From Words to Worlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation
Culture-expressions, such as idioms, slang, and culture-specific items (CSIs), are pervasive in natural language and encode meanings that go beyond literal linguistic form. Accurately translating such expressions remains challenging for machine trans…
Authors: Bangju Han, Yingqi Wang, Huang Qing
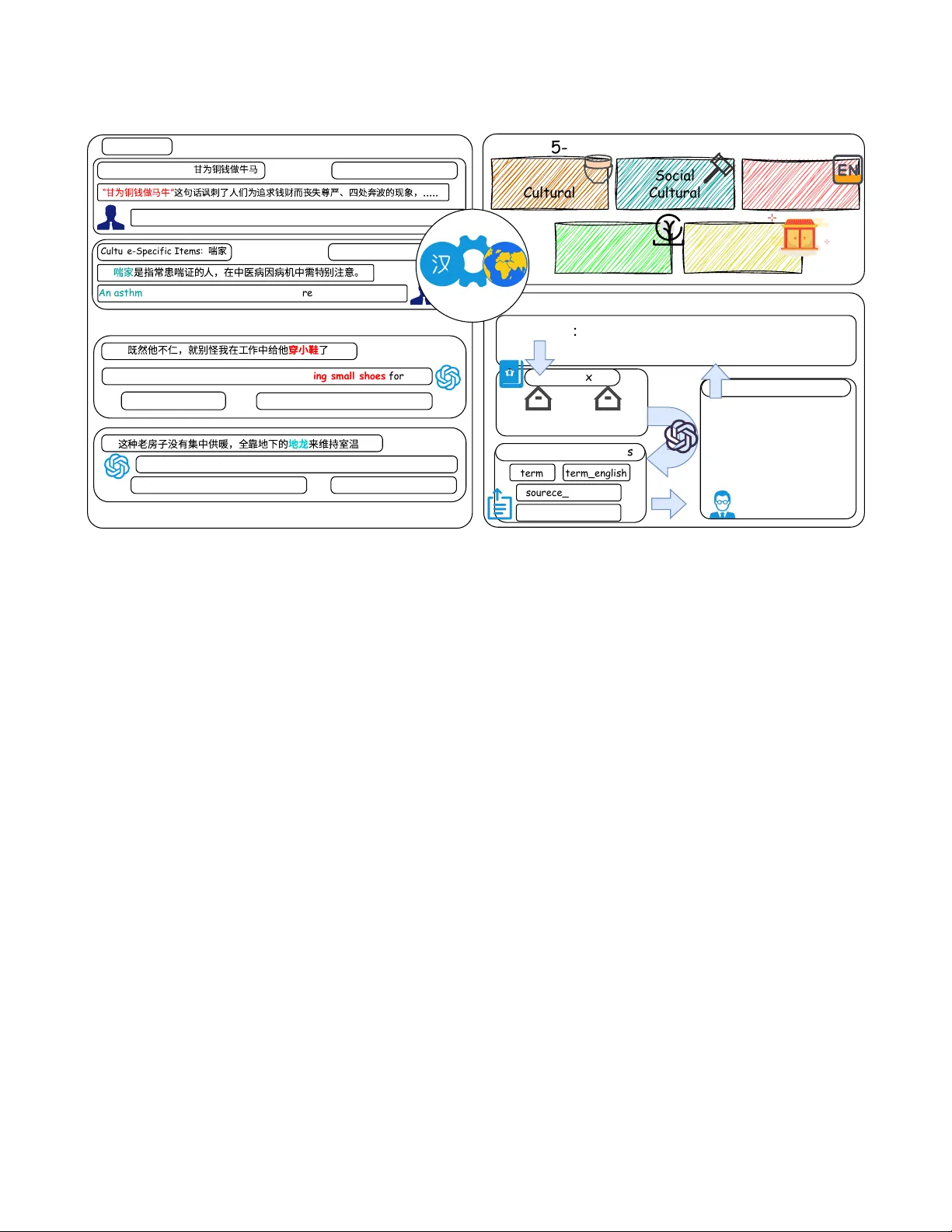
From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Bangju Han ∗ † ‡ hanbangju23@mails.ucas.ac.cn Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Yingqi W ang ∗ † ‡ wangyingqi23@mails.ucas.ac.cn Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Qing Huang † ‡ huangqing24@mails.ucas.ac.cn Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Tiyuan Li † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Fengyi Y ang † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Ahtamjan Ahmat † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Abibulla Atawulla † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Ran Bi † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Y ating Y ang † ‡ Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Xi Zhou † ‡ § Xinjiang T echnical Institute of Physics & Chemistr y , Chinese Academy of Sciences Urumqi, China Abstract Culture-expressions, such as idioms, slang, and culture-spe cic items (CSIs), are pervasive in natural language and encode mean- ings that go beyond literal linguistic form. A ccurately translating such expressions remains challenging for machine translation sys- tems. Despite this, existing benchmarks remain fragmented and do not provide a systematic framew ork for evaluating translation performance on culture-loaded expressions. T o address this gap, we introduce CulT -Eval, a b enchmark designed to evaluate how models handle dierent types of culturally grounded e xpressions. ∗ Both authors contributed equally to this research. † University of Chinese Academy of Sciences, Beijing, China (second aliation) ‡ Xinjiang Laboratory of Minority Speech and Language Information Processing, Urumqi, China (third aliation) § Corresponding author Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, r equires prior spe cic permission and /or a fee. Request permissions from permissions@acm.org. Conference acronym ’XX, W oo dstock, NY © 2018 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX CulT -Eval comprises over 7,959 carefully curated instances span- ning multiple types of culturally grounded expressions, with a comprehensive err or taxonomy covering culturally grounded ex- pressions. Through extensive evaluation of large language mod- els and detailed analysis, we identify recurring and systematic failure modes that are not adequately captured by existing auto- matic metrics. Accordingly , we propose a complementary evalu- ation metric that targets culturally induced meaning deviations overlooked by standard MT metrics. The results indicate that cur- rent models struggle to preserve culturally grounded meaning and to capture the cultural and contextual nuances essential for accurate translation. Our b enchmark and code are available at https://anonymous.4open.science/r/CulT - Eval- E75D/. CCS Concepts • General and reference → Evaluation ; • Computing method- ologies → Machine translation . Ke ywords Culture-loaded expressions, Machine translation e valuation, Cul- tural grounding, Error analysis, benchmark A CM Reference Format: Bangju Han, Yingqi W ang, Qing Huang, Tiyuan Li, Fengyi Y ang, Ahtamjan Ahmat, Abibulla Atawulla, Ran Bi, Y ating Y ang, and Xi Zhou. 2018. From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. in Machine Translation. In Procee dings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX). A CM, New Y ork, N Y , USA, 13 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Rooted in shared cultural knowledge and so cial conv entions, many expressions in natural language conve y meanings that rely on im- plicit cultural knowledge rather than explicit linguistic forms. W e refer to these expressions as culture-loaded expressions, such as idioms, slang, literary allusions, and culture-specic items (CSIs). Figure 1 presents representativ e instances across idioms, proverbs, and culture-specic items. Recent studies indicate that cultural grounding poses persistent challenges for modern large language models. Evaluations of LLMs consistently show that these mod- els struggle with culturally grounded e xpressions such as idioms and idiomatic language, whose meanings dep end on shared cul- tural and historical background that is not explicitly encode d in the linguistic form[ 6 , 9 ]. These limitations directly aect translation quality: studies on interpretative slang and cultur e-specic items demonstrate that accurate translation often requires reconstruct- ing intended meaning under context, rather than relying on direct lexical mapping[16, 33]. Despite the growing awareness of these model limitations, cur- rent evaluation frame works remain poorly equipped to detect or characterize culturally grounded translation errors. Standard auto- matic metrics such as BLEU and ChrF mainly reward surface lexical similarity , while learned metrics such as COMET often favor con- ventional phrasing and penalize stylistic variation, which makes them unreliable for evaluating culturally nuanced translations[ 8 , 17 ]. As a result, gurativ e, cultural, and context dependent errors frequently go unnoticed. Translating idioms, resolving cultural am- biguity , or conveying implicit references across languages requires more than lexical delity , but these asp ects are only weakly re- ected in standard evaluation signals[ 24 , 30 ]. For instance, literal translations of idioms that preserve surface form but lose gura- tive meaning may still score highly under BLEU[ 2 ]. In response, recent work has proposed more context sensitive and culturally informed evaluation methods, including challenge sets that isolate cases requiring pragmatic reasoning or shared cultural knowledge, as well as metrics tailored to specic phenomena such as idiomatic- ity , metaphor , or cultural references[ 28 , 33 ]. Still, these advances remain limited in scope, since most evaluation datasets focus on iso- lated phenomena and lack a unie d structur e for taxonomy driven analysis of culturally induced meaning deviations in translation outputs. T o address these gaps, we introduce CulT -Eval, a benchmark de- signed to systematically evaluate machine translation p erformance on culture-loaded expressions. CulT -Eval provides curated source sentences and human reference translations, together with struc- tured annotations that enable diagnostic analysis beyond sentence- level accuracy . Crucially , CulT -Eval is coupled with a unied er- ror taxonomy that makes culturally induced meaning deviations explicit and measurable. Building on this taxonomy , we further propose a complementary evaluation metric that operationalizes these error categories and quanties cultural meaning preservation beyond what standard automatic metrics can capture. T ogether , the benchmark and the metric form a coherent evaluation framework Term : 迷途 知 返 Term_Type: Idiom Term_English: Retract from the wrong path Source_Sentence: 他 犯 了 错 误 后 迷途 知 返 , 避 免 了 更 ⼤ 的 损 失 。 Translation_Sentence:After making a mistake, he promptly retracted from the wrong path, avoiding greater losses. Term : 好 ⻢ 不 吃 回 头 草 Term_Type: Proverb Term_English: A good man never looks back once he has moved on Source_Sentence: 好 ⻢ 不 吃 回 头 草 , 既 然 他 已 经 离 开 了 ⽼ 窝 , 就 决 ⼼ 在 外 ⾯ 的 世 界 闯 荡 下 去 。 Translation_Sentence: A good man never looks back once he has moved on, since he has left the nest, he has made a decision to make a living in the outside world. Term : 站 票 Term_Type: CSIs Term_English: standing-room-only tickets Source_Sentence: 由 于 ⾳ 乐 会 太 受 欢 迎 , 我 们 只 能 买 到 站 票 。 Translation_Sentence:Because the concert was so popular, we could only get standing-room-only tickets. Figure 1: Representative CulT -Eval instances. for analyzing how translation systems handle culturally grounded meaning. Using CulT -Eval, we conduct extensive evaluations of machine translation specialist systems and large language mod- els, revealing systematic failure patterns that are not exposed by existing benchmarks or metrics. • W e present CulT -Eval, a benchmark for evaluating machine translation of culture-loaded expr essions, comprising over 7,900 carefully curated instances with structured coverage across diverse culturally grounded phenomena and diagnos- tic annotations. • Through extensive evaluations of neural machine transla- tion systems and large language models on CulT -Eval, we provide insights into recurring and systematic failure pat- terns in translating culturally grounded meaning, revealing challenges that are not exposed by existing benchmarks. • W e further nd that widely used automatic evaluation met- rics, such as BLEU and COMET , ar e insucient for assessing culturally induced meaning deviations, motivating the use of a complementary , taxonomy-aware evaluation metric for more reliable analysis. 2 Related W ork Culture-loaded Expressions in Machine Translation. Re cent research has increasingly recognized the challenge of translat- ing culture-loaded expressions, leading to the creation of numer- ous specialized evaluation b enchmarks. Existing resour ces cover a wide range of culture-loaded content, spanning idioms[ 15 ] and proverbs[ 29 ], slang[ 16 ]and social-media expressions[ 12 ], classi- cal poetry[ 4 ] and culture-specic items[ 33 ], as well as domain- anchored terminology including recipes[ 3 ]. Despite this progress, existing resour ces remain fragmented along multiple axes, they are often bounded to a single cultural domain or register , focus on iso- lated linguistic phenomena, and employ incompatible annotation From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Category Count Ratio A vg. T erm Len. (Char) A vg. Context (%) Source (Zh) T arget (En) Sour ce (Zh) Linguistic 2,512 31.6 5.13 29.43 22.29 Social 2,399 30.1 3.21 24.22 23.72 Material 1,594 20.0 3.06 22.97 24.39 Ecological 833 10.5 2.82 20.13 22.66 Religious 621 7.8 3.13 23.01 24.22 T otal / A vg. 7,959 100.0 3.74 25.09 23.33 T able 1: Statistics of the CulT-Ev al benchmark. schemes and evaluation criteria, which limits cross-benchmark com- parability and cumulative analysis of culture-related meaning shifts in MT . These limitations motivate the ne ed for a unied taxonomy that can serve as a shared interface to characterize culture-loaded expressions and align evaluation across domains and phenomena. Evaluation Metrics in Machine Translation. Alongside frag- mented resources, cultural evaluation is frequently conducted with general-purpose MT metrics that primarily capture surface ov erlap or holistic semantic similarity , including BLEU[ 19 ], ChrF++[ 20 ], BERTScore[ 34 ], COMET[ 23 ], and QE-based variants[ 11 , 13 , 22 ]. Howev er , cultural meaning shifts often appear as dimension-spe cic errors, including culture-specic referent mismatch, loss of allusive meaning, and register or so cio-pragmatic mismatch, which may not be reliably reected by aggregate scores[ 5 , 32 ]. Overlap-based metrics can under-reward legitimate paraphrases or lo calization choices, while semantic-similarity and learne d metrics may still fail to identify which cultural dimension is violated, limiting di- agnostic value and impeding cross-benchmark interpretability[21, 27 ]. These limitations highlight the need for evaluation that is taxonomy-grounded and dimension-aware, enabling consistent and ne-grained assessment of cultural meaning preser vation acr oss diverse benchmarks. 3 CulT -Eval Benchmark This section presents CulT -Ev al , a b enchmark designed to eval- uate machine translation of culture-loaded expressions. W e rst delineate the data sources (§3.1), followed by the process of expres- sion identication and taxonomy-based classication (§3.2). W e then detail the construction of human-veried refer ences and the associated quality control procedures (§3.3). An overview of the CulT -Eval is illustrated in Figure 2. 3.1 Data Source CulT -Eval is constructed from two major domains of culturally rich Chinese-English parallel data, selected to ensure diverse registers and translation ambiguity . Literary and Narrative Ar chives. W e selected bilingual excerpts from regional literature, folklore chronicles, and movie subtitles. This domain captures the e xpressive richness of the language , serv- ing as the primary sour ce for idioms, slang, and Ecological/Material CSIs. By including both standardized idiomatic expressions and colloquial usage, this subset presents culturally nuanced phrasing that often requires interpretation b e yond literal translation, and may or may not have established equivalents in the target language. Metric Pearson 𝑟 Spearman 𝜌 BLEU 30.2 28.4 ChrF++ 22.4 20.1 BERTScore 27.5 25.3 COMET 44.5 39.0 MetricX-QE 24.6 22.8 A CRE (Ours) 68.4 65.1 T able 2: Pearson ( 𝑟 ) and Sp earman ( 𝜌 ) correlation coecients between metrics and human annotations on CulT -Eval. Public and Institutional Communication. W e aggregated data from ocial publicity materials, news reports, and documentaries. This category focuses on formal and communicative precision, pro- viding a rich source for Social/Political CSIs and statutory terms. In contrast, the public/institutional subset fo cuses on consistent mappings of formalized terminology and policy-oriented expres- sions, which are typically expecte d to conform to existing bilingual conventions in cross-cultural communication. 3.2 Cultural T axonomy T o facilitate ne-grained diagnostic evaluation, each instance in CulT -Ev al is annotated with a cultural category . W e adopt a ve- way taxonomy adapted from established frameworks in translation studies and intercultural communication [ 1 , 18 ]. This taxonomy systematizes the underlying cultural grounding into the following ve dimensions: (1) Material Culture : Encompasses tangible artifacts, traditional attire, and architectural styles (e.g., Majiazi [ 马 架 子 ], a log shel- ter). (2) Social Culture : Pertains to sociopolitical systems, his- torical movements, and institutional roles (e.g., Red T ourism [ 红 色 旅 游 ]). (3) Linguistic Culture : Covers idiomatic expressions, proverbs, and metaphors with non-compositional meanings ( e.g., Three cobblers [ 三 个 臭 皮 匠 ]). (4) Religious Culture : Refers to belief systems, ritualistic practices, and philosophical frameworks (e .g., Confucianism). (5) Ecological Culture : Includes terms rooted in seasonal cycles, calendrical systems, and geography-based cosmo- logical concepts (e .g., Grain Rain [ 谷 雨 ]). Each instance is assigned a single primary lab el based on its predominant contextual func- tion. T o ensure diagnostic clarity , we prioritize mutually exclusive assignments even for expr essions that exhibit categorical overlap. 3.3 Benchmark Construction Pipeline The construction of CulT -Eval followed a semi-automate d pipeline combining LLM assistance with human annotation. LLM- Assisted Candidate Extraction. W e employed GPT -5 to iden- tify candidate sentences from raw Chinese corpora likely to contain culture-loaded expressions. Source te xts spanned the domains, in- cluding literary works, documentaries, movie subtitles. The model was prompted with domain-adapted instructions (see T able 6) to overgenerate p otentially culture-specic content, prioritizing r ecall over precision. Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Trovato et al. Data Example CulT-Eval Colloquial Expression: The phrase "Life of human, all for gold" satirizes the phenomenon ... ⽢ 为 铜钱 做 ⽜ ⻢ “ ⽢ 为 铜钱 做 ⻢ ⽜ ” 这 句 话讽 刺 了 ⼈们 为 追 求 钱 财 ⽽ 丧 失 尊 严 、 四 处奔 波 的 现 象 , ...... Culture-Specific Items: 喘 家 An asthma patient refers to someone who frequently suffers .... LinguisticCultural SocailCultural Model Translation Failures 既 然 他 不 仁 , 就 别 怪 我 在 ⼯ 作 中 给 他 穿 ⼩ 鞋 了 Since he is unkind, don't blame me for wearing small shoes for ...... ......making things difficult for him Literalization Senese Error 这 种 ⽼ 房 ⼦ 没 有 集 中 供 暖 , 全 靠 地 下 的 地 ⻰ 来 维 持 室 温 ...underfloor heating flues... ........ Seven Error Types Material Cultural Social Cultural 5-Dimensional Cultural Taxonomy Linguistic Cultural Ecological Cultural Religious Cultural Source : Literature , Documentaries , Public Media Scale: 7959 Chinese-English pairs CulT-Eval Raw Text Data Construction Pipeline Literary and Narrative Archives Public Communication. 喘 家 是 指 常 患 喘 证 的 ⼈ , 在 中 医 病 因 病 机 中 需 特 别 注 意 。 .......on underground earth dragons to maintain room temperature. Bilingual sentence pairs term term_english sourece_sentence translation_sentence Human Annotation 1. Culture Label Annotation 2. Culture Meaning Annotation 3. Quality Contorl: ( 1)insufficient cultural salience (2) weak contextual support (3)semantic misalignment 4. Span-Level Check Figure 2: Over vie w of the CulT -Eval benchmark. Human A nnotation and Cultural T erm Lab eling. All GPT -extracted candidates were revie wed by trained annotators to verify the pres- ence of at least one genuine culture-loaded expr ession. Sentences deemed culturally irr elevant or ambiguous were e xcluded. For each retained sentence, annotators identied the minimal span of the culture-specic term in both the Chinese source and the English target, and assigned a categor y label from the taxonomy dened in Section 3.2. In addition to span identication and classication, annotators enriched each instance with: (1) a veried English reference transla- tion drawn from the original bilingual sour ce; (2) a cultural e xplica- tion, a one-sentence contextual denition that explains the term’s cultural or historical signicance; and (3) a standardized English equivalent when applicable. 3.4 Dataset Statistics and Quality Control After annotation, we applied post hoc ltering to ensure consis- tency and interpretability of the b enchmark. Annotators rened span boundaries, normalized terminology , and excluded instances that did not meet the dataset criteria. Specically , instances were removed if they e xhibited: (1) insucient cultural salience, where the expression did not encode a clear culture-dependent concept; (2) weak contextual support, where the surrounding sentence was insucient to disambiguate meaning; or (3) semantic misalignment, where the sour ce and target sentences showed low correspondence due to overly literal translation or structural mismatch. English reference translations were drawn from the original bilin- gual sources, including subtitles, literary translations, and ocial publications. These translations were manually inspected to verify basic pragmatic adequacy . Instances were excluded if the English side consisted primarily of unglossed transliterations or if the trans- lation failed to reect the intended meaning of the culture-loaded expression. In addition to sentence-level alignment, we annotated the corre- sponding spans of culture-loaded expressions on the English ref- erence side. Each instance therefore contains an e xplicit mapping between the source-language cultural span and its realization in the target language, enabling span-level inspection during evaluation. From a linguistic perspective, the dataset encompasses culture- loaded expressions realized as idioms, slang, and colloquialisms, alongside literary and po etic forms and entity-base d culture-specic items. After rigorous ltering, the dataset was rened from an initial pool of approximately 12,000 candidates to ( see T able 1 for detailed statistics). 4 Evaluation and Metric Analysis This se ction evaluates translation models on CulT -Eval and analyzes the adequacy of commonly use d evaluation metrics for culture- loaded translation. W e begin with standard sentence-level metrics, and then examine their behavior on culturally salient spans. 4.1 Sentence-Level Evaluation with Standard Metrics W e evaluate a set of representative translation systems on CulT - Eval, including both multilingual NMT mo dels and instruction- tuned large language models (LLMs) used in a zero-shot translation setting. The MT baselines include publicly released mo dels such as NLLB-200-3.3B[ 26 ], hunyuan-7B[ 35 ] and MADLAD-400-10B[ 14 ]. From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Model BLEU CHRF++ BERTScore COMET MetricX -QE 0-shot 1-shot 0-shot 1-shot 0-shot 1-shot 0-shot 1-shot 0-shot 1-shot Machine Translation Models Hunyuan-MT -7B – – – – – – – – – – Madlad400-10B-MT – – – – – – – – – – NLLB200-3-3B – – – – – – – – – – Open-Sourced and Proprietary LLMs Llama-3.1-8B-Instruct – – – – – – – – – – DS-R1-D-Qwen-7B – – – – – – – – – – Qwen3-8B-Instruct – – – – – – – – – – Qwen3-32B-Instruct – – – – – – – – – – DeepSeek-v3 – – – – – – – – – – GPT -5.1 – – – – – – – – – – T able 3: Comprehensive evaluation results across ve metrics. In addition, we evaluate several LLM-based systems, including GPT - 5.1 [ 25 ], Llama-3.1-Instruct [ 10 ], and Qwen3-Instruct series [ 31 ] and DeepSeek- V3 [ 7 ]. All systems are evaluated in a sour ce-only setting, where models generate English translations directly from Chinese source sentences. For LLMs, we employ two prompting paradigms: (i) a vanilla zero-shot translation prompt, and (ii) a one- shot prompt containing a single illustrativ e example. T o ensure a rigorous evaluation, the one-shot example is held-out from the test set, and no supplementary cultural explications or reference trans- lations are provided at inference time. NMT systems are e valuated under their standard inference settings without prompt variations. 4.2 Sentence-level Metrics under Cultural Evaluation In T able 3,sentence-level metrics distinguish translation systems on CulT -Eval, with both NMT and LLM-base d models achieving competitive scores and clear p erformance dierences. However , these metrics do not explicitly evaluate whether culturally salient content is correctly preserved, which is central to the CulT -Eval task. T o assess whether sentence-level metrics reect cultural correct- ness, we analyze their alignment with human judgments, dened as whether the annotated culture-loaded span is correctly expressed in the translation. T able 2 reports segment-level correlations between automatic metrics and human judgments of cultural correctness. Across metrics, BLEU, ChrF, BLEURT , and COMET exhibit weak and unstable correlations, indicating that higher sentence-level scor es do not reliably correspond to correct translation of culture-loaded spans. Representative examples in T able 4 further illustrate this mis- alignment. W e observe translations that receive high sentence-level scores despite literalization, over-generalization, or omission of cultural meaning, as well as translations that accurately convey cultural meaning through paraphrasing or explicitation but r eceive low scores due to surface-lev el divergence from the refer ence. T yp e Content Analysis Score V alid High Error SRC . . . 强 调 自 己 吃 软 不 吃 硬 , 如 果 . . . REF . . . amenable to coaxing but not coercion. . . SYS . . . better to persuasion than force. . . 32.1 0.83 ✗ Low Good SRC . . . 典 型 的 关 系 户 问 题 , 在 一些 . . . REF . . . typical issue of nepotism, which. . . SYS . . . typical case of nepotism driven by. . . 20.3 0.64 ✓ * Score: BLEU (top) / COMET (bottom). T able 4: Performance Analysis. T ogether , these results demonstrate that sentence-level similarity is an unreliable proxy for cultural correctness. While standard met- rics capture overall translation quality , they fail to reect whether culturally salient meaning is preser v ed, motivating a more ne- grained analysis of cultural translation errors. 4.3 A T axonomy of Culture-related Translation Errors Beyond the empirical observations in Section 4.2, which suggest a systematic misalignment between metrics and cultural correctness, we conduct a structured error analysis to characterize the distortion of cultural meaning. W e introduce a taxonomy of culture-related translation errors to formalize these failure modes. By distinguish- ing specic types of cultural attrition, our taxonomy provides a rigorous framework for e valuating translation quality where con- ventional metrics fail. 4.3.1 A nnotation Principle. A key challenge in analyzing cultural translation errors is that multiple error phenomena may co-occur within a single instance. T o ensure consistency , we assign a primary error lab el according to a xed priority order , ranging from omission to over-interpretation. This ordering r eects a progression from the complete absence of cultural r ealization to distorted or excessive realization, and ensures that each instance is associated with the Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Trovato et al. Figure 3: Performance analysis of six selected models. The left chart displays the overall Cultural Correctness score. The right chart visualizes the distribution of seven specic error types within the incorrect samples. most fundamental source of cultural failure. Detailed denitions and examples are pro vided in the Appendix ?? . 4.3.2 Error Categories. W e identify seven recurrent error cate- gories that capture distinct ways in which cultural meaning may fail to be correctly realized in translation. All categories refer specif- ically to errors in the translation of culture-loaded spans, rather than to general translation err ors.(1) Omission: the culture-loaded span is not realized in the translation, either through deletion or re- placement with an empty or vacuous expression. (2) Literalization: the translation preserves surface meaning through wor d-by-word rendering but fails to activate the conv entional or idiomatic cultural sense. (3) Sense Error: an incorrect sense or referent is selecte d, resulting from misinterpretation rather than deliberate cultural substitution. (4) Neutralization: the functional meaning is br oadly conveyed, but culturally specic features are attened into generic expressions, weakening cultural salience . (5) Mis-substitution: a target-culture analogue is used as a replacement, but the analogy is misleading or non-e quivalent. (6) Pragmatic Shift: social or interactional meaning is altered, including changes in politeness, honorics, or perceived social relations. (7) Over-interpretation: additional cultural explanations, background information, or value judgments are introduced beyond what is explicit in the source . 4.3.3 Error Distributions across Systems. T o illustrate how the pro- posed taxonomy manifests in practice, w e examine the distribution of cultural correctness and error types across a set of representa- tive translation systems, all evaluated under the same source-only setting described in Section 4. Figure 3 presents the cultural correctness rate and the composi- tion of primary error categories for each system. The results show that cultural failures are systematic and vary in composition across systems, ev en when overall translation quality at the sentence lev el appears competitive. Importantly , these dierences arise from how culturally loaded spans are r ealized, such as through omission, liter- alization, neutralization, pragmatic distortion, or ov erinterpretation, rather than from uency or grammaticality on the surface. Error Type Lexical Semantic BLEU ChrF BERT COMET Omission ✓ ✓ ✓ ✓ Literalization ✗ ✗ ✗ ✗ Neutralization ✗ ✗ △ △ Over-interpretation ✗ ✗ ✗ ✗ T able 5: Metric sensitivity analysis. ( ✓ : Sensitive; ✗ : Insensi- tive; △ : Partial) 4.4 Structural Limitations of Sentence-level Evaluation for Cultural Correctness T aken together , the analyses reveal a structural mismatch between sentence-level evaluation and cultural correctness. Sentence-level metrics assume that overall similarity to a reference reects mean- ing preservation, an assumption that breaks down when culturally salient meaning is realized through sp ecic spans that may not substantially aect surface form. The error taxonomy makes this mismatch explicit by distin- guishing failure modes with dierent interactions with surface similarity . While omission errors remove content and are therefore often penalized, errors such as literalization, neutralization, and over-interpretation frequently preserve lexical or semantic over- lap while distorting culturally salient meaning, allowing aected translations to receive high sentence-level scor es. T able 5 shows that this asymmetr y is systematic. N-gram–based metrics consistently p enalize omission but are largely insensitive to error types that preserve surface overlap, while embedding-based metrics exhibit only limited improv ements and remain unreliable for detecting several prevalent cultural err or categories. These ndings indicate that the limitation of sentence-le vel met- rics stems from the evaluation obje ctiv e itself rather than from metric design. By aggregating similarity at the sentence level, dif- ferent cultural failure mechanisms are conated into a single score, motivating the need for an evaluation approach that explicitly tar- gets the realization of culture-loaded spans. In the next section, we introduce A CRE to operationalize this perspective. 5 A CRE W e propose ACRE ( A nchored C ultural R ealization E valuation), an automatic evaluation metric for assessing whether culturally salient meaning is correctly realized in translation. Unlike sentence-lev el similarity metrics that rely on surface o verlap, A CRE is explicitly anchored by Cultural Explication annotations, which provide ground-truth denitions of cultur e-loaded spans and frame cultural evaluation as a structured v erication problem rather than open- ended judgment. A CRE models cultural realization through tw o complementary components: V alidity and Quality . V alidity determines whether the intende d cultural referent is correctly instantiated, while Quality assesses how appropriately that meaning is expressed. Formally , let 𝑆 denote the source sentence, 𝐻 the hypothesis translation, 𝐸 the From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W o odstock, NY associated Cultural Explication, and 𝐶 the categor y of the cultur e- loaded span. ACRE is dened as: A CRE ( 𝑆 , 𝐻 , 𝐸, 𝐶 ) = I valid ( 𝐻 , 𝐸 ) · Φ quality ( 𝐻 , 𝑆 , 𝐶 ) (1) Here, I valid ( 𝐻 , 𝐸 ) ∈ { 0 , 1 } is the Semantic V alidity Indicator , computed by the Semantic V alidator , which veries whether the hypothesis instantiates the cultural referent dened in 𝐸 . Transla- tions that fail this check are assigne d a score of zero, preventing uent but semantically incorrect realizations from being rewarded. The Quality component Φ quality is compute d only for valid in- stances: Φ quality ( 𝐻 , 𝑆 , 𝐶 ) = 𝛼 𝐶 · S delity ( 𝐻 , 𝑆 ) + 𝛽 𝐶 · S clarity ( 𝐻 ) (2) where S delity is the Fidelity Score , assessing the preservation of intended meaning and pragmatic force, and S clarity is the Clarity Score , assessing communicative intelligibility for target-language readers. 5.1 Category-conditioned Evaluation and Reference Implementation Based on the taxonomy introduced in Section 4, ACRE adopts category-conditioned protocols that determine how Quality is as- sessed, while leaving the metric denition unchange d. A Category Check rst routes each instance to one of two evaluation protocols according to its category 𝐶 . For Protocol A (Fact-centric), which applies to categories such as specic cultural concepts, material artifacts, and social institu- tions, evaluation emphasizes referential validity . Under this proto- col, strict alignment with the Cultural Explication is required, and deviations in referential identity directly invalidate the translation via the Semantic V alidator . For Protocol B (Style-centric), which applies to idioms, literary ex- pressions, and slang, evaluation emphasizes functional e quivalence . Under this protocol, paraphrasing or re-expression is permitted as long as pragmatic force and register are pr eserved. These category-conditioned protocols are instantiated in a multi- agent evaluation framew ork, termed CulT -A gent, as illustrated in Figure 4. The framew ork operationalizes the V alidity and Quality components of ACRE through coordinated agents that correspond directly to the metric formulation. Within CulT - Agent, V alidity is assessed by the Semantic V al- idator . For instances that pass V alidity , Quality is assesse d by two complementary agents: the Fidelity Critic, which computes the Fidelity Score, and the Nuance Critic, which computes the Clar- ity Score. These agents implement the Quality function dened in Eq. (2). Throughout evaluation, refer ence translations are used only as stylistic anchors rather than semantic ground truth, while Cultural Explications ser ve as the authoritative basis for determining cultural correctness. Detailed descriptions of individual agents and their coordination protocols are provided in Appendix ?? . 5.2 Implementation Details In our experiments, ACRE is instantiate d through CulT -A gent, which realizes the Semantic V alidator , Fidelity Critic, and Nuance Critic using a large language model as a constrained judge. Each Source (S) Hypothesis(H) Explichesis(E) Category (C) Protocol A Input C Check Category C Protocol B Semantic Validator Input H+E Semance Critic Validator Nucance Critic Validator Output (0,1) Score Agent GPT-5.1_translation: 5 Qwen3-7B_translation: 3 LLama-3.1_translation: 4 Figure 4: Evaluation pipeline agent executes a specic functional role dened by the category- conditioned protocols. All evaluations are implemented with grok-4.1-fast, using de- terministic decoding and xed prompts. The prompts instantiate the roles of individual agents and their coordination protocol, and are held constant across all experiments to ensure r eproducibility . For transparency , all prompt templates and agent specications are provided in Appendix A 6 Experiments and Analyses 6.1 Cultural Correctness under ACRE W e e valuate ACRE using the same set of 4.1 translation systems and experimental conguration described in Section. T able 6 reports A CRE scores and their comp onents for representativ e machine translation systems and large language models on CulT -Eval. The results indicate that the realization of culture-loaded ex- pressions remains a challenging and unreliable aspect of current translation systems. Across models, validity aspect of current trans- lation systems. Acr oss models, validity failures are fr equent, sug- gesting that culture-loaded expressions are often misinterpreted, generalized, or omitted, even when translation appear uent at the sentence level. Such failures directly limit nal A CRE scores and reveal deciencies that are obscured by sentence-level similarity metrics. While stronger language models achieve higher validity rates than machine translation systems, these improvements are still in- cremental rather than dentiv e. Correct handling of culture-loaded expressions is not consistently guaranteed, and substantial varia- tion persists in how cultural meaning is preserved and expressed once referential corr ectness is satised. Importantly , these dier- ences are not driven by surface-lev el similarity or grammaticality , but by how systems handle culture-loaded expressions at both the referential and pragmatic lev els. By decomposing cultural correct- ness into semantic validity and realization quality , ACRE pr ovides a more informative view of translation b ehavior than aggregate Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Trovato et al. Model Stage I: V alidity Stage II: Quality Final A CRE 0-shot 1-shot Fidelity Clarity 0-shot 1-shot Machine Translation Models Hunyuan-MT -7B – – – – – – Madlad400-10B-MT – – – – – – NLLB200-3-3B – – – – – – Open-Sourced and Proprietary LLMs Llama-3.1-8B-Instruct – – – – – – DS-R1-D-Qwen-7B – – – – – – Qwen3-8B-Instruct – – – – – – Qwen3-32B-Instruct – – – – – – DeepSeek-v3 – – – – – – GPT -5.1 – – – – – – T able 6: Comprehensive ACRE evaluation results across proprietary and open-source models. Conguration Correlation ( 𝑟 ) Δ 𝑟 Full A CRE 0.88 – w/o V alidity Gate ( I valid ) 0.76 -0.12 w/o Adaptive Routing (Protocols) 0.81 -0.07 w/o Explication Anchor ( 𝐸 ) 0.62 -0.26 w/o Reference Anchor ( 𝑅 ) 0.85 -0.03 T able 7: Ablation study of ACRE. W e compare the semantic validity (Stage I) and quality proling (Stage II) across zero- shot and one-shot settings. sentence-level metrics, which conate distinct sources of cultural failure. 6.2 Ablation Study T o verify the contribution of each component in A CRE, we con- duct an ablation study on the translations generate d by Qwen3-8B. T able 7 reports the correlation results. Removing the semantic va- lidity gate leads to a drop in human alignment, conrming its role in ltering hallucinated but uent translations. The most signif- icant degradation o ccurs when excluding Cultural Explications, demonstrating that external semantic grounding is more critical for cultural evaluation than internal parametric knowledge alone. In contrast, the absence of reference translations causes only a marginal performance de cline , indicating that A CRE relies more on semantic denitions than on surface-form similarity . These re- sults underscore that A CRE’s components provide complementary diagnostic power , with explications serving as the primar y anchor for cultural correctness. 6.3 Diagnostic Sensitivity to Cultural Error T ypes Figure 5 compares the sensitivity of ACRE and sentence-lev el met- rics to representative cultural error typ es in the translation of culture-loaded expressions . A CRE exhibits substantial scor e drops Literalization Sense Error Neutralization 0 20 40 60 80 100 Metric Sensitivity (Score Drop % on Error) -62% -82% -48% Metric Sensitivity to Cultural Errors A CRE (Ours) COMET BLEU Figure 5: Sensitivity of evaluation metrics to cultural trans- lation errors. for sense errors, literalization, and neutralization, indicating strong responsiveness to failures that distort cultural meaning while pr e- serving surface overlap. In contrast, COMET shows only moderate sensitivity , and BLEU remains largely insensitive across all error types, with minimal score variation even when cultural meaning is severely distorted. These r esults demonstrate that A CRE captures diagnostic signals that are systematically missed by sentence-level similarity metrics, directly explaining the discr epancies observed in Section 6.1. 7 Conclusion In this pap er , we introduced CulT -Eval, a large-scale benchmark for evaluating machine translation of cultur e-loaded expressions, together with a unied cultural taxonomy and ne-grained error annotations. Through extensiv e evaluation, we showed that widely used sentence-level metrics fail to reliably r eect cultural correct- ness, often overlooking systematic meaning distortions. T o address this gap, we proposed A CRE, a taxonomy-aware evaluation metric anchored in cultural explications, which demonstrates substantially From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W o odstock, NY stronger alignment with human judgments and higher diagnos- tic sensitivity to culture-related errors. Our ndings highlight the limitations of surface-level evaluation and underscore the need for culturally grounded assessment frameworks. W e hope CulT -Eval and A CRE will facilitate more reliable evaluation and foster future research on culturally aware machine translation. 8 Acknowledgments Identication of funding sources and other support, and thanks to individuals and groups that assisted in the resear ch and the preparation of the work should be include d in an acknowledgment section, which is placed just b efor e the reference section in your document. This section has a special environment: \begin{acks} ... \end{acks} so that the information contained therein can be more easily col- lected during the article metadata extraction phase, and to ensure consistency in the spelling of the section heading. A uthors should not prepare this section as a numb er ed or un- numbered \section ; please use the “ acks ” environment. References [1] Javier Franco Aixela. 1999. 4 Culture-specic Items in Translation . Multilingual Matters, Bristol, Blue Ridge Summit, 52–78. doi:doi:10.21832/9781800417915- 005 [2] Christos Baziotis, Prashant Mathur , and Eva Hasler . 2023. Automatic Evaluation and Analysis of Idioms in Neural Machine Translation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics . A ssociation for Computational Linguistics, Dubrovnik, Croatia, 3682– 3700. doi:10.18653/v1/2023.eacl- main.267 [3] Y ong Cao, Y ova Kementchedjhieva, Ruixiang Cui, Antonia Karamolegkou, Li Zhou, Megan Dare, Lucia Donatelli, and Daniel Hershcovich. 2024. Cultural Adap- tation of Recipes. Transactions of the Association for Computational Linguistics 12 (2024), 80–99. doi:10.1162/tacl_a_00634 [4] Andong Chen, Lianzhang Lou, Kehai Chen, Xuefeng Bai, Yang Xiang, Muyun Y ang, Tiejun Zhao, and Min Zhang. 2025. Benchmarking LLMs for Translat- ing Classical Chinese Poetry: Evaluating Adequacy , F luency , and Elegance. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing . Association for Computational Linguistics, Suzhou, China, 33019–33036. doi:10.18653/v1/2025.emnlp- main.1678 [5] Shanbo Cheng, Yu Bao, Qian Cao, Luyang Huang, Liyan Kang, Zhicheng Liu, Y u Lu, W enhao Zhu, Jingwen Chen, Zhichao Huang, Tao Li, Yifu Li, Huiying Lin, Sitong Liu, Ningxin Peng, Shuaijie She, Lu Xu, Nuo Xu, Sen Y ang, Runsheng Y u, Yiming Yu, Liehao Zou, Hang Li, Lu Lu, Yuxuan Wang, and Y onghui Wu. 2025. Seed-X: Building Strong Multilingual Translation LLM with 7B Parameters. arXiv:2507.13618 [cs.CL] https://arxiv .org/abs/2507.13618 [6] Francesca De Luca Fornaciari, Begoña Altuna, Itziar Gonzalez-Dios, and Maite Melero. 2024. A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models. In Proce edings of the 4th W orkshop on Figurative Language Processing (FigLang 2024) . Association for Computational Linguistics, Mexico City , Mexico (Hybrid), 35–44. doi:10.18653/v1/2024.glang- 1.5 [7] DeepSeek-AI et al . 2025. DeepSeek-V3 T echnical Report. arXiv:2412.19437 [ cs.CL] https://arxiv .org/abs/2412.19437 [8] Markus Freitag, Ricardo Rei, Nitika Mathur , Chi-kiu Lo, Craig Ste wart, Eleftherios A vramidis, T om Kocmi, George Foster , Alon Lavie, and André F. T . Martins. 2022. Results of WMT22 Metrics Shared T ask: Stop Using BLEU – Neural Metrics Are Better and More Robust. In Procee dings of the Seventh Conference on Machine Translation (WMT) . Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), 46–68. https://aclanthology .org/2022.wmt- 1.2/ [9] Yicheng Fu, Zhemin Huang, Liuxin Y ang, Y umeng Lu, and Zhongdongming Dai. 2025. CHENGY U-BENCH: Benchmarking Large Language Models for Chinese Idiom Understanding and Use. In Proceedings of the 2025 Conference on Empir- ical Methods in Natural Language Processing . Association for Computational Linguistics, Suzhou, China, 2355–2366. doi:10.18653/v1/2025.emnlp- main.119 [10] Aaron Grattaori et al . 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] [11] Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luísa Coheur , Pierre Colombo, and André Martins. 2023. xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Compu- tational Linguistics 12 (2023), 979–995. https://api.semanticscholar .org/CorpusID: 264146484 [12] Hongcheng Guo, Fei Zhao, Shaosheng Cao, Xinze Lyu, Ziyan Liu, Yue W ang, Boyang W ang, Zhoujun Li, Chonggang Lu, Zhe Xu, and Y ao Hu. 2025. Redening Machine Translation on Social Network Services with Large Language Models. arXiv:2504.07901 [cs.CL] https://arxiv .org/abs/2504.07901 [13] Juraj Juraska, Mara Finkelstein, Daniel Deutsch, Aditya Siddhant, Mehdi Mirza- zadeh, and Markus Freitag. 2023. MetricX-23: The Google Submission to the WMT 2023 Metrics Shared Task. In Conference on Machine Translation . https://api.semanticscholar .org/CorpusID:265608038 [14] Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, and Orhan Firat. 2023. MADLAD-400: A Multilingual And Document- Level Large Audited Dataset. arXiv:2309.04662 [cs.CL] https://arxiv .org/abs/ 2309.04662 [15] Shuang Li, Jiangjie Chen, Siyu Yuan, Xinyi Wu, Hao Yang, Shimin Tao, and Y anghua Xiao. 2023. Translate Meanings, Not Just W ords: IdiomKB’s Role in Op- timizing Idiomatic Translation with Language Models. arXiv:2308.13961 [cs.CL] https://arxiv .org/abs/2308.13961 [16] Y unlong Liang, Fandong Meng, Jiaan W ang, and Jie Zhou. 2025. SlangDI T: Benchmarking LLMs in Interpretative Slang Translation. arXiv:2505.14181 [cs.CL] https://arxiv .org/abs/2505.14181 [17] Ananya Mukherjee, Saumitra Y adav , and Manish Shrivastava. 2025. Why should only High-Resource-Languages have all the fun? Pivot Based Evaluation in Low Resource Setting. In Proceedings of the 31st International Conference on Computational Linguistics . A ssociation for Computational Linguistics, Abu Dhabi, U AE, 4779–4788. https://aclanthology .org/2025.coling- main.320/ [18] P. Newmark. 1988. A pproaches to Translation . Prentice Hall. https://books. google.com/books?id=- lchAQ AAMAAJ [19] Kishore Papineni, Salim Roukos, T odd W ard, and W ei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine T ranslation. In A nnual Meeting of the Association for Computational Linguistics . https://api.semanticscholar .org/ CorpusID:11080756 [20] Maja Popović. 2017. chrF++: words helping character n-grams. In Proceedings of the Second Conference on Machine Translation . Association for Computational Linguistics, Copenhagen, Denmark, 612–618. doi:10.18653/v1/W17- 4770 [21] Lorenzo Proietti, Stefano Perrella, and Roberto Navigli. 2025. Has Machine Translation Evaluation Achiev ed Human Parity? The Human Reference and the Limits of Progress. arXiv:2506.19571 [cs.CL] https://ar xiv .org/abs/2506.19571 [22] Ricardo Rei, José G. C. de Souza, Duarte M. Alves, Chrysoula Zerva, Ana C. Farinha, T. Glushkova, Alon Lavie, Luísa Coheur , and André F. T . Martins. 2022. COMET -22: Unbab el-IST 2022 Submission for the Metrics Shared T ask. In Conference on Machine Translation . https://api.semanticscholar.org/CorpusID: 256461051 [23] Ricardo Rei, Craig Alan Stewart, Catarina Farinha, and Alon Lavie. 2020. Unba- bel’s Participation in the WMT20 Metrics Shared Task. In Conference on Machine Translation . https://api.semanticscholar .org/CorpusID:225103036 [24] Sheikh Shafayat, Dongkeun Y oon, W oori Jang, Jiwoo Choi, Alice Oh, and Seohyon Jung. 2025. A 2-step Framework for A utomated Literary Translation Evaluation: Its Promises and Pitfalls. arXiv:2412.01340 [cs.CL] 01340 [25] Aaditya Singh et al . 2025. OpenAI GPT -5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv .org/abs/2601.03267 [26] NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heaeld, Kevin Heernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler W ang, Guillaume W enzek, Al Y oungblo od, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Ho- man, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierr e Andrews, Necip Fazil A yan, Shruti Bhosale, Sergey Edunov , Angela Fan, Cynthia Gao, V edanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Sayyah Saleem, Holger Schwenk, and Je Wang. 2022. No Language Left Behind: Scaling Human-Centered Machine Translation. arXiv:2207.04672 [cs.CL] [27] Y anzhi Tian, Cunxiang W ang, Zeming Liu, Heyan Huang, W enbo Y u, Dawei Song, Jie T ang, and Y uhang Guo. 2026. Beyond Literal Mapping: Benchmarking and Improving Non-Literal T ranslation Evaluation. https://api.semanticscholar . org/CorpusID:284648564 [28] Bin W ang, Zhengyuan Liu, Xin Huang, Fangkai Jiao, Y ang Ding, Ai Ti A w , and Nancy F Chen. 2024. SeaEval for Multilingual Foundation Models: From Cross- Lingual Alignment to Cultural Reasoning. NAACL (2024). [29] Minghan W ang, Viet-Thanh P ham, Farhad Moghimifar , and Thuy- Trang Vu. 2025. Proverbs Run in Pairs: Evaluating Prov erb Translation Capability of Large Language Model. arXiv:2501.11953 [cs.CL] https://arxiv .org/abs/2501.11953 [30] Rachel Wicks and Matt Post. 2023. Identifying Context-Dependent Translations for Evaluation Set Production. arXiv:2311.02321 [cs.CL] https://arxiv .org/abs/ Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Trovato et al. 2311.02321 [31] An Y ang et al . 2025. Qwen3 T echnical Report. arXiv:2505.09388 [cs. CL] https: //arxiv .org/abs/2505.09388 [32] Cai Y ang, Y ao Dou, David Heineman, Xiaofeng Wu, and W ei Xu. 2025. Evaluating LLMs on Chinese Idiom Translation. arXiv:2508.10421 [cs.CL] https://ar xiv .org/ abs/2508.10421 [33] Binwei Y ao, Ming Jiang, T ara Bobinac, Diyi Y ang, and Junjie Hu. 2024. Bench- marking Machine Translation with Cultural A wareness. In Findings of the Associ- ation for Computational Linguistics: EMNLP 2024 . Association for Computational Linguistics, Miami, Florida, USA, 13078–13096. doi:10.18653/v1/2024.ndings- emnlp.765 [34] Tianyi Zhang, V arsha Kishore, Felix Wu, Kilian Q . W einberger , and Y oav Artzi. 2019. BERTScore: Evaluating T ext Generation with BERT . A rXiv abs/1904.09675 (2019). https://api.semanticscholar .org/CorpusID:127986044 [35] Mao Zheng, Zheng Li, Bingxin Qu, Mingyang Song, Y ang Du, Mingrui Sun, and Di W ang. 2025. Hunyuan-MT T e chnical Report. arXiv:2509.05209 [cs.CL] https://arxiv .org/abs/2509.05209 A Prompt A.1 Part T wo Etiam commodo feugiat nisl pulvinar p ellentesque . Etiam auctor sodales ligula, non varius nibh pulvinar semper . Suspendisse nec lectus non ipsum convallis congue hendrerit vitae sapien. Donec at laoreet eros. Vivamus non purus placerat, scelerisque diam eu, cursus ante. Etiam aliquam tortor auctor ecitur mattis. B Online Resources Nam id fermentum dui. Suspendisse sagittis tortor a nulla mollis, in pulvinar ex pretium. Sed inter dum orci quis metus euismod, et sagittis enim maximus. V estibulum gravida massa ut felis suscipit congue. Quisque mattis elit a risus ultrices commodo venenatis eget dui. Etiam sagittis eleifend elementum. Nam interdum magna at le ctus dignissim, ac dignissim lorem rhoncus. Maecenas eu arcu ac neque placerat aliquam. Nunc pulv- inar massa et mattis lacinia. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Prompt T emplate: Culture-Mining Agent (Data Extraction) System Instruction: Y ou are a bilingual data mining expert. Y our task is to extract "Culture-Loaded Sentence Pairs" from the provided raw bilingual text. IMPORT AN T CONSTRAIN TS: • Y ou must identify sentences containing Idioms, Slang, or Culture-Specic Items (e.g., history , food, traditions). • Y ou must extract both the Chinese source and the English translation. • Ignore common sentences that lack specic cultural depth. • Output must b e a strictly valid JSON list. User Input: [User] Extract cultural pairs from the following text chunk: Raw Text: {RAW_TEXT_CHUNK} Return format: [ { "src": "Chinese sentence...", "tgt": "English sentence...", "focus_term": "The specific cultural word" } ] Figure 6: The prompt template for the Culture-Mining. Prompt T emplate: Fine-grained T axonomy Classier System Instruction: Y ou are a Cultural Linguist. Y our task is to classify a specic Chinese term into one of the Five Cultural Categories . T axonomy Denitions: (1) Ecological Culture: T erms related to specic animals, plants, geography, climate , or natural phenomena unique to the region (e .g., 梅 雨 , 熊 猫 , 黄 河 ). (2) Material Culture: T erms related to food, clothing, architecture, artifacts, or daily necessities (e .g., 旗 袍 , 饺 子 , 炕 , 四 合 院 ). (3) Social Culture: T erms related to institutions, titles, festivals, customs, history , or social hierarchy (e .g., 高 考 , 春 节 , 尚 书 , 关 系 户 ). (4) Religious Culture: T erms related to beliefs, mythology , philosophy (Confucianism, T aoism, Buddhism), or taboos (e.g., 阴阳 , 菩 萨 , 玉 帝 ). (5) Linguistic Culture: T erms involving idioms (Chengyu), metaphors, slang, pr overbs, or witticisms (e .g., 吃 软 不 吃 硬 , 摸 鱼 , 破 防 ). User Input: [User] Context Sentence: {SOURCE_SENTENCE} Target Term: {FOCUS_TERM} Task: 1. Analyze the meaning of the term in context. 2. Assign strictly ONE category from the list above. 3. Provide a short explanation. Return Format JSON: { "term": "{FOCUS_TERM}", "category": "Social Culture", "reason": "It refers to a specific historical government position." } Figure 7: Prompt template for ne-grained cultural classication. Benchmark Multiple Cultur e-Specic Figurative or Context-Dependent Explicit Error Error-Level Evaluation Beyond Expression T ypes Meaning Non-Literal Meaning Interpretation Taxonomy Analysis Surface Metrics CHENGYU-BENCH ✗ ✓ ✓ ✗ ✗ ✗ ✗ Idio TS ✗ ✗ ✓ ✓ ✗ ✗ ✗ SlangDI T ✗ ✓ ✓ ✓ ✗ ✗ ✓ CAMT ✓ ✓ ✗ ✓ ✗ ✗ ✓ IdiomEval ✗ ✓ ✓ △ ✓ ✓ ✓ CulT -Eval ✓ ✓ ✓ ✓ ✓ ✓ ✓ T able 8: Comparison of CulT -Eval with existing culture-related translation benchmarks. ✓ : supported, ✗ : not supported, △ : partially supported. Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Trovato et al. Prompt T emplate: Core Dispatcher (Protocol Routing) System Instruction: Y ou are a taxonomy expert in cultural linguistics. Y our task is to classify the "Cultural Category" of a spe cic term within a sour ce sentence. IMPORT AN T DEFINI TIONS: • Protocol A (Fact-Centric): – Spe cic Concepts: Concr ete institutions, historical artifacts, unique objects, technical items. – Proper Nouns: Names of unique places, pe ople , organizations, festivals. – Core Logic: Referential Precision. The translation must point to the EXACT same entity . – Tie-Breaker: If a term has a spe cic history/material existence, choose A ( e.g., "Forbidden City"). • Protocol B (Style-Centric): – Figurative Language: Idioms (Chengyu), metaphors, allegories. – Slang/Pop Culture: Buzzwords, internet memes, dialect words used for eect. – Core Logic: Pragmatic Equivalence. Imagery and tone are more important than literal words. – Tie-Breaker: If the term describes a situation/fe eling rather than an object, choose B (e .g., "eating vinegar"). User Input: [User] Analyze the cultural term inside the brackets "[]" in the source sentence. [Input] Source: {SOURCE_WITH_BRACKETS} [Task] Classify the term based on its primary function in this specific context. Return ONLY one label: "Protocol A" or "Protocol B". Figure 8: The Core Dispatcher prompt. It routes instances to the correct evaluation protocol (Fact-Centric or Style-Centric) based on linguistic features and functional context. Prompt T emplate: Stage I - Semantic V alidator (The Gate) System Instruction: Y ou are a strict Semantic V alidator . Y our ONL Y goal is to detect "Hallucinations" (Error T ype B3) or "Severe Mis-substitutions" (Error T yp e B5). CRI TICAL GROUND TRUTH RULE: • Y ou must rely EX CLUSIVELY on the pro vided [Cultural Explication]. • If the Explication says X, and the Model translates it as Y (where Y!=X), it is INV ALID. • Ignore your own internal knowledge if it conicts with the Explication. NEGA TI VE CONSTRAINTS (What NOT to check): • DO NOT check for uency , grammar , or style. • DO NOT check for "neutralization" ( loss of av or). A boring but factually correct translation is V ALID . • DO NOT penalize literal translations here, provided they refer to the correct concepts. User Input: [User] [Data] Protocol: {PROTOCOL_LABEL} Source: {SOURCE} Cultural Term: {TERM} Cultural Explication (Ground Truth): {EXPLICATION} Model Hypothesis: {HYPOTHESIS} [Task] 1. Ignore whether the translation is elegant. 2. Check ONLY if the semantic meaning matches the Explication. 3. If the hypothesis invents a new entity (Hallucination) or refers to a completely wrong concept, mark INVALID. [Output format] Reasoning: [Brief analysis] Decision: VALID or INVALID Figure 9: The Semantic V alidator prompt. It acts as a strict "V alidity Gate" ( I 𝑣𝑎𝑙 𝑖𝑑 ), ltering out hallucinations by anchoring evaluation to the Cultural Explication. From W ords to W orlds: Benchmarking Cross-Cultural Cultural Understanding in Machine Translation Conference acronym ’XX, June 03–05, 2018, W o odstock, NY Prompt T emplate: Stage II-A - Fidelity Critic (Nuance Analysis) System Instruction: Y ou are a Translation Critic focusing on "Fidelity" and "Pragmatic Equivalence" . Y our job is to score how well the Model Hypothesis captures the intended nuance and force, strictly according to the activ e Protocol. REFERENCE USA GE RULE: • The [Reference Anchor] is just ONE possible translation. • DO NOT penalize the hyp othesis for using dier ent words than the reference . • DO judge based on whether the *meaning* and *eect* are equivalent. D YNAMIC GUIDELINE (Protocol-Dependent): {DYNAMIC_INSTRUCTION} SCORING SCALE: • 5 (Perfect): Captures full nuance, tone , and imagery . • 3 (Acceptable): Core meaning present, but signicant nuance lost (e.g., too generic). • 1 (Failure): Severe mistranslation or complete loss of meaning. User Input: [User] [Data] Protocol: {PROTOCOL_LABEL} Source: {SOURCE} Reference Anchor: {REFERENCE} Model Hypothesis: {HYPOTHESIS} [Task] Evaluate Fidelity (1-5). Focus: Does the hypothesis capture the {PROTOCOL_LABEL} constraints? [Output format] Reasoning: [Critique] Score: [1-5] Figure 10: The Fidelity Critic prompt. It dynamically adjusts criteria (e .g., penalizing literalism in Protocol B vs. generalization in Protocol A) to assess translation nuance. Prompt T emplate: Stage II-B - Clarity Critic (Communicative Intelligibility) System Instruction: Y ou are a T arget A udience Evaluator simulating an English native reader who has NO prior knowledge of Chinese culture. Y our goal is to assess "Communicative Intelligibility" . SCORING PHILOSOPHY (Thick Translation): • Bonus ( +): Reward **Explicitation** (e.g., in-text glosses, brief explanations, appositives like "Kang, a heated brick bed"). Reward **Transparency** (rephrasing for clarity). • Penalty (-): Penalize **Opaque T erms** (Pinyin without context). Penalize **Confusion** (if the reader would ask "What does that mean?"). SCORING SCALE: • 5 (Crystal Clear): Seamlessly bridged. The naive reader fully understands. • 3 (Gist Only): Reader gets the general idea but misses the cultural specic. • 1 (Incomprehensible): Complete communication breakdown. User Input: [User] [Data] Source: {SOURCE} Model Hypothesis: {HYPOTHESIS} [Task] Evaluate Clarity (1-5) for a non-Chinese reader. Did the translator build a bridge for the reader, or leave them confused? [Output format] Reasoning: [Analysis] Score: [1-5] Figure 11: The Communicator prompt. It rewards explicitation strategies consistent with Appiah’s "Thick Translation" theor y .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment