추론이 불러오는 과신: 비전‑언어 모델의 불확실성 추정이 무너지는 이유
본 논문은 체인‑오브‑쓰루(Chain‑of‑Thought, CoT) 추론이 비전‑언어 모델(VLM)의 불확실성 추정에 미치는 부정적 영향을 체계적으로 분석한다. 추론 과정에서 모델은 답변 토큰을 점점 자신의 추론 흐름에 맞춰 확률을 집중시키게 되며, 이는 “암묵적 답변 조건화(implicit answer conditioning)”라 불리는 현상을 초래한다. 결과적으로 답변 토큰 확률 기반의 불확실성 지표(예: 최대 시퀀스 확률, 퍼플렉시티, 평…
저자: Robert Welch, Emir Konuk, Kevin Smith
본 논문은 비전‑언어 모델(VLM)이 고위험 분야—예를 들어 의료 영상 해석이나 자율 주행—에 적용될 때 필수적인 불확실성 정량화(UQ)의 신뢰성을 검증한다. 최근 VLM 파이프라인에 널리 도입된 체인‑오브‑쓰루(Chain‑of‑Thought, CoT) 추론은 중간 단계에서 텍스트 형태의 단계별 추론을 생성하고, 이를 바탕으로 최종 답변을 도출한다. CoT는 복합적인 시각·수리 추론 과제를 크게 향상시켜, OK‑VQA와 MathVista 같은 멀티모달 벤치마크에서 정확도를 눈에 띄게 끌어올린다. 그러나 정확도 향상이 불확실성 추정의 품질을 보장하지는 않는다.
저자들은 CoT가 불확실성 추정에 미치는 영향을 체계적으로 조사하기 위해, 다양한 VLM 아키텍처(예: BLIP‑2, OFA, Flamingo 등)와 세 가지 멀티모달 데이터셋(OK‑VQA, MathVista, VQAv2)을 선택했다. 각 모델에 대해 CoT 프롬프트와 비CoT 프롬프트 두 조건을 적용하고, 선택적 생성(selective generation) 프레임워크를 사용해 모델이 자신감 점수가 임계값 이하일 경우 답변을 포기하도록 설계했다. 이 프레임워크는 커버리지(모델이 답변을 제공한 비율)와 리스크(포기하지 않은 답변 중 오류 비율) 사이의 트레이드오프를 평가한다.
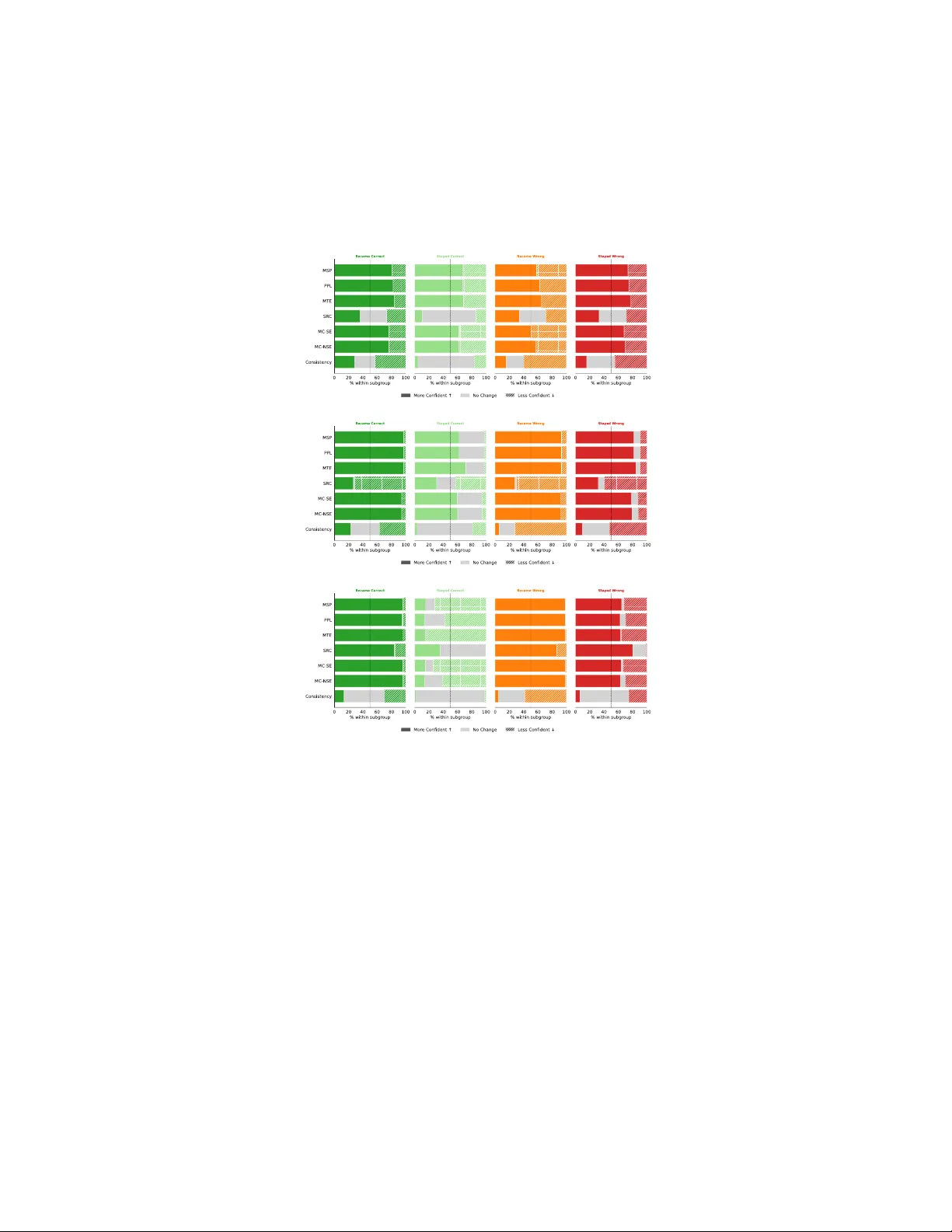
불확실성 추정 방법은 크게 세 가지 범주로 나뉜다. 첫 번째는 답변 토큰 확률(Answer‑Token Likelihood, ATL) 기반 지표로, 최대 시퀀스 확률(MSP), 퍼플렉시티(PPL), 평균 토큰 엔트로피(MTE), Monte‑Carlo 시퀀스 엔트로피(MC‑SE, MC‑NSE) 등이 포함된다. 두 번째는 자기‑보고식 자신감(Self‑Reported Confidence, SRC)으로, 메타‑프롬프트를 통해 모델이 “정답인지 여부”를 직접 묻고 ‘yes’ 토큰의 확률을 정규화한다. 세 번째는 agreement‑based consistency로, 다중 샘플을 생성한 뒤 다수결에 일치하는 비율을 불확실성 점수로 사용한다.
평가 지표로는 PRR(Prediction Rejection Ratio), Spearman 순위 상관계수, 그리고 AURC/AUGRC(Area Under Risk‑Coverage Curve) 등을 사용했다. PRR은 불확실성 순위가 무작위 기준보다 얼마나 개선되었는지를 비율로 나타내며, 1에 가까울수록 완벽한 순위(oracle)와 유사함을 의미한다. Spearman 상관계수는 불확실성 점수와 정답 여부 사이의 순위 일치를 비모수적으로 측정한다. AUGRC는 선택적 생성 시스템 전체의 성능을 종합적으로 평가한다.
실험 결과는 두드러진 패턴을 보였다. CoT를 적용했을 때, ATL 기반 지표는 전반적으로 PRR과 Spearman 상관계수가 크게 감소했다. 예를 들어, BLIP‑2 모델에서 MSP 기반 PRR은 비CoT 상황의 0.78에서 CoT 상황의 0.42로 떨어졌다. 이는 답변 토큰 확률이 모델의 내부 추론 흐름에 과도하게 맞춰지면서, 실제 이미지‑텍스트 불확실성을 반영하지 못하게 됨을 의미한다. 이러한 현상은 “암묵적 답변 조건화(implicit answer conditioning)”라는 메커니즘으로 설명된다. CoT 과정에서 모델은 점진적으로 자신의 추론 텍스트에 일관된 답변을 예상하고, 최종 답변 토큰을 생성할 때 이미 내부적으로 결론을 확정짓는다. 따라서 답변 토큰 확률은 정답 여부와 무관하게 급격히 상승해 과신을 유발한다.
반면, agreement‑based consistency는 CoT 적용 전후에 큰 변동이 없었으며, 오히려 복잡한 추론이 요구되는 질문일수록 일관성이 향상되는 경향을 보였다. 이는 다중 샘플 간의 다양성을 유지함으로써 토큰 확률이 특정 답변에 집중되는 현상을 완화하기 때문이다. Self‑Reported Confidence는 상황에 따라 혼재된 결과를 보였으며, 일부 경우에는 CoT가 자신감 점수를 개선했지만 전반적으로는 ATL 지표만큼 일관되지 않았다.
추가 실험으로 저자들은 “마스크드 토큰” 방식을 도입했다. 추론 텍스트 중 핵심 단어를 마스크하고 답변을 생성하면, 답변 토큰 확률이 다시 낮아지고 ATL 기반 불확실성 지표가 회복되는 현상이 관찰되었다. 이는 추론 텍스트 자체가 답변 확률을 조정한다는 가설을 뒷받침한다.
결론적으로, CoT는 VLM의 정확도를 크게 향상시키지만, 토큰‑레벨 확률에 기반한 불확실성 추정은 과신을 초래해 신뢰성을 크게 저하시킨다. 고신뢰가 요구되는 실제 시스템에서는 토큰‑독립적인 agreement‑based consistency와 같은 방법을 채택하는 것이 바람직하다. 또한, 모델 설계 단계에서 “답변을 스스로 확정짓는” 현상을 방지하기 위해 추론 텍스트와 답변 사이의 조건부 의존성을 완화하는 메커니즘(예: 마스크드 추론, 단계별 디커플링) 도입을 고려해야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기