QuantFL: Sustainable Federated Learning for Edge IoT via Pre-Trained Model Quantisation
Federated Learning (FL) enables privacy-preserving intelligence on Internet of Things (IoT) devices but incurs a significant carbon footprint due to the high energy cost of frequent uplink transmission. While pre-trained models are increasingly avail…
Authors: Charuka Herath, Yogach, ran Rahulamathavan
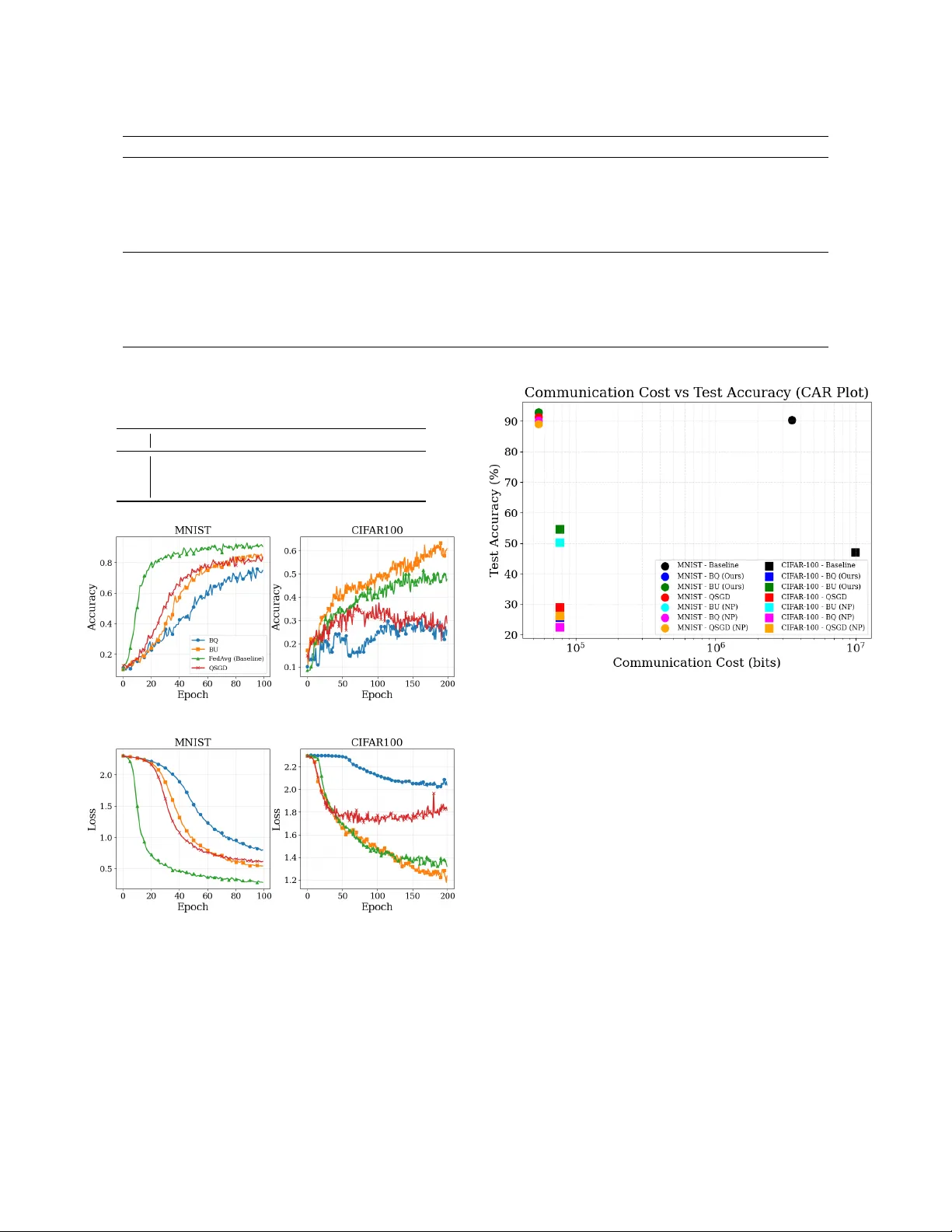
Q U A N T F L : Sustainable Federated Learning for Edge IoT via Pre-T rained Model Quantisation Charuka Herath ∗ , Y ogachandran Rahulamatha v an † , V aruna De Silv a ‡ , Sangarapillai Lambotharan ‡ ∗ Institute of Digital T echnologies, Loughborough Uni versity , UK Email: {c.herath, y .rahulamathav an, v .d.de-silva, s.lambotharan}@lboro.ac.uk Abstract —Federated Learning (FL) enables privacy-preserving intelligence on Internet of Things (IoT) de vices but incurs a significant carbon footprint due to the high ener gy cost of frequent uplink transmission. While pre-trained models ar e increasingly a vailable on edge devices, their potential to reduce the energy overhead of fine-tuning remains underexplor ed. In this work, we propose Q UA N T F L , a sustainable FL framework that leverages pr e-trained initialisation to enable aggressi ve, computationally lightweight quantisation. W e demonstrate that pre-training naturally concentrates update statistics, allowing us to use memory-efficient bucket quantisation without the energy- intensive ov erhead of complex error -feedback mechanisms. On MNIST and CIF AR-100, Q UA N T F L reduces total communication by 40% ( ≃ 40% total-bit reduction with full-precision downlink; ≥ 80% on uplink or when downlink is quantised) while matching or exceeding uncompressed baselines under strict bandwidth budgets; BU attains 89.00% (MNIST) and 66.89% (CIF AR-100) test accuracy with orders of magnitude fewer bits. W e also account for uplink and downlink costs and pro vide ablations on quantisation levels and initialisation. Q UA N T F L delivers a practical, "green" recipe for scalable training on battery- constrained IoT networks. Index T erms —Sustainable Federated Learning, Model Quanti- sation, Signal Processing, Communication-Efficiency , Internet of Things I . I N T RO D U C T I O N Federated Learning (FL) has emer ged as a po werful paradigm for decentralised machine learning, enabling multiple devices or organisations to collaboratively train models without sharing raw data [1]. This preserves data priv acy and security while enabling knowledge sharing across clients [2]. Howe ver , despite its advantages, FL faces critical challenges in real-world deployments, such as the high communication overhead caused by transmitting large model updates or gradients to a central server . This issue becomes particularly acute in bandwidth- limited en vironments, such as edge devices or mobile networks, where communication cost dominates overall training efficiency . One promising strategy to reduce communication rounds is to initialise training with pre-trained models [3], [4]. Such models provide rich feature representations and often require fewer local updates to con ver ge, making them attracti ve for FL settings. Howev er , pre-trained models are typically large and overparameterised, and transmitting them (or their updates) still incurs high communication costs unless compression is applied. Motiv ated by classical signal processing principles, we explore quantisation as a solution to this bottleneck. In this context, model updates in FL can be vie wed as high- dimensional signals, and structured quantisation can reduce their bit-length without significantly affecting learning perfor- mance. By compressing these updates using signal-inspired quantisation techniques, we aim to enable scalable and ef ficient FL systems. In this work, we propose Q U A N T F L , a communication- ef ficient FL framework that combines partial model pre-training with structured quantisation. Specifically , Q UA N T F L applies two bucket-based quantisation schemes: bucket-uniform (BU), which partitions update values into equal-width bins [5], and buck et-quantile (BQ), which adapts bins based on empirical data distribution [6]. Then we benchmark them against a stochastic baseline, QSGD [7] and Baseline FedA vg [1]. Unlike previous works that focus primarily on quantising gradients during training, Q U A N T F L compresses full pre- trained model updates, bridging a gap between model reuse and communication-efficient FL. A. Motivation In cross-device FL, uplink bandwidth is scarce: ev ery round, each selected client must transmit a large model update. Starting from a pre-trained model changes the statistics of these updates: they become smaller and less dispersed across parameters. Intuitiv ely , pre-training puts the model in a good region, so local steps are modest. This makes simple scalar quantisation far more effecti v e: with fewer bits per parameter , we reach the same accuracy , so total communication drops sharply . Our approach: Q UA N T F L takes a pre-trained initialisation and quantises each client’ s update ev ery round, sending compact indices plus occasionally refreshed side information. In practice, this yields order-of-magnitude uplink savings while matching uncompressed accuracy , even under non-independent and identically distributed (non-IID) data. In practical application scenarios in distributed settings, devices increasingly have access to pre-trained backbones; Q UA N T F L shows how to turn that into tangible communication savings during training. B. Contributions This paper introduces Q U A N T F L , a communication-ef ficient FL framework that couples pre-trained model initialisation with range-aw are bucketed scalar quantisation of client updates. Our key contributions are: 1) Pre-training-aware compression - W e empirically show pre-training concentrates ∆ w (smaller range/v ariance), enabling fewer bits for the same distortion. 2) Simple, deployable quantizers. Range-adaptiv e BU/BQ with mid-point decoding, per -layer boundaries, and e xplicit bit accounting for uplink/downlink. 3) Robustness under heterogeneity . BU remains stable under non-IID; we include and Dirichlet- α sweeps. 4) Communication–accuracy Pareto gains. ≥ 98% bit reduc- tion at parity/better accuracy across datasets and lower loss and communication cost reduction under tight bandwidth budgets. T ABLE I L I S T O F N OTA T I O N S Symbol Description N , S k T otal clients, Selected subset at round k w k , w k i Global model, Local model of client i ∆ w Model update ( w k i − w k ) L l , B l Quantization levels, Codebook boundaries for layer l T l , α Codebook refresh period, Dirichlet-sweeps I I . R E L A T E D W O R K Communication has long been the principal bottleneck in cross-device FL due to uplink constraints and frequent synchronisation. FedA vg [1] reduces the number of rounds via local computation, but still transmits full-precision parameters each round. Stochastic/bias-controlled quantisers such as QSGD [7] and T ernGrad [8] lower bit-widths while preserving conv ergence guarantees. Unified analyses of compressed optimisation in FL characterise the role of unbiasedness, variance, and error- feedback [9], and adapti ve compression schemes further tune the communication–accuracy trade-off during training [10]. Most of these works target online gradients (per mini-batch) rather than full per-round model updates. Update sparsification (e.g., top- k ) and sign-based compres- sors are widely used to cut uplink bits; periodic aggregation and momentum correction improve their stability in heterogeneous settings (e.g., FedP A Q [11]; see also SparseFL [12] and OCT A V [13]). These methods typically produce biased updates and often require explicit error-feedback to avoid accuracy degradation under non-IID data. FL optimisation often relies on complex compressors with Error Feedback (EF), where clients store and accumulate quantisation errors to correct future updates. While theoreti- cally powerful, EF increases the local memory footprint and computational logic required on resource-constrained Internet of Things (IoT) devices, contributing to higher battery drain. W e propose that pre-training serves as a cleaner, more energy- ef ficient alternativ e to EF . [14] By initialising from a pre-trained state, update variance is naturally minimised (as sho wn in Fig. 2), enabling Q UA N T F L to achieve high-fidelity compression using simple, memory-less scalar quantisation (BU/BQ). This eliminates the need for residual error storage, offering a "greener" trade-off that maintains accuracy while minimising the computational and energy burden on the edge device. Fig. 1. Q UA N T F L pipeline. Each client quantises its per-layer update using BU (equal-width) or BQ (equal-mass) buck ets and sends only indices ; boundaries are refreshed infrequently . The server applies mid-point decoding and aggregates. Pre-training makes updates narrowly distributed, enabling aggressiv e compression with little error . Matrix-structured compressors approximate updates with low-rank or sketch-based representations [15]. They are ef- fectiv e on large dense layers but introduce additional de- composition cost and hyperparameters (rank, sketch size), and are orthogonal to the scalar bucket approach we pursue. Beyond per-round compression, systems reduce the frequency of communication (local steps, partial participation) [11], and adapt compressor strength over time [10]. Q U A N T F L is complementary: we keep standard round scheduling and reduce bits per round. Post-training quantisation (PTQ) and quantisation-aware training (QA T) reduce model size and compute for deploy- ment [6], [16], including on large backbones and V iTs [17]. These methods primarily target inference efficienc y; the y neither account for per-round communication nor exploit pre-training to compress training-time updates. W arm starts and representation learning from pre-trained models accelerate conv er gence and improve personalisation in FL [3], [4], [18]. Howe ver , these lines of work do not specifically address how pre-training changes update statistics and can be lev eraged to increase compression without harming accuracy . Despite extensi v e research on gradient compression, sparsifi- cation, low-rank/sk etching, and inference quantisation, there is limited exploration of pre-training–aw are update quantisation in FL. Q U A N T F L focuses on a simple, deployable scalar bucket quantiser applied to per-trained model updates ev ery round, with explicit accounting of index bits and boundary refresh. Our key observation, that pre-training concentrates updates (smaller range/variance), connects classical scalar quantisation principles to modern FL: a reduced dynamic range yields lower distortion for a fixed number of levels, or equiv alently , the same distortion at fewer bits. This pre-training aware perspectiv e complements prior compressors and explains the robust communication savings we observe under non-IID data. I I I . S Y S T E M M O D E L A N D P RO B L E M F O R M U L AT I O N W e consider a classical FL setup consisting of a central server and N distributed clients, indexed by i ∈ { 1 , . . . , N } . The server coordinates K communication rounds to collaboratively train a global model w ∈ R d without directly accessing clients’ local data. At the beginning of training, the server initialises the global model w 0 with a partially pre-trained model. This initialisation captures general feature representations, enabling faster con v ergence. Ho we ver , even partially pre-trained models are often large, motiv ating the need for communication-ef ficient strategies. In each communication round k ∈ { 0 , . . . , K − 1 } : The server distributes the current global model w k to a subset of selected clients S k . Each client i ∈ S k locally updates the model using its priv ate dataset D i , by optimizing a local objectiv e function: min w F i ( w ) = 1 |D i | X ( x j ,y j ) ∈D i ℓ ( w ; x j , y j ) (1) where ℓ ( w ; x j , y j ) is the loss function ev aluated on data sample ( x j , y j ) . After local training, each client obtains a local model w k i and computes the model update: ∆ w k i = w k i − w k (2) A. Communication Cost Model In standard FL without compression, the communication cost per client per round is: C baseline = 32 × d (bits) (3) assuming 32-bit floating point representation per parameter . Equation. 3 gives the uplink cost. Our tables report up- link+downlink totals, hence C baseline,total = 64 d bits per client per round (32 d uplink + 32 d downlink). W ith quantisation, each client compresses its local update before transmission. The communication cost per client is modelled as: C uplink = X ℓ d ℓ · ⌈ log 2 L ℓ ⌉ + b · L ℓ T ℓ . (4) C downlink = X ℓ d ℓ · 32 , full precision , X ℓ d ℓ l log 2 L ↓ ℓ m + b L ↓ ℓ T ↓ ℓ ! , quantised . (5) where b is the number of bits per buck et boundary , L is the number of quantisation levels, and d is the model dimensionality . The first term, b × L , accounts for the total number of bits needed to transmit L buck et boundaries (each encoded with b bits). In Equation (4) , the term P ℓ d ℓ ⌈ log 2 L ℓ ⌉ counts indices : each of the d ℓ coordinates in layer ℓ uses ⌈ log 2 L ℓ ⌉ bits. The term P ℓ b L ℓ T ℓ accounts for the codebook , which is transmitted only once e very T ℓ rounds and amortised; if endpoints are also sent, replace L ℓ with L ℓ +1 . For a full- precision downlink, C downlink = P ℓ 32 d ℓ ; otherwise apply the same index+codebook decomposition as in Equation (4). Algorithm 1 Federated Learning with Bucketed Update Quantisation (Q UA N T F L ) 1: Server initialises global model w 0 (partially pre-trained) 2: f or round k = 0 , 1 , . . . , K − 1 do 3: Server samples clients S k and broadcasts w k 4: for each client i ∈ S k in parallel do 5: Local update: train on D i to obtain w k i ; set ∆ w k i ← w k i − w k 6: Per-layer quantise: ( ˜ w i,k , {B ℓ } if refresh ) ← Q (∆ w k i ) 7: Uplink: send indices (and boundaries if this is a refresh round) 8: end for 9: Server decodes by mid-points and aggregates: w k +1 = w k + 1 |S k | X i ∈S k ˜ w i,k 10: end f or B. Pr oblem F ormulation Our objectiv e is to minimise communication costs while preserving model accuracy . Formally: min Q C quantized subject to Acc ( ˜ w ) ≥ Acc 0 − ϵ (6) where ˜ w denotes the quantized model, Acc 0 is baseline accuracy , and ϵ is a small tolerance. In our training process, each client optimises its local objective F i ( w ) using stochastic gradient descent (SGD) during local model updates. W e now introduce the proposed Q U A N T F L frame work and the associated quantisation methodologies in detail as depicted in Fig. 1. I V . M E T H O D O L O G Y : Q UA N T F L F R A M E W O R K In this section, we describe the proposed Q U A N T F L frame- work, which incorporates quantised model updates to enable communication-ef ficient FL starting from a partially pre-trained model. W e consider cross-device FL initialised from a partially pre- trained global model. In each communication round, selected clients perform local training, compress their model updates with a simple buck eted scalar quantiser, and send compact indices (plus infrequently refreshed boundaries) to the server , which reconstructs by mid-point decoding and aggregates. W e compress updates in ev ery round, not the initial model. A. Buck eted Scalar Quantisation (P er-Layer) For each layer ℓ , we quantise the update vector ov er an estimated range [ m ℓ , M ℓ ] using L ℓ disjoint buck ets with boundaries B ℓ = { b 0 , . . . , b L ℓ } , where b 0 = m ℓ and b L ℓ = M ℓ . The ordered boundary list B ℓ is the codebook shared by client and server . Each scalar entry u is replaced by its bucket index q ( u ) ∈ { 0 , . . . , L ℓ − 1 } , costing ⌈ log 2 L ℓ ⌉ bits; the server reconstructs by the interval mid-point: ˆ u = 1 2 b j + b j +1 for u ∈ ( b j , b j +1 ] . (7) Mid-point decoding is MSE-optimal within an interval for scalar quantisers. Because pre-training typically reduces the dynamic range R ℓ = M ℓ − m ℓ , the step size ∆ ℓ ≈ R ℓ /L ℓ shrinks, yielding lower distortion at fixed L ℓ (or the same distortion with fewer lev els). B. Quantiser Instantiations W e study two boundary constructions for bucketed scalar quantisation and include a stochastic comparator . Buck et-Uniform (BU): Equal-width boundaries: b j = m ℓ + j · M ℓ − m ℓ L ℓ , j = 0 , . . . , L ℓ . (8) BU is simple, robust under heterogeneity , and our default unless stated. Buck et-Quantile (BQ): Equal-mass (empirical quantile) boundaries computed from the empirical CDF of the layer updates: each bucket contains approximately the same number of coordinates. BQ adapts to peaked distributions. Stochastic Quantisation (QSGD, comparator): Follo w- ing [7], each coordinate is quantised probabilistically relative to its magnitude and a fixed number of lev els, producing an unbiased estimate. W e include QSGD as a baseline comparator rather than as part of Q UA N T F L . C. Codebook Refr esh and Bit Budget For layer ℓ , the codebook B ℓ is the ordered list of bucket boundaries that partitions the update range [ m ℓ , M ℓ ] into L ℓ intervals. W e use B ℓ = { b 0 , . . . , b L ℓ } , b 0 = m ℓ , b L ℓ = M ℓ , so there are L ℓ +1 transmitted boundary values. During uplink, clients send only indices ; the server performs mid-point decoding with c j = b j + b j +1 2 . The codebook is refr eshed infr equently (e very T ℓ rounds) and broadcast by the server; we amortise its bit cost. For BU, B ℓ is determined by m ℓ , M ℓ , and L ℓ ; for BQ, B ℓ is computed from early-round quantiles on the server (bootstrap) and then refreshed. Boundaries change slowly . W e therefore r efr esh B ℓ infre- quently (every T ℓ rounds) and amortise their cost; per-round uplink consists primarily of indices. The per-client, per-round uplink cost is C uplink = X ℓ d ℓ · ⌈ log 2 L ℓ ⌉ + b · L ℓ T ℓ , (9) where d ℓ is the number of parameters in layer ℓ and b is the precision (bits) used per transmitted boundary . W e transmit only the L ℓ internal boundaries; endpoints are recov ered from ( m ℓ , M ℓ ) . The amortised codebook cost is therefore P ℓ b L ℓ T ℓ ; if endpoints are also sent, replace L ℓ with L ℓ +1 consistently throughout. Fig. 2. Update concentration with pre-training vs. training from scratch (simulated illustration). Pre-trained updates exhibit substantially smaller dynamic range R and variance, and reduced kurtosis (shorter tails), enabling lower quantisation error at fixed L. D. Implementation Details Per-layer ranges, for BU we estimate [ m ℓ , M ℓ ] from the pre-trained snapshot and refresh ev ery T ℓ rounds; for BQ we bootstrap quantile boundaries on the server from early-round statistics and refresh infrequently . In the default settings, unless noted, we use BU with L ℓ = L for all layers and a common refresh period T ℓ = T . During the aggregation phase, we use simple averaging in Algorithm 1; dataset-size weighting can be substituted without changing the compressor . E. Con vergence and Efficiency (Qualitative) W e do not optimise (9) directly . Instead, we select ( L ℓ , T ℓ ) to bound quantisation distortion so that FedA vg con vergence behaviour is preserved. Empirically (Section V), starting from a pre-trained model concentrates updates (smaller range/v ariance), so bucketed mid-point quantisation incurs lower error for a giv en budget; this reduces the loss and total communication compared with training from scratch. BU remains stable under non-IID data. V . R E S U LT S A N D D I S C U S S I O N A. Experimental setup The experiments were conducted on a high-performance computing setup, utilising an NVIDIA R TX 6000 GPU with 48GB of VRAM, coupled with an Intel Core i9-10980 processor . W e ev aluate our approach on two standard benchmarks: MNIST and CIF AR-100. T o reflect realistic FL scenarios, we use con v olutional neural networks (CNNs): a shallow CNN for MNIST and a moderately deeper CNN for CIF AR-100, which in v olved a more intricate model architecture (ResNet-18). ResNet-18 was chosen to accommodate the complexity of the dataset with its 100 classes. Experiments simulate a federated setup with 100 users, randomly selecting 10 clients per communication round. Each client performs two epochs of local training before transmitting updates. W e compare buck et- based quantisation methods (uniform and quantile) against QSGD and a non-quantised FedA vg baseline. Quantisation: L ∈ { 64 , 128 } , boundary precision b =16 bits, boundary refresh e very T rounds (we report T ), and identical coding for uplink and (when used) downlink broadcast. Baselines and ablations: Full precision FedA vg (NQ), QSGD, BU, and BQ; ablations for pre-trained vs. scratch initialisation and for dif ferent L . Metrics: T est accuracy , uplink+downlink bits per round, and T ABLE II T R A I N I N G A N D T E S T R E S U LT S W I T H C O M M U N I C A T I O N C O S T S O N M N I S T A N D C I FA R - 1 0 0 . N Q - N O N - Q UA N T I S E D , N P - N OT - P R E - T R AI N E D , B U C K E T - Q U A N T I L E ( B Q ) , B U C K E T - U N I F O R M ( B U ) Dataset Method T rain Accuracy T rain Loss T est Accuracy T est Loss Comm. Cost (64 / 128) ↓ vs NQ MNIST Baseline (NQ, NP) 90.37% 0.2760 90.01% 0.1789 3,494,400 - BQ (Ours) 78.84% 0.7964 77.67% 0.3452 2,074,903 / 2,129,605 40.62% / 39.06% BU (Ours) 89.18% 0.5376 89.00% 0.2407 2,074,903 / 2,129,605 40.62% / 39.06% QSGD 83.44% 0.6121 82.89% 0.2340 2,129,560 / 2,184,160 39.06% / 37.50% BU (NP) 70.45% 0.8421 69.78% 0.4020 2,074,903 / 2,129,605 40.62% / 39.06% BQ (NP) 78.12% 0.5910 77.32% 0.2950 2,074,903 / 2,129,605 40.62% / 39.06% QSGD (NP) 74.54% 0.6480 73.67% 0.3150 2,129,560 / 2,184,160 39.06% / 37.50% CIF AR-100 Baseline (NQ, NP) 66.00% 1.0200 47.00% 1.3100 5,891,001 / 6,046,446 - BQ (Ours) 28.75% 1.9940 25.78% 2.0380 5,891,001 / 6,046,446 40.62% / 39.05% BU (Ours) 66.74% 1.0520 66.89% 1.2430 5,891,001 / 6,046,446 40.62% / 39.05% QSGD 41.62% 1.6110 28.90% 1.8160 6,046,257 / 6,201,272 39.06% / 37.49% BQ (NP) 24.10% 2.1010 22.50% 2.2300 5,891,001 / 6,046,446 40.62% / 39.05% BU (NP) 60.50% 1.1100 50.30% 1.3100 5,891,001 / 6,046,446 40.62% / 39.05% QSGD (NP) 38.40% 1.7000 26.20% 1.9100 6,046,257 / 6,201,272 39.06% / 37.49% T ABLE III N O N - I I D R O B U S TN E S S O N C I F A R - 1 0 0 W I T H D I R I C H L E T H E T E R O G EN E I T Y ( L =64 ) . S M A L L E R α = S T RO N G E R S K E W . α BU Acc (%) BQ Acc (%) QSGD Acc (%) 1.0 68.28 31.0 31.8 0.5 66.89 25.78 28.90 0.1 52.1 23.4 27.1 (a) Accuracy against epoch (b) Loss against epoch Fig. 3. Training loss and test accuracy curves for MNIST and CIF AR-100 under different quantisation methods. Baseline FedA vg is a non-quantised and non-pre-trained setting. con vergence behaviour across communication rounds. T able II summarises the training and test performance, as well as the communication costs, across all methods at two quantisation lev els (64 and 128 buckets). B. Simulation Results T able II shows that under tight bit budgets, BU attains the highest test accuracy among quantised methods, reaching Fig. 4. T est accuracy vs. total bits per round (per client; uplink+downlink; log x-axis) on MNIST and CIF AR-100. Downlink is full-precision in all points unless stated. 89.00% at L =64 with a per-client, per-round total of 2,074,903 bits (uplink + downlink), and 2,129,605 bits at L =128 . This corresponds to 40.62% and 39.06% reductions versus the non- quantised (NQ) baseline, respectively . QSGD trails BU at 82 . 89% with totals of 2 , 129 , 560 (64) and 2 , 184 , 160 (128), i.e., 39 . 06% and 37 . 50% reductions. BQ is less competitive on MNIST (77.67%), consistent with its sensiti vity to distrib utional tails. The NP (scratch) ablations keep the same bit budgets (compression parameters unchanged) but show the expected accuracy drop (e.g., BU (NP) 69.78%), reinforcing that pre- training improv es both stability and the accuracy–bits trade-off. On the more challenging, heterogeneous task CIF AR-100 under ResNet-18, BU remains rob ust, achieving a test accuracy of 66.89% at L =64 with 5,891,001 bits/round, and L =128 with 6,046,446 bits/round 40.62% and 39.05% below the NQ baseline, respectiv ely (T able II). BQ degrades markedly on CIF AR-100 (25.78%), and QSGD attains 28 . 90% at similar budgets, indicating that a uniform buck et allocation is more tolerant to heavy-tailed, non-IID update distributions. The NP counterparts again underperform their pre-trained versions (e.g., BU (NP) 50.30%), showing that pre-training systematically improv es final accuracy for a fixed communication budget. T able III reports a Dirichlet heterogeneity sweep at L =64 . As ske w increases ( α ↓ ), all methods degrade, but BU remains clearly ahead ( 68 . 28% at α =1 . 0 , 66 . 89% at α =0 . 5 , 52 . 1% at α =0 . 1 ), while BQ and QSGD remain substantially lower . This aligns with the design intuition: BU’ s equal-width buckets are robust when update distributions have pronounced tails, whereas BQ’ s equal-mass b uckets are more brittle under skew . Overall, (i) Pre-training helps: for a fixed bit b udget, pre- trained initialisation consistently yields higher accuracy than scratch (NP) variants on both datasets. (ii) BU is a strong default: it dominates BQ and QSGD on CIF AR-100 and is best among compressed methods on MNIST . (iii) Energy- Accuracy Trade-of fs: While complex sparsification methods exist, they often degrade performance under non-IID data, a typical scenario in IoT sensor networks. As seen in the Fig. 4, Q UA N T F L sits on the Pareto frontier of accuracy vs. cost. Although our total reduction is ≈ 40% (due to the strategic choice of preserving a robust full-precision downlink), the uplink cost, which dominates the energy consumption of IoT transmitters is reduced by orders of magnitude (from 32 bits to ≈ 6 bits per coordinate). This makes Q U A N T F L uniquely suited for sustainable deployments where uplink battery life is the primary bottleneck. Thus, Q U A N T F L demonstrates that signal processing- inspired structured quantisation, combined with partial pre- training, enables scalable and ef ficient FL suitable for bandwidth-constrained edge IoT en vironments. V I . C O N C L U S I O N W e introduced Q U A N T F L , a sustainable FL framework designed for energy-constrained Edge IoT . By starting from a pre-trained model and quantising per-layer client updates e very round using simple b ucketed scalar quantisers. The core observation is that pre-training concentrates updates, reducing their dynamic range and variance. So a small number of code lev els with mid-point decoding yields lo w distortion. In our design, clients transmit only bucket indices each round, while codebooks (boundary lists) are refreshed infrequently and their cost is amortised; the bit budget explicitly separates index bits from codebook ov erhead. Across MNIST and CIF AR-100, Q UA N T F L deli vers large uplink savings while maintaining competitiv e accuracy . The approach is simple to implement, works with standard FedA vg aggregation, and is orthogonal to other compressors (e.g., sparsification, low-rank) and to potential downlink compression. Howe ver , our ev aluation focuses on image benchmarks and moderate backbones as future works; extending to larger models/datasets and more realistic cross-device settings (partial participation dynamics, stragglers, energy constraints) is a priority . An adaptiv e policy for ( L ℓ , T ℓ ) and codebook refresh, formal analysis of pre- training induced concentration with (biased) compressors and error feedback, and quantising the downlink are promising directions. Finally , combining Q UA N T F L with personalisation and foundation-model starts may further improv e both accuracy and communication. R E F E R E N C E S [1] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Federated learning of deep networks using model averaging, ” CoRR , vol. abs/1602.05629, 2016. [Online]. A vailable: http://arxiv .org/abs/1602. 05629 [2] C. Herath, Y . Rahulamathav an, V . D. Silva, and S. Lambotharan, “Dsfl: A dual-server byzantine-resilient federated learning framework via group-based secure aggregation, ” 2025. [Online]. A v ailable: https://arxiv .org/abs/2509.08449 [3] Y . T an, G. Long, J. Ma, L. LIU, T . Zhou, and J. Jiang, “Federated learning from pre-trained models: A contrastive learning approach, ” in Advances in Neural Information Pr ocessing Systems , S. Ko yejo, S. Mohamed, A. Agarwal, D. Belgrav e, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 19 332–19 344. [Online]. A vailable: https://proceedings.neurips.cc/paper_files/paper/ 2022/file/7aa320d2b4b8f6400b18f6f77b6c1535- Paper- Conference.pdf [4] W . Mohamad, O. Hakima, T . Chamseddine, M. Azzam, and G. Mohsen, “Priv acy-preserving continuous authentication for mobile and iot systems using warmup-based federated learning, ” IEEE Network , pp. 1–7, 2022. [5] A. Gersho and R. M. Gray , “V ector quantization and signal compression, ” Springer , 1992, chapter on Scalar Quantization. [6] Y . Zhou, S. Moosavi-Dezfooli, N. Cheung, and P . Frossard, “ Adaptive quantization for deep neural network, ” CoRR , vol. abs/1712.01048, 2017. [Online]. A v ailable: http://arxiv .org/abs/1712.01048 [7] D. Alistarh, J. Li, R. T omioka, and M. V ojnovic, “QSGD: randomized quantization for communication-optimal stochastic gradient descent, ” CoRR , vol. abs/1610.02132, 2016. [Online]. A v ailable: http://arxiv .org/abs/1610.02132 [8] A. Abdi and F . Fekri, “Quantized compressiv e sampling of stochastic gradients for efficient communication in distributed deep learning, ” Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 34, no. 04, pp. 3105–3112, Apr . 2020. [Online]. A vailable: https://ojs.aaai.org/inde x.php/AAAI/article/view/5706 [9] F . Haddadpour, M. M. Kamani, A. Mokhtari, and M. Mahdavi, “Federated learning with compression: Unified analysis and sharp guarantees, ” in Pr oceedings of The 24th International Conference on Artificial Intelligence and Statistics , ser . Proceedings of Machine Learning Research, A. Banerjee and K. Fukumizu, Eds., vol. 130. PMLR, 13–15 Apr 2021, pp. 2350–2358. [Online]. A vailable: https://proceedings.mlr .press/v130/haddadpour21a.html [10] S. Reddi, Z. Charles, M. Zaheer, Z. Garrett, K. Rush, J. Kone ˇ cný, and S. Kumar , “ Adaptive federated optimization, ” in International Conference on Learning Representations (ICLR) , 2021. [11] A. Reisizadeh, A. Mokhtari, H. Hassani, A. Jadbabaie, and R. Pedarsani, “Fedpaq: A communication-efficient federated learning method with periodic av eraging and quantization, ” CoRR , vol. abs/1909.13014, 2019. [Online]. A v ailable: http://arxiv .org/abs/1909.13014 [12] M. Kim, W . Saad, M. Abdelkader , and C. S. Hong, “SpaFL: Communication-efficient federated learning with sparse models and low computational overhead, ” 2024. [Online]. A vailable: https: //openrevie w .net/forum?id=DZyhUXpEee [13] Z. Bozorgasl and H. Chen, “Communication-efficient federated learning via clipped uniform quantization, ” in 2025 59th Annual Conference on Information Sciences and Systems (CISS) , 2025, pp. 1–6. [14] T . Li, A. K. Sahu, A. T alwalkar , and V . Smith, “Federated learning: Challenges, methods, and future directions, ” IEEE Signal Pr ocessing Magazine , vol. 37, no. 3, pp. 50–60, 2020. [15] T . V ogels, S. P . Karimireddy , and M. Jaggi, “Powersgd: Practical low-rank gradient compression for distributed optimization, ” CoRR , vol. abs/1905.13727, 2019. [Online]. A vailable: http://arxiv .org/abs/1905. 13727 [16] A. Gholami, S. Kim, Z. Dong, Z. Y ao, M. W . Mahoney , and K. Keutzer , “ A survey of quantization methods for efficient neural network inference, ” CoRR , vol. abs/2103.13630, 2021. [Online]. A vailable: https://arxiv .org/abs/2103.13630 [17] X. Li, S. Chen, and C. Dong, “Ptq4vit: Post-training quantization for vision transformers, ” in Proceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2022. [18] S. Y ue, Z. Qin, Y . Deng, J. Ren, Y . Zhang, and J. Zhang, “ Augfl: Aug- menting federated learning with pretrained models, ” IEEE T ransactions on Networking , pp. 1–16, 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment