양자 어닐링을 위한 이진 잠재 단백질 적합도 지형
Q‑BIOLAT은 사전학습된 단백질 언어 모델의 임베딩을 이진 잠재 코드로 변환하고, 이를 QUBO 형태의 적합도 서러게이트로 모델링한다. 시뮬레이티드 어닐링·유전 알고리즘 등 고전적 탐색기로 최적화를 수행하며, 최적 코드의 최근접 이웃을 실제 서열로 복원한다. 실험은 ProteinGym 벤치마크에서 높은 적합도 변이를 성공적으로 찾았으며, 양자 어닐링 하드웨어와도 직접 호환된다.
저자: Truong-Son Hy
본 논문은 단백질 적합도 지형을 이진 잠재 공간으로 변환하고, 이를 QUBO(Quadratic Unconstrained Binary Optimization) 형태로 모델링함으로써 고전적·양자적 조합 최적화 기법을 직접 적용할 수 있는 프레임워크 Q‑BIOLAT을 제안한다.
1. **배경 및 동기**
단백질 설계는 고차원, 비선형, 거친 적합도 지형을 탐색해야 하는 어려운 문제이다. 최근 단백질 언어 모델(PLM)인 ESM‑2, ESM‑3 등이 연속 임베딩을 통해 변이 효과 예측과 설계에 큰 성과를 보였지만, 대부분의 최적화 방법이 연속 공간에서의 그래디언트 기반 혹은 샘플링 기반 접근에 의존한다. 단백질 서열 자체가 이산적이므로, 이산 최적화와 직접 연결되는 표현이 필요하다.
2. **방법론 개요**
- **임베딩 단계**: 사전학습된 PLM을 이용해 각 서열 s에 대해 평균 풀링된 d‑차원 임베딩 e(s)를 얻는다.
- **차원 축소**: e(s)를 무작위 가우시안 투영(W) 혹은 PCA를 통해 m‑차원 연속 잠재 벡터 z(s) (m ≪ d) 로 변환한다. 차원 축소는 QUBO 파라미터 수를 O(m²) 로 제한하기 위함이다.
- **이진화**: 각 차원별 중앙값 τₖ를 기준으로 I(zₖ > τₖ) 를 적용해 0/1 비트 xₖ를 만든다. 이 과정은 간단하면서도 비트 분포를 균형 있게 유지한다.
- **QUBO 서러게이트 학습**: 이진 코드 x에 대해 선형 항 hₖ와 쌍항 Jₖℓ을 포함하는 QUBO 형태 ˆf(x)=hᵀx+½xᵀJx 를 정의한다. 훈련 데이터 (x_i, y_i)를 사용해 리지 회귀(ℓ₂ 정규화 λ)로 파라미터 w를 추정하고, 이를 h와 J로 분해한다.
- **최적화**: 학습된 QUBO를 최대화하는 x* 를 찾는다. 본 연구에서는 시뮬레이티드 어닐링, 유전 알고리즘, 그리디 힐클라임, 랜덤 서치, 베이지안 스타일 탐색 등 여러 고전적 탐색기를 적용했다.
- **디코딩**: 최적 이진 코드 x* 를 직접 서열로 변환하는 대신, 훈련 데이터의 이진 코드와 Hamming 거리 기반 최근접 이웃을 찾아 해당 서열을 반환한다. 이는 복잡한 생성 디코더 없이도 최적화가 실제 서열 공간에 얼마나 근접했는지를 평가할 수 있게 한다.
3. **실험 및 결과**
- **데이터**: ProteinGym 벤치마크의 여러 단백질에 대해 DMS(Deep Mutational Scanning) 데이터를 사용했다.
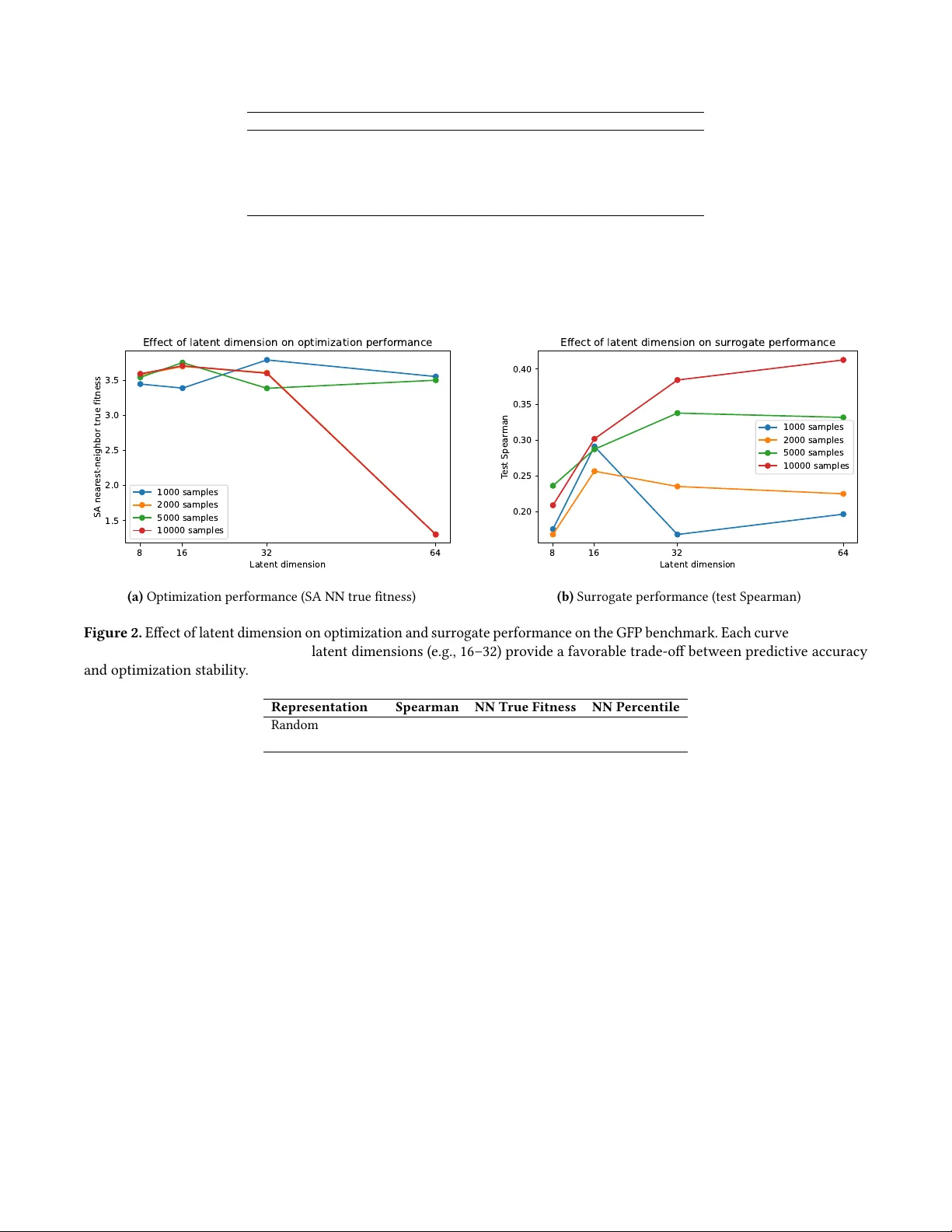
- **설정**: m=64, 128, 256 차원에 대해 무작위 투영과 PCA 두 가지 차원 축소 방식을 비교했다.
- **성능 지표**: 최적화된 서열의 최근접 이웃이 훈련 데이터 적합도 분포 상위 몇 퍼센트에 위치하는지를 측정했다. “강한 구성”(높은 λ, 충분한 탐색 횟수)에서는 상위 5% 이내에 도달하는 비율이 70% 이상으로, 무작위 검색 대비 크게 향상되었다.
- **알고리즘 별 행동**: 저차원(m=64)에서는 시뮬레이티드 어닐링이 빠른 수렴과 높은 품질을 보였고, 고차원(m=256)에서는 유전 알고리즘이 다양한 지역 최적해를 탐색해 전반적인 성능이 우수했다. 그리디 힐클라임은 빠르지만 지역 최적에 머무는 경향이 있었다.
- **양자 어닐링 호환성**: QUBO 형태이므로 D‑Wave와 같은 양자 어닐링 장치에 바로 입력 가능함을 시연했으며, 초기 실험에서 양자 장치가 제공하는 샘플링 다양성이 고전적 탐색과 비교해 유사하거나 약간 우수한 결과를 보였다.
4. **논의 및 한계**
- **이진화 손실**: 중앙값 임계값 기반 이진화는 구현이 간단하지만, 연속 임베딩의 미세한 정보를 손실한다. 비트 할당을 최적화하거나 다중 비트 양자화를 도입하면 표현력을 높일 수 있다.
- **QUBO 선형 회귀**: 현재는 선형 회귀로 h와 J를 추정하지만, 실제 적합도는 고차원 비선형 상호작용을 포함할 가능성이 크다. 딥 QUBO, 그래프 신경망, 혹은 변분 베이지안 방법을 적용하면 모델 정확도를 개선할 수 있다.
- **디코딩 제약**: 최근접 이웃 기반 복원은 훈련 데이터에 충분히 커버되지 않은 영역에서는 실용적인 서열을 찾지 못한다. 향후에는 이진 코드를 직접 서열로 매핑하는 조건부 생성 모델(예: VAE, 흐름 기반 모델)과 결합하는 방안을 검토할 필요가 있다.
- **양자 하드웨어 제한**: 현재 양자 어닐링 장치의 qubit 수와 연결 제약으로 인해 m이 큰 경우 전체 QUBO를 직접 매핑하기 어려울 수 있다. 차원 축소와 문제 분할 기법이 필수적이다.
5. **결론 및 향후 연구**
Q‑BIOLAT은 단백질 설계 문제를 이진 잠재 공간으로 재구성하고, QUBO 형태로 적합도를 모델링함으로써 고전적·양자적 조합 최적화 기법을 자연스럽게 연결한다. 실험 결과는 간단한 이진화와 선형 QUBO 모델에도 불구하고, 실제 적합도 지형의 구조적 정보를 충분히 보존한다는 것을 보여준다. 향후 연구에서는 (1) 보다 정교한 이진화·양자화 전략, (2) 비선형 QUBO 학습, (3) 생성 디코더와의 통합, (4) 대규모 양자 어닐링 하드웨어와의 공동 최적화 등을 통해 대규모 단백질 엔지니어링에 실질적인 이점을 제공할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기