Attention-guided Evidence Grounding for Spoken Question Answering
Spoken Question Answering (Spoken QA) presents a challenging cross-modal problem: effectively aligning acoustic queries with textual knowledge while avoiding the latency and error propagation inherent in cascaded ASR-based systems. In this paper, we …
Authors: Ke Yang, Bolin Chen, Yuejie Li
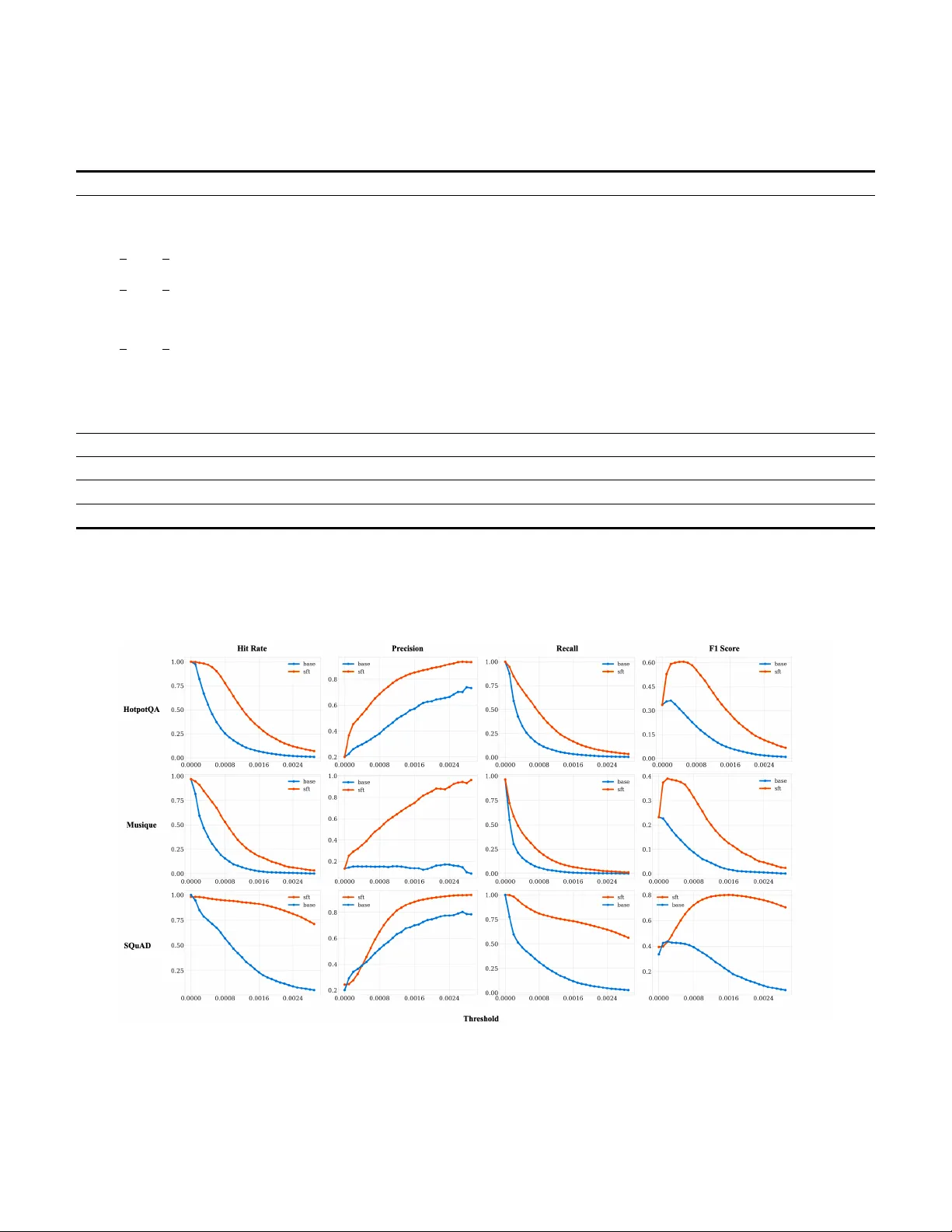
Attention-guided Evidence Grounding for Spoken Question Answering K e Y ang, Bolin Chen, Y uejie Li, Y ue ying Hua, Jianhao Nie, Y ueping He, Bo wen Li, Chengjun Mao Ant Gr oup Hangzhou, China { zhulang.yk, bolin.cbl, liyuejie.lyj, huayueying.hyy , niejianhao.njh, heyueping.hyp, zhikong.lbw , chengjun.mcj } @antgroup.com Abstract —Spoken Question Answering (Spoken QA) presents a challenging cross-modal pr oblem: effectively aligning acoustic queries with textual knowledge while avoiding the latency and error propagation inherent in cascaded ASR-based systems. In this paper , we intr oduce Attention-guided Evidence Grounding (AEG), a novel end-to-end framework that leverage s the inter- nal cross-modal attention of Speech Lar ge Language Models (SpeechLLMs) to explicitly locate and ground k ey evidence in the model’ s latent space. T o address the diffuse attention distribution in pre-trained models, we propose Learning to Focus on Evidence (LFE), a supervised fine-tuning paradigm that calibrates the model’ s attention mechanism to distinguish query-rele vant segments from irrele vant context. Experiments on SQuAD, HotpotQA, and MuSiQue demonstrate that AEG reduces hallucinations and achie ves str ong efficiency gains, out- performing large-scale cascaded baselines (Whisper -Large-v3 + Reranker) while reducing inference latency by approximately 62%. Index T erms —Spoken Question Answering, Speech Large Lan- guage Models, Cr oss-modal Attention, End-to-End Systems I . I N T R O D U C T I ON Spoken Question Answering (Spok en QA) [ 1 ], [ 2 ] is a cross-modal task that requires models to answer spoken queries based on textual contexts. Howe v er , ev en when pro- vided with the correct context, current Spoken QA sys- tems frequently generate responses that are inconsistent with the source content, resulting in hallucinations [ 3 ], [ 4 ]. This sev erely limits their deployment in critical, high-stakes scenar- ios such as medicine [ 5 ] and legal consultation [ 6 ]. Further- more, e xisting approaches lack explicit e vidence grounding, limiting interpretability and preventing user verification of supporting contexts. Therefore, improving the factual accuracy and interpretability of spoken QA systems is crucial for their reliable deployment in real-world applications. Inspired by human cogniti ve processes, our work explores a more intrinsic and intuitiv e approach to spoken QA. When humans perform a similar task, they intuitively follow a ”scan- then-focus” process: Gi v en a lar ge amount of context, they first scan and identify key information segments relev ant to the question—i.e., the ke y e vidence. Subsequently , they focus their attention on these key e vidence to construct an answer, rather than attempting to process all context simultaneously . This two-stage process helps to reduce irrelev ant interference during reasoning and ensures that the answer is based on verified information. W e posit that a similar mechanism can be instilled in Speech Large Language Models (SpeechLLMs). Intuiti v ely , as an LLM processes a query and its context, its internal attention mechanism is already dynamically computing the importance of different information segments [ 7 ], [ 8 ], creating a theoretical ”heat map” of relev ance. Hence, attention offers a promising but lar gely under -exploited signal for e vidence grounding [ 9 ], [ 10 ]. Motiv ated by this insight, we first propose Grounding with Attention , which lev erages the internal attention mechanism of a pre-trained SpeechLLM to locate and explicitly mark key evidence. These marked segments provide clear attribution for the model’ s responses, enhancing interpretability by re v ealing the specific context used during answer generation. While attention-based grounding works well in text-only settings, it is unreliable in cross-modal speech–text scenarios, where attention must align heterogeneous acoustic and text representations and thus requires explicit training. As a result, the raw attention of pre-trained SpeechLLMs is often dif fuse and uncalibrated, failing to clearly distinguish k ey evidence from related context, as illustrated in Figure 1 . T o address this issue, we propose Learning to Focus on Evidence (LFE) , a specialized training paradigm designed to ”teach” the LLM to perform the ”scan-then-focus” process. Through task-specific fine-tuning, LFE reshapes the model’ s attention distrib ution, producing a sharper distinction between key evidence and irrelev ant context. This enables the model to concentrate more effecti vely on key evidence. Overall, we present Attention-guided Evidence Ground- ing (AEG) , a controllable frame work that starts from ground- ing with attention and provides a trainable way to guide a model’ s focus on relev ant evidence. By transforming the model’ s implicit attention patterns into explicit evidence mark- ers, AEG significantly enhances both the factual accuracy and the interpretability of the generated responses. Our main contributions are as follows: • W e propose AEG , a frame work that le v erages the internal attention mechanism of SpeechLLMs to explicitly locate key evidence within the context, thereby guiding the model to generate well-grounded answers. AEG w/o LFE Baseline (no AEG) AEG with LFE Doc 1. Sacro Cuore di Cristo Re was designed ... Doc 2. ... into force on 22 February 2001. ... Doc 3. ... Governor of V atican City was held by Marchese Camillo Serafini ... his death in 1952. ... "When was Governor ended ... ?" Doc 2 Doc 3 Doc 1 Doc 2 Doc 3 Doc 1 Correct Evidence Grounding W rong Evidence Grounding Evidence Grounding 1. Sacro Cuore di Cristo Re was designed ... 2. ... into force on 22 February 2001... 3. Governor ... Marchese Camillo Serafini ... his death in 1952 ... 1952 22 Feb 2001 LLM Decoder Audio Encoder SFT Learn to Focus on Evidence (LEF) Attention Score Attention Score 22 Feb 2001 Fig. 1. A comparison demonstrating the critical role of Learning to Focus on Evidence (LFE). For the audio query ”When was the Governor ended?”, our complete AEG framework successfully grounds the answer in the correct evidence (Doc 3), while both AEG without LFE and baseline methods fail to identify relev ant evidence, resulting in incorrect responses. • W e introduce LFE , a specialized fine-tuning paradigm that calibrates the model’ s attention distrib ution. This pro- cess sharpens the focus on critical information, enabling the model to filter out irrelev ant noise effecti vely . • Experiments on multiple Spoken QA benchmarks demon- strate that AEG significantly improves evidence selection precision and enhances factual correctness, effecti vely boosting the o verall reliability of the system against hallucinations. I I . R E L A T E D W O R K Building on the success of Large Language Models (LLMs) in the text domain, a natural next step is extending this paradigm to other modalities, particularly speech. Tradition- ally , tasks like Spoken Question Answering have used cas- caded ASR-LLM-TTS architectures [ 11 ], but this approach suffers from error propagation, high latency , and loss of paralinguistic information. T o address these limitations, the research trend is shifting to wards integrated, end-to-end (E2E) SpeechLLMs [ 12 ]–[ 17 ]. These models directly process speech input and generate speech or text output, enabling a deeper fusion of acoustic and semantic information. Despite adv ancements in E2E architectures, SpeechLLMs still face the persistent challenge of ”hallucination”: the generation of outputs are plausible but factually incorrect or unfaithful to the context. Although Retriev al-Augmented Generation (RA G) can mitigate this issue, the ”faithfulness” of the model to the giv en context remains a critical concern. Research indicates that even when the correct documents are retrieved, models may still ignore context [ 18 ], become ”confused” by contradictory information, or ”selectiv ely” use information. Furthermore, model efficacy is often hampered by the ”lost in the middle” phenomenon [ 19 ], where LLMs exhibit a strong positional bias, fav oring information at the beginning and end of the conte xt while o verlooking critical evidence in the middle. Inspired by these challenges, recent research has explored more fine-grained contextual utilization, predominantly within the text modality . Relev ant efforts include re-ranking doc- uments based on attention scores to counteract positional bias [ 20 ], employing auxiliary evidence e xtractors [ 21 ], or lev eraging self-attention mechanisms to highlight evidence [ 22 ]. Howe v er , these methods are limited to processing purely textual information. They fail to address a critical issue in multimodal models: ho w to effecti vely align and ground the user’ s acoustic information with external textual kno wledge. In contrast, our work focuses on achieving direct alignment between speech queries and te xtual kno wledge passages within multimodal models. I I I . M E T H O D O L O G Y A. T ask Definition W e formally define the spoken question answering task as follows. Let Q A be an audio query and C T = { c 1 , c 2 , ..., c k } be a context set, which serves as the exclusi v e kno wledge source for answering the query . The task takes the audio query Q A and context set C T as inputs, which are processed by a speech large language model (SpeechLLM) to generate a textual response R T : R T = S peechLLM ( Q A , C T ) . (1) B. Over all F ramework The proposed Attention-guided Evidence Grounding (AEG) method, illustrated in Figure 2 , presents a novel framew ork for spoken question answering that leverages the internal attention mechanism of a SpeechLLM to ef fecti vely identify and ground key evidence. The inference pipeline begins with a spoken query Q A and a set of textual context segments C T = { c 1 , c 2 , ..., c k } . These inputs are processed by the Evidence Grounding Model , and attention weights are computed, typically during the prefill stage. The Attention Extraction module then deriv es the attention map (visualized as Masked Attention), reflecting the importance of each segment c i . Based on these attention weights, the model identifies and selects a subset of the most important contexts, which we refer to as key evidence . T o explicitly guide the model’ s response generation, we ”ground” this evidence by annotating it with special markers (e.g., Fig. 2. Overview of the proposed Attention-guided Evidence Grounding (AEG) method. AEG comprises two components: (1) Learning to Focus on Evidence —a supervised fine-tuning stage that calibrates the SpeechLLM’ s attention tow ard key e vidence, and (2) Grounding with Attention —an inference stage that leverages learned attention patterns to highlight and ground ke y e vidence. and ). Finally , the original query Q A and the annotated context C ′ T are passed to the SpeechLLM to generate the final response R T . Howe ver , we observe that current base models exhibit rela- tiv ely uniform attention distrib utions across context segments. T o improve this, we introduce a specialized training method, Learning to Focus on Evidence (LFE) . This method fine- tunes the SpeechLLM to enhance its attention mechanism, enabling it to better distinguish query-relev ant contexts from irrelev ant ones. This training process refines the initial Speech- LLM into an optimized Evidence Grounding Model . C. Gr ounding with Attention Large language models (LLMs) operate in two distinct phases during inference: prefill and decode. In our approach, we extract and analyze attention weights from the prefill phase to locate and mark key evidence that is most rele vant to answering the query . 1) Attention W eight Extraction: Gi v en a spoken query Q A and the textual context set C T = { c 1 , c 2 , ..., c k } , we first process them into a unified input sequence S . The audio query Q A is transformed via the AudioEncoder, and the textual context C T is processed using the T okenizer. The complete input sequence S is then constructed by concatenating these representations: S = AudioE ncoder ( Q A ) ⊕ T ok eniz er ( C T ) . (2) Our goal is to calculate the importance score for each context segment through a hierarchical aggregation of self- attention weights. Denote by α ( l,h ) j the attention weight at layer l ∈ 1 , ..., L end and head h ∈ 1 , ..., H . For each token t j belonging to conte xt c i , the head-a veraged attention in layer l is: A ( l ) ( t j ) = 1 H H X h =1 α ( l,h ) j . (3) Next, we aggregate across a selected range of layers. Based on empirical analysis (detailed in Section IV -C2 ), we identify a contiguous block of layers, from L start to L end , where attention patterns are most indicati ve of semantic relev ance. The attention weights for token t j is the average of its weights across these layers: ¯ A ( t j ) = 1 L end − L start + 1 L end X l = L start A ( l ) ( t j ) . (4) T o obtain attention weights of the context segment, we aggregate token-le vel attention weights within each context segment. The ov erall importance score for a context segment c i , denoted A ( c i ) , is calculated as the mean of the final weights of all its constituent tokens: A ( c i ) = 1 | c i | X t j ∈ c i ¯ A ( t j ) . (5) W e apply a threshold-based selection to determine the set of key evidence: C key = c i ∈ C T | A ( c i ) > τ , (6) where τ is a predefined threshold, and C key contains the set of candidates whose attention weights A ( c i ) exceed τ . 2) K ey Evidence Gr ounding: For each context segment c i ∈ C key , reserved marking tokens (e.g., and ) are inserted before and after its content, producing a tagged context set C ′ T . The original query Q A and the tagged context C ′ T are then provided to a generativ e QA LLM: R T = S peechLLM ( Q A , C ′ T ) . (7) D. Learning to F ocus on Evidence As shown in Eq. 5 , the passage-le vel attention weight A ( c i ) is computed by a v eraging token-le vel weights. Ho we ver , unmodified attention mechanisms often dilute high weights in long segments or overweight short irrelev ant segments. T o address this limitation, we fine-tune the SpeechLLM model via supervised fine-tuning (SFT) to enhance its ability to discriminate key evidence. W e formulate the SFT stage as a selection generation task, training the model to generate only the ground-truth e vidence. By forcing the model to reconstruct only the key evidence, the auto-regressi v e loss function naturally penalizes attention to non-e vidence tokens during generation. Giv en a spoken query Q A and a corresponding set of candidate context segments C T , we concatenate the input sequence X with a special separator token <|SEP|> : X = E audio ( Q A ) k M i =1 ( T ( c i ) ⊕ <|SEP|> ) . (8) Fig. 3. Heatmaps of attention weight ev olution across layers (y-axis, 1-32) and training steps (x-axis, 0-190) in Qwen2-Audio. (a) W eights allocated to ke y evidence. (b) W eights assigned to irrelev ant evidence. (c) The difference (diff) between key and irrelevant weights. Green boxes (10-28) highlight the most effecti ve layers. Here, E Audio is the Audio Encoder , T is the T ext T okenizer . The model is trained to generate an output text sequence Y that consists of the subset of context segments constituting the key evidence. Formally: Y = S peechLLM ( X ) . (9) The training objectiv e is the standard auto-regressi ve cross- entropy loss over the target sequence: L S F T = − | Y | X t =1 log P θ ( y i | x, y doc 2: doc 2 content < /EVIDENCE > . . . doc n: doc n content Please refer to the doc to answer the user’ s question. Y ou should focus on the doc between the < EVIDENCE > and < /EVIDENCE > tags, as it contains key information. Directly answer the user’ s questions, keep the answers as concise as possible, and do not output any irrelevant content. User Prompt
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment