프롬프트 프로그래밍으로 문화 편향 최소화와 대형 언어 모델 정렬
본 논문은 기존의 설문 기반 문화 정렬 프레임워크를 오픈소스 대형 언어 모델에 적용하고, DSPy를 활용한 프롬프트 프로그래밍으로 문화 조건화를 자동 최적화한다. 실험 결과, 오픈 모델에서도 문화 편향이 존재함을 확인했으며, 자동 최적화된 프롬프트가 수동 설계 프롬프트보다 문화 거리 감소에 더 효과적이었다.
저자: Maksim Eren, Eric Michalak, Brian Cook
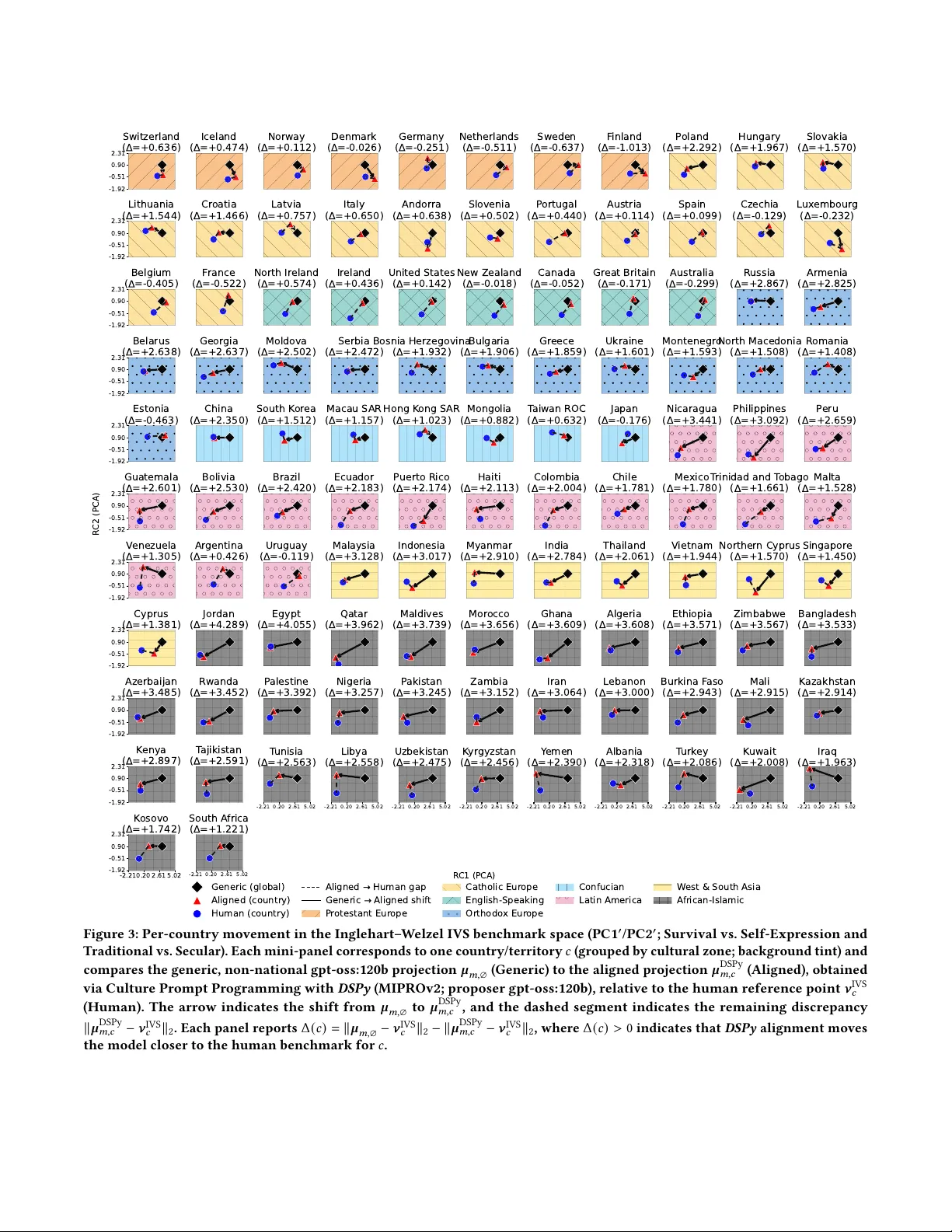
본 논문은 대형 언어 모델(LLM)의 문화 편향을 정량화하고, 이를 최소화하기 위한 새로운 프롬프트 프로그래밍 방법을 제시한다. 연구 배경은 문화가 인간의 의사결정, 가치 판단, 전략적 선택 등에 깊은 영향을 미치며, LLM이 이러한 영역에 점점 더 많이 활용됨에 따라 모델이 내재한 문화적 선입견이 실제 정책·전략 수립에 왜곡을 초래할 위험이 있다는 점이다. 기존 연구(Tao et al., 2022)는 설문 기반 문화 정렬 프레임워크를 도입해, “문화 프롬프트”를 삽입하면 모델의 응답이 목표 국가의 가치 프로파일에 더 가깝게 이동한다는 것을 보여주었다. 그러나 그 연구는 주로 OpenAI와 같은 폐쇄형 모델에 한정되었고, 프롬프트 설계가 전적으로 수동적인 전문가 작업에 의존했다는 제약이 있었다.
이에 저자들은 두 가지 목표를 설정했다. 첫째, 동일한 프레임워크를 오픈소스 LLM에 적용해 문화 편향이 동일하게 존재하는지 검증한다. 둘째, DSPy라는 프롬프트 프로그래밍 프레임워크를 이용해 프롬프트를 프로그램처럼 파라미터화하고, 문화 거리 최소화를 목표 함수로 삼아 자동 최적화를 수행함으로써 수동 설계보다 효율적이고 재현 가능한 문화 정렬 방식을 제시한다.
방법론은 크게 네 단계로 구성된다. (1) 문화 기준 맵 구축: Integrated Values Survey(IVS)를 기반으로 10개의 핵심 설문 항목을 선정하고, 각 국가·시기의 응답을 가중 평균한 뒤 PCA와 varimax 회전을 적용해 두 개의 주축(생존‑자기표현, 전통‑세속)으로 차원 축소한다. (2) 모델 응답 투영: 선정된 오픈소스 모델(Llama 3.3 70 B, Llama 4 16×17 B, Gemma 3 27 B, GPT‑OSS 20 B·120 B)에 대해 각 설문 항목을 “일반 프롬프트”와 “문화 전제 프롬프트(당신은 X 국가의 시민이다)” 두 형태로 질문하고, 응답을 설문 코딩 규칙에 맞춰 정량화한다. (3) 문화 거리 계산: 모델이 생성한 좌표와 목표 국가의 IVS 좌표 간 유클리드 거리를 문화 거리로 정의한다. (4) DSPy 기반 프롬프트 최적화: 프롬프트를 템플릿 변수와 조건문으로 구성하고, COPRO와 MIPROv2 텔레프롬프터를 사용해 자동 탐색한다. 목표 함수는 문화 거리 최소화이며, 제약조건으로는 설문 응답 형식(정수·범주) 유지가 포함된다. 최적화 과정에서 작은 1 B Llama 3.2와 대형 120 B GPT‑OSS를 각각 “instruction‑suggester”로 활용해 프롬프트 제안을 받았다.
실험 결과는 다음과 같다. (1) 오픈소스 모델에서도 일반 프롬프트만 사용할 경우 서구‑WEIRD(서구, 교육 수준 높음, 부유함) 축에 크게 편향되는 것이 확인되었다. (2) 문화 전제 프롬프트를 삽입하면 대부분의 모델에서 목표 국가(예: 인도, 브라질, 일본) 쪽으로 거리 감소가 관찰되었으며, 감소폭은 모델 규모와 아키텍처에 따라 차이가 있었다. (3) DSPy 최적화 프롬프트는 수동 설계 프롬프트 대비 평균 10‑15 % 추가 거리 감소를 달성했으며, 특히 비서구 국가에서 20 % 이상 개선된 사례도 있었다. (4) 대형 instruction‑suggester(GPT‑OSS 120 B)는 작은 모델에 비해 더 정교한 프롬프트 제안을 제공했으며, 최적화 반복 횟수와 계산 비용이 증가했음에도 불구하고 수렴 속도가 빠르고 안정적인 결과를 보였다.
논문의 주요 기여는 다음과 같다. 첫째, 문화 정렬 프레임워크를 오픈소스 LLM에 성공적으로 적용해, 문화 편향이 폐쇄형 모델에만 국한되지 않음을 입증하였다. 둘째, DSPy를 활용한 프롬프트 프로그래밍을 문화 정렬 문제에 도입해, 프롬프트를 코드처럼 최적화함으로써 재현 가능하고 확장 가능한 방법론을 제공하였다. 셋째, 작은 vs. 큰 instruction‑suggester 모델의 역할을 비교 분석해, 비용·성능 트레이드오프를 실증하였다. 넷째, 자동 최적화가 수동 설계보다 일관된 성능 향상을 제공함을 실험적으로 증명하였다.
한계점으로는 설문 항목이 10개에 불과해 문화의 복합성을 완전히 포착하지 못한다는 점, 문화 전제 프롬프트가 단순히 국가 라벨을 삽입하는 수준에 머물러 보다 미세한 문화·언어·역사적 차이를 반영하기엔 부족하다는 점, 그리고 최적화 과정이 고성능 GPU와 대형 모델을 필요로 하여 실용성에 제약이 있다는 점을 들 수 있다. 향후 연구에서는 (1) 다언어·다문화 설문을 확대해 보다 풍부한 문화 차원을 모델링하고, (2) 메타‑프롬프트 학습을 통해 비용 효율적인 프롬프트 제안을 자동 생성하며, (3) 실제 정책·문서 엔지니어링 파이프라인에 적용해 문화 정렬이 의사결정 품질에 미치는 영향을 정량화하는 실증 연구를 진행할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기