Public Profile Matters: A Scalable Integrated Approach to Recommend Citations in the Wild
Proper citation of relevant literature is essential for contextualising and validating scientific contributions. While current citation recommendation systems leverage local and global textual information, they often overlook the nuances of the human…
Authors: Karan Goyal, Dikshant Kukreja, Vikram Goyal
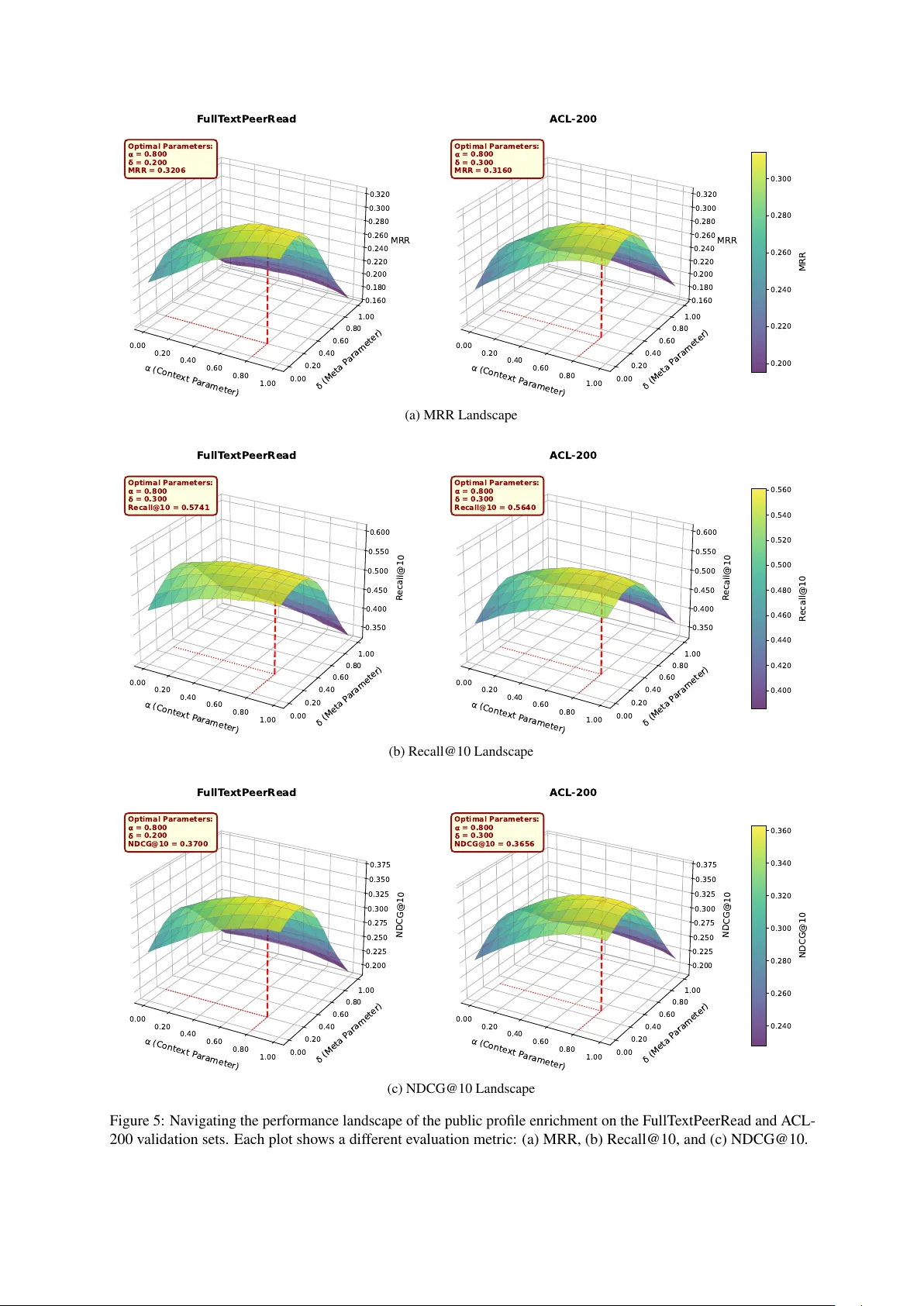
Public Pr ofile Matters: A Scalable Integrated A ppr oach to Recommend Citations in the W ild Karan Goyal IIIT Delhi, India karang@iiitd.ac.in Dikshant Kukr eja ** IIIT Delhi, India dikshant22176@iiitd.ac.in V ikram Goyal IIIT Delhi, India vikram@iiitd.ac.in Mukesh Mohania IIIT Delhi, India mukesh@iiitd.ac.in Abstract Proper citation of relev ant literature is essen- tial for contextualising and validating scientific contributions. While current citation recom- mendation systems le v erage local and global textual information, the y often ov erlook the nuances of the human citation behaviour . Re- cent methods that incorporate such patterns improv e performance but incur high compu- tational costs and introduce systematic biases into downstream rerank ers. T o address this, we propose Pr ofiler , a lightweight, non-learnable module that captures human citation patterns ef- ficiently and without bias, significantly enhanc- ing candidate retrie v al. Furthermore, we iden- tify a critical limitation in current ev aluation protocol: the systems are assessed in a trans- ducti ve setting, which fails to reflect real-world scenarios. W e introduce a rigorous Inductive ev aluation setting that enforces strict temporal constraints, simulating the recommendation of citations for newly authored papers in the wild. Finally , we present DA VINCI , a novel rerank- ing model that inte grates profiler -deri ved con- fidence priors with semantic information via an adaptiv e vector -gating mechanism. Our sys- tem achiev es new state-of-the-art results across multiple benchma rk datasets, demonstrating su- perior efficienc y and generalisability . 1 Introduction The rapid expansion of scientific research has led to an exponential sur ge in published literature ( Drozdz and Ladomery , 2024 ; Rousseau et al. , 2023 ). This information deluge presents a sig- nificant bottleneck for researchers attempting to identify and integrate relev ant prior work ( Datta et al. , 2024 ; Bhagav atula et al. , 2018 ). Conse- quently , there is a critical need for automated sys- tems that can ef ficiently streamline the citation pro- cess ( Goyal et al. , 2024 ; Gu et al. , 2022 ). ** implemented Profiler & ran open-source rerankers. Citation recommendation methodologies are generally categorised into tw o paradigms: “global" ( Ni et al. , 2024 ; Ali et al. , 2021 ; Xie et al. , 2021 ) and “local" ( Jeong et al. , 2020 ; Dai et al. , 2019 ; Ebesu and Fang , 2017 ; Huang et al. , 2015 ; Livne et al. , 2014 ; He et al. , 2010 ). While global rec- ommendation suggests papers based on the ov erall theme of a document, local citation recommenda- tion (LCR) operates at a fine-grained lev el, and is the focus of this research work. LCR targets specific “citation conte xts" or e xcerpts, aiming to suggest references that align semantically and con- ceptually with the immediate narrati ve of a passage. State-of-the-art (SO T A) LCR systems typically le verage metadata like titles and abstracts alongside citation contexts. For instance, SymT ax ( Goyal et al. , 2024 ) utilises a three-stage architecture in- volving a prefetcher , an “enricher" to capture sym- biotic neighbourhood relationships, and a reranker . Ho we ver , this approach faces three major chal- lenges. First, the enricher mimics human citation behaviour , i.e., specifically the tendency to cite from a narrow pool of seminal works, which while ef fecti ve, introduces and perpetuates inherent “con- firmation bias" in the citation ecosystem. Second, the three-stage candidate retriev al process imposes significant computational overhead. Third, its re- liance on paper-specific taxonomy limits general- isability , as such metadata is often unavailable in benchmark datasets. More recently , ( Çelik and T ekir , 2025 ) proposed CiteB AR T to generate parenthetical author-year strings directly for an input citation context. W e identify two critical fla ws in this setup: (i) the generati ve nature leads to hallucinations of non- existent citations, and (ii) the frame work is seman- tically decoupled from the research content. By focusing on “author-year" strings, the model treats research as a function of primary authors’ names (e.g., “Celik" or “Goyal") rather than the substan- ti ve scientific content, which is fundamentally in- dependent of such identifiers. Moreov er , we shed light on the current training and ev aluation practice of LCR systems operating in a setting that devi- ates from real-world scenarios. T o address these limitations, we make follo wing contributions : • W e introduce the Profiler , a lightweight, non- learnable module for candidate retrie v al. It is re- markably ef ficient and free from confirmational bias, yet it outperforms the sequential combina- tion of prefetcher and enricher . • W e demonstrate the importance of a paper’ s “pub- lic profile", i.e., how the research ecosystem per - cei ves a paper , as a remarkably vital signal for recommendation. • W e de velop the D A VINCI rerank er , which dis- criminati vely integrates confidence priors with textual semantics via an adaptiv e vector-gating mechanism. Unlike previous SO T A, it is architec- turally generalisable across di verse datasets with- out requiring special metadata like taxonomies. • W e establish a ne w state-of-the-art, demonstrat- ing that D A VINCI surpasses both specialised LCR systems and massive-scale open-source rerankers adapted for this task. • Finally , we introduce and benchmark LCR in an inductiv e setting , providing a more realistic e v aluation frame work for citations “in the wild." 2 Related W ork Early in vestigations, such as that by He et al. ( 2010 ); Li vne et al. ( 2014 ); Huang et al. ( 2015 ); Ebesu and Fang ( 2017 ); Dai et al. ( 2019 ), formally introduced local citation recommendation, utilising approachs ranging from TF-IDF based vector sim- ilarity to bidirectional LSTMs for modelling con- textual information. In an ef fort to integrate both contextual signals and graph-based signals, Jeong et al. ( 2020 ) proposed the BER T -GCN model. This model lev erages BER T ( Kenton and T outanov a , 2019 ) to generate contextualised embeddings for citation contexts, capturing semantic nuances. Si- multaneously , it employs a Graph Conv olutional Network (GCN) ( Kipf and W elling , 2017 ) extract- ing structural information from citation network, to determine the relev ance between context and po- tential citations. Howe ver , as noted by Gu et al. ( 2022 ), the computational intensity inherent in GCNs posed a significant practical challenge. Con- sequently , the BER T -GCN model’ s e v aluation was constrained to small datasets with only a few thou- sand citation contexts. This limitation emphasises a critical scalability bottleneck for GNN-based rec- ommendation models when applied to lar ge-scale datasets, highlighting the need for more computa- tionally ef ficient techniques. Medi ´ c and Šnajder ( 2020 ) e xplored the inte gra- tion of global document information to enhance citation recommendation. Ho wever , as reported in Gu et al. ( 2022 ) and Goyal et al. ( 2024 ), it creates an artificial setup which in reality does not exist. Ostendorf f et al. ( 2022 ) suggested a graph-centric approach (SciNCL), utilising neighbourhood con- trasti ve learning across the complete citation graph to generate informativ e citation embeddings. These embeddings facilitate ef ficient retriev al of top rec- ommendations using k-nearest neighbourhood in- dexing. Recently , Gu et al. ( 2022 ) introduced an ef ficient two-stage recommendation architecture (HAtten) which strate gically separates the recom- mendation process into rapid prefetching stage and a more refined reranking stage, optimising for both speed and accuracy . Building upon HAtten, Goyal et al. ( 2024 ) proposed a three-stage recommenda- tion architecture (SymT ax) composed of prefetcher , enricher and reranker , establishing state-of-the-art in local citation recommendation. V ery recently , Çelik and T ekir ( 2025 ) performed continual pre- training of BAR T -base to generate correct paren- thetical author-year citation for a gi ven context. Crucially , this generative approach relies heavily on author-year surface forms rather than the un- derlying research contributions. This creates a semantic bottleneck where the model prioritises bibliographic identifiers ov er the actual scientific content, which is inherently independent of the authors’ identities. 3 Proposed W ork Problem Formulation. W e formulate the task of local citation recommendation as a two-stage retrie v al and reranking problem, designed to han- dle the immense scale of modern scholarly corpora. Gi ven a query instance q = ( S q , M q ) — compris- ing a snippet of citation conte xt S q and the source document’ s meta information M q characterised by its title T q and abstract A q — and a lar ge corpus of scientific documents C = { D i } , the process is as follo ws. First, in the retrie val stage , our nov el Profiler module ef ficiently retriev es an initial can- didate set C q ⊂ C , where | C q | ≪ | C | . For each candidate document c i ∈ C q , Profiler also yields a confidence score, s i , which serves as an initial Dataset T ransductive Inductive # Contexts # Papers # Contexts # Corpus T rain V al T est T rain V al T est A CL-200 30,390 9,381 9,585 19,776 30,390 8,512 7,072 7,108 FTPR 9,363 492 6,814 4,837 9,363 472 5,918 3,313 RefSeer 3,521,582 124,911 126,593 624,957 3,521,582 117,724 105,411 580,059 arXiv 2,988,030 112,779 104,401 1,661,201 2,988,030 103,125 95,247 700,403 ArSyT a 8,030,837 124,188 124,189 474,341 8,030,837 123,515 122,989 412,127 T able 1: The impact of our rigorous inductive setting. Enforcing temporal consistency corrects the inflation in corpus and e v aluation sets seen in standard benchmarks, resulting in a markedly smaller and more realistic set of documents for training and inference. ‘FTPR’: Full- T extPeerRead. estimate of its rele vance. Second, in the rerank- ing stage , our proposed D A VINCI model ingests this candidate set and their associated confidence scores. It computes a final, fine-grained rele vance score, f D A VINCI ( q , c i , s i ) , by fusing a deep seman- tic analysis of the content with the discriminati ve priors obtained by refining the confidence signal from the Profiler . The final output is a ranked list L q of the documents in C q , sorted in descending order based on their D A VINCI scores, representing the most suitable citations for a gi ven conte xt. 3.1 Inductive Setting: Rethinking Ev aluation Protocol A central contribution of our work is to address a fundamental yet often overlook ed limitation in the standard e v aluation protocol for citation rec- ommendation. T raditionally , models are e valuated in a transductiv e setting. In this setup, the corpus of candidate documents is often constructed from the union of training, v alidation and test sets, and also the unparsable documents. While this does not lead to direct data leakage (i.e., using test labels for training), it creates an artificial ev aluation land- scape. Specifically , the ground truth citation for a gi ven test query itself may be another document within the test set. This means the system is e v alu- ated on its ability to find connections within a static collection where the query documents themselv es are pre-indexed and searchable which is a condi- tion that ne ver holds in a real-w orld application. T o faithfully address this shortcoming, we define and adopt a rigorous inducti ve e v aluation setting. The core principle of the inductiv e setting is to enforce a strict temporal separation between the ev aluation query and the candidate corpus, mirroring the natu- ral arro w of time in research. Formally , let D ev al be an e v aluation set (either the validation set, D val , or the test set, D test ), and let C be the candidate cor- pus a v ailable for recommendation. The inductiv e setting imposes two critical constraints: 1. Disjoint Sets: The set of ev aluation documents and the candidate corpus must be strictly dis- joint, as defined by: D ev al ∩ C = ∅ (1) 2. T emporal Consistency: For any query docu- ment D q ∈ D ev al , the candidate corpus C must only contain documents published strictly be- fore D q , formalised as: ∀ D q ∈ D ev al , ∀ D i ∈ C : date ( D i ) < date ( D q ) (2) This setup ensures that, at ev aluation time, a model is tasked with recommending citations for a “ne wly authored” paper ( D q ) using only the body of “e xisting” literature ( C ). By adopting this induc- ti ve protocol, we eliminate an y artificial adv antage gained from a pre-kno wn test set and obtain a more realistic and reliable assessment of a model’ s true generalisation capabilities. All experiments and benchmarks presented in this paper are conducted under this stringent inducti ve setting to ensure a fair and meaningful comparison. W e sho w the statistics for benchmark datasets in T able 1 . 3.2 Profiler: A Non-Lear nable First-Stage Retriev al The first stage of our system is the Profiler , a novel retrie v al module designed to ov ercome the compu- tational bottlenecks inherent in current state-of-the- art citation recommendation systems. Its design philosophy is rooted in decoupling the expensi ve process of representation enrichment of documents from the online query task. A ke y technical merit of Profiler is that it is entirely a non-learnable module. It operates as a principled, static transformation of the citation network, making it exceptionally fast and scalable. The name ‘Profiler’ reflects its core function: to compute a rich public pr ofile for e v- ery document. W e posit that a paper’ s relev ance is a function of both its intrinsic content and its percei ved identity within the scholarly network, i.e., an identity shaped by its citing papers and the contexts of those citations. Profiled Document Representations: A Static Enrichment Process. The Profiler’ s first task is a one-of f, offline pre-processing step: transforming the entire corpus into a pr ofiled citation network . For e very document D i ∈ C , we begin by initial- ising its base vector representation, v i ∈ R d ENC 1 , 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.350 0.400 0.450 0.500 0.550 R ecall@10 Optimal P arameters: = 0.800 = 0.300 Recall@10 = 0.5640 0.400 0.420 0.440 0.460 0.480 0.500 0.520 0.540 0.560 R ecall@10 Figure 1: Navigating the performance landscape of pub- lic profile on A CL-200 validation set. using a small pre-trained language model encoder , ENC 1 ( · ) . W e use specter2_base ( Singh et al. , 2022 ) as encoder due to its better performance observ ed with citation networks ( Goyal et al. , 2024 ). T o construct the profile of D i , we augment this base representation with signals from its inw ard e go net- work, N in ( D i ) , which is the set of documents that cite D i . F or each citing document D j ∈ N in ( D i ) , we extract tw o distinct signals: the representation of the citing paper’ s content, v j , and the representa- tion of the specific citation context snippet, v s j i , in which the citation is made. The final profiled repre- sentation, ˆ v i , for document D i is a static fusion of these signals as sho wn belo w: ˆ v i = v i + 1 |N in ( D i ) | X D j ∈N in ( D i ) ( α · v s j i + β · v j ) (3) Here, α ∈ [0 , 1] and β ∈ [0 , 1] are non-learnable hyperparameters, where α + β = 1 . This inher- ently rob ust design formulation pro vides a crucial regularising effect. For a very recent paper with no citations ( |N in ( D i ) | = 0 ), the profiled repre- sentation naturally defaults to its base semantic vector , v i , directly tackling the cold start problem. Concurrently , the av eraging mechanism ensures that the profiles of highly-cited papers are not un- duly skewed, while eff ecti vely modelling papers from emerging fields with sparse citations and in- terdisciplinary work with di verse citation patterns. Crucially , to eliminate potential biases, we delib- erately discard explicit signals of impact such as raw citation counts, v enue prestige, or publication timelines, irrespecti ve of presence. Query F ormulation and Efficient Cosine Sim- ilarity Search. For an incoming query q = ( S q , M q ) , we formulate a composite query repre- sentation, v q , using a similar curation strategy: v q = γ · ENC 1 ( S q ) + δ · ENC 1 ( M q ) = γ · ENC 1 ( S q ) + δ · ENC 1 ( T q ⊕ A q ) (4) where ⊕ denotes textual concatenation, and γ ∈ [0 , 1] and δ ∈ [0 , 1] are non-learnable hyperparam- eters constrained by γ + δ = 1 . W ith the entire corpus of profiled vectors ( ˆ v i ) pre-computed and index ed, the retrie val stage is reduced to a remark- ably ef ficient similarity search. W e employ cosine similarity to score the rele v ance of each candidate document against the query: Score ( q , D i ) = cosine ( v q , ˆ v i ) (5) The resulting similarity scores are not only used to rank the initial candidate list C q but are also passed directly to D A VINCI as a valuable set of confidence scores, { s i } . Hyperparameter Selection. The values for non- learnable hyperparameters ( α, β , γ , δ ) are deter- mined empirically via a systematic sweep anal- ysis on the validation sets of two of our smaller datasets. Crucially , as shown in Fig. 1 , the opti- mal set of values identified from this constrained analysis is then applied uni versally across all larger datasets without further tuning to ensure generalisa- tion. Our analysis re vealed that a specific ratio, i.e., the one that moderately prioritises the local con- text signal over the global document topic yields consistently strong performance. This finding un- derscores that the ef fecti veness of Profiler doesn’ t lie in dataset-specific tuning, but in its ability to capture a fundamental and generalisable structural property of scholarly networks. Please refer the technical appendix (Fig. 5 ) for a detailed analysis. 3.3 The DA VINCI Reranking Ar chitecture The ef ficacy of second-stage reranker is fundamen- tally constrained by its ability to enrich the seman- tic information of the query and the candidates obtained from the first-stage retriev al. W e posit that state-of-the-art performance hinges not merely on the power of semantic encoding, but also on the confidence priors. Moreo ver , it depends on the sophistication of fusion mechanism that reconciles these modalities. T o this end, we introduce D A VINCI (Discrim- inative & Adaptive V ector -gated Integration of Network Confidence & Inf ormation) . It is founded on two core concepts: (i) a principled, non-linear transformation to refine the lo w infor - mation signal from the retrie v al stage, and (ii) a Similarity Search ENC 2 [ CLS ] + Citation Context + T itle + Abstract + [ SEP ] + T itle + Abstract Query Candidate ENC 1 ENC 1 [citation context] [title + abstract] ENC 1 𝑣 q Citation Network [textual] Citation Network [vectorised] Retrieved Candidates Confidence Scores Candidate Set ( C q ) Citation Network [profiled] c i T op- k 𝑣 ᵢ Profiling 𝑣 ᵢ PROFILER 𝛾 𝛿 𝑣 ᵢ [ Soft Masking Layer ] + Output Head DA VINCI Static Enrichment Query Formulation S qi Retrieval s i Ordinal Abstraction Non-linear Remapping Prior Discriminator Linear Projection 1 Linear Projection 2 Score Projection T ower Linear Projection 1 Linear Projection 2 T ext Projection T ower Linear Projection 1 Linear Projection 2 Gating Network e cls h text h score h fused h concat g p i Learning Objective Citing Paper: Query ( q ) T itle Abstract Citation Context Recommended Papers ⍺ β ⍺ β Figure 2: The architecture of our two-stage citation recommendation system. (1) The non-learnable Profiler performs a scalable retriev al by matching the query against a corpus of documents enriched with their public pr ofile . (2) D A VINCI reranks the retrieved candidates using a v ector-g ated mechanism to integrate the discriminative retriev al priors with deep semantic features to produce a final ranked list of recommended papers for citation. nov el fashion that creates a soft masking mecha- nism to achiev e a dynamic and fine-grained fusion of signals. Finally , the reranker is optimised end- to-end using contrasti ve learning. From Degenerate Scores to Discriminati ve Pri- ors. A prerequisite for effecti ve fusion is the av ailability of well-informed input signals. Raw cardinal scores from dense retriev ers often ex- hibit se vere score compression, providing a low- information signal with poor discriminativ e capac- ity . W e therefore introduce a deterministic pre- processing block to transform this signal into a robust retrie val prior . (i) Ordinal Abstraction : W e obtain a 1-indexed rank list { r i } from the list of cardinal scores { s i }. For any ground-truth can- didate not found in the profiler’ s output (e.g., an oracle-provided positi ve injected for training), we assign a default rank of k + 1 , where k = | C q | . (ii) Non-Linear Remapping : The resulting inte- ger ranks, while robust, are both linearly spaced and numerically large, and thus fails to capture the po wer -law distrib ution of relev ance in ranked lists. These lar ge inte ger v alues can be problematic for gradient-based optimisation, potentially lead- ing to unstable training or exploding gradients. T o address both issues simultaneously , we apply a non- linear exponential decay function to map the rank r i to final transformed prior p i : p i = λ r i (6) where λ ∈ (0 , 1) is a decay-rate hyperparameter , empirically set to 0.95. This transformation yields a geometrically spaced, continuous prior that more accurately models the steep non-linear decay of rele v ance probability . This transformed prior p i serves as the definiti ve retrie v al signal for all sub- sequent model components. Adaptive Gated Fusion. The D A VINCI design is engineered to le verage the discriminati ve confi- dence prior p i and fuse it intelligently with the raw semantic information. The semantic information is obtained by textually concatenating query text with the candidate text using a [SEP] token and en- coding it using a small pretrained language model, ENC 2 ( · ) . W e use SciBER T ( Beltagy et al. , 2019 ) as encoder due to its better performance observ ed with non-graph fusion techniques ( Goyal et al. , 2024 ). W e extract the [CLS] token’ s final hidden state, e cls ∈ R d ENC 2 , as the ra w semantic representa- tion. T o enable fusion, the heterogeneous inputs are first mapped into a common d h -dimensional latent space via two independent Multi-Layer Perceptron (MLP) to wers representing modality specific pro- jection networks: • T ext Projection T ower ( MLP text ): Learns a non- linear mapping f text : R d ENC 2 → R d h , yielding a task-specific text representation h text . • Score Pr ojection T ower ( MLP score ): Learns a mapping f score : R → R d h , v ectorising the scalar prior p i into a dense score representation h score . T o obtain the final processed semantic information, projected representations are concatenated as: h concat = [ h text ; h score ] ∈ R 2 d h (7) A separate Gating Network , MLP gate , com- putes a vector -valued gate g . This network is con- ditioned on original input signals ( e cls and p i ) to form an unbiased assessment of the raw e vidence: g = σ ( MLP gate ([ e cls ; p i ])) ∈ R 2 d h (8) Here, σ is the element-wise sigmoid function, which constrains each element of the gating vector g to the range (0 , 1) . Each element g j can be inter- preted as a learned throughput coef ficient for the j -th feature. The final fusion is ex ecuted via the Hadamard product ( ⊙ ), which applies the gate g as a per -dimension soft mask : h fused = g ⊙ h concat (9) This operation constitutes a form of element-wise featur e modulation , providing a de gree of represen- tational flexibility unattainable with scalar fusion methods. The adaptiv ely fused vector , h fused , is passed to a dedicated Output Head , a final MLP ( MLP out ), which maps the 2 d h -dimensional repre- sentation to a single logit. A final sigmoid activ a- tion produces the final reranked D A VINCI score S q i = f D A VINCI ( q , c i , s i ) as sho wn belo w S q i = σ ( MLP out ( h fused )) ∈ (0 , 1) (10) It represents system’ s final confidence that candi- date document c i is a rele v ant citation for q . Learning Objective: Dir ect Optimisation of Ranking. T o align model’ s training with its do wnstream e v aluation, we use a loss function that directly optimises the relativ e ordering of candi- dates. The training process is structured around queries and their associated sets of k retrie ved doc- ument candidates, which are labeled as positiv e ( c + ) or negati ve ( c − ) based on ground-truth rele- v ance. T o construct robust training instances and expose the model to a div erse set of negativ e sig- nals, we adopt a ne gati ve sampling strategy . For a positive candidate c + associated with a query q , we compare it with randomly sampled n nega- ti ve candidates, denoted as { c − 1 , c − 2 , . . . , c − n } , from the pool of k retrie ved candidates for the query . This process yields n distinct training triplets for a positi ve e xample. F or each triplet ( q , c + , c − j ) , the model computes the respectiv e scores, S + and S − j . W e then optimise the model using the margin-based Model Comp. Time MRR Recall@K NDCG@K 10 50 300 10 50 300 A CL-200 Prefetcher 56.22m 21.14 40.33 65.37 86.98 24.57 30.11 33.30 Pref+Enr 64.43m 21.16 40.33 65.37 88.93 24.57 30.11 33.48 Profiler 2.52m 30.17 53.79 74.63 89.58 34.88 39.57 41.78 FullT extPeerRead Prefetcher 45.61m 21.73 39.17 63.43 87.16 24.78 30.15 33.63 Pref+Enr 49.20m 21.76 39.17 63.43 88.40 24.78 30.15 33.97 Profiler 1.12m 31.62 57.23 82.05 96.27 36.62 42.23 44.35 Refseer Prefetcher 99.17h 11.88 22.72 41.88 66.76 13.56 17.77 21.39 Pref+Enr 101.43h 11.92 22.72 41.88 69.91 13.56 17.77 21.88 Profiler 3.10h 16.65 32.18 52.46 72.17 19.40 23.91 26.80 arXiv Prefetcher 84.31h 13.78 27.09 48.83 74.16 15.94 20.73 24.43 Pref+Enr 85.94h 13.80 27.09 48.83 76.24 15.94 20.73 24.96 Profiler 2.72h 16.61 33.41 55.95 76.61 19.56 24.57 27.61 ArSyT a Prefetcher 225.88h 7.89 15.52 31.08 56.00 8.96 12.36 15.95 Pref+Enr 236.14h 7.94 15.52 31.08 66.59 8.96 12.36 17.31 Profiler 7.26h 13.01 26.36 47.46 69.35 15.17 19.84 23.04 T able 2: Our retrieval module ( Profiler ) consistently outperforms the SO T A baselines on all datasets across metrics and also with respect to the computational timing. Pref+Enr refers to sequential combination of Prefetcher follo wed by Enricher , leading to higher Re- call@300 and NDCG@300 while keeping the same metric values for K=10 and K=50 as per its enrichment principle. Experiments are run on NVIDIA A100 DGX. triplet loss, applied indi vidually to each pair: L ( S + , S − j ) = max(0 , S − j − S + + m ) (11) where m ∈ (0 , 1) is a margin hyperparameter . The total loss for a positi ve sample c + is the a verage sum of losses computed over these n sampled nega- ti ves: 1 n P n j =1 L ( S + , S − j ) .This objecti ve function directly penalises incorrect rank-ordering across a varied subset of competitors, forcing the model to learn a scoring function that produces a well- separated ranking of candidates (cf. Figure 2 ). 4 Experiments and Results Experimental Setup. W e benchmark all the baselines and datasets outlined in the current state- of-the-art work, SymT ax and conduct all exper- iments under the realistic inductive setting. W e exclude Çelik and T ekir ( 2025 ) as it relies on addi- tional task-specific parameters that are not defined for the problem setting considered in this work. T o provide a multi-faceted assessment of ranking performance, we employ a suite of standard infor - mation retrie v al metrics (%), namely , Mean Recip- rocal Rank (MRR), Recall@K, and NDCG@K. Model MRR Recall@K NDCG@K 5 10 20 5 10 20 A CL-200 BM25 10.53 15.45 20.82 26.71 10.71 12.44 13.92 SciNCL 15.41 21.39 30.04 39.76 15.01 17.79 20.24 HAtten 45.53 58.93 68.24 75.78 47.32 50.34 52.25 SymT ax 46.98 60.20 69.47 76.83 48.73 51.75 53.62 Ours 50.31 64.10 73.08 80.20 52.30 55.22 57.03 FullT extPeerRead BM25 16.60 24.50 31.15 38.23 17.27 19.42 21.23 SciNCL 17.80 25.31 35.43 46.48 17.53 20.77 23.57 HAtten 55.03 68.60 75.58 80.62 57.33 59.60 60.88 SymT ax 56.63 69.94 76.92 82.29 58.84 61.11 62.47 Ours 59.68 74.41 82.17 87.42 62.16 64.68 66.02 Refseer BM25 10.85 15.31 19.71 24.50 11.11 12.52 13.73 SciNCL 7.17 10.02 14.68 20.46 6.74 8.23 9.69 HAtten 30.64 39.41 45.78 51.41 32.01 33.72 34.98 SymT ax 31.80 40.61 47.24 53.25 32.79 34.94 36.46 Ours 32.57 42.19 49.52 56.37 33.62 36.00 37.73 arXiv BM25 10.28 14.64 19.04 23.89 10.50 11.93 13.15 SciNCL 9.22 13.06 18.37 24.89 8.91 10.61 12.25 HAtten 28.13 37.01 45.06 52.32 28.86 31.36 32.37 SymT ax 29.02 38.46 46.78 54.97 29.80 32.49 34.56 Ours 30.46 40.86 49.89 58.50 31.38 34.31 36.49 ArSyT a BM25 9.24 13.39 17.52 22.14 9.46 10.79 11.96 SciNCL 8.16 11.25 15.71 21.08 7.85 9.28 10.64 HAtten 19.92 27.70 34.90 42.25 20.50 22.83 24.69 SymT ax 22.00 30.16 38.06 46.03 22.49 25.05 27.07 Ours 24.01 33.74 42.83 51.56 24.73 27.67 29.89 T able 3: Our end-to-end citation recommendation sys- tem ( Ours ) consistently outperforming all baselines. Results: First Stage Retriev al. W e compare the results of our Profiler with the current state-of-the- art Prefetcher ( Gu et al. , 2022 ) and the sequential combination of Prefetcher followed by Enricher ( Goyal et al. , 2024 ). Prefetcher operates on a hier- archical attention based text encoding to obtain a retrie ved candidate list. Enricher ingests top 100 candidates from this prefetched list and models their symbiotic relationship embedded in the cita- tion network to curate an enriched list of retrie ved candidates, thus yielding a significantly higher Re- call@300. In T able 2 , results show that the non- learnable and scalable nature of Profiler makes it highly computationally efficient in reducing the re- trie v al time by 32 . 52 x and 43 . 92 x on the largest dataset (ArSyT a) and the smallest dataset (Full- T extPeerRead), respectiv ely . Results also show Profiler’ s merit to retrie ve better candidates by in- creasing the MRR by 63 . 85% and 45 . 3% on Ar- SyT a and FullT extPeerRead, respecti vely . Results: End-to-End System. W e ev aluate our complete system with other standard baselines in T able 3 as detailed in our experimental setup. W e outperform the SO T A citation recommendation sys- tems and establish a new state-of-the-art on all 0.0 0.2 0.4 0.6 0.8 1.0 (Meta P arameter) 0.0 0.1 0.2 0.3 0.4 R ecall@10 Arsyta (max=0.262 at =0.50) arXiv (max=0.289 at =0.50) R efseer (max=0.290 at =0.20) A CL -200 (max=0.386 at =0.40) F ullT e xtP eerR ead (max=0.436 at =0.30) Figure 3: The indispensable role of the public profile. Disabling profile enrichment causes a se vere and consis- tent collapse in retriev al performance across all datasets. datasets across all metrics. 5 Analysis T o dissect the contrib utions of our core design choices, we conduct a series of targeted ablation studies on both the Profiler and the DA VINCI reranker . These analyses are designed to vali- date our architectural hypotheses and quantify the impact of each no vel component. Additionally , we present both the quantitative analysis and the qualitative analysis in the technical appendix ( A.1 ) o wing to the page limit. Profiler . W e perform tw o key analyses to v alidate the efficac y of the public profile concept and its implementation in the Profiler . In Figure 1 , we vi- sualise and navigate the landscape of public profile corresponding to A CL-200 dataset for Recall@10, clearly depicting the entire spectrum of public pro- file. W e show further analyses in the technical appendix (Fig. 5 ). T o measure the performance gain enabled by profiling, we conduct an ablation where the profile enrichment is turned off (i.e., set- ting α = 0 and β = 0 in Equation 3 , so ˆ v i = v i ). As sho wn in Fig. 3 , we observe a sharp degrada- tion in retriev al performance for all datasets across v aried query compositions (i.e., dif ferent γ , δ v al- ues). Moreov er , we observe that large and tough datasets are relati vely more robust to varied query compositions in this case. This directly confirms that profiling is not merely a hypothetical construct but a vital signal for ef fectiv e first-stage retrie v al. Model MRR Recall@K NDCG@K 5 10 20 5 10 20 A CL-200 Ours 50.31 64.10 73.08 80.20 52.30 55.22 57.03 A1 48.42 62.42 71.32 78.38 50.44 53.34 55.13 A2 48.30 61.85 70.75 77.81 50.20 53.10 54.89 A3 49.46 62.67 71.83 78.49 51.27 54.26 55.96 A4 45.16 57.66 66.05 72.99 46.81 49.54 51.30 FullT extPeerRead Ours 59.68 74.41 82.17 87.42 62.16 64.48 66.02 A1 58.08 72.88 80.30 86.19 60.56 62.96 64.46 A2 58.20 72.78 80.20 86.26 60.61 63.03 64.56 A3 58.49 72.90 80.88 86.23 60.83 63.42 64.78 A4 53.58 68.04 75.90 82.22 55.90 58.46 60.08 T able 4: Ablation analysis showing the impact of our design choices w .r .t. our complete system, namely , A1 (Semantics Only), A2 (T urned-off Discriminator), A3 (Softmax Normalisation), and A4 (Scalar Gating). D A VINCI. T o isolate the contribution of each component within D A VINCI, we conduct four ab- lation studies, systematically deconstructing the full model. The results for these ablations on the FullT extPeerRead and A CL-200 datasets are pre- sented in T able 4 , and are described as follo ws (1) Semantics Only: W e discard the use of network confidence scores. This experiment is designed to quantify the value of inte grating the Profiler’ s retrie v al confidence into the reranking stage. (2) T urned-off Discriminator: W e bypass our signal refining process (ordinal abstraction and e xponen- tial remapping) and instead feed the raw , untrans- formed confidence scores from the Profiler to tes- tify the necessity of our proposed transformation for handling lo w-information retrie v al signals. (3) Softmax Normalisation: W e replace our discrimi- nati ve transformation with a standard softmax func- tion applied to the retriev al scores of the top- k can- didates. This pro vides a direct comparison of our principled remapping scheme against a common baseline for score normalisation. (4) Scalar Gat- ing: W e replace the vector -gating mechanism with scalar gating of semantic information controlled by discriminati ve prior . This experiment directly measures the performance gain attrib utable to our fine-grained, per-dimension adapti ve fusion policy . 6 Comparison with Massive-Scale Rerankers W e conduct an experiment to answer a critical ques- tion: Can a compact, purpose-b uilt reranker like D A VINCI outperform general-purpose reranking models with orders of magnitude more parame- ters? W e e v aluate against the current state-of-the- art reranking models, including the latest Qwen3- Model MRR Recall@K NDCG@K 5 10 20 5 10 20 A CL-200 D A VINCI 50.31 64.10 73.08 80.20 52.30 55.22 57.03 Qwen3-R-8B 36.44 50.96 63.06 72.83 38.02 41.94 44.42 bge-R-v2-m-40 33.52 45.27 55.23 64.70 34.55 37.78 40.17 FullT extPeerRead D A VINCI 59.68 74.41 82.17 87.42 62.16 64.68 66.02 Qwen3-R-8B 48.15 66.84 77.62 85.62 51.08 54.60 56.63 bge-R-v2-m-40 41.22 53.71 63.87 73.16 42.44 45.75 48.11 Refseer D A VINCI 32.57 42.19 49.52 56.37 33.62 36.00 37.73 Qwen3-R-8B 24.81 35.39 44.98 54.04 25.67 28.79 31.09 bge-R-v2-m-40 22.10 30.27 38.39 46.58 22.53 25.15 27.22 arXiv D A VINCI 30.46 40.86 49.89 58.50 31.38 34.31 36.49 Qwen3-R-8B 25.48 36.02 47.19 57.35 26.10 29.72 32.30 bge-R-v2-m-40 21.70 29.79 38.10 46.87 21.99 24.68 26.89 ArSyT a D A VINCI 24.01 33.74 42.83 51.56 24.73 27.67 29.89 Qwen3-R-8B 22.39 32.44 40.71 49.33 23.26 25.95 28.13 bge-R-v2-m-40 17.79 24.70 31.73 38.79 18.03 20.31 22.08 T able 5: Performance of DA VINCI (110M) vs. massiv e- scale rerankers. ‘R’: Reranker; ‘m’: minicpm. Reranker -8B ( Zhang et al. , 2025 ) and bge-reranker - v2-minicpm-40 having 2.72B parameters ( Chen et al. , 2024 ; Li et al. , 2023 ). In contrast, our D A VINCI model is e xceptionally lightweight, com- prising only 110M parameters. T o ensure a fair comparison, we standardise the retrie val stage for all models: each reranker is pro vided with the exact same list of candidate documents retrie ved by our Profiler module, and we e v aluate the performance on same test sets used for D A VINCI. Due to the immense size of these rerankers and their general- purpose pre-training, we employ instruction-aw are prompting to adapt them to our specific task and datasets, as detailed in the appendix ( A.3 ). De- spite being up to 70x smaller than the latest SO T A reranker , our specialised model markedly out- performs general-purpose models on all datasets, demonstrating the merit of task-specific design ov er raw parameter scale in an era of massi ve models. 7 Conclusion This work presents a principled re-ev aluation of the citation recommendation task, advancing the field on two fundamental fronts: the veracity of its benchmarks and the ef ficiency of its architec- tures. By instituting a rigorous inductiv e proto- col, we first establish a more faithful measure of the real-world performance. Next, our proposed two-stage system, pairing a non-learnable retrie ver with a specialised gated reranker , sets a new bench- mark for both retrie v al and end-to-end recommen- dation. The strong performance of our compact, 110M-parameter model against multi-billion pa- rameter rerank ers underscores a ke y finding: for specialised domains, architectural sophistication, task-aligned design choices and the inte gration of domain-specific kno wledge are more salient driv ers of success than just the raw parameter count. 8 Limitations This document purely presents a work of re- search and is not about productising via develop- ing a digital assistant. While our proposed frame- work achie ves state-of-the-art performance and ad- dresses sev eral systemic bottlenecks in citation rec- ommendation, it is subject to sev eral limitations. First, our ev aluation is primarily constrained to the English language and specific scientific domains, namely Computer Science. While the underly- ing mechanisms of the Profiler and the D A VINCI reranker are theoretically domain-agnostic, the stylistic nuances of “citation conte xts" in humani- ties or social sciences may dif fer . Second, although we introduce an inducti ve setting to better simu- late real-world conditions, our system still faces a partial cold-start challenge for “absolute" ne w papers. Since the Profiler lev erages the collectiv e perception of the research ecosystem, its utility may be diminished to an extent for extremely re- cent publications that hav e not yet been integrated into the citation network, leaving the recommenda- tion to rely solely on textual semantic alignment. Furthermore, like most Transformer -based archi- tectures, our reranker is limited by a maximum in- put sequence length. In instances where a citation requires a global understanding of a very long doc- ument or a complex multi-paragraph narrati ve, the 512-token windo w may truncate essential context. Lastly , performance of the system remains contin- gent on the quality of a vailable metadata; missing abstracts or poorly parsed titles in the source cor- pus could lead to suboptimal candidates during the retrie v al phase and thus the final recommendation. 9 Ethical Considerations The dev elopment of automated citation recommen- dation systems carries significant implications for the scientific community . A primary concern is the potential for popularity bias wherein already highly-cited papers are disproportionately recom- mended, further marginalising niche or emerging research. While we ha ve designed the Profiler to be more objecti ve than pre vious enricher module, any system trained on historical citation data inher- ently risks perpetuating existing human biases. W e emphasise that LCR systems should not replace a researcher’ s responsibility to conduct a thorough and critical literature revie w . Ov er-reliance on such systems could lead to lazy citing where authors cite suggested papers without fully engaging with the source material. Furthermore, we recognise the theoretical risk of citation manipulation, where recommendation algorithms could be gamed to ar - tificially boost the visibility of specific authors or institutions. T o mitigate this, we advocate for trans- parency and will make our code and trained models publicly a v ailable for community audit. Finally , we address the en vironmental impact of our work by prioritising computational efficienc y . By design- ing a lightweight, non-learnable retriev al module and a more efficient reranker than massive-scale open-source models, we significantly reduce the carbon footprint and hardw are requirements asso- ciated with training and deploying large-scale cita- tion systems. References Zafar Ali, Guilin Qi, Khan Muhammad, Pavlos K efalas, and Shah Khusro. 2021. Global citation recommen- dation employing generative adversarial network. Ex- pert Systems with Applications , 180:114888. Iz Beltagy , K yle Lo, and Arman Cohan. 2019. SciB- ER T : A pretrained language model for scientific text . In Pr oceedings of the 2019 Confer ence on Empirical Methods in Natural Languag e Processing and the 9th International J oint Confer ence on Natural Lan- guage Pr ocessing (EMNLP-IJCNLP) , pages 3615– 3620, Hong K ong, China. Association for Computa- tional Linguistics. Chandra Bhaga vatula, Sergey Feldman, Russell Po wer, and W aleed Ammar . 2018. Content-based citation recommendation . In Proceedings of the 2018 Con- fer ence of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage T echnologies, V olume 1 (Long P apers) , pages 238–251, New Orleans, Louisiana. Association for Computational Linguistics. Ege Y i ˘ git Çelik and Selma T ekir . 2025. CiteBAR T : Learning to generate citations for local citation rec- ommendation . In Pr oceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Pr ocessing , pages 1703–1719, Suzhou, China. Asso- ciation for Computational Linguistics. Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. M3- embedding: Multi-linguality , multi-functionality , multi-granularity te xt embeddings through self- knowledge distillation . In F indings of the Asso- ciation for Computational Linguistics: ACL 2024 , pages 2318–2335, Bangkok, Thailand. Association for Computational Linguistics. T ao Dai, Li Zhu, Y axiong W ang, and Kathleen M Car - ley . 2019. Attentiv e stacked denoising autoencoder with bi-lstm for personalized context-a ware citation recommendation. IEEE/ACM T ransactions on Audio, Speech, and Languag e Processing , 28:553–568. Priyangshu Datta, Suchana Datta, and Dwaipayan Ro y . 2024. Raging against the literature: Llm-po wered dataset mention extraction. In Proceedings of the 24th ACM/IEEE J oint Confer ence on Digital Li- braries , pages 1–12. John A Drozdz and Michael R Ladomery . 2024. The peer revie w process: past, present, and future. British Journal of Biomedical Science , 81:12054. T ra vis Ebesu and Y i Fang. 2017. Neural citation net- work for context-a ware citation recommendation. In Pr oceedings of the 40th international ACM SIGIR confer ence on r esearc h and development in informa- tion r etrieval , pages 1093–1096. Karan Goyal, Mayank Goel, V ikram Goyal, and Mukesh Mohania. 2024. SymT ax: Symbiotic relationship and taxonomy fusion for effecti ve citation recom- mendation . In F indings of the Association for Com- putational Linguistics: ACL 2024 , pages 8997–9008, Bangkok, Thailand. Association for Computational Linguistics. Nianlong Gu, Y ingqiang Gao, and Richard HR Hahn- loser . 2022. Local citation recommendation with hierarchical-attention text encoder and scibert-based reranking. In Eur opean Conference on Information Retrieval , pages 274–288. Springer . Qi He, Jian Pei, Daniel Kifer , Prasenjit Mitra, and Lee Giles. 2010. Context-a ware citation recommendation. In Pr oceedings of the 19th international confer ence on W orld wide web , pages 421–430. W enyi Huang, Zhaohui W u, Chen Liang, Prasenjit Mi- tra, and C Giles. 2015. A neural probabilistic model for context based citation recommendation. In Pr o- ceedings of the AAAI Conference on Artificial Intelli- gence , v olume 29. Chanwoo Jeong, Sion Jang, Eunjeong Park, and Sungchul Choi. 2020. A context-a ware citation rec- ommendation model with bert and graph con volu- tional networks. Scientometrics , 124:1907–1922. Jacob De vlin Ming-W ei Chang Kenton and Lee Kristina T outanov a. 2019. Bert: Pre-training of deep bidirec- tional transformers for language understanding. In Pr oceedings of naacL-HLT , volume 1, page 2. Thomas N. Kipf and Max W elling. 2017. Semi- supervised classification with graph con v olutional networks . In International Confer ence on Learning Repr esentations . Chaofan Li, Zheng Liu, Shitao Xiao, and Y ingxia Shao. 2023. Making large language models a better founda- tion for dense retriev al . Preprint , arXi v:2312.15503. A vishay Livne, V iv ek Gokuladas, Jaime T eev an, Su- san T Dumais, and Eytan Adar . 2014. Citesight: supporting contextual citation recommendation us- ing differential search. In Pr oceedings of the 37th international A CM SIGIR confer ence on Resear ch & development in information r etrieval , pages 807–816. Zoran Medi ´ c and Jan Šnajder . 2020. Improved local citation recommendation based on context enhanced with global information. In Pr oceedings of the first workshop on scholarly document pr ocessing , pages 97–103. Ping Ni, Xianquan W ang, Bing Lv , and Likang W u. 2024. Gtr: An explainable graph topic-aw are rec- ommender for scholarly document. Electr onic Com- mer ce Researc h and Applications , 67:101439. Malte Ostendorff, Nils Rethmeier , Isabelle Augenstein, Bela Gipp, and Georg Rehm. 2022. Neighborhood contrastiv e learning for scientific document represen- tations with citation embeddings . In Pr oceedings of the 2022 Confer ence on Empirical Methods in Natural Langua ge Pr ocessing , pages 11670–11688, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Ronald Rousseau, Carlos Garcia-Zorita, and Elias Sanz- Casado. 2023. Publications during covid-19 times: An unexpected ov erall increase. Journal of Informet- rics , 17(4):101461. Amanpreet Singh, Mike D’Arc y , Arman Cohan, Doug Downe y , and Sergey Feldman. 2022. Scirepev al: A multi-format benchmark for scientific document rep- resentations . In Confer ence on Empirical Methods in Natural Languag e Processing . Qianqian Xie, Y utao Zhu, Jimin Huang, Pan Du, and Jian-Y un Nie. 2021. Graph neural collaborati ve topic model for citation recommendation. A CM T ransac- tions on Information Systems (TOIS) , 40(3):1–30. Y anzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv pr eprint arXiv:2506.05176 . A A ppendix A.1 Analysis Quantitative Analysis. T o analyse the sensiti v- ity of our reranker to the candidate pool size, we present a quantitativ e analysis varying the num- ber of candidates (k) to be reranked. While the main experiments in this paper are conducted with k=300, T able 6 details the performance variation at k MRR Recall@K NDCG@K 5 10 20 5 10 20 A CL-200 50 46.97 59.62 67.02 71.75 49.04 51.46 52.67 100 48.92 62.08 70.36 76.46 50.92 53.62 55.17 300 50.31 64.10 73.08 80.20 52.30 55.22 57.03 1000 50.92 64.86 74.31 81.73 52.84 55.91 57.79 FullT extPeerRead 50 55.03 68.60 75.14 79.35 57.48 59.61 60.68 100 57.69 72.01 79.25 83.87 60.19 62.54 63.72 300 59.68 74.41 82.17 87.42 62.16 64.68 66.02 1000 60.20 75.14 82.84 88.43 62.71 65.22 66.64 Refseer 50 28.78 37.47 43.61 48.73 29.96 31.95 33.25 100 30.60 39.77 46.55 52.66 31.70 33.90 35.45 300 32.57 42.19 49.52 56.37 33.62 36.00 37.73 1000 32.74 42.01 49.11 55.89 33.68 35.98 37.70 arXiv 50 27.24 37.12 45.01 51.55 28.44 31.00 32.66 100 28.85 39.02 47.65 55.33 29.89 32.69 34.64 300 30.46 40.86 49.89 58.50 31.38 34.31 36.49 1000 30.06 39.82 48.62 56.97 30.81 33.66 35.78 ArSyT a 50 21.51 30.52 37.73 43.67 22.60 24.94 26.45 100 22.96 32.47 40.60 47.84 23.93 26.57 28.40 300 24.01 33.74 42.83 51.56 34.73 27.67 29.89 1000 20.74 29.24 38.37 47.98 21.02 23.96 26.39 T able 6: Analysis showing the impact of number of candidates ( k ) on reranking performance. W e found the value of 300 as an o verall better choice for the final reranking performance with respect to the metrics and the computational ov erhead. dif ferent v alues of k. The results re veal tw o distinct trends: on smaller datasets, performance scales positi vely with k; ho wev er , on larger datasets, per - formance peaks around k=300 and subsequently degrades. This degradation suggests that process- ing too many low-quality candidates introduces noise that can harm the reranker’ s precision. Gi ven that computational cost also gro ws linearly with k, this analysis confirms that k=300 represents an optimal trade-of f, maximising performance while av oiding the dual penalties of increased noise and computational ov erhead. Qualitative Analysis. T o complement our quan- titati ve results and provide deeper insight into the mechanisms dri ving our model’ s performance, we conduct a qualitative case study . By manually in- specting the recommendations for a representativ e query , we can better understand how our system compares with the state-of-the-art citation recom- mendation systems, as shown in T able 7 . W e se- lect a query paper from our test set whose topic is nuanced and requires a deep understanding of the semantics. The SOT A models demonstrate a classic failure mode of relying on broad and super- ficial topic matching. They correctly identify the general topic of ‘Machine T ranslation’ but com- pletely misses the critical and specific usage of the term ‘MER T’. Instead they focus on another term ‘Moses’ from both the citation context and the query abstract, and use these two signals to recom- mend from the candidate pool. On the other hand, our system also identify the same general topic of ‘Machine T ranslation’ but intelligently picking up the abbre viated term ‘MER T’ and using it ef fec- ti vely for recommending from the retriev ed candi- date set by comparing it with their titles. A.2 Implementation Details Our experimental pipeline is designed to reflect the distinct computational profiles of retrie v al and reranking. The coarse-grained retrie val stages for all systems are executed on NVIDIA A100 DGX clusters. The more computationally intensiv e, fine- grained reranking stages utilise NVIDIA H200 DGX systems to ensure ef ficient processing. Gi ven the substantial scale of the corpora and datasets, conducting multiple full training runs is computa- tionally prohibiti ve. T o ensure the robustness of our findings, we first perform a stability analysis. W e conduct three training trials on representati ve sub- sets of the training data and observed minimal vari- ance in performance, confirming the numerical sta- bility of our training procedure. Consequently , the final results reported in all tables are from a single, comprehensi ve run on the full-scale datasets. T o support open science and ensure full reproducibil- ity , we are committed to a comprehensi ve release upon acceptance. This will include the complete source code, detailed hyperparameter configura- tions for all experiments, and the pre-trained model checkpoints for each dataset. This will facilitate further research and allow the community to readily apply our models to similar reranking tasks. T o provide a multi-faceted assessment of ranking performance, we employ a suite of standard infor - mation retriev al metrics. W e measure Recall@K for dif ferent v alues of K to e valuate the fraction of queries for which the correct citation is found within the top-K recommendations. T o assess the quality of the ranking order, we use Mean Recipro- cal Rank (MRR), which re wards systems for plac- ing the correct item higher in the list by returning the av erage of the reciprocal ranks of the correct Citation Context:- “lation, phrases are extracted from this synthetic corpus and added as a separate phrase table to the combined system (CH1). The relative importance of this phrase table is estimated in standard MER T ( T ARGETCIT) . The final translation of the test set is produced by Moses (enriched with this additional phrase table) and additionally post-processed by Depfix. Note that all components of this combination hav e d" Query Title:- What a T ransfer-Based System Brings to the Combination with PBMT . Query Abstract:- W e present a thorough analysis of a combination of a statistical and a transferbased system for En- glish → Czech translation, Moses and T ectoMT . W e describe several techniques for inspecting such a system combination which are based both on automatic and manual evaluation. While T ectoMT often produces bad translations, Moses is still able to select the good parts of them. In many cases, T ectoMT provides useful no vel translations which are otherwise simply unav ailable to the statistical component, despite the very large training data. Our analyses confirm the expected behaviour that T ectoMT helps with preserving grammatical agreements and valenc y requirements, but that it also improv es a very di verse set of other phenomena. Interestingly , including the outputs of the transfer-based system in the phrase-based search seems to have a positiv e ef fect on the search space. Overall, we find that the components of this combination are complementary and the final system produces significantly better translations than either component by itself. # HAtten recommendation SymT ax recommendation Ours recommendation 1 Moses: Open Source T oolkit for Statistical Machine T ranslation Moses: Open Source T oolkit for Statistical Machine T ranslation Minimum Error Rate T raining in Statisti- cal Machine T ranslation 2 Combining Multi-Engine Translations with Moses Findings of the 2012 W orkshop on Statistical Machine T ranslation Statistical Phrase-Based T ranslation 3 SMT and SPE Machine T ranslation Systems for WMT’09 A ST A TISTICAL APPRO ACH TO MA- CHINE TRANSLA TION Moses: Open Source T oolkit for Statistical Machine T ranslation 4 MANY : Open Source MT System Combina- tion at WMT’10 Combining Multi-Engine Translations with Moses Findings of the 2012 W orkshop on Statistical Machine T ranslation 5 Edinbur gh’ s Machine Translation Systems for European Language Pairs Phrasetable Smoothing for Statistical Ma- chine T ranslation Improved Statistical Alignment Models 6 T ow ard Using Morphology in French-English Phrase-based SMT Minimum Error Rate T raining in Statisti- cal Machine T ranslation A ST A TISTICAL APPRO ACH TO MA- CHINE TRANSLA TION 7 Parallel Implementations of W ord Alignment T ool T raining Phrase Translation Models with Leaving-One-Out Improvements in Phrase-Based Statistical Ma- chine T ranslation 8 Improved Alignment Models for Statistical Machine T ranslation SMT and SPE Machine T ranslation Systems for WMT’09 Combining Multi-Engine Translations with Moses 9 In vestigations on T ranslation Model Adapta- tion Using Monolingual Data Statistical Phrase-Based T ranslation Hierarchical Phrase-Based T ranslation 10 A ST A TISTICAL APPRO ACH TO MA- CHINE TRANSLA TION MANY : Open Source MT System Combina- tion at WMT’10 Phrasetable Smoothing for Statistical Ma- chine T ranslation T able 7: Case study of citation recommendations for a sample from the A CL-200 dataset. The table contrasts the top-10 predictions from SO T A baseline models against our system, with ground-truth citation highlighted in bold to illustrate our model’ s improv ed relev ance. W e can see that our model is successfully able to predict the correct citation by checking the abbrev ation ‘MER T’ against the titles of the av ailable candidates whereas the other systems just focus on the term (‘Moses’) in the abstract of the citing paper and the citation conte xt, and use it for checking. # denotes the rank of the recommended citations. recommendations, and Normalised Discounted Cu- mulati ve Gain (NDCG@K), which similarly pro- vides a greater rew ard for correct items ranked at the very top by applying a logarithmic discount to the relev ance of items based on their position. For all metric s, we report the a verage ov er all test queries in percentage, where higher v alues indicate better performance, consistent with the established literature. A.3 Massive-Scale Open-Source Rerank ers For a rigorous comparison against the state-of-the- art, we select two notable massiv e-scale, general- purpose foundation models for reranking. These models represent the current paradigm of training extremely lar ge transformers on div erse, web-scale data to create po werful, zero-shot text understand- ing capabilities. Their inclusion establishes clear and challenging baselines, allo wing us to e v aluate the performance of our specialised, task-specific model against these lar ge generalist systems. Qwen Rerank er Series. The Qwen model series, de veloped by Alibaba Cloud, represents a signif- icant adv ancement in open-source language mod- els. The rerank ers from this series are specifically fine-tuned for rele v ance ranking tasks. Building upon the dense foundational models of the Qwen3 series, it pro vides a comprehensi ve range of rerank- ing models in various sizes (0.6B, 4B, and 8B). This series inherits the e xceptional multilingual capabilities, long-text understanding, and reason- ing skills of its foundational model. The Qwen rerankers based on a powerful transformer archi- tecture are trained on massiv e datasets of query- document pairs, learning to discern subtle rele- v ance signals far beyond simple ke yword matching. As instruction-tuned models, they operate as cross- encoders that expect a structured prompt. The model ingests the query and document by embed- ding them within a specific template that defines the task. This allo ws for deep, token-le vel interaction between the query and the document, conditioned on the explicit instruction. The model is trained to output a single logit, where a higher v alue indicates a higher probability of relev ance. W e select the Qwen reranker as it is widely regarded as a state- of-the-art, general-purpose reranker . Its strong per- formance across various public benchmarks mak es it a formidable baseline to measure against. W e use the latest and the largest a v ailable open-source version, Qwen3-Reranker -8B having 8.19B param- eters, from the Qwen series for our experiments. BGE Reranker v2 (B AAI General Embedding). The BGE model family , released by the Beijing Academy of Artificial Intelligence (B AAI), is an- other highly influential series of models optimised for text retrie val and ranking. The BGE-Reranker- v2 is particularly notable for its excellent perfor- mance and efficienc y . The BGE reranker is also a cross-encoder based on a transformer architec- ture. It has been fine-tuned on a mixture of public and proprietary datasets specifically for rele vance ranking. The model architecture, often based on ef ficient backbones like minicpm , is designed to deli ver high performance without the prohibitive computational cost of the largest models. The lay- erwise aspect in some v ariants refers to advanced techniques that lev erage representations from mul- tiple transformer layers, which can enhance per- formance. The usage is identical to that of Qwen where it ingests a query , document pair and pro- cesses it through its transformer layers. It outputs a rele v ance logit, which is used to re-sort the can- didates. BGE models are known for their strong performance on standardised retriev al benchmarks like the MTEB (Massi ve T ext Embedding Bench- mark). W e employ the bge-reranker -v2-minicpm- layerwise ha ving 40 layers and 2.72B parameters to provide another strong, publicly a vailable base- line from a diff erent lineage than Qwen. Its high ranking on public leaderboards and widespread adoption in the community make it an essential point of comparison for any ne w reranking model. Figure 4: Python functions for constructing the query and candidate document strings from the a v ailable ra w data. The create_query_from_citation function combines the citation context with metadata from the citing paper , while create_document_from_paper for- mats the candidate paper’ s information. Implementation and Usage. T o ensure a fair and direct comparison, we follo w a consistent protocol for all baseline models. The pre-trained checkpoints for both the Qwen and BGE rerankers are loaded directly from the Hugging Face Hub . For each query-document pair , we use the specific instruction-based prompt formats recommended for Qwen and bge, respectiv ely . For Qwen, an instruction, the query , and the candidate document text are combined into a single string template: “: {instruction}\n: {query}\n: {doc}" . For the {instruction} placeholder , we curate a clear task description as suggested in the Qwen guidelines: “Given a citation context and citing paper information, determine if the candidate paper is relevant to be cited in this context" . The sequences are truncated to the models’ maximum input length. For bge, we follo w its guidelines by choosing its recommended bge specific prompt: “Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either ‘Yes’ or ‘No’" . W e describe the query and candidate document construction using the functions as sho wn in Figure 4 . W e run the models in inference mode on our same ev aluation sets. For each formatted input, we extract the raw logit output before any final acti- v ation. This logit is used directly as the rele vance score for reranking. T o reiterate, the same set of retrie ved candidates and the same e valuation met- rics used for our own system are applied to these baselines to maintain experimental consistenc y . 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.160 0.180 0.200 0.220 0.240 0.260 0.280 0.300 0.320 MRR F ullT extPeerRead Optimal P arameters: = 0.800 = 0.200 MRR = 0.3206 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.160 0.180 0.200 0.220 0.240 0.260 0.280 0.300 0.320 MRR ACL-200 Optimal P arameters: = 0.800 = 0.300 MRR = 0.3160 0.200 0.220 0.240 0.260 0.280 0.300 MRR (a) MRR Landscape 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.350 0.400 0.450 0.500 0.550 0.600 R ecall@10 F ullT extPeerRead Optimal P arameters: = 0.800 = 0.300 Recall@10 = 0.5741 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.350 0.400 0.450 0.500 0.550 0.600 R ecall@10 ACL-200 Optimal P arameters: = 0.800 = 0.300 Recall@10 = 0.5640 0.400 0.420 0.440 0.460 0.480 0.500 0.520 0.540 0.560 R ecall@10 (b) Recall@10 Landscape 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.200 0.225 0.250 0.275 0.300 0.325 0.350 0.375 NDCG@10 F ullT extPeerRead Optimal P arameters: = 0.800 = 0.200 NDCG@10 = 0.3700 0.00 0.20 0.40 0.60 0.80 1.00 (Conte xt P arameter) 0.00 0.20 0.40 0.60 0.80 1.00 (Meta P arameter) 0.200 0.225 0.250 0.275 0.300 0.325 0.350 0.375 NDCG@10 ACL-200 Optimal P arameters: = 0.800 = 0.300 NDCG@10 = 0.3656 0.240 0.260 0.280 0.300 0.320 0.340 0.360 NDCG@10 (c) NDCG@10 Landscape Figure 5: Navigating the performance landscape of the public profile enrichment on the FullT extPeerRead and A CL- 200 validation sets. Each plot shows a dif ferent ev aluation metric: (a) MRR, (b) Recall@10, and (c) NDCG@10.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment