변동성 모델 구조 분석을 위한 네트워크 접근
본 논문은 5,709개의 특징 모델을 대상으로 의존성·충돌 그래프를 구축하고, 네트워크 지표를 적용해 구조적 패턴을 규명한다. 연구자는 도메인별 차이를 확인하고, 중심 특징·핵심·죽은 특징을 식별함으로써 유지보수와 모듈화에 활용 가능한 인사이트를 제공한다.
저자: Jose Manuel Sanchez, Miguel Angel Olivero, Ruben Heradio
본 논문은 소프트웨어 제품 라인(SPL)에서 핵심적인 역할을 하는 특징 모델(FM)의 구조적 특성을 대규모로 탐구한다. 기존 연구는 주로 논리적 검증(예: SAT 기반 분석, 이상 탐지)에 초점을 맞추었으나, FM이 수천 개의 변수와 복잡한 제약을 포함하게 되면서 전역적인 구조 파악이 어려워졌다. 이를 해결하고자 저자들은 네트워크 과학의 도구를 도입해 FM을 그래프 형태로 변환하고, 다양한 네트워크 지표를 적용한다.
연구는 세 가지 주요 질문(RQ1‑RQ3)을 제시한다. RQ1은 실제 FM에서 나타나는 구조적 패턴을 규명하고, RQ2는 이러한 패턴이 도메인·저장소별로 어떻게 변이하는지를 탐색한다. RQ3은 네트워크 기반 지표가 실무에서 FM의 이해·유지·진화에 어떻게 기여할 수 있는지를 평가한다.
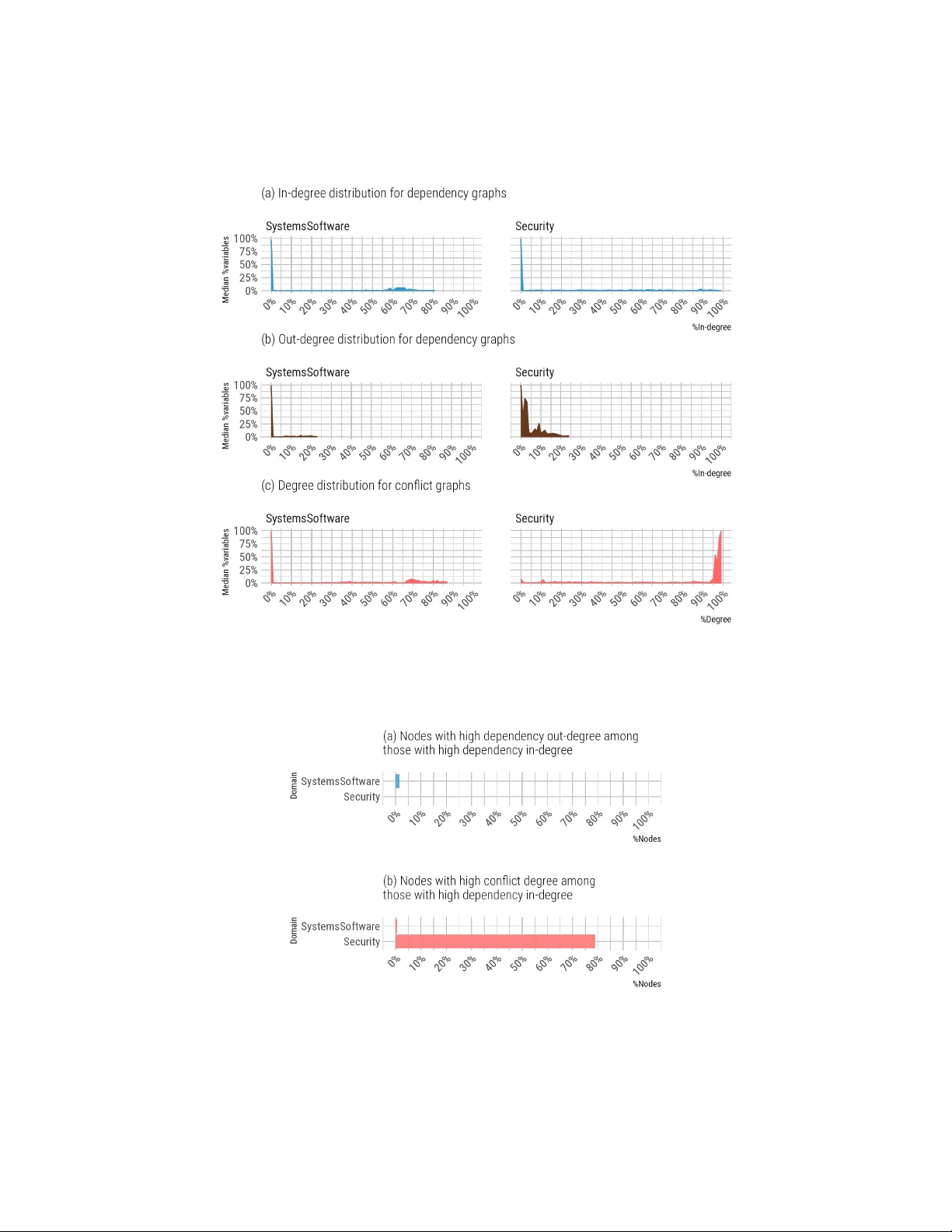
데이터 수집 단계에서 저자들은 20개의 공개 저장소(예: GitHub, SourceForge)에서 5,709개의 FM을 확보하였다. 모델 크기는 99개 변수에서 35,907개 변수까지 다양했으며, Boolean 번역을 통해 변수 간 관계를 명시적으로 표현한다. 이후 전이적 폐쇄를 적용해 ‘강한 의존성(strong dependency)’과 ‘강한 충돌(strong conflict)’을 추출한다. 강한 의존성 그래프는 방향성 아크 f→g 로, 강한 충돌 그래프는 무방향 에지 (f,g) 로 구성된다. 불필요한 자기 루프와 중복 관계는 제거하여 그래프의 가독성과 분석 효율을 높였다.
그래프 분석에서는 다음과 같은 지표를 사용하였다.
1. **노드 차수**: in-degree(다른 특징이 해당 특징을 요구하는 횟수)와 out-degree(해당 특징이 요구하는 다른 특징 수).
2. **중심성**: 페이지랭크, 베트위니 중심성 등, 핵심 특징을 식별.
3. **클러스터링 계수**: 지역적 밀집도 측정.
4. **연결성**: 강한 연결 요소(Strongly Connected Components)와 평균 최단 경로, 전체 네트워크의 응집력 평가.
5. **분포 형태**: 차수 분포가 멱법칙을 따르는지 여부 확인.
분석 결과, 대부분의 FM에서 의존성 관계가 지배적이며, 차수 분포는 ‘스케일 프리(scale‑free)’ 특성을 보였다. 즉, 소수의 특징이 다수의 다른 특징에 영향을 미치는 허브 구조가 존재한다. 도메인별 차이를 살펴보면, 자동차·임베디드 시스템 분야는 의존성 허브가 집중되어 있어 구조적 취약점이 특정 특징에 집중되는 경향이 있었다. 반면, 웹·e‑Commerce 분야는 충돌 관계가 더 고르게 분포되어, 구성 옵션 간의 상호 배제가 널리 퍼져 있었다.
코어 특징(core features)과 죽은 특징(dead features)도 그래프 분석을 통해 정량화하였다. 코어 특징은 모든 유효 구성에 반드시 포함되는 노드로, 전체 모델의 3~7% 수준이었다. 죽은 특징은 어떤 유효 구성에서도 등장하지 않는 노드로, 평균 15~22%를 차지했다. 이러한 비율은 도메인마다 차이를 보였으며, 특히 대형 시스템(예: Linux 커널)에서는 죽은 특징 비율이 높아 모델 정제 필요성을 시사한다.
실무 적용 측면에서 저자들은 네트워크 지표를 활용한 몇 가지 활용 방안을 제시한다. 첫째, 높은 in-degree를 가진 허브 특징은 변경 시 파급 효과가 크므로, 변경 관리와 회귀 테스트 우선순위 설정에 활용한다. 둘째, 높은 out-degree를 가진 특징은 많은 전제 조건을 필요로 하므로, 설계 단계에서 복잡도 감소를 위한 리팩터링 대상이 된다. 셋째, 충돌 그래프에서 차수가 높은 특징은 선택 시 다른 많은 옵션을 배제하므로, 사용자 인터페이스 설계 시 경고 메시지나 가이드라인 제공에 활용한다. 넷째, 코어·죽은 특징 비율을 지속적으로 모니터링함으로써 모델의 진화와 유지보수 비용을 예측한다.
마지막으로 논문은 한계점과 향후 연구 방향을 논의한다. 현재 분석은 정적 그래프에 국한되며, 시간에 따른 모델 진화(버전 변화)와 동적 구성 상황을 반영하지 않는다. 또한, 현재 사용된 네트워크 지표는 전통적인 소프트웨어 공학 분야에서 차용된 것이므로, 변동성 모델 특성에 맞는 새로운 지표 개발이 필요하다. 향후 연구에서는 모델 진화 추적, 도메인 특화 지표 설계, 그리고 자동화된 유지보수 지원 도구와의 연계 등을 제안한다.
전반적으로 이 연구는 대규모 FM을 네트워크 관점에서 체계적으로 분석함으로써, 기존 논리적 검증을 보완하고, 실무에서 구조적 위험 요소를 빠르게 식별·완화할 수 있는 실용적인 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기