다단계 흐름 스케줄링으로 LLM 서비스 TTFT 향상
본 논문은 대규모 언어 모델(LLM) 서비스에서 첫 토큰 응답 시간(TTFT)을 보장하기 위해, KV‑캐시 재사용·집합 통신·프리필‑디코드 전송이라는 세 단계가 겹치는 네트워크 흐름을 통합적으로 관리하는 MFS(Multi‑stage Flow Scheduling) 기법을 제안한다. LLF(Least‑Laxity‑First) 정책을 근사하는 ‘연기‑및‑승격(Defer‑and‑Promote)’ 원리를 Reverse Multi‑Level Queue(R…
저자: Yijun Sun, Xudong Liao, Songrun Xie
1. **연구 배경 및 문제 정의**
대규모 언어 모델(LLM)은 프리필(pre‑fill) 단계와 디코드(decode) 단계로 구성되며, 첫 토큰을 생성하기 위한 TTFT(Time‑to‑First‑Token) 응답 시간이 서비스 품질(SLO)의 핵심 지표이다. 최신 서비스 시스템은 KV‑캐시 재사용, 모델 병렬성을 위한 집합 통신, 그리고 프리필 결과를 디코드 유닛으로 전달하는 P2D 전송이라는 세 단계의 네트워크 흐름을 겹쳐 사용한다. 이러한 다단계 흐름은 동일 링크에서 intra‑request(동일 요청 내)와 inter‑request(다중 요청 간) 컨텐션을 일으키며, 기존의 단계‑무관 흐름 스케줄러는 이러한 의존성을 무시해 TTFT 지연과 SLO 위반을 초래한다.
2. **기존 접근법의 한계**
전통적인 흐름/코플로우 스케줄링(Fair‑Sharing, SJF, EDF 등)은 개별 흐름의 완료 시간이나 마감시간을 최적화하지만, LLM 서비스와 같이 여러 단계가 연쇄적으로 영향을 미치는 경우에는 전체 TTFT를 보장하지 못한다. 또한, 집합 통신 전용 최적화와 KV‑캐시 전송 전용 최적화가 각각 독립적으로 적용돼, 서로 다른 단계 간에 경쟁을 유발한다.
3. **MFS 설계 목표**
MFS(Multi‑stage Flow Scheduling)는 “전체 TTFT 마감시간을 단계별 마감시간으로 점진적으로 분해”한다는 핵심 아이디어에 기반한다. 목표는
- 슬랙(laxity)이 적은 흐름에 우선순위를 부여해 TTFT 마감시간을 만족,
- 슬랙이 풍부한 흐름이 네트워크 대역폭을 과도하게 차지하지 않도록 억제,
- 구현 복잡성을 최소화해 기존 LLM 서빙 스택(vLLM, NCCL, Mooncake 등)과 호환성을 유지하는 것이다.
4. **핵심 알고리즘: Defer‑and‑Promote & RMLQ**
MFS는 LLF(Least‑Laxity‑First) 정책을 근사한다. 정확한 슬랙을 알 수 없으므로, 흐름을 초기에는 낮은 우선순위 큐에 배치하고, 네트워크 링크 이용률(Minimal Link Utilization, MLU)이 사전 정의된 임계값을 초과하면 해당 흐름을 상위 큐로 승격한다. 이 구조를 Reverse Multi‑Level Queue(RMLQ)라 부른다.
- **Defer**: P2D 흐름은 최소한의 대역폭만 할당받아 “연기”된다.
- **Promote**: MLU가 임계값을 넘으면 흐름을 승격시켜, 남은 슬랙이 감소한 흐름이 먼저 전송되도록 한다. 승격은 레이어 단위로만 수행해 급격한 우선순위 변동을 방지한다.
5. **두 단계 스케줄링 전략**
① **Intra‑request**: 동일 프리필 유닛 내에서는 집합 통신을 먼저 수행해 후속 계산을 언블록하고, KV‑캐시 전송은 해당 단계가 병목이 될 경우에만 승격한다.
② **Inter‑request**: 여러 프리필 유닛 간에는 TTFT 마감시간 순으로 요청을 정렬하고, feasibility check을 통해 불가능한 흐름을 사전에 차단한다. 이는 “슬랙이 명확하지 않은 초기 단계”에서도 전체 시스템이 마감시간을 만족하도록 만든다.
6. **시스템 구현**
MFS는 가벼운 어댑터 레이어를 통해 NCCL·Mooncake와 연동한다. 어댑터는 호스트‑사이드 소프트웨어 큐에 흐름을 삽입하고, 우선순위 정보를 DSCP 값으로 매핑해 스위치 레벨 QoS와 연결한다. 이를 통해 패킷 재정렬 없이 하드웨어 우선순위 큐를 활용할 수 있다. vLLM 엔진에 플러그인 형태로 삽입돼, 기존 코드베이스를 크게 변경하지 않아도 된다.
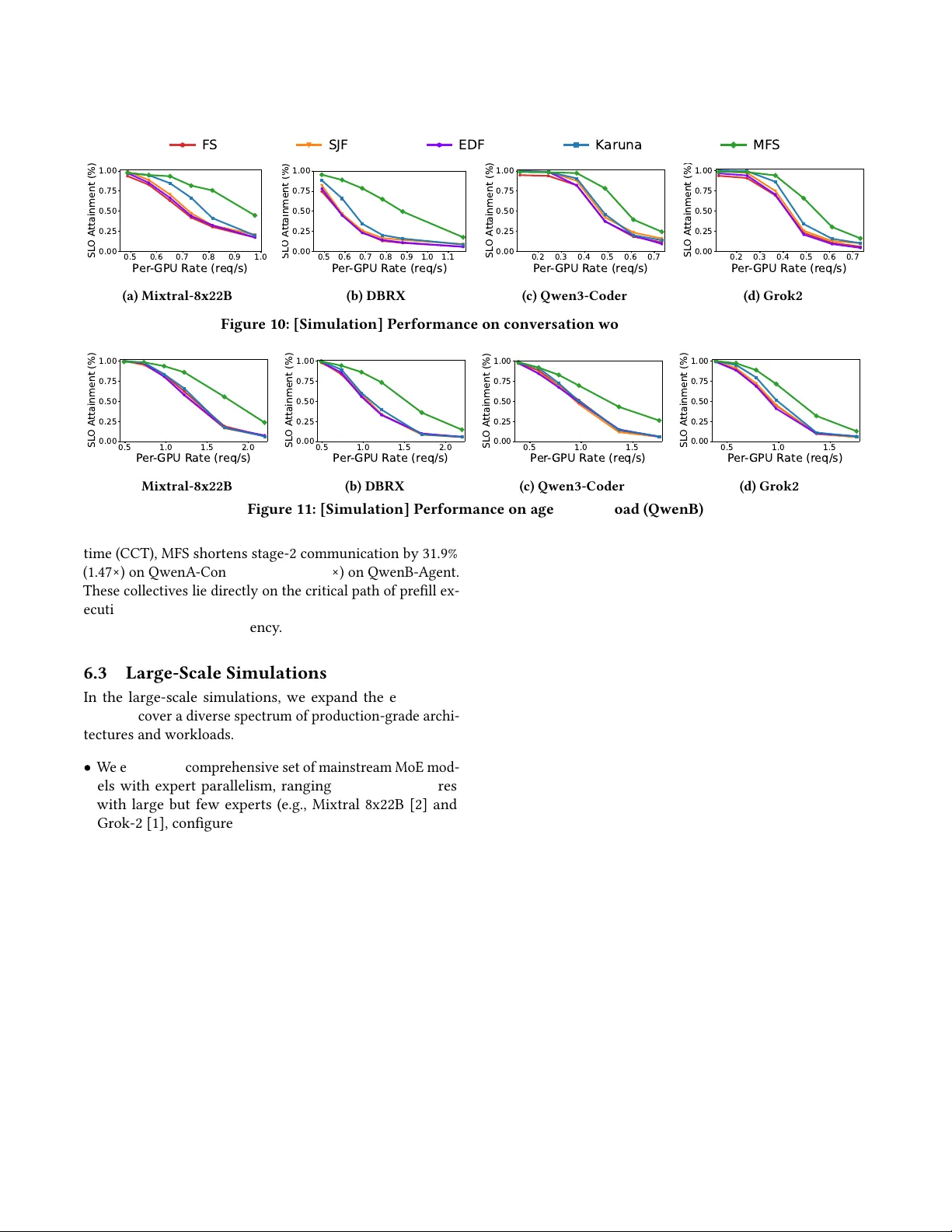
7. **실험 설정 및 결과**
- **베드 테스트**: 8서버·32GPU(NVIDIA 3090) 환경, 16 Mellanox NIC, 단일 Top‑of‑Rack 스위치 사용. QwenB‑agent 워크로드(평균 1k 토큰, 65% 프롬프트 재사용)로 평가.
- **성과**: MFS 적용 시 TTFT SLO 달성률이 1.2×‑2.4× 향상, All‑to‑All 집합 통신 시간 평균 50% 감소, 요청 조기 완료 비율 크게 증가.
- **시뮬레이션**: MoE 모델 4종(대표적인 대규모 모델)으로 대규모 시뮬레이션 수행, 동일하게 기존 스케줄러 대비 1.3×‑2.1× SLO 달성률 향상 확인.
8. **논의 및 한계**
MFS는 링크 이용률 기반 임계값에 크게 의존한다. 트래픽 패턴이 급변하거나 링크 이용률이 비정상적으로 변동할 경우, 임계값을 동적으로 조정하는 메커니즘이 필요하다. 또한, 하드웨어 우선순위 큐 수가 제한된 경우 RMLQ 깊이를 조절해야 하는 trade‑off가 존재한다.
9. **미래 연구 방향**
- 머신러닝 기반 슬랙 예측 모델을 도입해 보다 정밀한 LLF 근사,
- 다중 스위치 경로 최적화와 엔드‑투‑엔드 QoS 연계,
- GPU‑NIC 직접 통신(RDMA)과 결합해 네트워크 스택을 단순화하고 레이턴시를 최소화,
- 다양한 서비스 시나리오(멀티‑턴 대화, 연속 토큰 생성)에서의 적용 가능성 탐색.
10. **결론**
MFS는 LLM 서비스에서 다단계 네트워크 흐름을 전역적으로 조정함으로써 TTFT 마감시간을 효과적으로 보장한다. LLF 근사와 RMLQ 기반 Defer‑and‑Promote 메커니즘은 구현이 간단하면서도 기존 인프라와 호환 가능하며, 실험과 시뮬레이션 모두에서 기존 스케줄링 기법을 크게 능가한다. 이는 차세대 대규모 AI 서비스가 요구하는 초저지연 응답을 실현하기 위한 중요한 설계 원칙을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기