플러그인플레이 확산 샘플링을 위한 적응 모멘트의 놀라운 효과
본 논문은 플러그인‑플레이 확산 모델에서 조건부 샘플링에 사용되는 불안정한 likelihood gradient를 Adam과 같은 적응 모멘트 추정으로 평활화함으로써, 기존 방법보다 더 높은 이미지 복원·조건부 생성 성능을 달성한다는 것을 실험적으로 입증한다.
저자: Christian Belardi, Justin Lovelace, Kilian Q. Weinberger
본 논문은 플러그인‑플레이 확산 모델에서 조건부 샘플링을 수행할 때 발생하는 핵심 문제인 likelihood 점수 ∇ₓₜ log p(y|xₜ) 의 높은 변동성을 해결하고자 한다. 확산 모델은 사전 점수 ∇ₓₜ log p(xₜ) 를 학습된 네트워크 ε_θ 를 통해 정확히 제공하지만, 조건부 확률 p(y|xₜ) 는 일반적으로 직접 계산이 불가능하고, 대신 DPS, CG와 같은 기존 방법들은 근사식으로 이를 추정한다. 이러한 근사는 두 가지 주요 원천에서 노이즈를 유발한다. 첫째, x₀|t 와 같은 클린 추정이 완벽하지 않아 오차가 전파된다. 둘째, 복잡한 신경망을 역전파하면서 얻는 그라디언트 자체가 stochastic optimization 특성상 잡음이 많다.
저자들은 이 문제를 스토캐스틱 최적화 분야에서 검증된 Adam 알고리즘을 샘플링 단계에 그대로 적용함으로써 해결한다. 구체적인 절차는 다음과 같다. 매 타임스텝 t 에서 기존 방식대로 gₜ = −∇ₓₜ L(f_φ(·), y) 를 계산하고, 이를 적응 모멘트 추정기에 입력한다. 1차 모멘트 mₖ 와 2차 모멘트 vₖ 는 각각 β₁, β₂에 따라 지수 이동 평균을 구하고, 편향 보정 후 ĥgₜ = ĥmₖ / (√ĥvₖ + δ) 로 정규화한다. 이렇게 얻은 ĥgₜ 는 기존 gₜ 에 비해 평균은 유지하면서 분산이 크게 감소한다. 최종 샘플링 업데이트는 기존 확산 업데이트에 ρ · ĥgₜ 를 추가하는 형태이며, 이는 기존 DPS와 CG에 최소한의 코드 변경만으로 적용 가능하도록 설계되었다.
실험은 크게 두 파트로 나뉜다. 첫 번째는 합성 2차원 GMM 데이터에서 정확한 likelihood 점수를 알고 있는 상황에서, 인위적으로 잡음 계수 ζ 를 조절해 노이즈 강도를 변화시켰다. 결과는 KL 발산이 ζ 가 증가함에 따라 급격히 상승하는 DPS와 달리, AdamDPS는 낮은 KL을 유지하며 노이즈에 대한 강인성을 입증했다.
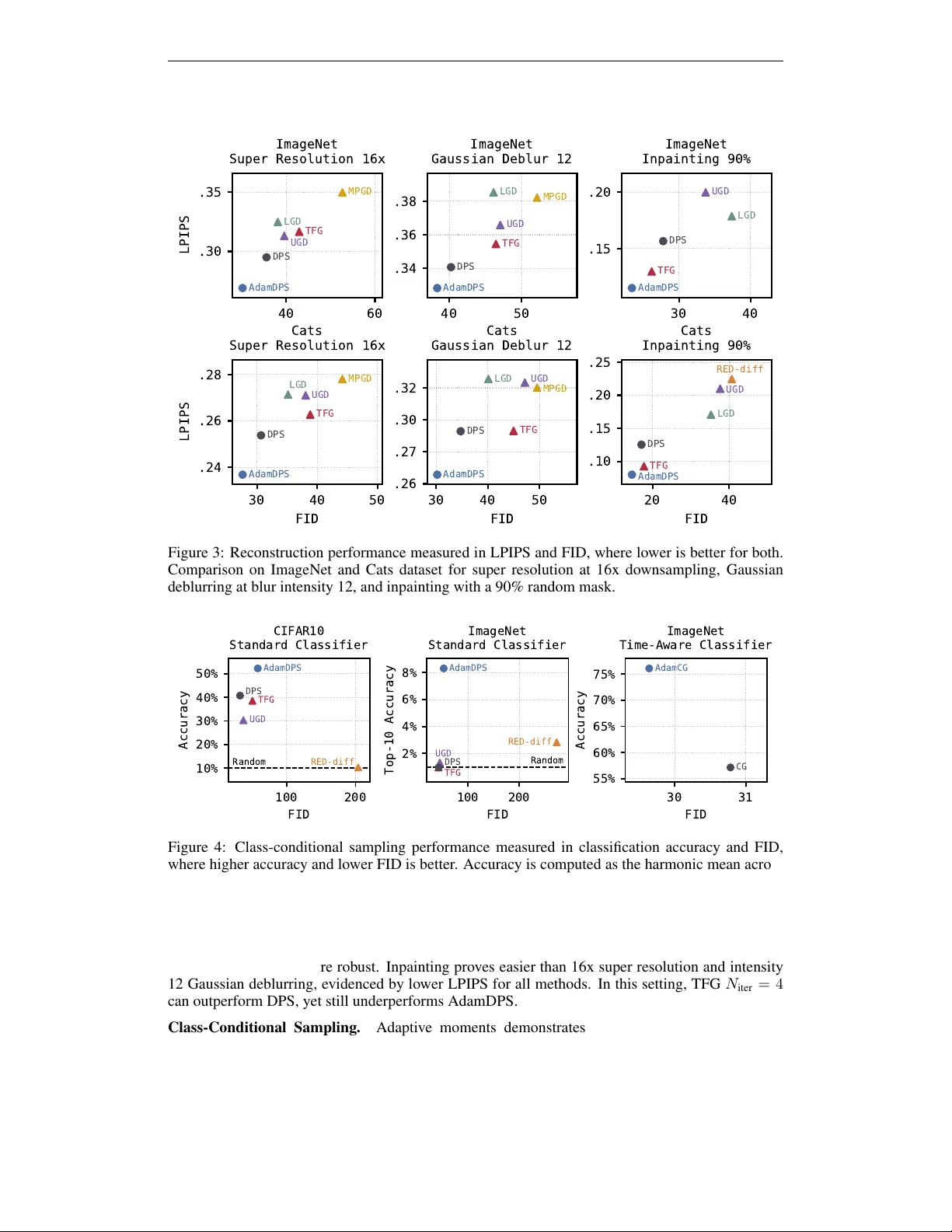
두 번째 파트는 실제 이미지 복원 및 클래스‑조건부 생성 작업이다. 복원 작업에는 ImageNet, CIFAR‑10, Cats 데이터셋에서 16× 초해상도, 가우시안 블러 복원(blur intensity 12), 90% 마스크 인페인팅을 수행하였다. 평가 지표는 LPIPS(시각적 유사도), FID(분포 일치도)이며, 조건부 생성에서는 세 개의 사전 학습된 분류기 평균 정확도를 사용했다. 모든 실험에서 AdamDPS는 기존 DPS, UGD, TFG, MPGD, LGD, RED‑diff 등과 비교해 가장 낮은 LPIPS와 FID, 가장 높은 정확도를 기록했다. 특히 어려운 16× 초해상도와 고강도 블러 복원에서는 다른 방법들이 성능이 급격히 저하되는 반면, AdamDPS는 일관된 품질을 유지했다.
하이퍼파라미터 튜닝은 베이지안 최적화를 이용해 검증 셋(32 이미지)에서 자동으로 수행했으며, 이는 적응 모멘트가 별도 복잡한 매개변수 설정 없이도 강력함을 보여준다. 코드와 실험 파이프라인은 GitHub에 공개돼 재현성을 보장한다.
결론적으로, 적응 모멘트 추정은 플러그인‑플레이 확산 가이드에 있어 “노이즈 억제기” 역할을 하며, 복잡한 추가 연산 없이도 기존 방법들을 크게 능가한다. 이는 향후 플러그인‑플레이 가이드의 설계 패러다임을 단순화하고, 고난이도 조건부 생성·복원 문제에 대한 실용적인 해결책을 제공한다는 점에서 의미가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기