문화적 의미를 잃은 번역 CulTEval로 진단
본 논문은 문화적 표현(관용구·속어·문화특수항목 등)의 번역 품질을 체계적으로 평가하기 위해 CulT‑Eval 벤치마크를 제안한다. 7,959개의 중‑영 병렬 문장을 5차원 문화 분류 체계에 따라 라벨링하고, 인간 검증된 참조 번역과 문화 설명을 제공한다. 기존 BLEU·COMET 등 자동 지표가 포착하지 못하는 의미 손실을 보완하기 위해 문화 의미 편차를 측정하는 새로운 평가 메트릭을 설계하고, 최신 대형 언어 모델과 신경 기계 번역 시스템을…
저자: Bangju Han, Yingqi Wang, Huang Qing
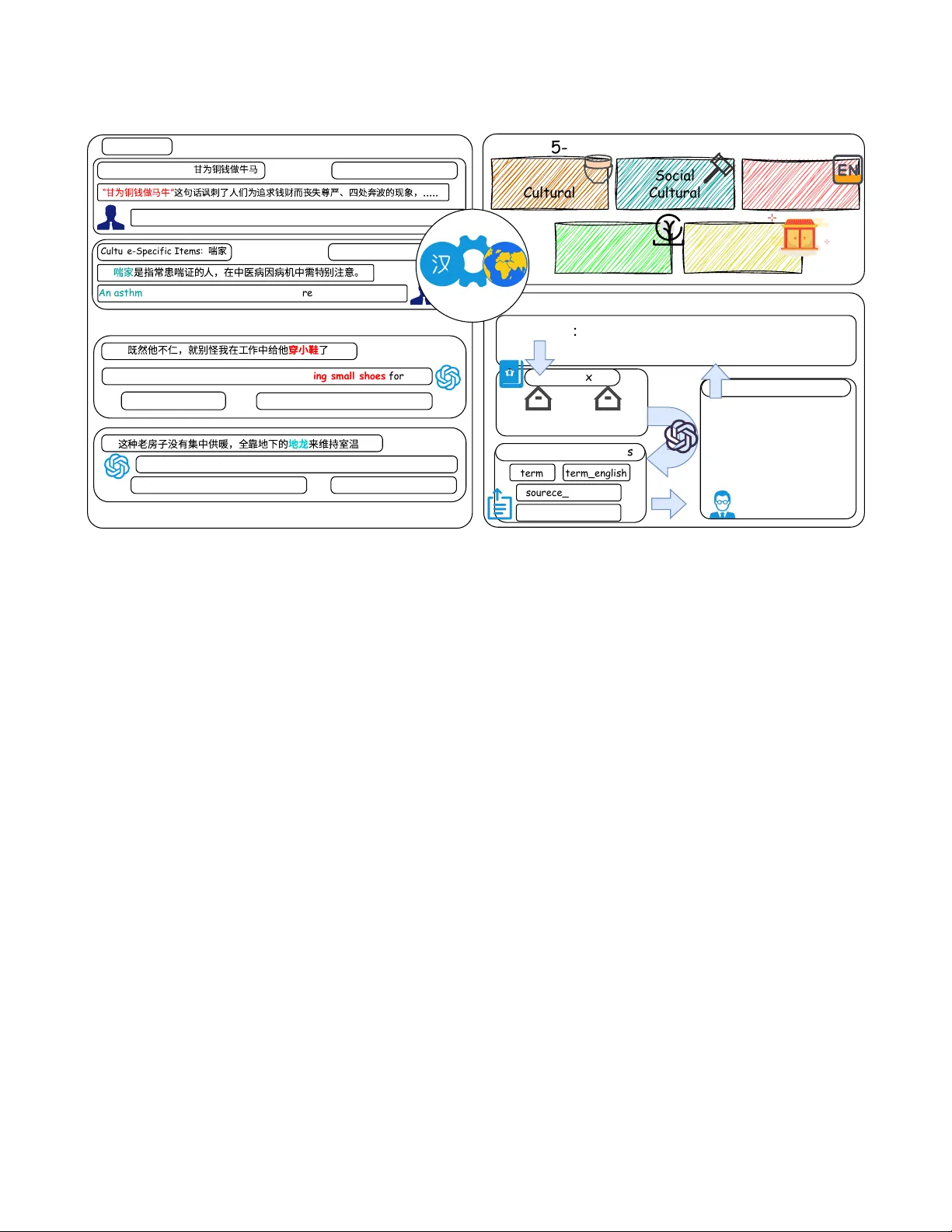
본 연구는 문화적 표현, 즉 관용구·속어·문화특수항목(CSI)과 같은 문화‑로드된 언어 현상이 기계 번역(MT)에서 어떻게 처리되는지를 체계적으로 평가하기 위한 새로운 벤치마크 CulT‑Eval을 제시한다. 기존 연구들은 개별 현상에 초점을 맞춘 소규모 챌린지 세트나 도메인‑특화 데이터에 의존해 왔으며, 평가 기준이 서로 달라 비교가 어려웠다. 이를 해결하고자 저자들은 먼저 문화‑로드된 표현을 다섯 차원(물질, 사회, 언어, 종교, 생태)으로 구분하는 오류 분류 체계를 설계하였다. 이 분류는 번역 오류를 문화적 의미 손실, 은유·비유 파괴, 레지스터 불일치 등 구체적인 오류 유형으로 정량화한다.
데이터 구축은 두 주요 도메인(문학·서사 아카이브와 공공·기관 커뮤니케이션)에서 진행되었다. GPT‑5를 활용해 문화‑로드된 문장을 과잉 추출한 뒤, 훈련된 인간 주석자가 문화적 현저성, 문맥적 지원, 의미 정합성을 검증하였다. 최종적으로 7,959개의 중‑영 병렬 문장이 확보되었으며, 각 인스턴스는 (1) 최소 스팬 표시, (2) 문화 차원 라벨, (3) 문화적 의미 설명, (4) 인간 검증 참조 번역, (5) 표준 영어 등가어를 포함한다. 품질 관리 단계에서는 문화적 의미가 약하거나 문맥이 부족한 사례, 직역으로 인해 의미가 왜곡된 사례를 제거해 데이터의 신뢰성을 높였다.
평가 실험에서는 최신 대형 언어 모델(GPT‑4, LLaMA‑2)과 상용 신경 MT 시스템을 CulT‑Eval에 적용하였다. 기존 자동 평가 지표인 BLEU, ChrF++, BERTScore, COMET은 문화적 의미 손실을 거의 반영하지 못했으며, 인간 평가와의 상관관계가 낮았다. 이를 보완하기 위해 저자들은 문화 의미 편차를 정량화하는 새로운 메트릭인 A CRE(문화 의미 보존 평가 지표)를 제안하였다. A CRE는 오류 분류 체계와 직접 연결돼 각 문화 차원별 오류 비율을 가중합산해 점수를 산출한다. 인간 평가와의 Pearson 상관계수는 0.68, Spearman 상관계수는 0.65로, 기존 지표보다 현저히 높은 일치도를 보였다.
실험 결과는 현재 MT 시스템이 특히 idiom·proverb 영역에서 literal translation을 선호해 의미를 상실하는 경향이 있음을 보여준다. 사회·종교 차원의 CSI는 문화적 배경 지식이 부족해 번역 오류가 집중되었으며, 레지스터·상황 부적합 오류도 빈번히 발생했다. 오류 유형 분석을 통해 (1) 문화적 참조 불일치, (2) 은유·비유 의미 손실, (3) 레지스터·사회적 상황 부적합, (4) 문화적 함축 의미 누락, (5) 비표준화된 용어 사용 등 다섯 가지 주요 패턴을 도출하였다. 이러한 오류는 기존 BLEU·COMET 등 표면적 유사도 기반 지표로는 탐지되지 않아, 실제 번역 품질을 과대평가하는 위험이 있다.
결론적으로, CulT‑Eval은 문화‑로드된 표현을 포괄적으로 다루는 최초의 대규모 벤치마크이며, 문화 차원 기반 오류 분류와 A CRE 메트릭을 통해 기존 평가 체계의 한계를 보완한다. 향후 연구에서는 다국어 확장, 문화 차원 간 상호작용 분석, 그리고 문화‑인식 번역 모델 개발을 위한 학습 목표 설계 등에 활용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기