SF-Mamba: Rethinking State Space Model for Vision
The realm of Mamba for vision has been advanced in recent years to strike for the alternatives of Vision Transformers (ViTs) that suffer from the quadratic complexity. While the recurrent scanning mechanism of Mamba offers computational efficiency, i…
Authors: Masakazu Yoshimura, Teruaki Hayashi, Yuki Hoshino
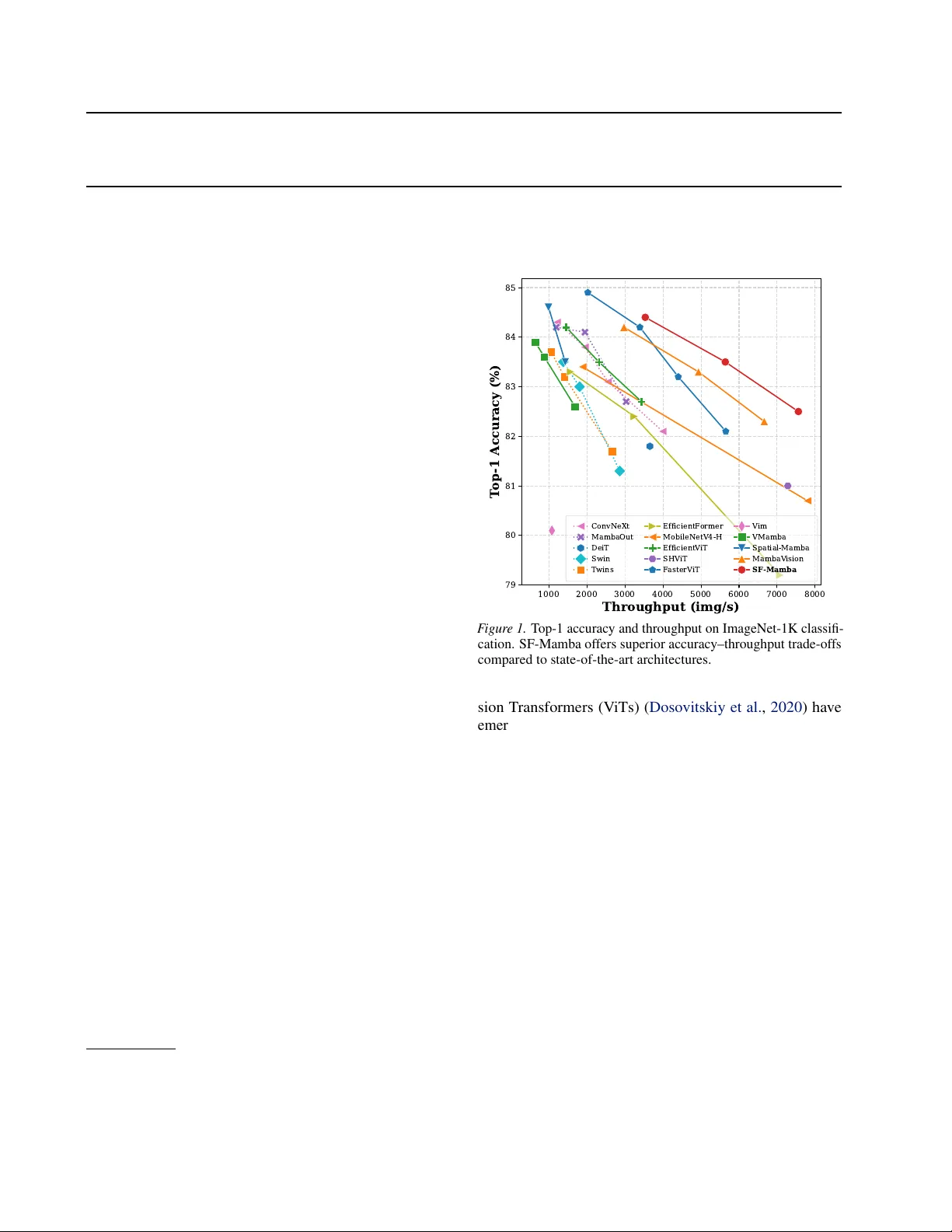
SF-Mamba: Rethinking State Space Model f or V ision Masakazu Y oshimura 1 T eruaki Hayashi 1 Y uki Hoshino 1 W ei-Y ao W ang 1 T akeshi Ohashi 1 Abstract The realm of Mamba for vision has been ad- v anced in recent years to strike for the alternati ves of V ision T ransformers (V iTs) that suffer from the quadratic complexity . While the recurrent scanning mechanism of Mamba of fers computa- tional efficienc y , it inherently limits non-causal interactions between image patches. Prior works hav e attempted to address this limitation through various multi-scan strategies; ho wever , these ap- proaches suffer from inef ficiencies due to subop- timal scan designs and frequent data rearrange- ment. Moreover , Mamba exhibits relati vely slow computational speed under short token lengths, commonly used in visual tasks. In pursuit of a truly ef ficient vision encoder , we rethink the scan operation for vision and the computational efficienc y of Mamba. T o this end, we propose SF-Mamba, a nov el visual Mamba with tw o ke y proposals: auxiliary patch sw apping for encoding bidirectional information flow under an unidirec- tional scan and batch folding with periodic state reset for advanced GPU parallelism. Extensiv e experiments on image classification, object de- tection, and instance and semantic se gmentation consistently demonstrate that our proposed SF- Mamba significantly outperforms state-of-the-art baselines while improving throughput across dif- ferent model sizes. W e will release the source code after publication. 1. Introduction The field of deep learning for vision has undergone se veral architectural shifts, driving progress across a wide range of applications including classification, se gmentation, and detection ( Deng et al. , 2009 ; Krizhe vsky et al. , 2012 ; He et al. , 2016 ; Simon yan & Zisserman , 2014 ; Ra vi et al. , 2025 ; Sim ´ eoni et al. , 2025 ; Bolya et al. , 2025 ). More recently , V i- 1 Sony Group Corporation, T okyo, Japan. Correspondence to: Masakazu Y oshimura < Masakazu.Y oshimura@sony .com > . Pr eprint. Mar ch 18, 2026. 1000 2000 3000 4000 5000 6000 7000 8000 Throughput (img/s) 79 80 81 82 83 84 85 T op-1 Accuracy (%) ConvNeXt MambaOut DeiT Swin T wins EfficientF ormer MobileNetV4-H EfficientV iT SHV iT F asterV iT V im VMamba Spatial-Mamba MambaV ision SF -Mamba F igure 1. T op-1 accurac y and throughput on ImageNet-1K classifi- cation. SF-Mamba of fers superior accuracy–throughput trade-of fs compared to state-of-the-art architectures. sion T ransformers (V iTs) ( Dosovitskiy et al. , 2020 ) have emerged as the dominant paradigm and offer strong flexibil- ity and generalizability compared to conv olution-based mod- els by tokenizing images into patches and applying the self- attention mechanism ( V aswani et al. , 2017 ). V iT -based vi- sion models hav e been widely used for multi-modal learning tasks ( Khan et al. , 2022 ; Elharrouss et al. , 2025 ); ho wev er , one of the main limitations of V iTs is the quadratic com- plexity for computing attention in terms of sequence length, which hinders the scalability to high-resolution inputs and large datasets with limited computational resources. Mamba ( Gu & Dao , 2023 ) introduces a selecti ve state-space model (SSM), which enables data-dependent flexible token scanning in a left-to-right order , thereby achieving po werful but ef ficient processing with linear-time complexity . Build- ing on its success, Mamba has been e xtended to the vision domain, achie ving higher accuracy while being ef ficient in terms of memory cost, FLOPs, and the number of param- eters ( Zhu et al. , 2024 ; Liu et al. , 2024 ; Pei et al. , 2025 ). In addition, recent studies suggest that visual Mamba has good transfer learning capabilities comparable to or even surpassing those of V iTs ( Y oshimura et al. , 2025 ; Galim 1 Submission and Formatting Instructions f or ICML 2026 et al. , 2025 ), and it has the potential to replace the V iT - based foundation model ecosystem. Howe ver , many visual Mamba models suffer from slow processing speeds, espe- cially on lo w-resolution images, which makes them not truly efficient. One reason is that Mamba adopts a recurrent left- to-right scanning mechanism, which prev ents earlier patches from accessing information in future patches. As a result, many visual Mamba methods employ a multi-directional scan strategy , where the input sequence is rearranged and processed from multiple directions (e.g., from top-left to bottom-right, bottom-right to top-left). This allows mod- els to compensate for the inability of standard Mamba to reference future patches and yields strong performance on vision tasks. Howe ver , such a rearrangement incurs substan- tial overhead during both training and inference. In fact, MambaV ision ( Hatamizadeh & Kautz , 2025 ) achie ves a f ast inference by avoiding costly multi-scan and instead rely on attention layers appended after the unidirectional scan. These attention layers enable information to flo w backw ard, allo wing earlier tokens to indirectly benefit from later tokens while retaining the efficienc y of unidirectional Mamba. Y et, relying solely on attention for backward information flow poses a limitation: backward conte xt can only be injected in deeper layers, lea ving shallower layers depri ved of future information and potentially restricting the expressiv eness of the representation. Another reason why visual Mamba is slow lies in Mamba itself. As reported in the Mamba paper , unless the tok en length exceeds around 1000–2000, it is slower than Attention. Unless the task in volves high- resolution images, the token length of the vision patches typically remains below 1000. In this paper , we rethink visual Mamba from two perspec- tiv es in pursuit of a truly efficient image encoder . The first is the data flow . Instead of using the slower multi- directional scan, we adopt a unidirectional scan. Ho wever , this approach lacks future-to-past information flo w , which is crucial to generate high-quality features. T o address this, we propose an auxiliary patch swapping that enables future-to- past information flo w within a unidirectional scan (Sec. 3.2 ). It introduces two additional tokens mixing the correspond- ing directional flow , which does not require significant b ur- den compared with existing multi-scan approaches. The sec- ond perspectiv e addresses the inef ficiency of Mamba when processing short sequences. W e attrib ute this limitation to suboptimal GPU parallelization, and to mitigate it, we in- troduce batch folding with periodic state reset (Sec. 3.3 ). This method reshapes batched inputs to maximize GPU thread utilization while preserving independence across se- quences, thereby enhancing parallel efficienc y . T o this end, we propose SF-Mamba , which is equipped with the tw o key innov ations of swapping and folding. Extensi ve exper - iments on image classification (Fig. 1 ), object detection, and semantic/instance segmentation demonstrate that SF- Mamba consistently outperforms state-of-the-art baselines while achieving f aster inference, paving a ne w path to ward efficient and ef fective Mamba architectures for vision. In summary , our main contributions are three-fold: • Efficient uni-scan f or non-causal ordering. W e pro- pose a lightweight mechanism, auxiliary patch swap- ping, that introduces two learnable auxiliary tokens and a parameter-free swap operation, enabling bidirec- tional information flow across layers with ne gligible ov erhead compared to existing multi-scan approaches. • Efficient GPU parallelism f or vision tasks. T o ad- dress inefficienc y in low-resolution vision tasks, we design a batch folding strategy that merges the batch and sequence dimensions, maximizing GPU utilization while preserving the independence of hidden states across sequences. This method can speed up any Mamba-based method especially with short sequence processing. • Empirical validation across various tasks. Ex- periments on classification, detection, and segmenta- tion show that SF-Mamba outperforms state-of-the-art CNN-, T ransformer-, h ybrid CNN-T ransformer-, and Mamba-based baselines. 2. Related W ork CNNs and V ision T ransformers. Con volutional Neural Networks (CNNs) first led to breakthroughs in large-scale image classification ( Deng et al. , 2009 ; Krizhe vsky et al. , 2012 ), with deeper networks such as VGG ( Simonyan & Zisserman , 2014 ) and ResNet ( He et al. , 2016 ) e xtending success to segmentation ( Long et al. , 2015 ) and detection ( Ren et al. , 2015 ). V ision Transformers (V iTs) ( Dosovitskiy et al. , 2020 ), inspired by self-attention ( V aswani et al. , 2017 ), hav e since become the dominant paradigm by effecti vely modeling long-range dependencies. Follo w-up works such as DeiT ( d’Ascoli et al. , 2021 ), and Swin Transformer ( Liu et al. , 2021 ) improved ef ficiency and scalability . Models trained on large-scale data are used as a foundation for a variety of tasks ( Oquab et al. , 2024 ; Sim ´ eoni et al. , 2025 ; Tschannen et al. , 2025 ). V isual State Space Models. T o address the quadratic cost of attention, state-space models (SSMs) ha ve emerged as efficient alternati ves. Mamba ( Gu & Dao , 2023 ) introduced selectiv e state spaces, enabling linear -time complexity with strong long-range modeling. Inspired by this success, many visual Mamba v ariants ( Zhu et al. , 2024 ; Liu et al. , 2024 ) extended SSMs to visual data. Hybrid Architectur es in V ision. Beyond single-paradigm designs, recent studies have demonstrated that hybrid architecture can lead to more efficient encoding. The CNN-T ransformer hybrids ( Hatamizadeh et al. , 2024 ; Li 2 Submission and Formatting Instructions f or ICML 2026 et al. , 2022 ; Zheng , 2025 ) lev eraged the local feature extraction and inductiv e biases of CNNs alongside the global context modeling of Transformers. More recently , Mamba–T ransformer hybrids ( Hatamizadeh & Kautz , 2025 ) hav e emerged, combining Mamba’ s computational effi- ciency with T ransformers’ receptive field. The hybrid archi- tecture achiev es superior efficienc y–performance trade-of fs and establishes state-of-the-art vision backbones. Causality Constraint of V isual SSMs. From another per- specti ve, visual SSMs face an inherent challenge: the causal- ity constraint , which is also observed in vision-language models ( W ang et al. , 2025c ). Since state-space models pro- cess inputs sequentially , each hidden state only depends on the past, pre venting access to the global spatial context. Many visual Mamba methods address causality constraints via multi-directional scans. Some approaches like V im ( Zhu et al. , 2024 ) and Mamba-R ( W ang et al. , 2025a ) adopt bi- directional scans, while recent models are based on cross- scan ( Liu et al. , 2024 ), which performs bi-directional scan along both horizontal and vertical axes, totaling four di- rections to better capture image structure. V ariants such as GroupMamba ( Shaker et al. , 2025 ), MSVMamba ( Shi et al. , 2024 ), Ef ficientVMamba ( Shak er et al. , 2025 ), and DefMamba ( Liu et al. , 2025 ) enhance cross-scan through zigzag patterns, multi-resolution scan, atrous sampling, or deformable directions. Despite being parameter -efficient, multi-directional scans are slow . Cross-scan based methods are particularly suffer from slow speed due to increased FLOPs from four parallel scans and costly data rearrange- ment between 2D formats (for 2D con volution) and 1D for- mats (for scanning). Rearranging tokens for four directions adds further overhead, especially in vertical scans, which in volve scattered memory access. While bi-directional scan av oids 2D/1D format switching, it still requires rearranging data for the backward scan and maintaining two parallel paths. The preliminary experiments in Appendix (Fig. 6 ) show that the multi-scan strate gy actually causes a signifi- cant degradation in inference speed. A recent study , Adventurer ( W ang et al. , 2025b ), tackles the causality constraint of Mamba2 ( Dao & Gu , 2024 ) using series bi-directional scans, which alternate scan directions between layers. It also inserts a globally av eraged token in ev ery layer to facilitate limited context exchange of series bi- directional scan. While this mechanism only requires single scan in each block, it requires explicit flipping operations with O ( n ) permutation cost and an additional averaging cost, resulting in reduced throughput. Sev eral methods are starting to achieve hi gh accuracy with unidirectional scan. Spatial-Mamba ( Xiao et al. , 2025 ) uses 2D atrous con volution with a wide receptiv e field to access future patches, although the 2D/1D format switching de- grades the speed. MambaV ision ( Hatamizadeh & Kautz , 2025 ) incorporates Attention in later layers to capture global context. Ho wev er , relying solely on attention for future-to- past information flow might not be optimal. Furthermore, although previous methods adopt Mamba due to its parameter efficienc y and superior accuracy , it remains slower than Attention for token lengths belo w 1000 to 2000 ( Gu & Dao , 2023 ). These limitations motiv ate the develop- ment of a truly efficient visual Mamba. 3. Method 3.1. Preliminaries Mamba State Space Model. Mamba ( Gu & Dao , 2023 ) is a selecti ve state space model (SSM) that processes a se- quence X = ( x 1 , . . . , x T ) by recurrently updating a hidden state h t : h t = A t h t − 1 + B t x t , y t = C t h t , (1) where h t is the hidden state, y t the output, and A t , B t , C t are input-dependent matrices. In the vision setting, an image is divided into T patches, each embedded as x t ∈ R D , forming a sequence X = ( x 1 , . . . , x T ) . A batch of such sequences is denoted as X in ∈ R B × T × D , where B is the batch size, T the num- ber of patches (sequence length), and D the embedding dimension. In this case, Mamba can be vie wed as a map- ping f θ : R T × D → R T × D that applies the recurrence in Equation ( 1 ) to patch sequences. Using a parallel scan algorithm, this recursive operation is efficiently computed. Specifically , Mamba uses a warp scan function ( NVIDIA , 2025a ) implemented in the CUDA backend, which enables high-speed parallel scan by allow- ing multiple threads to share data through the fast SRAM memory of the GPU. Since this warp scan function operates in groups of 32 threads, each sequence must be processed using at least 32 threads. Note that this is not a constraint of the operation itself, but a constraint imposed by modern GPU hardware. Any operations must be e xecuted in units of 32 threads internally . Mamba-T ransf ormer Hybrid Architectur e. W e employ a Mamba-T ransformer hybrid architecture, because pre vi- ous studies indicate that the hybrid architecture achiev es promising efficienc y . In other words, we employ MambaV i- sion ( Hatamizadeh & Kautz , 2025 ) architecture as a macro lev el. It uses a four-stage hierarchical design. The first two stages are CNN-based and serve as a kind of deep patch embedding. The latter two stages consist of several Mamba blocks followed by se veral Attention Blocks. MambaV ision accelerates processing by adopting a simple unidirectional scan. Ho wev er , due to the causality constraint , it cannot reference future patches from past ones, so future-to-past 3 Submission and Formatting Instructions f or ICML 2026 Auxiliary T oken Swap(ours) 😸 T + 2 token length 😸 O(1) permutation Bi-directional Scan 😿 T ・ 2 token length 😿 O(n) permutation F igure 2. Future-to-Past Information Routing via A uxiliary T oken Swapping. The left figure illustrates why the commonly used multi- directional scan in visual Mamba fails to achie ve high speed, while the right figure presents our proposed solution. W e prepend/append learnable auxiliary tokens to the patch sequence x aux head and x aux tail . Within each MambaV ision block, the causal selectiv e scan aggreg ates sequence-wide context into the tail token y aux tail . A lightweight, parameter-free Swap operation then moves this global summary to the sequence head, yielding ˜ X for the ne xt layer such that all patch states are conditioned on global context. It incurs negligible computational ov erhead while enabling effecti ve global-conte xt propagation across layers. information flow relies on subsequent Attention blocks. De- tailed structure and formulation of the MambaV ision-based blocks are provided in Appendix C.1 . 3.2. Rethinking V isual SSM from Data Flow P erspective Future-to-P ast Inf ormation Routing via A uxiliary T oken Swapping. Since image patches do not exhibit a strict causal ordering, restricting Mamba blocks to a unidirectional scan can be limiting: tokens in earlier regions (e.g., the top-left) cannot directly access information from later re gions (e.g., the bottom-right), which hinders representation learning. While multi-scan approaches such as bidirectional or cross- scan alleviate this issue, the y require repeated reordering of the data, which introduces substantial computational over - head and complicates implementation. Hence, we propose a future-to-past information flo w with minimal additional cost by introducing two auxiliary tokens . At the first Mamba block in each stage, the two auxiliary tokens, x aux , 1 head and x aux , 1 tail , are initialized as data-dependent values (i.e., x aux,1 head = x aux,1 tail = av g ( X ) , where av g ( ) av er- ages the sequential dimension). The tokens are then con- catenated at both ends of the input X for the first Mamba block: X ′ = ( x aux , 1 head , x 1 , . . . , x T , x aux , 1 tail ) . (2) After processed by the i -th Mamba block, we swap the two tokens for the input of the next Mamba block (see Fig. 2 ): x aux ,i +1 head = y aux ,i tail , x aux ,i +1 tail = y aux ,i head , (3) where y aux ,i head and y aux ,i tail are the output tokens with respect to x aux ,i head and x aux ,i tail . By training this architecture, we expect that y aux ,i tail extracts the necessary information from all tokens in the i -th layer , and y aux ,i head serves as a feature that deter- mines how y aux ,i +1 tail should be extracted in the next layer . Then, by swapping as sho wn in Eq. 3 , the patch tokens of the next layer ( x 1 , x 2 , ..., X T ) can refer to x aux ,i +1 head , which contains features from all positions, allowing future-to-past information routing. This intended operation is natural for the selective scan SSM and does not disrupt the original mechanism, which selecti vely extracts the necessary infor - mation as y t from hidden states that span from t = 0 to t = t . Similarly , we expect it selecti vely extracts the neces- sary information as y aux ,i tail from hidden states that span from t = 0 to t = T . In contrast to multi-scan strate gies, our approach does not rely on multiple parallel paths or global token rearrange- ments. Instead, it swaps only two tokens within the se- quence, introducing negligible computational o verhead. 3.3. Rethinking V isual SSM from Computational Perspecti ve Batch Folding with P eriodic State Reset. W e identify that Mamba’ s inefficienc y in lo w-resolution vision tasks arises from the war p-scan implementation, which achieves high throughput by utilizing 32 GPU threads per sequence (Sec. 3.1 ). In vision models, ho wever , the number of patches (i.e., sequence length) is relatively small (e.g., 196 and 49 for MambaV ision Stage 3 and 4), making the allocation of 32 threads per sequence highly underutilized and inefficient. T o address this, we propose a batch folding strategy that reshapes the input by merging the batch dimension into the 4 Submission and Formatting Instructions f or ICML 2026 Periodic State Reset T rick for t = 1 to B 2 · T if t mo d T = 0 A t ← 0 h t ← A t h t − 1 + B t x t y t ← C t h t F igur e 3. Batch folding with periodic state reset. ( Left ) An input tensor of shape [ B , D , T ] is reshaped into [ B 1 , D , ( B 2 · T )] , concatenating B 2 short sequences into a longer one. This reshaping mixes hidden states across batches. ( Right ) T o avoid information leakage, we reset the recurrence every T steps. Since h t ← A t h t − 1 + B t x t , setting A t = 0 at boundaries is equiv alent to re-initializing the hidden state. In contrast, B t (input projection) and C t (output projection) operate locally and therefore remain unchanged. sequence dimension (Fig. 3 , left). This improv es parallel efficienc y in scenarios with many short sequences while preserving the correctness of the computation. Let Z ∈ R B × D × T denote the batched tokens before entering the SSM. W e reshape Z into Z ′ ∈ R B 1 × D × ( B 2 · T ) , B = B 1 · B 2 , (4) which concatenates B 2 short sequences into one longer se- quence. This operation is a bijecti ve permutation of indices, so the original tensor can be e xactly recov ered. Intuitiv ely , this extends the ef fectiv e sequence length in a pseudo man- ner , allo wing the parallel scan to operate more efficiently by reducing kernel launch ov erhead and reducing inef ficient use of memory bandwidth. Howe ver , this reshaping mixes hidden states across dif ferent sequences. T o preserv e independence, we effecti vely use and improv e a computational trick implemented in vLLM software ( Kwon et al. , 2023 ), which was originally de vised for Mamba inference in LLMs to handle multiple sequences of v arying lengths without padding. Our trick for preserving the dependence of the folded data named periodic state r eset trick is as follo ws (Fig. 3 , right). In e very T step, we set A t = 0 , which remov es dependence on h t − 1 and resets the hidden state. Then, all the hidden states become identical to those without batch folding. By unfolding the output, the output becomes equiv alent to that obtained without applying batch folding. Note that B t and C t act only on the current input and hidden state, respectiv ely , and thus do not require resetting. Since it only resets A, there is only a minimal increase in processing time. Adaptive B 1 . In batch folding, it is not optimal to increase the virtual sequence size indefinitely . The ideal ratio be- tween B 1 and B 2 is determined in a complex manner based on factors such as batch size B , number of input tokens T , model dimension D , state dimension S , and the number of threads used when in voking CUD A. Therefore, we pre- compute and store combinations of (B, D, L, S), along with the optimal B 1 /B ratio, in a coarse-grained 4-dimensional lookup table ( LU T ). At runtime, we retriev e the optimal B 1 value from this LU T as follows: B 1 = f ( B , B · LU T ( B , D , S, L )) , (5) where f ( a, b ) is a function that returns a di visor of a , which is closest to b . 1-D Depthwise Con volution f or Batch F olded Data. Al- though batch folding impro ves the speed of the SSM com- ponent, the reshaping operation in Eq. 4 introduces a slow- down. T o mitigate this, we apply the transformation in Eq. 4 only at the initial Mamba block of each stage, and then continue computation using the batch-folded tensor shape. Since the Linear and LayerNorm layers operate per token, they do not pose any issues. Howe ver , the 1D depthwise con volution in the Mamba block presents a challenge. T o ad- dress this, we implement a con volution that supports batch- folded data, ensuring that no con volution occurs across the boundaries between T sequences. In other words, our con- volution CUDA kernel performs implicit padding at the boundary of each T sequence. 4. Experiments W e conduct comprehensive experiments to e valuate SF- Mamba across three fundamental computer vision tasks: im- age classification, semantic se gmentation, object detection with instance segmentation (Appendix D.4 and D.5 ). Our experimental setup follo ws the protocols established by pre- vious works ( Liu et al. , 2024 ; Xiao et al. , 2025 ; Hatamizadeh & Kautz , 2025 ) to ensure fair comparisons. W e e valuate three model variants (T/S/B) with dif ferent scales to ana- lyze the accuracy-throughput trade-of fs. For all downstream tasks, we use models pre-trained on ImageNet-1K as back- bones. Detailed training configurations and hyperparame- ters are provided in Appendix B . 4.1. Image Classification Experimental Setup. W e first e valuate our models on im- age classification task using ImageNet-1K ( Deng et al. , 2009 ), which contains 1.28M training images and 50K 5 Submission and Formatting Instructions f or ICML 2026 T able 1. Detailed comparison of image classification performance on ImageNet-1K. All models are ev aluated with 224 × 224 input resolution. In the tok en mixer type, C, P , A, and S denote Con volu- tion, Pooling, Attention, and SSM, respectiv ely . Model Mixer Params MA Cs img/s Acc. (%) Con vNeXt-T C 29M 4.5G 3990 82.1 MambaOut-T C 27M 4.5G 3031 82.7 Swin-T A 29M 4.5G 2863 81.3 T wins-S A 24M 2.9G 2669 81.7 EfficientF ormer-L3 P+A 31M 3.9G 3246 82.4 FasterV iT -0 C+A 31M 3.3G 5651 82.1 V im-S C+S 26M 5.3G 1079 80.1 VMamba-T C+S 30M 4.9G 1684 82.6 Spatial-Mamba-T C+S 27M 4.5G 1430 83.5 MambaV ision-T C+S+A 32M 4.4G 6662 82.3 SF-Mamba-T C+S+A 32M 4.5G 7600 82.5 Con vNeXt-S C 50M 8.7G 2552 83.1 MambaOut-S C 49M 9.0G 1948 84.1 Swin-S A 50M 8.7G 1805 83.0 T wins-B A 56M 8.6G 1409 83.2 FasterV iT -1 C+A 53M 5.3G 4402 83.2 EfficientV iT -B3 C+A 49M 4.0G 2315 83.5 VMamba-S C+S 50M 8.7G 879 83.6 Spatial-Mamba-S C+S 43M 7.1G 990 84.6 MambaV ision-S C+S+A 50M 7.5G 4933 83.3 SF-Mamba-S C+S+A 50M 7.6G 5639 83.5 Con vNeXt-B Con v 89M 15.4G 1943 83.8 MambaOut-B Con v 85M 15.9G 1195 84.2 Swin-B A 88M 15.4G 1377 83.5 T wins-L A 99M 15.1G 1059 83.7 EfficientF ormer-L7 P+A 82M 10.2G 1573 83.3 FasterV iT -2 C+A 76M 8.7G 3392 84.2 VMamba-B C+S 89M 15.4G 640 83.9 Spatial-Mamba-B C+S 96M 15.8G 670 85.3 MambaV ision-B C+S+A 98M 15.0G 2974 84.2 SF-Mamba-B C+S+A 98M 15.1G 3534 84.4 2 − 7 2 − 6 2 − 5 2 − 4 2 − 3 2 − 2 2 − 1 1 100 120 140 160 180 B 1 /B Speedup. (%) [128, 320, 8, 196] [128, 640, 8, 49] [128, 512, 8, 196] [128, 1024, 8, 49] F igur e 4. Ho w much we can speedup the SSM calculation by changing B 1 . The four configurations of [batch size, dimension, state dimension, sequence length] are exact settings for ours-T stage 3, ours-T stage 4, ours-B stage 3, ours-B stage 4. validation images across 1,000 categories. Models are trained from scratch for 300 epochs follo wing prior works ( Hatamizadeh & Kautz , 2025 ; Liu et al. , 2024 ). Throughput is measured on a single NVIDIA A100 GPU with a batch size of 128 (see Appendix B.4 for details). Results. As shown in Fig. 1 , SF-Mamba achieves supe- rior efficienc y-accuracy trade-of fs with consistent impro ve- ments across all model scales (T/S/B variants) compared to existing architectures including CNN-based models (Con- vNeXt ( Liu et al. , 2022 ), MambaOut ( Y u & W ang , 2025 )), T ransformer-based models (DeiT ( T ouvron et al. , 2021 ), Swin ( Liu et al. , 2021 ), T wins ( Chu et al. , 2021 )), hy- brid CNN-T ransformer architectures (Ef ficientFormer ( Li et al. , 2022 ), Ef ficientV it ( Cai et al. , 2023 ), MobileNetV4- H-M ( Qin et al. , 2024 ), SHV iT ( Y un & Ro , 2024 ), Faster - V iT ( Hatamizadeh et al. , 2024 )), and recent Mamba-based models (V im ( Zhu et al. , 2024 ), VMamba ( Liu et al. , 2024 ), Spatial-Mamba ( Xiao et al. , 2025 ), MambaV ision ( Hatamizadeh & Kautz , 2025 )). Note that some models in Fig. 1 have non-224 × 224 input resolution (see Appendix B . T able 1 provides a detailed comparison of models ev aluated at the standard 224 × 224 resolution. Analysis. T o analyze the ef fect of batch folding with peri- odic state reset , the speed of the SSM kernel part is mea- sured, as shown in Fig. 4 . A clear speedup of 110% to 180% is observed when the batch dimension is virtually shifted into the sequential dimension. This improv ement is especially significant when the sequential length is short. The reason lies in the CUDA parallel scan algorithm, which plays a crucial role in Mamba’ s speedup. This algorithm requires at least 32 threads per sequence, and when the sequence is short, the ov erhead of allocating 32 threads becomes substantial. By virtually e xtending the sequence length, we can utilize the allocated threads more efficiently , leading to a significant performance boost. T able 2. The computational speedup achiev ed by our method impl. opt. BFold B 1 con v img/s 6662 ✓ 6989 ✓ ✓ 1 ✓ 7601 ✓ ✓ 4 ✓ 7641 ✓ ✓ adaptiv e 7279 ✓ ✓ adaptiv e ✓ 7685 Next, we e valuate ho w much our proposed method can im- prov e the ov erall model speed, as sho wn in T able 2 . Our baseline is MambaV ision-T , and we measure the degree of speed improv ement from it. First, we improv e the im- plementation and observe a speedup, which we denote as impl. opt . This improvement primarily stems from the SSM CUD A kernel, which we rewrote based on the Mamba SSM 6 Submission and Formatting Instructions f or ICML 2026 CUD A kernel to suit our method. Building upon this, our batch folding with periodic state reset (BF old) technique achiev es a significant speedup. Furthermore, our adaptive B 1 approach, which adaptively adjusts B 1 according to input and weight sizes, enables further improvements in inference speed. Using our 1-D con volution compatible with batch-folded data mak es it unnecessary to repeatedly con vert the data back to the standard format, resulting in improv ed speed. Since MambaV ision is a hybrid model that combines Attention and Mamba, it goes without saying that it does not achieve the same le vel of speed improvement as described in Fig. 4 . Howe ver , it still deli vers significant performance gains compared to the baseline. T able 3. The ef fectiv eness of auxiliary token sw apping and its ablation results. swap aux. tok en discard timing IN1K ADE20K img/s 82.2 46.0 7645 learnable before attn 82.1 46.2 7613 ✓ learnable before attn 82.3 46.5 7585 ✓ data-dependent before attn 82.4 46.8 7602 ✓ data-dependent after 1st attn 82.5 47.2 7600 ✓ data-dependent after attn 82.4 46.6 7597 T able 3 presents an ablation study on auxiliary token swap- ping . The swapping improves performance with only a min- imal impact on inference speed. Simply adding learnable tokens without performing swapping degrades performance, indicating that the improvement does not come from the increased flexibility pro vided by the additional tokens, b ut rather from the bidirectional information flow enabled by swapping. Looking at Fig. 7 in the Appendix, we can clearly see that it indeed achieves substantial bi-directional infor- mation propagation. Initializing auxiliary tokens as globally av eraged data-dependent values pro ves more ef fective than employing a learnable token, which is commonly used as a class ( Dosovitskiy et al. , 2020 ; Zhu et al. , 2024 ). In addition, Initializing this token with global features may allo w sub- sequent layers to effecti vely acquire the global information needed for the next layer . As for where to discard this tok en, the most efficient approach is to remove it after the first attention layer . T able 4 demonstrates which scan method is most ef ficient. Here, we ev aluate with two macro-architectures. One is MambaV ision-T , and the other is an architecture in which all attention blocks in MambaV ision-T are replaced into Mamba blocks. The parallel bidirectional scan (bi-scan) requires twice the SSM computation cost due to its parallel nature, resulting in inefficient computation. Even in parallel bi-scan (cat), which halves the channel dimension to align MA Cs, the speed is slo w due to the tensor rearrangement cost. In contrast, the series bidirectional scan flips the tok en se- quence at each layer , with odd-numbered blocks scanning in the forward direction and even-numbered blocks scan- ning in the reverse direction. This design allows for the creation of global features without increasing the number of FLOPs. Howe ver , the accuracy improvement is not as sig- nificant as expected. W e hypothesize that DropOut ( Huang et al. , 2016 ), which is ef fective in pre venting ov erfitting and gradient v anishing, may not be compatible with the series bidirectional scan architecture, which has an asymmetric structure across layers. T o this end, Adventurer ( W ang et al. , 2025b ) style model does not achie ve high accurac y , although the introduced global av eraged token actually im- prov es from the normal series bi-scan setting. Also, the flipping operation needed for the bi-scan the block incurs the speed with an O ( n ) permutation cost. On the other hand, our auxiliary token swapping only swaps two tokens, minimizing the slo wdo wn while achieving com- parable or superior accuracy . The fact that the swapping improv es a lot from unidirectional scan with the Mamba only architecture indicates that it allows future-to-past token information flow with the swapping, thereby facilitating the creation of better features (See Fig. 7 in Appendix). W e also present the rob ustness of our proposed methods by applying them to V im ( Zhu et al. , 2024 ) macro-architecture in T able 11 in Appendix. 4.2. Semantic Segmentation 25 30 35 40 45 fps 45 46 47 48 49 50 mIoU (%) Swin F ocal MambaV ision SF -Mamba SF -Mamba F igur e 5. Throughput–accuracy trade-off on ADE20K. The x-axis denotes frames per second with batch size 1 setting (higher is better), and the y-axis sho ws mIoU (higher is better). SF-Mamba variants lie on the P areto front. Experimental Setup. W e ev aluate on ADE20K ( Zhou et al. , 2017 ) using UperNet ( Xiao et al. , 2018 ) as the segmenta- tion framework. This task requires assigning a semantic 7 Submission and Formatting Instructions f or ICML 2026 T able 4. Comparison of effectiv e scan designs. The “series bi-scan + gap token” follows Adventurer ( W ang et al. , 2025b ), where a global token obtained via global a verage pooling is used. In parallel bi-scan, ”cat” splits the input along channels, applies bi-scan, and concatenates the results, while ”add” duplicates the input, applies bi-scan, and sums the outputs. The ”V im block” indicates exact V im block is used instead of making MambaV ision block bi-directional. macro-arch. MambaV ision-T MambaV ision-T w/o Attention scan Params MA Cs img/s acc. Params MA Cs img/s acc. uni-scan 31.8M 4.4G 6979 82.2 29.4M 4.2G 6238 80.2 series bi-scan 31.8M 4.4G 6911 82.3 29.4M 4.2G 6113 80.4 series bi-scan+gap token (Adv enturer) 31.8M 4.5G 6856 82.3 29.4M 4.3G 6027 80.7 parallel bi-scan (cat) 31.8M 4.4G 6834 82.2 29.4M 4.2G 5987 80.8 parallel bi-scan (add) 31.9M 4.5G 6235 82.3 29.7M 4.3G 5138 81.1 parallel bi-scan (add) (V im block) 33.5M 4.6G 4612 82.4 32.8M 4.6G 3256 81.7 uni-scan + swap (ours) 31.8M 4.5G 6926 82.5 29.4M 4.3G 6171 81.0 uni-scan + swap (ours) + Bfold 31.8M 4.5G 7600 82.5 29.4M 4.3G 7306 81.0 class label to each pixel in the image across 150 cate gories. Models are trained with 512 × 512 crop resolution follo w- ing standard protocols ( Liu et al. , 2024 ; Xiao et al. , 2025 ). Performance is measured by mean Intersection ov er Union (mIoU) ( Csurka et al. , 2013 ). Results. Fig. 5 summarizes the semantic segmentation per- formance on ADE20K. Segmentation, unlike image clas- sification, requires both fine-grained pixel-le vel boundary detection and global structural understanding to accurately identify object classes. Therefore, enabling the Mamba block to incorporate future patch information through state swapping significantly improv es the accuracy compared to the baseline MambaV ision. During inference, the model processes images at a resolution of 512×2048, which dif- fers from the training resolution. T o accommodate this discrepancy , both Mamba and Attention are implemented to process per windowed region, where the window size matches the training image dimensions (see Appendix C.3 for details). Therefore, although the inference speed is mea- sured with a batch size of 1, the model still benefits from batch folding based on the number of windows, resulting in an improv ed speed. Our base size model is faster com- pared to the T iny versions of Swin and Focal T ransformer, while achieving o ver 4 points higher mIoU. The best trade- off of SF-Mamba among recent visual backbones indicates that the proposed auxiliary patch sw apping improv es both efficienc y and generalization capability , offering superior accuracy-cost trade-of f. The SF-Mamba ♣ configuration in T able 6 adopts more gran- ular windo w attention to reduce the quadratic computational cost of Attention by di viding the image into smaller win- dows. Meanwhile, we do not use a window size smaller than the training image size for the Mamba blocks to cap- ture global conte xt, resulting in better efficiency in terms of FLOPs as shown in 6 . Because windowing incurs a reshape ov erhead, the inference speed of SF-Mamba and SF-Mamba ♣ is comparable on an A100 GPU. Howe ver , in en vironments where FlashAttention2 cannot be used and the quadratic cost of Attention is directly incurred, SF-Mamba ♣ becomes particularly important. The nature of Mamba being not af fected by long tokens is the explicit merit of Mamba ov er Attention. More details can be found in Appendix D.6 . Furthermore, T able 12 in Appendix indicates that much larger input images benefit a lar ge speed gain in SF- Mamba ♣ configuration. 5. Conclusion In this paper , we rethink the recently ef fective visual Mamba approach from two perspectiv es. The first is an efficient scanning method for vision tasks. Previous studies have addressed the causality constraint of SSM by introducing multiple scan directions, b ut this comes with a significant drop in inference speed. T o ov ercome this, we propose auxiliary token sw apping, which enables future-to-past in- formation flow without sacrificing inference speed, thereby achieving ef ficient scanning. The second perspectiv e in ves- tigates why Mamba tends to be slow in image processing. W e identified the bottleneck and proposed batch folding, a method that virtually extends the sequence length while keeping the identical SSM output, resulting in faster pro- cessing without accurac y drop. SF-Mamba, a no vel Mamba- based frame work with these proposals, achie ves a superior accuracy-speed trade-of f compared to existing methods. Al- though the latter technique may not provide benefits dur- ing inference with batch size = 1, training typically uses batch size > 1, so the speed-up advantage is expected in most training scenarios. Moreov er , ev en with a batch size of 1, Mamba-based approaches–such as those employing local windows as in our se gmentation experiments or multi- directional scan–result in an effecti ve batch size lar ger than 1 for the SSM, thereby allo wing for performance acceleration. W e belie ve that this work will adv ance the dev elopment of efficient and ef fective image recognition models. 8 Submission and Formatting Instructions f or ICML 2026 References Bolya, D., Huang, P ., Sun, P ., Cho, J. H., Madotto, A., W ei, C., Ma, T ., Zhi, J., Rajasegaran, J., Rasheed, H., W ang, J., Monteiro, M., Xu, H., Dong, S., Ravi, N., Li, D., Doll ´ ar , P ., and Feichtenhofer , C. Perception encoder: The best visual embeddings are not at the output of the network. CoRR , abs/2504.13181, 2025. Cai, H., Li, J., Hu, M., Gan, C., and Han, S. Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In 2023 IEEE/CVF International Con- fer ence on Computer V ision (ICCV) , pp. 17256–17267, 2023. Cai, Z. and V asconcelos, N. Cascade r -cnn: High quality object detection and instance segmentation. IEEE T rans- actions on P attern Analysis and Machine Intelligence , pp. 1–1, 2019a. ISSN 1939-3539. doi: 10.1109/tpami.2019. 2956516. URL http://dx.doi.org/10.1109/ tpami.2019.2956516 . Cai, Z. and V asconcelos, N. Cascade r -cnn: High quality object detection and instance segmentation. IEEE trans- actions on pattern analysis and machine intelligence , 43 (5):1483–1498, 2019b. Chen, K., W ang, J., P ang, J., Cao, Y ., Xiong, Y ., Li, X., Sun, S., Feng, W ., Liu, Z., Xu, J., et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv pr eprint arXiv:1906.07155 , 2019. Chu, X., Tian, Z., W ang, Y ., Zhang, B., Ren, H., W ei, X., Xia, H., and Shen, C. T wins: Revisiting the design of spatial attention in vision transformers. In Advances in Neural Information Pr ocessing Systems , volume 34, pp. 9355–9366, 2021. Contributors, M. MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark. https:// github.com/open- mmlab/mmsegmentation , 2020. Csurka, G., Larlus, D., Perronnin, F ., and Me ylan, F . What is a good ev aluation measure for semantic se gmentation? Pr oceedings of the British Machine V ision Confer ence , pp. 32.1–32.11, 2013. Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V . Ran- daugment: Practical automated data augmentation with a reduced search space. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern recognition workshops , pp. 702–703, 2020. Dao, T . and Gu, A. Transformers are ssms: generalized models and ef ficient algorithms through structured state space duality . In Pr oceedings of the 41st International Confer ence on Machine Learning , ICML ’24. JMLR.or g, 2024. Deng, J., Dong, W ., Socher , R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern r ecognition , pp. 248–255. Ieee, 2009. Ding, X., Zhang, X., Han, J., and Ding, G. Scaling up your kernels to 31x31: Re visiting large kernel design in cnns. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pp. 11963–11975, June 2022. Dosovitskiy , A., Beyer , L., Kolesniko v , A., W eissenborn, D., Zhai, X., Unterthiner , T ., Dehghani, M., Minderer, M., Heigold, G., Gelly , S., et al. An image is worth 16x16 words: T ransformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2020. d’Ascoli, S., T ouvron, H., Leavitt, M. L., Morcos, A. S., Biroli, G., and Sagun, L. Con vit: Improving vision trans- formers with soft con volutional inducti ve biases. In Inter- national conference on machine learning , pp. 2286–2296. PMLR, 2021. Elfwing, S., Uchibe, E., and Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural networks , 107:3–11, 2018. Elharrouss, O., Himeur , Y ., Mahmood, Y ., Alrabaee, S., Ouamane, A., Bensaali, F ., Bechqito, Y ., and Chouchane, A. V its as backbones: Leveraging vision transformers for feature extraction. Inf. Fusion , 118:102951, 2025. Galim, K., Kang, W ., Zeng, Y ., Koo, H. I., and Lee, K. Parameter -efficient fine-tuning of state space models. In F orty-second International Conference on Machine Learning , 2025. Gu, A. and Dao, T . Mamba: Linear -time sequence modeling with selectiv e state spaces. arXiv pr eprint arXiv:2312.00752 , 2023. Hatamizadeh, A. and Kautz, J. Mambavision: A hybrid mamba-transformer vision backbone. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pp. 25261–25270, 2025. Hatamizadeh, A., Heinrich, G., Y in, H., T ao, A., Alvarez, J. M., Kautz, J., and Molchanov , P . Fastervit: Fast vision transformers with hierarchical attention. In International Confer ence on Learning Repr esentations (ICLR) , 2024. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learn- ing for image recognition. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pp. 770–778, 2016. 9 Submission and Formatting Instructions f or ICML 2026 He, K., Gkioxari, G., Doll ´ ar , P ., and Girshick, R. Mask r- cnn. In Pr oceedings of the IEEE international conference on computer vision , pp. 2961–2969, 2017. Huang, G., Sun, Y ., Liu, Z., Sedra, D., and W einberger , K. Q. Deep netw orks with stochastic depth. In Eur opean confer ence on computer vision , pp. 646–661. Springer , 2016. Khan, S. H., Naseer, M., Hayat, M., Zamir, S. W ., Khan, F . S., and Shah, M. T ransformers in vision: A surve y . A CM Comput. Surv . , 54(10s):200:1–200:41, 2022. Krizhevsk y , A., Sutske ver , I., and Hinton, G. E. Imagenet classification with deep con volutional neural networks. Advances in neural information pr ocessing systems , 25, 2012. Kwon, W ., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Y u, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for lar ge language model serving with pagedattention. In Pr oceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , 2023. Li, Y ., Y uan, G., W en, Y ., Hu, J., Ev angelidis, G., T ulyako v , S., W ang, Y ., and Ren, J. Efficientformer: V ision trans- formers at mobilenet speed. In Advances in Neural Infor- mation Pr ocessing Systems , volume 35, pp. 12934–12949, 2022. Lin, T .-Y ., Maire, M., Belongie, S., Hays, J., Perona, P ., Ra- manan, D., Doll ´ ar , P ., and Zitnick, C. L. Microsoft coco: Common objects in context. In Eur opean confer ence on computer vision , pp. 740–755. Springer , 2014. Liu, L., Zhang, M., Y in, J., Liu, T ., Ji, W ., Piao, Y ., and Lu, H. Defmamba: Deformable visual state space model. In Pr oceedings of the Computer V ision and P attern Recog- nition Confer ence , pp. 8838–8847, 2025. Liu, Y ., T ian, Y ., Zhao, Y ., Y u, H., Xie, L., W ang, Y ., Y e, Q., Jiao, J., and Liu, Y . Vmamba: V isual state space model. In NeurIPS , 2024. Liu, Z., Lin, Y ., Cao, Y ., Hu, H., W ei, Y ., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pp. 10012–10022, 2021. Liu, Z., Mao, H., W u, C.-Y ., Feichtenhofer , C., Darrell, T ., and Xie, S. A con vnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 11976–11986, 2022. Long, J., Shelhamer , E., and Darrell, T . Fully conv olutional networks for semantic se gmentation. In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , pp. 3431–3440, 2015. Luo, W ., Li, Y ., Urtasun, R., and Zemel, R. Understanding the ef fectiv e receptiv e field in deep con volutional neural networks. Advances in neural information pr ocessing systems , 29, 2016. NVIDIA. cub::warpscan — cub 2.5 documenta- tion. https://wmaxey.github.io/cccl/cub/ api/classcub_1_1WarpScan.html , 2025a. Ac- cessed: 2025-09-15. NVIDIA. T ensorrt llm. https://github.com/ NVIDIA/TensorRT- LLM , 2025b. Accessed: 2025- 11-27. Oquab, M., Darcet, T ., Moutakanni, T ., V o, H., Szafraniec, M., Khalido v , V ., Fernandez, P ., Haziza, D., Massa, F ., El- Nouby , A., et al. Dinov2: Learning robust visual features without supervision. T ransactions on Machine Learning Resear ch Journal , 2024. Pei, X., Huang, T ., and Xu, C. Efficientvmamba: Atrous selectiv e scan for light weight visual mamba. In AAAI , pp. 6443–6451. AAAI Press, 2025. Qin, D., Leichner , C., Delakis, M., Fornoni, M., Luo, S., Y ang, F ., W ang, W ., Banbury , C. R., Y e, C., Akin, B., Aggarwal, V ., Zhu, T ., Moro, D., and How ard, A. G. Mobilenetv4: Uni versal models for the mobile ecosys- tem. In Computer V ision - ECCV 2024 - 18th Eur opean Confer ence, Milan, Italy , September 29-October 4, 2024, Pr oceedings, P art XL . Springer , 2024. Radosav ovic, I., K osaraju, R. P ., Girshick, R., He, K., and Doll’ar , P . Designing network design spaces. In CVPR , 2020. Ravi, N., Gabeur , V ., Hu, Y ., Hu, R., Ryali, C., Ma, T ., Khedr , H., R ¨ adle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K. V ., Carion, N., W u, C., Girshick, R. B., Doll ´ ar , P ., and Feichtenhofer , C. SAM 2: Segment anything in images and videos. In ICLR . OpenRevie w .net, 2025. Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn: T o wards real-time object detection with re gion proposal networks. Advances in neural information pr ocessing systems , 28, 2015. Shaker , A., W asim, S. T ., Khan, S., Gall, J., and Khan, F . S. Groupmamba: Efficient group-based visual state space model. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pp. 14912–14922, 2025. Shi, Y ., Dong, M., and Xu, C. Multi-scale vmamba: Hier- archy in hierarchy visual state space model. Advances in Neural Information Pr ocessing Systems , 37:25687– 25708, 2024. 10 Submission and Formatting Instructions f or ICML 2026 Simonyan, K. and Zisserman, A. V ery deep conv olu- tional networks for lar ge-scale image recognition. arXiv pr eprint arXiv:1409.1556 , 2014. Sim ´ eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F ., Oquab, M., Jose, C., Khalidov , V ., Szafraniec, M., Y i, S., Rama- monjisoa, M., Massa, F ., Haziza, D., W ehrstedt, L., W ang, J., Darcet, T ., Moutakanni, T ., Sentana, L., Roberts, C., V edaldi, A., T olan, J., Brandt, J., Couprie, C., Mairal, J., J ´ egou, H., Labatut, P ., and Bojanowski, P . Dinov3, 2025. URL . T ouvron, H., Cord, M., Douze, M., Massa, F ., Sablayrolles, A., and J ´ egou, H. Training data-efficient image transform- ers & distillation through attention. In ICML , volume 139, 2021. Tschannen, M., Gritsenko, A., W ang, X., Naeem, M. F ., Alabdulmohsin, I., Parthasarathy , N., Evans, T ., Beyer , L., Xia, Y ., Mustafa, B., et al. Siglip 2: Multilingual vision-language encoders with improved semantic under - standing, localization, and dense features. arXiv pr eprint arXiv:2502.14786 , 2025. V aswani, A., Shazeer , N., Parmar , N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser , Ł ., and Polosukhin, I. At- tention is all you need. Advances in neural information pr ocessing systems , 30, 2017. W ang, F ., W ang, J., Ren, S., W ei, G., Mei, J., Shao, W ., Zhou, Y ., Y uille, A., and Xie, C. Mamba-reg: V ision mamba also needs registers. In Pr oceedings of the Com- puter V ision and P attern Recognition Conference , pp. 14944–14953, 2025a. W ang, F ., Y ang, T ., Y u, Y ., Ren, S., W ei, G., W ang, A., Shao, W ., Zhou, Y ., Y uille, A., and Xie, C. Adventurer: Optimizing vision mamba architecture designs for ef fi- ciency . In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pp. 30157–30166, June 2025b. W ang, W ., W ang, Z., Suzuki, H., and K obayashi, Y . See- ing is understanding: Unlocking causal attention into modality-mutual attention for multimodal llms. CoRR , abs/2503.02597, 2025c. W ei, L. H. Mamba ssm cross-platform accelera- tion: Cuda & metal s6 kernel for jetson and ap- ple silicon. https://github.com/s990093/ Mamba- Orin- Nano- Custom- S6- CUDA , 2025. Ac- cessed: 2025-11-27. Xiao, C., Li, M., Zhang, Z., Meng, D., and Zhang, L. Spatial- mamba: Effecti ve visual state space models via structure- aw are state fusion. In International Confer ence on Learn- ing Repr esentations (ICLR) , 2025. Xiao, T ., Liu, Y ., Zhou, B., Jiang, Y ., and Sun, J. Unified per - ceptual parsing for scene understanding. In Pr oceedings of the Eur opean conference on computer vision (ECCV) , pp. 418–434, 2018. Y ang, J., Li, C., Zhang, P ., Dai, X., Xiao, B., Y uan, L., and Gao, J. Focal attention for long-range interactions in vision transformers. In Advances in Neural Information Pr ocessing Systems , volume 34, pp. 30008–30022, 2021. Y oshimura, M., Hayashi, T ., and Maeda, Y . Mambapeft: Exploring parameter-ef ficient fine-tuning for mamba. In The Thirteenth International Conference on Learning Repr esentations , 2025. Y ou, Y ., Li, J., Reddi, S., Hseu, J., Kumar , S., Bhojanapalli, S., Song, X., Demmel, J., K eutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv pr eprint arXiv:1904.00962 , 2019. Y u, W . and W ang, X. Mambaout: Do we really need mamba for vision? In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pp. 4484–4496, June 2025. Y un, S. and Ro, Y . Shvit: Single-head vision transformer with memory efficient macro design. In 2024 IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2024. Zheng, C. iformer: Integrating con vnet and transformer for mobile application. In The Thirteenth International Confer ence on Learning Repr esentations , 2025. Zhou, B., Zhao, H., Puig, X., Fidler , S., Barriuso, A., and T orralba, A. Scene parsing through ade20k dataset. In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , pp. 633–641, 2017. Zhu, L., Liao, B., Zhang, Q., W ang, X., Liu, W ., and W ang, X. V ision mamba: Efficient visual representation learning with bidirectional state space model. In ICML . OpenRe- view .net, 2024. 11 Submission and Formatting Instructions f or ICML 2026 A. Impact Statement Our work aims to improv e the computational ef ficiency of state-space models for vision tasks, which has potential benefits for both large-scale and resource-constrained deployment scenarios. The proposed swapping and batch-folding mechanisms offer improved throughput at lo w resolution and ultra-high resolution (See T able 12 ). This may reduce training and inference costs in high-resolution applications such as medical imaging, aerial monitoring, and robotics. Although we were unable to include e valuations on edge GPUs or mobile hardware in this submission, prior studies ( W ei , 2025 ; NVIDIA , 2025b ) ha ve sho wn that Mamba kernels can be deplo yed on devices such as NVIDIA Jetson and iOS through optimized runtimes (e.g., T ensorR T , mobile accelerators). Our method should be adaptable to these platforms since the same selecti ve scan is used in our core algorithm. Enabling ef ficient state-space model inference on edge de vices may broaden access to low-po wer real-time vision systems, but also calls for careful consideration of responsible deployment in safety-critical or priv acy-sensitiv e contexts. B. Experimental Setup Details B.1. Image Classification W e train our SF-Mamba v ariants (T iny/Small/Base) on the ImageNet-1K dataset ( Deng et al. , 2009 ), which contains 1.28M training images and 50K v alidation images across 1,000 categories. F ollowing the protocol of MambaV ision ( Hatamizadeh & Kautz , 2025 ), we adopt standard data augmentation (RandAugment, Mixup, CutMix) and re gularization (Label Smoothing, Stochastic Depth). The detailed hyperparameter settings are summarized in T able 5 . T able 5. T raining configurations for SF-Mamba variants on ImageNet-1K. All models are trained for 300 epochs following the MambaV ision configuration ( Hatamizadeh & Kautz , 2025 ). Configuration SF-Mamba-T SF-Mamba-S SF-Mamba-B Optimizer LAMB ( Y ou et al. , 2019 ) LAMB LAMB Base learning rate 5e-3 5e-3 5e-3 Learning rate schedule Cosine Cosine Cosine W armup epochs 20 20 35 W armup learning rate 1e-6 1e-6 1e-6 Minimum learning rate 5e-6 5e-6 5e-6 W eight decay 0.05 0.05 0.075 Optimizer momentum ( β 1 ) 0.9 0.9 0.9 Optimizer momentum ( β 2 ) 0.999 0.999 0.999 Optimizer epsilon 1e-8 1e-8 1e-8 Gradient clipping (norm) 5.0 5.0 5.0 T otal epochs 300 300 300 Batch size (total) 4,096 4,096 4,096 Input resolution 224 × 224 224 × 224 224 × 224 Mixup alpha 0.8 0.8 0.8 CutMix alpha 1.0 1.0 1.0 RandAug ( Cubuk et al. , 2020 ) rand-m9-mstd0.5 rand-m9-mstd0.5 rand-m9-mstd0.5 Label smoothing 0.1 0.1 0.1 Random erasing prob . 0.25 0.25 0.25 Model EMA ✓ ✓ ✓ EMA decay 0.9998 0.9998 0.9998 Mixed precision (AMP) ✓ ✓ ✓ B.2. Object Detection and Instance Segmentation For MS COCO ( Lin et al. , 2014 ), we use Cascade Mask R-CNN ( Cai & V asconcelos , 2019b ) implemented in MMDetection ( Chen et al. , 2019 ). All backbones are initialized from ImageNet-1K pre-training. W e use AdamW as the optimizer and adopt the commonly used 3 × training schedule. The batch size is 16. Further details follo w MambaV ision ( Hatamizadeh & 12 Submission and Formatting Instructions f or ICML 2026 Kautz , 2025 ). B.3. Semantic Segmentation For ADE20K ( Zhou et al. , 2017 ), we use UperNet ( Xiao et al. , 2018 ) implemented in MMSegmentation ( Contributors , 2020 ). Backbones are initialized with ImageNet-1K pre-training. W e use AdamW as the optimizer with batch size 16. A polynomial learning rate decay schedule is applied, consistent with MambaV ision ( Hatamizadeh & Kautz , 2025 ). B.4. Throughput Measur ement W e measure throughput on an NVIDIA A100 40GB GPU with a batch size of 128 and input images of size 224 × 224 using automatic mixed precision, follo wing established protocols ( Hatamizadeh et al. , 2024 ; Hatamizadeh & Kautz , 2025 ). Note that some models in Fig. 1 hav e non-224×224 input resolution following the original setup ( e.g. MobileNetV4-H-M ( Qin et al. , 2024 ): 256 × 256, MobileNetV4-H-L: 384 × 384, EfficientV iT -B2(r256) ( Cai et al. , 2023 ): 256 × 256, EfficientV iT - B3(r288): 288 × 288, SHV iT ( Y un & Ro , 2024 ): 384 × 384). Our software en vironment consists of CUDA 12.4, cuDNN 9, and PyT orch 2.6.0. T o ensure a fair comparison, we measure the throughput of all pre vious methods under the same experimental settings. W e report the speed of the f aster memory format between channel last and channel first. The reported throughput values are the medians o ver 500 inference runs, and for ours-T , the variation across 10 trials w as 7600 ± 11. C. Implementation Details C.1. Macro-Ar chitecture MambaV ision ( Hatamizadeh & Kautz , 2025 ) combining Attention and Mamba, is a state-of-the-art model as a macro-le vel structure for vision tasks, excelling in speed, performance, and scalability . Therefore, our macro-architecture follows MambaV ision with a four-stage hierarchical design. Giv en an input image I ∈ R H × W × 3 , the stem and successi ve stages transform the resolution and channel dimension as follows: Stage 1: I Stem + Con vBlock × N 1 − − − − − − − − − − − − − → H 4 × W 4 × D , Stage 2: H 4 × W 4 × D Downsample + Con vBlock × N 2 − − − − − − − − − − − − − − − − − → H 8 × W 8 × 2 D , Stage 3: H 8 × W 8 × 2 D Downsample + MambaBloc k × N 3 / 2 + AttenBloc k × N 3 / 2 − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − → H 16 × W 16 × 4 D , Stage 4: H 16 × W 16 × 4 D Downsample + MambaBloc k × N 4 / 2 + AttenBloc k × N 4 / 2 − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − − → H 32 × W 32 × 8 D , Classifier: H 32 × W 32 × 8 D Global A vgPool + Linear − − − − − − − − − − − − − → R # classes . (6) where N i denotes the number of blocks to apply sequentially . In Stage 3 and 4, N i Mamba Blocks are applied followed by N i Attention Blocks. The Mamba Block consists of a MambaV ision Mixer and an MLP . The MambaV ision Mixer tak es input as a patch sequence X in ∈ R B × T × D and processes it through two parallel branches: a selecti ve SSM and a local con volutional path. Formally , X 1 = SSM σ (Conv(Linear D → D ( X in ))) , X 2 = σ (Conv(Linear D → D ( X in ))) , Y = Linear 2 D → D (Concat( X 1 , X 2 )) . (7) Here, σ is a SiLU activ ation ( Elfwing et al. , 2018 ), Con v is a 1-D depthwise con volution, and SSM( · ) denotes the SSM with selectiv e scan h t = A t h t − 1 + B t x t , y t = C t h t . The two paths are fused and projected back to dimension D , yielding the output Y . Unlike many visual Mamba methods ( Liu et al. , 2024 ; W ang et al. , 2025a ), the MambaV ision Mixer accelerates processing by adopting a simple unidirectional scan. Ho wev er , due to the causality constraint , it cannot reference future patches from past ones, so future-to-past information flow relies on subsequent Attention blocks. C.2. Implementation Optimization for F aster Inference As indicated by “impl. opt” in T ab . 2 , we apply sev eral implementation lev el optimizations not written in the method section to accelerate inference. The details of these implementation optimizations are listed below: • Removal of unused row-dimension chunking in the Mamba SSM kernel : As with VMamba ( Liu et al. , 2024 ), 13 Submission and Formatting Instructions f or ICML 2026 we remove the unused ro w (channel) dimension chunking feature from the Mamba SSM kernel. This allo ws more intermediate variables to be handled as float v alues rather than float arrays, resulting in improved speed. • Suppressing hidden state output during inference : The Mamba SSM k ernel is modified so that it does not output hidden states except during training. Since hidden states are only needed for backpropag ation, av oiding their output during inference reduces unnecessary memory write time. • Replacing linear layers with pointwise 1D Con volution : As with VMamba, we replace the linear layer that output the ∆ t tensor with pointwise 1D con volutions. This reduces unnecessary tensor rearrangement. • A uxiliary token swapping with a T riton CUDA ker nel : Although the computational cost of the swapping is not significant, swapping data at non-contiguous positions is needed, especially with the batch folded data. Con verting this process to a T riton CUD A kernel improves throughput slightly by about 40 img/s for ours-T and about 10 imag/s for ours-B, although we can use none-T riton swapping for simplicity . C.3. Segmentation and Object Detection In image classification, we followed the MambaV ision meta-architecture. Howe ver , for object detection and instance segmentation on the COCO dataset ( Lin et al. , 2014 ), and semantic segmentation on ADE20K ( Zhou et al. , 2017 ), we make some modifications. The reason is that processing high-resolution images with Attention incurs significant computational cost. Based on our analysis, it appears that MambaV ision mistak enly omits the computational cost of Attention in terms of FLOPs for the COCO and ADE20K tasks. Therefore, the FLOPs values for MambaV ision in our table dif fer from those reported in the original paper . T o address this, we made two improv ements to create a more lightweight model architecture. The first is to remove excessiv e padding regions. In MambaV ision, large padding areas are added in both the Mamba Block and the Attention Block to serve as additional computation regions, thereby impro ving accuracy . Although it leads to a degradation in accurac y , we reduce computational cost by removing these e xtra padding regions and lo wering the resolution in Stage 3 and Stage 4 (e.g. Stage 3: 112 × 112 to 84 × 84, Stage 4: 56 × 56 to 42 × 42 for COCO). The second impro vement is the use of windo wed Attention. Since Attention has a quadratic cost with respect to tok en length, we reduce computational cost by applying local windowed Attention to Stage 3, which has a long sequence length. This also results in a slight drop in performance. After applying these changes, our model architecture is as follows: The stem layer , Stage 1, and Stage 2 are con volution- based and process the input image directly . Stage 3 processes features padded to a resolution of 84 × 84 for COCO and 64 × 64 for ADE20K. Stage 4 processes images at 42 × 42 for COCO and 32 × 32 for ADE20K. Padding is necessary because these tasks require handling images with v arious aspect ratios and resolutions. For task-specific decoders–Cascade Mask RCNN ( Cai & V asconcelos , 2019a ) (for COCO) and UperNet ( Xiao et al. , 2018 ) (for ADE20K)–the padding re gions are remov ed before input. When using windowed Attention, the window size in Stage 3 is set to 42 × 42 for COCO and 32 × 32 for ADE20K. During training on ADE20K, the model is trained with an input resolution of 512 × 512, whereas during ev aluation it needs to process resolutions up to 2048×512. Therefore, in Stage 3 and Stage 4 during the ev aluation, both the Mamba and Attention blocks handle feature maps lar ger than 64 × 64 or 32 × 32 by dividing them into windo wed patches for processing. D. Additional Experiments D.1. Pr eliminary Evaluation on Multi-dir ectional Scan Cost W e measure how much e xisting multi-directional scan methods affect throughput. As representati ve examples of multi- directional scan, we experiment with bi-directional scan ( Zhu et al. , 2024 ) and cross-scan ( Liu et al. , 2024 ), which are commonly used as the basis for man y scanning methods ( W ang et al. , 2025a ; Shi et al. , 2024 ; Pei et al. , 2025 ). T o accurately identify the causes of performance de gradation, we conduct the follo wing three simple experiments. The first e xperiment measures the throughput using the original model structure as proposed, which includes multi-directional scan. The second experiment measures the throughput of a model whose scan directions are replaced with forward-only scans. The last experiment measures the throughput of a model where all non-forw ard scan directions are remo ved from the original model. The difference between the first and second e xperiments reflects the time spent on reordering tokens, which is required by 14 Submission and Formatting Instructions f or ICML 2026 multi-directional scans. The difference between the second and third e xperiments indicates the time cost of performing scans in parallel. Fig. 6 sho ws ho w much of the total inference time is occupied by these components. Surprisingly , we found that tok en reordering, which is not reflected in FLOPs, accounts for 5–8% of the total processing time in models using multi-directional scan. Furthermore, performing parallel multi-directional scans consumes an additional 28–42% of processing time, which means that the accuracy gains of multi-directional scan must outweigh this cost. In the case of VMamba, the time spent rearranging the data between 2D and 1D formats is additionally hidden under the ”others” category . Our method is also included in the table as a reference. Direct comparison is dif ficult since our model uses Attention too and the proportion of Mamba blocks is relativ ely small. Howe ver , auxiliary token swapping in our method results in negligible processing time. As a result, in addition to the effecti veness of batch folding, our model is significantly faster , although all three models hav e nearly identical FLOPs. 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 ours-T (4.6GFLOPs) V im-S (5.3G FLOPs) VMamba-T (4.9 GFLOPs) 42.3% 28.0% 0.9% 5.4% 7.8% inference time [ms/img] token reordering for scan parallel path others F igur e 6. Computational cost of multi-directional scan. This includes the time required to reorder tokens for scanning from multiple directions, and the additional processing time incurred by setting up parallel paths. D.2. Effecti ve Receptive Field Analysis T o better understand ho w our model captures spatial dependencies, we conduct an Effecti ve Recepti ve Field (ERF) analysis ( Luo et al. , 2016 ; Ding et al. , 2022 ) follo wing the methodology of Liu et al. ( 2024 ). The ERF is computed by measuring the squared gradient of the output features with respect to the center pix el, which highlights the regions most influential for each prediction. Fig. 7 sho ws the ERF corresponding to the layers up to the Stage 3 Mamba blocks of tiny sized models. So, the ERF for only Con volution and two Mamba blocks is sho wn. MambaV ision uses a simple unidirectional scan, which prev ents it from accessing future tokens (i.e., the lower part of the image) beyond what can be captured by con volution. In contrast, SF-Mamba lev erages auxiliary token swapping, allowing it to account for both past and future tokens with similar strength. Since the information propagation of auxiliary token swapping follo ws the mechanism of SSM, it can be effecti vely achiev ed with only two tokens. Fig. 8 compares the ERFs of entire models. SF-Mamba lev erages auxiliary patch swapping to facilitate a global recepti ve field while maintaining high throughput. Unlike attention-based architectures whose cost scales quadratically with the sequence length, SF-Mamba a voids this ov erhead thanks to its state-space formulation. This demonstrates that SF-Mamba achiev es global context modeling with improved computational ef ficiency . D.3. Detailed Ev aluation in Semantic Segmentation T ab . 6 presents the detailed e valuation results for semantic segmentation shown in 5 . Comparing SF-Mamba and SF- Mamba ♣ , the use of windo w attention significantly reduces the FLOPs of SF-Mamba ♣ . The inference speed, howe ver , does not change much because ev en with long token sequences, FlashAttention2 provides considerable acceleration, which offsets the additional time required for reshaping operations introduced by windo w attention. On older GPUs such as the V100, where FlashAttention2 is not av ailable, SF-Mamba ♣ runs faster . 15 Submission and Formatting Instructions f or ICML 2026 before train after train MambaV ision-T ours-T F igure 7. Ef fectiv e Recepti ve Field (ERF) comparison. This ERF corresponds to the layers up to the Stage 3 Mamba blocks. MambaV ision uses a simple unidirectional scan, which pre vents it from accessing future tokens (i.e., the lo wer part of the image) beyond what can be captured by con volution. In contrast, SF-Mamba le verages auxiliary tok en swapping, allo wing it to account for both past and future tokens with similar strength. Since the auxiliary token swapping information propagation follo ws the mechanism of SSM, it can be ef fectively achiev ed with just two tokens. ResNet50 Swin-T Deit-S Vmamba-T MambaV ision-T ours-T before train after train F igure 8. Ef fective Recepti ve Field (ERF) comparison of the entire model. SF-Mamba achie ves globally distributed ERFs with reduced computational complexity . T able 6. Semantic segmentation performance on ADE20K dataset using UperNet. W e compare with Swin Transformer ( Liu et al. , 2021 ), Focal T ransformer ( Y ang et al. , 2021 ), and MambaV ision ( Hatamizadeh & Kautz , 2025 ). All models are trained at a resolution of 512 × 512 while FLOPs are calculated with an input size of 2048 × 512. Frames per second (FPS) are measured with a batch size of 1. SF-Mamba ♣ uses a windowed attention to sa ve computational cost. T iny-size Small-size Base-size Backbone Para FLOPs mIoU fps Para FLOPs mIoU fps Para FLOPs mIoU fps Swin 60M 945G 44.5 40.0 81M 1038G 47.6 25.7 121M 1188G 48.1 25.4 Focal 62M 998G 45.8 38.9 85M 1130G 48.0 24.0 126M 1354G 49.0 23.4 MambaV ision 62M 1085G 46.0 45.0 81M 1166G 48.2 40.9 130M 1520G 49.1 37.3 SF-Mamba 62M 1085G 47.2 47.9 81M 1166G 48.5 45.4 130M 1520G 50.1 42.6 SF-Mamba ♣ 62M 950G 46.5 48.7 81M 1014G 48.1 47.3 130M 1180G 49.1 42.7 16 Submission and Formatting Instructions f or ICML 2026 D.4. Object Detection and Instance Segmentation T able 7. Object detection and instance segmentation performance on MS COCO dataset using Cascade Mask R-CNN. All models are trained with 3 × schedule at 1280 × 800 resolution. W e compare with ConvNeXt ( Liu et al. , 2022 ), Swin T ransformer ( Liu et al. , 2021 ), and MambaV ision ( Hatamizadeh & Kautz , 2025 ). SF-Mamba ♣ uses a windowed Attention (no window for Mamba blocks) to sav e computational cost. Backbone Params FLOPs fps AP b AP b 50 AP b 75 AP m AP m 50 AP m 75 Swin-T 86M 745G 26.3 50.4 69.2 54.7 43.7 66.6 47.3 Con vNeXt-T 86M 741G 32.1 50.4 69.1 54.8 43.7 66.5 47.3 MambaV ision-T 89M 1118G 19.4 51.1 70.0 55.6 44.3 67.3 47.9 SF-Mamba-T 89M 741G 27.8 51.0 69.9 55.3 44.2 67.1 48.0 SF-Mamba ♣ -T 89M 659G 28.3 50.9 69.9 55.0 44.1 66.9 47.7 Swin-S 107M 838G 18.7 51.9 70.7 56.3 45.0 68.2 48.8 Con vNeXt-S 108M 827G 28.0 51.9 70.8 56.5 45.0 68.4 49.1 MambaV ision-S 107M 1192G 20.5 52.3 71.1 56.7 45.2 68.5 48.9 SF-Mamba-S 107M 817G 28.7 52.4 71.1 56.7 45.4 68.5 49.1 SF-Mamba ♣ -S 107M 731G 28.8 52.1 71.0 56.4 45.2 68.4 48.8 Swin-B 145M 982G 18.6 51.9 70.5 56.4 45.0 68.1 48.9 Con vNeXt-B 146M 964G 26.0 52.7 71.3 57.2 45.6 68.9 49.5 MambaV ision-B 155M 3000G 16.4 52.8 71.3 57.2 45.7 68.7 49.4 SF-Mamba-B 155M 1185G 26.8 52.8 71.3 57.2 45.8 68.9 49.4 SF-Mamba ♣ -B 155M 992G 27.6 52.6 71.3 57.2 45.7 69.0 49.2 Experimental Setup. W e ev aluate on MS COCO 2017 ( Lin et al. , 2014 ) using Cascade Mask R-CNN ( Cai & V asconcelos , 2019a ) as the detection framew ork. The task in volv es localizing objects with bounding boxes (detection) and predicting pix el- lev el masks for each instance (segmentation). W e follow the standard 3 × training schedule. W e report both bounding-box av erage precision (AP) and mask AP metrics following the COCO e valuation protocol ( Lin et al. , 2014 ). Results. T ab . 7 presents the object detection and instance se gmentation results on MS COCO. Our approach again achiev es improv ements in both accuracy and efficienc y o ver the baseline and also outperforms the Swin and F ocal T ransformer, indicating its general applicability . As discussed in Appendix D.6 , by removing the e xtensiv e padding region used in the baseline and replacing global attention with window-based attention, we achie ve substantial ef ficiency gains at the expense of some accuracy . For example, SF-Mamba ♣ -S, utilizing window Attention to sa ve computational cost, has smaller FLOPs than the tiny size models while achieving 1.0 and 0.9 points higher AP b and AP m . Thanks to the introduction of state swapping, we attain performance comparable to or e ven surpassing the baseline. The clear improv ement ov er the existing methods can be seen in Fig. 9 (a). D.5. Object Detection and Instance Segmentation with Other Detection Heads Experimental Setup. T o ev aluate the generality of our method on downstream tasks and compare it with other e xisting image encoders, we also perform experiments on the COCO dataset ( Lin et al. , 2014 ) using Faster R-CNN ( Ren et al. , 2015 ) and Mask R-CNN ( He et al. , 2017 ) detection heads. Follo wing prior work ( Radosav ovic et al. , 2020 ; Liu et al. , 2024 ), we train all models with the 1× schedule (12 epochs). The baselines we compare are RegNetX ( Radosav ovic et al. , 2020 ), VMamba ( Liu et al. , 2024 ), and MambaV ision ( Hatamizadeh & Kautz , 2025 ). For MambaV ision, we disable excessi ve padding and instead use the same minimal padding strate gy as our method to compare with a comparable computational cost. Results. W e first present the Faster R-CNN results in T able 8 . Under the aligned experimental settings and matched computational cost, our method achiev es a substantial performance improvement ov er MambaV ision. The results with Mask-RCNN is sho wn in T able 9 and Fig. 9 , sho wing consistent accuracy and speed impro vements o ver our baseline again. Although our method is weaker in accuracy compared to VMamba within the same categories (T , S, or B), when comparing VMamba- T and SF-Mamba- B , SF-Mamba-B surpasses VMamba-T in both speed and accuracy , clearly demonstrating a superior performance–throughput trade-off. The Fig. 9 (b) should be easy to understand the trade-of f. 17 Submission and Formatting Instructions f or ICML 2026 16 18 20 22 24 26 28 30 32 fps 50.5 51.0 51.5 52.0 52.5 53.0 A P b ( % ) Swin ConvNeXt MambaV ision SF -Mamba SF -Mamba 20 25 30 35 40 fps 43 44 45 46 47 48 49 A P b ( % ) VMamba MambaV ision SF -Mamba (a) (b) F igure 9. Accuracy-speed trade-of f on MS COCO using (a) Casecade Mask-RCNN ( Cai & V asconcelos , 2019b ) and (b) Mask R-CNN ( He et al. , 2017 ). Casecade Mask-RCNN is trained with the 3x schedule while Mask-RCNN is trained with the 1x schedule. In MambaV ision and in our model built on its macro-architecture, the tin y and small variants sho w a rev ersal in speed. This is because the tin y model has three Attention layers in stage 3 and two in stage 4, whereas the small model has two Attention layers in stage 3 and three in stage 4. When high-resolution images are used as input, Attention computation becomes the bottleneck. Consequently , ev en though the tiny model has fewer parameters, its throughput becomes lo wer due to the larger number of Attention layers in stage 3. T able 8. Detection on COCO dataset using Faster R-CNN. The models are trained with 1x schedule (12 epoch). Backbone AP box fps RegNetX-3.2GF 39.9 31.6 MambaV ision-T 42.4 37.2 SF-Mamba-T 43.2 41.7 MambaV ision-S 43.9 37.2 SF-Mamba-S 44.9 40.8 MambaV ision-B 46.2 30.0 SF-Mamba-B 47.6 34.8 T able 9. Detection and instance segmentation on COCO dataset using Mask R-CNN. The models are trained with 1x schedule (12 epoch). Backbone AP box AP mask FPS VMamba-T 47.3 42.7 29.9 MambaV ision-T 43.1 40.0 35.5 SF-Mamba-T 43.8 40.3 40.9 VMamba-S 48.7 43.7 23.3 MambaV ision-S 44.4 41.0 33.4 SF-Mamba-S 45.3 41.5 41.0 VMamba-B 49.2 44.1 20.0 MambaV ision-B 46.7 42.8 29.8 SF-Mamba-B 47.8 43.5 34.6 18 Submission and Formatting Instructions f or ICML 2026 D.6. Ev aluation of Excessive Padding and W indowed Attention in Segmentation and Detection T asks T able 10. The impact of excessiv e padding regions and the use of windowed Attention in terms of computational cost and accuracy . W ith the excessi ve padding setting, Stage 3 uses large padding sizes — 112 × 112 for COCO and 64 × 64 for ADE20K. In contrast, the w/o pad configuration minimizes padding to match the training image sizes, resulting in 84 × 84 for COCO and 32 × 32 for ADE20K. Regarding local windo ws: A3 refers to the windo wed Attention in Stage 3 and M3 refers to the windo wed Mamba in Stage 3. The configurations used for our models, SF-Mamba and SF-Mamba ♣ , are highlighted. For ADE20K, since lar ge images are processed during testing, we retain the large padding. number of window ADE20K COCO arch. w/o pad A3 A4 M3 M4 FLOPs mIoU FLOPs mAP b mAP m w/o swap 1085G 46.0 1118G 50.9 44.1 w/ swap 1085G 47.2 1118G 51.2 44.5 w/ swap ✓ 950G 45.8 741G 51.0 44.2 w/ swap 4 950G 46.2 741G 50.9 44.0 w/ swap ✓ 4 942G 45.6 736G 50.9 44.0 w/ swap ✓ 4 4 941G 45.6 649G 50.5 44.0 w/ swap ✓ 4 4 4 4 941G 45.4 649G 50.3 43.9 As outlined in Appendix C.3 , T ab . 10 presents an ablation study on the impact of excessiv e padding re gions and the use of windo wed Attention in terms of computational cost and accurac y . Introducing excessi ve padding enables the model to utilize additional spatial regions for additional computational area, which leads to a modest accuracy gain. Ho wev er , due to the quadratic scaling of Attention with respect to token length, this improvement comes at a substantial computational cost. W e further examine the ef fect of applying Attention or Mamba within local windo ws. This consistently resulted in accurac y degradation, suggesting that both mechanisms are effecti ve in capturing long-range dependencies. It is an advantage over con volutional approaches. Despite the drop in accuracy , windowed Attention significantly reduces computational ov erhead. In contrast, Mamba maintains linear complexity with respect to sequence length, which means that windowing does not reduce its computational cost. Based on these findings, our SF-Mamba ♣ applies windowing exclusi vely to Attention, while utilizing Mamba for global modeling. Since windowed Attention restricts complete future-to-past token information flow , our auxiliary token swapping mechanism plays a critical role in enabling bidirectional context propagation. For high-resolution inputs, the benefits of Mamba over Attention become e ven more pronounced. This indicates that increasing the use of Mamba may further enhance performance in high-resolution segmentation and detection tasks. D.7. A pplicability to other Vision Mamba V ariants Our two core contrib utions—auxiliary patch swapping and batch folding with periodic reset—can be integrated into other visual Mamba variants. T o demonstrate this, we add experiments on V im ( Zhu et al. , 2024 ) architecture as shown in T able 11 . When we remove the modules responsible for the in verse-direction scan in the V im-S architecture and mak e the model uni- directional, the accuracy drops, but the speed impro ves significantly . By introducing the proposed auxiliary tok en swapping, we can recover most of the lost accurac y while preserving the improv ed speed. Furthermore, unlike the MambaV ision macro-architecture, V im makes extensi ve use of Mamba blocks, which allows our batch folding to yield a substantial speed improv ement. The resulting model achiev es a speed similar to V im-T but with substantially better accuracy than V im-T , demonstrating that our method offers a clearly superior accurac y–throughput trade-off. Our method has prov en ef fectiv e for architectures such as MambaV ision and V im b ut, there are also limitations on which V isual Mamba models it can be applied to. For example, it is dif ficult to adapt our approach to architectures like VMamba ( Liu et al. , 2024 ), which incorporate 2D conv olutions inside the Mamba module. This is because these models must conv ert the data back into a 2D format at e very layer , but once auxiliary tokens are added, the data no longer conform to the original 2D format. In addition, they cannot process data in the batch-folded representation; instead, they must recon vert the data into the non-batch-folded format at ev ery layer, which de grades the speed-up. 19 Submission and Formatting Instructions f or ICML 2026 T able 11. Comparison on V im-S macro-architecture. T o match the parameter count, we increase the channel dimension from 384 to 400 in the uni-scan model. By applying our method to V im-S, we can significantly improve its performance o ver V im-T while maintaining inference speed comparable to V im-T . size scan Params MACs img/s acc. S parallel-bi scan (V im) 26M 5.3G 1079 80.3 S uni-scan 26M 4.9G 1639 79.3 S uni-scan + swap (ours) 26M 5.0G 1614 80.1 S uni-scan + swap (ours) + Bfold (ours) 26M 5.0G 2022 80.1 T parallel-bi scan (V im) 7M 1.5G 2094 76.3 D.8. Thr oughput Evaluation Under V arious Scenarios Here, we ev aluate throughput across a variety of scenarios. Higher Input Resolutions. A throughput comparison at higher input resolutions is sho wn in 12 . These results show that our proposed improv ements preserve their benefits ev en as resolution scales. The strategy using windowed Attention while using Mamba globally (SF-Mamba ♣ ) remains particularly robust under extremely lar ge inputs. This may reduce training and inference costs in high-resolution applications such as medical imaging, aerial monitoring, and robotics. T able 12. Throughput (images/s) for different models and resolutions. OOM denotes out-of-memory with an A100 40GB GPU. W e use a windowed Attention with a 32 × 32 size for SF-Mamba ♣ , the same as the ADE20K setup. The ”-” for SF-Mamba ♣ means that the feature sizes of both stage 3 and 4 are less than 32 × 32, so the same with SF-Mamba. Model (batch size) 224 448 896 1792 3584 VMamba-T (bs=32) 1384 402 107 5 OOM FasterV iT -0 (bs=32) 1415 1400 418 99 OOM MambaV ision-T (bs=32) 3770 1578 324 50 5 SF-Mamba-T (bs=32) 3962 1777 397 61 6 SF-Mamba ♣ -T (bs=32) - - 427 105 27 VMamba-T (bs=1) 62 62 62 24 5 FasterV iT -0 (bs=1) 44 43 43 43 12 MambaV ision-T (bs=1) 119 121 120 48 5 SF-Mamba-T (bs=1) 126 126 125 54 6 SF-Mamba ♣ -T (bs=1) - - 120 89 26 Different Batch Sizes. The throughput measured under different batch sizes is summarized in T able 13 . Although auxiliary token swapping introduces a slight increase in computational cost, the results sho w that throughput consistently improves thanks to batch folding and other optimizations. T able 13. Throughput with various batch sizes Arch. 1 32 128 256 512 1024 MambaV ision-T 119 3770 6662 7025 7134 7271 ours-T 126 3962 7600 7801 8009 8190 MambaV ision-B 96 2798 2974 3128 3176 3206 ours-B 98 3168 3534 3592 3641 3685 D.9. Contrib ution of Attention and Mamba Here, W e analyze the contrib ution of Attention and Mamba as sho wn in T able 14 . These results sho w that while Attention provides beneficial bidirectional information flow , it alone is not suf ficient to match the full hybrid model. In contrast, SSM alone lags behind, b ut incorporating the swapping mechanism yields a clear impro vement. The best performance is 20 Submission and Formatting Instructions f or ICML 2026 achiev ed only when both components–Attention and SSM (with swap)–are present. This supports our claim that token swapping plays a complementary role to Attention rather than replacing it. Thanks to our batch folding with periodic reset and auxiliary-token swapping, we can le verage Mamba to achiev e improv ements in the accuracy–speed trade-of f e ven for low-resolution inputs. T able 14. The contribution of Attention and Mamba. Arch. Params img/s acc. Attention only 34.2M 7803 82.3% SSM only 29.4M 6238 80.2% SSM only (w/ our Bfold and swap) 29.4M 7306 81.0% Hybrid 31.8M 6979 82.2% Hybrid (w/ our Bfold and swap) 31.8M 7600 82.5% 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment