Binary Latent Protein Fitness Landscapes for Quantum Annealing Optimization
We propose Q-BIOLAT, a framework for modeling and optimizing protein fitness landscapes in binary latent spaces. Starting from protein sequences, we leverage pretrained protein language models to obtain continuous embeddings, which are then transform…
Authors: Truong-Son Hy
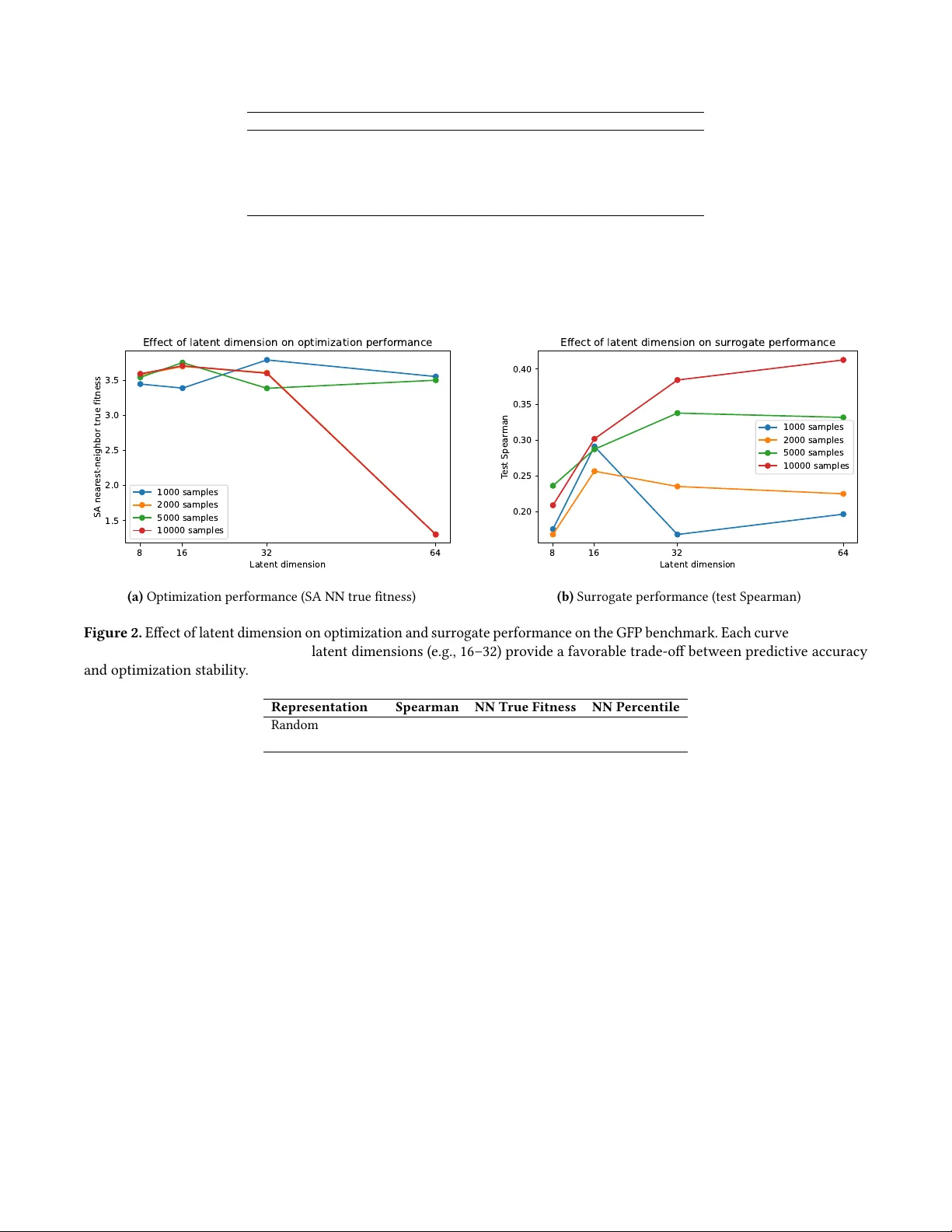
Binar y Latent Protein Fitness Landscapes for Quantum Annealing Optimization Truong-Son Hy University of Alabama at Birmingham Birmingham, Alabama, USA thy@uab.edu Abstract W e propose Q-BioLa t , a framework for modeling and opti- mizing protein tness landscapes in binary latent spaces. Starting from protein sequences, we le verage pretrained protein language models to obtain continuous embeddings, which are then transformed into compact binary latent rep- resentations. In this space , protein tness is approximated using a quadratic unconstrained binary optimization (QUBO) model, enabling ecient combinatorial search via classical heuristics such as simulated annealing and genetic algo- rithms. On the ProteinGym benchmark, we demonstrate that Q- BioLa t captures meaningful structure in protein tness land- scapes and enables the identication of high-tness variants. Despite using a simple binarization scheme , our metho d con- sistently retrie ves sequences whose nearest neighbors lie within the top fraction of the training tness distribution, particularly under the strongest congurations. W e further show that dier ent optimization strategies exhibit distinct behaviors, with evolutionary search performing b etter in higher-dimensional latent spaces and local search remaining competitive in preserving realistic sequences. Beyond its empirical p erformance, Q-BioLa t provides a natural bridge between protein representation learning and combinatorial optimization. By formulating protein tness as a QUBO problem, our framework is directly compatible with emerging quantum annealing hardware , opening new directions for quantum-assisted protein engineering. Our implementation is publicly available at: hps://github. com/HySonLab/Q- BIOLA T . Ke y words: Protein Fitness Landscapes, Protein Language Models, Binary Latent Representations, QUBO Optimization, Combinatorial Optimization, Simulated Annealing, Genetic Algorithms, Quantum Annealing, Protein Engineering, Bioin- formatics. 1 Introduction Understanding and optimizing protein tness landscapes is a central challenge in computational biology , with ap- plications spanning enzyme engineering, drug discovery , and synthetic biology . Protein tness landscapes are typ- ically high-dimensional, rugge d, and shape d by complex interactions between residues, making ecient exploration of sequence space dicult [ 1 – 3 ]. Recent advances in pro- tein language models (PLMs), such as ESM-2 [ 4 ] and ESM-3 [ 5 ], have enabled pow erful repr esentations of protein se- quences by learning from large-scale unlabeled data. These representations have signicantly improved performance on downstream tasks, including mutation eect prediction [6, 7] and protein design [8–10]. Despite these advances, most existing approaches rely on continuous neural predictors and gradient-based [ 9 ] or sampling-based optimization strategies [ 10 ], which are not naturally suite d for discrete combinatorial search. In par- ticular , protein sequences are inherently discrete obje cts, and many biologically relevant optimization problems can be more naturally formulated in discrete spaces. Classical approaches such as ev olutionar y algorithms [ 10 , 11 ] and Bayesian optimization [ 12 , 13 ] have been widely applied to protein engineering, but they often struggle with scalability or require large numbers of evaluations. In this work, w e introduce Q-BioLa t , a framework that maps protein sequences into binary latent spaces where t- ness landscapes can b e explicitly modeled and optimized. Starting from pretrained protein language model embed- dings, we construct compact binar y r epresentations that enable the formulation of protein tness as a quadratic un- constrained binary optimization (QUBO) [ 14 – 16 ] problem. This formulation allows us to leverage a wide range of com- binatorial optimization techniques, including simulated an- nealing and genetic algorithms, for ecient e xploration of protein tness landscapes. W e evaluate Q-BioLa t on real pr otein tness data from the ProteinGym benchmark [ 3 ] and show that ev en simple binary latent representations capture meaningful structur e in protein tness landscapes. Our results demonstrate that combinatorial optimization in latent space can consistently identify high-tness variants, with retrieved sequences lying in the top fraction of the training tness distribution. Fur- thermore, w e obser ve that dierent optimization strategies exhibit distinct behaviors depending on the dimensionality of the latent space, highlighting the importance of represen- tation design for eective search. Beyond its empirical p erformance, Q-BioLa t provides a natural bridge between protein representation learning and combinatorial optimization. By expressing protein tness landscapes as QUBO problems, our framework is directly Truong-Son Hy Figure 1. Over view of the Q-BioLa t framew ork. Protein se quences are rst encoded using a pretrained protein language model (ESM) to obtain continuous emb eddings. These emb eddings are transformed into binar y latent representations through projection and binarization, enabling protein tness to be mo deled as a quadratic unconstrained binar y optimization (QUBO) problem. The resulting latent tness landscap e can b e explored using combinatorial optimization methods and is directly compatible with quantum annealing hardware . Optimize d latent codes are mapped back to high-tness protein sequences. compatible with emerging quantum annealing hardware, of- fering a potential pathway towar d quantum-assisted protein engineering. While our experiments fo cus on classical op- timization metho ds, the proposed formulation opens new directions for integrating quantum optimization te chniques with modern protein language models. In summary , this work demonstrates that binary latent representations can transform protein tness pr e diction into a structured combinatorial optimization problem, enabling new opportunities for ecient sear ch and future integration with quantum computing paradigms. 2 Related W ork Protein language models and sequence representations. Recent advances in protein language models (PLMs) have signicantly improved the representation of biological se- quences by leveraging large-scale unlabeled protein data. Models such as ESM-2 [ 4 ] and its successor ESM-3 [ 5 ] learn contextual embeddings that capture structural and func- tional properties of proteins directly from sequence data. More recently , multimodal protein language models have been developed to integrate sequence information with ad- ditional modalities such as structure, function, and evolu- tionary context, further enhancing representation quality and downstream performance [ 17 , 18 ]. These models have demonstrated strong performance across a wide range of tasks, including structure prediction, mutation eect predic- tion, and protein design [ 19 , 20 ]. In this work, we build upon PLM embeddings as a foundation, but transform them into binary latent r epresentations to enable discrete optimization. Protein tness prediction and engineering. Predicting protein tness landscapes is a fundamental problem in com- putational biology , with applications in enzyme optimization, therapeutic design, and synthetic biology . Recent approaches combine machine learning models with experimental data, particularly from de ep mutational scanning (DMS) exper- iments, to predict the eects of mutations [ 21 , 22 ]. Large- scale benchmarks such as Pr oteinGym have b een introduced to systematically evaluate tness pr ediction mo dels across diverse proteins and mutation regimes [ 3 ]. While these meth- ods achieve strong predictive p erformance, they typically rely on continuous repr esentations and do not directly ad- dress the combinatorial nature of sequence optimization. Furthermore, these approaches primarily fo cus on predic- tion rather than explicitly enabling structured optimization over discrete sequence spaces. Optimization methods for protein design. A variety of optimization strategies have b een applie d to protein engi- neering, including evolutionary algorithms [ 9 – 11 , 13 ], Bayesian optimization [ 12 , 13 ], and reinforcement learning [ 23 , 24 ]. Evolutionary methods such as genetic algorithms are widely used due to their ability to explore large discrete search spaces, while Bayesian optimization oers sample-ecient search under expensive evaluation settings. Classical opti- mization techniques such as simulated annealing have also been applie d to combinatorial problems with rugged energy landscapes [ 25 , 26 ]. Howev er , many of these approaches op- erate directly in sequence space or continuous emb edding spaces, rather than explicitly modeling pr otein tness as a structured combinatorial optimization problem. In contrast, our approach explicitly models protein tness as a structured combinatorial optimization problem in a learned binary la- tent space. QUBO formulations and quantum annealing. Quadratic unconstrained binar y optimization (QUBO) [ 14 – 16 ] provides a unied framework for e xpressing a wide range of combi- natorial problems in terms of binary variables and pair wise interactions. QUBO formulations are closely r elated to the Ising model and form the basis of many optimization tech- niques, including quantum annealing [ 15 ]. Quantum anneal- ing hardware , such as that developed by D- W ave Systems, Binary Latent Protein Fitness Landscapes for antum Annealing Optimization has demonstrated the ability to solve certain classes of opti- mization problems by e xploiting quantum eects [ 27 ]. While applications of quantum optimization in computational bi- ology remain limited, recent work has begun to explore its potential for tasks such as molecular design and protein fold- ing. In this work, we formulate protein tness landscapes as QUBO problems in a binar y latent space, enabling di- rect compatibility with both classical combinatorial solvers and emerging quantum annealing hardware , and providing a unie d persp ective on protein design as discrete energy landscape optimization. Latent space optimization and discrete representations. Optimizing in learned latent spaces has become a common strategy in machine learning, particularly for generativ e modeling and design tasks [ 28 , 29 ]. Continuous latent spaces have been widely used for molecule and protein generation [ 9 , 30 , 31 ], but they often require gradient-base d optimization or sampling methods that do not naturally handle discr ete constraints. More recently , discrete and binar y latent repre- sentations have b een explored for enabling combinatorial search and ecient optimization [ 32 , 33 ]. Our work builds on this idea by constructing binary latent representations de- rived from protein language models and explicitly modeling the resulting tness landscape as a QUBO problem, bridging representation learning and combinatorial optimization. 3 Method 3.1 Overview W e propose Q-BioLa t , a framework for mo deling and op- timizing protein tness landscapes in a binary latent space. Given a protein se quence, Q-BioLa t rst computes a pre- trained protein language model embedding, then transforms this continuous representation into a compact binary latent code. In this binar y space, the tness landscape is approx- imated by a quadratic unconstrained binar y optimization (QUBO) surr ogate, which models both unar y and pairwise eects among latent variables. The learned surr ogate is then optimized using combinatorial search methods such as sim- ulated annealing and genetic algorithms. Because the nal objective is expressed in QUBO form, the framework is nat- urally compatible with both classical combinatorial solvers and quantum annealing hardware . Formally , the overall pipeline is 𝑠 → 𝑒 ( 𝑠 ) ∈ R 𝑑 → 𝑧 ( 𝑠 ) ∈ R 𝑚 → 𝑥 ( 𝑠 ) ∈ { 0 , 1 } 𝑚 → ˆ 𝑓 ( 𝑥 ) , where 𝑠 is a protein sequence, 𝑒 ( 𝑠 ) is the protein language model embe dding, 𝑧 ( 𝑠 ) is a reduced continuous latent repre- sentation, 𝑥 ( 𝑠 ) is the binarized latent code, and ˆ 𝑓 ( 𝑥 ) is the QUBO surrogate of protein tness. 3.2 Problem Setup Let D = { ( 𝑠 𝑖 , 𝑦 𝑖 ) } 𝑁 𝑖 = 1 denote a protein tness dataset, where 𝑠 𝑖 is a protein sequence and 𝑦 𝑖 ∈ R is its experimentally measured tness. Our goal is to learn a surr ogate model that maps each sequence to a compact binary latent represen- tation and predicts its tness, while also enabling ecient combinatorial optimization over the latent space. Unlike conventional approaches that optimize directly in sequence space or in continuous embedding space, we aim to transform protein tness prediction into a discrete optimiza- tion problem. This is motivated by two obser vations: rst, protein sequences are inherently discrete objects; se cond, binary latent spaces admit ecient combinatorial search and can be directly mapped to QUBO and Ising formulations. 3.3 Protein Language Model Embeddings For each protein sequence 𝑠 𝑖 , we obtain a continuous em- bedding using a pretrained protein language model. In our experiments, we use ESM-based sequence embeddings [ 4 , 5 ] due to their strong empirical p erformance and broad adop- tion in protein representation learning. Giv en a se quence 𝑠 𝑖 of length 𝐿 𝑖 , the language model produces contextualized residue-level r epresentations 𝐻 𝑖 ∈ R 𝐿 𝑖 × 𝑑 , where 𝑑 is the hidden dimension of the model. T o obtain a xed-length sequence representation, we apply mean pool- ing across residues: 𝑒 𝑖 = 1 𝐿 𝑖 𝐿 𝑖 𝑗 = 1 𝐻 ( 𝑗 ) 𝑖 ∈ R 𝑑 . This yields one dense embedding vector per se quence. The role of the pr otein language model in Q-BioLa t is not to directly predict tness, but rather to provide a biologically informed continuous representation that can later b e com- pressed into a discrete latent code suitable for combinatorial optimization. 3.4 Continuous-to-Binary Latent Mapping Dimensionality reduction. The dense embedding 𝑒 𝑖 ∈ R 𝑑 is rst mapped into a lower-dimensional latent space of dimension 𝑚 ≪ 𝑑 . W e consider two strategies in our experiments: • Random projection: 𝑧 𝑖 = 𝑊 𝑒 𝑖 , 𝑊 ∈ R 𝑚 × 𝑑 , where 𝑊 is sampled from a random Gaussian distri- bution with variance scaled by 1 / 𝑑 . • Principal comp onent analysis (PCA): the top 𝑚 principal dir e ctions are tted on the embedding matrix and used to obtain 𝑧 𝑖 = PCA ( 𝑒 𝑖 ) ∈ R 𝑚 . Truong-Son Hy The purpose of this step is twofold: to compr ess the repre- sentation and to control the size of the do wnstream QUBO model, whose parameter count scales quadratically with the latent dimension. Binarization. The reduced continuous latent vector 𝑧 𝑖 ∈ R 𝑚 is then transformed into a binary co de 𝑥 𝑖 ∈ { 0 , 1 } 𝑚 . In our main experiments, we use median-threshold binariza- tion: 𝑥 𝑖𝑘 = I 𝑧 𝑖𝑘 > 𝜏 𝑘 , where 𝜏 𝑘 is the me dian of the 𝑘 -th latent comp onent com- puted over the training set, and I ( ·) is the indicator function. This choice yields approximately balanced binary activations across dimensions and avoids degenerate codes with highly imbalanced bit frequencies. The resulting binary representation denes a discrete la- tent space in which each sequence corresponds to a v ertex of the Boolean hypercube. 3.5 QUBO Surrogate for Protein Fitness W e model protein tness in binary latent space with a QUBO surrogate. Given a binar y latent co de 𝑥 ∈ { 0 , 1 } 𝑚 , the pre- dicted tness is: ˆ 𝑓 ( 𝑥 ) = 𝑚 𝑘 = 1 ℎ 𝑘 𝑥 𝑘 + 1 ≤ 𝑘 < ℓ ≤ 𝑚 𝐽 𝑘 ℓ 𝑥 𝑘 𝑥 ℓ , where ℎ 𝑘 ∈ R captures the unar y contribution of latent bit 𝑘 , and 𝐽 𝑘 ℓ ∈ R captures the pairwise interaction between bits 𝑘 and ℓ . Equivalently , the model can be written in matrix form as: ˆ 𝑓 ( 𝑥 ) = ℎ ⊤ 𝑥 + 1 2 𝑥 ⊤ 𝐽 𝑥 , where 𝐽 ∈ R 𝑚 × 𝑚 is the symmetric Hamiltonian (i.e. pairwise interaction matrix) with zero diagonal, and ℎ ∈ R 𝑚 corre- sponds to the bias term. This representation connects the latent tness model to the classical QUBO formulation. Feature construction. For each binary code 𝑥 𝑖 , we con- struct a feature vector consisting of: • all linear terms { 𝑥 𝑖𝑘 } 𝑚 𝑘 = 1 , • all pairwise interaction terms { 𝑥 𝑖𝑘 𝑥 𝑖 ℓ } 1 ≤ 𝑘 < ℓ ≤ 𝑚 . The total number of features is therefore 𝑚 + 𝑚 ( 𝑚 − 1 ) 2 . Parameter estimation. W e t the QUBO surrogate using ridge regression. Let Φ ( 𝑋 ) denote the design matrix formed by the linear and pairwise features of the training binar y codes, and let 𝑦 denote the corresponding tness vector . W e solve 𝑤 ★ = arg min 𝑤 ∥ Φ ( 𝑋 ) 𝑤 − 𝑦 ∥ 2 2 + 𝜆 ∥ 𝑤 ∥ 2 2 , where 𝜆 > 0 is an ℓ 2 regularization coecient. The learned parameter vector 𝑤 ★ is then unpacked into the unar y coe- cients ℎ and pairwise coecients 𝐽 . This surrogate is attractive for three reasons. First, it is interpretable, since each term corresponds to a unary or pairwise latent ee ct. Second, it is computationally ecient to t and evaluate for moderate latent dimensions. Third, it directly yields a QUBO obje ctive suitable for classical and quantum combinatorial optimization. 3.6 Latent Space Optimization Once the QUBO surrogate has be en tted, we seek binar y latent codes that maximize the predicted tness: 𝑥 ★ = arg max 𝑥 ∈ { 0 , 1 } 𝑚 ˆ 𝑓 ( 𝑥 ) . Because this is a discrete combinatorial problem, we employ search strategies that operate directly in the binar y latent space. Simulated annealing [ 25 ]. Simulate d annealing starts from an initial latent code and iteratively proposes single-bit ips. Moves that impr ove the objective are accepted, while worse mov es may be accepted with a temperature-dependent probability , enabling escape from local optima. The temper- ature is gradually reduced during the search. Genetic algorithm [ 26 ]. The genetic algorithm main- tains a population of binary latent codes and evolves them through selection, crossov er , and mutation. This allows broader exploration of the latent space and is particularly useful in higher-dimensional settings where multiple promising re- gions may exist. Baselines. T o contextualize performance, we also com- pare against greedy hill climbing, random search, and a light- weight latent Bayesian-style search baseline. Greedy hill climbing iteratively ips the single bit that most impr oves the objective until convergence. Random search samples bi- nary codes uniformly and retains the best candidate. The latent Bay esian-style method uses a kernel-based uncertainty heuristic over binary latent codes. 3.7 Retrieval-Based Decoding of Optimized Latents A practical challenge in binar y latent optimization is how to map an optimized latent code back to a protein sequence. In this work, we adopt a retrieval-based decoding strategy rather than training a generative deco der . Given an opti- mized latent code 𝑥 ★ , we retriev e its nearest obser ved train- ing sequences under Hamming distance: 𝑑 𝐻 ( 𝑥 ★ , 𝑥 𝑖 ) = 𝑚 𝑘 = 1 | 𝑥 ★ 𝑘 − 𝑥 𝑖𝑘 | . The retrieved near est neighbors ser ve as real sequences asso- ciated with the optimized region of latent space. This strategy provides a conservative and interpretable way to evaluate Binary Latent Protein Fitness Landscapes for antum Annealing Optimization whether the optimization procedure ste ers search toward high-tness regions of the observed sequence manifold. W e emphasize that retrieval-based decoding is intention- ally simple and avoids introducing an additional generative model. Its role in this paper is to provide a rst practical proxy for mapping optimize d latent solutions back to real protein sequences. 3.8 Quantum Annealing Compatibility An important property of Q-BioLa t is that its optimization objective is already expressed in QUBO form. This means the learned latent tness landscape can be optimized not only with classical combinatorial solvers, but also with quantum annealing hardware or other Ising/QUBO solvers without changing the model formulation. In this sense, Q-BioLa t provides a quantum-compatible interface between protein representation learning and discrete optimization. In the present work, we focus on classical solvers to es- tablish the feasibility of the framework and to analyze the optimization behavior in binary latent space. Nevertheless, the QUBO formulation opens a clear pathway toward future quantum-assisted protein engineering, where learned latent tness landscapes could be deployed on quantum annealers or related specialized optimization hardware. 3.9 Computational Complexity Let 𝑚 denote the binary latent dimension. The QUBO surro- gate uses 𝑚 + 𝑚 ( 𝑚 − 1 ) 2 = O ( 𝑚 2 ) features. Therefore, increasing latent dimensionality increases expressive pow er but also increases both the numb er of sur- rogate parameters and the diculty of combinatorial search. This trade-o motivates our experimental study over multi- ple latent dimensions. By separating the dense pr otein language model emb ed- ding stage from the binar y optimization stage, Q-BioLa t keeps the most expensive neural computation xe d while enabling fast repeated optimization in the compact binary latent space. This makes the framework computationally attractive for studying representation–optimization trade- os. 4 Experiments 4.1 Dataset W e evaluate Q-BioLa t on protein tness prediction tasks using data from the ProteinGym benchmark [ 3 ], which ag- gregates large-scale deep mutational scanning (DMS) ex- periments across diverse proteins. In our experiments, we focus on the GFP (green uorescent protein) dataset, which contains experimentally measured tness values for a large number of sequence variants. T o study the eect of dataset size, we construct subsets of size { 1000 , 2000 , 5000 , 10000 } by random sampling with a xed seed. Each dataset is split into training and test sets using an 80/20 split. All r ep orted results are av eraged over multiple random seeds (i.e. 5) unless otherwise sp ecied. 4.2 Experimental Setup Protein representations. W e obtain protein embeddings using a pretrained protein language model (ESM-2) [ 4 ]. For each sequence, we compute a xed-length representation via mean pooling over residue-level embeddings. Latent representation. W e project emb eddings into a lower-dimensional latent space with dimension 𝑚 ∈ { 8 , 16 , 32 , 64 } using either random projection or principal component anal- ysis (PCA). The r esulting continuous vectors are binarized using median thresholding to produce binary latent codes. QUBO surrogate. W e t a quadratic surrogate model over binary latent co des using ridge regression. The surrogate includes both linear terms and pairwise interactions, corre- sponding to a QUBO formulation. Optimization methods. W e compare the following opti- mization strategies: • Simulated annealing (SA) • Genetic algorithm ( GA) • Gr e edy hill climbing • Random sear ch • Latent Bay esian-style search (BO) Evaluation metrics. W e evaluate performance using: • Spearman correlation : measures ranking accuracy of the surrogate. • Surrogate improvement : increase in pr e dicted t- ness relative to the starting point. • Nearest-neighbor true tness : tness of the closest observed sequence to the optimize d latent code. • Nearest-neighbor percentile : percentile rank of the retrieved sequence within the training set. 4.3 Surrogate Prediction Performance Unless otherwise spe cied, surrogate prediction results ar e reported from a single run, while optimization results are averaged over multiple random seeds. W e rst evaluate the pr e dictive performance of the QUBO surrogate across dierent dataset sizes and latent dimen- sions (see T able 1). W e obser ve that increasing dataset size improves surr ogate performance, while moderate latent di- mensions (e .g., 𝑚 = 16 or 𝑚 = 32 ) provide the b est balance between expressivity and generalization. V er y high latent dimensions (e .g., 𝑚 = 64 ) can lead to o vertting due to the quadratic growth in model parameters. Truong-Son Hy Samples Dim=8 Dim=16 Dim=32 Dim=64 1000 0.175 0.291 0.168 0.196 2000 0.168 0.257 0.235 0.225 5000 0.236 0.287 0.338 0.332 10000 0.209 0.302 0.385 0.413 T able 1. T est Spearman correlation of the QUBO surrogate across dataset sizes and latent dimensions. Best-performing latent dimension for each dataset size is highlighted in b old. 4.4 Optimization Performance W e next evaluate the ability of dierent optimization meth- ods to identify high-tness regions in the latent space. Re- sults are averaged over multiple random seeds (see T able 2). W e nd that all optimization methods are able to improve surrogate scores, but their eectiveness in identifying high- tness sequences varies. In particular , simulated annealing and genetic algorithms achieve strong improv ements in the surrogate objective, while random search remains compet- itive due to the relatively low dimensionality of the latent space. Greedy hill climbing tends to preserve pro ximity to the training data manifold, which can result in higher true tness in some cases. 4.5 Eect of Latent Dimension T o understand the role of representation dimensionality , we analyze optimization performance as a function of latent dimension (see Figure 2). W e observe that low-dimensional latent spaces are easier to optimize but may limit expr essivity , while higher-dimensional spaces provide richer repr esenta- tions but lead to more challenging optimization landscapes. In particular , we nd that 𝑚 = 16 and 𝑚 = 32 oer a goo d trade-o between representation quality and optimization stability . 4.6 Representation Comparison W e compare random projection and PCA-based methods for constructing binary latent representations. The r esults are summarized in T able 3. While both metho ds achieve nearly identical predictive performance in terms of Spearman correlation, we observe a consistent dierence in optimization behavior . In particular , PCA -based representations yield improved near est-neighb or true tness and higher percentile rankings of retrieved se- quences, indicating more stable and eective search in latent space. This result highlights an important distinction between predictive accuracy and optimization performance. Although random projection and PCA produce similar surrogate mo d- els, the geometric structure of the latent space diers sub- stantially between the two repr esentations. PCA preserves dominant directions of variance in the embedding space, which appear to b etter align with biologically meaningful variations and thus provide smoother tness landscapes for combinatorial search. In contrast, random projection intro- duces more isotropic mixing of features, which can degrade the alignment between latent directions and tness-relevant variations. These ndings suggest that the quality of latent represen- tations should be evaluated not only in terms of predictive metrics such as Spearman correlation, but also in terms of their induced optimization landscapes. In the context of Q- BioLa t , r epresentation geometry plays a critical role in deter- mining the eectiveness of combinatorial optimization, even when surrogate prediction performance remains unchanged. 4.7 Discussion of Optimization Behavior Across experiments, we observe that surrogate improvement does not always directly correlate with true tness gains. This highlights a key challenge in latent space optimization: the surrogate landscap e may contain regions that are fa- vorable under the model but less aligne d with true tness. Methods that constrain search near the training manifold, such as greedy hill climbing, can sometimes achieve higher true tness despite smaller surrogate improvements. Overall, these results demonstrate that Q-BioLat provides a viable framework for exploring protein tness landscap es in bi- nary latent space, while also revealing important trade-os between representation quality , mo del complexity , and opti- mization strategy . 5 Conclusion W e introduced Q-BioLa t , a framework for modeling and optimizing protein tness landscapes in binary latent spaces. By transforming protein language model embeddings into compact binary representations and tting a QUBO surro- gate, Q-BioLa t enables protein tness optimization to be formulated as a structured combinatorial problem. This for- mulation allows the use of classical optimization methods such as simulated annealing and genetic algorithms, while remaining directly compatible with emerging quantum an- nealing hardware . Through experiments on the ProteinGym GFP benchmark, we demonstrate d that Q-BioLa t can identify high-tness regions of the sequence space, with optimized latent codes retrieving sequences near the top of the obser ved tness distribution. Our results further rev eal imp ortant trade-os between latent dimensionality , surr ogate generalization, and optimization stability , as well as a key distinction between predictive accuracy and optimization eectiveness. In partic- ular , we showed that representation geometry signicantly impacts optimization performance, even when surrogate prediction metrics remain similar . Overall, this work highlights the potential of binary latent representations for bridging protein representation learn- ing and combinatorial optimization. By e xpressing protein Binary Latent Protein Fitness Landscapes for antum Annealing Optimization Method Improvement NN True Fitness NN Percentile Simulated Annealing 1.529 ± 0.239 3.675 ± 0.192 84.65 ± 16.93 Genetic Algorithm 1.529 ± 0.239 3.675 ± 0.192 84.65 ± 16.93 Random Search 1.448 ± 0.276 3.602 ± 0.233 77.45 ± 19.95 Greedy Hill Climb 1.127 ± 0.510 3.723 ± 0.084 88.21 ± 8.68 Latent BO -0.104 ± 0.523 3.216 ± 0.746 64.93 ± 21.54 T able 2. Multi-se ed optimization results on the GFP b enchmark using Q-BioLat with PCA-based binary latent representations (10,000 samples, 16 latent bits). Improvement denotes surrogate scor e gain relative to the starting point. NN True Fitness and NN Percentile are compute d from the near est retrieved training sequence to the optimized latent code. Best values in each column are highlighted in bold. 8 16 32 64 Latent dimension 1.5 2.0 2.5 3.0 3.5 S A near est-neighbor true fitness Effect of latent dimension on optimization perfor mance 1000 samples 2000 samples 5000 samples 10000 samples (a) Optimization performance (SA NN true tness) 8 16 32 64 Latent dimension 0.20 0.25 0.30 0.35 0.40 T est Spear man Effect of latent dimension on sur r ogate perfor mance 1000 samples 2000 samples 5000 samples 10000 samples (b) Surrogate performance (test Spearman) Figure 2. Eect of latent dimension on optimization and surrogate performance on the GFP benchmark. Each curve corresponds to a dierent dataset size. Moderate latent dimensions (e .g., 16–32) provide a favorable trade-o between predictive accuracy and optimization stability . Representation Spearman NN True Fitness NN Percentile Random Projection 0.302 3.622 ± 0.123 74.76 ± 13.35 PCA Projection 0.302 3.675 ± 0.192 84.65 ± 16.93 T able 3. Comparison of latent representation metho ds on the GFP benchmark (10,000 samples, 16 latent bits). Although both methods achieve similar Spearman correlation, PCA yields improved optimization performance, highlighting the role of representation geometry in guiding combinatorial search. tness landscapes as QUBO problems, Q-BioLa t opens a new direction toward quantum-compatible protein engine er- ing. Future work includes developing learned binary rep- resentations, improving surrogate models b eyond pairwise interactions, and exploring integration with quantum anneal- ing hardware to enable scalable, quantum-assisted protein design. References [1] Philip A Romero and Frances H Arnold. Exploring protein tness landscapes by directed evolution. Nature reviews Molecular cell biology , 10(12):866–876, 2009. [2] Lin Chen, Zehong Zhang, Zhenghao Li, Rui Li, Ruifeng Huo, Lifan Chen, Dingyan W ang, Xiaomin Luo, Kaixian Chen, Cangsong Liao, and Mingyue Zheng. Learning protein tness landscapes with deep mutational scanning data from multiple sources. Cell Systems , 14(8): 706–721.e5, 2023. ISSN 2405-4712. doi: https://doi.org/10.1016/j.cels. 2023.07.003. URL hps://w ww .sciencedirect.com/science/article/pii/ S2405471223002107 . [3] Pascal Notin, Aaron Kollasch, Daniel Ritter , Lood van Niekerk, Stef- fanie Paul, Han Spinner , Nathan Rollins, Ada Shaw , Rose Orenbuch, Ruben W eitzman, Jonathan Frazer , Mafalda Dias, Dinko Franceschi, Y arin Gal, and Debora Marks. Proteingym: Large-scale benchmarks for protein tness prediction and design. In A. Oh, T . Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 64331–64379. Curran Associates, Inc., 2023. URL hps://proceedings.neurips. cc/paper_files/paper/2023/file/cac723e529f65e3fcbb0739ae91bee- Paper- Datasets_and_Benchmarks.p df . [4] Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, W ent- ing Lu, Nikita Smetanin, Robert V erkuil, Ori Kabeli, Y aniv Shmueli, Truong-Son Hy Allan dos Santos Costa, Maryam Fazel-Zarandi, T om Sercu, Sal- vatore Candido, and Alexander Rives. Evolutionary-scale predic- tion of atomic-level protein structure with a language model. Sci- ence , 379(6637):1123–1130, 2023. doi: 10.1126/science.ade2574. URL hps://www.science .org/doi/abs/10.1126/science.ade2574 . [5] Thomas Hayes, Roshan Rao, Halil Akin, Nicholas J. Sofroniew , Deniz Oktay , Zeming Lin, Robert V erkuil, Vincent Q. T ran, Jonathan Deaton, Marius Wiggert, Rohil Badkundri, Irhum Shaf kat, Jun Gong, Alexander Derry , Raul S. Molina, Neil Thomas, Y ousuf A. Khan, Chetan Mishra, Carolyn Kim, Liam J. Bartie , Matthew Nemeth, Patrick D. Hsu, T om Sercu, Salvatore Candido, and Alexander Rives. Simulating 500 million years of evolution with a language model. Science , 387(6736):850–858, 2025. doi: 10.1126/science.ads0018. URL hps://w ww .science.org/doi/ abs/10.1126/science.ads0018 . [6] Céline Marquet, Julius Schlensok, Marina Abakarova, Burkhard Rost, and Elodie Laine. Expert-guided protein language models enable accurate and blazingly fast tness prediction. Bioinformatics , 40(11): btae621, 11 2024. ISSN 1367-4811. doi: 10.1093/bioinformatics/btae621. URL hps://doi.org/10.1093/bioinformatics/btae621 . [7] Dan Liu, Francesca Y oung, Kieran D Lamb, Adalberto Claudio Quiros, Alexandrina Pancheva, Crispin J Miller , Craig Macdonald, David L Robertson, and Ke Yuan. P lm-interact: extending protein language models to predict protein-protein interactions. Nature Communica- tions , 16(1):9012, 2025. [8] Joseph L W atson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, W oody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiusion. Nature , 620(7976):1089–1100, 2023. [9] Thanh V T T ran, Nhat Khang Ngo, Viet Thanh Duy Nguyen, and Truong-Son Hy . Latentde: latent-base d directed evolution for protein sequence design. Machine Learning: Science and T e chnology , 6(1): 015070, mar 2025. doi: 10.1088/2632- 2153/adc2e2. URL hps://doi.org/ 10.1088/2632- 2153/adc2e2 . [10] Thanh V . T . Tran and Truong Son Hy . Protein design by directed evolution guided by large language models. IEEE Transactions on Evolutionary Computation , 29(2):418–428, 2025. doi: 10.1109/TEVC. 2024.3439690. [11] Hiroki Ozawa, Ibuki Unno, Ryohei Sekine, T aichi Chisuga, Sohei Ito, and Shogo Nakano. Development of evolutionary algorithm- based protein redesign method. Cell Reports Physical Science , 5(1): 101758, 2024. ISSN 2666-3864. doi: https://doi.org/10.1016/j.xcrp. 2023.101758. URL hps://w ww .sciencedirect.com/science/article/pii/ S2666386423006033 . [12] Timothy Atkinson, Thomas D Barrett, Scott Cameron, Bora Guloglu, Matthew Greenig, Charlie B T an, Louis Robinson, Alex Graves, Liviu Copoiu, and Alexandre Laterre. Protein sequence modelling with bayesian ow networks. Nature Communications , 16(1):3197, 2025. [13] Ruyun Hu, Lihao Fu, Y ongcan Chen, Junyu Chen, Y u Qiao, and T ong Si. Protein engineering via bayesian optimization-guided ev olutionar y algorithm and robotic experiments. Briengs in Bioinformatics , 24(1): bbac570, 12 2022. ISSN 1477-4054. doi: 10.1093/bib/bbac570. URL hps://doi.org/10.1093/bib/bbac570 . [14] Gary Kochenberger , Jin-Kao Hao, Fred Glover , Mark Lewis, Zhipeng Lü, Haib o W ang, and Y ang W ang. The unconstrained binar y quadratic programming problem: a survey . Journal of combinatorial optimization , 28(1):58–81, 2014. [15] Andrew Lucas. Ising formulations of many np problems. Frontiers in Physics , V olume 2 - 2014, 2014. ISSN 2296-424X. doi: 10.3389/fphy .2014. 00005. URL hps://w ww .frontiersin.org/journals/physics/articles/10. 3389/fphy .2014.00005 . [16] Seongmin Kim, Sang- W oo Ahn, In-Saeng Suh, Alexander W Dowling, Eungkyu Lee, and T engfei Luo. Quantum annealing for combinatorial optimization: a benchmarking study . npj Quantum Information , 11(1): 77, 2025. [17] Viet Thanh Duy Nguyen and T ruong Son Hy . Multimodal pretrain- ing for unsupervised protein representation learning. Biology Meth- ods and Protocols , 9(1):bpae043, 06 2024. ISSN 2396-8923. doi: 10. 1093/biomethods/bpae043. URL hps://doi.org/10.1093/biometho ds/ bpae043 . [18] Nhat Khang Ngo and Truong Son Hy . Multimo dal protein repre- sentation learning and target-aware variational auto-encoders for protein-binding ligand generation. Machine Learning: Science and T echnology , 5(2):025021, apr 2024. doi: 10.1088/2632- 2153/ad3e e4. URL hps://doi.org/10.1088/2632- 2153/ad3ee4 . [19] Alexander Rives, Joshua Meier , T om Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proceedings of the National Academy of Sciences , 118(15):e2016239118, 2021. doi: 10.1073/pnas.2016239118. URL hps://ww w .pnas.org/doi/abs/10.1073/ pnas.2016239118 . [20] Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, W ent- ing Lu, Nikita Smetanin, Robert V erkuil, Ori Kabeli, Y aniv Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structur e with a language model. Science , 379(6637):1123–1130, 2023. [21] Kevin K Y ang, Zachary Wu, and Frances H Arnold. Machine-learning- guided directed evolution for pr otein engineering. Nature methods , 16 (8):687–694, 2019. [22] Surojit Biswas, Grigor y Khimulya, Ethan C Alley , Ke vin M Esvelt, and George M Church. Low-n protein engineering with data-ecient deep learning. Nature methods , 18(4):389–396, 2021. [23] Fanhao W ang, Tiantian Zhang, Jintao Zhu, Xiaoling Zhang, Chang- sheng Zhang, and Luhua Lai. Reinforcement learning-based target- specic de novo design of cyclic peptide binders. Journal of Medicinal Chemistry , 68(16):17287–17302, 2025. [24] Haoran Sun, Liang He, Pan Deng, Guoqing Liu, Zhiyu Zhao, Yuliang Jiang, Chuan Cao, Fusong Ju, Lijun Wu, Haiguang Liu, et al. Ac- celerating protein engineering with tness landscape modelling and reinforcement learning. Nature Machine Intelligence , 7(9):1446–1460, 2025. [25] Optimization by simulated annealing. science , 220(4598):671–680, 1983. [26] John H. Holland. Adaptation in Natural and A rticial Systems: An Introductory A nalysis with A pplications to Biology , Control, and Arti- cial Intelligence . The MI T Press, 04 1992. ISBN 9780262275552. doi: 10.7551/mitpress/1090.001.0001. URL hps://doi.org/10.7551/mitpress/ 1090.001.0001 . [27] Mark W . Johnson, Mohammad H. S. Amin, Gildert Suzanne, Trevor Lanting, Firas Hamze, Neil G. Dickson, Richard G. Harris, Andr ew J. Berkley , J. Johansson, Paul I. Bunyk, E. M. Chapple, Colin Enderud, Jeremy P. Hilton, Kamran K arimi, Eric Ladizinsky, Nicolas Ladizinsky , Travis Oh, I. G. Perminov , Chris Rich, Murray C. Thom, Elena T olka- cheva, C. J. S. Truncik, Sergey Uchaikin, J. W ang, Blake A. Wilson, and Geordie Rose. Quantum annealing with manufactured spins. Nature , 473:194–198, 2011. URL hps://api.semanticscholar .org/CorpusID: 205224761 . [28] André Hottung, Bhanu Bhandari, and Kevin Tierney . Learning a latent search space for routing problems using variational autoencoders. In International Conference on Learning Representations , 2021. URL hps://openreview .net/forum?id=90JprV rJBO . [29] Peter J. Bentley , Soo Ling Lim, Adam Gaier , and Linh Tran. Coil: Constrained optimization in learne d latent space: learning repre- sentations for valid solutions. In Proce edings of the Genetic and Evolutionary Computation Conference Companion , GECCO ’22, page 1870–1877, New Y ork, NY, USA, 2022. Association for Computing Machinery . ISBN 9781450392686. doi: 10.1145/3520304.3533993. URL hps://doi.org/10.1145/3520304.3533993 . [30] Dhruv Menon and Raghavan Ranganathan. A generative approach to materials discovery , design, and optimization. ACS Omega , 7(30): Binary Latent Protein Fitness Landscapes for antum Annealing Optimization 25958–25973, 2022. doi: 10.1021/acsomega.2c03264. URL hps://doi. org/10.1021/acsomega.2c03264 . [31] Truong Son Hy and Risi Kondor . Multiresolution equivariant graph variational autoencoder . Machine Learning: Science and T echnology , 4(1):015031, mar 2023. doi: 10.1088/2632- 2153/acc0d8. URL hps: //doi.org/10.1088/2632- 2153/acc0d8 . [32] Mingrui Jiang, Keyi Shan, Chengping He, and Can Li. Ecient com- binatorial optimization by quantum-inspired parallel annealing in analogue memristor crossbar . Nature Communications , 14(1):5927, 2023. [33] T etsuro Abe, Masashi Y amashita, and Shu Tanaka. Eectiveness of binary autoenco ders for qubo-based optimization problems. arXiv preprint arXiv:2602.10037 , 2026.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment