MemX: A Local-First Long-Term Memory System for AI Assistants
We present MemX, a local-first long-term memory system for AI assistants with stability-oriented retrieval design. MemX is implemented in Rust on top of libSQL and an OpenAI-compatible embedding API, providing persistent, searchable, and explainable …
Authors: Lizheng Sun
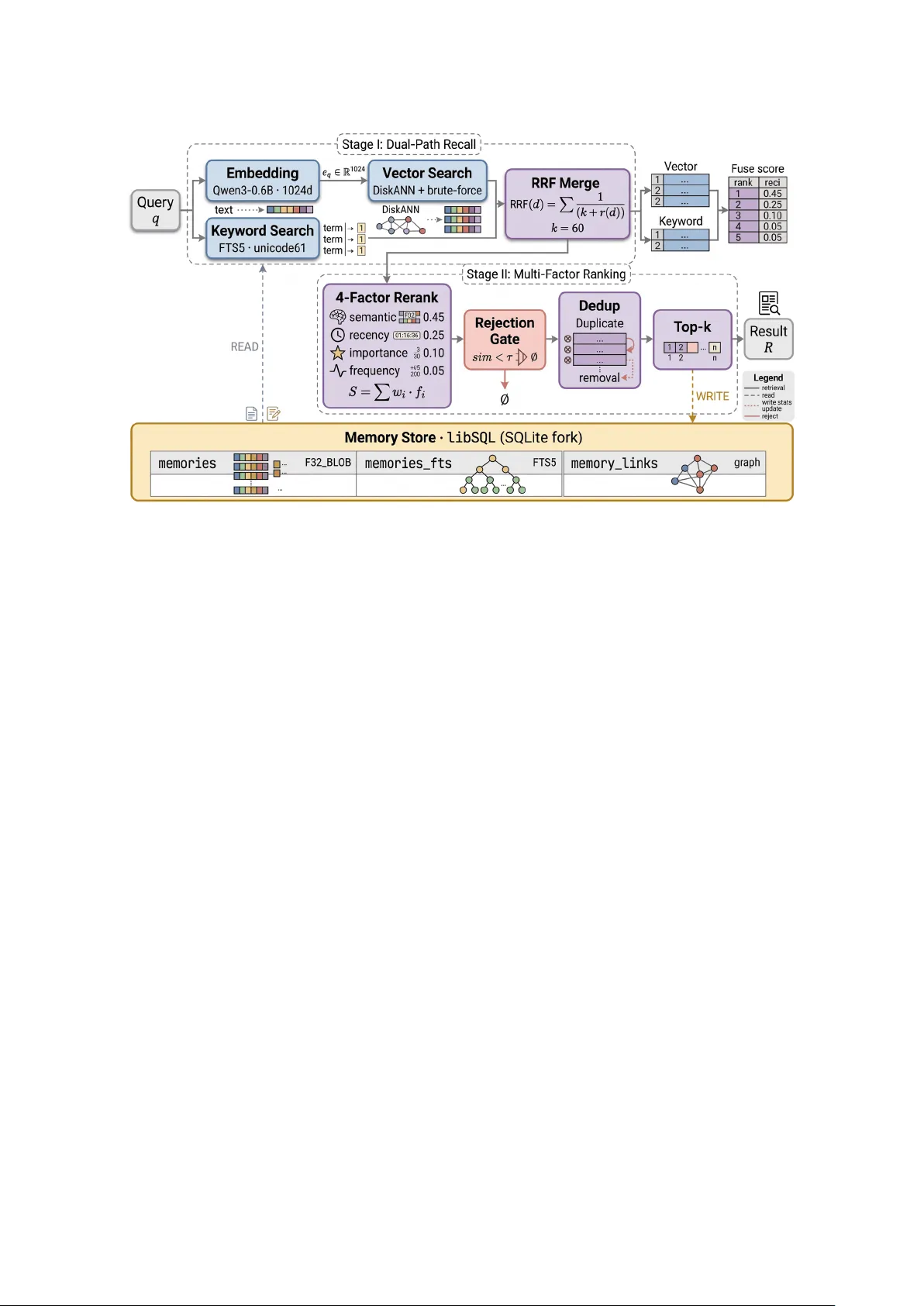
MemX: A Local-First Long-T erm Memory System for AI Assistants Lizheng Sun March 2026 Abstract W e present MemX , a local-first long-term memory system for AI assistants with stability- oriented retrieval design. MemX is implemented in Rust on top of libSQL and an OpenAI- compatible embedding API, providing persistent, searchable, and explainable memory for conversational agents. Its retrieval pipeline applies vector r ecall, keyword recall, Recip- rocal Rank Fusion (RRF), four-factor re-ranking, and a low-confidence rejection rule that suppresses spurious r ecalls when no answer exists in the memory store. W e evaluate MemX on two axes. First, two custom Chinese-language benchmark suites (43 queries, ≤ 1 , 014 records) validate pipeline design: Hit@1 = 91.3% on a default scenario and 100% under high confusion, with conservative miss-query suppression. Second, the LongMemEval benchmark (500 queries, up to 220,349 records) quantifies system boundaries across four ability types and thr ee storage granularities. At fact-level granularity the system reaches Hit@5 = 51.6% and MRR = 0.380, doubling session-level performance, while temporal and multi-session reasoning remain challenging ( ≤ 43.6% Hit@5). FTS5 full-text indexing reduces keywor d search latency by 1 , 100 × at 100k-recor d scale, keeping end-to-end search under 90 ms. Unlike Mem0 and related work that targets end-to-end agent benchmarks, MemX fo- cuses on a narr ower , r eproducible baseline: local-first deployment, structural simplicity , explainable retrieval, and stability-oriented design. Keywords: long-term memory , local AI assistant, hybrid retrieval, recipr ocal rank fusion, rejection r ule, benchmark 1 Introduction Large language models have achieved strong single-turn comprehension, yet they remain stateless across sessions. W ithout a persistent memory layer , an AI assistant cannot reliably retain user preferences, project conventions, operational procedures, incident r esolutions, or domain-specific constraints. This gap is especially pronounced for local AI assistants, where users expect the system to accumulate knowledge over time, avoid repetitive questioning, and refrain fr om fabricating answers when no r elevant memory exists. The challenge of equipping LLMs with long-term memory has been widely r ecognized as a key resear ch direction [ Zhang et al. , 2024 ]. While retrieval-augmented generation (RAG) [ Lewis et al. , 2020 ] has become the dominant paradigm for grounding LLM outputs in external knowledge, most RAG systems target document corpora rather than the incr emental, personalized memories that accumulate during daily assistant interactions. 1 Recent work has begun to address this gap through diverse architectural choices. Mem0 [ Chhikara et al. , 2025 ] frames long-term memory as an integral component of agent infras- tructur e, covering memory extraction, update, retrieval, and downstream task performance. MemGPT [ Packer et al. , 2024 ] introduces an operating-system metaphor for managing LLM memory hierarchies. Generative Agents [ Park et al. , 2023 ] demonstrate how persistent memory enables believable social simulation. MemLLM [ Modarressi et al. , 2024 ] takes a complemen- tary fine-tuning approach, augmenting the model itself with an explicit read–write memory module. A recent survey by Gao et al. [ 2024 ] highlights the growing diversity of RAG architec- tures, yet notes that most systems assume access to a pr e-existing knowledge base rather than incrementally constr ucted personal memories. Effective memory retrieval requir es combining semantic and lexical signals. Dense vector search, typically organized thr ough approximate nearest-neighbor structur es such as HNSW [ Malkov and Y ashunin , 2020 ], captur es meaning-level similarity but can miss keyword-specific cues. Sparse lexical methods, from classical BM25 [ Lin et al. , 2021 ] to lightweight full-text indexes such as SQLite FTS5, complement dense r etrieval by matching exact terms. Recent embedding models such as BGE-M3 [ Chen et al. , 2024 ] natively support both dense and sparse repr esentations, underscoring the importance of hybrid r etrieval. Reciprocal Rank Fusion (RRF) [ Cormack et al. , 2009 ] provides a simple, parameter -light method for combining ranked lists from heterogeneous retrievers, making it well-suited to systems that pair vector and full-text indexes. Most existing memory-augmented systems assume cloud-hosted deployment with ample compute and centralized storage, and their evaluations emphasize end-to-end agent task comple- tion rather than retrieval quality in isolation. However , the local-first software paradigm [ Klepp- mann et al. , 2019 ] ar gues that users should r etain full ownership of their data, with the ability to operate of fline and without depending on third-party services. For a personal AI assistant, local-first deployment of fers concrete advantages: lower latency , stronger privacy guarantees, and independence from external infrastructur e changes. Y et a narrower but critical gap remains: under these constraints, how should a memory system balance r ecall against the risk of spurious results when no r elevant memory exists? This gap motivates the following resear ch question: In a single-user , locally-deployed AI assistant scenario, can a structurally simple, explainable memory system achieve stable recall of relevant memories while minimizing spurious recalls on unanswerable queries? W e answer this question with MemX, a system built on four design principles (local-first deployment, structural simplicity , real-embedding evaluation, and stability-over-r ecall) and validate it on two custom benchmark suites with live embedding APIs as well as the external LongMemEval benchmark [ W ang et al. , 2024 ] (500 queries, up to 220k r ecords). Contributions. 1. A complete implementation of a local long-term memory system featuring hybrid retrieval with explicit access/retrieval tracking separation. 2. A repr oducible benchmark framework that directly invokes internal sear ch functions with real embeddings, supporting scenario extension, threshold sweeping, and structur ed JSON reporting. 2 3. Empirical evidence on two custom scenarios (43 queries) characterizing the pipeline’s strengths (stable single-topic r ecall, conservative miss handling) and boundaries (multi-topic coverage gaps, high-confusion false recalls). 4. A storage-granularity study on LongMemEval [ W ang et al. , 2024 ] (500 queries, up to 220k recor ds) showing that fact-level chunking doubles r etrieval quality over session-level storage, and quantifying per-ability-type performance boundaries. 2 Related W ork Long-term memory for LLM agents. The need for persistent memory in LLM-based systems has been widely recognized [ Zhang et al. , 2024 ]. Mem0 [ Chhikara et al. , 2025 ] pr oposes a production-oriented memory layer with extraction, update, and retrieval stages, evaluated on end-to-end agent tasks. MemGPT [ Packer et al. , 2024 ] draws an analogy to virtual memory , allowing an LLM to page information in and out of its context window . MemLLM [ Modarressi et al. , 2024 ] fine-tunes models to use an explicit r ead-write memory . MemX differs fr om these systems in scope: rather than targeting general agent benchmarks, we focus on a local, single- user deployment with repr oducible r etrieval evaluation. Retrieval-augmented generation. RAG [ Lewis et al. , 2020 ] established the paradigm of condi- tioning generation on r etrieved passages. Subsequent surveys [ Gao et al. , 2024 ] document the rapid diversification of RAG architectures. MemX can be viewed as a specialized RAG stor e whose retrieval pipeline is optimized for stability rather than maximum r ecall. V ector and hybrid retrieval. F AISS [ Johnson et al. , 2021 ] and HNSW [ Malkov and Y ashunin , 2020 ] are foundational approximate nearest-neighbor methods. Hybrid appr oaches that combine dense and sparse retrieval—fused via Reciprocal Rank Fusion [ Cormack et al. , 2009 ]—have shown consistent benefits in information retrieval [ Lin et al. , 2021 , Chen et al. , 2024 ]. MemX adopts RRF as the fusion step and adds a four -factor re-ranking stage tailor ed to memory retrieval. Graph-enhanced memory . GraphRAG [ Edge et al. , 2024 ] and related ef forts [ Guo et al. , 2024 ] enrich retrieval with graph str ucture. Mem0’s later work also explores graph-augmented memory where contradiction, supersession, and causality links participate in r etrieval. MemX maintains a link table ( memory_links ) supporting seven relation types, but does not yet integrate multi-hop traversal or graph-aware re-ranking into the search pipeline; we note this as a planned extension (Section 6 ). Local-first software. Kleppmann et al. [ 2019 ] articulate the principles of local-first software: data ownership, offline capability , and low-latency access. MemX embodies these principles by storing all data in a single libSQL [ T urso , 2023 ] file on the user ’s machine. 3 Figure 1: MemX sear ch pipeline. A query is embedded by Qwen3-0.6B (1024-dim) and r outed to two parallel r ecall paths: DiskANN/brute-force vector sear ch and FTS5 keywor d matching. Results ar e fused via RRF ( k = 60), re-ranked by four weighted factors (semantic similarity , recency , importance, frequency), and filter ed by a rejection gate that r eturns ∅ when similarity falls below threshold τ . After deduplication the top- k results ar e returned and r etrieval statistics are written back to the database. 3 System Design 3.1 Architecture Overview Figure 1 illustrates the end-to-end search pipeline. A query enters the system and is simulta- neously processed by a vector r ecall path (via an OpenAI-compatible embedding API) and a keyword r ecall path. The two candidate sets are mer ged using RRF , r e-ranked by a four-factor scoring function, filtered by a low-confidence rejection rule, and finally the top- k results are returned with r etrieval statistics r ecorded. The system is implemented in Rust. Storage uses libSQL [ T urso , 2023 ], an open fork of SQLite [ Hipp , 2000 ], which provides a single-file database with vector -sear ch extensions. 3.2 Data Model The primary table memories stores each memory entry with content, embedding, type, tags, meta- data, and importance fields, together with access and retrieval counters and their corr esponding timestamps. A secondary table memory_links recor ds dir ected relations between memories. Seven link types ar e curr ently defined: similar , r elated , contradicts , extends , supersedes , caused_by , and temporal . Although the graph infrastructure exists, multi-hop traversal and graph-awar e retrieval ar e not yet integrated into the search pipeline. 4 Algorithm 1: Hybrid Search with Low-Confidence Rejection Input: Query q ; candidate limit n ; rejection thr eshold τ ; result limit k Output: Ranked memory set R (possibly empty) 1 e q ← E M B E D ( q ) ; 2 V ← V E C T O R R E C A L L ( e q , n ) ; // cosine similarity 3 K ← K E Y W O R D R E C A L L ( q , n ) ; // FTS5 full-text match 4 C ← R R F ( V , K ) ; // Reciprocal Rank Fusion 5 S ← F O U R F A C T O R R E R A N K ( C ) ; // Eq. 1 – 3 6 ˆ S ← Z S C O R E N O R M A L I Z E ( S ) ; // Eq. 4 7 if K = ∅ and max m ∈ V sim ( e q , e m ) < τ then 8 return ∅ ; // reject low-confidence result 9 D ← D E D U P ( ˆ S ) ; // content + tag-signature 10 R ← T O P K ( D , k ) ; 11 R E C O R D R E T R I E V A L S TAT S ( R ) ; 12 return R ; 3.3 Hybrid Search Pipeline The search pipeline is deterministic and pr oceeds in the fixed stages formalized in Algorithm 1 . 3.4 Four-Factor Re-ranking After RRF fusion, each candidate memory m is assigned a composite scor e: score ( m ) = α s · f sem ( m ) + α r · f rec ( m ) + α f · f freq ( m ) + α i · f imp ( m ) (1) where the four factors and their default weights ar e: T able 1: Default re-ranking weights. Factor Signal source W eight f sem Semantic similarity (from RRF scor e) α s = 0.45 f rec Recency (prefer last_retrieved_at , α r = 0.25 fallback to created_at ) f freq Frequency (pr efer retrieval_count , α f = 0.05 fallback to access_count ) f imp Importance (explicit annotation) α i = 0.10 The weights sum to 0.85, not 1.0; because the subsequent z-scor e normalization (Equation 4 ) removes absolute scale dependence, only the ratios among weights affect the final ranking. The remaining capacity leaves r oom for additional factors in futur e extensions. The recency factor uses last_retrieved_at rather than last_accessed_at , and the fr equency factor uses retrieval_count rather than access_count . Ranking therefor e reflects how often a memory has been useful in search rather than how often it has been explicitly viewed , avoiding signal pollution from administrative access. 5 Factor computation. Each factor is computed from the memory’s metadata. Let t m be the effective timestamp (prefer last_retrieved_at , fall back to created_at ) and c m the effective count (prefer retrieval_count , fall back to access_count ). Recency follows an exponential half-life decay: f rec ( m ) = 2 − d m / h (2) where d m = ( now − t m ) / 86400 is the age in days and h is a configurable half-life (default h = 30 days). This gives a smooth, parameter-transpar ent curve: a memory’s recency score halves every h days with no hard cutof fs. Fr equency is log-normalized and capped: f freq ( m ) = min 1, ln ( c m + 1 ) / 10 (3) The logarithm pr events highly-accessed memories from dominating the score, while the cap ensures the factor stays in [ 0, 1 ] . Score normalization. After the composite scores ar e computed across all candidates, the system applies z-score normalization followed by a sigmoid transformation: ˆ s ( m ) = sigm s ( m ) − µ σ s = 1 1 + exp − ( s ( m ) − µ ) / σ s (4) where µ and σ s are the mean and standar d deviation of { s ( m ) } over the candidate set. Z-score centering makes scores comparable across queries with dif ferent candidate-set distributions; the subsequent sigmoid compresses outliers while spr eading scores near the center , improving the discriminability of the final ranking. If σ s < 10 − 6 (all candidates scor e identically), normalization is skipped to avoid division instability . 3.5 Result Deduplication T emplate-based memory stor es and repeated ingestion can pr oduce near-identical r ecords that, without intervention, would occupy multiple top- k slots and reduce topic diversity . The system applies two deduplication layers after scoring: 1. Content deduplication. Memories with identical trimmed content are collapsed; only the highest-scoring instance is retained. 2. T ag-signature deduplication. A tag signature is defined as the concatenation of a memory’s type and its sorted tag set (e.g., procedural::ops|release ). At most one memory per tag signature is r eturned. This prevents a cluster of same-topic r ecords (common when procedural memories shar e identical tags) fr om crowding out r esults from other topics. Memories without tags are exempt from tag-signatur e filtering and compete solely on score. In the benchmark’s 3 × -scaled datasets (up to 1,014 r ecords), this mechanism matters in practice: without it, the top-5 r esults for procedural queries consist entirely of template variants of the same topic, and Coverage@5 drops accor dingly . 3.6 Low-Confidence Rejection Rule T o suppress spurious recalls when the memory store contains no relevant entry , the system applies a conservative rejection r ule: 6 If the keyword recall set K is empty and the maximum vector similarity score is below threshold τ , return an empty r esult set. The current r ecommended threshold is τ = 0.50, determined empirically through the thr eshold sweep experiment described in Section 5.3 . This rule trades a small amount of recall for a meaningful reduction in false positives on unanswerable queries. Section 5.7 formalizes five candidate rejection r ules and evaluates them against the benchmark data. 3.7 Access vs. Retrieval Separation The system explicitly distinguishes two types of interactions: Access — A user or system explicitly reads a memory entry (e.g., viewing details). T racked by access_count and last_accessed_at . Retrieval — A memory is returned as a search result. T racked by retrieval_count and last_retrieved_at . This separation pr events explicit r eads fr om inflating r etrieval-based ranking signals. Section 6.2 quantifies the ranking impact of this design choice through a worked numerical example. 4 Benchmark Framework 4.1 Design Rationale Many memory system evaluations r ely on single demonstrations or manually curated examples, which suf fice for showcasing behavior but are insufficient for locating failure modes. W e implement a standalone benchmark framework with the following properties: • Directly invokes the system’s internal search functions (bypassing HTTP routing), measur- ing intrinsic retrieval performance. • Uses a live OpenAI-compatible embedding API rather than pre-computed or random vectors. • Automatically constructs an isolated test database per run. • Outputs structured JSON r eports supporting downstream analysis. • Supports threshold sweeping and scenario extension. 4.2 Scenario Design W e construct two benchmark scenarios in Chinese, r eflecting the target deployment language. Default scenario. This scenario models r ealistic usage of a local AI assistant, covering user prefer ences (e.g., cof fee habits), job r ole, code style conventions, deployment checklists, client demo constraints, database incident procedur es, Rust debugging strategies, budget thr esholds, travel prefer ences, and multiple noise topics. After 3 × scaling, the scenario contains 1,014 memory recor ds and 25 queries spanning seven query kinds: keyword_exact , semantic_paraphrase , procedur e_r ecall , long_context , reflective , multi_fact , and miss . High-confusion scenario. This scenario deliberately places semantically overlapping top ics adjacent to each other: local deployment vs. vendor switching messaging, migration root cause vs. release compatibility checks, search stability vs. sear ch speed prefer ences, budget caps vs. 7 ROI exceptions, and Rust borrow err ors vs. trait bound errors. After 3 × scaling it contains 600 recor ds and 18 queries. It is designed to stress-test false-recall suppression, multi-topic coverage, and miss-query convergence. LongMemEval scenario. T o evaluate at larger scale, we adopt the LongMemEval bench- mark [ W ang et al. , 2024 ], which pr ovides 500 annotated questions derived fr om 19,195 multi-turn conversation sessions. Questions span four ability types: information extraction , knowledge update , multi-session reasoning , and temporal reasoning . W e convert the dataset into three MemX scenarios at differ ent storage granularities (session, r ound, fact); fact-level extraction uses DeepSeek- Chat to decompose each session into atomic statements. Details and results are presented in Section 5.4 . T otal query budget. Across all scenarios the evaluation uses 543 queries: 43 from the two custom scenarios (25 default + 18 high-confusion) and 500 from LongMemEval. 4.3 Metrics The benchmark reports the following metrics (T able 2 ): T able 2: Benchmark metrics. Metric Description Hit@ k ( k = 1, 3, 5) Fraction of relevant queries where at least one correct memory appears in the top- k results. T opic Coverage@ k For multi-topic queries, the fraction of expected topics covered in the top- k results. MRR Mean Reciprocal Rank over r elevant queries. Miss-Empty-Rate Fraction of miss queries (no correct answer exists) for which the system returns an empty r esult set. Miss-Strict-Rate Fraction of miss queries for which the top vector scor e stays below the miss threshold (more stringent than Miss-Empty-Rate). A vg/P95 Search (ms) A verage and 95th-percentile end-to-end sear ch latency . For binary metrics (Hit@ k , Miss-Empty-Rate, Miss-Strict-Rate) we report 95% W ilson score confidence intervals where the sample size is finite. The W ilson interval for a proportion ˆ p observed in n trials is ˆ p + z 2 2 n ± z q ˆ p ( 1 − ˆ p ) n + z 2 4 n 2 1 + z 2 n , z = 1.96 . This interval has better coverage than the normal approximation when n is small or ˆ p is near 0 or 1 [ W ilson , 1927 ]. 5 Experiments 5.1 Setup All experiments use the following configuration: 8 T able 3: Retrieval quality and latency acr oss the two benchmark scenarios ( τ = 0.50). 95% W ilson confidence intervals are shown in brackets for binary metrics. Metric Default High-Confusion Records 1,014 600 Queries (rel / miss) 23 / 2 14 / 4 Hit@1 91.3% [73, 98] 100.0% [78, 100] Hit@5 95.7% [79, 99] 100.0% [78, 100] Coverage@5 91.3% 75.0% MRR 0.935 1.000 Miss-Empty-Rate 50.0% [9, 91] 75.0% [30, 95] Miss-Strict-Rate 100.0% [34, 100] 75.0% [30, 95] A vg Sear ch (ms) 538.32 397.68 P95 Search (ms) 679.01 459.84 • Embedding model: Qwen3-Embedding-0.6B [ Qwen T eam , 2025 ] • Embedding dimension: 1,024 • Rejection threshold: τ = 0.50 • Re-ranking weights: as in T able 1 • V ector index: DiskANN (via libSQL vector extension) • Keyword index: FTS5 with unicode61 tokenizer The benchmark framework invokes internal search functions dir ectly; reported latencies ther e- fore r eflect intrinsic r etrieval cost, not full HTTP round-trip time. 5.2 Scenario-Level Results T able 3 summarizes the key metrics for both scenarios. Default scenario. W ith the expanded 25-query set, Hit@1 r eaches 91.3% (W ilson 95% CI [73, 98]%) and MRR is 0.935. The two misses at rank 1 are keyword-exact queries whose target memories share vocabulary with higher-scoring distractors: travel_network is recovered at rank 2 (Hit@3 = 95.7%), while deploy_rollback is not recover ed within the top-5. Coverage@5 is 91.3%, with gaps on the two multi_fact queries that each require two distinct topics. Of the two miss queries, one ( “What is the user ’ s favorite gym brand?” ) is correctly r ejected ( v max = 0.453), while the other ( “What breed is the user ’ s pet?” ) produces a bor derline v max that exceeds τ , giving Miss-Empty-Rate = 50% [9, 91]%. Miss-Strict-Rate remains 100% [34, 100]%. High-confusion scenario. Hit@1 is 100% [78, 100]% across all 14 r elevant queries, confirm- ing that the system r eliably identifies the primary r elevant topic even under high semantic overlap. Coverage@5 is 75.0%, reflecting the difficulty of multi-topic queries where each ex- pected topic competes with a semantically similar neighbor . Of the four miss queries, thr ee are corr ectly rejected (Miss-Empty-Rate = 75% [30, 95]%), while “Which public cloud r egion does the client requir e?” produces v max = 0.621, exceeding τ and resulting in a spurious recall of the local_storage_policy topic. This failure case is analyzed further in Section 6.1 . 9 T able 4: Threshold sweep r esults (averaged across both scenarios, 43 queries). τ A vg Hit@1 A vg Miss-Empty A vg Miss-Strict Note 0.48 95.7% 62.5% 87.5% T ied with 0.50 0.50 95.7% 62.5% 87.5% Recommended 0.52 93.5% 62.5% 87.5% Begins to hurt recall 0.64 87.0% 100.0% 87.5% Significantly hurts r ecall 5.3 Threshold Sweep W e sweep the r ejection threshold τ over { 0.48, 0.50, 0.52, 0.64 } , running both scenarios at each value. T able 4 reports the cr oss-scenario averages. At τ = 0.48 and τ = 0.50, A vg Hit@1 is highest at 95.7% with identical Miss-Empty-Rate (62.5%) and Miss-Strict-Rate (87.5%). Raising the threshold to τ = 0.52 causes one additional false rejection (the deploy_rollback query in the default scenario, whose top vector scor e is 0.513), reducing A vg Hit@1 to 93.5%. At τ = 0.64, A vg Hit@1 drops sharply to 87.0% as six default-scenario queries are r ejected, although Miss-Empty-Rate reaches 100%. W e r ecommend τ = 0.50 as the operating point: it ties with τ = 0.48 on all accuracy metrics and is the highest threshold that does not sacrifice r ecall. 5.4 LongMemEval Evaluation T o evaluate MemX beyond the two custom scenarios (43 queries over ≤ 1 , 014 recor ds), we apply it to the LongMemEval benchmark [ W ang et al. , 2024 ], which provides 500 annotated questions derived from 19,195 multi-turn conversation sessions spanning four ability types: information extraction (156 queries), knowledge update (78), multi-session r easoning (133), and temporal r easoning (133). Storage granularity . W e convert the LongMemEval dataset into three MemX scenarios at differ ent storage granularities: • Session — each conversation session becomes one memory (19,195 records). • Round — each user–assistant turn pair becomes one memory (100,486 recor ds). • Fact — each atomic fact, extracted from sessions by an LLM (DeepSeek-Chat), becomes one memory (220,349 recor ds). This granularity axis is orthogonal to the pipeline-component ablation in Section 5.6 : it asks how should raw conversations be chunked before indexing? Overall results. T able 5 shows that finer granularity consistently improves retrieval quality . Fact-level storage doubles Hit@5 and MRR relative to session-level storage. Per-ability-type breakdown. T able 6 reveals that the improvement fr om fact-level storage is not uniform across ability types. Three findings emerge. First, knowledge update benefits most from fact-level storage (Hit@5: 30.8% → 75.6%, + 44.8 pp), because LLM-extracted facts explicitly surface the updated information that a full conversation buries in dialogue context. Second, temporal reasoning 10 T able 5: LongMemEval retrieval quality across thr ee storage granularities (500 queries, τ = 0.50, FTS5 keyword index). Granularity Records Hit@1 Hit@5 MRR TC@5 Session 19,195 14.8% 24.6% 0.183 19.5% Round 100,486 17.2% 27.0% 0.207 21.0% Fact 220,349 29.8% 51.6% 0.380 41.5% T able 6: Hit@5 and MRR by LongMemEval ability type across thr ee storage granularities. Session Round Fact Ability type n Hit@5 MRR Hit@5 MRR Hit@5 MRR Information extraction 156 36.5 .298 39.7 .324 55.8 .379 Knowledge update 78 30.8 .218 44.9 .360 75.6 .624 Multi-session reasoning 133 18.0 .117 15.0 .110 43.6 .323 T emporal reasoning 133 13.5 .093 13.5 .078 40.6 .296 and multi-session reasoning show the largest absolute gaps from custom-scenario performance ( ≤ 43.6% Hit@5 at best), confirming that these abilities requir e mechanisms beyond single- query vector recall—e.g., temporal indexing or cr oss-session linking—that MemX does not yet implement. Third, moving from session to round granularity yields modest gains ( + 2.4 pp Hit@5 overall), while moving from r ound to fact produces a lar ge jump ( + 24.6 pp), suggesting that semantic density per record is the primary driver of r etrieval quality at scale. Pipeline baseline comparison. T o isolate the contribution of pipeline components at this scale, we compare a vector -only baseline (no keyword sear ch, no rejection, no deduplication) against the full pipeline on the fact-granularity dataset. Counter-intuitively , the full pipeline under performs the vector-only baseline by 5.0 pp on Hit@5 (T able 7 ). The cause is tag-signatur e deduplication: in the fact-granularity dataset, all memories are typed semantic with no tags, producing an identical tag signatur e. The deduplication rule ther efore l imits each query to at most one r esult per signatur e, discarding co-relevant facts fr om the same session that would otherwise occupy top- k slots. On the custom scenarios, where template-generated memories carry explicit tags and 3 × scaling creates genuine duplicates, deduplication improves Hit@3 by + 2.7 pp (T able 9 ). This contrast reveals that deduplication is data-dependent : it helps when memories have structured tags and r epetitive content, but harms recall on tag-fr ee atomic facts. Section 6.4 discusses adaptive deduplication strategies that could address this. 5.5 Latency Analysis T able 8 reveals a scale-dependent latency picture. On the custom scenarios ( ≤ 1 , 014 records), keyword sear ch is negligible ( < 3 ms) and latency is dominated by the remote embedding API call. On LongMemEval at 100k+ records, however , the naive LIKE keyword sear ch becomes the dominant bottleneck: at 100,486 recor ds it consumes 3,305 ms per query (95% of total latency), making it 1,500 × slower than at 1k records. 11 T able 7: V ector-only baseline vs. full pipeline on LongMemEval fact granularity (220,349 r ecords, 500 queries). Config Hit@1 Hit@5 MRR TC@5 A vg ms V (vector-only) 30.2% 56.6% 0.406 44.2% 89.6 Full pipeline 29.8% 51.6% 0.380 41.5% 88.2 T able 8: Latency breakdown (milliseconds) across custom and LongMemEval scenarios. Custom scenarios use the remote embedding API; LongMemEval scenarios use cached embeddings (query_embed ≈ 0 ms). Rows marked (LIKE) use LIKE substring search; rows marked (FTS5) use FTS5 full-text indexing. All runs use DiskANN vector indexing where supported. Scenario Records V ector Keyword T otal P95 Custom scenarios (Section 5.2 ) Default 1,014 545 2.2 538 679 High-Confusion 600 389 1.6 398 460 LongMemEval (Section 5.4 ) Session (LIKE) 19,195 98.6 286.7 385 1,418 Session (FTS5) 19,195 15.8 1.6 17.3 20 Round (LIKE) 100,486 177.8 3,305 3,483 6,919 Round (FTS5) 100,486 31.7 2.9 34.6 60 Fact (FTS5) 220,349 87.1 1.1 88.2 134 Replacing LIKE with an FTS5 full-text index eliminates this bottleneck entirely . On the same 100,486-recor d dataset, FTS5 keywor d search takes 2.9 ms—a 1,100 × speedup—reducing total search latency from 3,483 ms to 34.6 ms. At 220,349 recor ds (fact granularity), FTS5 keyword search r emains at 1.1 ms and total latency is 88 ms. V ector search latency also benefits from the DiskANN index (Section 3.1 ): at 100k recor ds, DiskANN achieves 31.7 ms compar ed to the brute-for ce O ( n ) path that would scale linearly with dataset size. Figure 2 visualizes the contrast between vector and keywor d latency across all scenarios. 5.6 Ablation Study T o quantify the contribution of each pipeline component, we evaluate four cumulative configu- rations acr oss both scenarios: V (vector search only), V+K (add keyword search and RRF fusion), V+K+Rej (add low-confidence rejection r ule), and Full (add tag-signature deduplication). All other parameters ( τ = 0.50, four-factor weights, 3 × scaling) are held constant. Three observations emerge from T able 9 . First, adding keyword search and RRF fusion ( V → V+K ) pr oduces no change in any metric. This confirms that with the curr ent query distribu- tion, semantic similarity alone is sufficient for ranking; keyword overlap adds no discriminative power beyond what vector search alr eady pr ovides. Second, the rejection rule ( V+K → V+K+Rej ) is the sole contributor to Miss-Empty-Rate, raising it fr om 0% to 66.7%. W ithout the rejection rule, the system r eturns results for every query 12 Figure 2: V ector vs. keyword search latency across custom and LongMemEval scenarios (log scale). At 100k recor ds, LIKE -based keyword search dominates total latency (3,305 ms); FTS5 indexing reduces it to 2.9 ms (1,100 × speedup). T able 9: Ablation study: cumulative effect of pipeline components averaged over both scenarios. 95% W ilson confidence intervals are shown for binary metrics. n rel and n miss denote the number of relevant and miss queries r espectively . Config Hit@1 Hit@3 TC@ k Miss-Empty Miss-Strict V 94.6 [82, 99] 94.6 [82, 99] 81.0 0.0 [0, 39] 83.3 [44, 97] V+K 94.6 [82, 99] 94.6 [82, 99] 81.0 0.0 [0, 39] 83.3 [44, 97] V+K+Rej 94.6 [82, 99] 94.6 [82, 99] 81.0 66.7 [30, 90] 83.3 [44, 97] Full 94.6 [82, 99] 97.3 [86, 100] 83.2 66.7 [30, 90] 83.3 [44, 97] All values in %. Pooled over n rel = 37 relevant and n miss = 6 miss queries. W ilson 95% CI in brackets. including those with no corr ect answer . Hit@ k and TC@ k are unaf fected, confirming that the rule never r ejects valid queries at τ = 0.50. Third, deduplication ( V+K+Rej → Full ) lifts Hit@3 from 94.6% to 97.3% and TC@ k from 81.0% to 83.2% on the custom scenarios. However , on LongMemEval’s fact-granularity dataset the same mechanism reduces Hit@5 by 5.0 pp (Section 5.4 , T able 7 ). This divergence arises because the custom scenarios use structured tags that produce meaningful tag signatur es, while the fact dataset stores tag-free atomic statements that all shar e an identical signature. Deduplication is therefor e data-dependent : beneficial for tagged, template-generated data but harmful for homogeneously-typed atomic facts. Granularity ablation. A second, orthogonal ablation axis is explor ed in Section 5.4 : storage granularity (session → round → fact). Fact-level storage doubles Hit@5 and MRR relative to session-level storage (T able 5 ), an effect far larger than any pipeline-component change observed above. This suggests that for large-scale memory stores, investment in upstream chunking and 13 T able 10: Five candidate rejection rules. v max is the top vector similarity score, kw indicates non-empty keyword r ecall, and τ is the rejection thr eshold. Rule Condition to reject Intuition R1 ¬ kw ∧ v max < τ Current system: r eject only when both signals are weak. R2 v max < τ V ector-only gate; ignores keyword signal. R3 ¬ kw Keyword-r equired gate; ignor es vec- tor signal. R4 ¬ kw ∨ v max < τ Strict dual gate: r eject if either signal is weak. R5 ¬ kw ∧ v max < 0.55 Same as R1 but with a raised thr esh- old ( τ = 0.55). T able 11: Rejection rule simulation on four r epresentative queries. FN = false negatives (valid queries rejected); FP = false positives (miss queries accepted). Counts are from the original 24-query subset where per -query vector scor es were r ecorded. R1 R2 R3 R4 R5 job_lookup (0.504, ¬ kw) ✓ ✓ × × × incident_kw (0.490, kw) ✓ × ✓ × ✓ hard_miss (0.453, ¬ kw) × × × × × cloud_region_miss (0.621, ¬ kw) ✓ ∗ ✓ ∗ × × ✓ ∗ FN (of 21 valid) 0 1 18 19 1 FP (of 3 miss) 1 1 1 0 1 ✓ = correctly handled; × = incorrectly r ejected/accepted; ∗ = false positive (miss query accepted). fact extraction yields greater r eturns than additional r etrieval pipeline stages. 5.7 Rejection Rule Design Space T o justify the choice of r ejection rule used throughout this work, we define five candidate r ules (T able 10 ) and evaluate them against the actual per-query data fr om both benchmark scenarios. Let v max denote the maximum vector similarity for a query and kw a Boolean indicating whether the keyword r ecall set is non-empty . W e apply each r ule to the original 24-query subset (21 relevant + 3 miss) for which per-query vector scores wer e recor ded. T able 11 summarizes the outcomes as false negatives (valid queries incorrectly rejected) and false positives (miss queries incorrectly accepted). Four r epresenta- tive queries illustrate the key distinctions: job_lookup ( v max = 0.504, no kw), incident_keyword ( v max = 0.490, kw), hard_miss ( v max = 0.453, no kw), and public_cloud_region_miss ( v max = 0.621, no kw). Three findings emer ge fr om this analysis. First, R1 is the only rule with zero false negatives . It preserves all 21 valid queries because its conjunctive structur e ( ¬ kw ∧ v max < τ ) requir es both signals to be absent before r ejecting. All other rules sacrifice at least one valid query: R2 r ejects incident_keyword ( v max = 0.490 < τ despite a keyword hit); R3 and R4 r eject 18 and 19 valid queries r espectively because only 3 of 14 the 24 queries produce keywor d hits; R5 r ejects job_lookup ( v max = 0.504 < 0.55). Second, R3 and R4 are unusable in practice . Because keyword r ecall relies on token overlap between query and stor ed memories (whether via FTS5 or substring matching), only 3 of 24 queries produce non-empty keywor d sets. Any rule that r equires a keywor d hit as a necessary condition for acceptance will reject almost all valid queries. Third, the fundamental limit is the score gap between the hardest valid query ( job_lookup , v max = 0.504) and the easiest false recall ( public_cloud_region_miss , v max = 0.621). No single- threshold rule over v max can separate these two queries: any τ that accepts job_lookup must also accept the false recall. Improving miss suppr ession beyond the current level ther efore r equir es a dif ferent kind of signal, such as cross-encoder r e-scoring, which can model fine-grained query–document interaction rather than relying on a single similarity scor e. 6 Discussion 6.1 Failure Cases and System Boundaries Multi-topic coverage gap. In both scenarios, queries that r equir e two topics consistently retrieve only the most semantically prominent one. For example, the query “Which metric should matter besides budget when r ecommending a tool?” retrieves budget_threshold but not search_expectation . The current pipeline is optimized for single-topic “needle-in-a-haystack” retrieval and lacks mechanisms for multi-facet query decomposition. High-confusion false recall. The public_cloud_region_miss query shares substantial vocabu- lary with local_storage_policy (both discuss deployment, data location, and cloud infrastruc- ture). The resulting vector similarity (0.621) exceeds τ , producing a false r ecall. The rejection rule, while ef fective for topically distant miss queries, can be defeated by carefully constr ucted adversarial overlaps. The systematic analysis in Section 5.7 confirms that no single-thr eshold rule can separate this false r ecall from valid queries. Graph structure not yet in the search path. The memory_links table and its seven relation types provide the scaf folding for graph-enhanced retrieval. However , the current search pipeline does not perform multi-hop traversal or graph-awar e re-ranking, so the graph cannot yet resolve contradictions or surface causally linked memories. T emporal and multi-session reasoning. The LongMemEval evaluation (Section 5.4 ) r eveals that temporal reasoning ( ≤ 40.6% Hit@5 at fact granularity) and multi-session reasoning ( ≤ 43.6%) are the weakest ability types. These queries requir e capabilities that single-query vector r ecall cannot provide: temporal ordering of events acr oss sessions, and synthesis of information scattered across multiple conversations. Addr essing these gaps likely requir es temporal indexing (e.g., date-aware r etrieval) and cr oss-session linking mechanisms. No task-level attribution. The system tracks which memories are returned by search, but does not recor d whether a returned memory was actually used by the downstr eam agent or whether it improved task completion. W ithout this closed-loop signal, the system cannot automatically learn which memories are most valuable. 15 T able 12: Three memory pr ofiles with contrasting access and retrieval histories. All three shar e f sem = 0.70 and f imp = 0.80. Profile Access Retrieval Last accessed Last retrieved A Admin-heavy 50 2 1 d ago 15 d ago B Search-heavy 3 25 30 d ago 1 d ago C Stale 40 40 60 d ago 60 d ago T able 13: Composite scores under two tracking strategies. W eights: α s = 0.45, α r = 0.25, α f = 0.05, α i = 0.10. Ranking r eversal between A and B is highlighted. Strategy 1 (retrieval) Strategy 2 (access) f rec f freq Score f rec f freq Score A 0.707 0.110 0.577 0.977 0.393 0.659 B 0.977 0.326 0.656 0.500 0.139 0.527 C 0.250 0.371 0.476 0.250 0.371 0.476 Ranking B > A > C A > B > C 6.2 Impact of Access/Retrieval Separation Section 3.7 described the design rationale for separating access and retrieval counters. Because the benchmark creates all memories fresh with zero counters, it cannot dir ectly exer cise this design choice: recency and frequency factors contribute equally (and minimally) regar dless of tracking strategy . T o illustrate the practical impact, we construct a worked example with thr ee hypothetical memory profiles exhibiting dif fer ent access/retrieval patterns. W e compute the composite score (Equation 1 ) for each pr ofile under two strategies. Strat- egy 1 (retrieval-pr eferred, the current design) uses retrieval_count for frequency and last_re- trieved_at for r ecency . Strategy 2 (access-based) uses access_count for fr equency and last_ac- cessed_at for recency . Both strategies use the same factor formulas defined in Section 3.4 : recency f rec = 2 − d / h with h = 30 days (Equation 2 ) and frequency f freq = min ( 1, ln ( c + 1 ) / 10 ) (Equation 3 ), dif fering only in which timestamp and counter they read. Semantic and importance factors are held constant at f sem = 0.70 and f imp = 0.80. The ranking r eversal between profiles A and B is driven almost entirely by the recency factor ( α r = 0.25), not by frequency ( α f = 0.05). Under Strategy 1, profile B ranks first because it was retrieved one day ago; under Strategy 2, profile A ranks first because it was accessed one day ago. Strategy 2 therefore pr omotes memories that are fr equently viewed (e.g., for administrative purposes) but rarely useful in search, while demoting memories that are genuinely search- relevant. This confirms the design motivation in Section 3.7 : retrieval-based tracking better reflects a memory’s utility in the sear ch pipeline. 6.3 Threats to V alidity 1. T emplate-driven data. Benchmark records ar e generated from templates with repetition- based scaling. While mor e structured than ad-hoc examples, they do not capture the distribu- tional complexity of real long-term interaction logs. 2. Single embedding configuration. All results ar e obtained with Qwen3-Embedding-0.6B 16 at 1,024 dimensions. The system accepts any OpenAI-compatible embedding model via environment variables, but the optimal r ejection threshold τ must be r ecalibrated for each model, as cosine-similarity distributions vary across embedding spaces. 3. Intrinsic vs. end-to-end latency . Reported latencies bypass HTTP routing and full request handling; production latency will be higher . 4. No human evaluation. The current evaluation measures r etrieval quality , not downstr eam task completion. Whether impr oved r etrieval translates to better agent output requires task-level human assessment. 5. Scenario diversity . The custom evaluation uses 43 queries acr oss two scenarios; the addition of LongMemEval (500 queries, four ability types) substantially br oadens coverage, but all LongMemEval conversations are in English while the custom scenarios ar e in Chinese. Cross- lingual generalization remains untested. 6.4 Future Directions Five directions ar e most pr omising for extending the current baseline: 1. T emporal and cross-session reasoning. The LongMemEval evaluation identifies temporal reasoning and multi-session reasoning as the weakest ability types. Date-aware r etrieval (e.g., temporal indexing of memory creation times) and cross-session linking could substantially improve these categories. 2. Stronger rejection rules. Cross-encoder re-scoring or lightweight classifier-based r ejection could improve miss-query handling under high semantic overlap. 3. Adaptive deduplication. The current tag-signature deduplication helps on template-generated data but harms recall on tag-fr ee atomic facts (Section 5.4 ). Content-similarity–based dedupli- cation (e.g., collapsing results only when cosine similarity exceeds a threshold) would adapt to both regimes without r equiring explicit tags. 4. Multi-topic coverage. Query decomposition (splitting a compound query into sub-queries) or diversity-aware r e-ranking could impr ove Coverage@ k on multi-facet queries. 5. T ask-level attribution. Recording whether a retrieved memory was used by the agent and whether it impr oved the final output would enable credit assignment and a closed-loop memory lifecycle. 7 Conclusion W e have presented MemX, a local-first long-term memory system for AI assistants, featuring a hybrid retrieval pipeline with RRF fusion, four-factor r e-ranking, and a low-confidence r ejection rule. On two custom Chinese-language scenarios (43 queries), the pipeline achieves Hit@1 = 91– 100% with conservative miss-query suppression, validating its component design. On the Long- MemEval benchmark (500 queries, up to 220k recor ds), fact-level storage reaches Hit@5 = 51.6% and MRR = 0.380—doubling session-level performance—while temporal and multi-session r ea- soning remain at ≤ 43.6% Hit@5, defining clear impr ovement targets. A storage-granularity study shows that semantic density per recor d is the primary driver of r etrieval quality at scale, with knowledge-update queries benefiting most (Hit@5: 30.8% → 75.6%). On the systems side, replacing LIKE -based keywor d sear ch with FTS5 full-text indexing yields a 1 , 100 × latency reduction at 100k r ecords, keeping end-to-end search under 90 ms at 17 220k recor ds. T wo supplementary analyses strengthen these findings: a rejection r ule design space study (Section 5.7 ) shows that the current conjunctive rule is the only candidate with zer o false negatives, and an access/retrieval separation analysis (Section 6.2 ) demonstrates that r etrieval- based tracking prevents ranking distortion fr om administrative access patterns. W ithin the scope of a local, single-user AI assistant, MemX pr ovides a solid v1 baseline whose retrieval pipeline, explicit tracking separation, and repr oducible benchmark framework can be extended with temporal indexing, cross-session linking, and task-level attribution without architectural r edesign. Source code and r eproduction scripts ar e available at https://github. com/memxlab/memx . References Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. BGE M3- embedding: Multi-lingual, multi-functionality , multi-granularity text embeddings through self-knowledge distillation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , 2024. Prateek Chhikara, V ansh Khindri, Deshraj Udasi, and Dev Thakkar . Mem0: Building production- ready ai agents with scalable long-term memory . arXiv preprint , 2025. Gordon V . Cormack, Charles L. A. Clarke, and Stefan Buettcher . Reciprocal rank fusion outper - forms Condor cet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 758–759, 2009. Darren Edge, Ha T rinh, Newman Cheng, Joshua Bradley , Alex Chao, Apurva Mody , Steven T ruitt, and Jonathan Larson. GraphRAG: Unlocking LLM discovery on narrative private data. arXiv preprint arXiv:2404.16130 , 2024. Y unfan Gao, Y un Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y i Dai, Jiawei Sun, Meng W ang, and Haofen W ang. Retrieval-augmented generation for lar ge language models: A survey . arXiv pr eprint arXiv:2312.10997 , 2024. Jiajun Guo et al. A survey on knowledge graph-enhanced lar ge language models. arXiv preprint arXiv:2404.14741 , 2024. D. Richard Hipp. SQLite. https://www.sqlite.org/ , 2000. Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity sear ch with GPUs. IEEE T ransactions on Big Data , 7(3):535–547, 2021. Martin Kleppmann, Adam W iggins, Peter van Har denberg, and Mark McGranaghan. Local-first software: Y ou own your data, in spite of the cloud. Pr oceedings of the ACM on Human-Computer Interaction , 3(CSCW):1–24, 2019. Patrick Lewis, Ethan Per ez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Y ih, T im Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS) , 2020. 18 Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Y ang, Ronak Pradeep, and Rodrigo Nogueira. Pyserini: A python toolkit for repr oducible information retrieval research with sparse and dense r epr esentations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 2356–2362, 2021. Y u A. Malkov and D. A. Y ashunin. Ef ficient and r obust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE T ransactions on Pattern Analysis and Machine Intelligence , 42(4):824–836, 2020. Ali Modarressi, A yyoob Imani, Mohsen Fayyaz, and Hinrich Schütze. MemLLM: Finetuning LLMs to use an explicit read-write memory . arXiv preprint , 2024. Charles Packer , Sarah W ooders, Kevin Lin, V ivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: T owards LLMs as operating systems. In Proceedings of the International Conference on Learning Repr esentations (ICLR) , 2024. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Mer edith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior . In Proceedings of the 36th Annual ACM Symposium on User Interface Softwar e and T echnology (UIST) , 2023. Qwen T eam. Qwen3 embedding and r eranker: T owards unified versatile embedding and reranking. Qwen T echnical Blog , 2025. https://qwenlm.github.io/blog/qwen3- embedding/ . T urso. libSQL: An open contribution fork of SQLite. https://github.com/tursodatabase/ libsql , 2023. Di W ang et al. Longmemeval: Benchmarking chat assistants on long-term interactive memory . arXiv preprint arXiv:2410.10813 , 2024. Edwin B. W ilson. Pr obable inference, the law of succession, and statistical infer ence. Journal of the American Statistical Association , 22(158):209–212, 1927. Zeyu Zhang, Xiaohe Bo Zhang, Chen Jiang, Bin Liu, Zhenyu Fan, Fei Guo, and Mingyu Gong. A survey on the memory mechanism of large language model based agents. arXiv preprint arXiv:2404.13501 , 2024. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment