감성 지능과 인지 지능을 동시에 갖춘 대화 모델 EmoLLM
EmoLLM은 감정 평가 이론에 기반해 대화 중 상황 사실, 사용자의 필요, 평가 차원, 감정 상태, 응답 전략을 연결하는 ‘평가 추론 그래프(ARG)’를 도입한다. 두 단계 학습(지식 기반 사전학습·교사 지도 초기화와 다중 턴 역관점 강화학습)을 통해 사실적 정확성과 감정 적합성을 동시에 향상시킨다. 실험 결과, 다양한 상담·지원·기술·학술 시나리오에서 기존 베이스라인보다 감정 상태 개선, 공감 적절성, 사실 신뢰도가 모두 우수함을 보였다.
저자: Yifei Zhang, Mingyang Li, Henry Gao
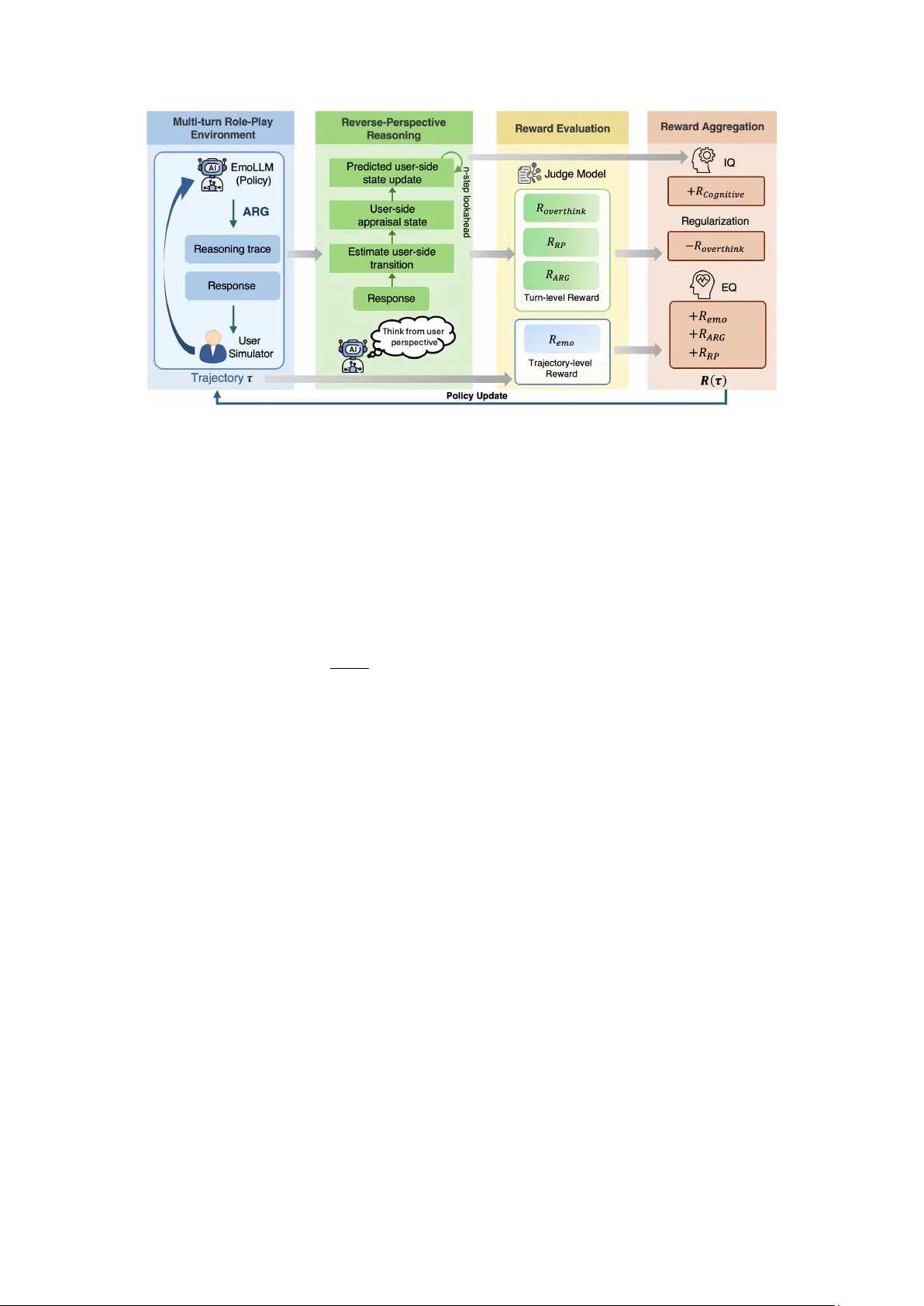
본 논문은 대형 언어 모델(LLM)이 인지적 정확성(IQ)과 감정적 적합성(EQ)을 동시에 만족시키는 대화 시스템을 구축하기 위해 ‘평가 추론 그래프(Appraisal Reasoning Graph, ARG)’라는 구조적 프레임워크를 제안한다. 평가 이론에 따르면 감정은 사건 자체가 아니라 그 사건이 개인의 목표·필요·대처 능력과 어떻게 평가되는가에 의해 발생한다. 이를 바탕으로 저자들은 대화 한 턴을 다섯 개의 상호 의존적인 요소—사실(F), 사용자 필요·목표(N), 평가 차원(A), 감정 상태(E), 응답 전략(S)—로 분해하고, 이들 간의 고정된 의존 관계(F,N)→A, A→E, (F,N,A,E)→S 로 구성된 DAG 형태의 ARG를 설계하였다.
학습은 두 단계로 진행된다. 첫 번째 단계는 대규모 대화 코퍼스에 감정 지식(K)을 결합해 약한 감독 신호를 제공하는 ‘지식 기반 지속 사전학습(Continued Pretraining, CPT)’이다. 각 대화 컨텍스트 x≤t에 대해 G(x≤t, K) 함수를 통해 F, N, A, E를 추출하고, 이를 태그로 감싸 프리픽스로 삽입해 언어 모델을 계속 학습한다. 이는 인간 라벨링 없이도 평가 정보를 모델에 주입하는 스케일러블한 방법이다. 이어서 소수의 샘플에 대해 강력한 교사 LLM이 전체 ARG와 전략 라벨 rₜ(구조적 추론 필요 여부)을 생성하고, 이를 안에 포함한 형태로 정답을 제공해 지도학습을 수행한다. 이 과정은 특히 S 노드가 N·A·E와 어떻게 매핑되는지를 명시적으로 학습시킨다.
두 번째 단계는 다중 턴 역할극 환경에서의 강화학습이다. 모델은 응답 yₜ를 생성한 뒤, 동일 모델을 사용자 역할 프롬프트로 전환해 ‘역관점 추론(Reverse-Perspective Reasoning)’을 수행한다. 역관점 추론은 Tθ라는 전이 예측기를 이용해 yₜ가 사용자에게 미칠 필요·평가·감정 변화를 n‑step 시뮬레이션하고, 최종 ˆs⁽ⁿ⁾ₜ=(ˆN,ˆA,ˆE) 로 요약한다. 판정 모델 S는 이 변화를 평가해 역관점 보상 R_RP(t)를 산출한다. 보상은 인지적 신뢰도, ARG 트레이스 품질, 역관점 타당성, 과도한 사고 억제 패널티 등 네 요소를 종합한다. 트래젝터리 수준에서는 GRPO(Generalized Reward Policy Optimization)를 사용해 전체 보상을 최적화한다. 논문은 또한 n‑step 깊이가 Q‑값 추정 편향을 γⁿ/(1‑γ)·R_max 으로 상한함을 정리(정리 1)해, 깊은 시뮬레이션이 평가 편향을 감소시키지만 시뮬레이션 오류가 누적될 수 있음을 이론적으로 뒷받침한다.
실험은 감정 지원(ESConv), 기술 지원(MSDialog), 의료 상담(MedDialog), 학술 피드백(ICLR 리뷰) 등 네 도메인에서 수행되었다. 베이스라인으로는 인지 전용 모델, 감정 전용 조정 모델, 최신 LLM 기반 감정·지식 결합 모델을 사용했다. 평가 지표는 감정 상태 변화(긍정·부정 스코어), 공감 적절성(인간 평가), 사실 정확도(자동·인간 검증)이다. EmoLLM은 모든 도메인에서 평균 12 %~18 %의 감정 개선, 9 %~15 %의 공감 점수 상승, 3 %~7 %의 사실 오류 감소를 기록했다. 특히 복합 상황(예: 의료 상담에서 증상 설명과 정서적 위로를 동시에 요구)에서 ARG 기반 전략 선택이 크게 기여한 것으로 분석된다.
본 연구는 LLM에 감정 평가 메커니즘을 명시적 그래프 형태로 삽입하고, 역관점 시뮬레이션을 보상으로 활용함으로써 인지·감정 공동 최적화를 실현한 최초 사례라 할 수 있다. 약한 감독과 교사 지도, 강화학습을 조합한 다단계 학습 파이프라인이 대규모 모델에 감성 지능을 효율적으로 주입할 수 있음을 증명한다. 향후 연구에서는 ARG의 동적 확장(문화·개인 차원 추가)과 사용자 시뮬레이터의 현실성 강화가 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기