RAG 기반 LLM을 위한 컨포멀 사실성 검증의 견고성 및 효율성
본 논문은 검색‑증강 생성(RAG)과 컨포멀 예측을 결합해 LLM의 사실성 보장을 시도하지만, 실제 배포 환경에서 정보성 손실, 분포 이동에 대한 취약성, 그리고 경량 검증기의 효율성 문제를 체계적으로 분석한다. 새로운 비공허성 지표와 충분한 정확도 지표를 제안하고, 세 가지 벤치마크와 다양한 모델·스코어러에 대해 실험한 결과, 높은 사실성 수준에서는 빈 답변이 늘어나 유용성이 급감하고, 캘리브레이션 데이터와 배포 데이터가 다를 경우 보장이 깨…
저자: Yi Chen, Daiwei Chen, Sukrut Madhav Chikodikar
본 논문은 대형 언어 모델(LLM)이 지식‑집약형 응용에서 자주 발생하는 ‘환각(hallucination)’ 문제를 해결하기 위한 두 가지 주요 접근법, 즉 검색‑증강 생성(RAG)과 컨포멀 예측(Conformal Prediction, CP)을 결합한 프레임워크를 제안하고, 그 실효성과 한계를 다각도로 평가한다. RAG는 외부 문서를 검색해 LLM의 생성 과정을 grounding하지만, 최종 출력이 사실인지에 대한 정량적 보장은 제공하지 않는다. 반면 CP는 사후 처리 단계에서 원자적 클레임을 점수화하고, 캘리브레이션 데이터로부터 구한 임계값을 이용해 사실이 아닌 클레임을 필터링함으로써 ‘1‑α’ 수준의 사실성 보장을 제공한다. 그러나 CP는 필터링이 과도하면 빈 답변을 내놓아 정보성이 사라지는 문제와, 캘리브레이션 데이터와 실제 배포 환경 사이의 분포 차이로 인해 보장이 깨지는 취약성을 가지고 있다.
논문은 이러한 문제점을 정량화하고, 실제 시스템 설계에 도움이 되는 새로운 평가 지표를 도입한다. 기존의 ‘Empirical Factuality’는 빈 출력도 사실로 간주해 과대평가되는 경향이 있었으므로, ‘Non‑empty Rate(NR)’를 통해 최소 하나 이상의 클레임을 유지하는 비율을 측정하고, ‘Non‑vacuous Empirical Factuality(NvEF)’는 비공허한 출력에 한정해 사실성을 평가한다. 또한 ‘Sufficient Correctness(SC)’와 ‘Conditional Sufficient Correctness(CSC)’는 출력이 질문에 대한 충분한 정보를 제공하는지를 판단한다. 이러한 지표들은 사실성 보장과 정보성 사이의 트레이드오프를 명확히 드러낸다.
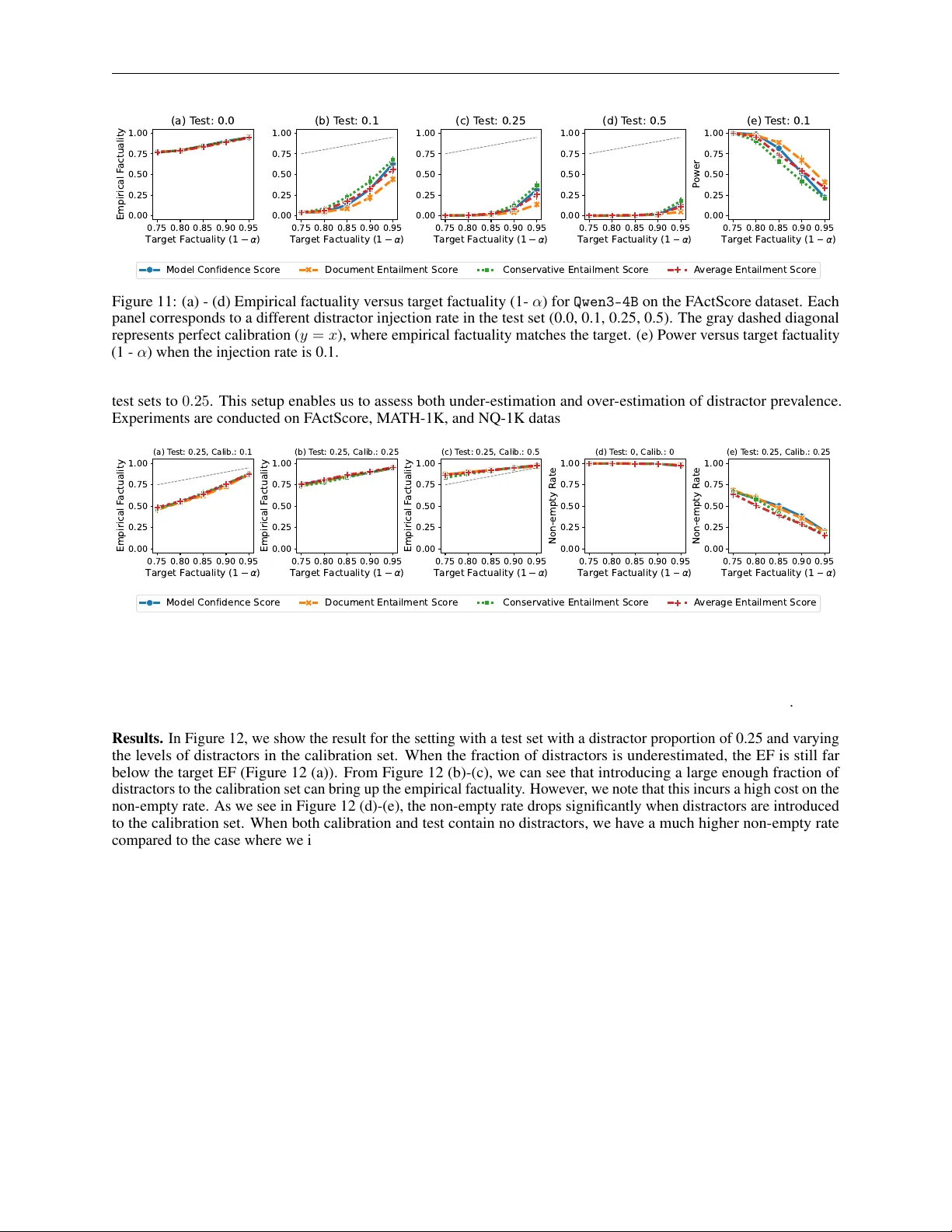
실험은 네 가지 데이터셋을 사용한다. FactScore는 위키피디아 인물 페이지를 기반으로 인물 전기를 생성하는 과제이며, FactScore Rare는 지식이 적은 인물에 대한 질문으로 모델의 파라미터 지식 의존성을 검증한다. Math 데이터셋은 수학 문제 풀이를 위한 전제 지식을 생성하고, Natural Questions(NQ)는 실제 검색 질의와 긴 답변(레퍼런스) 및 짧은 정답을 제공한다. 이들 데이터는 사실성 평가와 동시에 답변의 유용성을 검증할 수 있는 다양한 특성을 갖는다.
모델 측면에서는 Qwen3(0.6B~32B), Qwen3‑Think(추론 활성화 버전), Llama‑3.x(1B~8B), SmolLM2(135M~1.7B), gpt‑oss(20B, 120B) 등 12개 이상의 모델을 포함한다. 모델은 밀집(Dense)과 전문가 혼합(MoE) 구조로 구분되며, 추론 기능이 있는 버전과 없는 버전을 비교해 추론 능력이 사실성 점수와 필터링에 미치는 영향을 분석한다.
스코어링 함수는 두 갈래로 나뉜다. 첫 번째는 엔텔먼트 기반 NLI 스코어러로, 문서‑레벨와 문장‑레벨 두 방식이 있다. 문장‑레벨은 ‘보수적(Conservative)’과 ‘평균(Average)’ 두 집계 전략을 사용한다. 두 번째는 LLM 기반 모델 신뢰도 스코어러로, 다양한 프롬프트 설계(참조 포함 여부, 증거 강조, CoT 사용, 연속형·이진 출력, 다중 샘플 평균)를 실험해 최적 구성을 찾았다.
주요 발견은 다음과 같다. (1) 높은 사실성 목표(α≥0.85)에서는 필터링이 과도해 ‘Non‑empty Rate’가 급격히 감소하고, ‘NvEF’는 유지되지만 실제 유용한 정보는 거의 사라진다. 즉, 사실성 보장은 정보성 손실을 초래한다는 트레이드오프가 명확히 존재한다. (2) 캘리브레이션 데이터와 실제 입력 분포가 다르면 임계값이 부적절해져 보장 수준이 크게 저하된다. 특히 FactScore Rare와 같은 드문 엔티티에 대해서는 사실성 보장이 거의 무의미해진다. (3) 경량 NLI 검증기(예: roberta‑large‑mnli)와 문서‑레벨 엔텔먼트 모델은 FLOP 기준 0.01% 수준의 연산량으로도 LLM‑based 신뢰도 스코어러와 동등하거나 더 높은 ‘Power’와 낮은 ‘False Positive Rate’를 달성한다. 이는 실제 서비스에서 비용 효율적인 검증기로 활용 가능함을 시사한다. (4) ‘Sufficient Correctness’와 ‘Conditional Sufficient Correctness’ 지표는 기존 정확도(metric)보다 실제 질문 해결 능력을 더 잘 반영한다.
결론적으로, 컨포멀 사실성 필터링은 이론적 사실성 보장을 제공하지만, 배포 환경에서의 견고성·유용성·효율성 측면에서 한계가 있다. 저자들은 향후 연구 방향으로 (i) 온라인 적응형 캘리브레이션, (ii) 정보 손실을 최소화하는 스마트 병합 전략, (iii) 멀티‑모달·다중‑증거 기반 검증기 설계 등을 제시한다. 또한, 제안된 비공허성 및 충분성 지표는 향후 사실성 보장 시스템의 평가 표준으로 활용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기