vs. 0.8470). The generator–detector iden tit y confound is critical. Mistral-7B-Instruct, used to generate the ELI5 llm answers, p erformed near or b elow random as a detector ( aur oc 0.363–0.540). A mo del cannot reliably detect its own outputs. No llm-as-detector configuration approaches sup ervised fine-tuned enco ders. The b est result — GPT-4o-mini zero-shot on ELI5 at aur oc 0 . 9093 — remains w ell b elow RoBER T a in-distribution ( aur oc 0 . 9994). 6.7 Con trastiv e Lik eliho o d Detection The con trastive score is defined as: S ( x ) = log P large ( x ) − log P small ( x ) (1) T able 23. Contrastiv e likelihoo d dete ction results. V ariant Dataset auro c Score Sep. base contrast HC3 0.5007 0.0007 base contrast ELI5 0.6873 0.1873 multi scale HC3 0.5007 0.0007 multi scale ELI5 0.6873 0.1873 token variance HC3 0.6323 0.1323 token variance ELI5 0.5644 0.0644 hybrid HC3 0.5999 0.0446 hybrid ELI5 0.7615 0.1463 The h ybrid score achiev es aur oc of 0.762 on ELI5 but near-random on HC3 (0.600 and b elo w). The p erformance gap is explained b y a r epr esentational affinity c onstr aint : GPT-2 and Mistral-7B share arc hitectural and pretraining characteristics, while ChatGPT (GPT-3.5) underw en t extensive RLHF alignmen t at a larger parameter scale. 7 P erplexit y-Based Detectors 7.1 Metho d P erplexity-based detection is unsup ervised and training-free. Because GPT-2 and GPT-Neo family mo dels assign systematically lower p erplexity to llm -generated text than to human-written text, the detectabilit y score is an in version of the ra w p erplexit y signal: PPL( x ) = exp − 1 T T X t =1 log P ( x t | x 1 , . . . , x t − 1 ) ! (2) Fiv e reference mo dels are ev aluated: GPT-2 Small (117M), GPT-2 Medium (345M), GPT-2 XL (1.5B), GPT-Neo-125M, and GPT-Neo-1.3B. All mo dels are run in FP16 on the full HC3 and 19 Preprin t — arXiv Detecting the Machine ELI5 test sets. A sliding windo w (512-tok en window, 256-token stride) handles long texts. Outlier p erplexities are clipp ed at 10,000 for rank stability . Ra w perplexities are con v erted to [0 , 1] detectability scores via four normalization metho ds: r ank-b ase d , lo g-r ank , minmax , and sigmoid . The b est metho d p er condition is selected by aur oc , with optimal decision thresholds iden tified via Y ouden’s J statistic. 7.2 Results T able 24. Perplexit y-based detector results. Metho d = b est normalization by aur oc . Mo del Data Metho d auro c Brier Acc@Opt Hum. llm Sep. GPT-2 Small HC3 rank 0.9099 0.1284 0.8805 0.2950 0.7050 0.4100 GPT-2 Small ELI5 rank 0.9073 0.1297 0.8378 0.2963 0.7037 0.4074 GPT-2 Medium HC3 rank 0.9047 0.1310 0.8804 0.2976 0.7024 0.4047 GPT-2 Medium ELI5 rank 0.9275 0.1196 0.8546 0.2862 0.7138 0.4276 GPT-2 XL HC3 rank 0.8917 0.1375 0.8609 0.3041 0.6959 0.3918 GPT-2 XL ELI5 rank 0.9314 0.1176 0.8660 0.2843 0.7157 0.4315 GPT-Neo-125M HC3 rank 0.9173 0.1247 0.8860 0.2913 0.7087 0.4173 GPT-Neo-125M ELI5 minmax 0.8968 0.4597 0.8177 0.9578 0.9857 0.0279 GPT-Neo-1.3B HC3 rank 0.8999 0.1334 0.8785 0.3000 0.7000 0.3999 GPT-Neo-1.3B ELI5 rank 0.9261 0.1203 0.8534 0.2869 0.7131 0.4261 T able 25. Cross-mo del median perplexity statistics. llm text exhibits p erplexity consistently 0 . 24–0 . 45 × that of human text. Mo del Data Hum. Med. llm Med. Ratio GPT-2 Small HC3 44.31 11.35 0.256 GPT-2 Small ELI5 40.43 17.99 0.445 GPT-2 Medium HC3 33.09 8.17 0.247 GPT-2 Medium ELI5 30.92 12.95 0.419 GPT-2 XL HC3 26.42 6.38 0.242 GPT-2 XL ELI5 25.08 10.02 0.400 GPT-Neo-125M HC3 46.52 11.20 0.241 GPT-Neo-125M ELI5 42.02 18.99 0.452 GPT-Neo-1.3B HC3 26.82 6.38 0.238 GPT-Neo-1.3B ELI5 25.45 10.48 0.412 P erplexity-based detection achiev es a uroc ranging from 0 . 891 to 0 . 931 across all well-behav ed conditions. Reference mo del scale has negligible impact: GPT-2 Small and GPT-2 XL achiev e nearly iden tical aur oc on HC3 (0 . 910 vs. 0 . 892). Rank-based normalization is selected as optimal in 9 of 10 conditions. 8 Cross-LLM Generalization Study 8.1 Exp erimental Design and Dataset Construction Stage 3 ev aluates whether detectors trained on ChatGPT-generated text ( HC3 ) generalize to outputs from unseen llm s. Five open-source mo dels serv e as unseen source llm s: Tin yLlama-1.1B, Qwen2.5- 1.5B, Qw en2.5-7B,Llama-3.1-8B-Instruct, and LLaMA-2-13B. Each generates 200 resp onses p er dataset, yielding 2,000 llm -generated samples p er dataset against h uman p o ols of 4,621 ( HC3 ) and 2,858 ( ELI5 ) texts. All detectors are ev aluated zero-shot — with no retraining on any unseen llm ’s outputs. 20 Preprin t — arXiv Detecting the Machine 8.2 Neural Detector Cross-LLM Ev aluation Setup. Five HC3 -trained transformer detectors — BER T, RoBER T a, ELECTRA, DistilBER T, and DeBER T a-v3-base — are ev aluated zero-shot against outputs from all fiv e unseen source llm s on b oth HC3 and ELI5 domains, using the fiv e-metric suite ( a uroc , aupr c , eer , Brier, FPR@95%TPR) with 1,000-iteration b o otstrap CIs. T able 26. Cross- llm generalization results for HC3 -trained neural detectors (selected conditions). Detector Source llm Dataset auro c auroc CI auprc eer Brier FPR@95 BER T-HC3 Tin yLlama-1.1B-Chat-v1.0 HC3 0.960 [0.942, 0.977] 0.952 0.075 0.130 0.165 BER T-HC3 Tin yLlama-1.1B-Chat-v1.0 ELI5 0.952 [0.929, 0.973] 0.940 0.097 0.174 0.115 BER T-HC3 Qw en2.5-1.5B-Instruct HC3 0.917 [0.887, 0.943] 0.898 0.140 0.150 0.335 BER T-HC3 Qw en2.5-1.5B-Instruct ELI5 0.876 [0.842, 0.913] 0.845 0.190 0.197 0.370 BER T-HC3 Llama-2-13b-c hat-hf HC3 0.969 [0.952, 0.984] 0.965 0.067 0.126 0.080 BER T-HC3 Llama-2-13b-c hat-hf ELI5 0.973 [0.956, 0.988] 0.965 0.075 0.163 0.095 RoBER T a-HC3 Llama-3.1-8B-Instruct HC3 0.993 [0.987, 0.997] 0.993 0.040 0.051 0.030 RoBER T a-HC3 Qwen2.5-1.5B-Instruct ELI5 0.858 [0.820, 0.893] 0.823 0.217 0.273 0.410 RoBER T a-HC3 Llama-2-13b-chat-hf HC3 0.990 [0.980, 0.999] 0.993 0.025 0.047 0.005 ELECTRA-HC3 Qw en2.5-7B-Instruct ELI5 0.942 [0.917, 0.965] 0.922 0.105 0.207 0.175 ELECTRA-HC3 Llama-3.1-8B-Instruct ELI5 0.951 [0.926, 0.973] 0.928 0.090 0.203 0.125 ELECTRA-HC3 Llama-2-13b-c hat-hf ELI5 0.968 [0.949, 0.986] 0.951 0.067 0.203 0.075 DistilBER T-HC3 Qw en2.5-1.5B-Instruct ELI5 0.845 [0.806, 0.882] 0.800 0.232 0.260 0.445 DistilBER T-HC3 Llama-2-13b-c hat-hf ELI5 0.985 [0.976, 0.993] 0.985 0.055 0.079 0.055 DeBER T a-HC3 Qwen2.5-1.5B-Instruct HC3 0.923 [0.891, 0.953] 0.867 0.092 0.103 0.105 DeBER T a-HC3 TinyLlama-1.1B-Chat-v1.0 ELI5 0.500 [0.441, 0.560] 0.451 0.512 0.434 0.595 DeBER T a-HC3 Llama-2-13b-chat-hf ELI5 0.499 [0.436, 0.561] 0.451 0.522 0.431 0.590 Key observ ations. Cross- llm generalization within a fixed domain is broadly achiev able: RoBER T a achiev es HC3 aur oc 0.976–0.993 across all unseen source llm s. Domain shift is the primary generalization b ottleneck — DeBER T a collapses to near-random on ELI5 (0.499–0.607) regardless of source llm . ELECTRA is the most domain-robust detector, with ELI5 scores ranging 0.910–0.968. Llama-2-13b-chat-hf is the most consistently detectable source llm ; Qw en2.5-1.5B- Instructis the hardest to detect. 8.3 Em b edding-Space Generalization via Classical Classifiers All texts are enco ded using all-MiniLM-L6-v2 (384-dimensional em b eddings), and three classical classifiers — LR, SVM (RBF), and RF (200 trees) — are trained and ev aluated under a full 5 × 5 train-test matrix. Human texts are split in to disjoint train/test partitions for leak age-free ev aluation. T able 27. Stage 3B embedding-space generalization on HC3 (selected). In-distribution conditions in b old . Classifier T rain llm T est llm auro c SVM Tin yLlama-1.1B-Chat-v1.0 Tin yLlama-1.1B-Chat-v1.0 0.976 SVM Tin yLlama-1.1B-Chat-v1.0 Llama-3.1-8B-Instruct 0.844 SVM Qw en2.5-7B-Instruct Qw en2.5-1.5B-Instruct 0.941 SVM Llama-2-13b-c hat-hf Llama-2-13b-c hat-hf 0.992 SVM Llama-2-13b-c hat-hf Llama-3.1-8B-Instruct 0.818 RF Tin yLlama-1.1B-Chat-v1.0 TinyLlama-1.1B-Chat-v1.0 1.000 RF Tin yLlama-1.1B-Chat-v1.0 Llama-3.1-8B-Instruct 0.812 RF Llama-2-13b-c hat-hf Qwen2.5-1.5B-Instruct 0.755 LR Llama-2-13b-c hat-hf Llama-3.1-8B-Instruct 0.760 LR Qw en2.5-1.5B-Instruct Qwen2.5-7B-Instruct 0.885 SVM is the most generalizable classifier (off-diagonal aur oc 0.818–0.941). Sen tence embedding 21 Preprin t — arXiv Detecting the Machine classifiers are substan tially more domain-robust than fine-tuned neural detectors, with HC3 / ELI5 div ergence < 0 . 03 aur oc on a verage. 8.4 Distribution Shift Analysis in Represen tation Space Em b eddings are extracted from DeBER T a-v3-base’s p enultimate CLS lay er, PCA-pro jected to 64 dimensions, and three distance metrics are computed under a Gaussian appro ximation: KL Div ergence captures the information lost when appro ximating the source LLM’s em b edding distribution with ChatGPT’s training distribution. Its asymmetry is deliberate: w e are sp ecifically in terested in regions where the unseen LLM’s outputs hav e probability mass that the detector’s training distribution do es not co ver — precisely the scenario that causes detection failure. D KL ( P ∥ Q ) = 1 2 tr(Σ − 1 Q Σ P ) + ( µ Q − µ P ) ⊤ Σ − 1 Q ( µ Q − µ P ) − d + ln | Σ Q | | Σ P | (3) W asserstein-2 Distance measures the minimum transp ort cost b et ween the tw o distributions under the squared Euclidean metric, providing a geometrically in terpretable and symmetric char- acterization of distributional shift. Unlike KL div ergence, it remains w ell-defined even when the t wo distributions hav e non-ov erlapping supp ort — an imp ortan t prop erty given that different LLM families ma y o ccupy disjoint regions of em b edding space. W 2 ( P , Q ) = s ∥ µ P − µ Q ∥ 2 + tr Σ P + Σ Q − 2 Σ 1 / 2 P Σ Q Σ 1 / 2 P 1 / 2 (4) F r´ ec het Distance is included as a cross-v alidation of the W asserstein estimate, drawing on its established use in generative model ev aluation (FID) as a measure of representational div ergence b et ween tw o Gaussian-approximated distributions. Its close relationship to W 2 2 allo ws direct compar- ison, with any divergence b et ween the t wo metrics indicating sensitivit y to the symmetrizing square ro ot in the co v ariance term. FD( P , Q ) = ∥ µ P − µ Q ∥ 2 + tr Σ P + Σ Q − 2(Σ P Σ Q ) 1 / 2 (5) Sp earman rank correlation is used rather than Pearson’s r to test the distance-degradation relationship, as it mak es no assumption ab out the linearity of the asso ciation b etw een embedding- space distance and aur oc drop — a sensible precaution given that detection failure may saturate or threshold at extreme distances. Correlations are computed separately for HC3 and ELI5 domains, with 500-iteration bo otstrap confidence bands on regression lines, to assess whether domain modulates the distance-difficult y relationship. T able 28. Sp earman rank correlations b etw een distributional distance and a uroc drop. ∗ = p < 0 . 05. Metric HC3 ρ HC3 p ELI5 ρ ELI5 p KL Div ergence − 0.298 0.148 − 0.443 0.027 ∗ W asserstein-2 − 0.369 0.070 − 0.322 0.117 F r ´ ec het − 0.369 0.070 − 0.322 0.117 22 Preprin t — arXiv Detecting the Machine T able 29. Per-detector distributional distances and aur oc drop on HC3 . Note: Baseline aur oc v alues for drop com putation are taken from the 200-sample ev aluation subsets used in Stage 3, not from the full test sets in T ables 7–11. Negative drop indicates cross- llm performance exceeds the Stage 3 subset baseline. Detector Source llm KL W 2 FD auro c Drop BER T-HC3 Tin yLlama-1.1B-Chat-v1.0 1.019 0.934 0.872 +0.006 BER T-HC3 Qw en2.5-1.5B-Instruct 0.471 0.682 0.465 +0.050 BER T-HC3 Qw en2.5-7B-Instruct 0.741 0.633 0.400 +0.033 BER T-HC3 Llama-3.1-8B-Instruct 2.015 0.808 0.652 +0.023 BER T-HC3 Llama-2-13b-c hat-hf 1.105 0.822 0.676 − 0.003 RoBER T a-HC3 Tin yLlama-1.1B-Chat-v1.0 1.019 0.934 0.872 +0.019 RoBER T a-HC3 Qw en2.5-1.5B-Instruct 0.471 0.682 0.465 +0.020 RoBER T a-HC3 Llama-3.1-8B-Instruct 2.015 0.808 0.652 +0.005 RoBER T a-HC3 Llama-2-13b-c hat-hf 1.105 0.822 0.676 +0.007 ELECTRA-HC3 Qw en2.5-1.5B-Instruct 0.471 0.682 0.465 +0.020 ELECTRA-HC3 Llama-3.1-8B-Instruct 2.015 0.808 0.652 +0.009 ELECTRA-HC3 Llama-2-13b-c hat-hf 1.105 0.822 0.676 − 0.011 DistilBER T-HC3 Qwen2.5-1.5B-Instruct 0.471 0.682 0.465 +0.085 DistilBER T-HC3 Qwen2.5-7B-Instruct 0.741 0.633 0.400 +0.080 DistilBER T-HC3 Llama-3.1-8B-Instruct 2.015 0.808 0.652 +0.053 DistilBER T-HC3 Llama-2-13b-chat-hf 1.105 0.822 0.676 +0.009 DeBER T a-HC3 TinyLlama-1.1B-Chat-v1.0 1.019 0.934 0.872 − 0.026 DeBER T a-HC3 Qwen2.5-1.5B-Instruct 0.471 0.682 0.465 − 0.046 DeBER T a-HC3 Llama-3.1-8B-Instruct 2.015 0.808 0.652 − 0.045 DeBER T a-HC3 Llama-2-13b-chat-hf 1.105 0.822 0.676 − 0.034 All three distance metrics pro duce negative rather than p ositive Sp earman correlations with aur oc drop, directly con tradicting the exp ectation that geometrically more distant llm s should b e harder to detect. Qwen2.5-1.5B-Instructand Qwen2.5-7B-Instructexhibit the smallest embedding distances from ChatGPT y et cause the largest aur oc drops — supp orting a pr oximity-c onfusion hyp othesis . 9 Adv ersarial Humanization Setup. Paraphrase-based attac ks hav e b een sho wn to substan tially reduce detector accuracy [Krishna et al., 2023]. F ollo wing this motiv ation, t wo h undred ChatGPT-generated samples are dra wn from each dataset ( HC3 and ELI5 ) and sub jected to t wo rounds of h umanization using Qwen2.5-1.5B-Instruct (4-bit NF4 quan tized), pro ducing three ev aluation conditions: • L0 — original AI-generated text, unmo dified. • L1 — light humanization: v aried sentence length, informal register, a v oidance of form ulaic structure; seman tic conten t preserved. • L2 — hea vy h umanization: applied iterativ ely on L1 output; aggressiv e remo v al of AI-lik e patterns (n umbered lists, formal transitions), delib erate con versational imp erfections, minor grammatical relaxation p ermitted. A t each lev el, detector scores are computed against a fixed p o ol of 200 human-authored texts from the same dataset. Metrics rep orted: aur oc , detection rate (prop ortion of AI texts scoring > 0 . 5), mean P ( llm ) score, and Brier score. 23 Preprin t — arXiv Detecting the Machine T able 30. Stage 4 adversarial humanization results. Detector Dataset Lev el auroc Det. Rate Mean AI Mean Human Brier BER T-HC3 HC3 L0 0.9637 1.000 0.9998 0.2736 0.1278 BER T-HC3 HC3 L1 0.9749 1.000 0.9997 0.2736 0.1278 BER T-HC3 HC3 L2 0.8792 0.870 0.8696 0.2736 0.1914 BER T-HC3 ELI5 L0 0.9530 0.930 0.9249 0.2454 0.1480 BER T-HC3 ELI5 L1 0.9945 0.995 0.9949 0.2454 0.1154 BER T-HC3 ELI5 L2 0.8989 0.850 0.8553 0.2454 0.1817 RoBER T a-HC3 HC3 L0 0.9896 1.000 1.0000 0.0775 0.0374 RoBER T a-HC3 HC3 L1 0.9911 1.000 1.0000 0.0775 0.0374 RoBER T a-HC3 HC3 L2 0.9621 0.910 0.9071 0.0775 0.0819 RoBER T a-HC3 ELI5 L0 0.9443 0.990 0.9899 0.4849 0.2370 RoBER T a-HC3 ELI5 L1 0.9699 1.000 1.0000 0.4849 0.2320 RoBER T a-HC3 ELI5 L2 0.8757 0.905 0.9049 0.4849 0.2794 ELECTRA-HC3 HC3 L0 0.9424 1.000 0.9997 0.4092 0.1958 ELECTRA-HC3 HC3 L1 0.9652 1.000 0.9997 0.4092 0.1958 ELECTRA-HC3 HC3 L2 0.8574 0.890 0.8883 0.4092 0.2497 ELECTRA-HC3 ELI5 L0 0.9540 0.980 0.9795 0.3501 0.1744 ELECTRA-HC3 ELI5 L1 0.9854 1.000 0.9997 0.3501 0.1645 ELECTRA-HC3 ELI5 L2 0.8972 0.885 0.8888 0.3501 0.2184 DistilBER T-HC3 HC3 L0 0.9900 0.995 0.9948 0.1204 0.0580 DistilBER T-HC3 HC3 L1 0.9506 0.895 0.8886 0.1204 0.1036 DistilBER T-HC3 HC3 L2 0.8567 0.675 0.6608 0.1204 0.2131 DistilBER T-HC3 ELI5 L0 0.9462 0.825 0.8203 0.0850 0.1248 DistilBER T-HC3 ELI5 L1 0.9521 0.835 0.8387 0.0850 0.1088 DistilBER T-HC3 ELI5 L2 0.8707 0.645 0.6349 0.0850 0.2089 DeBER T a-HC3 HC3 L0 0.8851 1.000 0.9999 0.2311 0.1140 DeBER T a-HC3 HC3 L1 0.9226 1.000 1.0000 0.2311 0.1140 DeBER T a-HC3 HC3 L2 0.8998 0.910 0.9090 0.2311 0.1584 DeBER T a-HC3 ELI5 L0 0.5252 1.000 0.9999 0.8521 0.4232 DeBER T a-HC3 ELI5 L1 0.5936 1.000 1.0000 0.8521 0.4232 DeBER T a-HC3 ELI5 L2 0.5887 0.915 0.9151 0.8521 0.4655 Ligh t humanization do es not reduce detectability . L1 aur oc ≥ L0 across all detectors and b oth domains without exception. Ligh t paraphrasing b y a small instruction-tuned mo del superimp oses additional mo del-sp ecific patterns, rendering the comp osite text more detectable. Hea vy humanization pro duces consisten t but incomplete ev asion. RoBER T a is most resistan t (L0 → L2 drop: 0 . 028 on HC3 ). DistilBER T is most susceptible (drop: 0 . 133; detection rate: 99 . 5% → 67 . 5%). No detector falls b elow a uroc 0 . 857 on HC3 at L2. auro c and detection rate div erge at L2 , indicating that L2 humanization shifts AI texts to ward the uncertain region around the 0.5 decision b oundary rather than cleanly in to the h uman score region. DeBER T a’s ELI5 collapse is unaffected by h umanization (L0: 0.525, L1: 0.594, L2: 0.589), confirming that its ELI5 w eakness is a domain-level structural limitation. Mean h uman scores are inv arian t across lev els , v alidating exp erimental design. 10 Discussion 10.1 The Cross-Domain Challenge Cross-domain degradation is the central finding of this b enchmark. Ev ery detector family suffers aur oc drops of 5–30 p oints when trained on one corpus and tested on the other. The most severe 24 Preprin t — arXiv Detecting the Machine case is the classical Random F orest (eli5-to-hc3: 0 . 634). Fine-tuned transformers maintain the highest cross-domain p erformance (RoBER T a eli5-to-hc3: 0 . 966). The st ylometric h ybrid XGBoost ac hieves comp etitive cross-domain aur oc (0 . 904 eli5-to-hc3), substan tially exceeding classical baselines. W e attribute this to the p erplexity CV feature: the c onsistency of fluency across sentences is a generator-agnostic signal that transfers across b oth ChatGPT and Mistral-7B outputs. 10.2 The Generator–Detector Iden tit y Problem The Mistral-7B llm -as-detector results rev eal a fundamental confound: a mo del cannot reliably detect its own outputs. If a detector is trained or prompted using the same mo del family as the target generator, its p erformance will b e systematically underestimated. 10.3 The P erplexit y In v ersion Mo dern llm s pro duce text that is significantly mor e pr e dictable than human writing, because their optimization ob jectiv es push strongly tow ard high-probability , fluent outputs. In our exp erimental setting, naiv e p erplexit y thresholding assigns higher scores to human text, yielding b elow-random p erformance. 10.4 In terpretabilit y vs. P erformance The X GBo ost stylometric hybrid nearly matc hes the in-distribution auroc of the b est transformer (0 . 9996 vs. 0 . 9998) while remaining fully in terpretable. 10.5 Limitations This study has sev eral limitations. First, the ev aluation cov ers only tw o llm sources (ChatGPT/GPT- 3.5 and Mistral-7B-Instruct); generalization to frontier mo dels (Claude, Gemini, GPT-4) remains to b e tested. Second, the adversarial humanization study uses only Qwen2.5-1.5B-Instructas the h umanizer; different humanizer mo dels ma y yield different ev asion rates. Third, the llm -as-detector exp erimen ts use relatively small ev aluation subsets ( n = 30 for CoT ) due to computational cost. F ourth, the ev aluation is limited to English Q&A text; p erformance on other genres and languages is unknown. Fifth, the Stage 3C distribution shift analysis uses 200-sample ev aluation subsets as baselines rather than the full test sets, which should b e noted when interpreting aur oc drop v alues. 11 F uture W ork 1. Expansion to fron tier mo dels. Ev aluation on Claude-3, Gemini, LLaMA-3, and GPT-4 outputs, probing whether the p erplexity inv ersion and contrastiv e lik eliho o d signals hold for hea vily RLHF-aligned generators. 2. Non-Q&A domains. Ev aluation on essa ys, news articles, and scientific abstracts. 3. Ensem ble metho ds. Systematic exploration of ensembles com bining fine-tuned transformers with in terpretable stylometric features. 4. Multilingual ev aluation. Extension to non-English corp ora. 5. Adaptiv e adv ersarial h umanization. Ev aluation of h umanizers that are aw are of sp ecific detector arc hitectures and craft targeted ev asion strategies. 12 Conclusion W e ha v e presented one of the most comprehensiv e ev aluations to date, spanning multiple dete ctor families, t wo carefully controlled corp ora, four ev aluation conditions, and detectors ranging from 25 Preprin t — arXiv Detecting the Machine logistic regression on 22 hand-crafted features to fine-tuned transformer enco ders and llm -scale promptable classifiers. Our cen tral findings are: fine-tuned enco der transformers ac hiev e near-p erfect in-distribution detection ( a uroc ≥ 0 . 994) but degrade universally under domain shift; an in terpretable X GBo ost st ylometric h ybrid matc hes this p erformance with negligible inference cost; the 1D-CNN ac hieves near-transformer performance with 20 × few er parameters; p erplexity-based detection rev eals a critical p olarit y inv ersion that inv erts naive h yp otheses ab out llm text distributions; and prompting-based detection, while requiring no training data, lags far b ehind fine-tuned approaches and is strongly confounded b y the generator–detector identit y problem. Collectiv ely , these results paint a clear picture: robust, generalizable, and adversarially resistan t AI-generated text detection remains an op en problem. No single detector family dominates across all conditions. Closing the cross-domain gap — particularly in the presence of adv ersarial humanization — is the most critical op en challenge in the field. Ac kno wledgmen ts The authors thank the Indian Institute of T echnology (BHU) and I IT Gu w ahati for computational resources and supp ort. The authors also ackno wledge the maintainers of the HC3 and ELI5 datasets, the HuggingF ace op en-source ecosystem, and the developers of the op en-source mo dels ev aluated in this b enc hmark. The full ev aluation pip eline and b enchmark co de are av ailable at our GitHub repository . All fine-tuned transformer mo dels are a v ailable as priv ate rep ositories at https://huggingface. co/Moodlerz . References Bhattac harjee, A., Kumarage, T., Moraffah, R., and Liu, H. ConDA: Contrastiv e domain adaptation for AI-generated text detection. In Pr o c e e dings of the 13th International Joint Confer enc e on Natur al L anguage Pr o c essing and the 3r d Confer enc e of the Asia-Pacific Chapter of the A CL (IJCNLP-AA CL) , pages 598–610, 2023. Clark, K., Luong, M.-T., Le, Q. V., and Manning, C. D. ELECTRA: Pre-training text enco ders as discriminators rather than generators. In International Confer enc e on L e arning R epr esentations (ICLR) , 2020. Devlin, J., Chang, M.-W., Lee, K., and T outano v a, K. BER T: Pre-training of deep bidirectional transformers for language understanding. In Pr o c e e dings of the 2019 Confer enc e of the North A meric an Chapter of the Asso ciation for Computational Linguistics: Human L anguage T e chnolo gies (NAA CL-HL T) , pages 4171–4186, 2019. F an, A., Jernite, Y., P erez, E., Grangier, D., W eston, J., and Auli, M. ELI5: Long form question answ ering. In Pr o c e e dings of the 57th A nnual Me eting of the Asso ciation for Computational Linguistics (A CL) , pages 3558–3567, Florence, Italy , 2019. Guo, B., Zhang, X., W ang, Z., Jiang, M., Nie, J., Ding, Y., Y ue, J., and W u, Y. How close is ChatGPT to h uman exp erts? Comparison corpus, ev aluation, and detection. arXiv pr eprint arXiv:2301.07597 , 2023. He, P ., Liu, X., Gao, J., and Chen, W. DeBER T a: Deco ding-enhanced BER T with disentangled atten tion. In International Confer enc e on L e arning R epr esentations (ICLR) , 2021. Kirc henbauer, J., Geiping, J., W en, Y., Katz, J., Miers, I., and Goldstein, T. A watermark for large language mo dels. In Pr o c e e dings of the 40th International Confer enc e on Machine L e arning (ICML) , v olume 202, pages 17061–17084. PMLR, 2023. 26 Preprin t — arXiv Detecting the Machine Ko jima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iw asaw a, Y. Large language mo dels are zero-shot reasoners. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 35, pages 22199–22213, 2022. Krishna, K., Song, Y., Karpinsk a, M., Wieting, J., and Iyyer, M. P araphrasing ev ades detectors of AI-generated text, but retriev al is an effective defense. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 36, 2023. La vergne, T., Urv oy , T., and Yv on, F. Detecting fake conten t with relative entrop y scoring. In Pr o c e e dings of P AN at CLEF 2008 , 2008. Liu, Y., Ott, M., Go yal, N., Du, J., Joshi, M., Chen, D., Levy , O., Lewis, M., Zettlemo yer, L., and Sto y anov, V. RoBER T a: A robustly optimized BER T pretraining approac h. arXiv pr eprint arXiv:1907.11692 , 2019. Mitc hell, E., Lee, Y., Khazatsky , A., Manning, C. D., and Finn, C. DetectGPT: Zero-shot mac hine- generated text detection using probability curv ature. In Pr o c e e dings of the 40th International Confer enc e on Machine L e arning (ICML) , volume 202, pages 24950–24962. PMLR, 2023. Ro driguez, P . A., Sheppard, T., Jiang, B., and Hu, Z. Cross-domain detection of GPT-2-generated tec hnical text. In Pr o c e e dings of the 60th A nnual Me eting of the Asso ciation for Computational Linguistics (A CL) , 2022. Sanh, V., Debut, L., Chaumond, J., and W olf, T. DistilBER T, a distilled version of BER T: Smaller, faster, c heap er and lighter. arXiv pr eprint arXiv:1910.01108 , 2019. Solaiman, I., Brundage, M., Clark, J., Ask ell, A., Herbert-V oss, A., W u, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, J., Newhouse, A., Blazakis, J., McGuffie, K., and W ang, J. Release strategies and the so cial impacts of language mo dels. arXiv pr eprint arXiv:1908.09203 , 2019. Uc hendu, A., Le, T., Shu, K., and Lee, D. Authorship attribution for neural text generation. In Pr o c e e dings of the 2020 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing (EMNLP) , pages 8384–8395, 2020. W olff, M. and W olff, R. A ttacking neural text detectors. arXiv pr eprint arXiv:2002.11768 , 2022. Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., F arhadi, A., Ro esner, F., and Choi, Y. Defending against neural fake news. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 32, 2019. Zeng, Z., Shi, J., Gao, Y., and Gao, B. Ev aluating large language mo dels at zero-shot machine- generated text detection. arXiv pr eprint arXiv:2310.03395 , 2023. Bro wn, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariw al, P ., Neelak an tan, A., Sh y am, P ., Sastry , G., Askell, A., et al. Language mo dels are few-shot learners. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 33, pages 1877–1901, 2020. Bommasani, R., Hudson, D. A., Aditi, E., Altman, R., Arora, S., et al. On the opp ortunities and risks of foundation mo dels. arXiv pr eprint arXiv:2108.07258 , 2021. Chen, T. and Guestrin, C. XGBoost: A scalable tree b o osting system. In Pr o c e e dings of the 22nd A CM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining (KDD) , pages 785–794, 2016. Floridi, L. and Chiriatti, M. GPT-3: Its nature, scop e, limits, and consequences. Minds and Machines , 30(4):681–694, 2020. Gehrmann, S., Strob elt, H., and Rush, A. M. GL TR: Statistical detection and visualization of generated text. In Pr o c e e dings of the 57th A nnual Me eting of the Asso ciation for Computational Linguistics (A CL): System Demonstr ations , pages 111–116, 2019. 27 Preprin t — arXiv Detecting the Machine Ipp olito, D., Duckw orth, D., Callison-Burc h, C., and Ec k, D. Automatic detection of generated text is easiest when h umans are fo oled. In Pr o c e e dings of the 58th Annual Me eting of the Asso ciation for Computational Linguistics (A CL) , pages 1808–1822, 2020. Juola, P . Authorship attribution. F oundations and T r ends in Information R etrieval , 1(3):233–334, 2006. Kim, Y. Con volutional neural net works for sentence classification. In Pr o c e e dings of the 2014 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing (EMNLP) , pages 1746–1751, 2014. Op enAI. AI text classifier: A fine-tuned language mo del that predicts how lik ely it is that a piece of text was generated by AI. T echnical rep ort, Op enAI, 2023. https://openai.com/blog/ new- ai- classifier- for- indicating- ai- written- text . Ouy ang, L., W u, J., Jiang, X., Almeida, D., W ainwrigh t, C., Mishkin, P ., Zhang, C., Agarw al, S., Slama, K., Ra y , A., et al. T raining language mo dels to follow instructions with h uman feedbac k. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 35, pages 27730–27744, 2022. Stamatatos, E. A survey of mo dern authorship attribution methods. Journal of the Americ an So ciety for Information Scienc e and T e chnolo gy , 60(3):538–556, 2009. W ei, J., W ang, X., Sch uurmans, D., Bosma, M., Ich ter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-though t prompting elicits reasoning in large language mo dels. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 35, pages 24824–24837, 2022. 13 Implemen tation Details 13.1 F amily 1 — Statistical Machine Learning Detectors Tw ent y-tw o hand-crafted linguistic features w ere extracted from each text sample across sev en categories: surface statistics (word count, character count, sentence coun t, av erage word/sen tence length); lexical diversit y (t yp e-token ratio, hapax legomena ratio); punctuation (comma densit y , p erio d density , question mark and exclamation ratios); rep etition (bigram and trigram rep etition rates); en tropy (word-frequency and sen tence-length entrop y); syntactic complexit y (sentence-length v ariance and standard deviation); and discourse mark ers (hedging densit y , certaint y density , connector densit y , con traction ratio, and burstiness). All features were extracted without normalisation b eyond p er-feature standardisation applied at training time. Three classifiers w ere trained on this feature vector: Logistic Regression ( max iter=1000 ), Ran- dom F orest ( n estimators=100 , max depth=10 ), and SVM with RBF kernel ( probability=True ). Lab els w ere enco ded as binary v alues (human = 0, llm = 1). Each classifier was ev aluated under four conditions: HC3 → HC3 , HC3 → ELI5 , ELI5 → ELI5 , and ELI5 → HC3 . 13.2 F amily 2 — Fine-T uned Enco der T ransformers Fiv e pre-trained enco der transformers were fine-tuned for binary AI-text classification under a shared proto col: a t wo-class classification head attac hed to the [CLS] tok en, AdamW optimisation ( lr = 2 × 10 − 5 , w eight decay = 0 . 01), w armup ov er 6% of training steps, drop out = 0 . 2, one training ep o ch, and a 90/10 stratified train/v alidation split. Inputs w ere tokenised to a maximum of 512 tok ens. No intermediate chec kp oints w ere sa ved; final in-memory weigh ts were used directly for all do wnstream ev aluation. Mo del-sp ecific deviations from this shared proto col are noted in T able 31. 28 Preprin t — arXiv Detecting the Machine T able 31. Fine-tuned enco der transformer configurations. En tries marked “—” follow the shared proto col describ ed ab ov e. Mo del Params Precision Batch (tr/ev) W armup Notes BER T 110M FP16 32 / 64 6% ratio — RoBER T a 125M FP16 32 / 64 6% ratio Dynamic masking, no NSP ELECTRA 110M FP16 32 / 64 6% ratio Discriminator fine-tuned DistilBER T 66M FP16 32 / 64 6% ratio Mo del-sp ecific drop out params DeBER T a-v3-base 184M FP32 16 / 32 500 steps See note b elow DeBER T a-v3-base: arc hitecture-sp ecific adjustmen ts. Both FP16 and BF16 w ere disabled; the mo del w as trained in full FP32 throughout, as BF16 silently zero e d gradien ts due to the small gradien t magnitudes pro duced b y disen tangled atten tion, and FP16 caused gradient scaler instability . Chec kp oint saving was disabled entirely ( save strategy="no" , load best model at end=False ) to a void a Lay erNorm key mismatc h during chec kp oint reloading that caused all 24 Lay erNorm la yers to reinitialise to random weigh ts and collapse aur oc to approximately 0.50. Explicit gradient clipping was applied ( max grad norm=1.0 ). token type ids w ere omitted as DeBER T a-v3 do es not use segment IDs. All fiv e mo dels w ere uploaded to the Hugging F ace Hub under Moodlerz/ follo wing training. 13.3 F amily 3 — Shallow 1D-CNN Detector A ligh t weigh t multi-filter 1D-CNN was implemented with under 5M parameters. The architecture follo ws Kim [2014]: a shared embedding lay er ( vocab size=30,000 , embed dim=128 ) feeds four parallel con volutional branches with k ernel sizes { 2 , 3 , 4 , 5 } and 128 filters each (BatchNorm1d + ReLU + global max p o oling), pro ducing a 512-dimensional concatenated representation. A classification head (Drop out(0.4) → Linear(512 → 256) → ReLU → Drop out(0.2) → Linear(256 → 1)) with BCEWithLogitsLoss and Kaiming normal weigh t initialisation completes the arc hitecture. Sequences were truncated or padded to 256 tok ens. T raining used Adam ( lr = 10 − 3 , w eigh t - deca y= 10 − 4 ), ReduceLR OnPlateau scheduling (patience= 1, factor= 0 . 5), gradien t clipping ( max - norm=1.0 ), and early stopping (patience= 3) o ver a maximum of 10 ep o c hs with batch size 64. 13.4 F amily 4 — Stylometric and Statistical Hybrid Detector An extended feature set of 60+ hand-crafted features substantially augmen ts the F amily 1 set with the follo wing additions: POS tag distribution (10 univ ersal POS tags via spaCy en core web sm ); dep endency tree depth (mean and maximum p er sentence); function word frequency profiles (10 high-frequency tokens plus aggregate ratio); punctuation en tropy; AI hedge phrase density (16 c haracteristic AI-generated phrases, normalised by sen tence count); six readability indices (Flesch Reading Ease, Flesch-Kincaid Grade, Gunning F og, SMOG, ARI, Coleman-Liau via textstat ); and sen tence-level p erplexity from GPT-2 Small (117M) ov er up to 15 sentences per text, yielding mean, v ariance, standard deviation, and co efficient of v ariation. Lo w p erplexity v ariance is treated as a p oten tial AI signal due to the characteristically uniform fluency of llm -generated text. Three classifiers were trained on this feature v ector: Logistic Regression, Random F orest, and X GBo ost [Chen and Guestrin, 2016]. Key hyperparameters are listed in T able 32. All features were standardised via StandardScaler fitted on the training partition only . Missing v alues arising from short texts or parsing failures w ere imputed with p er-column training medians. T able 32. Stylometric hybrid classifier hyperparameters. Classifier Key Parameters Logistic Regression max iter=2000 , C=1.0 , solver=lbfgs , class weight=balanced Random F orest n estimators=300 , max depth=12 , class weight=balanced X GBo ost n estimators=400 , max depth=6 , lr=0.05 , subsample=0.8 29 Preprin t — arXiv Detecting the Machine 13.5 F amily 5 — LLM-as-Detector All llm -as-detector exp erimen ts shared a four-comp onen t pip eline applied in sequence: p olarity correction, task prior calibration, constrained deco ding, and (for CoT regimes) h ybrid ensemble scoring. Constrained Deco ding. Detection scores w ere derived by extracting next-token logits following the prompt’s final Answer: tok en. The maxim um logit within the set of single-tok en surface forms of yes and no w as tak en for eac h p olarity class, and a softmax o v er the t wo v alues yielded a con tinuous P ( llm ) ∈ [0 , 1]. P olarit y Correction. A systematic lab el bias was observed across all mo dels: Qw en-family and LLaMA-2 mo dels produced stronger no logits for b oth h uman and llm text, making the ra w P ( yes = AI ) signal non-discriminativ e. Prompts for these mo dels were therefore reframed so that yes = h uman and no = AI , with P ( llm ) read directly from P ( no ) with flip=False . TinyLlama-1.1B, Qw en2.5-1.5B, andLlama-3.1-8B-Instruct used the standard orien tation ( flip=True ); Qw en2.5-7B, Qw en2.5-14B, and Llama-2-13b-chat-hf used the swapped orientation ( flip=False ). T ask Prior Calibration. A task-specific prior w as computed by av eraging yes / no logits o ver 50 real task prompts drawn equally from HC3 and ELI5 ev aluation sets using the exact inference-time prompt template. These av eraged logits were subtracted from each sample’s token logits b efore softmax, correcting mo del-lev el base rate biases without requiring a lab elled calibration set. TF-IDF F ew-Shot Retriev al. F or few-shot regimes, k examples w ere retriev ed from a po ol of 30 balanced training samples p er dataset using TF-IDF cosine similarity ( max features=5,000 , bigrams), with balanced class represen tation enforced p er query . CoT Ensem ble Scoring. In CoT regimes, the mo del generated up to 350–500 tok ens of free-form reasoning. A numeric AI CONFIDENCE score on a 0–10 scale w as extracted via regex and normalised to [0 , 1]. A zero-shot constrained logit score w as computed separately using the same task prior. The t wo signals were com bined as: score = 0 . 6 × conf + 0 . 4 × logit score (6) When the confidence score fell within a mo del-sp ecific dead zone (indicating uninformative reasoning), only the logit score w as used. All op en-source mo dels w ere loaded in 4-bit NF4 quantisation with BitsAndBytes double quantisa- tion ( bnb 4bit compute dtype=float16 , except Qwen2.5-14B-Instruct which used bfloat16 ). CoT generation used greedy deco ding ( do sample=False ). Mo del-sp ecific configurations are summarised in T able 33. T able 33. Per-model configuration for llm -as-detector exp erimen ts. “Swap” indicates swapped p olarity con ven tion ( yes = h uman, no = AI). n ZS/FS and n CoT denote ev aluation sample sizes. Mo del Quan t. Polarit y Prior Regimes n ZS/FS n CoT Max New T okens TinyLlama-1.1B-Chat-v1.0 FP16 Standard None ZS, FS 500 — — Qwen2.5-1.5B-Instruct FP16 Standard None ZS, FS 500 — — Llama-3.1-8B-Instruct NF4/FP16 Standard 50 prompts ZS, FS, CoT 500 70 350 Qwen2.5-7B-Instruct NF4/FP16 Sw ap 50 prompts ZS, FS, CoT 500 70 350 Llama-2-13b-chat-hf NF4/FP16 Swap 50 prompts ZS, FS, CoT 200 30 400 Qwen2.5-14B-Instruct NF4/BF16 Swap 50 prompts ZS, FS, CoT 200 30 500 GPT-4o-mini API — — ZS, FS, CoT 200 50 180 / 600 Mo del-sp ecific notes. Llama-2-13b-c hat-hfrequired a manual [INST]...<>...< > ...[/INST] template fallbac k for c heckpoints without a registered chat template field, and CoT prompts used “stylometric analysis” framing to circum ven t safet y-oriented refusal b eha viors. Qw en2.5- 14B-Instructrequired pad token id=tokenizer.pad token id (not eos token id ) in generate() — using eos as padding caused premature generation termination and an ≈ 90% unkno wn verdict rate in the original implementation. GPT-4o-mini w as prompted via a structured 7-dimension scoring format requiring explicit p er-dimension scores b efore a final AI SCORE tag (0 = h uman , 100 = AI ); temp erature w as set to 0 with seed=42 . 30 Preprin t — arXiv Detecting the Machine A Hyp erparameter T ables A.1 Enco der T ransformer Common T raining Proto col T able 34. Shared fine-tuning proto col for all encoder transformer detectors. DeBER T a-v3-sp ecific deviations are noted in parentheses. P arameter V alue Optimiser AdamW Learning rate 2 × 10 − 5 W eight decay 0.01 W armup 6% of total steps (500 fixed steps for DeBER T a-v3) Drop out 0.2 T raining ep o chs 1 Max sequence length 512 T rain batch size 32 (16 for DeBER T a-v3) Ev al batch size 64 (32 for DeBER T a-v3) Precision FP16 (FP32 for DeBER T a-v3) Chec kp oint strategy None — final in-memory weigh ts used Ev al frequency Ev ery 200 steps V alidation split 10% stratified A.2 Enco der T ransformer Mo del Sp ecifications T able 35. Enco der transformer mo del chec kp oints and architectural notes. Mo del Chec kp oint P arams Notes BER T bert-base-uncased ∼ 110M Standard MLM pre-training RoBER T a roberta-base ∼ 125M Dynamic masking, no NSP ELECTRA google/electra-base-discriminator ∼ 110M Replaced token detection DistilBER T distilbert-base-uncased ∼ 66M Kno wledge distillation from BER T DeBER T a-v3 microsoft/deberta-v3-base ∼ 184M FP32 only; no chec kp ointing; ex- plicit grad clip A.3 1D-CNN Hyp erparameters T able 36. 1D-CNN architecture and training h yp erparameters. P arameter V alue V o cabulary size 30,000 Minim um word frequency 2 Max sequence length 256 Em b edding dimension 128 Filter sizes { 2 , 3 , 4 , 5 } Filters p er size 128 T otal filter dimension 512 Hidden lay er dimension 256 Drop out 0.4 (head), 0.2 (second lay er) Optimiser Adam Learning rate 10 − 3 W eight decay 10 − 4 Batc h size 64 Max ep o chs 10 Early stopping patience 3 LR scheduler ReduceLROnPlateau (patience= 1, factor= 0 . 5) Gradien t clipping max norm=1.0 31 Preprin t — arXiv Detecting the Machine A.4 St ylometric Hybrid Hyp erparameters T able 37. Stylometric hybrid classifier and feature extraction hyperparameters. P arameter V alue Logistic Regression C 1.0 Logistic Regression solver lbfgs Logistic Regression max iter 2,000 Random F orest n estimators 300 Random F orest max depth 12 Random F orest min samples leaf 5 X GBo ost n estimators 400 X GBo ost max depth 6 X GBo ost learning rate 0.05 X GBo ost subsample 0.8 X GBo ost colsample bytree 0.8 F eature scaling StandardScaler (fit on train only) Missing v alue imputation Column-wise training medians Class weigh ting Balanced (Logistic Regression, Random F orest) Sen tence p erplexity mo del GPT-2 Small (117M) Max sentences for p erplexity 15 p er text A.5 llm-as-Detector Configuration Summary T able 38. llm -as-detector p er-mo del configuration. Mo del Size Quant. Polarit y Prior n ZS/FS n CoT Tin yLlama-1.1B-Chat-v1.0 1.1B FP16 yes=AI Neutral 500 — Qw en2.5-1.5B-Instruct 1.5B FP16 yes=AI Neutral 500 — Llama-3.1-8B-Instruct 8B NF4/FP16 yes=AI T ask ( n = 50) 500 70 Qw en2.5-7B-Instruct 7B NF4/FP16 yes=human T ask ( n = 50) 500 70 Llama-2-13b-c hat-hf 13B NF4/FP16 yes=human T ask ( n = 50) 200 30 Qw en2.5-14B-Instruct 14B NF4/BF16 yes=human T ask ( n = 50) 200 30 GPT-4o-mini API — AI SCORE — 200 50 A.6 CoT Ensem ble P arameters b y Mo del T able 39. CoT h ybrid ensemble parameters. The dead zone defines the confidence in terv al within which the logit-only score is used instead of the ensemble. Mo del Conf. w eight Logit weigh t Dead zone V erdict o v erride Max tokens Llama-3.1-8B-Instruct 0.6 0.4 [0 . 40 , 0 . 60] [0 . 35 , 0 . 65] 350 Qw en2.5-7B-Instruct 0.6 0.4 [0 . 35 , 0 . 65] [0 . 35 , 0 . 65] 350 Llama-2-13b-c hat-hf 0.6 0.4 [0 . 40 , 0 . 60] [0 . 35 , 0 . 65] 400 Qw en2.5-14B-Instruct 0.6 0.4 [0 . 35 , 0 . 65] [0 . 35 , 0 . 65] 500 B Prompt T emplates All prompts are repro duced v erbatim. [TEXT] denotes the target text placeholder. 32 Preprin t — arXiv Detecting the Machine B.1 Zero-Shot Prompts --- TinyLlama-1.1B-Chat-v1.0/Llama-3.1-8B-Instruct (standard polarity: yes=AI) --- System: You detect AI-generated text. Answer with ONE word only: yes or no. yes = AI-generated. no = human-written. No explanation. No punctuation. One word. User: Was this text generated by an AI language model? Text: """[TEXT]""" Answer yes or no. Answer: Figure 7. Zero-shot prompt for TinyLlama-1.1B-Chat-v1.0andLlama-3.1-8B-Instruct (standard p olarity). --- Qwen2.5-7B-Instruct(swapped polarity: yes=human) --- System: You detect AI-generated text. Answer with ONE word only: yes or no. yes = human-written. no = AI-generated. No explanation. No punctuation. One word. User: Was this text written by a human? Text: """[TEXT]""" Answer yes or no. Answer: Figure 8. Zero-shot prompt for Qwen2.5-7B-Instruct(sw app ed p olarity). --- Llama-2-13b-chat-hf(swapped polarity, stylometric framing) --- System: You are a linguistics researcher studying writing styles. Answer with ONE word only: yes or no. yes = written by a human. no = written by an AI system. No explanation. No punctuation. One word only. User: Was this text written by a human? Text sample: """[TEXT]""" Answer yes or no. Answer: Figure 9. Zero-shot prompt for Llama-2-13b-chat-hf(sw app ed p olarity , st ylometric framing). --- Qwen2.5-14B-Instruct(swapped polarity, authorship framing) --- System: You are an expert in authorship attribution and AI-generated text analysis. Answer with ONE word only: yes or no. yes = human-written. no = AI-generated. No explanation. No punctuation. One word. User: Was this text written by a human? Text: """[TEXT]""" Answer yes or no. Answer: Figure 10. Zero-shot prompt for Qwen2.5-14B-Instruct(sw app ed p olarity , authorship framing). 33 Preprin t — arXiv Detecting the Machine --- GPT-4o-mini (7-dimension structured scoring) --- System: You are an expert forensic linguist specialising in authorship attribution. AI-generated text is very common, including short conversational-looking text from older models like ChatGPT-3.5. Score honestly based on the dimensions provided. Use the full 0-10 range for each dimension. Complete every analysis. User: Score this passage on each dimension from 0 (strongly human) to 10 (strongly AI). Passage: [TEXT] HEDGING/FORMULAIC: ’it is important’, ’certainly’, numbered sections, safe generalisations COMPLETENESS: Covers every sub-angle even when not asked PERSONAL VOICE: Opinions, errors, tangents, emotional register LEXICAL UNIFORMITY: Vocabulary register stays perfectly consistent STRUCTURAL NEATNESS: Clear intro/body/conclusion or logical flow RESPONSE FIT: Directly and precisely addresses the apparent question FORMULAIC TELLS: Restates question, tidy closing, ’I hope this helps’ Then write: AI_SCORE: [arithmetic mean of 7 scores x 10, rounded to nearest integer] Format: 1:[score] 2:[score] 3:[score] 4:[score] 5:[score] 6:[score] 7:[score] AI_SCORE: [mean] Figure 11. Zero-shot prompt for GPT-4o-mini (structured 7-dimension rubric scoring). B.2 F ew-Shot Prompt Structure --- Few-Shot Structure (Llama-3.1-8B-Instruct/ Qwen2.5-7B-Instruct/ Llama-2-13b-chat-hf / Qwen2.5-14B) --- System: [same as zero-shot for respective model] User: Examples: Text: "[EXAMPLE_1_TEXT]" [Human-written? / AI-generated?] [yes/no] Text: "[EXAMPLE_2_TEXT]" [Human-written? / AI-generated?] [yes/no] Text: "[EXAMPLE_3_TEXT]" [Human-written? / AI-generated?] [yes/no] Now answer: Text: "[TARGET_TEXT]" [Human-written? / AI-generated?] yes or no. Answer: Figure 12. F ew-shot prompt structure. k = 3 TF-IDF-retrieved examples are prep ended to the zero-shot prompt. Lab el phrasing follows eac h mo del’s p olarit y conv ention. 34 Preprin t — arXiv Detecting the Machine B.3 Chain-of-Though t Prompts ---Llama-3.1-8B-Instruct CoT (7-dimension scoring with AI_CONFIDENCE) --- System: You are an expert forensic linguist. Determine whether a passage was written by a human or generated by an AI. Think carefully and be precise. User: Analyse whether this passage was written by a HUMAN or an AI. Passage: """[TEXT]""" Score each dimension 0 (strongly human) to 10 (strongly AI): STRUCTURE: Neatly organised with clear sections or numbered points? COMPLETENESS: Covers the topic comprehensively without gaps? HEDGING: Acknowledges uncertainty or says "I’m not sure"? PERSONAL VOICE: Personal opinions, anecdotes, slang, contractions, typos? LEXICAL RANGE: Broad, polished vocabulary even in casual answers? RESPONSE FIT: Directly addresses the question or wanders? SHORT-FORM TELLS: Starts "Certainly!", restates question, unnaturally tidy closing? BREVITY PATTERN: Ends with an unnatural one-sentence summary? QUESTION ECHO: Begins by restating or paraphrasing the question? GENERIC EXAMPLES: Placeholder examples ("consider X") where X is suspiciously apt? IMPORTANT: Short answers can still be AI-generated. Do not assume short = human. After scoring, state on the LAST TWO LINES exactly: AI_CONFIDENCE: [average of 7 scores, 0-10] VERDICT: yes (if AI-generated) VERDICT: no (if human-written) Figure 13. CoT prompt forLlama-3.1-8B-Instruct. --- Llama-2-13b-chat-hfCoT (stylometric framing) --- System: You are an expert in stylometric analysis and authorship attribution. Analyse writing samples to determine if written by a human or AI. Always complete your analysis. Always end with AI_CONFIDENCE and VERDICT. User: Perform a stylometric analysis of this writing sample. Sample: """[TEXT]""" Score each dimension 0 (strongly human) to 10 (strongly AI): STRUCTURAL REGULARITY: Uniform sentence length, predictable paragraph transitions? LEXICAL POLISH: Consistently formal/polished vocabulary? TOPIC COVERAGE: Suspiciously complete, covering all sub-aspects? HEDGING STYLE: Confident and authoritative vs uncertain and personal? PERSONAL MARKERS: Opinions, anecdotes, typos, contractions, informal phrasing? RESPONSE ALIGNMENT: Tightly matches the implied question? FORMULAIC OPENING: Starts with "Certainly!", "Great question!", or restates question? Note: Short answers can still be AI-generated. Final output (EXACTLY these two lines): AI_CONFIDENCE: [average of 7 scores, 0-10] VERDICT: yes (if AI-generated) VERDICT: no (if human-written) Figure 14. CoT prompt for Llama-2-13b-chat-hf(st ylometric framing to reduce safet y refusals). 35 Preprin t — arXiv Detecting the Machine --- Qwen2.5-14B-InstructCoT (explicit completion constraint) --- System: You are an expert forensic linguist performing authorship attribution analysis. You ALWAYS complete your full analysis and ALWAYS end with AI_CONFIDENCE and VERDICT. Never leave your analysis incomplete or refuse to give a verdict. User: Analyse this passage to determine if written by a HUMAN or generated by an AI. Passage: """[TEXT]""" Score each dimension 0 (strongly human) to 10 (strongly AI): STRUCTURE (0-10): Organised with clear sections/numbered points? COMPLETENESS (0-10): Covers topic without obvious gaps? HEDGING (0-10): Confident authoritative tone, lacks uncertainty? PERSONAL VOICE (0-10): Lacks personal opinions/anecdotes/typos? LEXICAL POLISH (0-10): Uniformly formal/polished vocabulary? RESPONSE FIT (0-10): Directly and completely addresses question? FORMULAIC TELLS (0-10): Restates question, "Certainly!", unnaturally tidy closing? IMPORTANT: Short texts CAN be AI-generated. Score all 7 dimensions regardless of length. You MUST end with EXACTLY: AI_CONFIDENCE: [average score 0-10] VERDICT: yes OR VERDICT: no Begin your analysis now: Figure 15. CoT prompt for Qwen2.5-14B. Explicit completion directives were added to resolve the ≈ 90% unkno wn verdict rate in the original implementation. --- GPT-4o-mini CoT (evidence-plus-score format) --- System: You are an expert forensic linguist specialising in authorship attribution. Score honestly based on evidence. Use the full 0-10 range. Complete every dimension. User: Analyse whether this passage was written by a HUMAN or generated by an AI. Passage: [TEXT] For each dimension write ONE evidence sentence, then a score 0 (human) to 10 (AI): HEDGING/FORMULAIC -- ’it is important’, ’certainly’, numbered sections: Evidence: ... Score (0-10): COMPLETENESS -- covers every sub-angle even when not asked: Evidence: ... Score (0-10): PERSONAL VOICE -- opinions, errors, tangents, emotional register: Evidence: ... Score (0-10): LEXICAL UNIFORMITY -- vocabulary register stays perfectly consistent: Evidence: ... Score (0-10): STRUCTURAL NEATNESS -- clear intro/body/conclusion or logical flow: Evidence: ... Score (0-10): RESPONSE FIT -- directly and precisely addresses the apparent question: Evidence: ... Score (0-10): FORMULAIC TELLS -- restates question, tidy closing, ’I hope this helps’: Evidence: ... Score (0-10): Then write: AI_SCORE: [mean of 7 scores x 10, rounded to nearest integer] VERDICT: ai OR VERDICT: human Figure 16. CoT prompt for GPT-4o-mini (evidence-plus-score format). 36
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment