Adaptive Moments are Surprisingly Effective for Plug-and-Play Diffusion Sampling
Guided diffusion sampling relies on approximating often intractable likelihood scores, which introduces significant noise into the sampling dynamics. We propose using adaptive moment estimation to stabilize these noisy likelihood scores during sampli…
Authors: Christian Belardi, Justin Lovelace, Kilian Q. Weinberger
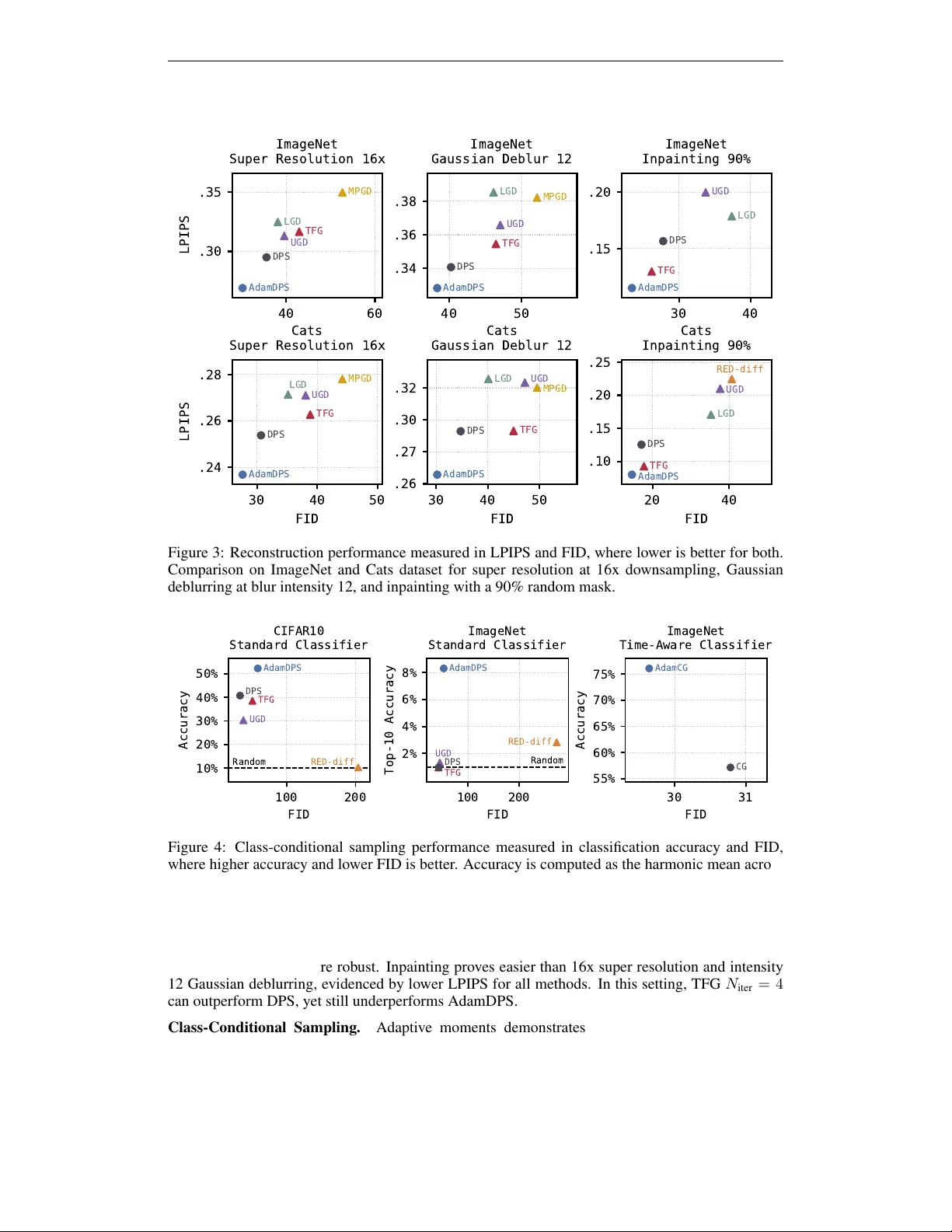
Published as a conference paper at ICLR 2026 A D A P T I V E M O M E N T S A R E S U R P R I S I N G L Y E FF E C T I V E F O R P L U G - A N D - P L A Y D I FF U S I O N S A M P L I N G Christian Belardi Justin Lov elace Kilian Q. W einber ger Carla P . Gomes Cornell Univ ersity ckb73@cornell.edu A B S T R A C T Guided diffusion sampling relies on approximating often intractable likelihood scores, which introduces significant noise into the sampling dynamics. W e pro- pose using adaptive moment estimation to stabilize these noisy lik elihood scores during sampling. Despite its simplicity , our approach achie ves state-of-the- art results on image restoration and class-conditional generation tasks, outper- forming more complicated methods, which are often computationally more ex- pensiv e. W e provide empirical analysis of our method on both synthetic and real data, demonstrating that mitigating gradient noise through adaptiv e mo- ments offers an effecti ve way to improv e alignment. Our code is av ailable at https://github.com/christianbelardi/adam- guidance . 1 I N T R O D U C T I O N Diffusion models (Sohl-Dickstein et al., 2015; Song & Ermon, 2019; Ho et al., 2020) hav e become one of the most prev alent approaches to generati ve modeling, achieving state-of-the-art results in many domains, including text-to-image synthesis (Rombach et al., 2022; Ramesh et al., 2022; Sa- haria et al., 2022a), image-to-image translation (Saharia et al., 2022b), audio generation (K ong et al., 2020; Liu et al., 2023), video synthesis (Ho et al., 2022; Brooks et al., 2024), and molecular design (Hoogeboom et al., 2022; W atson et al., 2023). Plug-and-play conditional generation enables sampling from a conditional distrib ution p ( x | y ) using a dif fusion model trained only on the mar ginal distribution p ( x ) . These methods guide the sam- pling process toward desired conditions y without task-specific training. While some approaches like Classifier Guidance (CG) (Dhariwal & Nichol, 2021) train time-aware models directly on the diffusion latents, man y plug-and-play methods le verage e xisting models that operate on clean data – whether analytical forward operators for inv erse problems or pre-trained classifiers – making them highly flexible for di verse applications. The plug-and-play guidance literature has e volved from early methods like Diffusion Posterior Sam- pling (DPS) (Chung et al., 2023) to increasingly sophisticated techniques. Recent work such as Univ ersal Guidance for Diffusion Models (UGD) (Bansal et al., 2023) and Training-Free Guidance (TFG) (Y e et al., 2024) compose multiple algorithmic components, gradient computations in both latent and data spaces, Monte Carlo approximations, and iterativ e refinement procedures. At the heart of plug-and-play guidance lies the challenge of incorporating the desired condition into the diffusion sampling process. Sampling in diffusion models can be understood as annealed Langevin dynamics using the score function ∇ x t log p ( x t ) (Song & Ermon, 2019; Karras et al., 2022). For plug-and-play dif fusion sampling, Bayes’ rule giv es us: ∇ x t log p ( x t | y ) | {z } Posterior Score = ∇ x t log p ( x t ) | {z } Prior Score + ∇ x t log p ( y | x t ) | {z } Likelihood Score (1) While the prior score is pro vided by the unconditional dif fusion model, the likelihood score ∇ x t log p ( y | x t ) is often intractable to compute directly , necessitating approximation strate gies (Chung et al., 2023; He et al., 2023; Song et al., 2023b). Prior work has predominantly studied improving the likelihood score approximation. Orthogonal to this, we in vestigate whether information from earlier sampling steps can help mitigate approx- 1 Published as a conference paper at ICLR 2026 imation errors in later sampling steps. Instead of developing more sophisticated approximation methods, we use adaptive moment estimation—a technique from stochastic optimization, Adam (Kingma, 2014)—to stabilize the noisy guidance gradients that arise in plug-and-play methods. Our approach maintains exponential moving a verages of the first and second moments of the likeli- hood score estimates across sampling steps, dampening noise while preserving the guidance signal. Despite its simplicity , this modification yields substantial improv ements for DPS and CG. W e also examine how task difficulty affects performance. T ypically , plug-and-play methods are ev aluated under mild de gradations that pro vide strong guidance signal (e.g., 4× super-resolution). W e show as dif ficulty increases (e.g., 16× super-resolution), many methods de grade rapidly . W e find that across all difficulties, adapti ve moment estimation consistently improves the DPS baseline while other guidance methods fall belo w DPS alone. Our contributions are: (i) we demonstrate that adaptiv e moment estimation can substantially improv e plug-and-play guidance methods, achie ving state-of-the-art results with minimal added complexity; (ii) we provide a variety of empirical analyses that illustrate how our method stabilizes noisy gradi- ents and improves performance; and (iii) we reveal that task difficulty significantly impacts relative method performance, suggesting the need for more comprehensiv e e valuation standards. 2 B AC K G R O U N D Diffusion Models and Score-Based Sampling. Dif fusion models (Sohl-Dickstein et al., 2015; Song & Ermon, 2019; Ho et al., 2020) learn to re verse a gradual process that adds noise to data. Starting from a clean data sample x 0 , we repeatedly add small amounts of Gaussian noise until the result becomes almost pure noise. W e describe this process using a timestep t ∈ [0 , T ] , where each t corresponds to a noise level σ t . The variable σ t measures how much total noise has been added at that step, and x t denotes the resulting noisy version of the data. As t increases, the amount of noise also increases, so that σ 0 < · · · < σ T . In practice, we set σ 0 so that x 0 is the original data, and we choose σ T large enough that x T is indistinguishable from Gaussian noise. The specific schedule of noise lev els { σ t } T t =0 can vary , but it alw ays follows this pattern of gradually increasing noise. For two timesteps s and t with s < t , the noising process describes ho w a partially noised sam- ple x s becomes a noisier sample x t . This transition follows a Gaussian distrib ution p ( x t | x s ) = N ( x t ; x s , σ 2 t | s I ) , where the variance between the two steps is giv en by σ 2 t | s = σ 2 t − σ 2 s . 1 Because the sum of Gaussian variables is also Gaussian, we can treat many small noising steps as one com- bined step. Thus, the noising process also defines a direct mar ginal distribution from the original data x 0 to any timestep t , p ( x t | x 0 ) = N ( x t ; x 0 , σ 2 t I ) . Equiv alently , we can express the noisy sam- ple as x t = x 0 + σ t ϵ , where ϵ ∼ N (0 , I ) . This form shows that x t is simply the clean data x 0 plus Gaussian noise scaled by the noise lev el σ t . T o rev erse the noising process, we train a neural network ϵ θ to predict the noise that was added to the clean data x 0 in order to produce the noisy sample x t . The standard training objectiv e minimizes the difference between the true noise ϵ and the network’ s prediction (Ho et al., 2020): L ϵ ( θ ) = E t,x 0 ,ϵ ∥ ϵ θ ( x t , t ) − ϵ ∥ 2 2 . (2) By learning to predict this noise, the network implicitly learns the gradient of the log-probability density of the data—also known as the scor e function (Kingma & Gao, 2023): s θ ( x t , t ) = − ϵ θ ( x t , t ) σ t ≈ ∇ x t log p ( x t ) . (3) Intuitiv ely , the added noise mov es data away from regions of high likelihood. Thus, predicting the noise tells us how to move x t to increase its probability under the data distribution, which is precisely the meaning of the gradient ∇ x t log p ( x t ) . Once the score function is known, we can generate new data by starting from pure noise x T ∼ N (0 , σ 2 T I ) and gradually denoising it. This sampling procedure follows annealed Langevin dynamics (Song & Ermon, 2019; Karras et al., 2022): x s = x t + ( σ 2 t − σ 2 s ) ∇ x t log p ( x t ) + q σ 2 t − σ 2 s σ s σ t ϵ. (4) 1 W e adapt the notation of Kingma et al. (2021) to the variance exploding formulation for simplicity . 2 Published as a conference paper at ICLR 2026 This update incrementally removes noise until we obtain a clean sample from the data distribution. At any timestep t , the denoising network pro vides an estimate of the underlying clean data: x 0 | t = E [ x 0 | x t ] = x t − σ t ϵ θ ( x t , t ) , (5) which corresponds to the minimum mean squared error estimator under optimal training (Efron, 2011). This estimate, denoted x 0 | t , plays a central role in many plug-and-play guidance methods. The Plug-and-Play Guidance Challenge. The goal of plug-and-play diffusion sampling is to draw samples from the posterior distribution p ( x 0 | y ) , which represents data consistent with the observa- tion y . This approach relies on the decomposition of the posterior score described in Equation 1. The first term, the prior score , is provided by the diffusion model itself and well approximated using the trained network ϵ θ . The second term, the lik elihood scor e , expresses how the observation y changes the probability of a noisy sample x t . Howe ver , this term is much harder to compute in practice. T o ev aluate the likelihood score, we would need to marginalize over all possible clean samples x 0 that could hav e produced x t : p ( y | x t ) = Z p ( y | x 0 ) p ( x 0 | x t ) dx 0 . (6) This integral is generally intractable, since it requires integrating over the entire data space. Even if we train a neural network to approximate p ( y | x t ) directly , its gradients tend to be noisy and unstable, leading to poor guidance during sampling. 3 G U I D A N C E W I T H A D A P T I V E M O M E N T E S T I M A T I O N Plug-and-play dif fusion sampling requires approximating the often intractable likelihood score ∇ x t log p ( y | x t ) to guide the sampling process toward desired conditions. In practice, this score is typically approximated by −∇L ( x t , y ) , where L is the negati ve log likelihood and y the condition. Existing Likelihood Score Appr oximations. There are tw o foundational approaches for this ap- proximation, distinguished by the domain in which the guidance function operates. DPS (Chung et al., 2023), a widely adopted plug-and-play method, approximates the likelihood score as, ∇ x t log p ( y | x t ) ≈ ∇ x t log p ( y | x 0 | t ) ≈ −∇ x t L ( f ϕ ( x 0 | t ) , y ) (7) where x 0 | t is the predicted clean sample from Equation 5. The DPS approximation replaces the noisy latent x t with the denoising model’ s estimate x 0 | t , providing a point estimate of the likelihood. This allo ws the guidance model f ϕ : X → Y to be an y dif ferentiable function that operates on clean data—both learned models (e.g., pretrained neural networks) and analytical models (e.g., Gaussian blur kernels)—though it requires backpropagation through the denoising network. Alternativ ely , Classifier Guidance (CG) (Dhariwal & Nichol, 2021) uses the approximation, ∇ x t log p ( y | x t ) ≈ −∇ x t L ( f ϕ ( x t , t ) , y ) . (8) In contrast to DPS, CG trains a specialized guidance model f ϕ : X t × T → Y that operates directly on noisy latents x t , conditioning on the diffusion timestep t , making the guidance model time-aware. This eliminates the need for DPS’ s point estimate approximation and pro vides a more direct estimate of the likelihood score, though it requires training a classifier that depends on t . The Plug-and-Play Sampling Update. W e can now examine the typical plug-and-play sampling update by replacing the prior score in Equation 4 with the posterior score and decomposing it as shown in Equation 1. Finally replacing the prior score with the denoising networks approximation s θ , and the likelihood score with either of the approximations gi ven in Equation 7 or Equation 8, we observ e that the plug-and-play sampling update is performing gradient descent on the likelihood component at each timestep: x s = x t + ( σ 2 t − σ 2 s ) s θ ( x t , t ) − ∇L ( · ) + q σ 2 t − σ 2 s σ s σ t ϵ. (9) Stabilization via Adaptive Moments. Regardless of the approximation strategy , guidance methods suffer from substantial noise in likelihood score estimates. In stochastic optimization, prominent 3 Published as a conference paper at ICLR 2026 Algorithm 1 Adam Diffusion Posterior Sampling (AdamDPS) Require: Diffusion Model θ , Guidance Model f ϕ , Condition y , Guidance Strength ρ , Sampling Timesteps t n , . . . , t 0 ⊆ T , First Moment m = 0 , Second Moment v = 0 , Adam Step k = 0 , First Moment Exponential Decay Rate β 1 , Second Moment Exponential Decay Rate β 2 1: x t n ∼ N (0 , I ) 2: for t = t n , . . . , t 1 do 3: g t = −∇ x t L ( f ϕ ( x 0 | t ) , y ) 4: ˆ g t , m, v , k = Adaptiv eMomentEstimate ( g t , m, v , k , β 1 , β 2 ) 5: x s = Sample ( x 0 | t , x t , t, s ) + ρ ˆ g t 6: end for 7: return x t 0 Algorithm 2 Adam Classifier Guidance (AdamCG) Require: Diffusion Model θ , Guidance Model f ϕ , Condition y , Guidance Strength ρ , Sampling Timesteps t n , . . . , t 0 ⊆ T , First Moment m = 0 , Second Moment v = 0 , Adam Step k = 0 , First Moment Exponential Decay Rate β 1 , Second Moment Exponential Decay Rate β 2 1: x t n ∼ N (0 , I ) 2: for t = t n , . . . , t 1 do 3: g t = −∇ x t L ( f ϕ ( x t , t ) , y ) 4: ˆ g t , m, v , k = Adaptiv eMomentEstimate ( g t , m, v , k , β 1 , β 2 ) 5: x s = Sample ( x 0 | t + ρ ˆ g t σ 2 t , x t , t, s ) 6: end for 7: return x t 0 methods like RMSProp (T ieleman & Hinton, 2012) and Adam (Kingma, 2014) use adaptiv e moment estimation to stabilize noisy gradients. Inspired by this insight, we propose maintaining e xponential moving a verages of the likelihood score estimates and their squared v alues across sampling steps, m k = β 1 m k − 1 + (1 − β 1 ) g t v k = β 2 v k − 1 + (1 − β 2 ) g 2 t (10) where k is a step counter , g t = −∇L ( · ) , and g 2 t denotes element-wise squaring. The stabilized likelihood score is then computed as, ˆ g t = ˆ m k √ ˆ v k + δ (11) with bias-corrected moments ˆ m k = m k / (1 − β k 1 ) and ˆ v k = v k / (1 − β k 2 ) , and δ a small constant for numerical stability (Kingma, 2014). Adaptiv e moment estimation serves two purposes: the first moment (momentum) smooths the op- timization trajectory by accumulating gradient information across steps, while the second moment adaptiv ely scales the updates based on the historical variance of each gradient component. Since likelihood score approximations can vary dramatically across noise lev els during diffusion sam- pling, this stabilization is essential for improving performance. W e denote the resulting methods as AdamDPS (Algorithm 1) when applied to DPS and AdamCG (Algorithm 2) when applied to CG, and demonstrate that this simple modification yields substantial improv ements in sample quality . 4 S Y N T H E T I C S T U DY W e be gin by comparing DPS and AdamDPS in a synthetic setting, where both the true likelihood score and the ideal DPS likelihood score approximation can be computed exactly in closed form. This allo ws us to study the ef fect noise has on guidance. T o this end, the data distribution is defined by a 2 dimensional Gaussian Mixture Model (GMM) with three components. Guidance methods typically suffer from noisy lik elihood score estimates due to limited conditioning information and taking gradients through large neural netw orks. Since our synthetic setting is free of these noise sources, we simulate them by adding to the guidance term Gaussian noise of magnitude ζ ∥∇ x t log p ( y | x 0 | t ) ∥ . In Figure 1 (Left), we measure how close the empirical distributions are to the target distribution as a function of the guidance noise coefficient ζ . W e find that AdamDPS is much more robust to noise than DPS, achieving lower KL di ver gence with the target distribution as ζ increases. Figure 1 (Right) sho ws this qualitatively for a specific ζ . 4 Published as a conference paper at ICLR 2026 0.0 0.2 0.4 0.6 Guidance Noise Coefficient 0 5 10 15 20 KL Divergence Unconditional DPS AdamDPS Unconditional Oracle DPS AdamDPS Empirical vs. Target Distributions Figure 1: Left: The KL div ergence between each method’ s empirical distribution and the target distribution as a function of the guidance noise coefficient ζ . Right: V isualization of the empirical and target distrib utions at ζ = 0 . 175 . Super Resolution Condition Ground Truth AdamDPS DPS TFG Gaussian Deblur Figure 2: Qualitative comparison of AdamDPS, DPS, and TFG on Cats dataset for super resolution at 12x downsampling and Gaussian deblurring at blur intensity 9. 5 E X P E R I M E N T S W e ev aluate adaptiv e moments for plug-and-play guidance across a range of tasks. All methods benchmarked were tuned with Bayesian Optimization (Jones et al., 1998) on a held-out validation set of 32 images. Reconstruction tasks were tuned to minimize LPIPS (Zhang et al., 2018), while class-conditional sampling was tuned for CMMD (Jayasumana et al., 2024) since tuning for accu- racy encouraged generating adv ersarial examples. W e measure alignment with the desired condition using LPIPS for reconstruction tasks, and accuracy for class-conditional sampling. Accuracy is com- puted as the harmonic mean across three held-out classifiers. W e also report FID (Heusel et al., 2017) as a measure of fidelity , computed on 2048 samples following the ev aluation procedure from Y e et al. (2024). W e benchmark a variety of methods including Loss Guided Diffusion (LGD) (Song et al., 2023b), Manifold Preserving Guided Dif fusion (MPGD) (He et al., 2023), Re gularization by dif- fusion (RED-diff) (Mardani et al., 2024), DPS, UGD, and TFG on ImageNet (Deng et al., 2009), CIF AR10 (Krizhevsk y et al., 2009), and the Cats subset of the Cats vs. Dogs dataset (Elson et al., 2007). W e set N recur = 1 for TFG and sweep N iter = 1 , 2 , 4 for UGD and TFG, while tuning the remaining hyperparameters as recommended by Y e et al. (2024). Additional details in Appendix A. Reconstruction. Qualitati vely , AdamDPS generates sharper, more realistic details in re gions un- derdetermined by the conditioning information, where other methods tend to produce blurred or artifacted outputs. TFG reconstructions frequently exhibit visual artif acts, and DPS lacks the fine detail achiev ed by AdamDPS, see Figure 2. Quantitati vely , for both ImageNet and the Cats dataset, AdamDPS outperforms all other methods on all reconstruction tasks: super resolution at 16x do wn- sampling, Gaussian deblurring at blur intensity 12, and inpainting with a 90% random mask, see Fig- ure 3. Interestingly , the second best performing method across datasets in super resolution and Gaussian deblurring is DPS. W e observe this happens in challenging settings where the condition- ing information does not fully determine the target image, causing other methods to degrade signif- 5 Published as a conference paper at ICLR 2026 40 60 .30 .35 LPIPS ImageNet Super Resolution 16x MPGD LGD TFG UGD DPS AdamDPS 40 50 .34 .36 .38 ImageNet Gaussian Deblur 12 MPGD LGD TFG UGD DPS AdamDPS 30 40 .15 .20 ImageNet Inpainting 90% LGD TFG UGD DPS AdamDPS 30 40 50 FID .24 .26 .28 LPIPS Cats Super Resolution 16x LGD MPGD TFG UGD DPS AdamDPS 30 40 50 FID .26 .27 .30 .32 Cats Gaussian Deblur 12 LGD MPGD TFG UGD DPS AdamDPS 20 40 FID .10 .15 .20 .25 Cats Inpainting 90% RED-diff LGD TFG UGD DPS AdamDPS Figure 3: Reconstruction performance measured in LPIPS and FID, where lower is better for both. Comparison on ImageNet and Cats dataset for super resolution at 16x downsampling, Gaussian deblurring at blur intensity 12, and inpainting with a 90% random mask. 100 200 FID 10% 20% 30% 40% 50% Accuracy Random CIFAR10 Standard Classifier RED-diff TFG UGD DPS AdamDPS 100 200 FID 2% 4% 6% 8% Top-10 Accuracy Random ImageNet Standard Classifier RED-diff TFG UGD DPS AdamDPS 30 31 FID 55% 60% 65% 70% 75% Accuracy ImageNet Time-Aware Classifier CG AdamCG Figure 4: Class-conditional sampling performance measured in classification accuracy and FID, where higher accuracy and lo wer FID is better . Accurac y is computed as the harmonic mean across three held-out classifiers. Left & Center: Comparison of plug-and-play methods with a standard classifier on CIF AR-10 and ImageNet, respectively . Right: Comparison of plug-and-play methods with a time-aware classifier on ImageNet. icantly while DPS is more robust. Inpainting proves easier than 16x super resolution and intensity 12 Gaussian deblurring, evidenced by lower LPIPS for all methods. In this setting, TFG N iter = 4 can outperform DPS, yet still underperforms AdamDPS. Class-Conditional Sampling. Adapti ve moments demonstrates strong performance on class- conditional tasks, see Figure 4. On CIF AR-10, AdamDPS outperforms the next best method, DPS, by 9.86% in classification accuracy . On ImageNet, all approaches except AdamDPS achie ve top-10 classification accuracies at approximately 1%, equi v alent to random chance. In contrast, AdamDPS achiev es 10.49%, demonstrating substantial improv ement for conditional generation in challenging settings. W e also ev aluate adapti ve moments in the time-aw are classifier guidance setting, where AdamCG improv es upon CG by more than 19 percentage points in classification accuracy . 6 Published as a conference paper at ICLR 2026 4x 8x 12x 16x Super Resolution Factor 0% 20% 40% Relative Improvement 3 6 9 12 Gaussian Deblur Intensity AdamDPS T F G N i t e r = 4 T F G N i t e r = 2 T F G N i t e r = 1 Figure 5: Relativ e improv ement o ver DPS on ImageNet as task dif ficulty increases for super resolu- tion and Gaussian deblurring. 12 25 50 100 DDPM Sampling Steps 0% 20% Relative Improvement 12 25 50 100 DDIM Sampling Steps AdamDPS T F G N i t e r = 4 Figure 6: Relativ e improv ement over DPS for super resolution at 16x downsampling on ImageNet, across DDPM and DDIM sampling step budgets. T ask Difficulty Ablation. W e examine how task dif ficulty af fects the relativ e performance of AdamDPS and TFG compared to DPS. Figure 5 shows the relative LPIPS improvement of AdamDPS and TFG ov er DPS on ImageNet as super resolution and deblurring tasks increase in difficulty . F or super resolution, AdamDPS consistently outperforms TFG, maintaining a substan- tial impro vement over DPS across all difficulty lev els. TFG only improves upon DPS in the tw o easiest settings, and performs noticeably worse in the two hardest. W e see a similar trend for Gaus- sian deblurring. TFG only meaningfully improves upon DPS in the easiest setting, performing equiv alently to or worse than DPS as difficulty increases. AdamDPS demonstrates robust positive improv ement that becomes more pronounced at higher blur intensities, as TFG variants show de- clining performance and ultimately underperform DPS on the most challenging tasks. AdamDPS remains effecti ve ev en as conditioning information becomes increasingly limited. Sampling Steps Ablation. W e analyze the effect of reducing the sampling step budget on AdamDPS and TFG relative to DPS for super resolution at 16x downsampling on ImageNet, see Figure 6. For both DDPM and DDIM sampling, AdamDPS consistently improves over DPS across all step counts. TFG N iter = 4 fails to outperform at high step counts, consistent with Figure 3. Ho we ver , TFG becomes competitive at lower step counts, possibly because TFG performs 1 + N iter updates to the image per step, whereas DPS and AdamDPS only perform 1 update per step. Across both samplers, AdamDPS provides reliable gains o ver DPS re gardless of step budget. W all Clock. Figure 7 shows wall clock time averaged over 5 trials for ImageNet class-conditional sampling with 100 steps on a single H100 GPU, generating a batch of 8 256×256 images. AdamDPS adds negligible overhead compared to DPS. Both AdamDPS and DPS outpace TFG, whose gradi- ent computations scale with N recur (1 + N iter ) through the guidance model and N recur through the denoising network. Adam β 1 , β 2 Ablation. Figure 7 shows an ablation of Adam hyperparameters β 1 and β 2 for AdamDPS across super resolution at 16x downsampling, Gaussian deblurring at blur intensity 12, and inpainting with a 90% random mask. W e compare the relati ve LPIPS improvement over DPS for three configurations: default AdamDPS, AdamDPS with β 1 = 0 , and AdamDPS with β 2 = 0 . AdamDPS consistently outperforms both ablated variants across all tasks, demonstrating that both momentum and adaptive scaling are essential for optimal performance, with their relati ve impor- tance varying by task. 7 Published as a conference paper at ICLR 2026 Inpainting Super Resolution Gaussian Deblur 0% 10% 20% 30% Relative Improvement AdamDPS A d a m D P S 1 = 0 A d a m D P S 2 = 0 0 10 20 30 40 Wall Clock (s) DPS AdamDPS T F G N i t e r = 1 T F G N i t e r = 2 T F G N i t e r = 4 Figure 7: Left: Ablation of Adam β 1 , β 2 for super resolution at 16x downsampling, Gaussian deblurring at blur intensity 12, and inpainting at 90% random mask on the Cats dataset. Right: W all clock comparison on a single H100 GPU of 100 step class-conditional sampling with a standard classifier on ImageNet for a batch of 8 256x256 images. Sampling Analysis. W e visualize the sampling trajectories of DPS and AdamDPS for super resolu- tion at 16x do wnsampling on ImageNet in Figure 8. W e project the trajectories onto two dimensions of interest: the first defined by the difference between the initial noise and the target image, and the second defined by the difference between the AdamDPS and DPS solutions. The contours indicate the Mean Squared Error (MSE) loss surface with respect to the target. Across samples, AdamDPS trajectories more directly approach the ground truth, while DPS trajectories may stray from the target, resulting in solutions less aligned with the condition. T o better understand the performance gap between AdamDPS and DPS, we examine the cosine similarity between sequential guidance terms g t and g s throughout sampling for both methods. As shown in Figure 9, DPS guidance terms in adjacent steps frequently disagree in direction, with nega- tiv e cosine similarity for the majority of sampling. This suggests that DPS guidance is often fighting itself, pushing the sample in conflicting directions across consecutive steps. In contrast, AdamDPS maintains consistently positiv e cosine similarity between adjacent guidance terms, indicating that its Noise Target DPS Sample AdamDPS Sample AdamDPS DPS Initial Noise Target DPS Sample AdamDPS Sample DPS Sample AdamDPS Sample Figure 8: Sampling trajectories for DPS and AdamDPS projected onto two dimensions for super resolution at 16x downsampling on ImageNet. The y-axis is defined by the difference between the initial noise and the tar get, and the x-axis by the dif ference between the AdamDPS and DPS solutions. Contours depict the MSE loss surface with respect to the target. 0 200 400 600 800 1000 T i m e s t e p t 1 0 1 Cosine Similarity AdamDPS DPS Figure 9: Cosine similarity between sequential guidance terms g t and g s throughout sampling for DPS and AdamDPS. Guidance terms collected from 16x super resolution task on ImageNet. Shading denotes the 25th to 75th percentile. 8 Published as a conference paper at ICLR 2026 1 0 5 1 0 3 1 0 1 1 0 1 Loss Class-Conditional (Time-Aware Classifier) AdamCG CG 1 0 1 1 0 2 1 0 3 Super Resolution (4x) AdamDPS DPS T F G N i t e r = 4 0 200 400 600 800 1000 Timestep 1 0 1 1 0 0 1 0 1 Loss Class-Conditional (Standard Classifier) 0 200 400 600 800 1000 Timestep 1 0 1 1 0 0 1 0 1 1 0 2 Super Resolution (16x) Figure 10: The guidance loss throughout sampling for class-conditional and super resolution tasks on ImageNet. Shading denotes the 25th to 75th percentile. TFG t = 9 9 9 t = 9 1 8 t = 8 3 8 t = 7 5 7 t = 6 7 6 t = 0 Original Condition DPS AdamDPS Figure 11: Qualitativ e example of sampling trajectory for super resolution at 16x downsampling on ImageNet. Displayed are the intermediate clean data predictions x 0 | t throughout sampling. updates agree in direction for most of sampling. This coherence allows AdamDPS to make steady progress tow ards aligning with the condition rather than oscillating unproductiv ely . W e track the loss L ( f ϕ ( · ) , y ) along the sampling trajectory to compare how each method mini- mizes the guidance objective, see Figure 10. For 4x super resolution on ImageNet, where condi- tioning information is relativ ely dense, TFG reduces loss more quickly than DPS and AdamDPS initially , though all methods achiev e similar terminal loss values. Despite comparable final losses, AdamDPS still slightly outperforms TFG in reconstruction quality . For 16x super resolution on Ima- geNet, TFG struggles to reduce loss early in sampling, only achie ving a rapid decrease near the end. Importantly , this lower terminal loss compared to DPS and AdamDPS does not translate to better reconstruction performance, as e vident in Figure 3. When conditioning information is sev erely lim- ited, o ver -optimizing to the sparse signal can be detrimental rather than beneficial. In this case, TFG effecti vely ov erfits to the low-resolution image, producing the visual artif acts observed in Figure 2. For class-conditional sampling on ImageNet with a standard classifier—a particularly challenging setting where baselines achie ve near-random accuracy—neither DPS nor TFG can meaningfully re- duce the guidance loss, as sho wn in Figure 10. In contrast, AdamDPS achiev es slo w initial progress that accelerates tow ard the end of sampling, successfully reducing the guidance loss when all other methods could not, consistent with its accurac y improv ement in Figure 4. For time-aware classifiers, 9 Published as a conference paper at ICLR 2026 both CG and AdamCG reduce loss throughout sampling, but AdamCG continues improving while CG plateaus, ultimately achieving substantially lo wer loss. W e visualize intermediate clean data predictions x 0 | t during the early stages of sampling for 16x super resolution on ImageNet in Figure 11. DPS and AdamDPS produce reasonable predictions of the target image from the earliest timesteps, with structure and color emerging quickly . In contrast, TFG’ s predictions vary wildly and bear little resemblance to either the target image or conditioning image. This is consistent with the guidance loss curv es in Figure 10, where TFG fails to reduce loss early in sampling for 16x super resolution. These erratic early predictions further suggest that TFG’ s guidance is ineffecti ve when conditioning information is sparse, leaving the model unable to identify a coherent trajectory tow ard aligning with the condition. Moreover , TFG’ s final sample exhibits visual artifacts despite its aggressive loss reduction late in sampling, illustrating how overfitting to sparse conditioning information degrades reconstruction quality . Additional quantitativ e and qualitati ve results are provided in Appendix C and Appendix D. 6 R E L A T E D W O R K Beyond DPS and CG, numerous methods hav e been proposed to improv e conditional gener- ation through more sophisticated likelihood score approximations and algorithmic refinements. MPGD (He et al., 2023) sidesteps backpropagation through the diffusion model by optimizing di- rectly in data space on the clean data estimate x 0 | t , while LGD (Song et al., 2023b) applies Monte Carlo smoothing to stabilize the DPS likelihood score approximation. Building upon these ap- proaches, compositional framew orks combine multiple guidance strategies. UGD (Bansal et al., 2023) unifies DPS and MPGD with recurrence, introducing separate hyperparameters to control the contribution of different components. Recurrence is a key technique employed by guidance methods such as FreeDoM (Y u et al., 2023), which enables iterativ e refinement by revisiting timesteps (Mokady et al., 2023; W ang et al., 2022; Lugmayr et al., 2022; Du et al., 2023). TFG (Y e et al., 2024) further extends this by combining DPS, MPGD, LGD, UGD and FreeDoM into a uni- fied framework. TFG introduces hyperparameters for various algorithmic components, along with schedules that adjust some of these hyperparameters throughout sampling. Additional methods exist which lev erage specific structural assumptions about the guidance model to achiev e improved performance. DDRM (Kawar et al., 2022) assumes linearity of the in verse problem for efficient posterior sampling through v ariational inference, while Π GDM (Song et al., 2023a) handles non-differentiable measurements by assuming the av ailability of a pseudoinv erse. TMPD (Boys et al., 2023) and FreeHunch (Rissanen et al., 2025) assume access to linear measure- ment operators to estimate denoiser cov ariance, yielding impro ved likelihood score approximations. In contrast to these approaches, which focus on improving the lik elihood score approximation itself, we focus on reducing the noise in guidance updates that arises from approximate likelihood scores and limited conditioning information. Our work is orthogonal to these plug-and-play methods; adaptiv e moment estimation can be applied to any of these methods to stabilize guidance updates. 7 C O N C L U S I O N W e demonstrate that adaptiv e moment estimation, which stabilizes noisy guidance during sampling, can substantially improve plug-and-play dif fusion sampling. AdamDPS and AdamCG achie ve state- of-the-art performance across div erse reconstruction and class-conditional generation tasks with minimal computational ov erhead. Adding adaptive moments is typically only a fe w-line modifi- cation to an existing guidance implementation, and we show in Appendix C that it extends beyond DPS and CG, yielding improv ements when applied to other plug-and-play guidance methods. Im- portantly , our e valuation across a range of task difficulties reveals that complex methods like TFG which outperform simpler baselines on easy tasks often degrade substantially as conditioning infor - mation becomes limited, ultimately underperforming DPS. More broadly , plug-and-play guidance with adaptiv e moments opens a promising direction for solving underdetermined inv erse problems in scientific domains, where conditioning information is sparse and noisy . Noise mitigation of fers a simple yet effecti ve alternativ e to increasingly sophisticated likelihood score approximations. 10 Published as a conference paper at ICLR 2026 A C K N O W L E D G M E N T S W e thank Chia-Hao Lee and Da vid A. Muller for productiv e discussions which motiv ated this work. CB is supported by the National Science Foundation (NSF) through the NSF Research Traineeship (NR T) program under Grant No. 2345579. JL is supported by a Google PhD Fellowship. This work is also supported by the NSF through Grant No. O A C-2118310 and the AI Research Institutes program A ward No. DMR-2433348; the National Institute of Food and Agriculture (USD A/NIF A); the Air Force Of fice of Scientific Research (AFOSR); New Y ork-Presbyterian for the NYP-Cornell Cardiov ascular AI Collaboration; and a Schmidt AI2050 Senior Fello wship. R E F E R E N C E S Sebastian Ament, Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy . Un- expected impro vements to e xpected improv ement for bayesian optimization. Advances in Neural Information Pr ocessing Systems , 36:20577–20612, 2023. Arpit Bansal, Hong-Min Chu, A vi Schw arzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and T om Goldstein. Uni versal guidance for diffusion models. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pp. 843–852, 2023. Benjamin Boys, Mark Girolami, Jakiw Pidstrigach, Sebastian Reich, Alan Mosca, and O Deniz Akyildiz. T weedie moment projected diffusions for inv erse problems. arXiv preprint arXiv:2310.06721 , 2023. T im Brooks, Bill Peebles, Connor Holmes, W ill DePue, Y ufei Guo, Li Jing, David Schnurr , Joe T aylor, T roy Luhman, Eric Luhman, et al. V ideo generation models as world simulators. OpenAI Blog , 1(8):1, 2024. Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky , and Jong Chul Y e. Dif fusion posterior sampling for general noisy in verse problems. In The Eleventh Interna- tional Confer ence on Learning Representations , 2023. Jia Deng, W ei Dong, Richard Socher , Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hi- erarchical image database. In 2009 IEEE conference on computer vision and pattern reco gnition , pp. 248–255. Ieee, 2009. Prafulla Dhariw al and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information pr ocessing systems , 34:8780–8794, 2021. Y ilun Du, Conor Durkan, Robin Strudel, Joshua B T enenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, and W ill Sussman Grathwohl. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. In International con- fer ence on machine learning , pp. 8489–8510. PMLR, 2023. Bradley Efron. T weedie’ s formula and selection bias. Journal of the American Statistical Associa- tion , 106(496):1602–1614, 2011. Jeremy Elson, John (JD) Douceur , Jon Howell, and Jared Saul. Asirra: A captcha that exploits interest-aligned manual image categorization. In Pr oceedings of 14th ACM Confer ence on Com- puter and Communications Security (CCS) . Association for Computing Machinery , Inc., October 2007. Y utong He, Naoki Murata, Chieh-Hsin Lai, Y uhta T akida, T oshimitsu Uesaka, Dongjun Kim, W ei- Hsiang Liao, Y uki Mitsufuji, J Zico K olter, Ruslan Salakhutdino v , and Stefano Ermon. Manifold preserving guided diffusion. arXiv preprint , 2023. Martin Heusel, Hubert Ramsauer , Thomas Unterthiner , Bernhard Nessler , and Sepp Hochreiter . Gans trained by a two time-scale update rule con verge to a local nash equilibrium. Advances in neural information pr ocessing systems , 30, 2017. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Pr ocessing Systems , volume 33, pp. 6840–6851, 2020. 11 Published as a conference paper at ICLR 2026 Jonathan Ho, T im Salimans, Alex ey Gritsenko, W illiam Chan, Mohammad Norouzi, and Da vid J Fleet. V ideo dif fusion models. Advances in neural information pr ocessing systems , 35:8633– 8646, 2022. Emiel Hoogeboom, Vıctor Garcia Satorras, Cl ´ ement V ignac, and Max W elling. Equiv ariant diffu- sion for molecule generation in 3d. In International conference on machine learning , pp. 8867– 8887. PMLR, 2022. Sadeep Jayasumana, Srikumar Ramalingam, Andreas V eit, Daniel Glasner, A yan Chakrabarti, and Sanjiv Kumar . Rethinking fid: T o wards a better ev aluation metric for image generation. In Pr o- ceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 9307– 9315, 2024. Donald R Jones, Matthias Schonlau, and William J W elch. Ef ficient global optimization of expensiv e black-box functions. Journal of Global optimization , 13(4):455–492, 1998. T ero Karras, Miika Aittala, T imo Aila, and Samuli Laine. Elucidating the design space of diffusion- based generativ e models. Advances in neural information pr ocessing systems , 35:26565–26577, 2022. Bahjat Ka war , Michael Elad, Stefano Ermon, and Jiaming Song. Denoising dif fusion restoration models. Advances in neural information pr ocessing systems , 35:23593–23606, 2022. Diederik Kingma and Ruiqi Gao. Understanding diffusion objectiv es as the elbo with simple data augmentation. Advances in Neural Information Pr ocessing Systems , 36:65484–65516, 2023. Diederik Kingma, T im Salimans, Ben Poole, and Jonathan Ho. V ariational diffusion models. Ad- vances in neural information pr ocessing systems , 34:21696–21707, 2021. Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint , 2014. Zhifeng K ong, W ei Ping, Jiaji Huang, K exin Zhao, and Bryan Catanzaro. Diffwa ve: A v ersatile diffusion model for audio synthesis. arXiv preprint , 2020. Alex Krizhe vsky et al. Learning multiple layers of features from tin y images. 2009. Haohe Liu, Zehua Chen, Y i Y uan, Xinhao Mei, Xubo Liu, Danilo Mandic, W enwu W ang, and Mark D Plumbley . Audioldm: T ext-to-audio generation with latent diffusion models. arXiv pr eprint arXiv:2301.12503 , 2023. Andreas Lugmayr , Martin Danelljan, Andres Romero, Fisher Y u, Radu T imofte, and Luc V an Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pp. 11461–11471, 2022. Morteza Mardani, Jiaming Song, Jan Kautz, and Arash V ahdat. A v ariational perspectiv e on solving in verse problems with diffusion models. In The T welfth International Confer ence on Learning Repr esentations , 2024. Ron Mokady , Amir Hertz, Kfir Aberman, Y ael Pritch, and Daniel Cohen-Or . Null-text in version for editing real images using guided diffusion models. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pp. 6038–6047, 2023. Aditya Ramesh, Prafulla Dhariw al, Alex Nichol, Case y Chu, and Mark Chen. Hierarchical te xt- conditional image generation with clip latents. arXiv preprint , 2022. Sev eri Rissanen, Markus Heinonen, and Arno Solin. Free hunch: Denoiser covariance estimation for dif fusion models without e xtra costs. In The Thirteenth International Confer ence on Learning Repr esentations , 2025. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser , and Bj ¨ orn Ommer . High- resolution image synthesis with latent diffusion models. In Pr oceedings of the IEEE/CVF confer- ence on computer vision and pattern r ecognition , pp. 10684–10695, 2022. 12 Published as a conference paper at ICLR 2026 Chitwan Saharia, W illiam Chan, Saurabh Sax ena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour , Raphael Gontijo Lopes, Burcu Karagol A yan, T im Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural informa- tion pr ocessing systems , 35:36479–36494, 2022a. Chitwan Saharia, Jonathan Ho, W illiam Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. Image super-resolution via iterati ve refinement. IEEE tr ansactions on pattern anal- ysis and machine intelligence , 45(4):4713–4726, 2022b. Jascha Sohl-Dickstein, Eric W eiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learn- ing , pp. 2256–2265. pmlr , 2015. Jiaming Song, Arash V ahdat, Morteza Mardani, and Jan Kautz. Pseudoinv erse-guided diffusion models for in verse problems. 2023a. Jiaming Song, Qinsheng Zhang, Hongxu Y in, Morteza Mardani, Ming-Y u Liu, Jan Kautz, Y ongxin Chen, and Arash V ahdat. Loss-guided dif fusion models for plug-and-play controllable generation. In International Confer ence on Machine Learning , pp. 32483–32498. PMLR, 2023b. Y ang Song and Stefano Ermon. Generativ e modeling by estimating gradients of the data distribution. In Advances in Neural Information Pr ocessing Systems , volume 32, pp. 11895–11907, 2019. T ijmen T ieleman and Geof frey Hinton. Lecture 6.5 - RMSProp. COURSERA: Neural Networks for Machine Learning , 2012. Y inhuai W ang, Jiwen Y u, and Jian Zhang. Zero-shot image restoration using denoising diffusion null-space model. arXiv preprint , 2022. Joseph L W atson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Y im, Helen E Eise- nach, W oody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiffusion. Natur e , 620(7976):1089–1100, 2023. Haotian Y e, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Y itao Liang, Jianzhu Ma, James Y Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models. Advances in Neural Information Pr ocessing Systems , 37:22370–22417, 2024. Jiwen Y u, Y inhuai W ang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: T raining-free energy-guided conditional diffusion model. In Proceedings of the IEEE/CVF International Con- fer ence on Computer V ision , pp. 23174–23184, 2023. Richard Zhang, Phillip Isola, Alex ei A Efros, Eli Shechtman, and Oli ver W ang. The unreasonable effecti veness of deep features as a perceptual metric. In Pr oceedings of the IEEE confer ence on computer vision and pattern recognition , pp. 586–595, 2018. 13 Published as a conference paper at ICLR 2026 A A D D I T I O N A L E X P E R I M E N TA L D E T A I L S W e build on the TFG codebase 2 using their implementations for CG, MPGD, UGD, and TFG. W e slightly update the LGD and DPS implementations. For the TFG baseline itself we follow the authors’ recommendation, tuning ρ, µ, γ , sweeping N iter = 1 , 2 , 4 , setting N recur = 1 , and setting the schedules for ρ , µ, γ to be increasing, increasing, decreasing (Y e et al., 2024). All experiments use 100 step DDPM sampling unless stated otherwise. Gaussian deblurring blur intensity refers to the standard deviation of the Gaussian kernel used to blur the image. W e split the datasets into v alidation and test splits and tune our hyperparameters on the validation split. Our v alidation and test splits contain 32 and 2048 images respecti vely . W e use Bayesian Optimization to tune the hyperparameters of each method on our v alidation split. W e perform 150 trials, the first 50 trials select candidates by Sobol sampling, the remaining 100 trials use Log Noisy Expected Improvement (Ament et al., 2023). Accuracy on class-conditional sampling tasks is computed with three held-out classifiers for each dataset downloaded from HuggingFace. For CIF AR10: V iT 3 , V iT Finetuned 4 , and ConvNeXt 5 . For ImageNet: V iT 6 , DINO v2 7 , MobileV iT v2 8 . B A D D I T I O N A L P S E U D O C O D E Algorithm 3 Diffusion Posterior Sampling (DPS) Require: Diffusion Model θ , Guidance Model f ϕ , Condition y , Guidance Strength ρ t n , . . . , ρ t 0 , Sampling T imesteps t n , . . . , t 0 ⊆ T 1: x t n ∼ N (0 , I ) 2: for t = t n , . . . , t 1 do 3: g t = − ρ t ∇ x t L ( f ϕ ( x 0 | t ) , y ) 4: x s = Sample ( x 0 | t , x t , t, s ) + g t 5: end for 6: return x t 0 Algorithm 4 Classifier Guidance (CG) Require: Diffusion Model θ , Guidance Model f ϕ , Condition y , Guidance Strength ρ , Sampling Timesteps t n , . . . , t 0 ⊆ T 1: x t n ∼ N (0 , I ) 2: for t = t n , . . . , t 1 do 3: g t = −∇ x t L ( f ϕ ( x t , t ) , y ) 4: x s = Sample ( x 0 | t + ρg t σ 2 t , x t , t, s ) 5: end for 6: return x t 0 Algorithm 5 Adaptiv e Moment Estimate Require: Gradient g , First Moment Estimate m , Second Moment Estimate v , Adam Step k , First Moment Exponential Decay Rate β 1 , Second Moment Exponential Decay Rate β 2 , δ = 10 − 8 1: k = k + 1 2: m = β 1 m + (1 − β 1 ) g 3: v = β 2 v + (1 − β 2 ) g 2 4: ˆ m = m/ (1 − β k 1 ) 5: ˆ v = v / (1 − β k 2 ) 6: ˆ g = ˆ m/ ( √ ˆ v + δ ) 7: return ˆ g , m , v , k 2 https://github.com/YWolfeee/Training- Free- Guidance 3 https://huggingface.co/nateraw/vit- base- patch16- 224- cifar10 4 https://huggingface.co/aaraki/vit- base- patch16- 224- in21k- finetuned- cifar10 5 https://huggingface.co/ahsanjavid/convnext- tiny- finetuned- cifar10 6 https://huggingface.co/anonymous- 429/osf- vit- base- patch16- 224- imagenet 7 https://huggingface.co/facebook/dinov2- giant- imagenet1k- 1- layer 8 https://huggingface.co/apple/mobilevitv2- 1.0- imagenet1k- 256 14 Published as a conference paper at ICLR 2026 C A D D I T I O N A L Q U A N T I TA T I V E R E S U L T S T able 1: Reconstruction on ImageNet Inpainting Super Resolution 4x Super Resolution 16x Gaussian Deblur 3 Gaussian Deblur 12 Method LPIPS FID IS LPIPS FID IS LPIPS FID IS LPIPS FID IS LPIPS FID IS PiGDM 0.30 66.83 36.85 0.48 63.73 26.34 0.48 49.41 30.11 0.48 65.04 24.69 0.50 51.97 27.76 RED-diff 0.31 75.86 36.60 0.20 30.42 102.09 0.57 100.30 9.66 0.27 40.13 76.44 0.52 209.90 5.85 DPS 0.16 27.79 132.32 0.19 26.43 128.03 0.30 35.55 60.02 0.23 27.66 109.29 0.34 40.25 45.07 LGD 0.18 37.37 89.52 0.24 31.97 105.63 0.32 38.10 49.85 0.31 37.02 74.39 0.39 46.11 36.46 MPGD 0.45 142.47 14.47 0.16 27.75 120.52 0.35 52.66 35.93 0.23 31.18 107.18 0.38 52.11 34.34 UGD N iter =1 0.29 47.30 60.38 0.31 38.42 70.41 0.34 38.52 45.25 0.33 37.46 63.02 0.40 43.06 36.76 UGD N iter =2 0.20 33.18 95.94 0.18 28.31 123.13 0.32 40.05 49.68 0.26 32.76 98.00 0.38 44.48 40.11 UGD N iter =4 0.20 33.72 95.57 0.15 25.68 139.34 0.31 39.56 49.09 0.23 29.51 106.57 0.37 47.04 38.47 TFG N iter =1 0.20 41.49 81.77 0.14 25.37 132.58 0.32 42.27 46.69 0.20 27.21 113.49 0.36 47.34 36.11 TFG N iter =2 0.13 26.17 135.12 0.13 25.03 136.73 0.32 42.69 46.63 0.17 26.01 125.65 0.35 46.44 38.92 TFG N iter =4 0.13 26.87 125.08 0.14 26.62 128.90 0.32 42.92 45.20 0.16 25.74 128.00 0.36 49.55 38.74 AdamMPGD 0.48 142.78 13.39 0.15 27.06 120.36 0.35 56.51 32.74 0.20 29.96 114.47 0.37 51.43 35.29 AdamPiGDM 0.11 22.25 163.23 0.14 22.42 161.15 0.28 33.75 61.26 0.20 27.30 132.52 0.30 35.91 59.00 AdamDPS 0.12 23.42 160.63 0.12 20.92 180.91 0.27 30.16 65.69 0.17 23.45 144.23 0.33 38.35 49.11 T able 2: Reconstruction on ImageNet (Intermediate Dif ficulties) Super Resolution 8x Super Resolution 12x Gaussian Deblur 6 Gaussian Deblur 9 Method LPIPS FID IS LPIPS FID IS LPIPS FID IS LPIPS FID IS DPS 0.23 29.02 88.64 0.26 32.63 71.02 0.26 31.39 71.41 0.30 36.65 54.54 TFG N iter =1 0.22 31.76 79.87 0.27 41.54 52.95 0.29 35.43 63.57 0.33 42.91 46.36 TFG N iter =2 0.22 31.56 80.09 0.27 37.08 57.60 0.26 33.21 72.71 0.32 40.15 49.85 TFG N iter =4 0.22 32.26 76.58 0.27 39.84 53.69 0.26 33.58 73.29 0.31 39.58 49.63 AdamDPS 0.19 24.36 117.35 0.23 27.60 85.87 0.23 27.26 90.08 0.28 33.63 62.14 T able 3: Reconstruction on Cats Inpainting Super Resolution 4x Super Resolution 16x Gaussian Deblur 3 Gaussian Deblur 12 Method LPIPS FID LPIPS FID LPIPS FID LPIPS FID LPIPS FID PiGDM 0.32 80.77 0.40 60.26 0.44 52.76 0.42 58.80 0.46 58.48 RED-diff 0.22 40.72 0.12 22.04 0.35 103.73 0.16 32.82 0.40 120.05 DPS 0.13 17.13 0.14 17.74 0.25 30.68 0.18 23.58 0.29 34.74 LGD 0.17 35.29 0.14 19.63 0.27 35.15 0.20 25.72 0.33 40.10 MPGD 0.42 76.60 0.09 15.70 0.28 44.16 0.14 20.88 0.32 49.50 UGD N iter =1 0.32 64.22 0.25 38.53 0.29 33.60 0.26 35.70 0.35 43.10 UGD N iter =2 0.22 38.14 0.12 19.86 0.27 38.07 0.19 26.97 0.34 49.98 UGD N iter =4 0.21 37.68 0.11 18.56 0.27 38.07 0.17 23.91 0.32 47.14 TFG N iter =1 0.15 18.24 0.09 14.81 0.27 39.75 0.15 20.78 0.32 50.49 TFG N iter =2 0.09 17.78 0.08 13.54 0.26 38.82 0.12 18.20 0.31 46.90 TFG N iter =4 0.09 17.77 0.08 14.09 0.26 38.83 0.11 16.42 0.29 44.95 AdamMPGD 0.44 70.93 0.10 15.32 0.28 46.85 0.12 18.33 0.30 49.17 AdamPiGDM 0.08 14.54 0.09 13.82 0.24 26.51 0.13 17.79 0.25 29.94 AdamDPS 0.08 14.64 0.09 13.19 0.24 27.62 0.14 20.43 0.27 30.22 T able 4: Reconstruction on Cats (Intermediate Dif ficulties) Super Resolution 8x Super Resolution 12x Gaussian Deblur 6 Gaussian Deblur 9 Method LPIPS FID LPIPS FID LPIPS FID LPIPS FID DPS 0.21 25.36 0.22 25.22 0.22 26.99 0.26 31.44 TFG N iter =1 0.17 23.70 0.22 31.46 0.24 31.36 0.27 38.37 TFG N iter =2 0.16 22.10 0.22 29.77 0.21 27.40 0.27 36.95 TFG N iter =4 0.17 23.18 0.21 29.02 0.20 26.25 0.25 33.75 AdamDPS 0.16 19.45 0.20 22.64 0.20 24.32 0.23 26.48 15 Published as a conference paper at ICLR 2026 T able 5: Sampling Step Ablation for Super Resolution at 16x Do wnsampling on ImageNet DDPM DDIM LPIPS FID LPIPS FID Method 100 50 25 12 100 50 25 12 100 50 25 12 100 50 25 12 DPS 0.30 0.33 0.42 0.58 35.55 44.54 62.21 154.29 0.31 0.34 0.45 0.57 41.50 43.62 51.34 58.01 TFG N iter =4 0.32 0.34 0.39 0.50 42.92 44.55 52.35 118.59 0.35 0.35 0.35 0.41 58.38 59.20 53.84 60.34 AdamDPS 0.27 0.30 0.35 0.46 30.16 35.63 49.05 98.71 0.29 0.30 0.35 0.44 39.60 37.18 46.35 77.33 T able 6: Sampling Step Ablation for Super Resolution at 16x Do wnsampling on Cats DDPM DDIM LPIPS FID LPIPS FID Method 100 50 25 12 100 50 25 12 100 50 25 12 100 50 25 12 DPS 0.25 0.29 0.35 0.52 30.68 40.15 58.25 184.52 0.29 0.29 0.37 0.51 30.31 32.35 42.73 67.90 TFG N iter =4 0.26 0.29 0.34 0.40 38.83 39.72 44.83 70.17 0.35 0.34 0.33 0.34 55.81 51.70 49.85 47.33 AdamDPS 0.24 0.26 0.29 0.38 27.62 30.32 34.15 72.19 0.27 0.27 0.29 0.37 27.53 27.20 32.51 61.72 T able 7: Class-Conditional (Standard Classifier) on CIF AR10 Guidance Classifier Accuracy (%) Held-out Classifier Accuracy (%) FID Method V iT V iT Finetuned ConvNeXt RED-diff 10.7 9.9 10.2 10.7 203.8 DPS 42.8 39.4 40.3 42.8 32.3 LGD 21.8 19.6 18.1 21.8 31.0 MPGD 26.7 24.9 24.3 26.7 34.1 UGD N iter =1 9.3 9.7 10.2 9.3 25.4 UGD N iter =2 24.6 22.9 23.1 24.6 32.4 UGD N iter =4 31.9 28.9 30.3 31.9 37.2 TFG N iter =1 39.4 37.5 38.8 39.4 50.3 TFG N iter =2 17.0 15.4 14.7 17.0 25.1 TFG N iter =4 19.4 17.1 16.7 19.4 26.1 AdamMPGD 20.7 20.3 20.2 20.7 29.9 AdamDPS 52.6 53.2 51.2 52.6 58.0 T able 8: Class-Conditional (Standard Classifier) on ImageNet Guidance Classifier T op-10 Accuracy (%) Held-out Classifier T op-10 Accuracy (%) FID Method V iT DINO v2 MobileV iT v2 RED-diff 12.7 23.0 3.2 1.4 272.7 DPS 0.7 0.8 1.2 1.0 43.0 LGD 0.7 0.7 1.2 1.1 42.5 MPGD 0.9 0.8 1.2 1.4 43.6 UGD N iter =1 0.8 0.6 0.7 0.7 42.3 UGD N iter =2 1.4 1.1 1.4 1.6 45.3 UGD N iter =4 1.7 1.0 0.8 0.9 43.6 TFG N iter =1 1.0 0.9 0.9 1.1 42.7 TFG N iter =2 0.9 0.8 0.6 1.1 43.2 TFG N iter =4 1.4 0.8 0.9 1.0 43.1 AdamMPGD 1.4 1.5 1.6 1.8 45.8 AdamDPS 10.5 9.2 8.3 7.6 52.8 T able 9: Class-Conditional (T ime-A ware Classifier) on ImageNet Guidance Classifier Accuracy (%) Held-out Classifier Accuracy (%) FID Method V iT DINO v2 MobileV iT v2 CG 61.0 63.4 58.3 51.0 30.8 AdamCG 82.5 84.2 77.8 68.1 29.6 16 Published as a conference paper at ICLR 2026 D A D D I T I O N A L Q U A L I TA T I V E R E S U L T S Condition Ground Truth AdamDPS DPS TFG Super Resolution (16x) on ImageNet Figure 12: Additional qualitativ e results for super resolution at 16x downsampling on ImageNet. 17 Published as a conference paper at ICLR 2026 Condition Ground Truth AdamDPS DPS TFG Gaussian Deblur (12) on ImageNet Figure 13: Additional qualitativ e results for Gaussian deblurring at blur intensity 12 on ImageNet. 18 Published as a conference paper at ICLR 2026 Condition Ground Truth AdamDPS DPS TFG Super Resolution (12x) on Cats Figure 14: Additional qualitativ e results for super resolution at 12x downsampling on Cats. 19 Published as a conference paper at ICLR 2026 Condition Ground Truth AdamDPS DPS TFG Gaussian Deblur (9) on Cats Figure 15: Additional qualitativ e results for Gaussian deblurring at blur intensity 9 on Cats. 20 Published as a conference paper at ICLR 2026 Dog Condition AdamDPS DPS TFG Ship Automobile Deer Truck Ship Class-Conditional (Standard Classifier) on CIFAR10 Figure 16: Additional qualitati ve results for class-conditional sampling with a standard classifier on CIF AR10. 21 Published as a conference paper at ICLR 2026 Pirate Condition AdamDPS DPS TFG Hamster Refrigerator Tape Player Space Heater Gazelle Class-Conditional (Standard Classifier) on ImageNet Figure 17: Additional qualitati ve results for class-conditional sampling with a standard classifier on ImageNet. 22 Published as a conference paper at ICLR 2026 Espresso Condition AdamCG CG Black Stork Soccer Ball African Grey King Penguin Cowboy Boot Class-Conditional (Time-Aware Classifier) on ImageNet Figure 18: Additional qualitati ve results for class-conditional sampling with a time-aware classifier on ImageNet. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment