WebPII: Benchmarking Visual PII Detection for Computer-Use Agents
Computer use agents create new privacy risks: training data collected from real websites inevitably contains sensitive information, and cloud-hosted inference exposes user screenshots. Detecting personally identifiable information in web screenshots …
Authors: Nathan Zhao
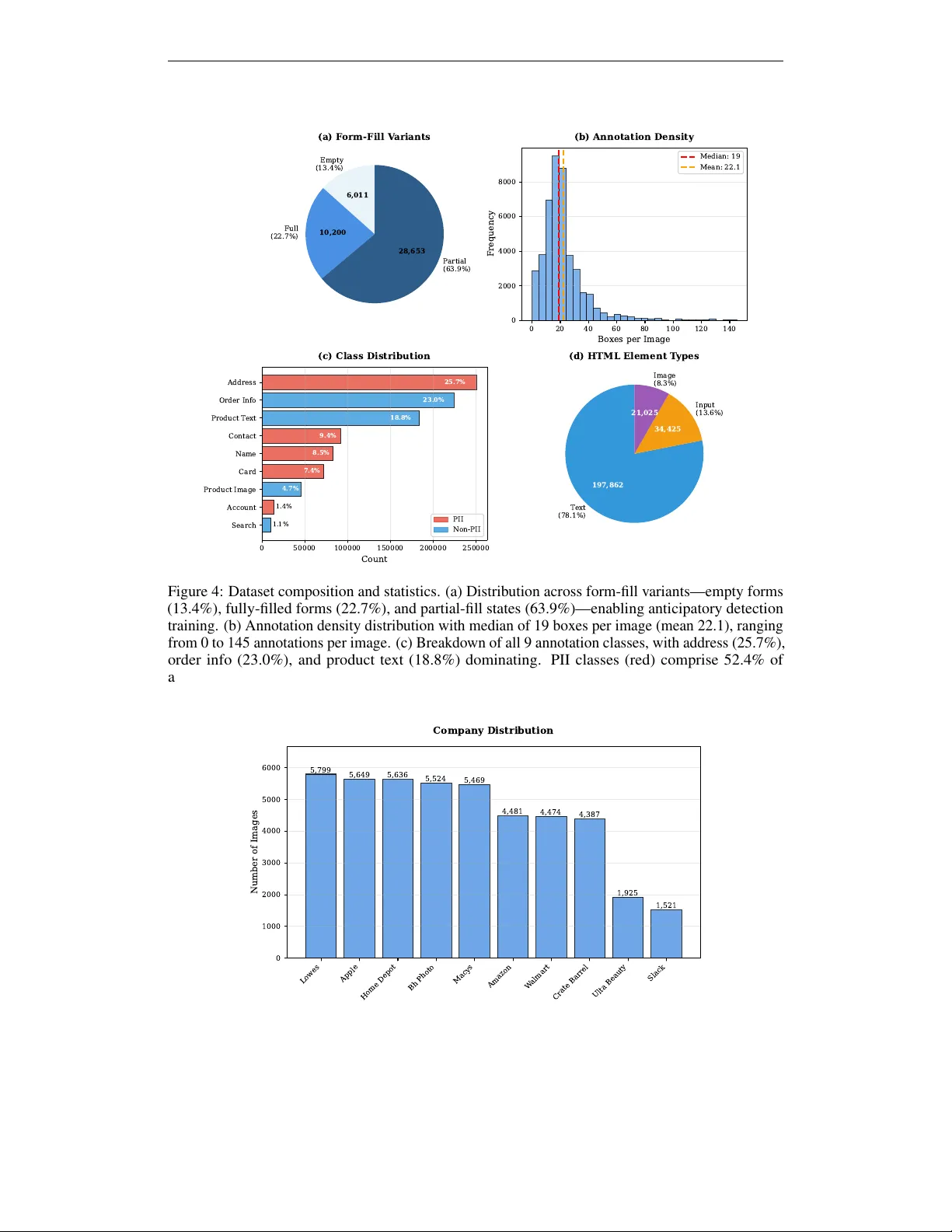
Published as a conference paper at ICLR 2026 W E B P I I : B E N C H M A R K I N G V I S U A L P I I D E T E C T I O N F O R C O M P U T E R - U S E A G E N T S Nathan Zhao Stanford Univ ersity nathanzh@stanford.edu A B S T R AC T Computer use agents create new pri v acy risks: training data collected from real web- sites inevitably contains sensiti ve information, and cloud-hosted inference exposes user screenshots. Detecting personally identifiable information in web screenshots is critical for pri vac y-preserving deployment, b ut no public benchmark e xists for this task. W e introduce W E B P I I , a fine-grained synthetic benchmark of 44,865 annotated e-commerce UI images designed with three key properties: extended PII taxonomy including transaction-lev el identifiers that enable reidentification, anticipatory detection for partially-filled forms where users are actively entering data, and scalable generation through VLM-based UI reproduction. Experiments validat e that these design choices improve layout-in variant detection across div erse interfaces and generalization to held-out page types. W e train W E B R E D A C T to demonstrate practical utility , more than doubling text-e xtraction baseline accuracy (0.753 vs 0.357 mAP@50) at real-time CPU latency (20ms). W e release the dataset and trained model to support priv acy-preserving computer use research. 1 I N T RO D U C T I O N Computer use agents—language models that operate graphical user interfaces through vision and action—represent a significant capability advance toward general-purpose AI assistants. Unlike traditional web automation that operates on structured HTML or APIs, vision-based systems observe rendered web pages as images and produce mouse and ke yboard actions to accomplish user goals. Recent systems such as Claude Computer Use Anthropic (2024) and Gemini 2.5 Comanici et al. (2025) demonstrate purely vision-driv en agents that can book flights, complete checkout flows, navigate e-commerce sites, and manage user accounts across arbitrary websites without access to DOM structure. As these systems scale from research prototypes to production deployments serving millions of sessions, their visual-first architecture creates fundamental priv acy problems: ev ery screenshot observation contains rendered PII, and standard cloud-hosted inference exposes sensiti ve user data during routine operation. The priv acy challenges span both training and inference. Training data collected from real websites inevitably contains PII that models memorize and leak Lukas et al. (2023); Nasr et al. (2023), while cloud-hosted inference routinely exposes user screenshots. Existing mitigations are insufficient: sandboxed benchmarks Zhou et al. (2023); Xie et al. (2024) use fabricated data that does not transfer to real sessions, crowdsourced datasets Deng et al. (2023); L ` u et al. (2024) lack real-time authenticated content, agentic pipelines W ang et al. (2025d) lack visual PII detection, and federated approaches W ang et al. (2025c;b) still leak information through gradient updates. Critically , no public benchmark exists for visual PII detection in web interfaces . T ext-based PII systems Microsoft (2024b); ai4Priv acy (2023); Selv am & Ghosh (2025) operate on extracted strings, missing rendered content where sensiti vity deriv es from visual context rather than surrounding words. Document-focused datasets Bulatov et al. (2021); Lerouge et al. (2024) target fix ed-layout identity documents with predictable field positions. Scene text datasets V eit et al. (2016); Gupta et al. (2016) localize text without distinguishing sensiti ve content from UI chrome. This paper presents a dataset-first contribution to address this gap. W e introduce W E B P I I , a fine-grained synthetic benchmark of e-commerce interface images designed with properties essential for visual PII detection in web interfaces. Our experiments validate ke y design choices—fill state 1 Published as a conference paper at ICLR 2026 (a) (b) (c) (d) (e) (f) Figure 1: Sample images from W E B P I I, rendered with different injected data. The dataset captures the visual comple xity of e-commerce interfaces: variable page heights reflecting div erse checkout flows and product displays (compare compact cart in (a) with extended layout in (d)), input fields and dropdown selectors, modal overlays with backdrops that occlude underlying content, ad hoc identifying information such as gift messages (c) and proposed pickup locations (e), and derived values requiring computation of tax es and totals. Bounding boxes respect occlusion boundaries. Pink indicates product annotations, purple denotes empty input fields, and red identifies PII. di versity , data injection density , e xtended identifier taxonomy—demonstrating that the dataset enables layout-in variant PII detection across di verse e-commerce layouts. Figure 1 illustrates the div ersity of PII contexts across e-commerce layouts that we can dynamically vary through data injection. Beyond this visual diversity , the dataset introduces three validated properties: 1. Extended PII taxonomy . Beyond traditional PII, W E B P I I annotates extended identifier s —order numbers, tracking IDs, deliv ery dates, purchase histories—that enable re-identification but fall outside con ventional PII definitions. 2. Anticipatory detection. W eb interfaces e xpose PII as it is being typed. W E B P I I generates anno- tations at each progressi ve state of form-filling, enabling models to trigger redaction proactively rather than after sensitiv e data is fully visible. 3. Scalable generation pipeline. Our VLM-based approach dynamically generates di verse layouts and injects varied PII configurations, producing pixel-le vel bounding boxes without manual annotation. Our generation pipeline exploits VLM-based UI reproduction Anthropic (2025a); SST (2025) to generate functional frontend code from screenshots, embedding annotation attributes during code generation for programmatic bounding box extraction. Section 2.1 documents the PII taxonomy underlying our annotations. W e v alidate the dataset’ s utility by training W E B R E DA C T , a visual detection model that more than doubles text-e xtraction baseline accuracy (0.753 vs. 0.357 mAP@50) at real-time CPU latency (20ms). Section 3 presents ablation studies v alidating our design choices. W e release W E B P I I, W E B R E DA C T , and W E B R E D A C T - L A R G E to support de velopment of pri vac y- preserving computer use systems. 1 1 Dataset and model av ailable at: https://webpii.github.io/ 2 Published as a conference paper at ICLR 2026 Configuration Key V alue Injected (F aker) PII FULLNAME Marc Arnold PII STREET 3400 Hester Green Suite 224 ORDER DATE October 17, 2021 ORDER DELIVERY DATE October 22, 2021 Injected (ABO) PRODUCT1 NAME 365 Everyday V alue, Fragra... PRODUCT1 IMAGE ( product image) LLM-Extracted SHIPPING COST 5.99 PRODUCT1 BRAND 365 Everyday V alue Randomized PRODUCT1 PRICE 4.49 PRODUCT1 RATING 4.7 Derived at Render T ime ORDER ID from SEED (647926) ORDER TOTAL subtotal + ship + tax Figure 2: Data injection maps configuration values to rendered UI elements. Left: annotated screenshot with bounding boxes. Right: selected subset of data injected for this page—Faker - generated PII, ABO product data, LLM-extracted metadata, and values deri ved at render time. The same layout rendered with different configurations produces di verse training e xamples with automatic annotations. 2 T H E W E B P I I D A T A S E T E-commerce interfaces present PII challenges distinct from documents or scene text. While an email address in a scanned form appears as static pixels, the same email in a web UI may be rendered through Jav aScript, styled with CSS, and wrapped in interactiv e elements. Moreover , web forms require anticipatory detection —identifying sensiti ve fields before users finish typing, as priv acy interventions should trigger during entry rather than after completion. Beyond traditional PII, these interfaces expose extended identifiers —order IDs, tracking numbers, delivery dates—that enable reidentification despite not constituting traditional PII. Our benchmark must capture this complexity . Generating annotated PII data at scale presents a dilemma: real screenshots contain real PII requiring manual annotation, while synthetic generation risks unrealistic layouts. W e resolve this through r epr oduction with annotation injection : collecting real e-commerce screenshots, then using vision- language models to recreate them as functional code with annotations embedded during generation. This produces pixel-accurate bounding box es without manual labeling. 2 . 1 E X T E N D E D I D E N T I FI E R S I N E - C O M M E R C E Beyond traditional PII (names, addresses, payment details), e-commerce interfaces display transaction- lev el attributes—order dates, merchants, item quantities, financial totals, deli very information—that enable reidentification despite not constituting traditional PII. Four credit card transactions containing just the merchant and date reidentify 90% of 1.1M users de Montjoye et al. (2015); eight movie ratings with dates reidentify 99% of Netflix users Narayanan & Shmatikov (2008). Cross-platform attacks link accounts by matching transaction patterns Archie et al. (2018). These identifiers also rev eal sensitiv e personal attributes—purchase patterns predict health con- ditions Aiello et al. (2019); Sasaya et al. (2026), socioeconomic status Hashemian et al. (2017), and personal characteristics Duhigg & Pole (2012); K osinski et al. (2013)—informing insurance underwriting Allen (2018), data broker segmentation Callanan et al. (2021), and surveillance T okson (2024); Kerr (2021); Sobel (2023). E-commerce interfaces also e xpose fields that are directly identifying yet absent from existing PII benchmarks: gift messages contain both sender and recipient names alongside personal notes; B2B purchase order numbers link individuals to corporate procurement systems and company names; deliv ery security codes enable package retriev al. V isual PII detection for agentic commerce must address these fields alongside traditional PII. 3 Published as a conference paper at ICLR 2026 2 . 2 D A TA C O L L E C T I O N A N D G E N E R A T I O N W e collected screenshots from 10 e-commerce brands across 19 page types—account dashboards, order history , order tracking, checkout flo ws, cart, billing address, deli very options, payment entry , gifting, store pickup, and product pages. Selection prioritized layouts exhibiting complex UI patterns: modal ov erlays, dynamic sidebars, embedded maps for store locators, cluttered multi-step forms, and responsive designs. W e source multiple distinct layouts, including both current designs and prior designs that remain accessible, and so on, yielding 408 unique layouts. All of these original screenshots serve as visual tar gets for reproduction; we do not use them directly in the dataset. For generation, we e valuated GPT -5.2 OpenAI (2025) with OpenCode SST (2025) and Claude Opus 4.5 Anthropic (2025b) with Claude Code Anthropic (2025a); Claude exhibited superior rule-follo wing on annotation con ventions, requiring fe wer iterations to reliably apply the schema. The model generates React components, reproducing each screenshot with two enforced constraints: (1) all PII and product information must reference data variables rather than hardcoded v alues, and (2) ev ery sensitiv e element must include a data attribute for annotation extraction. A V ite Y ou (2024) dev elopment server renders each component, and a Playwright Microsoft (2024a) harness captures screenshots while extracting bounding boxes for all attributed elements via DOM queries. W e pro vide the model with common e-commerce assets—company and payment method logos, security badges, shipping carrier icons, user av atar images, and map tiles—and pre-install icon libraries (Lucide, Heroicons, Phosphor) to av oid token-hea vy inline SVG generation. 2 Generating accurate reproductions requires decomposing the task into specialized prompts, with context cleared between stages to prev ent degradation. The pipeline proceeds in four stages: (1) struc- tur e , where the model generates a React component from the source screenshot, replacing all PII and product information with data v ariable references; (2) attrib ute marking , where a second pass tags each reference with annotation attributes for bounding box extraction; (3) input handling , where form fields are configured for partial-fill simulation (Section 2.4); and (4) visual r efinement , where the rendered output is compared against the source in partitioned regions, with targeted fix es applied only to sections with discrepancies. Beyond reproduction, the model extracts shipping costs and tax rates from source screenshots, deri ves order totals from item quantities, and infers platform-specific identifier formats. Human-in-the-loop validation corrects 39% of layouts (viewport overflo w , missing markup, initialization errors) via natural language instructions that delegate fix es back to Claude, typically requiring 1–2 iterations for any fix es. This v alidation amortizes across 25 data variants and all progressiv e fill states per layout. Section B provides more details on cost, human time spent handling, and decisions in volv ed in creating the annotation pipeline. 2 . 2 . 1 D A T A I N J E C T I O N The generated React components contain v ariable references rather than hardcoded values. At render time, data configurations populate these references with values from multiple sources: synthetic PII, product data, and attributes extracted or computed during generation. This enables the same layout to produce div erse screenshots with automatic annotations. W e define three annotation types— pii , product , and order —corresponding to data attributes in our generation schema, illustrated in Figure 2: PII annotations ( data-pii ) cov er traditional PII and context-specific fields. V alues are gener- ated via F aker Faraglia (2024) with locale-appropriate formatting; context-specific fields (delivery instructions, security codes) use templated generation matching observed platform con ventions. Product annotations ( data-product ) capture displayed merchandise: names, descriptions, prices, images, ratings, and quantities. Product images are sourced from Amazon Berkele y Ob- jects Collins et al. (2021) ( ∼ 147K products, 400K images). Since ABO products oftentimes lack well-structured metadata, we clean the dataset for site-specific identifiers, placeholder images, and use GPT -4o-mini OpenAI (2024) to extract brand names and item categories from titles and descrip- tions. For “recommended” and “frequently bought together” sections, we use fuzzy matching over 2 User av atars sourced from xsgames.co/randomusers; map tiles from openstreetmap.org (© OpenStreetMap contributors, ODbL). 4 Published as a conference paper at ICLR 2026 (a) (b) Figure 3: Form fill states for anticipatory detection. (a) Partial: mid-entry state with later fields incomplete (city field sho ws “New M” mid-typing). (b) Empty: pristine form with placeholder text and input field annotations. Y ellow indicates partially filled fields; gre y denotes empty fields. product descriptions to retriev e semantically similar items. V alues not provided by Faker or ABO are programmatically generated to follo w realistic patterns, including re vie w counts, ratings, and deli very dates. Order annotations ( data-order ) capture extended identifiers: order IDs, dates, tracking numbers, and financial totals. Order IDs and tracking numbers use seeded pseudo-random generation with platform-specific format templates. Shipping costs and tax percentages are extracted from the source screenshot during UI reconstruction, preserving realistic v alues for each layout. As shown in Figure 2, deriv ed v alues such as order subtotals and totals are computed at render time; the generation model must recognize these as deriv ed and apply appropriate attributes. Additional fields are generated via GPT -4o-mini when b uilding data configuration files to produce realistic content: navigation breadcrumbs referencing browsing history (Figure 1d), gift messages mentioning both recipient names and purchased items (Figure 1c), and promotional copy . Each component C i is rendered with m = 25 distinct data configurations, producing di verse screenshots with varied PII v alues, product images, and transaction details while maintaining automatic annotation alignment through DOM queries. 2 . 3 A N N OTA T I O N E X T R AC T I O N By requiring data attributes during generation, we extract pixel-coordinate bounding box es directly from the rendered DOM using the browser’ s Range API to match text content with PII values. Wrapped text is split into separate bounding boxes per line via vertical overlap detection. This approach adapts to responsiv e layouts and ensures deriv ed values receive proper attribution. Our extraction pipeline performs visibility analysis, excluding fully occluded elements and clipping partially visible ones to their visible extent. 2 . 4 A N T I C I PA T O RY D E T E C T I O N A key differentiator from te xt-based PII datasets is our support for anticipatory detection —identifying PII before the user has finished typing. In deployed systems, pri vac y-preserving interventions should trigger as sensiti ve data is being entered, not after completion. For each component C i containing N i form fields, we generate anticipatory variants across progressi ve fill states: for stage k (where 1 ≤ k < N i ), fields 1 through k − 1 are fully filled, field k is partially filled (mid-typing), and fields k + 1 through N i remain empty . Figure 3 illustrates two stages of this progression. This systematic progression mirrors actual user interaction and ensures balanced representation across fill states. Models observe each field in three contexts: empty (before the user reaches it), partially filled (activ e input), and fully filled (after completion). Rather than biasing towards any particular fill state, the dataset provides equal exposure to all stages of form completion. Additionally , forms with optional fields are rendered with these fields randomly included or e xcluded across data injections, exposing models to structural v ariability in form layouts. 5 Published as a conference paper at ICLR 2026 2 . 5 S U M M A RY A N D C O M P A R I S O N W E B P I I comprises 44,865 images spanning 10 e-commerce websites and 19 distinct page types, with 993,461 total bounding box annotations. This includes 10,200 base images with fully-filled forms, augmented by our anticipatory detection methodology that generates 28,653 partial-fill variants and 6,012 empty-form variants. Annotations span three categories (PII, product information, and order identifiers) across di verse HTML conte xts (rendered text, input fields, and images). Detailed breakdowns of annotation density , category distribution, HTML element types, company distrib ution, and page type distribution appear in Appendix A. W E B P I I is the first benchmark combining visual localization with semantic PII categories on rendered web interfaces, while annotating extended identifiers absent from prior w ork. T able 2 summarizes these distinctions. 3 E X P E R I M E N T S 3 . 1 E X P E R I M E N TA L S E T U P 3 . 1 . 1 D A T A S P L I T S The di versity of W E B P I I enables ev aluation of generalization at different le vels. W e render each of the 408 unique layouts with 25 data injection variants (dif ferent PII v alues, addresses, and product information), and for layouts with input fields, generate the fill states described in Section 2.4: full , partial , and empty . W e ev aluate three split strategies: T est Cross-Page holds out 20% of layouts randomly (82 layouts, 298 fill states), testing whether models learn layout-inv ariant features within a company’ s design system. T est Cross-Company holds out all Amazon layouts (56 layouts, 152 fill states) while training on 11 other companies (352 layouts, 1,416 fill states), ev aluating generalization to entirely ne w visual styles and brand identities. T est Cross-T ype holds out all receipt pages (20 layouts, 50 fill states) while training on 18 other page types (388 layouts, 1,518 fill states), measuring whether detection strategies transfer across functionally different page cate gories with distinct UI patterns. For all splits, we ensure no data leakage: the specific PII values, addresses, and product information in test images nev er appear in training. 3 . 2 B A S E L I N E M E T H O D S 3 . 2 . 1 T E X T - B A S E D M E T H O D S W e ev aluate text-based baselines using a two-stage pipeline: (1) OCR extraction to obtain text spans with bounding boxes, (2) classification to identify sensitive content. This approach mirrors existing PII detection systems that operate on extracted text rather than raw pix els. W e compare three approaches: Presidio Microsoft (2024b), an NER-based system using pattern matching and named entity recognition; GPT -4o-mini for LLM-based classification; and document understanding models LayoutLMv3 Huang et al. (2022) and Donut Kim et al. (2021) that encode visual layout alongside text. All document understanding pipelines use GPT -4o-mini for final classification to ensure fair comparison. W e e valuate multiple OCR engines T esseract Smith (2007), EasyOCR JaidedAI (2024), and PaddleOCR Cui et al. (2025), reporting the highest-accuracy configuration (LayoutLMv3) and fastest configuration (T esseract + Presidio). Note that text-based approaches can only e valuate te xt content—product images are excluded as OCR provides no signal for visual elements. Appendix D.1 presents detailed ablations across all OCR engines, language models, and classification approaches. 3 . 2 . 2 W E B R E DA C T W e train object detection models on W E B P I I as W E B R E DA C T , targeting real-time inference suitable for liv e redaction. While W E B P I I contains fine-grained annotations for different PII types, we train on two classes grouped by visual appearance: text (all text-based elements including PII fields, product descriptions, and order information) and image (product images). This simplification improves detection reliability by providing more training examples per class and clearer visual distinctions between categories. Training uses 100 epochs, batch size 16, with standard augmentations (random crops, flips, color jittering). W e train two model v ariants: W E B R E DA C T at 640 × 640 resolution for 6 Published as a conference paper at ICLR 2026 T able 1: Baseline results on T est Cross-Company (Amazon, full-fill images only). OCR+Presidio uses T esseract; LayoutLMv3 uses GPT -4o-mini for classification. M E T H O D M A P @ 5 0 L AT E N C Y O C R + P R E S I D I O 0 . 1 8 3 1 . 3 S L AYO U T L M V 3 + G P T - 4 O - M I N I 0 . 3 5 7 2 . 9 S W E B R E D A C T ( O U R S ) 0 . 7 5 3 2 0 M S W E B R E D A C T - L A R G E ( O U R S ) 0 . 8 4 2 3 1 2 M S real-time CPU inference, and W E B R E DA C T - L A R G E at 1280 × 1280 resolution for higher accurac y when near-real-time constraints can be relax ed. 3 . 3 R E S U LT S T able 1 presents main results on T est Cross-Company , ev aluating generalization to entirely new visual styles without seeing Amazon’ s design system during training. W e ev aluate text-based baselines only on full-filled images, as these approaches cannot identify empty or partially-filled input fields. Even on this fa vorable subset, both W E B R E D A C T variants substantially outperform text-based methods: W E B R E D AC T achieves 0.753 mAP@50, more than double the best te xt-based baseline (LayoutLMv3 at 0.357), while W E B R E DA C T - L A R G E reaches 0.842 mAP@50. Detailed failure mode analysis for OCR+LLM systems appears in Appendix D.1. W E B R E D AC T processes images in ∼ 20ms on mid-range consumer CPUs (Intel i5/AMD Ryzen 5), meeting real-time constraints for 30fps redaction, while W E B R E DA C T - L A R G E requires ∼ 312ms ( ∼ 3fps). Both models use OpenVINO for CPU inference. T ext-based methods are substantially slower: T esseract Smith (2007) OCR extraction alone (453ms, excluding classification) is slower than W E B R E DA C T - L A R G E ’ s full detection pipeline. 3 . 4 D A TA S E T A B L A T I O N S W e conduct ablations to v alidate W E B P I I ’ s design choices; full tables appear in Appendix D. Split strategies. W e compare three split strategies (T able 13). T est Cross-Page achiev es 0.797 mAP@50, indicating models learn layout-in variant features within a company’ s design system. T est Cross-Company degrades to 0.753 when generalizing to Amazon’ s distinct visual style. T est Cross-T ype shows the largest de gradation (0.728), rev ealing that page-type-specific patterns transfer less ef fectiv ely than company-specific design con ventions. Fill state diversity . Training on full screenshots alone achie ves 0.771 mAP@50 (T able 14). Adding empty screenshots without partials degrades performance to 0.758, while full+partial achiev es 0.797 (+0.026). Combining all three states achie ves 0.825 mAP@50, demonstrating that partial fills provide essential intermediate visual grounding. Progr essive fill density . Increasing partial-fill stages per layout from 1 to 5 impro ves performance from 0.758 to 0.802 mAP@50 (T able 15), with the strongest gains on partial-fill test images (0.774 to 0.835). Each additional stage exposes the model to ne w intermediate form states, providing non-redundant learning signal for field detection across the full spectrum of user interaction. T ext variant density . Increasing text variants per layout from 1 to 25 improv es performance from 0.795 to 0.820 mAP@50 (T able 16). Both precision and recall increase with more variants (0.805 to 0.842 and 0.713 to 0.731 respecti vely), confirming that div erse data injections—varying names, addresses, and products—improv e generalization beyond layout di versity alone. 4 D I S C U S S I O N 4 . 1 W H Y C P U - F I R S T D E T E C T I O N Our emphasis on lightweight CPU-executable models reflects deplo yment constraints for priv acy- sensitiv e applications: on-device processing k eeps screen content local rather than transmitting to 7 Published as a conference paper at ICLR 2026 cloud APIs Zhou et al. (2019), continuous detection must not ov erload local compute, and high- volume scenarios (browser extensions, OS-le vel priv acy layers) make per-inference GPU costs prohibitiv e. This aligns with broader trends to ward on-de vice computer use agents A wadallah et al. (2025); W ang et al. (2025a); Lin et al. (2024), where priv acy-preserving detection must operate within the same resource en velope. 4 . 2 L I M I T A T I O N S A N D F U T U R E W O R K Se veral limitations suggest directions for future work: domain scope is restricted to English-language e-commerce interfaces, with e xtension to other languages and domains (banking, healthcare, social media) requiring additional data collection; static image annotation does not capture challenges present in video streams with scrolling and state transitions; and our PII taxonomy conservati vely labels all products and order identifiers as potentially identifying, which may cause ov er-redaction without contextual understanding. Beyond priv acy protection, W E B P I I enables applications in computer use agent systems. PII, product, and input re gion detection provides semantic grounding for agent inference—extending GUI grounding approaches Lu et al. (2024); Cheng et al. (2024); Gou et al. (2024); Y ang et al. (2023); A wadalla et al. (2025); Feizi et al. (2025) to allo w agents to condition beha vior on field sensiti vity . The synthetic generation pipeline’ s controllability could enable RL environment construction for agent training, where programmatic trajectory specification Pahuja et al. (2025); W ang et al. (2025e) enables scalable production of training data compared to expensiv e manual demonstration Deng et al. (2023); L ` u et al. (2024). 5 C O N C L U S I O N W e introduced W E B P I I , a fine-grained synthetic benchmark for visual PII detection in web interfaces, designed with three v alidated properties: extended PII taxonomy including transaction-le vel identi- fiers, anticipatory detection for partially-filled forms, and scalable generation through VLM-based UI reproduction. Our generation pipeline produces annotated data at scale by instrumenting LLM-dri ven UI reproduction with programmatic annotation extraction, requiring human v alidation for 39% of layouts. Ablation studies validate these design choices, confirming that fill state di versity and data injection density each provide significant gains across split strate gies. W e trained W E B R E DA C T to validate practical utility: the model more than doubles text-extraction baseline accuracy (0.753 vs 0.357 mAP@50) while achieving real-time CPU inference (20ms). As computer use agents transition from research prototypes to deployed systems, W E B P I I provides a foundation for integrating pri v acy protection into their design. W e release the dataset and model to support priv acy-preserving computer use research. I M P A C T S TA T E M E N T This work aims to impro ve priv acy in computer use systems by enabling automated detection and redaction of sensitiv e information in web interfaces. While PII detection models could theoretically be misused for surveillance, actors with such intent can already extract PII through existing methods (foundation models, offline OCR) that do not require real-time visual localization. The av ailability of pri vac y-protectiv e tools for the broader research community represents a net positive for user priv acy . R E F E R E N C E S ai4Priv acy. pii-masking-43k (Re vision c47c98d), 2023. URL https://huggingface.co/ datasets/ai4privacy/pii- masking- 43k . L. Aiello, Rossano Schifanella, D. Quercia, and Lucia Del Prete. Large-scale and high-resolution analysis of food purchases and health outcomes. EPJ Data Science , 8, 2019. Marshall Allen. Health insurers are vacuuming up details about you — and it could raise your rates. ProPublica, July 2018. URL https://www.propublica.org/article/ health- insurers- are- vacuuming- up- details- about- you- and- it- could- raise- your- rates . 8 Published as a conference paper at ICLR 2026 Anthropic. Claude 3 Model Card Addendum: October 2024, 10 2024. URL https://assets.anthropic.com/m/1cd9d098ac3e6467/original/ Claude- 3- Model- Card- October- Addendum.pdf . Introducing computer use capability in Claude 3.5 Sonnet. Anthropic. Claude Code, 2025a. URL https://github.com/anthropics/ claude- code . Anthropic. System Card: Claude Opus 4.5. T echnical report, Anthropic, Nov em- ber 2025b. URL https://assets.anthropic.com/m/64823ba7485345a7/ Claude- Opus- 4- 5- System- Card.pdf . Maryam Archie, Sophie Gershon, Abigail Katcoff, and Aileen Zeng. Who ’ s watching ? de- anonymization of netflix re views using amazon re vie ws. 2018. Anas A wadalla, Dhruba Ghosh, A ylin Akkus, Y uhui Zhang, Marianna Nezhurina, Jenia Jitsev , Y ejin Choi, and Ludwig Schmidt. Gelato — From Data Curation to Reinforcement Learning: Building a Strong Grounding Model for Computer-Use Agents. https://github.com/ mlfoundations/gelato , 2025. Ahmed A wadallah, Y ash Lara, Raghav Magazine, Hussein Mozannar , Akshay Nambi, Y ash Pandya, Aravind Rajesw aran, Corby Rosset, Alex ey T aymanov , V ibha v V ineet, Spencer Whitehead, and Andrew Zhao. Fara-7B: An Efficient Agentic Model for Computer Use, 2025. K. Bulatov , E. Emelianova, D. Tropin, N. Skoryukina, Y . Chernyshov a, A. Sheshkus, S. Usilin, Zuheng Ming, J. Burie, M. Luqman, and V . Arlazaro v . MIDV -2020: A Comprehensiv e Benchmark Dataset for Identity Document Analysis. ArXiv , abs/2107.00396, 2021. G. Callanan, David F . Perri, and Sandra M. T omkowicz. T argeting vulnerable populations: The ethical implications of data mining, automated prediction, and focused marketing. Business and Society Revie w , 2021. Kanzhi Cheng, Qiushi Sun, Y ougang Chu, Fangzhi Xu, Y antao Li, Jianbing Zhang, and Zhiyong Wu. SeeClick: Harnessing GUI Grounding for Adv anced V isual GUI Agents. pp. 9313–9332, 2024. Jasmine Collins, Shubham Goel, Achleshw ar Luthra, Leon L. Xu, K enan Deng, Xi Zhang, T . F . Y . V icente, H. Arora, T . Dideriksen, M. Guillaumin, and J. Malik. ABO: Dataset and Benchmarks for Real-W orld 3D Object Understanding. In 2022 IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pp. 21094–21104, 2021. Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, Nov een Sachde va, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, Luke Marris, Sam Petulla, Colin Gaffne y , A. Aharoni, Nathan Lintz, T . C. Pais, Henrik Jacobsson, Idan Szpektor , Nan-Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mishra, Eric Chu, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and ne xt generation agentic capabilities. ArXiv , abs/2507.06261, 2025. Cheng Cui, T ing Sun, Manhui Lin, T ingquan Gao, Y ubo Zhang, Jiaxuan Liu, Xueqing W ang, Zelun Zhang, Changda Zhou, Hongen Liu, Y ue Zhang, W enyu Lv , Kui Huang, Y ichao Zhang, Jing Zhang, Jun Zhang, Y i Liu, Dianhai Y u, and Y anjun Ma. PaddleOCR 3.0 T echnical Report, 2025. URL https://arxiv.org/abs/2507.05595 . Yves-Ale xandre de Montjoye, Laura Radaelli, V i vek Kumar Singh, and Alex Pentland. Unique in the Shopping Mall: On the Reidentifiability of Credit Card Metadata. Science , 347(6221):536–539, 2015. Xiang Deng, Y u Gu, Boyuan Zheng, Shijie Chen, Samuel Ste vens, Boshi W ang, Huan Sun, and Y u Su. Mind2W eb: T ow ards a Generalist Agent for the W eb. ArXiv , abs/2306.06070, 2023. Charles Duhigg and A. Pole. How companies learn your secrets. 2012. Daniele Faraglia. Faker: A Python Package That Generates Fak e Data, 2024. URL https: //github.com/joke2k/faker . 9 Published as a conference paper at ICLR 2026 Aarash Feizi, Shrav an Nayak, Xiangru Jian, Ke vin Qinghong Lin, Kaixin Li, Rabiul A wal, Xing Han L ` u, Johan Obando-Ceron, Juan A. Rodriguez, Nicolas Chapados, David V azquez, Adriana Romero- Soriano, Reihaneh Rabbany , Perouz T aslakian, Christopher Pal, Spandana Gella, and Sai Rajeswar . Grounding Computer Use Agents on Human Demonstrations, 2025. URL https://arxiv. org/abs/2511.07332 . Boyu Gou, Ruohan W ang, Boyuan Zheng, Y anan Xie, Cheng Chang, Y iheng Shu, Huan Sun, and Y u Su. Navigating the Digital W orld as Humans Do: Univ ersal V isual Grounding for GUI Agents. ArXiv , abs/2410.05243, 2024. Gretel AI. GLiNER Models for PII Detection through Fine-T uning on Gretel-Generated Synthetic Documents, 10 2024. Ankush Gupta, A. V edaldi, and Andre w Zisserman. Synthetic Data for T e xt Localisation in Natural Images. In 2016 IEEE Conference on Computer V ision and P attern Recognition (CVPR) , pp. 2315–2324, 2016. Behrooz Hashemian, Emanuele Massaro, I. Bojic, Juan Murillo Arias, Stanislav Sobolevsk y , and C. Ratti. Socioeconomic characterization of regions through the lens of individual financial transactions. PLoS ONE , 12, 2017. Langdon Holmes, Scott Crossley , Harshvardhan Sikka, and W esley Morris. PIILO: An Open- Source System for Personally Identifiable Information Labeling and Obfuscation. Information and Learning Sciences , 124(9-10):266–284, 2023. doi: 10.1108/ILS- 04- 2023- 0032. Y upan Huang, T engchao Lv , Lei Cui, Y utong Lu, and Furu W ei. LayoutLMv3: Pre-training for Document AI with Unified T ext and Image Masking. In Pr oceedings of the 30th A CM International Confer ence on Multimedia , 2022. JaidedAI. EasyOCR, 2024. URL https://github.com/JaidedAI/EasyOCR . Computer software. Orin S. K err . Buying data and the fourth amendment. Aegis Series Paper 2109, Hoo ver Institution, 2021. A vailable at SSRN: https://ssrn.com/abstract=3880130 . Geew ook Kim, T eakgyu Hong, Moonbin Y im, JeongY eon Nam, Jinyoung Park, Jinyeong Y im, W onseok Hwang, Sangdoo Y un, Dongyoon Han, and Seunghyun Park. OCR-Free Document Understanding T ransformer. In Eur opean Confer ence on Computer V ision , pp. 498–517, 2021. Michal K osinski, D. Stillwell, and T . Graepel. Priv ate traits and attributes are predictable from digital records of human behavior . Pr oceedings of the National Academy of Sciences , 110:5802 – 5805, 2013. Julien Lerouge, Guillaume Betmont, Thomas Bres, Evgeny Stepankevich, and Alexis Berges. DocXPand-25k: a large and diverse benchmark dataset for identity documents analysis. ArXiv , abs/2407.20662, 2024. Raymond Li, Loubna Ben Allal, Y angtian Zi, Niklas Muennighoff, Denis K ocetkov , Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, T erry Y ue Zhuo, Thomas W ang, Oli vier Dehaene, Mishig Dav aadorj, J. Lamy-Poirier , Jo ˜ ao Monteiro, Oleh Shliazhko, Nicolas Gontier , Nicholas Meade, A. Zebaze, Ming-Ho Y ee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulo v , Zhiruo W ang, Rudra Murthy , J. Stillerman, Siv a Sankalp Patel, Dmitry Abulkhanov , Marco Zocca, Manan Dey , Zhihan Zhang, N. Fahmy , Urvashi Bhattacharyya, W . Y u, Swayam Singh, Sasha Luccioni, Paulo V illegas, M. Kunakov , Fedor Zhdanov , Manuel Romero, T ony Lee, Nadav T imor , Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jana Ebert, T ri Dao, Mayank Mishra, A. Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor , Siv a Reddy , Daniel Fried, Dzmitry Bahdanau, Y acine Jernite, Carlos Mu ˜ noz Ferrandis, Sean M. Hughes, Thomas W olf, Arjun Guha, L. V . W erra, and H. D. Vries. StarCoder: may the source be with you! T rans. Mac h. Learn. Res. , 2023, 2023. Ke vin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Y ang, Shiwei W u, Zechen Bai, W eixian Lei, Lijuan W ang, and Mike Zheng Shou. ShowUI: One V ision-Language-Action Model for GUI V isual Agent, 2024. 10 Published as a conference paper at ICLR 2026 Y adong Lu, Jianwei Y ang, Y elong Shen, and Ahmed A wadallah. OmniParser for Pure V ision Based GUI Agent. ArXiv , abs/2408.00203, 2024. Nils Lukas, Ahmed Salem, Robert Sim, Shruti T ople, Lukas W utschitz, and Santiago Zanella- B ´ eguelin. Analyzing Leakage of Personally Identifiable Information in Language Models. In 2023 IEEE Symposium on Security and Privacy (SP) , pp. 346–363, 2023. doi: 10.1109/SP46215.2023. 00038. Xing Han L ` u, Zden ˇ ek Kasner, and Siv a Reddy . W ebLINX: Real-W orld W ebsite Navigation with Multi-T urn Dialogue. ArXiv , abs/2402.05930, 2024. Microsoft. Playwright, 2024a. URL https://github.com/microsoft/playwright . Microsoft. Presidio: Data Protection and De-identification SDK, 2024b. URL https://github. com/microsoft/presidio . Arvind Narayanan and V italy Shmatikov . Robust de-anon ymization of large sparse datasets. 2008 IEEE Symposium on Security and Privacy (sp 2008) , pp. 111–125, 2008. Milad Nasr , Nicholas Carlini, Jonathan Hayase, Matthe w Jagielski, A. Feder Cooper , Daphne Ippolito, Christopher A. Choquette-Choo, Eric W allace, Florian Tram ` er , and Katherine Lee. Scalable Extraction of T raining Data from (Production) Language Models. ArXiv , abs/2311.17035, 2023. OpenAI. GPT -4o mini: Adv ancing cost-efficient intelligence, July 2024. https://openai. com/index/gpt- 4o- mini- advancing- cost- efficient- intelligence/ . OpenAI. GPT -5 System Card Update: GPT -5.2. T echnical report, OpenAI, December 2025. URL https://openai.com/index/gpt- 5- system- card- update- gpt- 5- 2/ . V ardaan Pahuja, Y adong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Y u Su, and Ahmed A wadallah. Explorer: Scaling Exploration-dri ven W eb T rajectory Synthesis for Multimodal W eb Agents. pp. 6300–6323, 2025. Naomi Sasaya, Shigefumi Kishida, Ryo Kikuchi, and Akira T ajima. V alidating behavioral proxies for disease risk monitoring via large-scale e-commerce data. 2026. Sriram Selvam and Anneswa Ghosh. P ANORAMA: A synthetic PII-laced dataset for studying sensitiv e data memorization in LLMs. ArXiv , abs/2505.12238, 2025. Ray Smith. An Overvie w of the T esseract OCR Engine. In Proceedings of the 9th International Confer ence on Document Analysis and Recognition (ICD AR 2007) , volume 2, pp. 629–633. IEEE Computer Society , 2007. doi: 10.1109/ICDAR.2007.4376991. Aaron Sobel. End-running warrants: Purchasing data under the fourth amendment and the state action problem. Y ale Law & P olicy Review , 2023. A vailable at SSRN: https://ssrn.com/ abstract=4480782 . SST. OpenCode: The Open Source AI Coding Agent, 2025. URL https://github.com/ opencode- ai/opencode . Amy Steier , Andre Manoel, Alexa Haushalter , and Maarten V an Segbroeck. Nemotron-PII: Synthe- sized Data for Pri v acy-Preserving AI, 2025. URL https://huggingface.co/datasets/ nvidia/Nemotron- PII . Matthew J. T okson. Go vernment purchases of pri vate data. W ake F or est Law Review , 59:269, 2024. Univ ersity of Utah College of La w Research Paper No. 573. Andreas V eit, T omas Matera, Luk ´ as Neumann, Jiri Matas, and Serge J. Belongie. COCO-T ext: Dataset and Benchmark for T ext Detection and Recognition in Natural Images. ArXiv , abs/1601.07140, 2016. Haoming W ang, Haoyang Zou, Huatong Song, et al. UI-T ARS-2 T echnical Report: Advancing GUI Agent with Multi-T urn Reinforcement Learning, 2025a. 11 Published as a conference paper at ICLR 2026 W enhao W ang, Zijie Y u, Rui Y e, Jianqing Zhang, Siheng Chen, and Y anfeng W ang. FedMABench: Benchmarking Mobile Agents on Decentralized Heterogeneous User Data. ArXiv , abs/2503.05143, 2025b. W enhao W ang, Mengying Y uan, Zijie Y u, Guangyi Liu, Rui Y e, Tian Jin, Siheng Chen, and Y anfeng W ang. MobileA3gent: T raining Mobile GUI Agents Using Decentralized Self-Sourced Data from Div erse Users. Pr oceedings of the F ourth W orkshop on Bridging Human-Computer Interaction and Natural Languag e Pr ocessing (HCI+NLP) , 2025c. Xinyuan W ang, Bowen W ang, Dunjie Lu, Junlin Y ang, Tianbao Xie, Junli W ang, Jiaqi Deng, Xiaole Guo, Y iheng Xu, Chen Henry W u, Zhennan Shen, Zhuokai Li, Ryan Li, Xiaochuan Li, Junda Chen, Bo Zheng, Peihang Li, Fangyu Lei, Ruisheng Cao, Y eqiao Fu, Dongchan Shin, M. Shin, Jiarui Hu, Y uyan W ang, Jixuan Chen, Y uxiao Y e, Danyang Zhang, Dikang Du, Hao Hu, Hua Chen, Zaida Zhou, Haotian Y ao, Ziwei Chen, Qizheng Gu, Y ipu W ang, Heng W ang, Diyi Y ang, V ictor Zhong, Flood Sung, Y .Charles, Zhilin Y ang, and T ao Y u. OpenCUA: Open Foundations for Computer-Use Agents. ArXiv , abs/2508.09123, 2025d. Zhaoyang W ang, Y iming Liang, Xuchao Zhang, Qianhui W u, Siwei Han, Anson Bastos, Rujia W ang, Chetan Bansal, Baolin Peng, Jianfeng Gao, Sara van Rajmohan, and Huaxiu Y ao. Adapting W eb Agents with Synthetic Supervision. ArXiv , abs/2511.06101, 2025e. T ianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, T . Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Y itao Liu, Y iheng Xu, Shuyan Zhou, Silvio Sa varese, Caiming Xiong, V ictor Zhong, and T ao Y u. OSW orld: Benchmarking Multimodal Agents for Open-Ended T asks in Real Computer En vironments. ArXiv , abs/2404.07972, 2024. Jianwei Y ang, Hao Zhang, Feng Li, Xueyan Zou, Chun yue Li, and Jianfeng Gao. Set-of-Mark Prompting Unleashes Extraordinary V isual Grounding in GPT -4V. 2023. Evan Y ou. V ite, 2024. URL https://github.com/vitejs/vite . Shuyan Zhou, Frank F . Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar , Xianyi Cheng, Y onatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. W ebArena: A Realistic W eb En viron- ment for Building Autonomous Agents. ArXiv , abs/2307.13854, 2023. Zhi Zhou, Xu Chen, En Li, Liekang Zeng, K e Luo, and Junshan Zhang. Edge Intelligence: Paving the Last Mile of Artificial Intelligence W ith Edge Computing. Pr oceedings of the IEEE , 107: 1738–1762, 2019. 12 Published as a conference paper at ICLR 2026 T able 2: Comparison of PII detection benchmarks. W E B P I I is the first to combine visual localization, semantic categories, web interface targeting, extended identifiers, and anticipatory form state support. D AT A S E T D O M A I N S I Z E V I S U A L S E M A N T I C W E B E X T . A N T I C . A I 4 P R I VACY AI 4 P R I VAC Y ( 2 0 2 3 ) T E X T 3 0 0 K ✗ ✓ ✗ ✗ ✗ P A N O R A M A S E LV A M & G H O S H ( 2 0 2 5 ) T E X T 3 8 5 K ✗ ✓ ✗ ✗ ✗ N E M OT RO N - P I I S T E I E R E T A L . ( 2 0 2 5 ) T E X T 1 0 0 K ✗ ✓ ✗ ✗ ✗ G R E T E L F I NA N C E G R E T E L A I ( 2 0 2 4 ) T E X T 56 K ✗ ✓ ✗ ✗ ✗ B I G C O D E P I I L I ET A L . ( 2 0 2 3 ) C O D E 1 2 K ✗ ✓ ✗ ✗ ✗ P I I L O H O L M E S E T A L . ( 2 0 2 3 ) E S S A Y S 2 2 K ✗ ✓ ✗ ✗ ✗ M I DV-2 0 2 0 B U L ATOV E T AL . (2 0 2 1 ) I D D O C S 7 2 K ✓ ✓ ✗ ✗ ✗ D O C X P AN D - 2 5 K L E R O U G E E T A L . ( 2 0 2 4 ) ID D O C S 2 5 K ✓ ✓ ✗ ✗ ✗ C O C O - T E X T V E I T E T A L . ( 2 0 1 6 ) S C E N E 6 3 K ✓ ✗ ✗ ✗ ✗ S Y N T H T E X T G U P TA E T A L . ( 2 0 1 6 ) S C E N E 8 0 0 K ✓ ✗ ✗ ✗ ✗ W E B P I I ( O U R S ) W E B U I 4 4 K ✓ ✓ ✓ ✓ ✓ A D A TA S E T S TA T I S T I C S The dataset comprises 44,865 images spanning 10 e-commerce websites and 19 page types. Figure 4 visualizes form-fill variants, annotation density , category breakdown, and HTML element types. Figures 5 – 6 show compan y and page type distributions. T able 2 compares W E B P I I against existing PII detection benchmarks. The 52.4%/47.6% split between PII and non-PII annotations ensures models learn to distinguish sensitiv e user data from product and order metadata. Most annotations (78.1%) tar get rendered text rather than input fields (13.6%), reflecting that PII appears predominantly on confirmation and revie w pages where entered data is displayed, not just in the form fields where users type. 13 Published as a conference paper at ICLR 2026 Empty (13.4%) 6,011 Full (22.7%) 10,200 P artial (63.9%) 28,653 (a) F orm-Fill V ariants 0 20 40 60 80 100 120 140 Boxes per Image 0 2000 4000 6000 8000 Frequency (b) Annotation Density Median: 19 Mean: 22.1 0 50000 100000 150000 200000 250000 Count Address Order Info Product T ext Contact Name Card Product Image Account Search 25.7% 23.0% 18.8% 9.4% 8.5% 7.4% 4.7% 1.4% 1.1% (c) Class Distribution PII Non-PII T ext (78.1%) 197,862 Input (13.6%) 34,425 Image (8.3%) 21,025 (d) HTML Element T ypes Figure 4: Dataset composition and statistics. (a) Distribution across form-fill v ariants—empty forms (13.4%), fully-filled forms (22.7%), and partial-fill states (63.9%)—enabling anticipatory detection training. (b) Annotation density distribution with median of 19 box es per image (mean 22.1), ranging from 0 to 145 annotations per image. (c) Breakdo wn of all 9 annotation classes, with address (25.7%), order info (23.0%), and product text (18.8%) dominating. PII classes (red) comprise 52.4% of annotations, while non-PII classes (blue) comprise 47.6%. (d) HTML element type distribution, sho wing most annotations target rendered te xt (78.1%) versus input fields (13.6%) and images (8.3%). Lowes Apple Home Depot Bh Photo Macys Amazon W almart Crate Barrel Ulta Beauty Slack 0 1000 2000 3000 4000 5000 6000 Number of Images 5,799 5,649 5,636 5,524 5,469 4,481 4,474 4,387 1,925 1,521 Company Distribution Figure 5: Distrib ution of base images across 10 e-commerce companies. Apple and Amazon ha ve the most coverage (1,400 images each), while Slack and Ulta Beauty represent smaller verticals (300 images each). T otal base images: 10,200 (multiplied across variants to produce 44,865 total dataset images). 14 Published as a conference paper at ICLR 2026 0 2000 4000 6000 8000 10000 Number of Images Customer Info Address Billing Address P ayment Account Selection Address V alidator Delivery Shipping Review Order Cart Receipt Gifting Store Pickup Newsletter Management Account Dashboard Stored Credit Cards Cross Sells Order Returns Order Tracking Orders Overview Added T o Cart 8,715 8,029 5,334 3,900 3,175 2,710 2,275 1,950 1,549 1,480 1,199 950 800 775 725 549 375 275 100 P age T ype Distribution Figure 6: Distribution of base images across 19 page types spanning checkout flows, account management, and product pages. Account selection (900) and deliv ery/shipping (875) pages dominate, representing critical moments where PII exposure is highest. 15 Published as a conference paper at ICLR 2026 B H U M A N Q UA L I T Y C O N T R O L P I P E L I N E B . 1 R E V I E W I N T E R FAC E A N D W O R K FL O W Manually editing generated React code for hundreds of layouts w ould impose prohibitiv e ov erhead and require deep technical expertise. W e instead developed a Flask-based web interface that accepts natural language correction instructions and delegates fixes to Claude. The interface operates on a queue system: layouts are displayed sequentially for revie w , with annotators able to examine the original screenshot, rendered reproduction, and all three annotated progressive fill states (empty , partial-fill, and fully-filled) to assess the full extent of data coverage. A code viewer provides access to the App.jsx source and data.json configuration for manual inspection when needed. When an annotator identifies an issue, they submit a text instruction describing the required change. The system appends this instruction to a specialized fixing prompt that includes the current App.jsx source code, the original screenshot, and context from any previous fix iterations for that layout. Claude modifies the code and returns the corrected version. The interface then triggers re-rendering and re-annotation across all progressi ve fill states, allo wing the annotator to verify the fix was applied correctly . Each layout underwent three re vie w passes to ensure quality and pro vide redundancy in catching errors that might hav e been missed in earlier passes. Refinement operates at the layout lev el rather than per-reproduction. Once a layout is corrected, the system re-screenshots across all three progressi ve fill states (empty , partial-fill, and fully-filled) to generate the final annotated dataset images, amortizing the cost of human revie w across multiple training samples. W e explicitly addressed the observ ed failure modes within the generation prompts themselv es, pro- viding specific instructions about viewport constraints, data attrib ute requirements, and form field initialization. Ho wev er , rule-following remained imperfect for very nuanced cases—Claude w ould occasionally still produce viewport overflo w or omit non-obvious data attributes despite explicit prompt guidance. Additionally , some errors were highly company-specific, and maintaining individ- ually fine-tuned prompts per company would hav e undermined system scalability . W e considered integrating more structured rubrics or checklists into the initial UI generation process to guide Claude through additional verification passes before human revie w . Ho wev er , this would ha ve introduced substantial costs through redundant forward passes that might not address the primary failure modes (viewport ov erflow detection, which requires human visual inspection, and context-dependent de- cisions about which non-obvious elements merit annotation). The con versational fixing interface prov ed more cost-ef fectiv e by allowing targeted corrections only where needed rather than exhausti ve verification on e very layout. B . 2 R E FI N E M E N T S TA T I S T I C S The final dataset comprises 408 unique layouts. Of these, 160 (39.2%) required human-initiated refinements, totaling 312 individual correction iterations. Figure 7 shows the distrib ution of iterations required per layout. The majority (55.6%) needed only a single correction, while 21.9% required two iterations. T otal generation cost was $649 using Claude Opus 4.5, comprising $606 (93%) for initial reproduction and $43 (7%) for refinements. This represents an av erage cost of $1.50 per successfully generated layout including refinements, or $1.41 per initial generation attempt. As expected, we observed notable variation according to page comple xity . T able 3 breaks down refinements by company and page type. Home Depot and Apple layouts required the most corrections (56 and 39 iterations respectively). Billing and payment pages accounted for 57 iterations across 29 layouts, the highest refinement density of any page type. B . 3 E R R O R A NA LY S I S A N D F A I L U R E M O D E S W e manually categorized all 312 refinement iterations to understand failure modes (Figure 8). Four primary error categories emer ged: 16 Published as a conference paper at ICLR 2026 T able 3: Distribution of human-initiated refinements across companies and page types, ordered by total fixes. C AT E G O RY S A M P L E S R E FI N E D T O TA L F I X E S By Company H O M E D E P OT 2 2 5 6 L O W E S 2 3 4 4 A M A Z O N 1 9 4 3 A P P L E 2 5 3 9 M A C Y ’ S 1 3 3 9 B H P H O T O 2 1 3 3 W A L M A RT 1 3 23 C R A T E & B A R R E L 1 5 2 0 O T H E R S 9 1 5 By P age T ype B I L L I N G / P A Y M E N T 2 9 5 7 C A RT 2 3 3 8 C U S T O M E R I N F O / A D D R E S S 1 3 2 3 A D D R E S S V A L I D A T O R 1 0 21 S T O R E P I C K U P 8 2 0 A D D E D T O C A RT 3 1 9 O T H E R S 7 4 1 3 4 T OTA L 1 6 0 3 1 2 1 2 3 4 5 Refinement Iterations Required 0 20 40 60 80 100 Number of Layouts 89 (55.6%) 35 (21.9%) 17 (10.6%) 7 (4.4%) 8 (5.0%) Figure 7: Distribution of refinement iterations required per layout across 160 layouts requiring refinement. Over half (55.6%) con verged after a single correction iteration, while 21.9% required two iterations. Four layouts required more than 5 iterations. Layout issues (53.8%). The dominant failure mode in volv ed UI elements being pushed outside the viewport width due to incorrect responsive sizing or fixed-width constraints. Claude’ s initial reproduction iterations included a visual refinement phase where a separate model in vocation would compare rendered output to the original screenshot and suggest corrections. Ho wev er , depsite iterating ov er various prompts, Claude remained lacking rob ust spatial reasoning in images—when elements ov erflowed horizontally beyond the vie wport boundary , the model could not detect the issue from the rendered screenshot alone. These errors required human annotators to identify clipped content (e.g., right-aligned cart summaries cut off at 1400px width, sidebar filters extending beyond vie wport) and explicitly instruct Claude to adjust container widths or implement proper responsi ve constraints. Missing or spurious data attrib utes (24.4%). These refinements predominantly in v olved product metadata fields like model numbers and item identifiers that were visually present but lacked proper data-product markup, likely do to the inapparent association with the general concept of PII. Ap- ple interfaces exhibited a distinct failure mode: spurious data-pii or data-product attributes 17 Published as a conference paper at ICLR 2026 added to decorativ e elements or redundant container divs that should not hav e been annotated. These false positi ve annotations required explicit remo val instructions. Incomplete fields (14.7%). Claude occasionally omitted input fields that did not match the common conceptual model of PII, requiring e xplicit addition instructions. A related issue in volved selection dropdown def aults: Claude would sometimes hardcode dropdo wns to specific v alues (e.g., “United States” for country selection) instead of initializing them to placeholder states (“Select a country”), which prev ented proper partial-fill behavior where the dropdo wn should appear unselected. Note that certain fields were intentionally left unannotated—newsletter subscription email inputs, for example, were excluded from annotation as they represent mark eting opt-ins rather than transaction-critical PII. Hardcoded store locations (7.1%). Some layouts contained store-specific location references that were not necessarily the user’ s personal location but could still be identifying or context-dependent— for example, “Presque Isle’ s Lowes” in headers where the store location was not the key focus of the page. Claude initially rendered these as literal placeholder te xt rather than parametrizing them, requiring explicit correction. Layout Issues (V iewport Overflow) Missing/Spurious Data Attributes Incomplete Fields Hardcoded Store Locations Error T ype 0 25 50 75 100 125 150 175 Number of Refinement Iterations 168 (53.8%) 76 (24.4%) 46 (14.7%) 22 (7.1%) Figure 8: Breakdo wn of 312 refinement iterations by error type across 160 layouts. Layout issues (53.8%, primarily viewport o verflo w) dominated refinements. Data attribute errors (24.4%) in volv ed spurious attributes on decorati ve components (particularly in Apple’ s minimalist interfaces) and miss- ing markup on product metadata fields. Incomplete fields (14.7%) included dropdo wn initialization issues. Hardcoded store locations (7.1%) required parametrization. B . 4 T H R O U G H P U T A N D P I P E L I N E E FFI C I E N C Y The Claude-mediated generation and refinement pipeline achie ved substantial throughput despite the human revie w requirement. A single annotator processed approximately 100 layouts per 2 hours during the re view phase. This high throughput was enabled by several factors. First, Claude handled the majority of actual code modifications—the annotator’ s role reduced to identifying errors and writing brief natural language correction instructions rather than performing manual code edits. Second, the interface provided immediate access to both the App.jsx source code and data.json configuration for manual inspection, allo wing annotators to quickly diagnose issues by e xamining the underlying implementation. Third, the pipeline automated the full re-rendering and screenshot capture process—after submitting a fix, the system would rebuild the layout, capture screenshots across all three progressiv e fill states (empty , partial, full), run the annotation extraction, and present updated results within seconds. This fast iteration cycle eliminated manual overhead and enabled annotators to verify fix es immediately without context switching. The primary bottleneck in dataset construction prov ed to be the collection of original e-commerce page screenshots rather than the generation or refinement process itself. Capturing diverse check out flows, account dashboards, and payment pages across 10 major retailers required na vigating authenticated sessions, filling realistic test data, and ensuring full-page screenshot capture across various UI states. Once source screenshots were collected, the automated pipeline consumed them rapidly . This architectural decision—delegating both generation and refinement to the model—prov ed essential for dataset feasibility , as manual HTML/CSS authoring or code-le vel deb ugging would ha ve required orders of magnitude more human time. 18 Published as a conference paper at ICLR 2026 C W E B R E DA C T - L A R G E A B L A T I O N S While W E B R E DA C T targets real-time inference at 30fps, W E B R E DA C T - L A R G E prioritizes accuracy while maintaining near-real-time performance ( ∼ 3fps on CPU). This section provides complete analysis of W E B R E DA C T - L A R G E trained at 1280 × 1280 resolution, including architectural compar - isons, per-v ariant performance breakdo wns, and inference latency measurements across hardware configurations. C . 1 A R C H I T E C T U R E C O M P A R I S O N T able 4 compares W E B R E DA C T and W E B R E DA C T - L A R G E on T est Cross-Page with 10 text v ariants. T able 4: Architecture comparison (2-class, cross-page, 10 text v ariants, trained on full+partial). M O D E L R E S O L U T I O N M A P @ 5 0 P R E C I S I O N R E C A L L W E B R E D A C T 6 4 0 × 6 4 0 0 . 8 0 7 0 . 8 4 8 0 . 7 6 2 W E B R E D A C T - L A R G E 1 2 8 0 × 1 2 8 0 0 . 9 0 9 0 . 8 6 8 0 . 8 3 4 W E B R E D AC T - L A R G E achieves 0.909 mAP@50—a 12.6% relati ve improv ement over W E B R E DA C T (0.807). Both precision and recall improve substantially (+2.0pp and +7.2pp respecti vely), indicating that higher resolution enables more accurate field boundary detection and reduces false positi ves. C . 2 P E R - V A R I A N T P E R F O R M A N C E T able 5 sho ws per-v ariant performance breakdown for W E B R E D A C T - L A R G E across test fill states. T able 5: W E B R E DA C T - L A R G E per-v ariant performance (2-class, cross-page, 10 text v ariants). T E S T V A R I A N T M A P @ 5 0 P R E C I S I O N R E C A L L F U L L 0 . 8 8 6 0 . 8 9 6 0 . 8 1 5 PART I A L 0 . 9 4 3 0 . 8 9 7 0 . 8 7 8 E M P T Y 0 . 8 9 8 0 . 8 0 9 0 . 8 0 9 A V E R AG E 0 . 9 0 9 0 . 8 6 8 0 . 8 3 4 The model achie ves particularly strong performance on partial-fill images (0.943 mAP@50), where the progressiv e fill training provides rich learning signal. Performance on fully-filled forms (0.886) is slightly lower , likely due to increased visual complexity when all fields contain te xt. C . 3 I N F E R E N C E L AT E N C Y T able 6 compares inference latency between W E B R E DA C T and W E B R E DA C T - L A R G E on both CPU and GPU hardware. T able 6: Inference latency comparison (milliseconds per image). M O D E L C P U ( I 5 / R Y Z E N 5 ) G P U ( RT X 3 0 X X ) W E B R E D A C T ∼ 2 0 M S < 5 M S W E B R E D A C T - L A R G E ∼ 3 1 2 M S ∼ 1 3 M S W E B R E D AC T satisfies real-time constraints on CPU ( < 33ms per frame for 30fps), while W E B R E D AC T - L A R G E requires 312ms ( ∼ 3fps)—nearly 16 × slower but still suitable for near-real- time applications where higher accurac y justifies relaxed frame rate requirements. On GPU hardware, W E B R E D AC T - L A R G E achiev es 13ms latency , enabling real-time operation with GPU acceleration. For CPU-only deplo yment scenarios prioritizing maximum throughput, W E B R E DA C T remains the optimal choice. 19 Published as a conference paper at ICLR 2026 D A D D I T I O NA L R E S U LT S D . 1 T E X T - B A S E D B A S E L I N E D E TA I L S D . 1 . 1 D O C U M E N T U N D E R S T A N D I N G M O D E L S V S . O C R P I P E L I N E S W e compare three cate gories of text-based baselines on T est Cross-Company (Amazon, full-fill images): document understanding models (LayoutLMv3 Huang et al. (2022), Donut Kim et al. (2021)), OCR+LLM pipelines, and OCR+NER systems. T able 7 shows that document understanding models outperform simple OCR+LLM pipelines, with LayoutLMv3 achieving the highest mAP@50 (0.357) among all text-based approaches. T o ensure fair comparison and bypass DocumentQA ’ s single-span extraction limitation, all document understanding pipelines use GPT -4o-mini for final classification after visual/layout encoding rather than extracti ve question answering. T able 7: Document understanding models vs. OCR+LLM baselines on T est Cross-Company (Amazon, full-fill images). All methods use GPT -4o-mini for classification. M E T H O D M A P @ 5 0 P R E C . R E C . F 1 L A T E N C Y L AYO U T L M V 3 H UA N G E T A L . ( 2 0 2 2 ) 0 . 3 5 7 5 8 . 5 % 4 5 . 1 % 5 0 . 9 % 2 . 9 S D O N U T K I M E T A L . ( 2 0 2 1 ) 0 . 3 5 0 5 5 . 8 % 4 3 . 6 % 4 8 . 9 % 3 . 5 S T E S S E R AC T S M I T H ( 2 0 0 7 ) + L L M 0 . 3 0 2 4 9 . 8 % 4 9 . 6 % 4 9 . 7 % 2 . 8 S Document understanding models le verage visual layout information alongside text content, pro viding better localization on complex layouts lik e Amazon’ s dense product grids and multi-column interfaces. Howe ver , this advantage remains modest (+18% mAP@50 ov er T esseract Smith (2007)+LLM), and the architectural mismatch between word-lev el detections and field-level ground truth limits all text-based approaches. D . 1 . 2 O C R E N G I N E A B L A T I O N T able 8 compares OCR engines with GPT -4o-mini classification. PaddleOCR Cui et al. (2025) achiev es the highest precision (78.7%) but lo west recall (31.0%), while T esseract Smith (2007) provides the best balance with competiti ve mAP@50 (0.302) at the fastest speed (2.8s). The narro w performance band (0.286–0.329 mAP@50) rev eals that OCR quality is not the primary bottleneck— the architectural mismatch between word-lev el detections and field-le vel annotations limits all engines. T able 8: OCR engine ablation with GPT -4o-mini classification. O C R E N G I N E M A P @ 5 0 P R E C . R E C . F 1 L A T E N C Y P A D D L E O C R C U I E T A L . ( 2 0 2 5 ) 0 . 3 2 9 7 8 . 7 % 3 1 . 0 % 4 4 . 5 % 6 . 6 S T E S S E R AC T S M I T H ( 2 0 0 7 ) 0 . 3 0 2 4 9 . 8 % 4 8 . 6 % 4 9 . 2 % 2 . 8 S E A S Y O C R J A I D E D A I ( 2 0 2 4 ) 0 . 2 8 6 6 7 . 6 % 3 0 . 7 % 4 2 . 2 % 3 . 8 S The classification latency (2.8–6.6s) is dominated by LLM inference rather than OCR extraction. T able 9 shows OCR-only latencies. T esseract Smith (2007) completes in 453ms on CPU, while GPU-accelerated engines (EasyOCR JaidedAI (2024), P addleOCR Cui et al. (2025)) are 1.6–4.7 × slower despite hardware acceleration, indicating that OCR speed is not a primary bottleneck for text-based baselines, although still slo wer than our W E B R E DA C T and W E B R E D A C T - L A R G E models. T able 9: OCR engine latency (e xtraction only , no classification). O C R E N G I N E L AT E N C Y T E S S E R AC T S M I T H ( 2 0 0 7 ) 4 5 3 M S E A S Y O C R J A I D E D A I ( 2 0 2 4 ) 7 1 5 M S P A D D L E O C R C U I E T A L . ( 2 0 2 5 ) 2 , 1 4 3 M S 20 Published as a conference paper at ICLR 2026 D . 1 . 3 O C R + P R E S I D I O B A S E L I N E T able 10 shows OCR+Presidio performance across engines. Presidio’ s rule-based NER achiev es only 0.176–0.183 mAP@50, approximately 40% worse than LLM-based classification. T esseract Smith (2007) provides the fastest configuration (1.3s), while P addleOCR’ s Cui et al. (2025) higher-quality extraction pro vides minimal benefit when the classifier lacks contextual understanding. T able 10: OCR + Presidio NER (no LLM). O C R E N G I N E M A P @ 5 0 P R E C . R E C . F 1 L A T E N C Y T E S S E R AC T S M I T H ( 2 0 0 7 ) 0 . 1 8 3 4 1 . 7 % 2 6 . 3 % 3 2 . 2 % 1 . 3 S E A S Y O C R J A I D E D A I ( 2 0 2 4 ) 0 . 1 7 8 4 2 . 1 % 2 8 . 3 % 3 3 . 9 % 2 . 3 S P A D D L E O C R C U I E T A L . ( 2 0 2 5 ) 0 . 1 7 6 4 4 . 5 % 2 5 . 1 % 3 2 . 1 % 4 . 8 S D . 1 . 4 D O C U M E N T Q U E S T I O N A N S W E R I N G An alternative to LLM classification is Document Question Answering (DocQA), where models answer explicit questions like “What is the customer name?” to extract PII. W e ev aluate two pure DocQA approaches—Donut-DocVQA and LayoutLM with extractiv e QA heads—against the hybrid configurations (LayoutLMv3 + LLM, Donut + LLM) described above. T able 11 compares all approaches on Amazon test images. T able 11: Document QA vs. LLM classification on Amazon test images. M E T H O D M A P @ 5 0 P R E C . R E C . F 1 L A T E N C Y L AYO U T L M V 3 H UA N G E T A L . ( 2 0 2 2 ) + L L M 0 . 3 5 7 5 8 . 5 % 4 5 . 1 % 5 0 . 9 % 2 . 9 S D O N U T K I M E T A L . ( 2 0 2 1 ) + L L M 0 . 3 5 0 5 5 . 8 % 4 3 . 6 % 4 8 . 9 % 3 . 5 S L AYO U T L M - Q A 0 . 1 3 9 2 4 . 1 % 4 7 . 8 % 3 2 . 0 % 1 . 5 S D O N U T -D O C V Q A 0 . 1 1 7 3 0 . 8 % 3 7 . 7 % 3 3 . 9 % 1 1 . 5 S DocQA approaches fail for sev eral reasons. First, DocVQA models are trained to extract single answer spans per question (e.g., “What is the date?” → “October 17”), not multiple items. This requires separate forward passes for each PII category (name, address, email, phone, card number, etc.), causing substantial latenc y: Donut’ s OCR-free architecture processes the full image for each question at ∼ 600ms per question (11.5s total), while LayoutLM’ s extractiv e QA operates on pre- extracted OCR te xt more efficiently (1.5s total). Second, both models are pre-trained on structured documents and forms, where PII appears in predictable locations with clear visual cues (labeled fields, tables). E-commerce screenshots present different visual hierarchies—gift recipient versus billing names, optional fields, promotional overlays—that deviate from the models’ training distribution. Third, rigid question templates often mismatch actual page content, requiring flexible contextual understanding that the single-span extraction paradigm cannot pro vide. Fourth, LayoutLM-QA uses a randomly initialized QA head (not fine-tuned), further degrading span e xtraction quality . LLM classification (sending all extracted text to GPT -4o-mini for contextual classification) achie ves 2.6 × higher mAP@50 (0.357 vs 0.139) than the best DocQA method while maintaining comparable or faster speed. The flexible classification paradigm handles div erse layouts without rigid question templates. D . 1 . 5 F A I L U R E M O D E S The two-stage architecture creates cascading errors where OCR misdetections propagate to classifica- tion. On sparse pages with few ground truth elements, OCR misreads generic footer text or company names, causing the LLM to aggressiv ely flag these misdetected strings as sensiti ve and producing false positi ves. Conv ersely , dense pages with complex product listings cause context rot in chunked LLM calls, where the model loses track of rele vant fields as listings overwhelm the limited conte xt window . Product names containing person names (e.g., “Kelse y V illages” as a street name versus “Kelse y” as a brand) are frequently misclassified, and gift messages containing potentially priv ate data are sometimes missed. 21 Published as a conference paper at ICLR 2026 D . 1 . 6 C L A S S I FI C A T I O N P RO M P T The OCR + LLM baselines use GPT -4o-mini to classify extracted text spans. The classification prompt is: You identify data values in e-commerce screenshot text. Flag ANY text that is actual data (not a UI label): Names, addresses, cities, states, zip codes Emails, phone numbers, dates Card numbers, CVV, expiry dates Product names, brands, prices, quantities, ratings Order totals, shipping costs, tracking numbers Search queries, gift messages Only skip pure UI labels like "Price:", "Quantity:", "Add to cart". When in doubt, include it. Return JSON: { "pii items": [ { "text": "exact text" } ] } D . 2 P E R - C L A S S P E R F O R M A N C E B R E A K D O W N T able 12 sho ws per-class AP@50 on fully-filled test images across split strategies for 2-class detection. T able 12: Per -class AP@50 on fully-filled test images (test full variant). S P L I T T E X T I M AG E C R O S S - P AG E 0 . 6 2 3 0 . 8 7 0 C R O S S - C O M PAN Y 0 . 4 7 1 0 . 8 5 5 C R O S S - T Y P E 0 . 5 5 2 0 . 8 7 5 Product images achie ve robust detection across all splits (0.855–0.875 AP@50), confirming that visual elements ha ve distincti ve signatures that generalize well regardless of compan y branding or page type. T ext detection shows more variation: cross-page performance reaches 0.623 AP@50, while cross-company and cross-type splits achie ve 0.471 and 0.552 AP@50 respectively . This degradation reflects the challenge of generalizing text field detection when visual styling (borders, fonts, spacing) varies across unseen companies or form types. D . 3 S P L I T S T R A T E G Y A B L AT I O N T able 13 compares three split strate gies that ev aluate generalization at dif ferent lev els. T est Cross-Page achiev es the strongest av erage performance (0.797 mAP@50), with particularly high partial-fill detection (0.842), indicating that models learn layout-in variant features within a compan y’ s design system. T est Cross-Company degrades to 0.753 when generalizing to Amazon’ s distinct visual style, with the lar gest drop on full-fill images (0.663) where dense product layouts and unique styling present the greatest challenge. T est Cross-T ype shows the most uniform degradation across fill states (0.713–0.744), rev ealing that page-type-specific patterns—such as dense tabular receipts versus interactiv e checkout forms—transfer less effecti vely than compan y-specific design con ventions. T able 13: Split strategy comparison ( W E B R E D A C T , 2-class, trained on full+partial). T est Cross-Page performs best, while T est Cross-T ype presents the strongest generalization challenge. S P L I T S T R A T E G Y F U L L PA RT I A L E M P T Y A V G T E S T C RO S S - P AG E 0 . 7 4 7 0 . 8 4 2 0 . 8 0 3 0 . 7 9 7 T E S T C RO S S - C O MPA N Y 0 . 6 6 3 0 . 8 3 9 0 . 7 5 6 0 . 7 5 3 T E S T C RO S S - T Y PE 0 . 7 1 3 0 . 7 2 7 0 . 7 4 4 0 . 7 2 8 22 Published as a conference paper at ICLR 2026 D . 4 F I L L S TA T E A B L A T I O N T able 14 ablates training data composition to isolate the contribution of each fill state. T raining on full screenshots alone achiev es 0.771 mAP@50. Counterintuitiv ely , adding empty screenshots without partials degrades performance to 0.758, likely because the visual g ap between empty forms (placeholder text, unfilled fields) and fully-filled forms is too lar ge for the model to bridge without intermediate examples. Adding partial-fill data resolves this: full+partial achiev es 0.797 (+0.026 ov er full-only), with the strongest gains on partial test images (0.842 versus 0.810), confirming that mid-entry states provide essential visual grounding. Combining all three states achie ves the best ov erall performance (0.825 mAP@50), demonstrating that empty forms become useful once partial fills provide the intermediate signal that bridges the visual gap. T able 14: Fill state ablation on T est Cross-Page (W E B R E DA C T , 2-class). Partial-fill data is essential; empty screenshots help only when combined with partials. T R A I N F U L L PA RT . E M P T Y A V G E M P T Y 0 . 6 7 2 0 . 8 1 8 0 . 7 7 7 0 . 7 5 6 F U L L 0 . 7 3 6 0 . 8 1 0 0 . 7 6 7 0 . 7 7 1 F U L L + E M P T Y 0 . 7 3 4 0 . 7 7 4 0 . 7 6 8 0 . 7 5 8 F U L L + PA RT . 0 . 7 4 7 0 . 8 4 2 0 . 8 0 3 0 . 7 9 7 F U L L + PA RT . + E M P T Y 0 . 7 6 2 0 . 8 8 1 0 . 8 3 1 0 . 8 2 5 D . 5 P R O G R E S S I V E F I L L D E N S I T Y A B L AT I O N W e ablate the number of partial-fill screenshots per layout to measure how progressi ve completion stages affect model performance. Each layout generates multiple partial-fill variants representing different stages of form completion. W e ev aluate 1, 3, and 5 partial stages; higher sampling counts would effecti vely approximate capturing all possible intermediate states (e.g., sampling 7 partials from a 7-field form would capture e very field-by-field completion step). T able 15: Progressi ve fill density ablation ( W E B R E DA C T , 2-class, cross-page, trained on full+partial). Sho ws per-v ariant breakdown and o verall metrics. P A RT I A L S T R A I N T E S T F U L L T E S T PA RT I A L T E S T E M P T Y A V G M A P P R E C . R E C . 1 5 2 1 0 . 7 2 7 0 . 7 7 4 0 . 7 7 4 0 . 7 5 8 0 . 7 9 3 0 . 6 8 8 3 7 6 3 0 . 7 3 8 0 . 7 9 4 0 . 7 7 9 0 . 7 7 0 0 . 8 1 1 0 . 7 0 9 5 9 3 8 0 . 7 6 2 0 . 8 3 5 0 . 8 1 0 0 . 8 0 2 0 . 8 2 2 0 . 7 2 7 Performance improves consistently with more partial stages, increasing from 0.758 mAP@50 (1 partial) to 0.802 (5 partials), with gains across all test variants. Both precision and recall improv e (0.793 to 0.822 and 0.688 to 0.727 respectiv ely), demonstrating that each progressiv e completion stage provides non-redundant learning signal. The model sho ws particularly strong gains on test partial images (0.774 to 0.835), confirming that training on multiple intermediate form-filling states enables more robust field detection patterns. D . 6 D A TA V A R I A N T A B L A T I O N D E TA I L S W e ablate the number of text variants per layout to measure ho w data diversity af fects generalization. Each unique layout is rendered with 1, 10, or 25 distinct PII data injections (v arying names, addresses, products, etc.). Performance improv es consistently with more text v ariants, rising through 0.795, 0.811, and 0.820, demonstrating that the injectable data system successfully provides training div ersity beyond layout div ersity alone. Both precision and recall increase with more v ariants (0.805 to 0.842 and 0.713 to 0.731 respectiv ely). The model shows particularly strong gains on test partial images (0.831 to 0.866), confirming that di verse PII data injections (varying names, addresses, products) enable the model to learn more robust patterns that generalize across dif ferent data instances. 23 Published as a conference paper at ICLR 2026 T able 16: T ext variant ablation on T est Cross-Page (W E B R E DA C T , 2-class, trained on full+partial). Sho ws per-v ariant breakdown and o verall metrics. V A R I A N T S T E S T F U L L T E S T PA RT I A L T E S T E M P T Y A V G M A P P R E C . R E C . 1 0 . 7 6 2 0 . 8 3 1 0 . 7 9 1 0 . 7 9 5 0 . 8 0 5 0 . 7 1 3 1 0 0 . 7 7 4 0 . 8 5 6 0 . 8 0 4 0 . 8 1 1 0 . 8 2 9 0 . 7 2 2 2 5 0 . 7 8 3 0 . 8 6 6 0 . 8 1 2 0 . 8 2 0 0 . 8 4 2 0 . 7 3 1 D . 7 Q U A L I TA T I V E P R E D I C T I O N A N A L Y S I S Figure 9 sho ws prediction patterns for W E B R E D AC T and W E B R E DA C T - L A R G E on cross-page test images. Both models demonstrate strong performance on core detection targets: all input fields, product images, and prices achiev e near-perfect detection. These well-represented patterns in the training data are reliably captured. Failures predominantly occur on underrepresented edge cases. The top image exhibits numerous false positiv es (red boxes), where the model over -detects elements that the ground truth does not annotate. W E B R E D AC T also annotates promotional text like “Save up to 15% on future auto deliv eries”, which represents marketing content rather than user-specific information. These false positiv es indicate the model responds to certain visual contexts (callouts, banners, emphasized te xt) where distinguishing promotional content from actual data fields remains challenging. Missed detections (blue boxes) occur when PII appears in atypical visual presentations: the recipient name “Gregory” rendered as a large bold callout at the top of the page rather than within a standard form field, and deli very dates like “T uesday , May 18” styled in green text rather than con ventional black typography . The bottom image shows detection patterns on a payment page, where both models successfully capture most standard form fields but e xhibit characteristic failures. W E B R E DA C T misses hard-to-notice form fields without observable borders when empty , and both models struggle with small numbers in densely packed locations like “2 item” quantity indicators. Both models also produce false positiv es on an unlabeled dropdown menu—though this reflects le gitimate annotation ambiguity , as the same dropdo wn could reasonably be tagged if rendered with a visible selected value. Despite these edge case failures, form field detection remains robust ov erall. These failures reflect the dataset’ s composition: while training data spans di verse e-commerce conte xts, forms and cart pages dominate and establish the primary visual patterns for input fields, product images, and prices. The model learns these dominant patterns robustly b ut struggles when sensitiv e information appears in more information-dense or ambiguous contexts. T o assess generalization to non-synthetic data, we qualitatively e v aluated the model on the original e- commerce screenshots used as generation targets, as well as 50 additional real e-commerce screenshots that were ne ver synthetically reproduced from the same brands. W e do not release these images due to their sensitiv e content. Upon observing the annotations, we recognize that input fields, prices, and product details demonstrate robust detection across v aried contexts, confirming that patterns learned from synthetic reproductions transfer to authentic interfaces. Ho wev er , shipping dates, cardholder names rendered on card images, and basket quantities exhibit inconsistent detection, consistent with the underrepresentation patterns observed on synthetic test data demonstrated in Figure 9. 24 Published as a conference paper at ICLR 2026 Figure 9: Qualitati ve comparison of W E B R E DAC T (left) and W E B R E D A C T - L A R G E (right) predictions on cross-page test images. Green boxes indicate correct alignment with ground truth, red boxes indicate false positi ves, and blue boxes indicate f alse negati ves. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment