Neuron-Level Emotion Control in Speech-Generative Large Audio-Language Models
Large audio-language models (LALMs) can produce expressive speech, yet reliable emotion control remains elusive: conversions often miss the target affect and may degrade linguistic fidelity through refusals, hallucinations, or paraphrase. We present,…
Authors: Xiutian Zhao, Ismail Rasim Ulgen, Philipp Koehn
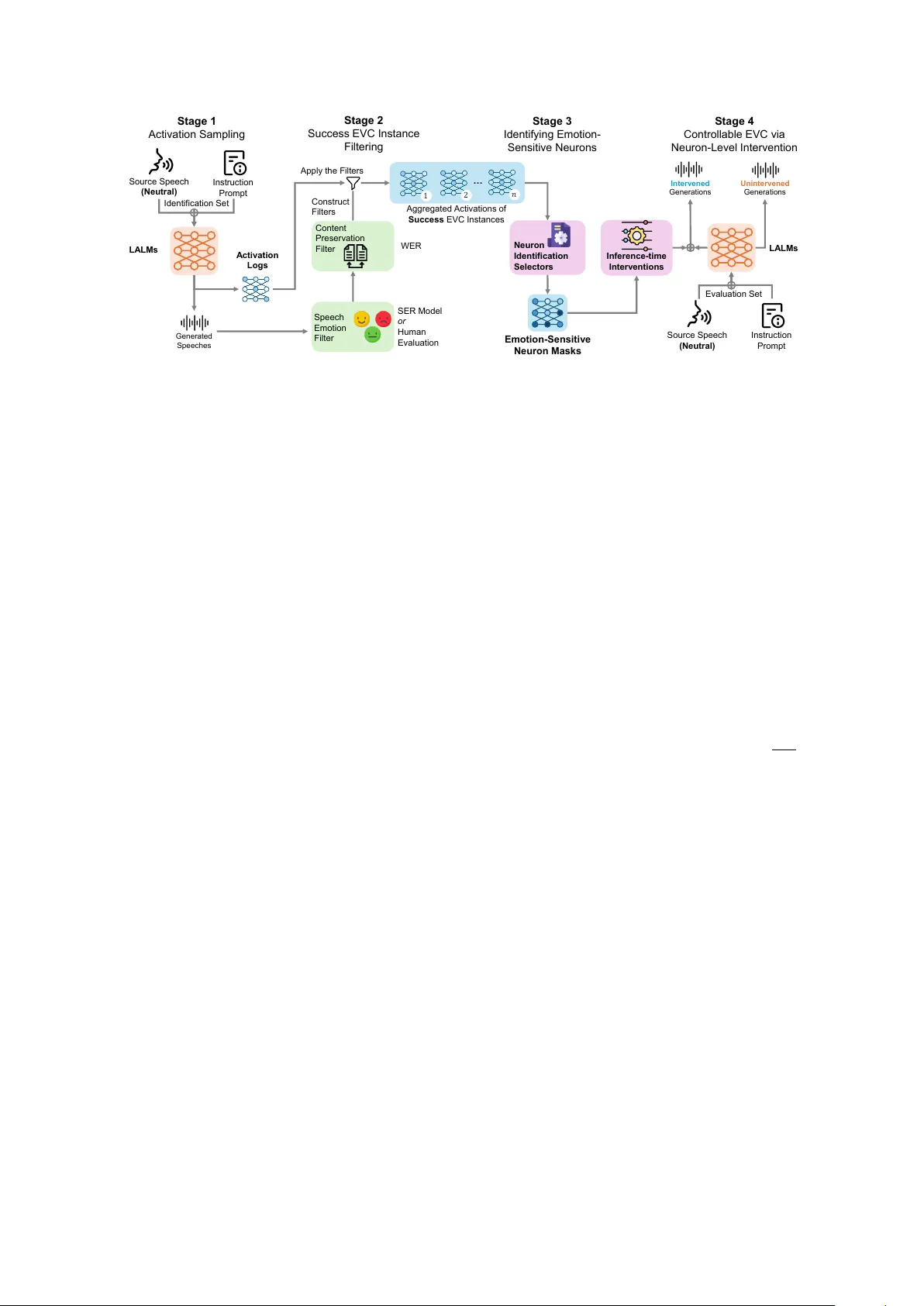
Neur on-Lev el Emotion Contr ol in Speech-Generativ e Large A udio-Language Models Xiutian Zhao ID 1 , Ismail Rasim Ulgen ID 1 , Philipp K oehn ID 1 , Björn Schuller ID 2 , Berrak Sisman ID 1 1 Center for Language and Speech Processing (CLSP), Johns Hopkins Uni versity , USA 2 Group on Language, Audio & Music (GLAM), Imperial College London, UK xzhao117@jhu.edu, sisman@jhu.edu Abstract Large audio-language models (LALMs) can produce ex- pressiv e speech, yet reliable emotion control remains elusive: con versions often miss the tar get affect and may de grade lin- guistic fidelity through refusals, hallucinations, or paraphrase. W e present, to our knowledge, the first neuron-level study of emotion control in speech-generati ve LALMs and demonstrate that compact emotion-sensitiv e neurons (ESNs) are causally ac- tionable, enabling training-free emotion steering at inference time. ESNs are identified via success-filtered activation aggre- gation enforcing both emotion realization and content preserv a- tion. Across three LALMs (Qwen2.5-Omni-7B, MiniCPM-o 4.5, Kimi-Audio), ESN interventions yield emotion-specific gains that generalize to unseen speakers and are supported by auto- matic and human e v aluation. Controllability depends on selector design, mask sparsity , filtering, and interv ention strength. Our re- sults establish a mechanistic frame work for training-free emotion control in speech generation. Index T erms : large audio-language models, speech, emotion, voice con version, neuron attrib ution 1. Introduction Emotion is a core dimension of spoken communication: be- yond lexical content, prosody , pitch, intensity , and speaking rate con vey af fect and shape percei ved intent and naturalness [1]. Recent large audio-language models (LALMs) that jointly pro- cess speech and text [2 – 5] enable expressi ve speech generation from natural-language instructions, supporting ne w workflows in con versational agents and speech editing. In practice, how- ev er, instruction-follo wing speech generation remains challeng- ing [6, 7], particularly for emotion control: the same prompt may produce unintended affect, and even when the tar get emotion is realized, linguistic fidelity can degrade. Content-preserv ation failures such as refusals, uncontrolled paraphrasing, and seman- tic hallucinations are well-documented in autoregressi ve lan- guage models [8]. Unlike conventional acoustic distortions, which reduce intelligibility but preserv e meaning, these failures alter the underlying message, as illustrated in Figure 1. Emotional voice con version (EVC) aims to modify the emo- tional style of a speech signal while preserving its linguistic con- tent [9 – 11]. Classical and neural approaches achie ve controllabil- ity by learning explicit style representations (e.g., reference en- coders or style tokens) [12, 13] or by modeling emotion strength as a continuous control variable [14, 15]. In large language model (LLM) research, training-fr ee control through activ ation manipulation has emer ged as an alternativ e to re-training [16]. In parallel, neuron-lev el interpretability studies show that indi vid- ual units can localize salient behaviors in deep networks [17 – 19] and can be exploited via tar geted interventions for controllable Gen e rati on s So urc e Spee ch Repeat the utteranc e w ord - for - w o rd ex ac tl y . Spea k w i th an A ng er emotion. Do not add or remov e any w ords. O utput s peec h onl y . Un interv e n e d Sp e e c h Em o ti o n : Ne u tr a l L ing u istic Co n ten t: The lad y b u g told the m p rou d ly . LA LM T ex tual In s truc tio n Input EVC Su c c e s s So urc e T ra nsc ri pt ( No t V isi ble to LA LMs ) T h e l a d y b u g told the m p rou d ly . M as k 1 M as k 2 M as k 3 Sp eech Emotion : Neut ral Sp e e c h Em o ti o n : A n g e r L ing u istic Co n ten t: The lad y b u g told the m p rou d ly . Sp e e c h Em o ti o n : A n g e r L ing u istic Co n ten t: The lady bu g told them an gri ly . Sp ee c h Emo ti on : Ne utr al L ing u istic Co n ten t : I' m so r ry , I c a n 't r e p e a t the au d io. Emo tio n - S ens itiv e Neuron Masks Figure 1: EVC with LALMs is inherently multi-objective: suc- cessful con version requir es both tar get-emotion r ealization and linguistic content pr eservation. behavior [16, 20]. Howe ver , for speech-generativ e LALMs, we lack a mechanistic account of whether neuron-le vel units are systematically in volved in emotional expressi veness during gen- eration, and whether compact neuron subsets can serve as a prac- tical control interface orthogonal to re-training or task-specific fine-tuning. This paper studies emotion controllability in LALMs from a neuron-le vel perspecti ve, focusing on instruction-following EVC. Our central hypothesis is that compact neuron subsets associated with emotional expression exist in speech-generati ve LALMs, and that intervening on these subsets can causally af- fect measured EVC outcomes. W e center the study around the following research questions: 1. Existence. Do ESNs exist in speech-generativ e LALMs, and does intervening on them causally affect EVC outcomes? If so, do these ef fects primarily alter emotional expressi veness or linguistic content? 2. Identification. Which neuron selection criteria most effec- tiv ely isolate ESNs for controllable EVC, and ho w do mask sparsity and identification data size influence results? 3. Inference-T ime Contr ollability . Ho w do intervention type and strength af fect emotion control and content preserv ation in EVC? 4. Localization. Where do ESNs concentrate across modules and across layers in LALMs, and what does this imply for controllable EVC? T o answer these questions, we adopt a four-stage activ ation- based pipeline: (1) activ ation sampling during EVC with hooks on decoder MLP gates; (2) filtering successful EVC in- stances for activation aggre gation; (3) ESN identification by various neuron ranking criteria: frequency-based, entropy-based, mean-deviation-based, and contrastiv e-margin-based; and (4) inference-time control via tar geted steering, additi ve injection, clamping, and deactiv ation, keeping model weights untouched. Howe ver , EVC’ s inherently multi-objectiv e nature makes isolating qualified con versions complex [9]. This motiv ates a multi-stage filtering and identification protocol (Figure 2) that aggregates acti vations only from outputs that achiev e both emo- tion realization and content preserv ation. W e later adapt the same two axes used for e valuating intervention ef fects. Using the Emotional Speech Dataset (ESD) [9], we evaluate three open speech-generati ve LALMs: Qwen2.5-Omni-7B [4], MiniCPM-o 4.5 [3], and Kimi-Audio [5]. Ev en without inter- vention, instruction-follo wing EVC prov es challenging: baseline emotion match rates are modest, tar get emotions v ary substan- tially in dif ficulty , and stronger af fect expression does not nec- essarily coincide with better content preserv ation. Despite this difficult baseline, neuron-le vel intervention produces consistent and interpretable ef fects. Compact ESN masks induce structured self–cross patterns rather than arbitrary degradation, indicating that they causally influence emotional rendering. Controllability first depends on the identification-time se- lection criteria. Our results show that the type of e vidence em- phasized by a selector directly impacts ESN effecti veness for emotion control. In particular, contrastiv e-margin- and mean- deviation-based selectors isolate substantially more ef fectiv e ESNs than frequency- or entropy-based ones. Masks that are too sparse fail to capture the distributed emotion signal, whereas ov erly large masks admit shared or generic generation features and reduce specificity . A similar trade-off holds for identifica- tion data: ESN estimates stabilize with a relativ ely small pool of qualified con versions, after which additional examples yield di- minishing returns and may increase cross-emotion interference. Intervention design then shapes inference-time controllabil- ity . In our Qwen2.5-Omni-7B strength sweep, moderate steering strengths yield the best observed balance between tar get-emotion gain and content preserv ation, whereas stronger interventions dramatically degrade linguistic fidelity , indicating that effecti ve EVC control depends on calibrated rather than brute-force manip- ulation. These gains are observed in both automatic e valuation and human listening, where intervened samples are preferred in 62% of pairwise comparisons on av erage, supporting that ESN-masked models generate more perceptible emotion shifts. Localization analyses further sho w that the most actionable ESNs concentrate in intermediate-to-late decoder MLP layers on the language-model side across all three LALMs, while analogous interventions in do wnstream synthesis MLPs are largely inert. This is consistent with the vie w that emotion-related control is more accessible on the LM side before acoustic rendering than in the late-stage synthesis modules we tested. Contributions. This paper provides, to our knowledge, one of the first systematic neuron-level analyses of emotion con- trol in speech-generativ e LALMs under an EVC setting. W e show that compact ESN masks are causally actionable, enabling training-free intervention that produces consistent tar get-emotion control beyond purely correlational analysis. W ithin a unified framew ork, we systematically compare ESN selectors, mask sparsity , success set size, and inference-time intervention de- signs, identifying contrastiv e-margin- and mean-de viation-based criteria as the most fav orable among the tested selectors for iso- lating actionable ESNs. W e further localize the most impactful emotion-control signals to intermediate-to-late decoder MLP lay- ers on the language-model side , while analogous interventions in the do wnstream synthesis stack are lar gely ineffecti ve. Finally , we sho w that these ef fects generalize be yond the identification split and are corroborated by human listening, establishing a practical and mechanistically grounded route to training-free emotion control in speech-generativ e LALMs. 2. Related W ork Affecti ve speech synthesis and con version aim to generate or transform speech while controlling paralinguistic affect, most prominently emotion [10]. In emotional speech synthesis, con- trollability is typically achie ved by learning e xplicit style or emo- tion representations and conditioning generation, such as via ref- erence encoders [12] or global style tokens [13], with subsequent extensions incorporating semi- or weak supervision [21 – 24]. Complementary work explores continuous af fect control, in- cluding emotion intensity prediction or transfer [14, 15, 25, 26], while recent approaches inv estigate token-level manipulation for expressi ve text-to-speech (TTS) [27]. EVC [9] further studies mapping between emotional states, including non-parallel adver- sarial and multi-domain frame works [28 – 31], dif fusion-based approaches [32], and representation-factorized models [33]. In parallel, neuron-le vel interpretability work that local- izes functional units in deep neural networks [17, 18, 34] has encouraged explorations on neuron/activ ation-lev el control in LLMs [16, 35 – 37], alongside emerging interests for LLM-centric multimodal models [38 – 41]. Among them, audio-language mod- els capable of speech understanding and generation [3 – 5] enable studying affecti ve control in instruction-following speech gen- eration settings. Recent studies report affecti ve circuits in te xt LLMs [42, 43], howe ver , there ha ve been very limited attempts to utilize emotion-related functional units in LALMs [20]. Unlike prior work, which primarily tar gets recognition, representation learning, or token-level manipulation, we probe the synthesis pathway in speech-generati ve LALMs by logging acti vations during EVC generation that yield successful con versions and applying training-free neuron-lev el interv entions to directly steer emotion expressi veness. 3. Methodology W e study emotion control in speech-generati ve LALMs through a neuron-level intervention framew ork tailored to instruction- following EVC. While acti vation-based interpretability and steer- ing methods hav e been explored in text and multimodal mod- els, applying them to speech generation is non-trivial. Unlike text classification probes, speech generation e xhibits two key challenges: (1) generation is harmed by diverse failure modes (hallucinated content, silence, refusals) that stem from language- model (LM) components; and (2) task success is inherently multi-objectiv e, requiring both emotional style transfer and lin- guistic content preservation. T o address these challenges, we design a four-stage pipeline that explicitly filters qualified EVC instances before activ ation aggregation (Figure 2). This struc- tured protocol enables more reliable identification of candidate emotion-sensitiv e neurons and interventional testing of their functional relev ance in speech-generative LALMs. 3.1. Activation Sampling For each source speech utterance x in the identification set, we instruct the LALM to perform EVC and generate audio y of the target emotion e tgt . The instruction prompt is fixed across conditions, and we record activ ations during the forward passes of the modules that mediate generation. Hooking Position. W e instrument the decoder-side feed- forward blocks (MLPs) because they offer a stable, high- bandwidth location for neuron-le vel interv entions [16, 17]. Many Stage 1 Activ ation S ampling Stage 2 Succ es s EV C Instanc e Filt er ing Stage 4 Co ntrollable EV C vi a Ne ur on - Le vel Int er vent ion LA LMs Spee c h Em oti on Fil ter Em oti on - Sensitiv e Ne uron Mas ks A cti v a ti on Lo gs Generate d Speeches Aggreg ate d Ac ti v ation s of Success EV C Ins tanc es … 1 2 𝑛 Neuron Iden tif ication Sele cto rs Sourc e Sp eec h (Neu tral) Ins tructi on Prompt Stage 3 Ident if y ing E mot ion - Sensitiv e Neur ons SER Model or Human Ev al uati on Content Preservati on Fil ter Appl y the Fil ter s W E R Cons truct Fil ters LA LMs Un i nterv en e d Generat io ns Source Speech (Neu tral) Ins tructi on Prompt I n ter v en ed Generatio ns Identi fi c ati on Set Ev aluati on Set Inf erence - tim e Int erv en tio ns Figure 2: The overview of our four -stage pipeline for identifying and manipulating emotion-sensitive neur ons in LALMs for EVC. LALMs employ gated MLPs (e.g., SwiGLU v ariants) [44], which of fer a natural position for hooking. Concretely , let u l,t , v l,t ∈ R D l be the two pre-activation streams at layer l and decoding step/token position t , and let g l,t = ϕ ( u l,t ) ∈ R D l (1) denote the gated branch after the nonlinearity ϕ ( · ) (e.g., SiLU ). The MLP output is h l,t = W o ( g l,t ⊙ v l,t ) , where ⊙ is elemen- twise product. W e log the scalar neuron activ ations a l,n,t = [ g l,t ] n , for neuron index n ∈ { 1 , . . . , D l } . These logged v alues serve as the basis for our identification statistics and intervention hooks. In addition to the MLPs in the language-model component of LALMs, we also examine whether the synthesis MLP layers also contain ESNs, which we analyze later in § 5.5. For each con version attempt, we store per -neuron counts and moments computed ov er the full activ ation tensor produced during genera- tion; we do not apply any success-based selection or modality restriction at this step. 3.2. Success Filtering and Set Construction A key design choice is to record and utilize activ ations only on con versions that plausibly satisfy EVC. Raw generations include div erse failures, as we sho wed in Figure 1, and mixing them into acti vation statistics can obscure emotion-related signals. For each generated audio y , we apply a two-axis filter aligned with the standard decomposition of v oice con version ev aluation into speaking style and linguistic content [9]. Emotion check via held-out judge. W e employ a held- out SER model as an automatic judge. It predicts an emotion label ˆ e ( y ) . W e accept the generation as emotion-matched if ˆ e ( y ) = e tgt . In a subset of experiments, we also conduct human listening experiments to validate the automatic judges’ reliability; § 5.4 discusses differences and agreement patterns. Content preserv ation via word error rate (WER) thr esh- old. W e examine linguistic content preservation by comparing the decoded te xt content produced by the LALM with the source transcription of x (or its reference transcript). Importantly , since the LALM emits decoded text alongside audio, we use the de- coded te xt directly rather than transcribing y with a separate automatic speech recognition (ASR) engine for e valuation of preservation. W e set a fix ed threshold τ wer = 0 . 15 to define/filter the successful instance across our experiments. Success instance sets. For each tar get emotion e ∈ E , we denote the filtered success set as S e . The size of this set is capped by a parameter c (the set is uniformly sampled if |S e | > c ) to balance emotions (later analyzed in § 5.2.3). 3.3. Activation Aggr egation and Emotion-Sensitive Neur on Identification 3.3.1. Activation Statistics on F iltered Successes Using only the filtered success set S e , our method computes neuron-wise activ ation pr obabilities from positi ve-acti vation counts. For each neuron ( l, n ) and emotion e , we accumulate K ( e ) l,n ← K ( e ) l,n + X ( x,y ) ∈S e X t I ( a ( x → y ) l,n,t > 0) , (2) T e ← T e + X ( x,y ) ∈S e X t 1 . (3) W e then define the activation probability P ( e ) l,n = K ( e ) l,n T e . Thus, P ( e ) l,n measures how often neuron ( l, n ) is active on successful EVC instances of target emotion e . Let N = P L l =1 D l denote the total number of neurons across all instrumented layers, and let r ∈ (0 , 1) be the selection rate. In all four methods below , the implementation selects N sel = ⌊ r N ⌋ neurons per emotion. 3.3.2. Neur on Ranking Methods • LAP (Activation Pr obability) [45 – 47]. For each emotion e , neurons are ranked directly by their activ ation probability , i.e., LAP ( e ) l,n = P ( e ) l,n , and the top N sel are selected. • LAPE (Activation Pr obability Entropy) [40, 48, 49]. This implementation applies a two-stage procedure. First, for each neuron, activ ation probabilities are normalized across emotions, ˜ P ( e ) l,n = P ( e ) l,n / P e ′ P ( e ′ ) l,n , and an entropy score H l,n = − P e ˜ P ( e ) l,n log ˜ P ( e ) l,n is computed, where lo wer en- tropy indicates stronger emotion selecti vity . Neurons that are globally too inactive are then remov ed using a probability threshold τ p computed from a global percentile ov er all P ( e ) l,n values; a neuron is kept only if it exceeds τ p for at least one emotion. Among the remaining neurons, the lo west-entropy N cand = ⌊ min(1 , 5 r ) N ⌋ form a candidate pool. Finally , for each target emotion e , the method selects the top N sel neurons from this pool by P ( e ) l,n . • MAD (Mean Activation Deviation) [19, 50, 51]. For each neuron, the implementation first computes its mean activ ation probability across emotions, ¯ P l,n = 1 |E | P e ′ P ( e ′ ) l,n . For tar get emotion e , the score is then the absolute deviation from this mean: MAD ( e ) l,n = P ( e ) l,n − ¯ P l,n . (4) Hence, this implementation fa vors neurons whose acti vation probability for emotion e differs strongly , in either direction, from their av erage behavior across emotions. • CAS (Contrastive Activation Selection) [20, 52]. For each neuron, let P (1) l,n and P (2) l,n denote its largest and second-largest activ ation probabilities across emotions, respectiv ely , and let e (1) l,n be the corresponding top emotion. The mar gin is ∆ l,n = P (1) l,n − P (2) l,n . For target emotion e , the method ranks a neuron by this margin only when e = e (1) l,n ; otherwise, its score is set to −∞ . It then selects the top N sel neurons for each emotion. • Random baseline. As a control, we additionally sample N sel = ⌊ r N ⌋ neurons uniformly at random without replace- ment from all N = L × D hooked neurons, and map them back to their layers to form a mask with the same sparsity as the other selectors. 3.4. Inference-T ime Emotion Control via Neuron-Lev el In- terventions T o test whether the identified neurons are causal for EVC, we intervene on the post-acti vation gate v alues of the hooked MLPs during generation, while keeping all model weights fix ed. Con- cretely , for a hooked layer l , let g l,t ∈ R D l denote the activ ated gate vector at generation step t , and let I ( m,e ) l be the set of selected neuron indices for method m and target emotion e . In- terventions are applied only on dimensions in I ( m,e ) l , before the elementwise product with the parallel MLP branch and the output projection. • T argeted steering (gain scaling) [16]. For selected neurons, we multiply the acti v ated gate v alues by a constant gain 1 + α ( α ≥ 0 ). In compact form, [ ˜ g l,t ] n = ( (1 + α )[ g l,t ] n , n ∈ I ( m,e ) l , [ g l,t ] n , otherwise. (5) • Additive shift [36]. As an alternative interv ention, we add a constant offset α ( α ≥ 0 ) to the selected gate dimensions: [ ˜ g l,t ] n = ( [ g l,t ] n + α, n ∈ I ( m,e ) l , [ g l,t ] n , otherwise. (6) Unlike steering, this is a uniform scalar shift and does not use neuron-specific reference values. • Floor clamping [53]. W e also test a minimum-activation constraint, in which each selected dimension is clamped from below by a scalar threshold α ( α ≥ 0 ): [ ˜ g l,t ] n = ( max ([ g l,t ] n , α ) , n ∈ I ( m,e ) l , [ g l,t ] n , otherwise. (7) This ensures that selected neurons remain at or abov e a fixed activ ation floor during generation. • Deactivation. Finally , we test necessity by zeroing the se- lected activ ated gate dimensions: [ ˜ g l,t ] n = ( 0 , n ∈ I ( m,e ) l , [ g l,t ] n , otherwise. (8) This removes the contrib ution of the selected neurons while leaving the rest of the computation unchanged. 3.5. Evaluation Metrics and Pr otocol Echoing the filtering protocol in § 3.2 and in accordance with the EVC objecti ves, we evaluate three aspects: emotion shift , content pr eservation , and naturalness . All generations are resampled to 16 kHz. • Emotion shift success. W e report Emotion match rate , the fraction of con verted samples whose predicted emotion matches e tgt . (1) SER judges are provided with ( x, ˆ x e tgt ) , for emotion2vec+large [54], we directly use the predicted label. For Qwen3-Omni-30B [55], we prompt the model to perform fiv e-way multiple-choice emotion classification. (2) Human evaluation uses pairwise A/B preference. See details in § 5.4. • Content preservation. W e compute WER between the ref- erence transcript and the extracted decoded text from the LALMs, normalized by the whisper-normalizer . 1 • Naturalness. W e estimate perceptual quality using the UT okyo-SaruLab Mean Opinion Score (UTMOS) [56], a non- intrusiv e mean opinion score (MOS) estimator . Interventions and evaluation conditions. For each emo- tion e mask ∈ E , we identify a set of ESNs using each selector on the I D E N T I FI C ATI O N split. W e then e valuate emotion sensi- tivity on held-out utterances by comparing generation with and without intervention under tw o complementary conditions: (1) self-effect ( e mask = e tgt ), where the model is instructed to generate emotion e tgt and is intervened with the ESN mask identified for that same emotion; and (2) cross-effect ( e mask = e tgt ), where the model is instructed to generate emotion e tgt but is interv ened with an ESN mask identified for a dif ferent emotion. For posi- tiv e interventions (scaling, additive, and clamping), the expected effect is to strengthen evidence associated with e mask . Comparing self- and cross-effect therefore helps distinguish emotion-specific modulation from broad degradation or nonspecific perturbation. 4. Experiment Setup 4.1. Models As outlined, we ev aluate three LALMs: Qwen2.5-Omni-7B [4], Kimi-A udio [5], MiniCPM-o 4.5 [3], all of which are mul- timodal models with audio-generation capability . They were selected for their strong benchmark performance and instruction- following ability . Their architectural differences further enable comparativ e interpretability analysis. For automated con version- success judgment, we employ two models: emotion2vec+large [54] serves as a speech emotion recognition (SER) judge from a primarily acoustic perspecti ve. On a 500-sample (100 per emo- tion) held-out subset of ESD, emotion2v ec+large achie ves 97.6% ov erall SER accuracy . In addition, we purposefully introduce an advanced LALM, Qwen3-Omni-30B [55] as a supplementary LALM-based judge to assess potential bias toward linguistic content in emotion ev aluation. 1 https://pypi.org/project/whisper- normalizer/ 4.2. Dataset Our primary test bed is the Emotional Speech Database (ESD) [9], which contains 20 speakers, each with 350 parallel utter- ances per emotion across fi ve cate gories (“neutral”, “happ y”, “angry”, “sad”, “surprise”). T o av oid language-dependent con- founds, we restrict the dataset to the 10 English speakers. W e further split the data by utterance index (parallel across emotions) to prev ent lexical leakage across emotions. As summarized in T able 1, we use a hybrid split: a 6/2/2 speaker partition, with utterance-index splits within the seen-speaker portion. Unless noted otherwise, all reported results are computed on T E S T - S E E N and T E S T - U N S E E N , with no overlap in speak ers or utter- ance indices relati ve to the identification or dev elopment splits. T able 1: Speak er and utterance-ID split of ESD. Utterance IDs ar e parallel acr oss the five emotions for each speak er . Speakers S1–S6 S7–S8 S9–S10 T otal I D E NT I FI C AT I O N 001–200 (200) – – 1200 D E V EL O P M E NT 201–250 (50) 001–250 (250) – 1100 T E S T - S E E N 251–350 (100) 251–350 (100) – 800 T E S T - U N S E EN – – 001–350 (350) 700 4.3. T ask Implementation Although EVC is inherently bidirectional, we focus on con verting neutral speech to a target emotion e tgt ∈ { happy , angry , sad, surprise } . For LALM-based conv ersion, we use a fixed, emotion-agnostic system prompt instructing the model to con vert speech emotion while preserving content, to- gether with a user prompt that pro vides (1) the input audio and (2) the EVC instruction that specifies a target emotion (Figure 1 shows an example). W e employ deterministic decoding when av ailable (greedy , temperature = 0 ) to facilitate reproducibility . 5. Results 5.1. Baseline Perf ormance T able 2: Baseline EVC perf ormance of the thr ee e valuated LALMs on ESD, before any neur on-level intervention. W e report the thr ee EVC axes used thr oughout the paper: targ et-emotion match rate in % (emotion2vec / Qwen3), content pr eservation (WER in %), and naturalness (UTMOS) on its 1–5 scale (the higher the mor e natural). Qwen2.5-Omni-7B MiniCPM-o 4.5 Kimi-Audio Angry 0.13 / 10.93 3.73 / 12.93 10.60 / 16.00 Happy 45.40 / 10.13 2.13 / 5.33 39.60 / 7.87 Sad 52.20 / 21.60 2.33 / 9.80 42.89 / 31.93 Surprise 2.67 / 5.07 0.07 / 3.47 7.13 / 6.67 A vg. 25.10 / 11.93 2.07 / 7.88 15.62 / 7.13 WER 19.00 2.95 2.82 UTMOS 4.00 4.26 3.18 Before applying neuron-lev el intervention, we establish the unintervened EVC baseline of the ev aluated LALMs on ESD. As sho wn in T able 2, baseline emotion match rates are modest across all three models, confirming that instruction-following EVC remains challenging in our setting. Notably , neutral is fre- quently predicted (e.g., 57.2% for Qwen2.5-Omni-7B), indicat- ing a strong bias to ward emotionally conserv ative outputs. Kimi- Audio achiev es the highest average emotion match rate (15.62%), followed by Qwen2.5-Omni-7B (11.93%) and MiniCPM-o 4.5 (7.88%). Across models, sad is the easiest target emotion, whereas surprise is consistently the hardest. Content preserv ation sho ws a contrasting trend: MiniCPM-o 4.5 and Kimi-Audio yield low WER (2.95% and 2.82%), while Qwen2.5-Omni-7B sho ws substantially higher WER (19.00%). This reveals a clear trade-off: models that produce stronger emotional shifts do not necessarily pr eserve linguistic content better . The mismatch between emotion success and content preservation motivates our tw o-stage success filtering (§ 3.2): ESN identification must be based on conv ersions satisfying both emotion correctness and linguistic fidelity . 5.2. Sensitivity to Identification Parameters 5.2.1. Identification Methods Building on the baseline EVC performances in T able 2, we next e xamine which selector produces ESN masks that deliver the most fa vorable intervention effects, ideally across all three ev aluation axes. W e compare the four selectors introduced in § 3.3.1 under a shared parameter setting ( c =50 , r =0 . 5% , steer- ing, α =1 . 0 ). T able 3 shows a clear ranking in emotion specificity . For Qwen2.5-Omni-7B, CAS and MAD produce the strongest positiv e self-effects together with the largest self–cross sepa- ration, whereas LAP and LAPE are notably weaker and less selectiv e. In particular , LAPE exhibits diffuse behavior in which off-tar get ef fects can ri val or e xceed on-target gains. MiniCPM-o 4.5 shows much smaller absolute changes o verall, suggesting that it is comparatively less responsi ve to this intervention de- sign; ho we ver , the same qualitative pattern remains. Kimi-Audio further reinforces this conclusion, but also highlights greater judge sensitivity: CAS again giv es the most fav orable self–cross profile, yet the effect size dif fers more between the two SER judge models than in the other LALMs. W e also notice that stronger emotion gains often come with some cost in content preservation, especially for Qwen2.5-Omni- 7B, where CAS and MAD increase WER more than weaker selectors. By contrast, naturalness remains remarkably sta- ble across methods. This highlights a k ey finding, that the main trade-off is not naturalness collapse but semantic drift . Across models and selectors, UTMOS shifts are generally small across settings, suggesting that interventions rarely cause the acoustic gibberish typical of failed con ventional VC; instead, the LALM outputs remain largely intelligible and natural-sounding, but may de viate in meaning from the instructed content. Meanwhile, WER can increase (especially for Qwen2.5- Omni-7B under CAS/MAD), which we interpret as reflecting semantic shift rather than degradation of basic speech formation. In this sense, selector comparison is primarily about how specif- ically we can modulate tar get emotion while minimizing unin- tended content changes, and T able 3 indicates that contrastive- margin-based selector (CAS) best satisfies this requirement. W e therefore adopt CAS as the default selector in subsequent experi- ments, as its margin-based assignment yields the most responsive and interpretable control behavior at inference time. 5.2.2. Selection Rate W e next examine the selection rate r , i.e., the fraction of top- ranked neurons retained for constructing ESN masks. By design, r controls mask sparsity and balance between specificity and cov- erag e : small r retains only the most confident neurons, whereas large r admits additional neurons that may encode weaker or non-specific signals [48]. Because ESN masks are subsequently T able 3: Comparison of ESN identification methods under activation steering, reported relative to the uninterv ened baseline in T able 2. ∆ Emotion Match vs. Base (emotion2vec / Qwen3) LALM Selector Self-Effect ↑ Cross-Effect A vg. ↓ Self–Cross Gap ↑ WER ↓ ( ∆ ) UTMOS ↑ ( ∆ ) Random +0.52 / +0.01 – – 22.54 (+3.54) 3.99 (-0.01) LAP -2.15 / +0.04 -1.89 / +0.07 -0.25 / -0.03 18.94 (-0.06) 3.92 (-0.08) Qwen2.5- LAPE +1.82 / +1.07 +2.21 / +1.83 -0.39 / -0.77 34.70 (+15.70) 3.94 (-0.06) Omni-7B MAD +2.62 / +2.82 +0.81 / +0.05 +1.81 / +2.30 24.22 (+5.22) 3.99 (-0.01) CAS +4.27 / +3.60 +0.34 / -0.05 +3.93 / +3.65 29.65 (+10.65) 3.99 (-0.01) CAS-H +3.15 / +2.92 +0.62 / +0.11 +2.53 / +2.81 24.56 (+5.56) 3.99 (-0.01) Random -0.05 / +0.14 – – 3.14 (+0.19) 4.25 (-0.01) LAP -0.33 / -0.38 -0.42 / -0.16 +0.09 / -0.23 8.98 (+6.03) 4.25 (-0.01) MiniCPM-o 4.5 LAPE -0.28 / +0.33 -0.18 / +0.34 -0.10 / -0.01 2.81 (-0.14) 4.25 (-0.01) MAD -0.22 / +0.33 -0.17 / +0.16 -0.05 / -0.18 2.84 (-0.11) 4.26 (0.00) CAS -0.20 / +0.40 -0.08 / +0.09 -0.12 / +0.31 2.95 (0.00) 4.25 (-0.01) Random -0.76 / -0.12 – – 3.72 (+0.90) 3.17 (-0.01) LAP +1.52 / +2.71 +0.35 / +1.49 +1.17 / +1.22 4.13 (+1.31) 3.15 (-0.03) Kimi-Audio LAPE -0.72 / -0.48 -0.89 / +0.46 +0.16 / -0.94 2.90 (+0.08) 3.16 (-0.02) MAD -0.90 / +1.17 -0.02 / +1.15 -0.88 / +0.02 4.69 (+1.87) 3.15 (-0.03) CAS +1.19 / +7.65 -0.19 / +0.96 +1.38 / +6.70 4.74 (+1.92) 3.16 (-0.02) (a) LAP (b) LAPE (c) MAD (d) CAS Figure 3: (Left) Intervention effects on EVC, under activation steering ( c =50 , α =1 . 0 ). F or each selector , we r eport changes in tar get-emotion match relative to the unintervened baseline in T able 2 , together with the corr esponding changes in content pr eservation (WER) and post-intervention naturalness (UTMOS). The CAS-H row r eports the results using human-filter ed instances, see explanations in § 5.4. (Right) P er-emotion emotion match rate changes by ESN selectors for Qwen2.5-Omni-7B , under the same intervention. In each heatmap, r ows denote the identified ESN mask emotion ( e mask ) and columns denote the instructed tar get emotion ( e tgt ); entries ar e signed changes (pp) in emotion match rate r elative to the unintervened baseline. Dia gonal cells r epr esent self-effects (wher e e mask = e tgt ), and off-dia gonal cells r epr esent cross-effects (avera ged over all e mask = e tgt pairs). used for inference-time intervention, rob ustness to r is critical. (a) r = 0 . 1% (b) r = 0 . 3% (c) r = 1% Figure 4: Sensitivity to ESN selection rate r (Qwen2.5-Omni-7B, CAS, c =50 , steering, α =1 . 0 ). Figure 4 suggests a largely monotonic trend within the tested range: with r =0 . 1% the effect is present but weak and sparse (consistent with under-selection), while increasing r to a moder- ate range, 0 . 3% and 0 . 5% (in Figure 3(d)) progressiv ely strength- ens the diagonal/self-ef fect and clarifies the specificity pattern. Howe ver , when r reaches 1 . 0% , of f-diagonal changes become more visible (e.g., +4.4 pp for Sad with a Happy-mask). This behavior supports that ESNs in LALMs are distributed rather than ultra-sparse, hence selecting too few neurons leav es part of the rele v ant signal unused. Since our sweep only extends to r =1 . 0% , we interpret this monotonicity as holding within the ex- plored range and retain r =0 . 5% as a practical default balancing compactness and effect strength. 5.2.3. Success Set Size W e then vary the success instance size c , the maximum number of filtered EVC successes retained per target emotion for activ ation aggregation. c changes the amount of evidence used to estimate the neuron statistics in § 3.3.1, so it is expected to affect the stability of ESN ranking. Figure 5 shows a clear sample-efficienc y trend. W ith very small caps ( c =10 ), the heatmaps are noisy and the diagonal is weak or inconsistent, indicating unstable ESN estimation (a) c =10 (b) c =20 (c) c =100 Figure 5: Sensitivity to success instance size c (Qwen2.5-Omni- 7B, CAS, r =0 . 5% , steering, α =1 . 0 ). from too few successful instances. As c increases to 20 or 50 (Figure 3(d)), the diagonal structure becomes noticeably clearer, suggesting that the selector now receives enough instances to retriev e more reliable emotion-conditioned activ ation patterns. While increasing further to c =100 does not improve self-ef fects proportionally , of f-diagonal changes diminish, sho wing a more denoised emotion-specific neuron separation. 5.3. Inference-T ime Intervention Design Having established that identification parameters can affect ESNs’ emotion control ef fects, we next analyze ho w inference- time intervention design affects the EVC outcome. W e focus on two orthogonal choices: (1) intervention method and (2) intervention strength. 5.3.1. Intervention Methods W e further examine alternati ve ESN intervention methods be- yond the scaling-style steering used in our main experiments. Figure 6 shows that, although additiv e and clamping interven- tions can induce partial target-emotion effects (e.g., a visible self-effect for sad under both methods), they do not yield consis- tent positiv e self-effects across emotions. The deactiv ation results provide two additional insights. First, for EVC, merely remo ving or suppressing non-target- (a) Add, α =0.30 (b) Clamp, α =0.10 (c) Deactivation Figure 6: Comparison of ESN intervention methods (Qwen2.5- Omni-7B, CAS, c =50 , r =0 . 5% ). As explained in § 3.4, α is method-specific, so we use differ ent values to keep intervention str ength r oughly comparable across methods. Deactivation is parameter -fr ee and hence reported without α . emotion acti vations is often insufficient to reliably induce the desired expressiv e changes. Second, the consistently negati ve diagonal under deacti v ation of fers additional e vidence support- ing the functional role of ESNs: when the identified neurons are silenced, target-emotion realization is impaired rather than improv ed. This pattern strengthens the interpretation that these neurons acti vely participate in emotion-related generation. Based on this comparison, we adopt the best-performing gain-scaling steering intervention as the default in subsequent intervention strength analyses. 5.3.2. Intervention Str ength T able 4: Emotion match and WER trade-of f when increas- ing the intervention strength (Qwen2.5-Omni-7B, CAS, c =50 , r =0 . 5% , steering). ∆ Emotion Match vs. Base (emotion2vec / Qwen3) α Self-Effect ↑ Cross-Effect A vg. ↓ Self–Cross Gap ↑ WER ↓ ( ∆ ) UTMOS ↑ ( ∆ ) 0.3 +0.78 / +0.37 +0.48 / -0.09 +0.30 / +0.45 19.33 (+0.33) 4.00 (0.00) 0.5 +2.00 / +1.13 -0.11 / -0.22 +2.11 / +1.36 20.67 (+1.67) 4.00 (0.00) 1.0 +4.27 / +3.60 +0.34 / -0.05 +3.93 / +3.65 29.65 (+10.65) 3.99 (-0.01) 2.0 +8.89 / +20.67 -0.14 / +0.02 +9.02 / +20.64 203.65 (+184.65) 3.91 (-0.09) (a) α =0.30 (b) α =0.50 (c) α =2.00 Figure 7: Sensitivity to interv ention strength α (Qwen2.5-Omni- 7B, CAS, c =50 , r =0 . 5% , steering). T aking activ ation steering as a probe method, we report the sensitivity of intervention ef fects to the intervention strength α in T able 4 and Figure 7. Increasing α consistently strengthens the intended self-effect on emotion match, as reflected in pro- gressiv ely darker diagonal cells in the heatmaps. Off-diagonal cross-effect, on the other hand, does not monotonically expand with α but rather fluctuates, leading to widening self–cross gaps. The largest α further highlights the trade-off with con- tent preservation. While α =2 . 0 yields the strongest emo- tion match gains (+8.89/+20.67 pp) and a large self–cross gap (+9.02/+20.64 pp), it catastrophically harms content preserva- tion (WER 203.65%, +184.65 pp ov er baseline) and slightly lowers naturalness. In contrast, in this setting, moderate steering ( α =0 . 3 – 0 . 5 ) keeps WER near the baseline and lea ves UTMOS unchanged, while still providing measurable improvements in target emotion match. 5.4. Human Evaluation and Human-Supervised ESN Identi- fication 62% 60% 64% 69% 54% 1 1% 14% 7% 10% 14% 27% 26% 29% 21% 32% 0% 20% 40% 60% 80% 100% Avg. Surp rise Sad Hap py Angry Win Tie Loss Figure 8: Human listening evaluation under the anchor inter- vention setting. W in/T ie/Loss rates comparing the intervened sys- tem (Qwen2.5-Omni-7B, CAS, c =50 , r =0 . 5% , steering, α =1 . 0 ) against the unintervened baseline. 20 participants. T o complement automatic SER ev aluation, we conduct a human listening study under our anchor configuration, matching the SER-filtered setting in Figure 3(d) for direct comparability . In each trial, participants listen to a pair of speech samples and select the clip that better matches a specified target emotion; an “indecisiv e” option is available if the dif ference is unclear . Each pair consists of (1) the baseline output and (2) the corresponding output generated with identical source speech and instruction under an ESN intervention. Each participant was provided with the same test set of 100 sample pairs (25 per emotion). Samples are randomized and volume-normalized, and raters are blind to model identity . W e collected valid responses from 20 partici- pants proficient in English. Listeners were aged 21–32 years; 7 identified as female, 13 as male. All reported normal hearing. Results are summarized in Figure 8: listeners prefer the inter- vened system in all four emotions, with av erage win/tie/loss rates of 62%/11%/27%. Gains are most pronounced for happy (69% win) and remain strong for sad and surprise, while angry is still fa vorable (54% win), supporting that ESN steering yields per- ceptible emotion shifts that are also reflected in human listening judgments. T able 5: Similarity between ESNs identified from human- vs. SER-filtered instances , measur ed in Jaccar d overlap, direct match r ate, and J ensen–Shannon diver gence (JSD). Emotion Jaccard Direct Match JSD Angry 0.217 35.71% 0.009 Happy 0.075 13.95% 0.040 Sad 0.109 19.57% 0.010 Surprise 0.071 13.27% 0.025 A verage 0.118 20.63% 0.021 T o assess the consistency between automatic and human su- pervision during ESN identification, we further compare neuron sets obtained from SER-filtered v ersus human-filtered success instances. T able 5 sho ws that ov erlap at the neuron le vel is par- tial, indicating that the two filtering strate gies select different specific units. Howev er, the layer-wise distrib utions between the two are highly similar (average JSD 0.021), suggesting that both supervision signals concentrate ESNs in similar MLP layers. Agreement is strongest for angry (Jaccard 0.217, JSD 0.009), whereas happy and surprise exhibit lower overlap, consistent with their weaker or more ambiguous emotion signals. The CAS-H row in T able 3 replaces SER-filtered successes with human-judged ones for ESN identification, and yields the same qualitative behavior: positiv e self-effects with limited cross-emotion spillov er . Compared to CAS, CAS-H slightly reduces self-effect and self–cross gap, b ut also substantially low- ers ∆ WER, suggesting that human supervision preferentially retains content-faithful successes and produces a more conserva- tiv e yet robust ESN set for controllable EVC. 5.5. Localization of Emotion-Sensitive Neur ons (a) Qwen2.5-Omni-7B (b) MiniCPM-o 4.5 (c) Kimi-Audio Figure 9: Layer-wise distribution of CAS-identified ESNs across three LALMs ( r =0 . 5% ). Heatmaps show the num- ber of selected ESNs per decoder layer and target emotion. Qwen2.5-Omni-7B and Kimi-Audio use 28-layer decoders, while MiniCPM-o 4.5 uses a 36-layer decoder . V alues indicate wher e selected neur ons are concentr ated, not intervention effect size . W e then visualize the concentrations of the ESNs across the MLP layers in Figure 9, which shows that ESNs are not uniformly distrib uted. Across all three LALMs, they concentrate primarily in intermediate-to-late layers of the language-model decoder , with relatively fe w units selected in the earliest layers. For Qwen2.5-Omni-7B, ESNs cluster most strongly in approx- imately layers 11–15, with pronounced peaks for happy and surprise. MiniCPM-o 4.5 exhibits a more diffuse distribution but still places greater mass in the latter half of the decoder . Kimi-Audio shows the strongest late-layer concentration, partic- ularly in layers 19–22, with marked peaks for happ y and angry in layer 26. This consistent pattern suggests that, in the tested models, emotion-relev ant control signals are more prominently captured in intermediate-to-late language-model layers than in earlier layers. T able 6: Activation steering in the speech synthesis module of Qwen2.5-Omni-7B. Results obtained by applying the same settings ( c =50 , r =0 . 5% , α =1 . 0 ) as in T able 3, but identified and intervening on the synthesis module MLP layers. ∆ Emotion Match vs. Base (emotion2vec / Qwen3) Selector Self-Effect ↑ Cross-Effect A vg. ↓ Self–Cross Gap ↑ WER ↓ ( ∆ ) UTMOS ↑ ( ∆ ) Random +0.52 / +0.02 – – 19.21 (+0.21) 4.01 (+0.01) LAP +0.32 / -0.08 +0.12 / +0.23 +0.20 / -0.32 19.00 (0.00) 3.96 (-0.04) LAPE -0.87 / -0.22 -0.13 / -0.27 -0.73 / +0.06 19.00 (0.00) 4.01 (+0.01) MAD -0.68 / 0.08 +0.51 / +0.13 -1.19 / -0.04 19.00 (0.00) 4.00 (0.00) CAS +0.12 / -0.42 +0.45 / -0.19 -0.33 / -0.22 19.19 (+0.19) 3.99 (-0.01) W e also explore an alternative module that could potentially contain ESNs. As demonstrated in T able 6, repeating the same identification-intervention pipeline in the speech synthesis MLP of Qwen2.5-Omni-7B under identical settings eliminates the clean positi ve self-ef fects observed in the language-model MLPs. Across selectors, self–cross gaps become near-zero or negativ e under both SER judges, regardless of selector . Minimal changes in WER and UTMOS further indicate that synthesis side inter- ventions are largely inert rather than emotion-specific. These results suggest that language-model decoder MLPs yield the most actionable ESNs, rather than the do wnstream synthesis modules. Practically , this means that monitoring and interv ening at the language-model side feed-forward blocks in LALMs is a more effecti ve strategy for controllable af fect steering than targeting the synthesis MLPs directly . 5.6. Do Interv ention Effects Generalize to Unseen Speakers? Figure 10: Intervention effect on seen and unseen speak ers. ∆ Emotion match size chang es (pp) of intervention (Qwen2.5-Omni- 7B, CAS, c =50 , r =0 . 5% , steering, α =1 . 0 ) in comparison with the unintervened baseline are shown for seen speakers ( T E S T - S E E N split) and unseen speakers ( T E S T - U N S E E N split), with 95% confidence intervals. Finally , we ev aluate whether ESN-based control generalizes beyond speakers used during neuron identification. Figure 10 shows that the intervention ef fect transfers to unseen speakers, but the magnitude of transfer is emotion-dependent. For an- gry , gains remain strong in both seen and unseen conditions, indicating a relati vely speak er-robust emotion signal. Surprise also maintains positi ve effects across splits, albeit at reduced magnitude. In contrast, sad exhibits a noticeable drop from seen to unseen speakers, suggesting partial speaker-specificity in the learned signal. Happy shows the weakest transfer , with modest gains on seen speakers and near-zero or slightly nega- tiv e effects on unseen speakers. A practical implication is that speaker -robust ESN control is feasible, b ut likely benefits from more div erse identification data. 6. Conclusion W e presented a systematic neuron-level in vestigation of emotion control in speech-generati ve LALMs under an emotional v oice con version setting. Our results suggest that compact emotion- sensitiv e neuron sets can be identified, are interventionally ac- tionable, and can be leveraged to steer emotional expressi veness at inference time without any weight updates. Crucially , we showed that reliable identification of ESNs requires success- filtered acti vation aggregation that respects the multi-objecti ve nature of EVC. Contrasti ve-mar gin- and mean-deviation-based selectors consistently outperform frequency- and entropy-based heuristics, yielding stronger self–cross separation and more emotion-specific control. W e further demonstrated a key trade- off between emotional e xpressi veness and content preserv ation: moderate interventions amplify tar get-emotion evidence, while excessi ve steering increases WER through semantic drift rather than a loss of intelligibility , as naturalness remains largely sta- ble. Localization analyses re veal that actionable emotion-control signals concentrate in intermediate-to-late decoder MLP layers on the language-model side, while analogous interventions in downstream speech synthesis modules are largely inert. This finding clarifies where emotion control is actually mediated in speech-generativ e LALMs and narrows the locus for future in- terpretability efforts. T ogether, these results establish a practical and mechanis- tically grounded pipeline for tr aining-fr ee emotion control in speech generation. Beyond emotional voice conv ersion, our framew ork opens the door to fine-grained, inference-time ma- nipulation of paralinguistic attributes in multimodal generative systems without re-training or task-specific fine-tuning. 7. Acknowledgments W e thank the National Science Foundation (NSF) for support under CAREER A ward IIS-2533652. 8. Generative AI Use Disclosur e Generativ e AI tools were employed solely for language polishing of text written by the authors. These tools were not used to gen- erate scientific content, results, experimental designs, analyses, or conclusions. All authors are responsible for the full content of this paper and consent to its submission. 9. References [1] T . M. W ani, T . S. Guna wan, S. A. A. Qadri, M. Kartiwi, and E. Ambikairajah, “ A comprehensive revie w of speech emotion recognition systems, ” IEEE access , vol. 9, pp. 47 795–47 814, 2021. [2] A. Défossez, L. Mazaré, M. Orsini, A. Royer , P . Pérez, H. Jégou, E. Grav e, and N. Zeghidour , “Moshi: a speech-text foundation model for real-time dialogue, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2410.00037 [3] Y . Y ao, T . Y u, A. Zhang, C. W ang, J. Cui, H. Zhu, T . Cai, H. Li, W . Zhao, Z. He, Q. Chen, H. Zhou, Z. Zou, H. Zhang, S. Hu, Z. Zheng, J. Zhou, J. Cai, X. Han, G. Zeng, D. Li, Z. Liu, and M. Sun, “Minicpm-v: A gpt-4v level mllm on your phone, ” 2024. [Online]. A vailable: https://arxi v .org/abs/2408.01800 [4] J. Xu, Z. Guo, J. He, H. Hu, T . He, S. Bai, K. Chen, J. W ang, Y . F an, K. Dang, B. Zhang, X. W ang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2503.20215 [5] KimiT eam, “Kimi-audio technical report, ” 2025. [Online]. A vailable: https://arxi v .org/abs/2504.18425 [6] B. W ang, X. Zou, G. Lin, S. Sun, Z. Liu, W . Zhang, Z. Liu, A. A w , and N. F . Chen, “AudioBench: A universal benchmark for audio large language models, ” in Pr oceedings of the 2025 Confer ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Languag e T echnologies (V olume 1: Long P apers) , L. Chiruzzo, A. Ritter , and L. W ang, Eds. Albuquerque, Ne w Mexico: Association for Computational Linguistics, Apr . 2025, pp. 4297–4316. [Online]. A vailable: https://aclanthology .org/2025.naacl- long.218/ [7] C.-K. Y ang, N. S. Ho, and H.-y . Lee, “T owards holistic ev aluation of large audio-language models: A comprehensive survey , ” in Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Language Pr ocessing , C. Christodoulopoulos, T . Chakraborty , C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov . 2025, pp. 10 144–10 170. [Online]. A vailable: https://aclanthology .org/2025. emnlp- main.514/ [8] L. Huang, W . Y u, W . Ma, W . Zhong, Z. Feng, H. W ang, Q. Chen, W . Peng, X. Feng, B. Qin, and T . Liu, “ A survey on hallucination in large language models: Principles, taxonomy , challenges, and open questions, ” ACM T rans. Inf. Syst. , vol. 43, no. 2, Jan. 2025. [Online]. A vailable: https://doi.org/10.1145/3703155 [9] K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional voice con version: Theory , databases and esd, ” Speech Commun. , vol. 137, no. C, p. 1–18, Feb. 2022. [Online]. A vailable: https://doi.org/10.1016/j.specom.2021.11.006 [10] A. T riantafyllopoulos, B. W . Schuller , G. ˙ Iymen, M. Sezgin, X. He, Z. Y ang, P . Tzirakis, S. Liu, S. Mertes, E. André, R. Fu, and J. T ao, “ An overview of af fectiv e speech synthesis and conv ersion in the deep learning era, ” Pr oceedings of the IEEE , vol. 111, no. 10, pp. 1355–1381, 2023. [11] Z. Y ang, X. Jing, A. T riantafyllopoulos, M. Song, I. Aslan, and B. W . Schuller , “An Overview & Analysis of Sequence-to- Sequence Emotional V oice Conv ersion, ” in Interspeec h 2022 , 2022, pp. 4915–4919. [12] R. Skerry-Ryan, E. Battenberg, Y . Xiao, Y . W ang, D. Stanton, J. Shor , R. W eiss, R. Clark, and R. A. Saurous, “T owards end-to- end prosody transfer for expressiv e speech synthesis with tacotron, ” in international confer ence on machine learning . PMLR, 2018, pp. 4693–4702. [13] Y . W ang, D. Stanton, Y . Zhang, R.-S. Ryan, E. Battenberg, J. Shor , Y . Xiao, Y . Jia, F . Ren, and R. A. Saurous, “Style tokens: Unsuper- vised style modeling, control and transfer in end-to-end speech syn- thesis, ” in International conference on mac hine learning . PMLR, 2018, pp. 5180–5189. [14] J. Lorenzo-T rueba, G. E. Henter, S. T akaki, J. Y amagishi, Y . Morino, and Y . Ochiai, “Inv estigating different representa- tions for modeling and controlling multiple emotions in dnn-based speech synthesis, ” Speech Communication , v ol. 99, pp. 135–143, 2018. [15] Y . Lei, S. Y ang, and L. Xie, “Fine-grained emotion strength trans- fer , control and prediction for emotional speech synthesis, ” in 2021 IEEE Spok en Language T echnology W orkshop (SLT) . IEEE, 2021, pp. 423–430. [16] A. M. T urner, L. Thiergart, G. Leech, D. Udell, J. J. V azquez, U. Mini, and M. MacDiarmid, “Steering language models with activ ation engineering, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2308.10248 [17] A. Bau, Y . Belinko v , H. Sajjad, N. Durrani, F . Dalvi, and J. Glass, “Identifying and controlling important neurons in neural machine translation, ” in International Conference on Learning Repr esentations , 2019. [Online]. A vailable: https: //openrevie w .net/forum?id=H1z- PsR5KX [18] D. Bau, J.-Y . Zhu, H. Strobelt, A. Lapedriza, B. Zhou, and A. T orralba, “Understanding the role of individual units in a deep neural network, ” Pr oceedings of the National Academy of Sciences , vol. 117, no. 48, p. 30071–30078, Sep. 2020. [Online]. A vailable: http://dx.doi.org/10.1073/pnas.1907375117 [19] F . Dalvi, N. Durrani, H. Sajjad, Y . Belinkov , A. Bau, and J. Glass, “What is one grain of sand in the desert? analyzing individual neurons in deep nlp models, ” in Proceedings of the Thirty-Thir d AAAI Conference on Artificial Intelligence and Thirty-Fir st Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence , ser. AAAI’19/IAAI’19/EAAI’19. AAAI Press, 2019. [Online]. A vailable: https://doi.org/10.1609/aaai.v33i01.33016309 [20] X. Zhao, B. Schuller , and B. Sisman, “Discovering and causally validating emotion-sensitiv e neurons in large audio-language models, ” 2026. [Online]. A vailable: https://arxi v .org/abs/2601. 03115 [21] P . W u, Z. Ling, L. Liu, Y . Jiang, H. W u, and L. Dai, “End-to-end emotional speech synthesis using style tok ens and semi-supervised training, ” in 2019 Asia-P acific Signal and Information Pr ocessing Association Annual Summit and Conference (APSIP A ASC) . IEEE, 2019, pp. 623–627. [22] R. Liu, B. Sisman, G. Gao, and H. Li, “Expressi ve tts training with frame and style reconstruction loss, ” IEEE/ACM T ransactions on Audio, Speec h, and Language Pr ocessing , vol. 29, pp. 1806–1818, 2021. [23] Y . Lei, S. Y ang, X. W ang, and L. Xie, “Msemotts: Multi-scale emotion transfer , prediction, and control for emotional speech syn- thesis, ” IEEE/ACM T ransactions on Audio, Speec h, and Language Pr ocessing , vol. 30, pp. 853–864, 2022. [24] G. Zhang, Y . Qin, W . Zhang, J. W u, M. Li, Y . Gai, F . Jiang, and T . Lee, “iemotts: T oward robust cross-speaker emotion transfer and control for speech synthesis based on disentanglement between prosody and timbre, ” IEEE/A CM T ransactions on Audio, Speec h, and Language Pr ocessing , vol. 31, pp. 1693–1705, 2023. [25] B. Schnell and P . N. Garner, “Improving emotional tts with an emotion intensity input from unsupervised e xtraction, ” in 11th ISCA Speech Synthesis W orkshop (SSW 11) , 2021, pp. 60–65. [26] D.-H. Cho, H.-S. Oh, S.-B. Kim, S.-H. Lee, and S.-W . Lee, “EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion V ector for Controllable Emotional T ext-to- Speech, ” in Interspeech 2024 , 2024, pp. 1810–1814. [27] T . Xie, S. Y ang, C. Li, D. Y u, and L. Liu, “Emosteer-tts: Fine-grained and training-free emotion-controllable text-to- speech via activ ation steering, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2508.03543 [28] Y . Cao, Z. Liu, M. Chen, J. Ma, S. W ang, and J. Xiao, “Nonparallel emotional speech con version using v ae-gan, ” in Interspeech 2020 , 2020, pp. 3406–3410. [29] X. He, J. Chen, G. Rizos, and B. W . Schuller , “ An impro ved stargan for emotional voice con version: Enhancing voice quality and data augmentation, ” in Interspeech 2021 , 2021, pp. 821–825. [30] K. Zhou, B. Sisman, R. Liu, and H. Li, “Seen and unseen emotional style transfer for voice con version with a new emotional speech dataset, ” in ICASSP 2021 - 2021 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2021, pp. 920–924. [31] C. Fu, C. Liu, C. T . Ishi, and H. Ishiguro, “ An improv ed cycleg an-based emotional voice con version model by augmenting temporal dependency with a transformer , ” Speech Commun. , vol. 144, no. C, p. 110–121, Oct. 2022. [Online]. A vailable: https://doi.org/10.1016/j.specom.2022.09.002 [32] N. R. Prabhu, B. Lay , S. W elker, N. Lehmann-Willenbrock, and T . Gerkmann, “Emoconv-dif f: Diffusion-based speech emotion con version for non-parallel and in-the-wild data, ” in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2024, pp. 11 651–11 655. [33] F . Kreuk, A. Polyak, J. Copet, E. Kharitonov , T . A. Nguyen, M. Rivière, W .-N. Hsu, A. Mohamed, E. Dupoux, and Y . Adi, “T extless speech emotion conversion using discrete & decomposed representations, ” in Pr oceedings of the 2022 Confer ence on Empirical Methods in Natur al Languag e Pr ocessing , Y . Goldberg, Z. K ozarev a, and Y . Zhang, Eds. Ab u Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 11 200–11 214. [Online]. A vailable: https://aclanthology .org/2022.emnlp- main.769/ [34] Y . K. Singla, J. Shah, C. Chen, and R. R. Shah, “What do audio transformers hear? probing their representations for language deliv ery & structure, ” in 2022 IEEE International Confer ence on Data Mining W orkshops (ICDMW) . IEEE, 2022, pp. 910–925. [35] Z. Y u and S. Ananiadou, “Neuron-lev el kno wledge attribution in large language models, ” in Pr oceedings of the 2024 Confer ence on Empirical Methods in Natur al Languag e Pr ocessing , Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov . 2024, pp. 3267–3280. [Online]. A vailable: https://aclanthology .org/2024.emnlp- main.191/ [36] N. Rimsky , N. Gabrieli, J. Schulz, M. T ong, E. Hubinger , and A. T urner , “Steering llama 2 via contrastive acti vation addition, ” in Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , L.-W . Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 504–15 522. [Online]. A vailable: https://aclanthology .org/2024.acl- long.828/ [37] P . Q. Da Silva, H. Sethuraman, D. Rajagopal, H. Hajishirzi, and S. Kumar , “Steering off course: Reliability challenges in steering language models, ” in Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , W . Che, J. Nabende, E. Shutov a, and M. T . Pilehvar , Eds. V ienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 19 856–19 882. [Online]. A vailable: https://aclanthology .org/2025.acl- long.974/ [38] T .-Y . Wu, Y .-X. Lin, and T .-W . W eng, “ And: audio network dissec- tion for interpreting deep acoustic models, ” in Proceedings of the 41st International Conference on Machine Learning , ser . ICML ’24. JMLR.org, 2024. [39] J. Fang, Z. Bi, R. W ang, H. Jiang, Y . Gao, K. W ang, A. Zhang, J. Shi, X. W ang, and T .-S. Chua, “T ow ards neuron attrib utions in multimodal large language models, ” in Pr oceedings of the 38th International Confer ence on Neural Information Pr ocessing Sys- tems , ser . NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2024. [40] J. Huo, Y . Y an, B. Hu, Y . Y ue, and X. Hu, “MMNeuron: Discovering neuron-level domain-specific interpretation in multimodal large language model, ” in Pr oceedings of the 2024 Conference on Empirical Methods in Natural Language Pr ocessing , Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov . 2024, pp. 6801–6816. [Online]. A vailable: https://aclanthology .org/2024.emnlp- main.387/ [41] C.-K. Y ang, N. Ho, Y .-J. Lee, and H. yi Lee, “ Audiolens: A closer look at auditory attribute perception of large audio-language models, ” 2025. [Online]. A vailable: https: //arxiv .org/abs/2506.05140 [42] J. Lee, W . Lee, O.-W . Kwon, and H. Kim, “Do large language models have “emotion neurons”? inv estigating the existence and role, ” in F indings of the Association for Computational Linguistics: ACL 2025 , W . Che, J. Nabende, E. Shutov a, and M. T . Pilehvar , Eds. V ienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 15 617–15 639. [Online]. A vailable: https://aclanthology .org/2025.findings- acl.806/ [43] C. W ang, Y . Zhang, R. Y u, Y . Zheng, L. Gao, Z. Song, Z. Xu, G. Xia, H. Zhang, D. Zhao, and X. Chen, “Do llms "feel"? emotion circuits discovery and control, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2510.11328 [44] N. Shazeer, “Glu variants improve transformer , ” 2020. [Online]. A vailable: https://arxi v .org/abs/2002.05202 [45] H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharke y , “Sparse autoencoders find highly interpretable features in language models, ” 2023. [Online]. A vailable: https://arxiv .org/abs/2309.08600 [46] W . Gurnee, T . Horsley , Z. C. Guo, T . R. Kheirkhah, Q. Sun, W . Hathaway , N. Nanda, and D. Bertsimas, “Univ ersal neurons in GPT2 language models, ” T ransactions on Machine Learning Resear ch , 2024. [Online]. A vailable: https://openrevie w .net/ forum?id=ZeI104QZ8I [47] E. V oita, J. Ferrando, and C. Nalmpantis, “Neurons in large language models: Dead, n-gram, positional, ” in F indings of the Association for Computational Linguistics: ACL 2024 , L.-W . Ku, A. Martins, and V . Srikumar , Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 1288–1301. [Online]. A vailable: https: //aclanthology .org/2024.findings- acl.75/ [48] T . T ang, W . Luo, H. Huang, D. Zhang, X. W ang, X. Zhao, F . W ei, and J.-R. W en, “Language-specific neurons: The key to multilingual capabilities in lar ge language models, ” in Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , L.-W . Ku, A. Martins, and V . Srikumar , Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 5701–5715. [Online]. A vailable: https://aclanthology .org/2024.acl- long.309/ [49] D. Namazif ard and L. G. Poech, “Isolating culture neurons in multilingual large language models, ” in Pr oceedings of the 14th International Joint Conference on Natur al Language Processing and the 4th Conference of the Asia-P acific Chapter of the Association for Computational Linguistics , K. Inui, S. Sakti, H. W ang, D. F . W ong, P . Bhattacharyya, B. Banerjee, A. Ekbal, T . Chakraborty , and D. P . Singh, Eds. Mumbai, India: The Asian Federation of Natural Language Processing and The Association for Computational Linguistics, Dec. 2025, pp. 768–785. [Online]. A vailable: https://aclanthology .org/2025.findings- ijcnlp.45/ [50] A. Bau, Y . Belinko v , H. Sajjad, N. Durrani, F . Dalvi, and J. Glass, “Identifying and controlling important neurons in neural machine translation, ” in International Conference on Learning Repr esentations , 2019. [Online]. A vailable: https: //openrevie w .net/forum?id=H1z- PsR5KX [51] O. Jorgensen, D. Cope, N. Schoots, and M. Shanahan, “Improving acti vation steering in language models with mean- centring, ” in Responsible Language Models W orkshop (ReLM) at AAAI-24 , Feb . 2024, responsible Language Models W orkshop at AAAI-24, ReLM@AAAI-24 ; Conference date: 26- 02-2024 Through 26-02-2024. [Online]. A vailable: https: //sites.google.com/vectorinstitute.ai/relm2024/home?authuser=0 [52] X. Zhao, R. Choenni, R. Saxena, and I. T itov , “Finding culture-sensitiv e neurons in vision-language models, ” 2025. [Online]. A vailable: https://arxi v .org/abs/2510.24942 [53] A. T empleton, T . Conerly , J. Marcus, J. Lindsey , T . Bricken, B. Chen, A. Pearce, C. Citro, E. Ameisen, A. Jones, H. Cun- ningham, N. L. Turner , C. McDougall, M. MacDiarmid, C. D. Freeman, T . R. Sumers, E. Rees, J. Batson, A. Jermyn, S. Carter , C. Olah, and T . Henighan, “Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet, ” T ransformer Cir cuits Thr ead , 2024. [Online]. A vailable: https://transformer- circuits. pub/2024/scaling- monosemanticity/index.html [54] Z. Ma, Z. Zheng, J. Y e, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion representation, ” in F indings of the Association for Computational Linguistics: A CL 2024 , L.-W . Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 747–15 760. [Online]. A vailable: https://aclanthology .org/2024.findings- acl.931/ [55] J. Xu, Z. Guo, H. Hu, Y . Chu, X. W ang, J. He, Y . W ang, X. Shi, T . He, X. Zhu, Y . Lv , Y . W ang, D. Guo, H. W ang, L. Ma, P . Zhang, X. Zhang, H. Hao, Z. Guo, B. Y ang, B. Zhang, Z. Ma, X. W ei, S. Bai, K. Chen, X. Liu, P . W ang, M. Y ang, D. Liu, X. Ren, B. Zheng, R. Men, F . Zhou, B. Y u, J. Y ang, L. Y u, J. Zhou, and J. Lin, “Qwen3-omni technical report, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2509.17765 [56] T . Saeki, D. Xin, W . Nakata, T . K oriyama, S. T akamichi, and H. Saruwatari, “UTMOS: UT okyo-SaruLab System for V oiceMOS Challenge 2022, ” in Interspeech 2022 , 2022, pp. 4521–4525.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment