SF‑Mamba: 효율적인 비인과적 비전 인코더 설계
SF‑Mamba는 단일 방향 스캔 기반의 비전 Mamba 모델에 두 가지 혁신을 도입한다. 첫째, 보조 패치 스와핑(auxiliary patch swapping)으로 앞쪽 토큰이 뒤쪽 정보를 간접적으로 활용하도록 하여 다방향 정보를 전달한다. 둘째, 배치 폴딩(batch folding)과 주기적 상태 초기화(periodic state reset)를 통해 짧은 시퀀스에서도 GPU 스레드 활용도를 극대화한다. 실험 결과, 이미지 분류, 객체 검출,…
저자: Masakazu Yoshimura, Teruaki Hayashi, Yuki Hoshino
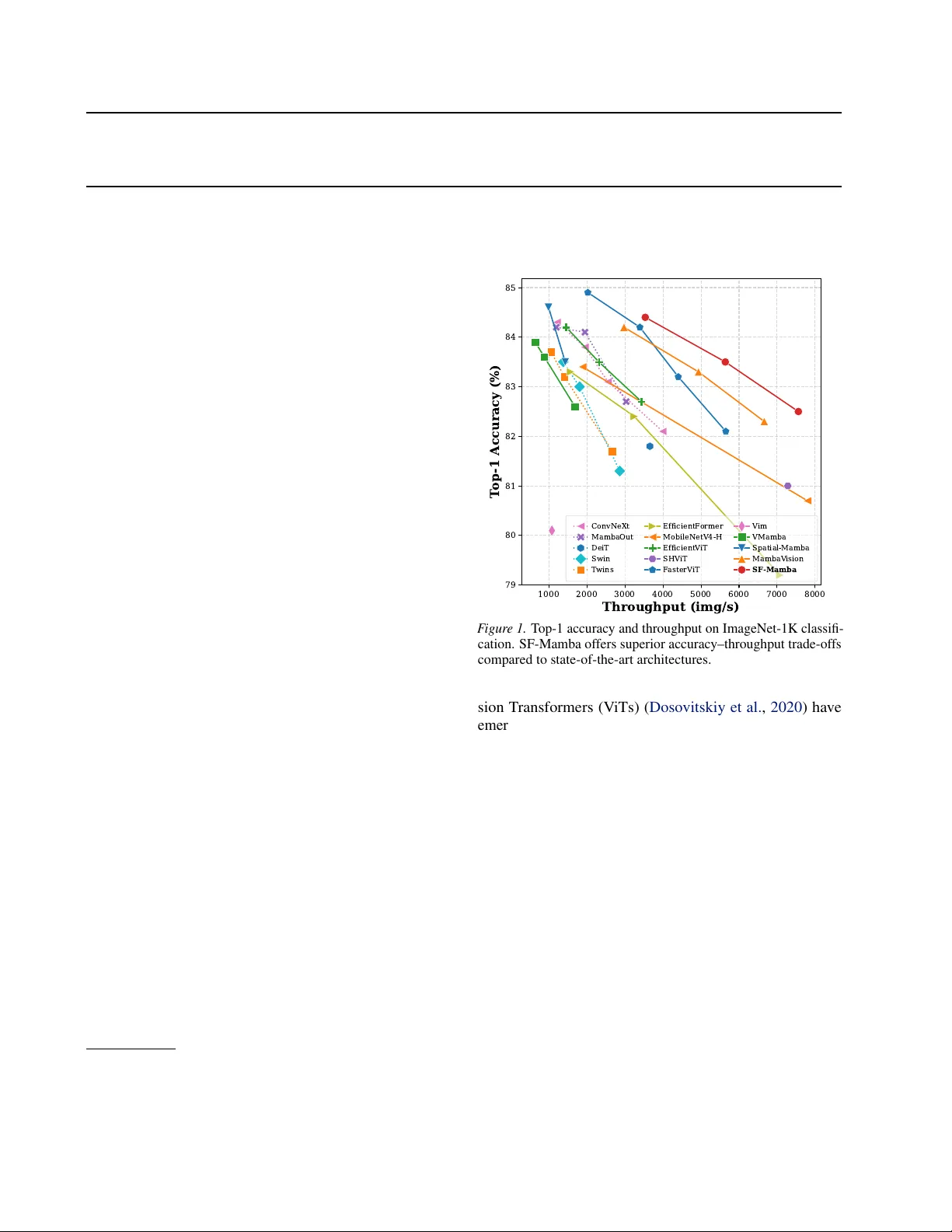
본 논문은 최근 비전 분야에서 주목받고 있는 Mamba 기반 모델이 갖는 두 가지 주요 한계—인과성 제약에 따른 비인과적 정보 흐름 부족과, 짧은 토큰 시퀀스에서 발생하는 GPU 활용도 저하—를 해결하고자 한다. 이를 위해 저자들은 “SF‑Mamba”라는 새로운 비전 Mamba 아키텍처를 제안한다.
1. **배경 및 동기**
- Vision Transformer(ViT)는 패치를 토큰화하고 전역 self‑attention을 적용해 높은 정확도를 달성했지만, 토큰 수가 늘어날수록 O(N²) 복잡도로 인해 고해상도 이미지 처리에 비효율적이다.
- Mamba는 선택적 상태공간 모델(Selective State‑Space Model, SSM)을 이용해 선형 시간 복잡도(O(N))를 제공하며, 메모리·연산 효율성에서 장점을 보인다. 그러나 Mamba는 기본적으로 왼‑오른(또는 위‑아래) 순서의 단일 방향 스캔을 사용하므로, 현재 토큰이 미래 토큰을 직접 참조하지 못한다. 이는 비전에서 “인과성”이 의미가 없기 때문에 성능 저하 요인으로 작용한다. 기존 연구들은 다방향 스캔, 교차 스캔, 혹은 후속 Attention 블록을 도입해 이를 보완했지만, 토큰 재배열·다중 경로 연산으로 인한 오버헤드가 크게 발생한다.
- 또한 Mamba는 CUDA warp‑scan 구현에 의존해 32개의 스레드가 하나의 시퀀스를 담당한다. 비전 작업에서는 시퀀스 길이(T)가 196 이하인 경우가 많아, 스레드 활용도가 낮아지고 실제 연산 속도가 기대 이하가 된다.
2. **핵심 아이디어**
- **보조 패치 스와핑(Auxiliary Patch Swapping)**
- 입력 시퀀스 양 끝에 두 개의 학습 가능한 보조 토큰(x_aux_head, x_aux_tail)을 삽입한다. 첫 번째 Mamba 블록에서는 이 토큰들을 평균값으로 초기화한다.
- 각 Mamba 블록이 끝난 뒤, 두 보조 토큰의 출력을 교환한다: 다음 블록의 head 토큰은 현재 블록의 tail 토큰 출력이 되고, 반대도 마찬가지다.
- 이렇게 하면 현재 레이어의 전체 컨텍스트가 tail 토큰에 요약되고, 교환을 통해 다음 레이어의 모든 패치 토큰이 이 전역 요약을 바로 입력받게 된다. 따라서 단일 방향 스캔이면서도 “미래→과거” 정보 흐름을 구현한다. 연산 비용은 단순 인덱스 교환(O(1))에 불과해 기존 다중 스캔 대비 크게 가벼우며, 파라미터도 거의 추가되지 않는다.
- **배치 폴딩과 주기적 상태 초기화(Batch Folding with Periodic State Reset)**
- 배치 차원을 시퀀스 차원과 결합해 입력 텐서를
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기