Multi-stage Flow Scheduling for LLM Serving
Meeting stringent Time-To-First-Token (TTFT) requirements is crucial for LLM applications. To improve efficiency, modern LLM serving systems adopt disaggregated architectures with diverse parallelisms, introducing complex multi-stage workflows involv…
Authors: Yijun Sun, Xudong Liao, Songrun Xie
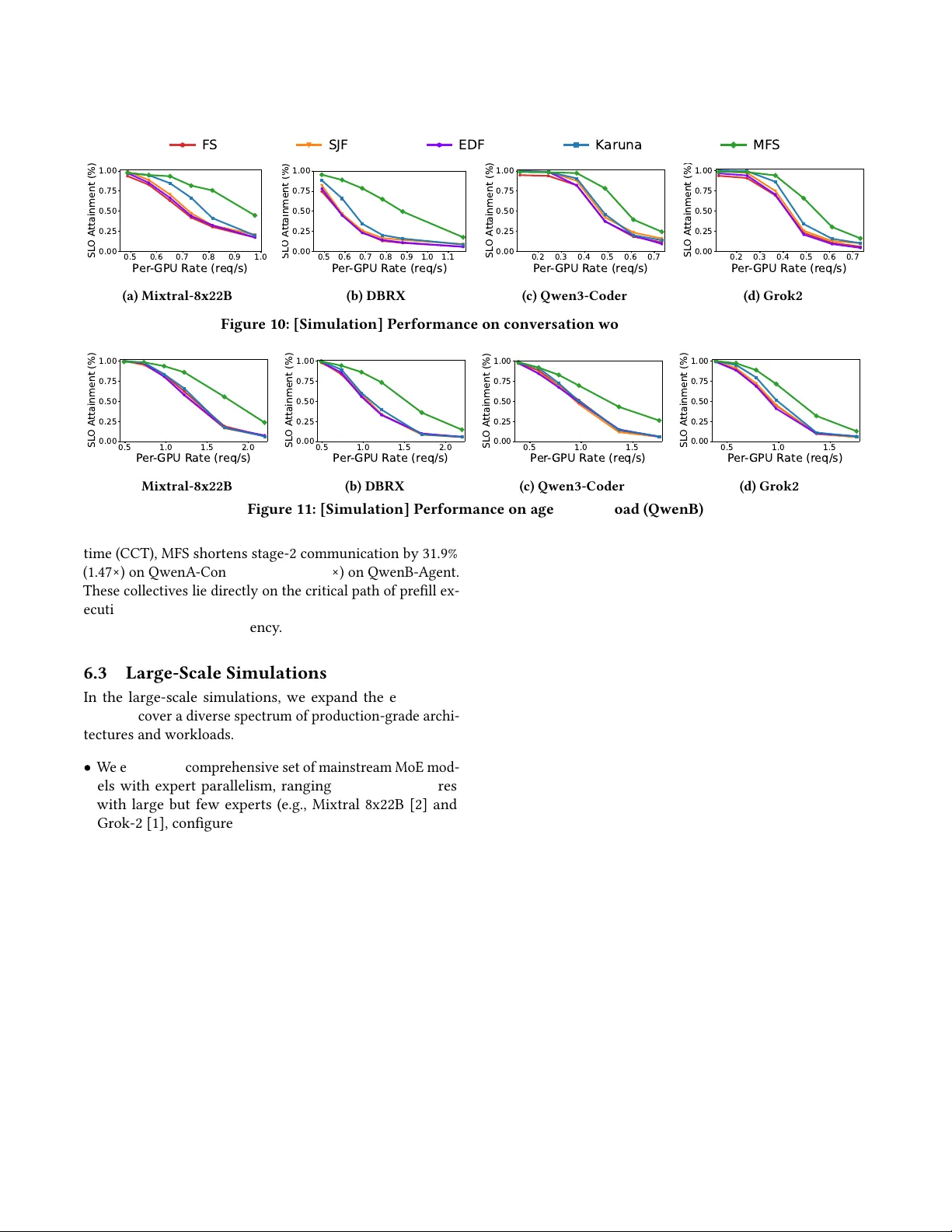
Multi-stage Flow Scheduling for LLM Ser ving Yijun Sun 1 Xudong Liao 1 Songrun Xie 1 Hao Chen 2 Han Tian 3 W enxue Li 1 Yiming Zhang 2 Kai Chen 1 1 iSING Lab , Hong K ong University of Science and T echnology 2 Shanghai Jiao T ong University 3 University of Science and T e chnology of China ABSTRA CT Meeting stringent Time- T o-First- T oken (T TFT) requirements is crucial for LLM applications. T o improve eciency , mod- ern LLM serving systems adopt disaggregated architectures with diverse parallelisms, introducing complex multi-stage workows involving r eusable KV-block retrie val, collective communication, and P2D transfer . Flows from dependent stages overlap within and across requests on shared bot- tleneck links, making T TFT highly susceptible to network contention and necessitating stage-aware scheduling. Un- fortunately , most existing w orks schedule ows in a stage- agnostic manner , leading to uncoordinated contention that constitutes a primary cause of SLO violations. In this paper , we present MFS, a holistic m ulti-stage f low s cheduling me chanism designed to maximize T TFT SLO attainment. At its core, MFS appr oximates the Least-Laxity- First (LLF) scheduling policy without requiring precise knowl- edge of a request’s remaining slack. It achieves this through a Defer-and-Promote principle implemented through a Reverse Multi-Level Queue (RMLQ) structure. By dynamically pro- moting task precedence as eective laxity diminishes, MFS prioritizes ows with less laxity while pr eventing requests with loose SLOs from prematurely consuming netw ork band- width. W e implement MFS as a pluggable module integrated into vLLM, and evaluate it on a 8-server , 32-GP U testb ed as well as through large-scale simulations. Our results demon- strate that MFS ee ctively outperforms state-of-the-art base- lines, improving the T TFT SLO attainment by 1.2 × –2.4 × . 1 IN TRODUCTION The rapid advancement of large language models (LLMs) has spawned a wide range of use cases, including interactive chatbots [ 20 , 65 , 101 ], code assistants [ 47 , 105 ], and agentic systems [ 27 , 81 , 95 ]. Modern serving systems must sustain massive request volumes while adhering to heter ogeneous service-level objectives (SLOs) [ 18 , 29 , 67 , 76 , 99 ] to meet stringent performance expectations. Among these metrics, time-to-rst-token (T TFT) remains particularly critical, as it governs both the responsiveness r equired for interactive users [ 25 , 87 ] and the strict timing constraints of agentic pipelines [ 37 , 45 , 57 ]. Violations of T TFT targets often trigger Deadline Tr a d i t i o n a l Flow / Coflow Multi - stage Flow Figure 1: Illustration of dierence between Multi-stage Flow Scheduling and prior stage-agnostic scheduling. repetitive request retries [ 52 , 53 ], leading to unnecessary resource consumption [ 70 ] and signicant revenue loss [ 73 ]. Modern LLM serving systems typically adopt disaggre- gated prell–decode architectures with K V -cache reuse [ 26 , 31 , 32 , 66 , 69 , 79 , 93 , 106 ] and leverage diverse forms of par- allelism [ 9 , 38 , 46 , 98 ] to improve eciency . Despite their promise, they still suer from substantial communication overhead during the prell phase. Sp ecically , generating the rst token involves multi-stage communication: (1) remote retrieval of r eusable K V -blocks, (2) colle ctive communication for the synchronization of intermediate activations, and (3) Prell-to-Decode (P2D) transfer . Flows from dierent stages frequently overlap and contend for shared network fabrics, which leads to intra-request contention , where dierent com- munication phases within the same request interfere with each other , and inter-request contention , where communi- cation from dierent batches or prell units competes for shared links. Such contention signicantly inates prell T TFT latency and heightens the risk of system-wide SLO violations. Unfortunately , prior works fail to meet end-to-end dead- lines under contention (Figure 1), largely because they treat ow in stage-agnostic manner (i.e., without awareness of their stage dependencies). Traditional ow scheduling schemes (e .g., Fair Sharing [ 7 , 107 ], SJF [ 8 , 10 , 28 , 41 ], EDF [ 28 , 83 , 88 ], etc.) operate on individual ows without holistic view . Even coow-based approaches [ 4 , 21 , 22 , 86 , 97 , 100 ] fall short: while they manage data-parallel ows as a group, they ig- nore the inherent dependencies across stages. Consequently , these schemes may over-prioritize early-stage communica- tion or starve latency-critical downstream stages, ultimately degrading T TFT SLO attainment. 1 T o this end, we ask: Can we schedule multi-stage communi- cation holistically in LLM ser ving systems to maximize ov erall T TFT SLO attainment? When exploring the design space, we note distinct ef- forts that optimize isolated stages, targeting either collec- tive communication [ 15 , 16 , 72 , 77 , 91 ] or K V -cache trans- fers [ 19 , 51 , 69 , 79 ]. Howev er , these specialized solutions remain insucient. The reason is that they often pursue conicting optimization objectives, naively combining them can inadvertently amplify network contention. W e answer this question armatively with MFS, a holistic multi-stage communication scheduler that jointly orches- trates dependent communication stages to maximize T TFT SLO attainment. Our key insight is that the global T TFT deadline can be gradually translated into explicit ow-level deadlines as prell execution progresses. Lev eraging this in- sight, MFS approximates the Least-Laxity-First (LLF) policy under uncertainty and r ealizes a Defer-and-Promote principle via a Reverse Multi-Level Queue (RMLQ). By dynamically promoting task pr ecedence based on diminishing eective slack, MFS prioritizes genuinely critical stages while prevent- ing requests with loose SLOs from prematur ely consuming network bandwidth. Although our insight is straightforward, translating it into an ecient, real-world system requires addressing several non-trivial challenges. First, how to schedule last-stage com- munications with explicit deadline without incurring ex- cessive prioritization? Second, how to schedule early-stage ows go verned by implicit T TFT bound under uncertain lax- ity? Third, how to ensure MFS’s compatibility with emerging collective communication and KV -cache libraries? For the rst challenge, we employ a lazy promotion strat- egy leveraging Minimal Link Utilization (MLU) as the trigger . P2D o ws initialize in low-priority queues and are pr omoted only when their MLU exceeds a predened threshold. This ensures that P2D ows receive only the minimum bandwidth for just-in-time completion, preser ving bandwidth headroom for early-stage communications. T o avoid priority thrashing, promotions occur only at layer granularity . This approach enables eective coarse-grained prioritization while facilitat- ing practical implementation on commodity switches with hardware priorities queues and lightweight packet tagging, thereby eliminating the risk of packet re-ordering. T o address the second issue, w e utilize a two-tier sched- uling strategy . For intra-request contention within a single prell unit, we prioritize collective communication that un- block subsequent computation, while elevating K V -cache transfers only when they threaten to stall the next lay er’s e x- ecution. For inter-request contention across the prell cluster , we order units based on T TFT deadlines and apply feasibility checks to prune infeasible communication tasks to avoid blocking. This design prevents pr emature promotion when GPU x8 DRAM NIC GPU x8 DRAM NIC GPU x8 DRAM NIC Prefill pool Decode poo l Decode unit Network Global request scheduler GPU x8 DRAM NIC PD disagg GPU x8 DRAM NIC KV cache re use Prefill unit TP/PP/EP/S P Figure 2: Illustration of LLM ser ving at scale. laxity is unclear , while keeping early-stage communication aligned with downstream T TFT requirements. Finally , to ensure compatibility , MFS integrates with exist- ing stacks (e.g., NCCL [ 60 ], Mooncake [ 36 ]) via lightweight task adapters. These adapters intercept tasks for precise host- side prioritization in software queues, while mapping priori- ties to DSCP values for robust trac isolation on switches. By employing hybrid priority enforcement, MFS ensures seam- less integration and eective contention resolution using standard network primitives. W e build a MFS prototype and evaluate it on a 8-ser ver testbed with 32 N VIDIA 3090 GP Us [ 59 ], 16 Mellanox NICs [ 61 ], all connected to a single T op-of-Rack (T oR) switch. W e imple- ment MFS as a pluggable module into NCCL and Mooncake, and integrate it with the vLLM inference engine. Using this prototype, we successfully demonstrated the b enets of MFS on the state-of-the-art LLM [3]. T o evaluate the performance of MFS at scale , we further perform large-scale simulations using four representative real-world MoE models [ 1 , 2 , 23 , 71 ]. Our results reveal that MFS signicantly outp erforms state-of-the-art scheduling schemes, improving the T TFT SLO attainment rate by 1.2 × - 2.4 × compared to baselines. W e also obser ve that MFS cutting down non-overlapped colle ctive completion time by 50 % and also improving the request earliness greatly . 2 BA CKGROUND AND MOTI V A TION 2.1 LLM Ser ving and T TFT Large language models have b ecome the foundation of mod- ern AI services. These models are inherently autoregressive: the system rst processes the entire prompt to generate the rst token (the prell stage), and then produces subse- quent tokens iteratively using the accumulated K V cache (the decode stage). Performance is typically characterized by Time-to-First- T oken (T TFT) for the prell phase and Time- Between- T okens (TBT) for the decode phase. T TFT is a critical service-level objective (SLO) for many LLM applications. In interactive scenarios like chatbots and voice assistants, users expect an immediate initial response, 2 GPU x8 GPU x8 GPU x8 GPU x8 leaf spine GPU x8 leaf GPU x8 leaf Prefill unit: 32 G PUs, 4 node EP = 32, DP = 4 Prefill unit EP = 32, DP = 4 Decode unit EP=64, DP=8 Stage - 1: KV cach e reuse Stage - 2: SP /EP Stage - 3: P2D Contention Bottleneck Li nk Flow A Flow B Flow C Stage -1 Stage -2 Stage -3 Figure 3: An example illustrating communication con- tention in LLM ser ving systems: K V cache transfers (Stage 1 & 3) and parallelism communication (Stage 2) compete for the same link bandwidth. and some studies indicate noticeable disengagement when la- tency exceeds a few hundr ed milliseconds and abandonment beyond seconds [ 35 , 49 , 84 ]. T TFT is also vital for automatic agentic frameworks, which rely on strict timeouts [ 37 , 45 ] for fault tolerance. A delay ed rst token triggers costly re- medial actions such as ser vice retries [ 52 , 53 ] or provider switching [ 57 ]. A recent report from Microsoft [ 73 ] reveals that the delayed rst token is one of the primary source ( ∼ 40% ) of ser vice failur e (reported as timeout error ), leading to revenue loss, higher support costs, and reputational risk. As depicted in Fig. 2, mo dern production systems [ 46 , 70 ] scale out to clusters comprising thousands of nodes intercon- nected with high-bandwidth links, where each node contains multiple xP Us (e.g., GP Us, TP Us, NP Us). Nodes are organized into individual serving units, each dedicated to host one model replica. Models are deploy ed using a combination of tensor [ 56 ], pipeline [ 55 , 102 ], sequence [ 48 , 89 , 92 ], and ex- pert parallelism [ 9 , 38 , 46 , 98 ]. T o further optimize eciency , recent work [ 32 , 66 , 79 , 106 ] proposes prell–decode disag- gregation , which assigns prell tasks to compute-optimized devices and decode tasks to memor y-rich devices, thereby ac- commodating their heterogeneous resource demands. In ad- dition, KV cache reuse [ 26 , 31 , 69 , 93 ] has been introduced to amortize prell costs across requests by transferring cached contexts between nodes. 2.2 Contention Across Multi-Stage Communication Generating the rst token in existing production systems (Fig. 2) consists of multi-stage communications: • Stage 1: KV-cache reuse : fetches reusable K V -cache blo cks from remote prell unit; • Stage 2: Collective communication : exchanges inter- mediate activations across devices via model parallelism; • Stage 3: Prell-to-Decode (P2D) transfer : delivers the full KV-cache history to the decode unit 1 . Prior literature has highlighted the substantial o verhead of individual stages, noting that collective communication (e .g, all-to-all, etc.) occupy 40–60% of end-to-end latency [ 39 , 40 , 92 , 98 ] and KV -cache movement contributes a non- trivial share [ 19 , 42 , 51 , 70 , 94 ]. In this paper , we further identify a critical yet underexplored problem: collective com- munication and KV -cache movement frequently o verlap in time and contend for shared network bandwidth. Fig. 3 illus- trates the spatial location of contention: K V -cache transfers (Stage 1&3) and collective communication (Stage 2) traverse shared physical interconnects. This spatial co-location cre- ates two primary forms of contention, as shown in Fig. 4: • Intra-request contention occurs when communication ows interfere within a single r equest. Specically , layer- wise K V -cache transfers (Stage 1&3) compete directly with the ongoing collective communication on other layers (Stage 2) for shared link bandwidth. • Inter-request contention arises when concurrent re- quests from dierent prell units interfere, resulting in frequent link competition in the switch links. Moreover , driven by skew ed block popularity , multiple prell units may converge on a single remote victim unit to fetch “hot” KV blo cks, causing contention between the victim unit’s local collective communication (Stage 2) and remote KV - cache fetching on its NIC bandwidth (Stages 1&3). T o quantify the performance degradation caused by such interference, we conduct measur ements on a 16-GP U prell cluster (50 Gbps/GP U) hosting two ser ving instances ( 𝑇 𝑃 = 1 , 𝐸 𝑃 = 8 ). W e use QwenB-agent, an agent workload from production-derived Qwen traces [ 6 ], with average sequence length 1k tokens, 65% prompt reuse, and per-GP U request rate 1 r e q/s; the full testbe d setup is describe d in Sec. 6.2. W e evaluate the impact of contention on two metrics: end-to-end T TFT and colle ctive communication time (CCT) of All-to- All operations (aggregating Dispatch and Combine phases). Specically , we perform a comparative analysis b etween an ideal baseline ( w/o contention ) and a realistic ser ving scenario ( w/ contention ). Fig. 5a illustrates the T TFT distribution. The results reveal that, under contention, the ov erall T TFT is prolonged by nearly 50% . W e attribute this ination primarily to the latency degradation in All-to- All communication on the critical path, whose CCT nearly doubles ( 1 . 8 × ) due to contention with concurrent K V -cache operations (as shown in Fig.5b). This substantial slowdown conrms that network contention is a major source of performance variability in the prell phase. 1 Mainstream open-source serving frameworks [ 63 , 74 , 85 ] explicitly incor- porate Stage 3 latency into the T TFT metric. 3 Case - 1: Intra - req ue st contention Case - 2: Inter - re qu es t contention Timeline R1 arrive KV 1 PD 1 EP 1 KV 3 La yer -1 La yer -3 L 1 L 2 L 3 EP 3 PD 3 R1 KV i PD i EP i R1 La yer -i L i L j L k KV 2 EP 2 La yer -2 PD 2 L i Prefill la yer -i (R1) L j Other req ue st’s Pre fil l layer - j (R2) L k Other instance’ s prefill lay er - k (R3 ) Comp . KV cache reus e / EP / Pref ill to decode of R1 EP i KV i PD i EP 1 KV j / EP j / PD j KV cache reus e / EP / Pref ill to decode of R2 KV cache reus e / EP / Pref ill to decode of R3 KV k / EP k / PD k Comm. KV k R3 La yer -k EP k PD k R2 R3 EP j R2 La yer -j PD j KV j Same instanc e Figure 4: Illustration of two primary forms of contention in LLM ser ving systems. 0.0 0.5 1.0 1.5 2.0 Nor malized T TF T 0 2 4 6 R elative F r equency (%) w/ Contention w/o Contention (a) Impact of contention on end-to-end T TFT . 0 20 40 60 80 100 Collective Completion T ime (ms) 0.0 0.2 0.4 0.6 0.8 1.0 CDF w/ Contention w/o Contention (b) Impact of contention on all-to-all latency . Figure 5: [T estbed] Impact of communication con- tention on Mixtral 8x7B model. 2.3 Limitation of Existing W ork The previous analysis identies unmanaged multi-stage com- munication contention as a primary source of T TFT viola- tions. W e categorize existing approaches into two groups: recent system-level communication optimizations and con- ventional scheduling algorithms. As detailed below , they both fall short in coordinating such contention due to the lack of a holistic view of multi-stage dependencies. Stage-agnostic o w scheduling. Conventional datacenter scheduling disciplines manage ows or coows individually to optimize network metrics, such as o w/coow completion time or deadline satisfaction. Howev er , these objectives are misaligned with end-to-end application goals (e.g., T TFT attainment), because T TFT is jointly determined by ows across multiple interdependent stages. Consequently , these approaches inevitably over-prioritize slack-rich ows while starving the critical transfers required to unlo ck downstream computation, ultimately degrading T TFT SLO attainment. Specialized optimization for isolated stages. W e no- tice some distinct eorts optimize isolate d stages, spe ci- cally targeting collective communication via algorithm syn- thesis [ 16 , 34 , 50 , 75 ], parameter tuning [ 91 ], and overlap- ping [ 46 , 98 , 103 , 104 ], or K V -cache transfers via pipelined prefetching [ 66 , 69 ] and block coalescing [ 19 , 42 , 79 ]. How- ever , these mechanisms often pursue conicting objectives. Many achieve speedups by increasing communication con- currency to hide latency , yet none coordinates this concur- rency across communication typ es. As a result, even with these optimizations, collective communication and K V -cache transfers often interfere with one another , which instead am- plies contention. 3 METHODOLOGY 3.1 Problem Formulation Simplied Abstraction. Without loss of generality , w e con- sider a single pr ell request processing thr ough 𝐿 sequential Transformer lay ers. The communication workload for each layer can be generally abstracted as Multi-stage Flow (Ms- Flow). An MsFlow consists of three temporally dependent stages, where each stage constitutes a set of ow (or coow) governed by the layer’s lifecycle , which is detailed below: • Stage 1: Initialization. Involves KV -cache reuse to trans- fer prerequisite states. This loosely couple d ow often overlaps with prior layer’s computation to hide latency . • Stage 2: Execution. Consists of colle ctive communication (e .g., alltoall) that strictly blocks the subse quent computa- tion. • Stage 3: Completion. Handles the P2D transfer of results to de coding workers. This dictates the nal token avail- ability without blocking the current prell computation. For a single request, MsFlows collectiv ely share one T TFT deadline and may partially overlap subject to layer dep en- dency (e.g., Stage 2 of layer 𝑙 must complete before computing layer 𝑙 + 1 ) Contention dynamics. Contention arises when concur- rent MsFlows comp ete for shared netw ork bandwidth. Recall Fig 4, intra-request contention occurs between MsFlows of dierent layers within the same request, while inter-request contention arises b etween MsFlows of distinct requests. Both 4 L1 L2 (c) Shortest job f irst (d) Defer - and - Promote 1 1 1 1 1 1 2 2 1 (b) Fair sharin g / Earliest deadline first (a) Pre fill D AG Reuse Under - utilization (bubble) Deferral L2 starts (T=3) L2 starts (T=3) L2 starts (T=2) Collective Communication Under - utilization ( Throttling) Figure 6: Comparison of scheduling policies for intra- request contention (ingress). (a) Ingress port con- tention during Layer-1 execution. ( b)-(c) FS/SJF/EDF delays the start of Layer-2 ( 𝑇 = 3 ). (d) The Defer-and- Promote strategy advances the Layer-2 start time to 𝑇 = 2 ( -33%). 2 2 1 1 1 1 1 1 1 1 1 1 L1 L2 (a) Pre fill D AG (b) Fair sharin g (c) Shortest job fir st / Earliest deadline first (d) Defer - and - Promote P2D Under - utilization (blocking) Deferral La yer ex ecution L2 ends (T=4) L2 ends (T=3) L2 ends (T=4) Computation Figure 7: Comparison of scheduling policies for intra- request contention (egress). (a) Egress port contention during Layer-2 execution. ( b)-(c) FS/SJF/EDF delays the end of Layer-2 ( 𝑇 = 4 ). (d) The Defer-and-Promote strat- egy reduces the Layer-2 nish time to 𝑇 = 3 ( -25%). cases simply reduce to contention between heterogeneous stages. Overall Objective. The goal is to meet end-to-end T TFT deadline (SLO attainment) rather than optimizing individual ow latencies. Specically , we must orchestrate the depen- dent MsF lows to ensure that all 𝐿 MsFlows are completed within the deadline constraint. T o achieve this, an ideal sched- uler must balance two complementary obje ctives tailored to the specic semantics of MsF low stages: (i) Minimizing Non-overlapped communication La- tency . For early stages (1&2), completing to o late di- rectly prolongs the current layer’s execution time, post- poning the release of the subsequent layer . (ii) Minimizing Earliness. For the nal Stage 3, complet- ing too early yields no gain for me eting deadline but exacerbates potential network contention. 3.2 Ke y Obser vation and Scheduling Principle Achieving optimality is theoretically intractable [ 11 , 12 ]. T o derive an eective heuristic, we rst look into the execution dynamics of prell. Our analysis reveals a structural prop- erty of request deadlines that motivates scheduling principle presented in this section. T able 1: An inter-request contention example. Req ID Flow ID Flow Size Remain time Deadline 1 A 2 9 18 2,3 B 4 6 12 4 C 3 0 7 A B C 18 6 7 8 9 12 15 Req 1 6 9 Req 2&3 9 Req 4 8 Bottleneck bandwidth A ends B ends C ends Fail Fail 6 Earliness (a) Fair Share Bottleneck bandwidth A 18 5 7 11 9 12 15 Req 1 2 9 Req 2&3 4 Req 4 3 C B 2 Fail A ends C ends B ends 6 Earliness (b) Shortest Job First 18 7 9 12 Req 1 4 9 Req 2&3 6 Req 4 3 Bottleneck bandwidth C 3 A 13 6 B C ends A ends B ends Fail Earliness (c) Earliest Deadline First Req 1 Bottleneck bandwidth A 18 5 7 13 9 12 2 9 Req 2&3 6 4 Req 4 3 C B 4 C ends B ends A ends Deferral Earliness (d) Defer-and-Promote T able 2: Comparison of scheduling policies for inter- request contention. The red vertical lines denote hard deadlines, and gray bars are subsequent durations. (a) Fair Share and ( b) SJF fail to protect the urgent F low-B due to lack of deadline awareness, while (c) EDF com- pletes ows with explicit but loose deadlines unneces- sarily early . (d) Defer-and-Promote strategically defers non-urgent ows to minimize earliness, and promotes them only when ne cessary to achieve just-in-time com- pletion . Ke y observation. In the prell stage, request deadlines progressively materialize into ow-level deadlines as the prell pipeline advances. Recalling Se c. 3.1, for the initial stages (1&2), the ow- level deadline is implicit, since it jointly determined by T TFT and duration of downstream tasks. As execution reaches the nal stage, this constraint materializes: the global T TFT di- rectly dictates the token r eturn time, becoming an explicit ow-level bound. W e b orrow the concept of laxity ( dened as the remaining budget b efore triggering deadline viola- tion) from real-time systems to repr esent ow-level urgency . The distinct laxity reveals a scheduling opportunity: we can safely defer last-stage ows (possessing deterministic lax- ity) to yield bandwidth for early-stage ows whose laxity is uncertain. Scheduling principle: Defer-and-Promote . Leveraging the observation ab ove , our key principle is to defer non-urgent transfer until the latest safe moment, promoting priority only as necessary , so as to minimize interference while ensuring 5 timely completion. This principle translates into two con- crete rules: • Principle #1 (Last stage ows with Explicit-deadline) are initially deferred to yield bandwidth but gradually promoted to guarantee compliance. • Principle #2 (Early stage ows with implicit-deadline) are deferred based on relative laxity and pr omoted as the laxity diminishes to mitigate the violation risks. Why this works. By deferring non-urgent ows and se- lectively promoting them when necessar y , the scheduler balances short-term eciency with long-term deadline guar- antees. This strategy improves T TFT SLO attainment along two axes: (i) minimizing the non-overlapping communica- tion latency to shorten the prell makespan, and (ii) regulat- ing earliness to prioritize tighter requests under contention. T o see why Defer-and-Promote b enets the prell DA G makespan, consider the consider the contention scenarios in Fig 6-(a) (ingr ess) and Fig 7-( a) (egress). Fair Sharing indis- criminately dilutes Stage 2 throughput; SJF (Fig. 6-(c), 7-( c)) preferentially prioritizes K V -movement ows (ow size typi- cally smaller); and EDF over-prioritizes Stage 3 due to explicit deadlines (Fig. 6-(c)) and degenerates into Fair Sharing when deadlines are implicit (Fig. 7-( b)). Conse quently , all three poli- cies inate the non-overlapped communication latency and stall computation. Defer-and-Promote resolves this by strate- gically deferring Stage 3 (higher laxity) to protect Stage 2, which demonstrating a signicant reduction in makespan (Fig. 6-(d), 7-( d)). Defer-and-Promote maximizes attainment under inter-request contention by strictly prioritizing truly urgent requests. Con- sider T able 1 as an example, where each request has an end- to-end T TFT constraint and implicit remaining time deter- mined by downstream tasks. As illustrate d in Fig. 2, three ows with varying sizes and deadlines contend for a bottle- neck link. Unlike standard policies (e.g., FS, SJF , EDF) that often misjudge urgency , Defer-and-Promote prioritizes Col- lective Communication, as deferral would immediately stall the execution pipeline. It strategically defers other trac: Stage 1 ows are promoted only when they threaten to stall the pipeline, while last-stage ows are delayed until their explicit deadlines. 4 DESIGN 4.1 Design Challenges While the Defer-and-Promote principle is conceptually sim- ple, realizing it in LLM ser ving is challenging in practice. MFS must make priority assignments in the dark , steering ows without precise laxity through a discrete multi level queue (e.g., nite switch queues). Specically , we identify the following two challenges. … Priority -1 Priority -2 Priority -3 Priority -k End hosts Queue-1 Queue-2 Queue-3 Queue-k Switch Ports Flows Flow with explicit deadline (4.3) Stage -3 comm. Stage -2 Comm. Stage -1 Comm. k k k k 3 3 3 3 2 2 2 2 1 1 1 1 Pkt tagged with priority 1 Pkt tagged with priority k Communication library Flow with implicit deadline (4.4) Figure 8: Design overview . C-1: Scheduling ows with explicit deadlines without excessive prioritization. Even when ows carry explicit deadlines (e .g., P2D transfers), determining when to switch from defer to promote is non-trivial under discrete priority levels. Pr omoting too early wastes scarce bottleneck band- width, while promoting too late risks deadline misses. The challenge lies in striking the right balance for just-in-time completion given nite priority classes. C-2: Scheduling implicit-deadline ows without pre- cise laxity . The absence of pr e cise laxity traps the sche duler in an error-pr one dilemma. On one hand, under estimating laxity incurs unintended execution stalls, as mistakenly de- ferring Stage 2 ows immediately idles the GP U and inates request latency . On the other hand, overestimating laxity results in priority inversion, squandering scarce bandwidth on deferrable work and starving truly urgent requests. 4.2 Overview Figure 8 illustrates MFS’s core abstraction: the Reverse Multi- Level Queue (RMLQ) . T o realize the Defer-and-Promote prin- ciple, RMLQ inverts the classic MLFQ paradigm (which de- motes ows over time); instead, it initializes ows in low- priority queues to enforce deferral, promoting them strictly when diminishing laxity necessitates immediate execution. At a high level, MFS schedules all multi-stage communica- tion through a shared RMLQ substrate, while applying sepa- rate rules (initial priority and promotion pace) for dier ent stages. For last stage ows with explicit deadlines, MFS em- ploys Minimal Link Utilization (MLU), pr omoting a ow only when the remaining bandwidth is just insucient to me et its deadline, thereby avoiding prematur e over-prioritization. For early stage ows with implicit deadline, MFS speculate relative urgency via Relative Layer Inde x (RLI). Flows begin at low er tiers climb up when it thr eaten to stall computation. Finally , to resolve potential cross-stage contention, MFS r e- serves the highest priority level for deadline-explicit ows to avoid violations, and prioritizes deadline-implicit ows in the remaining levels to opp ortunistically exploit available bandwidth. 6 The rest of this section is organized as follows. §4.3 intro- duces scheduling ows with explicit deadlines. §4.4 describes the strategy for implicit deadlines. Finally , §4.5 combines these components to present the complete RMLQ arbitration logic. 4.3 Scheduling with Explicit Deadline T o address C-1, w e need to ensure the last-stage communi- cation task is judiciously deferred—neither excessiv ely pri- oritized nor starved—while strictly guarante eing the request deadline. The challenge lies in mapping continuous urgency levels derived from these deadlines onto 𝐾 discrete prior- ity queues. Consequently , the sche duler needs a me chanism to approximate continuous deadline-deriv ed urgency using coarse-grained priority levels, which requires determining how to quantify urgency , when to trigger promotion, and at what granularity to apply scheduling decisions (e.g., per- packet or per-layer). Specically , consider an 𝐿 -layer model serving a batch of request. At each layer ℓ , the P2D stage emits a set of ows. Flows within the same request 𝑟 inherit its T TFT deadline 𝐷 𝑟 , while ows from dierent requests are scheduled indepen- dently . W e assume there are K priority queues 𝑃 𝑖 ( 1 ≤ 𝑖 ≤ 𝐾 ) where 𝑃 1 has the highest priority . W e denote the threshold for promoting the priority from 𝑃 𝑗 to 𝑃 𝑗 − 1 as 𝜏 𝑗 ( 2 ≤ 𝑗 ≤ 𝐾 ). we dene 𝜏 𝐾 = +∞ ensuring that even the extreme loose ows are captured in the low est-priority queue. Urgency metric. W e dene Minimal Link Utilization (MLU) : MLU 𝑖 ( 𝑡 ) = Size 𝑟 𝑒 𝑚 ( 𝑡 ) Time 𝑟 𝑒 𝑚 ( 𝑡 ) · 𝐵 · ( 1 − 𝜌 ) , where 𝐵 ( 1 − 𝜌 ) represents the eective bandwidth after accounting trac load 𝜌 . This met- ric repr esents the minimal share of the residual link capacity required to satisfy the deadline. Crucially , MLU 𝑖 ( 𝑡 ) > 1 signi- es an infeasible overload state; values approaching 1 signal critical urgency requiring exclusive service, while lower val- ues imply sucient slack for deferral. By contrast, purely deadline-based metrics (e.g., EDF) are ill-suite d since they suer from the domino eect under overload [ 13 ] and further degrade when constrained to discrete priority levels [14]. Optimizing promotion threshold. Deriving the glob- ally optimal thresholds that minimize deadline miss rates is computationally intractable (NP-hard). Therefore, we seek a robust, practical approximation by minimizing the rela- tive quantization error intr o duced when mapping continu- ous urgency to discrete levels. When a ow with urgency 𝑣 ∈ [ 𝑈 𝑚𝑖𝑛 , 𝑈 𝑚𝑎𝑥 ] is mapped to a discrete priority level 𝜏 𝑘 , it incurs a relative error of 𝜖 ≈ | 𝑣 − 𝜏 𝑘 | 𝑣 . Our intuition here is to minimize the worst-case r elative error acr oss all threshold. Î 𝐾 𝑘 = 1 𝑟 𝑘 = 𝑢 2 𝑢 1 · 𝑢 3 𝑢 2 · · · · · 𝑢 𝐾 𝑢 𝐾 − 1 = 𝑢 𝐾 𝑢 1 = 𝑈 max 𝑈 min . Mathematically , this minimum is achiev ed if and only if all ratios ar e equal ( 𝑟 𝑘 ≡ 𝑟 ). This necessitates a geometric progression for thresh- old generation (where 𝑟 = ( 𝑈 max / 𝑈 min ) 1 𝐾 − 1 ). Since the precise bounds 𝑈 max and 𝑈 min are often unknown or dynamic in prac- tice, we appro ximate this geometric spacing by conguring the promotion threshold as 𝑄 𝑖 = 𝐸 − 𝑖 · 𝑈 ( 1 ≤ 𝑖 ≤ 𝐾 − 1 ), where parameters 𝐸 and 𝑈 are set empirically (e .g., 𝐸 = 4 , 𝑈 = 0 . 5 ) to yield robust performance. Promotion behavior . Fine-grained promotion decision may adversely introduce practical concerns in network sched- uling. In particular , if promotion is applied at a ne granu- larity (e.g., per packet), a single message may b e fragmented across multiple priority queues. This can lead to packet re- ordering, where later packets ov ertake earlier ones, trigger- ing costly transport-layer recovery and reducing eective throughput. T o avoid this issue, we restrict promotion to layer boundaries, ensuring priority atomicity at the message level. Crucially , this coarser granularity do es not compro- mise scheduling expressiveness, as the substantial depth of modern LLMs ( 𝐿 > 𝐾 , e.g, L=64 and K=8/16) provides ample room for priority adjustments. Additionally , we enforce a monotonic promotion policy (i.e., only allowing promotion). This prevents priority oscillation and reinforces the Defer- and-Promote principle, ensuring that ows are conservatively maintained in lower tiers until urgency strictly necessitates promotion. 4.4 Scheduling with Implicit Deadlines T o address the lack of precise laxity under implicit deadlines (Challenge C-2), MFS e xploits structural determinism to infer relative urgency within requests, and resolv es residual con- tention across requests using robust arbitration mechanisms. 4.4.1 Intra-request Scheduling with Structural Determin- ism. While precise laxity is elusive due to dynamic schedul- ing shifts, the relative laxity within request is deterministic: ows blo cking imme diate execution strictly more urgent than lookahead transfers that enable future progress. W e quantify this using the Relative Layer Index , dened as RLI = 𝐿 target − 𝐿 curr , where 𝐿 curr is the index of the currently executing layer and 𝐿 target is the target layer index where the data is consumed. A smaller RLI indicates a tighter safe deferral window . MFS resolves contention by strictly priori- tizing o ws with the smallest RLI. W e apply it to r esolve two representative contention cases detailed below . Case I: Collective vs. KV Reuse. When collective 𝑖 com- petes with reuse 𝑗 ( 𝑗 > 𝑖 ), the collective targets the current layer ( 𝐿 target = 𝑖 ), yielding RLI ( coll ) = 0 . In contrast, the reuse targets layer 𝑗 with RLI ( reuse ) > 0 . W e therefore en- force collective 𝑖 ≻ reuse 𝑗 to avoid execution stalls. Case II: Inter-K V Reuse Contention. Under multi-layer lookahead, ows reuse 𝑗 and reuse 𝑘 ( 𝐿 curr < 𝑗 < 𝑘 ) often con- tend. Comparing their urgency , layer 𝑗 represents a near er deadline, implying RLI ( 𝑗 ) < RLI ( 𝑘 ) . Prioritizing the smaller 7 RLI eectively delays the onset of the earliest execution stall. Thus, we enforce reuse 𝑗 ≻ reuse 𝑘 . In summary , MFS unies these de cisions by strictly priori- tizing ows with the smallest RLI. The orem 1 formalizes the optimality of this structural ordering. Theorem 1. Assuming an ideal computation mo del without preemption overhead, the prell makespan is minimized by a schedule that strictly prioritizes ows with the smallest RLI. Proof sketch. Intuitively , prioritizing a high-RLI ow during a stall wastes the opportunity to overlap it with subsequent computation. W e pro ve this via an exchange argument: shift- ing any ow with a larger RLI out of a stall interval into a later overlapped region strictly reduces the current blocking duration without violating future dependencies. W e provide the detailed proof in Appendix. 4.4.2 Robust Inter-r equest Scheduling. With intra-request contention resolved by RLI (§4.4.1), the remaining challenge is breaking ties across requests when competing ows have similar RLI and simultaneously threaten execution. The sched- uler must protect requests with high SLO violation risks un- der imprecise laxity . However , synchronous batch execution exacerbates the impact of scheduling pitfalls, allo wing errors to propagate to all batched peers. Our intuition is not to re- cover exact laxity , but to make scheduling decisions robust to estimation errors , prioritizing requests/batches where delays would most sever ely hurt SLO attainment. Scheduling pitfalls under imprecise laxity . W e identify two representative failure cases arising from misjudging laxity: • The Piggyback eect. In batches with mixed deadlines, a small numb er of extremely tight requests can dominate the inferred batch-le vel urgency . Consequently , loose requests in the same batch inherit elevated priority , preempting other batches that are globally more urgent. • The Black Hole eect. Proximity to a deadline does not guarantee feasibility . Under overload, a batch may appear urgent while carrying a workload that e xceeds available bandwidth. Prioritizing such batches wastes resources on inevitable failures, blocking other viable batches. W e dene the Robust Eective Deadline ( 𝑅 𝐸 𝐷 ) to quan- tify urgency while counteracting the Piggyback ee ct. W e partition a batch into tight and loose sub-batches at the maximal deadline gap. With 𝐷 𝑇 min and 𝐷 𝐿𝑜 min representing the minimum deadline of each sub-batch, we dene 𝑅 𝐸 𝐷 = 𝑓 · 𝐷 𝑇 min + ( 1 − 𝑓 ) · 𝐷 𝐿𝑜 min , where 𝑓 is the proportion of tight requests. When tight requests are rare (small 𝑓 ), 𝑅 𝐸 𝐷 nat- urally shifts towards the loose deadline ( 𝐷 𝐿𝑜 min ), preventing outliers from hijacking the batch priority . Complementing RED-based or dering, we employ overload control to mitigate the Black Hole eect. The intuition is to prevent doomed or excessively heavy requests from blocking viable ones. W e perform a worst-case feasibility check by accumulating estimated computation and communication delays. W e iteratively prune the requests contributing the most to the cumulative delay to restore feasibility for the remainder of the batch. The full algorithm, detailed in the Appendix, synthesizes these strategies. Triggered upon batch arrival and departure, it outputs two key results: (1) an order ed sequence 𝜎 derived from RED, and (2) a set of pruned r equests H identied as in- feasible. W e deliberately avoid ne-grained p er-layer updates to pr event the scheduler from over-reacting to transient load estimation jitter . 4.5 Putting Ever ything T ogether MFS schedules all trac through a unied RMLQ substrate. W e classify ows according to stage feature and apply dis- tinct rules for initial priority assignment and subse quent promotion. • For last stage ows with explicit deadline, we calculate the MLU dened in§4.3 to determine the initial priority level. For promotion, MFS updates priority at layer boundaries while the request is computing, and switches to periodic updates at xed inter vals after computation nishes. • For early stage ows with implicit deadline, priority as- signment relies on the RLI dened in§4.4.1. Stage 1 ows are initialized based on RLI and pr omoted incrementally at layer boundaries to align with computation progress. Stage 2 ows directly enter the high priority queue. Arbitration. MFS strictly reserves the highest priority for the most urgent last-stage ows. Within the r emaining pri- ority le vels, MFS adopts a hierarchical policy: it grants prece- dence to early-stage ows over last-stage ows to oppor- tunistically exploit available bandwidth; to break ties among early-stage ows sharing the same RLI, MFS adheres to the rank determined by the inter-request scheduling (§4.4.2). 5 IMPLEMEN T A TION W e implement MFS in approximately 10,000 lines of code. MFS employ two-tier contr ol plane compose d of local dae- mons and a centralized coordinator . Local daemons maintain scheduling context and enforce scheduling decisions, while reporting request-level statistics to the coordinator up on scheduling and completion events. The coordinator operates at request granularity , aggregating these summaries to per- form inter-node tie-breaking, and disseminates the resulting decisions back to local daemons for enforcement. System Integration and Compatibility . W e implement MFS as a pluggable module that integrates transparently with 8 NCCL and Mooncake. Each no de runs a lightweight lo cal dae- mon that interfaces with runtimes via lock-free MPSC queues over shared memory , enabling low-latency intra-no de sig- naling. By intercepting low-level network primitives (e.g., RDMA V erbs), MFS redirects work requests from the library’s proxy threads to the lo cal daemon, which orchestrates task execution according to our sche duling logic. The interac- tion between the runtime and the scheduler is governed by three standardized primitives: (1) submit registers tasks with metadata, (2) permit gates transmission by granting specic priorities, and (3) completion updates the internal state upon hardware signals. Requests can be pruned by modifying their metadata to suppress communication. Priority enforcement. Commodity hardware typically ex- poses a limited numb er of priority classes ( 𝐾 ≪ 𝐿 ), making direct mapping infeasible. In practice, collective trac is typically conne d to a regional serving unit, whereas K V - cache trac spans the network across racks. W e employ a hybrid priority queue tailored for such trac. Specically , MFS enforces strict priority at the host via software queues (arbitration logic in §4.5), while leveraging DSCP-based hard- ware priorities to isolate KV -cache trac within the network fabric. For ows with e xplicit deadlines, we calculate MLU threshold derived from 𝐾 and the current network load 𝜌 , and assign DSCP tags according to this threshold. For ows with implicit deadlines, we map their RLI to the physical queue range [ 0 , 𝐾 − 1 ] by capping the RLI value at 𝐾 − 1 . 6 EV ALU A TION 6.1 Experiments setup T estbed setup. The testbed consists of 8 ser vers, each equipped with 4 N VIDIA GeForce RTX 3090 GP Us, 40 CP U cores (Intel(R) X e on(R) Gold 5218R CP U @ 2.10GHz), 128GB RAM, and two ConnectX-5 100Gbps NIC. The servers are connected via N VIDIA SN2700 Ethernet switches. Within each server , the GP Us communicate via PCIe Gen 3.0. All servers run Ubuntu 22.04 with CUDA 12.8, Py T orch 2.8.0, and NCCL 2.28. we congure a prell cluster comprising 16 GP Us, while decode workers are provisioned separately . For simplicity , we limit the decode output length to one token, since it does not aect T TFT . Simulation setup. Our simulator is built up on Vidur [ 5 ] and the ow-level simulator owsim [ 82 ]. W e extend Vidur to support the Mixtral mo del with expert and sequence par- allelism, as well as PD disaggregation with KV -cache reuse. The simulation workow begins with oine proling of op- erator latencies via Vidur proler . At runtime, we employ a unied event-driven mechanism: Vidur simulates the LLM serving behavior to generate computation and communica- tion tasks, while owsim parser the communication task and QwenA -Conv QwenB-agent W orkload 0.00 0.25 0.50 0.75 1.00 Nor malized T TF T Baseline MF S (a) Normalized T TFT . QwenA -Conv QwenB-agent W orkload 0.00 0.25 0.50 0.75 1.00 Nor m. CCT Baseline MF S (b) Normalized CCT . Figure 9: [T estb ed] Mixtral-8x7B trigger the underlying network events. Crucially , both com- putation events and network events are processed within a single event queue to ensure correctness. By default, we simulate a 256-ser ver cluster with a 1:1 pr ell-de code worker ratio, managed by a K V -cache aware scheduler similar to Dynamo [ 62 ]. Each server hosts eight GP Us interconnected via NVSwitch (900 GB/s) and eight NICs, connected via a 1:1 fat-tree network with link bandwidth 200Gbps. The latency proles are calibrated based on NVIDIA A100 GP U. Metrics. W e primarily evaluate Time-to-First- T oken (T TFT) and its Ser vice Level Objective (SLO) attainment rate. Fol- lowing the methodology in [ 29 , 67 , 78 ], we dene the SLO threshold as 3 × the T TFT measured under low-load condi- tions by default. W e also evaluate microbenchmarks such as the collective completion time (CCT) and r equest earliness to help interpret the observed performance gains. 6.2 T estbe d Experiments Model and workload. In the testbed experiment, W e eval- uate the Mistral 8x7B [ 3 ] MoE model (FP16, top- 𝑘 =2), con- gured with a tensor parallelism (TP) degr ee of 1 and expert parallelism (EP) of 8. For the workload, we utilize two produc- tion traces derived from Qwen [ 6 ]. QwenA -Conv represents a conversation workload with an average sequence length of 2k tokens and a 50% prompt reuse rate. QwenB-agent represents an agent workload , characterized by an average length of 1k tokens and a higher reuse rate of 65%. Request arrivals follow a Poisson process, where we vary the requests per se cond (RPS) to mo dulate system load. Due to testb ed capacity limits, we clip the rst 512 requests of each trace as a warm-up phase and use the subsequent 1024 requests for evaluation. Figure 9 reports how MFS on Q wenA -Conv and QwenB- Agent workload. W e congure vLLM with 8192 batched to- kens and set the per-GP U request rate to one r e quest p er se c- ond. MFS signicantly reduces T TFT across both workloads, optimizing the mean T TFT by 20.7% (1.26 × ) on Q wenA -Conv and 32.3% (1.48 × ) on QwenB-A gent. The T TFT reduction is primarily driven by faster completion of computation- blocking collectives. As shown by the all-to-all completion 9 F S SJF EDF K aruna MF S 0.5 0.6 0.7 0.8 0.9 1.0 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (a) Mixtral-8x22B 0.5 0.6 0.7 0.8 0.9 1.0 1.1 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (b) DBRX 0.2 0.3 0.4 0.5 0.6 0.7 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (c) Qwen3-Coder 0.2 0.3 0.4 0.5 0.6 0.7 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (d) Grok2 Figure 10: [Simulation] Performance on conversation workload (QwenA) 0.5 1.0 1.5 2.0 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (a) Mixtral-8x22B 0.5 1.0 1.5 2.0 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (b) DBRX 0.5 1.0 1.5 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (c) Qwen3-Coder 0.5 1.0 1.5 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) (d) Grok2 Figure 11: [Simulation] Performance on agent workload (QwenB) time (CCT), MFS shortens stage-2 communication by 31.9% (1.47 × ) on QwenA -Conv and 43.1% (1.76 × ) on QwenB- Agent. These collectives lie directly on the critical path of prell ex- ecution: delaying them immediately stalls GP U computation and inates end-to-end latency . 6.3 Large-Scale Simulations In the large-scale simulations, we expand the evaluation scope to cov er a div erse spectrum of production-grade ar chi- tectures and workloads. • W e examine a comprehensiv e set of mainstream MoE mod- els with expert parallelism, ranging from architectures with large but few experts (e.g., Mixtral 8x22B [ 2 ] and Grok-2 [ 1 ], congured with TP=4, EP=8) to models with small but many experts (e.g., DBRX [ 23 ] with TP=2, EP=16, and Qwen3-Coder [ 71 ] with TP=1, EP=32). These models are deployed with 32-GP U instance utilizing a hybrid par- allelism strategy . W e evaluate these MoE models using Qwen conversation and agent traces to r epresent typical interactive behaviors. • W e further assess the eectiveness of MFS on dense mo dels with se quence parallelism [ 48 ]. W e evaluate the Llama [ 54 ] model congur e d with a 1M token context window . In this setup, the model is deployed on 16-GP U instance using TP=4 and SP=4. W e pair this model with the Mo oncake dataset [ 70 ] to simulate r eal-world conversation and agent workloads characterized by similar reuse ratios ( ∼ 40% , ∼ 65% ) and extended context lengths ( ∼ 15 𝑘 , ∼ 9 𝑘 ). Baselines. W e compare MFS against four classic ow sche d- uling policies: • Fair Sharing enforces max-min fairness among concur- rent ows by allocating bandwidth equally , regardless of ow sizes or deadlines. • Shortest Job First (SJF) minimizes average ow comple- tion time by strictly prioritizing ows with smaller ow sizes. • Earliest Deadline First (EDF) prioritizes ows with ex- plicit deadlines. Since application-lev el deadlines do not directly translate to individual network ow deadlines, it applies fair sharing for ows with implicit deadlines. • Karuna [ 17 ] allocates the minimum required bandwidth to ows with deadlines to ensure on-time completion, while scheduling the remaining ows using SJF . End-to-End T TFT SLO Attainment. W e evaluate the end- to-end T TFT SLO attainment under var ying request rates across diverse mo dels and workloads. As shown in Fig 10, 11, and 12, MFS consistently outp erforms state-of-the-art baselines across all scenarios. Figure 10 details the performance of MFS on conv ersation workloads for diverse MoE models. Specically , under high request rates, MFS achieves 1 . 4 × – 1 . 8 × higher SLO attain- ment for Mixtral (Fig. 10a), Qwen Coder (Fig. 10c) and Grok (Fig. 10d), and up to 2 . 4 × for DBRX (Fig. 10b). Furthermore, MFS can sustain 1 . 17 × – 1 . 46 × higher request rates than the strongest baseline (Karuna) while maintaining the similar SLO attainment. In conversation workload, a small fraction of tail requests necessitates large K V -cache movements, which 10 0.40 0.45 0.50 0.55 0.60 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) F S SJF EDF K aruna MF S (a) Conversation workload 0.6 0.7 0.8 0.9 1.0 P er - GPU R ate (r eq/s) 0.00 0.25 0.50 0.75 1.00 SL O A ttainment (%) F S SJF EDF K aruna MF S (b) Agent workload Figure 12: [simulation] llama3-8B (Mooncake dataset) precipitate contention across Stage 1 to Stage 3 under high load. MFS outperform baselines signicantly since it suc- cessfully coordinates multi-stage contention. Among the baselines, Karuna performs relativ ely better be cause it hap- pens to defer non-urgent Stage 3 trac and provides partial relief; howe ver , without explicit multi-stage coordination, it eventually succumbs to contention as other baselines. Figure 11 details the performance of MFS on agent work- loads for diverse MoE models. Focusing on the mid-to-high load regime, MFS achieves 1 . 4 × – 1 . 7 × higher SLO attain- ment for Grok-2 and Mixtral, and reaches 2 . 0 × for DBRX and Qwen-Coder . Furthermore, MFS sustains 1 . 2 × higher re- quest rates for Grok-2, ∼ 1 . 3 × for Mixtral and Qwen-Coder , and up to 1 . 4 × for DBRX compared to the Karuna. Com- pared to conversation traces, agent requests have shorter prompt length but exhibit higher av erage reuse rates, with multiple concurrent requests sharing identical prexes. This pattern induces severe one-to-many sender-side contention, which primarily concentrates on Stage 1 and Stage 2 as mul- tiple workers simultaneously contend for the same cache d states. MFS eectively mitigates this contention by protect- ing urgent ows without requiring precise laxity . Notably , the performance gap between Karuna and other baselines narrows in this scenario. When contention is not dominated by Stage 3 trac, Karuna falls back to SJF (deadline is im- plicit) to schedule Stage 1 and Stage 2 ows; however , being unaware of stage semantics, this approach still exposes tight requests to SLO violations as other baselines. Figure 12 details the performance of MFS on tw o represen- tative long-context workloads using the Llama3-8B model with Sequence Parallelism (SP). For the Mo oncake dataset, the conversation and agent workloads follow request pat- terns similar to those in the Qwen experiments (e.g., reuse ra- tios, access patterns), but feature signicantly longer context lengths. In the conversation workload (Fig. 12a), MFS demon- strates robust performance under increasing load, achieving 1 . 3 × – 1 . 6 × higher SLO attainment against K aruna. This ad- vantage is further amplied in the agent workload(Fig. 12b), where MFS attains 1 . 4 × – 1 . 9 × higher SLO attainment and supports up to 1 . 15 × higher per-gpu request rates given tight SLO budget. 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 CDF F S SJF EDF K aruna MF S (a) Normalized CCT . 1.0 0.5 0.0 0.5 1.0 0.0 0.2 0.4 0.6 0.8 1.0 CDF F S SJF EDF K aruna MF S (b) Normalized earliness. Figure 13: [Simulation] Br eakdown on DBRX ( Qwen- A, Rate=0.7) 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 CDF F S SJF EDF K aruna V er ge (a) Normalized CCT . 0.5 0.0 0.5 1.0 0.0 0.2 0.4 0.6 0.8 1.0 CDF F S SJF EDF K aruna V er ge (b) Normalized earliness Figure 14: [Simulation] Breakdown on Llama3 (Mooncake-Conv , Rate=0.5) Breaking down the performance gains. W e further con- duct micro-benchmarks to analyze the source of the gains. As shown in Figure 13 and Figure 14, MFS successfully (i) minimizes Collective Completion Time (the non-overlapping communication latency) to shorten the prell makespan, and (ii) regulates earliness to protect truly urgent requests under contention. Figure 13 breaks down the performance gains that lead to the 2 . 2 × higher SLO attainment achieved by MFS on the DBRX model. The rst source of impr ovement comes fr om reduced execution time during the prell phase. Specically , MFS lowers the av erage CCT of expert parallel by 52% (Fig- ure 13a). This reduction is mainly attributed to our stage- aware policy , which protects ows that block computation while deferring non-critical trac to exploit available slack for o verlap. A s a result, MFS signicantly shortens the prell makespan by lowering the eective communication over- head. Beyond latency r eduction, MFS further improves SLO at- tainment by better prioritizing truly urgent requests under contention. W e characterize this eect using earliness of request, where large positive values indicate unnecessar y early completion that can block urgent requests, while nega- tive values correspond to deadline misses. A s shown in Fig- ure 13b, K aruna exhibits the smallest non-negativ e earliness, but at the cost of a high violation risk, as it conser vatively allocates near-minimal rates and fails to exploit available bandwidth. In contrast, other baselines show much larger non-negative earliness, indicating that the y schedule ows 11 without eectively prioritizing urgency . MFS reduces the non-negative portion of earliness by 42% comparing with FS, SJF, EDF . By deferring Stage 3 ows to complete just-in-time and regulating early-stage trac with a RED-based ording, MFS preserves resources for turely urgent requests. MFS adopts a priority-based sche duling that can exploit available bandwidth when no higher-priority ows are pending. W e observe a similar trend in Figure 14. Across both micro- benchmarks, MFS consistently achieves higher SLO attain- ment by simultaneously reducing the collective completion time of sequence parallel (Figure 14a) and regulating earli- ness under contention (Figure 14b). These results indicate that the performance gains of MFS are robust across models and are not tied to a specic workload or architecture. 7 DISCUSSION Additional parallelism. While MFS primarily focuses on Expert Parallelism and Se quence Parallelism, we acknowl- edge other strategies not explicitly cov ered in our evaluation. T ensor Parallelism, widely adopte d in ser ving, is typically conned to intra-node fabrics ( e.g., N VLink) without directly contending for inter-node bandwidth. Similarly , we do not explicitly discuss Pip eline Parallelism, as the prell stage is usually latency-sensitive (requiring low or zero PP de- grees [ 106 ]), and its communication volume is orders of mag- nitude smaller than KV cache movement or collective com- munications [ 44 ]. Should these ows appear on the shared network, they w ould b e identied as Stage 2 trac and re- main compatible with our analysis. This obser vation e xtends to emerging parallelism strategies, which may introduce novel communication patterns with enhanced ov erlapping capabilities, y et still block dependent computation if delayed. Hybrid model deployment. In practice, service providers often deploy a tiered model portfolio, consisting of a sin- gle large agship model alongside multiple smaller models serving diverse workloads [ 65 ]. In such settings, network contention primarily arises from concurrent KV cache trans- fers (Stage 1 and Stage 3) across dierent models, as collective communication is typically conned within isolate d racks or dedicate d p ods [ 46 ]. While MFS is not explicitly evalu- ated under multi-model deployment, its scheduling principle remains applicable to KV cache trac on shared networks. While promising, the holistic orchestration of such multi- model contention landscapes remains an under-explor ed design space. Applicability to scale-up fabrics. While MFS focuses on scale-out networks, its design principles could be extended to scale-up domains (e.g., NVL [ 58 ], UB [ 108 ],etc.). Contention between collective and K V Cache movement remains when multiple serving instance deployed together . MFS’s schedul- ing policy can be ee ctively adapted to such architectures by leveraging hardware-level isolation mechanisms (e.g., vir- tual channels or trac classes), which could be exploited to enable dierentiated prioritization. Compatibility with GP U-initiated collective communi- cation. While emerging GP U-initiated communication [ 24 , 64 ] optimizes small-message latency for the de coding phase, it remains uncommon in prell deployments due to strict hardware prer equisites and marginal gains for large-volume transfers. Nevertheless, even in such environments, MFS en- sures compatibility via CP U-assisted variants (e.g., host-side doorbells), while this method may introduce negligible la- tency overhead compared to a fully GP U-initiate d execution [68]. 8 RELA TED W ORK. Flow and co-ow scheduling. Traditional ow schedul- ing optimizes per-ow metrics such as average ow com- pletion time [ 7 , 8 , 10 , 28 , 41 , 43 , 107 ] or deadline satisfac- tion [ 28 , 83 , 88 , 96 ] using policies like SJF and EDF . Coow scheduling [ 4 , 21 , 22 , 80 , 86 , 97 , 100 ] e xtends this abstraction by grouping related ows and optimizing Coow Completion Time for data-parallel workloads, while mixe d-ow schedul- ing [ 17 ] considers the coexistence of deadline-sensitive and best-eort trac. In contrast, MFS explicitly accounts for multi-stage dependencies to schedule ows toward end-to- end T TFT attainments. Optimization for individual stages. Prior research fo- cuses on optimizing spe cic communication phases in isola- tion. For collective communication, eorts improv e p erfor- mance by algorithms synthesis [ 16 , 75 ], resolving potential contention [ 15 , 72 ], or enhancing overlap through system- level pip elining [ 30 , 98 , 103 ],. In parallel, other works op- timize K V cache transfers by hiding latency via prefetch- ing [ 66 , 69 ], improving eciency via block coalescing [ 19 , 42 ] and multi-path transmission [ 90 ], or reducing data volume by trading o mo del quality [ 51 ]. However , these approaches treat each stage in isolation, ov erlooking the potential con- tention between collective communication and KV cache transfers. LLM serving systems. Recent advancements in LLM ser v- ing have evolv ed along two complementary dimensions. Architecturally , systems adopt prell-decode disaggrega- tion [ 66 , 106 ] and KV-cache reuse [ 26 , 69 ] to improve through- put and avoid redundant computation. On the orchestration front, numerous r equest schedulers [ 18 , 29 , 33 , 78 , 99 ] have been proposed to maximize SLO attainment. However , these systems primarily focus on optimizing compute eciency under ideal network assumptions. MFS is orthogonal to these approaches. It bridges the gap by addressing the network contention that they overlook. 12 9 CONCLUSION This paper presented MFS, a holistic multi-stage ow schedul- ing framework for LLM ser ving that targets end-to-end T TFT SLO attainment. MFS is built on the observation that request- level deadlines progressively materialize into explicit ow level deadline as prell execution. At its core, MFS realizes a Defer-and-Promote scheduling principle that appro ximates Least-Laxity-First behavior without requiring precise laxity estimation. Through a prototype implementation and exten- sive evaluation, we show that MFS consistently improves T TFT SLO attainment acr oss diverse models and w orkloads. REFERENCES [1] [n. d.]. Grok. https://x . ai/news/grok- 2. ([n. d.]). [2] [n. d.]. Mixtral 8x22B. https://huggingface . co/mistralai/Mixtral- 8x22B- Instruct- v0 . 1. ([n. d.]). [3] [n. d.]. Mixtral-8x7B-Instruct-v0.1. https://huggingface . co/mistralai/ Mixtral- 8x7B- Instruct- v0 . 1. ([n. d.]). [4] Saksham Agarwal, Shijin Rajakrishnan, Akshay Narayan, Rachit Agarwal, David Shmoys, and Amin V ahdat. 2018. Sincronia: Near- optimal network design for coows. In Pr oceedings of the 2018 Con- ference of the ACM Special Interest Group on Data Communication . 16–29. [5] Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar , Nipun K watra, Bhargav S Gulavani, Ramachandran Ramjee, and Alexey T umanov . 2024. Vidur: A large-scale simulation framework for llm inference. Proceedings of Machine Learning and Systems 6 (2024), 351–366. [6] Alibaba-Edu. 2025. Qwen-Bailian Anonymous Dataset: Production- derived LLM Usage T races. https://github . com/alibaba- edu/qwen- bailian- usagetraces- anon. (2025). Accessed: 2026-02-06. [7] Mohammad Alizadeh, Albert Greenberg, David A Maltz, Jitendra Pad- hye, Parveen Patel, Balaji Prabhakar , Sudipta Sengupta, and Murari Sridharan. 2010. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM 2010 Conference . 63–74. [8] Mohammad Alizadeh, Shuang Y ang, Milad Sharif, Sachin K atti, Nick McKeown, Balaji Prabhakar , and Scott Shenker . 2013. pFabric: Mini- mal near-optimal datacenter transport. ACM SIGCOMM Computer Communication Review 43, 4 (2013), 435–446. [9] Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad A wan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Je Rasley , et al . 2022. Deepsp eed-inference: enabling ecient inference of transformer models at unprecedente d scale. In SC22: International Conference for High Performance Computing, Networking, Storage and A nalysis . IEEE, 1–15. [10] W ei Bai, Li Chen, K ai Chen, Dongsu Han, Chen Tian, and Hao W ang. 2015. { Information- Agnostic } ow scheduling for commodity data centers. In 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15) . 455–468. [11] Riccardo Bettati and Jane WS Liu. 1990. Algorithms for end-to-end scheduling to meet deadlines. In Proce edings of the Second IEEE Sym- posium on Parallel and Distributed Processing 1990 . IEEE, 62–67. [12] Riccardo Bettati and Jane W -S Liu. 1992. End-to-End Scheduling to Meet Deadlines in Distributed Systems.. In ICDCS . 452–459. [13] Giorgio Buttazzo, Marco Spuri, and Fabrizio Sensini. 1995. V alue vs. deadline scheduling in overload conditions. In Proceedings 16th IEEE Real- Time Systems Symp osium . IEEE, 90–99. [14] Giorgio C Buttazzo. 2005. Rate monotonic vs. EDF: Judgment day . Real- Time Systems 29, 1 (2005), 5–26. [15] Jiamin Cao, Yu Guan, Kun Qian, Jiaqi Gao, W encong Xiao, Jianb o Dong, Binzhang Fu, Dennis Cai, and Ennan Zhai. 2024. Crux: Gpu- ecient communication scheduling for deep learning training. In Proceedings of the ACM SIGCOMM 2024 Conference . 1–15. [16] Jiamin Cao, Shangfeng Shi, Jiaqi Gao, W eisen Liu, Yifan Y ang, Yichi Xu, Zhilong Zheng, Y u Guan, Kun Qian, Ying Liu, et al . 2025. SyCCL: Exploiting Symmetry for Ecient Collective Communication Sched- uling. In Proceedings of the ACM SIGCOMM 2025 Conference . 645–662. [17] Li Chen, Kai Chen, W ei Bai, and Mohammad Alizadeh. 2016. Schedul- ing mix-ows in commodity datacenters with karuna. In Proceedings of the 2016 ACM SIGCOMM Conference . 174–187. [18] Siyuan Chen, Zhipeng Jia, Samira Khan, Arvind Krishnamurthy , and Phillip B Gibbons. 2025. SLOs-Serve: Optimized Serving of Multi-SLO LLMs. arXiv preprint arXiv:2504.08784 (2025). [19] Shiyang Chen, Rain Jiang, Dezhi Y u, Jinlai Xu, Mengyuan Chao, Fanlong Meng, Chenyu Jiang, W ei Xu, and Hang Liu. 2024. K VDi- rect: Distribute d Disaggregated LLM Inference. arXiv preprint arXiv:2501.14743 (2024). [20] W ei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Y onghao Zhuang, Joseph E Gonzalez, et al . 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality . See https://vicuna. lmsys. org (accessed 14 A pril 2023) 2, 3 (2023), 6. [21] Mosharaf Chowdhury and Ion Stoica. 2015. Ecient coow schedul- ing without prior knowledge. ACM SIGCOMM Computer Communi- cation Review 45, 4 (2015), 393–406. [22] Mosharaf Chowdhury , Yuan Zhong, and Ion Stoica. 2014. Ecient coow scheduling with varys. In Proceedings of the 2014 ACM confer- ence on SIGCOMM . 443–454. [23] Databriks. [n. d.]. Introducing DBRX: A New State-of-the- Art Open LLM. https://ww w . databricks . com/blog/introducing- dbr x- new- state- art- open- llm. ([n. d.]). [24] DeepSeek-AI. 2024. DeepEP: An Ecient Expert-Parallel Commu- nication Library . https://github . com/deepseek- ai/DeepEP. (2024). GitHub repository , Accessed: 2026-02-07. [25] Vignesh Ethiraj, Ashwath David, Sidhanth Menon, and Divya Vijay . 2025. T oward Low-Latency End-to-End V oice Agents for T elecom- munications Using Streaming ASR, Quantized LLMs, and Real- Time T TS. arXiv preprint arXiv:2508.04721 (2025). [26] Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Je vd- jic, Junbo Deng, Xingkun Y ang, Zhou Yu, and Pengfei Zuo. 2024. { Cost-Ecient } large language model serving for multi-turn conver- sations with { CachedAttention } . In 2024 USENIX Annual T echnical Conference ( USENIX A TC 24) . 111–126. [27] Junda He, Christoph Tr eude, and David Lo. 2025. LLM-Based Multi- Agent Systems for Software Engineering: Literature Revie w , Vision, and the Road Ahead. A CM Transactions on Software Engine ering and Methodology 34, 5 (2025), 1–30. [28] Chi- Y ao Hong, Matthew Caesar , and P Brighten Godfrey . 2012. Fin- ishing ows quickly with preemptive scheduling. A CM SIGCOMM Computer Communication Review 42, 4 (2012), 127–138. [29] Ke Hong, Xiuhong Li, Lufang Chen, Qiuli Mao , Guohao Dai, Xuefei Ning, Shengen Y an, Y un Liang, and Yu W ang. [n. d.]. SOLA: Op- timizing SLO Attainment for Large Language Model Serving with State- A ware Scheduling. In Eighth Conference on Machine Learning and Systems . [30] Ke Hong, Xiuhong Li, Minxu Liu, Qiuli Mao, Tianqi Wu, Zixiao Huang, Lufang Chen, Zhong W ang, Yichong Zhang, Zhenhua Zhu, et al . 2025. FlashOverlap: A Lightweight Design for Eciently Overlapping Communication and Computation. arXiv preprint (2025). 13 [31] Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, T ao Xie, Chenxi W ang, Sa W ang, Yungang Bao, Ninghui Sun, et al . 2024. Memserve: Context caching for disaggr egated llm serving with elastic memory pool. arXiv preprint arXiv:2406.17565 (2024). [32] Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi W ang, Sa W ang, Yungang Bao, et al . 2024. Inference without interference: Disaggregate llm infer ence for mixed downstream workloads. arXiv preprint (2024). [33] Y ouhe Jiang, Fangcheng Fu, Xiaozhe Y ao, T aiyi W ang, Bin Cui, Ana Klimovic, and Eiko Y oneki. 2025. Thunderserve: High-performance and cost-ecient llm serving in cloud environments. arXiv preprint arXiv:2502.09334 (2025). [34] Heehoon Kim, Junyeol Ryu, and Jaejin Lee. 2024. T ccl: Discovering better communication paths for pcie gpu clusters. In Proceedings of the 29th A CM International Conference on A rchitectural Support for Programming Languages and Operating Systems, V olume 3 . 999–1015. [35] Kaeun Kim, Ghazal Shams, and Kawon Kim. 2025. From Seconds to Sentiments: Dierential Eects of Chatbot Response Latency on Customer Evaluations. International Journal of Human–Computer Interaction (2025), 1–17. [36] kimi. 2025. mooncake transfer engine. https://github . com/kvcache- ai/Mooncake/tree/main/mooncake- transfer- engine. (2025). [37] Langfuse. 2025. How to congure retries and timeouts when fetching prompts? https://langfuse . com/faq/all/error- handling- and- timeouts. (2025). [38] Dmitry Lepikhin, HyoukJoong Le e, Yuanzhong Xu, Dehao Chen, Orhan Firat, Y anping Huang, Maxim Krikun, Noam Shazeer , and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint (2020). [39] Jiamin Li, Yimin Jiang, Yibo Zhu, Cong W ang, and Hong Xu. 2023. Accelerating distributed { MoE } training and inference with lina. In 2023 USENIX Annual T echnical Conference (USENIX A TC 23) . 945–959. [40] Jialong Li, Shreyansh Tripathi, Lakshay Rastogi, Yiming Lei, Rui Pan, and Yiting Xia. 2025. Optimizing Mixture-of-Experts Inference Time via Model Deployment and Communication Scheduling. IEEE Transactions on Networking 34 (2025), 2478–2497. [41] W enxin Li, Xin He, Yuan Liu, Keqiu Li, Kai Chen, Zhao Ge , Zewei Guan, Heng Qi, Song Zhang, and Guyue Liu. 2024. Flow scheduling with imprecise knowledge. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) . 95–111. [42] W eiqing Li, Guochao Jiang, Xiangyong Ding, Zhangcheng T ao, Chuzhan Hao, Chenfeng Xu, Y uewei Zhang, and Hao W ang. 2025. FlowKV: A Disaggregated Inference Framework with Low-Latency KV Cache Transfer and Load- A ware Sche duling. arXiv preprint arXiv:2504.03775 (2025). [43] Ziyang Li, W ei Bai, Kai Chen, Dongsu Han, Yiming Zhang, Dong- sheng Li, and Hongfang Yu. 2017. Rate-aware ow scheduling for commodity data center networks. In IEEE INFOCOM 2017-IEEE Con- ference on Computer Communications . IEEE, 1–9. [44] Xudong Liao, Yijun Sun, Han Tian, Xinchen W an, Yilun Jin, Zilong W ang, Zhenghang Ren, Xinyang Huang, W enxue Li, Kin Fai T se, et al . 2025. Mixnet: A runtime recongurable optical-electrical fabric for distributed mixture-of-experts training. In Proce edings of the ACM SIGCOMM 2025 Conference . 554–574. [45] LiteLLM. 2025. Stream-timeout. https://docs . litellm . ai/docs/proxy/ timeout. (2025). [46] Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024). [47] Fang Liu, Y ang Liu, Lin Shi, Houkun Huang, Ruifeng W ang, Zhen Y ang, Li Zhang, Zhongqi Li, and Y uchi Ma. 2024. Exploring and evaluating hallucinations in llm-p owered code generation. arXiv preprint arXiv:2404.00971 (2024). [48] Hao Liu, Matei Zaharia, and Pieter Abb eel. 2023. Ring attention with blockwise transformers for near-innite conte xt. arXiv preprint arXiv:2310.01889 (2023). [49] Kaiyuan Liu, Xiaobo Zhou, and Li Li. 2025. m2LLM: A Multi- Dimensional Optimization Framework for LLM Inference on Mobile Devices. IEEE Transactions on Parallel and Distributed Systems (2025). [50] Xuting Liu, Behnaz Arzani, Siva Kesava Reddy K akarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth K andula, and Luke Marshall. 2024. Rethinking machine learning collective communication as a multi-commodity ow problem. In Proceedings of the ACM SIGCOMM 2024 Conference . 16–37. [51] Y uhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray , Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Y ao, Shan Lu, Ganesh Anantha- narayanan, et al . 2024. Cachegen: Kv cache compression and stream- ing for fast large language model ser ving. In Proceedings of the ACM SIGCOMM 2024 Conference . 38–56. [52] Medium. 2025. Robust LLM API Strategies. https://ai . gopubby . com/ robust- llm- api- strategies- retries- fallbacks- in- python- caf9efa96908. (2025). [53] Medium. 2025. Stream API and time outs. https:// diverger . medium . com/speeding- up- your- openai- llm- applications- f0e011f2f0d6. (2025). [54] Meta. 2025. llama. https://huggingface . co/meta- llama. (2025). [55] Deepak Narayanan, Aaron Harlap, Amar P hanishayee, Vivek Se- shadri, Nikhil R Devanur , Gregory R Ganger , Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized pipeline parallelism for DNN training. In Proceedings of the 27th A CM symp osium on operating systems principles . 1–15. [56] Deepak Narayanan, Mohammad Shoeybi, Jared Casper , Patrick LeGresley , Mostofa Patwary , Vijay K orthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer , Bryan Catanzaro, et al . 2021. Ecient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the international conference for high performance computing, networking, storage and analysis . 1–15. [57] notdiamond.ai. 2025. fallbacks-and-timeout. https: //docs . notdiamond . ai/docs/fallbacks- and- timeouts. (2025). [58] NVIDIA. 2024. NVIDIA GB200 N VL72: A Revolutionary Liquid- Cooled Rack Scale Solution. https://www . nvidia . com/en- us/data- center/gb200- nvl72/. (2024). Accessed: 2026-02-07. [59] NVIDIA. 2025. GeForce RTX 3090 Family . https://ww w . nvidia . com/ en- us/geforce/graphics- cards/30- series/rtx- 3090- 3090ti/. (2025). [60] NVIDIA. 2025. NVIDIA Collective Communication Librar y (NCCL). https://github . com/NVIDIA/nccl. (2025). [61] NVIDIA. 2025. NVIDIA Mellanox ConnectX-5. https:// www . nvidia . cn/networking/ethernet/connectx- 5/. (2025). [62] NVIDIA. 2026. Dynamo: A Datacenter Scale Distribute d Inference Serving Framework. https://github . com/ai- dynamo/dynamo. (2026). Accessed: 2026-02-06. [63] NVIDIA and D ynamo A uthors. 2025. Disaggregated Serving Design Document. https://github . com/ai- dynamo/dynamo/blob/main/do cs/ design_docs/disagg_serving . md. (2025). Accessed: 2026-02-06. [64] NVIDIA Corporation. 2024. NVSHMEM Documentation: Using the NVSHMEM InniBand GP UDirect Async Transport . N VIDIA Cor- poration. https://docs . nvidia . com/nvshmem/api/using . html#using- the- nvshmem- inniband- gpudirect- async- transport Release 3.0.6, Accessed: 2026-02-07. [65] OpenAI. 2025. ChatGPT . https://openai . com/index/chatgpt/. (2025). 14 [66] Pratyush Patel, Esha Choukse, Chaojie Zhang, A ashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Ecient generative llm inference using phase splitting. In 2024 A CM/IEEE 51st A nnual International Symposium on Computer A rchitecture (ISCA) . IEEE, 118–132. [67] Archit Patke, Dhemath Reddy , Saurabh Jha, Haoran Qiu, Christian Pinto, Chandra Narayanaswami, Zbigniew Kalbar czyk, and Ravis- hankar Iyer . 2024. Queue management for slo-oriented large language model serving. In Proceedings of the 2024 ACM Symposium on Cloud Computing . 18–35. [68] Sreeram Potluri, Pak Markthub, and Manjunath Gorentla V enkata. 2024. Enhancing Application Portability and Compatibility Across New Platforms Using N VIDIA Magnum IO NVSHMEM 3.0. https://developer . nvidia . com/blog/enhancing- application- portability- and- compatibility- across- new- platforms- using- nvidia- magnum- io- nvshmem- 3- 0/. (May 2024). Accessed: 2026-02-07. [69] Ruoyu Qin, Zheming Li, W eiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Y ongwei Wu, W eimin Zheng, and Xinran Xu. 2025. Mooncake: Trading more storage for less computation—a { KVCache-centric } architecture for serving { LLM } chatbot. In 23rd USENIX Conference on File and Storage T echnologies (F AST 25) . 155–170. [70] Ruoyu Qin, Zheming Li, W eiran He, Mingxing Zhang, Y ongwei Wu, W eimin Zheng, and Xinran Xu. 2024. Mooncake: A kvcache- centric disaggregated architecture for llm serving. arXiv preprint arXiv:2407.00079 (2024). [71] Qwen T eam. [n. d.]. Qwen3-Coder-Next T e chnical Rep ort . T echni- cal Report. https://github . com/QwenLM/Qwen3- Co der/blob/main/ qwen3_coder_next_tech_report . p df Accessed: 2026-02-03. [72] Sudarsanan Rajasekaran, Manya Ghobadi, and Aditya Akella. 2024. { CASSINI } : { Network- A ware } job scheduling in machine learning clusters. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) . 1403–1420. [73] Bhala Ranganathan, Mickey Zhang, and Kai Wu. 2025. Enhancing reli- ability in AI inference ser vices: An empirical study on real production incidents. arXiv preprint arXiv:2511.07424 (2025). [74] SGLang T eam. 2025. P/D Disaggregation Optimization. https: //docs . sglang . ai/advanced _ features/pd _ disaggregation . html. (2025). Accessed: 2026-02-06. [75] Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, T odd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. { T ACCL } : Guiding collective algorithm synthesis using communication sketches. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) . 593–612. [76] Haiying Shen and T anmoy Sen. 2025. AccelGen: Heterogeneous SLO- Guaranteed High- Throughput LLM Inference Serving for Diverse Applications. arXiv preprint arXiv:2503.13737 (2025). [77] Min Si, Pavan Balaji, Y ongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar , Dan Johnson, Bingzhe Liu, Jingliang Ren, et al . 2025. Collective Communication for 100k+ GP Us. arXiv preprint arXiv:2510.20171 (2025). [78] Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep T orrellas, and Esha Choukse. 2025. Dynamollm: Designing llm inference clusters for performance and energy eciency. In 2025 IEEE International Symposium on High Performance Computer Ar chitecture (HPCA) . IEEE, 1348–1362. [79] Foteini Strati, Sara Mcallister , Amar Phanishayee, Jakub T arnawski, and Ana Klimovic. 2024. D \ ’ej \ avu: Kv-cache streaming for fast, fault-tolerant generative llm serving. arXiv preprint (2024). [80] Hengky Susanto, Hao Jin, and Kai Chen. 2016. Stream: Decentralized opportunistic inter-coow scheduling for datacenter networks. In 2016 IEEE 24th International Conference on Network Protocols (ICNP) . IEEE, 1–10. [81] Y ashar T alebirad and Amirhossein Nadiri. 2023. Multi-agent collabo- ration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv:2306.03314 (2023). [82] TL-System. 2024. FlowSim. https://github . com/TL- System/F lowSim. (2024). Accessed: 2024-05-20. [83] Balajee V amanan, Jahangir Hasan, and TN Vijaykumar . 2012. Deadline-aware datacenter tcp (d2tcp). ACM SIGCOMM Computer Communication Review 42, 4 (2012), 115–126. [84] Abhishek Vijaya Kumar , Gianni Antichi, and Rachee Singh. 2025. Aqua: Network- Accelerated Memory Ooading for LLMs in Scale-Up GP U Domains. In Proceedings of the 30th A CM International Conference on A rchitectural Support for Programming Languages and Operating Systems, V olume 2 . 48–62. [85] vLLM T eam. 2025. Prell/Decode Disaggregation in vLLM. https:// docs . vllm . ai/en/stable/features/disagg _ prell . html. (2025). Accessed: 2026-02-06. [86] Xinchen Wan, Xinyu Y ang, Kaiqiang Xu, Xudong Liao, Yilun Jin, Yijun Sun, Zhenghang Ren, Han Tian, and Kai Chen. 2025. Coow Scheduling for LLM Training. In Pr oceedings of the ACM SIGCOMM 2025 Conference . 1232–1234. [87] Zhibin W ang, Shipeng Li, Y uhang Zhou, Xue Li, Rong Gu, Nguyen Cam- Tu, Chen Tian, and Sheng Zhong. 2024. Revisiting slo and good- put metrics in llm serving. arXiv preprint arXiv:2410.14257 (2024). [88] Christo Wilson, Hitesh Ballani, Thomas Karagiannis, and Ant Rowtron. 2011. Better never than late: Meeting deadlines in dat- acenter networks. ACM SIGCOMM Computer Communication Review 41, 4 (2011), 50–61. [89] Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. Lo ongserve: Eciently serving long-context large language models with elastic sequence parallelism. In Proceedings of the ACM SIGOPS 30th Symposium on Op erating Systems Principles . 640–654. [90] Y ongtong Wu, Shaoyuan Chen, Yinmin Zhong, Rilin Huang, Yixuan T an, W entao Zhang, Liyue Zhang, Shangyan Zhou, Y uxuan Liu, Shun- feng Zhou, et al . 2026. DualPath: Breaking the Storage Bandwidth Bottleneck in A gentic LLM Infer ence. arXiv preprint (2026). [91] Guanbin Xu, Zhihao Le, Yinhe Chen, Zhiqi Lin, Zewen Jin, Y oushan Miao, and Cheng Li. 2025. { AutoCCL } : Automated Collective Com- munication T uning for Accelerating Distributed and Parallel { DNN } Training. In 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) . 667–683. [92] Amy Y ang, Jingyi Y ang, A ya Ibrahim, Xinfeng Xie , Bangsheng T ang, Grigory Sizov , Jeremy Reizenstein, Jongsoo Park, and Jianyu Huang. 2024. Context parallelism for scalable million-token inference . arXiv preprint arXiv:2411.01783 (2024). [93] Jiayi Yao , Hanchen Li, Y uhan Liu, Siddhant Ray , Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. In Proceedings of the Twentieth European Confer- ence on Computer Systems . 94–109. [94] Dongha Y oon, Y ounghoon Min, Hoshik Kim, Sam H Noh, and Jongry- ool Kim. 2025. TraCT: Disaggregated LLM Serving with CXL Shared Memory KV Cache at Rack-Scale. arXiv preprint (2025). [95] Y angyang Yu, Zhiyuan Y ao, Haohang Li, Zhiyang Deng, Yuechen Jiang, Y upeng Cao, Zhi Chen, Jordan Suchow , Zhenyu Cui, Rong Liu, et al . 2024. Fincon: A synthesized llm multi-agent system with con- ceptual verbal reinfor cement for enhanced nancial decision making. Advances in Neural Information Processing Systems 37 (2024), 137010– 137045. 15 [96] Hong Zhang, Kai Chen, W ei Bai, Dongsu Han, Chen Tian, Hao W ang, Haibing Guan, and Ming Zhang. 2015. Guaranteeing deadlines for inter-datacenter transfers. In Proceedings of the T enth European Con- ference on Computer Systems . 1–14. [97] Hong Zhang, Li Chen, Bairen Yi, Kai Chen, Mosharaf Chowdhury , and Y anhui Geng. 2016. CODA: T oward automatically identifying and scheduling coows in the dark. In Proceedings of the 2016 ACM SIGCOMM Conference . 160–173. [98] Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, W enlei Bao, Chengquan Jiang, Qi Hou, W eihao Cui, Size Zheng, Li- W en Chang, et al . 2025. Comet: Fine-grained computation-communication overlap- ping for mixture-of-experts. arXiv preprint arXiv:2502.19811 (2025). [99] W ei Zhang, Zhiyu Wu, Yi Mu, Banruo Liu, Myungjin Lee, and Fan Lai. 2025. T empo: Application-aware LLM Serving with Mixed SLO Requirements. In arXiv preprint . [100] Y angming Zhao, Kai Chen, W ei Bai, Minlan Y u, Chen Tian, Y anhui Geng, Yiming Zhang, Dan Li, and Sheng W ang. 2015. Rapier: Integrat- ing routing and scheduling for coow-awar e data center networks. In 2015 IEEE Conference on Computer Communications (INFOCOM) . IEEE, 424–432. [101] Lianmin Zheng, W ei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al . 2023. Judging llm-as-a-judge with mt-b ench and chatbot arena. Advances in neural information processing systems 36 (2023), 46595–46623. [102] Lianmin Zheng, Zhuohan Li, Hao Zhang, Y onghao Zhuang, Zhifeng Chen, Y anping Huang, Yida W ang, Y uanzhong Xu, Danyang Zhuo, Eric P Xing, et al . 2022. Alpa: Automating inter-and { Intra-Operator } parallelism for distributed deep learning. In 16th USENIX Symp osium on Operating Systems Design and Implementation (OSDI 22) . 559–578. [103] Size Zheng, W enlei Bao, Qi Hou, Xuegui Zheng, Jin Fang, Chenhui Huang, Tianqi Li, Haojie Duanmu, Renze Chen, Ruifan Xu, et al . 2025. Triton-distributed: Programming Overlapping Kernels on Distributed AI Systems with the Triton Compiler . arXiv preprint (2025). [104] Size Zheng, Jin Fang, Xuegui Zheng, Qi Hou, W enlei Bao, Ningxin Zheng, Ziheng Jiang, Dongyang W ang, Jianxi Y e, Haibin Lin, et al . 2025. Tilelink: Generating ecient compute-communication overlapping kernels using tile-centric primitives. arXiv preprint arXiv:2503.20313 (2025). [105] Li Zhong and Zilong W ang. 2024. Can llm replace stack overow? a study on r obustness and reliability of large language model code gen- eration. In Pr oceedings of the AAAI conference on articial intelligence , V ol. 38. 21841–21849. [106] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. { DistServe } : Disaggregating prell and decoding for goodput-optimized large language model serving. In 18th USENIX Symp osium on Op erating Systems Design and Implementation (OSDI 24) . 193–210. [107] Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Y ehonatan Liron, Jitendra Padhye, Shachar Raindel, Mo- hamad Haj Y ahia, and Ming Zhang. 2015. Congestion control for large-scale RDMA deployments. ACM SIGCOMM Computer Commu- nication Review 45, 4 (2015), 523–536. [108] Pengfei Zuo, Huimin Lin, Junb o Deng, Nan Zou, Xingkun Y ang, Yingyu Diao, W eifeng Gao, Ke Xu, Zhangyu Chen, Shirui Lu, et al . 2025. Serving Large Language Models on Huawei CloudMatrix384. arXiv preprint arXiv:2506.12708 (2025). A PROOF FOR THEOREM 1 In this se ction, we provide the formal proof for the optimality of the Smallest-RLI-First policy stated in Theorem 1. A.1 Problem Setup and Denitions W e model the prell process as a sequence of alternating communication and computation stages across layers ℓ = 1 , . . . , 𝑁 .Let 𝐿 curr ( 𝑡 ) denote the layer index being computed or waiting to be computed at time 𝑡 .For any communication ow 𝑓 , let 𝐿 target ( 𝑓 ) be the layer wher e the data is consumed. The Relative Layer Index is dened as RLI ( 𝑓 , 𝑡 ) = 𝐿 target ( 𝑓 ) − 𝐿 curr ( 𝑡 ) . W e adopt the assumptions stated in the the orem: (i) Ideal Computation: Computation for layer ℓ starts immediately once its dependencies (ows with 𝐿 target = ℓ ) are met and runs for duration 𝐶 ℓ without interrup- tion. (ii) F luid Model: Communication ows are innitely di- visible, allowing preemption without ov erhead. (iii) Dedicated Bandwidth: W e fo cus on a single link constraint (e .g., ingress or egress bottleneck). A.2 Proof of Optimality Objective. Minimizing the prell makespan is equivalent to minimizing the completion time of the nal computation layer . Since the total volume of computation is xed, this is equivalent to minimizing the total duration of Execution Stalls (intervals where the GP U is idle waiting for data). Interval Classication. W e partition the timeline [ 0 , 𝑇 ] into two types of intervals base d on the state of the system: • Stall Intervals ( I stall ): Time periods where the GP U is idle because a ow 𝑓 with RLI ( 𝑓 , 𝑡 ) = 0 (i.e., targeting the current layer ) is p ending. • Overlap Inter vals ( I overlap ): Time perio ds where the GP U is actively performing computation. During these intervals, the link is available to transmit ows with RLI ( 𝑓 , 𝑡 ) > 0 (i.e., future layers). The Exchange Argument. Suppose there exists an optimal schedule S ∗ that minimizes the makespan but violates the Smallest-RLI-First rule. This implies that at some time 𝑡 ∈ I stall , the schedule assigns bandwidth to a ow 𝑦 with a larger RLI while a ow 𝑥 with a smaller RLI is pending.Specically , since 𝑡 is a stall inter val, there must be some pending ow 𝑥 with RLI ( 𝑥 ) = 0 (blocking the current layer). The violation implies S ∗ serves ow 𝑦 where RLI ( 𝑦 ) > RLI ( 𝑥 ) = 0 during [ 𝑡 , 𝑡 + 𝛿 ] . W e construct a new schedule S ′ by applying an exchange: (1) Swap: In S ′ , we assign the interval [ 𝑡 , 𝑡 + 𝛿 ] to ow 𝑥 instead of 𝑦 . 16 (2) Eect on Stall: By ser ving 𝑥 earlier , the dependency for the current layer 𝐿 curr is satised 𝛿 time units ear- lier (assuming 𝑥 was the bottleneck). This strictly re- duces the duration of the current I stall and advances the start of the next computation phase (and thus the next I overlap ). (3) Feasibility of 𝑦 : Flow 𝑦 is displaced from 𝑡 . Howev er , since RLI ( 𝑦 ) > 0 , ow 𝑦 is not required until a fu- ture layer . The completion of 𝑥 triggers the start of computation 𝐶 𝐿 curr , creating a new Overlap Interval. W e can safely move the transmission of 𝑦 into this newly created Overlap Interval. Since 𝑦 ’s deadline is strictly later than 𝑥 ’s, this deferral does not violate any dependencies. Conclusion. The constructed schedule S ′ reduces the cu- mulative stall duration by transforming a portion of I stall into I overlap . Repeating this exchange argument for all violations proves that the sche dule strictly prioritizing the smallest RLI (serving RLI = 0 ows immediately to minimize Stalls, and using O verlap inter vals for RLI > 0 ows) yields the minimum makespan. □ B F ULL ALGORI THM FOR ROBUST IN TER-REQUEST SCHEDULING The overall workow of the scheduling algorithm is illus- trated in Algorithm 1. In this se ction, we elaborate on the scheduling logic, providing the comprehensive mathemat- ical formulation of priority assignment and further details on the practical implementation of latency estimation and enforcement. This section details the robust scheduling algorithm de- signed to handle imprecise laxity and overload. The work- ow operates in three phases triggered by batch arrival and departure events. Step 1: Sorting via Robust Eective Deadline. T o miti- gate the "Piggyback Ee ct, " the sche duler employs the Robust Eective Deadline ( 𝑅 𝐸 𝐷 ) metric dened in §4.4.2. The prior- itization process executes in two stages. First, for each batch B with 𝑛 requests, the system sorts the requests internally by their deadlines 𝑑 1 ≤ 𝑑 2 ≤ · · · ≤ 𝑑 𝑛 . It then performs a linear scan to identify the partition point 𝑘 ∗ = arg max 1 ≤ 𝑘 < 𝑛 ( 𝑑 𝑘 + 1 − 𝑑 𝑘 ) that yields the maximal inter-request gap. This calcula- tion dynamically separates the outliers (Tight Set) from the majority (Loose Set). Based on this partition, the scheduler computes the 𝑅 𝐸 𝐷 score using the derived sub-batch dead- lines and the outlier ratio 𝑓 . Finally , all active batches are organized into a global priority queue sorted by ascending 𝑅 𝐸 𝐷 values. This ensures that the dispatch order eectively lters out transient urgency spikes from isolated outliers while preserving the priority of genuinely urgent workloads. Algorithm 1 Inter-request Scheduling 1: procedure InterScheduling ( B , 𝑀 , 𝐵 ) ⊲ input B , 𝑀 : Batches and Trac Matrices ⊲ input 𝐵 : Global total drop budget ⊲ output 𝜎 , H 2: 𝑆 ( ·) ← 0 ⊲ Interference fr om high-priority batches 3: P ← ∅ ; H ← ∅ ⊲ Step 1: Sorting via Eective Deadline 4: 𝜎 ← SortByRED ( B ) 5: Precompute load vectors 𝐿 from 𝑀 6: for 𝑘 ← 1 to | 𝜎 | do 7: Let 𝑖 ← 𝜎 [ 𝑘 ] 8: P ← P ∪ B 𝑖 ⊲ A dd to candidate pool 9: b 𝐹 𝑖 ← EstFinishTime ( 𝑆 , 𝐿 𝑖 ) ⊲ Step 2: Feasibility Check 10: while b 𝐹 𝑖 > 𝐷 𝐿𝑜 𝑖 and | H | < 𝐵 and P ≠ ∅ do 11: 𝑢 ★ ← arg max 𝑢 ( 𝑆 ( 𝑢 ) + 𝐿 𝑖 ( 𝑢 ) ) ⊲ Bottleneck ⊲ Step 3: selective pruning 12: 𝑟 ★ ← arg max 𝑟 ∈ P Load of 𝑟 on 𝑢 ★ 13: H ← H ∪ { 𝑟 ★ } ; P ← P \ { 𝑟 ★ } 14: if 𝑟 ★ ∈ B 𝑖 then ⊲ Drop request in current batch 15: 𝐿 𝑖 ( ·) ← 𝐿 𝑖 ( ·) − ℓ 𝑟 ★ ( ·) 16: else ⊲ Drop r equest in higher priority 17: 𝑆 ( · ) ← 𝑆 ( ·) − ℓ 𝑟 ★ ( ·) 18: b 𝐹 𝑖 ← EstFinishTime ( 𝑆 , 𝐿 𝑖 ) 19: 𝑆 ( ·) ← 𝑆 ( ·) + 𝐿 𝑖 ( ·) ⊲ Update 20: return 𝜎 , H Step 2: W orst-case Feasibility Check. Following prioriti- zation, we perform an admission control check to prevent the "Black Hole Eect. " W e estimate the completion time b 𝑇 𝑖 by strictly accumulating delays under a worst-case assump- tion (no overlap b etween batches). Computation latency is treated as deterministic, derived from the static computation graph of the Transformer model and oine proling on the target hardware [ 5 , 70 , 106 ]. Communication latency is es- timated by analyzing the batch’s trac matrix to identify the bottlene ck port 𝑝 ∗ in the network fabric; the delay is calculated as the cumulative load on 𝑝 ∗ divided by its band- width. For dynamic architectures like Mixture-of-Experts (MoE) where token routing is runtime-dependent, we rely on historical routing statistics. Prior studies [ 40 ] indicate that despite high noise in individual trac matrices, the end- to-end latency prediction error typically remains within 20%. This level of accuracy is sucient for our scheduling granu- larity , allowing us to reliably enforce feasibility against the target deadline ( 𝐷 𝐿𝑜 min ). Step 3: Sele ctive Pruning and Soft Enforcement. If a batch fails the feasibility check (i.e., b 𝑇 𝑖 > 𝐷 𝐿𝑜 min ), the sys- tem triggers a surgical pruning mechanism. W e identify the specic requests within the batch that contribute the maxi- mum load to the bottleneck port 𝑝 ∗ and iteratively remo ve 17 them from the feasible set until the predicted latency meets the deadline. Crucially , this pruning employs a soft enforce- ment strategy . Instead of immediately discarding the pruned requests, the scheduler demotes them to a "Scav enger" pri- ority class within a dual-queue system. The Main Queue is serviced with strict priority , while the Scavenger Queue is processed opp ortunistically only when the network is de- tected to be idle or when actual runtime latencies are lower than the pessimistic estimates. This hybrid approach ensures system stability under worst-case predictions while maxi- mizing throughput by reclaiming resources when congestion does not materialize. Summary . It is important to emphasize the design hierarchy within this workow . The RED metric acts as the primar y tie-breaker , governing the global dispatch order to maximize service-level objective (SLO) compliance under normal to moderate load. The feasibility check and selective pruning operate strictly as complementary safeguards, activated only during pathological overload to prevent resource exhaustion. This separation of concerns ensures that the sche duler re- mains stable and predictable—relying on robust prioritization for the vast majority of decisions—while retaining the capa- bility to degrade gracefully only when e xtreme contention makes it unavoidable. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment