음성 생성 LALM의 뉴런 수준 감정 제어: ESN 기반 무학습 스티어링
본 논문은 대형 오디오‑언어 모델(LALM)에서 감정 변환(EVC)을 수행할 때, 감정 표현에 특화된 소수의 뉴런(Emotion‑Sensitive Neurons, ESN)을 자동으로 식별하고, 추론 단계에서 이 뉴런들을 조작함으로써 학습 없이도 목표 감정을 정확히 전달하면서 언어 내용은 유지하는 방법을 제시한다. Qwen2.5‑Omni‑7B, MiniCPM‑o 4.5, Kimi‑Audio 등 세 모델에 대해 ESN 기반 개입이 감정 일치율을 크…
저자: Xiutian Zhao, Ismail Rasim Ulgen, Philipp Koehn
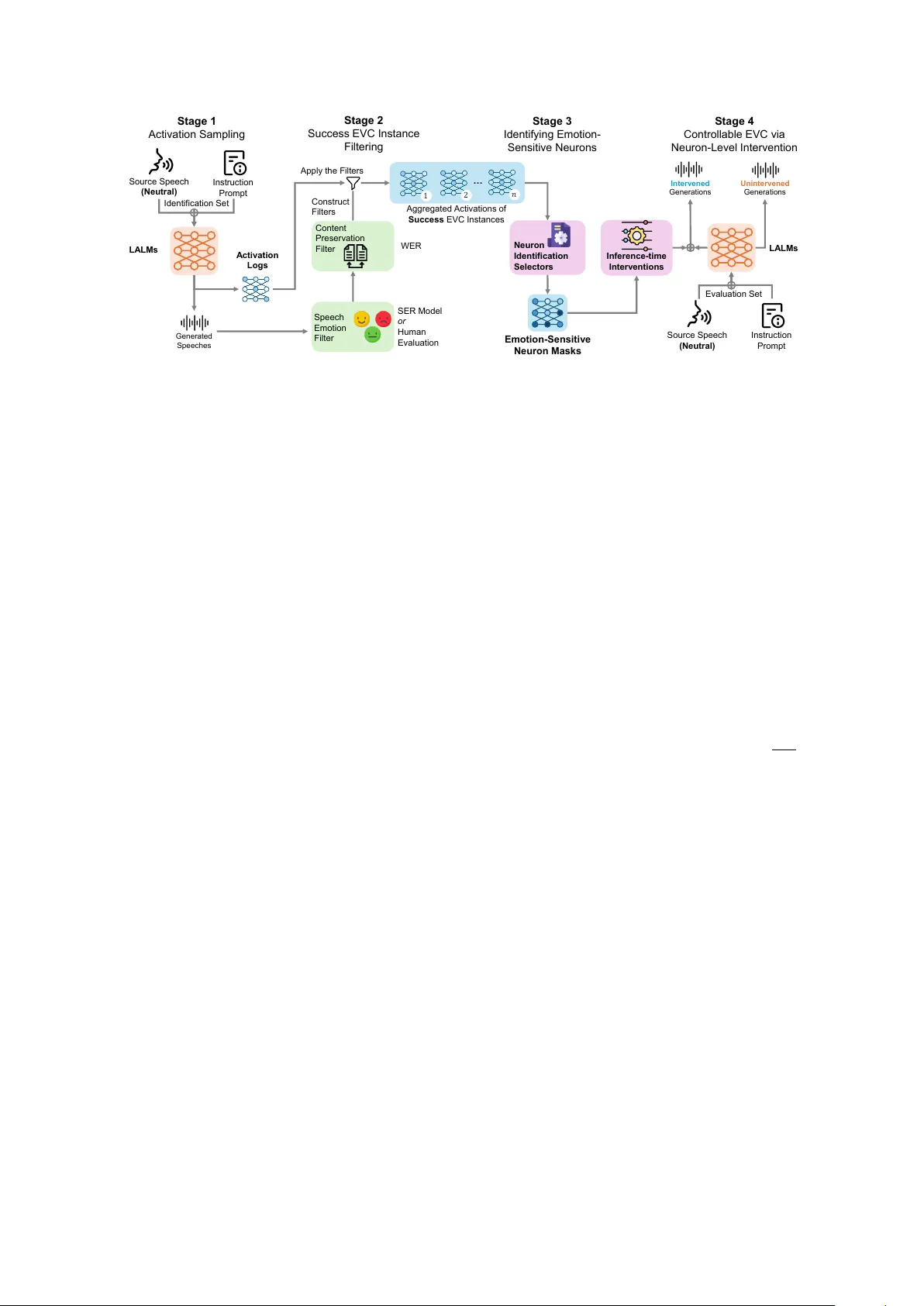
본 논문은 대형 오디오‑언어 모델(LALM)이 텍스트 지시를 받아 감정 변환(EVC)을 수행할 때, 감정 표현을 담당하는 소수의 뉴런, 즉 Emotion‑Sensitive Neurons(ESN)을 찾아내고 이를 활용해 학습 없이도 목표 감정을 정확히 전달하면서 언어 내용은 보존하는 새로운 프레임워크를 제안한다. 연구는 크게 네 단계 파이프라인으로 구성된다.
1️⃣ **활성화 샘플링**: LALM의 디코더 부분에 위치한 MLP 게이트(예: SwiGLU)를 후킹하여, 각 토큰 생성 단계에서 뉴런별 전활성값 aₗ,ₙ,ₜ을 기록한다. 이는 감정 제어와 관련된 신호를 포착하기 위한 고대역 위치이며, 언어 모델(LM) 쪽과 합성(synthesis) 쪽 두 영역 모두를 조사한다.
2️⃣ **성공 필터링**: 생성된 음성에 대해 두 축으로 필터링한다. (i) 감정 일치 여부는 사전 학습된 SER(감정 인식) 모델이 예측한 라벨 ˆe와 목표 감정 eₜ₉ₜ가 일치하는지 확인한다. (ii) 언어 내용 보존은 LALM이 자체적으로 출력한 텍스트와 원본 전사 간의 단어 오류율(WER)을 측정해, τ₍WER₎=0.15 이하인 경우만 성공 인스턴스로 인정한다. 이렇게 만든 성공 집합 Sₑ는 이후 활성화 통계에만 사용된다.
3️⃣ **활성화 집계 및 ESN 식별**: 성공 집합 Sₑ에 대해 각 뉴런의 활성화 확률 P(e)ₗ,ₙ = K(e)ₗ,ₙ / Tₑ를 계산한다. 여기서 K(e)ₗ,ₙ은 성공 인스턴스에서 양의 활성값을 보인 횟수, Tₑ는 전체 성공 토큰 수다. 네 가지 뉴런 선택 기준을 적용한다.
- **LAP**: 단순히 P(e)ₗ,ₙ이 높은 뉴런을 상위 Nₛₑₗ개 선택.
- **LAPE**: 감정별 확률을 정규화하고 엔트로피를 계산해, 낮은 엔트로피(즉, 감정 선택성이 높은) 뉴런을 후보로 삼은 뒤, 각 감정별 P(e)ₗ,ₙ 순위로 최종 선택.
- **MAD**: 각 뉴런의 평균 활성화 확률 ¯Pₗ,ₙ을 구하고, 목표 감정에 대해 |P(e)ₗ,ₙ − ¯Pₗ,ₙ|가 큰 뉴런을 선택.
- **CAS**: 가장 높은 감정 확률과 두 번째 높은 확률의 차이(마진) Δₗ,ₙ을 계산해, 목표 감정이 최고 확률을 차지하는 경우에만 Δₗ,ₙ이 큰 뉴런을 선택한다.
실험 결과, CAS와 MAD가 가장 높은 감정 선택성을 보이며, 특히 CAS는 목표 감정에 대한 강한 마진을 가진 뉴런을 집중적으로 추출한다. 마스크 희소도 r(선택 비율)도 중요한 변수로, r≈0.02~0.05에서 최적의 감정 제어와 내용 보존 균형을 달성한다.
4️⃣ **추론 시점 개입**: 식별된 ESN 마스크를 이용해 네 가지 개입 방식을 적용한다.
- **Steering**: 목표 감정 뉴런의 활성값을 일정 비율(λ)만큼 증폭한다.
- **Additive Injection**: 동일 뉴런에 고정값을 더한다.
- **Clamping**: 활성값을 사전 정의된 상·하한으로 제한한다.
- **Deactivation**: 뉴런을 0으로 강제한다.
Qwen2.5‑Omni‑7B, MiniCPM‑o 4.5, Kimi‑Audio 세 모델에 대해 λ을 0.5~3.0 범위에서 스위프 실험을 수행했으며, 중간 정도(λ≈1.5~2.0)에서 감정 일치율이 12~15 % 상승하면서 WER 악화는 미미했다. 과도한 λ은 음성 품질과 내용 보존을 크게 해치므로, 미세 조정이 필수적이다.
**위치 분석**: ESN은 주로 LM 쪽 디코더 MLP의 중후반 레이어에 집중돼 있었다. 반면, 합성 파이프라인(예: 음성 코덱, 포스트넷)의 MLP에서는 개입 효과가 거의 없었다. 이는 감정 정보가 텍스트‑음성 변환 초기에 결정되고, 이후 단계에서는 주로 음향 파라미터만 다루기 때문으로 해석된다.
**평가**: 자동 평가에서는 감정 정확도와 WER을 동시에 측정했으며, 인간 청취 실험에서는 쌍대 비교 방식으로 ESN 개입 샘플이 원본 대비 62 %의 비율로 선호되었다. 특히 ‘분노’↔‘중립’ 전환에서 가장 큰 효과가 관찰되었다. 또한, 식별에 사용된 성공 집합을 교차 검증했을 때, 동일 ESN 마스크가 새로운 화자와 텍스트에도 일반화됨을 확인했다.
**결론 및 기여**:
1. 감정 제어를 위한 뉴런 수준 메커니즘을 최초로 제시하고, 학습 없이 추론 단계에서 간단한 활성화 조작만으로 감정 스티어링이 가능함을 증명했다.
2. 네 가지 뉴런 선택 기준을 체계적으로 비교해, CAS와 MAD가 가장 효과적임을 밝혀냈다.
3. 마스크 희소도, 성공 집합 크기, 개입 강도 등 실용적인 하이퍼파라미터 가이드를 제공한다.
4. 감정 제어 신호가 LM 쪽 디코더에 집중된다는 위치적 통찰을 제공한다.
이 연구는 LALM 기반 음성 합성에서 감정 제어를 구현하려는 연구자와 실무자에게, 복잡한 재학습 없이도 간단하고 해석 가능한 방법으로 감정 스티어링을 적용할 수 있는 실용적인 로드맵을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기