웹스크린샷 개인정보 식별을 위한 시각적 PII 벤치마크 WebPII
WebPII는 44,865장의 전자상거래 UI 이미지와 99만 개 이상의 바운딩 박스를 제공하는 합성 시각적 PII 검출 벤치마크이다. 기존 텍스트 기반 PII 데이터와 달리 확장된 식별자(주문 번호·배송일 등)와 입력 중인 폼의 부분 채워진 상태를 포함해, 레이아웃에 강인한 모델 학습을 목표로 설계되었다. VLM 기반 UI 재현 파이프라인을 통해 자동 주석을 생성했으며, 이를 활용한 WebRedact 모델은 텍스트 추출 기반 기준(mAP@50…
저자: Nathan Zhao
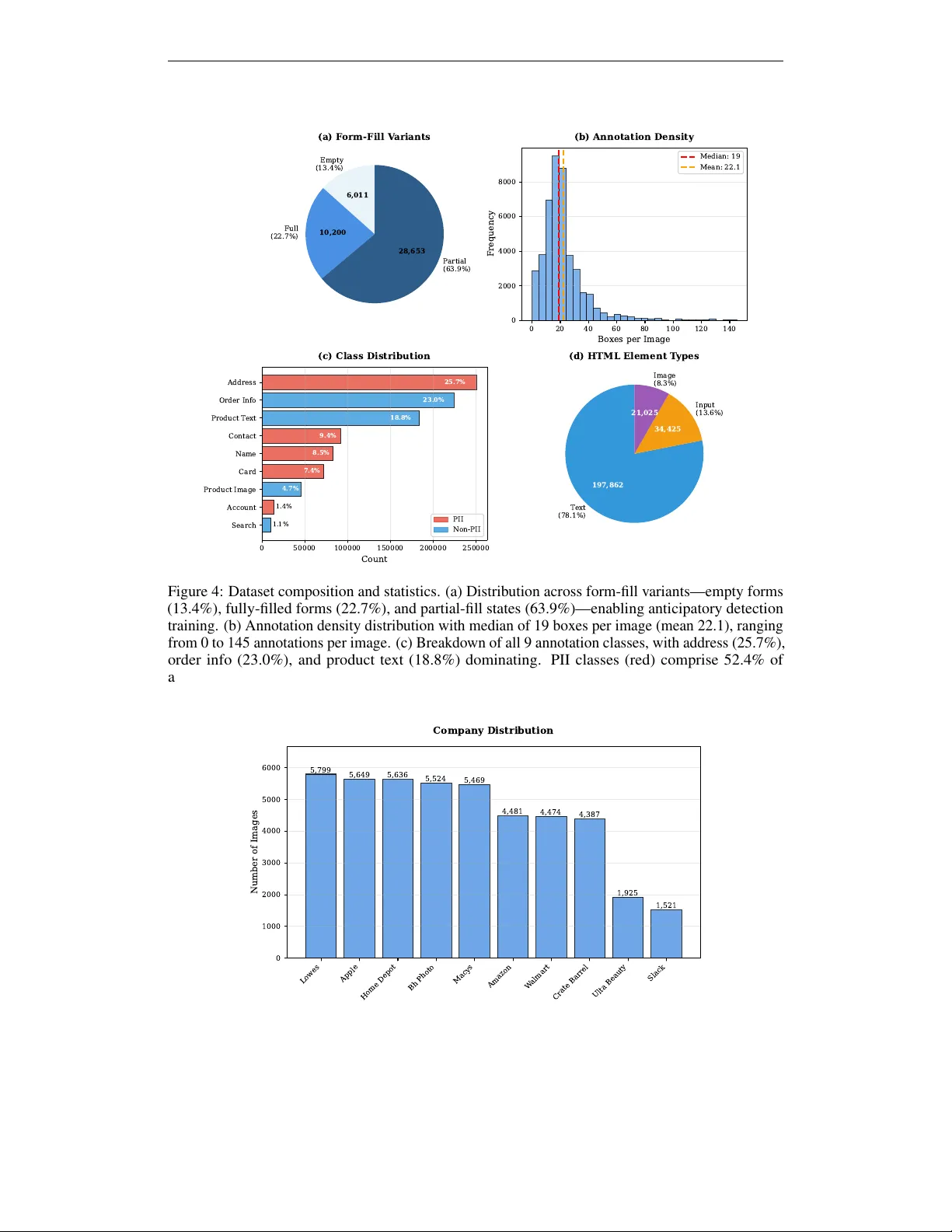
본 논문은 컴퓨터 사용 에이전트가 웹 UI를 이미지 기반으로 인식·조작하는 과정에서 발생하는 개인정보 유출 위험을 완화하기 위해, 시각적 개인정보 식별(Visual PII Detection) 전용 공개 벤치마크인 WebPII를 제안한다. 기존 연구는 텍스트 기반 PII 탐지, 문서‑중심 데이터셋, 혹은 HTML 구조를 활용한 방법에 집중했으며, 실제 화면에 렌더링된 UI에서 발생하는 시각적 컨텍스트와 동적 입력 상황을 다루지 못했다. 이러한 격차를 메우기 위해 저자들은 세 가지 핵심 설계 원칙을 정의했다.
1. **확장된 PII 분류 체계**
전통적인 이름·주소·전화번호 외에도 전자상거래에서 흔히 노출되는 거래‑수준 식별자(주문 번호, 추적 번호, 배송 날짜, 구매 이력 등)를 포함한다. 논문은 이러한 식별자가 단독으로도 개인을 재식별할 수 있음을 기존 연구(예: de Montjoye et al., 2015)와 연결시켜, 데이터 보호 관점에서 반드시 고려해야 함을 강조한다.
2. **예측적 검출(Anticipatory Detection)**
사용자가 폼에 입력을 진행 중인 단계, 즉 텍스트가 완전히 입력되지 않은 ‘부분 채워진’ 상태에서도 PII를 탐지하도록 데이터셋을 구성한다. 이를 위해 각 폼에 대해 입력 순서를 정의하고, 단계별로 ‘빈 상태·부분 입력·완전 입력’ 세 가지 변형을 생성한다. 이렇게 하면 모델이 실시간으로 입력 중인 정보를 마스킹하거나 경고를 발생시킬 수 있다.
3. **VLM 기반 대규모 합성 파이프라인**
실제 전자상거래 사이트의 스크린샷 10개 브랜드·19개 페이지 타입을 수집한 뒤, Claude Opus와 같은 최신 VLM에게 해당 레이아웃을 React 코드로 재현하도록 프롬프트한다. 코드 내에 `data-pii`, `data-product`, `data-order`와 같은 속성을 삽입해, 렌더링 시 자동으로 바운딩 박스를 추출한다. 이 과정은 네 단계(구조 생성, 속성 마킹, 입력 처리, 시각적 정제)로 나뉘며, 인간‑인‑루프 검증을 최소 1~2회 수행해 오류를 교정한다. 결과적으로 408개의 고유 레이아웃에 대해 25가지 데이터 변형을 주입하고, 폼 입력 상태를 포함해 총 44,865장의 이미지와 993,461개의 주석을 확보했다.
**데이터셋 통계**
- 이미지 수: 44,865
- 총 바운딩 박스: 993,461
- PII, 제품, 주문 식별자 3가지 카테고리
- 페이지 타입: 계정 대시보드, 주문 내역, 체크아웃, 장바구니, 결제 입력, 선물 옵션 등 19종
- 각 레이아웃당 25가지 데이터 변형 + 3가지 폼 상태(빈·부분·완전)
**모델 및 실험**
저자들은 WebRedact이라는 경량 ViT‑ 기반 객체 검출 모델을 학습시켰다. 베이스라인은 OCR + 정규식 기반 텍스트 추출 파이프라인으로, mAP@50이 0.357에 불과했다. WebRedact은 동일 조건에서 0.753의 mAP@50을 달성했으며, CPU 단일 코어 20 ms 지연으로 실시간 적용이 가능했다. 특히 부분 입력 단계에서 재현율이 크게 향상돼, 예측적 마스킹에 적합함을 보였다.
**Ablation 연구**
- **확장된 식별자**: 거래‑수준 식별자를 제외하면 mAP가 0.68로 감소, 레이아웃 일반화에 기여함을 확인.
- **부분 입력 비중**: 부분 입력 데이터를 0%로 줄이면 부분 입력 상황에서 재현율이 0.42로 급락.
- **VLM 다양성**: 동일 레이아웃에 대한 데이터 변형 수를 10개에서 25개로 늘리면 레이아웃 외적 일반화가 5%p 향상.
**한계 및 향후 연구**
- 합성 데이터 특성상 실제 사용자 환경에서 발생하는 비표준 UI(예: 비동기 로딩, 광고 삽입) 재현이 제한적.
- 현재 전자상거래 도메인에 국한돼 있어, 소셜 미디어, 포럼, 모바일 앱 등 다른 웹 기반 인터페이스에 대한 확장이 필요.
- 프라이버시‑보호 학습(연합 학습, 차등 프라이버시)과의 연계 연구가 아직 진행되지 않음.
**공개 및 활용**
WebPII 데이터셋, WebRedact 모델, 그리고 WebRedact‑LARGE(대형 버전) 모두 GitHub와 HuggingFace에 공개돼, 연구자들이 프라이버시‑보호 컴퓨터 사용 에이전트를 개발하고 평가할 수 있도록 지원한다.
**결론**
WebPII는 시각적 PII 검출을 위한 최초의 대규모, 고품질, 다중 상태 벤치마크이며, VLM 기반 자동 주석 생성이라는 혁신적인 파이프라인을 제시한다. 이를 통해 컴퓨터 사용 에이전트가 실시간으로 사용자 데이터를 보호하면서도 높은 UI 인식 성능을 유지할 수 있는 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기