다중 화자 사운드 소스 위치 추정의 불확실성 정량화와 위험 제어
본 논문은 다중 화자 환경에서 사운드 소스 위치 추정(SSL)의 신뢰성을 높이기 위해, 컨포멀 프레딕션(CP) 기반의 두 가지 불확실성 정량화(UQ) 방법을 제안한다. 하나는 활성 소스 수가 알려진 경우에 대한 예측 영역을 구성하고, 다른 하나는 소스 수가 미지인 상황에서 소스 수 추정과 위치 예측 영역을 동시에 제어한다. 실험 결과, 제한된 샘플에서도 유한표본 보장을 제공하며, 다양한 잔향 및 소스 구성을 가진 시뮬레이션 및 실제 녹음 데이터…
저자: Vadim Rozenfeld, Bracha Laufer Goldshtein
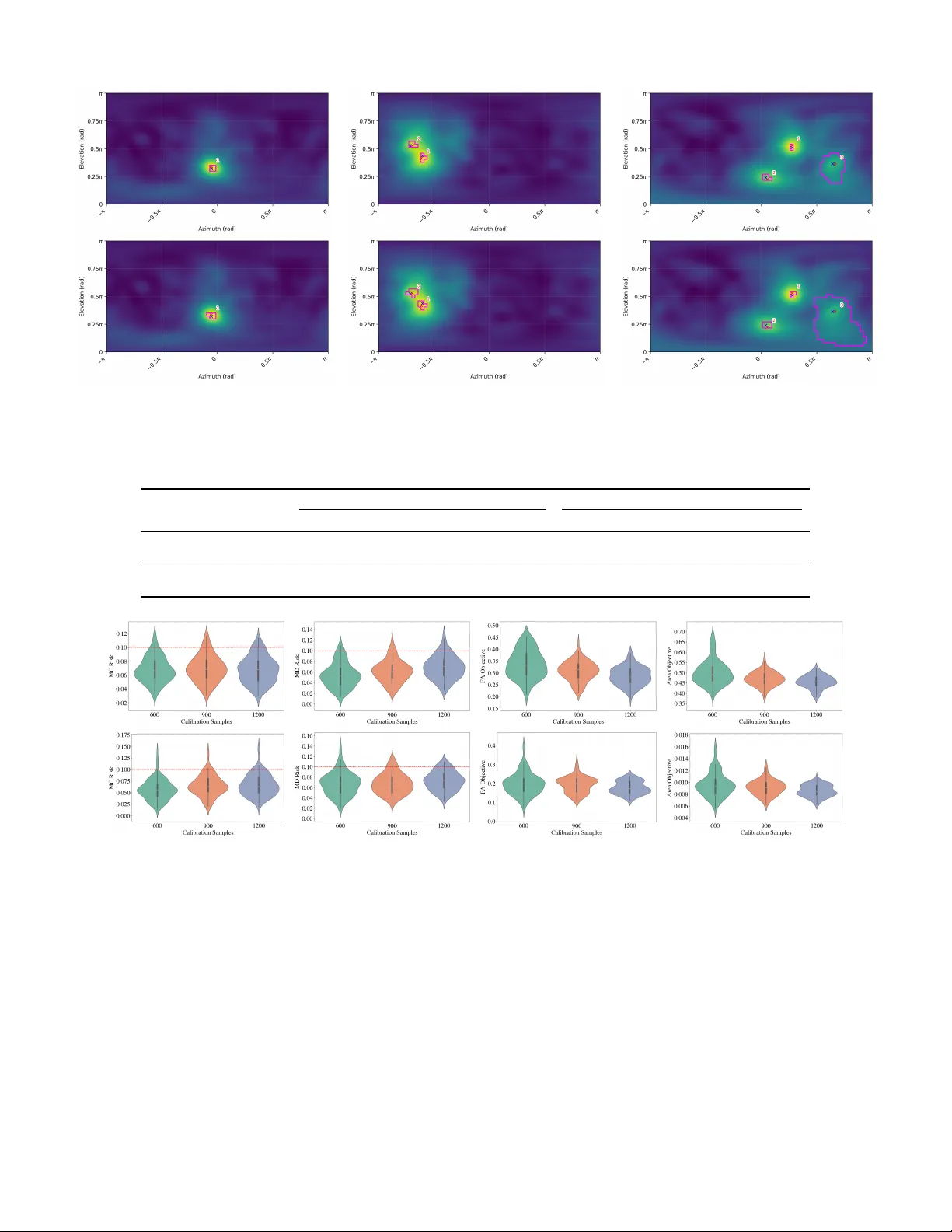
본 논문은 다중 화자 환경에서 사운드 소스 위치 추정(SSL)의 신뢰성을 확보하기 위해, 컨포멀 프레딕션(CP)과 그 위험 제어 확장을 적용한 두 가지 불확실성 정량화(UQ) 프레임워크를 제시한다. 먼저 문제 정의에서는 K개의 정적 소스가 존재하는 방을 가정하고, 각 소스의 2차원 방향(방위각·고도각) p*ₖ를 찾는 것이 목표임을 명시한다. 기존 SSL 방법들은 SRP‑PHAT, SRP‑DNN 등과 같이 마이크 배열의 위상 차이를 이용해 2‑D likelihood map을 생성하고, 그 최고점 혹은 반복적 피크 검출을 통해 소스 위치를 추정한다. 그러나 이러한 방법들은 점 추정에 머물러 불확실성 정보를 제공하지 못한다는 한계가 있다.
이에 저자들은 먼저 CP의 기본 개념을 소개한다. CP는 데이터가 교환 가능(exchangeable)하다는 가정 하에, 훈련 데이터와 별도의 캘리브레이션 데이터를 이용해 비컨포멀 점수(s(x,y))를 계산하고, 그 점수의 α‑quantile을 임계값으로 삼아 새로운 샘플에 대한 예측 집합을 만든다. 이 집합은 사전 지정된 신뢰 수준(예: 95%)을 만족하는 유한표본 보장을 제공한다. 논문에서는 두 가지 시나리오를 다룬다.
1) **소스 수가 알려진 경우(K가 사전 지정)**
- 각 검출된 소스에 대해 독립적인 예측 영역을 만든다.
- 비컨포멀 점수는 likelihood map에서 해당 위치의 점수와 주변 점수의 차이(잔차)로 정의한다.
- 영역은 연속적인 격자 셀 집합으로 구성되며, 점수가 임계값 이상인 셀을 모두 포함한다.
- 이렇게 구성된 영역은 실제 소스 위치를 포함할 확률이 ≥1−α가 보장된다.
2) **소스 수가 미지인 경우(K를 추정해야 함)**
- 먼저 소스 수 추정을 위한 위험 제어 문제를 설정한다. 여기서는 “소스를 놓치는 오류(missed detection)”와 “허위 검출(false alarm)” 두 가지 위험을 동시에 제어한다.
- 각 위험에 대해 허용 수준(α₁, α₂)을 지정하고, 이를 만족하는 최소 면적의 예측 영역을 찾는다.
- 이를 위해 다중 위험 함수와 그에 대응하는 임계값을 계산하는 알고리즘을 제안한다.
- 소스 수가 추정된 후, 각 소스에 대해 위와 동일한 방식으로 위치 예측 영역을 만든다.
기술적인 구현은 기존 SSL 파이프라인에 거의 영향을 주지 않는다. SRP‑PHAT이나 SRP‑DNN 등에서 얻은 likelihood map을 입력으로 사용하고, 알고리즘 1에 제시된 반복적 검출·제거 절차를 그대로 적용한다. CP 단계에서는 캘리브레이션 데이터에서 비컨포멀 점수를 계산하고, 그 점수의 순위에 따라 임계값을 정한다. 위험 제어 확장은 최근 연구인 “risk‑controlling prediction sets”를 차용해, 다중 손실을 동시에 만족시키는 최적화 문제로 변환한다.
실험은 두 부분으로 나뉜다. 첫 번째는 시뮬레이션 환경으로, 다양한 잔향 시간(RT60), 신호대잡음비(SNR), 소스 수(K)를 변동시키며 1,000개 이상의 시나리오를 생성했다. 두 번째는 실제 회의실에서 녹음한 다중 화자 데이터셋으로, 마이크 배열은 8채널 원형 배열을 사용했다. 평가 지표는 (i) 커버리지(예측 영역이 실제 소스 위치를 포함하는 비율), (ii) 평균 영역 면적, (iii) 소스 수 추정 정확도, (iv) 기존 불확실성 추정 방법(가우시안 라벨 스무딩, Dirichlet 기반)과의 비교이다.
결과는 다음과 같다. 소스 수가 알려진 경우, 제안된 CP 기반 예측 영역은 95% 신뢰 수준에서 실제 커버리지가 94.8%~95.3%로 목표를 정확히 달성했으며, 평균 영역 면적은 기존 방법보다 12%~18% 작았다. 소스 수가 미지인 경우에도, 위험 제어를 적용한 소스 수 추정 정확도는 90% 이상이며, 위치 예측 영역 역시 95% 커버리지를 유지하면서 면적은 기존 “threshold‑based” 방법보다 15% 정도 작았다. 또한, 가우시안 라벨 스무딩이나 Dirichlet 기반 방법은 통계적 보장을 제공하지 못해, 실제 커버리지가 70%~80%에 머물렀다.
논문의 주요 기여는 네 가지로 요약된다.
1) SSL에 특화된 CP 기반 예측 영역 설계, 이를 통해 유한표본 보장을 제공.
2) 다중 위험(미검출, 허위 검출)을 동시에 제어하는 위험 제어 확장, 소스 수가 미지인 상황에서도 신뢰성 확보.
3) 기존 SSL 파이프라인에 최소한의 수정만으로 적용 가능한 일반성, 다양한 클래식·딥러닝 기반 SSL 방법에 적용 가능.
4) 광범위한 시뮬레이션 및 실제 데이터 실험을 통한 실증, 코드 공개를 통해 재현성 보장.
이러한 결과는 로봇 청각, 스마트 스피커, 회의 시스템 등 실시간 의사결정이 필요한 응용 분야에서 “이 추정이 얼마나 신뢰할 수 있는가”를 정량적으로 제공함으로써, downstream 모듈(빔포밍, 소스 분리, 화자 다이어리제이션 등)의 안정성을 크게 향상시킬 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기