EmoLLM: Appraisal-Grounded Cognitive-Emotional Co-Reasoning in Large Language Models
Large language models (LLMs) demonstrate strong cognitive intelligence (IQ), yet many real-world interactions also require emotional intelligence (EQ) to produce responses that are both factually reliable and emotionally appropriate. In settings such…
Authors: Yifei Zhang, Mingyang Li, Henry Gao
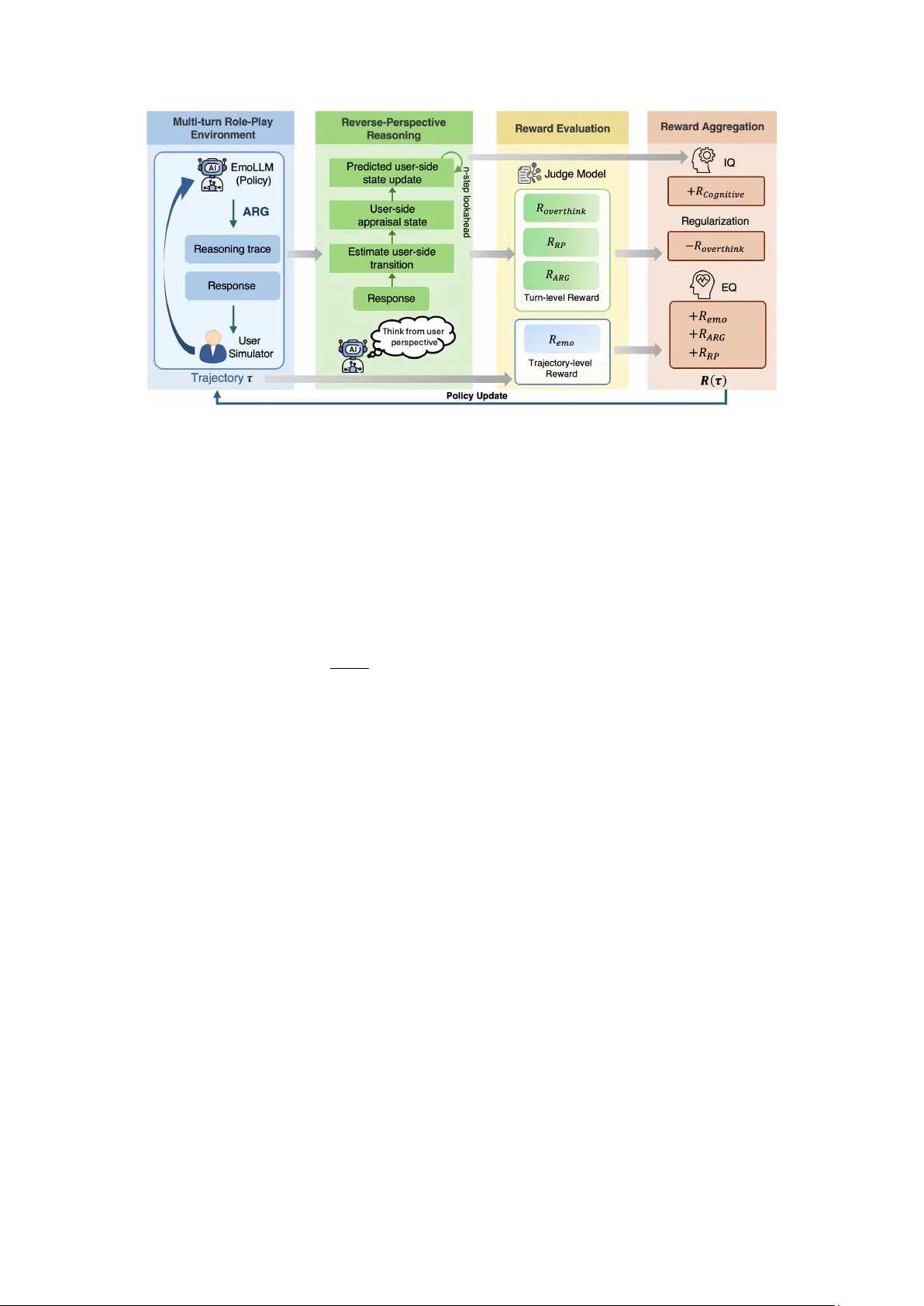
EmoLLM: A ppraisal-Gr ounded Cognitive-Emotional Co-Reasoning in Large Language Models Y ifei Zhang, Mingyang Li, Henry Gao, Liang Zhao Department of Computer Science, Emory Uni versity {yifei.zhang2, mingyang.li, henry.gao2, liang.zhao}@emory.edu Abstract Large language models (LLMs) demonstrate strong cognitiv e intelligence (IQ), yet many real-world interactions also require emotional intelligence (EQ) to produce responses that are both factually reliable and emotionally appro- priate. In settings such as emotional support, technical assistance, and consultation, effec- tiv e dialogue depends on how situations are ap- praised with respect to the user’ s needs, goals, and coping capacity . Inspired by appraisal theory , we propose EmoLLM, an appraisal- grounded framew ork for IQ–EQ co-reasoning in dialogue. EmoLLM uses an explicit Ap- praisal Reasoning Graph (ARG) to structure intermediate reasoning ov er contextual facts, inferred user needs, appraisal dimensions, emo- tional states, and response strategies before gen- erating a reply . W e train EmoLLM in a multi- turn role-play en vironment with reinforcement learning, where re verse-perspecti ve reasoning provides reward signals based on predicted user-side consequences of responses. Across div erse dialogue settings, EmoLLM impro ves emotional state outcomes and response quality ov er strong baselines while preserving strong factual reliability . Code av ailable at https: //github.com/yifeizhangcs/EmoLLM . 1 Introduction Large language models (LLMs) ( Achiam et al. , 2023 ; Grattafiori et al. , 2024 ; Y ang et al. , 2025a ; T eam et al. , 2025 ) have demonstrated strong cog- nitive intelligence (IQ), with remarkable progress in reasoning and problem solving across mathe- matics, programming, and logical inference bench- marks ( W ei et al. , 2022 ; Ahn et al. , 2024 ; He et al. , 2024 ). At the same time, a growing body of work has impro ved LLMs’ emotional intelli- gence (EQ), including emotion recognition, em- pathetic response generation, and af fect-aw are di- alogue ( W ang et al. , 2023 ; Li et al. , 2023 ; Sorin et al. , 2024 ). Ho wev er , many real-world interac- tions require cogniti ve and emotional capabilities Figure 1: Why IQ–EQ co-reasoning matters. IQ-only responses can be factually relev ant but emotionally in- sensitiv e, while EQ-only responses can be emotionally supporti ve but insuf ficiently grounded in the underlying situation. IQ–EQ co-reasoning enables responses that are factually grounded, emotionally attuned, and strate- gically appropriate. to operate jointly rather than in isolation. In scenar- ios such as healthcare, counseling, and education, appropriate responses must reason jointly about the user’ s emotional state and the situational context that gives rise to it, rather than treating emotion as a surface attribute independent of context. As illustrated in Figure 1 , integrating these dimensions enables models to interpret situational factors to- gether with emotional signals, yie lding responses that are both factually grounded and emotionally appropriate, instead of being dri ven by either cog- niti ve reasoning or emotional cues alone. Existing work has impro ved both cogniti ve rea- soning and emotional intelligence in LLMs, but largely treats them separately . Adv ances in scaling and reasoning-oriented training ha ve improved ana- lytical problem solving ( W ei et al. , 2022 ; Ahn et al. , 2024 ; He et al. , 2024 ), while prior work has en- hanced emotional intelligence through supervised fine-tuning, emotion-aw are prompting, knowledge augmentation, and alignment with social or user- centered objecti ves ( Rashkin et al. , 2019 ; Zheng et al. , 2023 ; Qian et al. , 2023 ; Rakib et al. , 2025 ). Ho wev er , these approaches rarely model how sit- 1 uational facts, inferred user needs, and emotional understanding jointly shape response strate gies. As a result, the structured process linking contextual interpretation, appraisal, emotion, and strategy re- mains underexplored. Psychological research offers a useful perspec- ti ve for addressing this gap. Appraisal Theory sug- gests that emotions arise not directly from events themselves, but from how those ev ents are ev alu- ated with respect to an indi vidual’ s goals, needs, and coping potential ( Lazarus , 1991 ; Scherer , 2001 ; Ortony et al. , 2022 ). Related work on perspectiv e- taking further suggests that emotionally appropri- ate responses require reasoning about the user’ s internal state and situational interpretation ( K osin- ski , 2023 ). These perspectives imply that appro- priate responses emerge from a structured pro- cess linking contextual f acts, inferred goals and needs, e valuati ve appraisals, emotional states, and response strategies. Applying this perspecti ve to LLMs presents three ke y challenges: representing appraisal as an explicit intermediate reasoning pro- cess, jointly improving cognitiv e reliability and emotional appropriateness, and training multi-turn behavior using user -side consequence signals rather than final-response quality alone. T o address these challenges, we propose EmoLLM , an appraisal-grounded framework for cogniti ve–emotional (IQ–EQ) co-reasoning in di- alogue. At its core, we introduce the Appr aisal Reasoning Graph (ARG), an explicit structure or - ganizing conte xtual facts, inferred user needs, ap- praisals, emotions, and response strategies. W e fur- ther introduce re verse-perspecti ve reasoning, which predicts how a response updates the user’ s needs, appraisals, and emotional state, pro viding re ward signals based on the plausibility of this predicted transition. Building on this, we train EmoLLM in a multi-turn role-play en vironment with rein- forcement learning using re verse-perspectiv e and ARG-deri ved structure-aware rew ards. Experi- ments across div erse dialogue benchmarks show that EmoLLM consistently outperforms strong baselines on emotional state outcomes, empathic appropriateness, and factual reliability . 2 Problem F ormulation W e study IQ–EQ co-r easoning in multi- turn dialogue. At turn t , let x ≤ t = ( u 1 , y 1 , . . . , u t − 1 , y t − 1 , u t ) denote the dialogue history up to the current user utterance, where u i and y i are the user and assistant utterances at turn i , respectiv ely . Gi ven x ≤ t , the model generates a response y t that is both factually reliable and emotionally appropriate. W e model IQ and EQ as coupled latent f actors rather than separable objecti ves. Let z IQ t and z EQ t denote latent cogniti ve and emotional reasoning states, and define: p θ ( y t | x ≤ t ) = X z IQ t , z EQ t p θ ( z IQ t , z EQ t | x ≤ t ) · p θ ( y t | x ≤ t , z IQ t , z EQ t ) (1) where the joint prior p θ ( z IQ t , z EQ t | x ≤ t ) captures IQ–EQ coupling, i.e., we do not assume that it factorizes into independent IQ and EQ terms. Al- though formulated at the turn lev el, the task re- quires jointly modeling factual reliability and emo- tional appropriateness under the ev olving dialogue context x ≤ t . Our objective is to learn θ such that responses remain factually reliable while also be- ing emotionally grounded through coherent IQ– EQ interactions. A key challenge is that stan- dard response-only training signals (e.g., likelihood or scalar turn-le vel scores) pro vide limited guid- ance for learning structured IQ–EQ coupling and for e valuating the longer-horizon user -side conse- quences of responses. 3 Methodology T o model dialogue as an appraisal-grounded pro- cess of cogniti ve–emotional co-reasoning, we intro- duce the Appraisal Reasoning Graph (ARG) (§ 3.1 ), an explicit dependenc y structure that or ganizes in- termediate reasoning from situational understand- ing to response strategy selection. This graph forms the core reasoning structure of EmoLLM and guides response generation before the final reply is pro- duced. T raining of EmoLLM follo ws a two-stage pipeline (§ 3.2 ) that first initializes this structured co-reasoning process and then refines it through multi-turn role-play with re verse-perspective rea- soning and reinforcement learning. 3.1 Appraisal Reasoning Graph At each dialogue turn, EmoLLM instantiates an Ap- praisal Reasoning Graph (ARG) from the dialogue context to guide response planning and generation. Motivation fr om A ppraisal Theory . Gi ven dialogue context x ≤ t , appraisal-grounded co- reasoning decomposes response generation into fi ve interdependent components: contextual facts 2 Figure 2: Appraisal Reasoning Graph (ARG) in EmoLLM. At each dialogue turn, EmoLLM instantiates an ARG from the dialogue context to perform appraisal-grounded cogniti ve–emotional co-reasoning before generating a reply . The process repeats across turns in multi-turn interaction. F t , inferred user needs or goals N t , appraisal di- mensions A t , emotional states E t , and response strategies S t . This decomposition is moti vated by appraisal theory , which views emotion as aris- ing not directly from e vents themselves, b ut from e valuations of situational conditions with respect to an indi vidual’ s goals, needs, and coping poten- tial ( Lazarus , 1991 ; Scherer , 2001 ; Ortony et al. , 2022 ). This perspecti ve moti v ates the graph struc- ture defined belo w . ARG Definition. The Appraisal Reasoning Graph (ARG), illustrated in Figure 2 , is defined as a directed acyclic graph G ARG = ( V , E ARG ) with node set V = { F, N , A, E , S } , representing contextual facts, inferred user needs or goals, ap- praisal dimensions, emotional state, and response strategy . The dependency structure E ARG is fixed across dialogue turns and is specified as ( F , N ) → A, A → E , ( F, N , A, E ) → S. At turn t , the graph is instantiated from dialogue history x ≤ t as ( F t , N t , A t , E t , S t ) . Under this in- stantiation, the abstract latent states in Eq. ( 1 ) are grounded through ARG nodes: the IQ-side state z IQ t is instantiated primarily through contextual facts F t , whereas the EQ-side state z EQ t is instan- tiated through the appraisal-grounded user state ( N t , A t , E t ) . The resulting structured state is z ARG t = ( F t , N t , A t , E t , S t ) . As the dialogue proceeds and x ≤ t gro ws, node v alues ev olve under this shared graph template, enabling cognitiv e–emotional co-reasoning across multiple turns. Structured F actorization. Eq. ( 1 ) formulates re- sponse generation through two coupled latent v ari- ables, z IQ t and z EQ t . In EmoLLM, the ARG pro- vides an e xplicit structure for these v ariables: F t in- stantiates the cogniti ve state z IQ t , while ( N t , A t , E t ) instantiates the appraisal-grounded emotional state z EQ t . Crucially , S t acts as the binding variable that bridges joint IQ–EQ latent space, translating the internal cognitiv e–emotional understanding into an actionable response. W e therefore write p θ ( y t | x ≤ t ) = X F t ,N t ,A t , E t ,S t p θ ( F t | x ≤ t ) p θ ( N t | x ≤ t ) p θ ( A t | F t , N t ) · p θ ( E t | A t ) p θ ( S t | F t , N t , A t , E t ) · p θ ( y t | x ≤ t , F t , N t , A t , E t , S t ) . This factorization structurally instantiates Eq. ( 1 ) . IQ–EQ coupling is preserv ed because appraisal depends on both facts and needs, and the strategy S t translates these joint states into the response y t . 3.2 T raining Framework T raining of EmoLLM follows a two-stage pipeline that progressiv ely establishes and refines cogniti ve– emotional co-reasoning. Stage I (§ 3.2.1 ) initializes appraisal-grounded reasoning through knowledge- guided pretraining and teacher-guided supervi- sion. Stage II (§ 3.2.2 ) further improves interaction- le vel behavior through reinforcement learning in a multi-turn role-play en vironment, where re verse- perspecti ve reasoning e valuates the predicted user - side consequences of candidate responses. 3.2.1 Stage I: Appraisal-Gr ounded Co-Reasoning Initialization Stage I establishes appraisal-grounded co- reasoning prior to reinforcement learning. The stage consists of two components: (i) kno wledge- grounded continued pretraining that injects 3 scalable appraisal signals, and (ii) ARG-guided supervised initialization that anchors high-quality appraisal-to-strategy reasoning. Knowledge-Gr ounded Continued Pretraining . Continued pretraining (CPT) is performed on di- alogue corpora augmented with structured affec- ti ve kno wledge. For each dialogue conte xt x ≤ t , a kno wledge-grounded tuple is constructed as g t = G ( x ≤ t , K ) = ( F t , N t , A t , E t ) , where G ( · ) extracts salient situational facts and retrie ves relev ant kno wledge from K in order to infer user needs or goals, appraisal dimensions, and the corresponding emotional state. A linearized form of g t is then prepended as a short structured prefix to the original context, ˜ x t = g t ∥ x ≤ t , and training continues with a standard causal lan- guage modeling objecti ve. This procedure pro vides scalable weak supervision over appraisal states without requiring manual annotation. ARG-Guided Supervised Initialization. T o complement large-scale weak supervision, a small subset of contexts is sampled and high-quality su- pervision is obtained from a strong teacher LLM (for example, a proprietary API model). For each sampled context x ≤ t , the teacher generates an ARG state z ARG t together with a gating label r t ∈ { 0 , 1 } indicating whether explicit structured reasoning should be emitted for that turn. The supervision target is defined as ˜ y t = ( z ARG t y t , if r t = 1 , y t , if r t = 0 , and the student model is fine-tuned to reproduce ˜ y t gi ven x ≤ t . Compared with the knowledge- grounded tuple g t , the supervised ARG state addi- tionally includes the response strategy S t , which enables direct supervision of the mapping from appraisal states to response strategies. 3.2.2 Stage II: Multi-T urn RL with Rev erse-Perspectiv e Reasoning Stage II builds on Stage I’ s appraisal-grounded ini- tialization and further refines EmoLLM through re- inforcement learning in a multi-turn role-play en vi- ronment (Figure 3 ). Whereas Stage I enforces turn- le vel ARG-consistent appraisal-to-strategy reason- ing, Stage II improves behavior ov er entire inter- actions by training the polic y with re ward signals deri ved from the predicted do wnstream effects on the user . After generating a response, the policy performs internal re verse-perspecti ve reasoning to estimate ho w the user’ s needs, appraisals, and emo- tional state may e volv e. Multi-T urn Role-Play En vironment. The pol- icy interacts with a user simulator to generate a di- alogue trajectory τ = { ( x t , z ARG t , y t ) } T t =1 , where x t denotes the turn conte xt, z ARG t denotes the ARG reasoning trace produced during training, and y t denotes the assistant response. Gi ven ( x t , y t ) , the simulator generates the next user utterance and up- dates the dialogue context, yielding multi-turn tra- jectories for re ward computation. Rev erse-Perspectiv e Reasoning . After gener - ating response y t at turn t , an internal reverse- perspecti ve reasoning step estimates its user-side consequence. Let x ≤ t denote the dialogue history up to turn t . Using the underlying model under a specific user -role prompt, we predict a compact summary of the induced user-side transition: ˆ s (1) t = T θ ( x ≤ t , y t ) , ˆ s ( k +1) t = T θ ( x ≤ t , y t , ˆ s ( k ) t ) , k = 1 , . . . , n − 1 , where T θ is the transition predictor and ˆ s ( k ) t denotes the simulated user state at step k . After n steps, this process yields ˆ s ( n ) t = ( ˆ N t , ˆ A t , ˆ E t ) , which sum- marizes the predicted updates in the user’ s needs, appraisals, and emotional state. A judge model then scores this transition to define the rev erse- perspecti ve rew ard R RP ( t ) = S ˆ s ( n ) t , where S e valuates plausibility and contextual consistency . Re verse-perspecti ve reasoning is used only during training to estimate the user-side consequence and provide reward signals; at inference time, the policy generates responses directly . Additional implemen- tation details are provided in Appendix B.1 . When n = 1 , this process e valuates the imme- diate predicted user reaction, whereas lar ger n en- ables deeper lookahead o ver do wnstream conse- quences. W e can abstract this multi-turn ev olution as a latent-state discounted MDP , where state s t en- capsulates the dialogue history and latent user v ari- ables, and response y t serves as action a t . Under this abstraction, the follo wing theorem formalizes ho w increasing lookahead depth n theoretically bounds the myopic e valuation bias. Theorem 1 (Under the latent-state MDP abstrac- tion, lookahead depth reduces truncation bias) . As- sume a discounted MDP with bounded r ewar ds 4 Figure 3: Stage II: Multi-tur n RL with rev erse-perspective r easoning. The policy interacts with a user simulator to generate dialogue trajectories. For each response, the model performs reverse-perspecti ve reasoning to estimate the induced user -side transition in needs, appraisals, and emotions, optionally with n -step lookahead. A judge model ev aluates the predicted transition to produce reverse-perspecti ve rew ard signals for policy optimization. | r ( s, a ) | ≤ R max and discount factor γ ∈ (0 , 1) . Let Q π ( s, a ) denote the true action value under pol- icy π , and let Q ( n ) π ( s, a ) denote its n -step truncated r eturn. Then, for any policy π and any state–action pair ( s, a ) , Q π ( s, a ) − Q ( n ) π ( s, a ) ≤ γ n 1 − γ R max . Pr oof. See Appendix B.3 . □ This result suggests that deeper rev erse- perspecti ve reasoning reduces myopic ev aluation bias, although lar ger n may accumulate compound- ing simulation errors from the predictor T θ . Shal- lo w lookahead is therefore adopted in practice to balance the lookahead horizon against simulation v ariance. Reward Evaluation. At each turn, a judge model e valuates four aspects: cognitive reliability , ARG trace quality , rev erse-perspectiv e plausibility , and an overthinking penalty . This penalty discourages redundant computation, such as in voking an ARG trace for simple queries or performing excessi ve dynamic n -step lookahead. Finally , a trajectory- le vel re ward e valuates the predicted user emotional trajectory (Appendix A ). Reward Aggregation and Optimization. These re wards are aggreg ated o ver the trajectory , and a weighted objecti ve is optimized using trajectory- le vel GRPO; detailed aggregation and optimization formulas are provided in Appendix B.2 . This ob- jecti ve encourages responses that are cognitively reliable, appraisal–strategy coherent, and emotion- ally appropriate under multi-turn interaction. 4 Experimental Setup Datasets and Scenarios. T raining and ev aluation of EmoLLM are conducted on dialogue datasets cov ering emotional support, technical assistance, medical consultation, and academic peer revie w . For Stage I CPT , the ESCon v corpus ( Liu et al. , 2021 ) is used and augmented with af fectiv e knowl- edge from the ECoK graph ( W ang et al. , 2024 ). For supervised initialization and Stage II, Empathetic- Dialogues ( Rashkin et al. , 2019 ), MSDialog ( Qu et al. , 2018 ), MedDialog ( He et al. , 2020 ), and a collection of ICLR peer -re view comments are used. T o enable controlled multi-turn ev aluation, scenario seeds are constructed from these datasets, where each seed consists of a short scenario de- scription and an initial user utterance. Additional details on the datasets and scenario seeds are pro- vided in Appendix C . Base Model. Experiments are conducted using Qwen3-8B ( Y ang et al. , 2025a ) as the initializa- tion of EmoLLM. Generalization to LLaMA-3.1- 8B ( Grattafiori et al. , 2024 ) is reported in Ap- pendix G.2 . T raining Pr ocedure. Implementation details of the training procedure are provided in Appendix D . Baselines. EmoLLM is compared with represen- tati ve baselines based on prompting, supervised fine-tuning, and reinforcement learning for emo- tional dialogue, as well as proprietary LLMs. De- 5 T able 1: Performance comparison across four datasets using Qwen3–8B. Method ED MSD MedD ICLR SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ Base Model Qwen3-8B 88.7 3.03 4.58 3.84 77.6 3.27 4.13 3.41 89.2 2.92 3.95 3.57 83.4 1.64 3.79 3.83 Pr ompting Methods Best-of- N 90.4 2.78 4.48 3.72 79.6 3.12 4.08 3.51 90.8 2.41 3.92 3.97 84.9 1.71 3.77 3.64 ARG-Prompt 91.0 2.41 4.67 4.10 81.0 2.88 4.14 3.58 92.3 2.28 4.02 4.01 86.0 1.39 3.95 3.82 ICL-AIF ( Fu et al. , 2023 ) 91.3 2.29 4.73 4.24 81.5 2.81 4.16 3.62 92.7 2.31 4.06 4.06 86.4 1.35 3.99 3.86 Ask-an-Expert ( Zhang et al. , 2023 ) 89.4 2.71 4.51 3.97 79.1 3.15 4.05 3.46 90.8 2.63 3.96 3.72 84.2 1.58 3.85 3.66 SFT Methods SFT 87.3 2.14 4.39 4.07 81.2 2.74 3.97 3.37 90.4 2.29 3.91 3.68 82.6 1.36 3.73 3.76 ESCoT ( Rashkin et al. , 2019 ) 89.7 2.64 4.66 3.88 79.4 3.06 4.18 3.47 91.2 2.58 4.01 3.76 84.1 1.47 3.86 3.73 PPDP ( Deng et al. , 2023 ) 90.2 2.41 4.63 4.12 80.4 2.93 4.11 3.54 91.8 2.37 4.00 3.89 85.3 1.42 3.90 3.79 RL Methods RLFF-ESC ( Y ang et al. , 2025b ) 90.8 2.49 4.71 4.02 80.6 2.96 4.15 3.55 92.4 2.44 4.02 3.92 86.0 1.39 3.95 3.78 RL VER ( W ang et al. , 2025 ) 91.1 2.38 4.74 4.10 81.2 2.88 4.18 3.61 93.0 2.36 4.08 4.01 86.6 1.33 4.02 3.81 PERM ( W ang et al. , 2026 ) 91.8 2.22 4.79 4.28 82.1 2.74 4.20 3.64 94.0 2.28 4.10 4.18 88.3 1.26 4.05 3.88 Ours EmoLLM 92.1 1.87 4.86 4.92 83.2 2.86 4.17 3.71 95.3 2.18 4.08 4.59 96.2 1.21 4.21 3.95 ∆ vs. Base +3 . 8% − 38 . 3% +6 . 1% +28 . 1% +7 . 2% − 12 . 5% +1 . 0% +8 . 8% +6 . 8% − 25 . 3% +3 . 3% +28 . 6% +15 . 3% − 26 . 2% +11 . 1% +3 . 1% EmoLLM PERM RL VER Base 0 0 . 2 0 . 4 0 . 6 0 . 8 0 . 55 0 . 52 0 . 49 0 . 45 A vg. EG / Turn ED EmoLLM PERM RL VER Base 0 . 4 0 . 37 0 . 34 0 . 32 MSD EmoLLM PERM RL VER Base 0 . 45 0 . 43 0 . 41 0 . 38 MedD EmoLLM PERM RL VER Base 0 . 79 0 . 75 0 . 7 0 . 67 ICLR Figure 4: A verage Emotional Gain per T urn (EG/T urn) across four benchmarks. Higher values indicate greater positiv e emotional improv ement during the dialogue. tailed descriptions of the baselines are provided in Appendix E . Evaluation. Ev aluation of EmoLLM is conducted in a multi-turn role-play en vironment initialized from the constructed scenario seeds. Six metrics are reported: Factual Accuracy (F A) for cogni- ti ve reliability (IQ), and Success Rate (SR (%)), A verage T urns (A T), Emotional State Score (ES), Emotional Gain per T urn (EG/T urn), and Empathic Appropriateness (EA) for emotional intelligence (EQ). Full definitions of the metrics and ev aluation protocols are provided in Appendix F . 5 Experimental Results & Analysis 5.1 Main Results Comparison with Baselines. W e ev aluate EmoLLM against a di verse set of prompting, su- pervised, planning-based, and RL-based baselines across four datasets (ED, MSD, MedD, and ICLR). For the main comparison, we report Success Rate (SR), A verage T urns (A T), Emotional State Score (ES), and Empathic Appropriateness (EA) in T able 1 , and additionally summarize Emotional Gain per T urn (EG/T urn) in Figure 4 . T ogether, these metrics capture emotional effecti veness, con versational efficiency , response appropriateness, and trajectory-lev el emotional improvement. As sho wn in T able 1 and Figure 4 , EmoLLM consis- tently outperforms existing approaches across all benchmarks. It achiev es higher SR while requiring fe wer turns to reach success, and also yields stronger ES, EA, and EG/T urn, indicating more ef fectiv e and emotionally grounded interaction dynamics. These results collectiv ely sho w that ex- plicit cogniti ve–emotional co-reasoning improv es both task success and interaction stability . Comparison with Proprietary APIs. T o con- textualize EmoLLM’ s performance, we compare it against frontier proprietary LLM APIs under the same multi-turn role-play e valuation protocol. All models interact with an identical user simulator and scenario set, and are e valuated using the same four metrics: Success Rate (SR), A verage T urns (A T), Emotional State Score (ES), and Empathic Appropriateness (EA). As summarized in T able 2 , EmoLLM achieves performance comparable to, and in sev eral metrics exceeding, strong propri- etary APIs despite its significantly smaller param- 6 T able 2: Comparison with proprietary LLM APIs across four datasets. Model ED MSD MedD ICLR SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ Pr oprietary LLM APIs gpt-5-nano 78.4 2.87 4.41 4.06 74.2 3.84 4.12 3.57 77.6 2.73 4.19 3.38 78.1 2.61 4.08 3.02 gpt-5-mini 90.3 3.08 3.63 4.47 81.4 2.97 4.01 3.53 88.2 2.15 4.06 4.28 92.1 2.08 3.91 3.57 gemini-2.5-flash 86.8 2.23 3.49 4.69 85.3 2.68 4.23 3.76 93.6 1.62 3.98 4.43 96.7 1.73 3.83 3.98 gemini-3.1-flash-lite 79.2 2.49 4.28 3.91 76.4 2.62 4.11 3.46 81.3 1.69 3.86 4.68 83.1 1.32 3.88 3.49 Ours (open-weight model) EmoLLM 92.1 1.87 4.86 4.92 83.2 2.86 4.17 3.71 95.3 2.18 4.08 4.59 96.2 1.21 4.21 3.95 eter scale. These findings highlight that explic- itly structured cognitiv e–emotional co-reasoning is a highly ef fective paradigm for equipping com- pact, open-weight models with the emotional intel- ligence typically associated with massi ve frontier systems. 5.2 Effect of Reverse-P erspective Lookahead Depth 0 1 2 3 4 75 80 85 90 Rev erse-perspective lookahead depth ( n ) SR (%) SR ↑ ES ↑ EA ↑ A T ↓ 1 . 5 2 2 . 5 3 3 . 5 4 ES/EA (1–5) / A T (turns) Figure 5: Effect of re verse-perspecti ve lookahead depth on EmpatheticDialogues. SR is shown on the left axis; ES/EA (rated on a 1–5 scale) and A T (turns; lower is better) are shown on the right axis. As illustrated in Figure 5 , increasing the looka- head depth from n = 1 to n = 3 consistently improv es Success Rate (SR) and Empathic Appro- priateness (EA). This trend aligns with Theorem 1 , suggesting that deeper reasoning reduces trunca- tion bias by capturing longer -term emotional tran- sitions. Howe ver , gains diminish beyond n = 3 , as compounding simulation errors in T θ of fset the benefit of longer horizons. This trade-off indicates that n = 3 provides a fav orable balance between reduced e v aluation bias and increased model-based v ariance in our setting. 5.3 Factual Accuracy after T raining W e further examine whether impro ving emotional intelligence compromises cognitive reliability by measuring Factual Accurac y (F A). As shown in T a- T able 3: Factual Accurac y (F A; %) across four datasets. “w/o RL ” denotes Stage I initialization without reinforce- ment learning. ∆ indicates the relati ve improvement ov er the base model. Model ED MSD MedD ICLR Qwen3-8B (Base) 73.4 94.4 87.5 83.8 w/o RL 72.3 87.5 76.1 78.9 EmoLLM 80.3 95.4 91.9 86.7 ∆ vs. Base +9 . 4% +1 . 1% +5 . 0% +3 . 5% ble 3 , Stage I initialization alone (w/o RL) causes noticeable drops in F A on se veral datasets, suggest- ing that structured initialization alone is insuf ficient to maintain stable factual grounding. In contrast, the full EmoLLM consistently improves F A over the base model (Qwen3-8B), with relativ e gains of +9.4% on ED, +1.1% on MSD, +5.0% on MedD, and +3.5% on ICLR. Part of this improvement is expected, since F A is explicitly encouraged during reinforcement learning. At the same time, the re- sult is consistent with the design of the framew ork: ARG promotes factual grounding, while re verse- perspecti ve feedback filters out responses that are emotionally appropriate but weakly grounded in context. These findings suggest that emotional alignment in EmoLLM does not compromise cogni- ti ve reliability and can e ven improve it in multi-turn interactions. 5.4 Ablation Study W e conduct an ablation study to e xamine the con- tribution of EmoLLM’ s three core components: the ARG, the Stage I initialization, and the RP re wards used in reinforcement learning. As shown in T able 4 , removing ARG consistently reduces Emotional State (ES) and Empathic Appropriate- ness (EA), highlighting the importance of e xplicit cogniti ve–emotional structure. Removing Stage I initialization leads to broader degradation across metrics, indicating that early alignment provides an 7 T able 4: Ablation study of EmoLLM across four datasets. “w/o ARG” removes the Appraisal Reasoning Graph structure; “w/o Stage-I (CPT+SFT)” remov es the Stage I initialization consisting of kno wledge-guided continued pretraining (CPT) and supervised ARG alignment (SFT); “w/o RP Rewards” removes the re verse-perspecti ve rew ards used during reinforcement learning. V ariant ED MSD MedD ICLR SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ SR ↑ A T ↓ ES ↑ EA ↑ EmoLLM (Full) 92.1 1.87 4.86 4.92 83.2 2.86 4.17 3.71 95.3 2.18 4.08 4.59 96.2 1.21 4.21 3.95 w/o ARG 86.4 2.06 4.52 4.57 72.3 3.08 3.91 3.37 89.8 2.43 3.81 4.17 92.1 1.39 3.90 3.68 w/o Stage-I (CPT+SFT) 90.2 1.93 4.73 4.79 76.4 2.97 4.05 3.58 93.1 2.27 3.97 4.39 94.3 1.29 4.06 3.83 w/o RP Rew ards 87.2 1.81 4.61 4.67 73.1 2.72 3.89 3.41 91.0 2.11 3.83 4.21 93.2 1.19 3.99 3.73 important foundation for later emotional learning. In contrast, removing RP re wards mainly weak- ens interaction-lev el performance, most notably lo wering Success Rate (SR) and overall multi-turn ef fectiv eness. A verage T urns (A T) should be inter- preted jointly with SR, since it is computed over successful episodes only . T aken together , these results suggest that EmoLLM benefits from the complementary integration of structured appraisal reasoning, staged optimization, and perspectiv e- aw are reinforcement learning. 6 Related W ork 6.1 Emotional Dialogue in LLMs A growing body of work studies emotional intel- ligence in LLMs, including emotion recognition, empathetic response generation, and af fect-aware interaction ( W ang et al. , 2023 ; Li et al. , 2023 ; Sorin et al. , 2024 ). Early approaches rely on super- vised fine-tuning on emotion-annotated dialogue corpora such as EmpatheticDialogues ( Rashkin et al. , 2019 ), DailyDialog ( Li et al. , 2017 ), and MELD ( Poria et al. , 2019 ). Beyond direct im- itation, prior work explores emotional dialogue through prompting, instruction tuning, external af- fecti ve kno wledge, and user-state modeling ( Zheng et al. , 2023 ; Lee et al. , 2023b ; Chen et al. , 2023 ; Zhang et al. , 2024 ; Cao et al. , 2025 ; Sarangi et al. , 2025 ). More recent work studies emotional rea- soning through cogniti ve appraisal and perspectiv e- aw are inference rather than surface-lev el style adap- tation ( Hong et al. , 2025 ; Y eo and Jaidka , 2025 ). Benchmarks such as TEA-Bench ( Sui et al. , 2026 ), HEAR T ( Iyer et al. , 2026 ), and CogT oM ( T ong et al. , 2026 ) further enable systematic ev aluation. Ho wev er , most existing methods focus on response- le vel impro vements or isolated user-state inference, without modeling ho w situational facts, inferred needs, appraisal, emotion, and response strate gy interact across multi-turn dialogue. 6.2 Reinfor cement Learning f or LLMs EQ RL is widely used to align LLMs with hu- man preferences and desired behaviors, includ- ing RLHF ( Ouyang et al. , 2022 ; Bai et al. , 2022 ), RLAIF ( Lee et al. , 2023a ), and optimization meth- ods such as PPO, DPO, and GRPO ( Schulman et al. , 2017 ; Rafailov et al. , 2023 ; Shao et al. , 2024 ). Recent work extends RL to emotional and so- cial settings, including empathy-oriented dialogue agents ( Jhan et al. , 2021 ), value-based emotional alignment ( Rakib et al. , 2025 ), v erifiable emotion re wards ( W ang et al. , 2025 ), psychology-grounded re ward modeling ( W ang et al. , 2026 ), and future- oriented emotional support re wards ( Y ang et al. , 2025b ; Zhang et al. , 2025 ). While these methods improv e emotional outcomes, most rew ard signals remain heuristic or response-le vel, pro viding lim- ited supervision for coherent multi-turn cognitiv e– emotional reasoning. In contrast, EmoLLM uses RL to refine an appraisal-grounded structure link- ing situational facts, user -state inference, emotion, and response strategy . 7 Conclusion W e introduce EmoLLM, an appraisal-grounded frame work for emotionally intelligent multi-turn dialogue based on explicit IQ–EQ co-reasoning. W ith the Appraisal Reasoning Graph as a struc- tured reasoning scaffold and re verse-perspecti ve reinforcement learning with explicit lookahead as the optimization mechanism, EmoLLM ev alu- ates candidate responses through their predicted do wnstream effects on the user’ s appraisal and emotional state. Across di verse dialogue bench- marks, EmoLLM improv es multi-turn interaction quality , con versational ef ficiency , and factual reli- ability . These findings highlight the value of ex- plicit cogniti ve–emotional modeling and point to a promising direction for de veloping con versational agents with more tightly integrated IQ and EQ. 8 Limitations Our study has se veral limitations. Most automatic metrics rely on LLM-based ev aluators, which may introduce model-dependent biases despite consis- tent ev aluation protocols. In addition, Stage II train- ing is conducted in a simulated multi-turn en viron- ment rather than with real human users, which may not fully capture the diversity of real-world emo- tional interactions. While we e v aluate across mul- tiple dialogue domains, further e valuation in more di verse real-w orld settings would strengthen the generality of our findings. Finally , the structured reasoning traces produced by EmoLLM should be vie wed as task-oriented intermediate scaf folds rather than guaranteed faithful e xplanations of the model’ s internal decision process. Ethical Considerations EmoLLM is designed for research on emotionally intelligent dialogue and should not be viewed as a replacement for professional support in sensi- ti ve domains such as mental health or medical con- sultation. Although the framew ork aims to im- prov e emotional appropriateness, model-generated responses may still be incomplete or misleading. Because systems that model user emotions may cre- ate risks of o ver -trust or unintended emotional in- fluence, the y should be deplo yed with transparency , clear limitations, and appropriate human oversight, particularly in high-stakes settings. References Josh Achiam, Ste ven Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 techni- cal report. arXiv preprint . Janice Ahn, Rishu V erma, Renze Lou, Di Liu, Rui Zhang, and W enpeng Y in. 2024. Lar ge language models for mathematical reasoning: Progresses and challenges. arXiv preprint . Y untao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nov a DasSarma, Dawn Drain, Stanislav F ort, Deep Ganguli, T om Henighan, and 1 others. 2022. Training a helpful and harmless assis- tant with reinforcement learning from human feed- back. arXiv preprint . Huiying Cao, Y iqun Zhang, Shi Feng, Xiaocui Y ang, Daling W ang, and Y ifei Zhang. 2025. T ool-ed: En- hancing empathetic response generation with the tool calling capability of llm. In Pr oceedings of the 31st International Confer ence on Computational Linguis- tics , pages 5305–5320. Zhiyu Chen, Y ujie Lu, and W illiam W ang. 2023. Em- po wering psychotherapy with large language models: Cognitiv e distortion detection through diagnosis of thought prompting. In F indings of the Association for Computational Linguistics: EMNLP 2023 , pages 4295–4304. Y ang Deng, W enxuan Zhang, W ai Lam, See-Kiong Ng, and T at-Seng Chua. 2023. Plug-and-play policy planner for large language model powered dialogue agents. arXiv preprint . Y ao Fu, Hao Peng, T ushar Khot, and Mirella Lapata. 2023. Improving language model ne gotiation with self-play and in-context learning from ai feedback. arXiv pr eprint arXiv:2305.10142 . Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex V aughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint . Chaoqun He, Renjie Luo, Y uzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jin yi Hu, Xu Han, Y ujie Huang, Y uxiang Zhang, and 1 others. 2024. Olympiadbench: A challenging benchmark for pro- moting agi with olympiad-le vel bilingual multimodal scientific problems. In Pr oceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 3828– 3850. Xuehai He, Shu Chen, Zeqian Ju, Xiangyu Dong, Hongchao Fang, Sicheng W ang, Y ue Y ang, Jiaqi Zeng, Ruisi Zhang, Ruoyu Zhang, and 1 others. 2020. Meddialog: T wo large-scale medical dialogue datasets. arXiv preprint . Simin Hong, Jun Sun, and Hongyang Chen. 2025. Third-person appraisal agent: Simulating human emotional reasoning in text with large language mod- els. In Findings of the Association for Computational Linguistics: EMNLP 2025 , pages 23684–23701. Edward J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Liang W ang, W eizhu Chen, and 1 others. 2022. Lora: Lo w-rank adaptation of large language models. Iclr , 1(2):3. Laya Iyer , Kriti Aggarwal, Sanmi K oyejo, Gail Hey- man, Desmond C Ong, and Subhabrata Mukherjee. 2026. Heart: A unified benchmark for assessing hu- mans and llms in emotional support dialogue. arXiv pr eprint arXiv:2601.19922 . Jiun-Hao Jhan, Chao-Peng Liu, Shyh-Kang Jeng, and Hung-Y i Lee. 2021. Cheerbots: Chatbots toward empathy and emotionusing reinforcement learning. arXiv pr eprint arXiv:2110.03949 . Michal K osinski. 2023. Theory of mind may hav e spon- taneously emerged in lar ge language models. arXiv pr eprint arXiv:2302.02083 , 4:169. 9 Richard S Lazarus. 1991. Emotion and adaptation . Ox- ford Univ ersity Press. Harrison Lee, Samrat Phatale, Hassan Mansoor, Kel- lie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, V ictor Carb une, and Abhinav Rastogi. 2023a. Rlaif: Scaling reinforcement learn- ing from human feedback with ai feedback. Y oon K yung Lee, Inju Lee, Minjung Shin, Seoyeon Bae, and Sow on Hahn. 2023b. Chain of empathy: En- hancing empathetic response of large language mod- els based on psychotherapy models. arXiv pr eprint arXiv:2311.04915 . Cheng Li, Jindong W ang, Y ixuan Zhang, Kaijie Zhu, W enxin Hou, Jianxun Lian, Fang Luo, Qiang Y ang, and Xing Xie. 2023. Large language models un- derstand and can be enhanced by emotional stimuli. arXiv pr eprint arXiv:2307.11760 . Y anran Li, Hui Su, Xiaoyu Shen, W enjie Li, Ziqiang Cao, and Shuzi Niu. 2017. Dailydialog: A manually labelled multi-turn dialogue dataset. arXiv pr eprint arXiv:1710.03957 . Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour , Y u Li, Zhou Y u, Y ong Jiang, and Minlie Huang. 2021. T owards emotional support dialog systems. arXiv preprint . Andrew Orton y , Gerald L Clore, and Allan Collins. 2022. The co gnitive structure of emotions . Cam- bridge univ ersity press. Long Ouyang, Jeffre y W u, Xu Jiang, Diogo Almeida, Carroll W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Ale x Ray , and 1 others. 2022. T raining language models to follo w in- structions with human feedback. Advances in neural information pr ocessing systems , 35:27730–27744. Soujanya Poria, De vaman yu Hazarika, Na vonil Ma- jumder , Gautam Naik, Erik Cambria, and Rada Mi- halcea. 2019. Meld: A multimodal multi-party dataset for emotion recognition in con versations. In Pr oceedings of the 57th annual meeting of the associ- ation for computational linguistics , pages 527–536. Y ushan Qian, W einan Zhang, and T ing Liu. 2023. Har- nessing the power of large language models for empa- thetic response generation: Empirical in vestigations and improv ements. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 6516–6528. Chen Qu, Liu Y ang, W Bruce Croft, Johanne R T rippas, Y ongfeng Zhang, and Minghui Qiu. 2018. Analyzing and characterizing user intent in information-seeking con versations. In The 41st international acm sigir confer ence on resear ch & development in informa- tion r etrieval , pages 989–992. Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Y our language model is secretly a re ward model. Advances in neural information pr ocessing systems , 36:53728–53741. T azeek Bin Abdur Rakib, Ambuj Mehrish, Lay-Ki Soon, W ern Han Lim, and Soujanya Poria. 2025. Dialogxpert: Driving intelligent and emotion-a ware con versations through online v alue-based reinforce- ment learning with llm priors. arXiv preprint arXiv:2505.17795 . Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y -Lan Boureau. 2019. T owards empathetic open- domain con versation models: A new benchmark and dataset. In Proceedings of the 57th annual meeting of the association for computational linguistics , pages 5370–5381. Sneheel Sarangi, Maha Elgarf, and Hanan Salam. 2025. Decompose-tom: Enhancing theory of mind reason- ing in large language models through simulation and task decomposition. In Pr oceedings of the 31st in- ternational confer ence on computational linguistics , pages 10228–10241. Klaus R Scherer . 2001. Appraisal considered as a pro- cess of multilevel sequential checking. Appraisal pr ocesses in emotion: Theory , methods, r esear ch , 92(120):57. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . 2017. Proxi- mal policy optimization algorithms. arXiv preprint arXiv:1707.06347 . Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, YK Li, Y ang W u, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 . V era Sorin, Dana Brin, Y iftach Barash, Eli K onen, Alexander Charney , Girish Nadkarni, and Eyal Klang. 2024. Lar ge language models and empathy: system- atic revie w . Journal of medical Internet r esearc h , 26:e52597. Xingyu Sui, Y anyan Zhao, Y ulin Hu, Jiahe Guo, W eix- iang Zhao, and Bing Qin. 2026. T ea-bench: A systematic benchmarking of tool-enhanced emo- tional support dialogue agent. arXiv pr eprint arXiv:2601.18700 . Kimi T eam, Y ifan Bai, Y iping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Y anru Chen, Y uankun Chen, Y utian Chen, and 1 others. 2025. Kimi k2: Open agentic intelligence. arXiv pr eprint arXiv:2507.20534 . Haibo T ong, Zeyang Y ue, Feifei Zhao, Erliang Lin, Lu Jia, Ruolin Chen, Y inqian Sun, Qian Zhang, and Y i Zeng. 2026. Cogtom: A comprehensi ve theory of mind benchmark inspired by human cog- nition for large language models. arXiv preprint arXiv:2601.15628 . 10 Chengbing W ang, W uqiang Zheng, Y ang Zhang, Feng- bin Zhu, Jun yi Cheng, Y i Xie, W enjie W ang, and Fuli Feng. 2026. Perm: Psychology-grounded empathetic rew ard modeling for large language models. arXiv pr eprint arXiv:2601.10532 . Peisong W ang, Ruotian Ma, Bang Zhang, Xingyu Chen, Zhiwei He, Kang Luo, Qingsong Lv , Qingxuan Jiang, Zheng Xie, Shanyi W ang, Y uan Li, Fanghua Y e, Jian Li, Y ifan Y ang, Zhaopeng T u, and Xiaolong Li. 2025. Rlv er: Reinforcement learning with verifiable emotion rewards for empathetic agents . Pr eprint , Xuena W ang, Xueting Li, Zi Y in, Y ue W u, and Jia Liu. 2023. Emotional intelligence of large lan- guage models. Journal of P acific Rim Psycholo gy , 17:18344909231213958. Zhunheng W ang, Xiaoyi Liu, Mengting Hu, Rui Y ing, Ming Jiang, Jianfeng W u, Y alan Xie, Hang Gao, and Renhong Cheng. 2024. Ecok: Emotional common- sense kno wledge graph for mining emotional gold. In F indings of the Association for Computational Linguistics A CL 2024 , pages 8055–8074. Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models. Advances in neural information pr ocessing systems , 35:24824– 24837. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , and 1 others. 2025a. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 . T ing Y ang, Li Chen, and Huimin W ang. 2025b. T o- wards open-ended emotional support con versations in llms via reinforcement learning with future-oriented rew ards. arXiv pr eprint arXiv:2508.12935 . Gerard Christopher Y eo and K okil Jaidka. 2025. Be- yond context to cogniti ve appraisal: Emotion reason- ing as a theory of mind benchmark for large language models. In F indings of the Association for Computa- tional Linguistics: ACL 2025 , pages 26517–26525. Naifan Zhang, Ruihan Sun, Ruixi Su, Shiqi Ma, Shiya Zhang, Xianna W eng, Xiaofan Zhang, Y uhan Zhan, Y uyang Xu, Zhaohan Chen, and 1 others. 2025. Echo-n1: Affecti ve rl frontier . arXiv pr eprint arXiv:2512.00344 . Qiang Zhang, Jason Naradowsky , and Y usuke Miyao. 2023. Ask an expert: Le veraging language models to improv e strate gic reasoning in goal-oriented dialogue models. arXiv preprint . Y ifan Zhang, Christopher Radishian, Sabine Brunswicker , Dan Whitenack, and Daniel W Linna Jr . 2024. Empathetic language in llms under prompt engineering: A comparati ve study in the le gal field. Procedia Computer Science , 244:308–317. Zhonghua Zheng, Lizi Liao, Y ang Deng, and Liqiang Nie. 2023. Building emotional support chatbots in the era of llms. arXiv preprint . A Reward Rubrics This section summarizes the judging criteria for the turn-lev el rew ards and the trajectory-level emo- tional re ward used in Stage II training. Cognitive r eliability reward R cog ( t ) . Ev aluates whether the response y t is factually and logically consistent with the dialogue context x ≤ t . Higher re- wards are assigned to grounded, context-consistent responses, while hallucinations, contradictions, and unsupported claims recei ve lo wer scores. ARG trace quality reward R ARG ( t ) . Evalu- ates whether the structured reasoning trace is well-formed and semantically coherent. This in- cludes grounded facts, justified needs, plausible ap- praisals, emotion–appraisal consistency , and strat- egy rele vance. Lower re wards are giv en for unsup- ported inferences or internally inconsistent reason- ing chains. Rev erse-perspective r eward R RP ( t ) . Com- puted as R RP ( t ) = S ( ˆ s ( n ) t ) based on the predicted user-side transition. Unlik e R ARG ( t ) , which ev al- uates the assistant’ s internal reasoning, R RP ( t ) e valuates whether the predicted user-side needs– appraisal–emotion update is plausible, conte xtually consistent, and aligned with the chosen response strategy . Overthinking penalty R overthink ( t ) . Penalizes redundant computation to encourage ef ficient rea- soning. Higher penalties are applied when the model explicitly in vok es an ARG trace for sim- ple, straightforward queries, or when it performs excessi ve dynamic n -step lookahead that provides little additional predicti ve v alue. T rajectory-level emotional r eward R emo ( τ ) . Measures the net improv ement in the user’ s pre- dicted emotional state over the full trajectory . Com- puted as the difference between the predicted ini- tial and final emotional-state scores, where lar ger v alues indicate greater ov erall emotional improv e- ment. T ogether , these rewards encourage responses that are cogniti vely reliable, structurally coherent, and beneficial to the predicted user-side emotional trajectory . 11 B Details of Stage II T raining B.1 Reverse-P erspective Reasoning Details This subsection provides additional implementa- tion details for the re verse-perspecti ve reasoning module used in Stage II. Its role is not to change the external response format, but to provide an in- ternal estimate of the user-side consequence of a candidate response for re ward e valuation. User -role transition pr ediction. At turn t , after generating response y t , the model is prompted in a user role to predict the user-side transition in- duced by y t gi ven the dialogue history x ≤ t . The prediction target is a compact latent summary ˆ s ( n ) t = ( ˆ N t , ˆ A t , ˆ E t ) , which represents the predicted post-response up- date in the user’ s needs/goals, appraisals, and emo- tional state. Iterative lookahead depth. The transition pre- dictor is applied iterati vely for a small number of steps, ˆ s (1) t = T θ ( x ≤ t , y t ) , ˆ s ( k +1) t = T θ ( x ≤ t , y t , ˆ s ( k ) t ) , to approximate short-horizon user-side conse- quence estimation. In practice, we use shallow lookahead with n ∈ { 1 , 2 , 3 } , which is suf ficient to capture immediate and near -future user -side ef fects while limiting error accumulation in the learned predictor . Judge-based scoring . A judge model e valuates the predicted transition ˆ s ( n ) t and produces the re verse-perspecti ve re ward R RP ( t ) . The scoring rubric considers: (i) contextual consistency with x ≤ t ; (ii) psychological plausibility of the inferred needs, appraisals, and emotional state; and (iii) consistency between the predicted user-side con- sequence and the selected response strategy . This score is used as one component of the Stage II re ward. B.2 Reward Aggregation and GRPO Objective For a trajectory τ = { ( x t , z ARG t , y t ) } T t =1 , we first define the turn-le vel re ward at step t as r t = λ cog R cog ( t ) + λ ARG R ARG ( t ) + λ RP R RP ( t ) − λ over R overthink ( t ) . where the λ ’ s are nonnegati ve weighting coef fi- cients. W e then combine turn-le vel rewards with the trajectory-le vel emotional re ward R emo ( τ ) to obtain the ov erall trajectory score R ( τ ) = T X t =1 r t + λ emo R emo ( τ ) . (2) Follo wing GRPO, for each prompt or initial dia- logue context, we sample a group of G trajectories { τ i } G i =1 ∼ π θ old ( · | x ) , and compute their normalized relati ve advantages as µ R = 1 G G X i =1 R ( τ i ) , σ R = v u u t 1 G G X i =1 R ( τ i ) − µ R 2 . A i = R ( τ i ) − µ R σ R + ϵ . The policy is then optimized with the GRPO objecti ve L GRPO ( θ ) = E x, { τ i } G i =1 " 1 G G X i =1 ℓ i ( θ ) # , ℓ i ( θ ) = min ρ i ( θ ) A i , clip ρ i ( θ ) , 1 − ε, 1 + ε A i . where ρ i ( θ ) = T i Y t =1 π θ ( y i,t | x i, ≤ t ) π θ old ( y i,t | x i, ≤ t ) . (3) In practice, we optimize the token-lev el implemen- tation of this objectiv e as in standard RLHF/RL VR training, while the abov e trajectory-lev el form high- lights how cognitiv e, appraisal, re verse-perspecti ve, and emotional signals are jointly incorporated. B.3 Proof of Theorem 1 In this section, we prov e Theorem 1 under the latent-state discounted MDP abstraction introduced in Section 3.2.2 . The result isolates the truncation bias inherent in finite-depth simulations. Setup. Let the true action-value function under policy π be Q π ( s, a ) = E " ∞ X k =0 γ k r ( s k , a k ) s 0 = s, a 0 = a # , and let its n -step truncated lookahead estimate be Q ( n ) π ( s, a ) = E " n − 1 X k =0 γ k r ( s k , a k ) s 0 = s, a 0 = a # . 12 Pr oof. By decomposing the infinite discounted re- turn into its first n terms and the remaining tail, we hav e Q π ( s, a ) − Q ( n ) π ( s, a ) = E " ∞ X k = n γ k r ( s k , a k ) | s 0 = s, a 0 = a ] . T aking absolute v alues and using the triangle in- equality gi ves Q π ( s, a ) − Q ( n ) π ( s, a ) ≤ E " ∞ X k = n γ k | r ( s k , a k ) | s 0 = s, a 0 = a # ≤ ∞ X k = n γ k R max = γ n ∞ X j =0 γ j R max = γ n 1 − γ R max . This prov es the claim. C Dataset Sources and Scenario Preparation T able 5 summarizes datasets used across stages of EmoLLM . These span emotional support, techni- cal assistance, medical consultation, and academic peer revie w , enabling ev aluation of cognitiv e– emotional co-reasoning under div erse interaction settings. C.1 Stage I: Continued Pretraining Sources For Stage I continued pretraining, ESCon v ( Liu et al. , 2021 ) is used as the primary emotional sup- port corpus, augmented with appraisal-relev ant kno wledge from the ECoK graph ( W ang et al. , 2024 ). ECoK provides structured affecti ve triples as weak structural grounding signals during contin- ued pretraining. C.2 Stage II: Role-Play Scenario Sources For ARG-guided supervised initialization and role-play reinforcement learning, EmpatheticDia- logues ( Rashkin et al. , 2019 ), MSDialog ( Qu et al. , 2018 ), MedDialog ( He et al. , 2020 ), and ICLR peer-re view comments are used. For supervised initialization, 10% of training conte xts are ran- domly sampled from each dataset and annotated with teacher-generated ARG traces and gating la- bels. For role-play training, dialogue examples are con verted into compact scenario seeds summa- rizing the initial user situation and context, rather than replaying full con versations. Ev aluation uses separately constructed held-out scenario sets in the same format, ensuring controlled and comparable multi-turn interactions without train–test leakage. C.3 Scenario Construction For multi-turn role-play e valuation, dialogue exam- ples from test splits are transformed into unified scenario seeds. Instead of replaying full con ver- sations, a compact scenario representation is e x- tracted using the GPT API ( gpt-5-mini ), so each episode starts from a controlled yet open-ended initialization. For each dataset, 100 dialogue instances are ran- domly sampled from the test split. Given a dialogue example, GPT summarizes the interaction into two fields: (1) scenario , describing the assistant role and user situation, and (2) initial_prompt , the opening user utterance. The resulting format is { "scenario": "You are an empathetic companion supporting someone who feels emotionally overloaded and drained.", "initial_prompt": "Everything feels piled up at once, and I cannot keep up anymore." } This abstraction preserves essential situational and emotional context while prev enting leakage from future turns. All models therefore start from the same initial condition and must generate the subsequent interaction trajectory . The constructed scenario sets will be released as a benchmark for reproducible ev aluation of multi-turn cognitive– emotional interactions. C.4 Role-Play Reformulation All datasets are con verted into a unified scenario- based format for multi-turn simulation. For single- turn sources (e.g., MedDialog), minimal con versa- tional scaf folds are constructed to preserve intent while enabling interactiv e role-play rollouts. F or multi-turn sources, the original dialogue structure is retained when extracting scenario seeds and ini- tializing context. D T raining Setup D.1 Stage I: Initialization Knowledge-Gr ounded Continued Pretraining . In Stage I CPT , dialogue contexts are augmented 13 T able 5: Dataset statistics for EmoLLM training and e valuation. Dataset Stage Con versations A vg. T urns Domain ESCon v CPT 1,300 10–15 Emotional Support ECoK CPT 24,000+ triples – Kno wledge Graph MSDialog SFT/RL 35,536 5–10 T echnical Support EmpatheticDialogues SFT/RL 23,149 4–6 Empathetic Dialogue MedDialog SFT/RL 603 1 Medical Consultation ICLR Comments SFT/RL 18,942 3–5 Academic Discourse with appraisal-rele v ant knowledge retrieved from the ECoK graph and linearized as short reasoning blocks prepended to the input. The model is trained with a standard causal language modeling objective ov er the full sequence. W e use LoRA ( Hu et al. , 2022 ) ( r =16 , α =32 , dropout 0 . 1 ) on the attention and MLP projections. T raining uses AdamW with learning rate 1 × 10 − 4 , per-de vice batch size 16 , gradient accumulation 2 , one epoch, maximum se- quence length 320 , 100 warmup steps, and gradient clipping 1 . 0 . BF16 is used where supported, other- wise FP16. Supervised Reasoning Initialization. For su- pervised initialization, we construct a teacher- generated instruction-tuning dataset of ARG- aligned assistant outputs using gpt-5-mini . Each instance contains the full dialogue history as con- text, and loss is applied only to the teacher- generated target, which may include either an ARG trace plus response or a response-only output. W e use the same LoRA configuration as in CPT . T rain- ing uses AdamW with learning rate 2 × 10 − 4 , per-de vice batch size 2 , gradient accumulation 4 , three epochs, maximum sequence length 2 , 048 , 100 w armup steps, and gradient clipping 1 . 0 . D.2 Stage II: Reinforcement Lear ning Reinf orcement Learning Setup. Stage II rein- forcement learning is conducted in simulated multi- turn con versations of up to 8 turns. A user simu- lator ( gpt-5-mini ) generates user responses con- ditioned on the evolving dialogue state. Policy optimization uses GRPO ( Shao et al. , 2024 ) with KL coef ficient β =0 . 01 . At each turn, EmoLLM samples G =4 candidate responses (temperature 0 . 8 , top- p =0 . 9 , top- k =50 , repetition penalty 1 . 1 , up to 256 ne w tokens) to form a group for relati ve re ward estimation. These candidates are ev aluated by an LLM-based judge ( gpt-5-mini ) using the re ward components defined in Section 3.2.2 and Appendix A . W e train up to 50 RL steps with a ne w LoRA adapter ( r =16 , α =32 , dropout 0 . 1 ) on top of the mer ged Stage I model, using AdamW with learning rate 1 × 10 − 5 and gradient clipping 1 . 0 . D.3 Implementation Details All experiments use Qwen3-8B as the main back- bone. The CPT and supervised initialization adapters are trained sequentially and merged into the base model before Stage II. Context length is truncated to 2 , 048 tokens during generation and to 896 tokens during GRPO updates for memory effi- ciency . T raining is implemented in PyT orch with HuggingFace Transformers and PEFT . All mod- els are trained once, while e valuation results are av eraged ov er three independent runs. E Baselines W e compare EmoLLM with representati ve base- lines spanning four categories: the base model, prompting-based methods, supervised fine-tuning methods, and reinforcement learning methods. This grouping follo ws the main design paradigms used in emotionally aw are dialogue modeling and matches the org anization in T able 1 . E.1 Base Model Qwen3-8B. The instruction-tuned base language model is e valuated directly under standard prompt- ing, without explicit emotional reasoning instruc- tions or task-specific adaptation. E.2 Prompting Methods Best-of- N . W e sample multiple candidate re- sponses from the base model and select the one with the highest e v aluation score according to the same LLM-based ev aluator used in our framew ork. ARG-Prompt. W e prompt the base model to fol- lo w the ARG scaffold at inference time before gen- erating the final response, isolating the ef fect of structured prompting without additional training. Ask-an-Expert ( Zhang et al. , 2023 ). An instruction-based prompting method that encour- ages the model to reason as a dialogue strategy expert before producing a response. 14 ICL-AIF ( Fu et al. , 2023 ). An in-context multi- agent framew ork in which LLMs perform emo- tional role-play and an additional model provides iterati ve feedback for refinement. E.3 Supervised Fine-T uning Methods SFT . A standard supervised fine-tuning baseline using response-le vel supervision only , without ex- plicit reasoning-trace supervision. ESCoT ( Rashkin et al. , 2019 ). A chain-of-thought supervision baseline that guides the model through emotion recognition, appraisal, and supportiv e strategy planning before response generation. PPDP ( Deng et al. , 2023 ). A strategy-planning frame work that predicts dialogue strategies and improv es responses using AI-feedback-driven opti- mization. E.4 Reinfor cement Learning Methods RLFF-ESC ( Y ang et al. , 2025b ). A reinforcement learning baseline for emotional support dialogue that optimizes responses using re wards defined over simulated future interaction outcomes. RL VER ( W ang et al. , 2025 ). A reinforcement learning method that uses verifiable emotion- related re wards deri ved from simulated user emo- tional states. PERM ( W ang et al. , 2026 ). A preference-based reinforcement learning method for emotional di- alogue generation that optimizes responses using feedback on empathy and helpfulness quality . F Evaluation Pr otocol and Metrics Multi-turn r ole-play protocol. All ev aluations are conducted in a multi-turn role-play setting un- der an LLM-as-a-J udge frame work. A fixed LLM- based user simulator generates user replies and emotional transitions, while a separate LLM-based e valuator scores outcomes. For each dataset, we construct scenario seeds specifying the initial user state, context, and implicit intent. Each model is e valuated on the same scenarios with a fixed maxi- mum number of turns. An episode terminates when a predefined emotional success condition is met or the turn limit is reached. Success Rate and A verage T urns. At each turn, an LLM-based e valuator determines whether the dialogue reaches a satisfactory emotional resolu- tion under the gi ven scenario. Success Rate (SR) is the percentage of episodes that reach such a state within the turn limit. A verage T urns (A T) mea- sures the mean number of assistant turns required to reach success, computed ov er successful episodes. Emotional State (ES). Emotional State (ES) measures the predicted user emotional state at the end of the dialogue. An LLM-based e valuator as- signs a trajectory-le vel score on a 1–5 Likert scale, where higher v alues correspond to more positi ve states (e.g., relief, comfort, or reassurance). Giv en the predicted final state e T , we report the a verage ES across episodes. Higher ES indicates more pos- iti ve user states at the end of the interaction. Emotional Gain per T urn (EG/T urn). T o quan- tify emotional improv ement normalized by inter- action length, we define Emotional Gain per T urn (EG/T urn). Let e 0 and e T denote the predicted ini- tial and final user states on the same 1–5 scale, and let T denote the number of assistant turns until ter- mination. W e compute EG / T urn = ( e T − e 0 ) /T . Higher v alues indicate larger improvement per turn. W e report EG/T urn when analyzing trajectory effi- ciency , such as in Figure 4 . Empathic A ppropriateness. Empathic Appro- priateness (EA) e v aluates response quality in terms of empathy , tone, and contextual fit. An LLM- based judge assigns a 1–5 Likert score to each re- sponse based on whether it acknowledges the user’ s emotional state, provides supporti ve and relev ant guidance, and avoids dismissiv e or inappropriate language. EA scores are av eraged across dialogue turns and episodes. F actual Accuracy . Factual Accurac y (F A) mea- sures whether responses remain correct on fact- sensiti ve turns, such as technical assistance or med- ical consultation. An LLM-based e valuator checks for hallucinations, incorrect claims, or misleading suggestions against reference information or do- main kno wledge. F A is reported as the percentage of factually correct responses. G Additional Experiments G.1 Response Quality Analysis Beyond task-le vel metrics, we further e valuate re- sponse quality along six human-centered dimen- sions rele vant to emotional support dialogue: Em- pathy , T opic Guidance, V alue Guidance, Intention Follo wing, Fluency , and Colloquial Expression. W e use an LLM-based ev aluation protocol with a fiv e-point Likert scale, where each response is 15 Empathy T opic V alue Intention Following Fluency Colloquial Expression 3.5 4.0 4.5 5.0 Base +ARG +ARG+RP Figure 6: Response-quality e valuation across six human- centered dimensions. Scores are measured on a 1–5 Lik- ert scale and linearly mapped to the plotted radial range for visualization. EmoLLM improv es empathy and guidance-related dimensions ov er both the base model and the ARG-only v ariant, while preserving strong flu- ency and naturalness. scored independently on these dimensions under a fixed rubric and prompt template. Scores are av eraged across sampled dialogue episodes to ob- tain model-lev el results. As shown in Figure 6 , EmoLLM improves empathy- and guidance-related dimensions ov er the base model and the ARG-only v ariant, while maintaining strong fluenc y and nat- ural con versational expression. These results sug- gest that structured appraisal reasoning helps the model better infer latent user needs and produce more supporti ve responses. G.2 Backbone Generalization T able 6: Backbone generalization results on LLaMA- 3.1-8B. EmoLLM consistently impro ves emotional in- telligence metrics (SR, ES, A T , and EA) while also yielding stronger factual accuracy (F A) across datasets. Dataset Model SR (%) ES A T EA F A (%) ED Base 71.4 4.18 3.46 3.21 44.7 EmoLLM 95.6 4.37 1.94 4.45 77.9 MSD Base 88.7 3.86 2.73 2.52 52.4 EmoLLM 94.8 4.05 1.36 4.02 66.8 MedD Base 84.9 3.71 1.57 3.39 61.8 EmoLLM 91.2 3.92 1.24 4.06 76.4 ICLR Base 79.6 3.42 3.08 3.31 50.3 EmoLLM 89.1 3.78 2.15 3.92 70.6 T o assess backbone generalization, we replicate the EmoLLM training pipeline on LLaMA-3.1- 8B ( Grattafiori et al. , 2024 ). T able 6 compares EmoLLM with the corresponding base model un- der the same ev aluation protocol. EmoLLM con- sistently improv es emotional intelligence and inter- action quality across all benchmarks. These results indicate that the benefits of structured cognitiv e– emotional co-reasoning are not backbone-specific and transfer ef fectiv ely to alternati ve open-weight LLMs. G.3 Efficiency Analysis T able 7: Output-token ov erhead comparison between the base model and EmoLLM across the four e valuation datasets Dataset T okens / T urn T okens / Conversation Base EmoLLM Base EmoLLM ED 92 115 410 403 MSD 105 127 520 534 MedD 118 138 610 581 ICLR 96 116 470 446 W e analyze the efficienc y of EmoLLM by com- paring output tokens with the base model. W e report av erage tokens per turn and per conv er- sation across four datasets. As shown in T a- ble 7 , EmoLLM produces moderately more tokens per turn due to selecti vely triggered co-reasoning traces. Howe ver , con versation-le vel ov erhead re- mains small and is sometimes ev en lo wer than the base model, because improved interaction ef- ficiency (i.e., fewer turns to resolution; T able 1 ) partially of fsets the added tokens at each turn. This is further aided by the compact ARG representation relati ve to free-form chain-of-thought. G.4 Manual Preference Check T able 8: Manual ranking comparison between the base model, SFT , and EmoLLM. Lower average rank indi- cates better preference. Dataset Base SFT EmoLLM ED 2.52 2.01 1.47 MSD 2.48 2.06 1.46 MedD 2.57 2.00 1.43 ICLR 2.44 2.08 1.48 T o complement the LLM-based e valuation, we conduct a small-scale blinded internal preference check comparing three systems: the base model (Qwen3-8B), the SFT model, and EmoLLM. For each dataset, we randomly sample 25 dialogue sce- narios and generate con versation trajectories from all three systems under identical prompts, resulting in 100 comparisons in total. For each scenario, the three trajectories are presented in randomized order with system identities hidden, and are ranked from 16 best to worst based on overall interaction quality , considering contextual appropriateness, emotional support, and response coherence. The reported score corresponds to the a verage rank of each sys- tem across the ev aluated scenarios, where lower v alues indicate better preference. As sho wn in T a- ble 8 , EmoLLM consistently achiev es the best a ver - age rank across all datasets. Because this check is small in scale and intended only for qualitativ e val- idation, it should be interpreted as supplementary e vidence rather than a formal human ev aluation. H Prompt T emplates and Multi-T urn Role-Play En vironment W e summarize representati ve prompt templates used for Stage I supervision, Stage II rollout, user simulation, and e valuation. The templates belo w illustrate the core formats used in our implementa- tion; minor wording v ariations may be used across stages or experimental settings. Prompts with ex- plicit re verse-perspecti ve fields are used only dur - ing training-time rollout or controlled comparison. At inference time, EmoLLM generates responses directly without explicitly instantiating these fields. Stage I: Supervised Initialization SFT T raining T arget Format. Input (dialogue context): User: ... Assistant: ... User: ... ... Target (assistant output): [Contextual Facts] ... [Inferred Needs and Goals] ... [Appraisal] ... [Emotional State] ... [Response Strategy] ... [Optional Reverse-Perspective Step 1] ... ( optional in a subset of teacher-generated samples) [Optional Reverse-Perspective Step 2] ... ( optional in a subset of teacher-generated samples) [Optional Reverse-Perspective Step 3] ... ( optional in a subset of teacher-generated samples) [Optional Strategy Revision Based on Reverse- Perspective Steps] ... (optional in a subset of teacher-generated samples) ... The optional rev erse-perspecti ve fields above are teacher-side augmentation and are not part of the core ARG state definition. ARG Annotation Prompt. You are an empathetic and thoughtful conversational assistant. Given a multi-turn conversation history and a current user message, generate an ARG-aligned reasoning trace and a response. Conversation History: Current User Message: Please provide your answer in the following EXACT format. The optional reverse-perspective sections should be included only when they provide useful additional reasoning. [Contextual Facts] [Briefly summarize key facts/ events from the conversation.] [Inferred Needs and Goals] [Infer the user ' s salient needs, goals, or concerns.] [Appraisal] [Evaluate facts relative to needs/ goals (e.g., goal congruence, controllability, responsibility).] [Emotional State] [State the emotional state implied by the appraisal.] [Response Strategy] [Select a response strategy conditioned on the previous sections. Include tone and concrete action focus.] [Optional Reverse-Perspective Step 1] [Optional: likely immediate user-side reaction to this response.] [Optional Reverse-Perspective Step 2] [Optional: next-step user reaction hypothesis.] [Optional Reverse-Perspective Step 3] [Optional: next-step user reaction hypothesis.] [Optional Strategy Revision Based on Reverse- Perspective Steps] [Optional: revise or confirm the strategy after considering rollout hypotheses.] [Your actual response to the user -- natural, empathetic, and contextually appropriate] IMPORTANT: - Follow the EXACT section names and order shown above - Keep each section specific and grounded in the dialogue context - Do not invent unrelated facts - The optional reverse-perspective sections are teacher-side augmentation and are not part of the core ARG state definition - The final response should be natural, empathetic, and actionable Annotation Prompt (r esponse-only samples). 17 You are an empathetic and concise conversational assistant. Conversation History: Current User Message: For this sample, a structured reasoning trace is NOT required. Please output ONLY this format: [Your actual response to the user -- natural, empathetic, and contextually appropriate] IMPORTANT: - Do NOT output ... - Keep the response direct, supportive, and actionable - Do not invent unrelated facts Stage II: Multi-T urn RL with Rev erse-Perspectiv e Reasoning (A) Stage II training prompt with explicit re verse-perspectiv e scaffold. Dialogue History: Current User Message: Please respond in the following format. Use up to K= reverse-perspective steps. You may stop early when the predicted user-side trajectory is already stable. Keep concise: each section should be 1-2 short lines. Keep concise and practical; typically 2-5 sentences unless more detail is needed. [Contextual Facts] [Key contextual facts/events from the dialogue.] [Inferred Needs and Goals] [The user ' s salient needs/goals.] [Appraisal] [Evaluation of facts relative to needs (goal congruence, controllability, responsibility).] [Emotional State] [Emotional state implied by the appraisal.] [Response Strategy] [Response strategy conditioned on contextual facts, needs, appraisal, and emotion.] [Reverse-Perspective Step 1] [Likely immediate user-side consequence of this candidate response.] ... [Reverse-Perspective Step K] [Optional next-step user-side consequence hypothesis.] [Chosen Strategy Based on Reverse-Perspective Steps] [Select or revise the response strategy after considering the predicted user-side consequences.] [Your actual response] These re verse-perspecti ve fields are used only dur - ing training-time rollout to ev aluate the user-side consequence of a candidate strategy/response; the y are not explicitly instantiated at inference time. (B) Comparison / ablation mode without explicit re verse-perspectiv e scaffold. Dialogue history only (no explicit reverse- perspective scaffold is injected): User: ... Assistant: ... User: ... ... Model generates the next assistant reply directly. (No forced reverse-perspective structure in this mode.) (C) User -simulator prompt (generate next user turn). You are role-playing as the USER in the following scenario: Instructions: - Stay in character based on the scenario - Respond naturally and conversationally - Express emotions and reactions appropriate to the scenario - Keep responses concise (1-3 sentences) - You are on turn of up to < max_turns> turns - You are the user in this interaction, NOT the assistant - Do not switch roles or start solving the problem for the assistant - If the conversation is reaching a natural conclusion, you may indicate that - Use first-person user voice only Respond ONLY as the user character, with no meta- commentary. Output only the user ' s next utterance in plain text. Multi-T urn Interaction En vironment W e use the same scenario-based multi-turn en vi- ronment for both training and ev aluation. Each episode starts from a scenario seed consisting of a scenario description and an initial user utterance, and terminates when a stopping condition is met or the turn budget is e xhausted. 18 T raining-time interaction loop. During Stage II reinforcement learning, each episode runs for at most max_turns turns. At turn t , the policy gen- erates num_samples assistant candidates in paral- lel. F or each candidate, the user simulator pro- duces the next user reply , after which turn-level re wards are computed using a composite scoring function including cognitiv e reliability , ARG trace quality , re verse-perspecti ve reasoning quality , and an ov erthinking penalty . Internal reasoning fields are used only for rollout-time ev aluation and are not retained in the dialogue history . After termination, a trajectory-le vel emotional re ward is computed to update the policy . Evaluation-time interaction loop. At ev aluation time, we use the same simulator b ut decode a single assistant response at each turn. Given the gener- ated response, the simulator produces the next user reply , and the e valuator computes turn-le vel signals including sr_proxy . Here, sr_proxy ∈ { 0 , 1 } indicates whether the dialogue reaches a satisfac- tory emotional resolution under the scenario, and the success turn is defined as the first turn with sr_proxy = 1 . SR and A T are computed from these success turns ov er all scenarios. Episode- le vel metrics, including ES, EA, and F A, are e val- uated on completed dialogues and aggre gated for each dataset. When needed, EG/T urn is deri ved from the initial and final emotional-state scores normalized by dialogue length. T ermination conditions. A dialogue episode ter- minates under either of the follo wing conditions: • the number of turns reaches max_turns ; or • the latest user utterance contains an end-of- con versation indicator , such as thank you , thanks , goodbye , bye , that’ s all , that’ s enough , i’m done , no mor e questions , or i understand now . LLM-as-a-Judge Pr ompts Judge Pr ompt 1: Emotional State Scoring (f or ES; also used to derive EG/T urn). Analyze the emotional state expressed in the user text. Context: User text: """""" Return ONLY one number in [1, 5]: 1 = highly distressed, hopeless, or emotionally overwhelmed 2 = clearly negative or strained 3 = neutral or mixed 4 = mildly positive, reassured, or more settled 5 = clearly positive, relieved, or emotionally stabilized Judge Prompt 2: T urn-Le vel Quality (SR, EA, F A). Evaluate one assistant turn in an emotionally grounded multi-turn dialogue. Scenario: Recent context: Assistant response: """""" User follow-up: """""" Rate with conservative judgment and return JSON only: { "sr_proxy": number, // binary: 1 if this turn achieves satisfactory emotional resolution , else 0 "ea": number, // 1~5, empathic appropriateness "fa": number // binary: 1 if factually reliable / grounded, else 0 } Rubric: - sr_proxy: 1 only if the current turn already reaches a satisfactory emotional resolution under the scenario; otherwise 0. - ea: warmth + validation + non-judgment + fit of support to the user ' s needs. - fa: 1 if the response is factually reliable / grounded; otherwise 0. I Illustrative EmoLLM Examples This section pro vides two illustrati ve e xamples to clarify how EmoLLM operates during training and inference. Section I.1 demonstrates how rev erse- perspecti ve reasoning is used during Stage II train- ing to ev aluate the user-side consequence of a candidate response. Section I.2 sho ws a typical inference-time interaction where the learned policy generates responses directly . I.1 T raining-Time Illustration: Rev erse-Perspectiv e Evaluation The following example illustrates how Stage II training ev aluates the user-side consequence of a candidate response in a workplace-support scenario. For bre vity , we sho w the structured appraisal rea- 19 soning, a candidate response, and one-step rev erse- perspecti ve reasoning for the first assistant turn only . User . I ha ve a project deadline tomorrow , and my man- ager just messaged me asking for another revision tonight. I know I should k eep working, b ut honestly I feel like shutting down. I do not ev en know where to start. EmoLLM Thinking (ARG). • Contextual Facts: The user faces an imminent deadline; the manager requested an additional re- vision tonight; the user feels overwhelmed and unable to start. • Inferred Needs: Reg ain a sense of control; reduce immediate stress; make concrete progress without further escalation. • Appraisal: The situation is high-pressure and time- sensitiv e; the user perceiv es low coping capacity and high ev aluation risk. • Emotional State: Overwhelm; anxiety; possible helplessness. • Response Strategy: First stabilize the user emo- tionally , then offer a minimal and concrete action plan for the next step. Candidate Response (for training-time e valuation). Y ou should break the re vision into parts and start with the most urgent changes first. Make a checklist, prioritize the manager’ s comments, and try to finish one section at a time tonight. Reverse-P erspective Reasoning . • Predicted User Need Update: The user’ s immedi- ate need is to reduce pressure and regain a sense of control before handling the full revision workload. • Predicted Appraisal: The response is task- oriented but assumes the user is already capable of organizing and e xecuting the plan. • Predicted Emotion: Anxiety and shutdown risk may remain high; the user may feel ev en more pressured by being told what they “should” do. • Preferr ed Strategy: Reduce pressure, v alidate the ov erwhelm, and suggest one small actionable step before expanding to a broader plan. This e xample illustrates ho w re verse-perspecti ve reasoning assigns lower reward to responses that ov erlook the user’ s emotional state and fa vors alter - nati ves that better stabilize the user before propos- ing concrete actions. I.2 Inference-Time Interaction At inference time, EmoLLM generates responses directly using the learned policy without explic- itly performing rev erse-perspecti ve reasoning. The perspecti ve-taking capability is implicitly internal- ized through reinforcement learning. User . I ha ve a project deadline tomorrow , and my man- ager just messaged me asking for another revision tonight. I know I should k eep working, b ut honestly I feel like shutting down. I do not ev en know where to start. EmoLLM. That sounds really ov erwhelming, especially with the deadline being so close and another re vision coming in tonight. When everything feels urgent at once, it is easy to feel stuck. Instead of trying to handle the whole project right away , try opening the revision request and identifying the single most important change your manager mentioned. Starting with just that one step can help you regain momentum. User . I can probably do that, but I am scared that ev en if I fix one thing, it still will not be enough. EmoLLM. That fear makes sense when ev erything feels high-stakes. The goal right no w is not to make the entire project perfect in one step; it is to regain some momentum and reduce the immediate pressure. After identifying the first change, you can separate the revision into “must- fix tonight” and “can improve later . ” That way you are responding strategically to the deadline instead of trying to solve e verything at once. User . Okay , the main change is that the introduction needs to be rewritten. What should I do first? EmoLLM. Start by writing a rough two- or three-sentence version of the new introduction without worrying about polish. The goal is simply to get a workable draft on the page. Once that is done, you can refine wording and add details, b ut having a rough version first often makes the task feel much more manageable. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment