The Cost of Reasoning: Chain-of-Thought Induces Overconfidence in Vision-Language Models
Vision-language models (VLMs) are increasingly deployed in high-stakes settings where reliable uncertainty quantification (UQ) is as important as predictive accuracy. Extended reasoning via chain-of-thought (CoT) prompting or reasoning-trained models…
Authors: Robert Welch, Emir Konuk, Kevin Smith
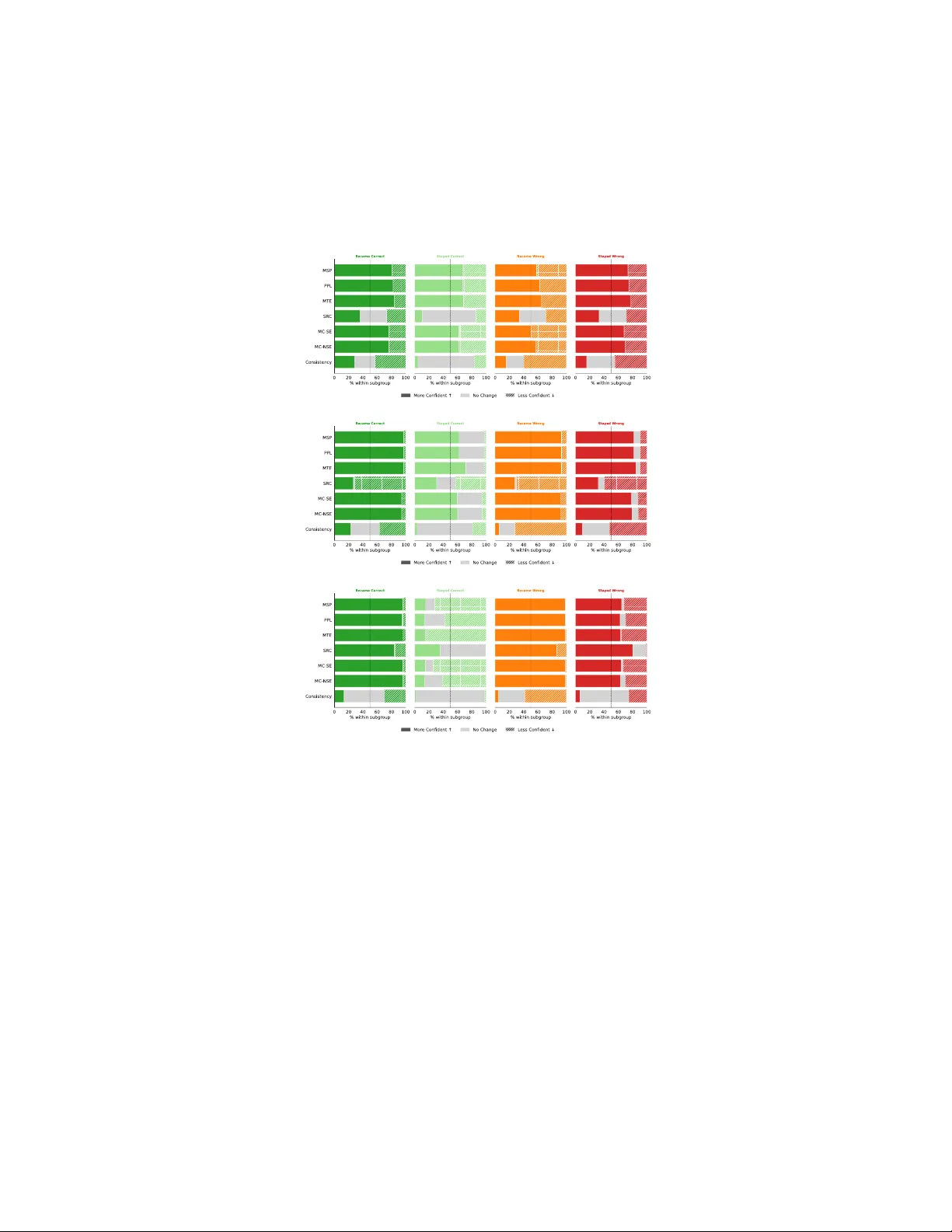
The Cost of Reasoning: Chain-of-Though t Induces Ov erconfidence in Vision-Language Mo dels Rob ert W elc h 1 , 2 , Emir Kon uk 1 , 2 , and Kevin Smith 1 , 2 1 KTH Ro yal Institute of T echnology , Sto c kholm, Sweden 2 Science for Life Lab oratory , Sto c kholm, Sw eden rwe2@kth.se Abstract. Vision-language mo dels (VLMs) are increasingly deplo yed in high-stak es settings where reliable uncertain ty quan tification (UQ) is as imp ortan t as predictive accuracy . Extended reasoning via chain- of-though t (CoT) prompting or reasoning-trained models has become ubiquitous in mo dern VLM pip elines, y et its effect on UQ reliability re- mains po orly understoo d. W e show that reasoning consistently degrades the qualit y of most uncertain ty estimates, even when it impro ves task accuracy . W e identify implicit answ er conditioning as the primary mech- anism: as reasoning traces con verge on a conclusion b efore the final an- sw er is generated, tok en probabilities increasingly reflect consistency with the mo del’s own reasoning trace rather than uncertaint y ab out correct- ness. In effect, the mo del b ecomes ov erconfident in its answer. In con- trast, agreement-based consistency remains robust and often improv es under reasoning, making it a practical c hoice for uncertaint y estimation in reasoning-enabled VLMs. Keyw ords: Vision-Language Mo dels · Chain-of-Though t · Uncertaint y Quan tification 1 In tro duction Vision-language models (VLMs) are increasingly deplo yed in high-stak es set- tings where reliable predictions are as imp ortant as accurate ones, from in- terpreting medical images [15] to autonomous na vigation [29]. Modern VLM pip elines increasingly rely on c hain-of-thought (CoT) prompting and reasoning- orien ted models that generate in termediate, step-b y-step inference b efore pro- ducing a final answ er. Reasoning substantially improv es p erformance on chal- lenging m ultimo dal benchmarks requiring multi-step visual and mathematical reasoning [17, 32]. Ho wev er, accuracy alone is insufficient for safe deploymen t. Sele ctive gener- ation addresses this issue by ensuring that the mo dels can abstain when un- certain [2]. In this setting, uncertaint y quality is determined by ho w well con- fidence scores rank correct predictions abov e incorrect ones, and is typically ev aluated using ranking-based metrics suc h as the Prediction Rejection Ratio (PRR) [19, 20] and AUGR C [25]. 2 R. W elc h et al. User Prompt Q: Name the t yp e of plant. Ground T ruth vine VLM Responses No Reasoning vertical garden Reasoning 1 The image shows a vertical garden with lush green foliage , including broad leaves and some reddish variegation . vertical garden Reasoning 2 The image shows a vertical garden with lush green foliage . This appearance is characteristic of a vertical garden , commonly using species like pothos , philodendron , or ivy . vertical garden Answer token likelihood Figure 1: Example: image (left), highligh ted tok en traces (righ t), and a color scale. 1 Fig. 1: Example illustrating reasoning-induced ov erconfidence. Color intensit y reflects answer-tok en likelihoo d, which increases as the reasoning trace conv erges. As the model generates a c hain-of-thought explanation, the evolving reasoning increasingly constrains the answer tokens (“v ertical garden”), making predictions ov erly confiden t, ev en when the prediction is incorrect (ground truth: vine ). W e refer to this effect as implicit answer c onditioning : the model progressively shifts from groun ding the answer in the image to reinforcing its own reasoning trace, which in turn degrades reliability of many uncertaint y estimates. Giv en the widespread adoption of reasoning, a natural question arises. How do es reasoning affect uncertain ty estimation in m ulti-mo dal generation? One migh t expect that deliberate reasoning impro ves b oth accuracy and UQ relia- bilit y . How ever, across the VLM families and b enc hmarks we ev aluated, w e find that this intuition fails for most uncertaint y estimates. While reasoning typically impro ves task accuracy , it degrades the ranking quality of uncertaint y measures that rely on answ er-token lik eliho o ds, including maxim um sequence probabil- it y , p erplexity , mean token entrop y , and Mon te Carlo sequence en tropy [4, 14]. The issue is not merely that additional conditioning c hanges token probabilities (whic h is exp ected) but that reasoning changes what the answer-tok en likelihoo d represen ts. Rather than reflecting uncertaint y ab out correctness, it increasingly captures in ternal semantic commitmen t to the mo del’s own reasoning trace. In m ultimo dal settings, this misalignment is esp ecially consequen tial: VLMs must ground their conclusions in perceptual evidence that may remain am biguous ev en as the reasoning trace conv erges. T oken-lev el probabilities can signal con- sistency with the mo del’s internal reasoning while failing to capture uncertaint y ab out the visual signal. As a result, mo dels may abstain less often on difficult or visually am biguous samples, pro ducing ov erconfiden t errors despite improv ed a verage accuracy . Our analysis suggests that this arises from what we term implicit answer c on- ditioning : as a reasoning trace unfolds, it progressiv ely constrains the conditional The Cost of Reasoning in VLMs 3 distribution ov er the forthcoming answer tokens. By the time the final answer is generated, the mo del has already committed to a sp ecific conclusion within its o wn reasoning trace, making the answer highly predictable. In la yman’s terms, it talks itself in to its answer. This inflates answer-tok en likelihoo ds, whether or not the conclusion is correct. Imp ortan tly , this effect is not attributable to verbosity: longer reasoning traces are, on av erage, asso ciated with low er confidence. Rather, it is the conditioning effect of the reasoning con text (i.e. the answ er implicit in the reasoning) that concentrates probability mass on the predicted answer. W e pro vide con trolled masking interv entions and reasoning trace analyses that offer evidence consistent with this explanation. Imp ortan tly , not all uncertaint y estimates are equally affected. Those that do not rely directly on answer-tok en likelihoo ds, such as agreement-based con- sistency [27], whic h measures agreement across sampled answ ers via a ma jority v ote, remain stable and often improv e under reasoning. Asking the mo del to self- rep ort confidence [10, 24] shows mixed b eha vior. This pap er mak es the following con tributions: 1. W e empirically demonstrate that reasoning degrades the qualit y of uncer- tain ty estimates that rely on answer-tok en likelihoo d (A TL). 2. W e provide evidence p oin ting to wards implicit answer c onditioning as a key driv er of this degradation. 3. W e show that applying agreement-based consistency is robust under reason- ing, offering a practical solution for UQ in reasoning VLMs. 2 Related W ork The interaction b etw een chain-of-though t reasoning and uncertaint y estimation has recently b een explored in text-only large language m odels. Y o on et al. [31] rep ort that CoT-induced “slow-thinking” behaviours can improv e self-rep orted confidence calibration, while Lyu et al. [18] study whether consistency enhances calibration in LLMs. Lanham et al. [16] inspect reasoning traces to analyze their causal role in shaping mo del predictions. Ho w ever, these w orks fo cus on calibration or reasoning faithfulness in text-only settings. They do not examine ho w reasoning alters the pragmatic ranking reliability of uncertaint y estimates or the selective generation setting. Crucially , prior studies do not consider multimodal mo dels, where reasoning m ust reconcile visual p erceptual uncertain t y with linguistic inference. In mul- timo dal mo dels, the reasoning pro cess can con verge on a confiden t conclusion ev en if the visual evidence is unclear, pro ducing mismatc hes b etw een in ternal confidence and p erceptual uncertain ty that do not o ccur in text-only mo dels. T o our knowledge, no prior work analyzes how reasoning alters uncertain ty ranking in multimodal generation. Chain-of-though t prompting [28] and reasoning-nativ e (“Thinking”) mod- els [7, 8] generate in termediate reasoning traces prior to pro ducing final answ ers, 4 R. W elc h et al. and are no w widely adopted. Self-Consistency [27] aggregates m ultiple reason- ing paths via ma jority voting. Despite their widespread use, their impact on uncertain ty estimation remains largely unexplored. Uncertain ty Estimation in Language and Vision-Language Mo dels. Comprehensiv e b enc hmarks such as LM-Polygraph [4] and subsequent large-scale ev aluations [26, 30] compare a wide range of white-b o x and black-box uncertaint y metho ds for LLMs. These studies, ho wev er, ev aluate static uncertaint y quantifi- cation for non-reasoning settings and do not analyze ho w reasoning b ehaviour systematically mo difies them. In multimodal settings, uncertaint y for VLMs has thus far b een studied via conformal prediction on multiple-c hoice tasks without reasoning [13]. While use- ful, conformal metho ds assume fixed answer sets and do not address op en-ended generation or tok en-lev el lik eliho o d-based uncertaint y . In this paper, w e ana- lyze a broad sp ectrum of uncertain ty measures including token-lik eliho o d-based, agreemen t-based, and introspective measures for multimodal settings. Bey ond b enc hmark comparisons, prior w ork explores b ehavioural pro xies for uncertaint y . Khan and F u [11] examine answer consistency under prompt rephrasing for selective visual question answ ering. Devic et al. [3] prop ose rea- soning trace length as an uncertain ty signal in reasoning-oriented text-only mo d- els. While related, these approaches do not analyze ho w reasoning changes the seman tics of token-lev el likelihoo d or its reliability as an uncertaint y estimate in m ultimo dal mo dels. Kuhn et al. [14] in tro duce Seman tic Entrop y , whic h esti- mates predictive uncertain ty by sampling multiple generations, clustering them in to seman tic equiv alence classes using an external natural language inference (NLI) mo del, and computing entrop y ov er clusters. Seman tic Entrop y captures seman tic diversit y across sampled outputs, whereas our analysis fo cuses on how reasoning distorts token-lev el likelihoo d within a single conditioned generation. Moreo ver, Seman tic En tropy relies on an auxiliary NLI oracle; we instead ev alu- ate uncertaint y signals computed directly from mo del outputs to enable consis- ten t m ultimo dal comparison. Kada v ath et al. [10] demonstrate that mo dels can estimate the probabilit y that a giv en answ er is correct via the P(T rue) self-probing signal. Our Self- Rep orted Confidence measure is closely related; follo wing [24], w e normalize this score and ev aluate it under ranking-based selective generation metrics. Ev aluating Uncertain ty Under Selective Generation. W e ev aluate un- certain ty within the selectiv e generation framework, where a model ma y ab- stain when its confidence falls below a threshold. This paradigm reflects safet y- critical deplo yment and assesses unc ertainty by how wel l it r anks c orr e ct pr e- dictions ab ove inc orr e ct ones under abstention . Metrics suc h as the Area Un- der the Risk–Cov erage Curve (AUR C) [5] and the Prediction Rejection Ratio (PRR) [4, 20] directly quantify this ranking qualit y . T raditional calibration met- rics such as Expected Calibration Error (ECE) are less informative here since man y effective uncertain ty signals are not calibrated probabilities [23]. This framew ork therefore provides a pragmatic and mo del-agnostic ev aluation of un- The Cost of Reasoning in VLMs 5 certain ty quality . W e build on it to show that reasoning systematically alters the reliabilit y of token-lev el uncertaint y signals. 3 Metho d Selectiv e Generation F ramew ork W e ev aluate uncertaint y under reasoning within the selective generation framework, where a mo del may abstain from an- sw ering when its confidence falls below a threshold. In this setting, the mo del pro duces answ ers for only a subset of inputs (co verage), rejecting uncertain pre- dictions and trading off cov erage against error rate (risk). Giv en a confidence score g ( x ) for input x , predictions are accepted only when g ( x ) ≥ τ for some threshold τ , otherwise w e abstain from providing an answ er. V arying τ rev eals a trade-off b etw een cov erage level and risk, and provides a pragmatic ev aluation of how effectiv ely an uncertain ty estimate identifies unreliable predictions. 3.1 Uncertain ty Estimation Metho ds Deco der-st yle VLMs output a probability distribution ov er a vocabulary V con- taining h undreds of thousands of tokens. T o decide whether to answer or ab- stain, this distribution must b e reduced to a scalar uncertaint y score. W e ev al- uate established uncertain ty estimation strategies, grouped in to three categories: Answ er-T oken Likelihoo d (A TL) Estimates, Self-Probing Estimates, and Agreement- Based Estimates. Answ er-T ok en Likelihoo d (A TL) Estimates. These measures compress tok en-level probabilities into a single scalar calculated ov er the answ er tokens. Let y = ( y 1 , . . . , y L ans ) denote the answ er sequence, where y l is the l -th token. Maximum Se quenc e Pr ob ability (MSP). The joint probability of the generated answ er sequence is used directly: P ( y | x, θ ) = L ans Y l =1 P ( y l | y Question: {question} Options: {options} Without CoT answer mo de only Respond ONLY in the following wrapped format: your thought process
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment