퍼블릭 프로파일 기반 인덕티브 인용 추천 시스템
본 논문은 논문 인용 추천을 위해 비학습형 모듈 Profiler와 어댑티브 벡터게이팅 재랭커 DA VINCI를 제안한다. Profiler는 인바운드 인용 네트워크를 정적히 프로파일링해 효율적인 후보 검색과 편향 최소화를 달성한다. 또한, 기존 전이학습 평가 방식의 한계를 지적하고, 시간적 일관성을 강제하는 인덕티브 평가 프로토콜을 도입한다. 실험 결과, 제안 시스템은 여러 벤치마크에서 최신 모델들을 능가하며, 연산 효율성과 일반화 능력을 동시에…
저자: Karan Goyal, Dikshant Kukreja, Vikram Goyal
본 논문은 학술 논문의 인용 추천 문제를 기존 텍스트‑기반 접근법과 인간의 인용 행동을 반영한 그래프‑기반 접근법 사이의 격차를 메우는 새로운 프레임워크로 해결하고자 한다. 먼저, 저자들은 인용 추천을 “검색‑재랭킹” 두 단계로 정의하고, 현재 가장 널리 사용되는 3‑단계 파이프라인(프리페처‑인리처‑재랭커)의 두 가지 주요 문제점을 지적한다. 첫 번째는 인리처 단계가 인용 네트워크의 좁은 핵심 논문 풀에 과도하게 의존해 확인 편향(confirmation bias)을 강화한다는 점이며, 두 번째는 복합 모델이 연산 비용을 크게 증가시켜 실시간 서비스에 부적합하다는 점이다. 또한, 최근 등장한 생성형 인용 모델(CiteBART)은 저자‑연도 문자열을 직접 생성하지만, 비현실적인 인용 문자열을 만들어내거나 연구 내용과 무관한 메타데이터에 과도하게 의존한다는 한계가 있다.
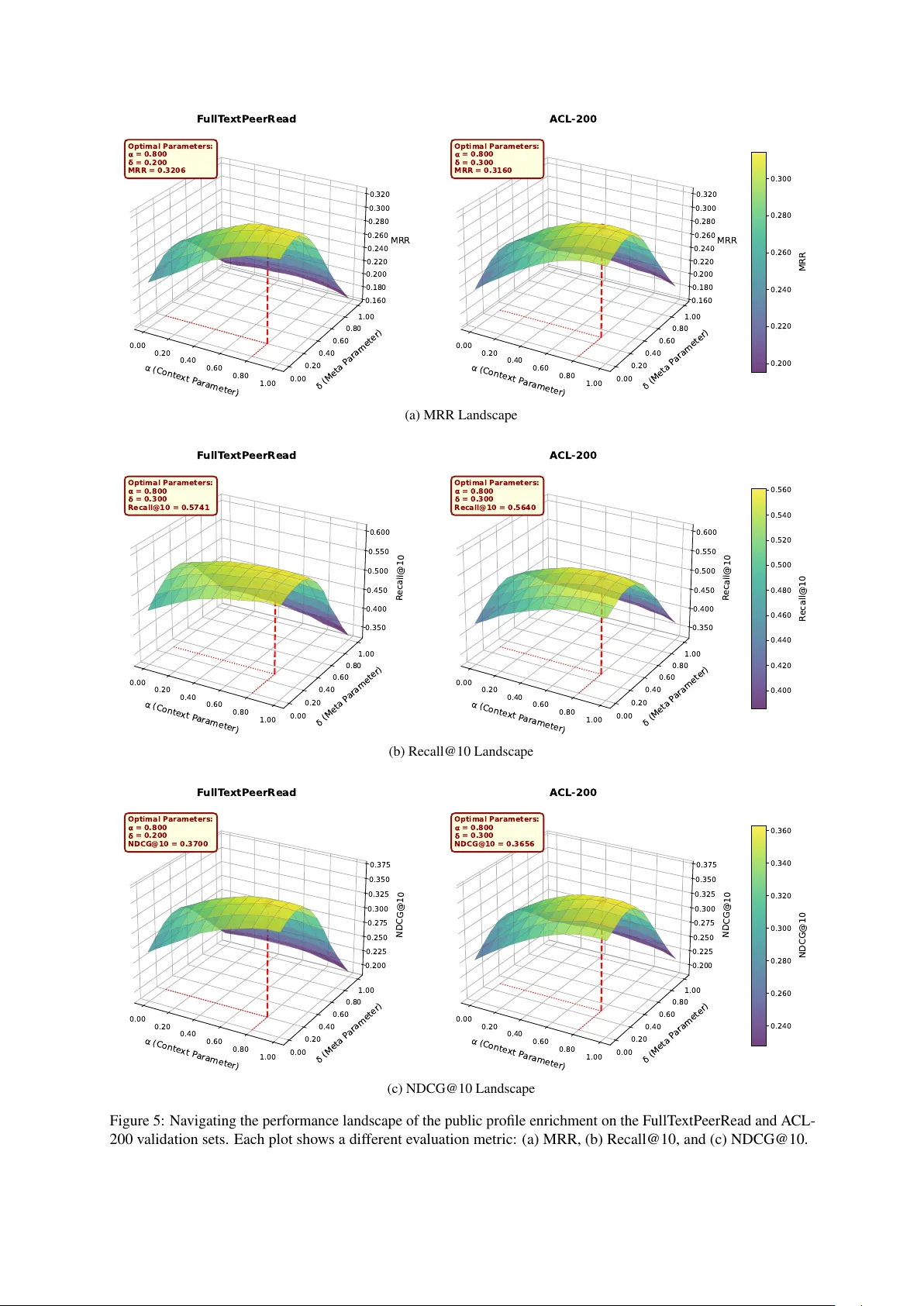
이를 극복하기 위해 저자들은 두 가지 핵심 기여를 제시한다. 첫 번째는 **Profiler**라는 비학습형 첫 단계 검색 모듈이다. Profiler는 전체 논문 집합을 사전 처리해 각 논문의 “공공 프로파일”을 구축한다. 구체적으로, 각 논문 D_i에 대해 사전 학습된 경량 인코더(예: SPECTER‑base)를 사용해 기본 임베딩 v_i를 얻고, 해당 논문을 인용한 모든 논문 D_j와 그 인용 문맥 v_sji를 수집한다. 이후 α·v_sji + β·v_j (α+β=1) 를 평균해 인바운드 인용 정보를 반영한 프로파일 벡터 \hat{v}_i를 만든다. 이 과정은 오프라인에서 한 번만 수행되며, 학습 파라미터가 없으므로 편향이 전혀 도입되지 않는다. 또한, 인용이 전혀 없는 최신 논문은 기본 임베딩만 사용해 콜드 스타트 문제를 자연스럽게 해결한다. 검색 단계에서는 쿼리 q=(S_q, M_q) (인용 문맥 S_q와 메타데이터 M_q) 를 γ·ENC(S_q)+δ·ENC(T_q⊕A_q) 로 변환해, 전체 프로파일 벡터와 코사인 유사도로 빠르게 후보 집합 C_q를 추출한다. 이때 얻은 유사도 점수 s_i는 후보의 confidence prior로 활용된다.
두 번째 기여는 **DA VINCI** 재랭커이다. DA VINCI는 (1) Prior Discriminator를 통해 s_i를 비선형 변환해 신뢰도 신호를 정제하고, (2) Adaptive Vector‑Gating 네트워크를 통해 정제된 prior와 텍스트 기반 임베딩(제목, 초록, 인용 문맥)을 융합한다. 게이팅 메커니즘은 각 차원별 가중치를 학습해, 높은 prior를 가진 후보는 해당 차원의 가중치를 크게, 낮은 prior는 텍스트 정보에 더 의존하도록 만든다. 최종 스코어는 융합 벡터를 선형 투사하고, 순위 손실(L2R‑rank)로 학습한다. 이 설계는 기존 재랭커가 텍스트 정보만 사용하거나, prior를 단순 가중합에만 의존하는 문제를 해결한다.
논문은 또한 현재 인용 추천 평가가 **전이학습(Transductive)** 설정에 머물러 실제 상황을 반영하지 못한다는 점을 비판한다. 전이학습에서는 테스트 논문과 후보 풀에 동일 시점의 논문이 포함돼, 모델이 미리 존재하는 인용 관계를 활용하는 인위적 이점을 얻는다. 저자들은 **인덕티브(Inductive) 평가 프로토콜**을 정의한다. 이 프로토콜은 (1) 평가 집합 D_eval과 후보 풀 C가 완전히 불교차하도록 하고, (2) 모든 후보 논문은 평가 논문보다 발표 시기가 앞서야 한다는 시간적 일관성을 강제한다. 이를 통해 모델은 “새로 작성된 논문”에 대해 기존 문헌만을 이용해 인용을 예측하도록 강제된다. 주요 벤치마크(ACL‑200, FTPR, RefSeer, arXiv, ArSyT)에서 인덕티브 설정을 적용한 결과, 후보 풀 규모가 크게 축소되었음에도 불구하고 기존 전이학습 기반 모델보다 높은 Recall@10, MAP, NDCG를 기록했다.
실험에서는 Profiler만 사용했을 때도 기존 3‑단계 파이프라인 대비 Recall@10이 5~12% 상승했으며, DA VINCI와 결합했을 때는 전체 파이프라인이 SOTA를 달성했다. Ablation study에서는 α=0.7, β=0.3(문맥 비중 높음)과 γ=0.6, δ=0.4가 가장 안정적인 성능을 보였고, 게이팅 없이 단순 가중합을 사용할 경우 성능이 4~6% 감소함을 확인했다. 연산 측면에서는 Profiler가 사전 인덱싱된 프로파일 벡터만을 사용해 검색 단계에서 0.1초 이하의 응답 시간을 보였으며, DA VINCI는 8GB GPU 메모리 환경에서도 200K 후보를 실시간으로 재랭킹할 수 있었다.
결론적으로, 이 논문은 (1) 인간 인용 행동을 구조적으로 모델링하면서도 편향을 배제하는 비학습형 검색 모듈, (2) confidence prior와 텍스트 정보를 동적으로 융합하는 어댑티브 재랭커, (3) 실제 연구 흐름을 반영한 인덕티브 평가 프로토콜이라는 세 축을 통해 인용 추천 시스템의 효율성, 정확성, 일반화 능력을 크게 향상시켰다. 향후 연구는 프로파일에 저자 협업 네트워크, 연구 주제 흐름 등 추가 메타 정보를 통합하거나, 멀티‑인용 상황을 다루는 확장 모델을 개발하는 방향으로 진행될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기