Is Conformal Factuality for RAG-based LLMs Robust? Novel Metrics and Systematic Insights
Large language models (LLMs) frequently hallucinate, limiting their reliability in knowledge-intensive applications. Retrieval-augmented generation (RAG) and conformal factuality have emerged as potential ways to address this limitation. While RAG ai…
Authors: Yi Chen, Daiwei Chen, Sukrut Madhav Chikodikar
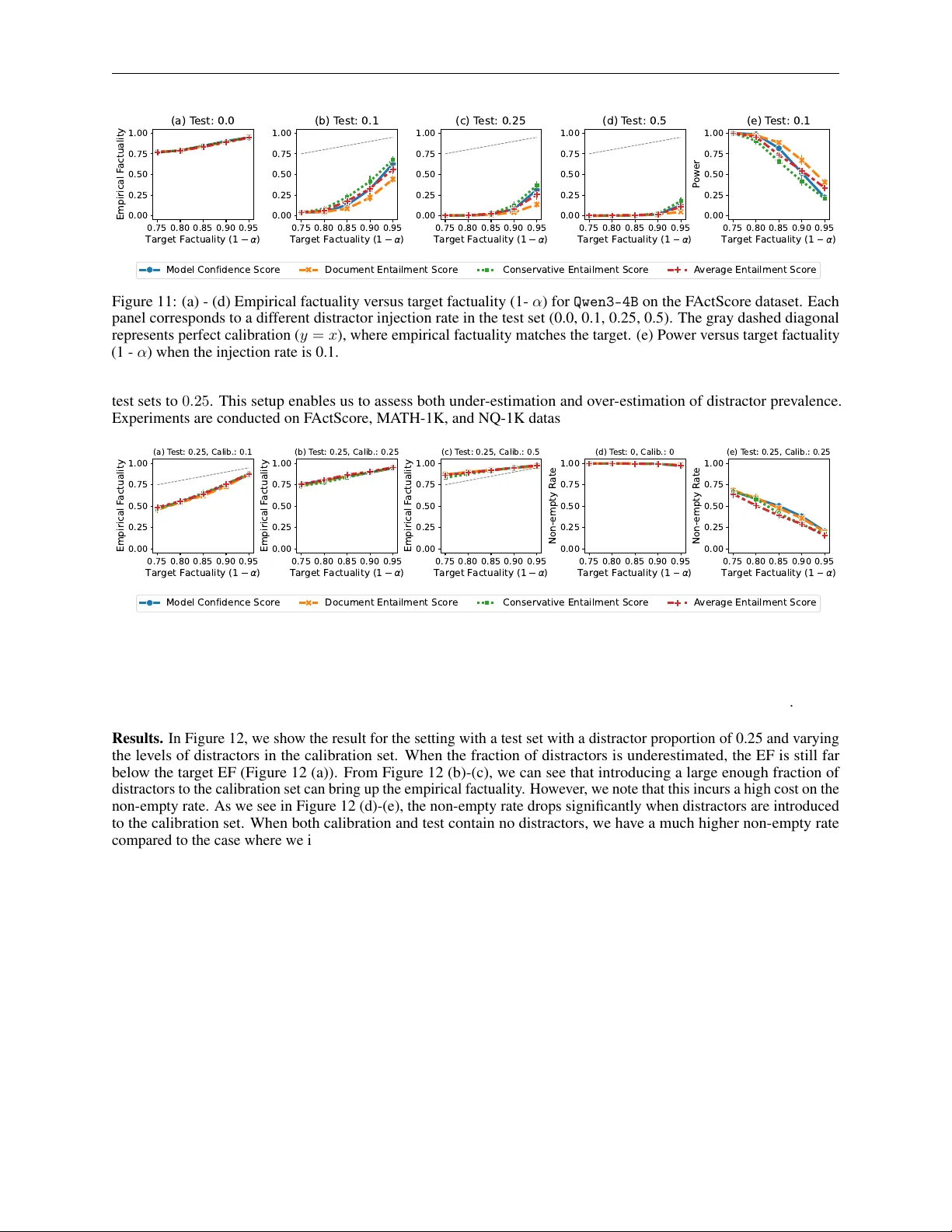
I S C O N F O R M A L F A C T U A L I T Y F O R R AG - B A S E D L L M S R O B U S T ? N OV E L M E T R I C S A N D S Y S T E M A T I C I N S I G H T S A P R E P R I N T Y i Chen Univ ersity of Wisconsin-Madison yi.chen@wisc.edu Daiwei Chen Univ ersity of Wisconsin-Madison daiwei.chen@wisc.edu Sukrut Madhav Chik odikar Univ ersity of Wisconsin-Madison chikodikar@wisc.edu Caitlyn Heqi Y in Univ ersity of Wisconsin-Madison hyin66@wisc.edu Ramya Korlakai V inayak Univ ersity of Wisconsin-Madison ramya@ece.wisc.edu March 17, 2026 A B S T R AC T Large language models (LLMs) frequently hallucinate, limiting their reliability in knowledge- intensi ve applications. Retriev al-augmented generation (RA G) and conformal factuality have emer ged as potential ways to address this limitation. While RA G aims to ground responses in retriev ed e vi- dence, it provides no statistical guarantee that the final output is correct. Conformal factuality filtering offers distribution-free statistical reliability by scoring and filtering atomic claims using a threshold calibrated on held-out data, ho we ver , the informativ eness of the final output is not guaranteed. W e systematically analyze the reliability and usefulness of conformal factuality for RA G-based LLMs across generation, scoring, calibration, robustness, and ef ficiency . W e propose nov el informativ eness- aware metrics that better reflect task utility under conformal filtering. Across three benchmarks and multiple model families, we find that (i) conformal filtering suffers from low usefulness at high factuality levels due to vacuous outputs, (ii) conformal factuality guarantee is not r ob ust to distribution shifts and distr actors , highlighting the limitation that requires calibration data to closely match deployment conditions, and (iii) lightweight entailment-based verifiers match or outperform LLM-based model confidence scorers while requiring over 100 × fewer FLOPs. Ov erall, our results expose factuality–informativeness trade-of fs and fragility of conformal filtering framework under distribution shifts and distractors , highlighting the need for ne w approaches for reliability with robustness and usefulness as k ey metrics, and provide actionable guidance for b uilding RA G pipelines that are both reliable and computationally efficient. Keyw ords RA G · LLM · hallucination mitigation · conformal prediction · factuality guarantee · calibration 1 Introduction Large language models (LLMs) hav e demonstrated remarkable capabilities across open-domain question answering, reasoning, and scientific discov ery [Bro wn et al., 2020, Guo et al., 2025, Zhang et al., 2025]. Y et, a persistent barrier to their reliable deployment is the phenomenon of hallucinations : outputs that are fluent and confident but factually incorrect [Ji et al., 2023, Nadeau et al., 2024, Huang et al., 2025]. Such errors are not merely cosmetic. In safety-critical settings, such as medicine, la w , or finance, a single fabricated claim can erode trust, propagate misinformation, and incur high societal or financial costs. This mak es hallucination mitigation one of the central challenges in advancing trustworthy LLMs. A rich body of work has emerged to address this challenge along two main directions: (1) retrie v al- augmented generation (RA G) and (2) conformal methods. RA G aims to reduce hallucinations by grounding responses in trusted external kno wledge sources, typically by conditioning generation on retriev ed passages [Le wis et al., 2020, Gao et al., 2023, Siriwardhana et al., 2023]. While RA G reduces the lik elihood of unsupported claims, it does not of fer Is Conformal Factuality for RA G-based LLMs Robust? A P R E P R I N T Query x ∈ X Reference R ( x ) Response Generator G Output y Conformal Factuality Framew ork Calibration Data e X Filtered Output y ′ Input to LLM Conformal Filtering Figure 1: Overvie w of our framework. Given a query x and retrieved references R ( x ) , the Response Generator G produces an output y . The conformal factuality framew ork utilizes a separate calibration data to determine a threshold used to filter out information from the output y and yield y ′ . (See Figure 2 for the details of different stages in volved in conformal filtering.) statistical guarantees on the factuality of the final response. Even with reference, LLMs can produce hallucinations in the generated response [Huang et al., 2025]. The conformal prediction (CP) framework, on the other hand, aims to provide a statistical guarantee on the final output, often via post-processing of the initial LLM response. CP frameworks usually first decompose the initial LLM output into atomic claims, score each claim with a factuality scoring function, and filter those falling belo w a threshold determined using a calibration dataset [Mohri and Hashimoto, 2024, Cherian et al., 2024]. This procedure pro vides formal cov erage guarantees b ut often at the expense of informati veness, since aggressiv e filtering may yield empty or vacuous outputs. Furthermore, CP filtering cannot improv e the usefulness or accuracy of the LLM response; it can only remo ve hallucinations. Despite their complementary strengths, it is unclear whether conformal prediction (CP) can improve reliability of RA G-based LLMs. While sev eral recent works integrate RAG with CP methods [Li et al., 2023, Rouzrokh et al., 2024, Feng et al., 2025], they fall short of a systematic analysis that disentangles where gains come from and when guarantees break do wn. A comprehensiv e understanding of the strengths and limitations of this combination requires not only integrating the two frameworks, but also developing principled evaluation. In particular , standard metrics such as empirical factuality can exhibit multiple failure modes and obscure real utility—for example, an empty answer is trivially “factually correct” under such measures. Additionally , it remains unclear whether improved factuality necessarily requires larger , more computationally expensi ve v erifiers, or whether lightweight alternati ves can achie ve comparable or superior performance. This raises a scaling-law-style question for factuality filtering: how do reliability and utility scale with v erifier capacity and inference cost, and where are the diminishing returns? Understanding the relationship between factuality , model scale, and computational cost is critical for deplo ying reliable LLM systems in practice, where both latency and compute budgets constrain end-to-end RA G pipelines. W e address these issues in this work. Our Contributions : W e systematically inv estigate the conformal factuality filtering framew ork for RA G-based LLMs (Figure 1) making the following contrib utions: • W e propose novel metrics to capture informati veness component that is often missed by traditional metrics: non-empty rate and non-vacuous empirical factuality , which jointly capture both correctness and information retention, and sufficient corr ectness and conditional sufficient correctness , which measure whether an output contains enough correct information to infer the final answer to the query . These novel metrics capture the trade-of f between factual correctness and informativ eness, providing practical insights and tools for future work on hallucination mitigation. • W e conduct comprehensi ve e v aluation that spans div erse datasets (questions with free form answers, math and natural question answering), various open-source model families and sizes (with and without reasoning), and scoring functions (entailment-based and LLM-based scorers). Furthermore, we ev aluate robustness against distribution shifts and distractors, shedding light on both the capabilities and limitations of this approach. Our e v aluation highlights the key issues – limited usefulness at high factuality levels and non-r obustness to distribution shifts and distractor s . This raises the need for new approaches for guaranteeing f actuality with usefulness and rob ustness as important metrics. • In addition, we analyze the trade-offs between verification accurac y and computational efficiency , demonstrating that lightweight verifiers can outperform lar ger LLM-based scorers while requiring orders-of-magnitude fe wer FLOPs. 2 Is Conformal Factuality for RA G-based LLMs Robust? A P R E P R I N T 2 Problem Setting, Datasets, Models, and Metrics In this section, we describe the conformal filtering frame work for RA G-based LLMs (Figure 1), introduce the scoring functions, datasets and ev aluation metrics used in this work. Let x ∈ X denote an input query . Let R ( x ) denote the reference material suf ficient to answer x . W e assume the existence of an oracle retriev er that can retriev e R ( x ) such that the true answer y ⋆ is either in or can be deduced from R ( x ) . This enables us to focus on ev aluating the effecti veness of conformal filtering of answers generated by RA G-based LLMs by decoupling the ef fects of specific methods used for retriev al. A response generator G , instantiated as a large language model (LLM), is prompted with both x and R ( x ) to produce an output y = G ( x, R ( x )) . The goal of the conformal filtering is to create a final output y ′ such that each statement in y ′ is factually correct at a user’ s expected lev el, e.g., 85%, while being useful in answering the query . Conformal filtering method as applied to this system is described below . Conformal Filtering. Let e X denote a calibration set that is exchangeable with X . For each query ˜ x ∈ e X , a set of claims { c i } is obtained by parsing the corresponding y using a parser P . These claims are then scored by a factuality scoring function f . For each calibration query ˜ x , the candidate threshold is defined as the smallest value of τ such that all claims with score abo ve τ are factual: inf { τ | ∀ c ∈ F ( τ ) , c is factual } , where F ( τ ) = { c | f ( c ) > τ } denotes the set of claims scoring abov e τ . Giv en a specified error le vel α ∈ (0 , 1) , the conformal filtering frame work determines a threshold τ α from the calibration set. Specifically , τ α is chosen as the ⌈ ( n +1)(1 − α ) ⌉ n quantile of a set of candidate thresholds, where n = | e X | is the size of calibration data. The resulting guarantee is that P ∀ c ∈ F ( τ α ) , c is factual ≥ 1 − α . At inference time, for each query x , the generated output y is decomposed into atomic claims by a parser P , yielding C ( y ) = { c i } k i =1 . Each claim c i is scored with f , and those exceeding the threshold are retained: C ′ ( y ) = { c i | f ( c i ) > τ α , i = 1 , . . . , k } . Finally , the retained claims C ′ ( y ) are merged by a merger M into a single filtered response: y ′ = M ( C ′ ( y )) . Figure 2 illustrates the entire conformal filtering pipeline. W e use gpt-5-nano [gpt, 2025] in our experiments for tasks such as claim parsing, claim merging and factuality labeling 1 . Input x Reference Response Generator Output y Parser Claim 1 Claim 2 . . . Claim k Scoring function f Score 1 Score 2 . . . Score k Conformal Threshold Calibration Data e X Filtered Claim 1 Filtered Claim 2 . . . Filtered Claim k ′ Merger Filtered Output y ′ Figure 2: Giv en an input x and a reference text related to x , the Response Generator produces an output y , which is then parsed by the Parser into a list of claims. Each individual claim is subsequently scored by the Scorer , conditioned on the input x and, optionally , the reference text. These scores are passed to the conformal prediction algorithm, which filters out claims whose scores fall below a learned threshold. Finally , the remaining claims are merged into a single paragraph and returned to the user . 1 W e validate the factuality labeling quality of using a gpt-5-nano as a judge by comparing with human labeling (See Appendix A.3 for details of the human ev aluation). 3 Is Conformal Factuality for RA G-based LLMs Robust? A P R E P R I N T 2.1 Scoring Functions Scoring function f is a core component of the conformal factuality frame work, the determination of which claims are retained or filtered depends on the score. W e study two main families of scoring functions: (a) Entailment-based scorers are natural language inference (NLI) models to assess whether the reference text supports a claim. W e use both document-level and sentence-le vel variants. 1. For document-le vel entailment , the entailment score is computed directly between the entire reference R ( x ) and the claim c i . W e use the entailment model from [Laurer et al., 2022] trained on the DocNLI dataset [Y in et al., 2021]. 2. In the sentence-level entailment setting, entailment scores are computed between the claim c i and each sentence in R ( x ) , and then aggregated in two dif ferent ways: (a) Conservati ve entailment , where a claim is marked as contradictory if any sentence in the reference contradicts it. It is marked as entailed only if there are no contradictions and there is at least one sentence supporting it. (b) A verage entailment , which averages the scores of all non-neutral sentence-le vel comparisons. For sentence- lev el entailment, we use roberta-large-mnli as the entailment model [Liu et al., 2019]. (b) LLM-based model confidence scorers. In this family , we prompt a language model to assign a factuality score to each claim. W e explore the design space of the prompt by varying fiv e dimensions: (i) the inclusion of retrieve d references R ( x ) , (ii) evidence highlighting within R ( x ) , (iii) the use of Chain-of-Thought (CoT) reasoning, (iv) output granularity for v erbalizing (continuous [0 , 1] vs. Boolean) , and (v) e v aluation consistenc y (single generation vs. av eraging ov er fi ve independent generations). W e refer to this scoring function as model confidence score . 2.2 Datasets W e perform ev aluations on three datasets that span open-ended summarization, mathematical reasoning, and question answering tasks. This diversity allo ws us to assess both the factual reliability and the task-lev el utility of our approach. • F ActScore dataset [Min et al., 2023] consists of 601 individuals, each paired with a W ikipedia page. Queries are: “T ell me a paragraph biography about [person] , ” where the reference R ( x ) is the W ikipedia page of the person. Because no canonical ground-truth answers are pro vided, this dataset is well-suited for e valuating factuality in open-ended generation and for testing whether models can produce faithful summaries grounded in external references. W e additionally consider F ActScore Rar e , a subset of 198 queries focusing on less well-known indi viduals. This subset probes the robustness of models when the model’ s parametric knowledge is not enough to answer the question, a regime where hallucinations are more likely , if a reference is not giv en. • MA TH dataset [Hendrycks et al., 2021] contains 12,446 competition-style mathematics problems spanning fiv e difficulty lev els and se ven categories. Each problem pro vides a question x and a ground-truth answer y ⋆ . T o construct reference materials, we prompted gpt-5-nano to generate prerequisite knowledge rele v ant to solving each problem, which serves as R ( x ) . • Natural Questions (NQ) dataset [Kwiatko wski et al., 2019] consists of 10K real-world queries collected from search engines. Each query is annotated with both a long answer and a short answer; we use the long answer as the reference R ( x ) and the short answer as the ground-truth. T ogether , these datasets provide cov erage ov er distinct capabilities: factual summarization (F ActScore), mathematical reasoning (MA TH), and reference-based question answering (NQ). 2.3 Language Models W e ev aluate our framework over sev eral open-source language models in order to systematically ev aluate different components of the factuality and RA G pipeline under varying architectures, reasoning modes, and parameter scales. Our open-source suite includes multiple families. The Qwen3 models [Y ang et al., 2025] are ev aluated both in their base form and in a reasoning-enabled variant, Qwen3-Think , where reasoning with the
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment