음성 질문응답을 위한 주의 기반 증거 정렬 기법
본 논문은 음성 질문응답(Spoken QA)에서 음성 입력과 텍스트 지식 사이의 정합성을 강화하기 위해, SpeechLLM 내부의 교차‑모달 어텐션을 활용해 핵심 증거를 명시적으로 찾아내는 Attention‑guided Evidence Grounding(AEG) 프레임워크를 제안한다. 또한, 사전 학습 모델의 퍼지한 어텐션 분포를 교정하고 증거 선택 정확도를 높이기 위해 Learning to Focus on Evidence(LFE)라는 지도형 …
저자: Ke Yang, Bolin Chen, Yuejie Li
본 논문은 음성 질문응답(Spoken QA)이라는 교차‑모달 과제에서, 기존의 “음성 → 텍스트 → LLM” 파이프라인이 초래하는 오류 전파와 높은 지연을 극복하고, 모델의 사실성(factuality)과 해석 가능성을 동시에 향상시키는 새로운 프레임워크인 Attention‑guided Evidence Grounding(AEG)을 제시한다. AEG는 크게 두 단계로 구성된다. 첫 번째 단계인 “Evidence Grounding with Attention”에서는 SpeechLLM의 내부 어텐션을 활용해 입력 음성 질문과 텍스트 컨텍스트 사이의 연관성을 정량화한다. 구체적으로, 음성 입력은 AudioEncoder를 통해 토큰 시퀀스로 변환되고, 텍스트 컨텍스트는 일반 토크나이저로 처리된다. 두 시퀀스를 결합한 뒤, 모델의 프리필 단계에서 각 레이어와 헤드의 어텐션 가중치를 평균해 토큰‑레벨 어텐션 A(t_j)를 계산하고, 이를 다시 선택된 레이어 구간(L_start~L_end)에서 평균해 최종 토큰 어텐션을 얻는다. 이후 같은 문단에 속한 토큰들의 어텐션을 평균해 문단‑레벨 점수 A(c_i)를 산출하고, 사전 정의된 임계값 τ를 초과하는 문단을 “키 증거”로 선정한다. 선택된 증거 문단은 와 태그로 감싸져 원본 질문과 함께 SpeechLLM에 재입력되며, 모델은 이 정제된 컨텍스트를 기반으로 최종 답변을 생성한다.
두 번째 단계인 “Learning to Focus on Evidence”(LFE)는 사전 학습된 SpeechLLM이 갖고 있는 퍼지하고 균일한 어텐션 분포를 교정하기 위한 지도형 미세조정 방법이다. LFE는 증거 선택을 목표로 하는 “selection‑generation” 태스크를 정의한다. 각 학습 샘플은 음성 질문과 N개의 후보 문단(정답 증거 포함)으로 구성되며, 모델은 정답 증거만을 출력하도록 학습한다. 이 과정에서 자동 회귀 교차 엔트로피 손실이 정답이 아닌 토큰에 대한 확률을 낮추어, 어텐션이 자연스럽게 증거 토큰에 집중하도록 만든다. 실험에서는 Qwen2‑Audio‑7B 모델을 기반으로, AdamW(learning rate 1e‑5, cosine schedule)와 2 epoch 학습을 수행했으며, 배치 사이즈 2에 8 step accumulation을 적용해 8×A100 GPU 환경에서 학습했다. LFE를 적용한 후, 어텐션 히트맵은 핵심 증거에 높은 가중치를, 비관련 문단에는 낮은 가중치를 명확히 구분하는 형태로 변하였다.
성능 평가를 위해 SQuAD v1.1, HotpotQA, MuSiQue 세 가지 텍스트 QA 데이터셋을 활용해 음성 질문을 합성(Higgs Audio)하고, 정확도(Exact Match)와 증거 선택 지표(Precision, Recall, F1) 모두에서 AEG + LFE가 기존 ASR‑LLM 파이프라인 대비 우수한 결과를 보였다. 구체적으로, GPT‑4o Audio 모델에서는 HotpotQA EM이 79.07 %→79.16 %(+0.09), MuSiQue F1이 51.51 %→53.99 %(+2.48), SQuAD EM이 88.49 %→88.94 %(+0.45)로 향상되었다. Qwen3‑Omni‑30B‑A3B 모델에서는 HotpotQA EM이 75.02 %→76.95 %(+1.93), MuSiQue F1이 45.88 %→48.61 %(+2.73), SQuAD EM이 88.37 %→89.24 %(+0.87)로 개선되었다. 특히, 파라미터 규모가 560B에 달하는 LongCat‑Flash‑Omni 모델에서는 증거 선택 F1이 49.57 %→53.99 %(+4.42)까지 크게 상승했다. 이는 AEG + LFE가 모델 크기에 관계없이 증거 정렬 능력을 강화한다는 것을 의미한다.
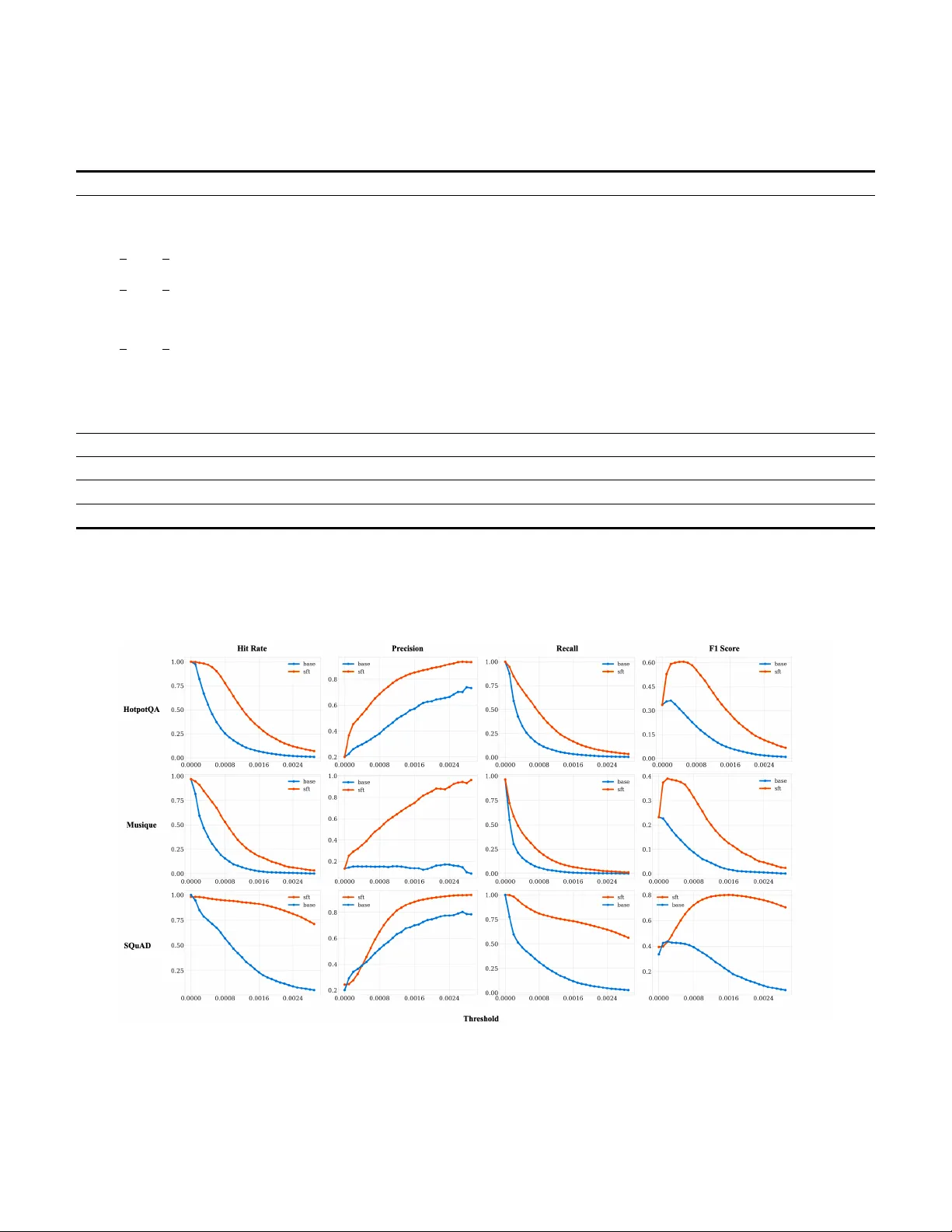
Ablation 실험에서는 LFE 없이 AEG만 적용했을 때도 베이스라인보다 약간의 개선이 있었지만, LFE를 포함한 전체 모델이 가장 높은 증거 선택 정확도와 답변 정확도를 달성함을 확인했다. 또한, τ 값에 대한 민감도 분석(Fig. 4)에서는 LFE 적용 모델이 τ 변화에 대해 더 안정적인 F1 성능을 유지함을 보여, LFE가 어텐션 분포를 보다 뚜렷하게 만든 결과임을 시사한다.
논문의 주요 기여는 다음과 같다. (1) SpeechLLM 내부 어텐션을 활용해 증거를 명시적으로 정렬하는 AEG 프레임워크 제안, (2) 어텐션을 증거에 집중시키는 지도형 미세조정 기법 LFE 도입, (3) 다양한 규모의 SpeechLLM과 여러 QA 벤치마크에서 일관된 성능 향상 및 지연 감소(≈62 %) 입증, (4) 증거 정렬 과정을 시각화해 모델 해석 가능성을 제공. 한계점으로는 τ 임계값 튜닝 필요성, 멀티모달(이미지·표 등) 증거에 대한 확장성 부족, 라벨링 비용이 있다는 점을 언급한다. 향후 연구에서는 자동 τ 최적화, 멀티모달 증거 정렬, 라벨이 없는 약한 지도 학습을 통한 LFE 확장 등을 탐구할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기