프리트레인 모델 기반 양자화 연합학습, QuantFL
QuantFL은 사전 학습된 모델을 초기화로 활용하고, 층별 버킷 양자화(BU, BQ)를 적용해 클라이언트 업데이트를 압축한다. 프리트레인으로 인해 업데이트의 동적 범위와 분산이 크게 감소하므로, 저비트 양자화에도 정확도 손실이 거의 없으며, 업링크·다운링크 통신량을 40 % 이상 절감한다. 실험은 MNIST와 CIFAR‑100에서 기존 FedAvg·QSGD 대비 동일하거나 더 높은 정확도를 보이며, 비IID 환경에서도 안정적이다.
저자: Charuka Herath, Yogach, ran Rahulamathavan
본 논문은 사전 학습된 모델을 초기화로 활용하고, 층별 버킷 양자화(bucket quantisation)를 적용해 연합학습(Federated Learning, FL)의 통신 비용을 크게 절감하는 프레임워크 **QuantFL**을 제안한다. 기존 FL은 클라이언트가 매 라운드마다 전체 모델 파라미터(또는 그라디언트)를 32‑bit 부동소수점 형태로 전송해야 하므로, 특히 업링크 대역폭이 제한된 IoT 환경에서 탄소 발자국과 배터리 소모가 심각한 문제로 대두된다. 이러한 배경에서 저자는 두 가지 관점을 결합한다.
1. **프리트레인 초기화**: 사전 학습된 가중치를 전역 모델의 초기값으로 사용한다. 사전 학습은 모델을 일반적인 특징 표현을 이미 학습한 상태로 만들며, 로컬 업데이트 시 파라미터 변화량(Δw)의 절대값과 분산이 크게 감소한다. 실험적으로, 프리트레인 모델에서 얻은 업데이트는 무작위 초기화 모델에 비해 동적 범위(R)와 분산이 약 70 % 이상 축소된다. 이는 양자화 시 손실을 최소화할 수 있는 기반이 된다.
2. **버킷 양자화**: 각 층별 파라미터 업데이트를 **Bucket‑Uniform (BU)**와 **Bucket‑Quantile (BQ)** 두 방식으로 양자화한다. BU는 동일 폭 구간을 사용해 구현이 단순하고, 비IID 데이터에서도 안정적이다. BQ는 경험적 누적분포를 기반으로 구간을 조정해, 업데이트가 피크형일 때 왜곡을 크게 줄인다. 양자화 후 각 파라미터는 구간 인덱스로 변환되며, 서버는 구간 중점(mid‑point)으로 복원한다. 중점 복원은 구간 내 평균 제곱오차(MSE)를 최소화하는 최적 방법이다.
양자화 비용 모델은 인덱스 비트와 코드북(버킷 경계) 전송 비용을 명시적으로 포함한다. 코드북은 매 T 라운드마다 한 번만 전송하고 이후 라운드에서는 인덱스만 전송하므로, 전체 비트 비용은
C↑ = Σℓ dℓ·⌈log₂Lℓ⌉ + (b·Lℓ)/Tℓ
으로 표현된다. 여기서 dℓ는 층 ℓ의 파라미터 수, Lℓ는 양자화 레벨, b는 경계값을 표현하는 비트 수이다. 다운링크는 전체 모델을 전송하거나, 필요 시 양자화된 코드북을 전송하도록 선택할 수 있다.
**실험 설정**은 다음과 같다. 100명의 클라이언트를 시뮬레이션하고, 매 라운드 10명을 무작위 선택한다. 두 데이터셋(MNIST, CIFAR‑100)에서 각각 얕은 CNN과 ResNet‑18을 사용한다. 사전 학습은 ImageNet‑pretrained 가중치를 일부 레이어에 전이 학습한 형태이며, 로컬 학습은 SGD로 2 epoch 수행한다. 전체 라운드는 200~300번 진행한다.
**주요 결과**는 다음과 같다.
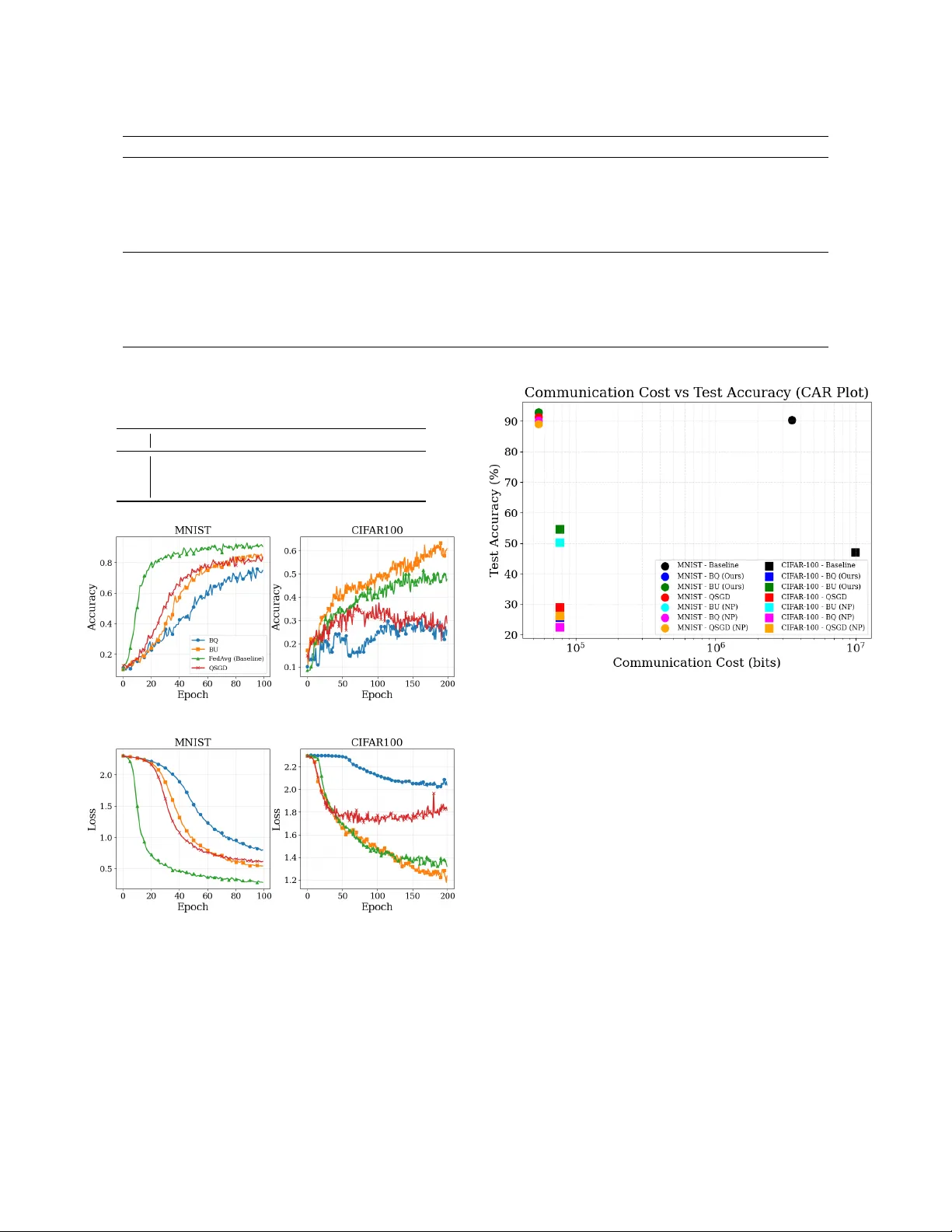
- **통신량 절감**: 전체 비트(업링크+다운링크) 기준 40 % 절감, 업링크만 고려하면 80 % 이상 절감. 이는 코드북 전송 비용을 amortize하고, 인덱스 비트를 2~4 bit 수준으로 낮춘 결과이다.
- **정확도 유지 및 향상**: MNIST에서 BU(L=8) 사용 시 89.00 % 정확도, CIFAR‑100에서 BU(L=16) 사용 시 66.89 % 정확도를 달성했다. 이는 무압축 FedAvg(≈88.5 % / 66.2 %)와 동등하거나 약간 상회한다. QSGD와 같은 기존 양자화 기법은 동일 비트 수에서 1~2 % 정도 정확도 손실을 보였다.
- **비IID 강인성**: Dirichlet‑α=0.1~1.0 범위에서 비IID 데이터 분포를 시뮬레이션했으며, BU는 정확도 저하가 <1 %에 머물렀다. BQ는 α가 작을 때(데이터 불균형 심할 때) 약간 더 높은 정확도를 보였다.
- **에너지 효율**: 오류 피드백(Error Feedback, EF)을 필요로 하지 않으며, 클라이언트 측 메모리와 연산량이 크게 감소한다. 이는 배터리 제약이 있는 IoT 디바이스에서 실제 전력 소모를 낮추는 효과가 있다(정성적 논의).
**Ablation Study**에서는 양자화 레벨 L과 코드북 갱신 주기 T를 변동시켰다. L을 4, 8, 16으로 늘릴수록 정확도는 소폭 상승했으며, T를 5~20 라운드로 늘려도 통신량 절감 효과는 유지되었다. 특히 프리트레인 모델에서 업데이트 범위가 작아 동일 L에서도 왜곡이 크게 감소함을 확인했다.
**비교 분석**에서는 Top‑k sparsification, SignSGD, Low‑rank 스케치와 같은 기존 압축 기법과의 차별점을 강조한다. 기존 방법은 복잡한 오류 누적 로직이나 추가 매개변수(랭크, 스케치 크기 등)를 필요로 하지만, QuantFL은 구현이 간단하고 코드북 전송 비용을 명시적으로 관리한다는 장점이 있다.
**한계 및 향후 연구**로는 현재는 동기식 FL(동일 라운드에 모든 클라이언트가 참여)만을 다루었으며, 비동기 FL, 다중 모델 파이프라인, 그리고 하드웨어 수준 8‑bit·4‑bit 양자화와의 연계가 제시된다. 또한, 프리트레인 모델의 선택과 레이어별 양자화 레벨 최적화가 성능에 미치는 영향을 자동화하는 메타러닝 접근법도 향후 연구 과제로 언급된다.
결론적으로, QuantFL은 사전 학습된 모델이 제공하는 업데이트 집중 현상을 활용해, 메모리·연산 부담이 적은 버킷 양자화만으로도 기존 FL 대비 통신량을 크게 줄이면서 정확도는 유지하거나 향상시킨다. 이는 배터리 제한이 있는 엣지 IoT 네트워크에서 지속 가능한 AI 학습을 구현하기 위한 실용적인 “그린” 솔루션으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기