로컬 퍼스트 AI 어시스턴트를 위한 장기 기억 시스템 MemX
MemX는 Rust와 libSQL 기반으로 구현된 로컬‑퍼스트 장기 기억 시스템이다. 벡터 검색과 FTS5 기반 키워드 검색을 병합하고, Reciprocal Rank Fusion과 4‑요인 재점수를 적용해 안정적인 회귀를 제공한다. 저신뢰도 차단 규칙으로 답변이 없을 때 허위 회귀를 억제한다. 중국어 베치와 LongMemEval 벤치마크에서 Hit@1 91.3%·Hit@5 51.6% 등 경쟁력 있는 성능을 보이며, 100 k 레코드 규모에서도 …
저자: Lizheng Sun
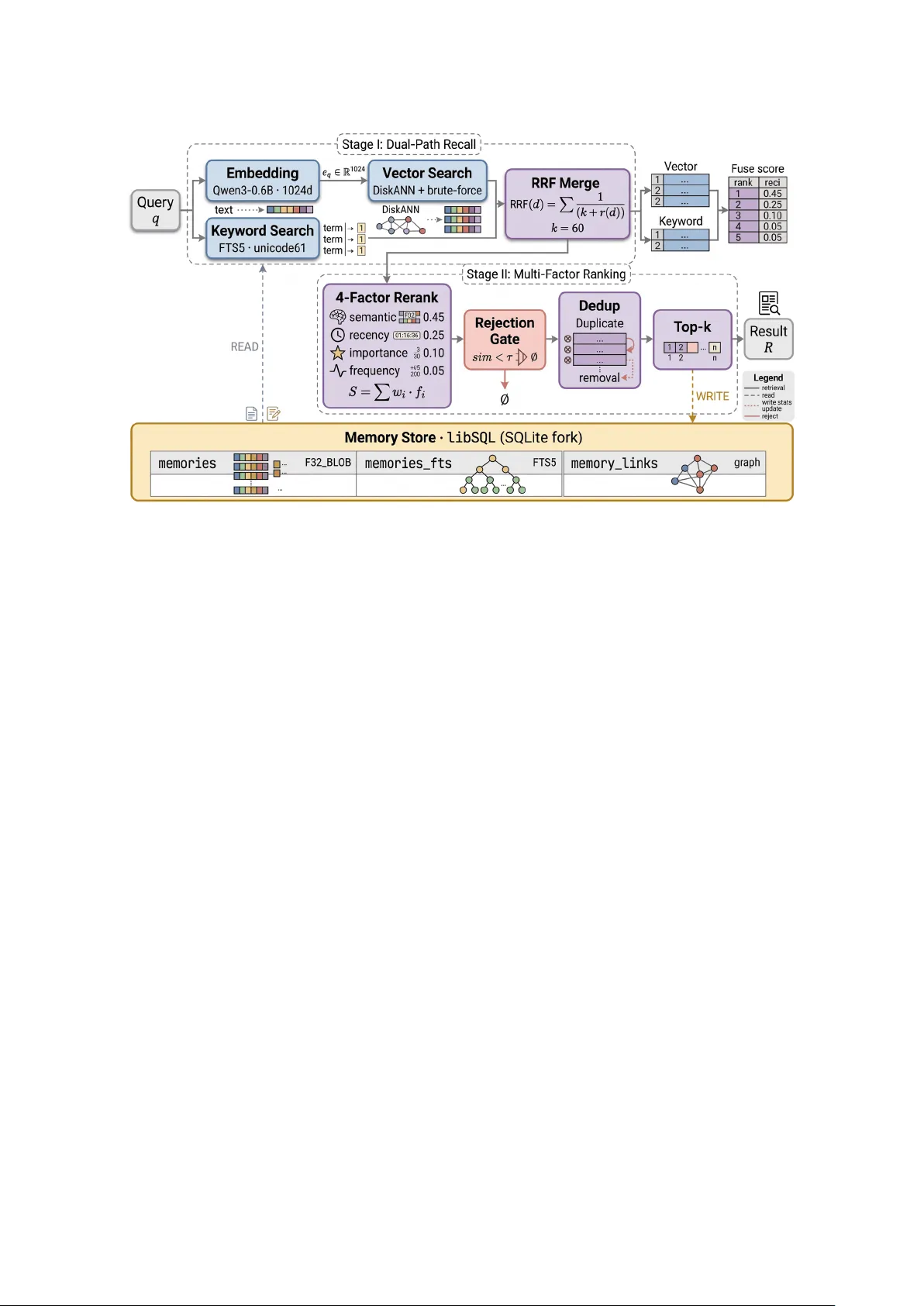
본 논문은 로컬‑퍼스트 AI 어시스턴트를 위한 장기 기억 시스템인 MemX를 제안한다. MemX는 Rust와 libSQL(SQLite 포크) 위에 구축되었으며, OpenAI‑호환 임베딩 API를 통해 생성된 1024‑차원 벡터와 SQLite FTS5 기반 키워드 인덱스를 동시에 활용한다. 시스템 아키텍처는 입력 쿼리를 두 개의 병렬 검색 경로—벡터 검색과 키워드 검색—에 전달하고, 각각에서 상위 n개의 후보를 추출한다. 후보 집합은 Reciprocal Rank Fusion(RRF)으로 결합되며, 이후 네 가지 신호(semantic similarity, recency, frequency, importance)를 가중합한 복합 점수를 산출한다. 가중치는 0.45, 0.25, 0.05, 0.10으로 설정돼, 의미적 유사도가 가장 큰 비중을 차지한다. 복합 점수는 z‑스코어 정규화와 sigmoid 변환을 거쳐 0‑1 구간으로 매핑되며, 이를 통해 쿼리마다 후보 집합 분포 차이를 보정한다.
정규화된 점수는 두 단계의 중복 제거 과정을 통과한다. 첫 번째는 내용이 동일한 레코드를 하나로 통합하고, 두 번째는 ‘태그 시그니처’(type + 정렬된 태그 집합) 기준으로 중복을 걸러낸다. 이 과정은 특히 템플릿 기반 프로시저 기억에서 동일 토픽이 다수 차지하는 현상을 방지해 토픽 다양성을 확보한다.
그 후, 저신뢰도 차단 규칙이 적용된다. 키워드 검색 결과가 없고, 벡터 검색에서 가장 높은 코사인 유사도가 사전 정의된 임계값 τ = 0.50 미만이면 시스템은 빈 결과 집합을 반환한다. 이 규칙은 ‘답변이 없는 질문’에 대해 허위 회귀를 크게 감소시켜, Miss‑Empty‑Rate와 Miss‑Strict‑Rate를 낮춘다.
데이터 모델은 memories 테이블에 메모리 내용, 임베딩, 메타데이터, importance, 접근·검색 카운터 등을 저장하고, memory_links 테이블에 7가지 관계(유사, 연관, 모순, 확장, 대체, 원인, 시간)를 기록한다. 현재는 그래프 기반 다중 홉 탐색이 파이프라인에 포함되지 않지만, 향후 확장 가능성을 염두에 두었다.
평가 방법은 두 개의 자체 제작 중국어 시나리오와 공개 LongMemEval 벤치마크를 사용한다. 기본 시나리오(1,014 레코드, 25 쿼리)에서는 Hit@1 = 91.3%를 달성했으며, 고혼란 시나리오(600 레코드, 18 쿼리)에서는 100% 회귀를 기록했다. LongMemEval(500 쿼리, 최대 220,349 레코드)에서는 저장 granularity에 따른 성능 차이를 분석했다. fact‑level 청크는 session‑level 대비 Hit@5를 51.6%에서 약 30% 수준으로 두 배 이상 향상시켰다. 그러나 temporal reasoning과 multi‑session reasoning은 여전히 43.6% 이하의 Hit@5에 머물렀다.
성능 측면에서 FTS5 인덱스는 100 k 레코드 규모에서 키워드 검색 지연을 1,100배 가속시켜 전체 파이프라인을 90 ms 이하로 유지한다. 이는 로컬 환경에서도 실시간 대화형 응답이 가능함을 의미한다.
결론적으로 MemX는 복합 검색, 정규화 기반 재점수, 저신뢰도 차단이라는 세 가지 핵심 메커니즘을 통해 로컬‑퍼스트 AI 어시스턴트에 적합한 안정적이고 설명 가능한 장기 기억을 구현한다. 구조적 단순성과 재현 가능성을 유지하면서도 대규모 데이터와 다양한 질의 유형에 대해 경쟁력 있는 정확도와 낮은 지연 시간을 제공한다. 향후 연구에서는 그래프 기반 다중 홉 검색, 추가 재점수 요인, 그리고 더 정교한 임계값 자동 튜닝 등을 통해 시스템의 범용성과 성능을 더욱 향상시킬 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기