Prompt Programming for Cultural Bias and Alignment of Large Language Models
Culture shapes reasoning, values, prioritization, and strategic decision-making, yet large language models (LLMs) often exhibit cultural biases that misalign with target populations. As LLMs are increasingly used for strategic decision-making, policy…
Authors: Maksim Eren, Eric Michalak, Brian Cook
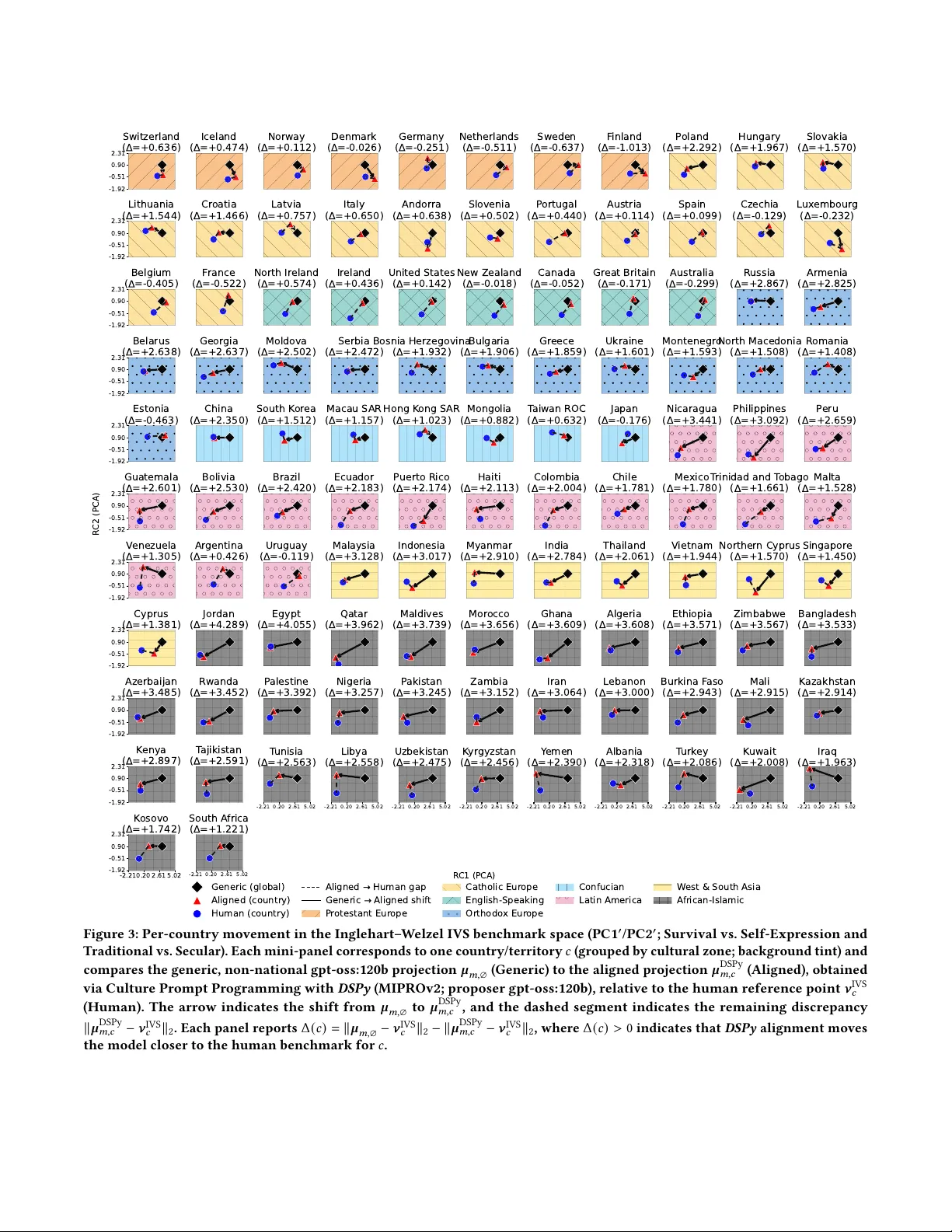
Prompt Programming for Cultural Bias and Alignment of Large Language Mo dels Maksim E. Eren ∗ maksim@lanl.gov Information Systems and Modeling, Los Alamos National Laboratory Los Alamos, New Mexico, USA Eric Michalak ∗ emichalak@lanl.gov Advanced Research in Cyber Systems, Los Alamos National Laboratory Los Alamos, New Mexico, USA Brian Cook cook_b@lanl.gov Center for National Security and International Studies Los Alamos, New Mexico, USA Johnny Seales Jr . jseales@lanl.gov Analytics Division, Los Alamos National Laboratory Los Alamos, New Mexico, USA Abstract Culture shapes reasoning, values, prioritization, and strategic decision- making, yet large language models (LLMs) often exhibit cultural biases that misalign with target populations. As LLMs are incr eas- ingly used for strategic decision-making, policy support, and doc- ument engineering tasks such as summarization, categorization, and compliance-oriented auditing, improving cultural alignment is important for ensuring that downstream analyses and recommen- dations reect target-population value proles rather than default model priors. Pre vious work introduced a survey-grounded cultural alignment framework and show ed that culture-specic prompting can reduce misalignment, but it primarily evaluated proprietary models and relied on manual prompt engineering. In this pap er , we validate and e xtend that framework by reproducing its social sciences survey based projection and distance metrics on open- weight LLMs, testing whether the same cultural skew and benets of culture conditioning persist outside closed LLM systems. Build- ing on this foundation, we introduce use of pr ompt programming with DSPy for this problem—treating prompts as modular , opti- mizable programs—to systematically tune cultural conditioning by optimizing against cultural-distance objectives. In our experiments, we show that pr ompt optimization often impro ves upon cultural prompt engineering, suggesting prompt compilation with DSPy can provide a more stable and transferable route to culturally aligned LLM responses. CCS Concepts • Computing methodologies → Articial intelligence ; Natu- ral language processing ; Machine learning . Ke ywords LLM, Culture, Bias, Prompt Engineering, Prompt Pr ogramming 1 Introduction Cultural systems shape how individuals interpret uncertainty , pri- oritize social goals, e valuate authority , and resolv e moral trade-os. ∗ Both authors contributed equally to this work. This work is licensed under a Creativ e Commons Attribution 4.0 International License. These dimensions inuence strategic decision-making in domains such as governance, organizational leadership, education, and pub- lic communication. For the purpose of this paper , we dene cultur e as a system of societal norms and the way of life that are learned and shared among major groups in a population [ 17 ] [ 42 ]. As large language models (LLMs) increasingly assist in drafting policies, gen- erating recommendations, categorizing and analyzing documents, and me diating cross-cultural interactions, their implicit value orien- tations can meaningfully aect downstream reasoning. Culture can also shape document engineering itself: it aects how prompts, tem- plates, and schemas dene salient categories, acceptable evidence, and legitimate justications. Because LLMs are increasingly used for document engineering tasks such as summarization, categoriza- tion, classication, and auditing supp ort, prompts and templates function as interaction specications through which cultural as- sumptions enter via what the artifacts request, prioritize, and treat as a valid rationale. Cultural misalignment in model outputs is therefore not merely representational, but it can shift which op- tions are surfaced, how trade-os are justied, and what is treated as legitimate or desirable. T ao et al. [ 42 ] introduced a social sciences base d survey-grounded framework for measuring cultural alignment by mapping LLM re- sponses to standardized value instruments and computing distance from nationally representative benchmarks. They showed that, un- der generic prompting, models concentrate around W estern value proles, and that explicit culture conditioning through prompt en- gineering can reduce misalignment, pushing LLM responses to the target countries/territories. Although inuential, T ao et al. [ 42 ] evaluated only proprietary models and relied solely on manual prompt engineering. In con- trast, open-source models oer research advantages that closed systems typically cannot—democratized access, reproducibility , and broader support for diverse do wnstream applications [ 28 ]. More- over , while prompt engineering can improv e LLM outputs [ 38 ], it is increasingly complemented, and in some settings supplante d, by programmatic prompt optimization frameworks such as DSPy [ 24 ], which treat prompts as optimizable components and automatically search for prompts that b est satisfy an explicit objective and for- mat constraints. Our work here, therefor e, addresses two r esearch questions: Eren and Michalak et al. (1) Do the ndings of T ao et al. [ 42 ] hold for open-source LLMs? (2) Does prompt optimization culturally align LLM responses better than prompt engineering? T o address the rst research question, we reproduce Tao et al. [ 42 ] on open-weight mo dels spanning scales and training regimes: Llama 3.3 (70B) [ 29 ], Llama 4 (16 × 17B) [ 30 ], Gemma 3 (27B) [ 12 ], and GPT -OSS (20B/120B) [ 35 ]. Across these mo dels, we obser ve that culture conditioning remains dete ctable and consistent, indi- cating that T ao et al. ’s ndings extend beyond proprietary systems and persist across architectures and scales. T o address the second research question, we compare manual cultural prompt engineering against DSPy -based prompt optimization, which treats prompting as a parameterized program and compiles prompts against explicit objectives under strict response-format constraints [ 24 ]. By cast- ing cultural alignment as an optimization problem—minimizing human survey–derived cultural distance—we nd that DSPy moves responses closer to the target cultures than manual prompting, often reducing cultural distance b eyond generic prompting and hand-designed cultural templates. T ogether , these results suggest that programmatic prompt optimization yields more stable and transferable cultural conditioning across open-weight models, in- cluding for non- W estern cultural positions relevant to strategic decision-making settings. In summary , our contributions include: (1) V alidating and extending the prior work by T ao et al. [ 42 ] on ve dierent open-source LLMs. (2) Introducing use of prompt programming with DSPy [ 24 ] for cultural alignment of LLMs. (3) Evaluating the cultural alignment performance of prompt programming using two DSPy teleprompters COPRO and MIPROv2 [ 7 , 8 ], and comparing the impact of a small vs. large instruction-suggester model during optimization (Llama 3.2 1B vs. GPT -OSS 120B). (4) Comparing the performance of prompt programming to prompt engineering for cultural alignment. 2 Related W ork Recent work by Tao et al. [ 42 ], on which we build upon in this paper , introduced a sur vey-grounded framework for measuring cultural alignment by mapping LLM responses to W orld V alues Survey (WVS) items into the Inglehart– W elzel (IW) cultural map and computing distance to nationally repr esentative benchmarks. Their evaluation of proprietary OpenAI models showed that generic prompting induces a consistent W estern concentration in the re- sponses, while culture-specic prompting can reduce cultural dis- tance for many targets. Our work extends this work by replicating the full pipeline on open-weight models and additionally by in- troducing DSPy prompt programming as an alternative to manual cultural prompt engineering. As LLMs are incorporated into document-centric systems, docu- ment engineering —spanning multi-do cument summarization, cate- gorization pipelines, auditing workows, and the construction of prompts, templates, schemas, and do cumentation artifacts [ 13 , 46 ]— provides the interface through which mo dels are applied. These artifacts are not culturally invariant: schema and template choices shape which distinctions are encoded and what counts as evidence, and summarization can introduce systematic distortions in what is selected and emphasized [ 41 ]. More broadly , task and evaluation design embed cultural assumptions [ 33 ], and prompt language or explicit cultural framing shifts expressed values, indicating that interaction specications can act as cultural cues [ 6 ]. Further , docu- mentation supports auditability and certication, with scope var y- ing by perceived risk [ 27 ]. From a cross-cultural tooling perspective, O’Neil et al. [ 34 ] emphasize linguistic sov ereignty , cultural speci- city , and reciprocity , while Bravansky et al. [ 5 ] frame cultural alignment as context-dependent and shaped by interaction scaold- ing. T aken together , these ndings imply that as LLMs are increas- ingly used for document analysis, their cultural priors and biases can shape summarization, categorization, and auditing behaviors within document-engineering workows. Subsequent work has expanded survey-based evaluation and persona conditioning at scale. Zhao et al. [ 47 ] introduce W orld- V aluesBench (WVB), a large-scale b enchmark derived from WVS W ave 7 with over 20 million ( demographics , question ) → answer instances, and evaluate models using W asserstein distance to hu- man answer distributions. AlKhamissi et al. [ 1 ] simulate socio- logical sur veys across persona specications and show that cul- tural misalignment varies systematically with prompt language and demographic conditioning, proposing anthropological prompt- ing as a mitigation strategy . T una et al. [ 44 ] similarly compare GPT -3.5-turb o and GPT -4 responses across ve language areas and ten subcultures, nding substantial variation in cultural alignment by linguistic region and subculture specication. K wok et al. [ 26 ] evaluate synthetic personas against real participants and show that nationality conditioning improves alignment, while native- language prompting alone does not reliably do so. Complementing these, Gr eco et al. [ 14 ] generate WVS-grounded synthetic personas and analyze their placement on the IW map and Moral Foundations Theory (MFT) dimensions, demonstrating structured cross-cultural variation but also highlighting representation biases in p ersona generation. Broader analyses of cultural skew conte xtualize these ndings. Atari et al. [ 3 ] query OpenAI mo dels with WVS items mo dels and show that responses cluster closest to W estern, Educate d, Indus- trialized, Rich, and Democratic (WEIRD) societies, with similarity decreasing as countries become more culturally distant from the United States. Zhou et al. [ 48 ] further examine this WEIRDness – rights trade-o, using the Universal Declaration of Human Rights (UDHR) and r egional charters to show that models less aligned with WEIRD p opulations produce more culturally variable responses but are mor e likely to generate outputs that conict with human-rights principles. Arora et al. [ 2 ] evaluate multilingual pretrained lan- guage models (PLMs) using W VS- and Hofstede-derived templates and nd that while models encode cross-cultural variation, their induced value rankings correlate weakly with sur vey ground truth and vary across architectures. At a systems level, Pawar et al. [ 36 ] survey work on cultural awareness in language and multimo dal models, emphasizing that evaluation remains fragmented across datasets, modalities, and alignment obje ctives, motivating more con- sistent cross-cultural benchmarking grounded in social-scientic theory . Complementary task-based b enchmarks document op erational considerations of cultural perspective. Naous et al. [ 31 ] introduce Prompt Programming for Cultural Bias and Alignment of Large Language Models the Cultural A wareness in Arabic language Models benchmark ( CAMeL ) and show that multilingual models systematically pre- fer W estern-associated entities across generation, inlling, named entity recognition (NER), and sentiment analysis, with prompt adap- tations r educing but not eliminating these eects. Navigli et al. [ 32 ] argue that such disparities often originate in upstream data selection bias, including domain, temporal, and demographic skew , and ad- vocate data-centric interventions alongside model-level mitigation. Similarly , Johnson et al. [ 20 ] examine GPT -3 through summariza- tion tasks and document shifts towar d mainstream United States positions, consistent with training-data dominance ee cts [ 31 ]. T o- gether with distributional distance analyses, these results suggest that cultural skew can inuence not only surface-level outputs but also which trade-os are framed as legitimate or desirable. W ork in psycholinguistic modeling reinforces that culturally in- ected language patterns correlate with consequential institutional outcomes. Sigdel and Panlova [ 39 ] develop RusLICA , a Russian- language adaptation of Linguistic Inquir y and W ord Count (LI WC) incorporating morphology-aware lexical resources, highlighting that culturally aligned op erationalization of linguistic categories is necessary for valid inference. In an applied governance setting, Gandall et al. [ 11 ] show that LI WC-deriv ed rhetorical and psy- chological features in United Nations ( UN) deliberations predict policy passage and co ercive-intervention context substantially bet- ter than procedural-motion baselines. These ndings imply that linguistic signals correlate with institutional decisions, motivating careful measurement of cultural alignment when LLMs are used in policy-adjacent contexts. Finally , strategic and agentic evaluations demonstrate that LLMs increasingly participate in decision-making envir onments where value orientation can shape outcomes. Bakhtin et al. [ 4 ] introduce Cicero , an agent that achieves human-lev el performance in the ne- gotiation game Diplomacy by coupling intent-conditioned dialogue generation with explicit strategic planning over belief states and joint actions. Payne [ 37 ] extends this line to nuclear crisis simu- lations, showing that fr ontier models exhibit structured strategic reasoning, including deception, theory-of-mind modeling, and sta- ble “strategic personalities, ” with escalation dynamics sensitive to temporal framing. Similarly , Hogan and Brennen [ 18 ] introduce Snow Glob e , an open-source framework for simulating and playing open-ended wargames with multi-agent LLMs for understanding real-world decision making. As LLMs mov e from passive text gen- erators to agents emb edded in planning loops, governance, and scientic workows, their implicit value priors can inuence which options are s urfaced, how commitments are framed, and how risk is evaluated. Gridach et al. [ 15 ] sur vey agentic systems in scientic dis- covery and emphasize reliability , calibration, and ethical oversight as core challenges, while Eren and Perez [ 9 ] argue that articial intelligence (AI) systems increasingly shape hypothesis generation, literature synthesis, and collaborative decision-making under in- formation overload. In such settings, cultural misalignment is not merely representational: it can structure reasoning trajectories and aect policy , gov ernance, and scientic judgments, motivating our work on building up on and extending the work from T ao et al. [ 42 ] with prompt optimization for cultural alignment, and testing it with across open-weight models. 3 Methods W e largely follow the I VS-based cultural alignment pip eline of T ao et al. [ 42 ], replicating their benchmark projection and distance met- rics, and then extending the evaluation to open-weight models and DSPy -based prompt programming. This section rst describ es the replicated baseline pipeline in full for completeness, then our DSPy - based prompt-programming additions are detailed in Section 3.4. 3.1 Cultural map of countries/territories W e rst replicate the cultural map of countries/territories as de- scribed in [ 42 ], which we summarize here for completeness. First, we construct the Integrated V alues Surveys (IVS) benchmark cul- tural space and the country/territor y reference locations using the IVS, a harmonize d integration of W orld V alues Sur vey (WVS) and European V alues Study (EVS) data [ 10 , 16 , 45 ]. Following the survey- grounded cultural alignment framew ork of [ 42 ], we focus on the three most recent joint waves (2005–2022) and retain all available country–wave observations within this window . W e use the same ten survey indicators from prior work, that build the Inglehart– W elzel cultural map, including but not limited to survey questions on happiness, social trust, authority , petition signing, national pride, and autonomy [ 19 , 42 ]. Question on happiness as prompt example is included in Box 3.2. Responses are transformed into numeric variables using the I VS/WVS/EVS co ding guidance [ 10 , 16 , 42 , 45 ]. W e t Principal Component Analysis (PCA) on standardized respondent-level values across the ten indicators, apply varimax rotation, and incorporate sur vey weights by using survey-weighted moments for standardization and survey-weighted aggregation for country–wave means [ 22 , 23 , 42 ]. The rst two rotated comp onents are interpreted as the canonical axes Sur vival vs. Self-Expression and Traditional vs. Se cular [ 19 , 42 ]. T o match the benchmark coordinate system, we apply the same linear rescaling used in [42]: PC1 ′ = 1 . 81 · PC1 + 0 . 38 , (1) PC2 ′ = 1 . 61 · PC2 − 0 . 01 . (2) Country/territor y reference points 𝝂 IVS 𝑐 ∈ R 2 are computed by rst taking survey-weighted means within each country–wave and then averaging the resulting country–wave points across waves in 2005– 2022. 1 W e visualize these country/territor y reference points as the IVS cultural map (Figure 1). 3.2 Open-source mo del projection into the I VS benchmark space With the benchmark space established, we next project open-weight LLM responses into the same co ordinate system to enable direct comparison to the I VS countr y/territor y map, replicating the ap- proach of [ 42 ], but on open-weight models rather than the closed- source systems emphasize d there. W e evaluate ve open-weight LLMs: Llama 3.3 (70B) [ 29 ], Llama 4 (16x17B) [ 30 ], Gemma 3 (27B) [ 12 ], GPT -OSS (20B), and GPT -OSS (120B) [ 35 ]. For each of the ten IVS indicators, we prompt mo dels with (i) a short persona state- ment and (ii) the survey question text paired with r esponse-format 1 W e average across waves with equal weight p er countr y–wave observation, consistent with treating each observed country–wave as one estimate of the country’s p osition in the shared IVS space. Eren and Michalak et al. constraints aligned with the survey coding scheme (e.g., one in- teger or one categorical option), enabling deterministic mapping from model outputs to the corresponding numeric variables [ 42 ]. In the generic setting (no cultural prompting), we ask the IVS sur vey question directly (with the same response-format constraints). In the cultural setting, we prepend the survey question with a light- weight country/territory prex of the form “Y ou are a citizen of X . ” to condition responses on the target cultural context. Example prompting (generic vs. cultural). A008 (Feeling of Happiness) Question from IVS Generic (no cultural prompting): Question: Taking all things together, rate how happy you would say you are. Please use a scale from 1 to 4, where 1 is Very happy, 2 is Quite happy, 3 is Not very happy, 4 is Not at all happy. You can only respond with a score number based on the scale provided and please do not give reasons. Your score number: Cultural prompting (country/territor y-conditioned): You are a citizen of United States of America (USA). Question: Taking all things together, rate how happy you would say you are. Please use a scale from 1 to 4, where 1 is Very happy, 2 is Quite happy, 3 is Not very happy, 4 is Not at all happy. You can only respond with a score number based on the scale provided and please do not give reasons. Your score number: Following [ 42 ], we explicitly account for prompt-phrasing vari- ance by evaluating a small set of semantically e quivalent respondent- descriptor personas and averaging results to reduce sensitivity to wording choices; concretely , we var y the respondent descrip- tor using synonymous terms such as average / typical , human being / person / individual , and world citizen and average the resulting projected coordinates across variants . W e use determinis- tic decoding (temperature = 0 ) and minimal output sanitation to extract the required option [42]. Let x 𝑚,𝑐,𝑣 ∈ R 10 be the code d response vector produced by model 𝑚 under country/territor y condition 𝑐 and persona variant 𝑣 , with 𝑐 = ∅ denoting a non-national generic persona. W e project each response vector into the IVS benchmark space by standardizing with IVS-derived moments and applying the IVS-tte d rotated two- dimensional scoring map: z 𝑚,𝑐,𝑣 = x 𝑚,𝑐,𝑣 − 𝝁 IVS raw ⊘ 𝝈 IVS raw , (3) s 𝑚,𝑐,𝑣 = W rot z 𝑚,𝑐,𝑣 , (4) where 𝝁 IVS raw ∈ R 10 and 𝝈 IVS raw ∈ R 10 are the (survey-weighted) I VS means and standard deviations for the ten indicators, ⊘ denotes el- ementwise division, and W rot ∈ R 2 × 10 are the rst-two-component varimax-rotated PCA scoring weights estimate d from I VS data [ 42 ]. W e then rescale s 𝑚,𝑐,𝑣 using Eqs. (1–2) to obtain 𝝅 𝑚,𝑐,𝑣 ∈ R 2 and average across persona variants: 𝝁 𝑚,𝑐 = 1 | 𝑉 | 𝑣 ∈ 𝑉 𝝅 𝑚,𝑐,𝑣 . (5) W e overlay 𝝁 𝑚, ∅ (generic, non-national prompting) for each open- weight model on the I VS cultural map to visualize how open-weight models cluster relative to country/territor y r eference locations (Fig- ure 1). 3.3 Country-level cultural distance under three prompting regimes Having embedded b oth IVS respondents and model responses in a common space, we quantify alignment using countr y-level Eu- clidean distance in the I VS benchmark co ordinates as described in [ 42 ]. Let 𝝂 IVS 𝑐 ∈ R 2 denote the IVS reference coordinate for coun- try/territor y 𝑐 (computed from human respondents). All distances are measured to the same human reference point 𝝂 IVS 𝑐 . W e compare three prompting regimes for cultural conditioning: (1) No culture conditioning. W e compute a single generic model point 𝝁 𝑚, ∅ and compare it to every country benchmark: 𝑑 nocond ( 𝑚, 𝑐 ) = 𝝁 𝑚, ∅ − 𝝂 IVS 𝑐 2 . (6) (2) Manual culture prompting. W e condition the model on country/territor y identity 𝑐 via a xed cultural prex while keeping the survey questions and answer constraints unchanged [ 42 ]. This yields 𝝁 man 𝑚,𝑐 and distance 𝑑 man ( 𝑚, 𝑐 ) = 𝝁 man 𝑚,𝑐 − 𝝂 IVS 𝑐 2 . (7) (3) Culture prompt programming ( DSPy ). W e replace the xed manual prex with a compiled prompt program produced by DSPy [ 24 ], as described in Se ction 3.4, yielding 𝝁 DSPy 𝑚,𝑐 and distance 𝑑 DSPy ( 𝑚, 𝑐 ) = 𝝁 DSPy 𝑚,𝑐 − 𝝂 IVS 𝑐 2 . (8) T o summarize changes relative to the no-conditioning baseline, we report paired country-level improv ements Δ 𝑑 man ( 𝑚, 𝑐 ) = 𝑑 man ( 𝑚, 𝑐 ) − 𝑑 nocond ( 𝑚, 𝑐 ) , (9) Δ 𝑑 DSPy ( 𝑚, 𝑐 ) = 𝑑 DSPy ( 𝑚, 𝑐 ) − 𝑑 nocond ( 𝑚, 𝑐 ) , (10) and the fraction of countries with Δ 𝑑 man ( 𝑚, 𝑐 ) < 0 and Δ 𝑑 DSPy ( 𝑚, 𝑐 ) < 0 . W e visualize the distances in Figure 2. 3.4 Culture prompt programming with DSPy W e use DSPy for prompt programming because it provides a way to treat cultural conditioning as an optimization pr oblem: instead of committing to a single hand-written persona template, we allow the culture-conditioning instruction to b e automatically tune d to reduce country-level cultural distance [ 24 ]. Concretely , we parameterize the culture-conditioning instruction by a discrete prompt parameter 𝜃 (a text instruction) that is inserte d upstream of the xed I VS question block; for a given ( 𝑚, 𝑐 , 𝜃 ) , the resulting program elicits the ten I VS responses under the same response-format constraints used throughout and projects them into the I VS space to obtain 𝝁 𝑚,𝑐 ( 𝜃 ) ∈ R 2 (Sections 3.2–3.3) [42]. W e train the compiler to reduce misalignment by directly op- timizing countr y-level cultural distance to I VS benchmarks. Let 𝝂 IVS 𝑐 ∈ R 2 be the IVS b enchmark coordinate for country/territory Prompt Programming for Cultural Bias and Alignment of Large Language Models 1.2 0.6 0.0 0.6 1.2 1.8 2.4 3.0 Survival vs. Self -Expr ession V alues 1.5 1.0 0.5 0.0 0.5 1.0 1.5 T raditional vs. Secular V alues Albania Algeria Andor ra Azerbaijan Ar gentina Australia Austria Bangladesh Ar menia Belgium Bolivia Bosnia Herzegovina Brazil Bulgaria Myanmar Belarus Canada Chile China T aiwan ROC Colombia Cr oatia Cyprus Norther n Cyprus Czechia Denmark Ecuador Ethiopia Estonia F inland F rance Geor gia P alestine Ger many Ghana Gr eece Guatemala Haiti Hong K ong S AR Hungary Iceland India Indonesia Iran Iraq Ir eland Italy Japan K azakhstan Jor dan K enya South K or ea K uwait K yr gyzstan L ebanon Latvia Libya Lithuania L ux embour g Macau S AR Malaysia Maldives Mali Malta Me xico Mongolia Moldova Montenegr o Mor occo Netherlands New Zealand Nicaragua Nigeria Norway P akistan P eru Philippines P oland P ortugal P uerto Rico Qatar R omania R ussia Rwanda Serbia Singapor e Slovakia V ietnam Slovenia South A frica Zimbabwe Spain Sweden Switzerland T ajikistan Thailand T rinidad and T obago T unisia T urk ey Ukraine North Macedonia Egypt Gr eat Britain United States Burkina F aso Uruguay Uzbekistan V enezuela Y emen Zambia North Ir eland K osovo P r otestant Eur ope Catholic Eur ope English-Speaking Orthodo x Eur ope Confucian Latin America W est & South Asia A frican-Islamic gemma3:27b gpt-oss:120b gpt-oss:20b llama3.3:70B llama4:16x17B Figure 1: Cultural map of countries/territories in the I VS benchmark space (Sur vival vs. Self-Expression; Traditional vs. Secular values). W e overlay points derived from op en-weight mo del responses (Llama 3.3 70B, Llama 4 16x17B, Gemma 3 27B, GPT -OSS 20B, GPT -OSS 120B) to the same IVS items, following the projection procedure of Tao et al. [ 42 ]. Colored area around each point is used as visual purposes of highlighting clustering of each categor y . 𝑐 , and let 𝝁 𝑚,𝑐 ( 𝜃 ) ∈ R 2 denote the persona-variant-averaged coor- dinate produced by the target model 𝑚 under the DSPy -compiled prompt instruction 𝜃 . W e dene the per-countr y objective 𝑑 ( 𝑚, 𝑐 ; 𝜃 ) = 𝝁 𝑚,𝑐 ( 𝜃 ) − 𝝂 IVS 𝑐 2 , (11) score ( 𝑚, 𝑐 ; 𝜃 ) = − 𝑑 ( 𝑚, 𝑐 ; 𝜃 ) , (12) so that maximizing score is equivalent to minimizing cultural dis- tance. In summar y , our objective to tune the prompt is by mini- mizing the cultural distance described above in Section 3.3. DSPy compilation selects 𝜃 to minimize mean distance over a training set of countries/territories C train : 𝐽 ( 𝜃 ; 𝑚, C train ) = 1 | C train | 𝑐 ∈ C train score ( 𝑚, 𝑐 ; 𝜃 ) = − 1 | C train | 𝑐 ∈ C train 𝑑 ( 𝑚, 𝑐 ; 𝜃 ) , (13) 𝜃 ★ = arg max 𝜃 𝐽 ( 𝜃 ; 𝑚, C train ) = arg min 𝜃 1 | C train | 𝑐 ∈ C train 𝑑 ( 𝑚, 𝑐 ; 𝜃 ) . (14) W e evaluate two DSPy teleprompters, COPRO and MIPROv2 [ 7 , 8 ]. Both methods treat the prompt text as a discrete param- eter 𝜃 of a xed DSPy program and iteratively improve 𝜃 using metric-based evaluation on a training set [ 24 ]. COPRO (Coopera- tive Prompt Optimization) focuses on instruction-level r enement: starting from a baseline instruction, it generates a pool of candi- date rewrites (and, when applicable, output-eld prexes) using a proposer model, executes the student program under each can- didate, scores candidates with the task metric, and then updates the instruction by selecting the best-performing candidate before repeating for multiple rounds [ 7 ]. Operationally , this behaves like a coordinate-ascent style search ov er prompt text: each iteration pr o- poses localized e dits conditioned on prior attempts and their scores, making COPRO a conservative optimizer that tends to steadily im- prove an initial template without substantially changing the ov erall program structure [7]. MIPROv2 (Multiprompt Instruction PRoposal Optimizer , ver- sion 2) performs a broader , multi-stage search that can jointly op- timize instructions and few-shot demonstrations [ 8 ]. It rst boot- straps candidate demonstration sets ( e.g., by sampling and/or gener- ating candidate exemplars consistent with the program signature), then proposes a diverse set of candidate instructions intended to capture dierent task “dynamics” (e.g., dierent ways of spe cify- ing constraints, emphasizing format, or prompting reasoning), and nally selects an optimize d combination of instruction and demon- strations by maximizing the evaluation metric using Bayesian Op- timization over this discrete conguration space [ 8 ]. In practice, Eren and Michalak et al. llama3.3:70B llama4:16x17B gemma3:27b gpt- oss:20b gpt- oss:120b 0 1 2 3 4 5 Cultural distance W ithout Cultur e P r ompt Engineering W ith Cultur e P r ompt Engineering Cultur e P r ompt P r ogramming (DSPy, MIPROv2 with llama3.2:1b) Cultur e P r ompt P r ogramming (DSPy, MIPROv2 with gpt- oss:120b) Cultur e P r ompt P r ogramming (DSPy, COPRO with llama3.2:1b) Cultur e P r ompt P r ogramming (DSPy, COPRO with gpt- oss:120b) Figure 2: Country-level cultural distance for open-source LLMs under three prompting regimes: (i) without culture conditioning, (ii) with manual culture prompt engine ering, and (iii) culture prompt programming with DSPy . Cultural distance is computed as Euclidean distance in the I VS cultural map space, consistent with T ao et al. [ 42 ]. Cultural distance is measured, for each country/territor y 𝑐 , as the Euclidean distance between the mo del’s projecte d co ordinate in the I VS cultural-map space (Figure 1) and the human reference coordinate 𝝂 IVS 𝑐 . W e report distances under three regimes: a generic (non-national, without culture prompt engine ering) model point compared to all countries, country-conditioned prompting using a xe d manual prex, and country-conditioned prompting using a DSPy -compiled prompt program. Smaller distances indicate closer alignment to the country/territor y b enchmark, and changes across regimes reect how cultural conditioning and prompt programming shift the model toward 𝝂 IVS 𝑐 . MIPROv2 evaluates candidates on minibatches and can use an ex- plicit development split during compilation, which helps scale can- didate testing and reduces the risk that a single high-variance batch drives selection [ 8 ]. In our setting, we use MIPROv2 in instruction- optimization mode (optionally with demonstrations), tr eating the culture-conditioning instruction as the primar y tunable comp o- nent while holding the I VS question block and response-format constraints xed. T o understand the role of the instruction-proposal model, we run each teleprompter twice: once using a small proposer (Llama 3.2:1B) and once using a large proposer ( GPT -OSS:120B). In all cases, the target model 𝑚 is the model being aligned and is used to generate survey responses for scoring; the proposer model is only used to gen- erate candidate instructions. Figure 3 visualizes how DSPy Culture Prompt Programming (MIPROv2; proposer gpt-oss:120b ) changes gpt-oss:120b ’s projected position on the Inglehart– W elzel map for each country/territory 𝑐 . Mini-panels (gr ouped by cultural zone) compare the generic, non-national model projection 𝝁 𝑚, ∅ (Generic) to the countr y-aligned projection 𝝁 DSPy 𝑚,𝑐 (Aligned), alongside the human reference point 𝝂 IVS 𝑐 (Human). The arrow denotes the shift from 𝝁 𝑚, ∅ to 𝝁 DSPy 𝑚,𝑐 , while the dashed segment shows the residual discrepancy after alignment. W e dene the generic and aligned distances to the human benchmark as 𝑑 gen ( 𝑚, 𝑐 ) = 𝝁 𝑚, ∅ − 𝝂 IVS 𝑐 2 , (15) 𝑑 align ( 𝑚, 𝑐 ) = 𝝁 DSPy 𝑚,𝑐 − 𝝂 IVS 𝑐 2 , (16) and summarize the improvement for each 𝑐 as Δ ( 𝑐 ) = 𝑑 gen ( 𝑚, 𝑐 ) − 𝑑 align ( 𝑚, 𝑐 ) = 𝝁 𝑚, ∅ − 𝝂 IVS 𝑐 2 − 𝝁 DSPy 𝑚,𝑐 − 𝝂 IVS 𝑐 2 . (17) Here, Δ ( 𝑐 ) > 0 indicates that DSPy tuning moves the model closer to the human benchmark for 𝑐 . W e assess generalization across cul- tures using 5-fold cross-validation (CV) ov er countries/territories. In each fold, 80% of countries form the compilation p ool and 20% are held out for testing. Compilation is performed only on the com- pilation p ool, and for MIPRO v2 we further split the compilation pool into training and development subsets for validation during compilation [8]. W e report mean held-out cultural distance: 𝑑 test = 1 | C test | 𝑐 ∈ C test 𝑑 ( 𝑚, 𝑐 ; 𝜃 ★ ) . (18) 4 Results Figure 1 shows that the generic (non-national) projections of all ve open-weight models fall within a relatively tight region of the IVS cultural map, rather than spreading across the full countr y and territor y distribution. This concentration indicates a strong shared default cultural orientation acr oss the models. The model points cluster toward the high self-expression side of the horizontal axis and away from many dense country and territory groupings. This suggests that, when answering IVS items without an explicit Prompt Programming for Cultural Bias and Alignment of Large Language Models -1.92 -0.51 0.90 2.31 Switzerland ( =+0.636) Iceland ( =+0.474) Norway ( =+0.112) Denmark ( =-0.026) Ger many ( =-0.251) Netherlands ( =-0.511) Sweden ( =-0.637) F inland ( =-1.013) P oland ( =+2.292) Hungary ( =+1.967) Slovakia ( =+1.570) -1.92 -0.51 0.90 2.31 Lithuania ( =+1.544) Cr oatia ( =+1.466) Latvia ( =+0.757) Italy ( =+0.650) Andor ra ( =+0.638) Slovenia ( =+0.502) P ortugal ( =+0.440) Austria ( =+0.114) Spain ( =+0.099) Czechia ( =-0.129) L ux embour g ( =-0.232) -1.92 -0.51 0.90 2.31 Belgium ( =-0.405) F rance ( =-0.522) North Ir eland ( =+0.574) Ir eland ( =+0.436) United States ( =+0.142) New Zealand ( =-0.018) Canada ( =-0.052) Gr eat Britain ( =-0.171) Australia ( =-0.299) R ussia ( =+2.867) Ar menia ( =+2.825) -1.92 -0.51 0.90 2.31 Belarus ( =+2.638) Geor gia ( =+2.637) Moldova ( =+2.502) Serbia ( =+2.472) Bosnia Herzegovina ( =+1.932) Bulgaria ( =+1.906) Gr eece ( =+1.859) Ukraine ( =+1.601) Montenegr o ( =+1.593) North Macedonia ( =+1.508) R omania ( =+1.408) -1.92 -0.51 0.90 2.31 Estonia ( =-0.463) China ( =+2.350) South K or ea ( =+1.512) Macau S AR ( =+1.157) Hong K ong S AR ( =+1.023) Mongolia ( =+0.882) T aiwan ROC ( =+0.632) Japan ( =-0.176) Nicaragua ( =+3.441) Philippines ( =+3.092) P eru ( =+2.659) -1.92 -0.51 0.90 2.31 Guatemala ( =+2.601) Bolivia ( =+2.530) Brazil ( =+2.420) Ecuador ( =+2.183) P uerto Rico ( =+2.174) Haiti ( =+2.113) Colombia ( =+2.004) Chile ( =+1.781) Me xico ( =+1.780) T rinidad and T obago ( =+1.661) Malta ( =+1.528) -1.92 -0.51 0.90 2.31 V enezuela ( =+1.305) Ar gentina ( =+0.426) Uruguay ( =-0.119) Malaysia ( =+3.128) Indonesia ( =+3.017) Myanmar ( =+2.910) India ( =+2.784) Thailand ( =+2.061) V ietnam ( =+1.944) Norther n Cyprus ( =+1.570) Singapor e ( =+1.450) -1.92 -0.51 0.90 2.31 Cyprus ( =+1.381) Jor dan ( =+4.289) Egypt ( =+4.055) Qatar ( =+3.962) Maldives ( =+3.739) Mor occo ( =+3.656) Ghana ( =+3.609) Algeria ( =+3.608) Ethiopia ( =+3.571) Zimbabwe ( =+3.567) Bangladesh ( =+3.533) -1.92 -0.51 0.90 2.31 Azerbaijan ( =+3.485) Rwanda ( =+3.452) P alestine ( =+3.392) Nigeria ( =+3.257) P akistan ( =+3.245) Zambia ( =+3.152) Iran ( =+3.064) L ebanon ( =+3.000) Burkina F aso ( =+2.943) Mali ( =+2.915) K azakhstan ( =+2.914) -1.92 -0.51 0.90 2.31 K enya ( =+2.897) T ajikistan ( =+2.591) -2.21 0.20 2.61 5.02 T unisia ( =+2.563) -2.21 0.20 2.61 5.02 Libya ( =+2.558) -2.21 0.20 2.61 5.02 Uzbekistan ( =+2.475) -2.21 0.20 2.61 5.02 K yr gyzstan ( =+2.456) -2.21 0.20 2.61 5.02 Y emen ( =+2.390) -2.21 0.20 2.61 5.02 Albania ( =+2.318) -2.21 0.20 2.61 5.02 T urk ey ( =+2.086) -2.21 0.20 2.61 5.02 K uwait ( =+2.008) -2.21 0.20 2.61 5.02 Iraq ( =+1.963) -2.21 0.20 2.61 5.02 -1.92 -0.51 0.90 2.31 K osovo ( =+1.742) -2.21 0.20 2.61 5.02 South A frica ( =+1.221) R C1 (PCA) R C2 (PCA) Generic (global) Aligned (country) Human (country) Aligned Human gap Generic Aligned shif t P r otestant Eur ope Catholic Eur ope English-Speaking Orthodo x Eur ope Confucian Latin America W est & South Asia A frican-Islamic Figure 3: Per-countr y movement in the Inglehart– W elzel I VS benchmark space (PC1 ′ /PC2 ′ ; Sur vival vs. Self-Expression and Traditional vs. Secular). Each mini-panel corresponds to one country/territor y 𝑐 (grouped by cultural zone; background tint) and compares the generic, non-national gpt-oss:120b projection 𝝁 𝑚, ∅ (Generic) to the aligne d projection 𝝁 DSPy 𝑚,𝑐 (Aligned), obtained via Culture Prompt Programming with DSPy (MIPROv2; proposer gpt-oss:120b), relative to the human reference point 𝝂 IVS 𝑐 (Human). The arrow indicates the shift from 𝝁 𝑚, ∅ to 𝝁 DSPy 𝑚,𝑐 , and the dashed segment indicates the remaining discrepancy ∥ 𝝁 DSPy 𝑚,𝑐 − 𝝂 IVS 𝑐 ∥ 2 . Each panel reports Δ ( 𝑐 ) = ∥ 𝝁 𝑚, ∅ − 𝝂 IVS 𝑐 ∥ 2 − ∥ 𝝁 DSPy 𝑚,𝑐 − 𝝂 IVS 𝑐 ∥ 2 , where Δ ( 𝑐 ) > 0 indicates that DSPy alignment moves the model closer to the human benchmark for 𝑐 . Eren and Michalak et al. national identity , open-weight models tend to draw from a com- paratively narrow cultural prior instead of adapting to the broader country-level structure represented in the benchmark. The tight clustering also helps interpret dierences among mo d- els. Although the model families o ccupy slightly dierent p ositions within the clustered region, these separations are small relative to the overall spread of countr y and territory locations in the IVS space. This r einforces that the dominant eect under generic prompting is a shared skew , with mo del-specic dierences acting as secondary variation. This b ehavior aligns with the pr oprietary-model results reported by T ao et al. [ 42 ] using the same cultural-map visualization. In their analysis, GPT -family systems under generic prompting also occupied a compact r egion of the IVS space that lay nearer to W est- ern cultural clusters than to the global distribution of countries and territories, reecting a similar default prior in the absence of country conditioning [ 42 ]. Our results suggest that this compressed footprint and systematic shift toward the self-expression side is not unique to closed models or a single vendor . At the same time, we observe small but visible separations across open-weight model families within the default region, while [ 42 ] emphasized dier- ences primarily across proprietary model versions. T ogether , these ndings suggest that architecture, scale , and training regimes can modulate the precise location of the default prior , but do not remove the overall clustering eect under generic prompting. Figure 2 reports country-level cultural distance (Euclidean dis- tance in the IVS map space) under three prompting regimes. Con- sistent with T ao et al. [ 42 ], distances are largest under generic prompting without culture conditioning, indicating that a single non-national "default" response prole remains far from many coun- try/territor y benchmarks. Which is also shown in Figure 1 wher e these LLMs are tightly clustered near W estern cultures. Also match- ing [ 42 ], manual culture prompt engineering substantially reduces distances across all evaluated mo dels: conditioning the persona on the target country shifts the distance distributions downward and narrows disp ersion, showing that explicit country identity moves model behavior closer to the intended cultural coordinates, although nontrivial tails remain. Prompt programming with DSPy provides a third regime that treats cultural alignment as an optimization objective, and the out- comes depend on b oth the target model family and the teleprompter (proposal-model) conguration. Overall, the strongest results ar e achieved by MIPROv2 when paired with the larger proposal model (GPT -OSS:120B): this setting yields the largest additional reduc- tions beyond manual prompting for every model except Llama 3.3, making it the most consistently eective DSPy conguration in our experiments. For Llama 4, all DSPy variants improve ov er manual prompt engineering, suggesting that this model family particularly benets from replacing a xed country-conditioning template with a compiled instruction that is tuned to the cultural-distance met- ric. For Gemma 3 and the GPT -OSS target models, the gains are more selective: only MIPRO v2 with the GPT -OSS:120B proposer consistently outperforms manual prompting, while other DSPy congurations provide smaller or negligible impro vements. For countr y-level observations, we additionally visualize per- country alignment shifts for GPT -OSS (120B) optimized with MIPRO v2 in Figure 3. The gure uses the same I VS benchmark coordinate sys- tem as Figure 1, but presents one mini-panel per countr y/territory , overlaying GPT -OSS (120B) projections with and without alignment against the human refer ence point. This makes the dir ection and magnitude of the model’s response shift—and the resulting change in cultural distance to humans—explicit for each country . A key takeaway from Figure 3 is that the alignment change for W estern countries is relatively small (e.g., the United States, Δ = + 0 . 142 ), whereas it is much larger for an African–Islamic countr y such as Jordan ( Δ = + 4 . 289 ). One possible explanation is that the model is already comparatively close to W estern cultural co ordinates, while prompt programming primarily induces a substantial shift along the Survival vs. Self-Expression V alues axis, moving the model leftward on the map and yielding larger distance reductions in countries where the initial mismatch is greater . T aken together , these results imply three broader points. First, the qualitative and quantitative eects of manual cultural prompt- ing appear to generalize from proprietary systems to open-weight models, reinforcing that generic prompting induces a systematic cultural prior that can be partially correcte d by explicit countr y conditioning [ 42 ]. Second, prompt programming can deliv er further improvements, but the benet depends on the optimizer’s search behavior and the capability of the proposal model, with larger pro- posal mo dels producing more consistently better compiled prompts. Third, the persistence of outliers and the model-dependent nature of DSPy gains indicate that cultural alignment via prompting remains incomplete: optimization can improve average alignment while still failing for a subset of countries, highlighting the nee d for evalu- ation protocols (such as country-disaggregated cross-validation) that explicitly test robustness and transfer rather than relying on a single global average. 5 Discussion and Future W ork Our ndings are consistent with several complementary threads in the cultural-awareness literatur e beyond [ 42 ]. First, the persis- tence of a single W estern-skewed “default” prole under generic prompting mirrors the WEIRD-centrism, where model responses tend to align most closely with W estern, Educate d, Industrialized, Rich, and Democratic populations [ 3 ]. Second, the fact that explicit country identity in the prompt reliably shifts model behavior to- ward the target reference location aligns with persona-simulation evidence that nationality conditioning impro ves agreement with human responses [ 26 ]. Third, our observation that alignment gains depend strongly on prompt formulation and optimization setup is consistent with prior evidence that measured cultural alignment can vary with prompt language, persona/demographic condition- ing, and evaluation protocol [ 1 , 44 ]. Finally , the model and countr y dependent hard cases that remain after manual prompting and DSPy compilation are compatible with the W orldV aluesBench evaluation framing, which assesses value alignment by comparing model and human response distributions across demographic conditions and shows that performance is not uniform across the b enchmark [ 47 ]. This validation-and-extension study has several limitations that motivate follow-on investigation. First, our primary measurement instrument is a collection of forced-choice sur vey items; while this design yields a standardized, population-grounded signal, it may Prompt Programming for Cultural Bias and Alignment of Large Language Models not reect how cultural values surface in open-ende d generation, multi-turn dialogue, or decision-support deployments, where mo d- els can justify , hedge, and reframe rather than select among xed options. Se cond, although both cultural prompting and prompt programming reduce cultural distance on average, we observe het- erogeneous eects: some prompts/optimizers impr ove alignment for many targets while degrading it for particular countries or re- gions, suggesting incomplete controllability that may depend on pretraining coverage, safety behavior , and sensitivity to prompt wording. Third, our experiments are English-only and short-form; since results can depend on prompt language and phrasing [ 42 ], a more realistic robustness test would extend the framework to multilingual and native-language elicitation, as well as longer-form tasks that involve r easoning, trade-os, and deliberation. Finally , improved agreement on survey-style items should not be assumed to transfer wholesale to broader r eal-world behavior without direct downstream evaluation [ 42 ]. Addressing these limitations would clarify when survey-grounded cultural alignment generalizes be- yond questionnaires and how prompt optimization can be made more reliable across div erse cultural contexts. Finally , future research related to LLMs and cultural bias could be explored specically around strategic culture. Strategic culture was rst dened by Jack L. Snyder in 1977 with a focus on the Soviet Union’s nuclear strategy . He p osited that Soviet strategic thinking was a unique strategic culture, made up of a general set of beliefs, attitudes, and behavioral patterns, which was in a state of semiper- manence making it a culture more than a policy [ 40 ]. As the study of strategic culture has grown, “generations” of thinking and deni- tional debates have emerged and evolv ed over time [ 21 ]. Recently , Kuzner et al. [ 25 ] took 22 denitions of strategic culture and created an overarching denition of the term, being “an actor’s strategic culture is composed of beliefs, experiences, assumptions, attitudes, and patterne d b ehaviors that shape perceptions and preferences about its security-related interests, objectives, and activities. ” Strate- gic culture dierentiates from the wider culture with a focus on security-related topics, the pursuit of which can help inform the elds of national security and strategic studies. There has been lim- ited research on the nexus of AI/ML and strategic culture. T app e and Doeser [ 43 ] used super vised machine learning to analyze changes to German strategic culture and the impact of strategic culture on Germany’s military engagement between 1990 and 2017. 6 Conclusion W e extend sur vey-grounded cultural alignment evaluation from pro- prietary systems to open-weight LLMs by reproducing Integrated V alues Sur veys (IVS)-based projections onto the Inglehart– W elzel cultural map and countr y-level cultural distance distributions, with and without cultural prompting. Using ten IVS items and bench- mark PCA pipeline, we nd that open models show systematic cultural skew under generic prompting, and that country-identity prompting reduces misalignment for many countries. W e also intro- duce prompt programming with DSPy as a scalable alternative to manual cultural prompt engineering. Optimizing prompt programs directly against cultural distance, specically using MIPROv2 with GPT -OSS:120B instruction-proposal model as prompt optimizer improve alignment. Acknowledgments This manuscript has been approved for unlimited release and has been assigned LA-UR-26-21996. The funding for this paper was provided by Los Alamos National Laborator y (LANL). LANL is operated by Triad National Security , LLC, for the National Nuclear Security Administration of the U.S. Department of Energy (Contract No. 89233218CNA000001). References [1] Badr AlKhamissi, Muhammad N. ElNokrashy , Mai Alkhamissi, and Mona T . Diab. 2024. Investigating Cultural Alignment of Large Language Models. A rXiv abs/2402.13231 (2024). https://api.semanticscholar .org/CorpusID:267759574 [2] Arnav Arora, Lucie- Aimée K aee, and Isabelle A ugenstein. 2022. Probing Pre- Trained Language Mo dels for Cross-Cultural Dierences in V alues. A rXiv abs/2203.13722 (2022). https://api.semanticscholar .org/CorpusID:247748753 [3] Mohammad Atari, Mona J. Xue, Peter S. Park, Damián E. Blasi, and Joseph Henrich. 2023. Which Humans? Psy A rXiv (2023). doi:10.31234/osf.io/5b26t [4] Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty , Daniel Fried, Andrew Go, Jonathan Gray , Hengyuan Hu, Athul Paul Jacob, Mo jtaba Komeili, K arthik Konath, Minae K won, A dam Lerer , Mike Lewis, Alexan- der H. Miller , Sandra Mitts, A dithya Renduchintala, Stephen Roller , Dirk Rowe, W eiyan Shi, Joe Spisak, Alexander W ei, David J. W u, Hugh Zhang, and Markus Zijlstra. 2022. Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science 378 (2022), 1067 – 1074. https://api.semanticscholar .org/CorpusID:253759631 [5] Michal Bravansky, Filip Trhlík, and Fazl Barez. 2025. Rethinking AI Cultural Alignment. https://api.semanticscholar .org/CorpusID:275515905 [6] Bram Bult’e and A yla Rigouts T erryn. 2025. LLMs and Cultural Values: the Impact of Prompt Language and Explicit Cultural Framing. A rXiv abs/2511.03980 (2025). https://api.semanticscholar .org/CorpusID:282812238 [7] DSPy Contributors. 2024. DSPy Do cumentation: COPRO T eleprompter. https: //dspy .ai/api/teleprompt/COPRO/. Accessed: 2026-02-24. [8] DSPy Contributors. 2024. DSPy Documentation: MIPRO v2 Optimizer . https: //dspy .ai/api/optimizers/MIPRO v2/. Accessed: 2026-02-24. [9] Maksim E Eren and Dorianis M Perez. 2025. Rethinking Science in the Age of Articial Intelligence. arXiv preprint arXiv:2511.10524 (2025). [10] European Values Study. 2022. European V alues Study 2017–2022: Trend File. https://europeanvaluesstudy .eu/. Accessed: 2026-02-24. [11] Kimo Gandall, Juliana Chhouk, Alex W ang, and Logan Knight. 2022. Predicting Policy: A Psycholinguistic Articial Intelligence in the United Nations. Social Science Computer Review 41 (2022), 410 – 437. https://api.semanticscholar.org/ CorpusID:248896975 [12] Gemma T eam. 2024. Gemma: Op en Models Based on Gemini Research and T echnology . https://arxiv.org/abs/2403.08295. Accessed 2026-02-24. [13] Aditi Go dbole, Jabin Geevarghese Ge orge, and Smita Shandilya. 2024. Leveraging Long-Context Large Language Models for Multi-Document Understanding and Summarization in Enterprise Applications. A rXiv abs/2409.18454 (2024). https: //api.semanticscholar .org/CorpusID:272969413 [14] Candida Maria Greco, Lucio La Cava, and Andrea T agarelli. 2026. Culturally Grounded Personas in Large Language Mo dels: Characterization and Alignment with Socio-Psy chological V alue Frame works. ArXiv abs/2601.22396 (2026). https: //api.semanticscholar .org/CorpusID:285241197 [15] Mourad Gridach, Jay Nanavati, Khaldoun Zine El Abidine, Lenon Mendes, and Christina DeFilippo Mack. 2025. Agentic AI for Scientic Discovery: A Survey of Progress, Challenges, and Future Directions. A rXiv abs/2503.08979 (2025). https://api.semanticscholar .org/CorpusID:276937648 [16] Christian Härpfer , Ronald Inglehart, et al . 2022. W orld Values Survey: Round Seven — Countr y-Pooled Datale (2017–2022), V ersion 5.0. https://www. worldvaluessurvey .org/W VSDocumentationW V7.jsp. Accessed: 2026-02-24. [17] Geert Hofstede. 2001. Culture’s Consequences: Comparing V alues, Behaviors, Institutions and Organizations Across Nations. https://api.semanticscholar .org/ CorpusID:145428141 [18] Daniel P. Hogan and Andrea Brennen. 2024. Open-Ended Wargames with Large Language Models. ArXiv abs/2404.11446 (2024). https://api.semanticscholar .org/ CorpusID:269187731 [19] Ronald Inglehart and Christian W elzel. 2005. Modernization, Cultural Change, and Democracy: The Human Development Se quence . Cambridge University Press. [20] Rebecca L Johnson, Giada Pistilli, Natalia Menédez-González, Leslye Denisse Dias Duran, Enrico Panai, Julija Kalpokiene, and Donald Jay Bertulfo . 2022. The Ghost in the Machine has an American accent: value conict in GPT -3. arXiv preprint arXiv:2203.07785 (2022). [21] Alastair Iain Johnston. 1995. Thinking about strategic culture. International security 19, 4 (1995), 32–64. Eren and Michalak et al. [22] I. T . Jollie and J. Cadima. 2016. Principal Comp onent A nalysis (2 ed.). Springer . doi:10.1007/978- 1- 4757- 1904- 8 [23] Henry F. Kaiser . 1958. The V arimax Criterion for Analytic Rotation in Factor Analysis. Psychometrika 23, 3 (1958), 187–200. doi:10.1007/BF02289233 [24] Omar Khattab , Arnav Singhvi, Paridhi Maheshwari, et al . 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv preprint arXiv:2310.03714 (2023). https://arxiv .org/abs/2310.03714 [25] Lawrence Kuznar , Nicole Heath, and George Popp. 2023. Strategic culture— Its histor y , issues, and complexity . (2023). Prepared for Strategic Multilayer Assessment, Joint Sta, J3. [26] Louis Kwok, Michal Bravansky, and Lewis Grin. 2024. Evaluating Cultural Adaptability of a Large Language Model via Simulation of Synthetic Personas. In First Conference on Language Modeling . https://openrevie w .net/forum?id= S4ZOkV1AHl [27] Florian Königstorfer and Stefan Thalmann. 2022. AI Documentation: A path to accountability . Journal of Responsible Technology 11 (2022), 100043. doi:10.1016/ j.jrt.2022.100043 [28] Jiya Manchanda, Laura Boettcher, Matheus W estphalen, and Jasser Jasser . 2024. The Open Source Advantage in Large Language Models (LLMs). A rXiv abs/2412.12004 (2024). https://api.semanticscholar .org/CorpusID:274788875 [29] Meta. 2024. Llama 3 Mo del Card. https://github.com/meta- llama/llama3/blob/ main/MODEL_CARD.md. Accessed 2026-02-24. [30] Meta. 2025. Llama 4 Model Card. https://github.com/meta- llama/llama- models/ blob/main/models/llama4/MODEL_CARD.md. Accessed 2026-02-24. [31] T arek Naous, Michael Joseph Ryan, and W ei Xu. 2023. Having Beer after Prayer? Measuring Cultural Bias in Large Language Models. In Annual Meeting of the Asso- ciation for Computational Linguistics . https://api.semanticscholar.org/CorpusID: 258865272 [32] Roberto Navigli, Simone Conia, and Björn Ross. 2023. Biases in Large Language Models: Origins, Inventory , and Discussion. J. Data and Information Quality 15, 2, Article 10 (June 2023), 21 pages. doi:10.1145/3597307 [33] Juhyun Oh, Inha Cha, Michael Saxon, Hyunseung Lim, Shaily Bhatt, and Alice Oh. 2025. Culture is Everywhere: A Call for Intentionally Cultural Evaluation. ArXiv abs/2509.01301 (2025). https://api.semanticscholar .org/CorpusID:281079526 [34] Alexandra O’Neil, Daniel Swanson, and Shobhana Chelliah. 2024. Computational Language Documentation: Designing a Modular Annotation and Data Manage- ment T o ol for Cross-cultural Applicability . In Proceedings of the 2nd W orkshop on Cross-Cultural Considerations in NLP , Vinodkumar Prabhakaran, Sunipa Dev, Luciana Benotti, Daniel Hershcovich, Laura Cabello, Y ong Cao, Ife Adebara, and Li Zhou (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 107–116. doi:10.18653/v1/2024.c3nlp- 1.9 [35] OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. 2508.10925. Accessed 2026-02-24. [36] Siddhesh Milind Pawar , Junyeong Park, Jiho Jin, Arnav Arora, Junho Myung, Srishti Y adav , Faiz Ghifari Haznitrama, Inhwa Song, Alice Oh, and Isabelle Augenstein. 2024. Survey of Cultural A wareness in Language Models: T ext and Beyond. ArXiv abs/2411.00860 (2024). https://api.semanticscholar .org/CorpusID: 273811670 [37] Kenneth Payne. 2026. AI Arms and Inuence: Frontier Models Exhibit Sophisti- cated Reasoning in Simulated Nuclear Crises. arXiv preprint (2026). [38] Sander Schulho, Michael Ilie, Nishant Balepur , K onstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulho, Pranav Sandeep Dulepet, Saurav Vidyadhara, Dayeon Ki, Sweta Agrawal, Chau Pham, Gerson C. Kroiz, Feileen Li, Hudson T ao, Ashay Srivastava, Hevander Da Costa, Saloni Gupta, Megan L. Rogers, Inna Goncearenco , Giuseppe Sarli, Igor Galynker , Denis Pesko, Marine Carpuat, Jules White, Shyamal Anadkat, Alexan- der Hoyle, and Philip Resnik. 2024. The Prompt Rep ort: A Systematic Sur vey of Prompt Engineering T echniques. https://api.semanticscholar .org/CorpusID: 276617957 [39] Elina Sigdel and Anastasia Panlova. 2026. RusLICA: A Russian-Language Platform for Automated Linguistic Inquiry and Category Analysis. arXiv preprint arXiv:2601.20275 (2026). [40] Jack Snyder . 1977. The Soviet Strategic Culture. Implications for Limited Nuclear Operations. https://api.semanticscholar .org/CorpusID:150401111 [41] Julius Steen and Katja Markert. 2023. Bias in News Summarization: Measures, Pitfalls and Corp ora. In A nnual Meeting of the Association for Computational Linguistics . https://api.semanticscholar .org/CorpusID:262013727 [42] Y an T ao, Olga Viberg, Ryan S Baker , and René F Kizilcec. 2024. Cul- tural bias and cultural alignment of large language models. PNAS Nexus 3, 9 (09 2024), pgae346. arXiv:https://academic.oup.com/pnasnexus/article- pdf/3/9/pgae346/59151559/pgae346.pdf doi:10.1093/pnasnexus/pgae346 [43] Jonathan T appe and Fredrik Doeser . 2021. A machine learning approach to the study of German strategic culture. Contemporary Security Policy 42, 4 (2021), 450–474. [44] Mustafa T una, Kristina Schaa, and Tim Schlippe. 2024. Ee cts of Language- and Culture-Specic Prompting on ChatGPT . In 2024 2nd International Conference on Foundation and Large Language Models (FLLM) . 73–81. doi:10.1109/FLLM63129. 2024.10852463 [45] W orld V alues Sur vey Association and European V alues Study. 2023. Inte- grated Values Surveys (I VS) — Codeb ook and Documentation. https://w ww. worldvaluessurvey .org/W VSDocumentationW VL.jsp. Accessed: 2026-02-24. [46] Xufeng Yao , Xiaoxu Wu, Xi Li, Huan Xu, Chenlei Li, Ping Huang, Sitong Li, Xiaoning Ma, and Jiulong Shan. 2024. Smart Audit System Empowered by LLM. A rXiv abs/2410.07677 (2024). https://api.semanticscholar .org/CorpusID: 273233253 [47] W enlong Zhao, Debanjan Mondal, Niket Tandon, Danica Dillion, Kurt Gray , and Y u Gu. 2024. W orldV aluesBench: A Large-Scale Benchmark Dataset for Multi- Cultural V alue A wareness of Language Models. In International Conference on Language Resources and Evaluation . https://api.semanticscholar .org/CorpusID: 269362884 [48] Ke Zhou, Marios Constantinides, and Daniele Quercia. 2025. Should LLMs be WEIRD? Exploring WEIRDness and Human Rights in Large Language Mod- els. ArXiv abs/2508.19269 (2025). https://api.semanticscholar .org/CorpusID: 280919174
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment